

Data Balancing Techniques for Predicting Student Dropout Using Machine Learning

Abstract
1. Introduction
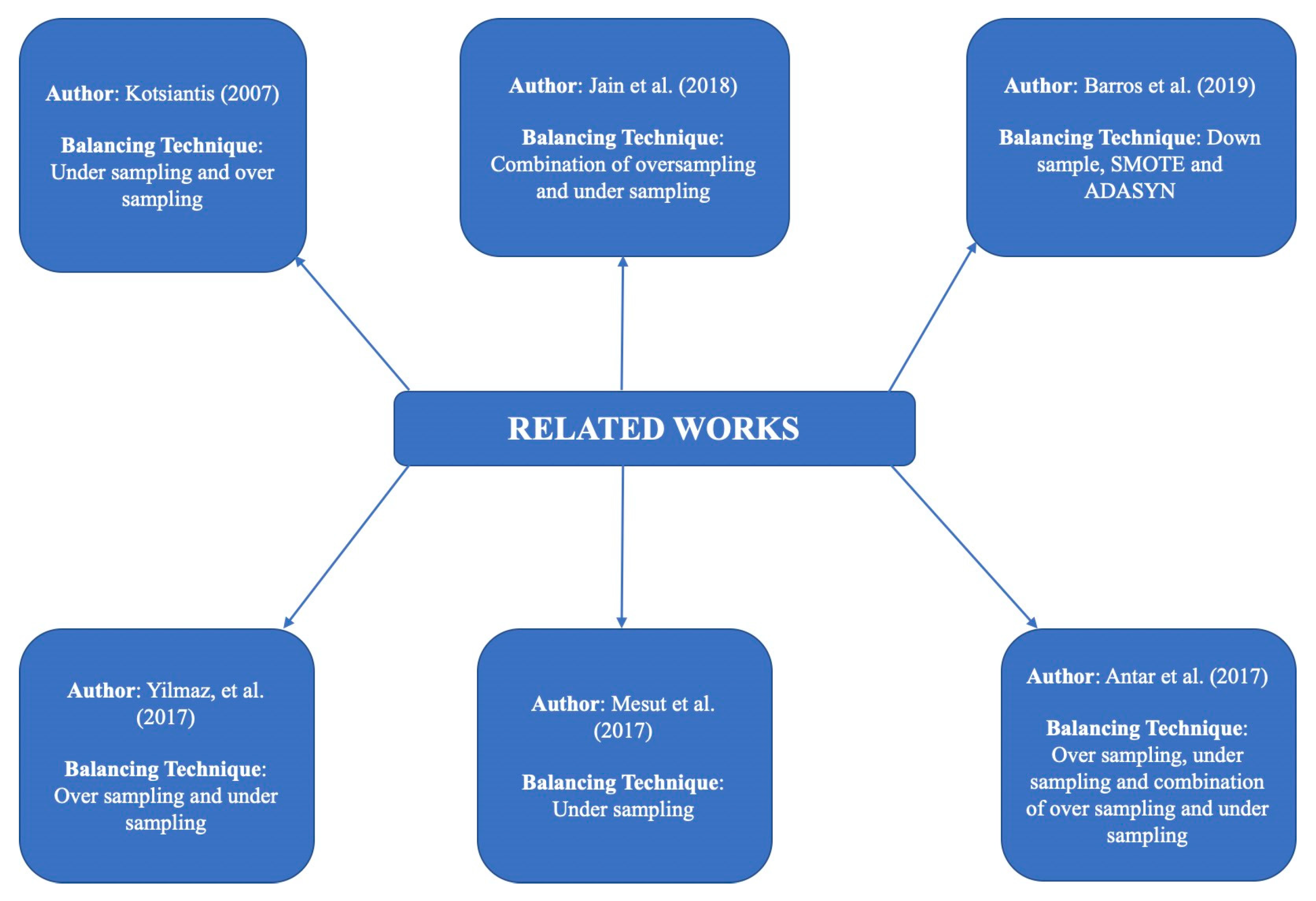
2. Literature Review
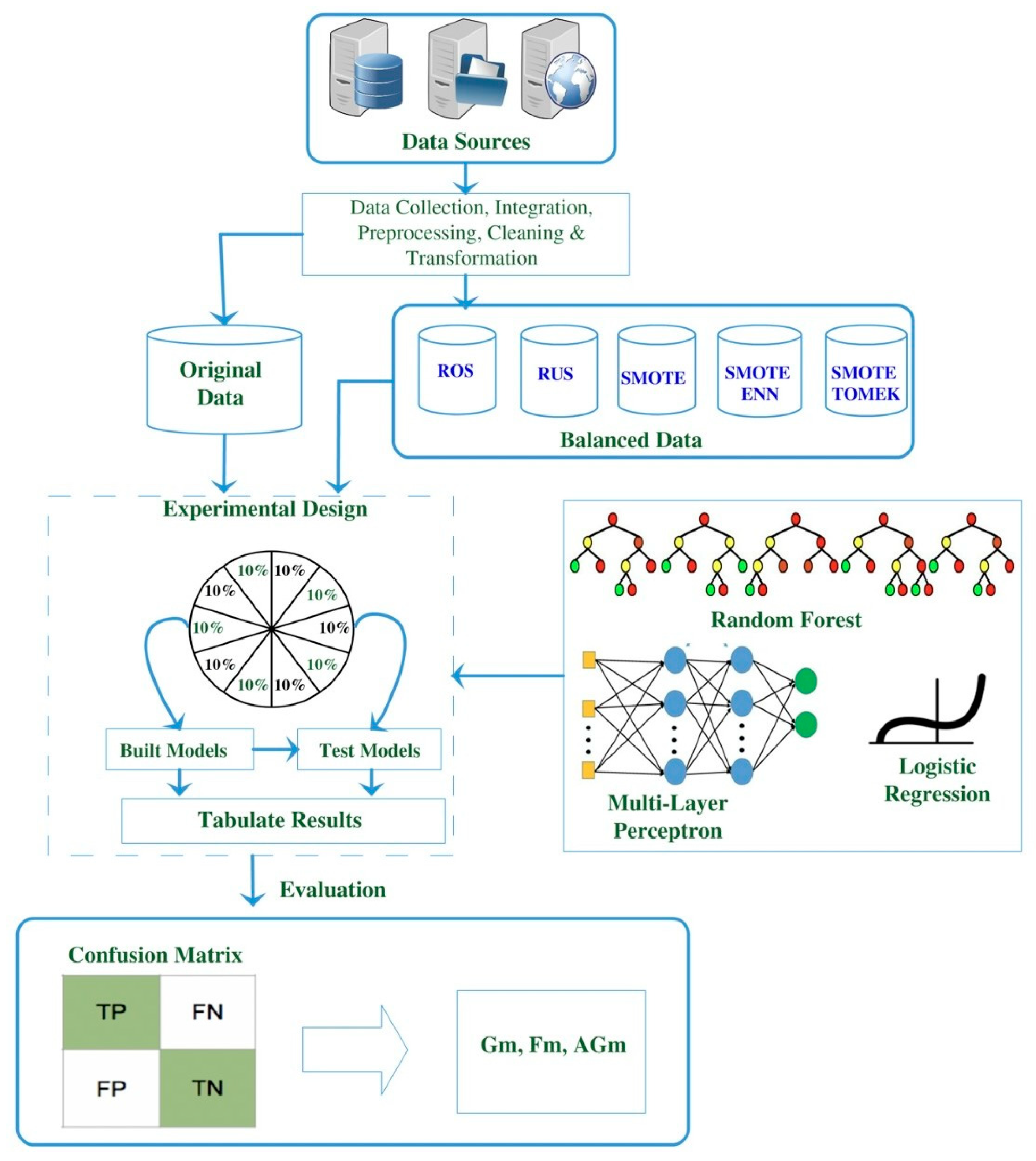
3. Materials and Methods
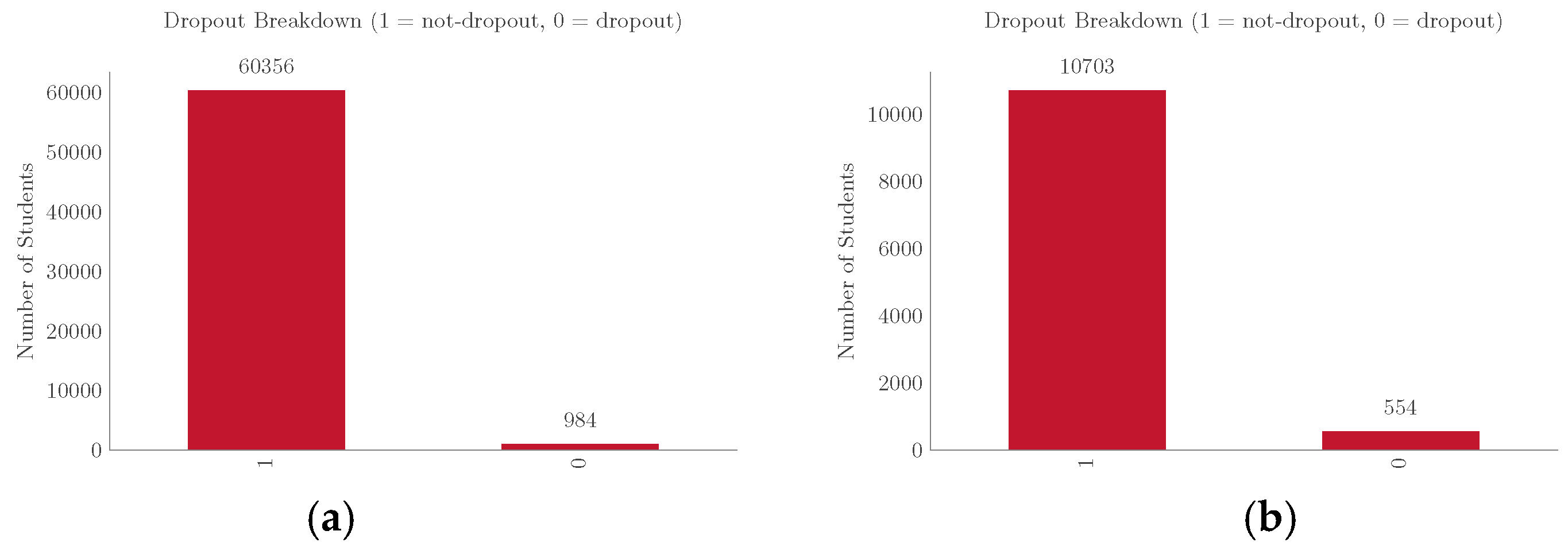
3.1. Dataset
3.2. Data Pre-Processing
3.3. Data Sampling Techniques
3.4. Classification Models
3.5. Evaluation Metrics
3.6. Experimental Design
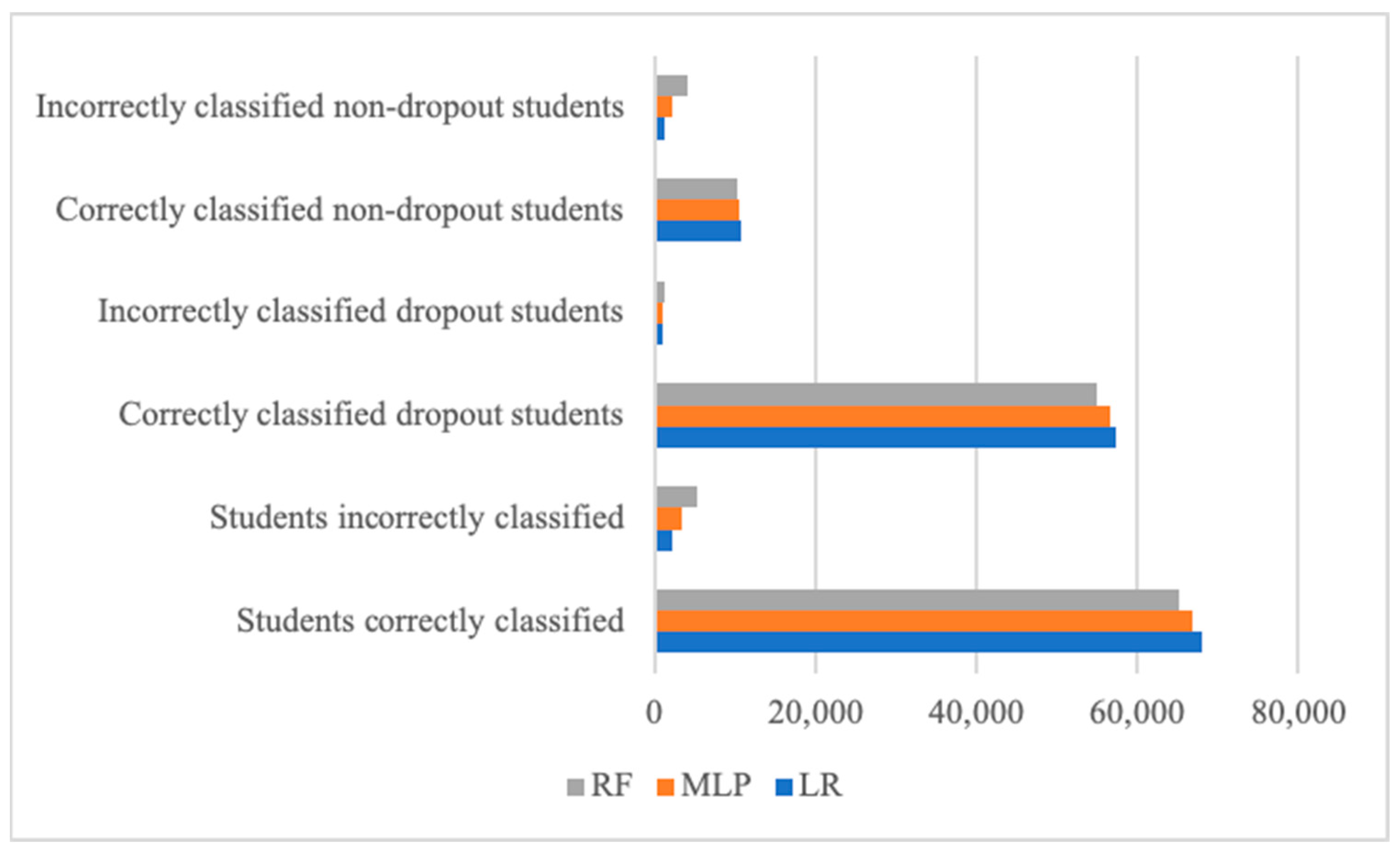
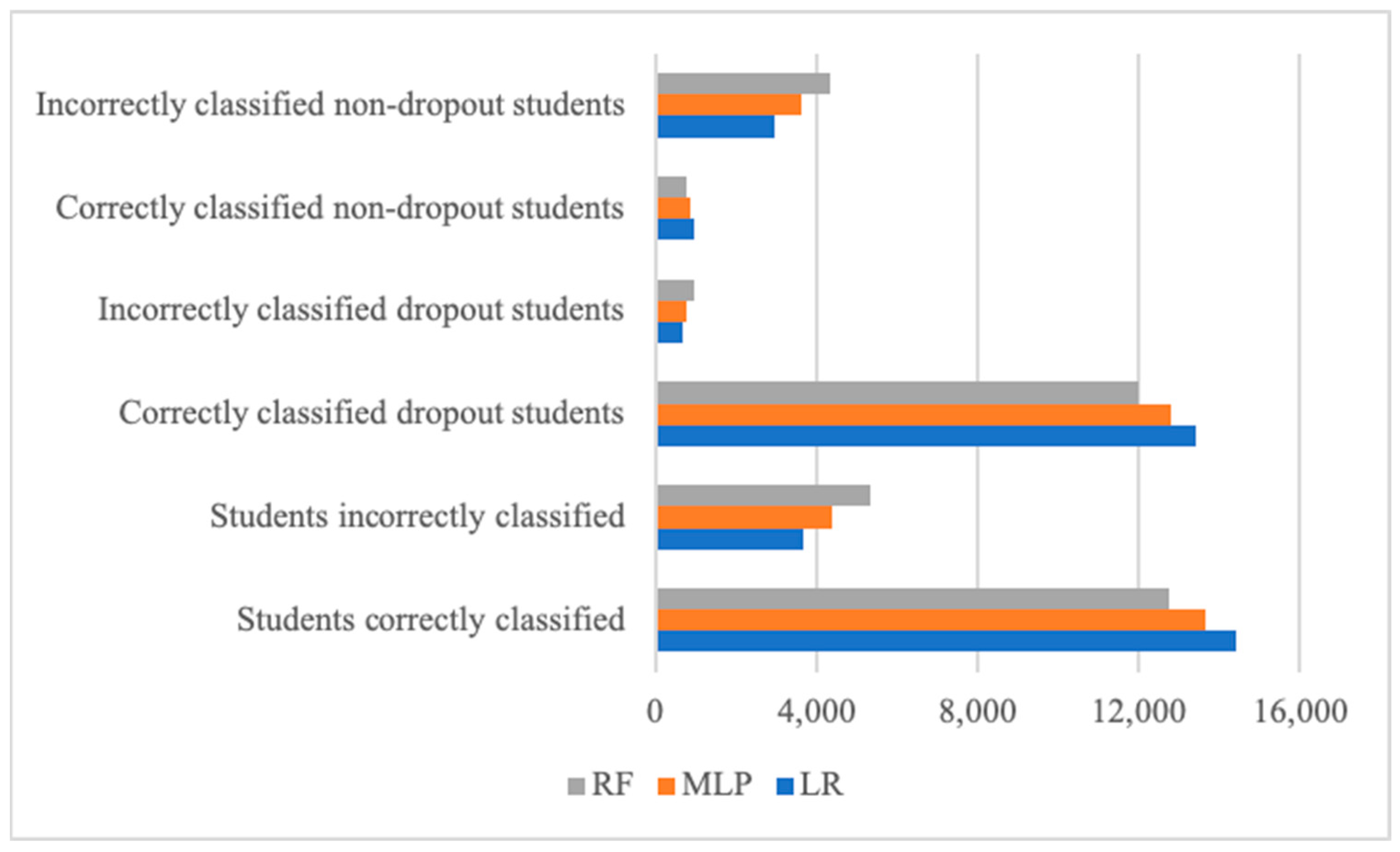
4. Results and Discussion
Models Performance
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RUS | Random Under Sampling |
| ROS | Random Over Sampling |
| SMOTE | Synthetic Minority Over Sampling Technique |
| SMOTE ENN | Synthetic Minority Over Sampling Technique with Edited Nearest Neighbor |
| SMOTE TOMEK | Synthetic Minority Over Sampling Technique with Tomek links |
| LR | Logistic Regression |
| RF | Random Forest |
| MLP | Multi-Layer Perceptron |
| Gm | Geometric Mean |
| Fm | F-measure |
| AGm | Adjusted Geometric Mean |
| 1 | http://www.twaweza.org/go/uwezo-datasets (accessed on 30 January 2017). |
| 2 | https://www.kaggle.com/imrandude/studentdropindia2016 (accessed on 30 January 2017) |
References
- Lin, W.J.; Chen, J.J. Class-imbalanced classifiers for high-dimensional data. Brief. Bioinform. 2013, 14, 13–26. [Google Scholar] [CrossRef] [PubMed]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Krawczyk, B. Combining One-vs-One Decomposition and Ensemble Learning for Multi-class. In Proceedings of the 9th International Conference on Computer Recognition Systems CORES 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 27–36. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. New Ordering-Based Pruning Metrics for Ensembles of Classifiers in Imbalanced Datasets. In Proceedings of the 9th International Conference on Computer Recognition Systems CORES 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Borowska, K.; Topczewska, M. New Data Level Approach for Imbalanced Data Classification Improvement. In Proceedings of the 9th International Conference on Computer Recognition Systems CORES 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 283–294. [Google Scholar] [CrossRef]
- Mazumder, R.U.; Begum, S.A.; Biswas, D. Rough Fuzzy Classi fi cation for Class Imbalanced Data. In Proceedings of Fourth International Conference on Soft Computing for Problem Solving; Springer: Delhi, India, 2015. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. An Ensemble Pruning Approach Based on Reinforcement Learning in Presence of Multi-class Imbalanced Data. In Proceedings of the Third International Conference on Soft Computing for Problem Solving; Springer: Delhi, India, 2014. [Google Scholar] [CrossRef]
- Sonak, A.; Patankar, R.A. A Survey on Methods to Handle Imbalance Dataset. Int. J. Comput. Sci. Mob. Comput. 2015, 4, 338–343. [Google Scholar]
- Ali, H.; Salleh, M.N.M.; Saedudin, R.; Hussain, K.; Mushtaq, M.F. Imbalance class problems in data mining: A review. Indones. J. Electr. Eng. Comput. Sci. 2019, 14, 1552–1563. [Google Scholar] [CrossRef]
- Realinho, V.; Machado, J.; Baptista, L.; Martins, M.V. Predicting Student Dropout and Academic Success. Data 2022, 7, 146. [Google Scholar] [CrossRef]
- Thammasiri, D.; Delen, D.; Meesad, P.; Kasap, N. A critical assessment of imbalanced class distribution problem: The case of predicting freshmen student attrition. Expert Syst. Appl. 2013, 41, 321–330. [Google Scholar] [CrossRef]
- UNESCO. Estimation of the Numbers and Rates of Out-of-school Children and Adolescents Using Administrative and Household Survey Data; UNESCO Institute for Statistics: Montreal, QC, Canada, 2017; pp. 1–33. [Google Scholar] [CrossRef]
- Valles-coral, M.A.; Salazar-ram, L.; Injante, R.; Hernandez-torres, E.A.; Ju, J.; Navarro-cabrera, J.R.; Pinedo, L.; Vidaurre-rojas, P. Density-Based Unsupervised Learning Algorithm to Categorize College Students into Dropout Risk Levels. Data 2022, 7, 165. [Google Scholar] [CrossRef]
- Mduma, N. Data Driven Approach for Predicting Student Dropout in Secondary Schools. Ph.D. Thesis, NM-AIST, Arusha, Tanzania, 2020. [Google Scholar]
- Gao, T. Hybrid Classification Approach of SMOTE and Instance Selection for Imbalanced Datasets. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 2015. [Google Scholar]
- Hoens, T.R.; Chawla, N.V. Imbalanced Datasets: From Sampling to Classifiers. In Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Inc.: Hoboken, NJ, USA, 2013; pp. 43–59. [Google Scholar] [CrossRef]
- Elhassan, T.; Aljurf, M.; Shoukri, M. Classification of Imbalance Data using Tomek Link (T-Link) Combined with Random Under-sampling (RUS) as a Data Reduction Method. J. Inform. Data Min. 2016, 1, 1–12. [Google Scholar]
- Santoso, B.; Wijayanto, H.; Notodiputro, K.A.; Sartono, B. Synthetic Over Sampling Methods for Handling Class Imbalanced Problems: A Review. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2017. [Google Scholar] [CrossRef]
- Skryjomski, P. Influence of minority class instance types on SMOTE imbalanced data oversampling. Proc. Mach. Learn. Res. 2017, 74, 7–21. [Google Scholar]
- Yu, X.; Zhou, M.; Chen, X.; Deng, L.; Wang, L. Using Class Imbalance Learning for Cross-Company Defect Prediction. Int. Conf. Softw. Eng. Knowl. Eng. 2017, 117–122. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Geometric SMOTE: Effective oversampling for imbalanced learning through a geometric extension of SMOTE. arXiv 2017, arXiv:1709.07377. [Google Scholar]
- Shilbayeh, S.A. Cost Sensitive Meta Learning Samar Ali Shilbayeh School of Computing, Science and Engineering; University of Salford: Salford, UK, 2015. [Google Scholar]
- Kumar, M.; Singh, A.; Handa, D. Literature Survey on Educational Dropout Prediction. Int. J. Educ. Manag. Eng. 2017, 7, 8–19. [Google Scholar] [CrossRef]
- Siri, A.; Siri, A. Predicting Students’ Dropout at University Using Artificial Neural Networks. Ital. J. Sociol. Educ. 2015, 7, 225–247. [Google Scholar]
- Oancea, B.; Dragoescu, R.; Ciucu, S. Predicting Students’ Results in Higher Education Using Neural Networks. In Proceedings of the International Conference on Applied Information and Communication Technologies, Baku, Azerbaijan, 23–25 October 2013; pp. 190–193. [Google Scholar]
- Saranya, A.; Rajeswari, J. Enhanced Prediction of Student Dropouts Using Fuzzy Inference System and Logistic Regression. ICTACT J. Soft Comput. 2016, 6, 1157–1162. [Google Scholar] [CrossRef]
- Fei, M.; Yeung, D.Y. Temporal Models for Predicting Student Dropout in Massive Open Online Courses. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 256–263. [Google Scholar] [CrossRef]
- Goga, M.; Kuyoro, S.; Goga, N. A Recommender for Improving the Student Academic Performance. Procedia Soc. Behav. Sci. 2015, 180, 1481–1488. [Google Scholar] [CrossRef]
- Sales, A.; Balby, L.; Cajueiro, A. Exploiting Academic Records for Predicting Student Drop Out: A case study in Brazilian higher education. J. Inf. Data Manag. 2016, 7, 166–180. [Google Scholar]
- Nagrecha, S.; Dillon, J.Z.; Chawla, N.V. MOOC Dropout Prediction: Lessons Learned from Making Pipelines Interpretable. In Proceedings of the 26th International Conference on World Wide Web Companion; ACM: New York, NY, USA, 2017; pp. 351–359. [Google Scholar] [CrossRef]
- Aulck, L.; Velagapudi, N.; Blumenstock, J.; West, J. Predicting Student Dropout in Higher Education. ICML Workshop on #Data4Good: Machine Learning in Social Good Applications 2016. arXiv 2017, 16–20. [Google Scholar] [CrossRef]
- Halland, R.; Igel, C.; Alstrup, S. High-School Dropout Prediction Using Machine Learning: A Danish Large-scale Study. In Proceedings of the 23rd European Symposium on Artificial Neural Networks, Bruges, Belgium, 22–23 April 2015; pp. 22–24. [Google Scholar]
- Kemper, L.; Vorhoff, G.; Wigger, B.U. Predicting student dropout: A machine learning approach. Eur. J. High. Educ. 2020, 10, 28–48. [Google Scholar] [CrossRef]
- de Oliveira Durso, S.; da Cunha, J.V. Determinant Factors for Undergraduate Student’s Dropout in Accounting Studies Department of A Brazilian Public University. Fed. Univ. Minas Gerais 2018, 34, 186332. [Google Scholar] [CrossRef]
- Nath, S.R.; Ferris, D.; Kabir, M.M.; Chowdhury, T.; Hossain, A. Transition and Dropout in Lower Income Countries: Case Studies of Secondary Education in Bangladesh and Uganda. World Innov. Summit Educ. 2017. Available online: https://www.wise-qatar.org/app/uploads/2019/04/rr.3.2017_brac.pdf (accessed on 1 January 2023).
- Wang, X.; Schneider, H. A Study of Modelling Approaches for Predicting Dropout in a Business College; Louisiana State University: Baton Rouge, LA, USA, 2018; pp. 1–8. [Google Scholar]
- Franklin, B.J.; Trouard, S.B. An Analysis of Dropout Predictors within a State High School Graduation Panel. Schooling 2014, 5, 1–8. [Google Scholar]
- Helou, I. Analytical and experimental investigation of steel friction dampers and horizontal brake pads in chevron frames under cyclic loads. Issues Inf. Sci. Inf. Technol. Educ. 2018, 15, 249–278. [Google Scholar]
- Aguiar, E.; Dame, N.; Miller, D.; Yuhas, B.; Addison, K.L. Who, When, and Why: A Machine Learning Approach to Prioritizing Students at Risk of not Graduating High School on Time. ACM 2015, 93–102. [Google Scholar] [CrossRef]
- Rovira, S.; Puertas, E.; Igual, L. Data-driven System to Predict Academic Grades and Dropout. PLoS ONE 2017, 12, e0171207. [Google Scholar] [CrossRef]
- Mgala, M.; Mbogho, A. Data-driven Intervention-level Prediction Modeling for Academic Performance. In Proceedings of the Seventh International Conference on Information and Communication Technologies and Development, Singapore, 15–18 May 2015; pp. 2:1–2:8. [Google Scholar] [CrossRef]
- Voyant, C.; Paoli, C.; Nivet, M.l.; Notton, G. Multi-layer Perceptron and Pruning. Turk. J. Forecast. 2017, 1, 1–6. [Google Scholar]
- Ramchoun, H.; Amine, M.; Idrissi, J.; Ghanou, Y.; Ettaouil, M. Multilayer Perceptron: Archi-tecture Optimization and Training. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 26. [Google Scholar] [CrossRef]
- Fesghandis, G.S. Comparison of Multilayer Perceptron and Radial Basis Function Neural Networks in Predicting the Success of New Product Development. Eng. Technol. Appl. Sci. Res. 2017, 7, 1425–1428. [Google Scholar] [CrossRef]
- Rani, K.U. Advancements in Multi-Layer Perceptron Training to Improve Classification. Int. J. Recent Innov. Trends Comput. Commun. 2017, 5, 353. [Google Scholar] [CrossRef]
- Ahmed, K.; Shahid, S.; Haroon, S.B.; Xiao-jun, W. Multilayer perceptron neural network for downscaling rainfall in arid region: A case study of Baluchistan, Pakistan. J. Earth Syst. Sci. 2015, 124, 1325–1341. [Google Scholar] [CrossRef]
- Taravat, A.; Proud, S.; Peronaci, S.; Del Frate, F.; Oppelt, N. Multilayer perceptron neural networks model for meteosat second generation SEVIRI daytime cloud masking. Remote Sens. 2015, 7, 1529–1539. [Google Scholar] [CrossRef]
- Wu, Z.; Lin, W.; Zhang, Z.; Wen, A.; Lin, L. An Ensemble Random Forest Algorithm for Insurance Big Data Analysis. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering and IEEE/IFIP International Conference on Embedded and Ubiquitous Computing, CSE and EUC 2017, Guangzhou, China, 21–24 July 2017; Volume 1, pp. 531–536. [Google Scholar] [CrossRef]
- Compo, P.; Pca, E.; Variances, A.U.; Analysis, B.S. Submitted to the Annals of Statistics. Ann. Stat. 2017, 45, 1–37. [Google Scholar]
- Biau, G.; Scornet, E. A Random Forest Guided Tour. TEST 2015, 25, 197–227. [Google Scholar] [CrossRef]
- Prajwala, T.R. A Comparative Study on Decision Tree and Random Forest Using R Tool. Ijarcce 2015, 4, 196–199. [Google Scholar] [CrossRef]
- Ibrahim, M. Scalability and Performance of Random Forest based Learning-to-Rank for Information Retrieval. In ACM SIGIR Forum; ACM: New York, NY, USA, 2017; Volume 51, pp. 73–74. [Google Scholar]
- Kulkarni, A.D.; Lowe, B. Random Forest for Land Cover Classification. Int. J. Recent Innov. Trends Comput. Commun. 2016, 4, 58–63. [Google Scholar]
- Fabris, F.; Doherty, A.; Palmer, D.; de Magalhães, J.P.; Freitas, A.A. A new approach for interpreting Random Forest models and its application to the biology of ageing. Bioinformatics 2018, 34, 2449–2456. [Google Scholar] [CrossRef]
- Goel, E.; Abhilasha, E. Random Forest: A Review. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2017, 7, 251–257. [Google Scholar] [CrossRef]
- Aydın, C. Classification of the Fire Station Requirement with Using Machine Learning Algorithms. I.J. Inf. Technol. Comput. Sci. 2019, 11, 24–30. [Google Scholar] [CrossRef]
- Klusowski, J.M. Complete Analysis of a Random Forest Model; Rutgers University: New Brunswick, NJ, USA, 2018. [Google Scholar]
- Tyralis, H.; Papacharalampous, G. Variable selection in time series forecasting using random forests. Algorithms 2017, 10, 114. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Delavar, M.R.; Shafizadeh-Moghadam, H.; Tayyebi, A. Modeling urban dynamics using random forest: Implementing Roc and Toc for model evaluation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 41, 285–290. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C.; Villa-Vialaneix, N. Random Forests for Big Data. Big Data Res. 2015, 9, 28–46. [Google Scholar] [CrossRef]
- Kudakwashe, M.; Mohammed Yesuf, K. Application of Binary Logistic Regression in Assessing Risk Factors Affecting the Prevalence of Toxoplasmosis. Am. J. Appl. Math. Stat. 2014, 2, 357–363. [Google Scholar] [CrossRef]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Park, H.A. An introduction to logistic regression: From basic concepts to interpretation with particular attention to nursing domain. J. Korean Acad. Nurs. 2013, 43, 154–164. [Google Scholar] [CrossRef] [PubMed]
- Shu, D.; He, W. A New Method for Logistic Model Assessment. Int. J. Stat. Probab. 2017, 6, 120. [Google Scholar] [CrossRef]
- Ameri, S.; Fard, M.J.; Chinnam, R.B.; Reddy, C.K. Survival Analysis based Framework for Early Prediction of Student Dropouts. ACM 2016, 903–912. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Aguiar, E.; Shan, C.; Miller, D.; Bhanpuri, N.; Ghani, R.; Addison, K.L. A Machine Learning Framework to Identify Students at Risk of Adverse Academic Outcomes. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10-13 August 2015; pp. 1909–1918. [Google Scholar] [CrossRef]
- Susheel Kumar, S.M.; Laxkar, D.; Adhikari, S.; Vijayarajan, V. Assessment of various supervised learning algorithms using different performance metrics. IOP Conf. Ser. Mater. Sci. Eng. 2017, 263, 042087. [Google Scholar] [CrossRef]
- Maggo, S.; Gupta, C. A Machine Learning based Efficient Software Reusability Prediction Model for Java Based Object Oriented Software. I.J. Inf. Technol. Comput. Sci. 2014, 1–13. [Google Scholar] [CrossRef]
- Liang, J.; Li, C.; Zheng, L. Machine learning application in MOOCs: Dropout prediction. In Proceedings of the ICCSE 2016 11th International Conference on Computer Science and Education, Nagoya, Japan, 23–25 August 2016; pp. 52–57. [Google Scholar] [CrossRef]
- Longadge, R.; Dongre, S.S.; Malik, L. Class imbalance problem in data mining: Review. Int. J. Comput. Sci. Netw. 2013, 2, 83–87. [Google Scholar] [CrossRef]
- Yilmaz, D.; Boz, H.; Yücel, M.; Günay, E. Prediction of student dropout from a university in Turkey using data balancing techniques. Comput. Educ. 2020, 108, 11–29. [Google Scholar] [CrossRef]
- Mesut, G.; Demir, I.; Batur, K.; Sahin, F. Applying data balancing techniques to predict student dropout using machine learning. Int. J. Adv. Comput. Technol. 2017, 5, 1–8. [Google Scholar]
- Antar, K.; Al-Dmour, R.; Zbaidieh, M.; Al-Kabi, M. Prediction of Student Dropouts Using Machine Learning Techniques. Int. J. Comput. Appl. 2020, 5, 1–8. [Google Scholar] [CrossRef]
- Jain, A.; Singh, U.; Kumar, S. Application of data balancing techniques to predict student dropout using machine learning. Int. J. Comput. Appl. 2018, 11, 430–439. [Google Scholar]
- Barros, T.M.; Neto, P.A.; Silva, I.; Guedes, L.A. Predictive models for imbalanced data: A school dropout perspective. Educ. Sci. 2019, 9, 275. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Farquad, M.A.; Bose, I. Preprocessing Unbalanced Data Using Support Vector Machine. Decis. Support Syst. 2012, 53, 226–233. [Google Scholar] [CrossRef]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RSB *: A Hybrid Preprocessing Approach Based on Oversampling and Undersampling for High Imbalanced Data-sets Using SMOTE and Rough Sets Theory. Knowl. Inf. Syst. 2012, 33, 245–265. [Google Scholar] [CrossRef]
- Yen, S.J.; Lee, Y.S. Cluster-based Under-sampling Approaches for Imbalanced Data Distributions. Expert Syst. Appl. 2009, 36, 5718–5727. [Google Scholar] [CrossRef]
- Wang, S.; Yao, X. Using Class Imbalance Learning for Software Defect Prediction. IEEE Trans. Reliab. 2013, 62, 434–443. [Google Scholar] [CrossRef]
- Burez, J.; Van den Poel, D. Handling Class Imbalance in Customer Churn Prediction. Expert Syst. Appl. 2009, 36, 4626–4636. [Google Scholar] [CrossRef]
- Prusa, J.; Khoshgoftaar, T.M.; DIttman, D.J.; Napolitano, A. Using Random Undersampling to Alleviate Class Imbalance on Tweet Sentiment Data. In Proceedings of the IEEE 16th International Conference on Information Reuse and Integration, IRI 2015, San Francisco, CA, USA, 13–15 August 2015; pp. 197–202. [Google Scholar] [CrossRef]
- Aulck, L.; Aras, R.; Li, L.; Heureux, C.L.; Lu, P.; West, J. STEM-ming the Tide: Predicting STEM Attrition Using Student Transcript Data. arXiv 2017, arXiv:1708.09344. [Google Scholar] [CrossRef]
- Batuwita, R.; Palade, V. Adjusted Geometric-mean: A Novel Performance Measure for Imbalanced Bioinformatics Datasets Learning. J. Bioinform. Comput. Biol. 2012, 10, 1250003. [Google Scholar] [CrossRef]
- Kim, M.J.; Kang, D.K.; Kim, H.B. Geometric mean based boosting algorithm with over-sampling to resolve data imbalance problem for bankruptcy prediction. Expert Syst. Appl. 2015, 42, 1074–1082. [Google Scholar] [CrossRef]
- Mgala, M. Investigating Prediction Modelling of Academic Performance for Students in Rural Schools in Kenya. Ph.D. Thesis, University of Cape Town, Cape Town, South Africa, 2016. [Google Scholar]
- Kuncheva, L.I.; Arnaiz-González, Á.; Díez-Pastor, J.F.; Gunn, I.A. Instance Selection Improves Geometric Mean Accuracy: A Study on Imbalanced Data Classification. Prog. Artif. Intell. 2019, 8, 215–228. [Google Scholar] [CrossRef]
- Hakim, A. Performance Evaluation of Machine Learning Techniques for Early Prediction of Brain Strokes. Ph.D. Thesis, United International University, Dhaka, Bangladesh, 2019. [Google Scholar]
- Amin, M.Z.; Ali, A. Performance Evaluation of Supervised Machine Learning Classifiers for Predicting Healthcare Operational Decisions. Tech. Rep. 2017. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Preprocessing | Models | Gm | Fm | AGm | Gm | Fm | AGm |
|---|---|---|---|---|---|---|---|
| Uwezo dataset | India dataset | ||||||
| None | LR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| MLP | 0.011 | 0.002 | 0.012 | 0.000 | 0.000 | 0.000 | |
| RF | 0.004 | 8.32 × 10−5 | 0.004 | 0.031 | 0.002 | 0.031 | |
| ROS | LR | 0.536 | 0.547 | 1.010 | |||
| MLP | 0.499 | 0.438 | 0.920 | 0.524 | 0.450 | 0.957 | |
| RF | 0.293 | 0.270 | 0.449 | 0.707 | 0.667 | 1.207 | |
| RUS | LR | 0.548 | 0.546 | 1.042 | 0.582 | 0.570 | 1.085 |
| MLP | 0.512 | 0.332 | 1.031 | 0.515 | 0.139 | 0.925 | |
| RF | 0.624 | 0.561 | 1.192 | 0.711 | 0.667 | 1.210 | |
| SMOTE | LR | 0.551 | 0.556 | 1.034 | 0.648 | 0.603 | 1.190 |
| MLP | 0.525 | 0.475 | 0.967 | 0.555 | 0.410 | 1.032 | |
| RF | 0.661 | 0.645 | 1.138 | 0.707 | 0.667 | 1.207 | |
| SMOTE ENN | LR | 0.562 | 0.572 | 1.079 | 0.722 | 0.638 | 1.343 |
| MLP | 0.577 | 0.491 | 1.104 | 0.791 | 0.438 | 1.531 | |
| RF | 0.676 | 0.666 | 1.176 | 0.738 | 0.706 | 1.283 | |
| SMOTE Tomek | LR | 0.550 | 0.556 | 1.032 | 0.655 | 0.605 | 1.201 |
| MLP | 0.546 | 0.508 | 1.015 | 0.735 | 0.441 | 1.390 | |
| RF | 0.663 | 0.646 | 1.140 | 0.707 | 0.667 | 1.206 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mduma, N. Data Balancing Techniques for Predicting Student Dropout Using Machine Learning. Data 2023, 8, 49. https://doi.org/10.3390/data8030049
Mduma N. Data Balancing Techniques for Predicting Student Dropout Using Machine Learning. Data. 2023; 8(3):49. https://doi.org/10.3390/data8030049
Chicago/Turabian StyleMduma, Neema. 2023. "Data Balancing Techniques for Predicting Student Dropout Using Machine Learning" Data 8, no. 3: 49. https://doi.org/10.3390/data8030049
APA StyleMduma, N. (2023). Data Balancing Techniques for Predicting Student Dropout Using Machine Learning. Data, 8(3), 49. https://doi.org/10.3390/data8030049