

American Sign Language Alphabet Recognition Using Inertial Motion Capture System with Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
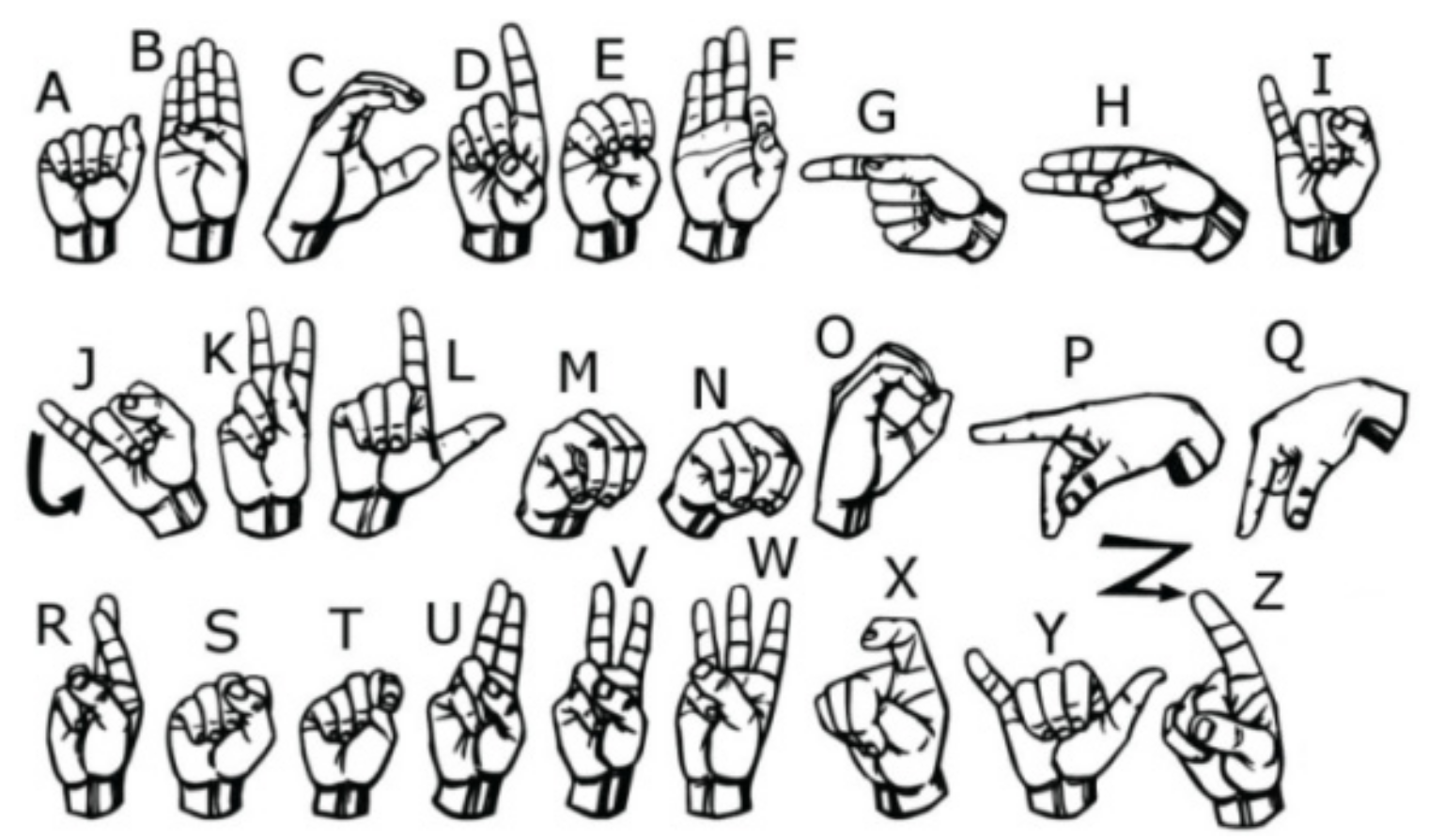
2.1. Isolated Hand Gestures Recognition of Twenty-Six Letters in the Alphabet
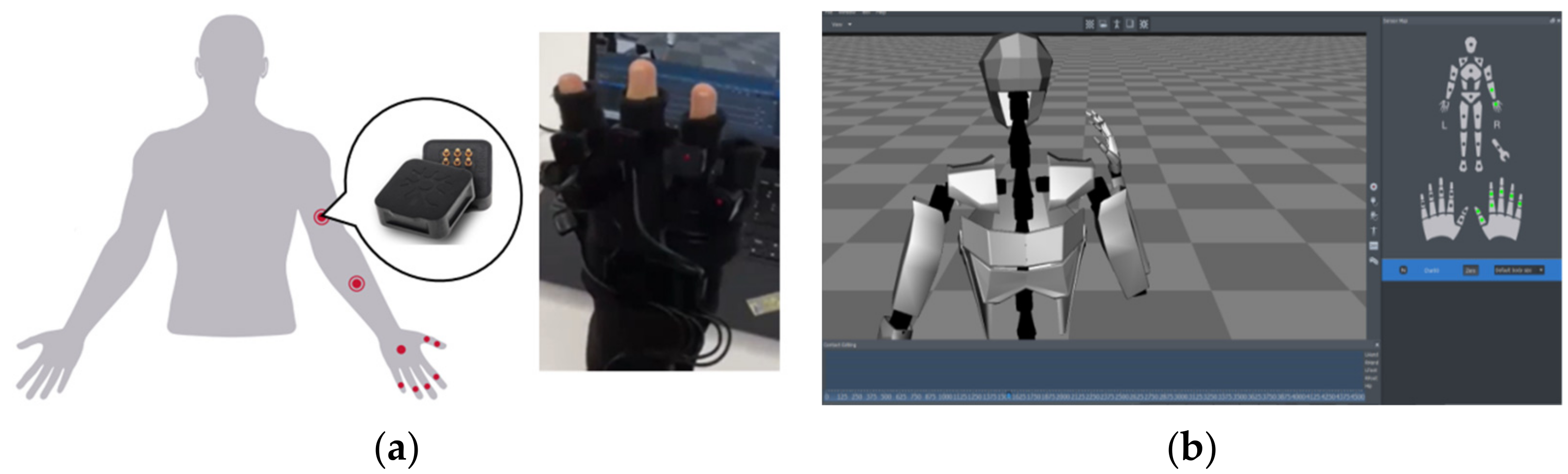
2.1.1. Dataset Collection
2.1.2. Data Preprocessing
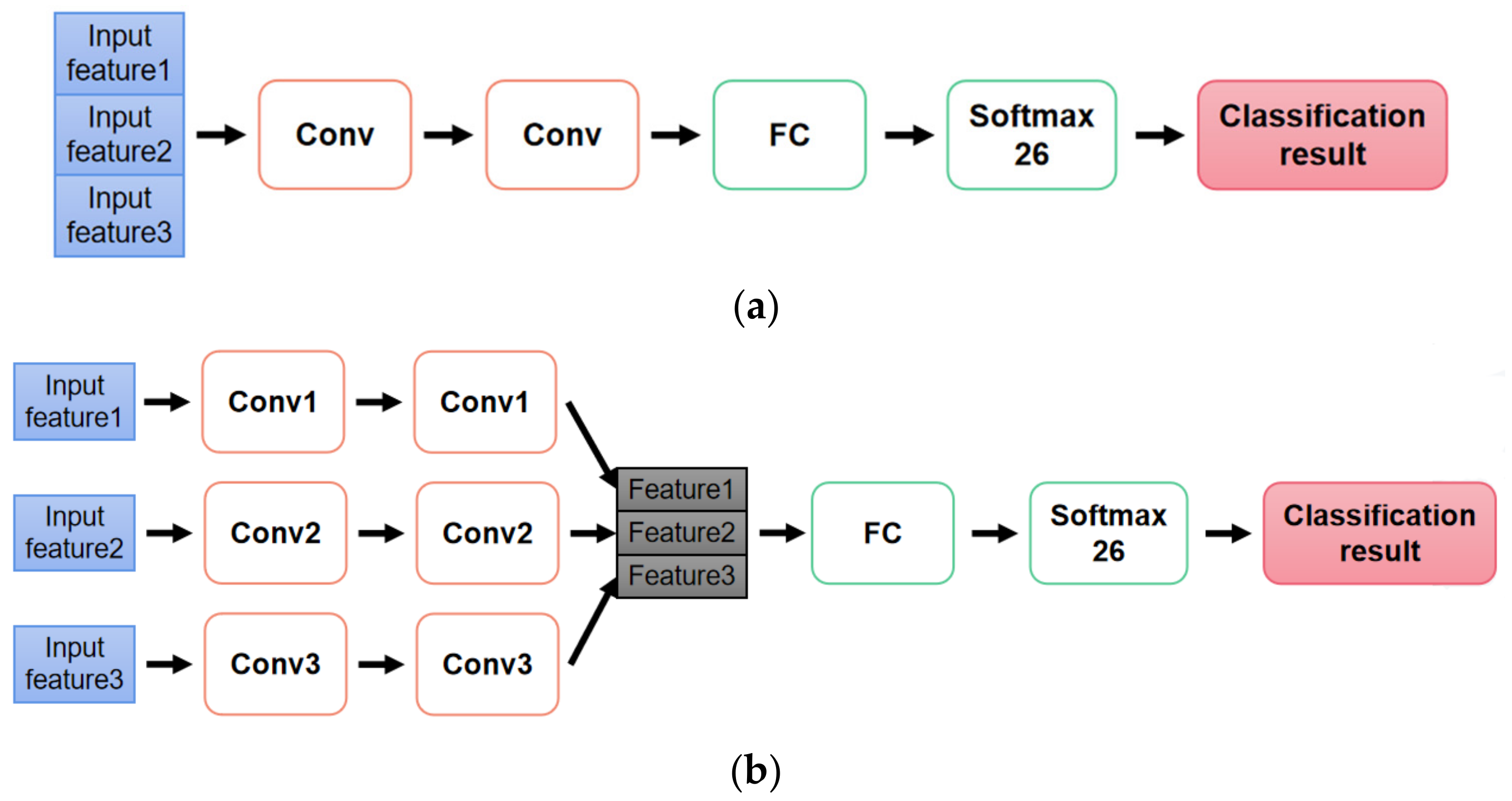
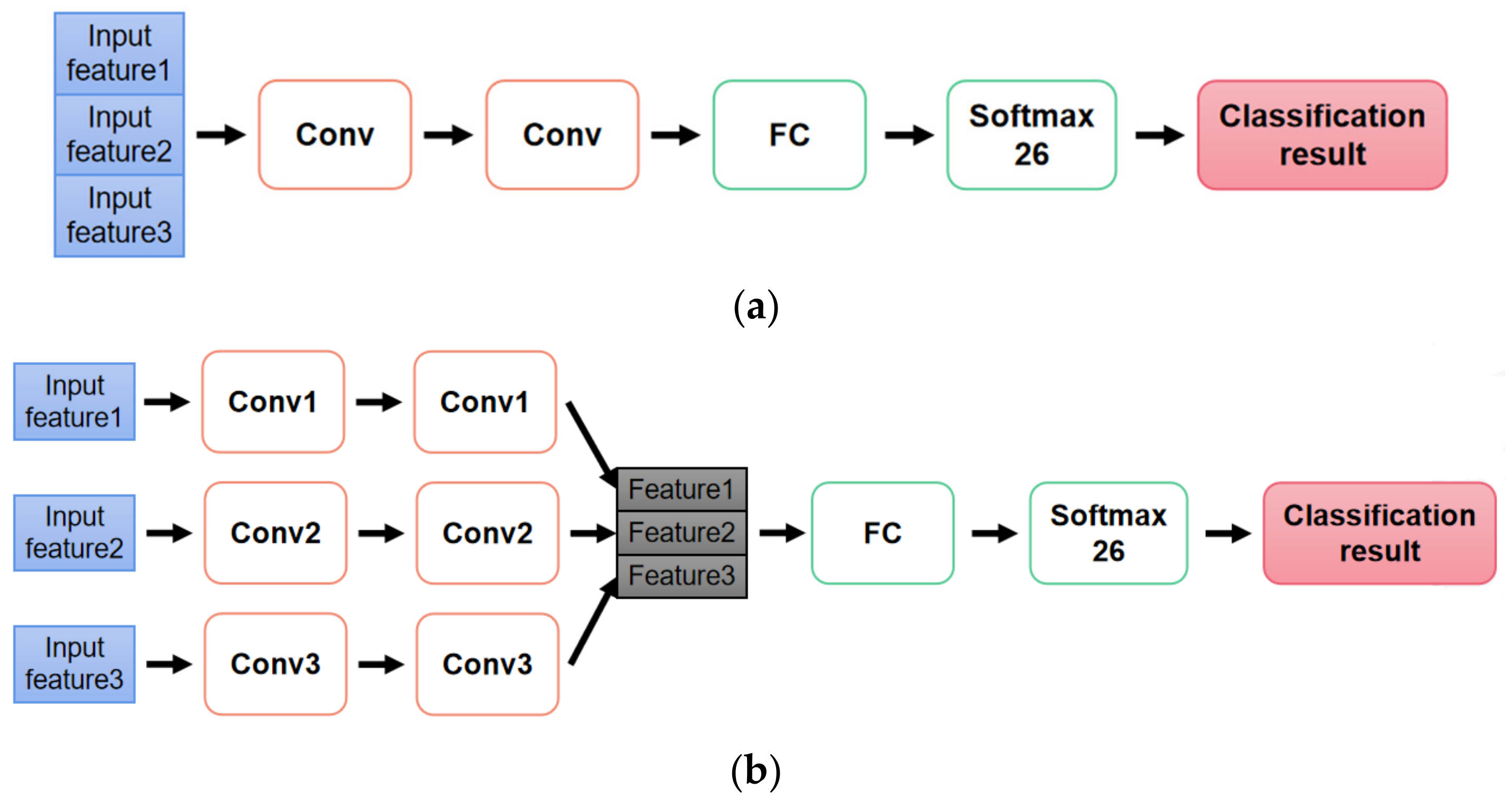
2.1.3. Classification Model Design
2.2. American Sign Language Fingerspelling Recognition
2.2.1. Dataset of Fifty Commonly Used English Words
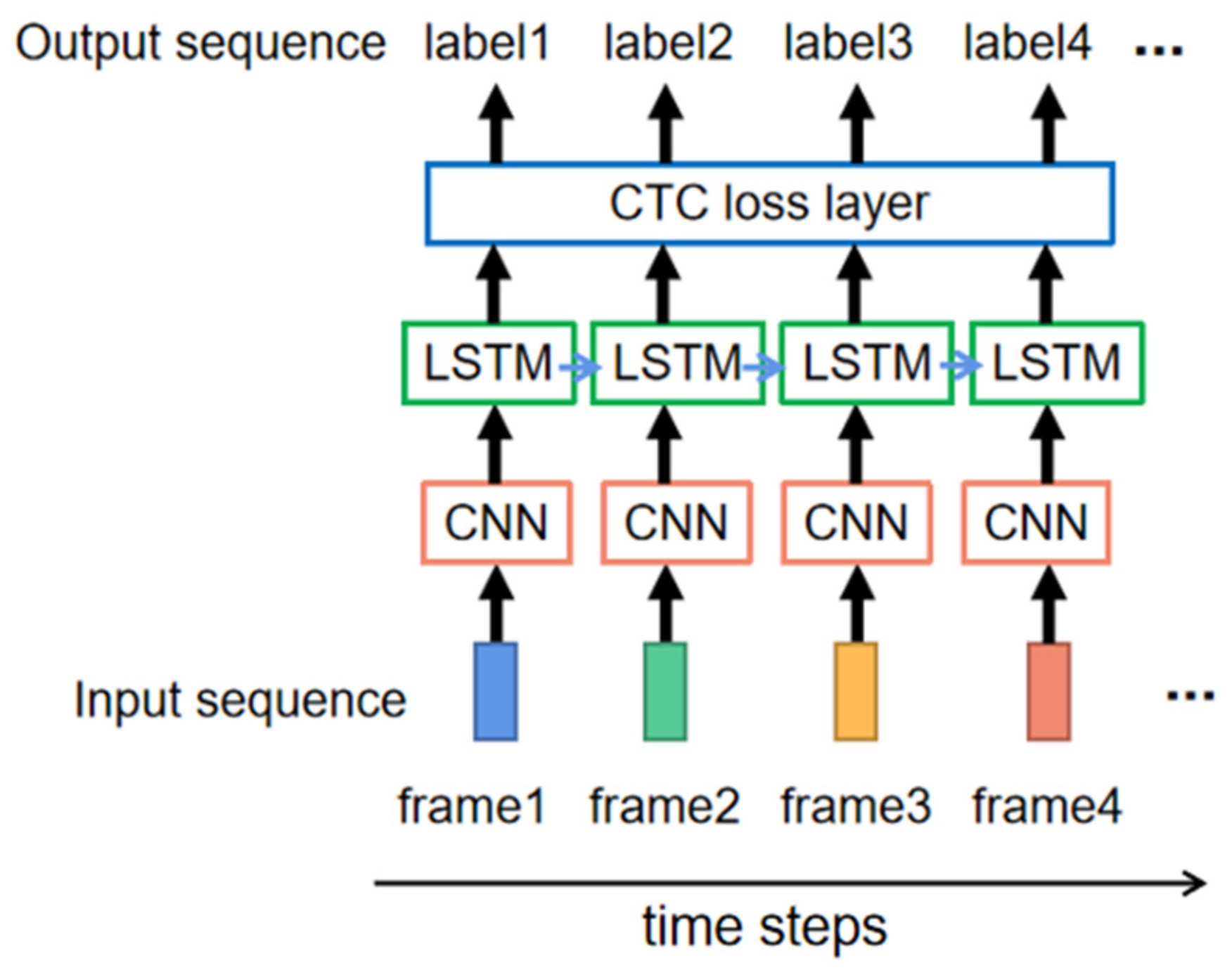
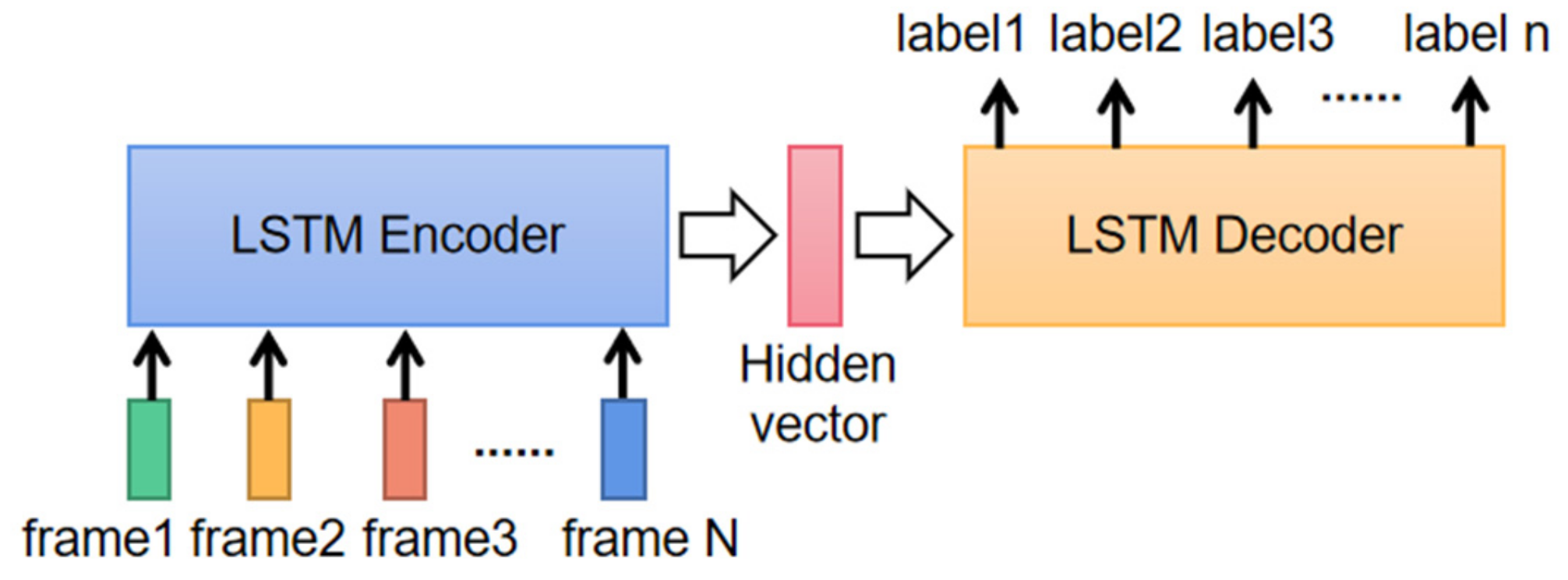
2.2.2. Sequence Recognition Model Design
3. Results
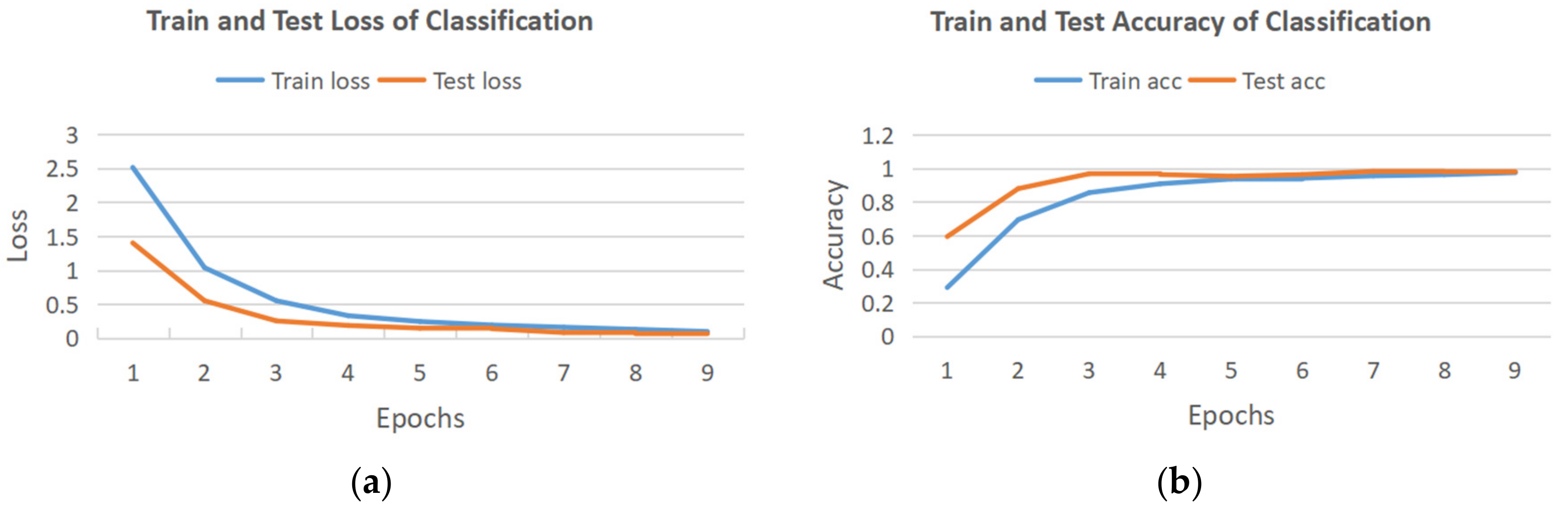
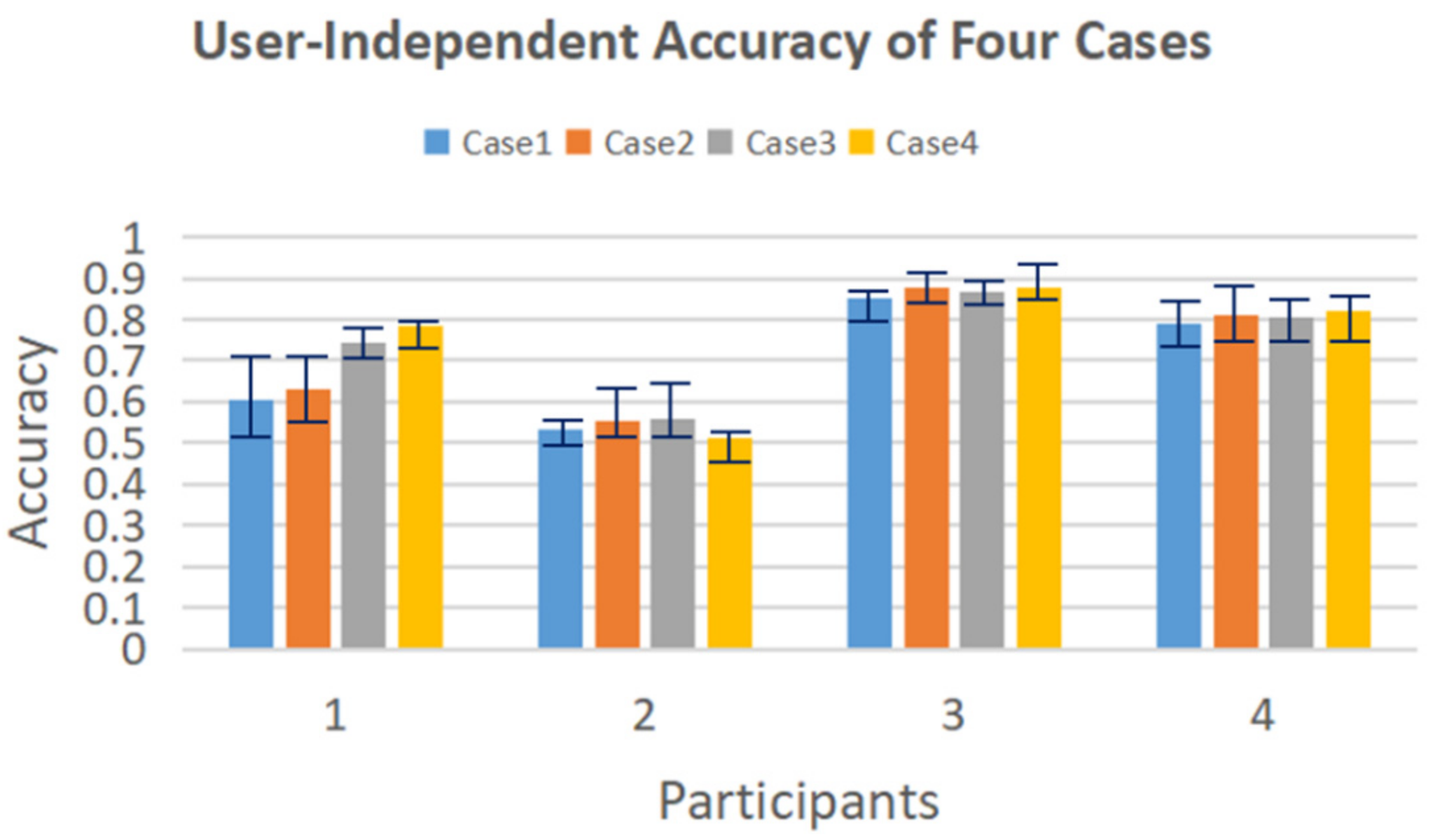
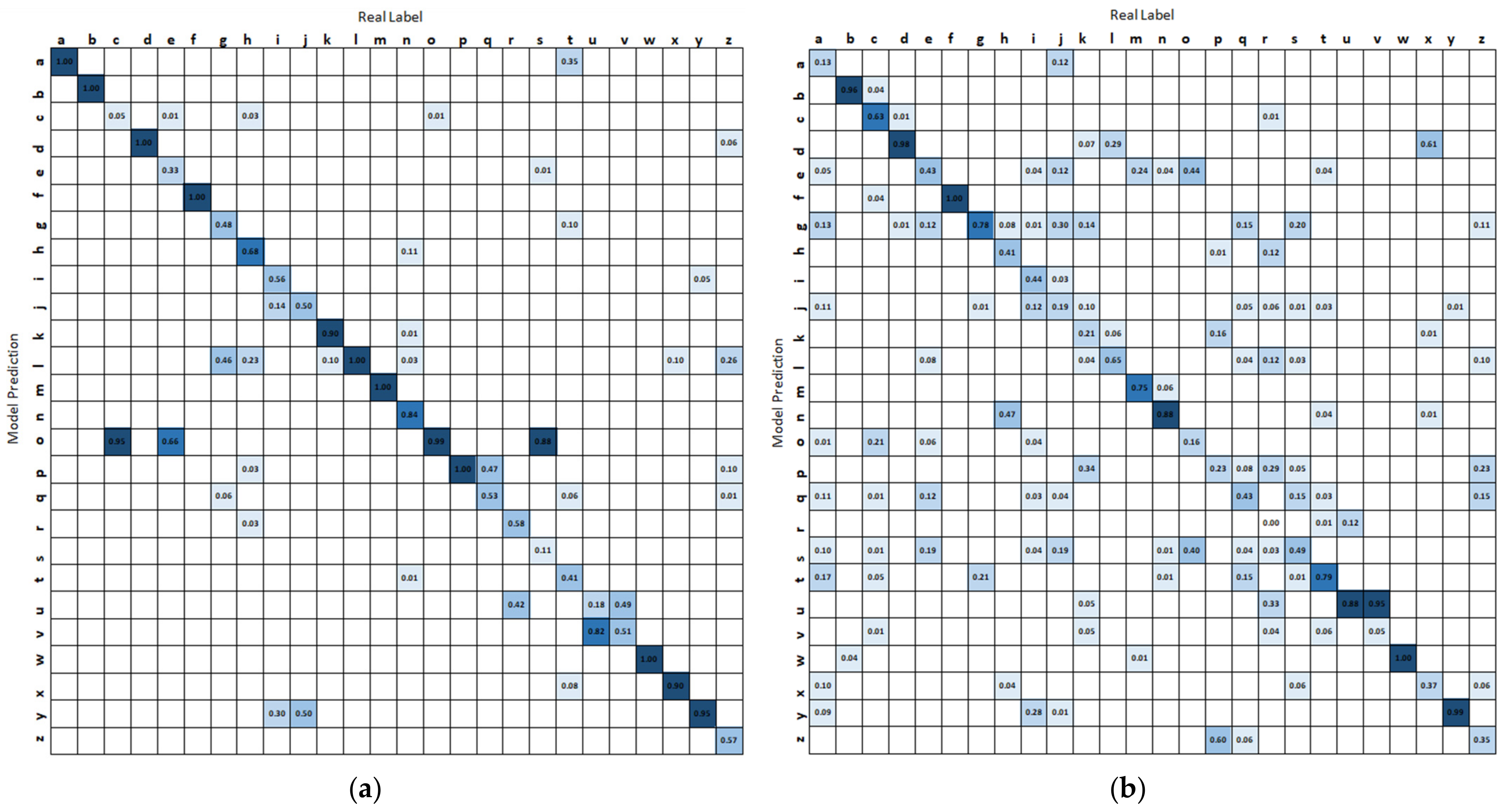
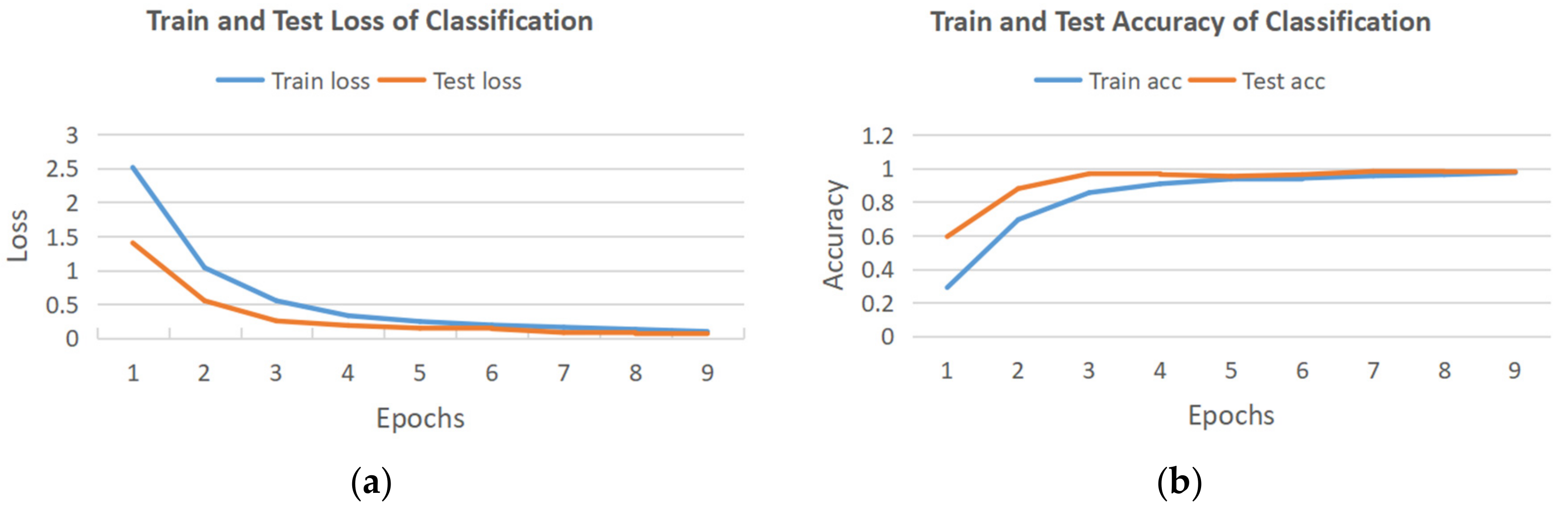
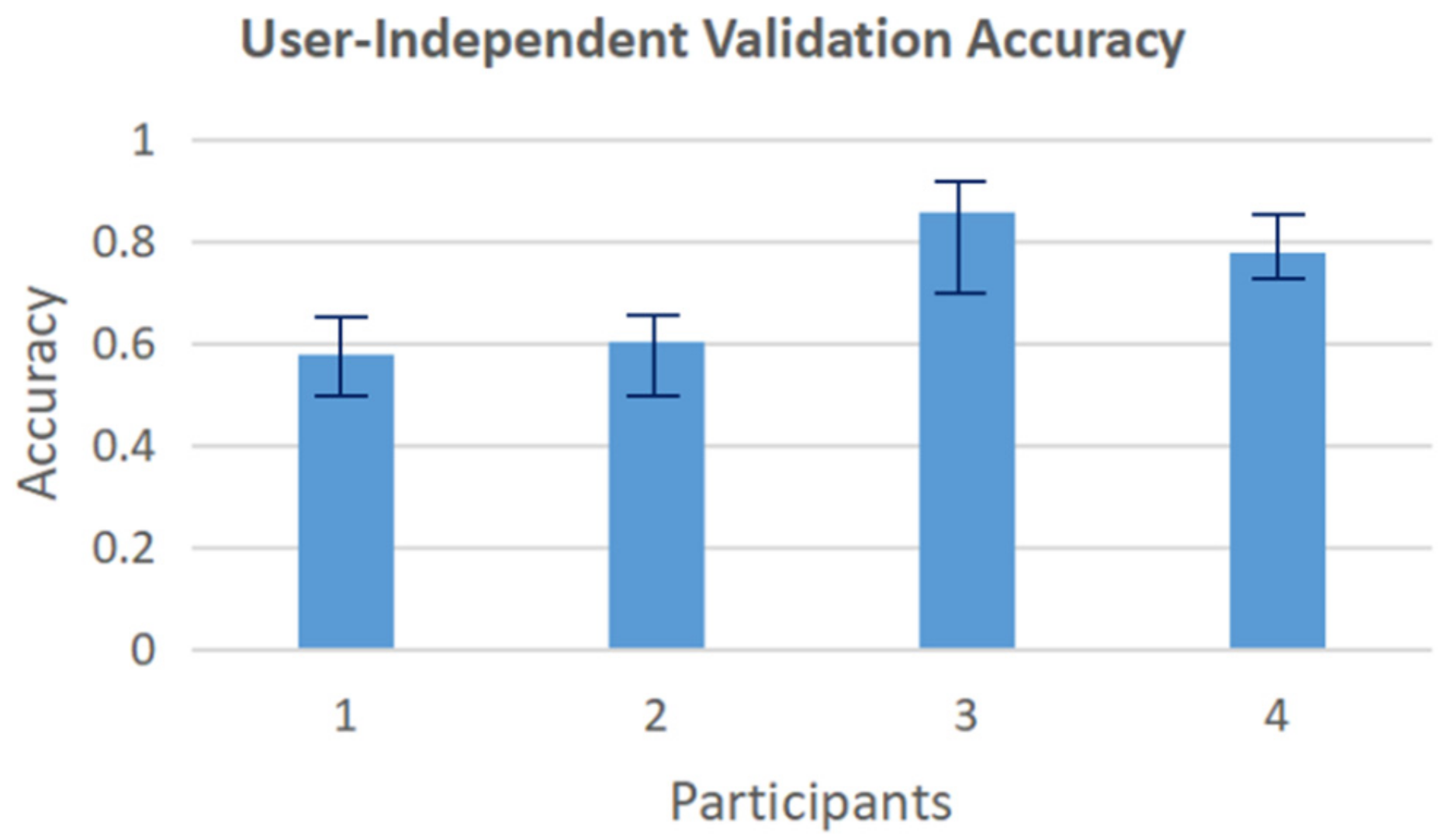
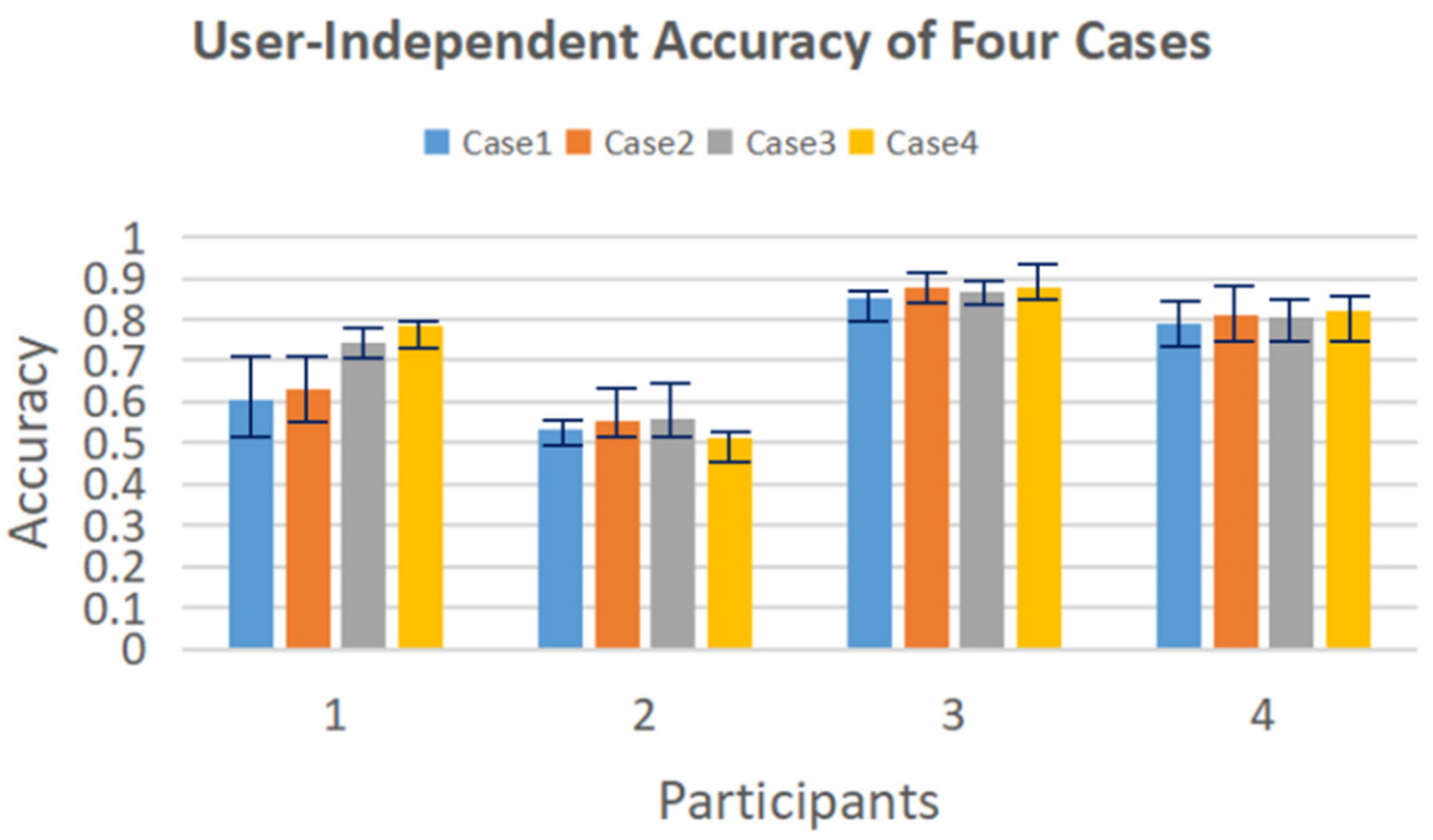
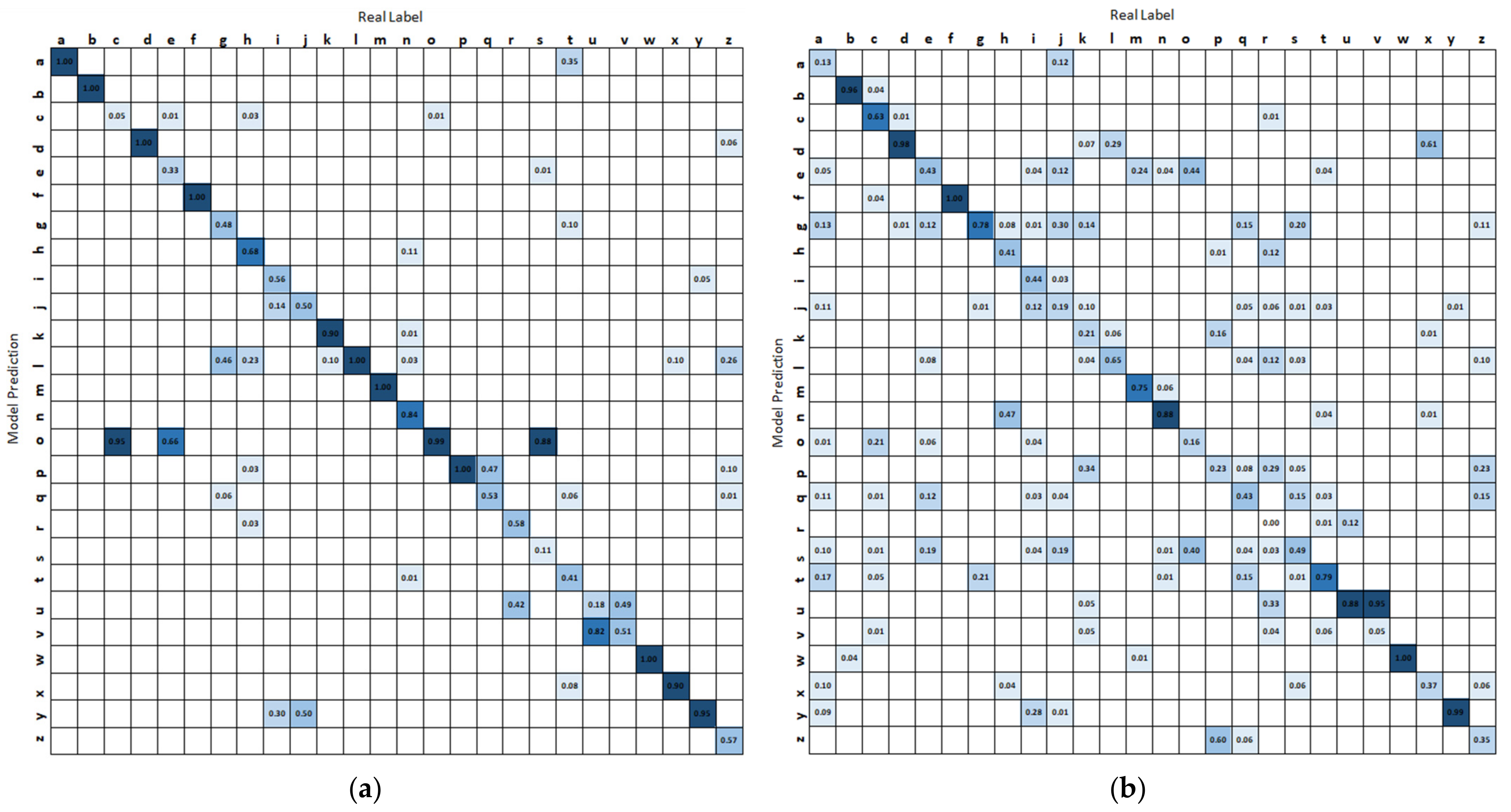
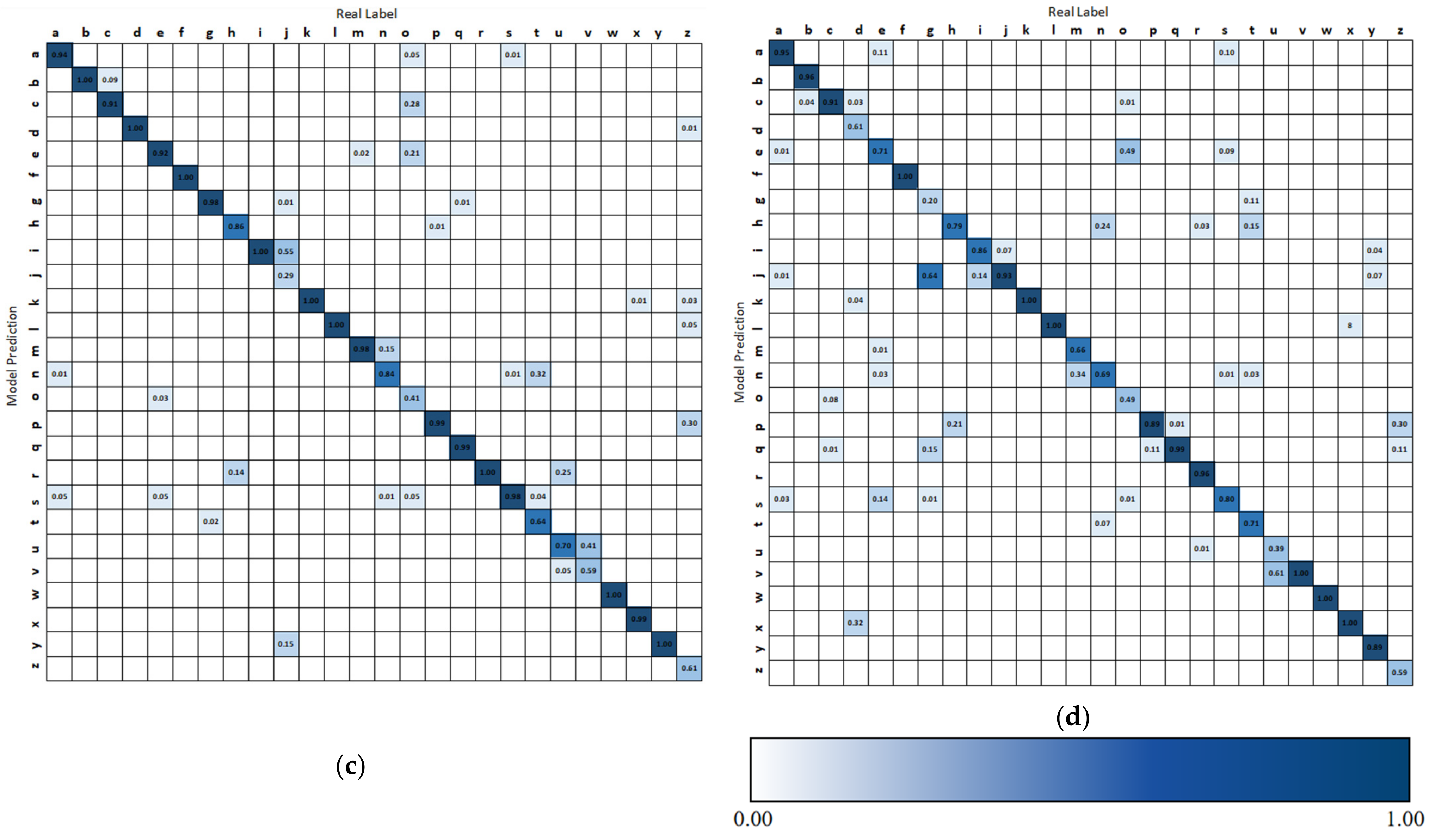
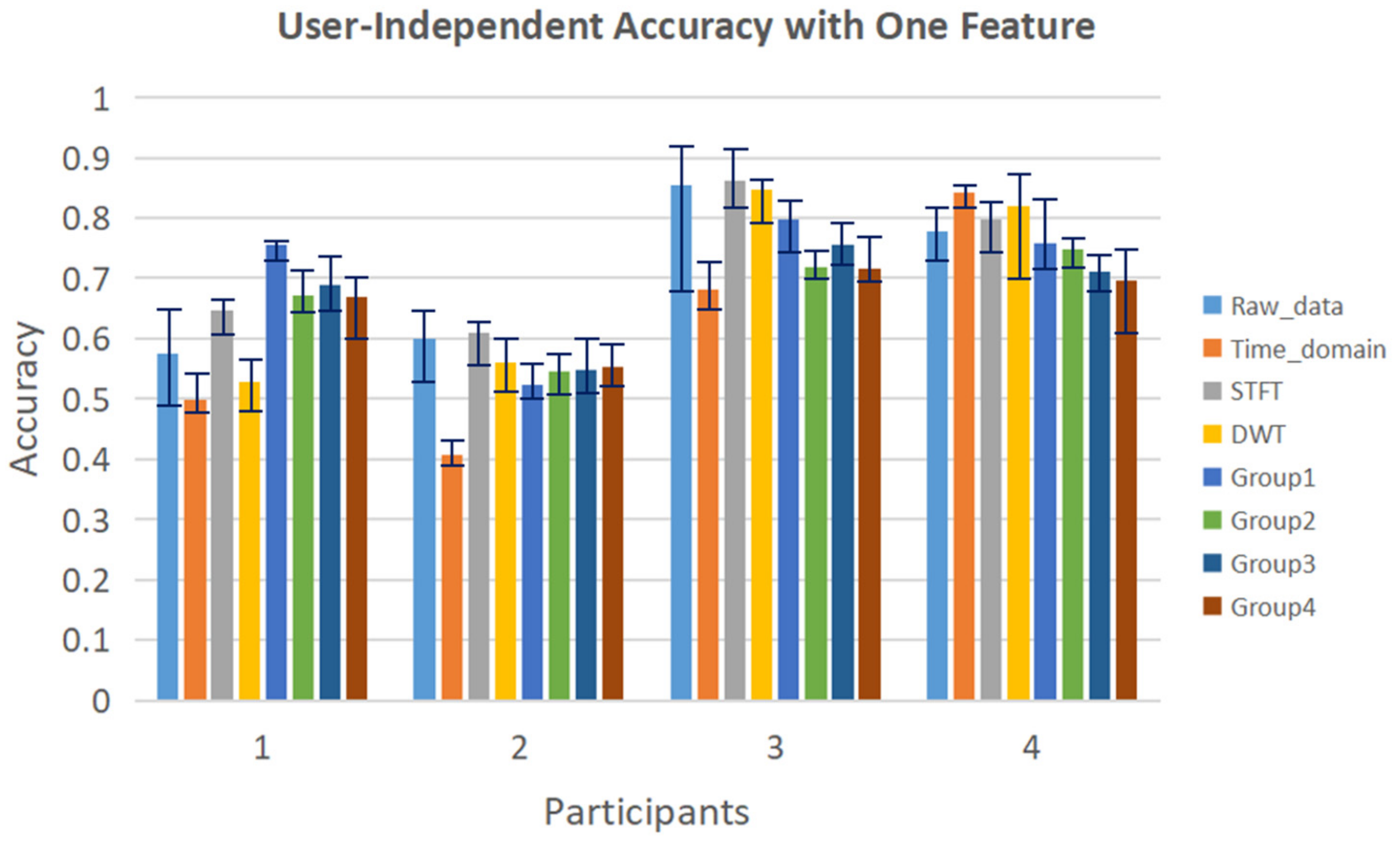
3.1. Isolated Hand Gesture Recognition
- Case 1: Input: time and time-frequency domain features; Model: early fusion model.
- Case 2: Input: time and time-frequency domain features; Model: late fusion model.
- Case 3: Input: four groups of differences in R_Z between non-adjacent joints; Model: early fusion model.
- Case 4: Input: four groups of differences in R_Z between non-adjacent joints; Model: late fusion model.
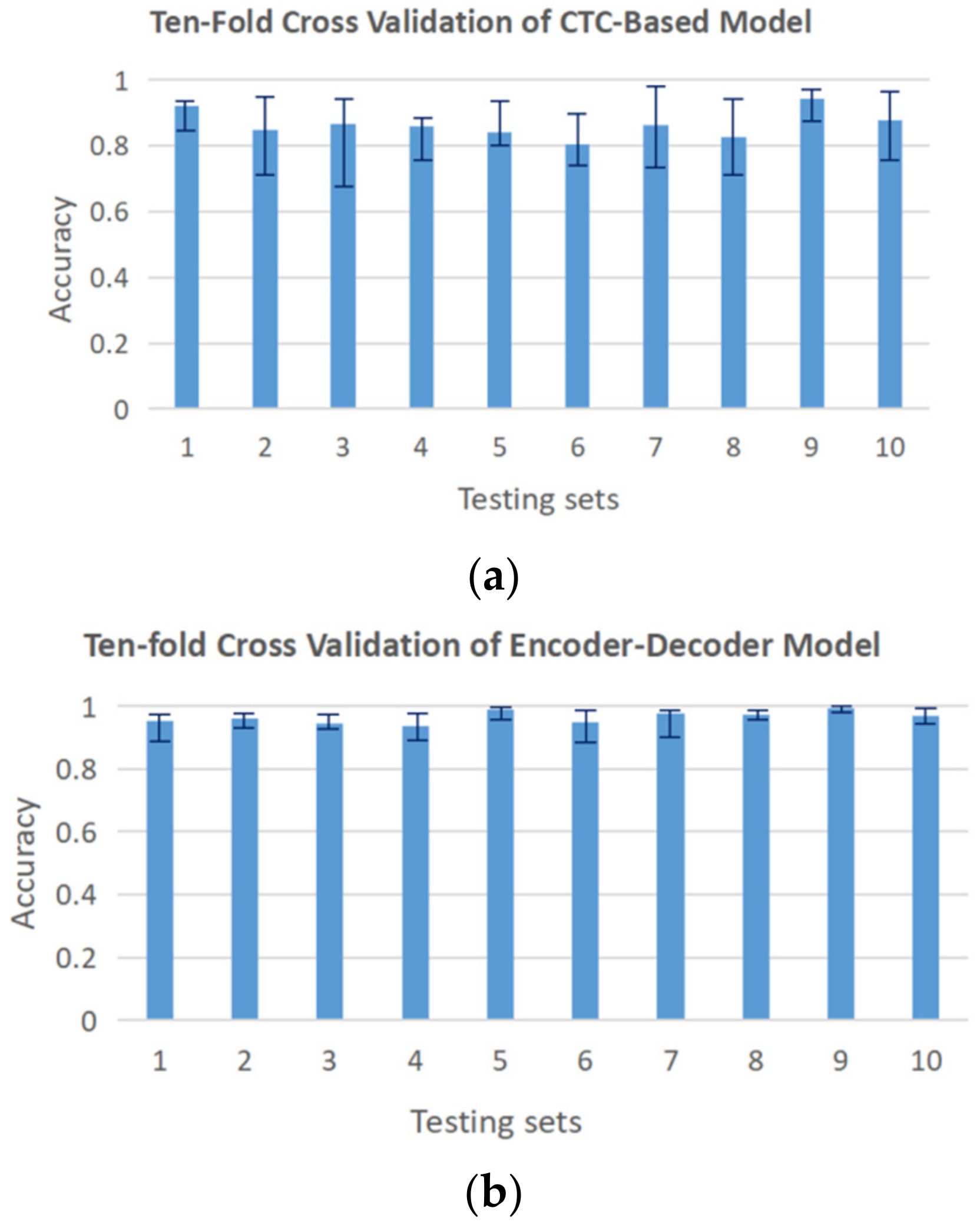
3.2. ASL Fingerspelling Results
4. Discussion
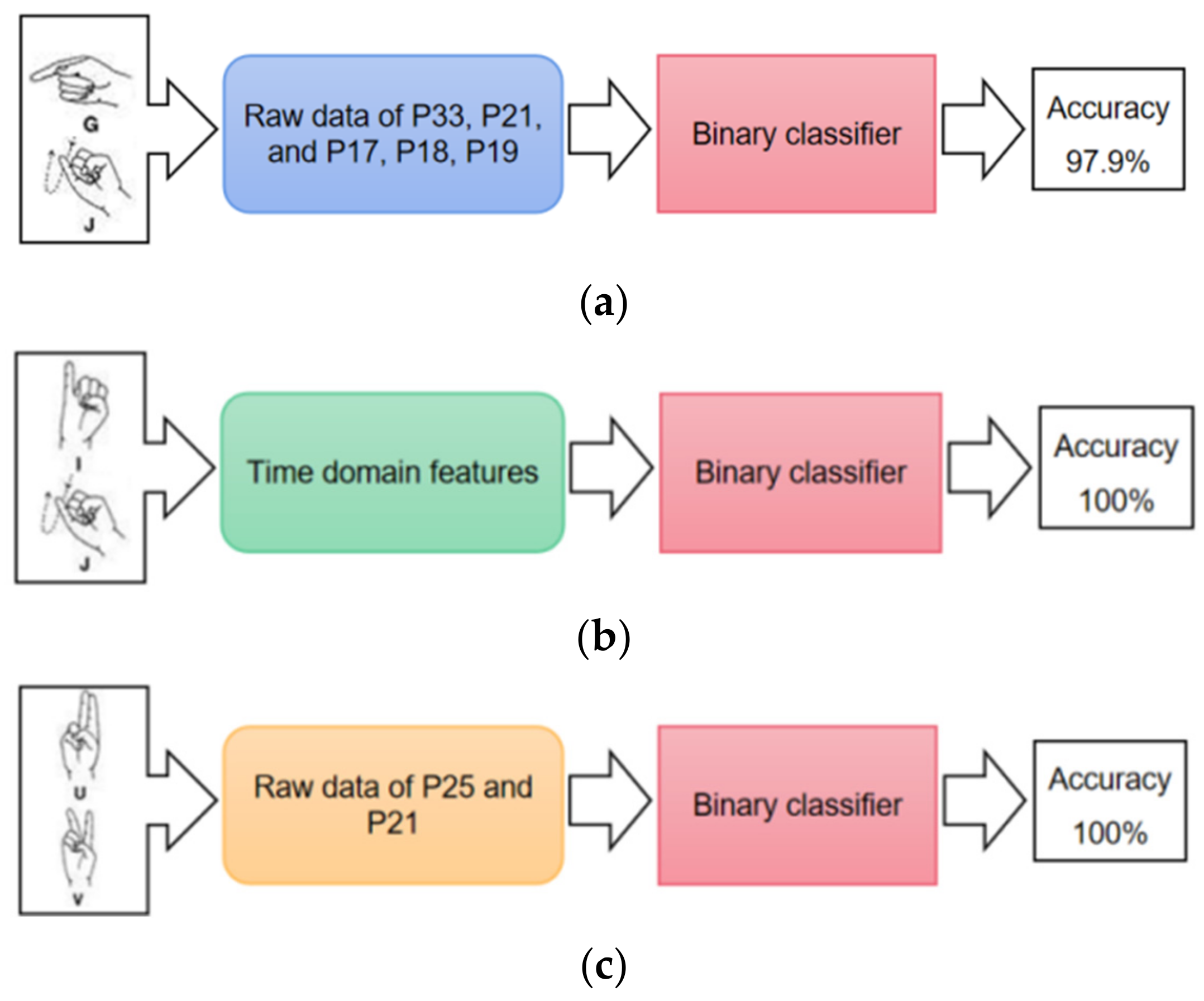
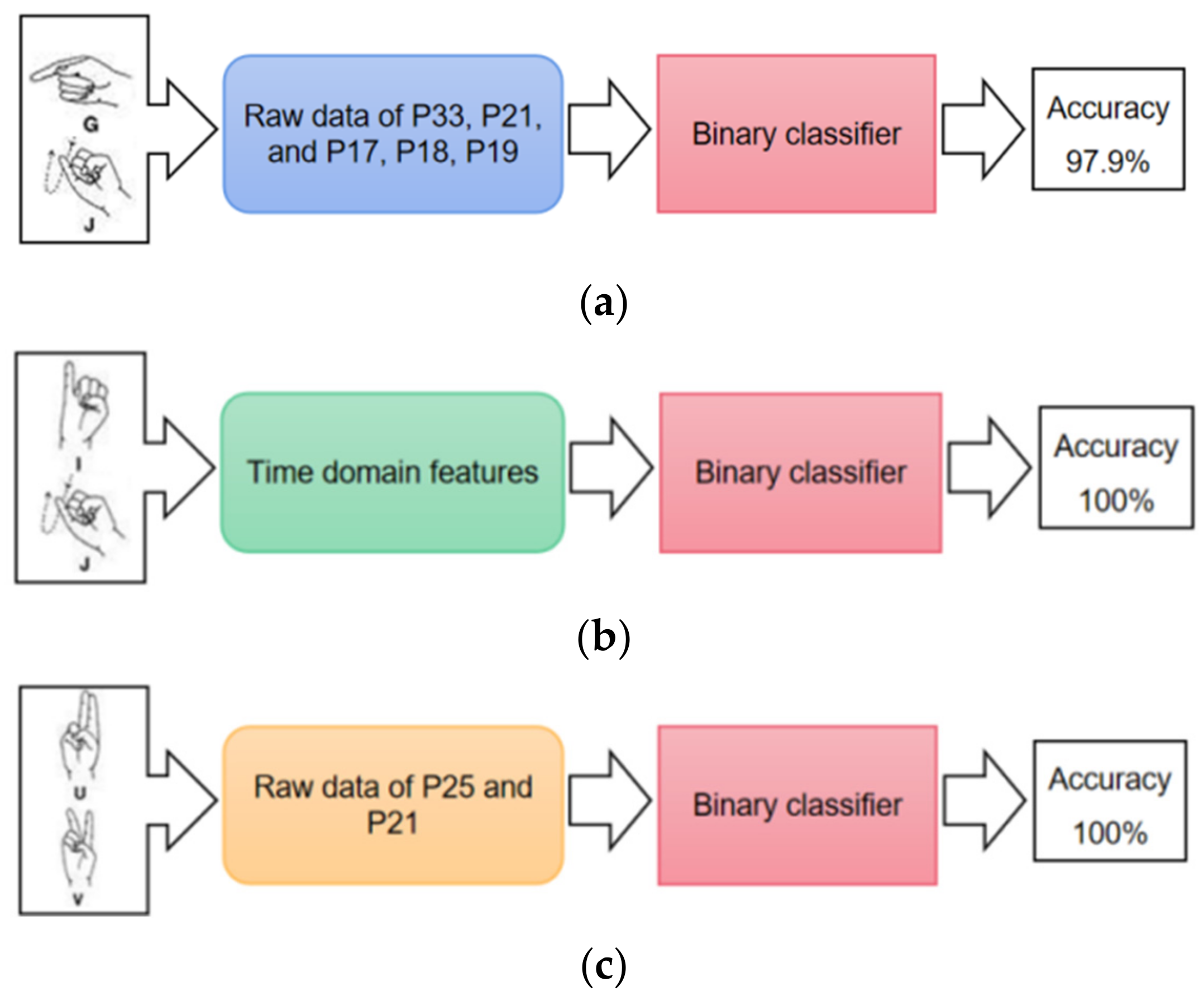
4.1. Binary Classification of Easily Confused Gestures
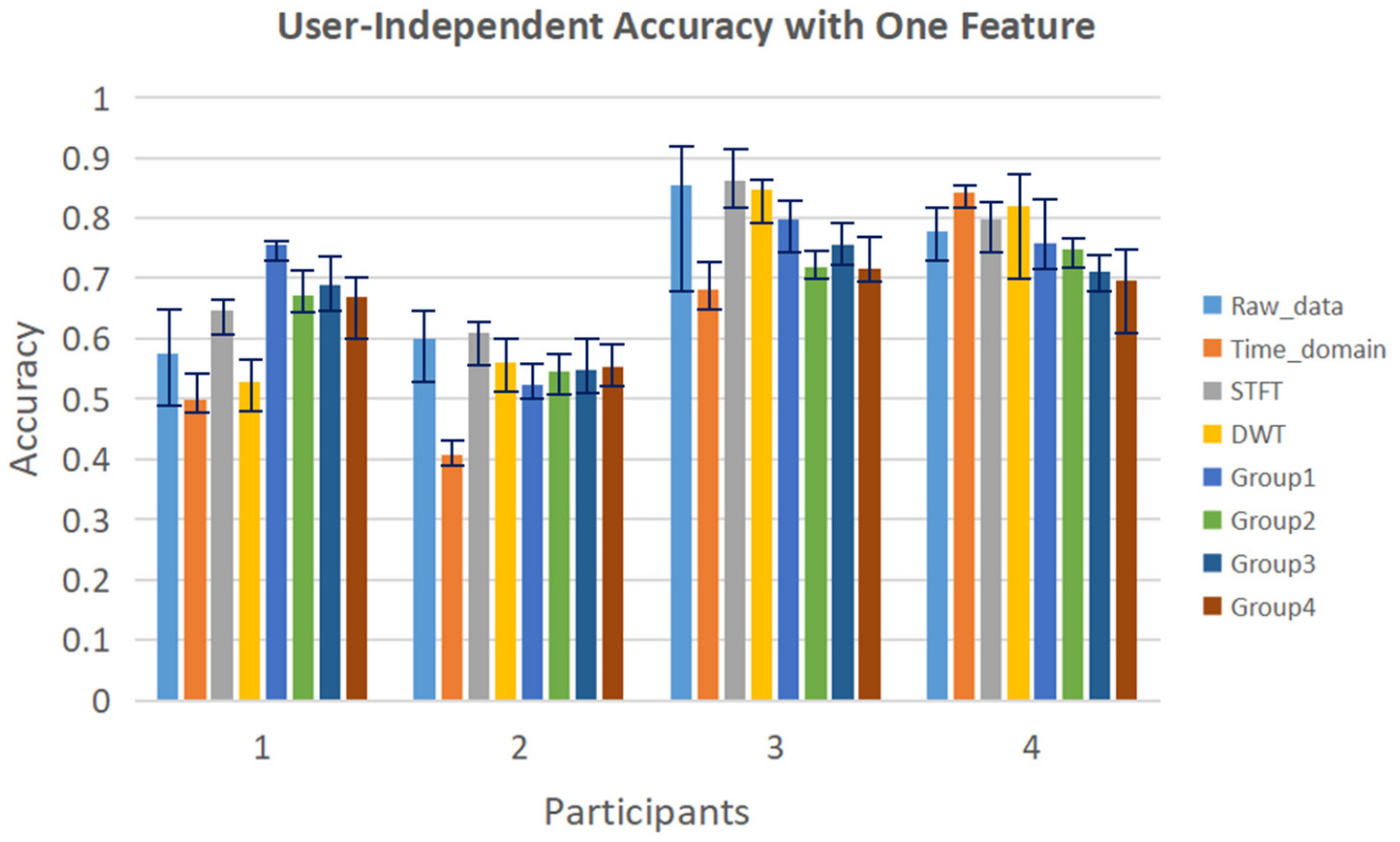
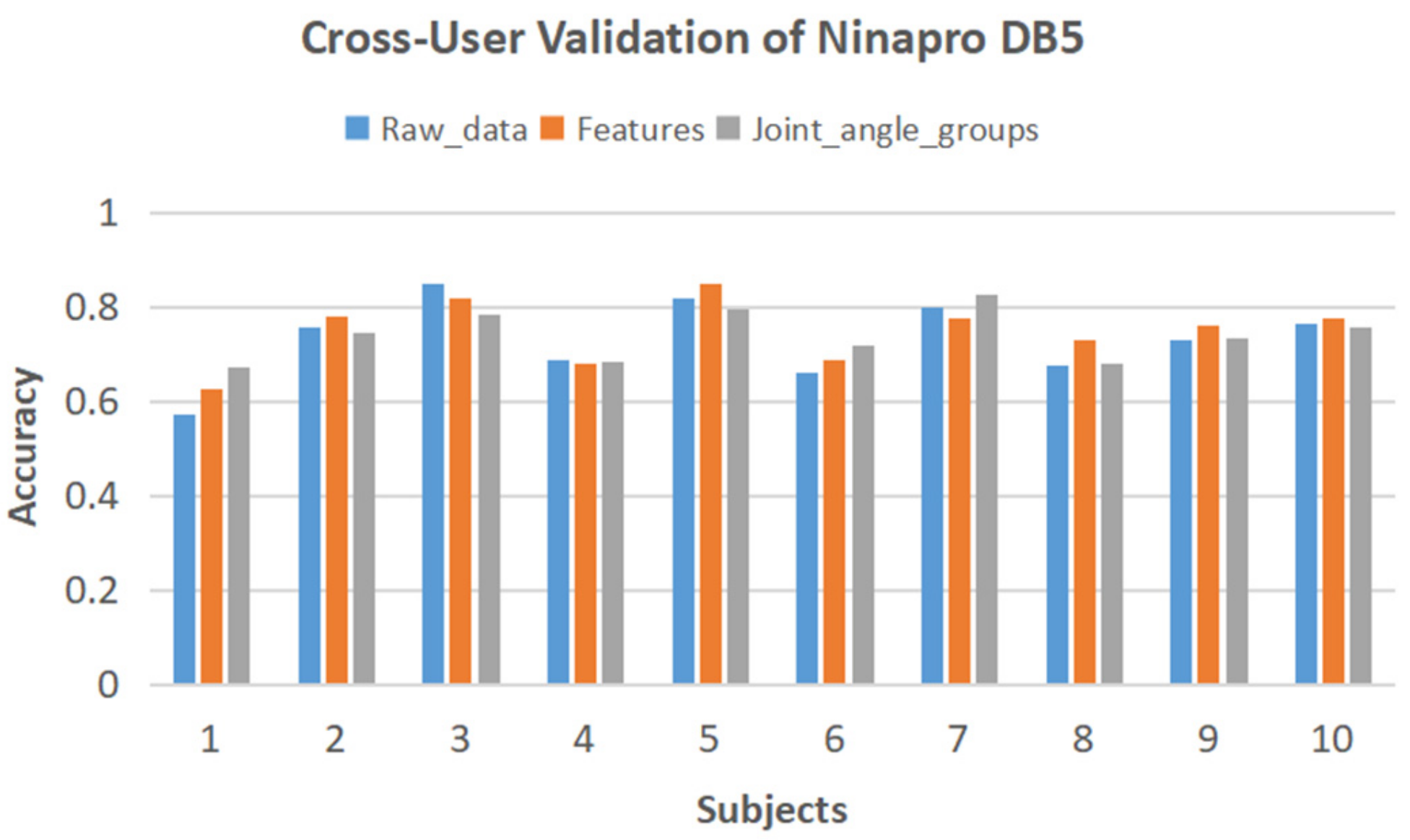
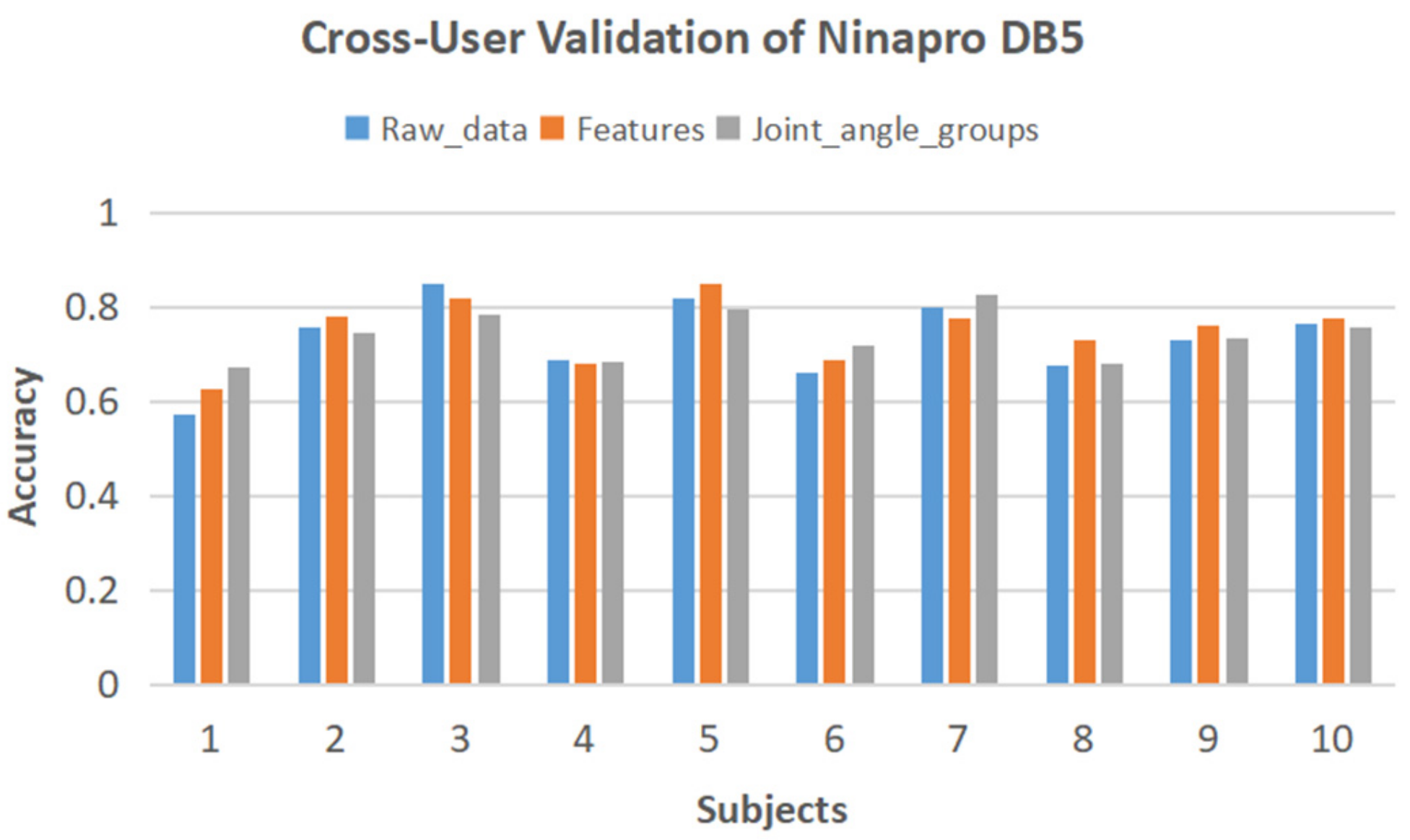
4.2. Application of the Proposed Method on Public Dataset
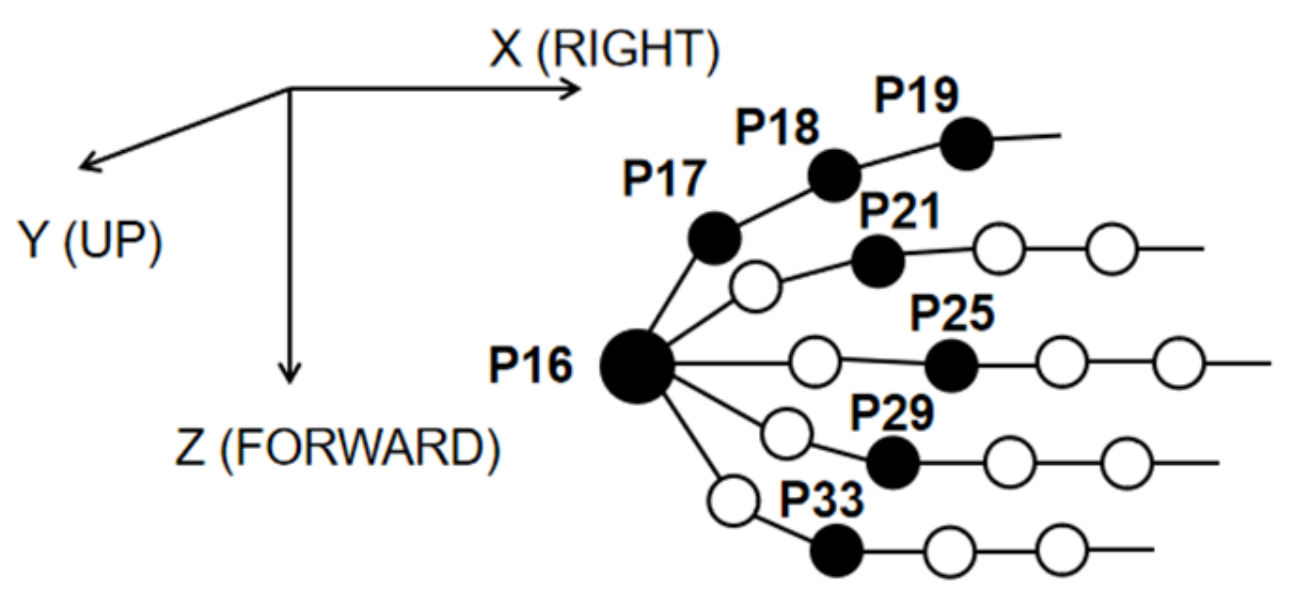
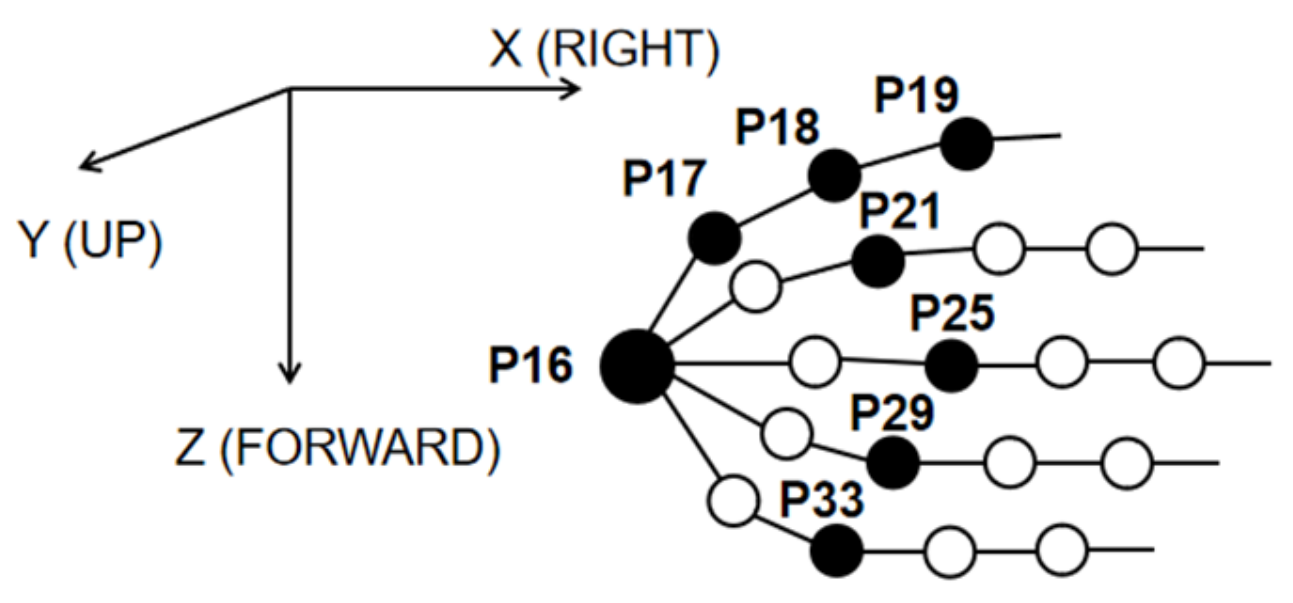
- Group 1: Angle differences in the direction of hand extension/flexion with P17 (Wrist joint) as the reference. {P2(Proximal end of thumb)–P17, P3(Distal end of thumb)–P17, P5(Proximal end of index finger)–P17, P6(Middle of index finger)–P17, P7(Proximal end of middle finger)–P17, P8(Middle of middle finger)–P17, P10(Proximal end of ring finger)–P17, P11(Middle of ring finger)–P17, P13(Proximal end of pinky finger)–P17, P14(Middle of pinky finger)–P17}
- Group 2: Sensors between the fingers. {P4(Sensor between thumb and index finger), P9(Sensor between index finger and middle finger), P12(Sensor between middle finger and ring finger), P15(Sensor between ring finger and pinky finger)}
- Group 3: Other sensors. {P1(Arch sensor in wrist), P16(Arch sensor in palm), P18(Wrist abduction sensor)}
4.3. Comparison of Results with Related Works
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Padden, C.A. The ASL lexicon. Sign Lang. Linguist. 1998, 1, 33–51. [Google Scholar] [CrossRef]
- Padden, C.A.; Gunsals, D.C. How the alphabet came to be used in a sign language. Sign Lang. Stud. 2003, 4, 10–13. [Google Scholar] [CrossRef]
- Bheda, V.; Radpour, D. Using deep convolutional networks for gesture recognition in american sign language. arXiv 2017, arXiv:1710.06836v3. [Google Scholar]
- Rivera-Acosta, M.; Ruiz-Varela, J.M.; Ortega-Cisneros, S.; Rivera, J.; Parra-Michel, R.; Mejia-Alvarez, P. Spelling correction real-time american sign language alphabet translation system based on yolo network and LSTM. Electronics 2021, 10, 1035. [Google Scholar] [CrossRef]
- Tao, W.; Leu, M.C.; Yin, Z. American Sign Language alphabet recognition using Convolutional Neural Networks with multiview augmentation and inference fusion. Eng. Appl. Artif. Intell. 2018, 76, 202–213. [Google Scholar] [CrossRef]
- Aly, W.; Aly, S.; Almotairi, S. User-independent american sign language alphabet recognition based on depth image and PCANet features. IEEE Access 2019, 7, 123138–123150. [Google Scholar] [CrossRef]
- Jalal, M.A.; Chen, R.; Moore, R.K.; Mihaylova, L. American sign language posture understanding with deep neural networks. In Proceedings of the 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 573–579. [Google Scholar]
- Kaggle. ASL Alphabet. Available online: https://www.kaggle.com/grassknoted/asl-alphabet (accessed on 18 September 2022).
- Ranga, V.; Yadav, N.; Garg, P. American sign language fingerspelling using hybrid discrete wavelet transform-gabor filter and convolutional neural network. J. Eng. Sci. Technol. 2018, 13, 2655–2669. [Google Scholar]
- Nguyen, H.B.; Do, H.N. Deep learning for american sign language fingerspelling recognition system. In Proceedings of the 26th International Conference on Telecommunications (ICT), Hanoi, Vietnam, 8–10 April 2019; pp. 314–318. [Google Scholar]
- Barczak, A.L.C.; Reyes, N.H.; Abastillas, M.; Piccio, A.; Susnjak, T. A new 2D static hand gesture colour image dataset for ASL gestures. Res. Lett. Inf. Math. Sci. 2011, 15, 12–20. [Google Scholar]
- Pugeault, N.; Bowden, R. Spelling it out: Real-time ASL fingerspelling recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1114–1119. [Google Scholar]
- Rajan, R.G.; Leo, M.J. American sign language alphabets recognition using hand crafted and deep learning features. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 430–434. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American sign language alphabet recognition by extracting feature from hand pose estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef] [PubMed]
- Thongtawee, A.; Pinsanoh, O.; Kitjaidure, Y. A novel feature extraction for American sign language recognition using webcam. In Proceedings of the 11th Biomedical Engineering International Conference (BMEiCON), Chiang Mai, Thailand, 21–24 November 2018; pp. 1–5. [Google Scholar]
- Chong, T.W.; Lee, B.G. American sign language recognition using leap motion controller with machine learning approach. Sensors 2018, 18, 3554. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dawod, A.Y.; Chakpitak, N. Novel technique for isolated sign language based on fingerspelling recognition. In Proceedings of the 13th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Island of Ulkulhas, Maldives, 26–28 August 2019; pp. 1–8. [Google Scholar]
- Paudyal, P.; Lee, J.; Banerjee, A.; Gupta, S.K. A comparison of techniques for sign language alphabet recognition using armband wearables. ACM Trans. Interact. Intell. Syst. 2019, 9, 1–26. [Google Scholar] [CrossRef]
- Hou, J.; Li, X.Y.; Zhu, P.; Wang, Z.; Wang, Y.; Qian, J.; Yang, P. Signspeaker: A real-time, high-precision smartwatch-based sign language translator. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–15. [Google Scholar]
- Saquib, N.; Rahman, A. Application of machine learning techniques for real-time sign language detection using wearable sensors. In Proceedings of the 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 8–11 June 2020; pp. 178–189. [Google Scholar]
- Rinalduzzi, M.; De Angelis, A.; Santoni, F.; Buchicchio, E.; Moschitta, A.; Carbone, P.; Serpelloni, M. Gesture recognition of sign language alphabet using a magnetic positioning system. Appl. Sci. 2021, 11, 5594. [Google Scholar] [CrossRef]
- Lee, B.G.; Chong, T.W.; Chung, W.Y. Sensor fusion of motion-based sign language interpretation with deep learning. Sensors 2020, 20, 6256. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Wang, X.; Kapoor, A.; Zhang, Z.; Pan, T.; Yu, Z. EIS: A wearable device for epidermal American sign language recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–22. [Google Scholar] [CrossRef]
- Shi, B.; Brentari, D.; Shakhnarovich, G.; Livescu, K. Fingerspelling Detection in American Sign Language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20-25 June 2021; pp. 4166–4175. [Google Scholar]
- Shi, B.; Del Rio, A.M.; Keane, J.; Michaux, J.; Brentari, D.; Shakhnarovich, G.; Livescu, K. American sign language fingerspelling recognition in the wild. In Proceedings of the IEEE Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 145–152. [Google Scholar]
- Shi, B.; Rio, A.M.D.; Keane, J.; Brentari, D.; Shakhnarovich, G.; Livescu, K. Fingerspelling recognition in the wild with iterative visual attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–02 November 2019; pp. 5400–5409. [Google Scholar]
- Perception Neuron Products. Available online: https://neuronmocap.com/perception-neuron-series (accessed on 18 September 2022).
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995; Volume 3361. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, New York, NY, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Pizzolato, S.; Tagliapietra, L.; Cognolato, M.; Reggiani, M.; Müller, H.; Atzori, M. Comparison of six electromyography acquisition setups on hand movement classification tasks. PLoS ONE 2017, 12, e0186132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- CyberGlove. Available online: https://ninapro.hevs.ch/DB7_Instructions (accessed on 29 October 2022).
- Ahmed, M.A.; Zaidan, B.B.; Zaidan, A.A.; Salih, M.M.; Al-Qaysi, Z.T.; Alamoodi, A.H. Based on wearable sensory device in 3D-printed humanoid: A new real-time sign language recognition system. Measurement 2021, 168, 108431. [Google Scholar] [CrossRef]
- Saggio, G.; Cavallo, P.; Ricci, M.; Errico, V.; Zea, J.; Benalcázar, M.E. Sign language recognition using wearable electronics: Implementing k-nearest neighbors with dynamic time warping and convolutional neural network algorithms. Sensors 2020, 20, 3879. [Google Scholar] [CrossRef] [PubMed]
- Alrubayi, A.H.; Ahmed, M.A.; Zaidan, A.A.; Albahri, A.S.; Zaidan, B.B.; Albahri, O.S.; Alazab, M. A pattern recognition model for static gestures in malaysian sign language based on machine learning techniques. Comput. Electr. Eng. 2021, 95, 107383. [Google Scholar] [CrossRef]
- Wu, J.; Sun, L.; Jafari, R. A wearable system for recognizing American sign language in real-time using IMU and surface EMG sensors. IEEE J. Biomed. Health Inform. 2016, 20, 1281–1290. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Joint Name | Coordinates Selection |
|---|---|
| P16: Right Hand | R_Y, R_X, R_Z |
| P17: Right Thumb 1 | R_Y, R_Z |
| P18: Right Thumb 2 | R_Y, R_Z |
| P19: Right Thumb 3 | R_Y |
| P21: Right Hand Index 1 | R_Z |
| P25: Right Hand Middle 1 | R_Z |
| P29: Right Hand Ring 1 | R_Z |
| P33: Right Hand Pinky 1 | R_Z |
| Group Name | Reference | Coordinates |
|---|---|---|
| Group 1 | P16: Right Hand | P33–P16, P29–P16, P25–P16, P21–P16, P19–P16, P18–P16 |
| Group 2 | P17: Right Thumb 1 | P33–P17, P29–P17, P25–P17, P21–P17 |
| Group 3 | P18: Right Thumb 2 | P33–P18, P29–P18, P25–P18, P21–P18 |
| Group 4 | Other non-adjacent joints | P33–P29, P33–P25, P33–P21, P29–P25, P29–P21, P25–P21 |
| time | person | year | way | day | thing |
| man | world | life | hand | part | child |
| eye | woman | place | work | case | point |
| company | number | group | problem | fact | be |
| have | do | say | get | make | go |
| know | take | come | think | want | give |
| use | find | ask | try | leave | new |
| first | last | long | great | own | other |
| old | right |
| Precision | Recall | F-1 Score | |
|---|---|---|---|
| Participant 1 | 0.800 | 0.788 | 0.761 |
| Participant 2 | 0.553 | 0.525 | 0.476 |
| Participant 3 | 0.886 | 0.881 | 0.870 |
| Participant 4 | 0.859 | 0.819 | 0.814 |
| Word-Level Accuracy | Letter-Level Accuracy | |
|---|---|---|
| CTC-based model | 55.1% | 86.5% |
| Encoder-decoder model | 93.4% | 97.9% |
| Raw Data | Time and Time-Frequency Domain Features | Groups of Joint-Angle Data |
|---|---|---|
| 90.2% | 91.0% | 91.8% |
| Reference | Signs | Sensors | Signers | Repetitions | Within-User Accuracy | Cross-User Accuracy |
|---|---|---|---|---|---|---|
| Saquib & Rahman [20] | 26 letters | Data glove | 5 | 10 | 96% | |
| Rinalduzzi et al. [21] | 24 letters | Magnetic sensors | 3 | 40 | 97% | |
| Lee et al. [22] | 27 words | IMU | 12 | 120 | 99.81% | |
| Zhu et al. [23] | 26 letters and 9 digits | Epidermal iontronic sensors | 8 | 10 | 99.6% | 76.1% |
| Ahmed et al. [33] | 24 letters | Data glove | 5 | 20 | 96% | |
| Saggio et al. [34] | 10 words | Data glove | 7 | 100 | 98% | |
| Alrubayi et al. [35] | 21 letters | Data glove | 4 | 25 | 99% | |
| Wu et al. [36] | 80 words | IMU & EMG | 4 | 75 | 96.16% | 40% |
| Proposed method | 26 letters | IMU | 4 | 20 | Nearly 100% | 74.8% |
| Proposed method on Ninapro DB5 | 52 hand movements | Data glove | 10 | 6 | 91.8% | 74.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Sherrine; Wei, W.; Li, X.; Yuan, J.; Todoh, M. American Sign Language Alphabet Recognition Using Inertial Motion Capture System with Deep Learning. Inventions 2022, 7, 112. https://doi.org/10.3390/inventions7040112
Gu Y, Sherrine, Wei W, Li X, Yuan J, Todoh M. American Sign Language Alphabet Recognition Using Inertial Motion Capture System with Deep Learning. Inventions. 2022; 7(4):112. https://doi.org/10.3390/inventions7040112
Chicago/Turabian StyleGu, Yutong, Sherrine, Weiyi Wei, Xinya Li, Jianan Yuan, and Masahiro Todoh. 2022. "American Sign Language Alphabet Recognition Using Inertial Motion Capture System with Deep Learning" Inventions 7, no. 4: 112. https://doi.org/10.3390/inventions7040112
APA StyleGu, Y., Sherrine, Wei, W., Li, X., Yuan, J., & Todoh, M. (2022). American Sign Language Alphabet Recognition Using Inertial Motion Capture System with Deep Learning. Inventions, 7(4), 112. https://doi.org/10.3390/inventions7040112