1. Introduction
Improving road safety has been a key issue for road management in the last decades. According to the Global Status Report on Road Safety 2018 [
1], the number of annual road traffic deaths has reached 1.35 million and traffic injuries represent the leading cause of death for people aged 5–29 years. Together with driver behaviour and vehicles, infrastructure is one of the five pillars identified by the World Health Organisation to be adequately managed for ensuring high levels of safety in road traffic [
2].
Since 1980, when the concept of infrastructure safety monitoring was born in the United Kingdom [
3], several directives and mandatory procedures related to this topic have been published. In response to this concept, the European Union policy for road safety across the Trans-European Transport Network (TEN–T), the European Directive 2008/96/EC [
4] was published as a set of rules aimed at the identification of adequate strategies and appropriate safety management practices to reduce and prevent accident risk as well as fatality frequency and severity. The target to be reached is that of reducing road deaths by 2020, by activities conducted at the national, regional, and global levels, as stated by the United Nations General Assembly [
5]. In particular, the 5th Road Safety Action Programme [
6] encourages the extension of the measures of Directive 2008/96/EC to all EU co-financed roads and to main urban and main rural roads and to invest in high-risk roads with a high percentage of traffic, with the specific goal to reduce the number of road traffic fatalities and injuries by 50% between 2020 and 2030.
The Directive 2008/96/EC [
4] requires member states to establish and carry out adequate procedures for the following: (i) identification and monitoring of unsafe features of existing infrastructures, i.e., road safety inspections (RSIs); (ii) analysis of potential road unsafe characteristics from planning to early operation, i.e., road safety audits (RSAs); (iii) management of road network safety, network safety ranking (NSR); and (iv) analysis of the impact of a new road on the safety performance of the existing road network, i.e., road safety impact assessments (RSIAs). Other procedures are also covered by Directive 2008/96/EC, such as efficiency assessment tools (EATs), network operation (NO), road infrastructure safety performance indicators (SPIs), road assessment programs (RAPs), high risk sites (HRSs), and in-depth study (IDS) [
7,
8]. These procedures cover all life cycle phases of a road infrastructure, from planning to maintenance, integrating safety in every stage, thus, leading to a comprehensive reactive and proactive approach to safety management known as RISM (road infrastructure safety management) [
8]. RISM procedures support authorities in decision making, ensuring the optimization of the benefit–cost ratio through the investment of resources in road safety interventions with high crash reduction potential [
8]. Furthermore, RISM outlines a minimum set of mandatory road safety management rules [
9,
10,
11] and the exchange of good practice in road safety management [
7,
9]. The weakest element of Directive 2008/96/EC is the restricted application to the trans-European road network [
9]. This Directive has been amended by Directive 2019/1936/EC which includes, in this scope, motorways and other primary roads [
12]. Higher road safety levels have been achieved from member states which have applied RISM procedures to their roads that are not included in the TEN-T network [
13,
14].
Today, RSIs have a unique way of being carried out throughout the European territory by the entry into force of the European Directive 2019/1936/EC that univocally coded these procedures.
For existing roads, safety inspection procedures are strictly related to infrastructure improvements and, consequently, to the need of defining and implementing several remedial measures for treatment of risk sections. However, figuring out a plan of remedial measures is hindered by the lack of economic resources. Consequently, a short-term implementation is not always possible. At the operational stage, in order to prevent accidents and obtain safer road conditions, it is important to identify all the elements to be improved with low-cost treatments during routine maintenance, given the impossibility of directly intervening on roadway geometric features [
15]. In the design phase, RSAs represent a detailed systematic and technical safety check relating to the design characteristics of a road infrastructure in order to identify potential unsafe features, contributing also to a reduction in the cost of accidents.
In light of the above, competent authorities could possibly minimize on-site interventions after construction and maximize benefits by targeting investments using the limited resources available for roads construction and maintenance [
16]. However, it is important to highlight that common reasons which do not facilitate the application of RISM procedures are the lack of resources, appropriate tools (such as software applications), and dedicated manuals and guidelines [
8,
17,
18,
19]. Furthermore, it is difficult to estimate and assign to the RISM procedures a specific impact in terms of a reduction of traffic victims [
11]. Although not many studies show the effectiveness of the measures adopted to correct safety deficiencies identified during an inspection, it can be said that a reduction in the frequency and magnitude of accidents and a decrease in potential accident costs are the most important benefits derived from road safety inspections [
20,
21]. The impacts of the most common RISM procedures (RSI and RSA) on accident data are summarized in
Table 1, where reference values are derived from a deep bibliographic analysis of previous studies. Collected data are briefly discussed below
Table 1.
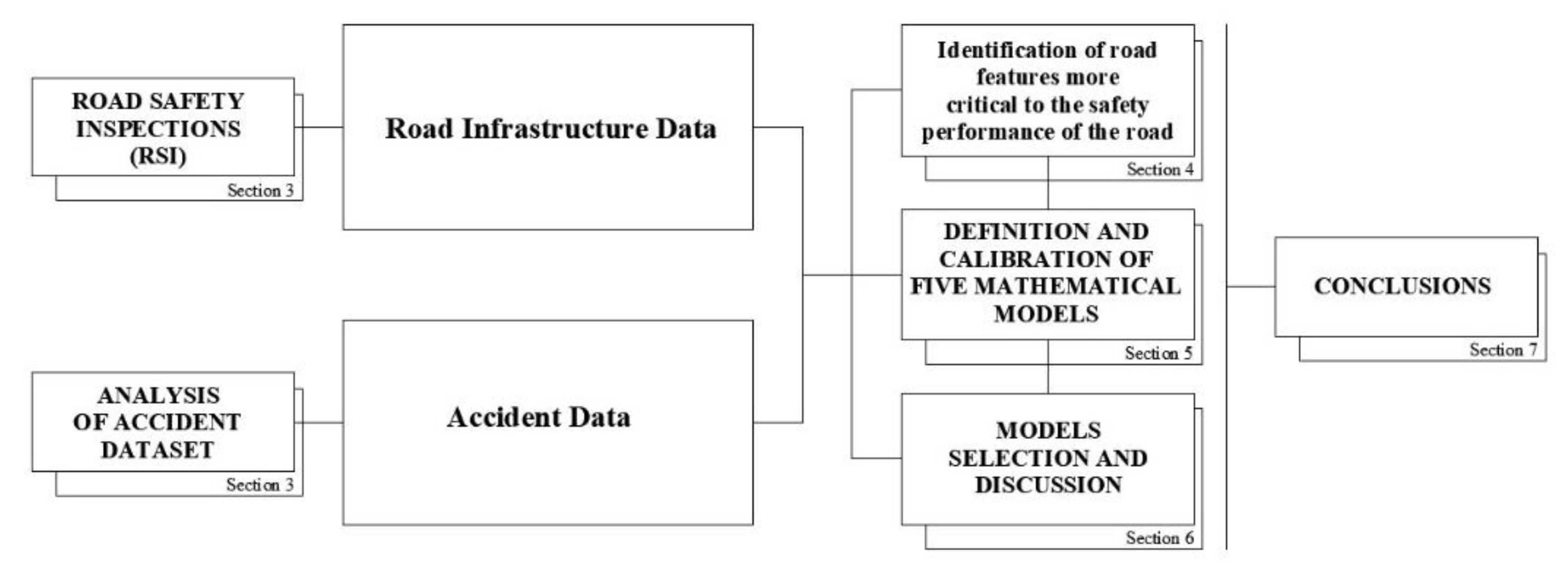
In this paper, the authors propose a methodology based on a quantitative evaluation of RSIs which can be useful for a definition of accident reduction potential. RSIs output is correlated to accident data to converge to an accident prediction model. This aspect is highlighted in
Section 5, where a concise analysis of the main prediction methods found in literature is reported. These models were used to study the influence of the infrastructure-related variables (
Section 4) on accident occurrence.
Road Safety Inspection in Italy
At the national level, member states shall adopt the measures of Directive 2019/1936/EC by December 2021. In Italy, several laws are related to traffic safety management, mainly the New Highway Code of 1992, the Guidelines for Urban Traffic Plans (PUT) of 1995, and the Geometric and Functional Rules for the Construction of Roads of 2001. Furthermore, Italy adopted a National Road Safety Plan, which is called “Piano Nazionale per la Sicurezza Stradale” (PNSS) originated from the need to decrease the frequency and severity of road accidents. The PNSS has been carried out so far through five annual programs [
30].
Directive 2008/96/EC was adopted through the Decree 35/2011 [
31]; this legislative decree was followed, in September 2012, by the ministerial Decree 137/2012 [
32] which contains the guidelines for safety management of road infrastructure and describes step-by-step how to undertake safety audits and inspections. In particular, the Decree 35/2011 [
31] introduces a series of instructions for the implementation of procedures aimed at assessing projects safety impacts, carrying out road safety audits and inspections, managing safety for all roads within the trans-European road network, both planned and in-operation roads [
33]. The annex of Decree 137/2012 [
32] (guidelines) can be considered to be the legislative Italian reference for road infrastructure safety management. The main aim of these technical guidelines (Article 2) is to identify criteria and methods for carrying out road safety audits and inspections and for implementing the network safety ranking. Moreover, they represent a reference for the training of road safety auditors, and an important tool coordinating all the activities of the competent entities involved in the road safety management process.
According to the definition provided by Directive 2019/1936/EC, targeted road safety inspection is a “targeted investigation to identify hazardous conditions, defects and problems that increase the risk of accidents and injuries, based on a site visit of an existing road or section of road” (Article 2) [
12]. The basic approach of this procedure is characterised by the identification of all road features with poor safety performance and provision of the measures of treatment that could improve these safety deficiencies [
34]. In fact, RSIs are a preventive safety tool, i.e., they aim at highlighting possible safety threats before an accident takes place, and therefore at prioritising possible interventions. Moreover, their application does not require specific information on the safety level of the road [
35]. RSI implementation is a powerful example of a proactive road safety approach that could help to overcome the limitations of a conventional reactive road safety strategy based on the analysis of crash history data; the proactive approach to the potential of road accident frequency and severity reduction is associated with the identification of safety issue locations and the definition of countermeasures to improve the safety of the roadway before accidents occur [
3,
36,
37]. Consequently, the main difference with the traditional safety analysis is independence from accident statistics [
38].
RSIs must be conducted first on road segments with the highest accident rates and afterwards on the rest of the existing road network, both for urban and rural areas. Inspections are detailed analyses to be carried out for individual critical (or potentially critical) points, such as frequent accident sites (the so-called black spots), and road segments with work zones. They can be managed on homogeneous road segments, including also inspections for singular points such as junctions, accesses points, and tunnels. A RSI during roadwork is aimed at verifying the suitability of the temporary safety measures adopted, including methods for delimiting construction sites, advising road users (work zones traffic signs), and ensuring the visibility of the workers both during the day and the night.
RSAs and RSIs are not independent procedures but they are included in a cyclical process. The complete cycle of road infrastructure safety management for existing roads includes the following four macro activities: road network screening, safety inspections, safety ranking of the road network, and the definition of treatment measures [
32]. The process starts with an examination of the functioning of the road network in operation, aimed at identifying homogeneous road segments and at ranking of high accident concentration sections (sections with many fatal accidents) [
39]. This classification constitutes the input process for the definition of the inspection program which establishes their implementation priority.
Once the safety inspections have been completed and safety defects attributable to the road infrastructure have been identified [
40], a new network safety classification is carried out for planning and scheduling of the remedial measures to correct issues and eliminate hazards highlighted during the inspection process.
The classification aimed at planning the treatment measures, corresponding to the third macro-phase of this cycle, defines the priority of intervention and the type of measure such as routine maintenance, extraordinary maintenance, or no measures necessary. The implementation of adequate measures and their subsequent monitoring completes this set of road safety management procedures [
21]. The monitoring phase is essential to verify the effectiveness of the implemented treatments, updating the documentation about the road network safety condition, and providing a new safety classification involving the definition of a new inspection program. For this reason, every time the monitoring activities close a cycle, they base the foundations for a new process aimed at the improvement of safety [
32].
3. Materials and Methods
3.1. Case Study Description
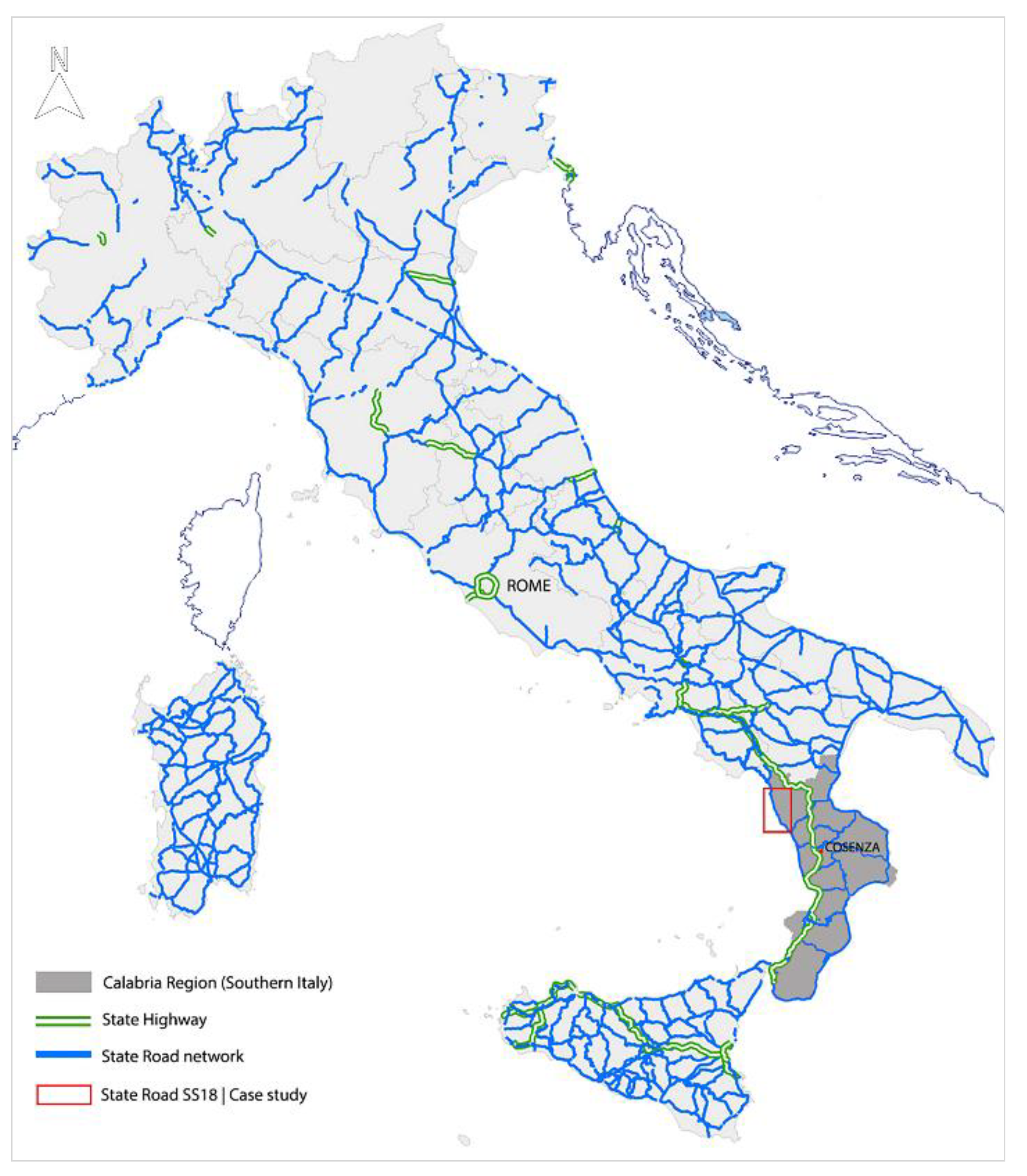
The state road SS18, selected as case study, represents an important axis of the Southern Italy road network and the main link along the Tyrrhenian coast since it ensures connections between internal areas and coastal settlements. The SS18 state road can be classified as a secondary rural road (C1 class road) for its technical and constructive characteristics, in accordance with the D.M. 5/11/01 “Functional and Geometric Norms for Road Building”, with the function of penetration towards the local network [
41]. Moreover, in many sections it constitutes an urban crossing, passing through built-up areas. Therefore, the selected road network is characterized by several safety deficiencies, strictly related to the frequent transition from rural sections to urban sections and the relative changing of operative speeds [
42]. It is a single carriageway road with one lane in each travel direction, except at the intersections where left-turn lanes can be found.
The annual average daily traffic is about 15,000 vehicles per day; the highest traffic volumes are recorded in summer given the road function of connecting urban and natural coastal areas. Furthermore, seasonal traffic variations also affect the frequency and severity of accidents.
The inspected road has a length of 31 km (11.356 km of rural sections and 19.644 km of urban sections. Tunnels (around 750 m of the entire length) were not analysed because they are excluded from the 35/2011 Decree field of application. The test site length was chosen to allow a more accurate analysis of road infrastructure features that concern safety issues. The aim of the described methodology is to define a sequence of steps that could be easily exported to other roads.
Figure 2 shows the geographical location of the test site, whereas
Table 2 summarizes the geometric characterization of each section type (straight/curve). According to the guidelines, an inspection of the geometric features of the horizontal alignment is not included in the RSI procedure. However, the collection of these data adds useful information to the analysis of the test site; a brief discussion on their relationship with accident data is reported in the next section.
3.2. RSI Procedure Implementation: From a Qualitative to a Quantitative Evaluation
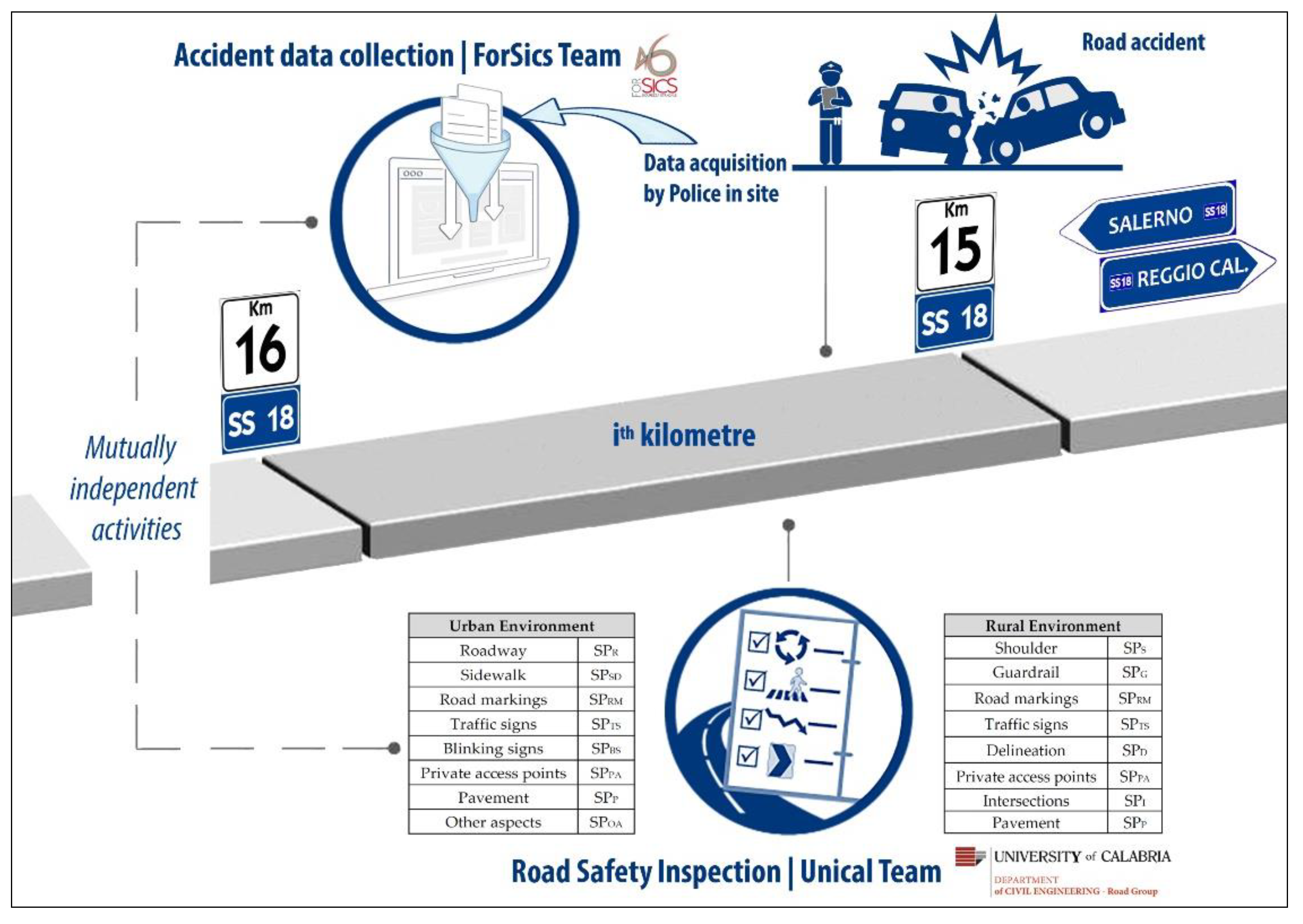
Carrying out RSIs does not require knowledge of accident data; in fact, a safety inspection is aimed at characterizing road networks only through the infrastructure safety issues. In this study RSIs and accident data collection are separate activities that carried were out by different teams, see
Figure 3; moreover, in order to not influence road infrastructure data collection, accident statistics were investigated after the RSI procedure. Inspections were carried out in relation to road section location (inside or outside built-up areas) because of the different technical and functional characteristics of the road. Checklists [
32] were used for implementing inspections on homogeneous sections of 200 m in rural areas and 100 m in the urban ones. The procedure included inspection of the following main items:
The inspection activity focused attention on those road deficiencies that required specific treatments. The most frequent issues investigated were related to the absence or insufficient width of the shoulder, the presence of pavement unevenness that compromises regularity, the inadequacy of road markings, and incorrect installation of guardrails.
The outcome of the RSI procedure was transformed in a quantitative evaluation that defined an indicator which was obtained by assigning a score to each safety deficiency found during the inspection phase. The safety performance (
) indicator for the ith kilometre is defined as follows:
where w
ski represents the score associated with the safety issue identified for the selected parameter (k) and for each road section (s). Equation (1) refers to rural environment where five sections 200 m long were analysed for each kilometre. Equation (2) is applied for the urban environment; in this case, ten sections 100 m long were investigated for each kilometre. The “w” value depends on the condition of the severity of each safety issue; therefore, the following values were set: w = 1 high severity, w = 0.5 medium severity, and w = 0 safe condition. These values were set according to the assessment of the inspector who carried out the RSI procedure following the indications of [
32] and on the basis of previous studies [
43,
44,
45].
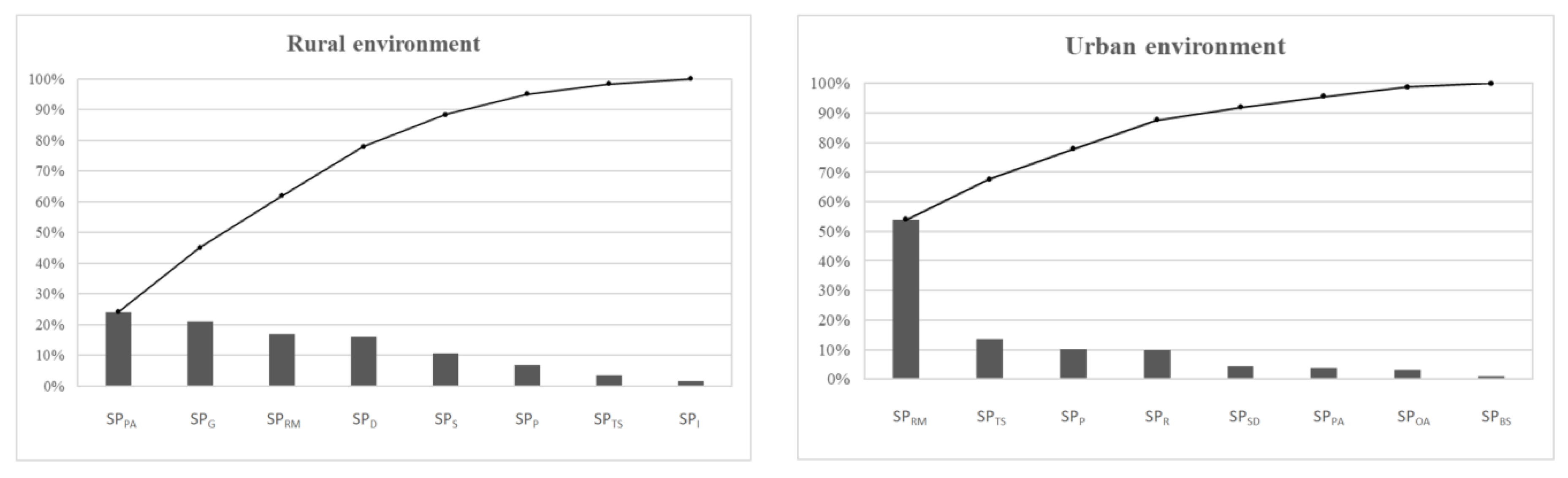
The evaluation of k parameter involved the analysis of several items defined in the checklists. In this study, the main safety issues were selected for both the rural and urban context, as shown in
Table 3 [
32].
Figure 4 reports an example of the assessment of SP
RM (for road markings) and of the framework of the checklists [
32]:
3.3. Accident Data Collection
Accident data collection is one of the essential activities for assessing the dangerousness of a road infrastructure and for identifying critical sections to be included in targeted remedial treatment planning. Accuracy, complexity, availability, and uniformity are some parameters influencing the accident database quality [
46]. The availability and completeness of a system for collecting and processing accident information contributes to the improvement of road safety conditions by locating high accident concentration sections of the road network and also obtaining validation of theoretical studies, hypotheses, and traffic safety simulations [
39]. The precise location and the dynamics of the accidents, the severity and concentration of accident phenomena, the types of vehicles involved, and information on the road and weather conditions are some of the data needed to conduct a rational network safety ranking [
4]. The lack of data relating to accidents with only material damage, often not included in the accident databases, results in a loss of information that is certainly not negligible, affecting the quality and reliability of the analysis.
The road crash data used in this study were directly acquired from police records, for the period from January 2014 to June 2016 (the safety inspections were carried out between February and September 2016), and they also include accidents with only material damage. The road items involved in the methodology (see
Table 3) did not have significant maintenance measures that changed their conditions in the investigation period. As regards accident data, accidents strictly related to a “temporary” condition of the road (roadworks zones) were not taken into account.
The following elements were available for each accident:
accident date and hour;
accident precise location;
information on the alleged circumstances of the accident, collision type, driver’s manoeuvre and characteristics of the persons involved;
accident consequences (number of fatalities and injured persons).
During the reference period, 147 accidents were identified on the 31 km under investigation.
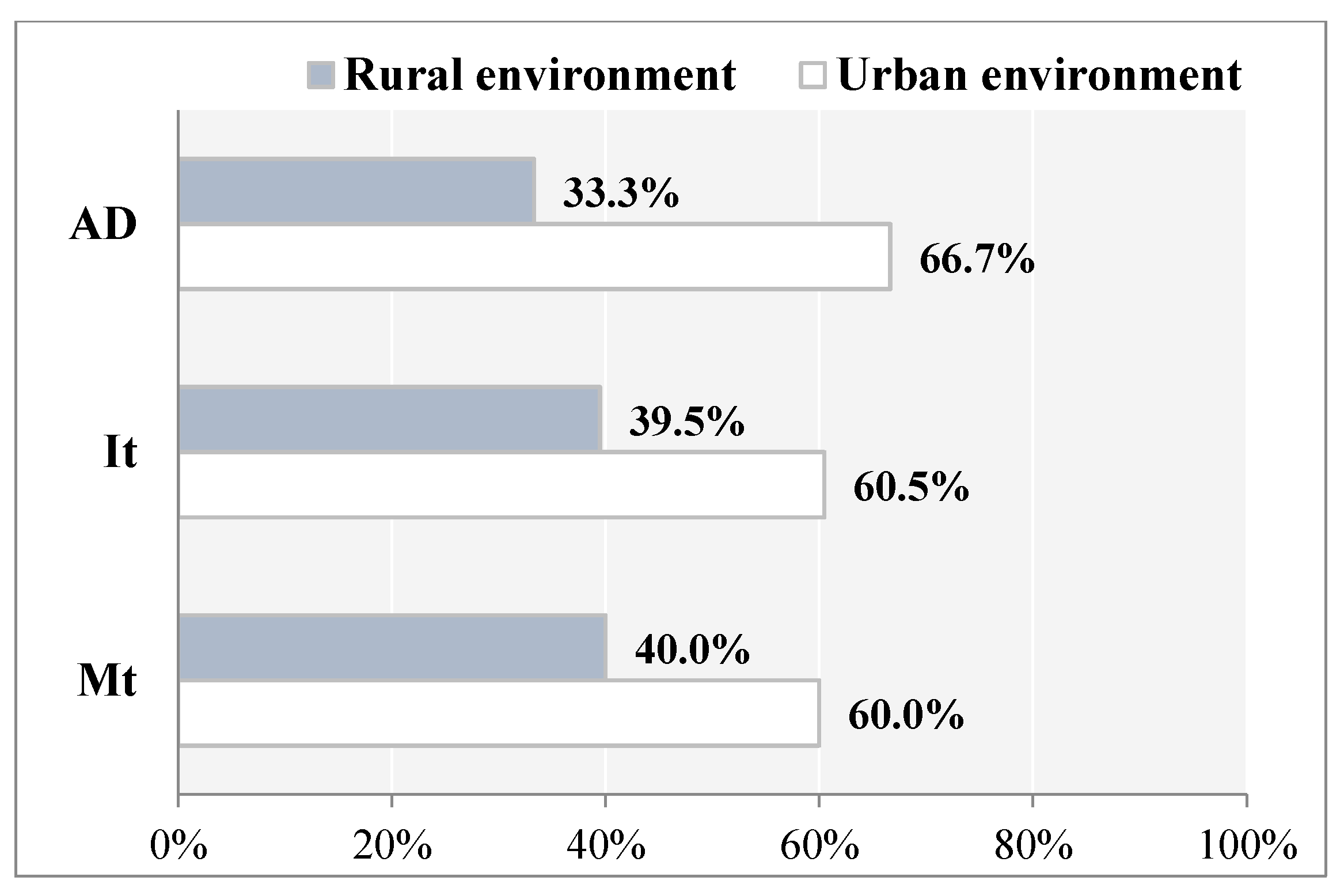
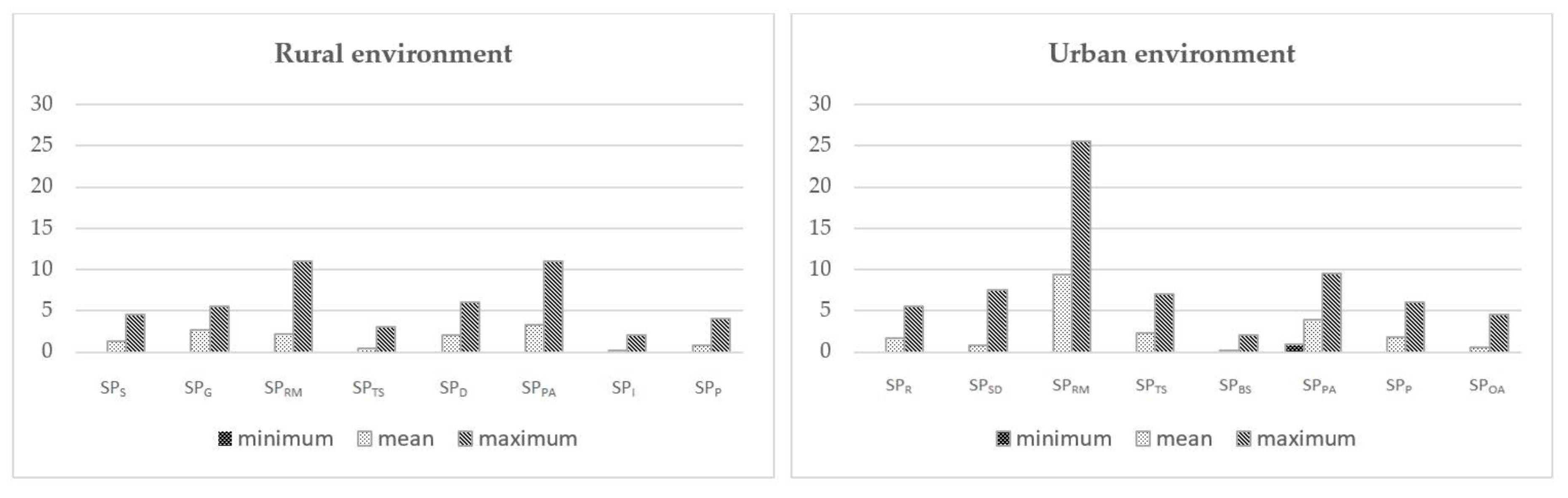
Figure 5 shows the percentage of accident density (AD, accidents per kilometre) observed in rural and urban environment, separately.
Figure 5 also reports information on crashes severity in terms of percentage of road accident injuries (I
t, total number of injured people per kilometre) and fatalities (M
t, total number of deaths per kilometre due to traffic accidents).
Accident data analysis provides concrete documentation on the obvious criticality that characterizes the road as regards safety performance. According to investigations conducted at accident sites, it was found that around 44% of crashes occurred on curves. In rural sections, curves with smaller radii had higher accident rates than curves with larger radii. This confirmed some research results in which curves with sharp radii as a contributing factor to run-off-road accidents were clearly associated with an increase in crash numbers [
47,
48].
3.4. Considerations for Accident and Safety Performance Indicators (SPk)
As previously stated, an RSI considers the road network without prior knowledge of accident data. The aim is to find out all road elements with an inadequate safety performance, and therefore, road characterization from a safety point of view is strictly related to those deficiencies related to road infrastructure. In this approach, RSI procedures and accident analysis are not considered to be independent activities, in order to determine a potential link among the infrastructure deficiencies, the localisation, and the severity of accidents.
In this work, the first step of the analysis concerns the evaluation of correlations between two sets of variables. In particular, for the purpose of this study, the “y” variable is an accident indicator, and the “x” variable is the indicator for different infrastructure features. Among accident indicators, the following were used:
Accident density (AD, accidents per kilometre, calculated as the number of crashes on each kilometre for both urban and rural road sections);
Total number of injured people per kilometre (It);
Total number of deaths per kilometre due to traffic accidents (Mt);
Fatality rate (FR, which is defined as the relationship between the number of road accidents deaths and the total number of accidents Mt/AD);
Injury rate (IR, calculated as the relationship between the total number of persons injured and the total number of accidents It/AD);
Total injury rate (TIR, which is obtained using the sum between the number of deaths and the number of injured people as numerator, and the accident density as denominator (Mt + It)/AD).
Sometimes the variable of safety performance in some kilometres is zero because no problems have been highlighted during inspections. In particular, for the ith kilometre the following cases related to SP values must be considered:
SPki = 0 (no safety issues have been highlighted for the “k” parameter during the inspection, i.e., safe condition) and accident indicators are not null in the same section;
SPki is too low (the “k” parameter is close to a safe condition) and accident indicators are not null in the same section;
SPki has significant scores, but they are roughly constant on all sections, therefore, it is not possible to find a significant relationship with accident indicators by a correlation analysis.
For the first case, the analysis highlights that the frequency or severity of crashes cannot be related to the road item considered (k). In the second case, the SPki low value means that it is needed to consider other “k” parameters in a range of priority; for these last, correlations might be more significant. The lack of a significant correlation (third case) should be related to the absence of a strong and univocal causal link between infrastructure and accidents. Probably, when this case occurs, a crash is primarily related to other causal factors that, together with the infrastructure, may contribute to the accidental event (driver, vehicle, environment, etc.). Therefore, similar SPki values on different road sections imply that accident density variability is not directly influenced by road safety deficiencies. This consideration, in fact, is in accordance with the aim of the present study, which was to investigate exclusively the causal links among road infrastructures (by RSI) and accidents. Nevertheless, a greater test site length could allow a more accurate analysis, overcoming the limitations of the third case.
5. Model Calibration
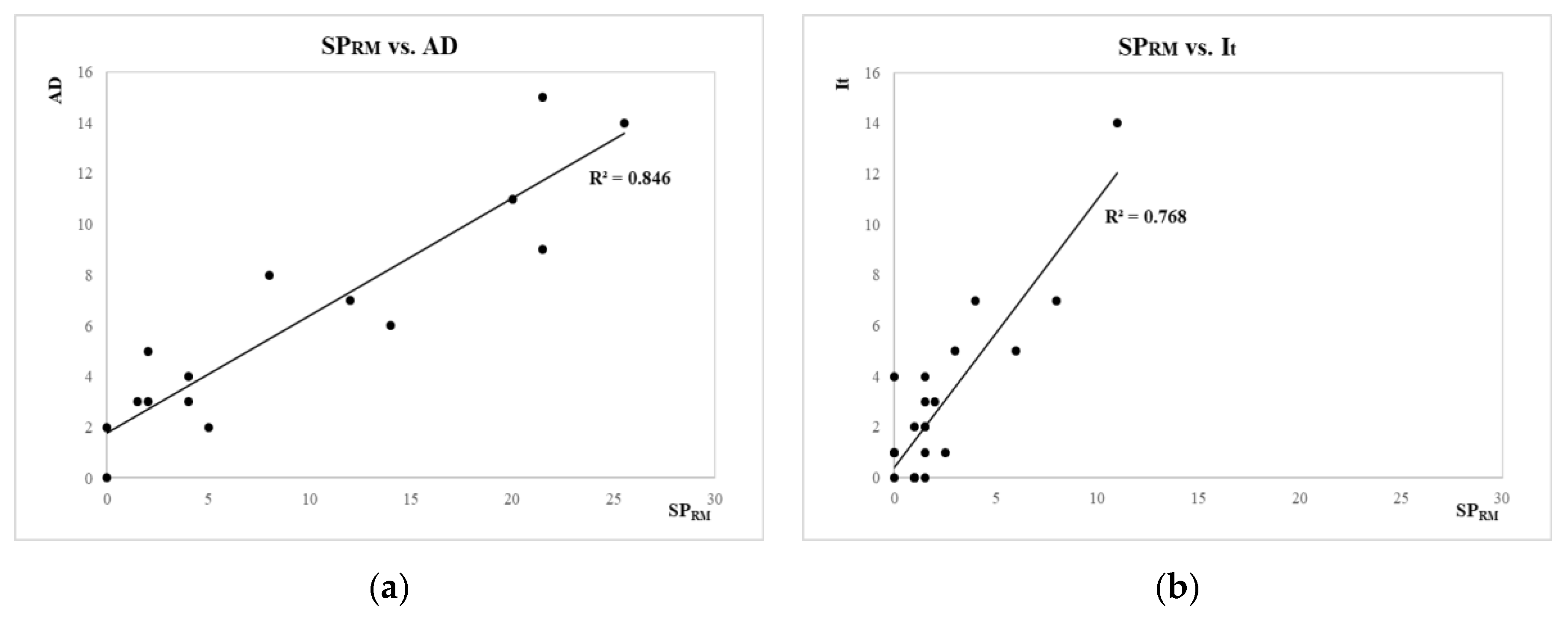
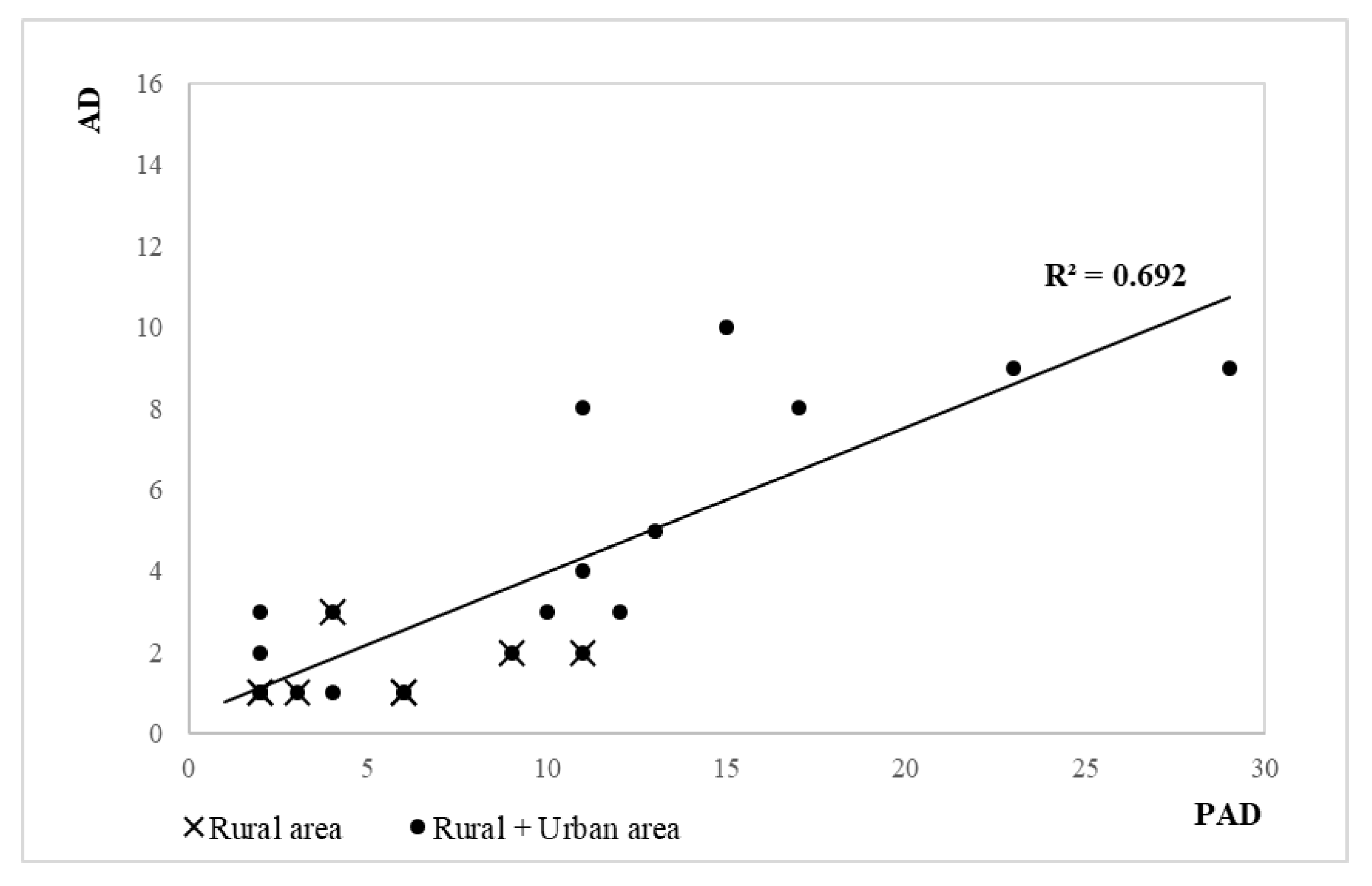
The outcome of the correlation analysis carried out in
Section 4 shows that the most significant relationships were registered between accident density and two variables, i.e., the safety performance indicator for road markings and the access density per kilometre. Afterwards, herein, authors investigate on the possibility to carry out a mathematical relationship between accidents and those infrastructure-related parameters that significantly reduce safety.
A traffic crash is a complex event due to interactions among several factors such as road infrastructure, vehicle, environment, traffic, and human behaviour [
59]. Data availability is conditioned by the randomness of crash occurrence due to the abovementioned factors and the absence of information on unobserved effects; therefore, the potential bias in estimation could be amplified [
60]. Some researchers [
61,
62] have suggested contemplating a component related to design choices, human behaviour, and traffic characteristics to take into account the rate of the total risk level that cannot be completely eliminated. This variation due to omitted or unmeasured variables is statistically significant even if the causes are unexplained [
63,
64,
65].
Several studies have examined the likelihood of road crashes and their relationship with road conditions in order to quantify the effect of one or more road-related elements on the safety level. An exhaustive review was carried out by Praticò and Vaiana [
66].
In this paragraph, the simultaneous influence of several infrastructure-related variables on accident occurrence is investigated through an empirical equation that has the following characteristics:
Provides quantitative information about the relationships among injuries and road features;
It is useful for making future accident predictions;
Takes into account the contribution of multiple infrastructure-related variables on crash occurrences;
Gives the best data fitting, minimizing differences between experimental values and those calculated through the mathematical model.
It is important to highlight that this analysis is affected by the uncertainties related to accident occurrences. Moreover, the lack of data about factors affecting these events imply an incomplete description of the phenomenon through the predictive capacity of mathematical models. Models are different in some statistical properties such as the assumption of the distribution of the occurrence of accidents, the choice of variables, and the functional form that describes the cause–effect link [
67,
68]. The most common types of mathematical models are summarized in
Table 7 [
66,
69].
In the light of the above, the target of this analysis is to determine a mathematical law such as the following:
which is valid for the case study, describing the contemporary effect of a set of
n variables (
) requiring a maintenance intervention on accident occurrence (y); “
” are the regression parameters (constant coefficients) to be determined from the available dataset. The analysis of this cause–effect relationship is carried out by identifying a mathematical model using a calibration procedure for the test site.
This approach is organized into four phases which can be summarized as follows [
66,
70]:
In particular, the total variation of accident density (effect) can be decomposed into the following two contributions (causes): a first component strictly related to road features and a component influenced by variations among factors (vehicle, environment, traffic, and human behaviour). In this study, the second contribution is considered to be a constant value U
e (unobserved effects); U
e is the adjustment constant taking into account an intrinsic threshold of accident rating not depending on infrastructure variables. The absence of road safety issues, in fact, is not always related to a zero-risk level. The infrastructure-related variables involved in defining the models are PAD (density of private access points), SP
RM (safety performance, road markings), and ƩSP; ƩSP is a vector that considers the effects of multiple observed road conditions. The subset of variables includes SP
S (safety performance, shoulder), SP
G (safety performance, guardrail), SP
TS (safety performance, traffic signs), SP
D (safety performance, delineation), SP
PA (safety performance, private access points), SP
P (safety performance, pavement), SP
R (safety performance, roadway), SP
SD (safety performance, sidewalk) (see
Table 3). The variable related to intersections (SP
I) was not considered in the analysis. A different type of inspection (for singular points) is needed to identify all the safety issues which affect junctions as expressly indicated in [
32].
Herein, the distinction between rural and urban sections is managed implicitly in the use of the infrastructure-related variables. The type of environment of each section (rural/urban) defines the variables to be used in the vector ƩSP, according to
Table 3.
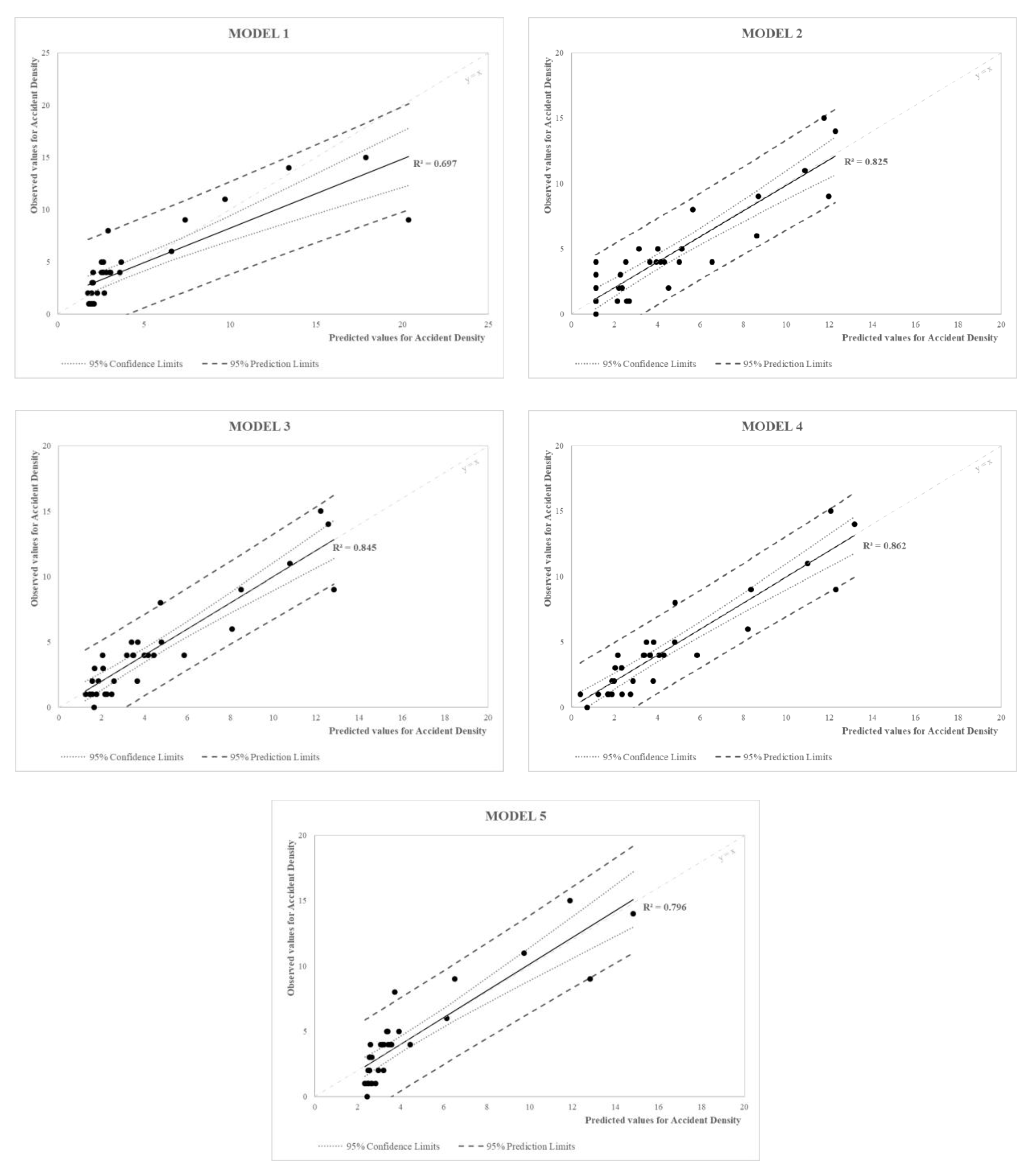
Table 8 shows the functional laws of each model and the value assumed by the unknown parameters estimated using the least squares method. Models 1 and 2 are obtained starting from the basic forms of Poisson regression models [
69]. Model 3 is based on a multiple linear regression approach, Model 4 on a non-linear form. An exponential equation is considered for Model 5.
The definition of R
2 for each of the previous models obtains a first level of assessment on the adequacy of fitting experimental data of each calibrated model identifying some validity limits. A qualitative evaluation of models fitting is showed in
Figure 10 by plotting observed and model-estimated values. For a comprehensive analysis, the 95% confidence interval and the 95% prediction interval are also reported for each regression model. As it is possible to see in
Table 8 and
Figure 10, the best fit to experimental data (R
2 higher than 0.8) was found for the nonlinear model (Model 4, R
2 = 0.862), the multiple linear regression model (Model 3, R
2 = 0.845), and a model obtained starting from the basic forms of Poisson regression models (Model 2, R
2 = 0.825). The other investigated models show correlation coefficients always higher than 0.6; however, a great dispersion of data is registered for high accident density values.
It is well known that R
2 provides only a qualitative evaluation of prediction model’s goodness-of-fit [
64], consequently, comparisons of models is investigated, as discussed in
Section 6, using a second-order Akaike’s information criterion.
6. Model Selection: Akaike’s Information Criterion and Discussion
In order to better investigate fitted models, the Akaike’s information criterion was used for a comparison among them. According to this criterion, the preferred model is the one with the minimum AIC value, defined as follows:
where n is the sample size, K is the number of estimable parameters, and
is the log-likelihood at its maximum point of the model estimated [
71,
72].
In this study, a second-order AIC was used which has been demonstrated to be more accurate for a small sample size [
73]. Burnham and Anderson [
73] provided an examination of AIC techniques for model selection and indicated that this corrected version should be used unless the ratio between the number of data points and the number of parameters (n/K) is higher than about 40 for the model with the maximum number of parameters. The correction of AIC score, AIC
c, is a function of the sample size
n and of the number of parameters
K and it is defined by:
The AICc values can be used for a ranking of the fitted models (see the first row of
Table 9). These results show that Model 3 seems to be the most adequate for the dataset (AICc = 30.79) and Model 2 has an AICc score close to Model 3. On the contrary, Model 1 and Model 5 are characterized by the highest AICc scores. The difference in AIC
c between each model and the model with the lowest AIC
c score is reported in the second row of
Table 9. The equation used is the following:
where AIC
c(i) is the AIC
c value for each analysed model and AIC
c(min) is the minimum among the AIC
c(i) scores.
As it is possible to note in
Table 9, the ΔAIC
c value is 0 for the best model (Model 3). In particular, the ΔAIC
c values confirm the conclusions drawn above about the inadequacy of Model 1 and Model 5 to fit experimental data [
73]. However, Models 2, 3, and 4 have close ΔAIC
c values; therefore, they have the same importance in assessing criterion preference [
74]. According to Burnham and Anderson [
73], ranges of ΔAIC values (Δ
i = AIC
i − AIC
min) were calculated for the evaluation of models ranking; the following classification was carried out in their study:
Δi 2, substantial support;
4 Δi 7, less support;
Δi 10, no support.
On the basis of these rules, only the models with ΔAIC
c lower than two units were considered to be adequate for the analysis. Consequently, Models 1, 2, and 5 were not investigated. In order to select the best regression equation, Akaike’s weights were estimated for Model 3 and 4 by the following:
where ΔAIC
c is the difference in AIC
c scores for the selected models (ΔAIC
c = 1.75,
Table 9), whereas w estimates the relative probability of the two models. The result (w = 0.29) shows that about 29% is the percent chance that Model 4 is more adequate than Model 3.
For this comparison procedure, the evidence ratio (ER) was also estimated as [
75]:
Equation (8) is equivalent to the ratio between the Akaike’s weight of the best model and the weight of the other model considered (Model 3 and Model 4, respectively) [
72]. The ER value (ER = 2.40) provides the information that Model 3 is about two times more likely to be correct than Model 4.
The comprehensive analysis of the AICc approach allows us to draw the following conclusions:
(i) The nonlinear model (Model 4) is the best model for the dataset looking at the fitting graphs (
Figure 10) and the relative R
2 values (
Table 8). Furthermore, Model 4 is characterized by the lowest sum-of-squares. However, using the AIC
c method, the multiple linear regression model (Model 3) is more likely to be correct than Model 4. The analysis shows that Model 3 has the lowest score of AIC
c and the probability that it is more correct than the nonlinear model is 71% (w = 0.71, according to Equation (7)). These results confirm that the best fit of data is always achieved through the more complicated model (more parameters) regardless of its adequacy for the dataset [
75]. The additional parameters of the nonlinear equation, as compared with the multiple linear equation, affect the AIC
c score, which gives the information that the simplest model is the most adequate. However, as suggested by Motulsky and Christopoulos [
75], it is not possible to reject a model or conclude that one model is more statistically significant than others using only the AIC
c approach, as it is based on the information theory.
(ii) From the analysis carried out by the AIC
c method, interesting information about the importance of the variables was obtained. Variables contained in the models with the highest AIC
c value and not included in those with a lower AIC
c score have considerably less importance in modelling the dataset [
72]. Road infrastructure-related variables that appear in Model 3 and Model 4 are PAD (density of private access points) and SP
RM (safety performance, road markings). Therefore, these can be considered to be the variables that add useful information in establishing model adequacy; on the contrary, the contribution of Ʃ
SP that appears in Model 1 and in Model 5 can be ignored in modelling.
7. Conclusions
Among the safety management procedures on existing road networks, road safety analysis is a powerful preventive tool for eliminating and reducing the number of accidents. The application of road safety inspections can identify all road infrastructure-related features with poor safety conditions affecting the safety level of the existing road network. The most frequent issues investigated are related to the absence or insufficient width of the shoulder, the presence of pavement unevenness that compromises regularity, the inadequacy of road markings, and incorrect installation of guardrails. The outcome of the RSI procedure is transformed in a quantitative evaluation, through a safety performance indicator affected by all the safety deficiencies highlighted during the inspection phase. Carrying out RSIs does not require knowledge of accidents’ data, due to the fact that the main feature of this analysis is aimed at characterizing the road network through the infrastructure safety issues.
In this study, accident analysis and RSIs are not considered to be two independent procedures. In fact, the aim of the authors was to identify the potential relationships among infrastructure deficiencies (the outcome of RSI) and the frequency and severity of accidents (from accident analysis), and to try to investigate how a specific condition of a road element could represent a safety problem for traffic circulation.
The analysis shows that the most statistically significant relationship was found between the accident density/total number of injured people and the safety performance parameter of road markings, for both rural and urban environments. Road markings are an essential tool for the optical driving of road users; they must guarantee an adequate perception of the road layout in all operating conditions, providing essential information for road users. The relationship between the density of private access roads, considered to be a risk factor for the network test site, and the number of accidents (per kilometre of road) was also investigated. As stated in
Section 4.2, a high density of driveways strongly impacts crash frequency, i.e., a higher number of private access points per kilometre determines a higher level of risk. Each driveway is an opportunity for conflicts between the traffic flows; consequently, access points are a contributing element to accident potential increase. The analysis of the contribution of multiple infrastructure-related variables on the occurrence of traffic crashes, from a quantitative point of view, was carried out through the identification of a mathematical model which was also useful for making accident predictions. Looking at the fitting and the coefficient of determination values, among the calibrated models the nonlinear equation and the multiple linear regression equation are the best models for the dataset; in particular, the higher R
2 value and the lower sum-of-squares obtained for the nonlinear function quantify the goodness-of-fit for this model. The analysis was extended to a second-order AIC approach (AIC
c) in order to compare the fitted models. The results show that the multiple linear model is more likely to be correct than the nonlinear model. The first model has a lower score in AIC
c and there is a 71% probability that it is more adequate than the nonlinear model. The AIC
c score that is affected by the number of parameters adds the information that the simplest model is also adequate for the dataset. From the analysis carried out by the AIC
c method, the importance of the variables considered in the five fitted models was also investigated. The results show that the road infrastructure-related variables (access density and the safety performance indicator for road markings) are the most significant for accident density prediction.
In this study, the authors intended to provide a methodology through a detailed descriptive analysis of a case study, in order to facilitate the implementation of this procedure to other contexts. In future studies, limitations of this methodology due to the amount of data could be overcome by extension of this approach to road infrastructures with similar technical and functional features. These findings could obtain a more correct calibration and validation of the accident prediction models. This approach could benefit both practitioners and researchers by evaluating the relationship between accident frequency and safety inspections in order to identify items that require a priority intervention in light of an adequate maintenance policy of road network. This could facilitate road authorities in the selection of the most effective preventive measures to improve specific safety aspects. From this point of view, road safety inspections represent an important investment for improving the level of road safety for all road users.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}