
A Profit Maximization Model for Data Consumers with Data Providers’ Incentives in Personal Data Trading Market


Abstract
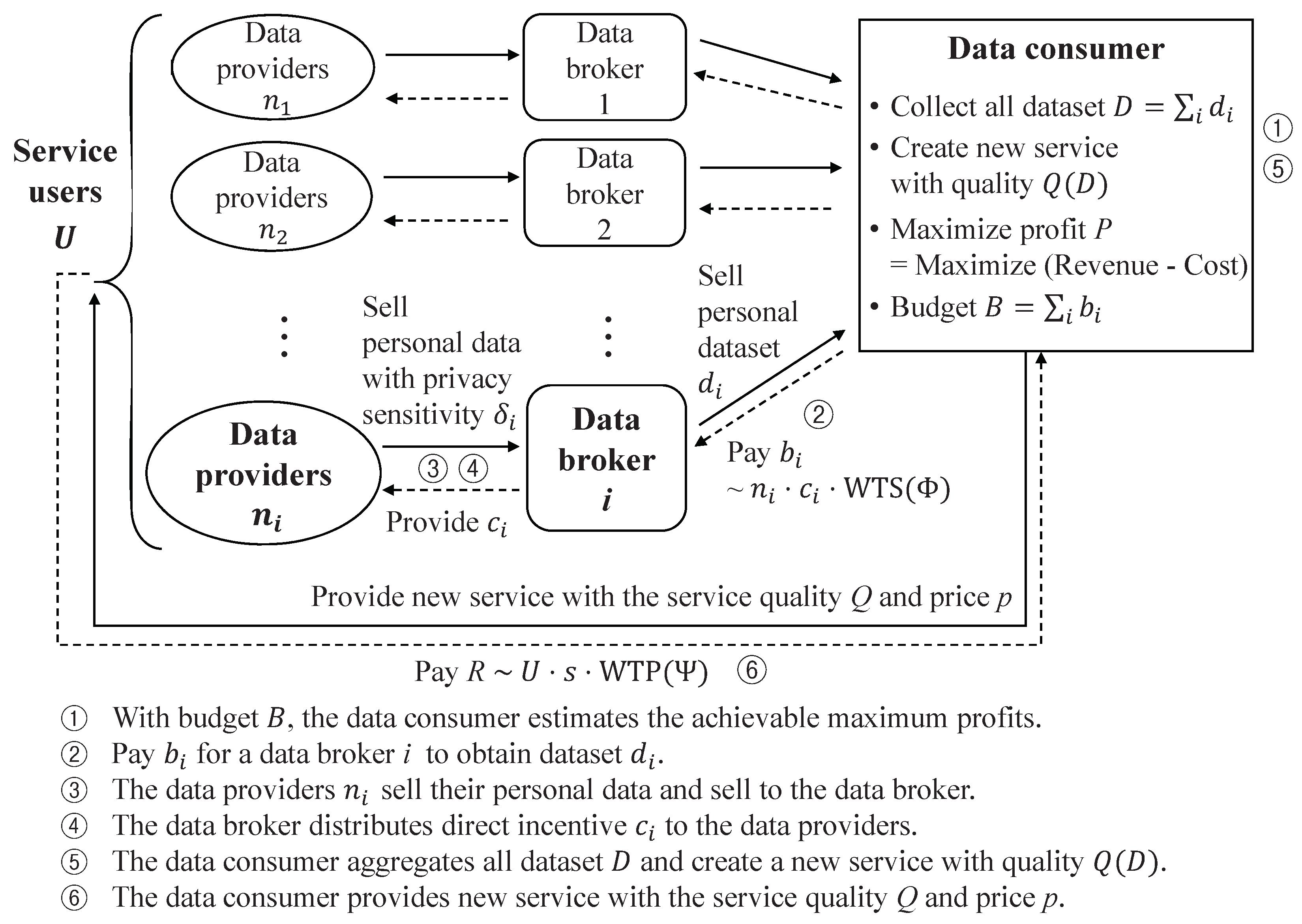
:1. Introduction
- This paper proposes a personal data trading model considering payments of direct incentives to the data providers, in which a data consumer collects personal data from data providers with explicit consent about providing direct incentives through data brokers and creates a new service for targeting the same data providers.
- This paper proposes new revenue and cost models for a data consumer by considering the behavioral models (i.e., willingness-to-pay of service users and willingness-to-sell of data providers) adopted from the authors’ previous works [25,26], which are inspired by the real-world surveys and observations [6,28].
- According to the revenue and cost models, this paper proposes a profit maximization problem. By applying convex optimization techniques, this paper transforms the problem to be more practical. Consequently, this paper finally proposes a constrained profit maximization problem with the limited budget of the data consumer under the practical boundary of cost allocation, which is a constrained nonlinear optimization problem.
- With parameters inspired by real-world survey [29] on data providers, which provided the results with about 1000 respondents regarding willingness-to-share their personal information in exchange for money (i.e., willingness-to-sell personal data), this paper shows various numerical results to check the feasibility of the proposed models. Moreover, this paper identifies several discussion points regarding the proposed model and the analytical results.
2. Related Work
3. System Model
- Data providers: a group of candidate individuals who may provide their own personal data according to their informed consent of using personal data while receiving direct incentives as compensation;
- Data brokers: a group of data brokers who participate data trading market to intermediate between data providers and the data consumer;
- Data consumer: a data consumer who processes personal data and creates new services for service users. The data consumer wants to maximize its profit by providing good quality services to service users while minimizing budget consumption (note that it is a main target for profit maximization analysis in this paper);
- Service users: a group of candidate individuals who may use a service that is provided by the data consumer.
3.1. Cost Model of Data Consumer
3.1.1. Willingness-to-Sell of Data Providers
3.1.2. The Size of Collected Dataset
3.1.3. The Expected Costs of the Data Consumer
3.2. Revenue of Data Consumer
3.2.1. A Service Quality of the Data Consumer
3.2.2. Willingness-to-Pay of the Service Consumers
3.2.3. The Expected Revenue of Data Consumer
4. Proposed Personal Data Trading Model for Data Consumer
4.1. Profit Maximization Model for Data Consumer
Profit Maximization Problem
4.2. Constrained Profit Maximization Problem
5. Numerical Results
5.1. Theoretical Analysis
5.1.1. Data Trading with a Single Data Broker
5.1.2. Data Trading with Two Data Brokers
5.2. Experiments with Real-World Parameters
5.3. Discussions
5.3.1. The Correlation among , , and Data Quality
5.3.2. Time Complexity of SLSQP
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Symbol | Definition |
| N | Number of data brokers in the market |
| Number of potential data providers with data broker i | |
| Privacy sensitivity of data providers | |
| Data provider’s willingness-to-sell function | |
| B | The entire budget of the data consumer |
| budget allocation for data brokers | |
| cost allocation for each data provider | |
| U | Number of potential service users |
| s | Service fee paid by each service user |
| Service user’s willingness-to-pay function | |
| P | Profit function of the data consumer |
| Q | Service quality function of the data consumer |
| D | Size of the entire dataset collected by all data brokers |
| Size of dataset collected by data broker i |
References
- Liang, F.; Yu, W.; An, D.; Yang, Q.; Fu, X.; Zhao, W. A Survey on Big Data Market: Pricing, Trading and Protection. IEEE Access 2018, 6, 15132–15154. [Google Scholar] [CrossRef]
- Azcoitia, S.A.; Laoutaris, N. A Survey of Data Marketplaces and Their Business Models. SIGMOD Rec. 2022, 51, 18–29. [Google Scholar] [CrossRef]
- Zhang, M.; Beltrán, F.; Liu, J. A Survey of Data Pricing for Data Marketplaces. IEEE Trans. Big Data 2023, 9, 1038–1056. [Google Scholar] [CrossRef]
- Transparency Market Research. Data Brokers Market [Data Type: Unstructured Data, Structured Data, Custom Structure Data]—Global Industry Analysis, Size, Share, Growth, Trends, and Forecast, 2022–2031. Available online: https://www.transparencymarketresearch.com/data-brokers-market.html (accessed on 3 August 2023).
- Rieke, A.; Yu, H.; Robinson, D.; von Hoboken, J. Data Brokers in an Open Society: An Upturn Report; Open Society Foundations: New York, NY, USA, 2016. [Google Scholar]
- Niyato, D.; Alsheikh, M.A.; Wang, P.; Kim, D.I.; Han, Z. Market model and optimal pricing scheme of big data and Internet of Things (IoT). In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Yoshihiro, T.; Hosio, S. Simulation-Based IoT Stream Data Pricing Incorporating Seller Competition and Buyer Demands. IEEE Access 2023, 11, 16213–16225. [Google Scholar] [CrossRef]
- Jang, B.; Park, S.; Lee, J.; Hahn, S.G. Three Hierarchical Levels of Big-Data Market Model Over Multiple Data Sources for Internet of Things. IEEE Access 2018, 6, 31269–31280. [Google Scholar] [CrossRef]
- Seo, E.; Kim, H.; Krishnamachari, B.; Elmroth, E. An ICN-Based Data Marketplace Model Based on a Game Theoretic Approach Using Quality-Data Discovery and Profit Optimization. IEEE Trans. Cloud Comput. 2023, 11, 2110–2126. [Google Scholar] [CrossRef]
- Schäfer, F.; Gebauer, H.; Gröger, C.; Gassmann, O.; Wortmann, F. Data-driven business and data privacy: Challenges and measures for product-based companies. Bus. Horiz. 2023, 66, 493–504. [Google Scholar] [CrossRef]
- General Data Protection Regulation (GDPR). Available online: http://data.europa.eu/eli/reg/2016/679/oj (accessed on 13 June 2023).
- California Consumer Privacy Act (CCPA). Available online: https://oag.ca.gov/privacy/ccpa/ (accessed on 13 June 2023).
- Kakarlapudi, P.V.; Mahmoud, Q.H. A Systematic Review of Blockchain for Consent Management. Healthcare 2021, 9, 137. [Google Scholar] [CrossRef] [PubMed]
- Park, H.; Oh, H.; Choi, J.K. A Consent-Based Privacy-Compliant Personal Data-Sharing System. IEEE Access 2023, 11, 95912–95927. [Google Scholar] [CrossRef]
- Datacoup. Datacoup—Reclaim Your Personal Data. Available online: https://datacoup.com/ (accessed on 26 September 2023).
- Langford, J.; Poikola, A.; Janssen, W.; Lähteenoja, V.; Rikken, M. Understanding MyData Operators. Available online: https://mydata.org/publication/understanding-mydata-operators/ (accessed on 3 October 2023).
- Mazurek, G.; Małagocka, K. What if you ask and they say yes? Consumers’ willingness to disclose personal data is stronger than you think. Bus. Horiz. 2019, 62, 751–759. [Google Scholar] [CrossRef]
- Alfnes, F.; Wasenden, O.C. Your privacy for a discount? Exploring the willingness to share personal data for personalized offers. Telecomm. Policy 2022, 46, 102308. [Google Scholar] [CrossRef]
- D’Annunzio, A.; Menichelli, E. A market for digital privacy: Consumers’ willingness to trade personal data and money. J. Ind. Bus. Econ. 2022, 49, 571–598. [Google Scholar] [CrossRef]
- Morel, V.; Santos, C.; Lintao, Y.; Human, S. Your Consent Is Worth 75 Euros A Year—Measurement and Lawfulness of Cookie Paywalls. In Proceedings of the 21st Workshop on Privacy in the Electronic Society (WPES’22), Los Angeles, CA, USA, 7 November 2022; pp. 213–218. [Google Scholar]
- Wein, T. Data Protection, Cookie Consent, and Prices. Economies 2022, 10, 307. [Google Scholar] [CrossRef]
- Wu, J. Secondary Market Monetization and Willingness to Share Personal Data. Available online: https://ssrn.com/abstract=4269334 (accessed on 1 October 2023).
- Parra-Arnau, J. Optimized, direct sale of privacy in personal data marketplaces. Inf. Sci. 2018, 424, 354–384. [Google Scholar] [CrossRef]
- Su, Z.; Qi, Q.; Xu, Q.; Guo, S.; Wang, X. Incentive Scheme for Cyber Physical Social Systems Based on User Behaviors. IEEE Trans. Emerg. Topics Comput. 2020, 8, 92–103. [Google Scholar] [CrossRef]
- Oh, H.; Park, S.; Lee, G.M.; Heo, H.; Choi, J.K. Personal Data Trading Scheme for Data Brokers in IoT Data Marketplaces. IEEE Access 2019, 7, 40120–40132. [Google Scholar] [CrossRef]
- Oh, H.; Park, S.; Lee, G.M.; Choi, J.K.; Noh, S. Competitive Data Trading Model With Privacy Valuation for Multiple Stakeholders in IoT Data Markets. IEEE Internet Things J. 2020, 7, 3623–3639. [Google Scholar] [CrossRef]
- Moyopo, S.; Qu, Y. Quantifying the Data Currency’s Impact on the Profit Made by Data Brokers in the Internet of Things Based Data Marketplace. European J. Electr. Eng. Comput. Sci. 2023, 7, 7–16. [Google Scholar] [CrossRef]
- Benndorf, V.; Normann, H.T. The Willingness to Sell Personal Data. Scand. J. Econ. 2018, 120, 1260–1278. [Google Scholar] [CrossRef]
- Ponemon Institute. Privacy and Security in a Connected Life: A Study of US, European and Japanese Consumers; Ponemon Institute LLC: Traverse City, MI, USA, 2015. [Google Scholar]
- Durand-Hayes, S.; Gooding, M.; Crane, B.; Roesch, H.; Pedersen, K. June 2023 Global Consumer Insights Pulse Survey. Available online: https://www.pwc.com/gx/en/industries/consumer-markets/consumer-insights-survey.html (accessed on 15 November 2023).
- Armstrong, W.E. The Determinateness of the Utility Function. Econ. J. 1939, 49, 453–467. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Berkovitz, L.D. Convexity and Optimization in n; Wiley Inter-Science: Hoboken, NJ, USA, 2001. [Google Scholar]
- Scipy.org. Scipy Reference Guide—Optimization and Root Finding (scipy.optimize.minimize). Available online: https://docs.scipy.org/doc/scipy/reference/optimize.html (accessed on 12 July 2023).
- Feng, Z.; Chen, J.; Zhu, Y. Uncovering Value of Correlated Data: Trading Data based on Iterative Combinatorial Auction. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 260–268. [Google Scholar] [CrossRef]
- Varelas, K.; Dahito, M.A. Benchmarking Multivariate Solvers of SciPy on the Noiseless Testbed. In Proceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO ’19), New York, NY, USA, 13–17 July 2019; pp. 1946–1954. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 5 data brokers, , , | ||||||
| Problem 3 without boundary condition (24) | Problem 3 with boundary condition (24) | |||||
| Case 1: Sufficient budget 200,000 | (17.9, 33.6, 41.6, 57.8, 77.6) | 1,002,123 | 945,146 | |||
| WTS (%) | WTS (%) | |||||
| (, , , , ) | 109,262 | (, , , , ) | 64,619 | |||
| Case 2: Tight budget 50,000 | 927,297 | 919,124 | ||||
| WTS (%) | WTS (%) | |||||
| (, , , , ) | 50,000 | (, , , , ) | 50,000 | |||
| Case 3: Inadequate budget 10,000 | 584,408 | 584,408 | ||||
| WTS (%) | WTS (%) | |||||
| (, , , , ) | 10,000 | (, , , , ) | 10,000 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, H.; Oh, H.; Choi, J.K. A Profit Maximization Model for Data Consumers with Data Providers’ Incentives in Personal Data Trading Market. Data 2024, 9, 6. https://doi.org/10.3390/data9010006
Park H, Oh H, Choi JK. A Profit Maximization Model for Data Consumers with Data Providers’ Incentives in Personal Data Trading Market. Data. 2024; 9(1):6. https://doi.org/10.3390/data9010006
Chicago/Turabian StylePark, Hyojin, Hyeontaek Oh, and Jun Kyun Choi. 2024. "A Profit Maximization Model for Data Consumers with Data Providers’ Incentives in Personal Data Trading Market" Data 9, no. 1: 6. https://doi.org/10.3390/data9010006
APA StylePark, H., Oh, H., & Choi, J. K. (2024). A Profit Maximization Model for Data Consumers with Data Providers’ Incentives in Personal Data Trading Market. Data, 9(1), 6. https://doi.org/10.3390/data9010006