
HAGDAVS: Height-Augmented Geo-Located Dataset for Detection and Semantic Segmentation of Vehicles in Drone Aerial Orthomosaics


Abstract
:1. Summary
- The fusion of height information of vehicles in one channel of the image. This aims to help with segmenting vehicles of surrounding objects such as buildings and roads, and perhaps enhancing model behavior in the case of shadows or partial occlusions affect vehicle segmentation.
- Inclusion of ghost class. This dataset becomes the first in this category, which serves the purpose of creating applications to improve orthomosaic quality and visualization.
2. HAGDAVS Dataset Description
3. Methods
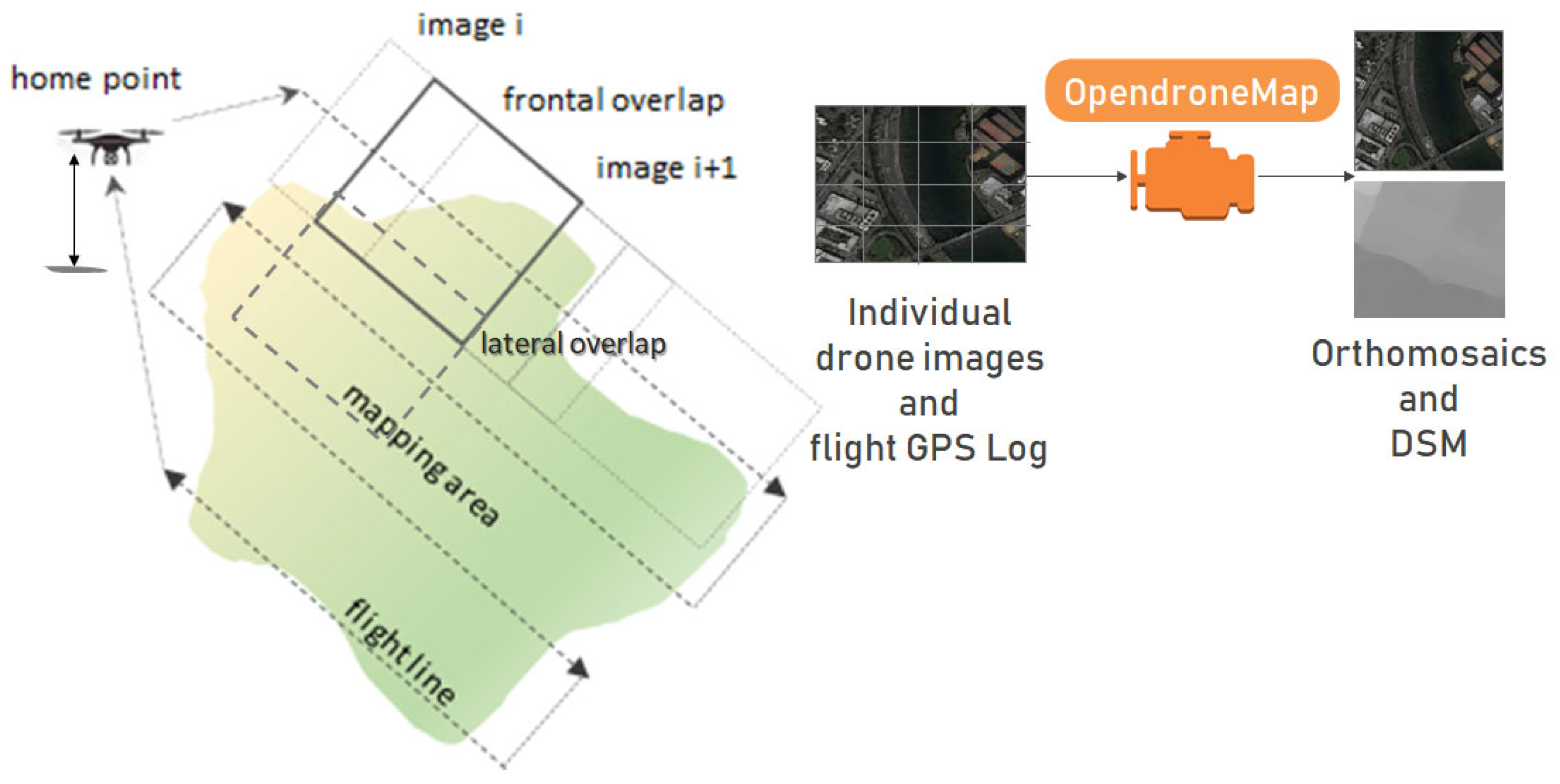
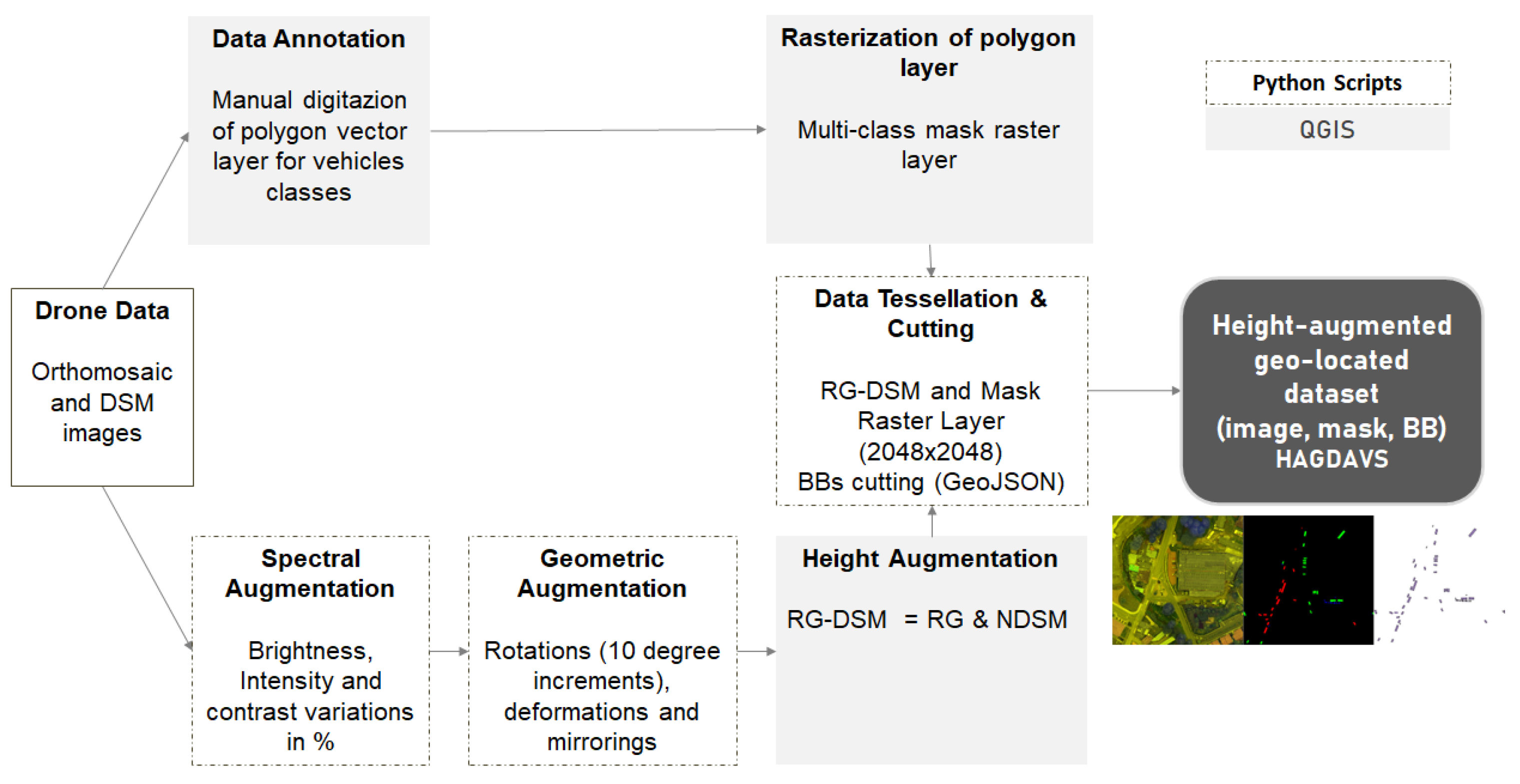
3.1. Data Acquisition and Processing
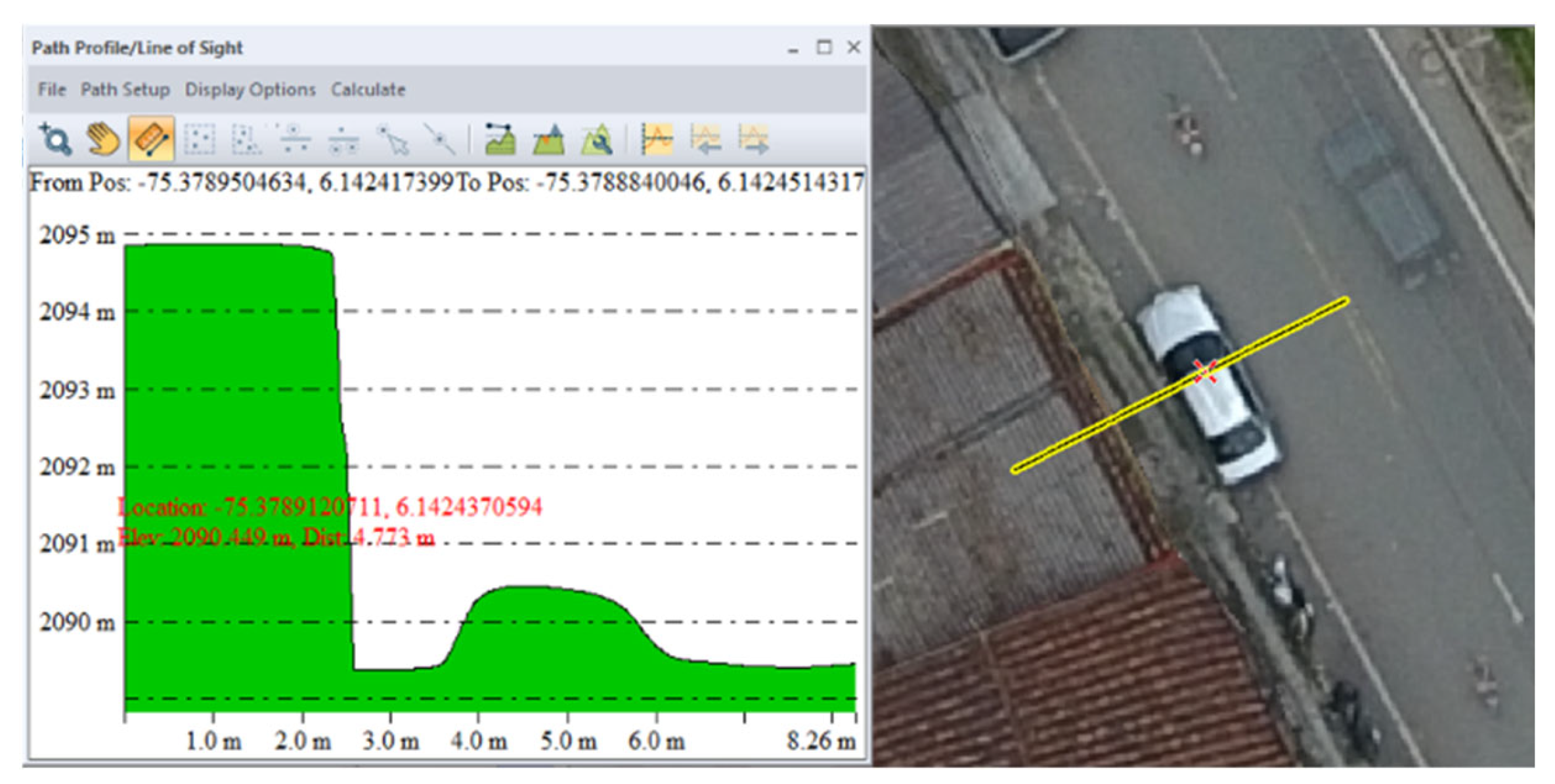
3.2. Height Augmentation
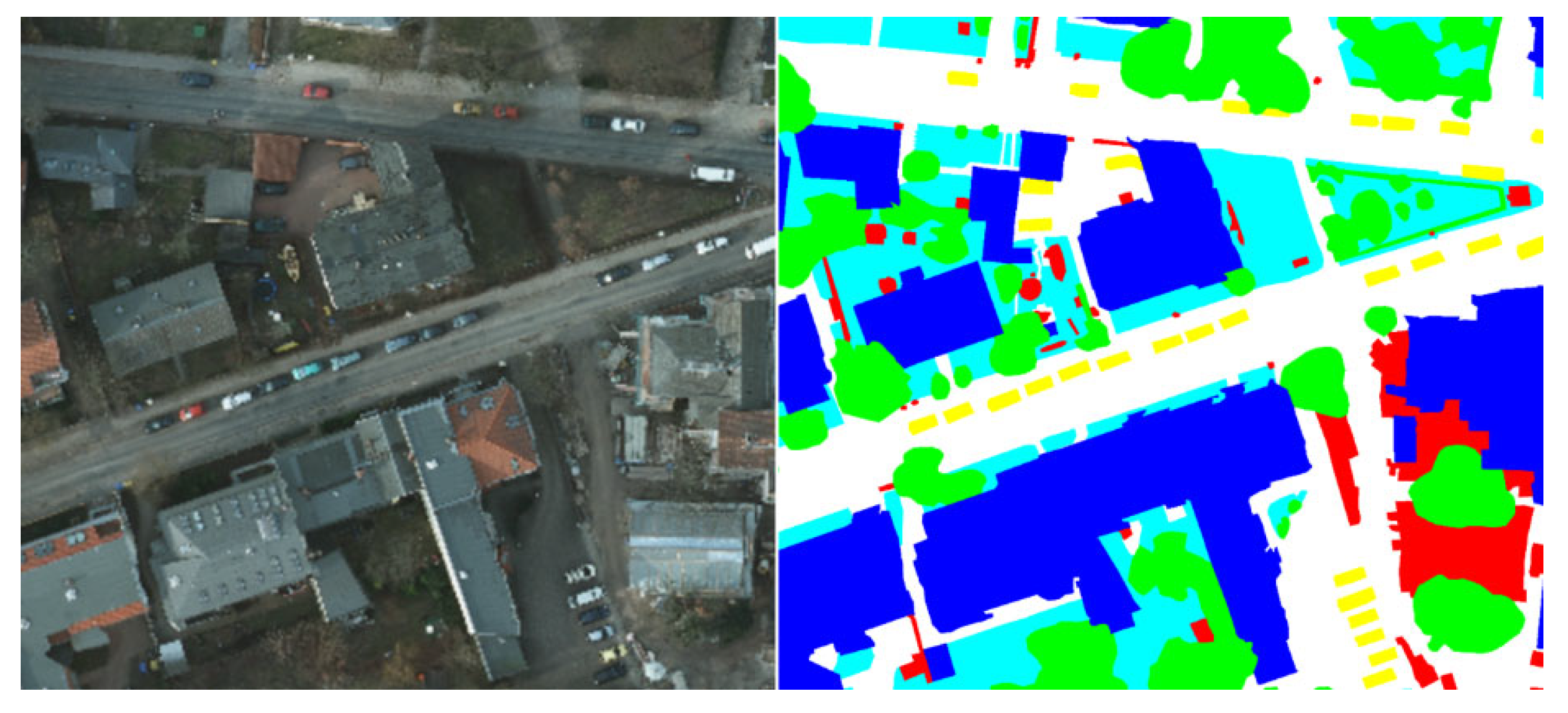
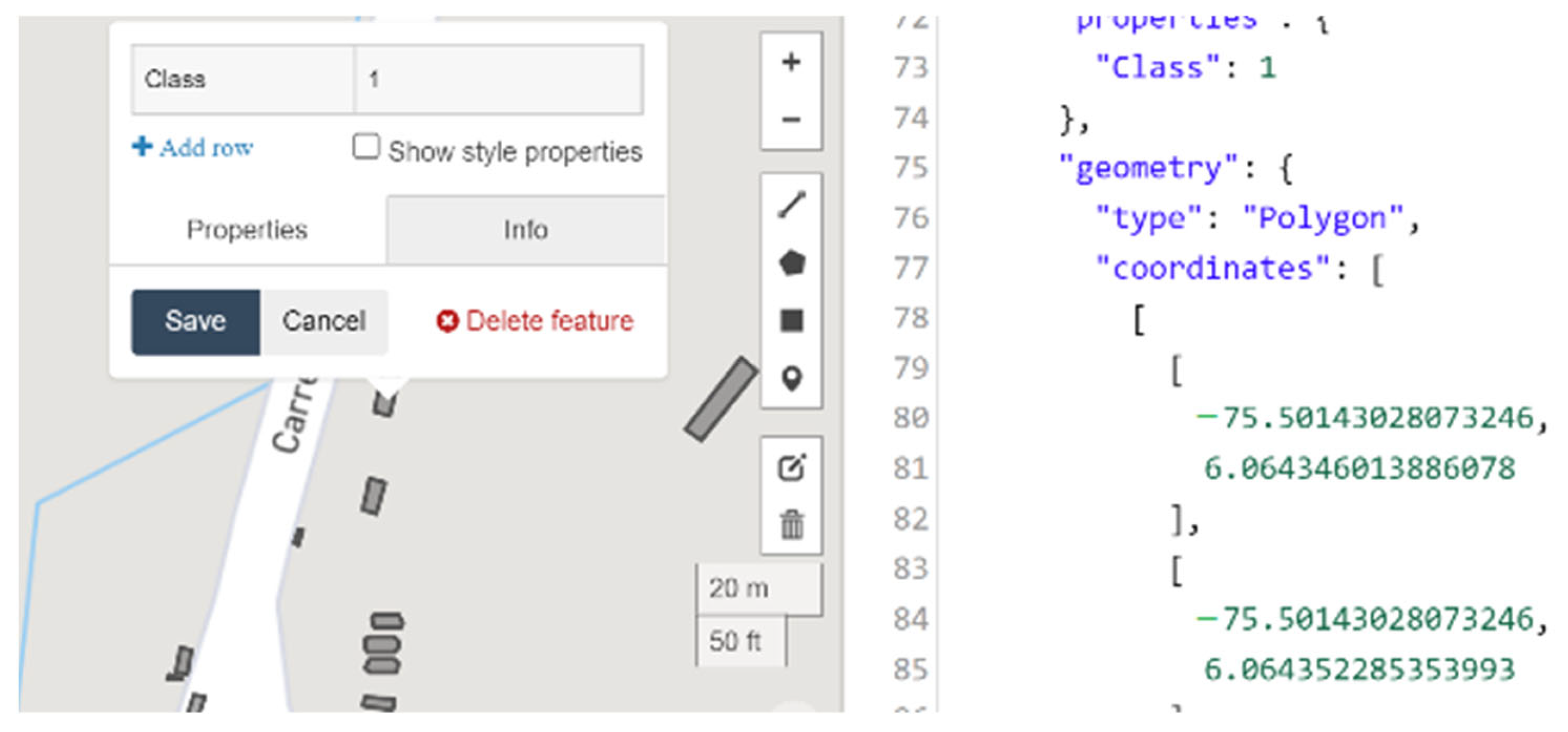
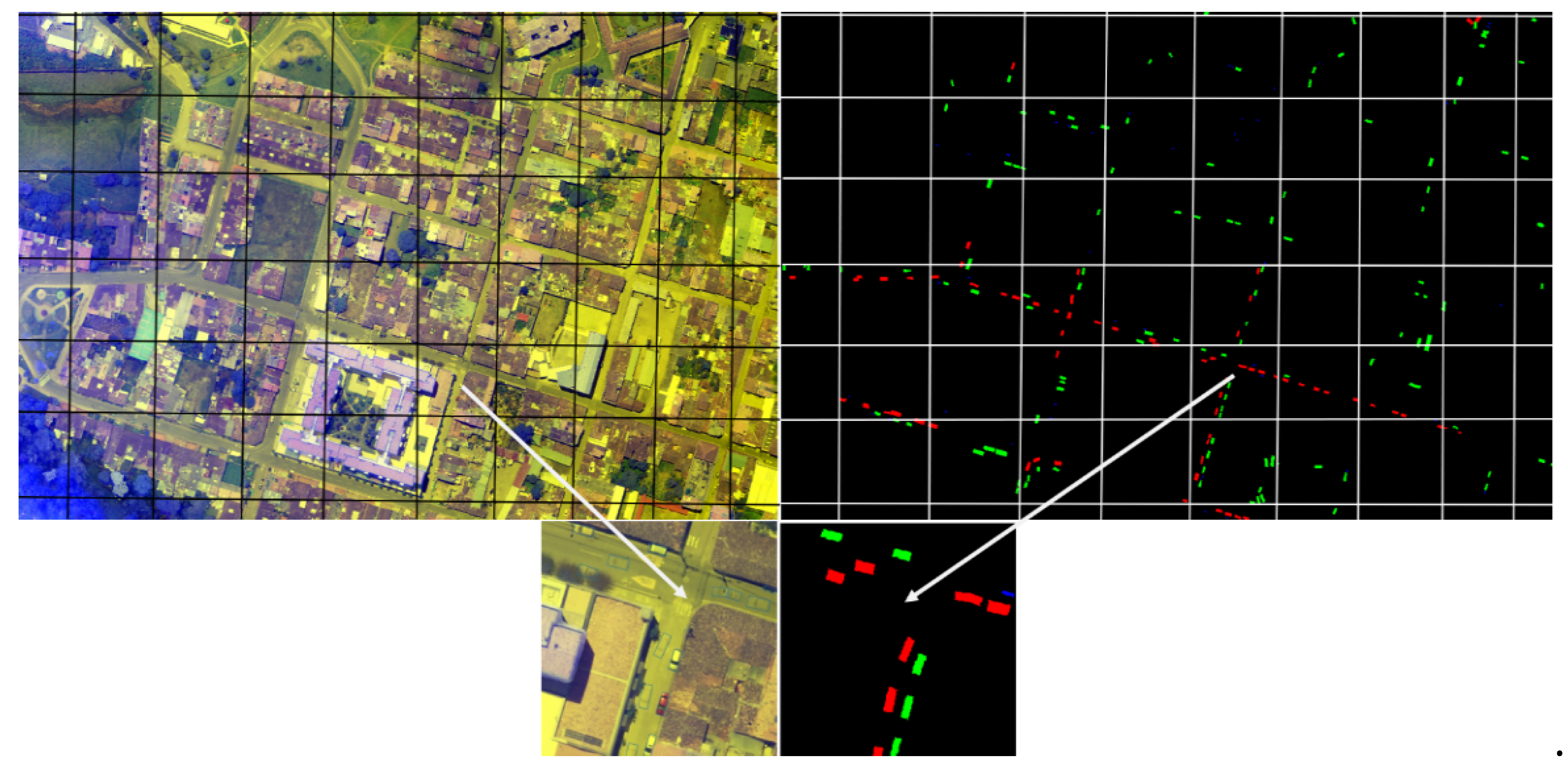
3.3. Data Annotation and Data Curation
3.4. Data Tessellation and Cutting
3.5. Dataset Bias
3.5.1. Data Augmentation and Splitting
3.5.2. Data Imbalance and Sample Weights
3.6. Practical Applications of the HAGDAVS Dataset
- Detecting and enumerating vehicles over large areas is one of the primary interests in aerial imagery analytics [6]. End-to-end automation of vehicle detection and segmentation helps security and traffic agencies with quick processing and analysis of images.
- The creation of a ghost cleaner for orthomosaics to improve drone imagery quality.
4. Conclusions
5. Future Work
- Increase the dataset size in terms of more images or the inclusion of additional classes of vehicles, vehicle models, and traffic signs.
- Create a drone thermal infrared image dataset. Images that include a spectral band that senses heat could make the detection of vehicles easier.
- Employ automatic data annotation. This makes the dataset production task simpler and quicker.
- Use of Deep Learning models on the proposed dataset to evaluate and compare its performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ballesteros, J.R.; Sanchez-Torres, G.; Branch, J.W. Automatic Road Extraction in Small Urban Areas of Developing Countries Using Drone Imagery and Image Translation. In Proceedings of the 2021 2nd Sustainable Cities Latin America Conference (SCLA), Medellin, Colombia, 25–27 August 2021; pp. 1–6. [Google Scholar]
- Weir, N.; Lindenbaum, D.; Bastidas, A.; Etten, A.; Kumar, V.; Mcpherson, S.; Shermeyer, J.; Tang, H. SpaceNet MVOI: A Multi-View Overhead Imagery Dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2 November 2019; pp. 992–1001. [Google Scholar]
- Fan, Q.; Brown, L.; Smith, J. A Closer Look at Faster R-CNN for Vehicle Detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 1 June 2016; IEEE Press: Gotenburg, Sweden; pp. 124–129. [Google Scholar]
- Yang, J.; Xie, X.; Yang, W. Effective Contexts for UAV Vehicle Detection. IEEE Access 2019, 7, 85042–85054. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the Proceedings—2021 IEEE Winter Conference on Applications of Computer Vision, WACV 2021, Wailoloa, HI, USA, 3–8 January 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA; pp. 2149–2158. [Google Scholar]
- Hsieh, M.-R.; Lin, Y.-L.; Hsu, W.H. Drone-Based Object Counting by Spatially Regularized Regional Proposal Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4165–4173. [Google Scholar]
- Pawełczyk, M.Ł.; Wojtyra, M. Real World Object Detection Dataset for Quadcopter Unmanned Aerial Vehicle Detection. IEEE Access 2020, 8, 174394–174409. [Google Scholar] [CrossRef]
- Wang, L.; Liao, J.; Xu, C. Vehicle Detection Based on Drone Images with the Improved Faster R-CNN. In Proceedings of the Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; Association for Computing Machinery: New York, NY, USA; pp. 466–471. [Google Scholar]
- Weber, I.; Bongartz, J.; Roscher, R. ArtifiVe-Potsdam: A Benchmark for Learning with Artificial Objects for Improved Aerial Vehicle Detection. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 1214–1217. [Google Scholar]
- Blaga, B.-C.-Z.; Nedevschi, S. A Critical Evaluation of Aerial Datasets for Semantic Segmentation. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 353–360. [Google Scholar]
- Bisio, I.; Haleem, H.; Garibotto, C.; Lavagetto, F.; Sciarrone, A. Performance Evaluation and Analysis of Drone-Based Vehicle Detection Techniques From Deep Learning Perspective. IEEE Internet Things J. 2021, 1. [Google Scholar] [CrossRef]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study Over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy; pp. 2242–2251. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019; pp. 7354–7363. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; He, C.; Fang, J.; Fu, H. Semantic Segmentation Based Building Extraction Method Using Multi-Source GIS Map Datasets and Satellite Imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 233–2333. [Google Scholar]
- Setting a Foundation for Machine Learning: Datasets and Labeling | by Adam Van Etten | The DownLinQ | Medium. Available online: https://medium.com/the-downlinq/setting-a-foundation-for-machine-learning-datasets-and-labeling-9733ec48a592 (accessed on 29 December 2021).
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Understanding in Crowded Scenes. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switerland, 2016; pp. 549–565. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 71, 1. [Google Scholar] [CrossRef] [PubMed]
- Al-Najjar, H.A.H.; Kalantar, B.; Pradhan, B.; Saeidi, V.; Halin, A.A.; Ueda, N.; Mansor, S. Land Cover Classification from Fused DSM and UAV Images Using Convolutional Neural Networks. Remote Sens. 2019, 11, 1461. [Google Scholar] [CrossRef] [Green Version]
- Song, A.; Kim, Y. Semantic Segmentation of Remote-Sensing Imagery Using Heterogeneous Big Data: International Society for Photogrammetry and Remote Sensing Potsdam and Cityscape Datasets. ISPRS Int. J. Geo-Inf. 2020, 9, 601. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Butler, H.; Daly, M.; Doyle, A.; Gillies, S.; Schaub, T.; Hagen, S. The GeoJSON Format. Internet Engineering Task Force: Fremont, CA, USA, 2016. [Google Scholar]
- Kameyama, S.; Sugiura, K. Effects of Differences in Structure from Motion Software on Image Processing of Unmanned Aerial Vehicle Photography and Estimation of Crown Area and Tree Height in Forests. Remote Sens. 2021, 13, 626. [Google Scholar] [CrossRef]
- Xue, W.; Zhang, Z.; Chen, S. Ghost Elimination via Multi-Component Collaboration for Unmanned Aerial Vehicle Remote Sensing Image Stitching. Remote Sens. 2021, 13, 1388. [Google Scholar] [CrossRef]
- Jian, D.; Jizhe, L.; Hailong, Z.; Shuang, Q.; Xiaoyue, J. Ghosting Elimination Method Based on Target Location Information. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 281–285. [Google Scholar]
- Seidaliyeva, U.; Akhmetov, D.; Ilipbayeva, L.; Matson, E. Real-Time and Accurate Drone Detection in a Video with a Static Background. Sensors 2020, 20, 3856. [Google Scholar] [CrossRef] [PubMed]
- How to Create Your Own False Color Image. Available online: https://picterra.ch/blog/how-to-create-your-own-false-color-image/ (accessed on 29 December 2021).
- A Unique Photogrammetry Software Suite for Mobile and Drone Mapping. Available online: www.pix4d.com/ (accessed on 2 January 2022).
- We’re Creating the Most Sustainable Drone Mapping Software with the Friendliest Community on Earth. Available online: www.opendronemap.org/ (accessed on 12 January 2022).
- Vanschoren, J. Aerial Imagery Pixel-Level Segmentation Aerial Imagery Pixel-Level Segmentation. Available online: https://www.semanticscholar.org/paper/Aerial-Imagery-Pixel-level-Segmentation-Aerial-Vanschoren/7dadc3affe05783f2b49282c06a2aa6effbd4267 (accessed on 26 February 2022).
- Shermeyer, J.; Van Etten, A. The Effects of Super-Resolution on Object Detection Performance in Satellite Imagery. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1432–1441. [Google Scholar]
- Avola, D.; Pannone, D. MAGI: Multistream Aerial Segmentation of Ground Images with Small-Scale Drones. Drones 2021, 5, 111. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K. Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning. Drones 2021, 5, 66. [Google Scholar] [CrossRef]
- A Free and Open Source Geographic Information System. Available online: www.qgis.org (accessed on 15 December 2021).
- Torralba, A.; Efros, A.A. Unbiased Look at Dataset Bias. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Mejorar El Brillo, El Contraste o El Valor Gamma de La Capa Ráster—ArcMap | Documentación. Available online: https://desktop.arcgis.com/es/arcmap/latest/manage-data/raster-and-images/improving-the-brightness-or-contrast-of-your-raster-layer.htm (accessed on 27 February 2022).
- Van Etten, A. Satellite Imagery Multiscale Rapid Detection with Windowed Networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 735–743. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Orthomosaics | DSM | Class 1 (Motorcycle) | Class 2 (Car) | Class 3 (Ghost) | Total |
|---|---|---|---|---|---|
| El Retiro Cols, Rows: 8721, 15,332 GSD 7.09, Size: 510.1 MB Format: TIFF, Bands: 3 Pixel Depth: 8 Bit Spatial Reference: GCS_WGS1984 | Height-Range: 2169–2314 m Xmin,Ymin (−755,057,859, 60,534,441) Xmax,Ymax (−754,977,854, 60,654,446) | 209 examples | 527 examples | 94 examples | 830 examples |
| La Ceja Cols, Rows: 8361, 5375 GSD 5.51, Size: 171.4 MB Format: TIFF, Bands: 3 Pixel Depth: 8 Bit Spatial Reference: GCS_WGS1984 | Height-Range: 2158–2214 m Xmin,Ymin (−754,379,007, 60,342,695) Xmax,Ymax (−754,332,962, 60,313,098) | 47 examples | 120 examples | 71 examples | 238 examples |
| Rionegro Cols, Rows: 8847, 18,895 GSD 6.08, Size: 637.7 MB Format: TIFF, Bands: 3 Pixel Depth: 8 Bit Spatial Reference: GCS_WGS1984 | Height-Range: 2065–2135 m Xmin,Ymin (−753,809,074, 61,394,740) Xmax,Ymax (−753,760,197, 614,98,805) | 271 examples | 1051 examples | 321 examples | 1643 examples |
| Pradolargo Cols, Rows: 14,919, 6666 GSD 6.30, Size: 379.4 MB Format: TIFF, Bands: 3 Pixel Depth: 8 Bit Spatial Reference: GCS_WGS1984 | Height-Range: 2493–2605 m | 12 examples | 32 examples | 104 examples | 148 examples |
| Xmin,Ymin (−755,311,888, 61,563,654) Xmax,Ymax (−755,226,877, 61,601,860) | |||||
| TOTAL | 539 | 1730 | 590 | 2859 |
| Item | Description |
|---|---|
| Field of application | Vehicle detection or segmentation |
| Collected data | Aerial images |
| Method for data acquisition | Drone flights |
| Used drone | DJI Phantom 4 Pro V2 |
| Camera resolution and sensor size | 20Mpx, 1 inch CMOS |
| Software for processing of collected data and products | Opendronemap [1], Orthomosaics and DSM |
| GSD of obtained orthomosaics and DSM | 5.5 to 7.1 cm/px |
| Method of annotation | Manually in GIS and semi-automated via Python scripts |
| Dataset production | GDAL scripts in Jupyter Notebook |
| Language for scripts | Python 3.7 |
| Used GIS software | QGIS V3.22.2-Białowieża, ArcGIS |
| Number of classes and objects | 4: motorcycle, car, and ghost (motorcycle or car), background |
| Number of orthomosaics | 4 |
| Data collected by | Authors of this paper |
| Year of collection | 2018–2020 |
| Detection dataset | GeoJSON bounding boxes |
| Segmentation dataset | RG-NDSM 1, Multi-class color mask images |
| Additional information | RGB, DSM |
| Dataset size | 1.34 Gb compressed |
| Image format | .tiff |
| Image quantity | 83 images |
| Cols, Rows of images | 2048 × 2048 px |
| RGB, RG-DSM1 Image average memory size | 16 Mb |
| RGB, RG-DSM1, Mask, Image spectral resolution | 3 bands |
| RGB, RG-DSM, Mask Image radiometric resolution | 8 bit |
| RGB, RG-DSM, Mask Image Coordinate System | WGS1984 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ballesteros, J.R.; Sanchez-Torres, G.; Branch-Bedoya, J.W. HAGDAVS: Height-Augmented Geo-Located Dataset for Detection and Semantic Segmentation of Vehicles in Drone Aerial Orthomosaics. Data 2022, 7, 50. https://doi.org/10.3390/data7040050
Ballesteros JR, Sanchez-Torres G, Branch-Bedoya JW. HAGDAVS: Height-Augmented Geo-Located Dataset for Detection and Semantic Segmentation of Vehicles in Drone Aerial Orthomosaics. Data. 2022; 7(4):50. https://doi.org/10.3390/data7040050
Chicago/Turabian StyleBallesteros, John R., German Sanchez-Torres, and John W. Branch-Bedoya. 2022. "HAGDAVS: Height-Augmented Geo-Located Dataset for Detection and Semantic Segmentation of Vehicles in Drone Aerial Orthomosaics" Data 7, no. 4: 50. https://doi.org/10.3390/data7040050
APA StyleBallesteros, J. R., Sanchez-Torres, G., & Branch-Bedoya, J. W. (2022). HAGDAVS: Height-Augmented Geo-Located Dataset for Detection and Semantic Segmentation of Vehicles in Drone Aerial Orthomosaics. Data, 7(4), 50. https://doi.org/10.3390/data7040050