
Do the European Data Portal Datasets in the Categories Government and Public Sector, Transport and Education, Culture and Sport Meet the Data on the Web Best Practices?

 , , and
, , and
Abstract
:1. Summary
- Best Practice 1: Provide metadata—provide metadata for both human users and computer applications. This BP provides the following benefits: reuse, understanding, discovery, and processability.
- Best Practice 2: Provide descriptive metadata—the general characteristics of datasets and their distributions, facilitating their discovery on the web, as well as the nature of the datasets. Benefits: reuse, comprehension, and discoverability.
- Best Practice 3: Provide structural metadata—the schema and internal structure of distribution (e.g., description of a CSV file, an API, or an RSS feed). Benefits: reuse, comprehension, and processability.
- Best Practice 4: Provide data license information—using a link or copy of the data license agreement. Benefits: reuse and trust.
- Best Practice 5: Provide data provenance information—the origins of the data and also of all the changes they have already undergone. Benefits: reuse, comprehension, and trust.
- Best Practice 6: Provide data quality information—“provide information about data quality and fitness for particular purposes”. The quality of data should be documented and explicitly. Benefits: reuse and trust.
- Best Practice 7: Provide a version indicator—“assign and indicate a version number or date for each dataset”. Benefits: reuse and trust.
- Best Practice 8: Provide version history—making a description for each version available that explains how it differs from the previous version. Benefits: reuse and trust.
- Best Practice 9: Use persistent URIs as identifiers of datasets—enables the identification of datasets in a persistent way. Benefits: reuse, interoperability, and linkability.
- Best Practice 10: Use persistent URIs as identifiers within datasets—reuse URIs between datasets and ensure that their identifiers can be referred to by other datasets consistently. Benefits: reuse, interoperability, linkability, and discoverability.
- Best Practice 11: Assign URIs to dataset versions and series—to individual versions of datasets, as well as to the overall series. Benefits: reuse, discoverability, and trust.
- Best Practice 12: Use machine-readable standardized data formats—to minimize the limitations on the use of data. Benefits: reuse and processability.
- Best Practice 13: Use locale-neutral data representations—to limit misinterpretations; if this is not possible, metadata on the locality used by the data values must be provided. Benefits: reuse and comprehension.
- Best Practice 14: Provide data in multiple formats—to reduce costs in transforming datasets and mistakes during the process. Benefits: reuse and processability.
- Best Practice 15: Reuse vocabularies, preferably standardized ones—to encode data and metadata. Benefits: reuse, processability, comprehension, trust, and interoperability.
- Best Practice 16: Choose the right formalization level—the level that fits the most likely data and applications. Benefits: reuse, comprehension, and interoperability.
- Best Practice 17: Provide bulk download—in a way that allows consumers to retrieve the complete dataset with a single request. Benefits: reuse and access.
- Best Practice 18: Provide subsets for large datasets—so that data users can download only the subset they need. Benefits: reuse, linkability, access, and processability.
- Best Practice 19: Use content negotiation for serving data available in multiple formats—to serve data available in various formats. Benefits: reuse and access.
- Best Practice 20: Provide real-time access—for immediate access to encourage the development of real-time applications. “Applications will be able to access time-critical data in real-time or near real-time, where real-time means a range from milliseconds to a few seconds after the data creation”. Benefits: reuse and access.
- Best Practice 21: Provide data that is up to date—and make the frequency of updating explicit. Benefits: reuse and access.
- Best Practice 22: Provide an explanation for data that is not available—“provide an explanation of how the data can be accessed and who can access it”, to provide full context for potential data consumers. Benefits: reuse and trust.
- Best Practice 23: Make data available through an API—to offer the greatest flexibility and processability for the data consumers. Benefits: reuse, processability, interoperability, and access.
- Best Practice 24: Use web standards as the foundation of APIs—so that they are more usable and leverage the strengths of the web. APIs should be built on web standards to leverage the strengths of the web (e.g., REST). Benefits: reuse, processability, access, discoverability, and linkability.
- Best Practice 25: Provide complete documentation for your API—in a way that developers perceive its quality and usefulness. “Update documentation as you add features or make changes”. Benefits: reuse and trust.
- Best Practice 26: Avoid breaking changes to your API—so that the client code does not stop working. Benefits: trust and interoperability.
- Best Practice 27: Preserve identifiers—if it is necessary to remove the data from the web, it is necessary to preserve the respective identifiers so that the user is not directed to the 404 response code (not found). Benefits: reuse and trust.
- Best Practice 28: Assess dataset coverage—assess the coverage of a dataset before its preservation. Benefits: reuse and trust.
- Best Practice 29: Gather feedback from data consumers—through an easily detectable mechanism. “Data consumers will be able to provide feedback and ratings about datasets and distributions”. Benefits: reuse, trust, and comprehension.
- Best Practice 30: Make feedback available—give publicly available consumer feedback about datasets and distributions datasets. Benefits: reuse and trust.
- Best Practice 31: Enrich data by generating new data—to enhance their value. Benefits: reuse, comprehension, trust, and processability.
- Best Practice 32: Provide complementary presentations—such as visualizations, tables, web applications, and summaries. Benefits: reuse, comprehension, access, and trust.
- Best Practice 33: Provide feedback to the original publisher—on, for example, when and how their data are being reused or aspects of improvement. Benefits: reuse, interoperability, and trust.
- Best Practice 34: Follow licensing terms—in order to maintain a good relationship with the original publisher. Benefits: reuse and trust.
- Best Practice 35: Cite the original publication—in order to generate trust in the data. Benefits: reuse, trust, and discoverability.
2. Data Description
3. Methods
3.1. Exploratory Study
| Algorithm 1 Algorithm for datasets selection—Exploratory study |
| START FILTER datasets by Excellent to a new list; FILTER datasets by Good+ and ADD them to the list; count = 0; WHILE (count < 20) ADD dataset to the sample; REMOVE dataset from the list; count = count + 1; END_WHILE END |
3.2. Final Study
| Algorithm 2 Algorithm for datasets selection—Final study |
| START FILTER datasets by Excellent to a new list; FILTER datasets by Good+ and ADD them to the list; REMOVE datasets from the exploratory study from the list; count = 0; WHILE (count < 50) IF new dataset is very similar to dataset already included in the sample THEN REMOVE dataset from the list; ELSE ADD dataset to the sample; REMOVE dataset from the list; count = count + 1; END_IF END_WHILE END |
4. User Notes
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Santos, P.L.V.A.C.; Sant’Ana, R.C.G. Dado e granularidade na perspectiva da informação e tecnologia: Uma interpretação pela ciência da informação. Ciênc. Inf. 2013, 42, 199–209. [Google Scholar]
- Albertoni, R.; Cox, S.; Beltran, A.G.; Perego, A.; Winstanley, P. Data Catalog Vocabulary (DCAT—Version 2. W3C Recommendation 4 February 2020). Available online: https://www.w3.org/TR/vocab-dcat/ (accessed on 18 February 2021).
- Greenberg, J. Metadata and the World Wide Web. Encyclopedia of Library and Information Science. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.134.4528&rep=rep1&type=pdf (accessed on 28 May 2021).
- Riley, J. What Is Metadata, and What Is It for? NISO: Baltimore, MD, USA, 2017; Available online: https://groups.niso.org/apps/group_public/download.php/17446/Understanding%20Metadata.pdf (accessed on 28 May 2021).
- Lee-Berners, T. Weaving the Web: Glossary. 23 July 1999. Available online: https://www.w3.org/People/Berners-Lee/Weaving/glossary.html (accessed on 28 May 2021).
- Simperl, E.; Walker, J. Analytical Report 8: The Future of Open Data Portals; Publications Office of the European Union: Luxembourg, 2017; pp. 1–26. Available online: https://www.europeandataportal.eu/sites/default/files/edp_analyticalreport_n8.pdf (accessed on 5 October 2020).
- Carrara, W.; Fischer, S.; van Steenbergen, E. Open Data Maturity in Europe 2015: Insights into the European State of Play. 2020. Available online: https://beta.op.europa.eu/en/publication-detail/-/publication/0e95f3cb-141c-11eb-b57e-01aa75ed71a1 (accessed on 13 October 2020).
- Berends, J.; Carrara, W.; Radu, C. Analytical Report 9: The Economic Benefits of Open Data; Publications Office of the European Union: Luxembourg, 2017. [Google Scholar] [CrossRef]
- European Comission. Open Data Portals. 2021. Available online: https://digital-strategy.ec.europa.eu/en/policies/open-data-portals (accessed on 28 May 2021).
- Van Knippenberg, L. Analytical Report 16: Open Data Best Practices in Europe: Learning from Cyprus, France, and Ireland; Publications Office of the European Union: Luxembourg, 2020. [Google Scholar] [CrossRef]
- Data.Europa.Eu. About Data.Europa.Eu. (2021 Update). Available online: https://data.europa.eu/de/highlights/open-regions-and-cities-data-european-data-portal (accessed on 21 June 2021).
- National Spatial Data Infrastructure. About nipp.hr. 2021. Available online: https://www.nipp.hr/default.aspx?id=1728. (accessed on 19 June 2021).
- Lóscio, B.F.; Burle, C.; Calegari, N. (Eds.) Data on the Web Best Practices. 31 January 2017. Available online: https://www.w3.org/TR/dwbp/#intro. (accessed on 13 October 2020).
- Wilkinson, M.D.; Dumontier, M.; Jan Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.; Santos, L.B.D.; Bourne, P.E.; et al. The FAIR guiding principles for scientific data management and stewardship. Sci. Data 2016, 3, 60018. [Google Scholar] [CrossRef] [Green Version]
- Torino, E.; Trevisan, G.L.; Vidotti, S.A.B.G. Dados abertos CAPES: Um Olhar à Luz dos Desafios para Publicação de Dados na Web. Ciênc. Inf. 2019, 48, 38–46. Available online: https://repositorio.utfpr.edu.br/jspui/handle/1/4812. (accessed on 1 June 2021).
- Provenance. Linked Data Glossary. 2013. Available online: https://www.w3.org/TR/ld-glossary/#provenance. (accessed on 5 May 2021).
- Hartig, O. Provenance Information in the Web of Data. 2009. Available online: http://ceur-ws.org/Vol-538/ldow2009_paper18.pdf (accessed on 28 May 2021).
- Carrara, W.; Fischer, S.; Oudkerk, F.; van Steenbergen, E.; Tinholt, D. Analytical Report 1: Digital Transformation and Open Data; Publications Office of the European Union: Luxembourg, 2015; pp. 1–22. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
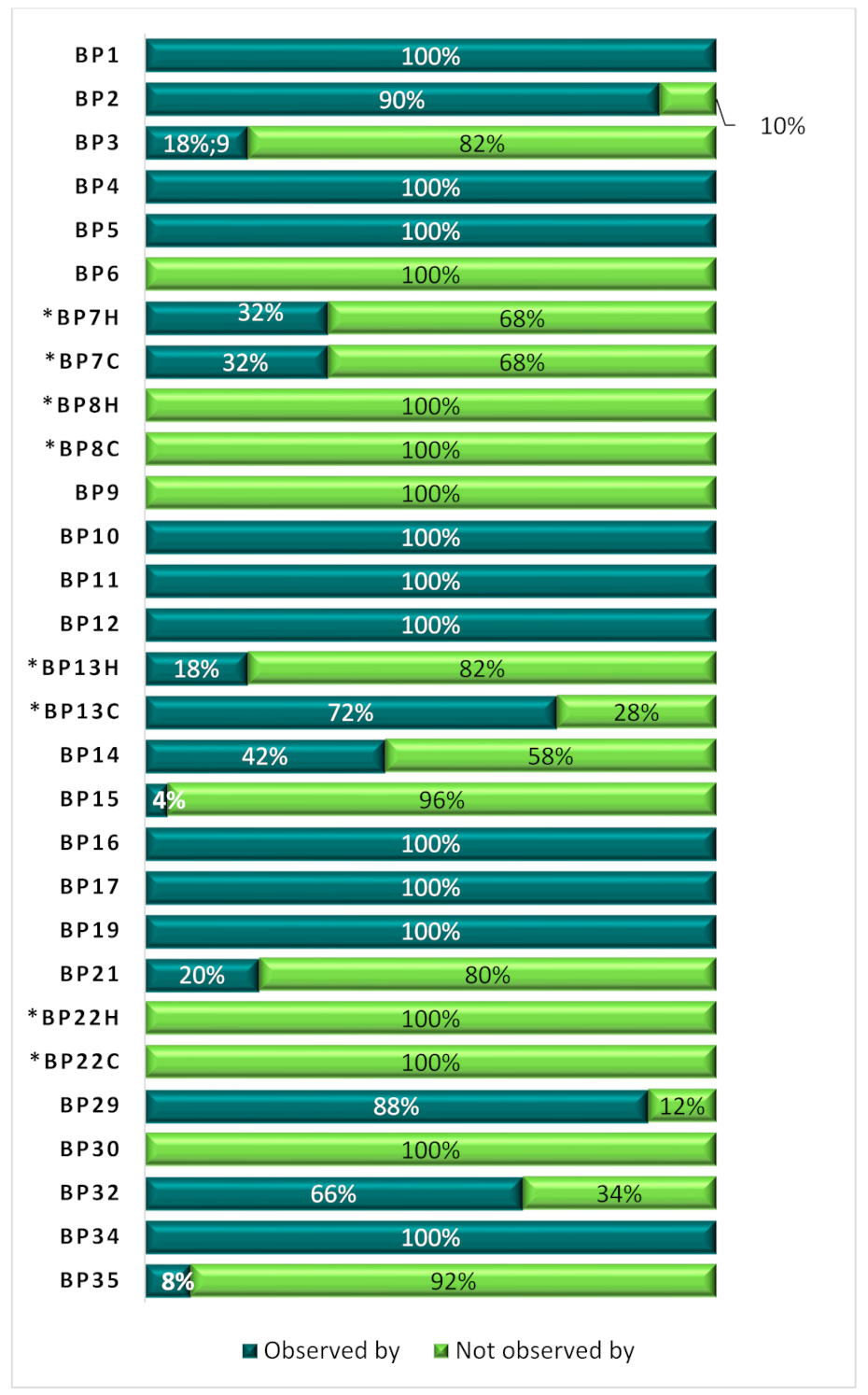
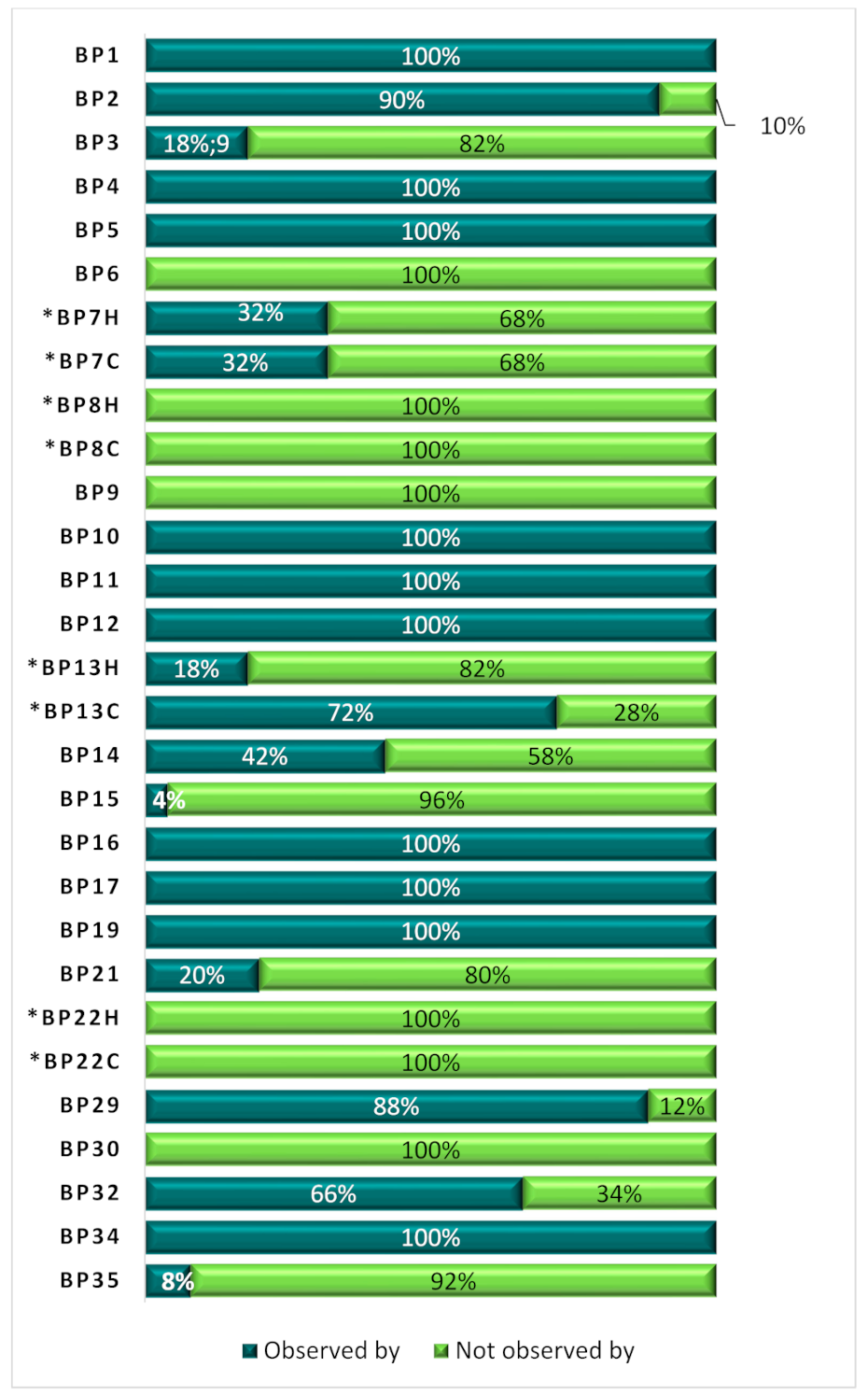
| Best Practices | Observed by | Not Observed by |
|---|---|---|
| BP1 | 50 | |
| BP2 | 38 | 12 |
| BP3 | 50 | |
| BP4 | 50 | |
| BP5 | 49 | 1 |
| BP6 | 50 | |
| BP7H, the human-readable version of BP7 | 5 | 45 |
| BP7C, the computer-readable version of BP7 | 5 | 45 |
| BP8H, the human-readable version of BP8 | 50 | |
| BP8C, the computer-readable version of BP8 | 50 | |
| BP9 | 50 | |
| BP10 | 48 | 2 |
| BP11 | 49 | 1 |
| BP12 | 49 | 1 |
| BP13H, the human-readable version of BP13 | 17 | 33 |
| BP13C, the computer-readable version of BP13 | 37 | 13 |
| BP14 | 19 | 31 |
| BP15 | 18 | 32 |
| BP16 | 49 | 1 |
| BP17 | 50 | |
| BP19 | 50 | |
| BP21 | 23 | 27 |
| BP22H, the human-readable version of BP22 | 50 | |
| BP22C, the computer-readable version of BP22 | 50 | |
| BP29 | 42 | 8 |
| BP30 | 50 | |
| BP32 | 23 | 27 |
| BP34 | 50 | |
| BP35 | 7 | 43 |
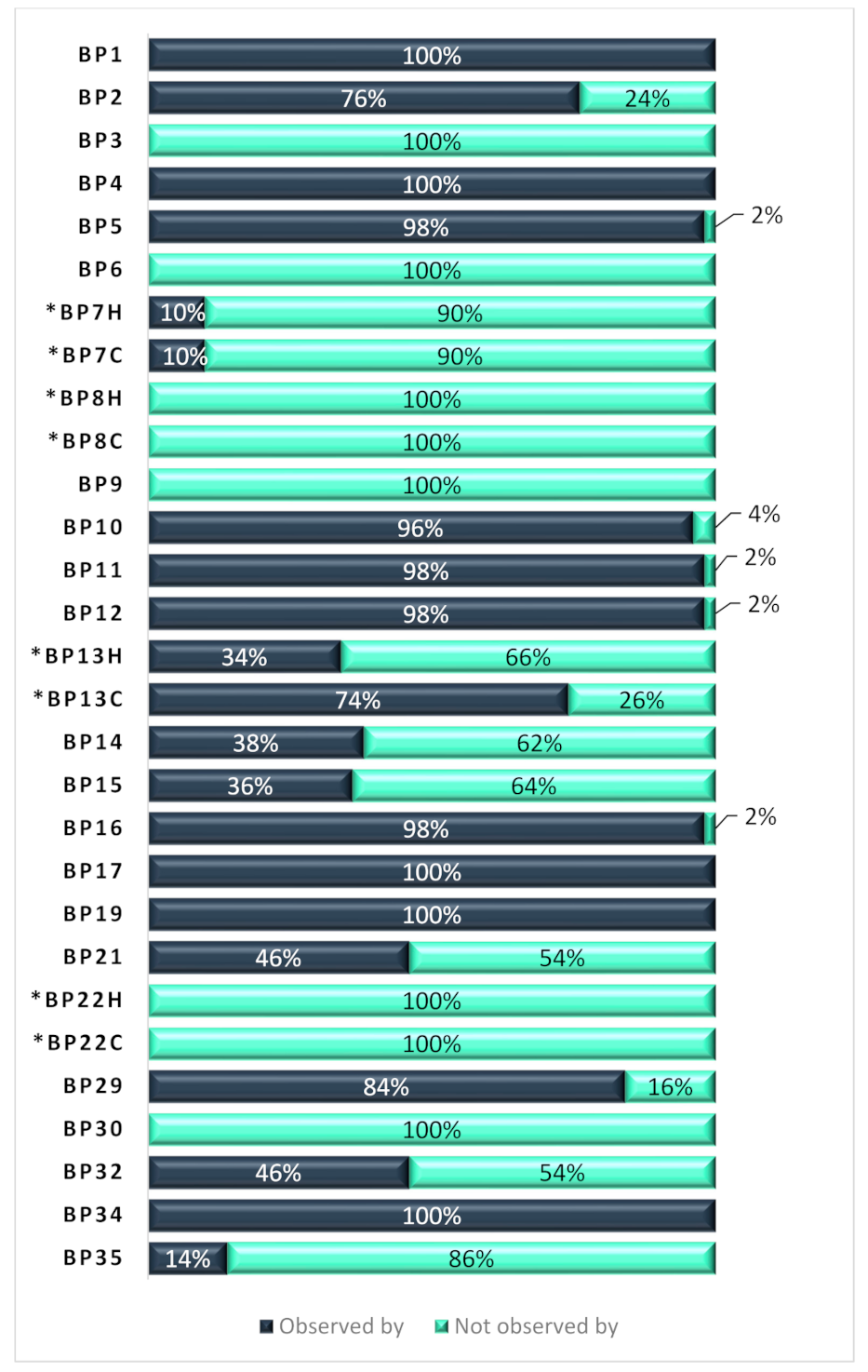
| Best Practices | Observed by | Not Observed by |
|---|---|---|
| BP1 | 50 | |
| BP2 | 45 | 5 |
| BP3 | 9 | 41 |
| BP4 | 50 | |
| BP5 | 50 | |
| BP6 | 50 | |
| BP7H, the human-readable version of BP7 | 16 | 34 |
| BP7C, the computer-readable version of BP7 | 16 | 34 |
| BP8H, the human-readable version of BP8 | 50 | |
| BP8C, the computer-readable version of BP8 | 50 | |
| BP9 | 50 | |
| BP10 | 50 | |
| BP11 | 50 | |
| BP12 | 50 | |
| BP13H, the human-readable version of BP13 | 9 | 41 |
| BP13C, the computer-readable version of BP13 | 36 | 14 |
| BP14 | 21 | 29 |
| BP15 | 2 | 48 |
| BP16 | 50 | |
| BP17 | 50 | |
| BP19 | 50 | |
| BP21 | 10 | 40 |
| BP22H, the human-readable version of BP22 | 50 | |
| BP22C, the computer-readable version of BP22 | 50 | |
| BP29 | 44 | 6 |
| BP30 | 50 | |
| BP32 | 33 | 17 |
| BP34 | 50 | |
| BP35 | 4 | 46 |
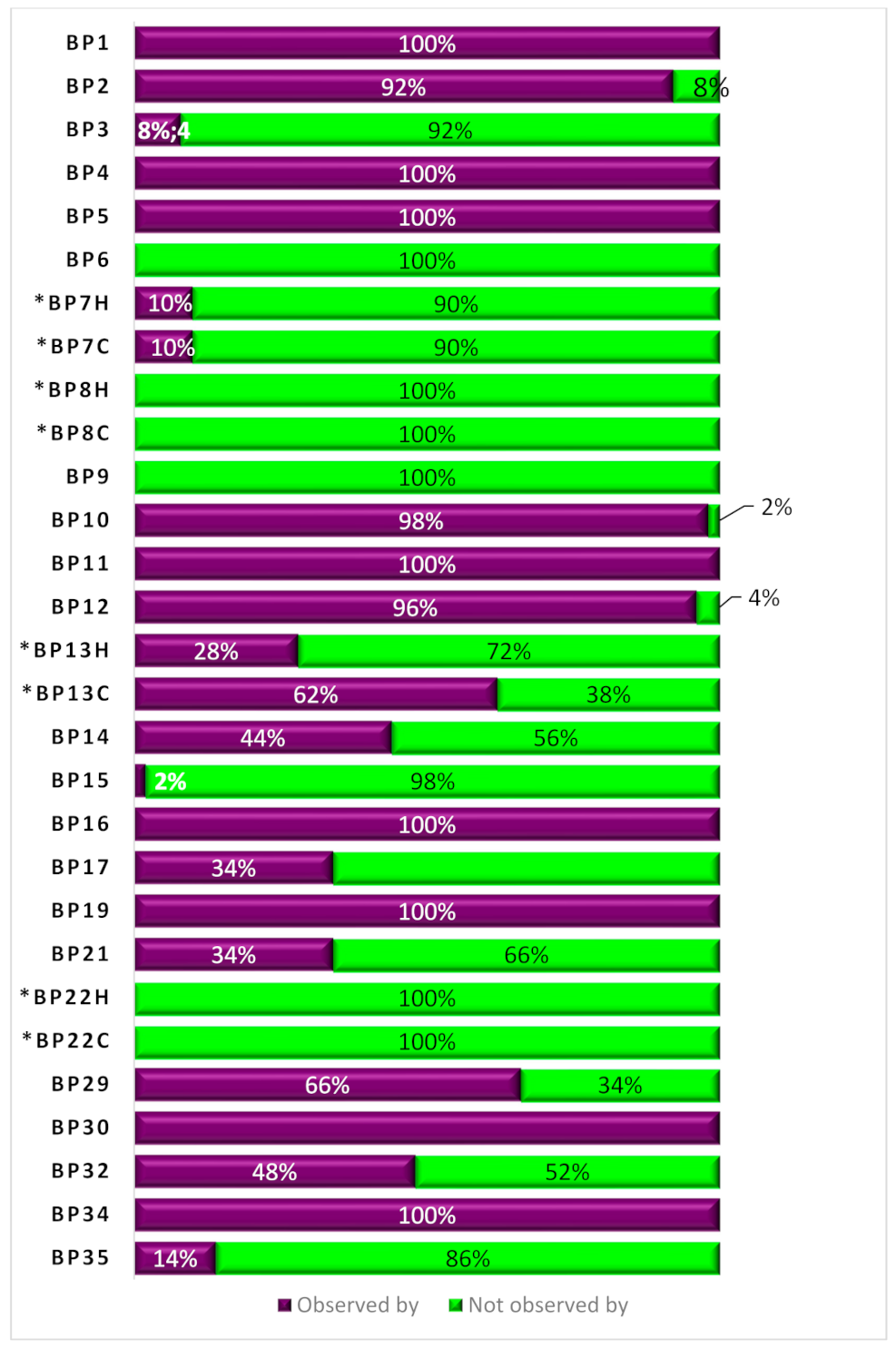
| Best Practices | Observed by | Not Observed by |
|---|---|---|
| BP1 | 50 | |
| BP2 | 46 | 4 |
| BP3 | 4 | 46 |
| BP4 | 50 | |
| BP5 | 50 | |
| BP6 | 50 | |
| BP7H, the human-readable version of BP7 | 5 | 45 |
| BP7C, the computer-readable version of BP7 | 5 | 45 |
| BP8H, the human-readable version of BP8 | 50 | |
| BP8C, the computer-readable version of BP8 | 50 | |
| BP9 | 50 | |
| BP10 | 49 | 1 |
| BP11 | 50 | |
| BP12 | 48 | 2 |
| BP13H, the human-readable version of BP13 | 14 | 36 |
| BP13C, the computer-readable version of BP13 | 31 | 19 |
| BP14 | 22 | 28 |
| BP15 | 1 | 49 |
| BP16 | 50 | |
| BP17 | 50 | |
| BP19 | 50 | |
| BP21 | 17 | 33 |
| BP22H, the human-readable version of BP22 | 50 | |
| BP22C, the computer-readable version of BP22 | 50 | |
| BP29 | 33 | 17 |
| BP30 | 50 | |
| BP32 | 24 | 26 |
| BP34 | 50 | |
| BP35 | 7 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrade, M.C.; Cunha, R.O.d.; Figueiredo, J.; Baptista, A.A. Do the European Data Portal Datasets in the Categories Government and Public Sector, Transport and Education, Culture and Sport Meet the Data on the Web Best Practices? Data 2021, 6, 94. https://doi.org/10.3390/data6080094
Andrade MC, Cunha ROd, Figueiredo J, Baptista AA. Do the European Data Portal Datasets in the Categories Government and Public Sector, Transport and Education, Culture and Sport Meet the Data on the Web Best Practices? Data. 2021; 6(8):94. https://doi.org/10.3390/data6080094
Chicago/Turabian StyleAndrade, Morgana Carneiro, Rafaela Oliveira da Cunha, Jorge Figueiredo, and Ana Alice Baptista. 2021. "Do the European Data Portal Datasets in the Categories Government and Public Sector, Transport and Education, Culture and Sport Meet the Data on the Web Best Practices?" Data 6, no. 8: 94. https://doi.org/10.3390/data6080094
APA StyleAndrade, M. C., Cunha, R. O. d., Figueiredo, J., & Baptista, A. A. (2021). Do the European Data Portal Datasets in the Categories Government and Public Sector, Transport and Education, Culture and Sport Meet the Data on the Web Best Practices? Data, 6(8), 94. https://doi.org/10.3390/data6080094