
Multi-Layer Web Services Discovery Using Word Embedding and Clustering Techniques




Abstract
:1. Introduction
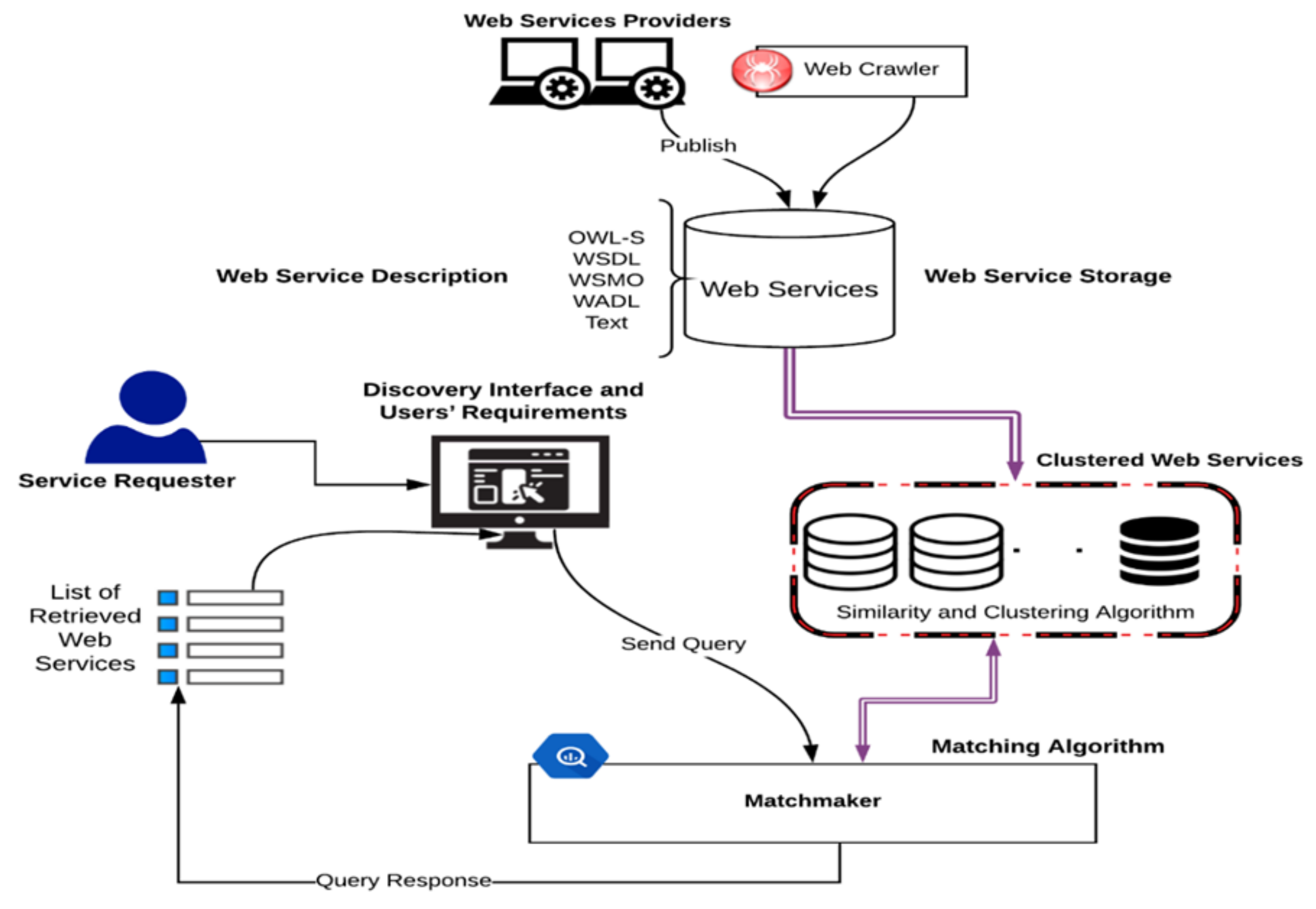
2. The Proposed Multi-Layer Architecture for Clustering of Web Services
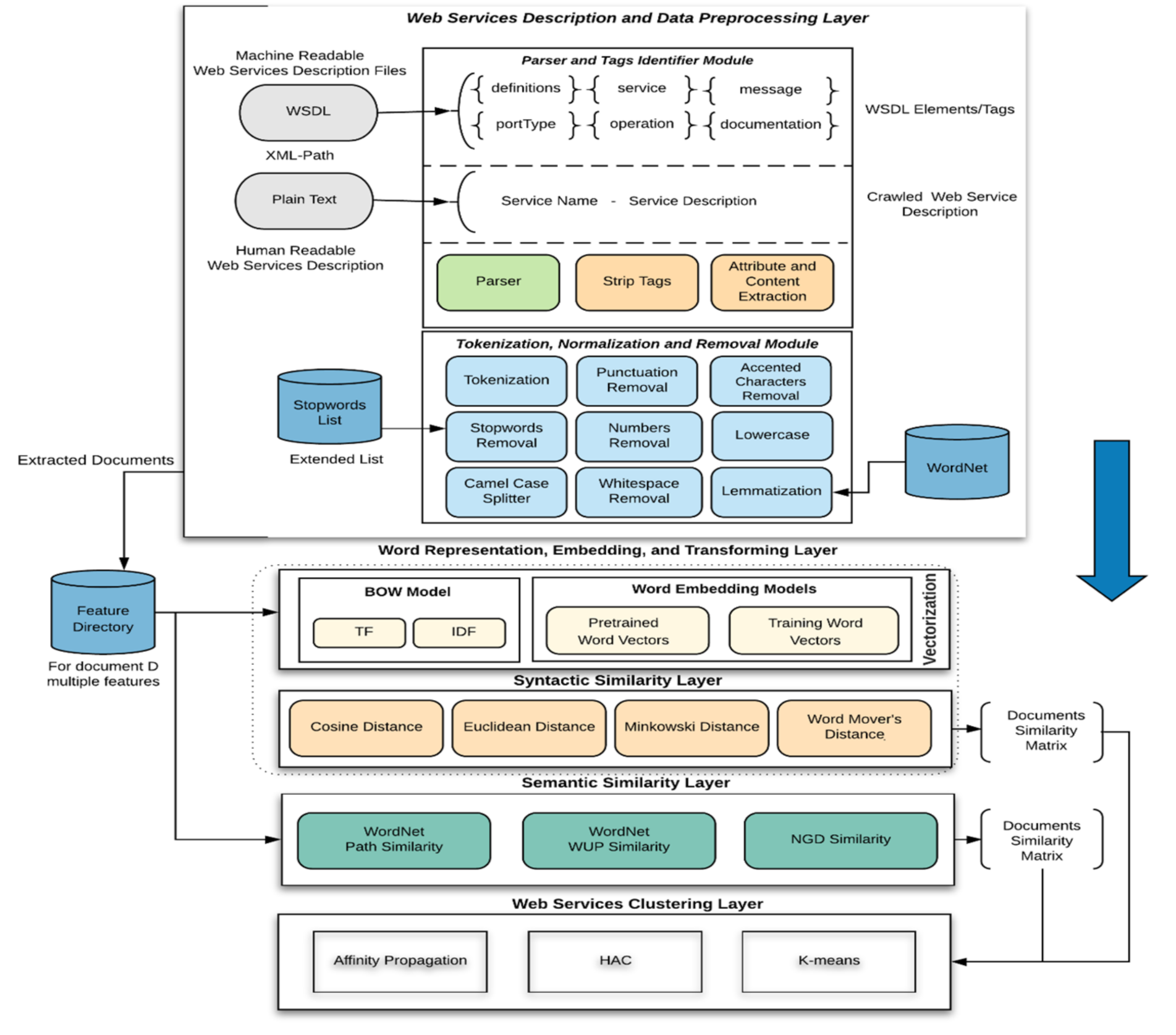
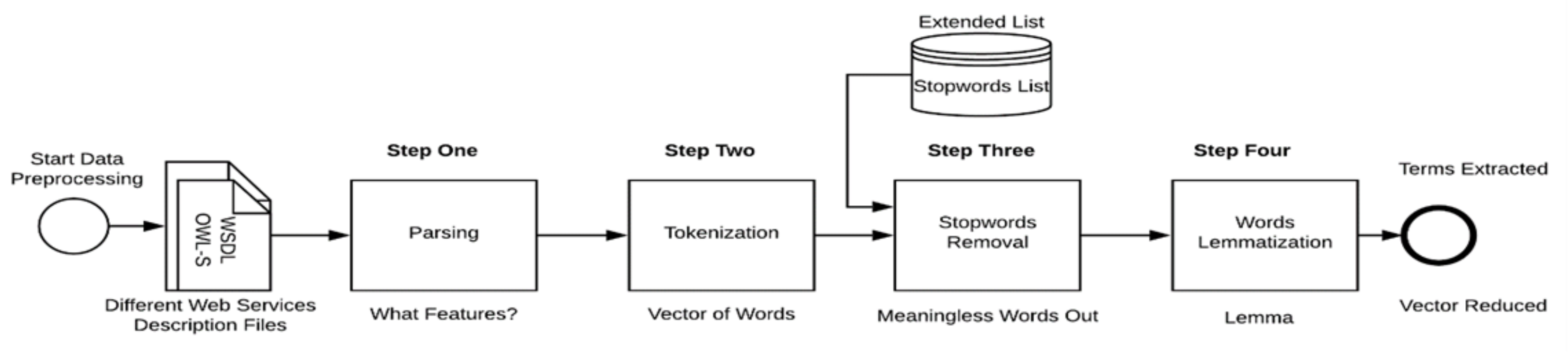
- Web Services Description and Data Preprocessing: In this layer, NLP techniques are applied to select and extract terms (features) from Web services description files. This includes several different steps, starting with parsing selected features from the Web services description files, then tokenizing, removing stopwords, and lemmatizing words. Feature selection depends on the type of Web services description documents.
- Word Representation, Embedding, and Transformation: In this layer, two types of NLP models are considered to transform the extracted terms into a computer-understandable and processable form. This includes Bag of Words (BOW) with Term Frequency-Inverse Document Frequency (TFIDF) as a weighted scheme as well as three word-embedding models; these models include two pre-trained models and one self-trained model.
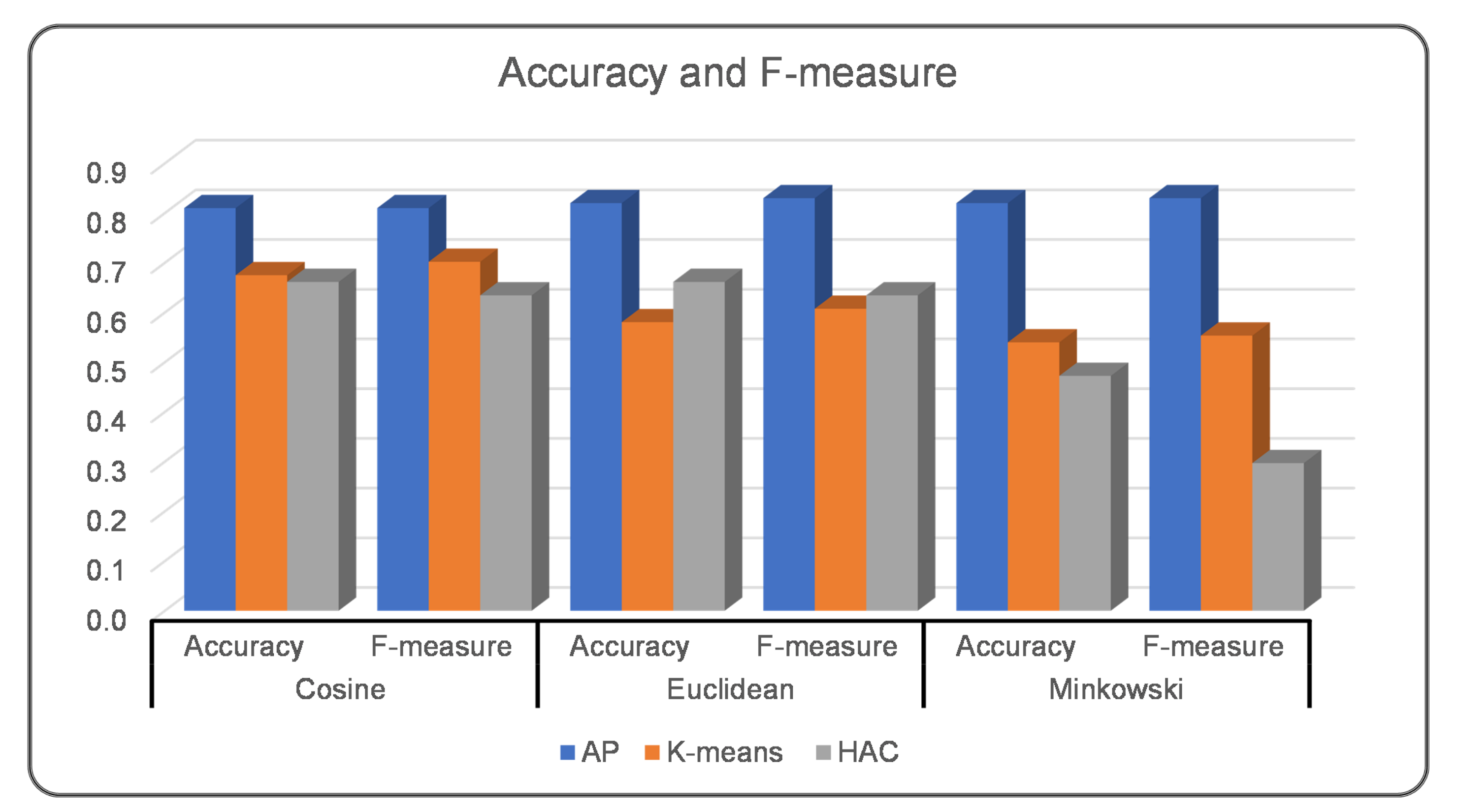
- Syntactic Similarity: Four syntactic similarity measures are implemented in this layer to find the similarity between Web services, namely, Cosine, Euclidean, Minkowski, and Word Mover’s distance;
- Semantic Similarity: In this layer, two WordNet-based similarity measures are employed to find similarities between Web services, including path and WUP similarities. Normalized Google Distance (NGD), sometimes called Normalized Web Distance (NWD), is employed to find the semantic similarity between Web services.
- Web Services Clustering: In this layer, affinity propagation (AP), K-means, and hierarchical agglomerative clustering (HAC) are studied and implemented in order to cluster Web services into a certain number of clusters based on their functionalities. Search engines or matchmakers use this step as a precursor by categorizing Web services based on their functionality in Web services sources.
2.1. Layer 1: Web Services Description and Data Preprocessing
2.2. Layer 2: Word Representation, Embedding, and Transforming
- Preprocessing and conversion of text into a suitable format for training: the collected Web services corpus include 918 Web services documents utilized for training purposes. The documents need to go through preprocessing steps, which include tokenization and removal of accent marks, stopwords, punctuation, and white space. Then, the lowercase and lemmatization steps are applied. Training a Word2Vec model requires that every Web service document is represented as a list and every list contain a list of tokens/words in that document. This requirement leads to the conversion of all text into a list of lists for each token in the collected corpus.
- Choosing the right Word2Vec models: the choice of the right training algorithm is a task-specific decision [19]. The Word2Vec algorithm has two models for representing words as a dense vector, the CBOW (Continuous Bag of Words) and skip-gram models [20]. Both models use shallow neural networks to map words to the target variable considering the context. We selected the skip-gram architecture to train our model based on the fact that we had a limited amount of text for training purposes. According to [19,20,21], the process of learning is faster for CBOW than for skip-gram, which takes a long time. Skip-gram works better for a small amount of training data due to its ability better represent rare words. As we had a small amount of text for training purposes, skip-gram was a better choice to train our model based on the collected corpus, despite the added time and resource restrictions.
- Setting up the learning hyperparameter configurations. We adjusted the following hyperparameters:
- Size: each word or token is represented as a dense vector, and the size of the vector is significant in the learning process. As we had limited data, the size of the vector was set to a smaller value. This was because there are only a few unique neighbors for any given word. We set the size of the vector as 50.
- Window: this is related to the maximum distance between the target word and its surrounding words (neighbors). The value of the window indicates the number of neighbors to the left and right of the target word. As such, considering our limited data a smaller window can result in words that are more closely related [20]. We selected value three as the window size for training the model.
- Minimum count: this is related to the frequency count of words, with uncommon words usually being unimportant. As our data had a small amount of text, we set the minimum count as one to allow all words to be considered when training the model.
2.3. Layer 3: Syntactic Similarity
2.4. Layer 4: Semantic Similarity
2.5. Layer 5: Web Services Clustering
3. Performance Evaluation and Analysis
3.1. Datasets
3.2. Experimental Environment
3.3. Evaluation Metrics
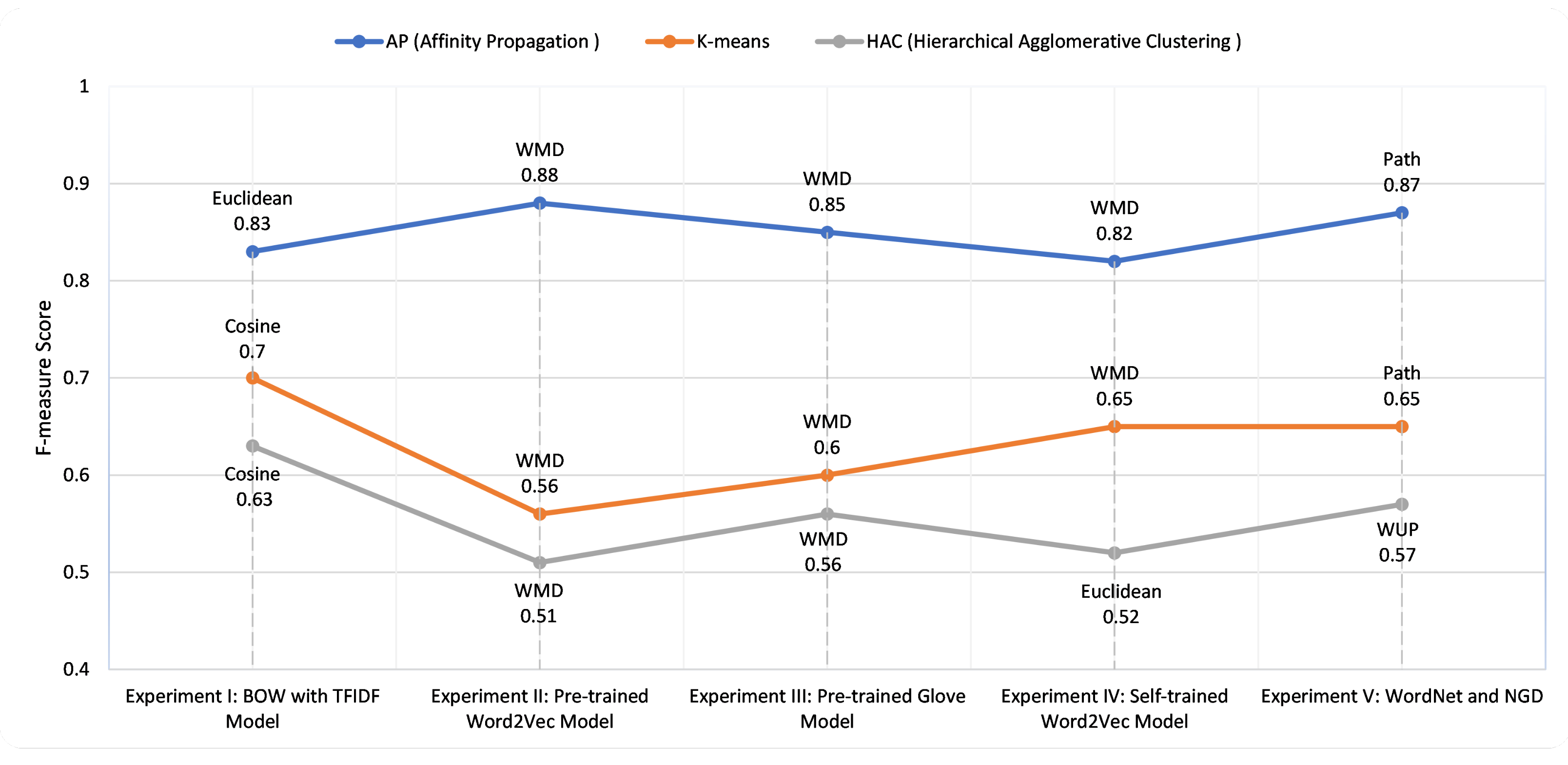
3.4. Experiments and Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Crasso, M.; Zunino, A.; Campo, M. Easy web service discovery: A query-by-example approach. Sci. Comput. Program. 2008, 71, 144–164. [Google Scholar] [CrossRef] [Green Version]
- Klusch, M. Service Discovery. In Encyclopedia of Social Networks and Mining (ESNAM); Springer: Berlin/Heidelberg, Germany, 2014; pp. 1707–1717. [Google Scholar] [CrossRef]
- Grefenstette, G. Tokenization. In Syntactic Wordclass Tagging; Number October, Springer: Dordrecht, The Netherlands, 1999; pp. 117–133. [Google Scholar] [CrossRef]
- Obidallah, W.J.; Ruhi, U.; Raahemi, B. Clustering and Association Rules for Web Service Discovery and Recommendation: A Systematic Literature Review. SN Comput. Sci. 2020, 1, 27. [Google Scholar] [CrossRef] [Green Version]
- Obidallah, W.J.; Ruhi, U.; Raahemi, B. Current Landscape of Web Service Discovery: A Typology Based on Five Characteristics. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016; pp. 678–683. [Google Scholar] [CrossRef]
- Obidallah, W.J.; Raahemi, B. A Taxonomy to Characterize Web Service Discovery Approaches, Looking at Five Perspectives. In Proceedings of the 2016 IEEE Symposium on Service-Oriented System Engineering (SOSE), Oxford, UK, 29 March–2 April 2016; pp. 458–459. [Google Scholar] [CrossRef]
- Richardson, L. Beautiful Soup Documentation. 2007. Available online: https://buildmedia.readthedocs.org/media/pdf/beautiful-soup-4/latest/beautiful-soup-4.pdf (accessed on 1 April 2022).
- Rasmussen, E. Stoplists. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 2794–2796. [Google Scholar] [CrossRef]
- Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the COLING/ACL on Interactive Presentation Sessions; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 69–72. Available online: https://dl.acm.org/doi/10.3115/1225403.1225421 (accessed on 1 April 2022).
- Stanford-University. Stemming and Lemmatization. 2008. Available online: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html (accessed on 1 April 2022).
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Almeida, F.; Xexéo, G. Word Embeddings: A Survey. arXiv 2019, arXiv:1901.09069. [Google Scholar]
- Yan, J. Text Representation. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 3069–3072. [Google Scholar] [CrossRef]
- De Boom, C.; Van Canneyt, S.; Demeester, T.; Dhoedt, B. Representation learning for very short texts using weighted word embedding aggregation. Pattern Recognit. Lett. 2016, 80, 150–156. [Google Scholar] [CrossRef] [Green Version]
- Gudivada, V.N.; Rao, D.L.; Gudivada, A.R. Chapter 11—Information Retrieval: Concepts, Models, and Systems. In Handbook of Statistics: Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications; Gudivada, V.N., Rao, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Volume 38, pp. 331–401. [Google Scholar] [CrossRef]
- Wikimedia. Wikimedia Downloads. 2005. Available online: https://dumps.wikimedia.org/backup-index.html (accessed on 1 April 2022).
- Parker, R.; Graff, D.; Kong, J.; Chen, K.; Maeda, K. Gigaword. In English Gigaword Fifth Edition—Linguistic Data Consortium; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- Crawl, C. Common Crawl. Available online: https://commoncrawl.org/ (accessed on 1 April 2022).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, 1–12. [Google Scholar] [CrossRef]
- Camacho-Collados, J.; Pilehvar, M.T. From word to sense embeddings: A survey on vector representations of meaning. J. Artif. Intell. Res. 2018, 63, 743–788. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Kamber, M.; Pei, J. Getting to Know Your Data. In Data Mining; Elsevier: Amsterdam, The Netherlands, 2012; pp. 39–82. [Google Scholar] [CrossRef]
- Kusner, M.J.; Sun, Y.; Kolkin, N.I.; Weinberger, K.Q. From Word Embeddings to Document Distances. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 957–966. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitanyi, P.M. The Google Similarity Distance. IEEE Trans. Knowl. Data Eng. 2007, 19, 370–383. [Google Scholar] [CrossRef]
- Vitányi, P.M.; Cilibrasi, R.L.; Vitanyi, P.M.B. Normalized web distance and word similarity. arXiv 2009, arXiv:0905.4039. [Google Scholar]
- Wu, Z.; Palmer, M. Verbs semantics and lexical selection. In Proceedings of the 32nd annual meeting on Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 1994; pp. 133–138. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by Passing Messages Between Data Points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Hierarchical Clustering. In Cluster Analysis; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011; pp. 71–110. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Gensim. Gensim: Topic Modelling for Humans. Available online: https://radimrehurek.com/gensim/ (accessed on 1 April 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Algorithm | Vector Size | Window | Vocabulary Size |
|---|---|---|---|---|
| English Wikipedia | Word2Vec | 300 | 3 | 249,212 |
| ENC3 Common Crawl | GloVe | 300 | 10 | 2,000,000 |
| Web Services Documents | Word2Vec | 50 | 3 | 5563 |
| Clustering Algorithms | AP | HAC | K-Means | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Syntactic Similarity | Cosine | Euclidean | Minkowski | WMD | Cosine | Euclidean | Minkowski | WMD | Cosine | Euclidean | Minkowski | WMD |
| First Experiment: BOW with TFIDF Model | ||||||||||||
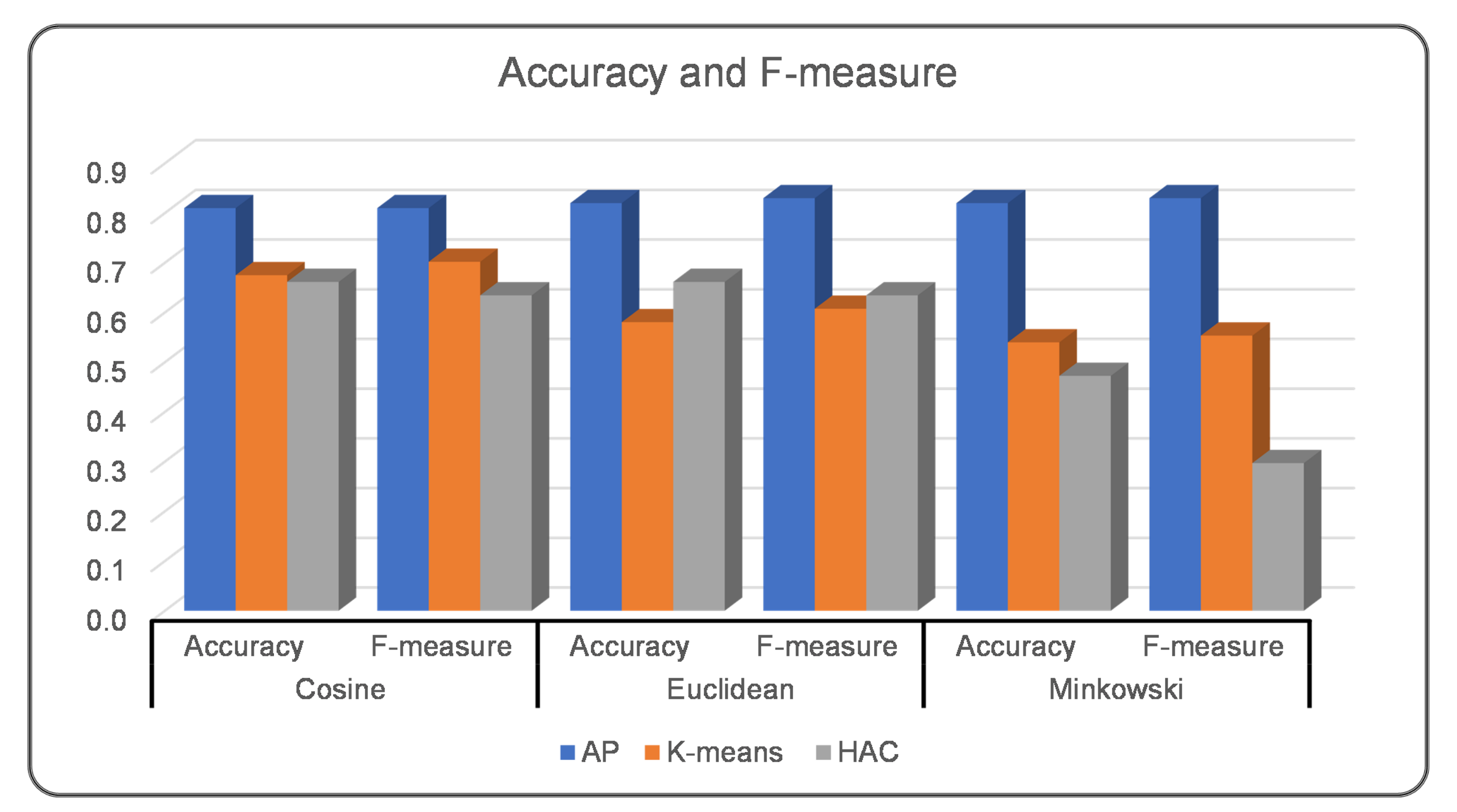
| Accuracy | 0.81 | 0.82 | 0.82 | 0.66 | 0.66 | 0.47 | 0.68 | 0.58 | 0.54 | |||
| Precision | 0.83 | 0.84 | 0.84 | 0.81 | 0.81 | 0.89 | 0.86 | 0.77 | 0.65 | |||
| Recall | 0.81 | 0.82 | 0.82 | 0.66 | 0.66 | 0.46 | 0.68 | 0.58 | 0.54 | |||
| F-measure | 0.81 | 0.83 | 0.83 | 0.63 | 0.63 | 0.30 | 0.70 | 0.61 | 0.55 | |||
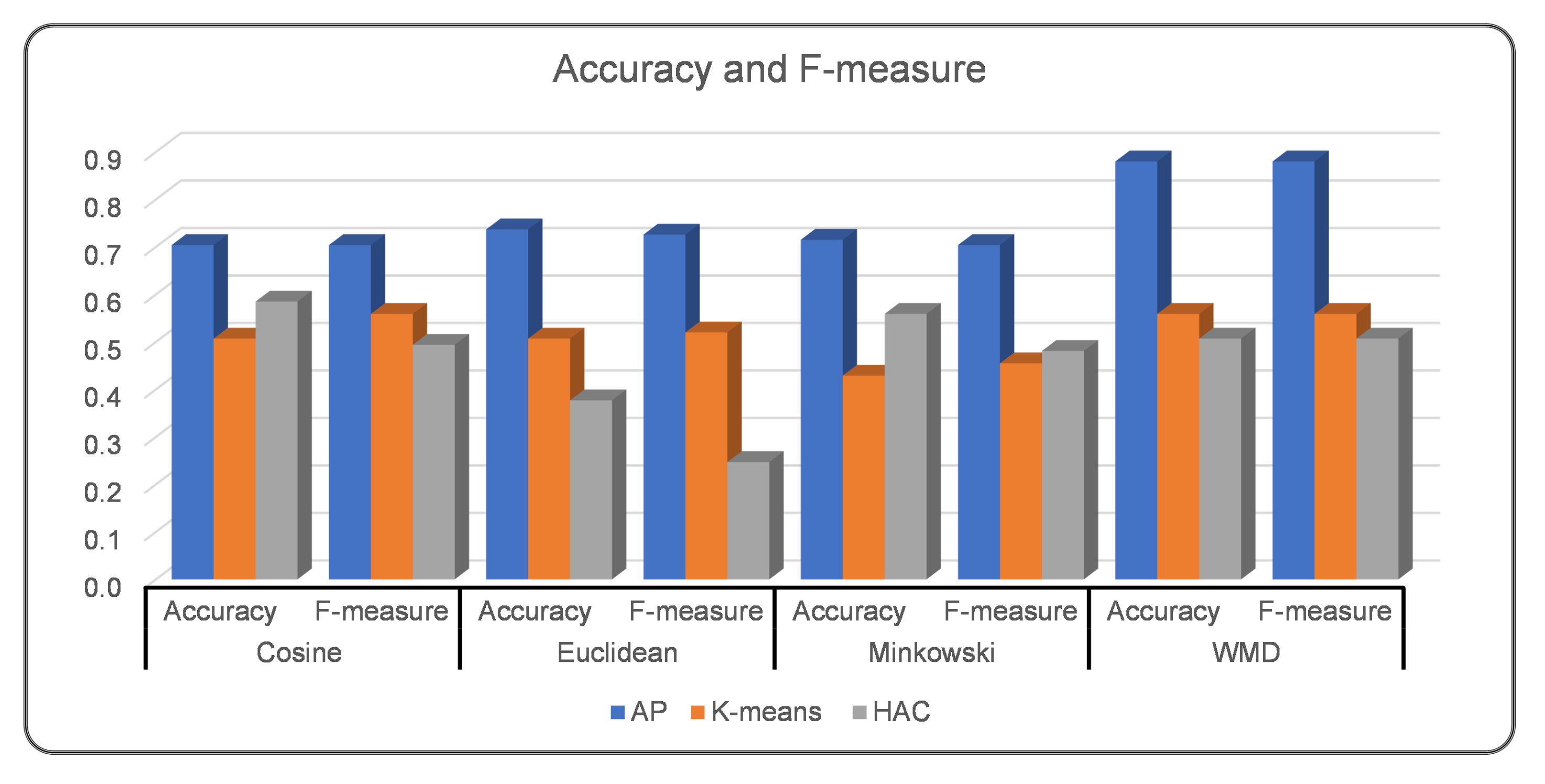
| Second Experiment: Pre-trained Word2Vec Model | ||||||||||||
| Accuracy | 0.70 | 0.74 | 0.72 | |0.88| | 0.59 | 0.38 | 0.56 | 0.51 | 0.51 | 0.51 | 0.43 | 0.56 |
| Precision | 0.76 | 0.78 | 0.76 | |0.91| | 0.70 | 0.68 | 0.70 | 0.61 | 0.73 | 0.70 | 0.57 | 0.73 |
| Recall | 0.70 | 0.74 | 0.72 | |0.88| | 0.59 | 0.38 | 0.56 | 0.51 | 0.51 | 0.51 | 0.43 | 0.56 |
| F-measure | 0.70 | 0.73 | 0.70 | |0.88| | 0.49 | 0.25 | 0.48 | 0.51 | 0.56 | 0.52 | 0.46 | 0.56 |
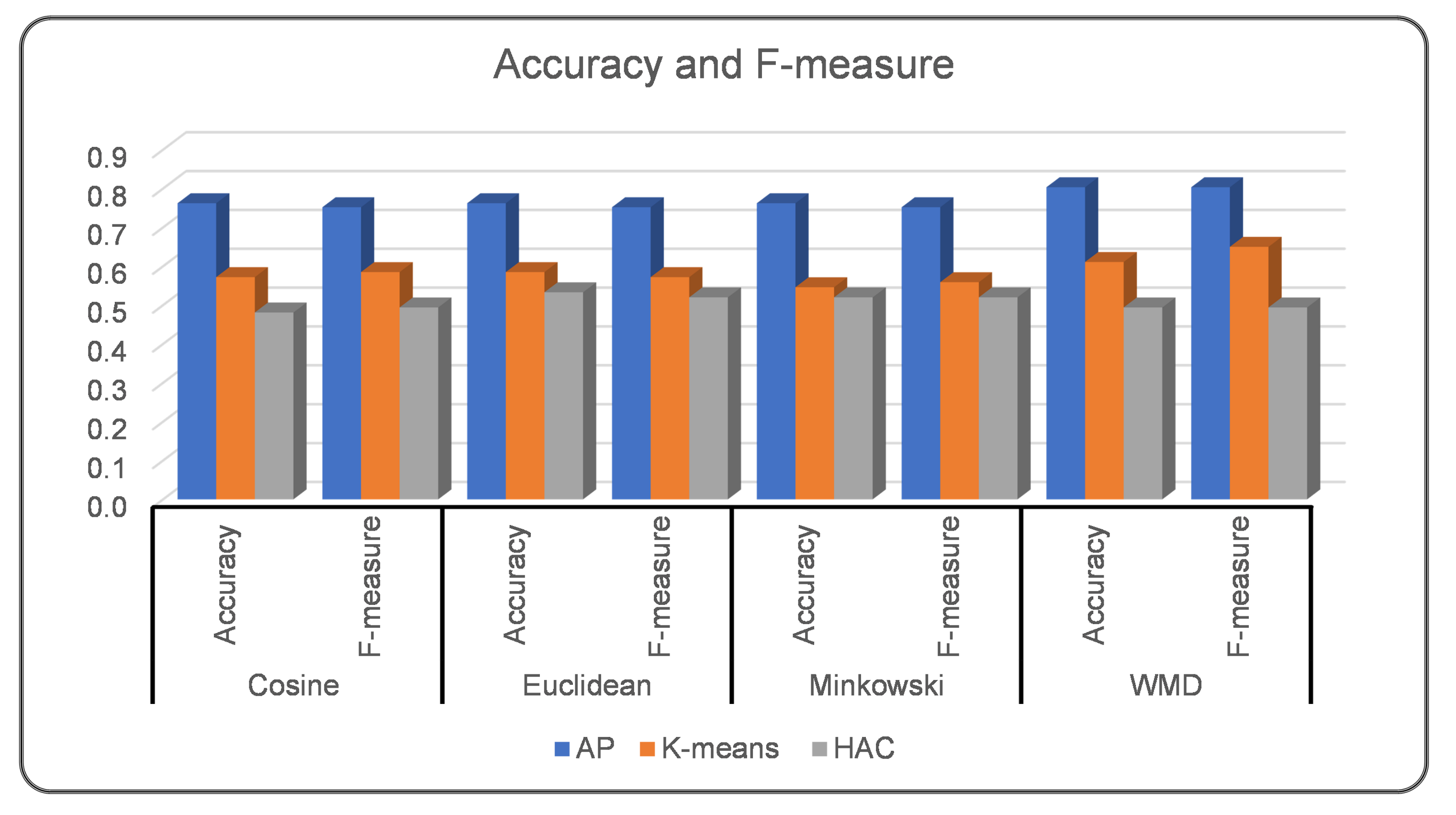
| Third Experiment: Pre-trained Glove Model | ||||||||||||
| Accuracy | 0.64 | 0.74 | 0.74 | 0.85 | 0.48 | 0.42 | 0.52 | 0.57 | 0.43 | 0.42 | 0.43 | 0.57 |
| Precision | 0.73 | 0.79 | 0.79 | 0.88 | 0.59 | 0.53 | 0.62 | 0.77 | 0.81 | 0.81 | 0.81 | 0.61 |
| Recall | 0.64 | 0.74 | 0.74 | 0.85 | 0.48 | 0.42 | 0.52 | 0.57 | 0.43 | 0.42 | 0.43 | 0.56 |
| F-measure | 0.65 | 0.74 | 0.74 | 0.85 | 0.48 | 0.44 | 0.53 | 0.60 | 0.31 | 0.29 | 0.29 | 0.56 |
| Fourth Experiment: Self-trained Word2Vec Model | ||||||||||||
| Accuracy | 0.76 | 0.76 | 0.76 | 0.80 | 0.48 | 0.53 | 0.52 | 0.49 | 0.57 | 0.59 | 0.55 | 0.61 |
| Precision | 0.80 | 0.82 | 0.81 | 0.82 | 0.60 | 0.61 | 0.61 | 0.60 | 0.73 | 0.68 | 0.72 | 0.81 |
| Recall | 0.76 | 0.76 | 0.76 | 0.80 | 0.48 | 0.53 | 0.52 | 0.49 | 0.57 | 0.59 | 0.55 | 0.61 |
| F-measure | 0.75 | 0.75 | 0.75 | 0.80 | 0.49 | 0.52 | 0.52 | 0.49 | 0.59 | 0.57 | 0.56 | 0.65 |
| Fifth Experiment: WordNet and NGD | ||||||||||||
| Semantic Similarity | Path | WUP | NGD | Path | WUP | NGD | Path | WUP | NGD | |||
| Accuracy | |0.87| | 0.73 | 0.83 | 0.55 | 0.58 | 0.58 | 0.65 | 0.50 | 0.53 | |||
| Precision | |0.89| | 0.78 | 0.84 | 0.55 | 0.67 | 0.75 | 0.84 | 0.67 | 0.71 | |||
| Recall | |0.85| | 0.72 | 0.82 | 0.55 | 0.58 | 0.58 | 0.65 | 0.50 | 0.53 | |||
| F-measure | |0.87| | 0.73 | 0.82 | 0.48 | 0.57 | 0.55 | 0.65 | 0.53 | 0.54 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
J. Obidallah, W.; Raahemi, B.; Rashideh, W. Multi-Layer Web Services Discovery Using Word Embedding and Clustering Techniques. Data 2022, 7, 57. https://doi.org/10.3390/data7050057
J. Obidallah W, Raahemi B, Rashideh W. Multi-Layer Web Services Discovery Using Word Embedding and Clustering Techniques. Data. 2022; 7(5):57. https://doi.org/10.3390/data7050057
Chicago/Turabian StyleJ. Obidallah, Waeal, Bijan Raahemi, and Waleed Rashideh. 2022. "Multi-Layer Web Services Discovery Using Word Embedding and Clustering Techniques" Data 7, no. 5: 57. https://doi.org/10.3390/data7050057
APA StyleJ. Obidallah, W., Raahemi, B., & Rashideh, W. (2022). Multi-Layer Web Services Discovery Using Word Embedding and Clustering Techniques. Data, 7(5), 57. https://doi.org/10.3390/data7050057