
Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus


Abstract
:1. Introduction
- To build annotated datasets for the mentions of hate crime types and the motivation(s) behind committing such hate crimes.
- The corpus is freely available to be used by the research community and will serve as a resource to train and evaluate text-mining (TM) tools, which in turn, can be used to automatically extract mentions of hate crimes and motivation. The TM tools can be used for the prediction of hate crime events and for better surveillance and mitigation efforts against discrimination. To the best of our knowledge, this is the first study pertaining to the investigation of Twitter data for hate crimes and the motivation(s) behind them.
- To create a hate crime and motivation vocabulary list specifically relating to hate crimes and their motivation(s). The vocabulary list is freely available and can be used as a resource for TM techniques and named entity recognition methods.
2. Related Work
3. Material and Methods
3.1. Corpus Construction
3.2. Annotation Process
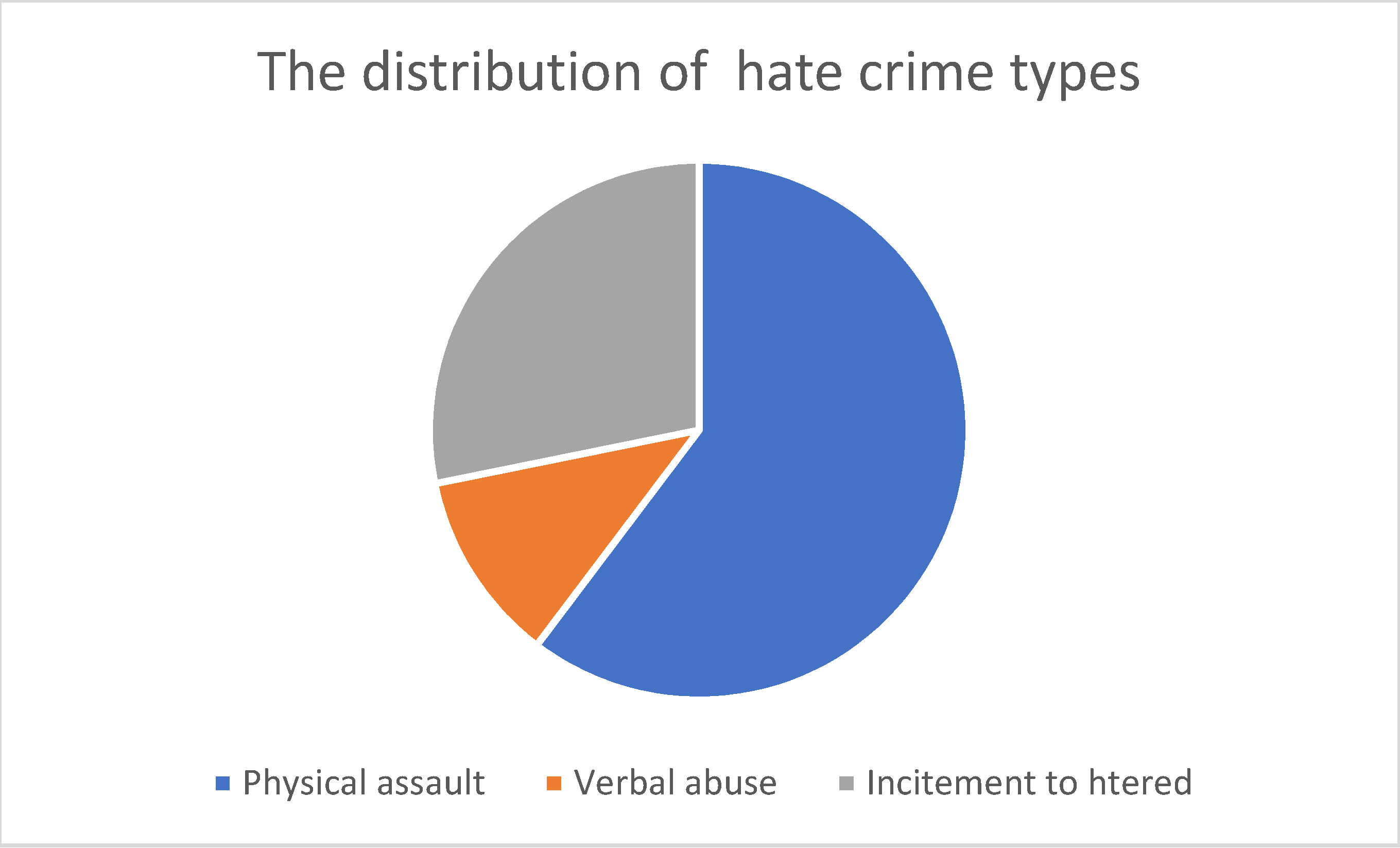
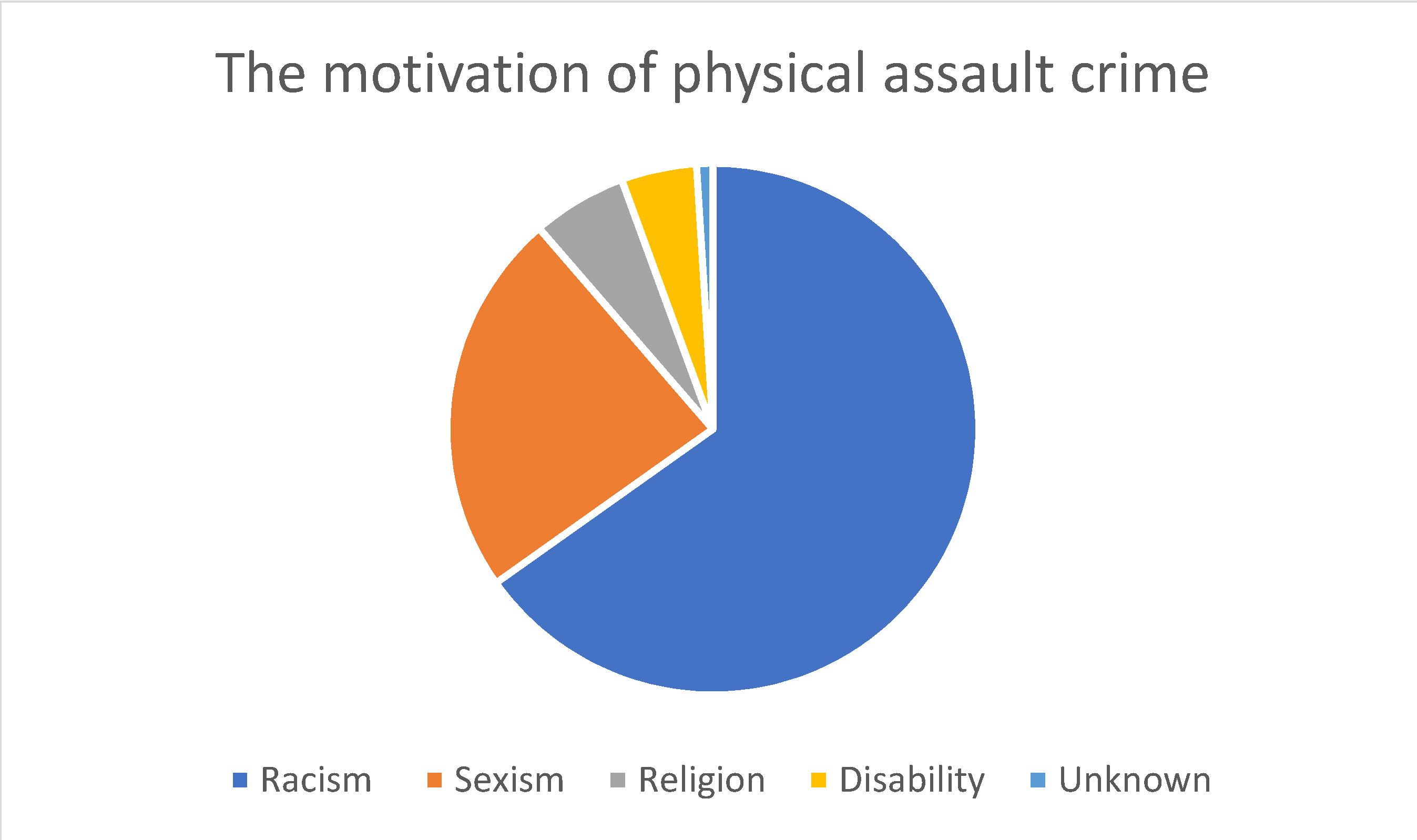
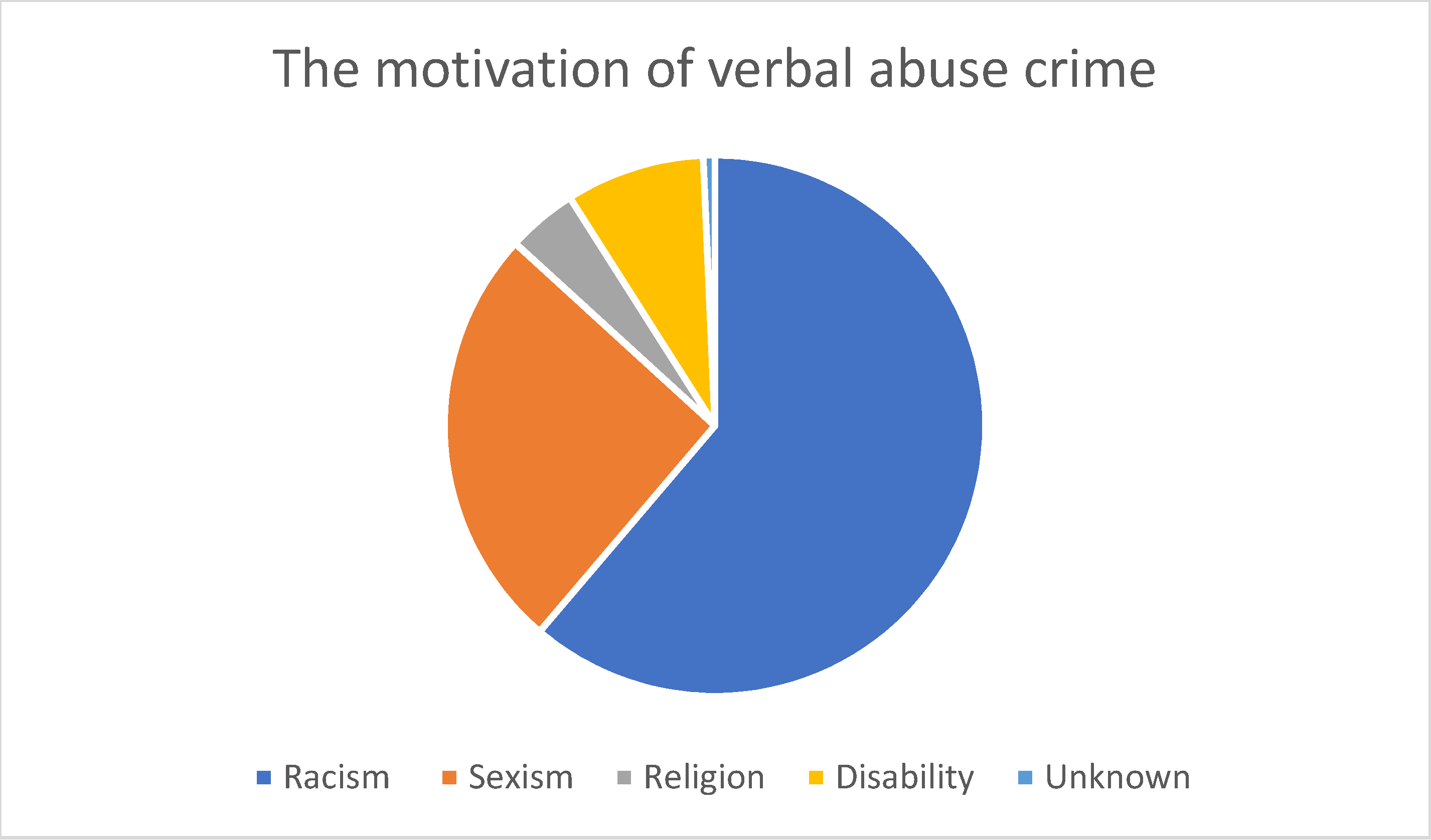
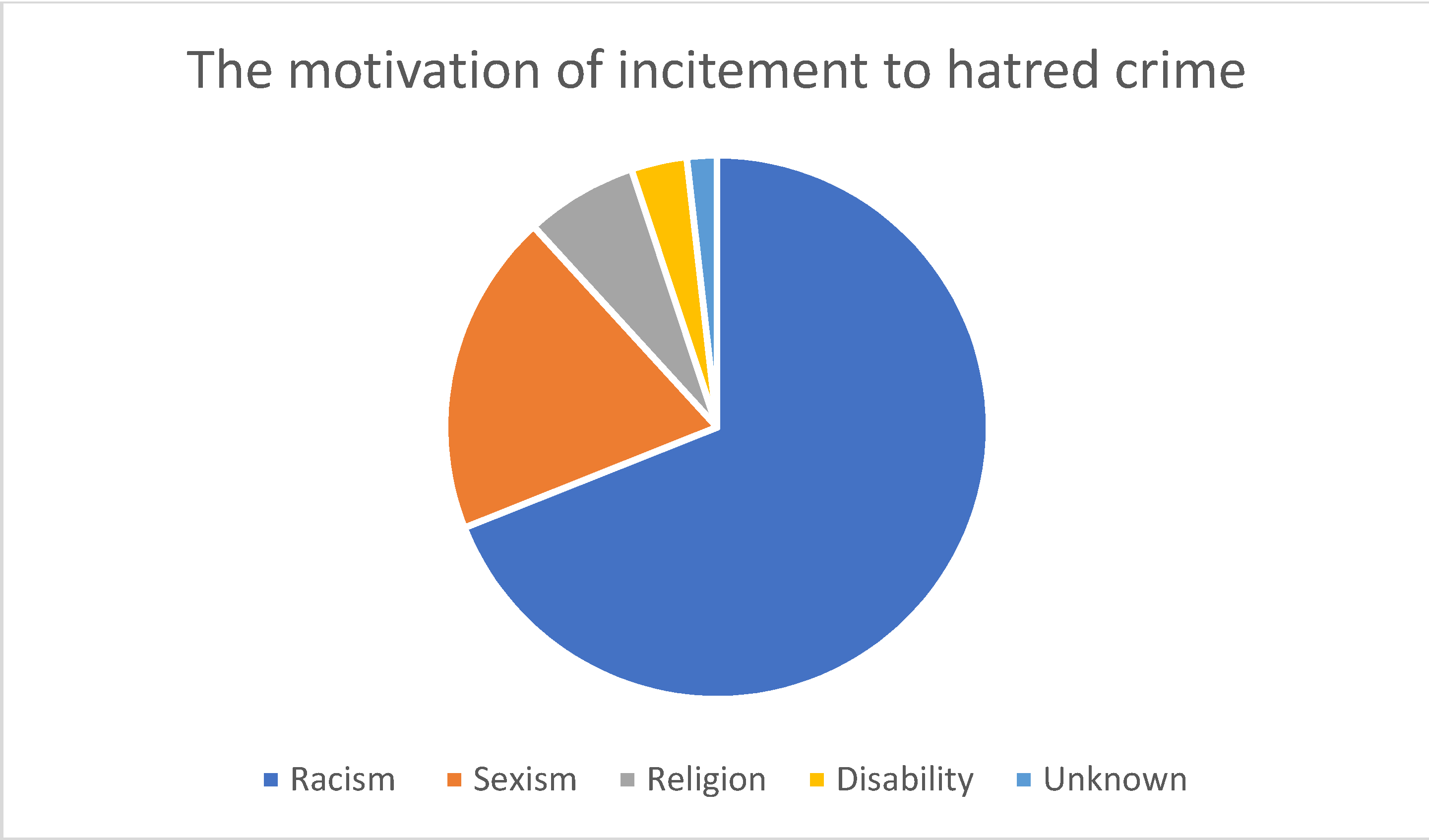
4. Results and Discussion
“She was killed by her brother in a hate crime. There is little doubt killing her because of her gender”.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Chen, L.; Thirunarayan, K.; Sheth, A.P. Cursing in English on Twitter. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; ACM: New York, NY, USA, 2014; pp. 415–425. [Google Scholar]
- Alorainy, W.; Burnap, P.; Liu, H.; Javed, A.; Williams, M.L. Suspended Accounts: A Source of Tweets with Disgust and Anger Emotions for Augmenting Hate Speech Data Sample. In Proceedings of the 2018 International Conference on Machine Learning and Cybernetics (ICMLC), Chengdu, China, 15–18 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 581–586. [Google Scholar]
- Bojarska, K. The Dynamics of Hate Speech and Counter Speech in the Social Media Summary of Scientific Research; Centre for Internet and Human Rights: Frankfurt, Germany, 2018. [Google Scholar]
- Sticca, F. Bullying Goes Online: Definition, Risk Factors, Consequences, and Prevention of (Cyber) Bullying; University of Zurich: Zürich, Switzerland, 2013. [Google Scholar]
- Hinduja, S.; Patchin, J.W. Connecting adolescent suicide to the severity of bullying and cyberbullying. J. Sch. Violence 2019, 18, 333–346. [Google Scholar] [CrossRef]
- Robertson, C.; Mele, C.; Tavernise, S. 11 Killed in Synagogue Massacre; Suspect Charged with 29 Counts. The New York Times. Available online: https://www.nytimes.com/2018/10/27/us/active-shooter-pittsburgh-synagogue-shooting.html(accessed on 20 May 2022).
- MacAvaney, S.; Yao, H.-R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef] [PubMed]
- Williams, M.L.; Burnap, P.; Sloan, L. Crime sensing with big data: The affordances and limitations of using open-source communications to estimate crime patterns. Br. J. Criminol. 2017, 57, 320–340. [Google Scholar] [CrossRef] [Green Version]
- Williams, M.L.; Burnap, P.; Javed, A.; Liu, H.; Ozalp, S. Hate in the machine: Anti-Black and anti-Muslim social media posts as predictors of offline racially and religiously aggravated crime. Br. J. Criminol. 2020, 60, 93–117. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Ojha, A.K.; Malmasi, S.; Zampieri, M. Benchmarking Aggression Identification in Social Media. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1–11. [Google Scholar]
- Relia, K.; Li, Z.; Cook, S.H.; Chunara, R. Race, Ethnicity and National Origin-Based Discrimination in Social Media and Hate Crimes Across 100 US Cities. In Proceedings of the International AAAI Conference on Web and Social Media, Munich, Germany, 11–14 June 2019; pp. 417–427. [Google Scholar]
- Kwok, I.; Wang, Y. Locate the Hate: Detecting Tweets Against Blacks. In Proceedings of the AAAI’13: Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; ACM: New York, NY, USA, 2013; pp. 1621–1622. [Google Scholar]
- Burnap, P.; Williams, M.L. Cyber hate speech on twitter: An application of machine classification and statistical modeling for policy and decision making. Policy Internet 2015, 7, 223–242. [Google Scholar] [CrossRef] [Green Version]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate Speech Detection with Comment Embeddings. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; ACM: New York, NY, USA, 2015; pp. 29–30. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Federal Ministry of Education and Research: Bonn, Germany, 2017; pp. 512–515. [Google Scholar]
- Malmasi, S.; Zampieri, M. Detecting hate speech in social media. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017, Varna, Bulgaria, 2–8 September 2017; INCOMA Ltd.: Seville, Spain, 2017; pp. 467–472. [Google Scholar]
- Malmasi, S.; Zampieri, M. Challenges in discriminating profanity from hate speech. J. Exp. Theor. Artif. Intell. 2018, 30, 187–202. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.-M.; Jun, K.-S.; Zhu, X.; Bellmore, A. Learning from Bullying Traces in Social Media. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; ACM: New York, NY, USA, 2012; pp. 656–666. [Google Scholar]
- Dadvar, M.; Trieschnigg, D.; Ordelman, R.; de Jong, F. Improving Cyberbullying Detection with User Context. In Proceedings of the ECIR 2013: Advances in Information Retrieval, Moscow, Russia, 24–27 March 2013; Serdyukov, P., Braslavski, P., Kuznetsov, S.O., Kamps, J., Rüger, S., Agichtein, E., Segalovich, I., Yilmaz, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 693–696. [Google Scholar]
- Fortuna, P.; Ferreira, J.; Pires, L.; Routar, G.; Nunes, S. Merging Datasets for Aggressive Text Identification. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 128–139. [Google Scholar]
- Georgakopoulos, S.V.; Tasoulis, S.K.; Vrahatis, A.G.; Plagianakos, V.P. Convolutional Neural Networks for Toxic Comment Classification. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; ACM: New York, NY, USA, 2018; p. 35. [Google Scholar]
- King, R.D.; Sutton, G.M. High times for hate crimes: Explaining the temporal clustering of hate-motivated offending. Criminology 2013, 51, 871–894. [Google Scholar] [CrossRef]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 88–93. [Google Scholar]
- Kumar, R.; Bhanodai, G.; Pamula, R.; Chennuru, M.R. TRAC-1 Shared Task on Aggression Identification: IIT (ISM)@ COLING’18. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 58–65. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Debora, N.; Patti, V.; Pardo, F.M.R.; Rosso, P.; Sanguinetti, M. Semeval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 54–63. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the Type and Target of Offensive Posts in Social Media. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technology (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1415–1420. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Semeval-2019 task 6: Identifying and categorizing offensive language in social media (offenseval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 75–86. [Google Scholar]
- Burnap, P.; Williams, M.L. Us and them: Identifying cyber hate on Twitter across multiple protected characteristics. EPJ Data Sci. 2016, 5, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hashtagify. Search And Find The Best Twitter Hashtags. Available online: https://hashtagify.me/ (accessed on 15 March 2022).
- Training Data for AI, ML with Human Empowered Automation | Cogit. Available online: https://www.cogitotech.com/about-us (accessed on 15 March 2022).
- Hripcsak, G.; Rothschild, A.S. Agreement, the f-measure, and reliability in information retrieval. J. Am. Med. Inform. Assoc. 2005, 12, 296–298. [Google Scholar] [CrossRef] [PubMed]
- Thompson, P.; Iqbal, S.A.; McNaught, J.; Ananiadou, S. Construction of an annotated corpus to support biomedical information extraction. BMC Bioinform. 2009, 10, 349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alnazzawi, N.; Thompson, P.; Ananiadou, S. Building a Semantically Annotated Corpus for Congestive Heart and Renal Failure From Clinical Records and the Literature. In Proceedings of the 5th International Workshop on Health Text Mining and Information Analysis (Louhi), Gothenburg, Sweden, 27–30 April 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 69–74. [Google Scholar]
- Thompson, P.; Daikou, S.; Ueno, K.; Batista-Navarro, R.; Tsujii, J.i.; Ananiadou, S. Annotation and detection of drug effects in text for pharmacovigilance. J. Cheminform. 2018, 10, 37. [Google Scholar] [CrossRef] [PubMed]
- Alnazzawi, N. Building a semantically annotated corpus for chronic disease complications using two document types. PLoS ONE 2021, 16, e0247319. [Google Scholar] [CrossRef] [PubMed]
- Brants, T. Inter-Annotator Agreement for a German Newspaper Corpus. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC’00), Athens, Greece, 31 May–2 June 2000; European Language Resources Association (ELRA): Paris, France, 2000; pp. 1435–1439. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Source | Label | Domain | Annotation Type | Size |
|---|---|---|---|---|---|
| Davidson et al. [15] | hate offensive neither | Hate speech | Tweet-level | 25,000 | |
| Waseem and Hovy [23] | Racism Sexism both neither | Hate speech | Tweet level | 16,914 | |
| TRAC-1 [24] | Twitter and Facebook | Non-aggressive Covertly aggressive Overtly aggressive | Trolling, aggression, and cyberbullying | Tweet level | 15,000 |
| HatEval [25] | hate not hate aggressive not aggressive | Hate speech against immigrants or women | Tweet level | 19,600 | |
| OLID [26,27] | Offensive Not offensive | Offensive language | Tweet level | 14,100 |
| Class Type | Description |
|---|---|
| Hate crime type | Hate crime type refers to a type of crime classified by the FBI as one of the following:
|
| Motivation | Motivation refers to the reason for committing a hate crime, such as bias related to the following:
|
| Hate Crime Types | P | R | F-Score |
|---|---|---|---|
| Physical assault | 0.629275 | 0.858253 | 0.72614 |
| Verbal abuse | 0.592703 | 0.917593 | 0.720203 |
| Incitement to hatred | 0.624517 | 0.822034 | 0.709791 |
| Macro-averaged | 0.86596 | 0.718712 | 0.718712 |
| Motivation | P | R | F-Score |
|---|---|---|---|
| Racism | 0.617124 | 0.724858 | 0.666667 |
| Religion | 0.813397 | 0.564784 | 0.666667 |
| Sexism | 0.6272 | 0.711434 | 0.666667 |
| Disability | 0.665025 | 0.668317 | 0.666667 |
| Unknown | 0.399225 | 0.664516 | 0.498789 |
| Macro-averaged | 0.624394 | 0.666782 | 0.633091 |
| Dataset | Size | Text Genre | Topic | Labels | Annotation Level | #of Annotators | Agreement Measurement |
|---|---|---|---|---|---|---|---|
| HateMotiv | 5000 | Hate crimes and their motivation | Hate crime types:
| mention | 2 annotators | F-score 0.66 for hate crimes type 0.71 for the motivation of hate crimes | |
| Waseem and Hovy [23] | 16,914 | Hate speech | Racism Sexism Both Neither | Tweet | Crowdsource workers | Cohen’s kappa = 0.57 | |
| Davidson et al. [15] | 25,000 | Hate speech | Hate Offensive Neither | Tweet | Crowdsource workers | InterCoder-agreement score 92% | |
| HatEval [25] | 19,600 | Hate speech against immigrants or women | Hate Not hate Aggressive Not aggressive | Tweet | Crowdsource workers | Average IAA at 0.75 | |
| OLID [26,27] | 14,100 | Offensive language | Offensive Not offensive | Tweet | Crowdsource workers | IAA at 60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alnazzawi, N. Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus. Data 2022, 7, 69. https://doi.org/10.3390/data7060069
Alnazzawi N. Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus. Data. 2022; 7(6):69. https://doi.org/10.3390/data7060069
Chicago/Turabian StyleAlnazzawi, Noha. 2022. "Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus" Data 7, no. 6: 69. https://doi.org/10.3390/data7060069
APA StyleAlnazzawi, N. (2022). Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus. Data, 7(6), 69. https://doi.org/10.3390/data7060069