1. Motivation
Recent years have seen some progress when it comes to the availability and analysis of crash data [
1,
2,
3], or [
4]. This has triggered new work and new methods, most notably from machine learning that have the potential to improve knowledge, models, and, ultimately, also the state of traffic safety.
In many cases, road safety work consists of identifying crash blackspots, determining corrective measures, implementing them, and later evaluating them. A reasonable definition of a road accident blackspot will involve the number of crashes per unit of exposure. This paper deals with the problem of modeling the relationship between crash rates and exposure. A better understanding of this relationship allows traffic safety management targeting hazardous locations more clearly based on risk and not merely on crash frequency.
Traditionally, one approach in this context is the development of crash prediction models. They estimate the impact of several variables
on crash frequencies. This is done by applying models of the type [
5,
6,
7,
8,
9]:
where
is the crash frequency at a certain instance
i (time, place,…),
is an exposure variable,
is a baseline flow,
is the mean value of the crash rate, the
are factors thought to influence the crash frequency, and the
are coefficients that quantify the strength of each factor. Moreover, there is a gamma-distributed noise term
here where exp
has mean one and variance
.
The crash frequencies themselves are then found as a realization of a stochastic process with a negative binomial distribution (NBD) with a mean
and variance
:
The parameter describes how much the NBD deviates from a Poisson distribution, with for a Poisson distribution.
The exposure variable, which in the following will be mainly the traffic flow, is difficult to include properly in traffic safety analyses. This is due to the fact that crashes are rare events, and that more often than not, a measurement of the exposure is not available at the site and time of the crash. If available, it is often only in the form of an average over a day, and very often from travel demand models instead of directly measured. Similar difficulties plague the other data source of exposure, which is the one that stems from travel surveys. In many cases, they are averages over large spatial areas (as in travel survey data) although attempts exist to integrate traffic flow with more detail [
10,
11,
12,
13]. However, it might be speculated that crash probabilities depend strongly on the traffic state itself, with traffic flow being one of the major influencing variable [
14,
15].
Especially of interest is the relationship between the crash frequency
N when displayed versus the traffic flow
Q, see [
14]. Note that often not
N itself is displayed as a function of
Q, the crash rate
is used instead:
The crash rate is the ratio between an average crash frequency and the corresponding average traffic flow, leading to a continuous variable. As is demonstrated in
Section 3.1, another interpretation is to use the discrete number of crashes in one hour and the associated traffic flow in this hour, which leads to a mixture between a discrete and a continuous distribution. (A similar approach can be found in [
16], they have used the mileage on the
x-axis.)
Some thoughts about the relationship between
and
are in order. It is very likely that the crash rate does not vanish as a function of
Q, even for very small exposure
Q we expect that the crash rate does not drop to zero, and the results of this work will lend additional credibility to this idea. So:
For freeway traffic, a good deal of results for
and
are available. The most commonly used model has a roughly U-shaped form for
, where crash rates are rather large for small and large flows and have a minimum for intermediate flows. e.g., the work [
17,
18] claims:
where the exponent
is around 1, and
is between 1 and 2. Note that it is assumed that the flow values are normalized to a constant flow so that the units drop out. The first term is for single-vehicle crashes, while the second term describes multi-car crashes. Ceder also observed that one should discern free traffic from congested traffic; this, however, raises the question of how to do this properly based on hourly values. Furthermore, a recent meta-analysis [
19] that used 118 studies come to a similar conclusion, albeit with different exponents
.
Similar results exist [
15,
20,
21] or the German study [
22], sometimes more symmetric second-order polynomial relationships
have been used to describe the data. The approach of [
23] is a bit different since it displays crash rate as a function of a novel indicator that is difficult to translate into traffic flow or volume/capacity ratios. Note as an oddity that one of the earliest models on this topic [
24] proposed an inverse U-shaped relationship, which is once again a second-order polynomial; this time, the crash rate is being small for small flow and large flows, which were in this case AADT values (AADT = annual average daily traffic). However, Veh’s data are also consistent with the assumption that the crash rate is constant, or a weakly increasing function of exposition.
In essence, it could be stated that currently there is no univocal picture about the relationship
for freeway data; for a more complete overview see [
25]. Note, however, that at least the idea of a diverging crash rate for
might be questionable; however, this is not the topic of this work.
Results are different when looking at the relationship between
and AADT as an exposure variable. In this case, crash rates increase with
Q, eventually again as a power-law
[
26].
Very little work has been done so far that looks at the relationship
on the basis for a whole city, with notable exceptions of [
27] with a more theoretical approach, and [
28] trying to test this theory without having real flow data available, and the recent work on a network-based macroscopic safety diagram [
29].
The hypothesis behind this work was the assumption that at least the crash frequency that involves two cars should be a second-order polynomial function of the traffic flow [
30]. A similar idea is also proposed in [
27,
31]. Therefore, a reasonable model for the crash frequency in a city is a combination of single-car crashes (which can be assumed to be proportional to the number of vehicles around
Q) and an interaction term proportional to
. This interaction term is due to a naive assumption that if vehicles move independently of each other, then there is a probability proportional to
that they meet:
Note that it is not easy to bring Equation (
6) in line with Equation (
1): the latter one is tailored towards the use of generalized linear models (GLM) with a logarithmic link function, and by exchanging
with
, the very character of this model is changed into something that no longer can be treated as GLM with a logarithmic link function.
However, this work deals only with the prefactor and ignores , so a GLM and its generalization GAM (generalized additive model) can still be used, but in most cases with the identity as the link function.
As a final remark, note that models with a power-law term as in Equation (
1) are not in line with the assumption in Equation (
4) that the crash rate becomes constant for small exposure. However, when looking closely into [
17,
18], then Equation (
5) function might be modified to avoid the divergence at
by modifying the first term in the equation into
.
2. The Data
This paper uses two types of data. The first one is a large crash database that contains all crashes reported by the Berlin police in the city of Berlin, Germany, during the years 2001–2019. The data are de-identified, i.e., they do not contain numberplates or names of the crash participants or any other information that can be used to identify them. Furthermore, for the subset of data used in the work reported here, the crash-time has been aggregated to the hour.
Note that common practice in Berlin is different from other German federal states since even a lot of property damage only (PDO) crashes are reported in the database. However, even here the analyst must be aware of the fact that these numbers are biased due to the under-reporting of small crashes. For this paper, only some part of the data in this database has been used, see below for a more detailed description.
The second set of data stems from the Traffic4cast competition [
32]. It contains de-identified data from most of the days of 2018 in Berlin, where the speeds and the number of probes of a certain vehicle fleet have been recorded. Since such a data set is a bit unusual, it has been complemented by two other de-identified data sets so that comparisons between the different data could be performed that are interesting in their own right. These are the annual hourly count data from 28 detection sites, which have been provided by the German Federal Highway Research Institute (BASt) and data from the latest travel survey in Germany named Mobility in Deutschland (MiD) [
33].
2.1. The Crash Database
The crash database has been provided by the Berlin police, and it is not publicly available. It contains for each crash
i about
variables (some redundant), where
is the number of people involved in the crash. Here, only the time
, the severity, and the vehicle types have been used. Time is described with minutes’ resolution; however, it is good not to use these numbers to this precision since preference for multiples of 15 min can be observed (see also [
3]). The severity of each crash is described by the number of lightly injured, the number of severely injured, the number of fatalities, and the damage.
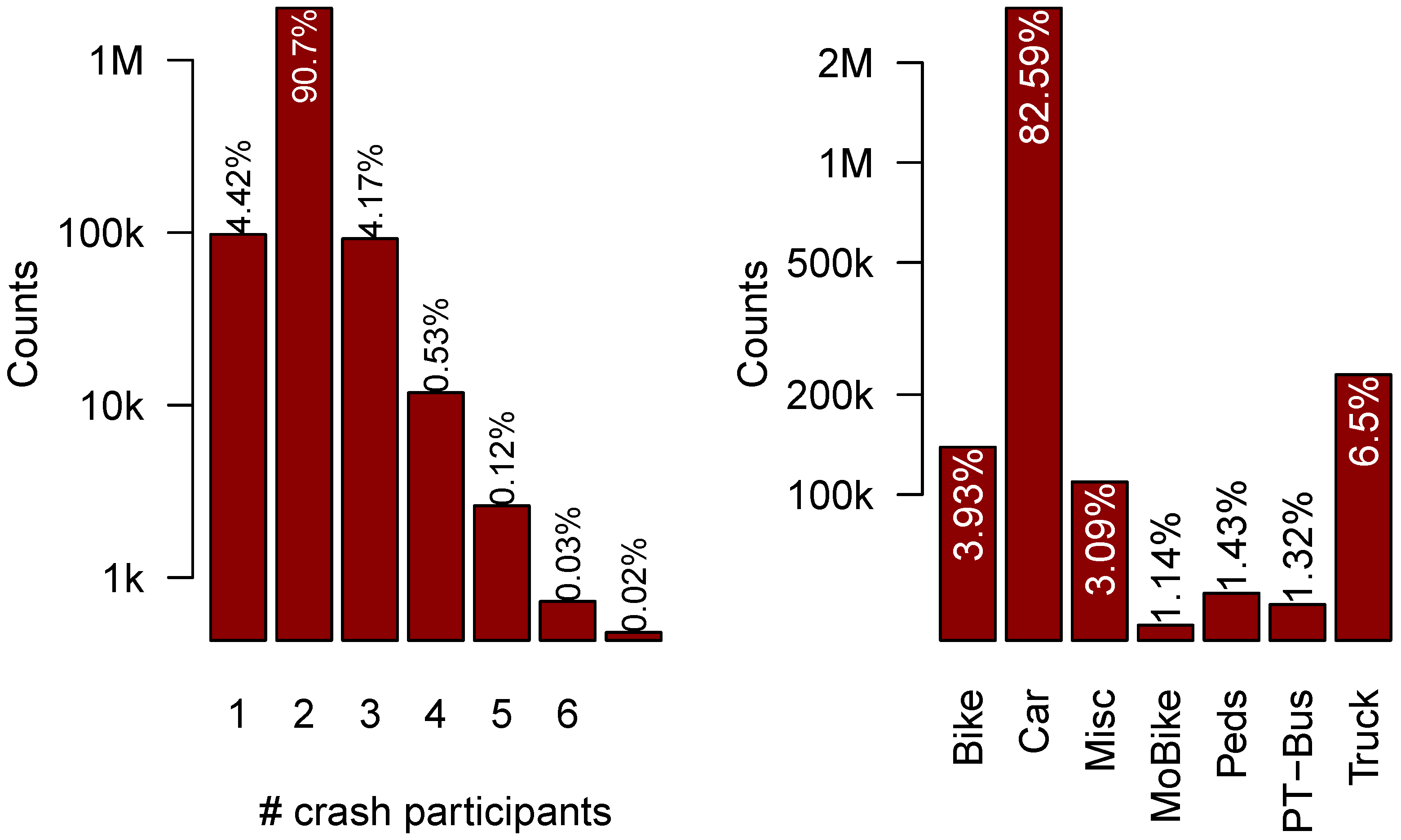
In the following, only severe (crashes with injured or killed participants) and non-severe PDO crashes will be distinguished. The database contains 1,888,038 crashes, and what is important for the analysis below: most of all crashes are between two cars, as can be seen in
Figure 1.
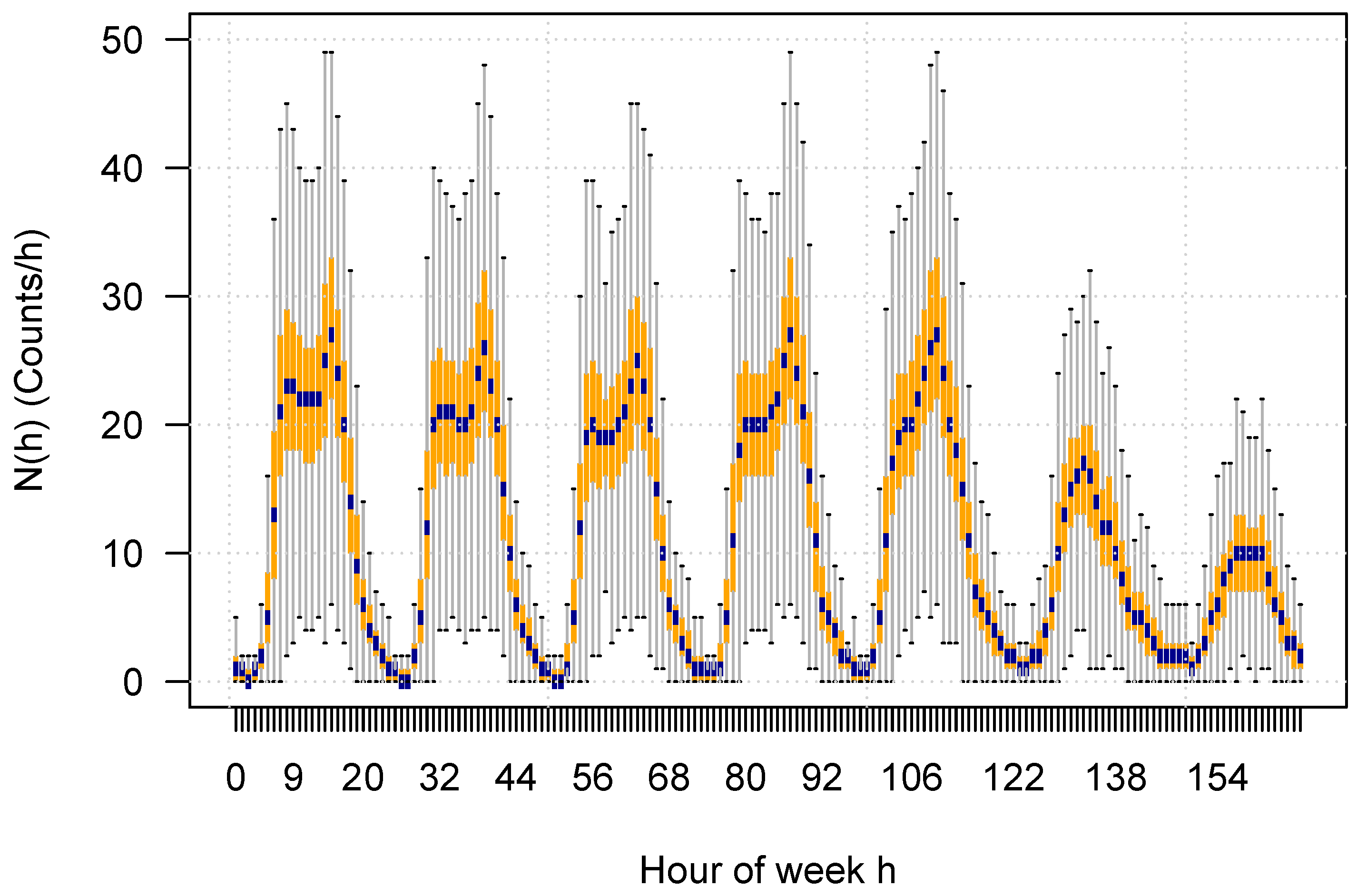
For this study, the timestamps of all crashes of the database have been rounded down to the nearest full hour and translated to the corresponding hour of the week (0–167). Since the data set spans 19 years, each hour occurs 992 times in the data set, resulting in 992 crash numbers for every hour of the week
h. Therefore, for each hour of the week, the distribution of counts can be determined directly. The results are displayed in
Figure 2 as a boxplot, and they display a strong weekly pattern. Very similar results have been reported recently by [
34].
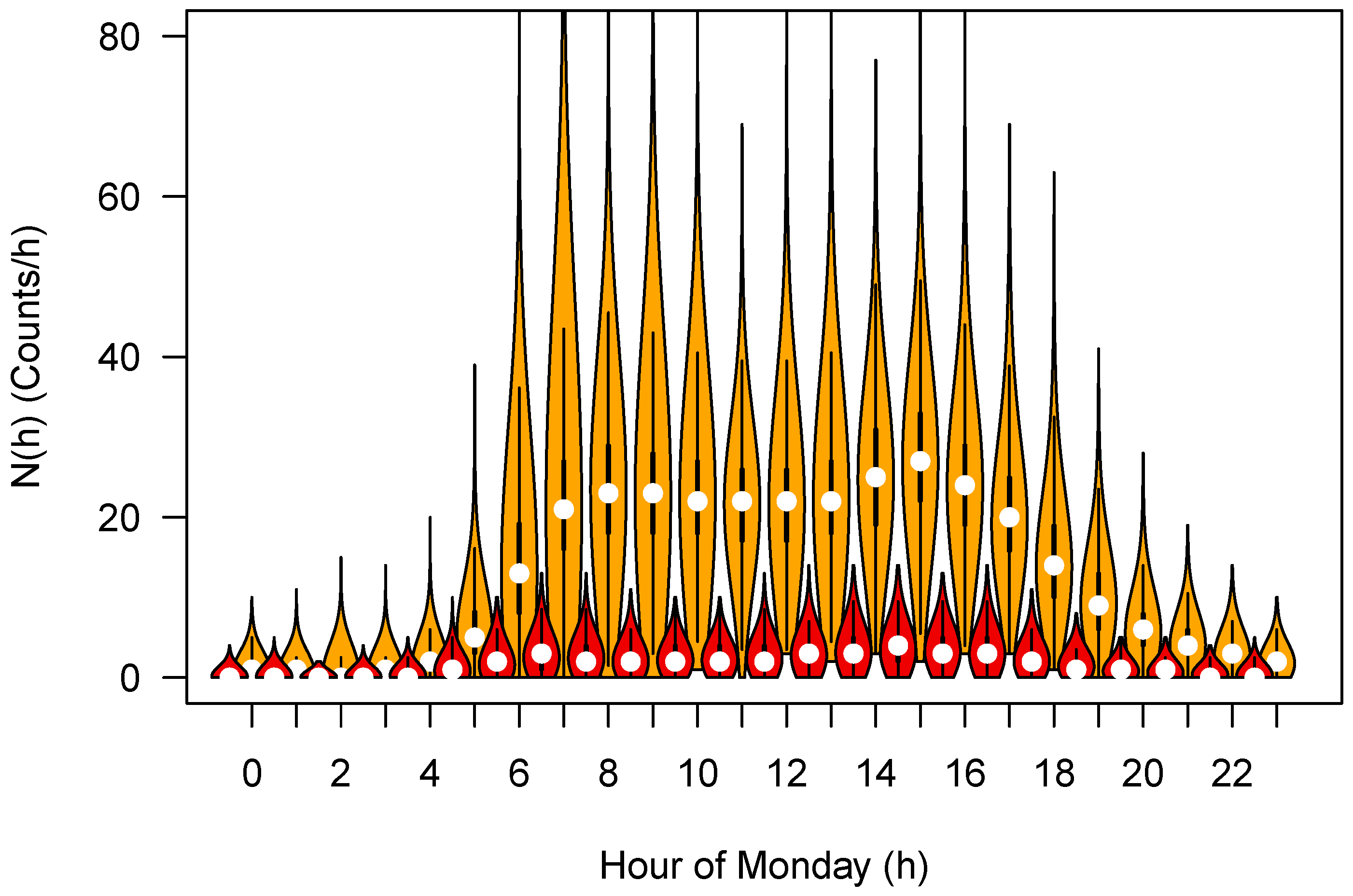
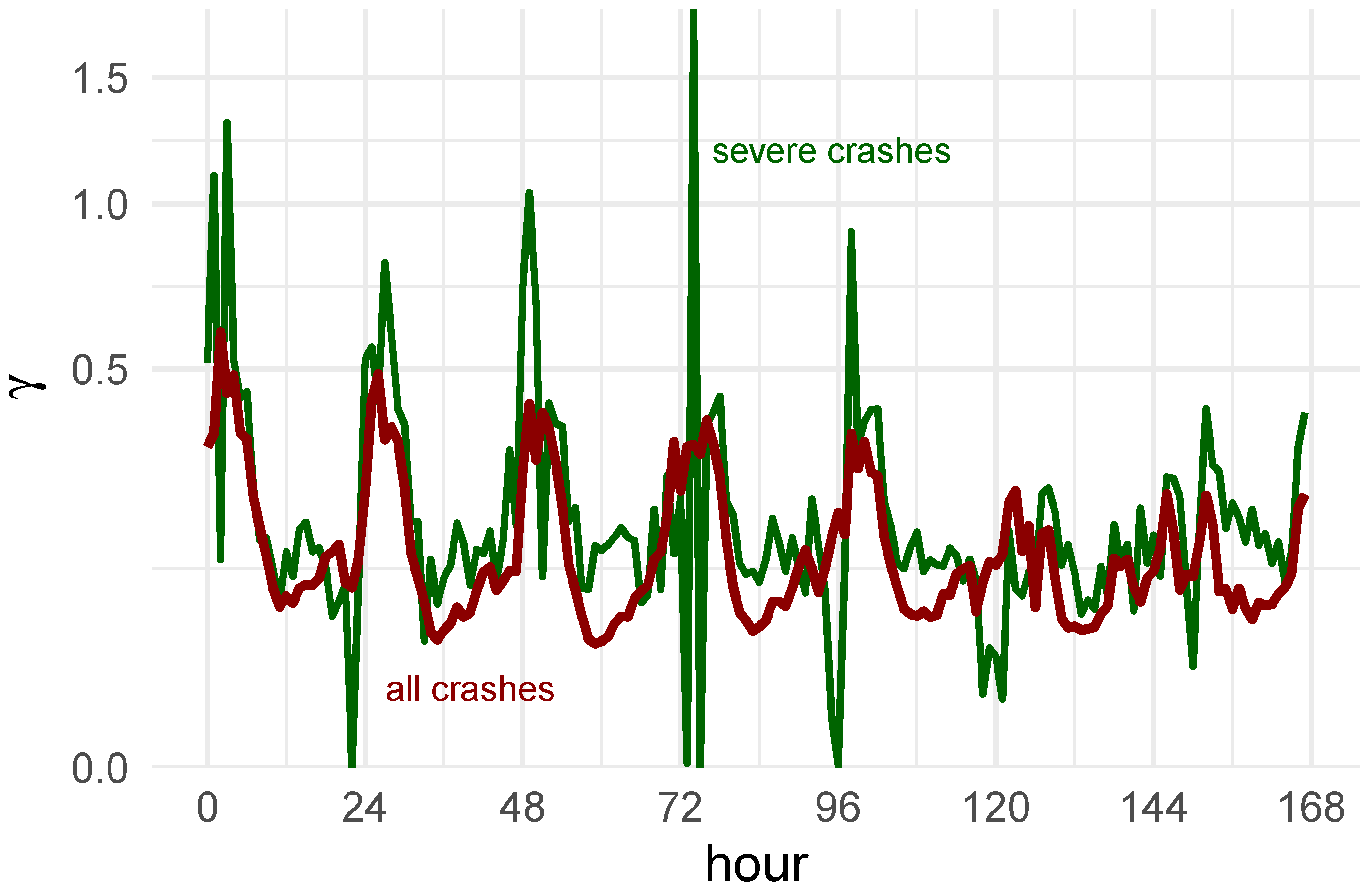
The
Figure 3 displays this result for the Monday only as a violin plot so that the shape of the distributions can be seen more clearly. Moreover, the distribution of severe crashes has been included in this Figure as well.
2.2. The Distribution of the Crash Frequency
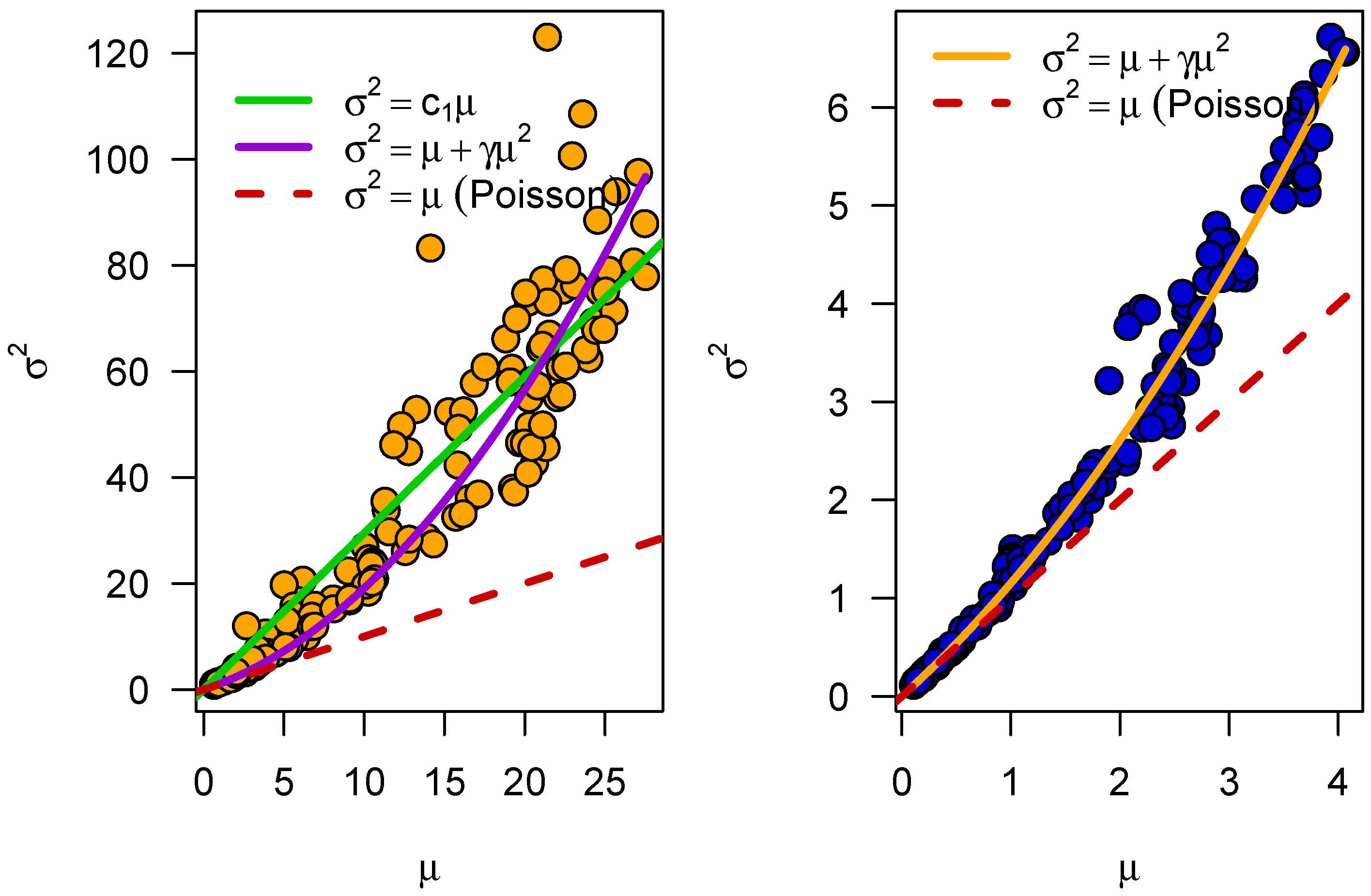
Most likely, the individual distributions in each hour are following an NBD. This can be tested by plotting their variance
against their mean value
. An NBD displays then a second-order polynomial relationship between
and
as stated already in Equation (
2), where the parameter
specifies the deviation of the distribution from a Poisson distribution. The results can be seen in
Figure 4.
Figure 4 shows that the data follow an NBD. Also, the same analysis has been performed for severe crashes only. Various fits to this cloud of data-points have been included in this Figure as well demonstrating that the assumption of the NBD fits these data quite well. All fits are done with R’s lm() function [
35], which executes a linear least-squares fit to these data. The fit for the severe crashes is even better (larger
), leading to two different estimates for the
variable. For all crashes,
is estimated as
, while it is larger for the severe crashes with
. All fits are highly significant, with
p-values for the parameters well below
, and
-values above 0.93.
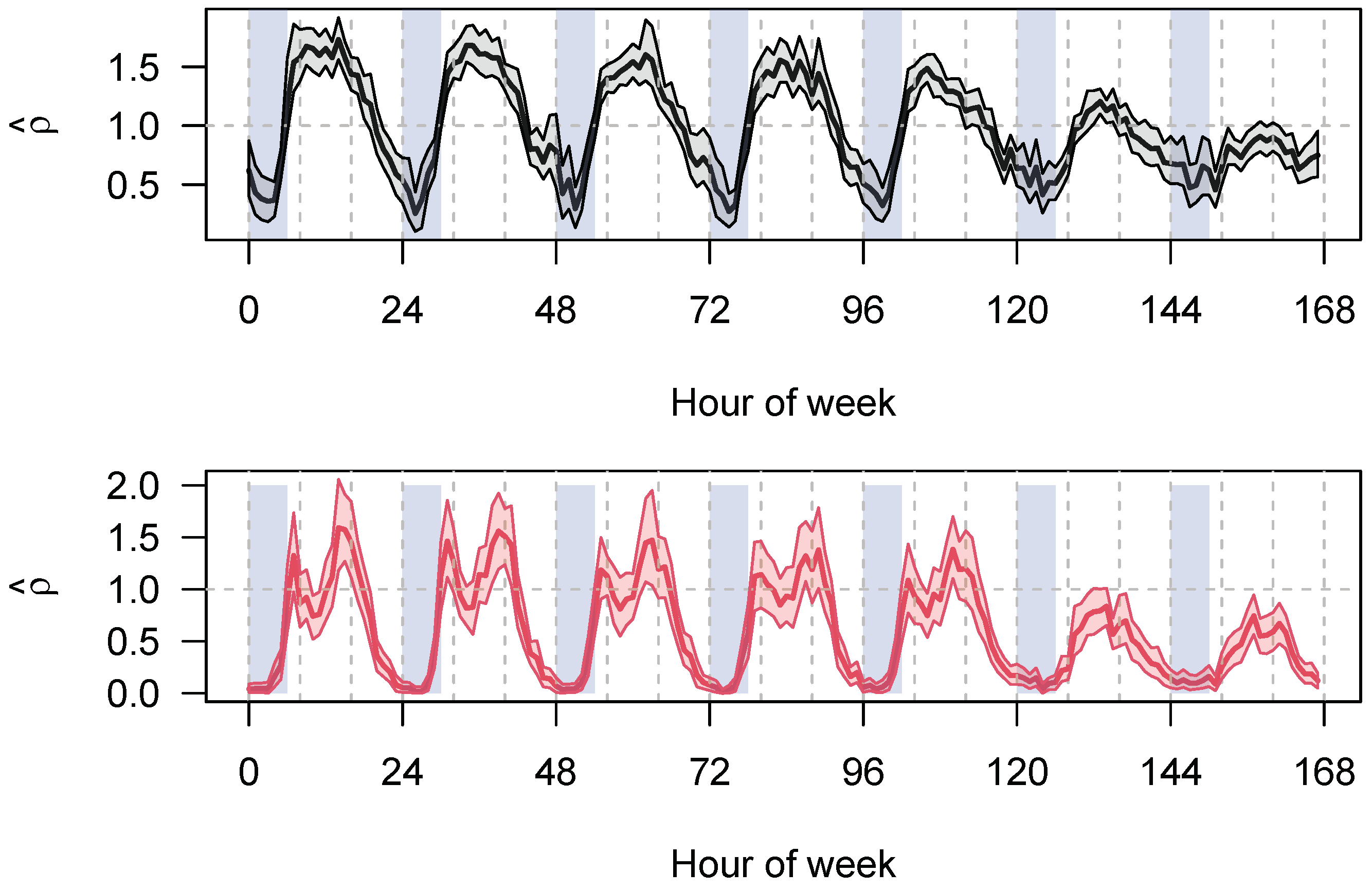
Furthermore, the distribution of each hour of the week can be fitted directly with an NBD. From this, it can be stated that not only
depends on the hour of the week (and presumably, on the traffic state during this hour), the same is true for
as well, see
Figure 5. We have found little work showing such a relationship between
and the traffic state; in [
36] it is shown that their parameter
depends on the length of a road section and that they have not found a dependence of
k on AADT.
2.3. The Traffic Flow Data
The traffic flow data are from the Traffic4cast challenge (T4C), where scientists were asked to find the best possible prediction of the traffic state in a city. Traffic state is defined as the speed and flow pattern , of the cars of a large vehicle fleet, resulting from about probe vehicle data. The index is running from 0 to respectively, while the time t is aggregated to five minutes intervals. Each refers to a specific box, where the boxes cover the whole area of Berlin. Note that the data have been aggregated so that in each of the spatial boxes an 8-bit number results for the flows , and the speeds .
Altogether, data of 273 days from the training-set have been used here, and have been aggregated into hourly values as well for the analysis here. Note that neither the flow nor the speed values can be related to ”real” numbers, they are in a complicated manner scaled variables. Nevertheless, especially the aggregated flow values have been used, they should be proportional to the real traffic flow in the city.
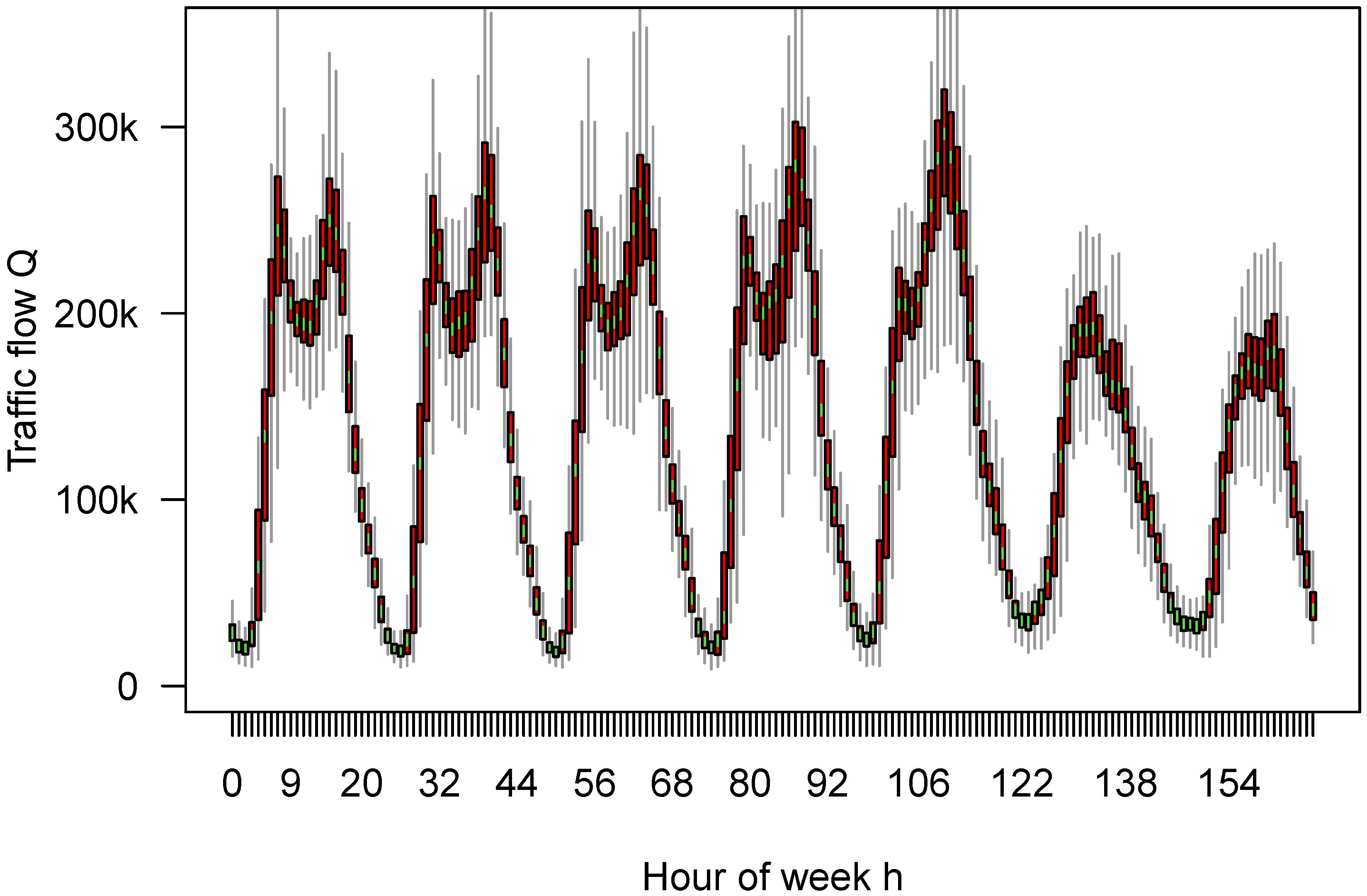
When doing the same aggregation as with the crash data (and taking care of the fact that the timestamps of the training data set are in UTC, Coordinated Universal Time), a similar plot as in
Figure 2 is obtained in
Figure 6.
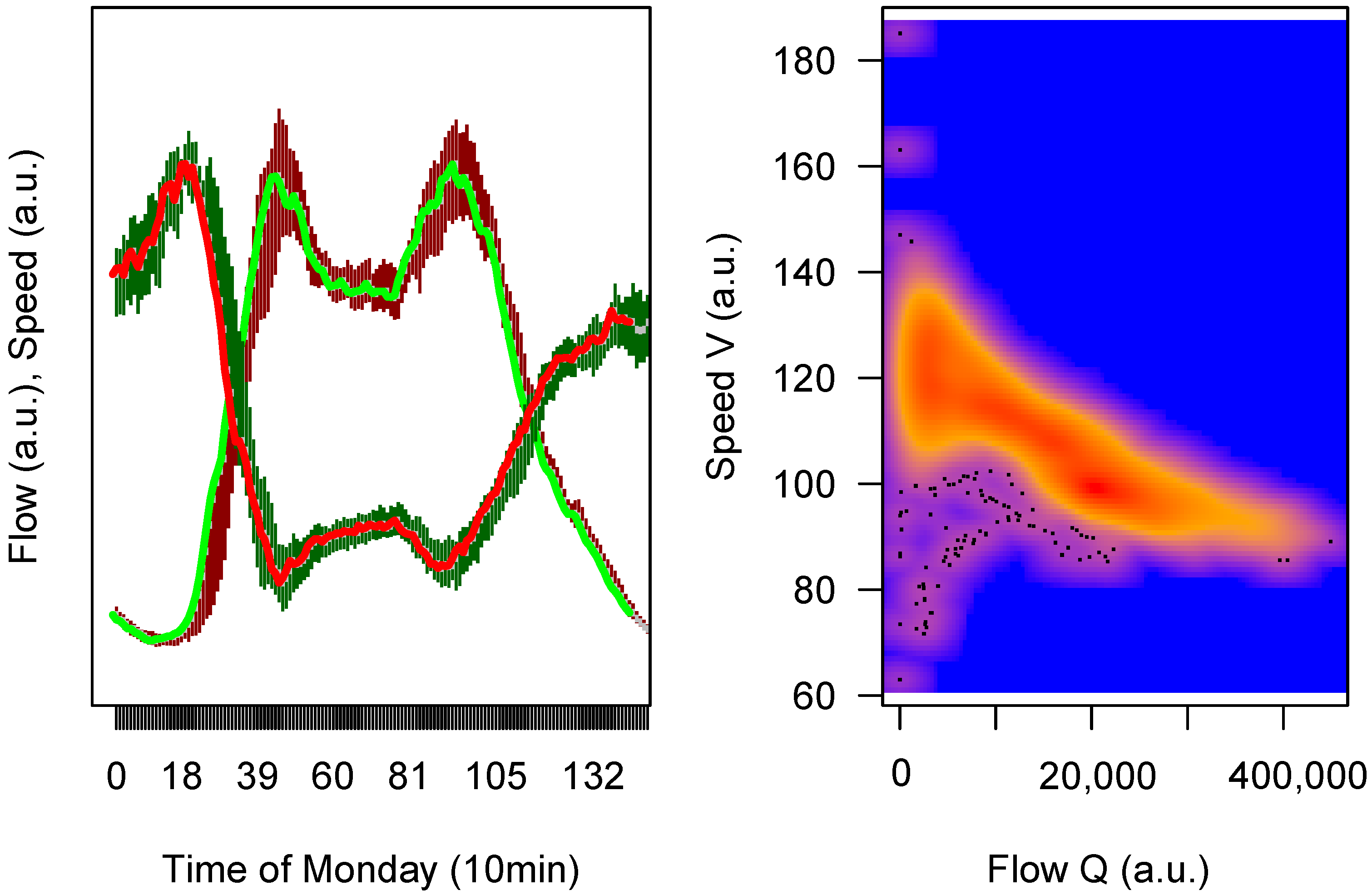
Again, a zoom-in of the flow data is provided in
Figure 7; moreover, the aggregated speed data have been drawn there as well, and a fundamental diagram (which is a so-called macroscopic fundamental diagram [
37]) to demonstrate that these data display a reasonable behavior [
29].
2.4. Supplemental Traffic Flow Data
Since this data set is unusual, it is compared to other data sets that describe the weekly pattern of demand for transport. As already mentioned, two of them have been used here: the annual hourly count data from 28 detection sites in Berlin [
38], which have been provided by the BASt, and data from the latest version of Germany’s travel survey MiD.
The BASt data [
38] are hourly counts for every hour of 2018, 12 of them are located on federal roads through Berlin, the other 16 are located on the freeways in Berlin. They count only motorized traffic (several types are recognized, here only the total count is used), and since they are installed on major roads only, there might be a certain tendency toward large demand values, which might be different from the T4C data set. To match the T4C data, and to ease later analyses, each weekly demand curve
where
h being the hour of the week, has been scaled to yield
so that its sum is one:
Subsequently, these scaled curves for the different sites have been added to get an aggregated traffic demand curve for this data, they are named LOOP in the following. This normalization has also been performed for all the other weekly demand patterns, to easily compare them with each other.
The MiD data set is different (the data can be obtained from [
39]), since it is from a travel survey conducted in 2016 and 2017. Altogether 960,619 trips have been collected for the MiD. They are distributed over all of Germany, and considerable efforts have been undertaken to make it a representative sample of the mobility of the German population. For the purpose here, all trips for large cities have been picked, which yields 172,761 trips in total, of which 73,696 belong to motorized traffic. Furthermore, trips with travel-speeds larger than 150 km/h have been eliminated, which left 58,525 trips in the final data set.
Each trip in this data set is described by 116 variables, of which only the starting time, the trip duration, the trip distance, and an expansion factor have been used. The expansion factor assigns a weight to each trip so that the MiD data are in line with the kilometers traveled in Germany.
They have been counted according to the starting time of the trip, and have been again aggregated to the number of trips per hour of the week (named MiD-Q in the following). Moreover, each trip has been multiplied either by its trip duration (named MiD-T) or by its trip-length (MiD-X) to yield an alternative exposure measure for inclusion into the analysis.
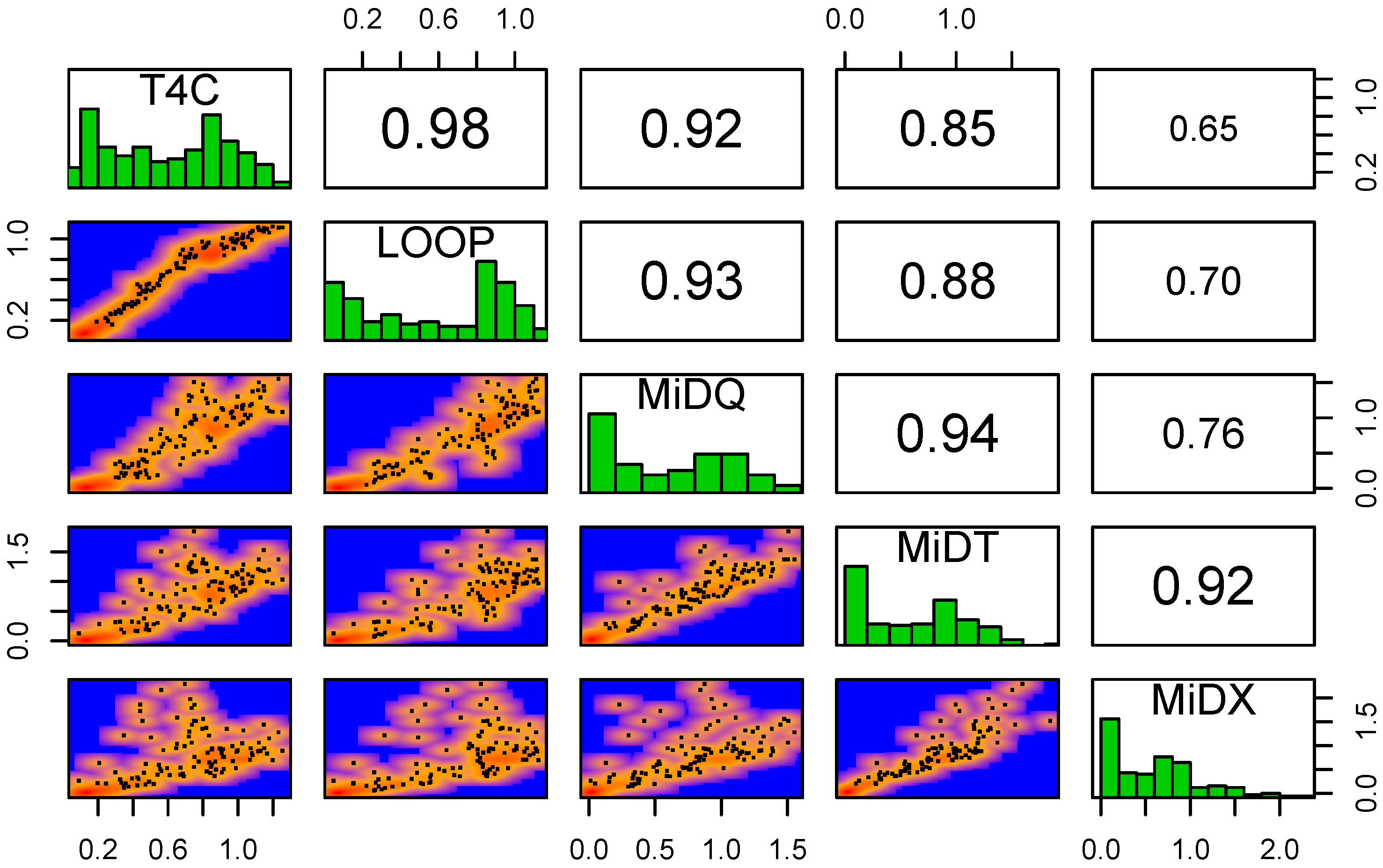
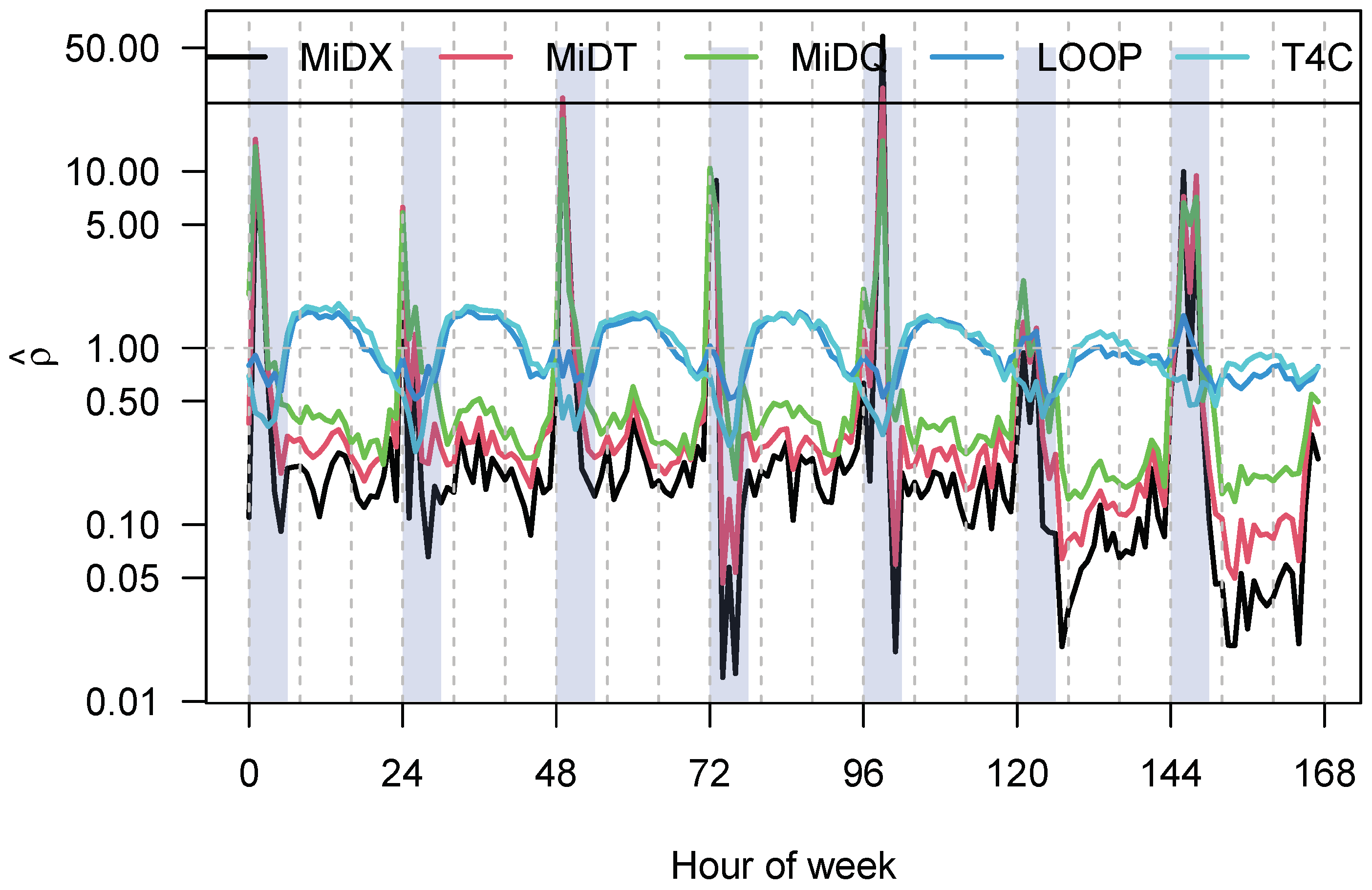
There are similarities between the flow patterns from the three sources, and this is at least satisfactorily given how very different they are. The correlation between them is between 0.65 for the worst pair (T4C and MiD-X) and 0.98 for the best pair (LOOP and T4C). See also the pairwise comparison below for more details. This correlation improves considerably if long trips (distance larger than 40 km, duration longer than 90 min) are excluded from the MiD data, but this has not been done in the following.
The MiD-T and MiD-X data are noisier than the MiD-Q data, which points to problems with the sampling, especially long trips that do not happen that often and may have an under-sampling issue, but also short trips may not have been faithfully recorded by the respondents.
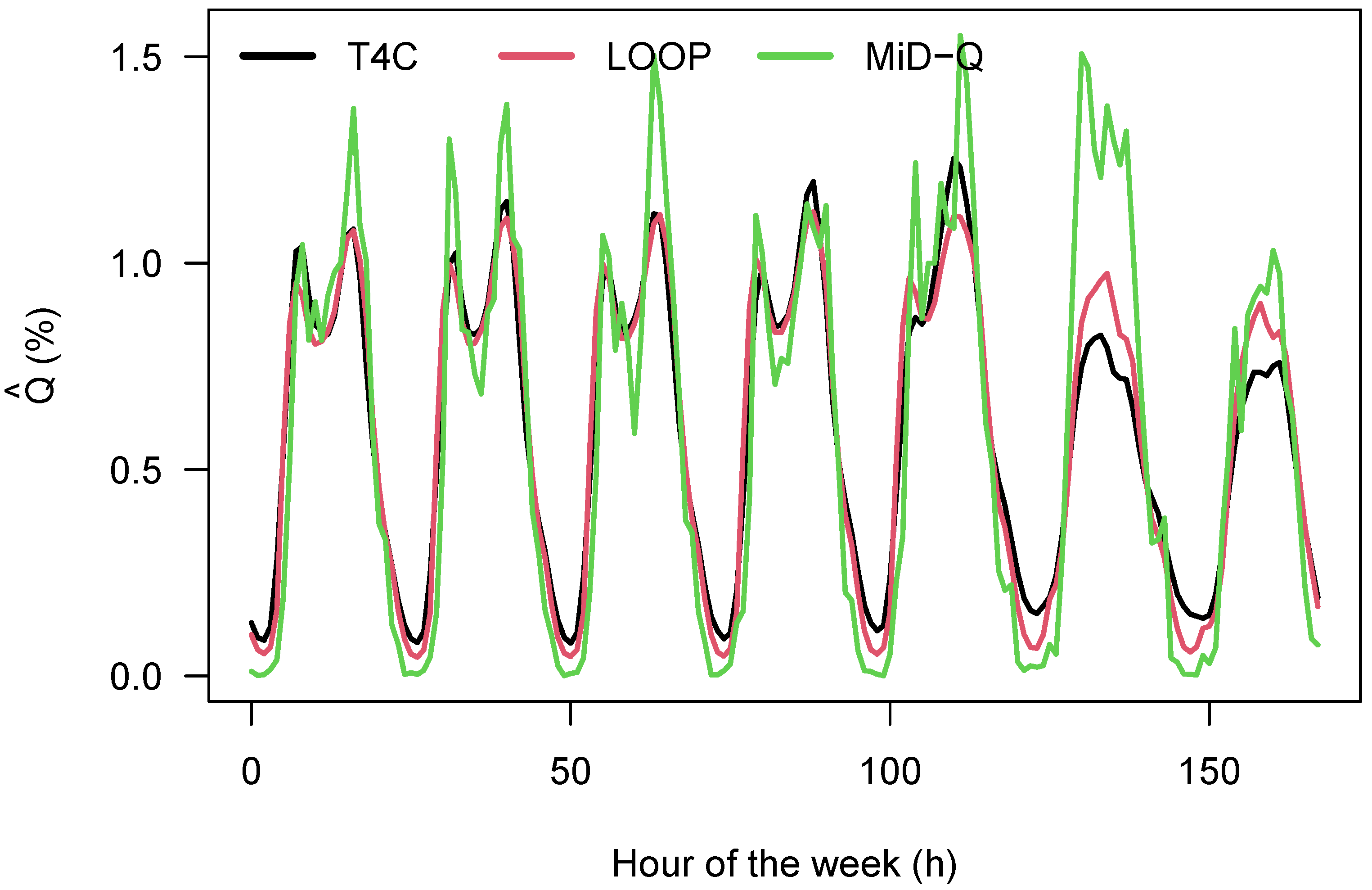
Figure 8 displays the weekly normalized pattern of the T4C, the LOOP, and the MiD-Q data, respectively. As can be seen from
Figure 8, there are differences between them: the MiD data display more pronounced weekly patterns, and the Saturdays and Sundays have too much traffic when compared to the T4C and LOOP data, but also when compared to the working days. Especially the small demand at night in the MiD data might be due to a sampling or under-reporting effect, for the excess on weekends, there is no explanation right now. However, this is a known effect [
40] and is therefore not a bug in the analysis done here.
The difference between the T4C and the LOOP data is more subtle: in essence, the pattern of the LOOP data is more pronounced (in most cases), this can be attributed to the fact that they are samples from roads with considerable demand, while the T4C data are samples over the whole Berlin road transport system. This sampling of the T4C data may tend to smooth out large amplitudes when compared to the LOOP data.
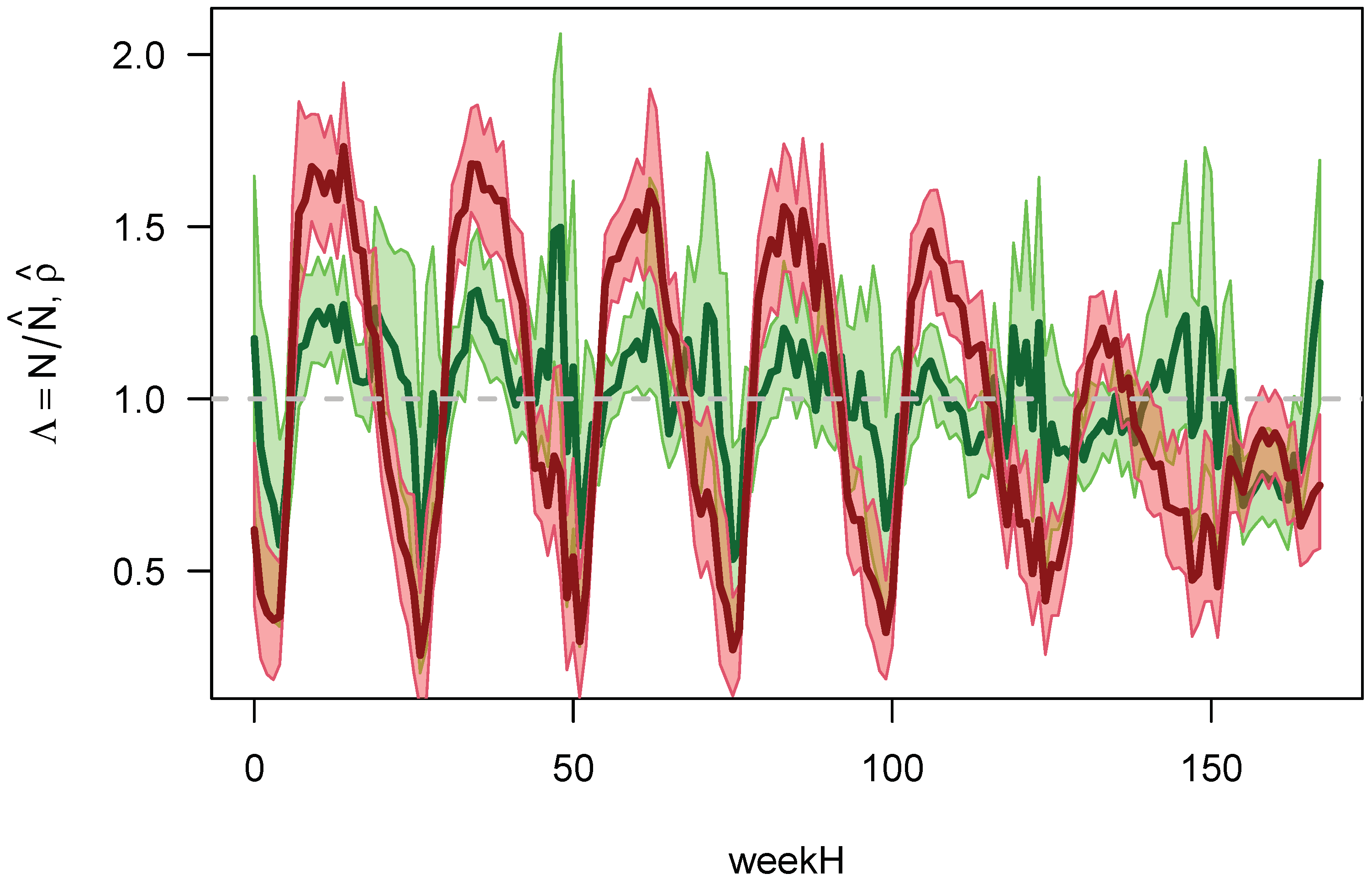
Figure 9 provides a more complete characterization of the correlation between the five different exposure data.
4. Summary and Conclusions
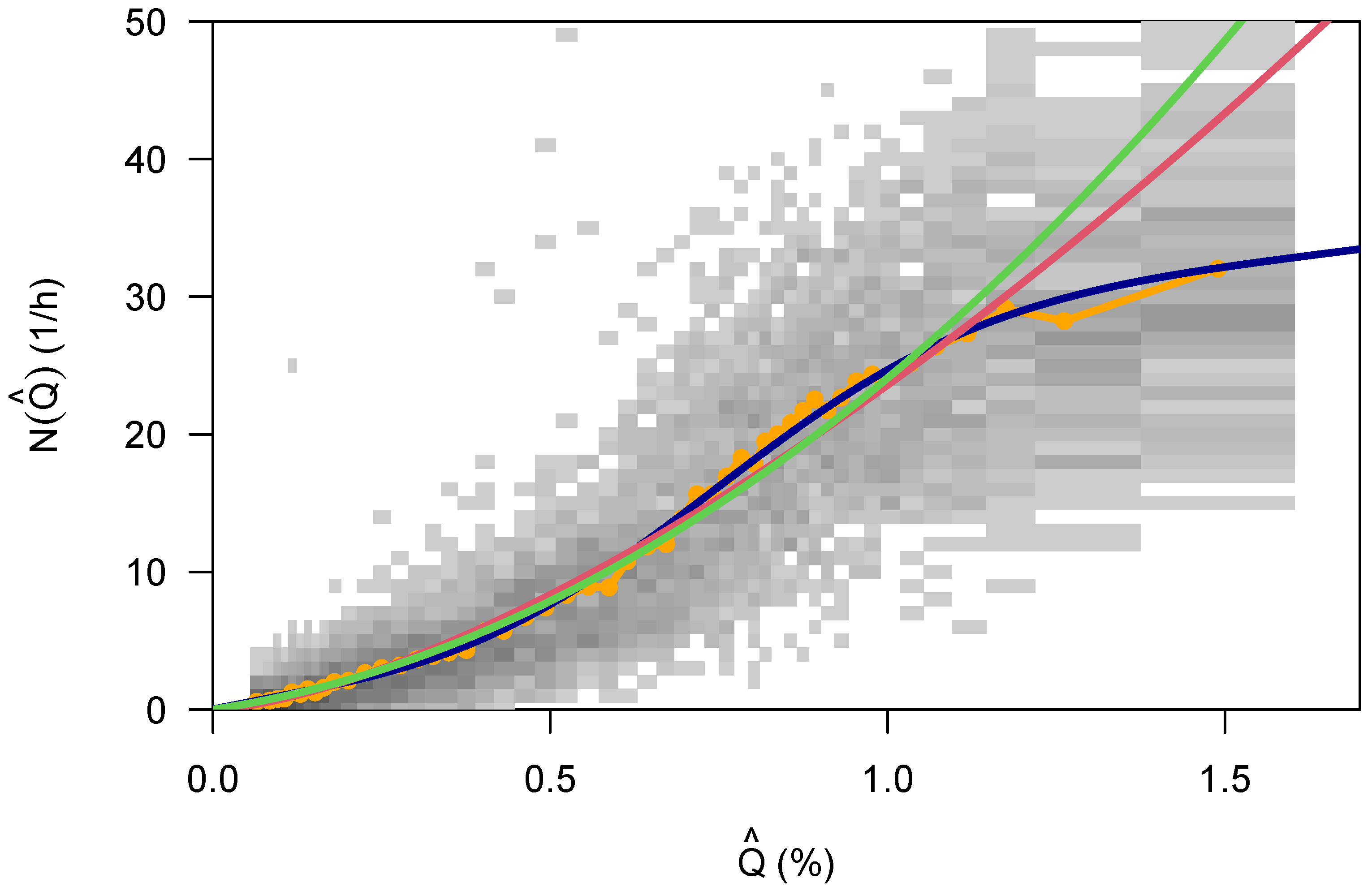
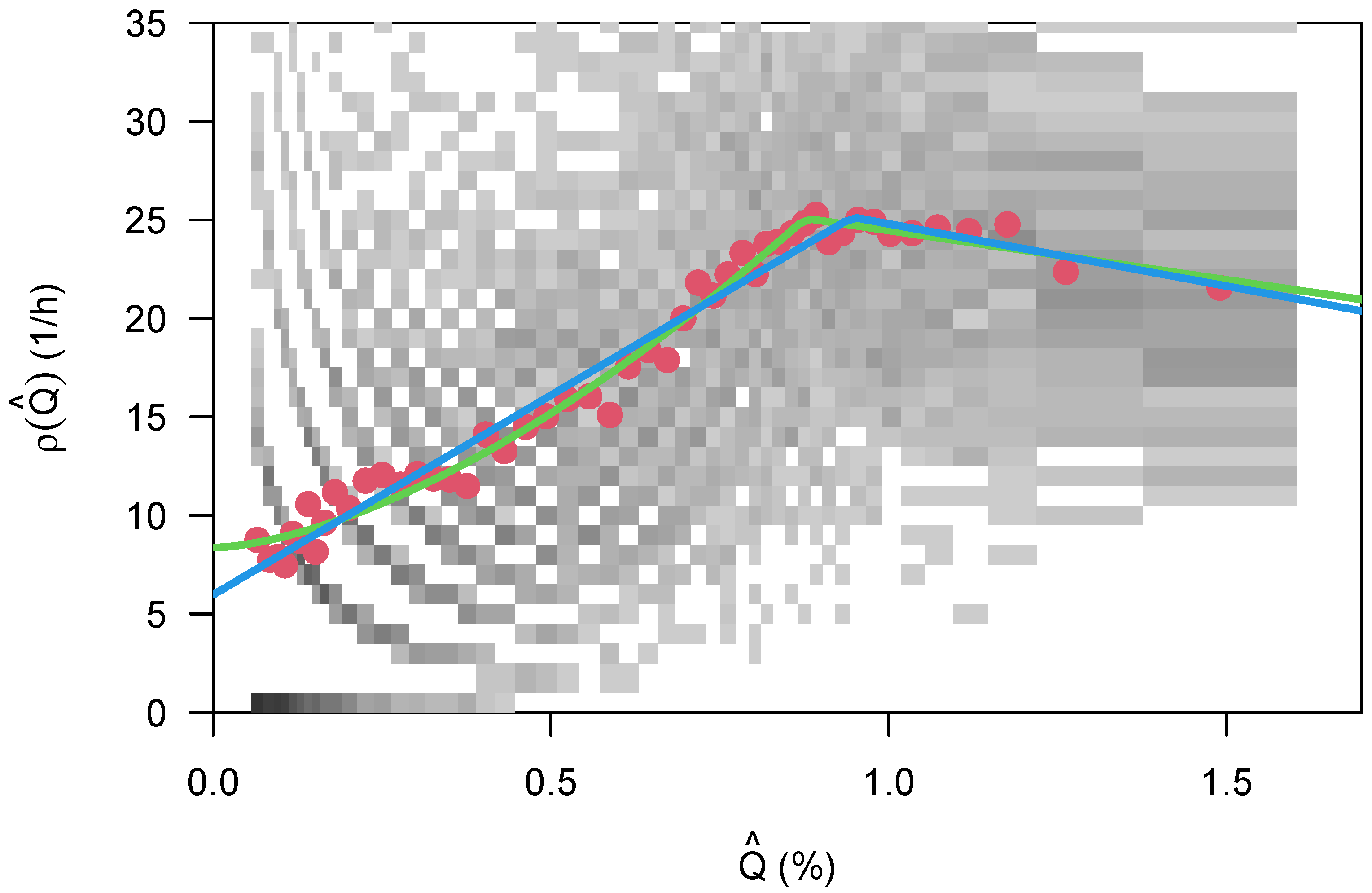
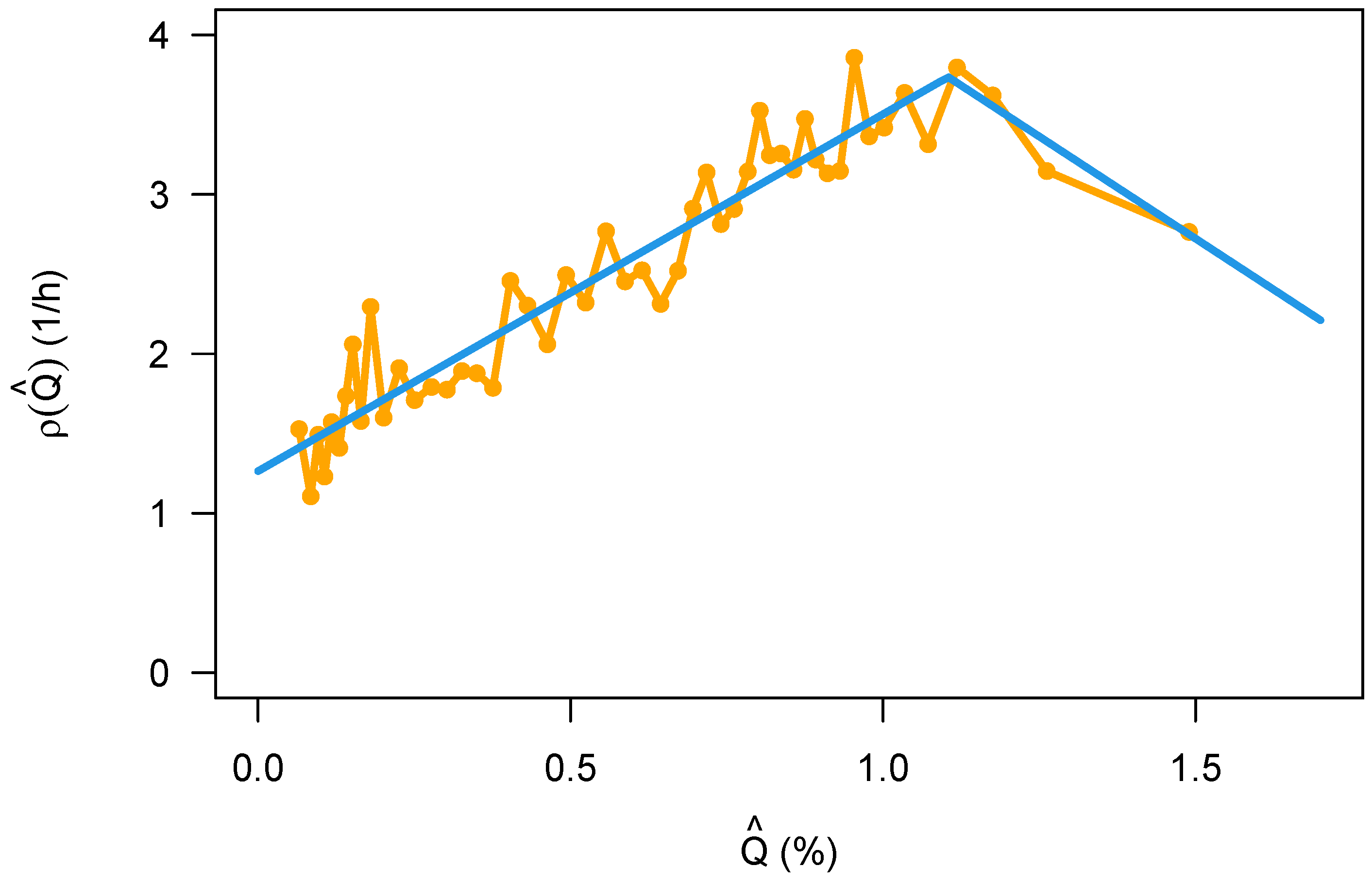
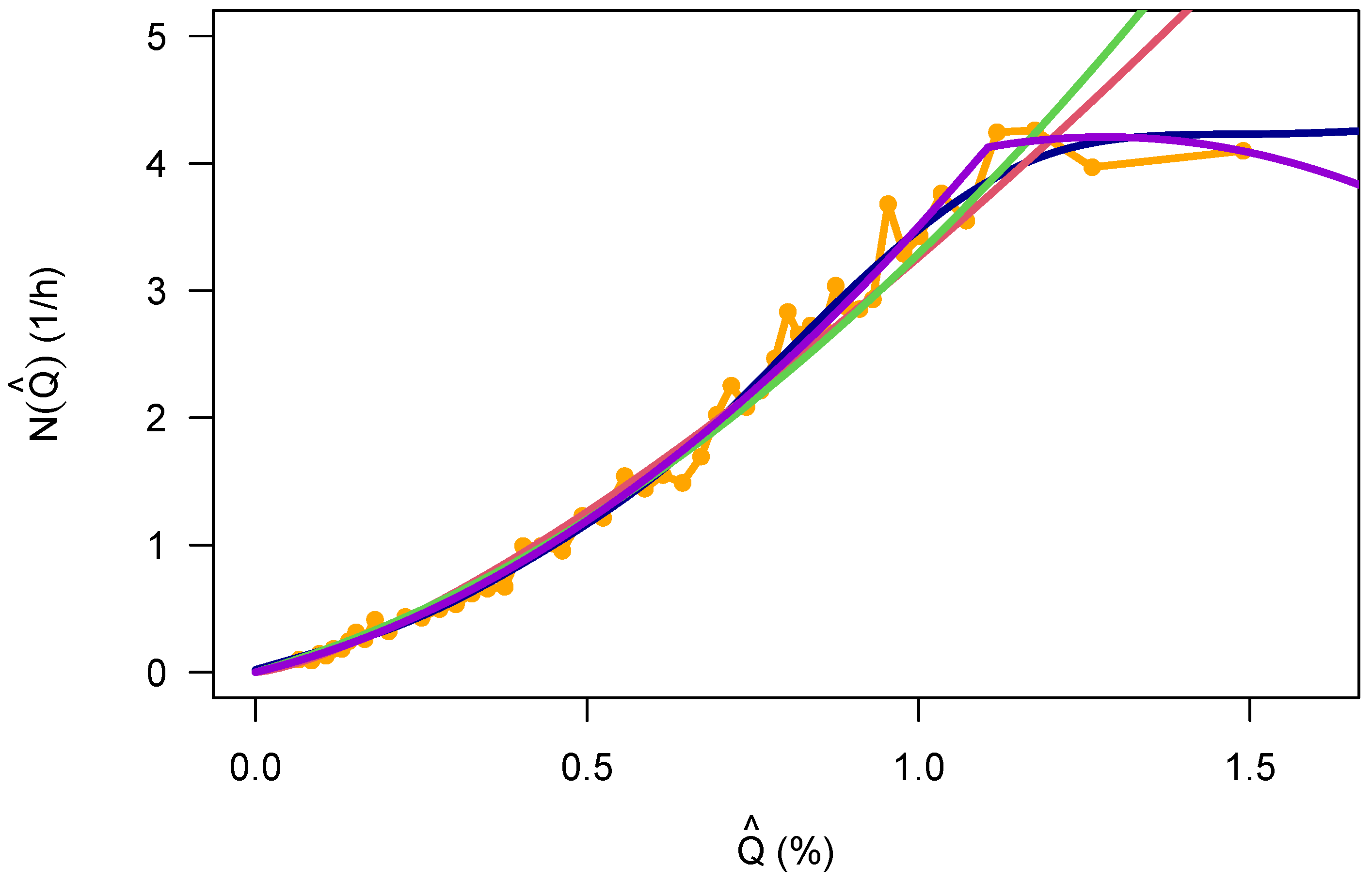
This work has analyzed several databases that allowed mapping the crash frequency to the number of vehicles on travel as an exposure variable, on a weekly basis with an aggregation time of one hour. From this, it was possible to find a parameterized form of the distribution of the crashes itself, the dependence of its parameters on the week of the hour (and therefore on the traffic state), and the relationship between the crash frequency and the exposure. The data indicate that the crash frequency saturates with larger traffic flow (which is also related to an increase in congestion).
The crash rate as a function of traffic flow displays an interesting bi-linear relationship that has a maximum at about
(Equation (
8)). This is similar to the inverse “U” that has been reported already in Veh’s work [
24], and it may have a connection to the theory proposed in [
27]. For small values of the traffic flow, this is suspiciously close to the naive approach Equation (
6), and this is at least satisfactorily since there is a simple mechanistic model available for this kind of relationship. If, however, the more complicated model in Equation (
9) turns out to be a better description, then the question might be asked where the additional
comes from (the exponent was
, 0.6 larger than 1).
These results suggest that the simple power-law model that comes with the traditional approach to road safety modeling (Equation (
1)) is not in line with the results presented here. However, these results are also not in line with most of the results from research on freeway traffic. There is, however, a certain similarity with what has been proposed in [
27].
The most surprising and conflicting result of this research is that the crash rate in the city of Berlin seems to be smaller during the night hours, so traveling is safer than it is during the day. If this is true in fact and not a glitch in the data or the data analysis, then a simple explanation might be that driving during the day with its much stronger traffic is more demanding, causing a higher error rate. However, this is for sure not the whole story behind since the crash rate from 8 a.m. to 6 p.m. for all the crashes (but not for the severe crashes, they still do display the double peak structure) is more or less constant within the analysis performed here, while the traffic flow changes considerably over this time.
Several things might have gone wrong with the approach presented here. First is that it is not clear that the traffic flows determined from the T4C database are a good measure of the real traffic flow, and whether this traffic flow is a good proxy for the exposure of cars to crashes. Or, for that matter, that there is a simple linear relationship between traffic flow and exposure. On the other hand, the comparisons to the loop data and the MiD data indicate that the usage of those data is an interesting investigation. In addition, as can be seen especially from
Figure 8 and
Figure 9, the survey data (MiD data in this case) seem to have issues of their own, which only might become visible in comparisons as the ones done here. Nevertheless, a recommendation for future research is to watch out more closely for the role of the traffic state in general on crash probability. Here, the traffic state is understood as the combination of flow and speed and maybe other variables as well that may influence traffic safety.
It will be interesting to see whether similar results can be found in other circumstances, or whether these results are just an oddity of research in traffic safety.
Another direction of research is related to the dependence of crash frequency on speed, or much better, its dependency on the two-dimensional description of the traffic state by flow and speed
, respectively, the fundamental diagram. For freeways, some steps have been done already in this direction [
15]. However, this is difficult since such a proposed relationship
cannot be formulated as a simple function, since there are values of
that are never realized in real traffic.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}