Abstract
Community-based monitoring programs (CBMPs) are a cost-effective option to collect the long-term data required to effectively monitor estuaries. Data quality concerns have caused some CBMP datasets, which could fill knowledge gaps for aquatic ecosystems, to go unused. The Community Aquatic Monitoring Program (CAMP) is a CBMP that has collected littoral nekton assemblage data from estuaries in the southern Gulf of St. Lawrence since 2003. Concerns with the CAMP sampling design (station placement and numbers) have prevented decision-makers from using the data to inform estuary health assessments. This study tested if CAMP’s sampling design that accommodates volunteer participation provides similar information as a scientific sampling approach. Six CAMP stations and six stations selected using a stratified random design were sampled at ten estuaries. A permutational-MANOVA revealed nekton assemblages were generally not significantly different between the two sampling designs. The current six CAMP stations are sufficient to detect the larger differences in species abundances that may indicate differences in estuary condition. The predicted increase in precision (2%) with twelve stations is not substantive enough to warrant an increased sampling effort. CAMP’s scientific utility is not limited by station selection bias or numbers. Furthermore, well-designed CBMPs can produce comparable data to scientific studies.
1. Introduction
Threats to the ecosystem health of estuaries, one of the most altered and at-risk aquatic environments [1], are predicted to worsen if development along estuaries and their watersheds continues unabated [2]. Thus, monitoring and assessment of the biota (including fishes and crustaceans) in these ecologically and economically important ecosystems are urgent and crucial [3,4]. However, monitoring estuaries is time consuming, and costly due to their high spatial and temporal variability that requires greater sampling effort than many other aquatic ecosystems [5,6].
Long-term monitoring programs provide the critical historical data required to define the natural variability of an estuary and capture change over time [7,8,9,10]. Both abiotic and biotic indicators are recommended to adequately monitor estuaries [11]. Yet, time and cost constraints can lead programs to sample only abiotic indicators [4], and estuary biological monitoring programs are constantly under threat of being canceled [12].
Resource managers tasked with designing a long-term environmental monitoring program have often found success in implementing a community-based monitoring program (CBMP). CBMPs come in various forms, including citizen science initiatives in which local community members volunteer their time to assist in the collection of environmental monitoring data [13]. Designing a monitoring program that can be executed by local volunteers can both reduce costs associated with monitoring programs and engage local community members [14,15]. Enlisting the help of volunteers also enables researchers to collect more data on a larger geographical scale and over a longer time period than would otherwise be possible [14,16,17,18,19]. CBMPs continue to gain recognition for their potential to fill data gaps, inform decision-makers, and educate communities [20]. As such, these programs are becoming increasingly popular among government and non-profit agencies [21,22] with millions of volunteers participating in CBMPs worldwide [18]. A downside of such programs is that professional scientists and decision-makers have expressed concerns regarding the quality of data collected by community members [15,20,23]). These concerns have limited the incorporation of CBMP data into the scientific literature [18,22] and its use to support decision-making. However, previous studies have detected no significant differences between the environmental data collected by the community members and professional scientists (e.g., Fore et al. [24]; Thériault et al. [25]; Danielsen et al. [26]; van der Velde et al. [27]).
The Community Aquatic Monitoring Program (CAMP) is a long-term CBMP that monitors estuaries in the southern Gulf of St. Lawrence, Canada. Implemented in 2003, CAMP continues to be administered by Fisheries and Oceans Canada (DFO) in collaboration with the Southern Gulf of St. Lawrence Coalition on Sustainability (Coalition-SGSL). DFO and Coalition-SGSL personnel work alongside volunteers from watershed groups, First Nation groups, and maritime universities to collect annual data [28]. Data include littoral nekton (i.e., fish, shrimp, and crabs) counts, estimates of aquatic vegetation cover, water quality measurements, and sediment characteristics [29]. The initial objective of CAMP was to provide an avenue for community outreach and interaction with Environmental Non-Government Organizations (ENGOs), and to raise awareness of estuarine ecology [28]. A current goal for the CAMP dataset is to determine if it can be used to assess the relationship between the health of an estuary and the diversity and abundance of nekton within it [28,29].
The objective of the present study was to determine if the CAMP sampling design that accommodates volunteer design and participation provides similar information as would be generated by a more rigorous sampling approach. Specifically, even though various sampling station selection criteria were established in the original CAMP design, most station locations were selected primarily to allow volunteers to easily access stations from the road [28]. In heterogeneous habitats, such as estuaries, a stratified random sample is recommended where the total area is divided into equal plots and a similar number of units is selected randomly from each plot [30]. Currently, six stations are sampled in each estuary, regardless of estuary size, because that is the number of stations that volunteers were assumed to be capable of sampling in one day [28]. Two hypotheses were tested: (1) Nekton assemblages observed at CAMP stations would be similar to those at stations located using a stratified random sampling design (SRD) and (2) Sampling a greater number of stations in an estuary would not substantively alter nekton community assemblage estimates.
2. Materials and Methods
2.1. Description of Estuaries Sampled in This Study
Ten estuaries, six in the province of New Brunswick and four in the province of Prince Edward Island, Canada, were sampled in this study (Figure 1, Table 1). The selected estuaries encompassed the range of estuary sizes sampled under CAMP to prevent estuary size influencing the results. Likewise, estuaries were selected to include some with CAMP sampling stations clustered in the lower estuary (i.e., closest to the marine environment), and some with CAMP stations spread throughout the estuary (Figures S1–S10). The initial CAMP sampling design suggested sampling stations should cover as much of the estuary as possible with stations located in the upper, middle, and lower estuary, and located equally on either side of the estuary [31]. Yet, the consideration of road access for volunteers resulted in many stations clustered in the lower estuary. The lower estuary tends to have more public road access for harbour activities, while private land, inaccessible to volunteers, is more common in the upper estuary.
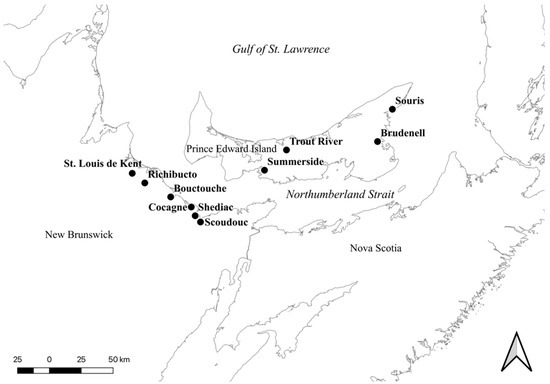
Figure 1.
Map of the ten CAMP estuaries sampled in 2016. Map created using the Free and Open Source QGIS.

Table 1.
Site information for the Canadian Aquatic Monitoring Program (CAMP) estuaries sampled in 2016, including estuary area and watershed characteristics.
2.2. Stratified Random Sampling Design (SRD)
Twelve sampling stations were designated within each estuary. Six stations were the established CAMP station locations, and six stations were randomly located and stratified among the upper, middle, and lower estuary. Estuary sampling maps were created using ArcGIS (Figures S1–S10). The lower extent of the estuary was marked at the mouth of the estuary and where fresh and saline water are fully mixed (i.e., where the coastline opens to a bay or open ocean) or to the lowest CAMP station when sampling extended into the bay. For the purpose of this study, the upper extent of the estuary was marked where (when information was available) the salinity is known to be 10, or where the estuary narrows to a stream channel. A minimum salinity of 10 was selected as the upper estuary benchmark, as that is the lowest average salinity that CAMP samples. Both shorelines were divided into three equal length sections and overlaid by a grid of 50 m2 squares. Numbers were assigned to each grid square. One station location was randomly assigned to each section using a random number generator. Once a number was randomly selected, the aerial imagery beneath the corresponding grid square was inspected to ensure there were no obvious impediments to seining (e.g., piers, docks). If an obstruction was observed, then a new station location was assigned using the random number generator.
2.3. Field Data Collection
All estuary sampling was completed by the same core team and was supplementary to the regular annual CAMP sampling. We did not use data collected by volunteers to ensure any detected differences were due to the sampling design and not a difference in sampling teams. Estuaries were sampled once in July or August 2016. The environmental data collected at each station are summarized in Table 2. SRD stations were accessed using a 19-foot Carolina Skiff at New Brunswick estuaries and a 17-foot Carolina Skiff at Prince Edward Island estuaries. One CAMP station at Souris was not sampled because members of the public were swimming at the station during the sampling time. One Summerside SRD station could not be sampled due to unsafe weather conditions. Figures S1–S10 display estuary maps with finalized station locations.
Table 2.
Summary of environmental data collected using the Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) sampling designs at each estuary sampled in 2016. Data are means (±standard error) of station data (n = 6) collected for each sampling design.
At each station, nekton and water quality parameters were collected using the CAMP methods outlined by Weldon et al. [31]. Nekton species were captured using a 30 m by 2 m beach seine with a mesh size of 6 mm and central bag measuring 2 m by 1 m, which samples a standardized area of 225 m2 at each station. All captured nekton were placed in a live-box with water exchange, identified, classified as either young-of-the-year (YOY) or adult, enumerated, and then released. All fish were handled in accordance with the approved University of Waterloo animal care protocol (AUPP #14–15). All fish collection activities complied with DFO Gulf Region License to Fish for Scientific Purposes, License No. SG-RHQ-16-016C. The following species counts were pooled together for data analysis due to the difficulty of field identification: alewife (Alosa pseudoharengus) young-of-the-year (YOY) and blueback herring (Alosa aestivalis) YOY counts were pooled as Gaspereau YOY; blackspotted stickleback (Gasterosteus wheatlandi) YOY and threespine stickleback (Gasterosteus aculeatus) YOY counts were pooled as Gasterosteus YOY; mummichog (Fundulus heteroclitus) YOY and banded killifish (Fundulus diaphanous) YOY counts were pooled as Fundulus YOY; and winter flounder (Pseudopleuronectes americanus) YOY and smooth flounder (Liopsetta putnami) YOY counts were pooled as flounder YOY.
Water quality data, including temperature, dissolved oxygen (DO) (mg/L), and salinity (PSU) were collected using a handheld YSI Professional Plus model at New Brunswick estuaries and a YSI model 6600 M at Prince Edward Island estuaries. Water quality was measured from the middle of the water column within the seined area. The tide height (m); above chart datum for each station at the time of sampling was documented by accessing the tide tables available on the DFO website [33].
2.4. Data Analysis and Statistics
Similarities between pairs of samples (i.e., sampling stations [six stations per estuary]) were defined with a similarity matrix generated using the Bray–Curtis similarity coefficient. A square-root transformation was applied to the nekton data to reduce the dominance of the highly abundant species prior to analysis while not overemphasizing rare species. The resulting Bray–Curtis similarity matrix was the basis for all multivariate analyses.
The nekton assemblages collected from the SRD and CAMP stations were compared to assess if sampling nekton in these estuaries at different sampling stations would result in a different nekton community. A hierarchical cluster analysis using a group average linkage was performed. A similarity profile (SIMPROF) test was applied to determine which groups created by the cluster analysis were significantly different. The SIMPROF significance level was set at 5% with 9999 permutations. The differences between the nekton assemblages collected were further visualized using non-metric Multi-Dimensional Scaling (nMDS) ordination.
A two-way, permutational MANOVA (PERMANOVA) was used to formally test the effects on nekton community assemblage of CAMP versus SRD “sampling design”, “Estuary”, and their interaction. A Type III sums of squares was used, because it is the most conservative approach to partitioning variability, which is appropriate for unbalanced designs [34]. p-values were obtained by applying 9999 permutations of residuals under a reduced model, because it yields the best power and most accurate type I error [34].
The distance-based linear models (DISTLM) routine was used to understand which (if any) environmental variables had the greatest influence on the nekton assemblage data to understand if environmental factors influenced any significant differences detected between sampling designs. The DISTLM routine determines the combination of environmental variables that best describe the multivariate data cloud produced by the Bray–Curtis similarity matrix on the nekton abundance data [34]. p-values were generated using 9999 permutations, to test the null hypothesis of no relationship between the environment data and nekton abundance data [34]. The test yields an R2 value that is the estimate of the amount of variation in the nekton assemblage explained by the variation in environmental variables [34]. The Best selection procedure and AICc selection criteria were used.
The CAMP and SRD datasets were merged to create a combined dataset to understand how the characterization of the nekton assemblages may change with additional station data. It is acknowledged that the combined dataset is not an ideal tool for evaluating CAMP station numbers, because the data were collected at different locations selected using two different approaches. Ideally, the 12 sampling stations would have been located using the same sampling design (e.g., 12 SRD stations within each estuary). However, employing the SRD stations as theoretical “new” CAMP stations is a pragmatic method to predict the potential for increased station data to alter conclusions based on nekton assemblages.
Species accumulation plots were generated for each estuary using the combined dataset (n = 12, except for Souris and Summerside with n = 11) to determine the typical number of stations required within each estuary to capture all potential nekton species. An ideal number of stations would be the number after which no new species are gained. The combined data were permuted 999 times for each estuary.
The combined dataset was also used to predict the potential for additional stations to alter conclusions of dissimilarities among estuaries (i.e., would additional stations change which estuaries are considered significantly similar/different?). An nMDS plot was generated using the combined dataset to visualize how the pattern of estuaries produced by their relative dissimilarities may change with additional station data. A one-way PERMANOVA was performed to assess if an increase in station numbers would result in different conclusions regarding estuary dissimilarities.
The ideal sample size for CAMP is one that yields sufficient precision to detect the typical differences in mean species abundance estimates among estuaries. The method for calculating measurement error introduced by Bailey and Byrnes [35] was used to define the precision of the CAMP stations and predict the precision that could be gained by sampling up to six additional stations. This analysis was completed using the data from the CAMP dataset. As a univariate method, the analysis focused on counts of the individual species that were determined to have the greatest influence on estuary dissimilarities. Influential species were identified by using the similarity percentages routine (SIMPER) in PRIMER. For each influential species, one-way, Model II ANOVAs were used to partition the total variance in counts of each species into among and within estuary components, as described by Bailey and Byrnes [35]. The within estuary mean square (MSwithin) is an estimate of the variance among stations within an estuary (). The among group mean square (MSamong) includes both among estuary and within estuary variability so among estuary variance () is calculated as follows:
The variance of the mean () was calculated using the within and among estuary component of variance, where n is the number of estuaries sampled and m is the number of stations sampled.
Values of m were then substituted with values of 7 through 12 to measure the reduction in the variance of the mean that could be obtained by sampling up to 12 stations at each estuary. Subsequently, 95% confidence intervals on the mean estimates of each influential species were calculated by multiplying the square-root of the variance of the mean by its corresponding t-value. The confidence intervals for station numbers 6 to 12 were used to understand the precision that could be gained with greater station numbers.
PRIMER 7 with the PERMANOVA add-on package was used to complete multivariate analyses to test for differences (a = 0.05) between the CAMP and the SRD data. The stations were treated as replicates within each estuary. All univariate analyses were completed using RStudio version 0.99.489.
3. Results
3.1. Detecting Differences in Nekton Assemblages between the Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) Samples
The cluster analysis grouped the two sampling designs together for each estuary, except for Cocagne, and the SIMPROF test designated these groupings as significant (Figure 2). Significant groups were groups of estuaries/sampling design within which the nekton have statistically indistinguishable patterns of nekton abundance, and the patterns of nekton abundance between groups do differ significantly [36]. The two sets of data for differing sample design at each estuary were generally more similar to each other than data collected from other estuaries (Figure 2). The estuaries with the greatest similarities between nekton assemblages with differing sampling designs (i.e., >80% similarity) were Trout River and Richibucto. The estuaries with the least similarities between nekton assemblages with differing sampling designs (i.e., <75% similarity) were Shediac, Scoudouc, Bouctouche, and Cocagne. Cocagne was the only estuary with <72% similarity between the nekton assemblages with differing sampling designs. Figure S11 presents a shade plot representing the abundances of the nekton species in each estuary/sampling design.
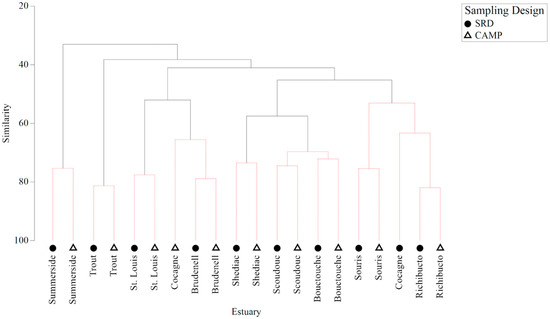
Figure 2.
Cluster analysis on Bray–Curtis similarities for nekton abundance data (square-root transformed) for each sampling design (Community Aquatic Monitoring Program [CAMP] vs. Stratified Random Design [SRD]—average of station data) for each estuary. Dotted lines represent similarity profile (SIMPROF) results where groups of samples are not significantly different (5% significance).
The nMDS ordination plot of the data collected from the CAMP stations and SRD stations (Figure 3) visually display the differences in the degree of dissimilarity between estuaries and sampling designs. The stress for the ordination plots is 0.15, which suggests a good representation of the distances between estuaries and sampling designs based on the dissimilarity of their nekton assemblages. The SIMPROF test grouped the sampling designs for each estuary together, other than Cogagne. These results suggest that generally, regardless of sampling design, the dissimilarity between estuaries would be similar.
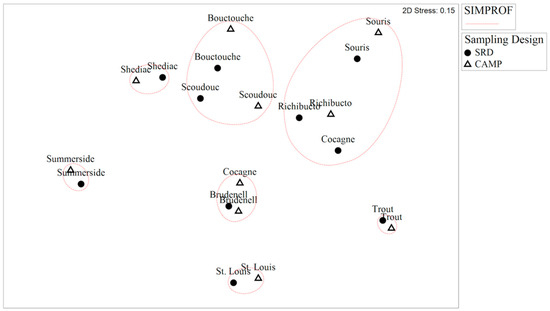
Figure 3.
non-metric Multidimensional Scaling ordination plot of square-root transformed nekton data averaged over sampling design (Community Aquatic Monitoring Program [CAMP] vs. Stratified Random Design [SRD]) within each estuary. Ellipses represent the estuary groupings identified as significant by the SIMPROF test.
Significant differences were detected among nekton assemblages at different estuaries (PERMANOVA pseudo-F = 12.95, p = 0.0001), but there was no significant difference between sampling designs (F = 1.44, p = 0.2073). However, the degree of difference between the sampling designs was somewhat dependent on the estuary (marginal interaction between Estuary x Sampling Design; F = 1.28, p = 0.0475). Therefore, differences between the sampling designs within each estuary were examined with pairwise tests. Significant differences were detected between the sampling designs only within Shediac, (t = 1.527, p = 0.035), and Cocagne (t = 1.819, p = 0.002) (Table 3). The difference detected in Cocagne supports the findings of the cluster analysis and nMDS ordinations. Pair-wise tests were also performed to look at differences between estuaries within each sampling design (Table 4). Significant differences were detected between all estuaries within both sampling designs except between Cocagne and Richibucto within the SRD sampling design (t = 1.27, p = 0.173).
Table 3.
Permutational-MANOVA (PERMANOVA) pair-wise test results for factor Sampling Design within factor Estuary for nekton data collected from the Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) stations.
Table 4.
Comparison of permutational-MANOVA (PERMANOVA) pair-wise tests among factor Estuary within factor Sampling Design for nekton data collected from the Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) stations.
The DISTLM was run using only data from the Cocagne stations to understand which environmental variables may have influenced the significant differences detected. The results of the DISTLM provide evidence that tide height was the most influential environmental variable (F = 2.89, p = 0.005), explaining 22% of the variability in the nekton assemblages (Table S1). Temperature was the only other environmental variable that had a significant influence (F = 2.05, p = 0.05) on the nekton assemblage data, explaining 17% of the variability in the nekton assemblages. The tide height was greater during CAMP station sampling, and water temperature was highest during the SRD station sampling (Figure S12). Tide height during CAMP station sampling ranged from 0.8 to 1.1 m, with an average of 1.0 m. Conversely, tide height during the SRD station sampling ranged from 0.1 to 0.8 m, with an average of 0.4 m.
Another DISTLM was run using data from Shediac stations. The results of the DISTLM provide evidence that salinity was the only influential environmental variable (F = 2.27, p = 0.04), explaining 19% of the variability in nekton assemblages (Table S2). Salinity was generally higher at the CAMP stations (Figure S13). Salinity at the CAMP stations ranged from 27.3 to 28.2, with an average of 27.8. Conversely, salinity at the SRD stations ranged from 19.7 to 27.7, with an average of 24.6. The SRD stations located in the upper and middle estuary had salinity values below the range of CAMP station salinities (SRD stations 1–4). All of these stations were further upstream from the CAMP stations, as the CAMP stations are clustered in the lower estuary (Figure S6).
3.2. Defining How Additional Station Data May Alter Estuary Assessments Based on Nekton Assemblages
There were discrepancies in the species detected by the two sampling designs, and neither sampling design consistently detected more species than the other (Table 5). The species richness (i.e., number of species detected) measured by the two sampling designs was the same at four estuaries, differed by one species at five estuaries, and differed by two species at one estuary. The greatest numbers of discrepancies in the species detected between sampling designs were in Shediac, St. Louis de Kent, Trout River, and Souris. These estuaries ranged in size from 53 to 360 km2. One of the most severe discrepancies was in Trout River where 16 cunner (Tautogolabrus adspersus) were captured over three CAMP stations, but none were captured at SRD stations. Trout River is a relatively small, 93 km2 estuary and the CAMP stations are spread throughout. The species accumulation plots indicate ten is a sufficient number of stations, because ten is the typical number of stations at which the maximum number of species was attained (Figure 4).
Table 5.
Number of species captured by each sampling design (Community Aquatic Monitoring Program [CAMP] and Stratified Random Sampling Design [SRD]), and the individual species captured by only one sampling design.
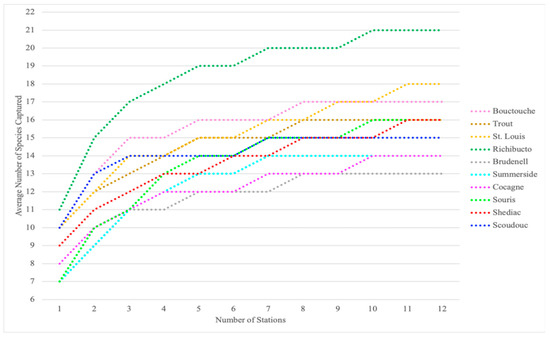
Figure 4.
Species accumulation plots generated using the combined nekton data collected from the Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) stations at each estuary. The plot displays the average number of new species detected with each increasing station number as defined by 999 permutations of station data.
The degree to which differences between CAMP and the combined CAMP+SRD data would affect the interpretation of the nekton assemblages, and consequently, management decisions was explored using PERMANOVA. The one-way PERMANOVA using the combined dataset suggested estuaries were significantly different (F = 12.6, p = 0.0001). A pair-wise test confirmed all estuaries were significantly different from each other (all pairwise comparisons p ≤ 0.003, Table S3).
3.3. Defining the Precision of the Six CAMP Stations in Estimating Influential Species Abundances
The results of the SIMPER analysis (Table 6) revealed the dissimilarities between estuaries, based on CAMP data, were governed by several abundant species. The four most influential species in defining the differences between the estuaries were adult mummichog (Fundulus heteroclitus), fourspine stickleback (Apeltes quadracus), sand shrimp (Crangon septemspinosa), and YOY Atlantic silverside (Menidia menidia). The one-way ANOVA results (Table S4) were used to calculate the variance of the mean for each of the influential species. The variance of the mean was used to formulate confidence intervals for six through 12 stations.
Table 6.
Results of the similarity percentages routine (SIMPER) measuring the contribution of each species to the dissimilarities between estuaries as defined by the Bray–Curtis dissimilarity between each pair of estuaries based on nekton data collected from the Community Aquatic Monitoring Program (CAMP) stations. In addition, the occurrence, median abundance, and range of average abundances within estuaries for each species.
Adult mummichog abundance among all stations ranged from 0 to 4277 per station. The smallest range within an estuary was 0 to 20 mummichog and the largest was 164 to 4277 mummichog (Table 7). The average abundances that contributed to the dissimilarity (at least 10%) between estuaries ranged from 11 to 994 mummichog (Table 8). The six CAMP stations could detect adult mummichog abundances with an estimated precision of +/− 276 individuals, and twelve stations would increase the precision to +/− 204 individuals (Figure S14). With the six CAMP stations, there was sufficient precision to be confident in the larger differences in mean adult mummichog abundance that differentiated the Trout River estuary from all other estuaries sampled (Figure 5). However, there was insufficient precision to be confident in the adult mummichog abundances that differentiated Scoudouc, Brudenell, and St Louis de Kent from the other estuaries. Twelve stations would still lack the precision to be confident in these smaller differences.
Table 7.
Minimum, maximum, and mean counts of the four influential species for each estuary.
Table 8.
The differences in mean influential species counts between estuaries.
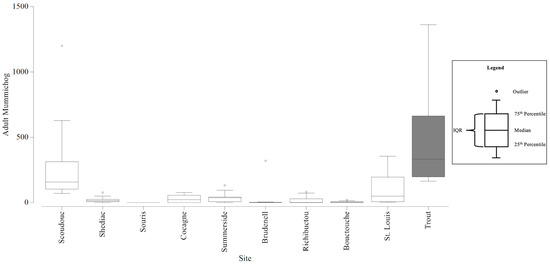
Figure 5.
Boxplots generated using the adult Mummichog counts collected from the Community Aquatic Monitoring Program (CAMP) stations at each estuary. The box shaded dark grey identifies the adult Mummichog abundances that are significantly different from the abundances at the other estuaries, and the difference is large enough to be detected, with confidence, in consideration of the precision of the CAMP sampling design.
Circles above the boxplots (i.e., outliers) are outside 1.5 times the interquartile range (IQR). One outlier removed from Trout estuary (4277).
Adult fourspine stickleback abundance among all stations ranged from 0 to 781 per station. The smallest range of fourspine stickleback counts within an estuary was 0 to 1 and the largest was 11 to 579 (Table 7). The average fourspine stickleback abundances that contributed to the dissimilarity (at least 10%) between estuaries ranged from 14 to 505 (Table 8). The six CAMP stations could detect adult fourspine stickleback abundances with an estimated precision of +/− 143 individuals, and twelve stations would increase the precision to +/− 120 individuals (Figure S15). With the six CAMP stations, there was sufficient precision to be confident in the larger differences in mean adult fourspine stickleback abundances that differentiated Trout River from all other estuaries sampled, except Richibucto (Figure 6). However, there was insufficient precision to be confident in the adult fourspine stickleback abundances that differentiated Richibucto from all other estuaries. Twelve stations would still lack the precision to be confident in these smaller differences. Seven stations would have a sufficient level of precision to be confident in the differences between Trout River and Richibucto.
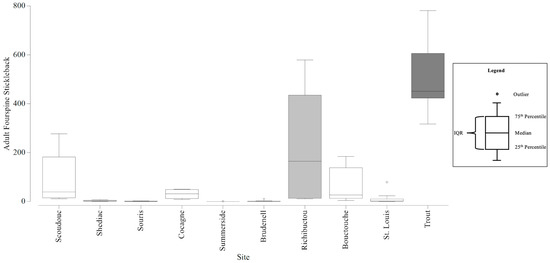
Figure 6.
Boxplots generated using the adult Fourspine Stickleback counts collected from the Community Aquatic Monitoring Program (CAMP) stations at each estuary. The box shaded dark grey identifies the adult Fourspine Stickleback abundances that are significantly different from the abundances at the other estuaries (except the light grey box), and the difference is large enough to be detected, with confidence, in consideration of the precision of the CAMP sampling design. Circles above the boxplots (i.e., outliers) are outside 1.5 times the interquartile range (IQR).
Adult sand shrimp abundance among all stations ranged from 0 to 3474 per station. The smallest range of adult sand shrimp counts within an estuary was 0 to 16 and the largest was 642 to 3747 (Table 7). The average adult sand shrimp abundances that contributed to the dissimilarity (at least 10%) between estuaries ranged from 21 to 1785 (Table 8). The six CAMP stations could detect adult sand shrimp abundances with an estimated precision of +/− 133 individuals, and twelve stations would increase the precision to +/− 107 individuals (Figure S16). With the six CAMP stations, there was sufficient precision to be confident in the larger differences in mean adult sand shrimp counts that differentiated Souris from all other estuaries sampled (Figure 7). In addition, six stations had sufficient precision to be confident in the abundance estimates that differentiated Richibucto and all estuaries, except for Scoudouc and Bouctouche. However, there was insufficient precision to be confident in the abundances that differentiated Scoudouc from the majority of estuaries. Twelve stations would still lack the precision to be confident in most of these smaller differences. Twelve stations would have a sufficient level of precision to be confident in the differences between Scoudouc and Summerside and Shediac.
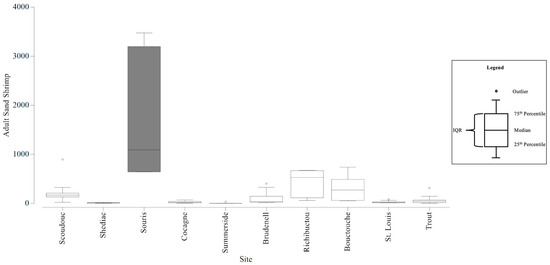
Figure 7.
Boxplots generated using the adult Sand Shrimp counts collected from the Community Aquatic Monitoring Program (CAMP) stations at each estuary. The box shaded dark grey identifies the adult Sand Shrimp abundances that are significantly different from the abundances at the other estuaries, and the difference is large enough to be detected, with confidence, in consideration of the precision of the CAMP sampling design. Circles above the boxplots (i.e., outliers) are outside 1.5 times the interquartile range (IQR).
YOY Atlantic silverside abundances among all stations ranged from 0 to 2689 per station. The smallest range in YOY Atlantic silverside counts within an estuary was 0 to 8 and the largest was 6 to 2689 (Table 7). The average YOY Atlantic silverside abundances that contributed to the dissimilarity (at least 10%) between estuaries ranged from 18 to 1096 (Table 8). The six CAMP stations could detect YOY Atlantic silverside abundances with an estimated precision of +/− 303 individuals, and twelve stations would increase the precision to +/− 246 individuals (Figure S17). With the six CAMP stations, there was sufficient precision to be confident in the larger differences in mean YOY Atlantic silverside abundances that differentiated Bouctouche from all other estuaries (Figure 8). However, there was insufficient precision to be confident in the abundances that differentiated Scoudouc, Shediac, and Summerside from the majority of estuaries. Twelve stations would still lack the precision to be confident in these smaller differences. Seven stations would have a sufficient level of precision to be confident in the abundance estimates that differentiated Trout River and Richibucto.
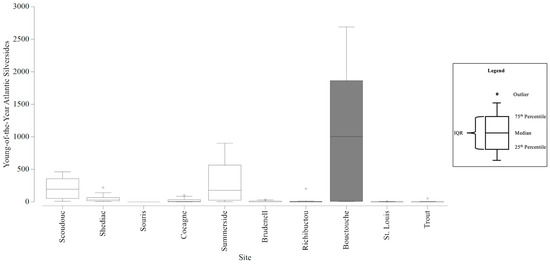
Figure 8.
Boxplots generated using the young-of-the-year (YOY) Atlantic Silverside counts collected from the Community Aquatic Monitoring Program (CAMP) stations at each estuary. The box shaded dark grey identifies the YOY Atlantic Silverside abundances that are significantly different from the abundances at the other estuaries, and the difference is large enough to be detected, with confidence, in consideration of the precision of the CAMP sampling design. Circles above the boxplots (i.e., outliers) are outside 1.5 times the interquartile range (IQR).
Overall, the six CAMP stations had the precision to detect 42% of the differences in mean abundances that accounted for at least 10% influence on the estuary dissimilarities (Table 8). Increasing the number of stations to 12 would likely only increase the detection rate by 2%. The difference between the confidence intervals of six stations versus the confidence intervals of 12 stations (72 adult mummichog, 23 adult fourspine stickleback, 26 adult sand shrimp, and 57 YOY Atlantic silverside) is small when considering the typical variability in counts of these species within estuaries.
4. Discussion
Previous studies have assessed the scientific utility of community-based monitoring programs (CBMPs) through comparisons of the data collected by community members and professional scientists (e.g., Fore et al. [24]; Thériault et al. [25]; Danielsen et al. [26]; van der Velde et al. [27]). This study took a different approach by testing if the CBMP data are biased due to the sampling design facilitating volunteer participation, rather than testing volunteer competency. Thériault et al. [25] previously tested the accuracy of the CAMP volunteers’ nekton identification skills and concluded they were comparable to DFO scientists (i.e., <10% disagreement in abundance counts).
The first objective of this study was to test the hypothesis that nekton assemblage data collected from the CAMP stations would not be significantly different than data collected from stations located through a stratified random design. The nekton assemblages collected with the two sampling designs were generally not significantly different. In addition, when observed individually, both study designs yielded the same result that all estuaries differ significantly in nekton structure. The exceptions were the Cocagne and Shediac estuaries, where significant differences were detected between the sampling designs. However, Shediac’s nekton assemblages differed from all estuaries, regardless of sampling design. Cocagne was not significantly different from Richibucto when considering the nekton data collected from the SRD stations, but was significantly different from all estuaries when considering the data collected from the CAMP stations. The potential causes for the differences detected between the sampling designs at Cocagne and Shediac were explored.
Of the environmental variables measured, tide height had the strongest influence on the differences in Cocagne nekton between the sampling designs. The average difference in tide height between the CAMP and SRD stations during sampling in Cocagne was 0.6 m. Conversely, the next largest difference in tide height between sampling designs within an estuary was 0.1 m. Since tides are known to influence the distribution of nekton within an estuary [37,38,39,40], studies typically standardize their sampling to a certain tide height (e.g., Schein et al. [41]; Ellis and Bell [42]; Gerwing et al. [43]). This study followed the CAMP protocol of beginning sampling at 8:00 AM every day, and sampled the different sampling designs only one day apart to maintain similar environment conditions. However, Cocagne CAMP station sampling began 1.75 h before the SRD sampling and finished 4.00 h before the SRD sampling. The difference in time was a consequence of the late start of the SRD sampling and longer sampling time due to shallow waters inhibiting boat access to the shoreline. Therefore, the difference in sampling timing (resulting in a difference in tide height) is likely the cause for the significant difference between the Cocagne datasets, rather than the difference in station locations. These results provide further support for estuary monitoring programs to standardize tide height among sampling locations and sampling dates. Further research is required to test the maximum difference in tide height that will not introduce significant variability.
Salinity had the strongest influence on the differences in Shediac nekton between the sampling designs. Salinity is an influential factor contributing to nekton variability within estuaries [10,44,45,46,47]. Shediac CAMP stations are clustered in the bay, resulting in those stations experiencing higher salinity concentrations than the majority of the SRD stations that were located further up the estuary (Figure S6). Yet, a greater difference in salinity was measured between sampling designs at the Bouctouche estuary, and CAMP stations are also clustered in the lower estuary at Brudenell and Scoudouc. Thus, there may have been other environmental variables not measured that had a greater influence on the differences between the sampling designs.
Overall, regardless of sampling design, the assessment of the nekton assemblage at each of these estuaries would not change. Therefore, if assessments of these estuaries were to be made using nekton assemblages as an indicator of estuary condition, the recommendations informed by the assessment would not change. These findings are evidence that a lack of station stratification and randomization does not limit the utility of CAMP for decision-makers.
The remaining question concerning the scientific utility of CAMP was whether the station number (i.e., six stations per estuary) is appropriate. When initiating a monitoring program, it is best to oversample initially to identify the sufficient number of samples. However, budget and time constraints often dictate sample numbers. Six stations were originally proposed for CAMP estuaries, because that was the number of stations that volunteers were predicted to be able to sample within one day [28], and considered the minimum to achieve sufficient power with multivariate analyses. Accordingly, this study’s second objective was to test the hypothesis that sampling an additional six stations would not significantly change the dissimilarities between estuaries or substantively improve the precision of nekton abundance estimates.
The results from analysis of the combined dataset (i.e., CAMP plus SRD station data) demonstrated collecting an additional six stations would not alter conclusions based on nekton assemblages. While the six CAMP and six SRD stations generally had similar species richness values, the species accumulation plots showed, on average, the species number continued to increase until ten stations. Yet, the one-way PERMANOVA results for the combined dataset suggested collecting data from an additional six stations would not alter the conclusion that all estuaries have dissimilar nekton assemblages. These results indicate that the additional species gained past six stations do not significantly influence the dissimilarity calculation for the multivariate analyses.
It was important to understand how confident one can be in the results that all estuaries are significantly different based on the nekton assemblage data from six stations. The nekton assemblage data are comprised of abundance estimates for individual species. The confidence in the accuracy of these abundance estimates is based on the number of samples and variability of the abundance data. Although accuracy cannot be determined because we have no independent estimate of species number, the precision of these estimates can be calculated to understand the likely range of values within which the mean truly falls. The precision of estimates will govern whether you can be confident in the conclusions and understand the risk of a Type I error (i.e., falsely concluding there are significant differences between the means). Increasing sample size is one way to increase sampling precision to detect biological differences between estuaries [48]. Therefore, the ideal sample size for CAMP is one that yields sufficient precision to detect the typical differences in mean species abundance estimates that are considered biologically meaningful.
The SIMPER analysis revealed the differences in nekton assemblages among estuaries were governed by four influential species (adult mummichog, fourspine stickleback, and sand shrimp, and young-of-the-year Atlantic silverside). Abundance estimates from the current six CAMP stations only have sufficient precision to be confident in the largest differences in species abundances that differentiated estuaries. However, even six additional stations would mostly still be insufficient for the numerous smaller differences recorded in mean species abundances. Abundance estimates of all four influential species can range in the 100′s within estuaries. This high within- and among- estuary variability makes it difficult to substantially increase the precision of abundance estimates by adding stations. Therefore, the results do not provide compelling evidence to suggest more stations would substantively increase the precision of nekton community descriptions enough to warrant additional sampling effort.
Restricting the number of CAMP stations in consideration of volunteer participation does not appear to have substantively limited the precision of nekton abundance estimates. Rather, the precision of nekton abundance estimates is limited by the naturally high variability in nekton abundances, which has been identified by other studies as a limiting factor in using nekton as an indicator of estuary health [42,49,50,51].
Future analysis and interpretation of the CAMP dataset should evaluate the precision of the influential species estimates to understand if there can be a reasonable level of confidence in the conclusions that nekton assemblages are dissimilar. This method will help to differentiate from the inherent variability in nekton assemblages within and among estuaries, and those differences that are large enough to signify a biologically meaningful change. These larger differences in nekton abundances should then be investigated to understand if they indicate healthy or degraded conditions relative to the other estuaries or the same estuary overtime. Both conclusions of either healthy or degraded conditions have implications for management decisions to restore habitat or protect what has yet to be impacted.
5. Conclusions
The findings of this study suggest that the CAMP dataset yields similar results as a program designed using more robust scientific methods. As such, the application of the CAMP dataset for decision-makers should not be inhibited by concerns for data quality due to volunteer participation. These findings contribute to the growing body of evidence supporting the use of CBMP data to inform decision-makers.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/fishes6030027/s1. Figure S1: Map of Bouctouche station locations, Figure S2: Map of Brudenell station locations; Figure S3: Map of Cocagne station locations; Figure S4: Map of Richibucto station locations; Figure S5: Map of Scoudouc station locations; Figure S6: Map of Shediac station locations; Figure S7: Map of Souris station locations; Figure S8: Map of St. Louis de Kent station locations; Figure S9: Map of Summerside station locations; Figure S10: Map of Trout River station locations; Figure S11: Shade plot displaying the square-root transformed abundances of each nekton species (y-axis) per sampling design (Community Aquatic Monitoring Program [CAMP] and Stratified Random Design [SRD]) for the ten estuaries (x-axis). The intensity of the shade signifies the relative abundance of each species and the contribution of each species to the similarity calculation. An (A) indicates the adult life stage of the species and YOY indicates Young-of-the-Year life stage. The species names are: BSS (blackspotted stickleback), 3SS (threespine stickleback), GAST (gasterosteus), GASP (gaspereau), 4SS (fourspine stickleback), 9SS (ninespine stickleback), MUM (mummichog), FUND (fundulus), SSH (sand shrimp), GSH (grass shrimp), SILV (Atlantic silverside), SFL (smooth flounder), WFL (winter flounder), WNFL (windowpane flounder), FLOU (flounder), KIL (banded killifish), SBA (striped bass), EEL (American eel), PIP (northern pipefish), CUN (cunner), TOM (Atlantic tomcod), RCR (rock crab), GCR (green crab), MCR (mud crab), SMEL (rainbow smelt), PER (white perch), and GRUB (grubby). Figure S12: Non-metric Multidimensional Scaling ordination plot of square-root transformed nekton data collected from Cocagne Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) stations. Vector overlay displays lines indicating increased temperature/tide height along that axes; Figure S13: Non-metric Multidimensional Scaling ordination plot of square-root transformed nekton data collected from Shediac Community Aquatic Monitoring Program (CAMP) and Stratified Random Design (SRD) stations. Vector overlay displays a line indicating increased salinity along that axes; Figure S14: Confidence interval values (+/−) of estimates of Adult Mummichog abundances; Figure S15: Confidence interval values (+/−) of estimates of adult Fourspine Stickleback abundances; Figure S16: Confidence interval values (+/−) of estimates of Adult Sand Shrimp abundances; Figure S17. Confidence interval values (+/−) of estimates of YOY Atlantic Silverside abundances; Table S1: Distance-based linear models (DISTLM) routine results for the analysis of the environmental variables that best describe the nekton assemblages in Cocagne; Table S2: Distance-based linear models (DISTLM) routine results for the analysis of the environmental variables that best describe the nekton assemblages in Shediac; Table S3: Permutational-MANOVA (PERMANOVA) pair-wise test among factor Estuary for nekton data collected from the combined data set (Community Aquatic Monitoring Program (CAMP) plus Stratified Random Design (SRD) station data); Table S4: Separate one-way analysis of variance (ANOVA) using the factor Estuary for the number of each species captured.
Author Contributions
Conceptualization, J.A.K., M.B. and S.C.C.; methodology, J.A.K., M.B., R.C.B., M.R.v.d.H., M.R.S. and S.C.C.; formal analysis, J.A.K., R.C.B. and S.C.C.; resources, M.B., M.R.v.d.H. and M.R.S.; writing—original draft preparation, J.A.K., R.C.B., M.R.S. and S.C.C.; writing—review and editing, J.A.K., M.B., R.C.B., M.R.v.d.H., M.R.S. and S.C.C.; supervision, M.R.S. and S.C.C.; funding acquisition, J.A.K. and S.C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by an NSERC Collaborative Research and Training Experience (CREATE-Water) Grant and the Canadian Water Network.
Institutional Review Board Statement
All fish were handled in accordance with the approved University of Waterloo animal care protocol (AUPP #14-15). All fish collection activities complied with DFO Gulf Region License to Fish for Scientific Purposes, License No. SG-RHQ-16-016C.
Data Availability Statement
The data presented in this study are openly available at: https://zenodo.org/badge/latestdoi/391195003 (accessed on 20 June 2021).
Acknowledgments
We would like to thank all of those who assisted in the collection of field data. Christina Pater, Kyle Knysh, and Carissa Grove participated in collecting data from the Prince Edward Island estuaries. Michelle Maillet from the Department of Fisheries and Oceans’ Gulf Fisheries Centre made sampling in New Brunswick possible. The CAMP coordinators Jolène Mazerolle and Taylor Sheidow were extremely helpful in the field and in providing CAMP sampling gear.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Blaber, S.J.M.; Cyrus, D.P.; Albaret, J.-J.; Ching, C.V.; Day, J.W.; Elliott, M.; Fonesca, M.S.; Hoss, D.E.; Orensanz, J.; Potter, I.C.; et al. Effects of fishing on the structure and functioning of estuarine and nearshore ecosystems. ICES J. Mar. Sci. 2000, 57, 590–602. [Google Scholar] [CrossRef]
- Lotze, H.K.; Lenihan, H.S.; Bourque, B.J.; Bradbury, R.H.; Cooke, R.G.; Kay, M.C.; Kidwell, S.M.; Kirby, M.X.; Peterson, C.H.; Jackson, J.B. Depletion, degradation, and recovery potential of estuaries and coastal seas. Science 2006, 312, 1806–1809. [Google Scholar] [CrossRef] [PubMed]
- Rothenberger, M.B.; Swaffield, T.; Calomeni, A.J.; Cabrey, C.D. Multivariate Analysis of Water Quality and Plankton Assemblages in an Urban Estuary. Estuaries Coasts 2014, 37, 695–711. [Google Scholar] [CrossRef]
- Chariton, A.A.; Stephenson, S.; Morgan, M.J.; Steven, A.D.L.; Colloff, M.J.; Court, L.N.; Hardy, C.M. Metabarcoding of benthic eukaryote communities predicts the ecological condition of estuaries. Environ. Pollut. 2015, 203, 165–174. [Google Scholar] [CrossRef]
- Caeiro, S.; Painho, M.; Goovaerts, P.; Costa, H.; Sousa, S. Spatial sampling design for sediment quality assessment in estuaries. Environ. Model. Softw. 2003, 18, 853–859. [Google Scholar] [CrossRef]
- Porter, A.; Scanes, P. Scavenging rate ecoassay: A potential indicator of estuary condition. PLoS ONE 2015, 10, e0127046. [Google Scholar] [CrossRef] [PubMed]
- Deeley, D.M.; Paling, E.I. Assessing the Ecological Health of Estuaries in Australia; Land and Water Resources Research and Development Corporation: Canberra, Australia, 1999. [Google Scholar]
- Tsou, T.-S.; Matheson, R.E. Seasonal changes in the nekton community of the Suwannee River Estuary and the potential impacts of freshwater withdrawal. Estuaries 2002, 25, 1372–1381. [Google Scholar] [CrossRef]
- Gorecki, R.; Davis, M.B. Seasonality and spatial variation in nekton assemblages of the Lower Apalachicola River. Southeas. Nat. 2013, 12, 171–196. [Google Scholar] [CrossRef]
- Schwartzkopf, B.D.; Whitman, A.D.; Lindsley, A.J.; Heppell, S.A. Temporal and habitat differences in the juvenile demersal fish community at a marine-dominated northeast Pacific estuary. Fish. Res. 2020, 227, 105557. [Google Scholar] [CrossRef]
- Scanes, P.; Coade, G.; Doherty, M.; Hill, R. Evaluation of the utility of water quality based indicators of estuarine lagoon condition in NSW, Australia. Estuar. Coast. Shelf Sci. 2007, 74, 306–319. [Google Scholar] [CrossRef]
- Mahoney, P.C.; Bishop, M.J. Assessing risk of estuarine ecosystem collapse. Ocean. Coast. Manag. 2017, 140, 46–58. [Google Scholar] [CrossRef]
- Danielsen, F.; Brugess, N.D.; Balmford, A.; Donald, P.F.; Funder, M.; Jones, J.P.G.; Alviola, P.; Balete, D.S.; Blomley, T.; Brashares, J.; et al. Local participation in natural resource monitoring: A characterization of approaches. Conserv. Biol. 2008, 23, 31–42. [Google Scholar] [CrossRef]
- Sharpe, A.; Conrad, C. Community based ecological monitoring in Nova Scotia: Challenges and opportunities. Environ. Monit. Assess. 2006, 113, 395–409. [Google Scholar] [CrossRef]
- Forrester, G.; Bailey, P.; Conetta, D.; Forrester, L.; Kintzing, E.; Jarecki, L. Comparing monitoring data collected by volunteers and professionals shows that citizen scientists can detect long-term change on coral reefs. J. Nat. Conserv. 2015, 24, 1–9. [Google Scholar] [CrossRef]
- Cohn, J.P. Citizen science: Can volunteers do real research? BioScience 2008, 58, 192–197. [Google Scholar] [CrossRef] [Green Version]
- Gura, T. Amateur experts: Involving members of the public can help science projects but researchers should consider what they want to achieve. Nature 2013, 496, 259–261. [Google Scholar] [CrossRef] [Green Version]
- Theobald, E.J.; Ettinger, A.K.; Burgess, H.K.; DeBey, L.B.; Schmidt, N.R.; Froehlich, H.E.; Wagner, C.; HilleRisLambers, J.; Tewksbury, J.; Harsch, M.A.; et al. Global change and local solutions: Tapping the unrealized potential of citizen science for biodiversity research. Biol. Conserv. 2015, 181, 236–244. [Google Scholar] [CrossRef] [Green Version]
- Ryan, W.H.; Gornish, E.S.; Christenson, L.; Halpern, S.; Henderson, S.; Lebuhn, G.; Miller, T.E. Initiating and managing long-term data with amateur scientists. Am. Biol. Teach. 2017, 79, 28–34. [Google Scholar] [CrossRef]
- Kanu, A.; DuBois, C.; Hendriks, E.; Cave, K.; Hartwig, K.; Fresque-Baxter, J.; Trembath, K.; Kelly, E. Realizing the Potential of Community-Based Monitoring in Assessing the Health of Our Waters. Our Living Waters, 2016. Available online: http://www.ourlivingwaters.ca/cbmreport_sep2016 (accessed on 1 March 2017).
- Conrad, C.; Hilchey, K.G. A review of citizen science and community-based environmental monitoring: Issues and opportunities. Environ. Monit. Assess. 2011, 176, 273–291. [Google Scholar] [CrossRef] [PubMed]
- Follett, R.; Strezov, V. An analysis of citizen science based research: Usage and publications patterns. PLoS ONE 2015, 10, e0143687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Savage, J.M.; Osborne, P.E.; Hudson, M.D. Effectiveness of community and volunteer based coral reef monitoring in Cambodia. Aquat. Conserv. Mar. Freshw. Ecosyst. 2017, 27, 340–352. [Google Scholar] [CrossRef]
- Fore, L.S.; Paulsen, K.; O’Laughlin, K. Assessing the performance of volunteers in monitoring streams. Freshw. Biol. 2001, 46, 109–123. [Google Scholar] [CrossRef]
- Thériault, M.-H.; Courtenay, S.; Weldon, J. Quality Assurance Quality Control (QA/QC) Program for the Community Aquatic Monitoring Program (CAMP); Canadian Technical Report of Fisheries and Aquatic Sciences 1488-53792823; Fisheries and Oceans Canada: Moncton, NB, Canada, 2008.
- Danielsen, F.; Jensen, P.M.; Burgess, N.D.; Altamirano, R.; Alviola, P.A.; Andrianndrasana, H.; Brashares, J.S.; Burton, A.C.; Coronado, I.; Corpuz, N.; et al. A multicountry assessment of tropical resource monitoring. BioScience 2014, 64, 236–251. [Google Scholar] [CrossRef] [Green Version]
- Van der Velde, T.; Milton, D.A.; Lawson, T.J.; Wilcox, C.; Lansdell, M.; Davis, G.; Perkins, G.; Hardesty, B.D. Comparison of marine debris data collected by researchers and citizen scientists: Is citizen science data worth the effort? Biol. Conserv. 2017, 208, 127–138. [Google Scholar] [CrossRef]
- DFO. Presented at the Proceedings of the Regional Advisory Process to Review the Community Aquatic Monitoring Program (CAMP) and Its Use to Infer the Ecological Health of Bays and Estuaries, St., Lawrence, MA, USA, 17–18 March 2010; DFO Canadian Scientific Advisory Secretariat Proceed. Ser. CSAS: Ottawa, ON, Canada, 2011.
- Thériault, M.H.; Courtenay, S. Overview Analysis of the Community Aquatic Monitoring Program (CAMP) in the Basin Head Lagoon from 2002 to 2008; Canadian Science Advisory Secretariat Research Document: Ottawa, ON, Canada, 2010; pp. iv + 34. [Google Scholar]
- Dytham, C. Choosing and Using Statistics: A Biologist’s Guide, 3rd ed.; John Wiley & Sons Ltd.: West Sussex, UK, 2011; pp. 26–27. [Google Scholar]
- Weldon, J.; Garbary, D.; Courtenay, S.; Ritchie, W.; Godin, C.; Thériault, M.-H.; Boudreau, M.; Lapenna, A. The Community Aquatic Monitoring Project (CAMP) for Measuring Marine Environmental Health in Coastal Waters of the Southern Gulf of St. Lawrence: 2004 Overview; Canadian Technical Report of Fisheries and Aquatic Sciences 2825; Fisheries and Oceans Canada: Moncton, NB, Canada, 2005; pp. vii + 53.
- Stantec Consulting Ltd. Land Use Database for Maritime Provinces; Report Prepared for Fisheries and Oceans Canada; Fisheries and Oceans Canada: Moncton, NB, Canada, 2014.
- Department of Fisheries and Oceans Canada (DFO). 7 Day Tidal Predictions Fisheries and Oceans Canada. 2016. Available online: http://www.waterlevels.gc.ca/eng/find/zone/4 (accessed on 20 January 2017).
- Anderson, M.J.; Gorley, R.N.; Clarke, K.R. PERMANOVA+ for PRIMER: Guide to Software and Statistical Methods; PRIMER-E: Plymouth, UK, 2008. [Google Scholar]
- Bailey, C.; Byrnes, J. A new, old method for assessing measurement error. Syst. Zool. 1990, 39, 124–130. [Google Scholar] [CrossRef]
- Clarke, K.R.; Gorley, R.N.; Somerfield, P.J.; Warwick, R.M. Change in Marine Communities: An Approach to Statistical Analysis and Interpretation, 3rd ed.; PRIMER-E: Plymouth, UK, 2014. [Google Scholar]
- Gibson, R.N. Go with the flow: Tidal migration in marine animals. Hydrobiologia 2003, 503, 153–161. [Google Scholar] [CrossRef]
- Wilcockson, D.; Zhang, L. Circatidal clocks. Curr. Biol. 2008, 18, 753–755. [Google Scholar] [CrossRef]
- Krumme, U. Diel and tidal movements by fish and decapods linking tropical coastal ecosystems. In Ecological Connectivity Among Tropical Coastal Ecosystems; Nagelkerken, I., Ed.; Springer Science: New York, NY, USA, 2009; pp. 271–324. [Google Scholar]
- Castellanos-Galindo, G.A.; Krumme, U. Tides, salinity, and biogeography affect fish assemblage structure and function in macrotidal mangroves of the neotropics. Ecosystems 2015, 18, 1165–1178. [Google Scholar] [CrossRef]
- Schein, A.; Courtenay, S.C.; Crane, C.S.; Teather, K.L.; van den Heuvel, M.R. The role of submerged aquatic vegetation in structuring the nearshore fish community within an estuary of the southern Gulf of St. Lawrence. Estuaries Coasts 2012, 35, 799–810. [Google Scholar] [CrossRef]
- Ellis, W.L.; Bell, S.S. Intertidal fish communities may make poor indicators of environmental quality: Lessons from a study of mangrove mangrove habitat modification. Ecol. Indic. 2013, 24, 421–430. [Google Scholar] [CrossRef]
- Gerwing, T.G.; Plate, E.; Sinclair, J.; Burns, C.; McCulloch, C.; Bocking, R.C. Short-term response of fish communities and water chemistry to breaching of a causeway in the Sarita River Estuary, British Columbia, Canada. Restor. Ecol. 2019, 27, 1473–1482. [Google Scholar] [CrossRef]
- Marshall, S.; Elliott, M. Environmental influences on the fish assemblage of the Humber Estuary, Estuarine, U.K. Coast. Shelf Sci. 1998, 46, 175–184. [Google Scholar] [CrossRef]
- Jaureguizar, A.J.; Menni, R.; Guerrero, R.; Lasta, C. Environmental factors structuring fish communities of the Rio de la Plata estuary. Fish. Res. 2004, 66, 195–211. [Google Scholar] [CrossRef]
- Harrison, T.D.; Whitfield, A.K. Temperature and salinity as primary determinants influencing the biogeography of fishes in South African estuaries. Estuar. Coast. Shelf Sci. 2006, 66, 335–345. [Google Scholar] [CrossRef]
- Araujo, A.V.; Dias, C.O.; Bonecker, S.L.C. Differences in the structure of copepod assemblages in four tropical estuaries: Importance of pollution and the estuary hydrodynamics. Mar. Pollut. Bull. 2017, 115, 412–420. [Google Scholar] [CrossRef]
- Raposa, K.B.; Roman, C.T.; Heltshe, J.F. Monitoring nekton as a bioindicator in shallow estuarine habitats. Environ. Monit. Assess. 2003, 81, 239–255. [Google Scholar] [CrossRef]
- Elliott, M.; Quintino, V. The Estuarine Quality Paradox, Environmental Homeostasis and the difficulty of detecting anthropogenic stress in naturally stressed areas. Mar. Pollut. Bull. 2007, 54, 640–645. [Google Scholar] [CrossRef] [PubMed]
- Sheaves, M.; Johnston, R.; Connolly, R.M. Fish assemblages as indicators of estuary ecosystem health. Wetl. Ecol. Manag. 2012, 20, 477–490. [Google Scholar] [CrossRef] [Green Version]
- Valesini, F.J.; Cottingham, A.; Hallett, C.S.; Clarke, K.R. Interdecadal changes in the community, population and individual levels of the fish fauna of an extensively modified estuary. J. Fish Biol. 2017, 90, 1734–1767. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).