As we discussed in the Introduction, the goal of this section is to compare the courses of the same teaching year over time by using classification and clustering techniques: in an ideal situation, where students are able to take all their exams on time and do not accumulate delays, the courses of the same teaching year should correspond to the same number of exams. Furthermore, if students had the same difficulties in the courses of the same teaching year, one might expect not to have large differences in the corresponding average grades. Unfortunately, this does not happen in reality and the number of exams and the grades can vary significantly from one course to another in the same teaching year. In order to analyze courses, we performed several data aggregations to apply different data mining algorithms and study the courses over time.
3.1. Descriptive Classification
In our first study, we processed the original data set containing the 6062 records corresponding to the exams taken by students during the years 2011–2020 and performed an aggregation according to teaching and calendar years; the resulting data set contains 154 instances and the following attributes:
: the description of a course in a given year, of the type and with and for courses of first, second and third year, respectively, and denoting the year of the course;
: I, II and III;
: total number of exams in a calendar year for a given course;
: total number of credits acquired by students in a calendar year for a given course;
: average grade of the exams taken in a calendar year for a given course;
: normalized average grade of the entrance test taken by students who took the exam in given calendar year.
In this first study, we also took into account the normalized average grade that students obtained in the entrance test because we think this value can be a good indicator of their initial preparation. We then used this data set as a training set for building a classification model with as the class attribute.
We tried several classification algorithms that are available in the
WEKA system, applying them both to the original data set and to the data set in which some of the attributes have been discretized. The best transformation in terms of accuracy for our analysis was the one in which the
and
attributes were discretized in 3 and 5 ranges, respectively, by using
WEKA filters, as reported in
Table 2. The pre-processing phase is fundamental in any data mining analysis and in particular the discretization of continuous variables is very important. The intervals chosen are the result of various tests carried out with
WEKA in which we tried to take into account the distribution of the values. Obviously we are not saying that this is always the choice to make, and with different data other discretizations could be more effective.
We compared the various algorithms by using evaluation on the training set since we are interested to understand how the model fits our data set and which records are wrongly classified; in particular, we compared the algorithms J48, NaiveBayes, and IBk with k = 2 and 3. In
Table 3 we give the results achieved by each of these algorithms, according to some of the most common evaluation metrics, such as the percentage of correctly classified records, precision, recall, Fmeasure and area under the ROC. In
Table 4 we give the evaluation metrics with the hold-out technique (with
for training and
for testing).
Since J48 performs quite well compared to the other algorithms and the model is represented by an easy-to-interpret decision tree, we decided to investigate this model in more depth. For the purposes of our work, we need to know the training error on the entire data set and to understand which records are wrongly classified. The decision tree is illustrated in
Figure 6 and classifies correctly ≈
of the 154 instances; the corresponding confusion matrix can be found in
Table 5.
The model incorrectly classifies ≈
of the instances. In particular, seven instances of class I are classified in class II, and six instances of class I are classified in class III. Moreover, four instances of the class II are classified in class I, and two instances of the class II are classified in class III. Seven instances of class III are classified in class I, and, finally, fourteen in class II; all these are illustrated in
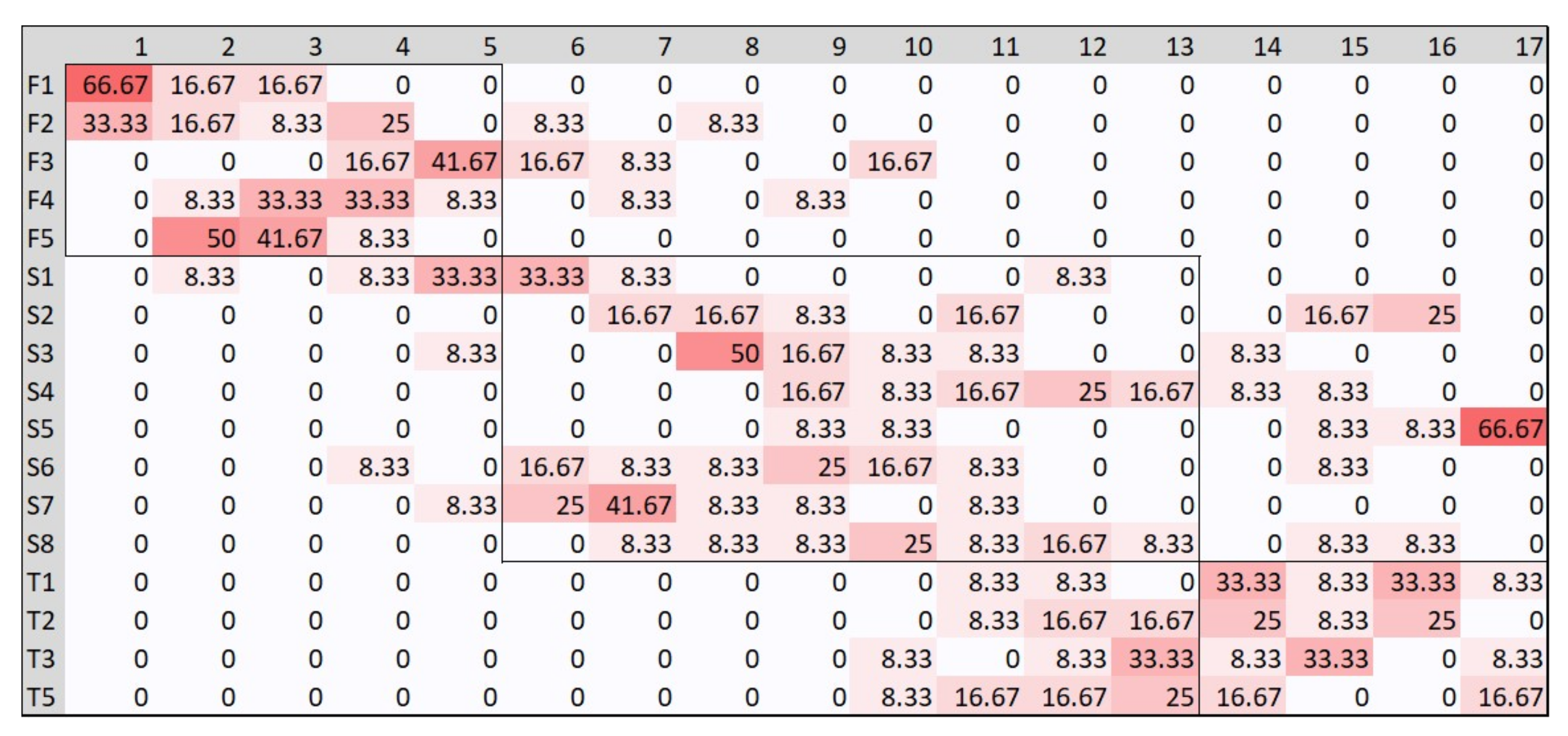
Table 6.
From
Table 6, we see that the courses
and
are the worst classified over the years. The result relative to
and
is not surprising since they are courses having a small number of exams and low grades, as illustrated in
Figure 2. It is interesting to note also that the students who took those exams are characterized by test results over the average value, as indicated in
Figure 5. This fact shows evidence that these exams constitute an obstacle for students and are taken by a small number of them and with low grades, despite having a fairly good initial level preparation. Vice versa, concerning exams
and
we note that they are taken by many students and with good grades, characteristics more similar to II teaching years. The
course is classified several times as a course of a previous year and in almost all cases it has associated a rather high number of exams, comparable to courses of the I and II years, probably due to the particular method of carrying out the corresponding exam.
Looking at the decision tree carefully, we see that there are two splits in the tree involving the average grade on the entry test, which give rise to some training errors. We, therefore, decided to investigate the corresponding records in more detail. The three badly classified records with avg_test ≤ 0.31 correspond to the courses , and , characterized by a small number of credits, a quite high average grade and with an avg_test value which is very close to split value the badly classified record with avg_test is In the set of the three badly classified records that correspond to the split avg_test we find , and , all with a test grade lower than the average value. Finally, in the leaf corresponding to avg_test we find , and In general, we believe that the value of the entrance test can give us indications regarding the productivity of the I year, so the previous errors identified on the splits that use the value of the test do not give us relevant information since they almost exclusively involve III year exams that are classified as exams of previous years. The only I year courses involved in these leaves are Calculus, , with an above-average test grade, and the Computer Architecture course, which appears with both above and below-average test grades. As far as is concerned, the same considerations already made for the course can be made, i.e., in the year 2011 that exam was taken by a few students who started from a rather high test grade and reached a high grade. Regarding the II year courses, the classification does not highlight particular problems, since only and are sporadically classified as III year exams.
The number of girls who enroll in Computer Science is very low, and for this reason we decided to make a separate analysis for them. In particular, we built a new classification tree by examining only the 864 exams taken by girls; however, this analysis did not reveal substantial differences.
We think that the results of the proposed classifications are interesting from a descriptive point of view because they highlight which courses over the years have created more difficulties for students: courses of I and II year erroneously classified as courses of subsequent years point out critical issues; vice versa, II and III year courses erroneously classified as courses of previous years indicate that students have no particular difficulty in taking the corresponding exams.
3.2. Descriptive Hierarchical Clustering
In our second study, data were aggregated with respect to the course and clustered with hierarchical clustering according to attributes average number of exams, average grade and the number of credits assigned to a given course; the attribute was used for labeling the tree leaves while the class attribute has been used to test the model on classes to clusters evaluation mode. The data set contains 17 instances, one for each course (courses and have been merged). Courses are studied on the basis of the average number of exams taken each year, therefore taking into account the number of years of activation of the course (10, 9 and 8 for I, II and III teaching years, respectively). Remember, however, that the number of students over the years changes, due to the dispersion already highlighted in the introduction, so the most correct comparison is always the one at the level of courses of the same year. Although the number of records is small, we think that from a descriptive point of view the hierarchical clustering can provide evidence of interesting similarities among courses.
More precisely, in this second study we consider a data set with attributes:
: I, II and III;
: the description of a course given in
Table 1;
: average number of exams in a calendar year for a given course;
: average grade of the exams taken in a calendar year for a given course;
: number of credits assigned to a given course.
In
Figure 7, the dendrograms corresponding to hierarchical clustering algorithms with single link and group average strategies are illustrated, while
Table 7 and
Table 8 show the confusion matrices corresponding to classes to clusters evaluation mode. Looking at these figures, the following comments come to mind: in both analyses, the
,
and
exams are indicated as similar and in fact they are first year exams that are often taken together, for first and with similar results. Somehow they constitute the first choices of exams that are faced. The
exam belongs to the same group but in both dendrograms (a) and (b) it is added last, as seen from the height of the corresponding branch, denoting a lower similarity with the other members of the cluster. Exam
, on the other hand, is aggregated to the second year exams
and
but added last to the group. Since the number of students decreases from the first to the second year and from the second to the third year, the exams that are assimilated with exams of subsequent years are usually made by fewer students. Therefore, this analysis also presents evidence of some critical issues for the
course when compared to the other courses of I teaching year. The remaining second year courses,
and
are grouped with third year courses: three of them are math courses, somehow more advanced than, for example,
. According to the link strategy, they are all classified as III (a) or II (b) years courses; however, in the dendrogram (b) the III cluster contains only the course
which, therefore, shows different behavior from all the other courses of the same teaching year.
The same analysis has been repeated considering only the exams taken by female students without highlighting different characteristics.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}