

Innovation through Artificial Intelligence in Triage Systems for Resource Optimization in Future Pandemics
Abstract
:
1. Introduction
2. Materials and Methods
Materials
3. Model Development
Performance Evaluation
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, K.J.W.; Ang, C.K.E.; Constantinides, T.; Rajinikanth, V.; Acharya, U.R.; Cheong, K.H. Artificial intelligence and machine learning in emergency medicine. Biocybern. Biomed. Eng. 2021, 41, 156–172. [Google Scholar] [CrossRef]
- Fernandes, M.; Vieira, S.M.; Leite, F.; Palos, C.; Finkelstein, S.; Sousa, J.M. Clinical decision support systems for triage in the emergency department using intelligent systems: A review. Artif. Intell. Med. 2020, 102, 101762. [Google Scholar] [CrossRef]
- Guo, Y.R.; Cao, Q.D.; Hong, Z.S.; Tan, Y.Y.; Chen, S.D.; Jin, H.J.; Tan, K.S.; Wang, D.Y.; Yan, Y. The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak—An update on the status. Mil. Med. Res. 2020, 7, 11. [Google Scholar] [CrossRef] [PubMed]
- Mehta, P.; McAuley, D.F.; Brown, M.; Sanchez, E.; Tattersall, R.S.; Manson, J.J. COVID-19: Consider cytokine storm syndromes and immunosuppression. Lancet 2020, 395, 1033–1034. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Hou, H.; Luo, Y.; Tang, G.; Wu, S.; Huang, M.; Liu, W.; Zhu, Y.; Lin, Q.; Mao, L.; et al. The laboratory tests and host immunity of COVID-19 patients with different severity of illness. JCI Insight 2020, 5, e137799. [Google Scholar] [CrossRef] [PubMed]
- Liao, D.; Zhou, F.; Luo, L.; Xu, M.; Wang, H.; Xia, J.; Gao, Y.; Cai, L.; Wang, Z.; Yin, P.; et al. Haematological characteristics and risk factors in the classification and prognosis evaluation of COVID-19: A retrospective cohort study. Lancet Haematol. 2020, 7, e671–e678. [Google Scholar] [CrossRef] [PubMed]
- Ge, H.; Wang, X.; Yuan, X.; Xiao, G.; Wang, C.; Deng, T.; Yuan, Q.; Xiao, X. The epidemiology and clinical information about COVID-19. Eur. J. Clin. Microbiol. Infect. Dis. 2020, 39, 1011–1019. [Google Scholar] [CrossRef]
- Lythgoe, M.P.; Middleton, P. Ongoing clinical trials for the management of the COVID-19 pandemic. Trends Pharmacol. Sci. 2020, 41, 363–382. [Google Scholar] [CrossRef]
- Bhimraj, A.; Morgan, R.L.; Shumaker, A.H.; Lavergne, V.; Baden, L.; Cheng, V.C.C.; Edwards, K.M.; Gandhi, R.; Muller, W.J.; O’Horo, J.C.; et al. Infectious Diseases Society of America Guidelines on the treatment and management of patients with coronavirus disease 2019 (COVID-19). Clin. Infect. Dis. 2020, 78, ciaa478. [Google Scholar]
- Lynch, J.B.; Davitkov, P.; Anderson, D.J.; Bhimraj, A.; Cheng, V.C.C.; Guzman-Cottrill, J.; Dhindsa, J.; Duggal, A.; Jain, M.K.; Lee, G.M.; et al. Infectious Diseases Society of America Guidelines on Infection Prevention for Healthcare Personnel Caring for Patients with Suspected or Known COVID-19. Clin. Infect. Dis. 2020, ciab953. [Google Scholar]
- Wang, M.; Cao, R.; Zhang, L.; Yang, X.; Liu, J.; Xu, M.; Shi, Z.; Hu, Z.; Zhong, W.; Xiao, G. Remdesivir and chloroquine effectively inhibit the recently emerged novel coronavirus (2019-nCoV) in vitro. Cell Res. 2020, 30, 269–271. [Google Scholar] [CrossRef]
- Rizk, J.G.; Forthal, D.N.; Kalantar-Zadeh, K.; Mehra, M.R.; Lavie, C.J.; Rizk, Y.; Pfeiffer, J.P.; Lewin, J.C. Expanded Access Programs, compassionate drug use, and Emergency Use Authorizations during the COVID-19 pandemic. Drug Discov. Today 2021, 26, 593–603. [Google Scholar] [CrossRef] [PubMed]
- Bassetti, M.; Giacobbe, D.R.; Bruzzi, P.; Barisione, E.; Centanni, S.; Castaldo, N.; Corcione, S.; De Rosa, F.G.; Di Marco, F.; Gori, A.; et al. Clinical management of adult patients with COVID-19 outside intensive care units: Guidelines from the Italian Society of Anti-Infective Therapy (SITA) and the Italian Society of Pulmonology (SIP). Infect. Dis. Ther. 2021, 10, 1837–1885. [Google Scholar] [CrossRef] [PubMed]
- Lim, W.T.; Fang, A.H.; Loo, C.M.; Wong, K.S.; Balakrishnan, T. Use of the National Early Warning Score (NEWS) to identify acutely deteriorating patients with sepsis in acute medical ward. Ann. Acad. Med. Singap. 2019, 48, 145–149. [Google Scholar] [CrossRef] [PubMed]
- Covino, M.; Sandroni, C.; Santoro, M.; Sabia, L.; Simeoni, B.; Bocci, M.G.; Ojetti, V.; Candelli, M.; Antonelli, M.; Gasbarrini, A.; et al. Predicting intensive care unit admission and death for COVID-19 patients in the emergency department using early warning scores. Resuscitation 2020, 156, 84–91. [Google Scholar] [CrossRef] [PubMed]
- Solà, S.; Jacob, J.; Azeli, Y.; Trenado, J.; Morales-Álvarez, J.; Jiménez-Fàbrega, F.X. Priority in interhospital transfers of patients with severe COVID-19: Development and prospective validation of a triage tool. Emergencias 2022, 34, 29–37. [Google Scholar] [PubMed]
- Khalsa, R.K.; Khashkhusha, A.; Zaidi, S.; Harky, A.; Bashir, M. Artificial intelligence and cardiac surgery during COVID-19 era. J. Card. Surg. 2021, 36, 1729–1733. [Google Scholar] [CrossRef] [PubMed]
- Piroth, L.; Cottenet, J.; Mariet, A.S.; Bonniaud, P.; Blot, M.; Tubert-Bitter, P.; Quantin, C. Comparison of the characteristics, morbidity, and mortality of COVID-19 and seasonal influenza: A nationwide, population-based retrospective cohort study. Lancet Respir. Med. 2021, 9, 251–259. [Google Scholar] [CrossRef] [PubMed]
- Hao, B.; Sotudian, S.; Wang, T.; Xu, T.; Hu, Y.; Gaitanidis, A.; Breen, K.; Velmahos, G.C.; Paschalidis, I.C. Early prediction of level-of-care requirements in patients with COVID-19. eLife 2020, 9, e60519. [Google Scholar] [CrossRef]
- Li, J.P.O.; Liu, H.; Ting, D.S.; Jeon, S.; Chan, R.P.; Kim, J.E.; Sim, D.A.; Thomas, P.B.; Lin, H.; Chen, Y.; et al. Digital technology, tele-medicine and artificial intelligence in ophthalmology: A global perspective. Prog. Retin. Eye Res. 2021, 82, 100900. [Google Scholar] [CrossRef]
- Aggarwal, P.; Mishra, N.K.; Fatimah, B.; Singh, P.; Gupta, A.; Joshi, S.D. COVID-19 image classification using deep learning: Advances, challenges and opportunities. Comput. Biol. Med. 2022, 144, 105350. [Google Scholar] [CrossRef]
- Tarek, Z.; Shams, M.Y.; Towfek, S.; Alkahtani, H.K.; Ibrahim, A.; Abdelhamid, A.A.; Eid, M.M.; Khodadadi, N.; Abualigah, L.; Khafaga, D.S.; et al. An Optimized Model Based on Deep Learning and Gated Recurrent Unit for COVID-19 Death Prediction. Biomimetics 2023, 8, 552. [Google Scholar] [CrossRef]
- Liu, T.; Siegel, E.; Shen, D. Deep learning and medical image analysis for COVID-19 diagnosis and prediction. Annu. Rev. Biomed. Eng. 2022, 24, 179–201. [Google Scholar] [CrossRef]
- Choudhry, I.A.; Qureshi, A.N.; Aurangzeb, K.; Iqbal, S.; Alhussein, M. Hybrid Diagnostic Model for Improved COVID-19 Detection in Lung Radiographs Using Deep and Traditional Features. Biomimetics 2023, 8, 406. [Google Scholar] [CrossRef]
- Avila-Tomás, J.; Mayer-Pujadas, M.; Quesada-Varela, V. Artificial intelligence and its applications in medicine I: Introductory background to AI and robotics. Aten. Primaria 2020, 52, 778–784. [Google Scholar] [CrossRef]
- Sánchez-Salmerón, R.; Gómez-Urquiza, J.L.; Albendín-García, L.; Correa-Rodríguez, M.; Martos-Cabrera, M.B.; Velando-Soriano, A.; Suleiman-Martos, N. Machine learning methods applied to triage in emergency services: A systematic review. Int. Emerg. Nurs. 2022, 60, 101109. [Google Scholar] [CrossRef]
- Lee, J.T.; Hsieh, C.C.; Lin, C.H.; Lin, Y.J.; Kao, C.Y. Prediction of hospitalization using artificial intelligence for urgent patients in the emergency department. Sci. Rep. 2021, 11, 19472. [Google Scholar] [CrossRef]
- Singh, K.; Kaur, N.; Prabhu, A. Combating COVID-19 Crisis using Artificial Intelligence (AI) Based Approach: Systematic Review. Curr. Top. Med. Chem. 2024, 24, 737–753. [Google Scholar] [CrossRef]
- Almotairi, K.H.; Hussein, A.M.; Abualigah, L.; Abujayyab, S.K.; Mahmoud, E.H.; Ghanem, B.O.; Gandomi, A.H. Impact of artificial intelligence on COVID-19 pandemic: A survey of image processing, tracking of disease, prediction of outcomes, and computational medicine. Big Data Cogn. Comput. 2023, 7, 11. [Google Scholar] [CrossRef]
- Park, C.W.; Seo, S.W.; Kang, N.; Ko, B.; Choi, B.W.; Park, C.M.; Chang, D.K.; Kim, H.; Kim, H.; Lee, H.; et al. Artificial intelligence in health care: Current applications and issues. J. Korean Med. Sci. 2020, 35, e379. [Google Scholar] [CrossRef]
- Bajwa, J.; Munir, U.; Nori, A.; Williams, B. Artificial intelligence in healthcare: Transforming the practice of medicine. Future Healthc. J. 2021, 8, e188. [Google Scholar] [CrossRef]
- Stewart, J.; Freeman, S.; Eroglu, E.; Dumitrascu, N.; Lu, J.; Goudie, A.; Sprivulis, P.; Akhlaghi, H.; Tran, V.; Sanfilippo, F.; et al. Attitudes towards artificial intelligence in emergency medicine. Emerg. Med. Australas. 2024, 36, 252–265. [Google Scholar] [CrossRef]
- Huang, D.; Wang, S.; Liu, Z. A systematic review of prediction methods for emergency management. Int. J. Disaster Risk Reduct. 2021, 62, 102412. [Google Scholar] [CrossRef]
- Chenais, G.; Lagarde, E.; Gil-Jardiné, C. Artificial intelligence in emergency medicine: Viewpoint of current applications and foreseeable opportunities and challenges. J. Med. Internet Res. 2023, 25, e40031. [Google Scholar] [CrossRef]
- Aslan, S.; Demirci, S.; Oktay, T.; Yesilbas, E. Percentile-Based Adaptive Immune Plasma Algorithm and Its Application to Engineering Optimization. Biomimetics 2023, 8, 486. [Google Scholar] [CrossRef]
- Shamman, A.H.; Hadi, A.A.; Ramul, A.R.; Zahra, M.M.A.; Gheni, H.M. The artificial intelligence (AI) role for tackling against COVID-19 pandemic. Mater. Today Proc. 2023, 80, 3663–3667. [Google Scholar] [CrossRef]
- Alkhammash, E.H.; Assiri, S.A.; Nemenqani, D.M.; Althaqafi, R.M.; Hadjouni, M.; Saeed, F.; Elshewey, A.M. Application of Machine Learning to Predict COVID-19 Spread via an Optimized BPSO Model. Biomimetics 2023, 8, 457. [Google Scholar] [CrossRef]
- Nijhawan, R.; Kumar, M.; Arya, S.; Mendirtta, N.; Kumar, S.; Towfek, S.; Khafaga, D.S.; Alkahtani, H.K.; Abdelhamid, A.A. A Novel Artificial-Intelligence-Based Approach for Classification of Parkinson’s Disease Using Complex and Large Vocal Features. Biomimetics 2023, 8, 351. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, X.; Zhang, H. A BDF3 and new nonlinear fourth-order difference scheme for the generalized viscous Burgers’ equation. Appl. Math. Lett. 2024, 151, 109002. [Google Scholar] [CrossRef]
- Li, C.; Zhang, H.; Yang, X. A new nonlinear compact difference scheme for a fourth-order nonlinear Burgers type equation with a weakly singular kernel. J. Appl. Math. Comput. 2024, 70, 2045–2077. [Google Scholar] [CrossRef]
- Shi, Y.; Yang, X. Pointwise error estimate of conservative difference scheme for supergeneralized viscous Burgers’ equation. Electron. Res. Arch. 2024, 32, 1471–1497. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, H.; Yang, X.; Wang, F. A second-order finite difference method for the multi-term fourth-order integral—Differential equations on graded meshes. Comput. Appl. Math. 2022, 41, 313. [Google Scholar] [CrossRef]
- Chen, W.; Lei, X.; Chakrabortty, R.; Pal, S.C.; Sahana, M.; Janizadeh, S. Evaluation of different boosting ensemble machine learning models and novel deep learning and boosting framework for head-cut gully erosion susceptibility. J. Environ. Manag. 2021, 284, 112015. [Google Scholar] [CrossRef] [PubMed]
- Budholiya, K.; Shrivastava, S.K.; Sharma, V. An optimized XGBoost based diagnostic system for effective prediction of heart disease. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4514–4523. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Amgad, M.; Atteya, L.A.; Hussein, H.; Mohammed, K.H.; Hafiz, E.; Elsebaie, M.A.; Mobadersany, P.; Manthey, D.; Gutman, D.A.; Elfandy, H.; et al. Explainable nucleus classification using decision tree approximation of learned embeddings. Bioinformatics 2022, 38, 513–519. [Google Scholar] [CrossRef] [PubMed]
- Kusudo, K.; Ochi, R.; Nakajima, S.; Suzuki, T.; Mamo, D.; Caravaggio, F.; Mar, W.; Gerretsen, P.; Mimura, M.; Pollock, B.G.; et al. Decision tree classification of cognitive functions with D2 receptor occupancy and illness severity in late-life schizophrenia. Schizophr. Res. 2022, 241, 113–115. [Google Scholar] [CrossRef] [PubMed]
- Ontivero-Ortega, M.; Lage-Castellanos, A.; Valente, G.; Goebel, R.; Valdes-Sosa, M. Fast Gaussian Naïve Bayes for searchlight classification analysis. Neuroimage 2017, 163, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Vedaraj, M.; Anita, C.; Muralidhar, A.; Lavanya, V.; Balasaranya, K.; Jagadeesan, P. Early Prediction of Lung Cancer Using Gaussian Naive Bayes Classification Algorithm. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 838–848. [Google Scholar]
- Ghasemkhani, B.; Balbal, K.F.; Birant, K.U.; Birant, D. A Novel Classification Method: Neighborhood-Based Positive Unlabeled Learning Using Decision Tree (NPULUD). Entropy 2024, 26, 403. [Google Scholar] [CrossRef]
- Dann, E.; Henderson, N.C.; Teichmann, S.A.; Morgan, M.D.; Marioni, J.C. Differential abundance testing on single-cell data using k-nearest neighbor graphs. Nat. Biotechnol. 2022, 40, 245–253. [Google Scholar] [CrossRef]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-nearest neighbor, genetic, support vector machine, decision tree, and long short term memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Lin, G.; Lin, A.; Gu, D. Using support vector regression and K-nearest neighbors for short-term traffic flow prediction based on maximal information coefficient. Inf. Sci. 2022, 608, 517–531. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support vector machine. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 101–121. [Google Scholar]
- Mourtas, S.D.; Katsikis, V.N.; Stanimirović, P.S.; Kazakovtsev, L.A. Credit and Loan Approval Classification Using a Bio-Inspired Neural Network. Biomimetics 2024, 9, 120. [Google Scholar] [CrossRef] [PubMed]
- Xie, G.; Li, Q.; Shi, Z.; Fang, H.; Ji, S.; Jiang, Y.; Yuan, Z.; Ma, L.; Xu, M. Generating Neural Networks for Diverse Networking Classification Tasks via Hardware-Aware Neural Architecture Search. IEEE Trans. Comput. 2023, 73, 481–494. [Google Scholar] [CrossRef]
- Feng, H.; Wang, F.; Li, N.; Xu, Q.; Zheng, G.; Sun, X.; Hu, M.; Xing, G.; Zhang, G. A random forest model for peptide classification based on virtual docking data. Int. J. Mol. Sci. 2023, 24, 11409. [Google Scholar] [CrossRef]
- Oehm, A.W.; Zablotski, Y.; Campe, A.; Hoedemaker, M.; Strube, C.; Springer, A.; Jordan, D.; Knubben-Schweizer, G. Random forest classification as a tool in epidemiological modelling: Identification of farm-specific characteristics relevant for the occurrence of Fasciola hepatica on German dairy farms. PLoS ONE 2023, 18, e0296093. [Google Scholar] [CrossRef]
- Martínez-Blanco, P.; Suárez, M.; Gil-Rojas, S.; Torres, A.M.; Martínez-García, N.; Blasco, P.; Torralba, M.; Mateo, J. Prognostic Factors for Mortality in Hepatocellular Carcinoma at Diagnosis: Development of a Predictive Model Using Artificial Intelligence. Diagnostics 2024, 14, 406. [Google Scholar] [CrossRef]
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, C.; Zeng, J.; Yuan, X.; Zhang, P. Combining structured and unstructured data for predictive models: A deep learning approach. BMC Med. Inform. Decis. Mak. 2020, 20, 280. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Sun, D. The improved AdaBoost algorithms for imbalanced data classification. Inf. Sci. 2021, 563, 358–374. [Google Scholar] [CrossRef]
- Hatwell, J.; Gaber, M.M.; Atif Azad, R.M. Ada-WHIPS: Explaining AdaBoost classification with applications in the health sciences. BMC Med. Inform. Decis. Mak. 2020, 20, 250. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Meng, F.; Yan, G.; Yan, H.; Chai, B.; Song, F. Diagnostic classification of cancers using extreme gradient boosting algorithm and multi-omics data. Comput. Biol. Med. 2020, 121, 103761. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Zhou, T.; Li, T. Detecting epileptic seizures in EEG signals with complementary ensemble empirical mode decomposition and extreme gradient boosting. Entropy 2020, 22, 140. [Google Scholar] [CrossRef] [PubMed]
- Ege, D.; Boccaccini, A.R. Investigating the Effect of Processing and Material Parameters of Alginate Dialdehyde-Gelatin (ADA-GEL)-Based Hydrogels on Stiffness by XGB Machine Learning Model. Bioengineering 2024, 11, 415. [Google Scholar] [CrossRef] [PubMed]
- Suárez, M.; Gil-Rojas, S.; Martínez-Blanco, P.; Torres, A.M.; Ramón, A.; Blasco-Segura, P.; Torralba, M.; Mateo, J. Machine Learning-Based Assessment of Survival and Risk Factors in Non-Alcoholic Fatty Liver Disease-Related Hepatocellular Carcinoma for Optimized Patient Management. Cancers 2024, 16, 1114. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Zhou, X.; Obuchowski, N.A.; McClish, D.K. Statistical Methods in Diagnostic Medicine, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Boonstra, A.; Laven, M. Influence of artificial intelligence on the work design of emergency department clinicians a systematic literature review. BMC Health Serv. Res. 2022, 22, 669. [Google Scholar] [CrossRef] [PubMed]
- Sanz-Muñoz, I.; Eiros, J.M. Old and new aspects of influenza. Med. Clín. 2023, 161, 303–309. [Google Scholar] [CrossRef]
- Yu, B.; Xiaonan, T. Comparison of COVID-19 and influenza characteristics. J. Zhejiang Univ. Sci. B 2021, 22, 87. [Google Scholar]
- Lawson, A.; López-Candales, A. COVID-19 and seasonal influenza. Postgrad. Med. 2022, 134, 148–151. [Google Scholar] [CrossRef] [PubMed]
- Barrezueta, L.B.; Zamorano, M.G.; López-Casillas, P.; Brezmes-Raposo, M.; Fernández, I.S.; Vázquez, M.d.l.A.P. Influence of the COVID-19 pandemic on the epidemiology of acute bronchiolitis. Enfermedades Infecc. Microbiol. Clin. 2023, 41, 348–351. [Google Scholar] [CrossRef] [PubMed]
- Radzikowska, U.; Eljaszewicz, A.; Tan, G.; Stocker, N.; Heider, A.; Westermann, P.; Steiner, S.; Dreher, A.; Wawrzyniak, P.; Rückert, B.; et al. Rhinovirus-induced epithelial RIG-I inflammasome suppresses antiviral immunity and promotes inflammation in asthma and COVID-19. Nat. Commun. 2023, 14, 2329. [Google Scholar] [CrossRef] [PubMed]
- Olsen, S.J. Changes in influenza and other respiratory virus activity during the COVID-19 pandemic—United States, 2020–2021. MMWR Morb. Mortal. Wkly. Rep. 2021, 70, 1013–1019. [Google Scholar] [CrossRef] [PubMed]
- Yadaw, A.S.; Li, Y.c.; Bose, S.; Iyengar, R.; Bunyavanich, S.; Pandey, G. Clinical features of COVID-19 mortality: Development and validation of a clinical prediction model. Lancet Digit. Health 2020, 2, e516–e525. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Cai, G.Y.; Fang, W.; Li, H.Y.; Wang, S.Y.; Chen, L.; Yu, Y.; Liu, D.; Xu, S.; Cui, P.F.; et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat. Commun. 2020, 11, 5033. [Google Scholar] [CrossRef] [PubMed]
- An, C.; Lim, H.; Kim, D.W.; Chang, J.H.; Choi, Y.J.; Kim, S.W. Machine learning prediction for mortality of patients diagnosed with COVID-19: A nationwide Korean cohort study. Sci. Rep. 2020, 10, 18716. [Google Scholar] [CrossRef]
- Moulaei, K.; Ghasemian, F.; Bahaadinbeigy, K.; Sarbi, R.E.; Taghiabad, Z.M. Predicting mortality of COVID-19 patients based on data mining techniques. J. Biomed. Phys. Eng. 2021, 11, 653. [Google Scholar] [CrossRef] [PubMed]
- Gil-Rojas, S.; Suárez, M.; Martínez-Blanco, P.; Torres, A.M.; Martínez-García, N.; Blasco, P.; Torralba, M.; Mateo, J. Application of Machine Learning Techniques to Assess Alpha-Fetoprotein at Diagnosis of Hepatocellular Carcinoma. Int. J. Mol. Sci. 2024, 25, 1996. [Google Scholar] [CrossRef]
- Parra, C.R.; Torres, A.P.; Sotos, J.M.; Borja, A.L. Classification of Moderate and Advanced Alzheimer’s Patients Using Radial Basis Function Based Neural Networks Initialized with Fuzzy Logic. IRBM 2023, 44, 100795. [Google Scholar] [CrossRef]
- Mora, D.; Mateo, J.; Nieto, J.A.; Bikdeli, B.; Yamashita, Y.; Barco, S.; Jimenez, D.; Demelo-Rodriguez, P.; Rosa, V.; Yoo, H.H.B.; et al. Machine learning to predict major bleeding during anticoagulation for venous thromboembolism: Possibilities and limitations. Br. J. Haematol. 2023, 201, 971–981. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Liu, Z.; Su, C.; Han, Y.; Duan, X.; Zhang, R.; Liu, X.; Yang, Y.; Xu, S. Copy number variation in plasma as a tool for lung cancer prediction using Extreme Gradient Boosting (XGBoost) classifier. Thorac. Cancer 2020, 11, 95–102. [Google Scholar] [CrossRef]
- Usategui, I.; Arroyo, Y.; Torres, A.M.; Barbado, J.; Mateo, J. Systemic Lupus Erythematosus: How Machine Learning Can Help Distinguish between Infections and Flares. Bioengineering 2024, 11, 90. [Google Scholar] [CrossRef] [PubMed]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E.; Baciu, M. Machine learning—XGBoost analysis of language networks to classify patients with epilepsy. Brain Inform. 2017, 4, 159–169. [Google Scholar] [CrossRef] [PubMed]
- Ogunleye, A.; Wang, Q.G. XGBoost model for chronic kidney disease diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 17, 2131–2140. [Google Scholar] [CrossRef]
- Moreno, G.; Carbonell, R.; Bodí, M.; Rodríguez, A. Systematic review of the prognostic utility of D-dimer, disseminated intravascular coagulation, and anticoagulant therapy in COVID-19 critically ill patients. Med. Intensiv. 2021, 45, 42–55. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Leal, C.M.; Garcia-del Salto, L.; Coperías, J.L.; Sanmartin-Fenollera, L.; Fraga-Rivas, P.; Ruiz-Grinspan, M.S. Usefulness of D-dimer concentration in the diagnosis of pulmonary thromboembolism in patients with COVID-19 in the emergency department: Estimating its discriminative capacity, sensitivity, and specificity. Emergencias 2022, 34, 150–152. [Google Scholar] [PubMed]
- Han, J.; Gatheral, T.; Williams, C. Procalcitonin for patient stratification and identification of bacterial co-infection in COVID-19. Clin. Med. 2020, 20, e47. [Google Scholar] [CrossRef]
- Julián-Jiménez, A.; Del Castillo, J.G.; Candel, F.J. Usefulness and prognostic value of biomarkers in patients with community-acquired pneumonia in the emergency department. Med. Clín. 2017, 148, 501–510. [Google Scholar] [CrossRef]
- World Health Organization. The Transition from the Acute Phase of COVID-19: Working towards a Paradigm Shift for Pandemic Preparedness and Response in the WHO European Region; Technical Report; World Health Organization. Regional Office for Europe: Copenhagen, Denmark, 2023. [Google Scholar]
- Yang, X.; Zhang, H.; Zhang, Q.; Yuan, G. Simple positivity-preserving nonlinear finite volume scheme for subdiffusion equations on general non-conforming distorted meshes. Nonlinear Dyn. 2022, 108, 3859–3886. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, H. The uniform l1 long-time behavior of time discretization for time-fractional partial differential equations with nonsmooth data. Appl. Math. Lett. 2022, 124, 107644. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, H.; Zhang, Q.; Yuan, G.; Sheng, Z. The finite volume scheme preserving maximum principle for two-dimensional time-fractional Fokker—Planck equations on distorted meshes. Appl. Math. Lett. 2019, 97, 99–106. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters |
|---|---|
| SVM | Kernel function: Gaussian |
| Sigma = 0.5 | |
| C = 1.0 | |
| Numerical tolerance = 0.001 | |
| Iteration limit = 100 | |
| DT | Minimum number of instances in leaves = 4 |
| Minimum number of instances in internal nodes = 6 | |
| Maximum depth = 100 | |
| BLDA | Kernel: Bayesian |
| NN | Number of hidden layers: 2 layers. |
| Max neurons per hidden layer: 64. | |
| Activation function: ReLU. | |
| Learning rate: 0.001. | |
| Batch size: 64. | |
| Number of epochs: 100. | |
| Regularization: L2 regularization (Ridge) | |
| Weight initialization: Glorot/Xavier initialization. | |
| GNB | Usekernel: False |
| fL = 0 | |
| Adjust = 0 | |
| CNN | Learning rate = 0.1 |
| Network section depth = 3 | |
| Pooling type: Max pooling. | |
| Momentum = 0.9 | |
| Pool size: 64 | |
| L2 regularization = 1 × 10−3 | |
| Adaboost | Base estimator: tree |
| Maximum number of splits = 20 | |
| Learning rate = 0.1 | |
| Number of learners = 50 | |
| KNN | Number of neighbors = 20 |
| Distance metric: Euclidean | |
| Weight: Uniform | |
| XGB | Eta = 0.20 |
| Minimum chil weight = 1 | |
| Maximum depth = 7 | |
| Number of learners = 50 | |
| Maximum delta step = 3 |
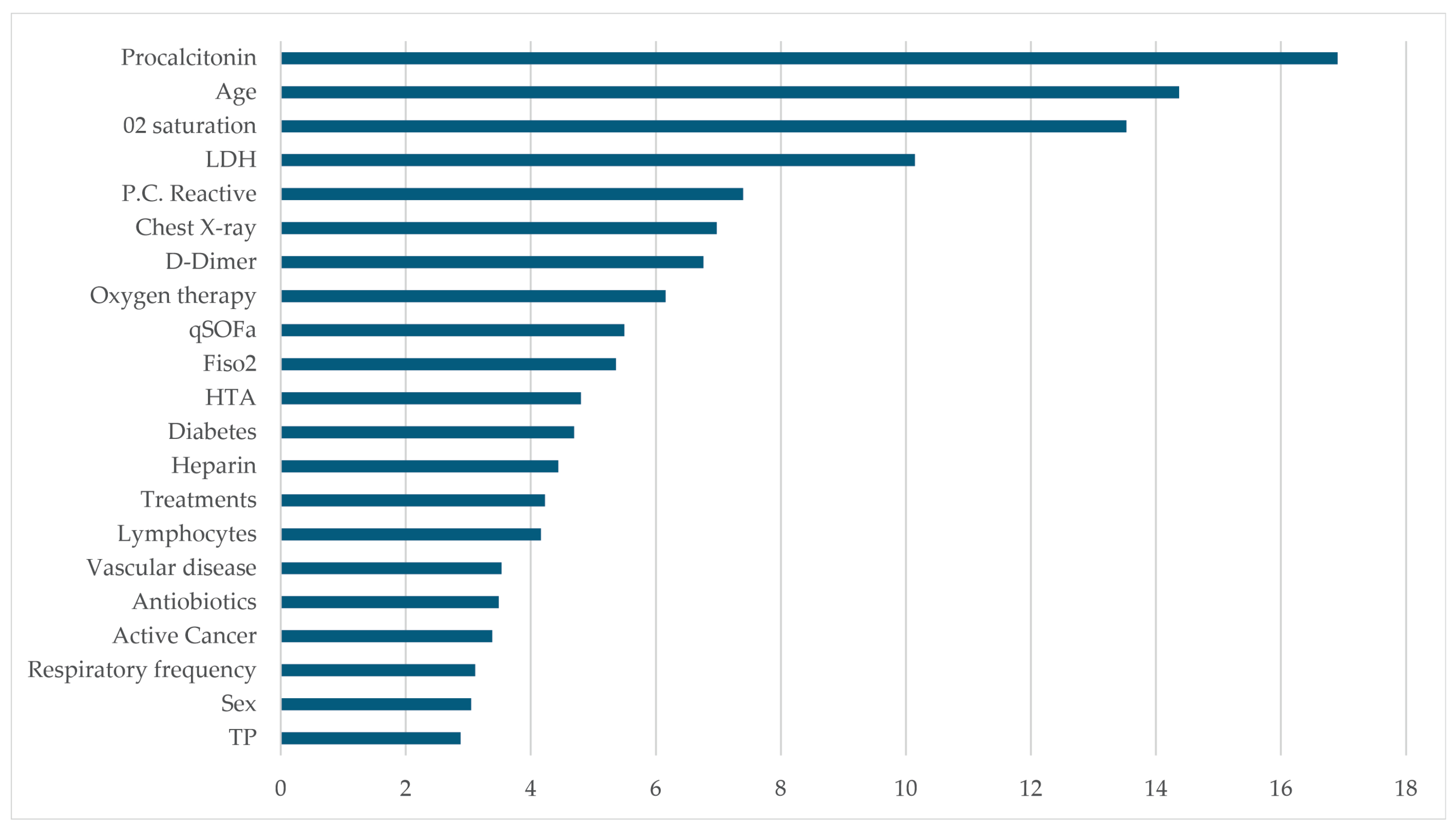
| n | % | |
|---|---|---|
| Male sex | 225 | 37.19 |
| HTA | 318 | 52.56 |
| Type 2 DM | 153 | 25.29 |
| EPOC | 54 | 8.93 |
| Severe asthma | 16 | 2.64 |
| ERC | 40 | 6.61 |
| Obesity | 45 | 7.44 |
| Pregnancy | 1 | 0.16 |
| Dyslipemia | 149 | 24.63 |
| Liver disease | 9 | 1.49 |
| ETV | 9 | 1.49 |
| Active cancer | 27 | 4.46 |
| Institutionalized | 50 | 8.26 |
| Cough | 378 | 62.48 |
| Fever | 438 | 72.4 |
| Dyspnea | 327 | 54.05 |
| Chest pain | 20 | 3.31 |
| Myalgia | 98 | 16.2 |
| Headache | 10 | 1.65 |
| Anosmia | 19 | 3.14 |
| Ageusia | 26 | 4.3 |
| Diarrhea | 65 | 10.74 |
| Asthenia | 136 | 22.48 |
| Admission | 495 | 81.82 |
| Exitus | 132 | 21.82 |
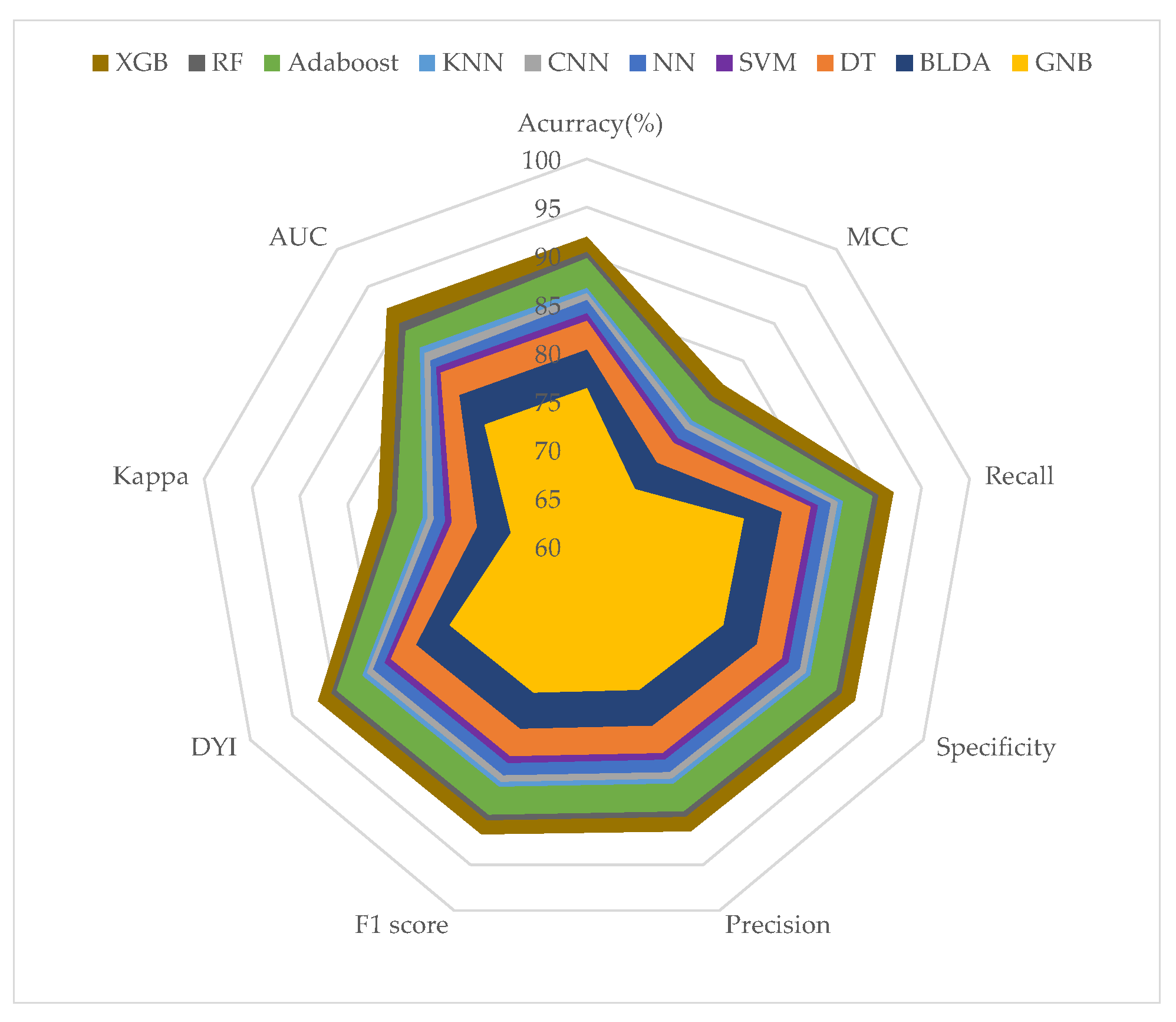
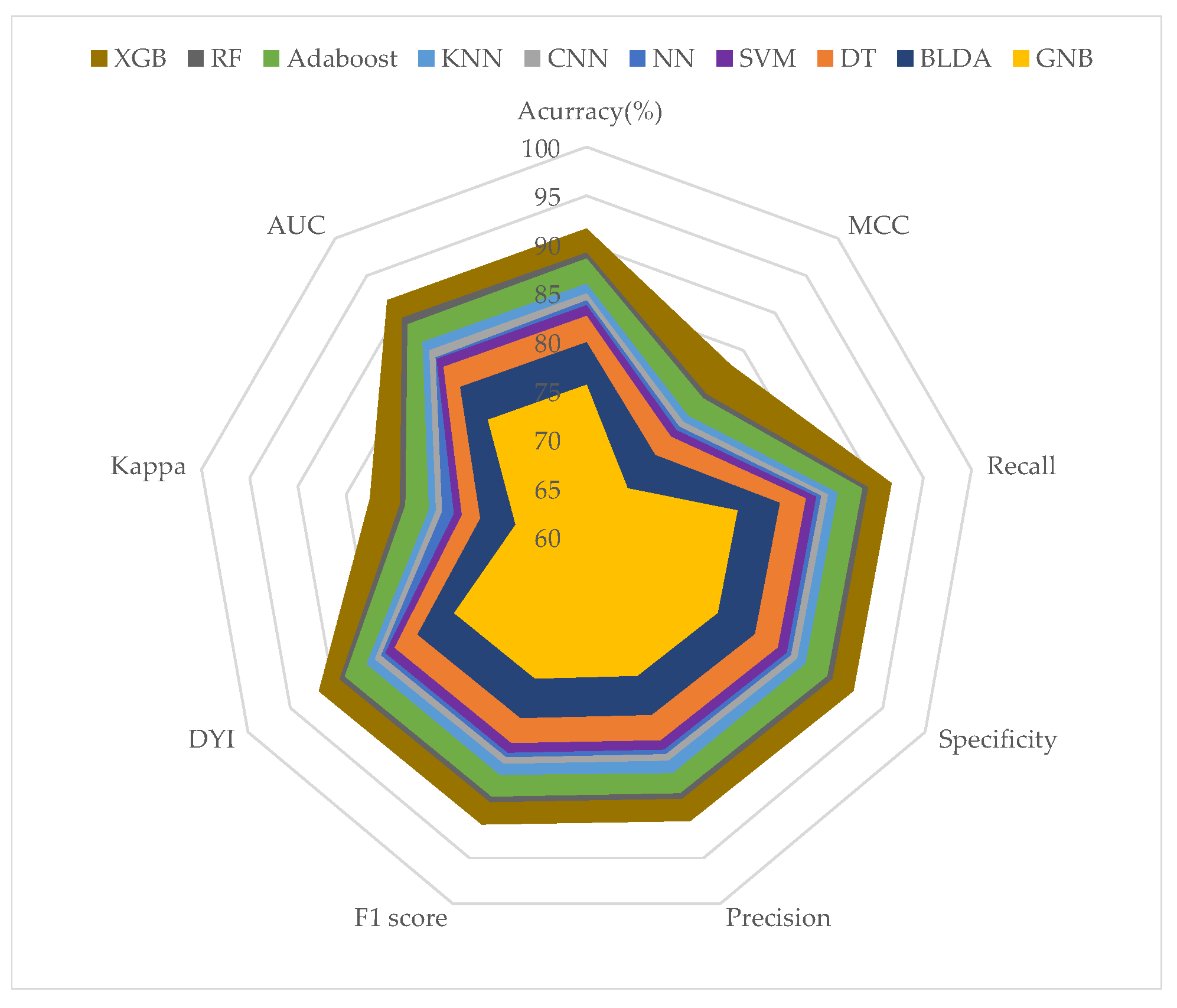
| Methods | Accuracy (%) | Recall (%) | Kappa (%) | Precision (%) |
|---|---|---|---|---|
| SVM | 83.74 ± 0.87 | 83.84 ± 0.85 | 73.77 ± 0.86 | 83.15 ± 0.85 |
| BLDA | 79.96 ± 0.92 | 80.06 ± 0.91 | 71.04 ± 0.90 | 79.36 ± 0.92 |
| DT | 82.65 ± 0.78 | 82.75 ± 0.79 | 72.93 ± 0.77 | 82.13 ± 0.78 |
| GNB | 75.59 ± 0.98 | 75.68 ± 0.97 | 67.36 ± 0.95 | 75.12 ± 0.96 |
| NN | 84.24 ± 0.73 | 84.01 ± 0.75 | 74.53 ± 0.74 | 84.58 ± 0.73 |
| KNN | 85.96 ± 0.68 | 86.09 ± 0.71 | 76.36 ± 0.69 | 85.70 ± 0.68 |
| CNN | 84.97 ± 0.71 | 85.04 ± 0.75 | 75.23 ± 0.73 | 85.02 ± 0.73 |
| AdaBoost | 88.53 ± 0.77 | 88.64 ± 0.74 | 78.82 ± 0.76 | 87.90 ± 0.75 |
| RF | 89.14 ± 0.65 | 89.25 ± 0.69 | 79.42 ± 0.67 | 88.51 ± 0.66 |
| XGB | 91.62 ± 0.47 | 91.71 ± 0.45 | 82.53 ± 0.46 | 90.97 ± 0.45 |
| Methods | AUC | F1 Score (%) | MCC (%) | DYI (%) |
|---|---|---|---|---|
| SVM | 0.84 ± 0.02 | 83.49 ± 0.84 | 74.31 ± 0.85 | 83.74 ± 0.85 |
| BLDA | 0.80 ± 0.02 | 79.71 ± 0.92 | 70.94 ± 0.91 | 79.96 ± 0.92 |
| DT | 0.83 ± 0.02 | 82.44 ± 0.79 | 73.39 ± 0.77 | 82.65 ± 0.78 |
| GNB | 0.76 ± 0.02 | 75.40 ± 0.98 | 66.51 ± 0.96 | 75.59 ± 0.97 |
| NN | 0.84 ± 0.02 | 84.46 ± 0.80 | 75.32 ± 0.78 | 84.45 ± 0.79 |
| KNN | 0.86 ± 0.02 | 85.90 ± 0.72 | 76.18 ± 0.75 | 85.96 ± 0.73 |
| CNN | 0.85 ± 0.02 | 85.17 ± 0.76 | 75.93 ± 0.73 | 85.01 ± 0.76 |
| AdaBoost | 0.88 ± 0.01 | 88.27 ± 0.72 | 78.56 ± 0.74 | 88.53 ± 0.73 |
| RF | 0.89 ± 0.01 | 88.91 ± 0.67 | 79.10 ± 0.68 | 89.13 ± 0.67 |
| XGB | 0.92 ± 0.01 | 91.34 ± 0.46 | 83.02 ± 0.45 | 91.62 ± 0.46 |
| Method | Number of Samples N | Big-O | |||
|---|---|---|---|---|---|
| 104 | 2 × 105 | 5 × 106 | 107 | ||
| SVM | 2634 | 5550 | 20,770 | 351,681 | O(N²) |
| BLDA | 3565 | 6980 | 13,970 | 27,470 | O(N) |
| DT | 3883 | 7169 | 9436 | 11,703 | O(log(N)) |
| GNB | 3161 | 6459 | 12,759 | 26,349 | O(N) |
| RF | 3345 | 4468 | 5695 | 9097 | O(log(N)) |
| NN | 3225 | 6898 | 12,224 | 25,361 | O(N) |
| KNN | 2307 | 4824 | 10,479 | 23,945 | O(N) |
| CNN | 5660 | 9689 | 16,407 | 28,736 | O(N) |
| AdaBoost | 3008 | 4358 | 7067 | 9312 | O(log(N)) |
| XGB | 2080 | 3002 | 4358 | 4413 | O(log(N)) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garrido, N.J.; González-Martínez, F.; Losada, S.; Plaza, A.; del Olmo, E.; Mateo, J. Innovation through Artificial Intelligence in Triage Systems for Resource Optimization in Future Pandemics. Biomimetics 2024, 9, 440. https://doi.org/10.3390/biomimetics9070440
Garrido NJ, González-Martínez F, Losada S, Plaza A, del Olmo E, Mateo J. Innovation through Artificial Intelligence in Triage Systems for Resource Optimization in Future Pandemics. Biomimetics. 2024; 9(7):440. https://doi.org/10.3390/biomimetics9070440
Chicago/Turabian StyleGarrido, Nicolás J., Félix González-Martínez, Susana Losada, Adrián Plaza, Eneida del Olmo, and Jorge Mateo. 2024. "Innovation through Artificial Intelligence in Triage Systems for Resource Optimization in Future Pandemics" Biomimetics 9, no. 7: 440. https://doi.org/10.3390/biomimetics9070440
APA StyleGarrido, N. J., González-Martínez, F., Losada, S., Plaza, A., del Olmo, E., & Mateo, J. (2024). Innovation through Artificial Intelligence in Triage Systems for Resource Optimization in Future Pandemics. Biomimetics, 9(7), 440. https://doi.org/10.3390/biomimetics9070440