
Analysis of Severe Injuries in Crashes Involving Large Trucks Using K-Prototypes Clustering-Based GBDT Model



Abstract
1. Introduction
2. Related Work
2.1. Unobserved Heterogeneity in Crash Data
2.2. Severity Modeling
3. Methodologies and Materials
3.1. The K-Prototypes Clustering Method
3.2. Gradient Boosted Decision Trees
- Initialize the model with a constant value ; here, is the observed values, L is the loss function and γ is the prediction of the model, which minimizes the loss function. In a classification task, γ is the value of the log (odds).
- For m = 1,2,3… to M:
- (a)
- Calculate the pseudo residuals, , for i = 1, 2, 3……, n.
- (b)
- Fit a decision tree to the pseudo-residuals and create the terminal regions. Each leaf of the tree represented by for j = 1, 2, 3..., .
- (c)
- For j = 1, 2, 3…, m, calculate .
- (d)
- Update the .
- Output .
3.3. Data Description
3.4. SHAP Method for Feature Analysis
3.5. Predicting Performance Evaluation Metrices
4. Results
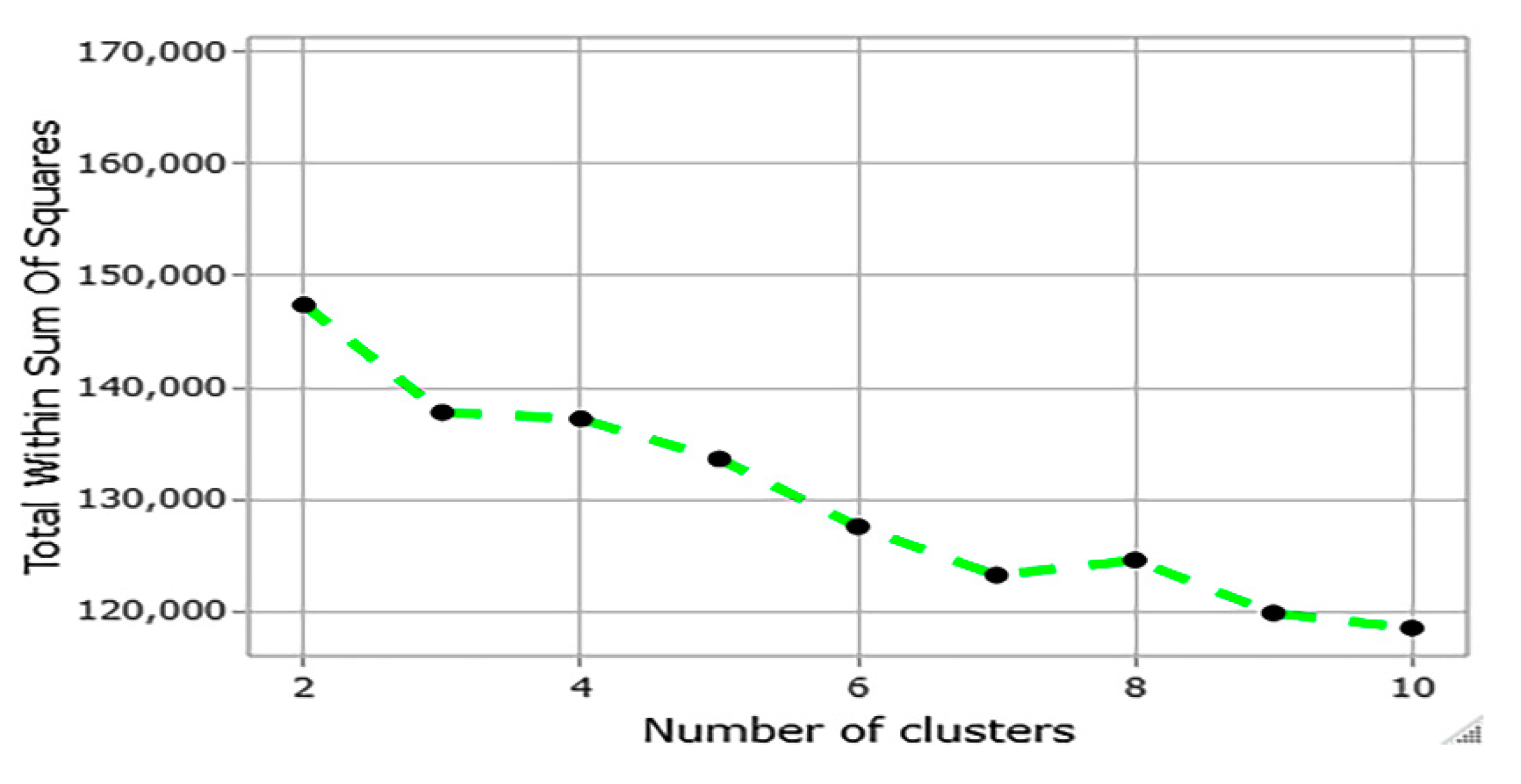
4.1. ClusterAnalysis
- CL1: “crashes on two-way divided with positive median barrier and in high posted speed limit zone”;
- CL2: “non-interstate highway crashes involving large trucks weighing over 26,000 (lb)”;
- CL3: “non-interstate highway crashes involving large trucks without trailing unit”.
4.2. Model Performance Evaluation
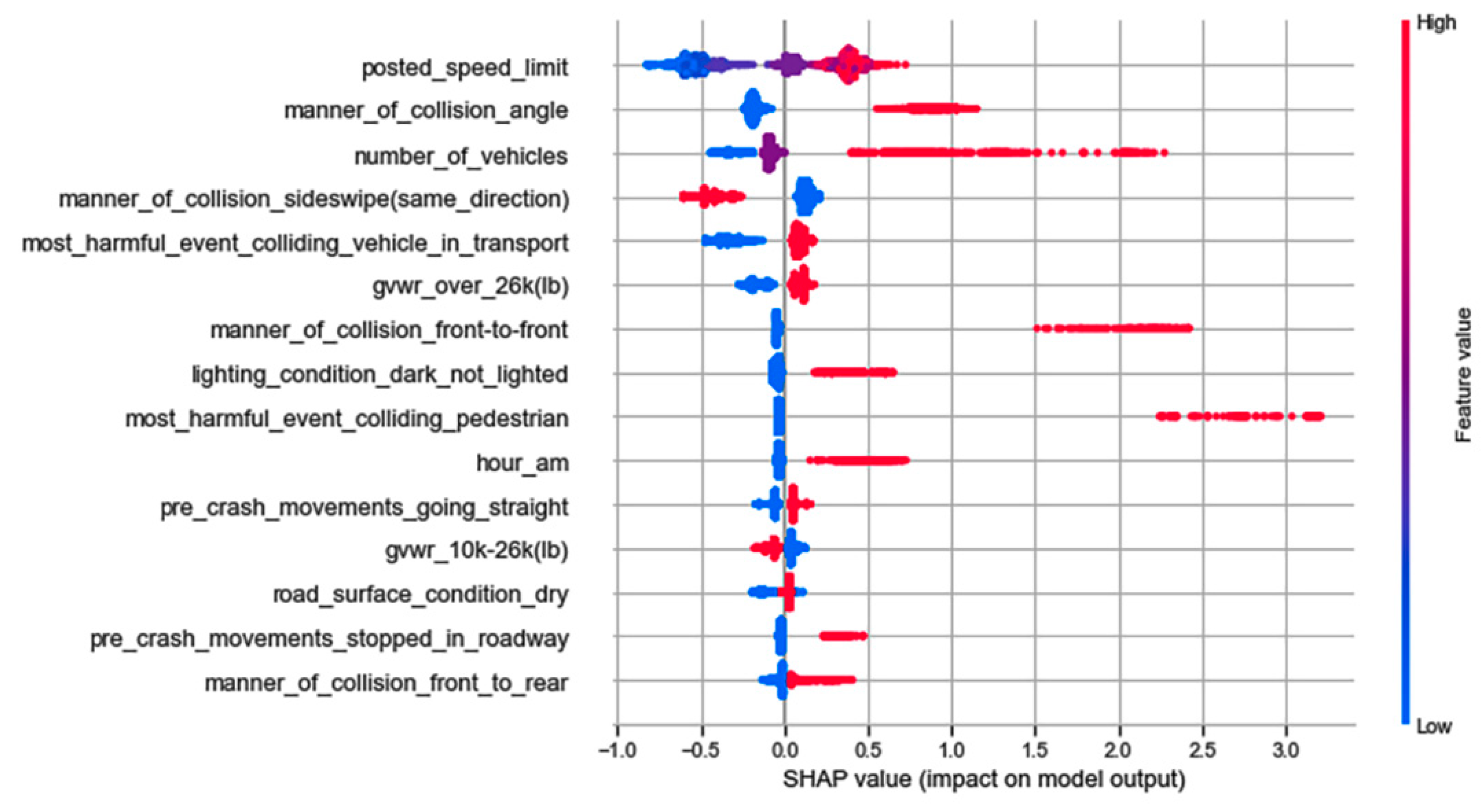
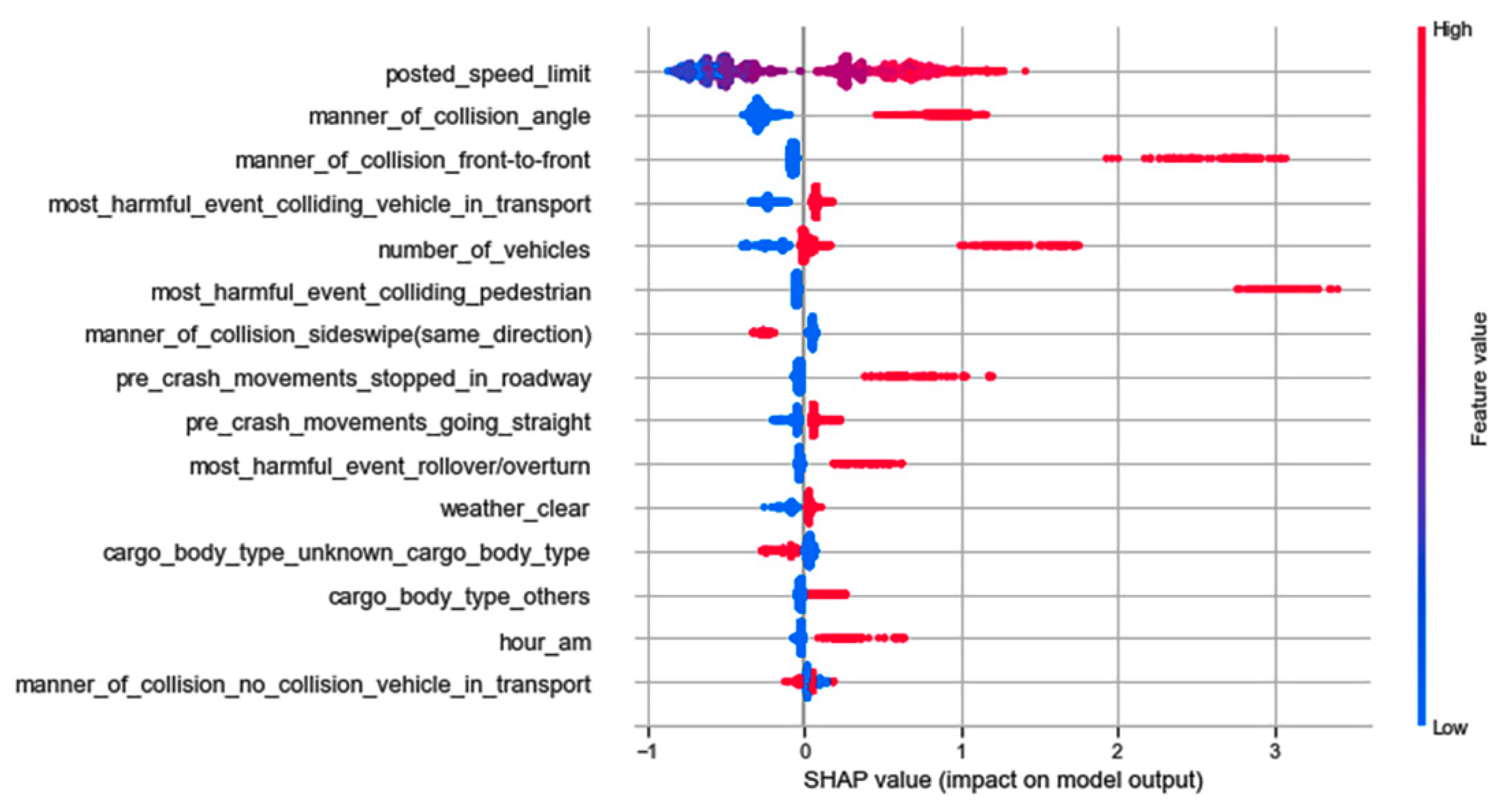
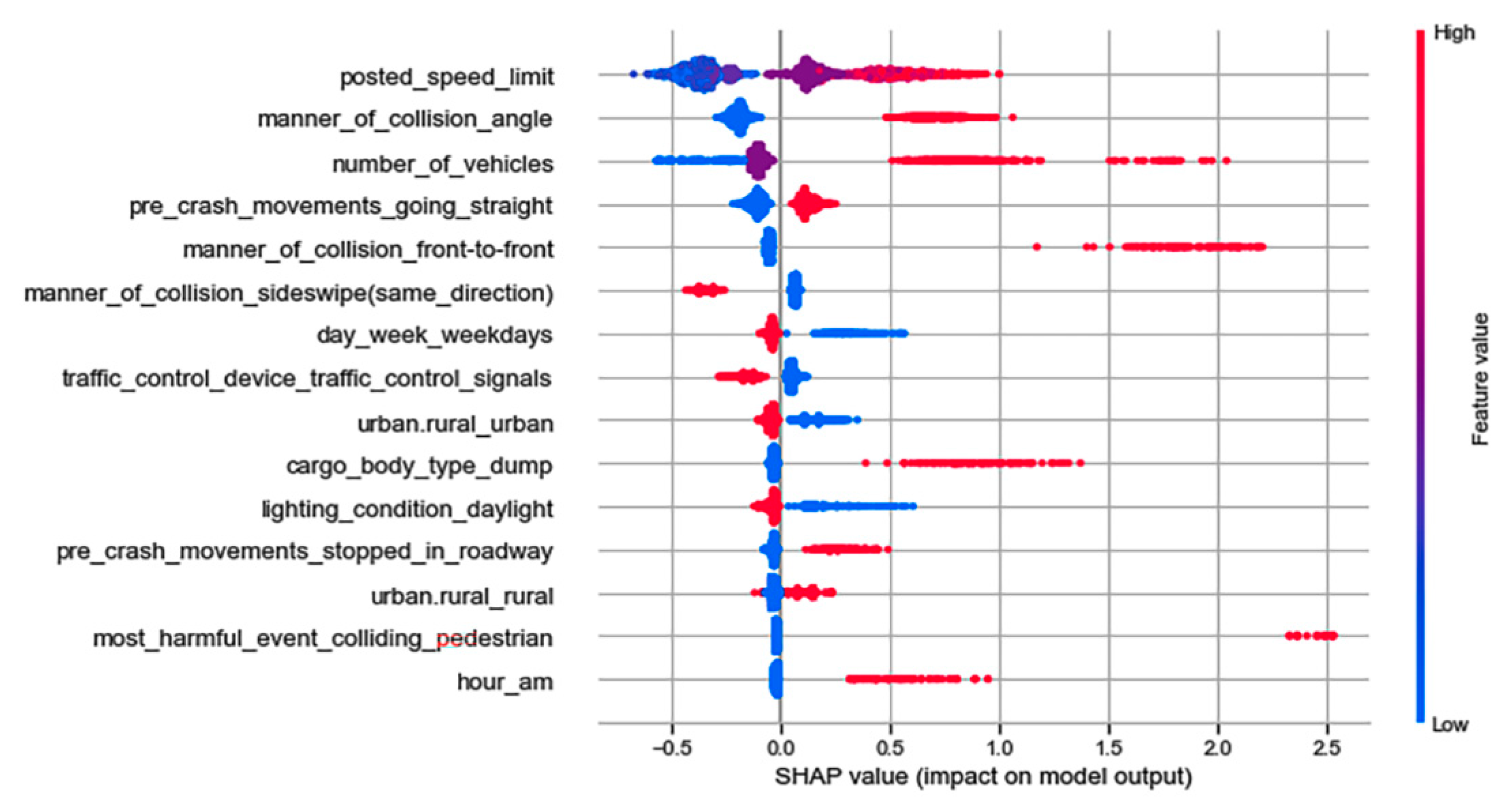
4.3. Feature Analysis
5. Discussion and Conclusions
Limitations and Future Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Large Truck and Bus Crash Facts 2018 [Internet]. Federal Motor Carrier Safety Administration Analysis Division. 2020; p. 2012. Available online: https://www.fmcsa.dot.gov/sites/fmcsa.dot.gov/files/2020-09/LTBCF2018-v5_FINAL-09-15-2020.pdf (accessed on 5 January 2021).
- Ahmed, M.M.; Franke, R.; Ksaibati, K.; Shinstine, D.S. Effects of truck traffic on crash injury severity on rural highways in Wyoming using Bayesian binary logit models. Accid. Anal. Prev. 2018, 117, 106–113. [Google Scholar] [CrossRef]
- Azimi, G.; Rahimi, A.; Asgari, H.; Jin, X. Severity analysis for large truck rollover crashes using a random parameter ordered logit model. Accid. Anal. Prev. 2020, 135, 105355. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Srinivasan, S. A comprehensive analysis of factors influencing the injury severity of large-truck crashes. Accid. Anal. Prev. 2011, 43, 49–57. [Google Scholar] [CrossRef] [PubMed]
- Al-bdairi, N.S.S.; Hernandez, S.; Anderson, J. Contributing Factors to Run-Off-Road Crashes Involving Large Trucks under Lighted and Dark Conditions. J. Transp. Eng. Part A Syst. 2018, 144, 04017066. [Google Scholar] [CrossRef]
- Islam, M.B.; Hernandez, S. An Empirical Analysis of Fatality Rates for Large Truck Involved Crashes on Interstate Highways. In Proceedings of the 3rd International Conference on Road Safety and Simulation, Indianapolis, IN, USA, 14–16 September 2011; pp. 1–19. [Google Scholar]
- Osman, M.; Paleti, R.; Mishra, S.; Golias, M.M. Analysis of injury severity of large truck crashes in work zones. Accid. Anal. Prev. 2016, 97, 261–273. [Google Scholar] [CrossRef]
- Naik, B.; Tung, L.W.; Zhao, S.; Khattak, A.J. Weather impacts on single-vehicle truck crash injury severity. J. Saf. Res. 2016, 58, 57–65. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.; Huynh, N. Injury severity analysis of truck-involved crashes under different weather conditions. Accid. Anal. Prev. 2020, 141, 105529. [Google Scholar] [CrossRef]
- Behnood, A.; Mannering, F. Time-of-day variations and temporal instability of factors affecting injury severities in large-truck crashes. Anal. Methods Accid. Res. 2019, 23, 100102. [Google Scholar] [CrossRef]
- Uddin, M.; Huynh, N. Factors influencing injury severity of crashes involving HAZMAT trucks. Int. J. Transp. Sci. Technol. 2018, 7, 1–9. [Google Scholar] [CrossRef]
- Islam, S.; Jones, S.L.; Dye, D. Comprehensive analysis of single- and multi-vehicle large truck at-fault crashes on rural and urban roadways in Alabama. Accid. Anal. Prev. 2014, 67, 148–158. [Google Scholar] [CrossRef]
- Depaire, B.; Wets, G.; Vanhoof, K. Traffic accident segmentation by means of latent class clustering. Accid. Anal. Prev. 2008, 40, 1257–1266. [Google Scholar] [CrossRef]
- Mannering, F.L.; Bhat, C.R. Analytic Methods in Accident Research Analytic methods in accident research: Methodological frontier and future directions. Anal. Methods Accid. Res. 2014, 1, 1–22. [Google Scholar] [CrossRef]
- Yau, K.K.W. Risk factors affecting the severity of single vehicle traffic accidents in Hong Kong. Accid. Anal. Prev. 2004, 36, 333–340. [Google Scholar] [CrossRef]
- Ulfarsson, G.F.; Mannering, F.L. Differences in male and female injury severities in sport-utility vehicle, minivan, pickup and passenger car accidents. Accid. Anal. Prev. 2004, 36, 135–147. [Google Scholar] [CrossRef]
- Islam, S.; Mannering, F. Driver aging and its effect on male and female single-vehicle accident injuries: Some additional evidence. J. Saf. Res. 2006, 37, 267–276. [Google Scholar] [CrossRef]
- Al-Bdairi, N.S.S.; Hernandez, S. An empirical analysis of run-off-road injury severity crashes involving large trucks. Accid. Anal. Prev. 2017, 102, 93–100. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Lu, M.; Theo, A.; Li, Y. Investigation on occupant injury severity in rear-end crashes involving trucks as the front vehicle in Beijing area, China. Chin. J. Traumatol. 2017, 20, 20–26. [Google Scholar] [CrossRef]
- Balakrishnan, S.; Moridpour, S.; Tay, R. Differences in single heavy vehicle crashes at intersections and midblocks. J. Adv. Transp. 2016, 50, 2150–2159. [Google Scholar] [CrossRef]
- Uddin, M.; Huynh, N. Truck-involved crashes injury severity analysis for different lighting conditions on rural and urban roadways. Accid. Anal. Prev. 2017, 108, 44–55. [Google Scholar] [CrossRef]
- Anderson, J.C.; Dong, S. Heavy-vehicle Driver Injury Severity Analysis by Time of Week. Inst. Transp. Eng. ITE J. 2017, 87, 41–50. [Google Scholar]
- De Ona, J.; López, G.; Mujalli, R.; Calvo, F.J. Analysis of traffic accidents on rural highways using Latent Class Clustering and Bayesian Networks. Accid. Anal. Prev. 2013, 51, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Toshniwal, D. A data mining framework to analyze road accident data. J Big Data. 2015, 2, 26. [Google Scholar] [CrossRef]
- Taamneh, M.; Taamneh, S.; Alkheder, S. Clustering-based classification of road traffic accidents using hierarchical clustering and. Int. J. Inj. Control Saf. Promot. 2016, 24, 388–395. [Google Scholar] [CrossRef] [PubMed]
- Sasidharan, L.; Wu, K.F.; Menendez, M. Exploring the application of latent class cluster analysis for investigating pedestrian crash injury severities in Switzerland. Accid. Anal. Prev. 2015, 85, 219–228. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Sun, X.; Shan, D. Pedestrian crash analysis with latent class clustering method. Accid. Anal. Prev. 2019, 124, 50–57. [Google Scholar] [CrossRef]
- Rahimi, A.; Azimi, G.; Asgari, H.; Jin, X. Clustering Approach toward Large Truck Crash Analysis. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 73–85. [Google Scholar] [CrossRef]
- Song, L.; Fan, W. Combined latent class and partial proportional odds model approach to exploring the heterogeneities in truck-involved severities at cross and T-intersections. Accid. Anal. Prev. 2020, 144, 105638. [Google Scholar] [CrossRef]
- Lin, Z.; David, W. Exploring bicyclist injury severity in bicycle-vehicle crashes using latent class clustering analysis and partial proportional odds models. J. Saf. Res. 2021, 76, 101–117. [Google Scholar] [CrossRef]
- Chang, F.; Xu, P.; Zhou, H.; Chan, A.H.S.; Huang, H. Investigating injury severities of motorcycle riders: A two-step method integrating latent class cluster analysis and random parameters logit model. Accid. Anal. Prev. 2019, 131, 316–326. [Google Scholar] [CrossRef]
- Rahimi, E.; Shamshiripour, A.; Samimi, A.; Kouros, A. Investigating the injury severity of single-vehicle truck crashes in a developing country. Accid. Anal. Prev. 2020, 137, 105444. [Google Scholar] [CrossRef]
- Assi, K.; Rahman, S.M.; Mansoor, U.; Ratrout, N. Predicting Crash Injury Severity with Machine Learning Algorithm Synergized with Clustering Technique: A Promising Protocol. Int. J. Environ. Res. Public Heal. 2020, 17, 5497. [Google Scholar] [CrossRef] [PubMed]
- Berkhin, P. Survey of Clustering Data Mining Techniques. In Grouping Multidimensional Data; Spinger: Berlin/Heidelberg, Germany, 2006; pp. 1–56. [Google Scholar]
- Huang, Z. Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Sohn, S.Y.; Lee, S.H. Data fusion, ensemble and clustering to improve the classification accuracy for the severity of road traffic accidents in Korea. Saf. Sci. 2003, 41, 1–14. [Google Scholar] [CrossRef]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef]
- Nandurge, P.A.; Dharwadkar, N.V. Analyzing road accident data using machine learning paradigms. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC 2017), Palladam, India, 10–11 February 2017; pp. 604–610. [Google Scholar]
- Kumar, S.; Semwal, V.B.; Solanki, V.K.; Tiwari, P.; Kalitin, D. A Conjoint Analysis of Road Accident Data using K-modes Clustering and Bayesian Networks (Road Accident Analysis using clustering and classification). In Proceedings of the Second International Conference on Research in Intelligent and Computing in Engineering, Gopeshwar, India, 24–26 March 2017; Volume 10, pp. 53–56. [Google Scholar]
- Khorashadi, A.; Niemeier, D.; Shankar, V.; Mannering, F. Differences in rural and urban driver-injury severities in accidents involving large-trucks: An exploratory analysis. Accid. Anal. Prev. 2005, 37, 910–921. [Google Scholar] [CrossRef]
- Islam, M.; Hernandez, S. Large truck-involved crashes: Exploratory injury severity analysis. J. Transp. Eng. 2013, 139, 596–604. [Google Scholar] [CrossRef]
- Chang, L.Y.; Chien, J.T. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Z.; Pu, Z.; Xu, C. Comparing prediction performance for crash injury severity among various machine learning and statistical methods. IEEE Access 2018, 6, 60079–60087. [Google Scholar] [CrossRef]
- Chen, M.M.; Chen, M.C. Modeling road accident severity with comparisons of logistic regression, decision tree and random forest. Information 2020, 11, 270. [Google Scholar] [CrossRef]
- Ghandour, A.J.; Hammoud, H.; Al-hajj, S. Analyzing Factors Associated with Fatal Road Crashes: A Machine Learning Approach. Int. J. Environ. Res. Public Health 2020, 17, 4111. [Google Scholar] [CrossRef] [PubMed]
- Eustace, D.; Alqahtani, T.; Hovey, P.W. Classification Tree Modelling of Factors Impacting Severity of Truck-Related Crashes in Ohio. In Transportation Research Board 97th Annual Meeting. 2018. Available online: https://trid.trb.org/view/1497050 (accessed on 23 December 2020).
- Zheng, Z.; Lu, P.; Lantz, B. Commercial truck crash injury severity analysis using gradient boosting data mining model. J. Saf. Res. 2018, 65, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4766–4775. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Popov, S.; Morozov, S.; Babenko, A. Neural oblivious decision ensembles for deep learning on tabular data. arXiv 2019, arXiv:1909.06312. [Google Scholar]
- National Center for Analysis and Statistics, Crash Report Sampling System. Available online: https://www.nhtsa.gov/crash-data-systems/crash-report-sampling-system (accessed on 13 October 2020).
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2013, 41, 647–665. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Alikhani, M.; Nedaie, A.; Ahmadvand, A. Presentation of clustering-classification heuristic method for improvement accuracy in classification of severity of road accidents in Iran. Saf. Sci. 2013, 60, 142–150. [Google Scholar] [CrossRef]
- Bin Islam, M.; Hernández, S. Modeling Injury Outcomes of Crashes Involving Heavy Vehicles on Texas Highways. Transp. Res. Rec. J. Transp. Res. Board 2013, 2388, 28–36. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Codes | Descriptions |
|---|---|
| 60 | Step van (GVWR > 10,000 lb) |
| 61 | Single-Unit Straight Truck or Cab-Chassis (10,000 lb < GVWR < 19,501 lb) |
| 62 | Single-Unit Straight Truck or Cab-Chassis (19,501 lb < GVWR < 26,000 lb) |
| 63 | Single-Unit Straight Truck or Cab-Chassis (GVWR > 26,000 lb) |
| 64 | Single Unit Straight Truck or Cab-Chassis (GVWR unknown) |
| 66 | Truck-Tractor (cab only or with any number of trailing units) |
| 67 | Medium/Heavy Pickup (GVWR > 4536 kg) |
| 71 | Unknown if Single-Unit or Combination-Unit Medium Truck (10,000 lb < GVWR < 26,000 lb) |
| 72 | Unknown if Single-Unit or Combination-Unit Heavy Truck (GVWR > 26,000 lb) |
| 78 | Unknown Medium/Heavy Truck Type |
| 79 | Unknown Truck Type (Light/Medium/Heavy) |
| Level of Injury | Frequency (%) |
|---|---|
| K = Fatal injury or killed: any injury that results in death of a living person immediately after the crash or within 30 days of a motor vehicle crash. | 323 (3.39%) |
| A = Suspected serious injury: any injury (except fatal injury) that prevents the injured person from continuing his/her usual activities like before the crash (e.g., lacerations, broken or distorted limbs, skull or chest injuries). | 865 (9.07%) |
| Severe injuries (K + A) | 1188 (12.46%) |
| B = Suspected minor injury: any injury that is evident to the observers at the scene (e.g., lump on the head, abrasions, bruises, minor lacerations). | 964 (10.12%) |
| C = Possible injury: any injury that was claimed or complained about but was not evident as fatal, serious injury, or minor injury (e.g., momentary unconsciousness, claim of injury but not evident). | 1298 (13.61%) |
| O = No injury: No person was injured, and only properties were damaged. | 6084 (63.81%) |
| Non-severe injuries (B + C + O) | 8346 (87.54%) |
| Feature Names | Frequency (%) | Feature Names | Frequency (%) |
|---|---|---|---|
| Vehicle Characteristics | Crash Characteristics | ||
| 1. Cargo body type (cargo_bt) | 15. Pre-crash movement | ||
| Van/enclosed box | 3041 (31.90%) | Going straight | 4846 (50.83%) |
| Other types | 2459 (25.79%) | Turning left | 765 (8.02%) |
| Unknown | 1859 (19.50 %) | Negotiating a curve | 697 (7.31%) |
| Flatbed | 864 (9.06%) | Stopped in roadway | 690 (7.24%) |
| Dump | 535 (5.61%) | Changing lanes | 660 (6.92%) |
| No cargo body | 435 (4.56 %) | Turning right | 580 (6.08%) |
| Cargo tank | 341 (3.58%) | Backing up | 438 (4.59%) |
| 2. Gross vehicle weight (gvwr) | Others (e.g., starting in road, entering parking position, merging, etc.) | 383 (4.02%) | |
| GVWR > 26,000 (26 k) (lb) | 6024 (63.18%) | Decelerating in road | 377 (3.95%) |
| 10 k (lb) < GVWR < 26 k (lb) | 3510 (36.82%) | Passing or overtaking another vehicle | 98 (1.03%) |
| 3. Trailing unit | 16. Manner of collision | ||
| Yes | 4962 (52.05%) | Front to rear | 2753 (28.88%) |
| No | 4572 (47.95%) | Sideswipe, same direction | 2306 (24.19%) |
| 4. Hazardous material involvement | No collision with motor vehicle in transport | 1926 (20.20%) | |
| No | 9421 (98.81%) | Angle | 1696 (17.79%) |
| Yes | 113 (1.19%) | Others | 332 (3.48%) |
| 5. Speed related | Sideswipe, opposite direction | 302 (3.17%) | |
| No | 9156 (96.04%) | Front-to-front | 219 (2.30%) |
| Yes | 378 (3.96%) | 17. Most harmful event | |
| 6. Number of vehicles in crash | Mean = 2, Std = 0.63 | Colliding vehicle in transport | 7529 (78.97%) |
| 7. Number of occupants | Mean = 1.18, Std = 0.53 | Colliding fixed object | 754 (7.91%) |
| Roadway Characteristics | Rollover/overturn | 347 (3.64%) | |
| 8. Trafficway type | Colliding parked motor vehicle | 261 (2.74%) | |
| Two-way, not divided | 3687 (38.67%) | Colliding vehicle outside trafficway | 169 (1.77%) |
| Two-way divided with positive median barrier | 3026 (31.74%) | Others | 127 (1.33%) |
| Two-way, divided, unprotected median | 1603 (16.81%) | Colliding pedestrian | 107 (1.12%) |
| Two-way, not divided with continuous left-turn lane | 419 (4.39%) | Colliding live animal | 101 (1.06%) |
| One-way | 280 (2.94%) | Hitting guardrail/face | 97 (1.02%) |
| Non-trafficway or driveway access | 267 (2.80%) | Colliding pedal cyclists | 42 (0.44%) |
| Entrance/exit ramp | 252 (2.64%) | Temporal Attributes | |
| 9. Roadway alignment | 18. Day of week | ||
| Straight | 8300 (87.06%) | Weekdays | 8338 (87.46%) |
| Curve left | 433(4.54%) | Weekends | 1196 (12.54%) |
| Others | 406(4.26%) | 19. Time of the day (hour) | |
| Curve right | 395(4.14%) | Non-peak (10 a.m.–16 p.m.) | 4238 (44.45%) |
| 10. Roadway grade | AM peak (5 a.m.–10 a.m.) | 2782 (29.18%) | |
| Level | 7573 (79.43%) | Pm Peak (16 p.m.–19 p.m.) | 1162 (12.19%) |
| Grade unknown slope | 885 (9.28%) | AM (0 a.m.–5 a.m.) | 732 (7.68%) |
| Downhill | 361 (3.79%) | Night (19 p.m.–23:59 p.m.) | 620 (6.50%) |
| Uphill | 284 (2.98%) | Environmental Characteristics | |
| Non trafficway/driveway access | 267 (2.80%) | 20. Road surface condition | |
| Others | 164 (1.72%) | Dry | 7662 (80.37%) |
| 11. Traffic control device | Wet | 1278 (13.40%) | |
| No controls | 7090(74.37%) | Others | 594 (6.23%) |
| Traffic control signals | 1601 (16.79%) | 21. Lighting condition | |
| Stop sign | 428 (4.49%) | Daylight | 7470 (78.35%) |
| Other sign signals | 415 (4.35%) | Dark-not lighted | 1007 (10.56%) |
| 12. Posted speed limit | Mean = 47.32, Std = 16.68 | Dark-lighted | 734 (7.70%) |
| 13. Interstate highway | Dark unknown light and others | 323 (3.39%) | |
| No | 7242 (75.96%) | 22. Weather condition | |
| Yes | 2292 (24.04%) | Clear | 6696 (70.23%) |
| 14. Location | Cloudy | 1667 (17.48%) | |
| Urban | 6583(69.05%) | Rain | 860 (9.02%) |
| Rural | 2951 (30.95%) | Snow | 182 (1.91%) |
| Others | 129 (1.35%) | ||
| Classes | Positive Prediction | Negative Prediction |
|---|---|---|
| Positive class | True Positive (TP) | False Negative (FN) |
| Negative class | False Positive (FP) | True Negative (TN) |
| Cluster Prototypes | EDS 9534 (100%) | CL1 2680 (28.11%) | CL2 3460 (36.29%) | CL3 3394 (35.6%) | |
|---|---|---|---|---|---|
| Trailing Unit | No | 47.95% | 19.25% | 25.75% | 93.25% |
| Yes | 52.05% | 80.75% | 74.25% | 6.75% | |
| GVWR | Over 26 k (lb) | 63.18% | 87.05% | 87.83% | 19.21% |
| 10 k–26 k (lb) | 36.82% | 12.95% | 12.17% | 80.79% | |
| Traffic way | Two-way, not divided | 38.67 % | 1.83% | 56.62% | 49.47% |
| Two-way divided with positive median barrier | 31.74% | 77.76% | 8.82% | 18.77% | |
| Two-way, divided, unprotected median | 16.81% | 15.49% | 18.01% | 16.65% | |
| Two-way, not divided with continuous left-turn lane | 4.39% | 0.37% | 5.49% | 6.45% | |
| One-way trafficway | 2.94% | 1.38% | 3.73% | 3.36% | |
| Non-trafficway or driveway access | 2.80% | 0% | 4.80% | 2.98% | |
| Entrance/exit ramp | 2.64% | 3.17% | 2.54% | 2.33% | |
| Posted speed limit | 25th percentile | 35 (mph) | 60 (mph) | 35 (mph) | 35 (mph) |
| 50th percentile | 45 (mph) | 65 (mph) | 40 (mph) | 45 (mph) | |
| 75th percentile | 55 (mph) | 70 (mph) | 55 (mph) | 55 (mph) | |
| Interstate highway | Yes | 75.96% | 76.42% | 1.45% | 5.72% |
| No | 24.04% | 23.58% | 98.55% | 94.28% | |
| Injury Severity | Non-severe | 87.54% | 85.11% | 87.2% | 89.81% |
| Severe | 12.46% | 14.89% | 12.8% | 10.19% | |
| Dataset | Validation | Accuracy | Precision | Sensitivity | Specificity | PR-AUC Score |
|---|---|---|---|---|---|---|
| EDS | Train | 88.73% | 70% | 16.83% | 98.97% | 49.53% |
| Test | 87.63% | 51.06% | 13.48% | 98.16% | 40.12% | |
| CL1 | Train | 87.69% | 78.57% | 23.66% | 98.87% | 58.40% |
| Test | 87.19% | 74.29% | 21.67% | 98.68% | 45.82% | |
| CL2 | Train | 89.68% | 78.3% | 26.77% | 98.91% | 61.88% |
| Test | 88.34% | 62% | 23.31% | 97.90% | 45.40% | |
| CL3 | Train | 91.03% | 78.43% | 16.53% | 99.48% | 52.60% |
| Test | 90.09% | 56.52% | 12.50% | 98.91% | 34.23% |
| Injury Outcome | Input Feature Names | EDS | CL1 | CL2 | CL3 |
|---|---|---|---|---|---|
| Severe injuries | Number of vehicles | √ | √ | √ | √ |
| Posted speed limit | √ | √ | √ | √ | |
| Manner of collision: angle | √ | √ | √ | √ | |
| Manner of collision: front-to-rear | √ | √ | |||
| Manner of collision: front-to-front | √ | √ | √ | ||
| Hour: am | √ | √ | √ | √ | |
| Pre-crash movements: stopped in roadway | √ | √ | √ | √ | |
| Pre-crash movements: going straight | √ | √ | √ | ||
| Most harmful event: colliding pedestrian | √ | √ | √ | ||
| Most harmful event: colliding vehicle in transport | √ | √ | √ | ||
| Most harmful event: rollover/overturn | √ | ||||
| Weather: clear | √ | ||||
| Trafficway type: two-way divided unprotected median | √ | ||||
| Cargo body type: van/enclosed | √ | ||||
| Cargo body type: others | √ | ||||
| Cargo body type: dump | √ | ||||
| Roadway alignment: curve left | √ | ||||
| Lighting condition: dark not lighted | √ | √ | |||
| Road surface condition: dry | √ | ||||
| GVWR: over 26 k (lb) | √ | ||||
| Urban/rural: rural | √ | ||||
| Non-severe injuries | Manner of collision: sideswipe same direction | √ | √ | √ | √ |
| Manner of collision: no collision with vehicle in transport | √ | ||||
| Urban/rural: urban | √ | ||||
| Day of week: weekdays | √ | ||||
| Cargo body type: unknown | √ | ||||
| Lighting condition: daylight | √ | √ | |||
| Traffic control device: traffic control signals | √ | ||||
| GVWR: 10 k–26 k (lb) | √ | ||||
| Hour: pm peak | √ | ||||
| Roadway grade: unknown slope | √ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tahfim, S.A.-S.; Yan, C. Analysis of Severe Injuries in Crashes Involving Large Trucks Using K-Prototypes Clustering-Based GBDT Model. Safety 2021, 7, 32. https://doi.org/10.3390/safety7020032
Tahfim SA-S, Yan C. Analysis of Severe Injuries in Crashes Involving Large Trucks Using K-Prototypes Clustering-Based GBDT Model. Safety. 2021; 7(2):32. https://doi.org/10.3390/safety7020032
Chicago/Turabian StyleTahfim, Syed As-Sadeq, and Chen Yan. 2021. "Analysis of Severe Injuries in Crashes Involving Large Trucks Using K-Prototypes Clustering-Based GBDT Model" Safety 7, no. 2: 32. https://doi.org/10.3390/safety7020032
APA StyleTahfim, S. A.-S., & Yan, C. (2021). Analysis of Severe Injuries in Crashes Involving Large Trucks Using K-Prototypes Clustering-Based GBDT Model. Safety, 7(2), 32. https://doi.org/10.3390/safety7020032