
Assessing the Effectiveness of Masking and Encryption in Safeguarding the Identity of Social Media Publishers from Advanced Metadata Analysis


Abstract
:1. Introduction
1.1. Reasons
1.1.1. Importance of Cybersecurity
1.1.2. Rule-Based Protection
1.1.3. Artificial Intelligence and Machine Learning Protection
- Data Collection: A large amount of relevant and representative data is collected from various sources, such as social media platforms, online transactions, or user interactions.
- Data Preparation: The collected data are cleaned, pre-processed, and transformed into a suitable format for training machine learning models. This may involve tasks such as data normalization, feature engineering, and data augmentation.
- Model Training: Machine learning models are trained on the prepared data using a variety of algorithms, such as supervised learning, unsupervised learning, or reinforcement learning. During training, the model learns to recognize patterns and relationships in the data.
- Model Evaluation: The trained model is evaluated on a separate set of data, called the validation or test set, to assess its performance, accuracy, and generalization ability. Model parameters may be adjusted and fine-tuned based on the evaluation results.
- Fine-tuning: If necessary, the hyperparameters of the classifier are adjusted to optimize its performance. This can be carried out using techniques such as grid search or randomized search, where different combinations of hyperparameters are evaluated to find the best configuration.
- Model Deployment: Once the model is trained and evaluated, it can be deployed in a real-world environment to make predictions, classifications, or decisions on new, unseen data.
- Model Monitoring and Maintenance: Machine learning models require continuous monitoring to ensure their accuracy and effectiveness. They may need to be updated or retrained periodically with new data to maintain their performance.
1.2. State of the Art and Related Works
1.3. Contributions
- Conducts an analysis of the advantages and disadvantages of the most relevant proposed solutions in the existing literature regarding the security of personal data.
- Provides comprehensive coverage of both textual and image metadata in our proposed work.
- Demonstrates the effectiveness of encryption and obfuscation methods in enhancing user privacy by limiting the accuracy of information obtained from encrypted metadata.
- Provides empirical evidence on the efficacy and precision of different classifiers in identifying online users by assessing their performance pre- and post-encryption of metadata.
- Assesses the potential information loss resulting from metadata encryption and obfuscation, providing insights into the trade-off between privacy and data utility.
- Provides strong experimental evidence that our proposed method minimally compromises data utility, indicating its viability and effectiveness in safeguarding user privacy while maintaining the usefulness of the data.
- Raises awareness about critical privacy issues related to metadata.
- Highlights the increasing importance of privacy concerns as social media platforms provide APIs for accessing data accompanied by metadata.
2. Dataset Collection and Preparation
2.1. Metadata Collection
2.2. Metadata Pruning
- We observed that some samples, particularly the metadata of images, were missing values for a common set of 31 features (out of 56 features). Therefore, we removed these samples with more than 31 missing features.
- We removed features with redundant values from the samples. For instance, the value of the MegaPixels feature is the result of the ImageHeight feature multiplied by the value of the ImageWidth feature. Therefore, we removed the ImageHeight and ImageWidth features from each sample in the metadata set. At this stage, each sample in the metadata set has 29 features.
- We adopted a consistent format for the values of the features. For example, if the “Location” feature had values such as “New York City,” “NYC,” and “New York,” we used a common format. Additionally, if the date format in the “User_Creation_Time” and “Tweet_Creation_Time” features was different, we used a common format.
- We removed samples from the metadata set with the source feature (Source = “TweetBot”), which indicates values of tweets placed by bots.
2.3. Normalization of Dataset
2.4. Feature Selection
3. Classifier Models
- Support Vector Machines (SVM): SVM is a supervised machine learning algorithm that constructs a hyperplane or set of hyperplanes to separate data points into different classes. It aims to find the optimal decision boundary that maximizes the margin between classes. SVMs can handle both linear and non-linear classification tasks effectively.
- K-Nearest Neighbors (KNN): KNN is a non-parametric supervised learning algorithm that classifies new instances based on their similarity to neighboring instances in the feature space. It assigns a class label to a new data point based on the majority class of its k nearest neighbors.
- Multilayer Perceptron (MLP): MLP is a type of artificial neural network with multiple layers of interconnected neurons. It uses feedforward propagation to classify data by learning the weights and biases associated with each connection. MLPs are capable of learning complex relationships and are widely used for classification tasks.
- Random Forest (RF): RF is an ensemble learning method that combines multiple decision trees. It generates a set of decision trees on different subsets of the training data and combines their predictions to make the final classification. RF is known for its ability to handle large datasets and provide robust performance.
- Multinomial Logistic Regression (MLR): MLR is a regression-based classification algorithm used for categorical dependent variables with more than two classes. It estimates the probabilities of each class using a logistic function and assigns the data point to the class with the highest probability.
3.1. Hyperparameter Tuning
- Grid Search: Grid search involves manually specifying a set of values for each hyperparameter and exhaustively evaluating the model’s performance on all possible combinations. It allows you to explore a predefined search space and find the best combination of hyperparameters based on a specified evaluation metric.
- Random Search: In contrast to grid search, random search selects hyperparameters randomly from a predefined distribution. This approach provides a more efficient way to explore the hyperparameter space, especially when certain hyperparameters are expected to have a stronger impact on model performance than others.
- Cross-Validation: Cross-validation is a technique used to estimate the performance of a model on unseen data. By dividing the available data into training and validation sets, you can iteratively train the model on different subsets of the data and evaluate its performance. This helps in assessing the generalizability of the model and can guide the selection of hyperparameters.
3.2. Data Split
4. Training-Validation and Testing
| Algorithm 1: Metadata Anonymization |
| Input: Metadata from Tweets and Images Output: Privacy-Preserving Anonymized data
|
4.1. Training and Validation
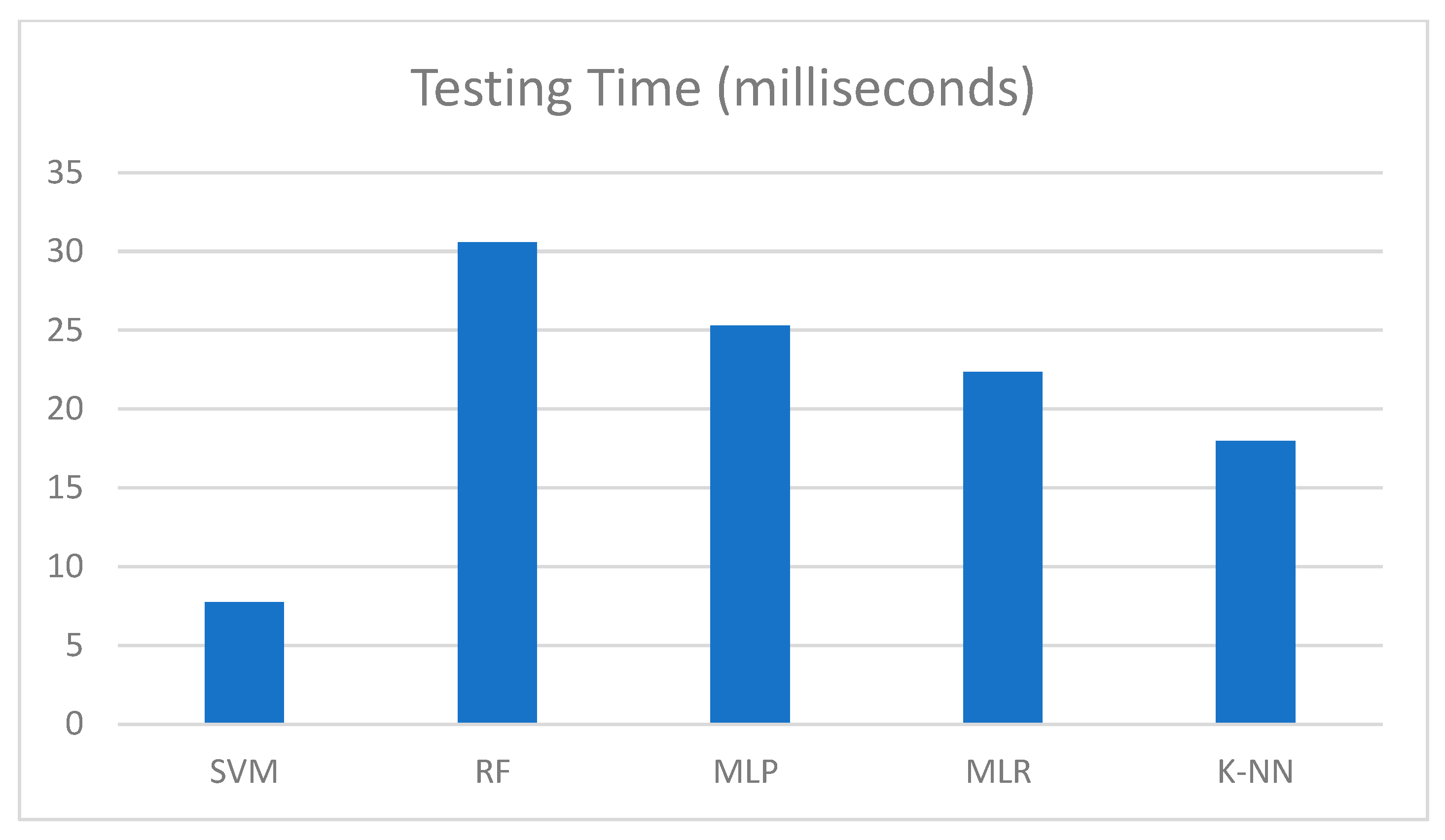
4.1.1. Runtime
4.1.2. Obfuscation
4.1.3. Data Anonymization
4.1.4. Advanced Encryption Standard (AES)
4.1.5. Precision, Recall, and F1-Score
4.2. Test Results
4.3. Information Loss
4.3.1. Generalization
Generalized Information Loss
Average Equivalence Class Size
4.3.2. Perturbation
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mislove, A.; Lehmann, S.; Ahn, Y.Y.; Onnela, J.P.; Rosenquist, J.N. Understanding the demographics of Twitter users. In Proceedings of the Fifth International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 554–557. [Google Scholar]
- Dhir, A.; Kaur, P.; Rajala, R. Social media research in advertising, communication, marketing, and public relations: Evolution and implications. Telemat. Inform. 2017, 34, 1–13. [Google Scholar]
- De Montjoye, Y.A.; Shmueli, E.; Wang, S.S.; Pentland, A.S. openPDS: Protecting the Privacy of Metadata through SafeAnswers. PLoS ONE 2014, 9, e98790. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 18–22 May 2008; pp. 111–125. [Google Scholar] [CrossRef]
- Cluley, G. Fugitive John McAfee’s Location Revealed by Photo Meta-Data Screw-Up. Available online: https://nakedsecurity.sophos.com/2012/12/03/john-mcafee-location-exif/ (accessed on 4 December 2012).
- Zook, M.; Graham, M.; Shelton, T.; Gorman, S. Volunteered Geographic Information and Crowdsourcing Disaster Relief: A Case Study of the Haitian Earthquake. World Med. Health Policy 2010, 2, 7–33. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharya, M.; Roy, S.; Chattopadhyay, S.; Das, A.K.; Shetty, S. A comprehensive survey on online social networks security and privacy issues: Threats, machine learning-based solutions, and open challenges. Secur. Priv. 2023, 6, e275. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Analysis, Design, and Comparison of Machine-Learning Techniques for Networking Intrusion Detection. Designs 2021, 5, 9. [Google Scholar] [CrossRef]
- Kumar, C.; Bharati, T.S.; Prakash, S. Online Social Network Security: A Comparative Review Using Machine Learning and Deep Learning. Neural Process. Lett. 2021, 53, 843–861. [Google Scholar] [CrossRef]
- Dini, P.; Begni, A.; Ciavarella, S.; De Paoli, E.; Fiorelli, G.; Silvestro, C.; Saponara, S. Design and Testing Novel One-Class Classifier Based on Polynomial Interpolation with Application to Networking Security. IEEE Access 2022, 10, 67910–67924. [Google Scholar] [CrossRef]
- Wijayanto, H.; Riadi, I.; Prayudi, Y. Encryption EXIF Metadata for Protection Photographic Image of Copyright Piracy. IJRCCT 2016, 5, 237–243. [Google Scholar]
- Delgado, J.; Llorente, S. Improving privacy in JPEG images. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Takbiri, N.; Houmansadr, A.; Goeckel, D.L.; Pishro-Nik, H. Limits of location privacy under anonymization and obfuscation. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 764–768. [Google Scholar] [CrossRef]
- Shozi, N.A.; Mtsweni, J. Big data privacy in social media sites. In Proceedings of the IST-Africa Week Conference (IST-Africa), Windhoek, Namibia, 31 May–2 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ghazinour, K.; Ponchak, J. Hidden Privacy Risks in Sharing Pictures on Social Media. Procedia Comput. Sci. 2017, 113, 267–272. [Google Scholar] [CrossRef]
- Perez, B.; Musolesi, M.; Stringhini, G. You are your metadata: Identification and obfuscation of social media users using metadata information. In Proceedings of the AAAI Conference on Web and Social Media (ICWSM), Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Macwan, K.R.; Patel, S.J. k-NMF Anonymization in Social Network Data Publishing. Comput. J. 2018, 61, 601–613. [Google Scholar] [CrossRef]
- Kim, J. Protecting Metadata of Access Indicator and Region of Interests for Image Files. Secur. Commun. Netw. 2020, 2020, 4836109. [Google Scholar] [CrossRef]
- Fukami, A.; Stoykova, R.; Geradts, Z. A new model for forensic data extraction from encrypted mobile devices. Forensic. Sci. Int. Digit. Investig. 2021, 38, 301169. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X. Large-Scale Social Network Privacy Protection Method for Protecting K-Core. Int. J. Netw. Secur. 2021, 23, 612–622. [Google Scholar]
- Yang, Q.; Wang, C.; Hu, T.; Chen, X.; Jiang, C. Implicit privacy preservation: A framework based on data generation. Secur. Saf. 2022, 1, 2022008. [Google Scholar] [CrossRef]
- Alyousef, A.S.; Srinivasan, K.; Alrahhal, M.S.; Alshammari, M.; Al-Akhras, M. Preserving Location Privacy in the IoT against Advanced Attacks using Deep Learning. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 416–427. [Google Scholar] [CrossRef]
- Maiano, L.; Amerini, I.; Celsi, L.R.; Anagnostopoulos, A. Identification of Social-Media Platform of Videos through the Use of Shared Features. J. Imaging 2021, 7, 140. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Singh, M. Social Networks Privacy Preservation: A Novel Framework. Cybern. Syst. 2022, 1–32. [Google Scholar] [CrossRef]
- Twitter Standard Search v1.1 API Documentation. Available online: https://developer.twitter.com/en/docs/twitter-api/v1 (accessed on 4 June 2023).
- Giorgi, S.; Guntuku, S.C.; Rahman, M.; Himelein-Wachowiak, M.; Kwarteng, A.; Curtis, B. Twitter Corpus of the #BlackLivesMatter Movement and Counter Protests: 2013 to 2020. arXiv 2020, arXiv:2009.00596. [Google Scholar] [CrossRef]
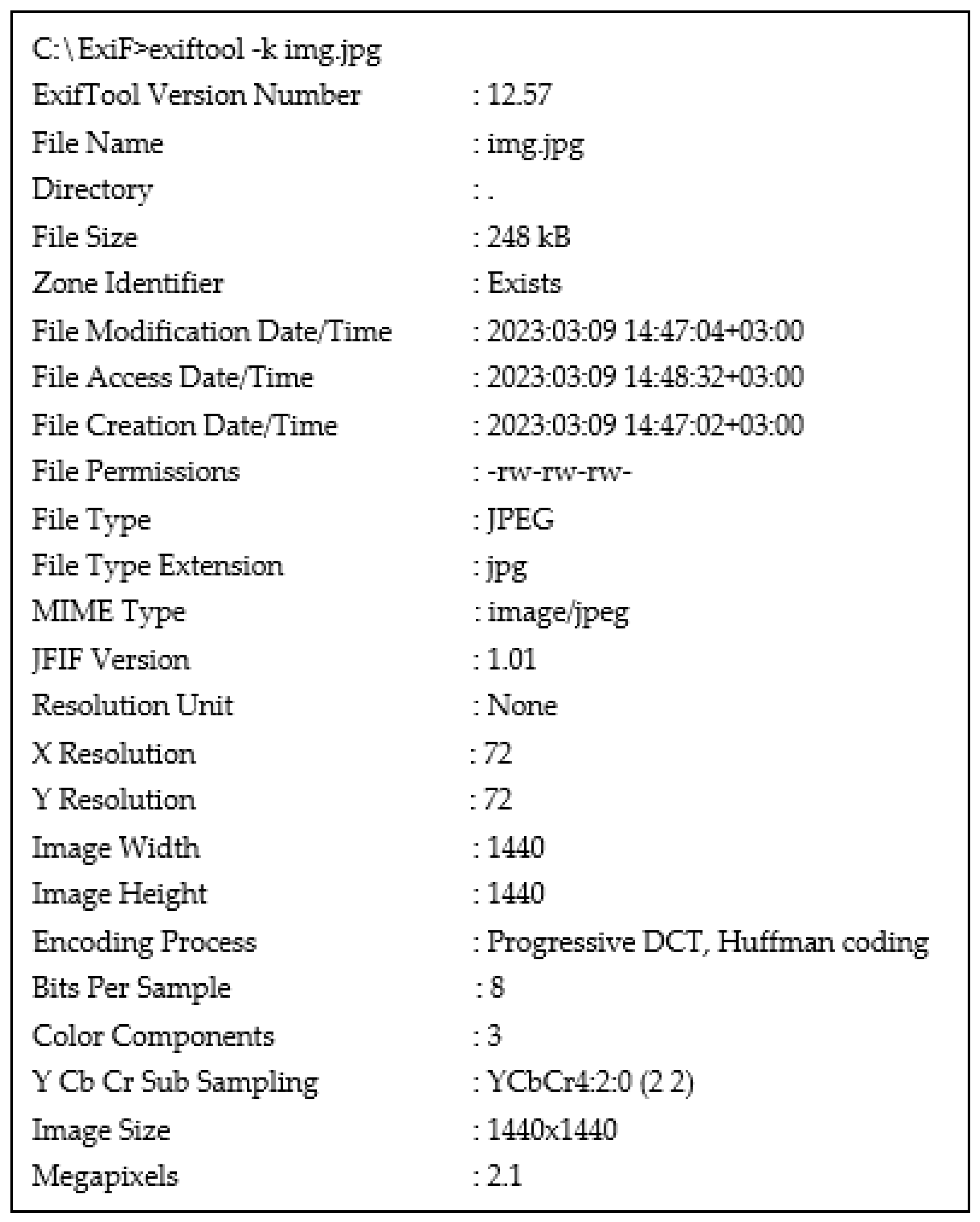
- Harvey, P. Exiftoolgui for Windows v12.62. 2023. Available online: https://exiftool.org/exiftool_pod.html (accessed on 4 June 2023).
- Henderi; Wahyuningsih, T.; Rahwanto, E. Comparison of Min-Max normalization and Z-Score Normalization in the K-nearest neighbor (KNN) Algorithm to Test the Accuracy of Types of Breast Cancer. Int. J. Inform. Inf. Syst. 2021, 4, 13–20. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Nnamoko, N.; Arshad, F.; England, D.; Vora, J.; Norman, J. Evaluation of Filter and Wrapper Methods for Feature Selection in Supervised Machine Learning. In Proceedings of the 15th Annual Postgraduate Symposium on the convergence of Telecommunication, Networking and Broadcasting, Liverpool, UK, 23–24 June 2014. [Google Scholar]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]
- Agrawal, T. Introduction to Hyperparameters. In Hyperparameter Optimization in Machine Learning; Apress: Berkeley, CA, USA, 2020; pp. 1–30. [Google Scholar] [CrossRef]
- Agrawal, T. Hyperparameter optimization using scikit-learn. In Hyperparameter Optimization in Machine Learning; Apress: Berkeley, CA, USA, 2021; pp. 31–51. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ren, W.; Tong, X.; Du, J.; Wang, N.; Li, S.; Min, G.; Zhao, Z. Privacy Enhancing Techniques in the Internet of Things Using Data Anonymisation. Inf. Syst. Front. 2021. [Google Scholar] [CrossRef]
- Advanced Encryption Standard. Available online: https://www.tutorialspoint.com/cryptography/advanced_encryption_standard.htm (accessed on 4 June 2023).
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. -Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Ismael, R.S.; Youail, R.S.; Kareem, S.W. Image encryption by using RC4 algorithm. Eur. Acad. Res. 2014, 4, 5833–5839. [Google Scholar]
- API Reference—Pandas 1.5.3 Documentation (pydata.org). Available online: https://pandas.pydata.org/docs/reference/index.html (accessed on 4 June 2023).
- AES 256 Encryption and Decryption in Python. Available online: https://www.quickprogrammingtips.com/python/aes-256-encryption-and-decryption-in-python.html (accessed on 4 June 2023).
- Narula, D.; Kumar, P.; Upadhyaya, S. Data Utility Metrics for k-anonymization Algorithms. Int. J. Sci. Eng. Res. 2016, 7, 79–83. [Google Scholar]
- Tasnim, A.; Saiduzzaman; Rahman, M.A.; Akhter, J.; Rahaman, A.S.M.M. Performance Evaluation of Multiple Classifiers for Predicting Fake News. J. Comput. Commun. 2022, 10, 1–21. [Google Scholar] [CrossRef]
- Kareem, S.W. A Nature-Inspired Metaheuristic Optimization Algorithm Based on Crocodiles Hunting Search (CHS). Int. J. Swarm Intell. Res. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar]
- Chen, K.; Liu, L. Geometric data perturbation for privacy preserving outsourced data mining. Knowl. Inf. Syst. 2010, 29, 657–695. [Google Scholar] [CrossRef]
- Alemerien, K. User-Friendly Privacy-Preserving Photo Sharing on Online Social Networks. J. Mob. Multimed. 2020, 16, 267–292. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Pros | Cons |
|---|---|---|
| Wijayanto et al. [11] (2016) | The primary objective of the study is to create effective methods and tools to preserve the copyright of digital images. The proposed approach involves encrypting the EXIF metadata using the XTEA algorithm and embedding it at the end of the image file while eliminating the original EXIF data. The results obtained from the encryption-decryption process demonstrate the successful protection of both the EXIF information and the digital image pixels. | The authors did not use similarity metrics to check the amount of change in the images and relied only on the visual differences. Also, they do not study the utility of the image metadata after encryption. |
| Delgado et al. [12] (2016) | This research aimed to enhance privacy in JPEG images by implementing access control policies determined by image owners and authorized users and encrypting both policies and images to perform access control based on those policies. | The use of double encryption in this approach proved to be resource-intensive. It may be more effective to explore solutions that preserve the privacy of specific areas of the image instead of encrypting the entire image. |
| Takbiri et al. [13] (2017). | The paper addresses concerns regarding privacy in mobile devices and location-based services (LBS). It highlights the potential compromise of LBS users’ privacy through statistical analysis of their movement patterns. The concept of perfect location privacy is introduced and the paper explores its achievability in anonymization-based LBS systems. These systems involve permuting user identifiers at regular intervals to prevent identification based on statistical analysis of long time sequences. | No clear trade-off between utility and privacy was established. |
| Shozi et al. [14] (2017) | The paper analyzes privacy policies of social media sites and presents an African perspective towards privacy. The paper provides recommendations towards data privacy in general and in the African context. It also explores the challenges and considerations associated with protecting privacy in the context of large-scale data collection and analysis on social media platforms. | The findings and conclusions of the paper are specific to certain social media platforms, user demographics, or cultural contexts. Generalizing the results to other platforms or populations is challenging. The paper may face limitations in providing up-to-date insights and recommendations, as privacy practices and regulations of social media platforms are constantly evolving. |
| Ghazinour and Ponchak [15] (2017) | The paper demonstrated the feasibility of using C# programming language to collect and alter photo metadata, highlighting the importance of addressing privacy concerns by providing users with tools to manage and protect their sensitive information before sharing images on social media platforms. | By enabling users to modify image metadata to safeguard their privacy, the trade-off is that it diminishes the usefulness or utility of the metadata itself. The scalability of their application was limited as it restricted users to extracting metadata for one image at a time. |
| Perez et al. [16] (2018) | The paper presents an in-depth analysis of the identification risk posed by metadata to a user account and treats identification as a classification problem. It uses supervised learning techniques to evaluate the effectiveness of different obfuscation strategies. | The authors of the paper did not consider the metadata related to the images being posted in the tweet, which could contain sensitive information. Additionally, the effect of obfuscation on data utility was not analyzed in their work. |
| Macwan and Patel [17] (2018) | The study proposes a method that utilizes k-Nonnegative Matrix Factorization (k-NMF) to anonymize sensitive information in social network datasets. The paper categorizes the state-of-the-art anonymization methods on simple graphs into three main categories: K-anonymity-based privacy preservation via edge modification, probabilistic privacy preservation via edge modification, and non-edge modification-based privacy preservation. | The k-NMF anonymity model performs edge insertion/deletion operation to achieve at least k edges that have the same mutual friend value. Edge inserted between two vertices brings change in mutual friend value of other edges, too. Thus, k-NMF anonymity is more complicated than k-anonymity. The effect of anonymization on data utility was not analyzed in their work. |
| JeongYeon Kim [18] (2020) | The research conducted a comprehensive review of image protection methods, focusing on regions of interest and various metadata in the context of JPEG privacy and security standards. The study found that suggested methods involve hiding sensitive areas of personal identifiable information by overlaying other images. In contrast to existing standards such as JPSEC, which primarily secure the entire code stream or segments of JPEG 2000 coded data, the new standards prioritize metadata and employ JPEG XT box formats instead of introducing new code stream methods. This approach offers greater flexibility by allowing data represented as XML or JSON and even code streams within metadata areas, enabling the application of additional security features such as XACML policies. The study highlights that important metadata, including payment or licensing data, can also be utilized for implementing access control policies. | The paper might not provide an in-depth analysis of the practical implementation challenges or considerations involved in applying the suggested image protection methods. This could include factors such as computational requirements, processing time, or compatibility issues with existing systems. The effectiveness of the techniques in handling large-scale image datasets or real-time scenarios could be a limitation that requires further investigation. The use of overlapping images or additional metadata might introduce overhead or affect image quality, which could impact the overall user experience. The research did not include comprehensive evaluation or validation of the proposed methods against real-world scenarios or diverse image datasets. The absence of extensive experimentation or empirical evidence could limit the confidence in the effectiveness and robustness of the suggested approaches. |
| Aya Fukami et al. [19] (2021) | The paper delves into the obstacles present in contemporary criminal investigations owing to the heightened security protocols in mobile devices. It accentuates the crucial role of mobile forensic techniques in the recovery of evidence from these devices, which has become imperative in investigations. The paper underlines the increasing concerns around security and privacy and demonstrates how encryption and other security measures inhibit traditional forensic data extraction. In response, the paper advocates for a new forensic acquisition model that hinges on circumventing security and leveraging vulnerabilities, and this approach is supported by a legal framework that prioritizes the usability of digital evidence obtained through vulnerability exploitation. | The paper does not include a comparative analysis of the proposed technique with similar state-of-the-art techniques. Additionally, it lacks experimental results of the framework on real-world systems and datasets. |
| Jian Li et al. [20] (2021) | The article proposes a new method for protecting the k-core of social networks to preserve user privacy. The k-core of a graph is the maximal subgraph in which all vertices have at least degree k. The proposed method uses a combination of node deletion and edge addition to protect the k-core of social networks. The proposed method is evaluated on real-world datasets and compared with other state-of-the-art methods. The results show that the proposed method outperforms other methods in terms of privacy protection and data utility. | |
| [21] Yang Q et al. (2022) | The paper proposes a framework for implicit privacy preservation based on data generation called IMPOSTER. The study introduces a method that aims to protect privacy by generating synthetic data that preserves the statistical characteristics and patterns of the original dataset. The framework provides a way to protect privacy while maintaining data utility and statistical fidelity. | The paper does not extensively evaluate the robustness of the proposed technique against potential privacy attacks. It is crucial to assess how effectively the framework can withstand different types of privacy attacks, such as inference attacks or membership attacks, to ensure the adequacy of privacy protection. Generating synthetic data using Generative Adversarial Network can be computationally expensive, and the feasibility of applying the technique to large-scale datasets or real-time scenarios is limited. |
| Alyousef et al. [22] (2021) | The paper proposes a novel approach to preserving location privacy in the Internet of Things (IoT) against advanced attacks by creating dummy locations using deep learning. The paper first generates sensitive weight documents based on the user’s different location semantics automatically, then obtains the best collaborative segment for k-anonymity of the user’s location by using the reinforcement learning algorithm, and finally, the bidirectional k-disturbance of the users’ location and query location are calculated using deep learning. The proposed system shows better results in terms of entropy (the privacy protection metric), accuracy (the deep learning metric), and total execution time (the performance metric) compared to the well-known DDA and BDA systems. | While the paper addresses location privacy, it does not extensively consider the issue of query privacy. In particular, the vulnerability of query privacy to query sampling attacks, where the analysis of sent queries can occur, is not thoroughly explored. These attacks exploit the connections between Points of Interest (PoI) and their associated locations. Thus, the paper’s limitation lies in the lack of emphasis on preserving query privacy. |
| Maiano et al. [23] (2021) | The paper proposes two methods for identifying the platform of origin for videos shared on different social networks using joint image features. The study shows that image and video forensics share common traces, and a mixed approach may be beneficial. The authors use transfer learning-based methods and find that low-level features generalize well across images and videos. They also show that a multitask-learning approach is more effective than single-task learning. | Firstly, the proposed method is susceptible to false positives, which can lead to incorrect platform identification. Secondly, the study only focuses on videos shared on a single social media platform and does not consider the case of multiple sharing. Thirdly, the training dataset used in the study is relatively small, and future work could aim to gather a larger dataset. Finally, the study does not consider other types of multimedia content, such as audio or text, which could also be used to identify the platform of origin. |
| Amardeep Singh and Monika Singh [24] (2022) | The paper presents a framework designed to protect the identity and sensitive information of users in a social network. The framework comprises two phases: Enhanced K-anonymization (Phase I) and Sensitive Attribute Perturbation (Phase II). The evaluation utilized real-time datasets from various online social networks (OSNs), and the results support the effectiveness of the technique in striking a balance between privacy protection and data utility in OSNs. | The extra phase that is proposed by the algorithm results in increased computational requirements and processing time. The proposed approach incorporates a reference attribute table (RAT) to protect users’ sensitive attributes. However, it should be noted that the algorithm may be vulnerable to potential threats related to the disclosure of the table itself. |
| Feature Name | Data Type | Feature Description |
|---|---|---|
| Language | String | Tweet Language |
| retweeted status | Binary (0 or 1) | Indicates whether the Tweet was a Retweet or not |
| from_user_followers_count | Integer | Number of Followers the User has |
| from_user_friends_count | Integer | Number of Friends the User has |
| from_user_listed_count | Integer | Number of public lists the user is a member of |
| from_user_favorites_count | Integer | Number of tweets user has liked |
| from_user_statuses_count | Integer | Number of tweets/ retweets user has posted |
| from_user_verified | Boolean (0 or 1) | Indicates whether the user has a Verified account |
| Geo_enabled | Boolean (0 or 1) | Indicates whether user has provided his location |
| from_user_location | String | If geo enabled is 1, this displays the user-defined location for his/her profile |
| tweet_creation_time | Date (MMM-DD) | The date on which the User created the tweet |
| num_characters | Integer | Number of characters in the tweet |
| Source | String | The Twitter source from which the tweet was posted |
| from_user_id | String | The user ID of the user (The target variable) |
| Megapixels | Float | The number of pixels of the image |
| ImageHeight | Float | The height of the image |
| ImageWidth | Float | The width of the image |
| File Size | Integer | In KB |
| MediaWhitePoint | String | Chromaticity of White point of the image |
| ProfileDescription | String | ICC color profile description |
| ProfileCreator | String | Creator name of ICC color profile |
| ProfileVersion | String | Embedded ICC color profile version |
| ProfileCopyright | String | Embedded ICC color profile |
| XResolution | Integer (1 to 72) | Horizontal resolution of Image |
| Rendering Intent | String | The method by which colors in the image will be compressed or clipped when separated to CMYK |
| Photo_spect_ratio | Float | Ratio of image width to its height |
| Longitude | Float | Location coordinates for the image |
| Latitude | Float | |
| exif_camera_make | String | The camera model used to capture the image |
| exif_ aperture_value | Float | The aperture value of the camera lens(in cm) |
| exif_focal_length | Float | The focal length of the camera lens(in cm) |
| Feature Name | Data Type | Feature Description |
|---|---|---|
| from_user_followers_count | Integer | Number of Followers the User has |
| from_user_friends_count | Integer | Number of Friends the User has |
| from_user_listed_count | Integer | Number of public lists the user is a member of |
| from_user_favorites_count | Integer | Number of tweets user has liked |
| from_user_statuses_count | Integer | Number of tweets/ retweets user has posted |
| num_characters | Integer | Number of characters in the tweet |
| Megapixels | Float | The number of pixels of the image |
| File Size | Integer | Size of the image file in KiloBytes |
| XResolution | Integer (1 or 72) | Horizontal resolution of Image |
| Photo_spect_ratio | Float | Ratio of image width to its height |
| Longitude | Float | Location coordinates of the image Location coordinates of the image |
| Latitude | Float | |
| exif_aperture_value | Float | The aperture value of the camera lens(in cm) |
| exif_focal_length | Float | The focal length of the camera lens (in cm) |
| Normalization Technique | Accuracy % |
|---|---|
| No Normalization | 82.55 |
| Min-Max Normalization | 68.45 |
| Z-score Normalization | 70.74 |
| Feature Selection Technique | No. of Features Selected |
|---|---|
| Pearson’s Correlation | None |
| Chi-Square Test | 25 out of 29 |
| Wrapper Method | 15 out of 29 |
| Feature Name | Data Type | Feature Description |
|---|---|---|
| retweeted_status | Boolean (0 or 1) | Indicates whether the Tweet was a Retweet or not |
| from_user_followers_count | Integer | Number of Followers the User has |
| from_user_friends_count | Integer | Number of Friends the User has |
| from_user_verified | Boolean (0 or 1) | Indicates whether the user has a Verified account |
| from_user_location | String | If geo enabled is 1, this displays the user-defined location for his/her profile |
| favorite_count | Integer | Number of Tweets the User has Liked |
| tweet_creation_time | Date (MMM-DD) | The date on which the User created the tweet |
| Source | String | The Twitter source from which the tweet was posted |
| from_user_id | String | The user ID of the user (The target variable) |
| Megapixels | Float | The number of pixels of the image |
| Longitude | Float | Location coordinates for the image |
| Latitude | Float | Location coordinates for the image |
| exif_camera_make | String | The camera model used to capture the image |
| exif_aperture_value | Float | The aperture value of the camera lens(in cm) |
| exif_focal_length | Float | The focal length of the camera lens(in cm) |
| Parameter | After GridSearchCV | Before GridSearchCV |
|---|---|---|
| N_neighbors | 5 | 3 |
| P | 1 | 2 |
| Parameter | After RandomizedSearchCV | Before RandomizedSearchCV |
|---|---|---|
| n_estimators | 800 | 100 |
| min_samples_split | 2 | 2 |
| min_samples_leaf | 1 | 1 |
| max_feaures | Auto | Auto |
| max_depth | 100 | None |
| bootstrap | True | True |
| Parameter | After GridSearchCV | Before GridSearchCV |
|---|---|---|
| solver | Newton-cg | Lbfgs |
| penalty | 12 | 12 |
| C | 1.0 | 1.0 |
| Model | Before Hyperparameter Tuning | After Hyperparameter Tuning |
|---|---|---|
| KNN | 82.25 | 93.3 |
| SVM | 87.58 | 95.81 |
| MLP | 86.65 | 94.51 |
| Random Forest | 85.78 | 95.72 |
| MLR | 86.49 | 92.58 |
| %Encryption | KNN | SVM | MLP | RF | MLR |
|---|---|---|---|---|---|
| 0 | 93.3 | 95.81 | 94.51 | 95.7 | 92.5 |
| 10 | 91.23 | 94.21 | 93.21 | 93.89 | 78.32 |
| 20 | 90.72 | 93.48 | 92.47 | 91.23 | 73.23 |
| 30 | 87.68 | 89.36 | 88.14 | 90.55 | 64.77 |
| 40 | 86.9 | 87.25 | 87.75 | 88.4 | 59.45 |
| 50 | 84.6 | 86.52 | 85.25 | 86.29 | 48.91 |
| 60 | 80.54 | 82.73 | 78.91 | 80.59 | 42.68 |
| 70 | 79.54 | 81.25 | 71.49 | 71.17 | 39.12 |
| 80 | 76.38 | 78.91 | 67.35 | 70.25 | 33.46 |
| 90 | 68.73 | 74.25 | 51.24 | 55.63 | 25.56 |
| 100 | 31.34 | 50.24 | 32.25 | 37.65 | 24.95 |
| Classification of Algorithms | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| KNN | 0.9297 | 0.9259 | 0.9278 | 93.3 |
| SVM | 0.9425 | 0.9774 | 0.9358 | 95.81 |
| MLP | 0.9241 | 0.9125 | 0.9124 | 94.51 |
| Random Forest | 0.9456 | 0.9723 | 0.9588 | 95.72 |
| MLR | 0.9233 | 0.8979 | 0.9103 | 92.58 |
| Classification Algorithms | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| KNN | 0.5524 | 0.4749 | 0.5108 | 31.34 |
| SVM | 0.6224 | 0.6715 | 0.6871 | 50.24 |
| MLP | 0.4587 | 0.4258 | 0.4125 | 32.25 |
| Random Forest | 0.4569 | 0.4263 | 0.4410 | 37.65 |
| MLR | 0.3823 | 0.3991 | 0.3906 | 24.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khader, M.; Karam, M. Assessing the Effectiveness of Masking and Encryption in Safeguarding the Identity of Social Media Publishers from Advanced Metadata Analysis. Data 2023, 8, 105. https://doi.org/10.3390/data8060105
Khader M, Karam M. Assessing the Effectiveness of Masking and Encryption in Safeguarding the Identity of Social Media Publishers from Advanced Metadata Analysis. Data. 2023; 8(6):105. https://doi.org/10.3390/data8060105
Chicago/Turabian StyleKhader, Mohammed, and Marcel Karam. 2023. "Assessing the Effectiveness of Masking and Encryption in Safeguarding the Identity of Social Media Publishers from Advanced Metadata Analysis" Data 8, no. 6: 105. https://doi.org/10.3390/data8060105
APA StyleKhader, M., & Karam, M. (2023). Assessing the Effectiveness of Masking and Encryption in Safeguarding the Identity of Social Media Publishers from Advanced Metadata Analysis. Data, 8(6), 105. https://doi.org/10.3390/data8060105