4.1. Deriving the Overall Approach
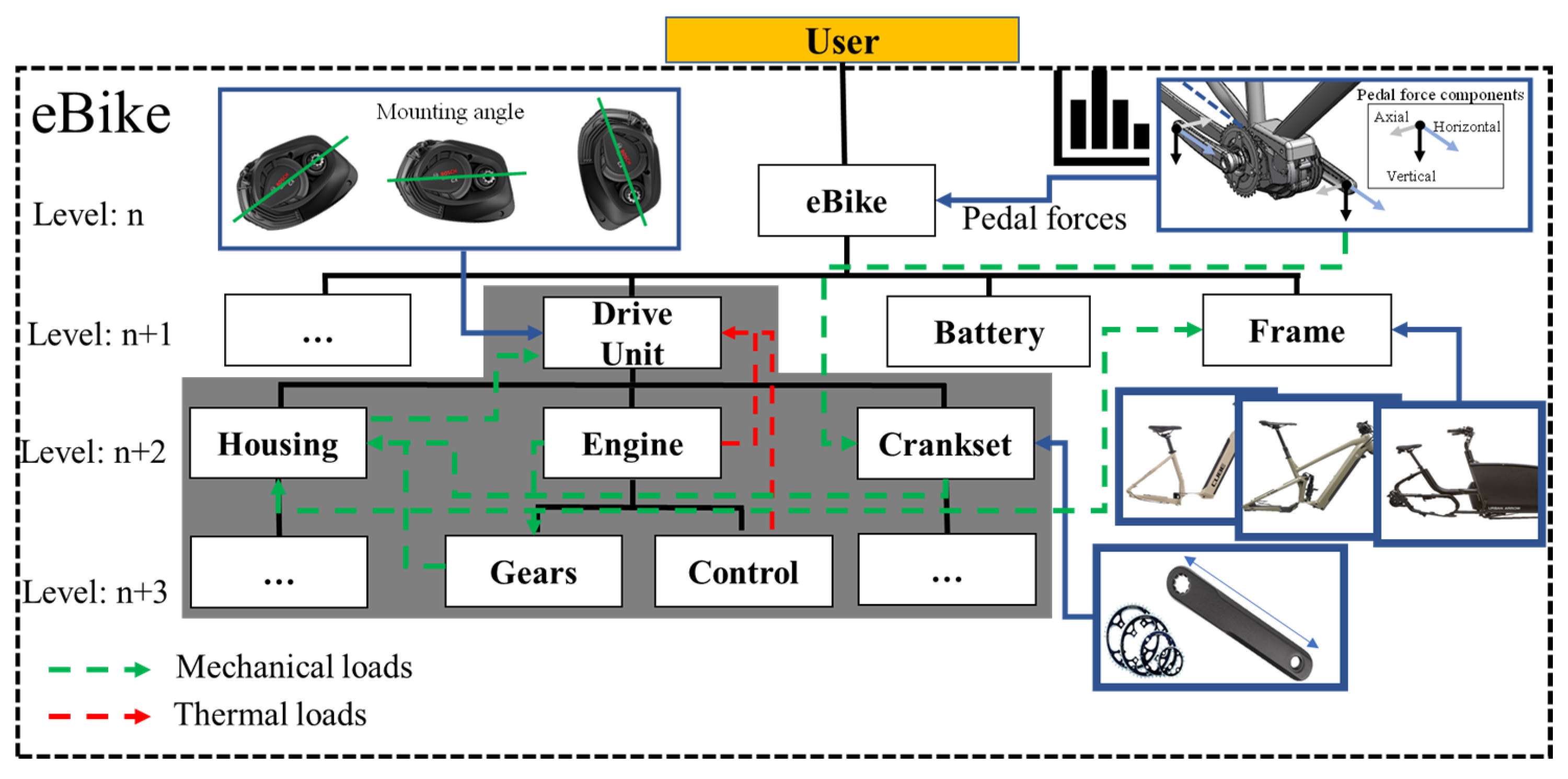
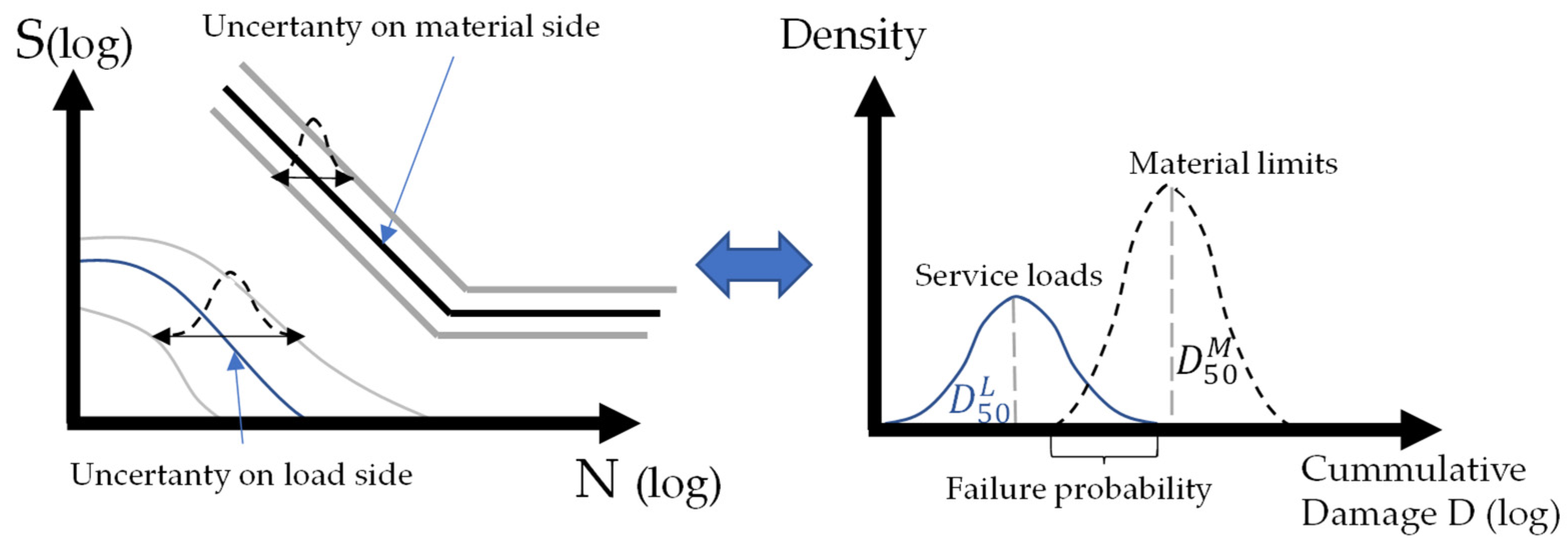
Based on the insights of the previous chapters, it can be stated that the Robust Design of a DU must consider the variance and noise of the load spectrum of both the external and internal DU loads, as well as the different system configurations of the eBike, consisting of its bicycle frame, the crank arrangement and the mounting angle. In Robust Design terminology, the load collective and manufacturing and assembly tolerances represent the noise and aleatory uncertainty and the topology of the housing represents the design parameters. The configurations of the eBike system constitute additional “system parameters”, like the frame or geometry data of the crankset, which must be varied to reduce epistemic uncertainties.
This necessity results in two potential optimization approaches. On the one hand, in order to meet the demand of the bicycle industry to install the DU as a standard component, the optimization of the design parameters can aim at reducing the impact of the noise parameters (or ensuring component safety) for as many system configurations as possible or for all system configurations. On the other hand, this necessity also opens up a new perspective wherein the system parameters can be restricted in order to find an optimal DU for a certain category of system parameters, e.g., based on the bicycle type. In the process, any objective can be selected for optimization, as can be seen in Formulas (2) and (3) below. Typical examples may include minimizing the component weight or dimensions and the product or manufacturing costs. However, as this paper is related to the formation of a probabilistic fatigue constraint, the objective function will not be discussed further. With regard to the targeted fatigue constraint, for each of the two approaches, the existing aleatory uncertainty regarding the diversity of static and rider-dependent dynamic loads must be considered to ensure component reliability.
Using differently sampled load sequences for each load channel, a certain failure probability can be determined across all assessed locations under consideration.
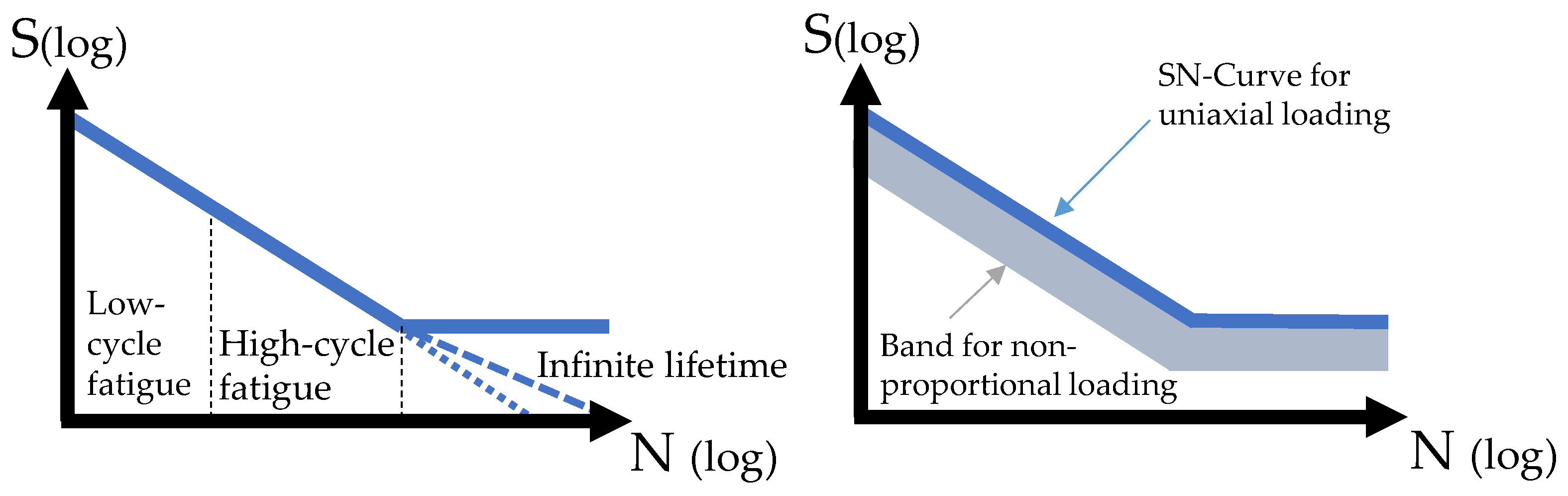
For the eBike DU, the objective is a design in the high-cycle fatigue range of the SN curve similar to the existing norm, which already defines the limit-state function for the fatigue constraint focused on the required service life of the DU. This constraint can be described by a fatigue calculation based on the damage accumulation in a local concept of a selected load sequence and the given design and system parameters. According to Formula (1), a limit for the fatigue constraint corresponding to the accumulated damage can be assumed from a damage sum of 1. The optimization problem can thus be formulated as follows:
with
F = objective function describing, e.g., the component weight, manufacturing costs, etc.
= matrix of sampled load sequences for each load channel according to the desired runtime
= vector of design variables according to the required application (e.g., bike type)
= vector of system variables according to the required application
f = scalar-valued safety factor
= damage accumulation
= vector of the failure probability for the assessed location
= constraint for the tolerated failure probability
To convert this constraint of the service-life requirement into a suitable calculation chain for the evaluation of the limit-state function, the following must be considered with regard to the current state of research (see
Section 2) on fatigue calculation:
Due to the complex geometry, the use of FEM methods is mandatory to evaluate the limit-state function based on fatigue lifetime.
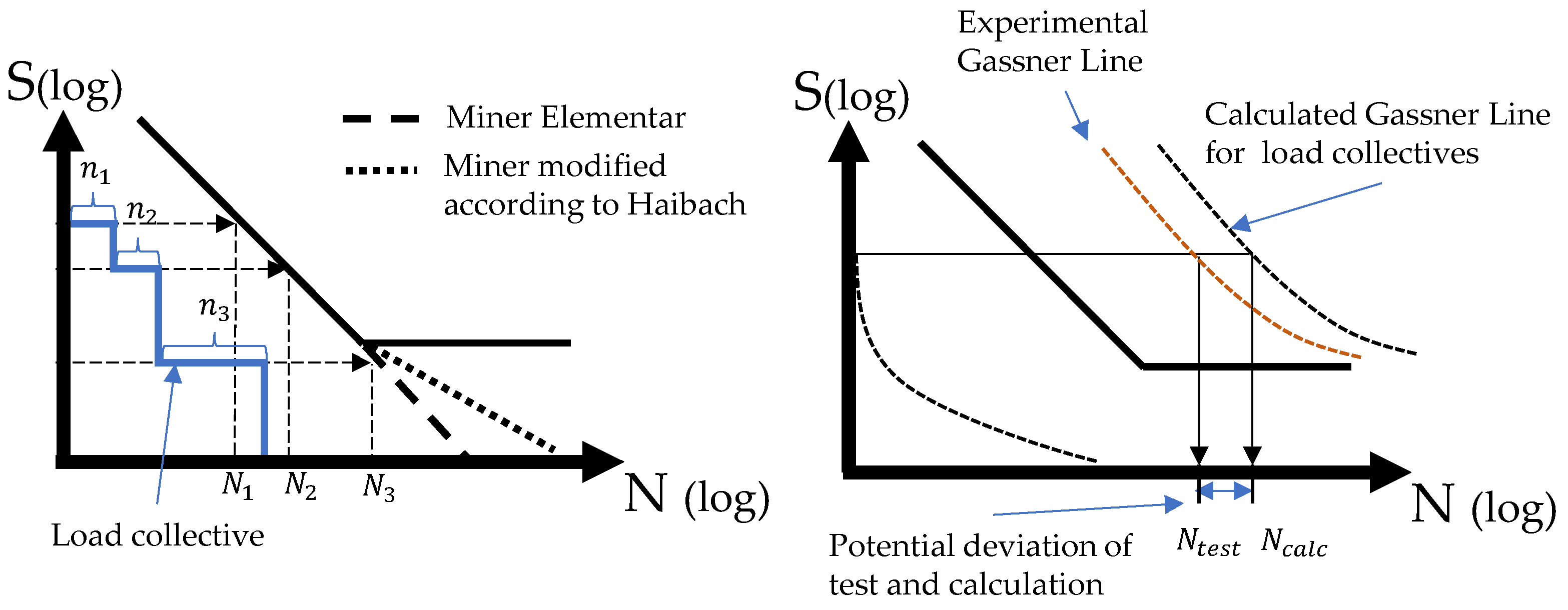
The fatigue calculation must be conducted in a cyclic and time-based calculation of realistic load collectives to address the effect of damage accumulation for the fatigue behavior.
The variance of the effective damage in relation to various load-collective compositions associated with different riders and riding situations must be determined to derive the failure probability.
The information about the correlation of the different load channels already acquired by measurement can be taken into account in order to characterize the real driving load more precisely.
As detailed measurements of the potential loading on the DU are already available, these loads should be considered to form potential load collectives for the fatigue assessment.
The multi-axial and simultaneously acting load channels, in combination with different static loads and the complex geometry, imply that a multi-axial and non-proportional load case must be expected at many local areas.
A stress-based approach based on the critical planes must be applied with respect to the HCF area in order to perform a suitable fatigue calculation.
No general static stress- or strain-based constraints, like those common in examples of RBDO and especially in FORM methods [
15,
16,
56,
57], can be applied in service-life calculation. This conclusion arises from the fact that the proper evaluation of reliability must be treated as time-dependent regarding both the calculation of equivalent stress amplitudes for multiaxial non-proportional load cycles and the damage accumulation of potential load collectives.
The geometry of the DU housing must be evaluated by multiple local-concept fatigue calculations because no clear critical area and most-likely failure point can be defined prior to the investigation.
Due to the complexity of the eBike DU and the necessity of an accurate fatigue estimation to avoid overly conservative or, worse, unsafe designs, the focus of this paper is on the inner loop of the fatigue calculation. This necessity of a detailed fatigue calculation can be derived from the fact that an uncertainty quantification and a Robust Design approach are not feasible if an unknown error and uncertainty in the fatigue calculation are tolerated by a simplified calculation of the target variable.
Based on the previously defined requirements, a methodical approach for the calculation of fatigue damage based on a simulation and sample-based method, a collective of load time sequences and a critical plane approach can be derived. A sample-based RBDO methodology (see
Section 2.2.2) was chosen because of the indisputable necessity of numerical FE simulation, the evaluation of multiple potential failure domains across the geometry and the requirement to evaluate a broadly distributed load collective instead of a single critical load combination. In the process, different load collectives must be formed by sampling techniques regardless of the methodology used.
Instead of the commonly used sampling methods based on statistical variation of individual load-channel amplitudes, samples are taken directly from the measured load sequences, wherein the correlation of each load cycle is already defined. On the one hand, this approach reduces the dimensions to be sampled from many load channels to one cycle, which makes it easier to estimate a representative sample number. On the other hand, unrealistic combinations of load channels and load-time sequences can be avoided, as the already-acquired correlations of the individual load channels are used, not discarded. Additionally, this variation across riders and riding scenarios enables a more explainable evaluation of the fatigue constraint and thus a bicycle-type-oriented design optimization.
To avoid inefficient MC sampling of all the measured load sequences, classifications of the ratio-load channels, the maximum pedal force or torque amplitude can be used to perform space-filling sampling techniques. These classifications can also depend on information about the measured driving situation or the rider, which may yield more interpretable results and the possibility of assessing different riding scenarios.
A probabilistic evaluation can then be obtained by calculating the equivalent stress amplitude for multiple load time sequences of crank cycles from different riding situations, bicycles and riders. In that way, the division into clearly defined sequences of pedal cycles can be seen as a natural separation of the load-time signal, without implementing further cycle-counting procedures. This approach directly enables fatigue calculation for different collectives of these cycles according to the linear damage accumulation.
For this subsequent step, it is crucial to assign the obtained equivalent stress amplitudes to a realistic frequency distribution reflecting the riding behavior. An incorrect frequency assignment will lead to over- or under-dimensioning in the probabilistic evaluation.
This step is decisive, as the main purpose of the existing measurements (
Section 3.1) was to predominantly cover higher-loaded sequences. Therefore, finding a reference to realistic frequency values and the probability of occurrence of the more severe load cycles in the field application is highly relevant to generating a realistic fatigue calculation.
This reference value can be obtained from the maximum occurring torque over one pedal cycle, which is recorded by the DU control, thus delivering a representative distribution. Hence, the equivalent stress amplitudes of the sampled and measured crankshaft revolutions can be assigned to their respective frequencies, considering their maximum torques to account for them in a probabilistic fatigue-damage or service-life calculation. The resulting two-dimensional distribution of the potential stress amplitude and its probability of occurrence can further be used for the probabilistic evaluation of the fatigue constraint.
However, for the simulation-based time-based evaluation and calculation of these crank cycles, enormous computing capacities are required. This requirement suggests the need to use surrogate models. In such models, the majority of the computational cost is devoted to the FEM calculation to determine the stress tensor across the time sequence, while a relatively small proportion is required for the calculation of the damage criterion and the critical-planes method.
This use of the surrogate model is supported by the comparatively low computation time of the critical-plane model and the fact that a direct prediction of the surrogate model for the damage of different load cycles and the underlying load time histories for a multi-axial load case is difficult to realize. The reasons for this difficulty lie in the quantity and variety of possible load signals, which are both difficult to parameterize or categorize, and also have far too different properties to allow for training with reasonable effort.
For this reason, the surrogate model should serve as a regressor that can predict or interpolate the local stress-tensor values according to the sampled design, eBike system and load parameters. In this way, the surrogate model delivers the local stress-tensor components of all observed areas of the DU housing for a defined quasi-static load and parameter combination. This approach makes it possible to obtain the sequence of local stress tensors for the fatigue calculation of an arbitrary discretized load-time sequence. The reasons for this approach lie in the quantity and variety of possible load channels, which are both difficult to parameterize or categorize and also have far too many different properties to allow for training with reasonable effort. Thus, by starting with high initial computational effort for the adequate sampling of the selected parameter space and the training and validation of the surrogate model, a regressor can be defined that allows the efficient computation of many load-time sequences due to the extremely low computational effort required for each additional sequence. To further increase the efficiency of the whole approach, the basic but high-fidelity FEM model, as well as the initial parameter space that is used for the calculation of the sample points and the generation of the training data, is subjected to further order reductions. The focus is thus on projective methods that minimize the number of input dimensions in the model. This approach brings the advantages of faster computation time and the ability to compute more sample points to generate a better-performing data-based surrogate model in the same time period. Such a model is crucial if new training data for a new product geometry must be calculated repeatedly in an iterative optimization. On the other hand, this initial dimension reduction generally also increases the efficiency of the data-based surrogate model, as it is (given the same amount of training data) more capable of interpolating between a few dimensions with many expressions than between many dimensions with only one or a few expressions. This difference arises due to the curse of multidimensionality and the exponentially increasing distances between the used samples.
To calculate this fatigue constraint in a local concept across the whole geometry, it is crucial to discretize the complex housing geometry and to evaluate the relevant and critical local areas in separate calculations of the local cumulative damage distribution. This approach is necessary because the enormous diversity of the load spectrum and changes in design and system parameters make it impossible to identify the most critical point in advance of the presented fatigue assessment.
Regarding this discretization, the question naturally arises as to in which steps the geometry must be divided to avoid the disadvantages of a too-large loss of information in an almost global evaluation, as well as the excessive calculation effort required for a very fine grid. Concerning the surrogate-model approach, this discretization offers the possibility of data reduction via a gradient-based clustering procedure to minimize the number of locations for which the surrogate model has to be trained. In summary, the requirements for the computational method consist of computationally efficient simulation and a surrogate model, as well as reasonable discretization and the data structure of the input and output data. In addition, these calculation processes and data evaluations must be implemented with the maximum degree of automation.
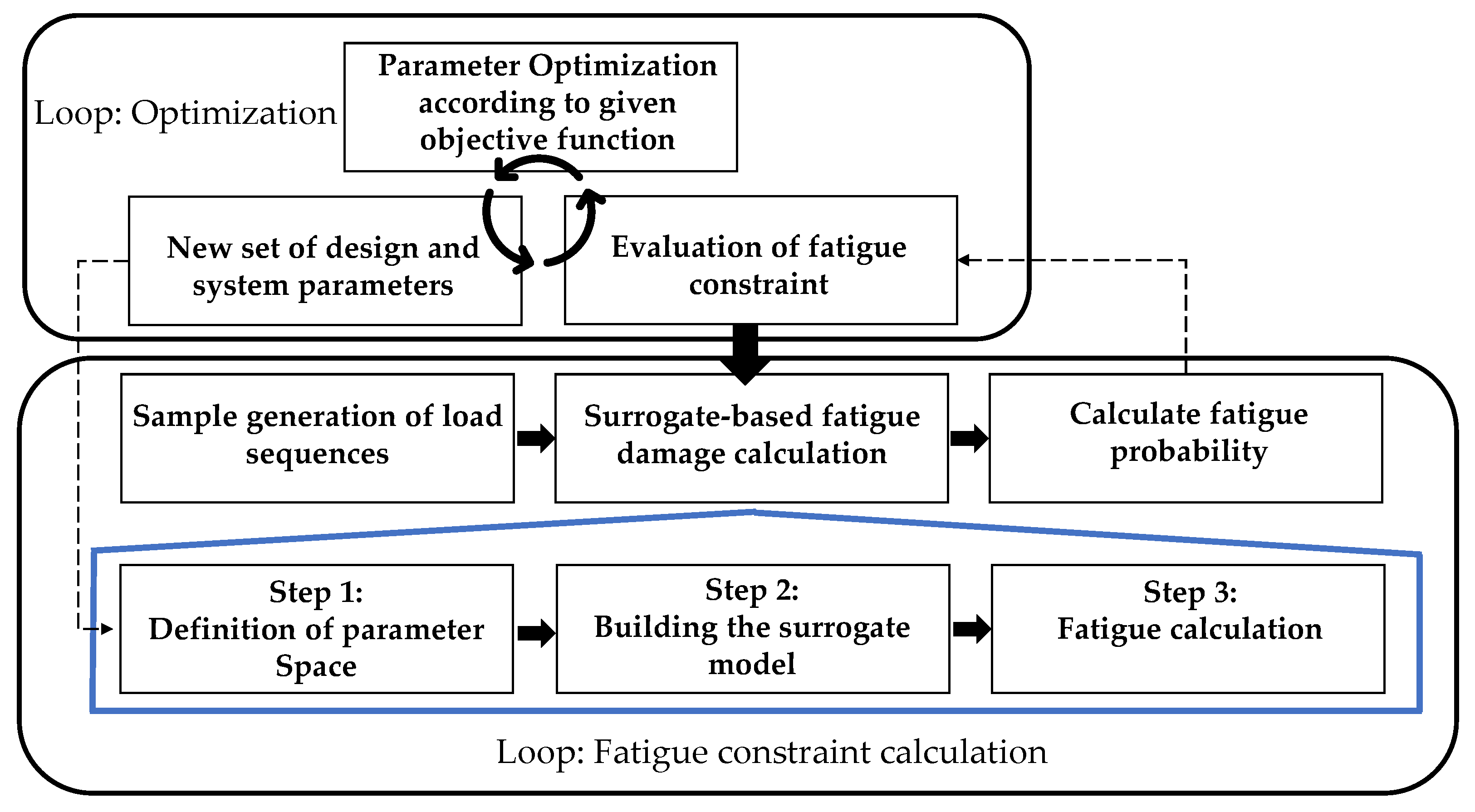
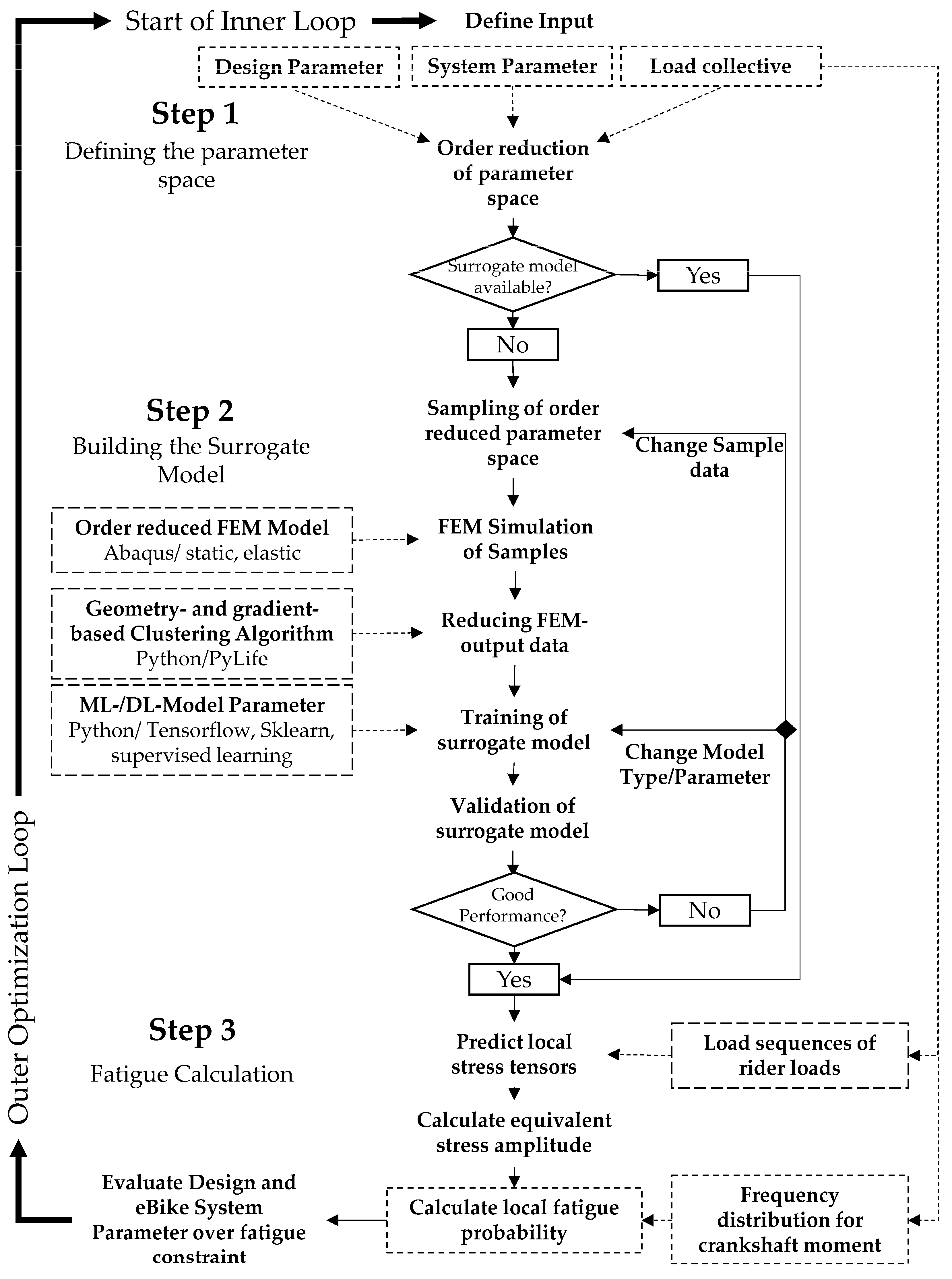
Overall, this necessity leads to a double-looped optimization approach wherein the inner loop calculates the fatigue probability, incorporating the variance in the load collective, and the outer loop is a deterministic parameter optimization of the system and design parameters that can be conducted, e.g., by an evolutionary optimization algorithm and a given objective function. This approach can be seen in
Figure 16. A more detailed overview of the proposed procedure and the central topic of the surrogate-based fatigue calculation can be seen in
Figure 17. Across the following sections, the individual areas of this methodical procedure and their application to the eBike case study will be addressed in detail.
4.2. Defining the Parameter Space
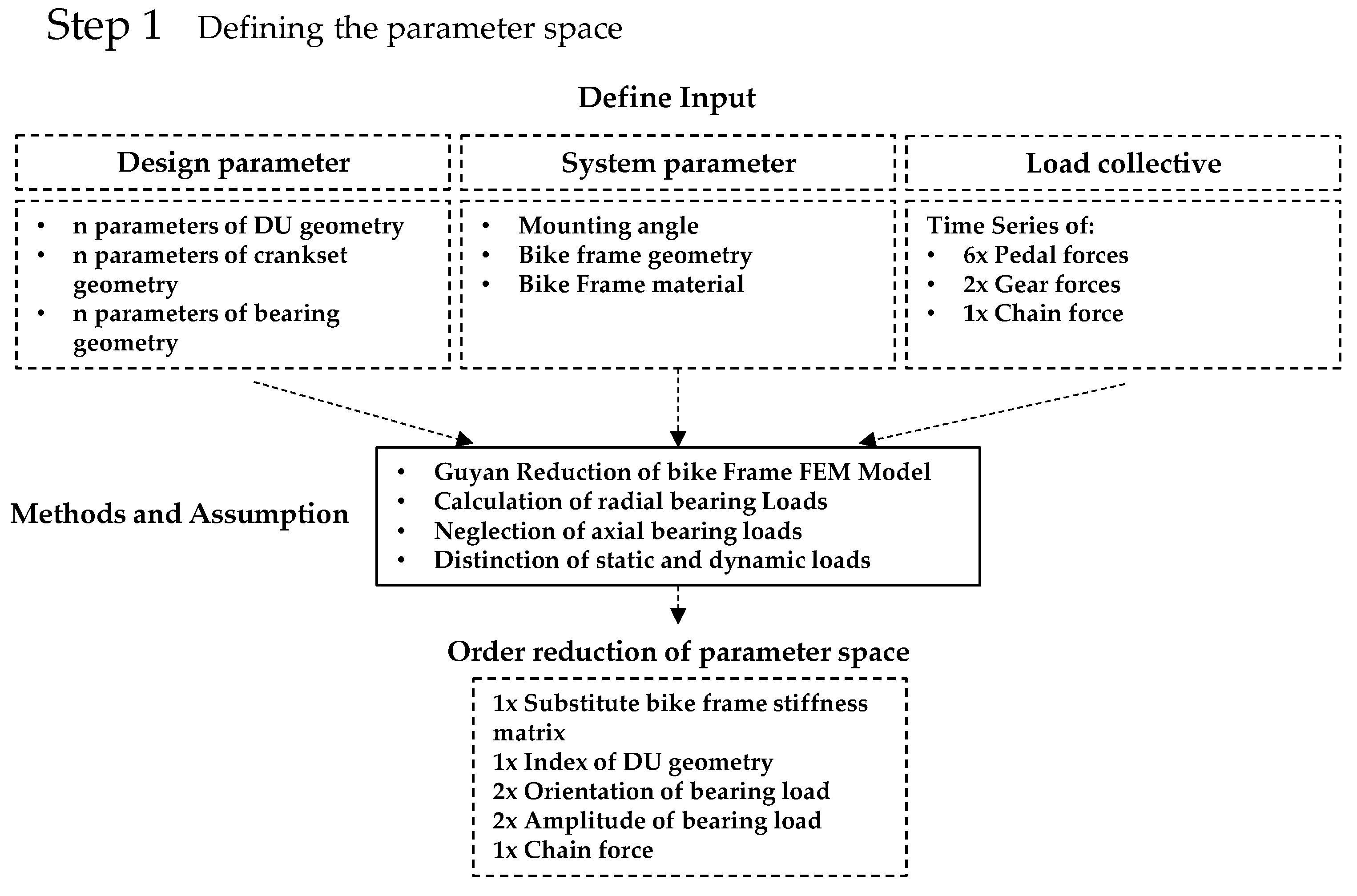
To avoid the curse of dimensionality and thus the need for an enormously increased amount of sample data, the parameter space for the generation of the training sample and the resulting surrogate model should be reduced as much as possible. To achieve this reduction of the input dimensions within the eBike system, substitute variables were identified inside the DU sub-system that can be described by a mathematical function and the combination of multiple input parameters without the loss of relevant information. To identify these variables, the top-down and bottom-up relationships between the individual components were investigated in a system analysis of the eBike system. The results of this analysis revealed that many relevant influences can be mapped via the stiffness at the frame interface and the resulting bearing load of the DU. With regard to the load and fatigue calculation, further dimension reductions can be achieved by separating the static and dynamic loads. The result is lower-dimension input.
A general overview of the eBike parameters and their dimensional reduction is shown in
Figure 18. The applied methods and assumptions are further described below.
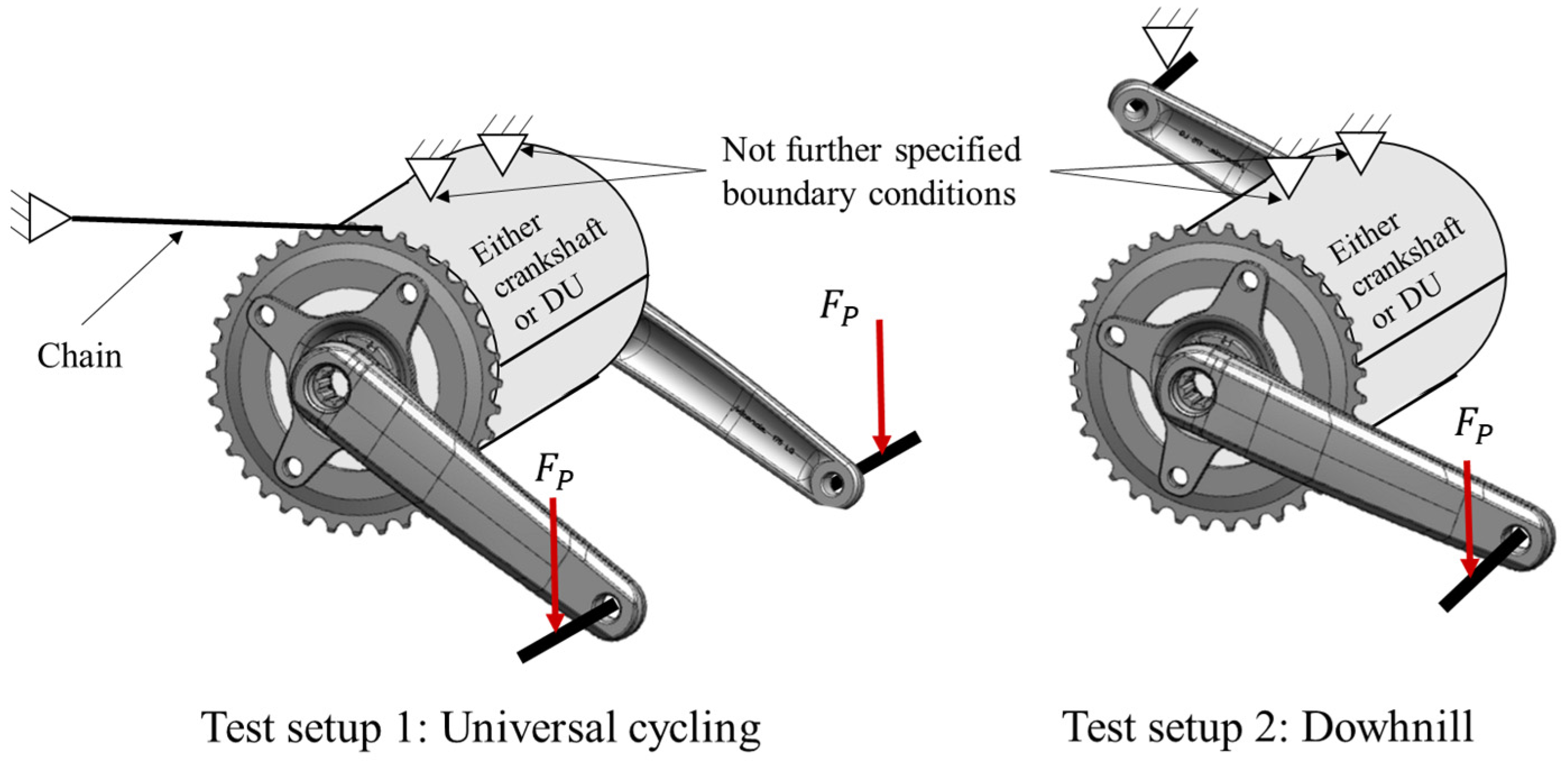
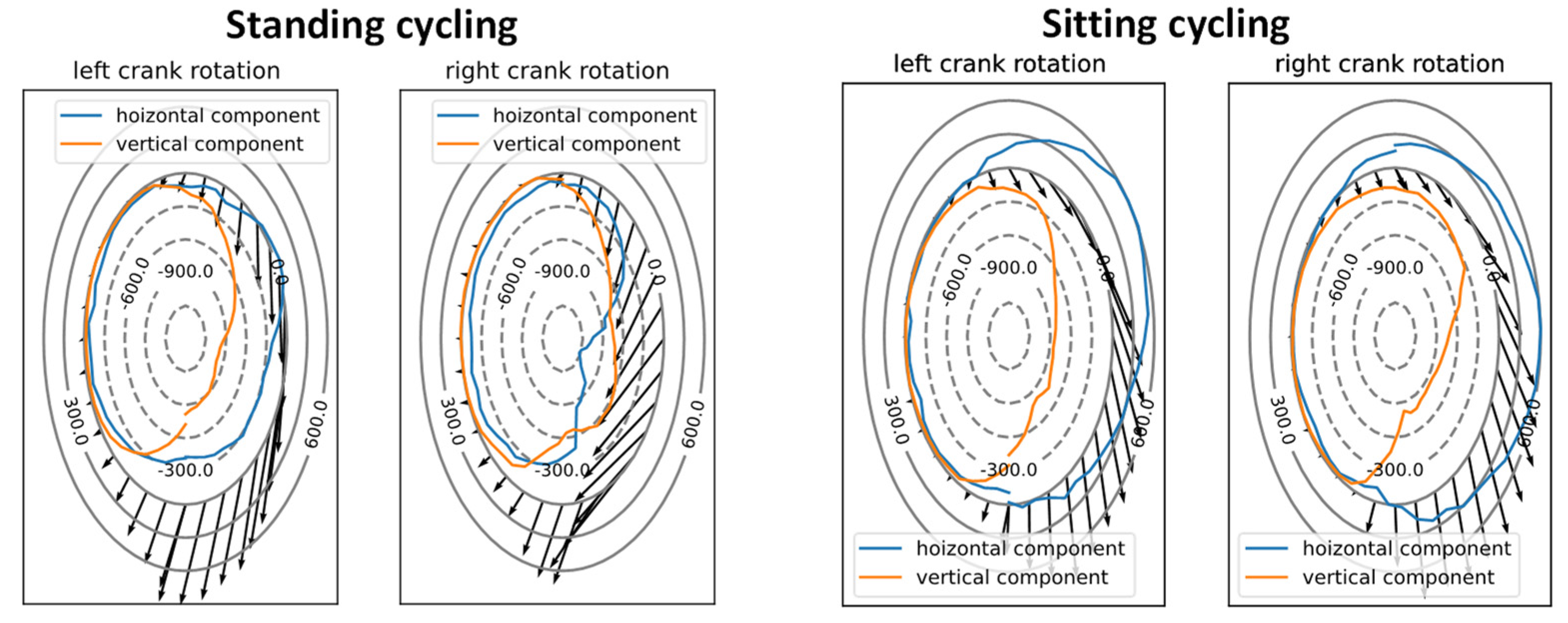
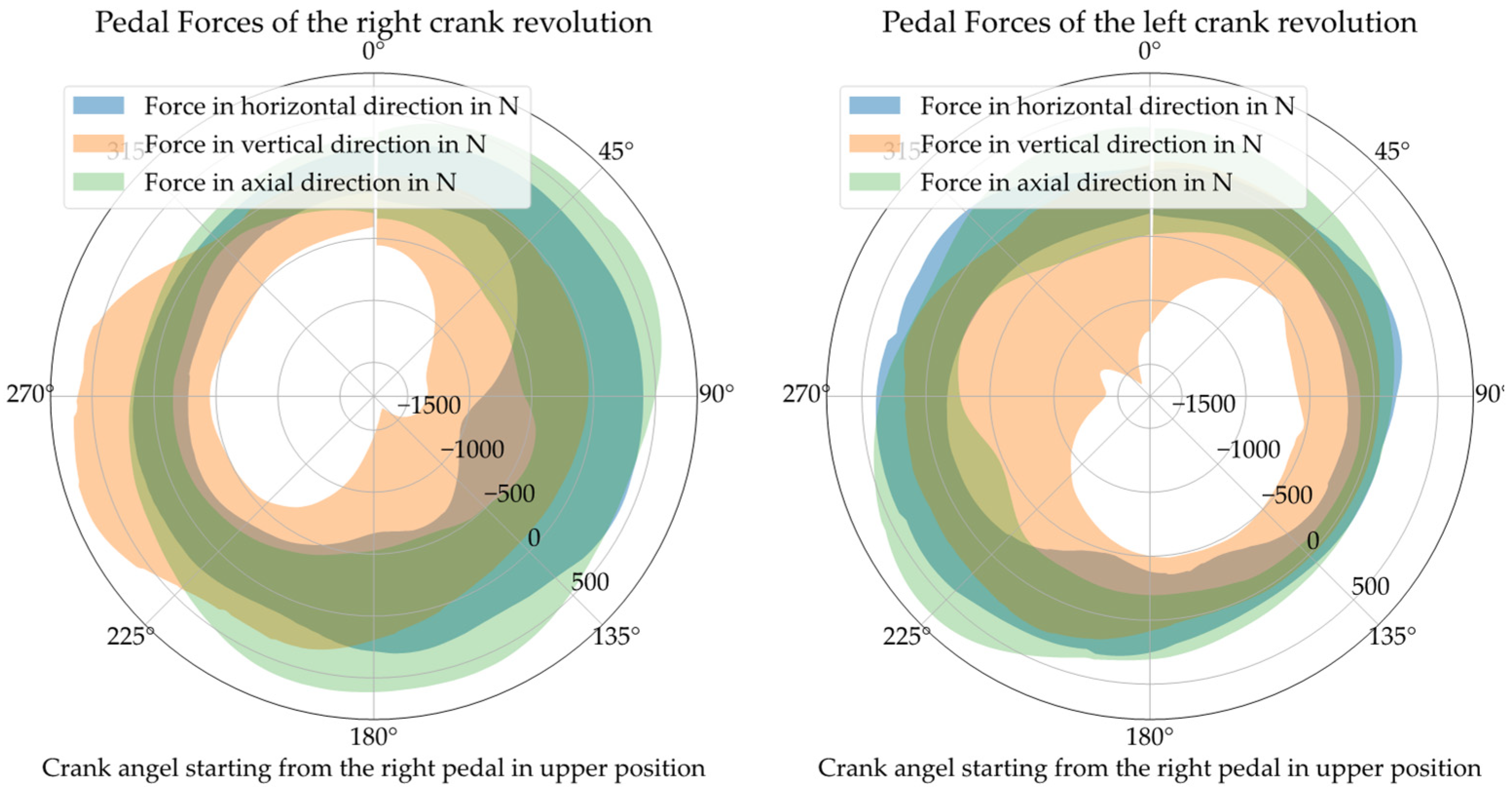
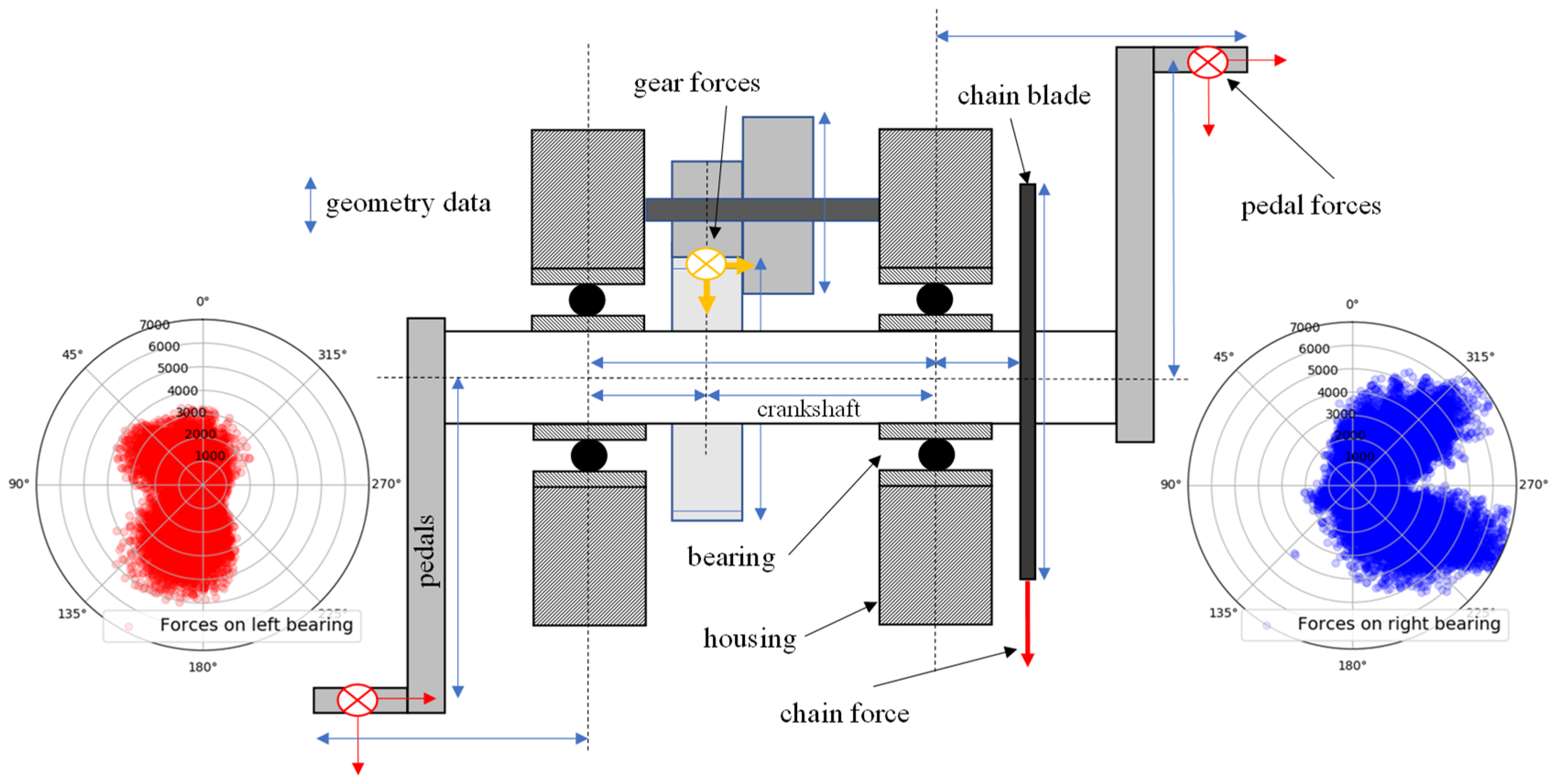
For the dimension reduction of the load channels, the high-resolution load-time sequences of the load-spectrum measurements were superimposed over all relevant geometry parameters of the crank setup and the DU in order to define a resulting radial-bearing load for each measured load situation based on its amplitude and orientation. The assumption was accordingly made that the axial bearing load can be neglected. The reason for this assumption was the low amplitude and relevance of the axial bearing load relative to the radial load. Regarding the overall DU load, the circumferential load resulting from the axial force and the adjusted bearing would be of negligible importance, but would require further input parameters to describe the load condition. Hence, the input dimension of the six pedal-force components, several geometry parameters and the DU engine support could be reduced to the five parameters of amplitude and orientation of the surface pressure in the right and left bearings, as well as the chain force (see
Figure 18). These values could be calculated using fundamental mechanical equations. The chain force still must be considered because it introduces a reaction force into the frame via the rear axis.
Figure 19, below, illustrates the mechanical forces and the relevant geometries around the crankshaft, as well as the potential range of loads on the right and left bearing. These values can be calculated by superimposing the channels of the measured load collective over all variable geometries of the DU Design. Because the mounting angle of the DU affects only the orientation of the bearing forces due to the rotation of the DU housing around the crankshaft, this system parameter can also be incorporated into the dimension reduction.
Hence, the input variable of the six pedal-force components, several geometry parameters and the DU motor support can be reduced to several correlated values of the five parameters for the amplitude and orientation of the surface pressure in the right and left bearings, as well as the chain force (see
Figure 18).
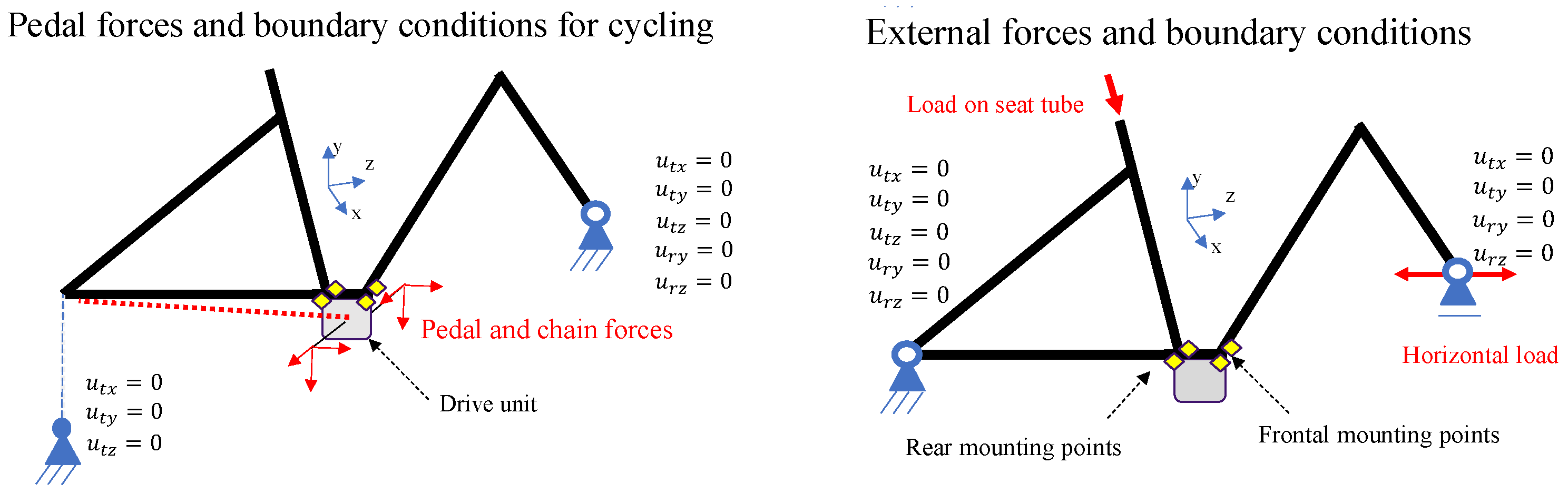
As a simplified description of the connection between the DU and the frame and its boundary conditions, a discrete equivalent-stiffness matrix can be derived for specific bicycle types as an alternative to considering different geometries and materials.
Further reductions can be achieved by the separate consideration of static (thermal and production-related stress conditions) and dynamic loads (depending on the load spectrum of the rider). Thus, the complexity and the size of the DoE can be significantly reduced. This approach is feasible because these two stress states can easily be superimposed in a later step. Obviously, this approach requires the assumption that static and dynamic loads have few to no dependencies and can be calculated separately.
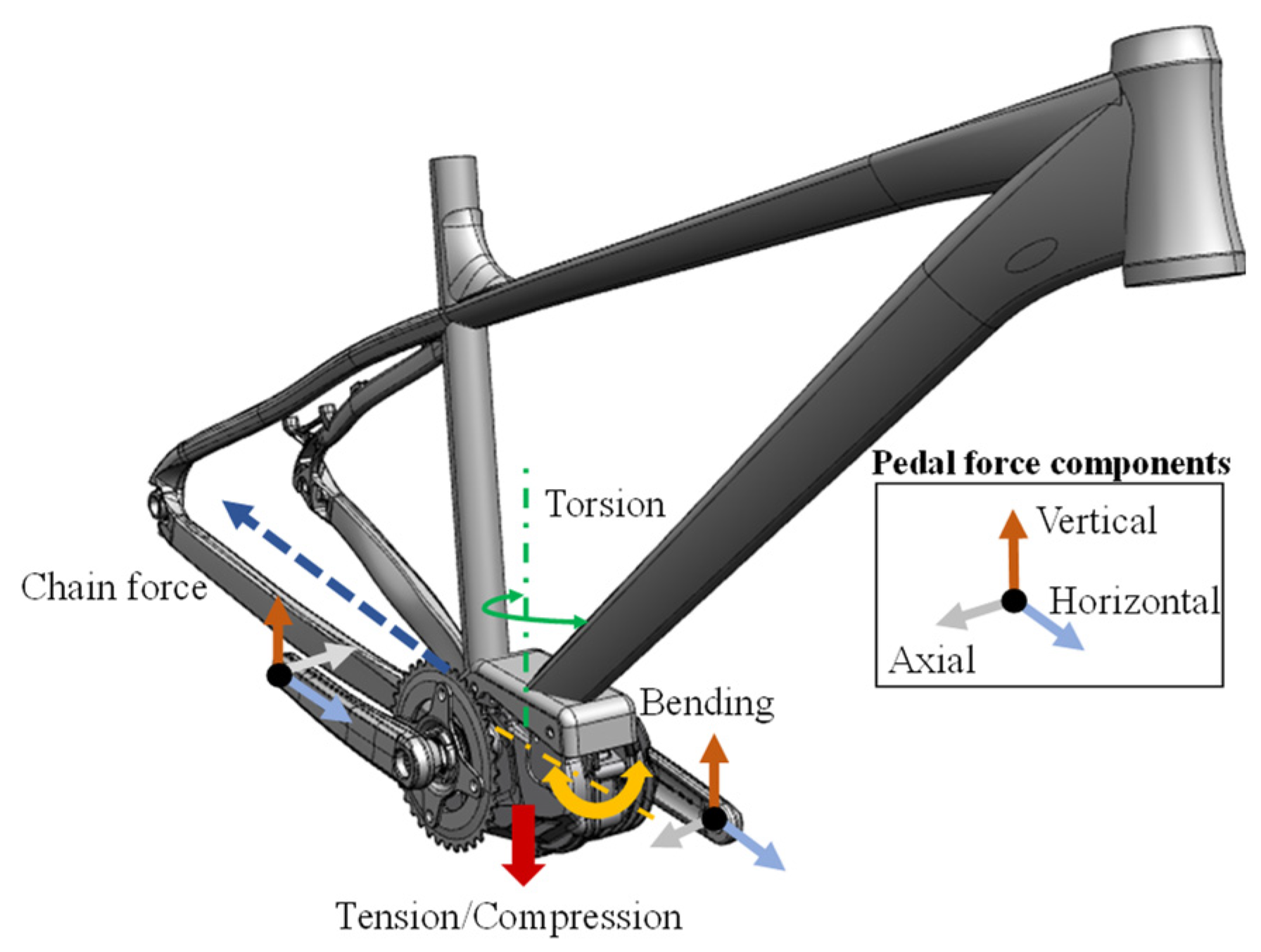
Here it should be mentioned that pretensioning forces that define the contact between the housing parts and the frame interface were also modeled to calculate the dynamic loads in order to ensure a feasible simulation. Following the order reduction of the input parameters and the replacement variables, modifications were also made to the existing and already-validated Abaqus FEM model, which was used for the calculation of the norm requirements. This model consists of the housing, bearing and crank geometry of the DU, which are assembled and pre-tensioned in two initial calculation steps. In a first step, the geometry of the crankshaft and its contact definitions at the DU bearing position were replaced by an analytical description of the surface-pressure profile defined by the orientation, amplitude clearance and geometry of the bearing. This analytical profile was calculated using a Python routine and integrated using a Abaqus subroutine. These routines deliver an easily editable interface for the required automatization of the calculation. Compared to bearing-and-contact modeling, the direct calculation and use of surface pressure is a numerically less error-prone and, above all, more computationally efficient. A comparison with the previously existing FEM model, which had already been validated in detail within the company on the basis of the standard load case, showed no notable differences in results and a significantly minimized computing time.
The Frame Interface was added and modeled by the aforementioned equivalent stiffness matrix, which was extracted by the Guyan-Reduction scheme [
62]. This scheme represents a projection-based reduced-order modelling technique for the completely meshed bike frame geometry. The Guyan-Reduction condenses the whole stiffness matrix to a linearized stiffness matrix for only a few remaining degrees of freedom. In this case, the remaining degrees of freedom were defined for nodes at the mounting points of the DU, as well as the front and rear axes. The retained nodes were coupled to the rest of the respective geometry by a coupling constraint. Thus, the DU can be mounted and pretensioned at the interface and the boundary conditions can be enforced at the retained nodes of the axis. Further hierarchical simplifications were carried out regarding the material model, which was set to be purely elastic given the targeted fatigue range in the HCF area. Due to the focus on the methodological steps, the already existing FEM model will not be discussed further at this point.
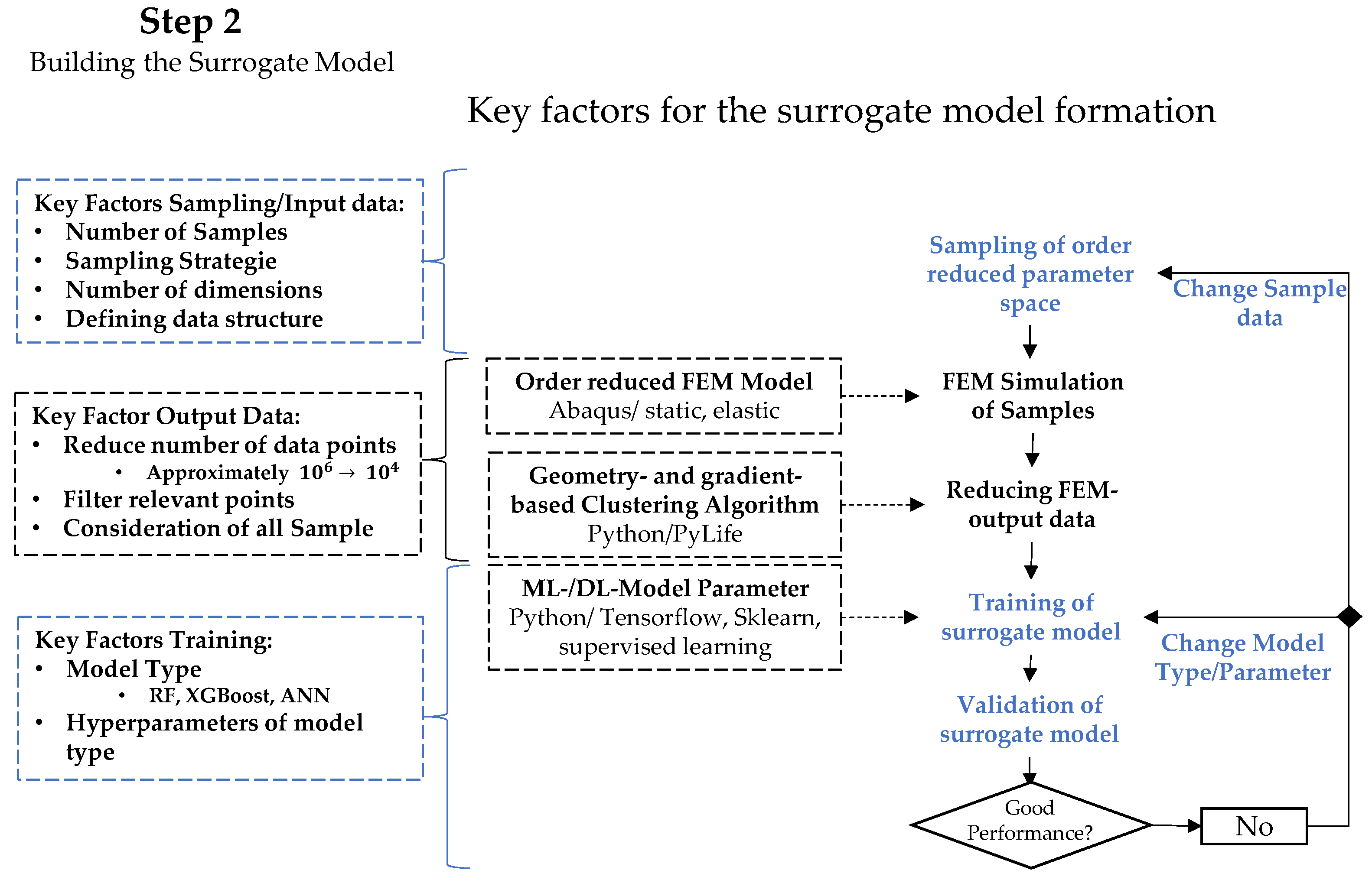
4.3. Building the Surrogate Model
The formation of the surrogate model depends on the two major steps of data generation, including a data reduction to form the output data and the generation of the data-based model. These two steps, as well as their key factors, are highlighted in
Figure 16 based on the general methodical approach shown in
Figure 20.
4.3.1. Data Generation and Reduction
As an initial step for the creation of the surrogate model, sample data must be created and calculated according to sampled input data and the simulation model. For an adequate representation of the parameter space, the LHS was selected as a space-filling sampling algorithm. To ensure that the FEM simulation model yields sufficient accuracy, a fine discretization and a high element count of more than one million elements must be expected. For this size, data processing and storage, as well as the planned construction of a data-based surrogate model, can be completed only with enormous computational resources.
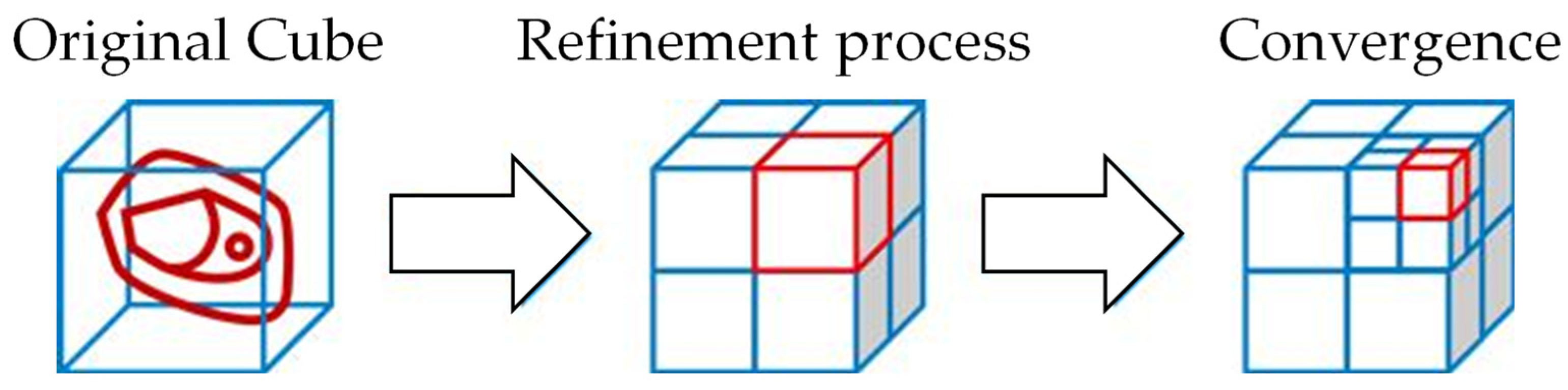
To achieve the required coordinate-based and simultaneously clustered and reduced data structure, a gradient- and volume-based clustering procedure was developed. This method identifies the local maxima of the selected target variable inside an observed volume to build a locally refined but generally coarser mesh via variable discretization. As a convergence condition for this algorithm, suitable threshold values for the gradient and the minimum value, as well as variable and maximum refinement steps of the discretization, are defined. The fundamental idea behind this method is that areas of the FEM mesh that possess nearly constant values over the entire output of the simulated samples can be clustered and described by only one representative value for this volume. Furthermore, areas associated with a very low target value and thus are not relevant to the fatigue calculation can be filtered and excluded.
To generate a clearly defined and coordinate-based discretization pattern of the geometry and the corresponding FEM output, the basic geometry of a cube covering the maximum component dimensions is defined as the starting volume. Subsequently, this initial volume is refined in a manner analogous to the scheme shown in
Figure 21, by bisecting the edge lengths of the original cube and its children. The refinement is performed if more than one local maximum of the target value above a certain threshold is detected within an observed volume. This refinement is executed until either a convergence criterion regarding the minimum stress gradient or the minimal cube size is reached.
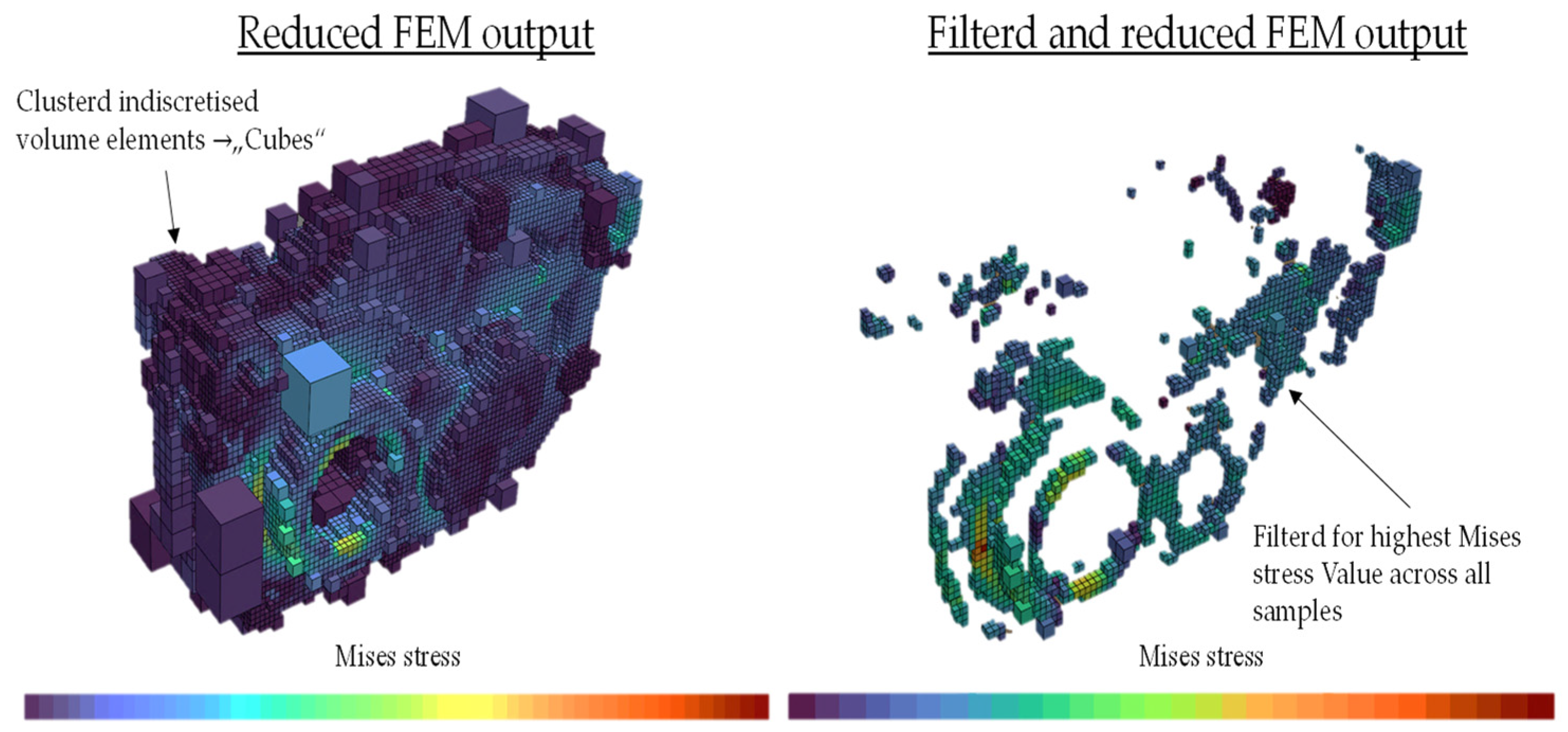
Finally, this algorithm is intended to provide a significantly reduced discretization with only a slightly reduced information density as a foundation for the training of the data-fit surrogate model. Hereby, of course, it is assumed that the previously simulation-generated sampling data is sufficient to be able to perform this clustering reasonably. However, as the formation of the data-fit surrogate model generally allows only the interpolation of the results, sufficient sampling is inevitable. Therefore, the derivation of the critical points based on the sampled data is seen as a reasonable assumption.
Thus, the relevant parts of the housing can be focused on and represented with a significantly smaller amount of data, leading to an efficient hierarchical order reduction for the database. The distinct algorithm of coordinate-dependent volumes additionally allows the integration of different meshes and simulations. Furthermore, the coordinate-related discretization allows the comparison of different geometries in different optimization loops. Although some cube volumes may be added or omitted due to the geometry change, a large part will remain and can thus contribute to the robust optimization process. Consequently, an application to arbitrary geometries is conceivable.
Each of these cube objects can then be assigned the output values of the target value, its coordinates and the exact parameter definitions of the simulation step, these being the essential information for the data-based surrogate model. Both the algorithm and the required data transfer from the Abaqus output file were programmed in Python.
Figure 22, below, shows an example of the reduced discretization of a DU geometry that was simulated for 400 sample points.
4.3.2. Generation of the Data-Based Surrogate Model
For the creation of a surrogate model, the initial task consists of forming the input and output data for supervised learning and selecting an appropriate model type and algorithm. In this case, the input data are built from the load, eBike system and design parameters of the individual samples, which are supplemented on the output side with the evaluated stress-tensor components. The details of the data structure depend on the arrangement and processing of the coordinates-based data of the adapted discretization.
In this way, either individual regression models can be created for each discretized data point, or the adapted and filtered mesh can be considered collectively in one single surrogate model by incorporating the coordinates into the input data to guarantee an unambiguous assignment.
To create individual surrogate models, however, a rapidly increasing memory requirement and high computational costs for the training of the individual models arise for each additional considered location. In light of the filtered yet still respectable number of potentially relevant points (see
Figure 19), the following assessment involves only the use of a cumulative data structure within a singular surrogate model, while the approach of several individual surrogate models is ruled out.
However, as this approach is associated with an increase in dimensionality due to the incorporation of the x-, y-, z-coordinates, this increased number of input dimensions is accompanied by a reduction in the sampling quality. The severity of this reduction depends on the number and density of the included data points. In addition to the pure number of incoming sampling points, their geometric distance in the x-, y-, z-coordinates is of particular importance, as this factor has an enormous effect on the spacing of the multidimensional dataset. As can be seen in
Figure 21, filtering the data sets to highly loaded locations will lead to an uneven distribution of the sample data. As a result, the training data become increasingly heterogeneous due to the varying influence of geometrically adjacent data points. Therefore, the possible influence of differently finely-distributed data points must be accounted for in model-building and validation.
Besides the data structure, the performance of the surrogate model depends in particular on the model type and its hyperparameters, as well as on the number and selection of the initially calculated training data. To reach a decision in this context, different model types and sample data sets are evaluated by their performance. Due to the iterative application of this fatigue calculation within an optimization loop, the performance is evaluated qualitatively from the ratio of computing time and prediction accuracy.
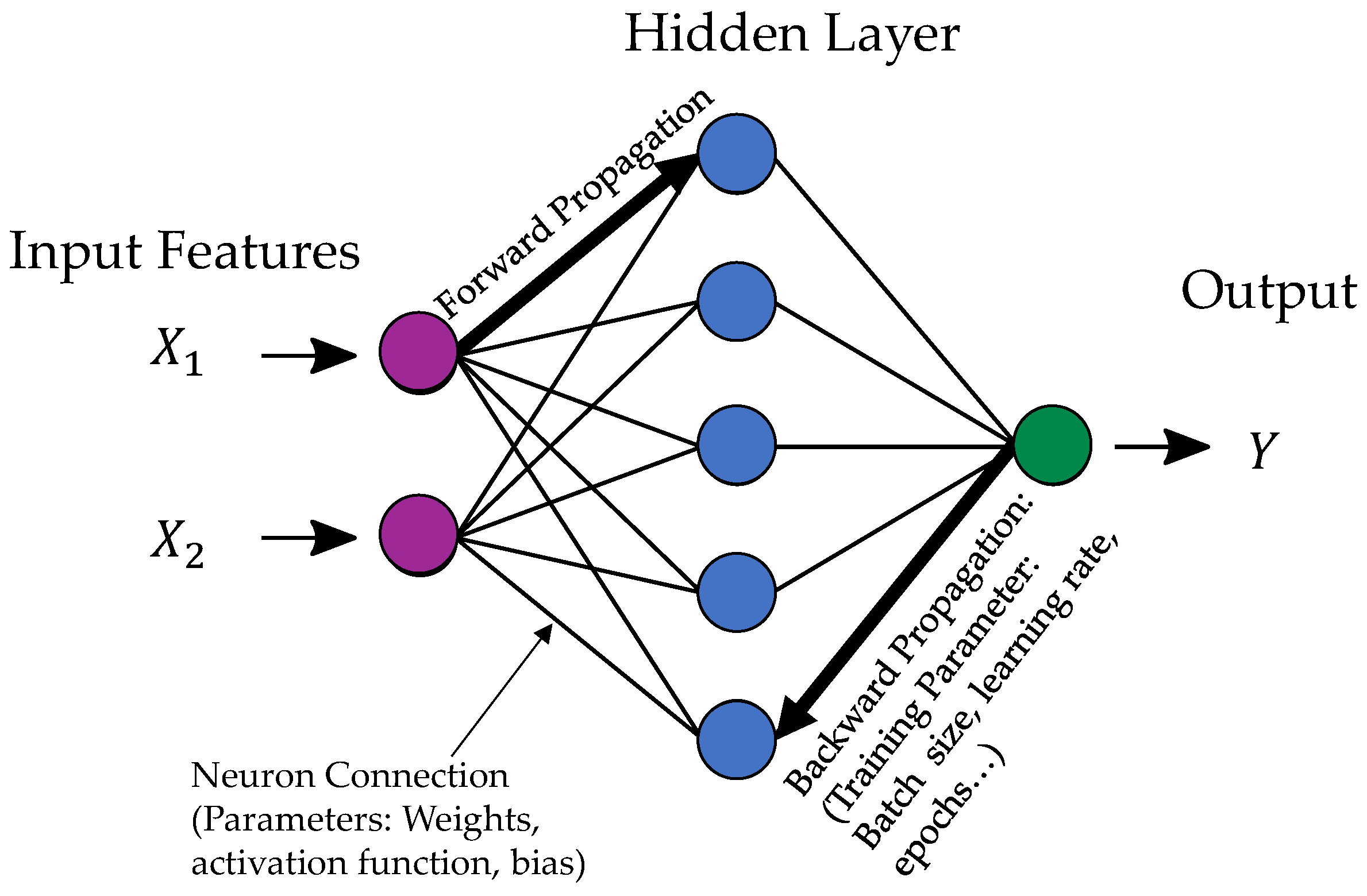
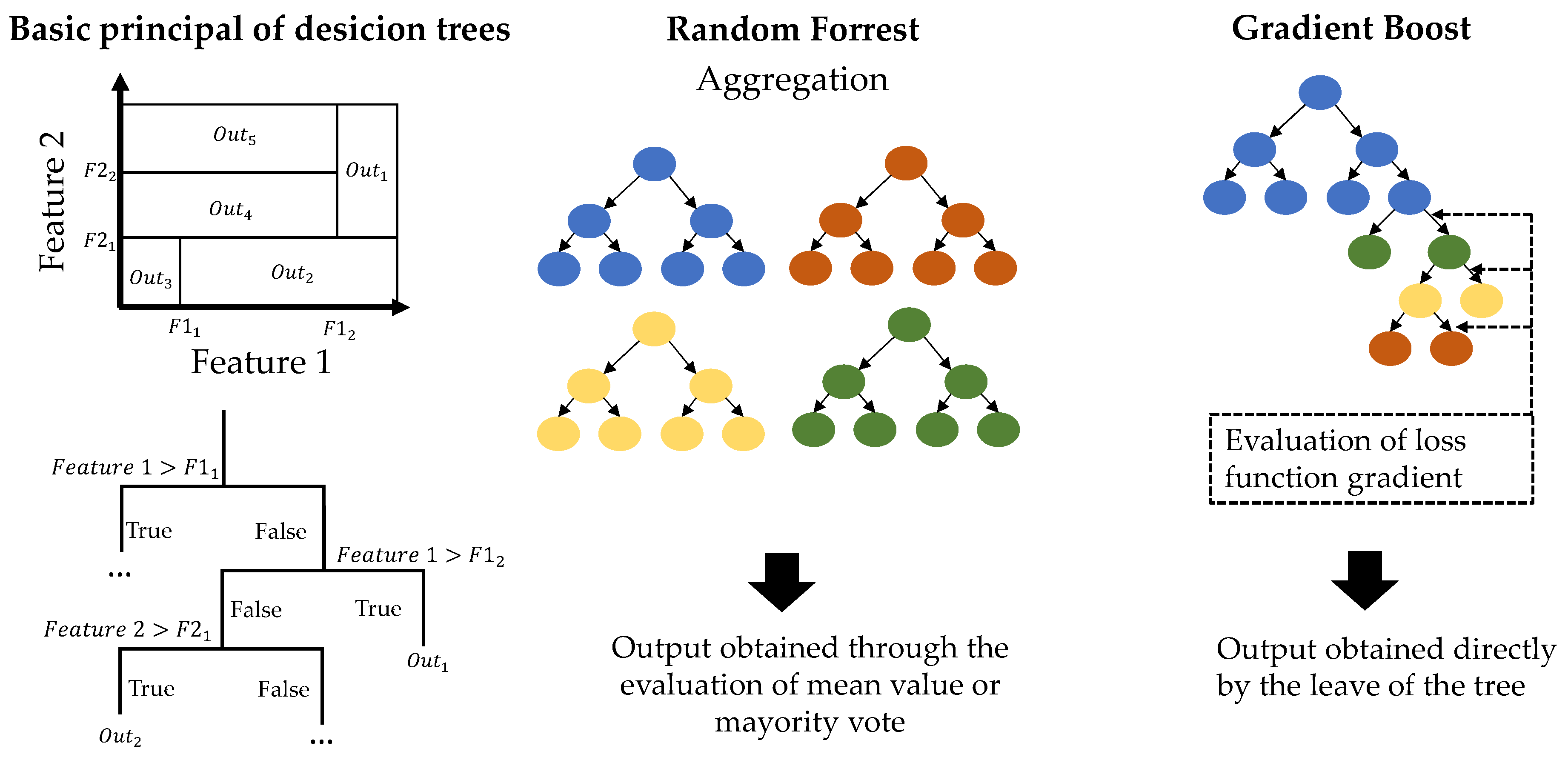
Regarding the algorithm used for building the surrogate model, this study considers supervised learning ML and DL approaches for regression, including tree-based machine learning algorithms in the form of XG and RF, as well as an ANN with multiple hidden layers, to explore this data-driven approach. The selection of these model types was derived from a literature study in which the most common algorithms were evaluated based on fundamental characteristics such as training time, prediction time, precision and their scope of application in terms of the number of features, data size and the number of outputs.
To define a suitable number of training samples, the metrics of the individual model types were evaluated for different sample sizes in steps of 100 FEM samples. This study revealed good model performance for the given input parameter space from a size of 400 sample data sets. The parameter space of this study was set for the entire driver load collective (including different crank-setup geometries), a bicycle frame and an installation position range of 20°. To eliminate the bias arising from different sampling variants, all of these samples were generated by the LHS method.
To evaluate the applicability of the method to different discretization filters and data sizes, the upper 5%, 12.5% and 20% of the data points were selected according to the height Mises equivalent stress across the sample range. Commonly, influences and dependencies from the chosen training and validation dataset were excluded by a ten-fold cross-validation. To evaluate the results, the common metrics of the RMSE and the value were considered. The RMSE was determined from the mean of all single-tensor component predictions, as well as their combination in the form of the equivalent von Mises stress. To ensure the comparability of the algorithms, an elementary hyperparameter optimization was performed. To keep the computing times for this optimization within a reasonable limit (that would also allow an iterative and practical application of the method), this hyperparameter optimization was carried out only for the lowest amount of data and, in the case of the ANN, only for a limited set of parameters. This approach was based on the assumption that the hyperparameter setting can also be applied to larger data sets without a significant reduction in performance.
The hyperparameter optimization was performed using a Bayesian Optimization algorithm based on the Python module Hyperopt. This optimization was based on minimizing the average RMSE value of the six output channels for the worst-performing data split of the cross-validation by adjusting the hyperparameter settings in a predefined range.
These computations were performed on a PC with a 12 Core CPU of 4,2 GHz and 32 Gb RAM. The data structure was processed using a Python code, and the model types for the ML and DL models were retrieved by the SKlearn and TensorFlow. The results are shown in
Table 1.
Based on these results, it can be confirmed that in general, all model types yield good-quality predictions of the results and a sufficient coefficient. This result is evident regardless of the number of data points considered. However, a general trend of increasing error values can be observed for decreasing numbers of data points. Similarly, the value decreases for larger sample sizes. This result may be explained by the filtering of the data points according to their quasi-static equivalent stress amplitude, which leads to generally higher absolute values for the collection of filtered data points. Further explanations for this outcome could include the lower dependence on individual mispredictions and the denser quantity of training data for higher numbers of data points.
Nonetheless, it is striking that this trend is significantly weaker for the XG and the ANN than for the RF. Here, the RF shows a generally larger scatter, but also better performance compared to the XG and ANN applications for larger data sets. This result can presumably be explained by the lack of generalization in the XG and ANN model types, which were hyperparameter-optimized only for the smallest data set. In contrast, the RF regressor, which is generally less sensitive to overfitting, shows a more robust performance and the expected trend for a larger and less-filtered data set based on the extreme values. On the other hand, the hyperparameter-optimized XG is the better-performing model for the small data set containing generally higher and more heterogeneous values. Such a result highlights the importance of the hyperparameter optimization. At this point, it may be assumed that the XG also provides the best performance for other sample sizes if a corresponding hyperparameter optimization is used.
Regarding the general model types, lower RMSE values can be seen for the tree-based models of the RF and the XG compared to ANN. This is an important finding, especially because of the significantly longer computing time of the ANN. Thus, the superiority of the tree-based regressors over the ANN for tabular data can be proven based on this data set, in a finding analogous to that of the benchmark study of [
42].
For all model types, the expected increase in the RMSE is apparent for the cumulative consideration of the output values based on the Mises stress. In view of the potential stress amplitudes, which amount to 0–200 MPa for this case study, this value also appears to represent a reasonable error. However, the results of the general cross-validation do not allow for a complete validation of the surrogate approach for the time-based assessment of a cyclic load. For this reason, a second validation loop was established to evaluate not only the performance of the surrogate model, but the results of the subsequential fatigue calculation for a series of predicted stress tensors. This validation consisted of a comparison of the results from the fatigue calculation of load sequences calculated by the surrogate model and an FEM simulation.
Therefore, the measurement data from two example crank rotations were discretized into 72 uniform sections of the crank angle and then processed by the FEM model to generate a validation data set for the evaluation of the entire calculation approach. Subsequently, these input data were also processed with the machine learning model of the XG and the RF. The use of the ANN was already excluded due to its poorer performance and the enormous computing time. The results of this second validation loop can be seen in
Table 2. For more details of this validation, please refer to [
50]. It became apparent that the evaluation of entire load sequences by the critical-planes model, which is fed by the surrogate model, results in even lower error values for the equivalent stress amplitude for this load cycle compared to the mean RMSE of the quasi-static mises equivalent stress of the general cross-validation. Therefore, the principle of a surrogate-based approach for fatigue calculation can be validated.
In addition, the influence of hyperparameter optimization on the two tree-based model types was considered in this second validation loop. For this purpose, both model types were used once with the default settings and once with the optimized hyperparameter settings. The results (
Table 2) reveal the robustness of the RF and highlight the necessity and benefit of hyperparameter optimization for the XG.
Overall, it can therefore be concluded that the ANN is not suitable for such high sample sizes and input dimensions due to the enormous computing time it requires. It can be assumed that further performance improvements for the ANN would be possible due to the ability of this model type to learn. Such improvements can be achieved only through investing significantly increased effort in the hyperparameter optimizations, which is simply not cost-effective with the data volumes required for this particular method. The use of the XG regressor is therefore recommended for accurate evaluation. However, hyperparameter optimization is necessary to achieve the necessary generalization and good results. As the computational effort for hyperparameter optimization is rapidly increasing with the number of data points, the sample size should be chosen with respect to the intended objective. For faster estimations that do not focus on low prediction errors, the RF is recommended and can also be used appropriately without hyperparameter optimization. Transferring these findings to the application of this method in different development stages, the RF can be recommended for the concept phase and the rapid testing of different parameter combinations. Conversely, the XG is preferable for more mature designs and especially in the validation phase.
4.4. Fatigue Calculation
To calculate the service life and the probabilistic fatigue constraint, measured load-time sequences are discretized into a sequence of quasi-static single loads. Subsequently, these loads are combined with the system and DU parameters to generate a sequence of input data for the surrogate model. As a result, the data-based surrogate model provides a sequence of the stress-tensors components for each local area considered during surrogate generation. Based on this sequence, a fatigue calculation incorporating a multiaxial non-proportional damage criterion and based on the critical-plane approach is performed to convert the multiaxial loading sequence to an equivalent cyclic-stress amplitude that can be compared to existing material data from the SN-Curve. The further application of this calculation chain for the formation of a probabilistic fatigue constraint is described in
Figure 23 and in the following section.
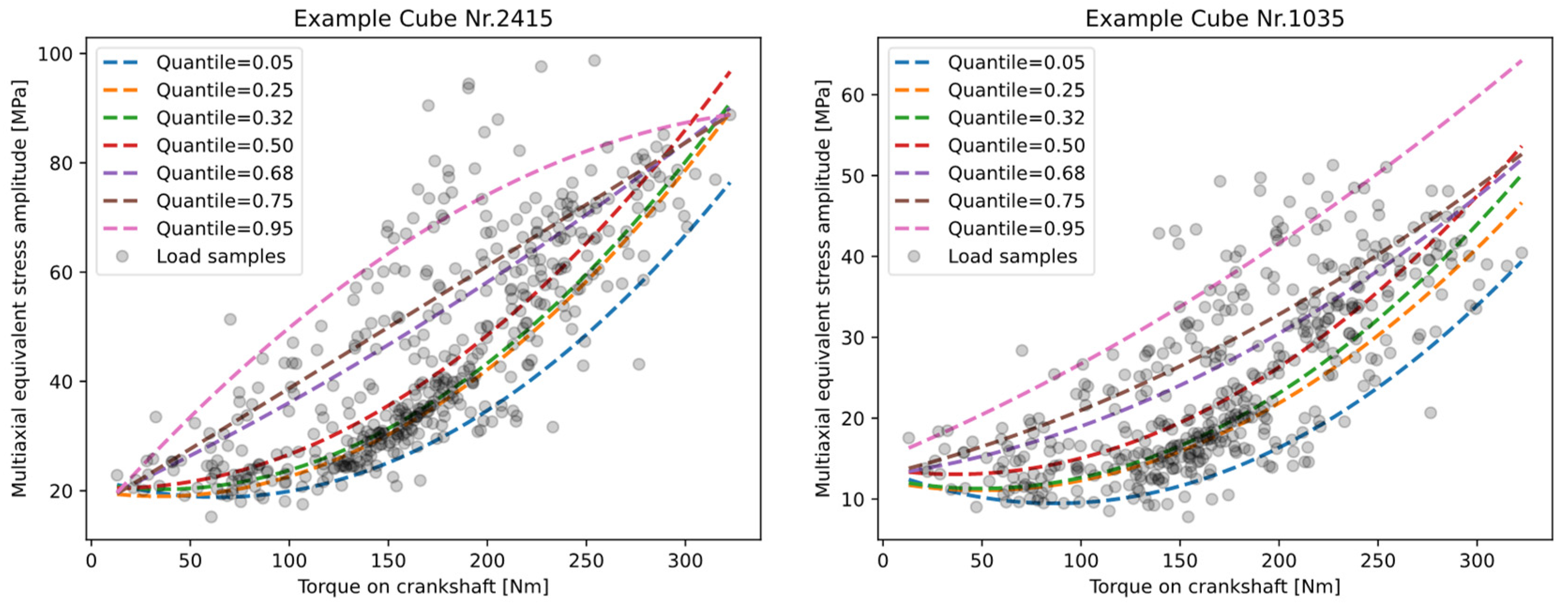
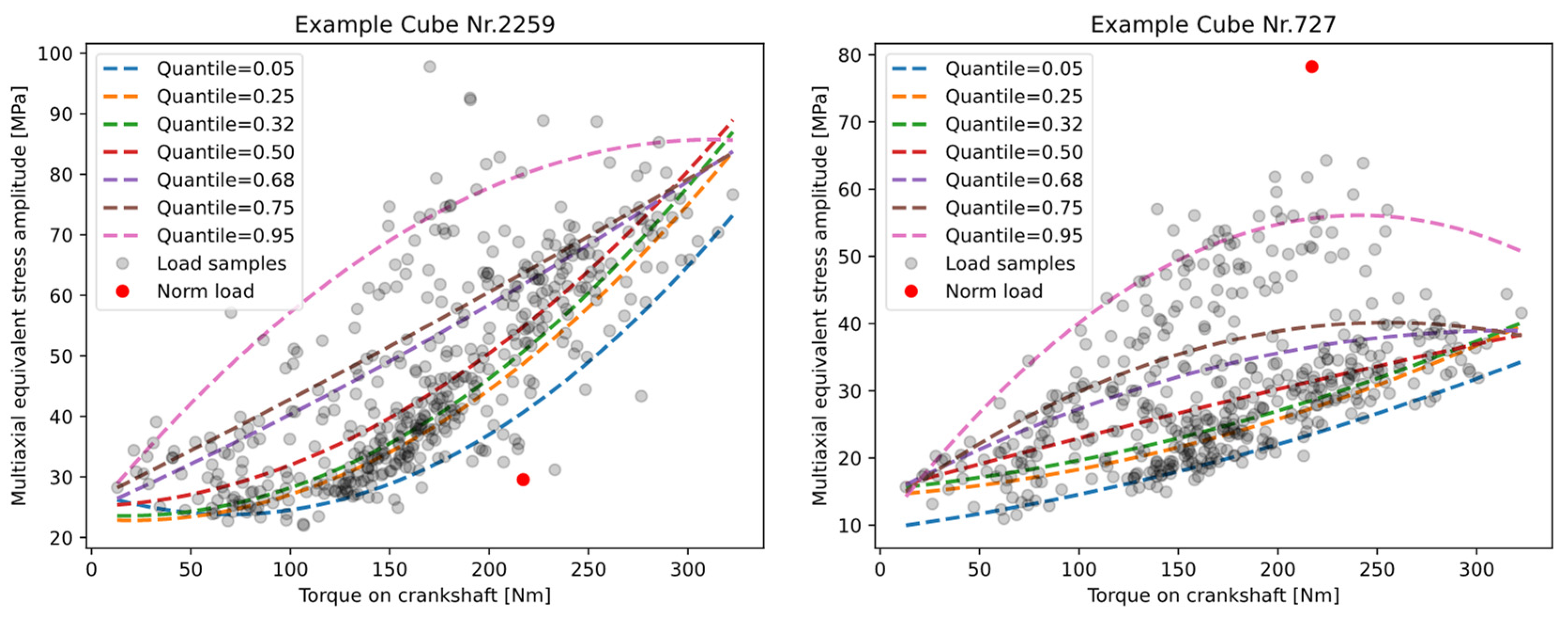
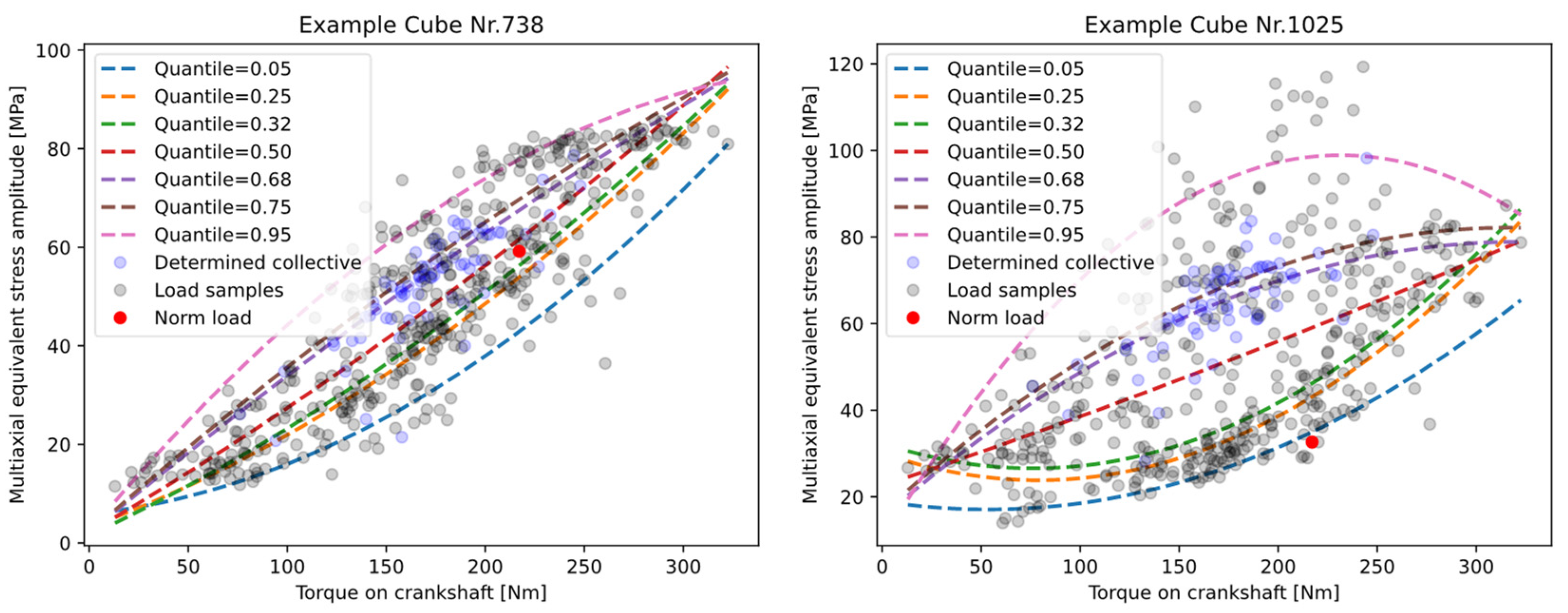
To represent the variance of the driver-load spectrum, multiple load sequences were sampled from the measurement data and evaluated for one configuration of the DU and the bicycle system. To obtain a reference value for the likelihood of occurrence of each load sequence, the maximum torque (where the distribution is known from the DU recording) on the crankshaft was captured for each sequence.
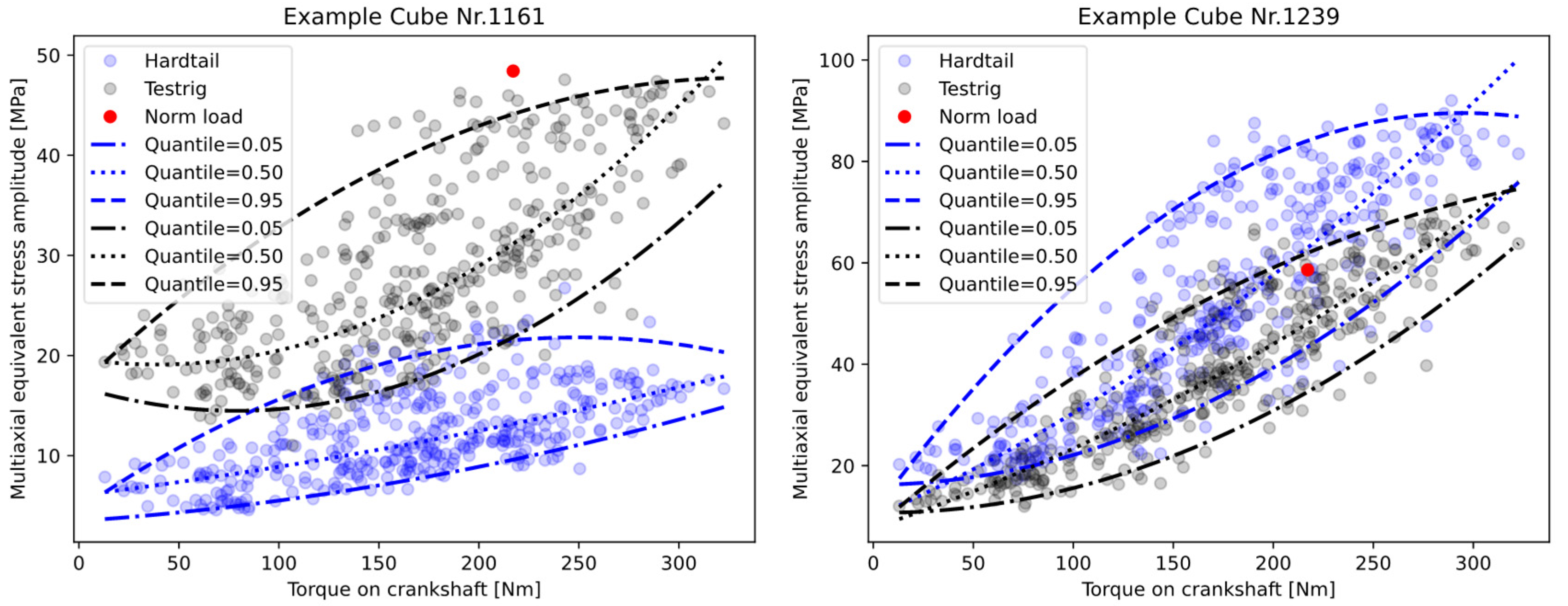
Subsequently, all the equivalent stress amplitudes of the selected load sequences wee assigned to their maximum torque. To evaluate this sample of a discrete 2D distribution, a regression fit based on the quantiles of this assignment was performed to evaluate and represent the variance. Thus, a system of functional descriptions was formed. This system extrapolates the statistical sample distribution to a continuously described distribution of equivalent stress amplitudes over the maximum acting crankshaft torque. Dependent on the order of the function type used for the regression, non-Gaussian distributions can also be determined along the driver torque. In the next step, these functions can be used to determine the load collective for an arbitrary confidence interval and a given torque distribution. This information can then be used to estimate the fatigue life for a given operating time or driving distance, which again can be converted to an effective damage value via the linear damage accumulation and the material data from the SN- curve. As this evaluation can be conducted for several confidence intervals, this information can be transferred to a probabilistic service-life constraint.
Figure 24 illustrates this evaluation based on the evaluation of the quantile regression fits for selected local areas of the housing. The function type for the regression was quadratic and according to Formula (4), with
,
and
as the variables for the regression fit, can be represented as follows:
Furthermore, this evaluation can provide vital information about the robustness of the evaluated local area of the housing to the potential load collectives. From the mean value and standard deviation of the accumulated damage over a given torque distribution and frequency, scalar values for the evaluation of the respective design and system parameter combinations can be determined. This evaluation of the damage must be performed based on the regression functions of a specified confidence interval or quantile, as a normal distribution cannot be assumed for this two-dimensional distribution. As an example, the damage evaluation of the 50% and 95% quantile can be conducted to derive the mean value and the variance. Next, the quantile functions can be used to calculate a load collective based on a required service life and torque distribution to obtain the load collective and the damage value according to the linear damage accumulation. Besides the binary information of failure or no failure for the fatigue constraint, this probability-based information can deliver key information for the evaluation and optimization of the robustness of the DU.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}