

Dataset of Public Objects in Uncontrolled Environment for Navigation Aiding



Abstract
1. Summary
2. Data Description
3. Methods
3.1. Target Object Selection
3.2. Model Selection
3.3. Data Pre-Processing
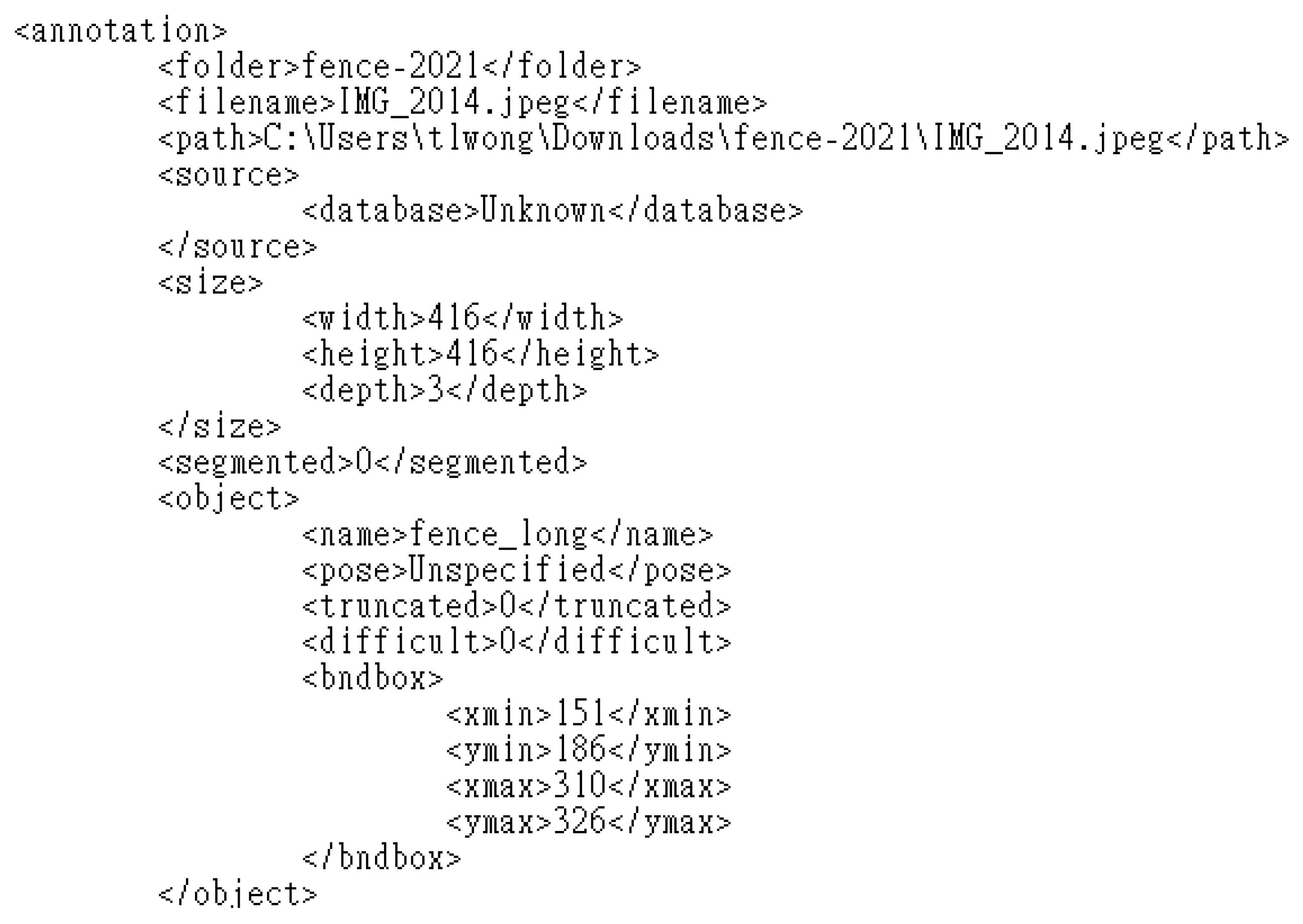
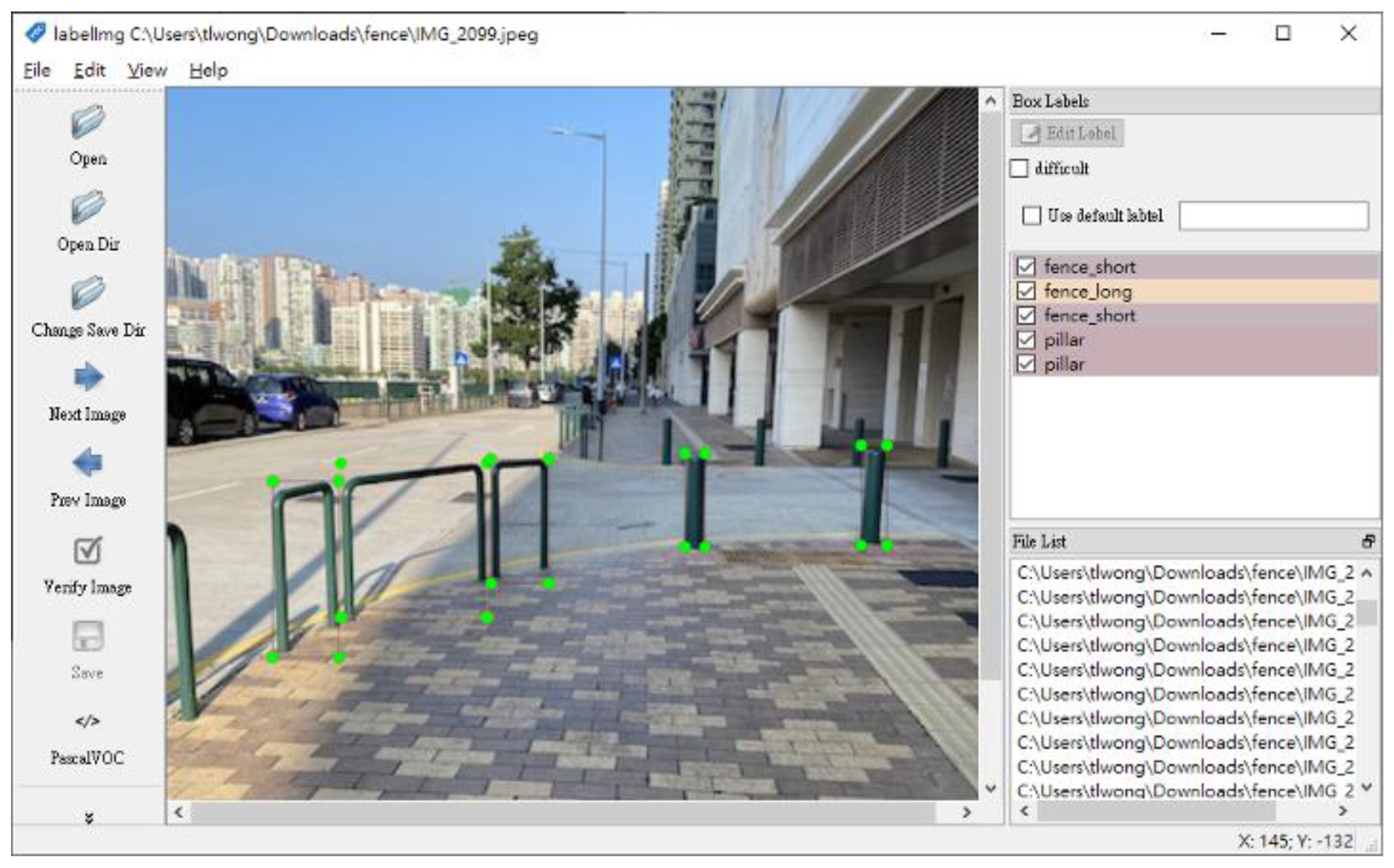
3.4. Labelling
3.5. Data Validation
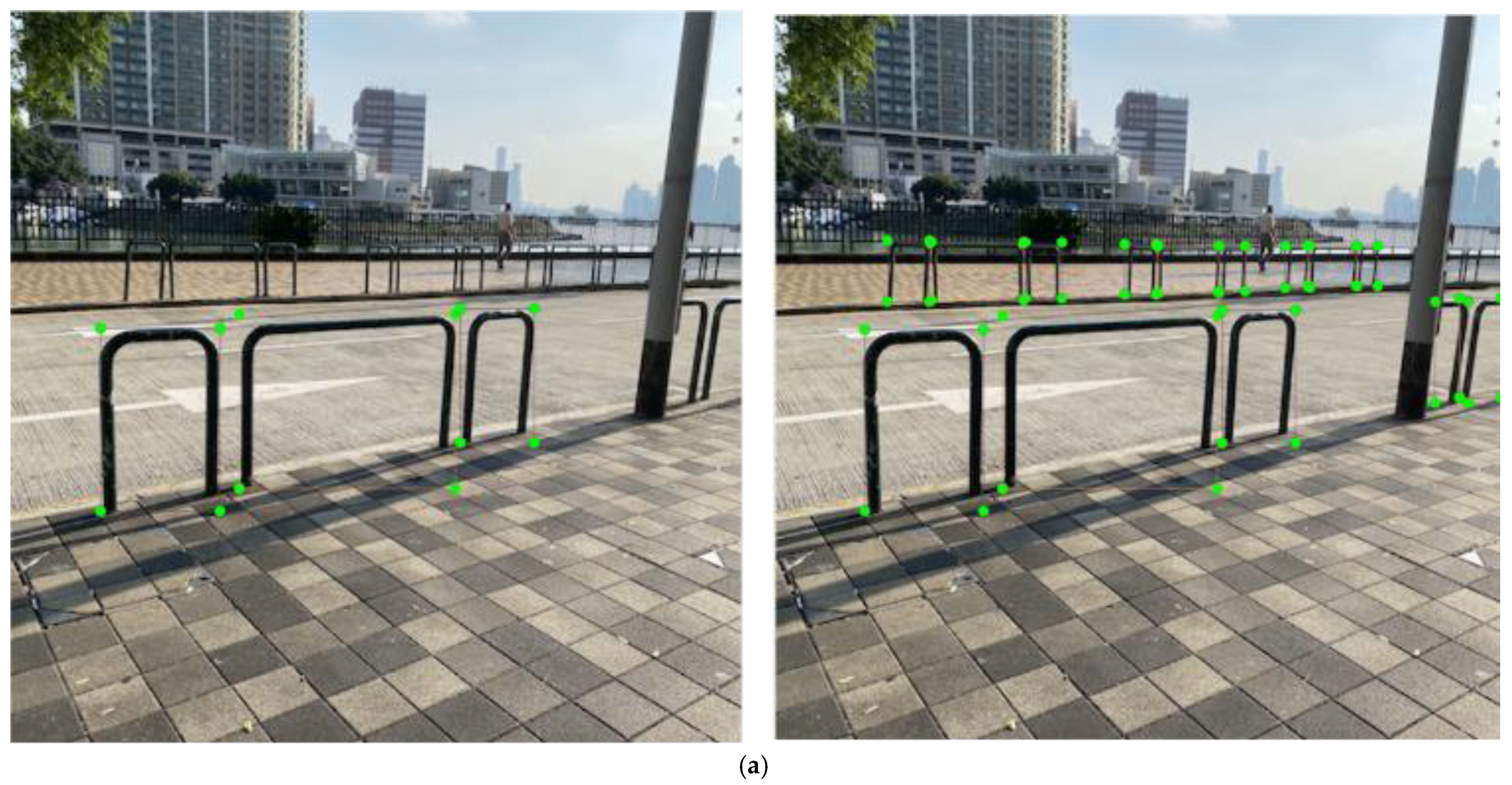
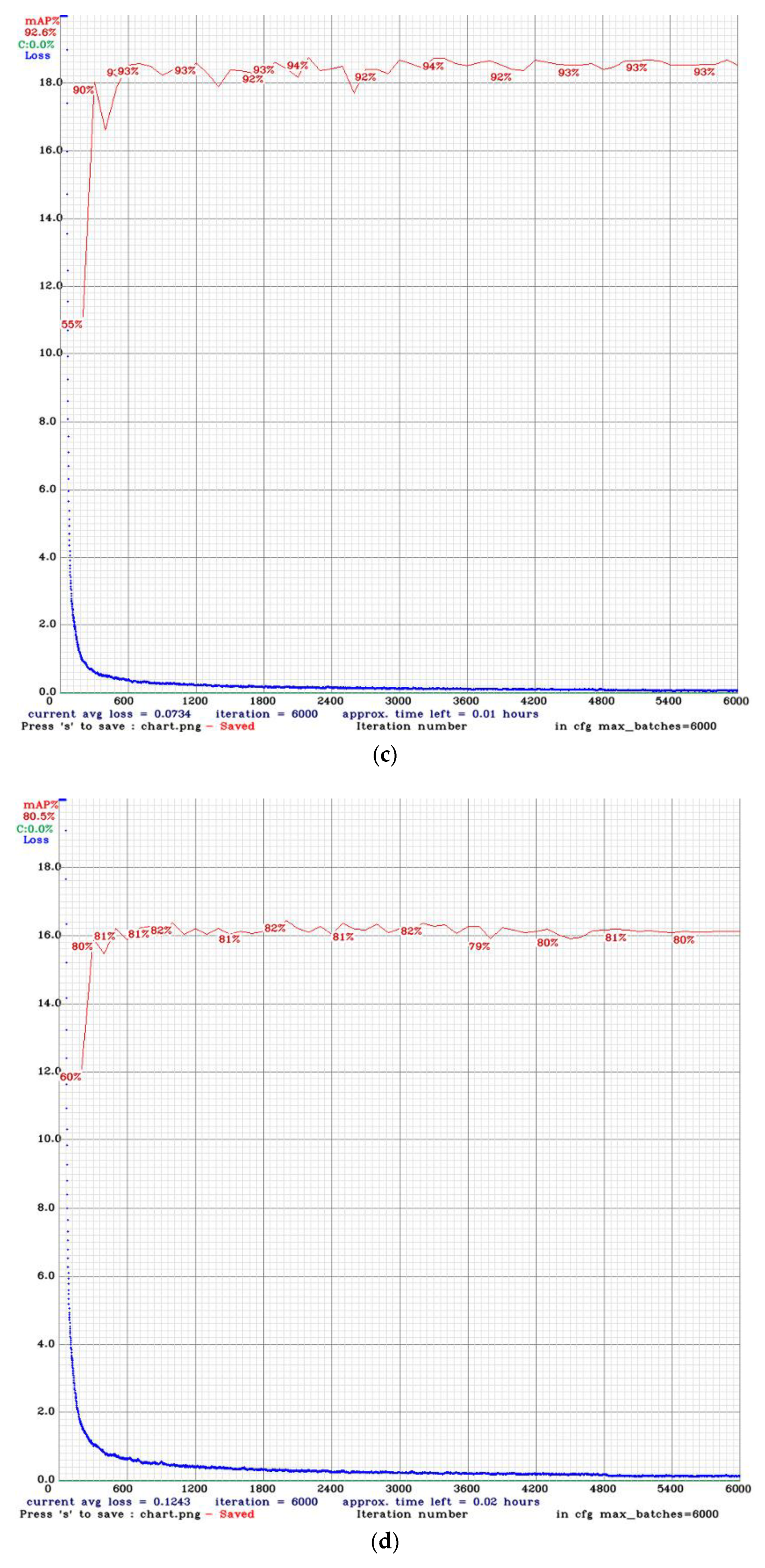
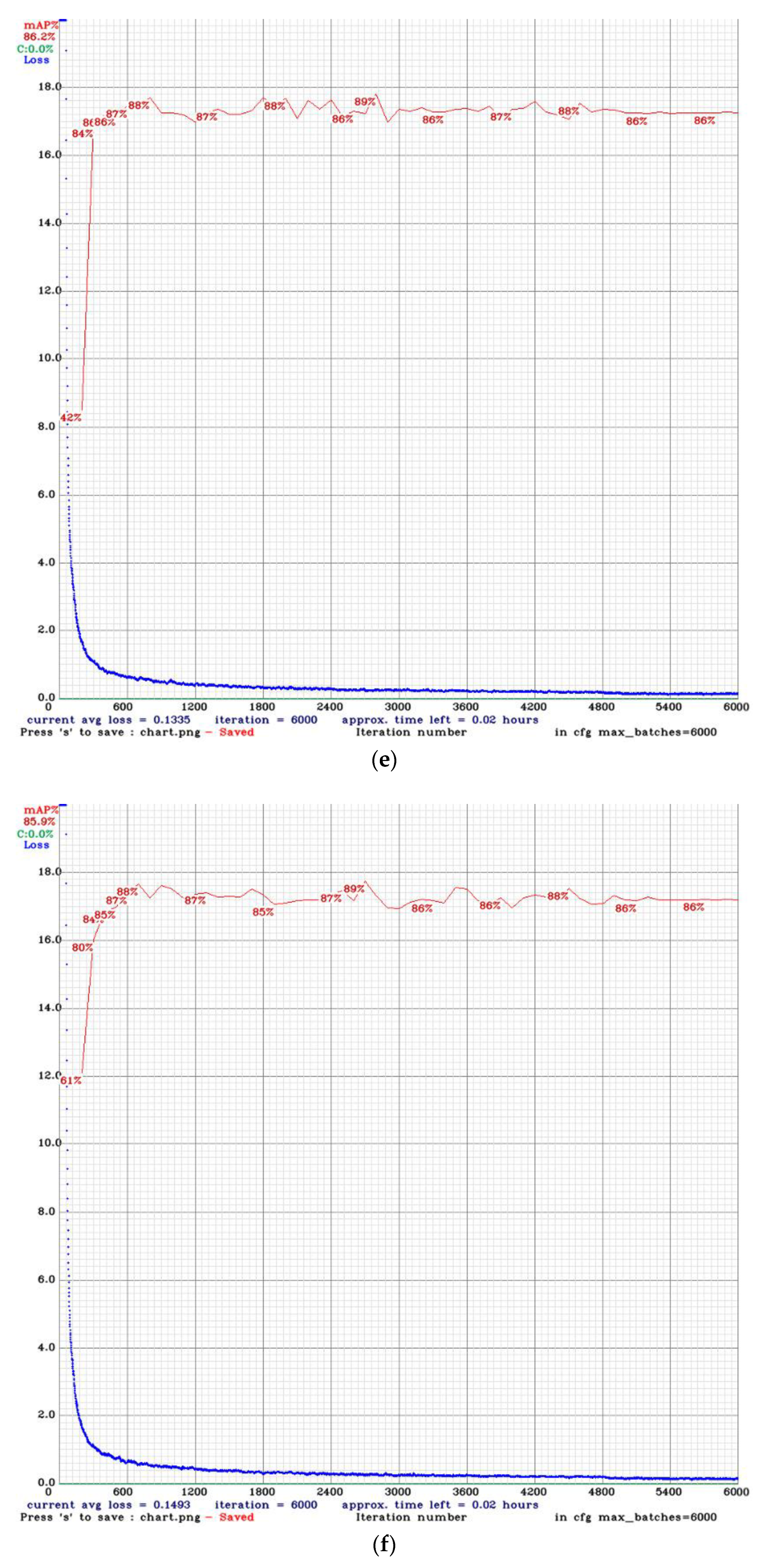
3.5.1. Comparison between Dataset Labelling Methods
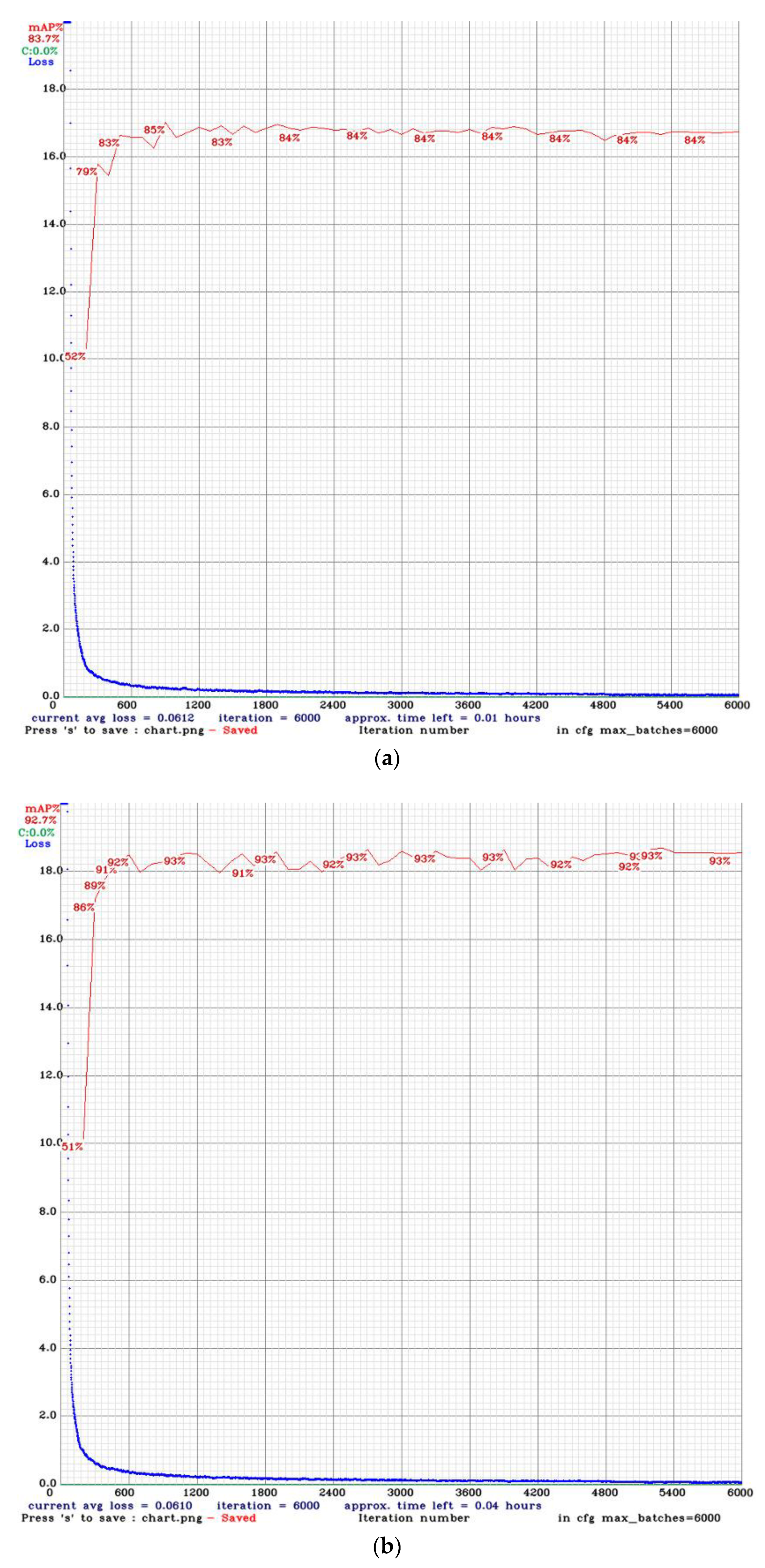
3.5.2. Comparison among Different Dataset Split Ratios
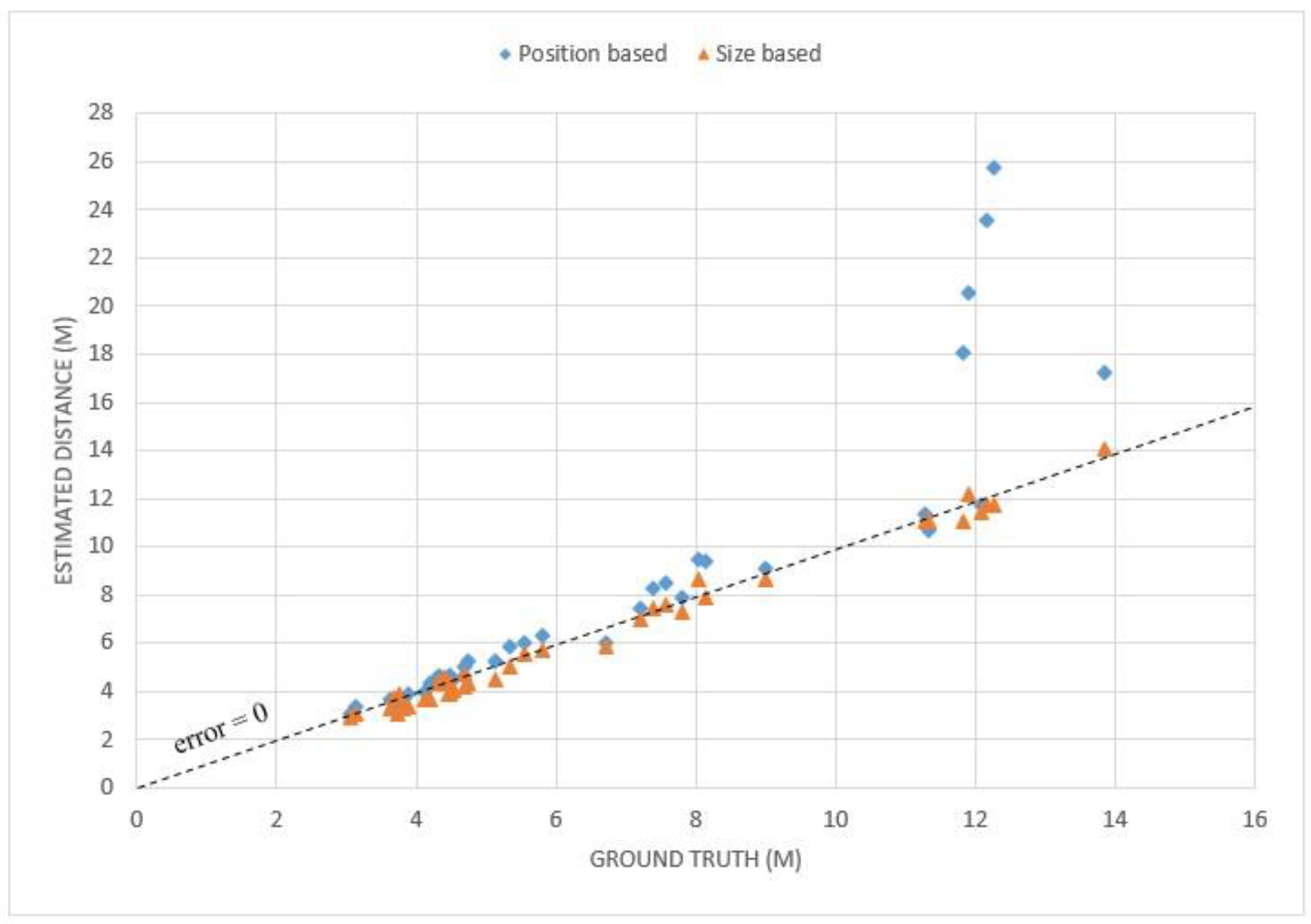
3.5.3. Distance Estimation Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bourne, R.R.A. Global Prevalence of Blindness and Distance and Near Vision Impairment in 2020: Progress towards the Vision 2020 Targets and What the Future Holds. Investig. Ophthalmol. Vis. Sci. 2020, 61, 2317. [Google Scholar]
- Rachburee, N.; Punlumjeak, W. An assistive model of obstacle detection based on deep learning: YOLOv3 for visually impaired people. Int. J. Electr. Comput. Eng. 2021, 11, 2088–8708. [Google Scholar] [CrossRef]
- Pehlivan, S.; Unay, M.; Akan, A. Designing an obstacle detection and alerting system for visually impaired people on sidewalks. In Proceedings of the 2019 Medical Technologies Congress (TIPTEKNO), Izmir, Turkey, 3–5 October 2019; pp. 1–4. [Google Scholar]
- Yadav, S.; Joshi, R.; Dutta, M.; Kiac, M.; Sikora, P. Fusion of object recognition and obstacle detection approach for assisting visually challenged person. In Proceedings of the 2020 43rd International Conference On Telecommunications And Signal Processing (TSP), Milan, Italy, 7–9 July 2020; pp. 537–540. [Google Scholar]
- Shimakawa, M.; Taguchi, I.; Okuma, C.; Kiyota, K. Smartphone application program of obstacle detection for visually impaired people. ICIC Express Lett. Part B Appl. Int. J. Res. Surv. 2019, 10, 219–226. [Google Scholar]
- Hussain, S.; Durrani, D.; Khan, A.; Atta, R.; Ahmed, L. In-door obstacle detection and avoidance system for visually impaired people. In Proceedings of the 2020 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, 29 October–1 November 2020; pp. 1–7. [Google Scholar]
- Masud, U.; Saeed, T.; Malaikah, H.; Islam, F.; Abbas, G. Smart assistive system for visually impaired people obstruction avoidance through object detection and classification. IEEE Access 2022, 10, 13428–13441. [Google Scholar] [CrossRef]
- Tse, R.; Mirri, S.; Tang, S.-K.; Pau, G.; Salomoni, P. Building an Italian-Chinese Parallel Corpus for Machine Translation from the Web. In Proceedings of the 6th EAI International Conference on Smart Objects and Technologies for Social Good, Antwerp, Belgium, 14–16 September 2020; ACM: New York, NY, USA, 2020. [Google Scholar]
- Cheok, S.M.; Hoi, L.M.; Tang, S.-K.; Tse, R. Crawling Parallel Data for Bilingual Corpus Using Hybrid Crawling Architecture. Procedia Comput. Sci. 2022, 198, 122–127. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W.T. Deep Learning in Computer Vision: A Critical Review of Emerging Techniques and Application Scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural Greenhouses Detection in High-Resolution Satellite Images Based on Convolutional Neural Networks: Comparison of Faster R-CNN, YOLO v3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.J.; Jeng, S.Y.; Lioa, H.W. A Real-Time Vehicle Counting, Speed Estimation, and Classification System Based on Virtual Detection Zone and YOLO. Math. Probl. Eng. 2021, 2021, 1577614. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hiemann, A.; Kautz, T.; Zottmann, T.; Hlawitschka, M. Enhancement of Speed and Accuracy Trade-off for Sports Ball Detection in Videos-Finding Fast Moving, Small Objects in Real Time. Sensors 2021, 21, 3214. [Google Scholar] [CrossRef] [PubMed]
- Programming Comments-Darknet FAQ. Available online: https://www.ccoderun.ca/programming/darknet_faq/ (accessed on 28 March 2022).
- labelImg: LabelImg Is a Graphical Image Annotation Tool and Label Object Bounding Boxes in Images. Available online: https://github.com/tzutalin/labelImg (accessed on 24 October 2021).
- Taylor, T.; Geva, S.; Boles, W.W. Monocular Vision as a Range Sensor. In Proceedings of the International Conference on Computational Intelligence for Modeling, Control and Automation, Gold Coast, Australia, 12–14 July 2004; Mohammadian, M., Ed.; 2004; pp. 566–575. [Google Scholar]
- Stein, G.P.; Mano, O.; Shashua, A. Vision-Based ACC with a Single Camera: Bounds on Range and Range Rate Accuracy. In Proceedings of the IEEE IV2003 Intelligent Vehicles Symposium, Columbus, OH, USA, 9–11 June 2003; Proceedings (Cat. No.03TH8683). IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Image | Fence_Short | Fence_Long | Pillar | Total Amount |
|---|---|---|---|---|---|
| 1 | 436 | 805 | 437 | 296 | 1538 |
| 2 | 436 | 1456 | 1077 | 405 | 2938 |
| Training | Dataset (Images) | Model | Split Ratio | Dataset Labelling Method |
|---|---|---|---|---|
| #1 | 436 | YOLOv4-tiny | 70:30 | 1 |
| #2 | 436 | YOLOv4-tiny | 80:20 | 1 |
| #3 | 436 | YOLOv4-tiny | 90:10 | 1 |
| #4 | 436 | YOLOv4-tiny | 70:30 | 2 |
| #5 | 436 | YOLOv4-tiny | 80:20 | 2 |
| #6 | 436 | YOLOv4-tiny | 90:10 | 2 |
| Training | Model | Class 0 1 AP (%) | Class 1 1 AP (%) | Class 2 1 AP (%) | mAP@ 0.5 (%) | Avg. Loss (%) |
|---|---|---|---|---|---|---|
| #1 | YOLOv4-tiny | 93.44 | 92.62 | 65.09 | 83.72 | 0.061 |
| #2 | YOLOv4-tiny | 97.47 | 95.94 | 84.62 | 92.68 | 0.061 |
| #3 | YOLOv4-tiny | 95.00 | 95.01 | 87.79 | 92.60 | 0.073 |
| #4 | YOLOv4-tiny | 90.75 | 92.91 | 57.95 | 80.54 | 0.124 |
| #5 | YOLOv4-tiny | 93.02 | 90.76 | 74.83 | 86.20 | 0.133 |
| #6 | YOLOv4-tiny | 91.08 | 94.26 | 72.39 | 85.91 | 0.149 |
| Training | Model | Precision | Recall | F1-Score | Avg. IoU (%) | |
| #1 | YOLOv4-tiny | 0.79 | 0.90 | 0.84 | 72.13 | |
| #2 | YOLOv4-tiny | 0.80 | 0.95 | 0.87 | 72.75 | |
| #3 | YOLOv4-tiny | 0.80 | 0.92 | 0.85 | 71.94 | |
| #4 | YOLOv4-tiny | 0.82 | 0.86 | 0.84 | 73.88 | |
| #5 | YOLOv4-tiny | 0.83 | 0.89 | 0.86 | 74.42 | |
| #6 | YOLOv4-tiny | 0.90 | 0.87 | 0.88 | 79.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wong, T.-L.; Chou, K.-S.; Wong, K.-L.; Tang, S.-K. Dataset of Public Objects in Uncontrolled Environment for Navigation Aiding. Data 2023, 8, 42. https://doi.org/10.3390/data8020042
Wong T-L, Chou K-S, Wong K-L, Tang S-K. Dataset of Public Objects in Uncontrolled Environment for Navigation Aiding. Data. 2023; 8(2):42. https://doi.org/10.3390/data8020042
Chicago/Turabian StyleWong, Teng-Lai, Ka-Seng Chou, Kei-Long Wong, and Su-Kit Tang. 2023. "Dataset of Public Objects in Uncontrolled Environment for Navigation Aiding" Data 8, no. 2: 42. https://doi.org/10.3390/data8020042
APA StyleWong, T.-L., Chou, K.-S., Wong, K.-L., & Tang, S.-K. (2023). Dataset of Public Objects in Uncontrolled Environment for Navigation Aiding. Data, 8(2), 42. https://doi.org/10.3390/data8020042