
SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We develop a scale-attention SR architecture that works for arbitrarily user-selected sampling factors with an overall satisfactory performance.
- We generalize the application of perceptual loss previously defined on 2D pre-trained VGG onto 3D medical images. Together with GAN, the new scheme with 3D perceptual loss significantly improves the perceived image quality over the MSE trained results.
- Two criteria of data preprocessing are proposed accounting for different acquisition protocols. Without examining the acquisition process carefully, the extracted datasets will not provide accurate mapping from LR slices into HR slices, and therefore may not work well for all the SR tasks.
- We evaluate the feasibility of designing one model that works for all the medical images. The proposed model is applied to datasets from other imaging modalities, e.g., T2-weighted MRI and CT, as well as many body parts.
2. Materials and Methods
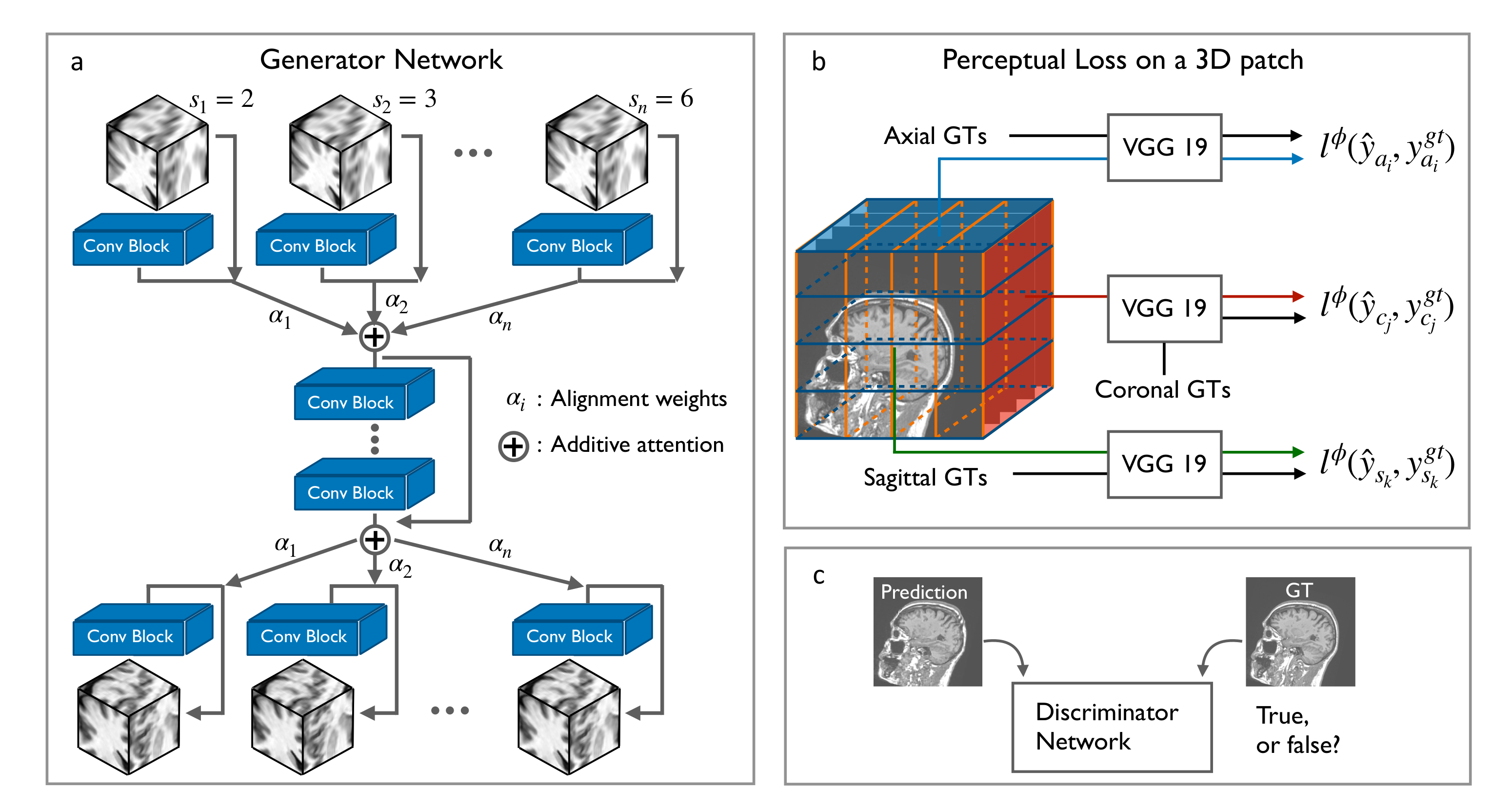
2.1. Residual CNNs for 3D SR-MRI
| Algorithm 1 Training the proposed framework SOUP-GAN. |
| Data: HR 3D MRI volume after data standardization. |
| Step (1) Data preprocessing: |
| Create LR volume by data-preprocessing following either the thick-to-thin or sparse-to-thin criteria. |
| Step (2) Prepare training dataset: |
| Partition the LR data as input and HR data as ground truth into pairs of patches. |
| Step (3) Scale-attention SR network: |
| Input LR patches to the attention-based multi-scale SR network with an appropriate module entrance and exit by the calculated alignment weights according to the associated sampling factor s. |
| Step (4) 3D perceptual loss with GAN: |
| Based on the pre-trained MSE results, further tune the model by employing the 3D perceptual loss with GAN. |
2.2. Data Preprocessing
2.3. Scale-Attention Model for SR Interpolation
2.4. 3D Perceptual Loss
3. Results
3.1. Training Details
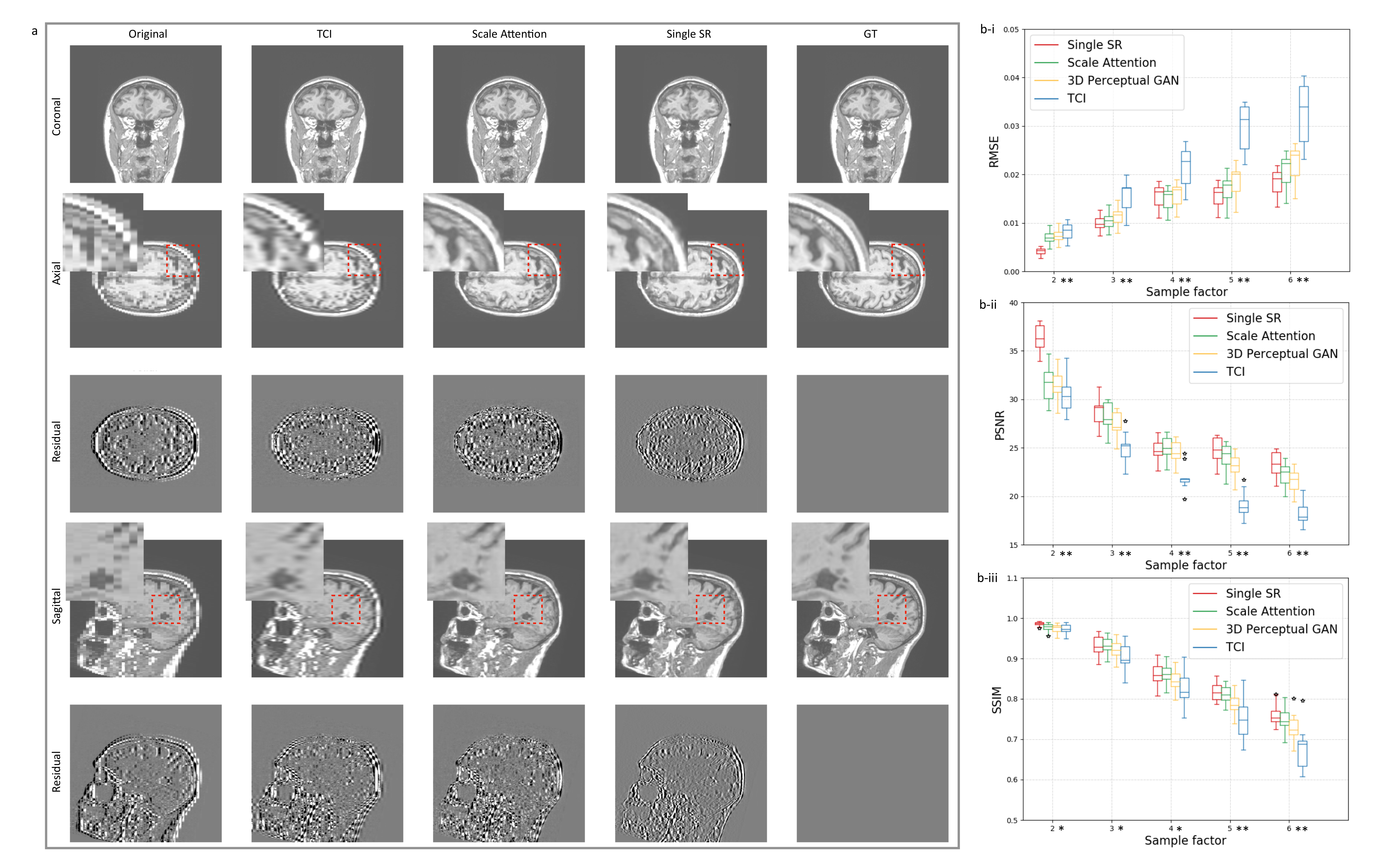
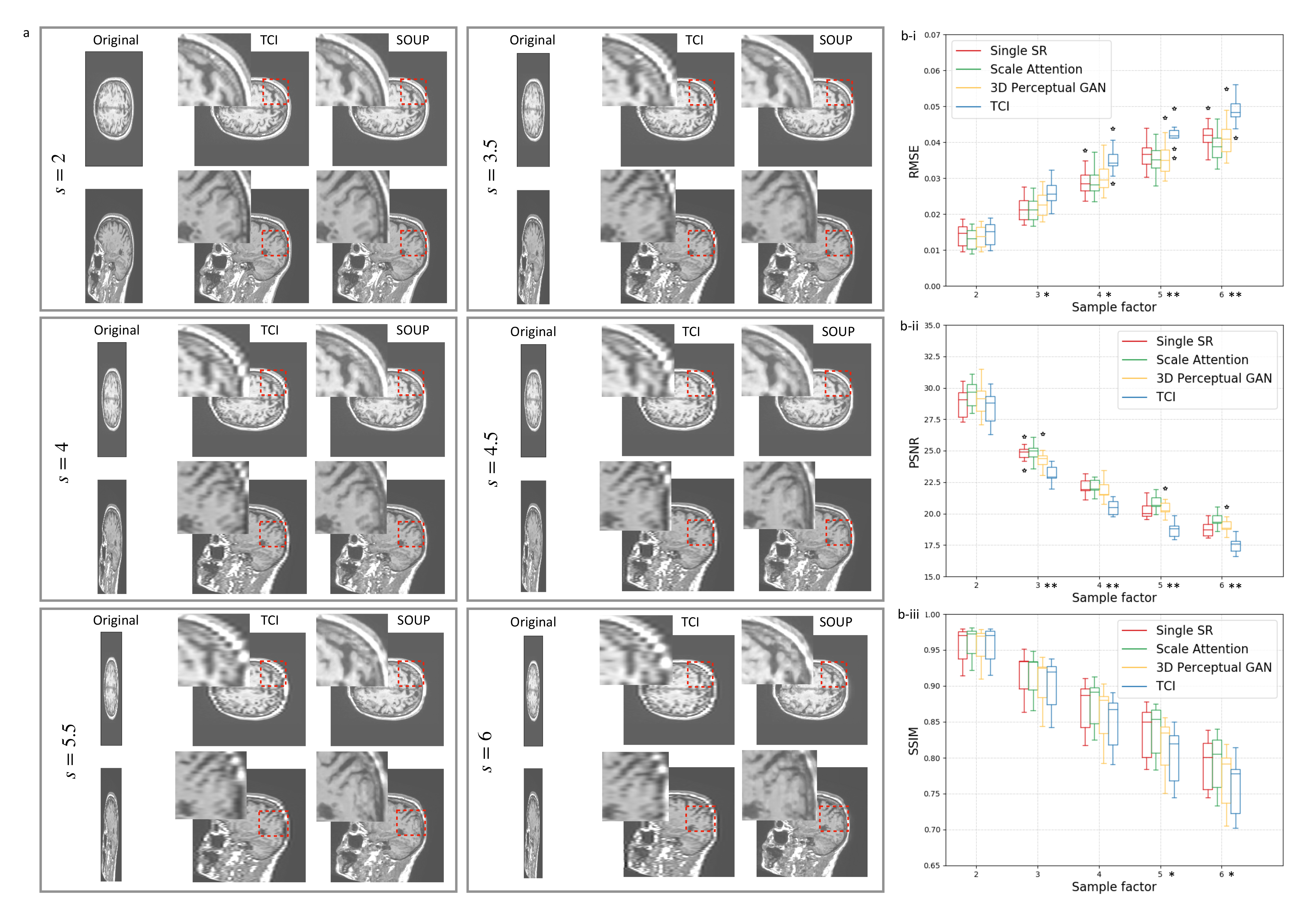
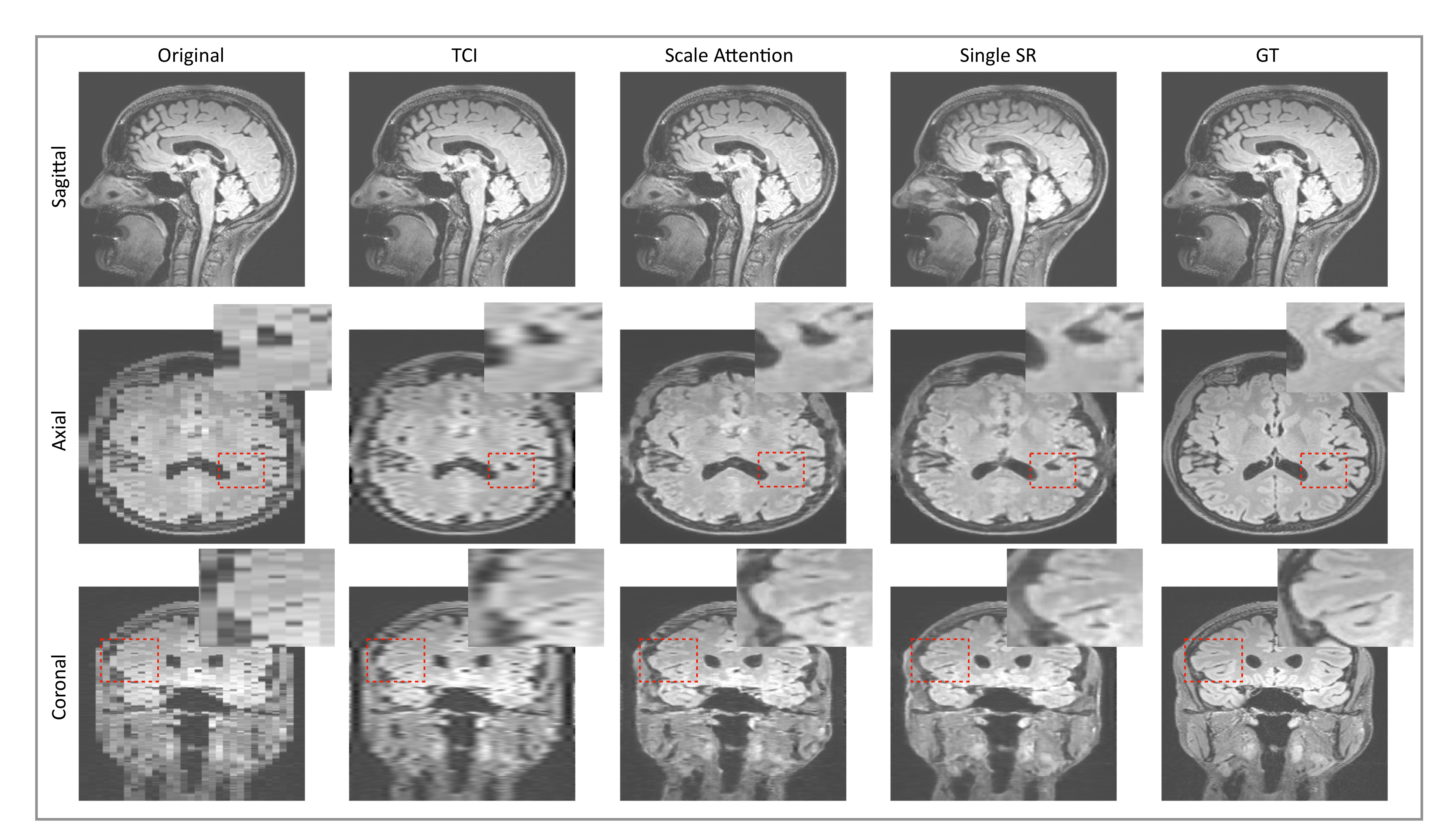
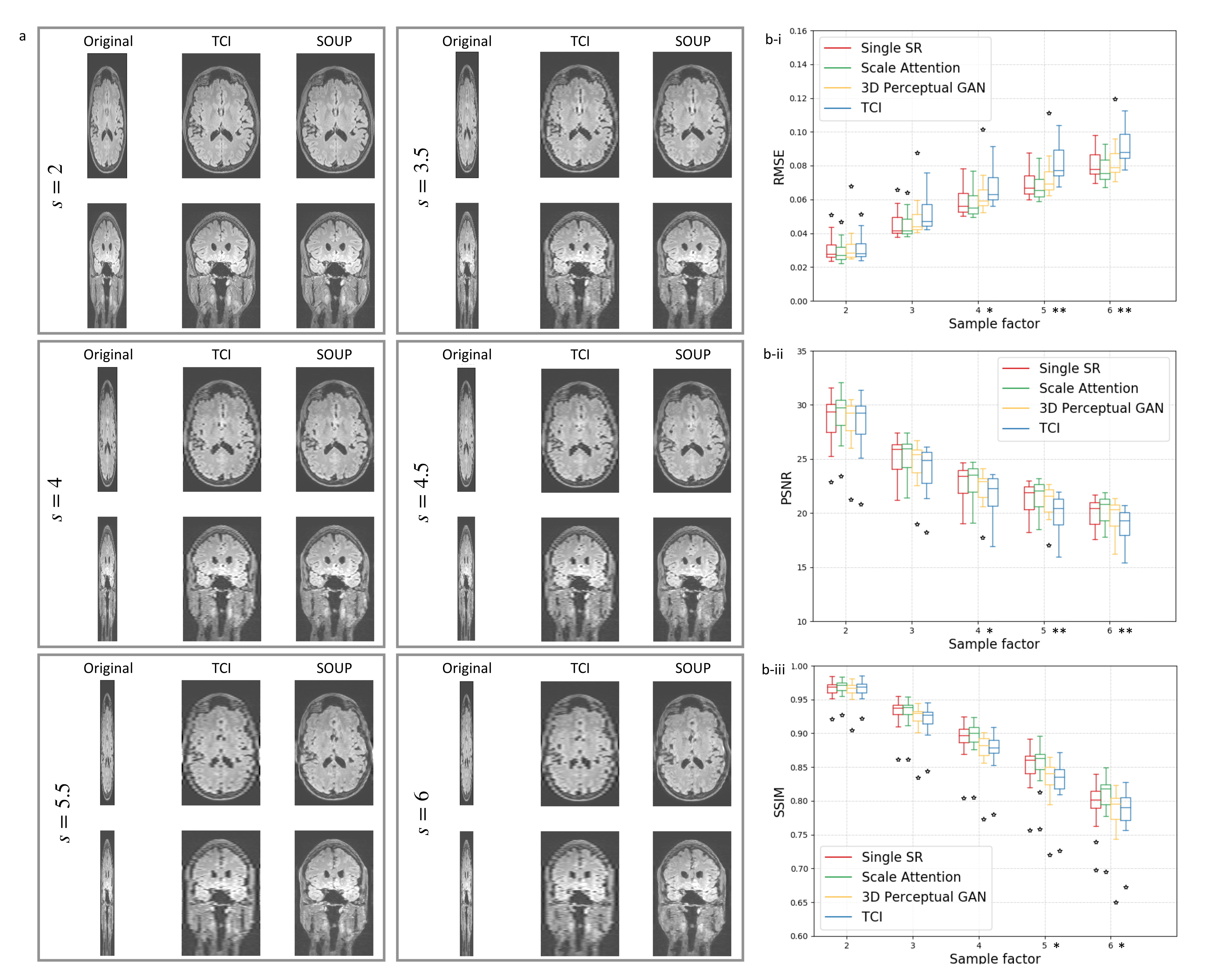
3.2. Single-Scale and Scale-Attention Model Comparison
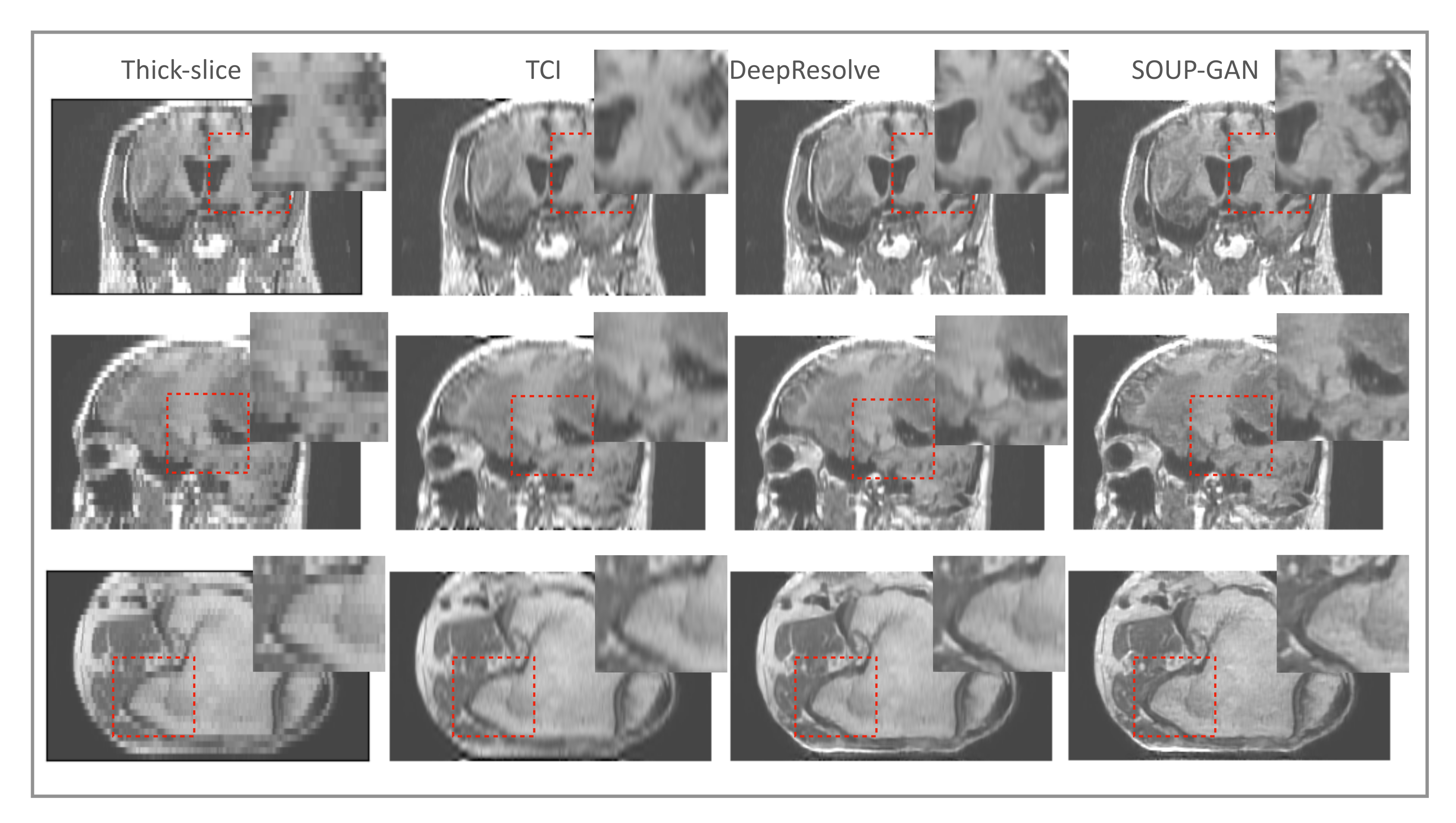
3.3. Application to Other Contrast Types of MRI Images
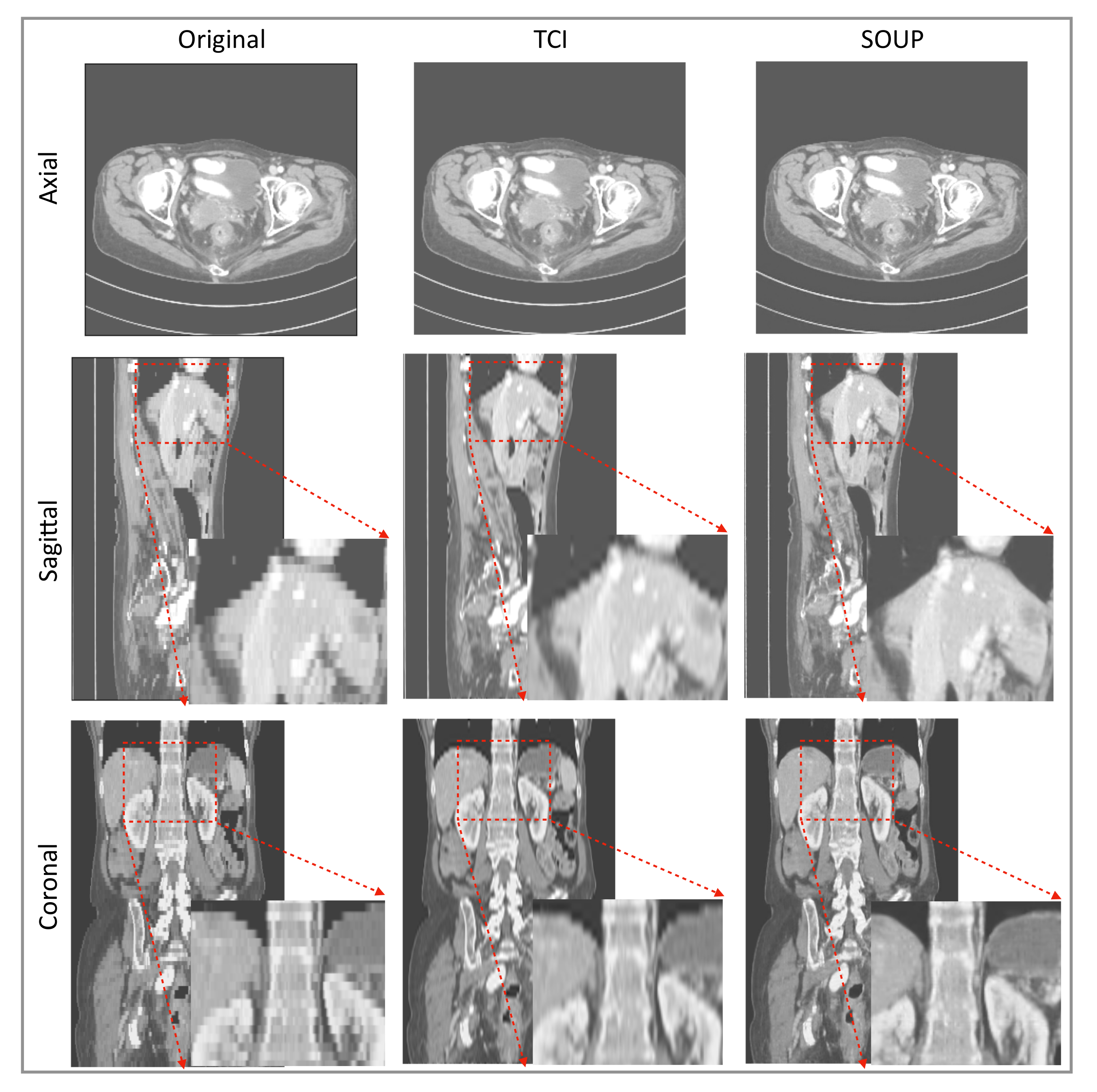
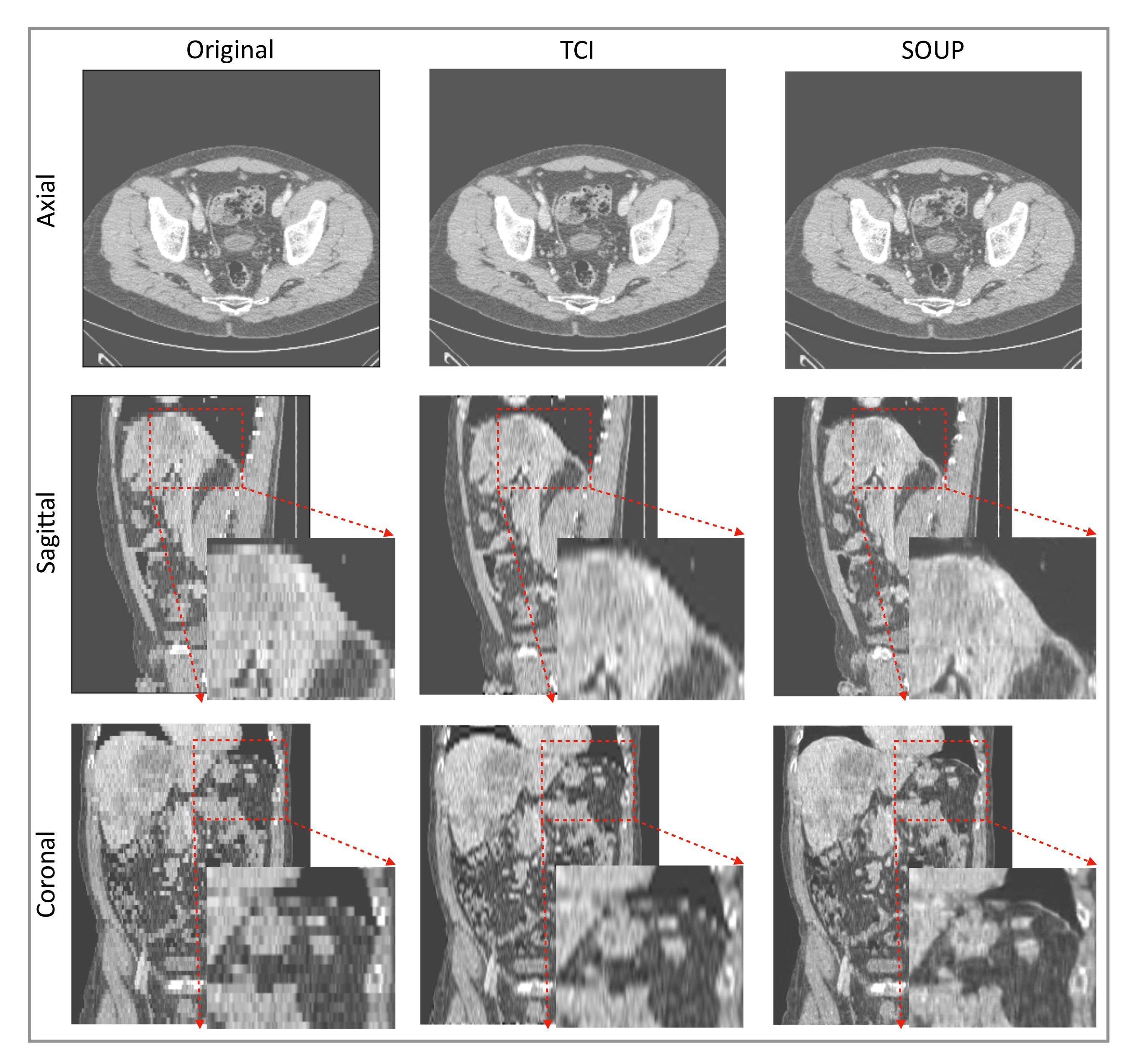
3.4. Generalization to Other Medical Imaging Modalities, e.g., CT
4. Discussion
5. Conclusions
6. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahesh, M. The Essential Physics of Medical Imaging, Third Edition. Med. Phys. 2013, 40, 077301. [Google Scholar] [CrossRef] [PubMed]
- Nyquist, H. Certain Topics in Telegraph Transmission Theory. Trans. Am. Inst. Electr. Eng. 1928, 47, 617–644. [Google Scholar] [CrossRef]
- Benning, M.; Burger, M. Modern regularization methods for inverse problems. Acta Numer. 2018, 27, 1–111. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Samsonov, A.; Chen, L.; Kijowski, R.; Feng, L. SANTIS: Sampling-Augmented Neural neTwork with Incoherent Structure for MR image reconstruction. Magn. Reson. Med. 2019, 82, 1890–1904. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans. Med. Imaging 2019, 38, 394–405. [Google Scholar] [CrossRef]
- Quan, T.M.; Nguyen-Duc, T.; Jeong, W.K. Compressed Sensing MRI Reconstruction Using a Generative Adversarial Network With a Cyclic Loss. IEEE Trans. Med. Imaging 2018, 37, 1488–1497. [Google Scholar] [CrossRef] [Green Version]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef] [PubMed]
- Sriram, A.; Zbontar, J.; Murrell, T.; Defazio, A.; Zitnick, C.L.; Yakubova, N.; Knoll, F.; Johnson, P. End-to-End Variational Networks for Accelerated MRI Reconstruction. arXiv 2020, arXiv:2004.06688. [Google Scholar]
- Zhang, K.; Philbrick, K.A.; Conte, G.M.; Huang, Q.; Cai, J.C.; Rouzrokh, P.; Hu, H.; Jons, W.A.; Jagtap, J.M.M.; Singh, Y.; et al. A Dual-space Variational Network for MR Imaging Reconstruction. In Proceedings of the SIIM CMIMI20, Online, 13–14 September 2020. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar] [CrossRef] [Green Version]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef] [Green Version]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced super-resolution generative adversarial networks. In Proceedings of the The European Conference on Computer Vision Workshops (ECCVW), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM Challenge on Perceptual Image Super-resolution. arXiv 2019, arXiv:1809.07517. [Google Scholar]
- Li, Y.; Sixou, B.; Peyrin, F. A Review of the Deep Learning Methods for Medical Images Super Resolution Problems. IRBM 2021, 42, 120–133. [Google Scholar] [CrossRef]
- Umehara, K.; Ota, J.; Ishida, T. Application of Super-Resolution Convolutional Neural Network for Enhancing Image Resolution in Chest CT. J. Digit. Imaging 2018, 31, 441–450. [Google Scholar] [CrossRef]
- Park, J.; Hwang, D.; Kim, K.Y.; Kang, S.K.; Kim, Y.K.; Lee, J.S. Computed tomography super-resolution using deep convolutional neural network. Phys. Med. Biol. 2018, 63, 145011. [Google Scholar] [CrossRef]
- Zeng, K.; Zheng, H.; Cai, C.; Yang, Y.; Zhang, K.; Chen, Z. Simultaneous single- and multi-contrast super-resolution for brain MRI images based on a convolutional neural network. Comput. Biol. Med. 2018, 99, 133–141. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, Y.; Zhang, T.; Zou, X. Channel Splitting Network for Single MR Image Super-Resolution. IEEE Trans. Image Process. 2019, 28, 5649–5662. [Google Scholar] [CrossRef] [Green Version]
- Mansoor, A.; Vongkovit, T.; Linguraru, M.G. Adversarial approach to diagnostic quality volumetric image enhancement. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 353–356. [Google Scholar] [CrossRef]
- Sood, R.; Rusu, M. Anisotropic Super Resolution In Prostate Mri Using Super Resolution Generative Adversarial Networks. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1688–1691. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Shen, S.; Gao, W.; Hsu, W.; Cong, J. Computed Tomography Image Enhancement using 3D Convolutional Neural Network. arXiv 2018, arXiv:1807.06821. [Google Scholar]
- Wang, Y.; Teng, Q.; He, X.; Feng, J.; Zhang, T. CT-image of rock samples super resolution using 3D convolutional neural network. Comput. Geosci. 2019, 133, 104314. [Google Scholar] [CrossRef] [Green Version]
- Kudo, A.; Kitamura, Y.; Li, Y.; Iizuka, S.; Simo-Serra, E. Virtual Thin Slice: 3D Conditional GAN-based Super-resolution for CT Slice Interval. arXiv 2019, arXiv:1908.11506. [Google Scholar]
- Chaudhari, A.S.; Fang, Z.; Kogan, F.; Wood, J.; Stevens, K.J.; Gibbons, E.K.; Lee, J.H.; Gold, G.E.; Hargreaves, B.A. Super-resolution musculoskeletal MRI using deep learning. Magn. Reson. Med. 2018, 80, 2139–2154. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Dewey, B.E.; Pham, D.L.; Calabresi, P.A.; Reich, D.S.; Prince, J.L. SMORE: A Self-supervised Anti-aliasing and Super-resolution Algorithm for MRI Using Deep Learning. IEEE Trans. Med. Imaging 2020, 40, 805–817. [Google Scholar] [CrossRef]
- Zhao, C.; Carass, A.; Dewey, B.E.; Prince, J.L. Self super-resolution for magnetic resonance images using deep networks. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 365–368. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Xie, Y.; Zhou, Z.; Shi, F.; Christodoulou, A.G.; Li, D. Brain MRI super resolution using 3D deep densely connected neural networks. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 739–742. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, I.; Vilaplana, V. Brain MRI super-resolution using 3D generative adversarial networks. arXiv 2018, arXiv:1812.11440. [Google Scholar]
- Wang, J.; Chen, Y.; Wu, Y.; Shi, J.; Gee, J. Enhanced generative adversarial network for 3D brain MRI super-resolution. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 3616–3625. [Google Scholar] [CrossRef]
- Shi, J.; Li, Z.; Ying, S.; Wang, C.; Liu, Q.; Zhang, Q.; Yan, P. MR Image Super-Resolution via Wide Residual Networks With Fixed Skip Connection. IEEE J. Biomed. Health Inform. 2019, 23, 1129–1140. [Google Scholar] [CrossRef]
- Du, J.; He, Z.; Wang, L.; Gholipour, A.; Zhou, Z.; Chen, D.; Jia, Y. Super-resolution reconstruction of single anisotropic 3D MR images using residual convolutional neural network. Neurocomputing 2020, 392, 209–220. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29, pp. 4898–4906. [Google Scholar]
- Greenspan, H.; Peled, S.; Oz, G.; Kiryati, N. MRI Inter-slice Reconstruction Using Super-Resolution. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2001, Utrecht, The Netherlands, 14–17 October 2001; Niessen, W.J., Viergever, M.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 1204–1206. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, C.; Wand, M. Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2021, 163, 113819. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Hu, H.; Philbrick, K.; Conte, G.M.; Sobek, J.D.; Rouzrokh, P.; Erickson, B.J. SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks. Tomography 2022, 8, 905-919. https://doi.org/10.3390/tomography8020073
Zhang K, Hu H, Philbrick K, Conte GM, Sobek JD, Rouzrokh P, Erickson BJ. SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks. Tomography. 2022; 8(2):905-919. https://doi.org/10.3390/tomography8020073
Chicago/Turabian StyleZhang, Kuan, Haoji Hu, Kenneth Philbrick, Gian Marco Conte, Joseph D. Sobek, Pouria Rouzrokh, and Bradley J. Erickson. 2022. "SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks" Tomography 8, no. 2: 905-919. https://doi.org/10.3390/tomography8020073
APA StyleZhang, K., Hu, H., Philbrick, K., Conte, G. M., Sobek, J. D., Rouzrokh, P., & Erickson, B. J. (2022). SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks. Tomography, 8(2), 905-919. https://doi.org/10.3390/tomography8020073