1. Introduction
The latest 2018 report of the World Health Organization states that more than 1.35 million people die each year from causes related to road accidents [
1]. Moreover, it declared that road accidents are the leading cause of death for children and young people aged between 5 and 29 years. These statements push us to research and improve processes aimed at enhancing the road safety level of infrastructures, moderating the number of accidents, and evaluating the key factors that are the cause or contributing factors to an accident. Only through a global awareness of the phenomenon, is it possible to define valuable tools for those who base their duties on the safety and health of people.
Crash severity is one of the road safety-related aspects that requires thorough investigation. In recent years, there has been extensive investigation of the relationship linking crash severity and its associated risk factors, as well as several studies that have involved the study of crash severity modeling for prediction purposes. Machine learning algorithms (MLAs) appear as one of the prominent and most exciting tools for modeling crash severity due to their outstanding outcomes. Nonetheless, there is a significant number of studies that omit the fact that, typically, crash datasets are acutely imbalanced. Indeed, the number of events that correspond to fatality or severe injury are generally far fewer than the number of events relating to property damage only or minor injury. Learning from datasets that include occasional events usually provides biased classifiers: they have higher predictive accuracy over the majority class, but weaker predictive capacities over the minority class [
2,
3,
4].
The purposes of this paper are manifold. Mostly, it considers the imbalance issue in crash datasets. First of all, recent studies on accident severity modeling are reviewed, showing that most of them employ imbalanced datasets to train MLAs. Next, a procedure for balancing them using the RUMC technique is provided. Furthermore, in order to show that RUMC is useful in defining non-weak classifiers in predicting the minority class, a direct comparison of two types of MLAs is proposed. They are trained in two ways: the first type, i.e., Random Tree (RT), K-Nearest Neighbor (KNN), Logistic Regression (LR), and Random Forest (RF), involves the use of an imbalanced training set, while the second type, i.e., RUMC-based Random Tree (RUMC-RT), RUMC-based K-Nearest Neighbor (RUMC-KNN), RUMC-based Logistic Regression (RUMC-LR), and RUMC-based Random Forest (RUMC-RF), involves the use of a RUMC-based balanced training set. Outcomes show that RUMC-based models are significantly more effective in recognizing the minority class by using the same test set for testing both types of algorithms. The paper also proposes the discussion of which are the best metrics for judging the performance of these classifiers and whether overall metrics, weighted averaged metrics, or specific metrics for each class are representative of the real performance of a classifier. Finally, the factors that are associated significantly with crash severity are computed and examined.
The study is organized as follows.
Section 2 describes the related works. The workflow, the dataset employed, the techniques, and the leading mathematical relations are introduced in
Section 3.
Section 4 reports the principal outcomes and discussions. Conclusion and References complete the paper.
2. Related Works
This part is focused on the review of significant and recent studies on road safety modeling with MLAs. It covers different aspects: (a) what tasks are generally solved with machine learning modeling in road safety analyses, (b) what MLAs are commonly used, (c) what performance metrics are usually computed to judge an MLA, (d) what imbalance ratio exists in road accident datasets, and (e) what techniques could be used to alleviate this issue.
2.1. Machine Learning Algorithms in Road Safety Analyses
Commonly, two different tasks are solved using MLAs: regression or classification. The former involves the prediction of a continuous value, while the latter is conceived for predicting a discrete (or class) output. Both types of prediction algorithms have a set of factors (or independent variables) as input. Although MLAs provide a black-box tool for predicting continuous or discrete outputs, they can identify the most significant features, i.e., the features that most affect the output response of the model; considering this, we can assess how a specific factor is related to the phenomenon analyzed.
In the last decade, different studies have provided machine learning regression algorithms for road safety analyses. Such algorithms have as input a set of roadway-, users-, vehicles-, and environment-related features of the network analyzed. Commonly, they aimed at predicting the crash frequency for stretches of road or intersections using different types of algorithms: k-nearest neighbor [
5], support vector machine [
6], and tree-based models, such as classification and regression tree, M5-tree, RF, extremely randomized trees, and gradient tree boosting [
7,
8,
9]. Moreover, there are studies [
10,
11] in which the authors suggested the use of neural networks. They showed that neural networks have better performance if compared with traditional negative binomial regression.
In addition to crash frequency prediction, some authors [
12] proposed the use of Multivariate Adaptive Regression Splines (MARS) for predicting the crash angle at unsignalized intersections.
Commonly, the performance of the referred to regression models has been evaluated using root mean square error, mean absolute error, or correlation coefficient.
As regards for machine learning classification algorithms, the analyzed topics related to road safety are manifold. Harb et al. [
13], for example, proposed the use of decision tree and RF for understanding pre-crash maneuvers. Some authors [
14,
15] aimed at the prediction of crash risk: the machine learning models calibrated provide low/high risk of a crash as output, relying on roadway-, vehicles-, and users-related input factors. Another widely studied application is road black spot detection [
16,
17,
18,
19,
20], in which the authors attempt to identify potential dangerous road sites. Therefore, the output labels of these MLAs can be an accident case or a non-accident case.
Several studies were related to crash severity prediction with MLAs. In these applications, the output classes can be two, such as Property Damage Only (PDO) accidents and Fatal+Injury (F + I) accidents [
21,
22,
23], three [
24,
25,
26], four [
27,
28,
29], or five [
30,
31,
32]. The authors suggested different MLAs to achieve the purpose: decision tree [
23,
24,
29,
30], KNN [
30], LR [
21,
22], and RF [
21,
28,
30,
32]. Other standard MLAs used for the same purpose are support vector machines [
22,
28,
30,
31,
32], neural networks [
14,
27,
28,
29], and naïve Bayes classifiers [
21,
33]. There is no rule of thumb in determining the most appropriate algorithm. Therefore, authors generally compare different types of algorithms to discover the most representative one for their framework. In order to evaluate the performance of such classification MLAs, usually, authors compute the overall accuracy of the classifier [
17,
32], precision [
22,
29], True Positive Rate (
TPR) [
16,
18], False Positive Rate (
FPR) [
14], True Negative Rate (
TNR) [
15,
20],
F1-score [
29], and the confusion matrix [
26,
28]. Using and comparing different metrics allows a better classifier to be represented; therefore, using a broad set of metrics can be useful to present the performance of a classification algorithm.
The aforementioned modeling strategies can be applied to a very broad set of road facilities. Indeed, it is possible to find research related to the study of road junctions, specifically signalized intersections [
25,
34,
35], stop and right-of-way intersections [
12,
36,
37], roundabouts [
38], freeway exit ramps [
32], road segments, such as highways [
5,
6,
10,
30], expressways [
14,
18,
39], arterials [
40], freeways [
16,
17,
21], and work zones [
22].
2.2. Resampling Techniques
Many practical classification problems are imbalanced. The class imbalance problem happens if there are several more samples of some classes than others. In such cases, standard machine learning classifiers tend to be overwhelmed by the majority classes and overlook the minority one [
41]. The performance of such classifiers in predicting the minority class decreases significantly. In order to overcome these issues, resampling approaches can be employed.
Mostly, there are two resampling approaches affirmed to handle imbalanced datasets: oversampling techniques and undersampling techniques. Oversampling concerns techniques that increase the number of minority class samples until the dataset is balanced. A relatively recent and well-known oversampling technique is the Synthetic Minority Oversampling Technique (SMOTE) defined in the study by Chawla et al. [
42]. SMOTE takes each minority class sample and creates new instances of the same class using k-nearest neighbors within a bootstrapping procedure. Moreover, SMOTE can be used for handling both continuous and categorical features. In the case of presence of categorical input factors, the technique is called SMOTE-NC, and it is introduced in [
42]. Conversely, undersampling techniques concern the methodologies to balance datasets by reducing the number of samples of the majority class. The RUMC approach is described in the study of Japkowicz [
43] and Batista et al. [
44] and consists of a random undersampling of the majority class until the dataset is balanced. Resampling techniques have the obvious advantage of being able to effectively handle imbalanced datasets by balancing them, thus defining training sets suitable for a satisfactory calibration of MLAs. There are also known drawbacks associated with the use of resampling techniques. The disadvantage with undersampling (e.g., with RUMC) is that it drops out potentially valuable data. Therefore, there is a possible information loss. The main disadvantage with oversampling (e.g., with SMOTE) is that by creating very similar observations of existing samples, it makes overfitting likely. Indeed, with oversampling the minority class, the MLAs tend to learn too much from the specifics of the few examples, and they cannot generalize well. A second disadvantage of oversampling is that it increases the number of training observations, thus increasing the learning time. Moreover, factors appear to have a lower variance than they have. In the present paper, due to the low size of the minority class compared to the majority one (ratio of about 1:6), the implementation of the RUMC process was preferred. Indeed, by using the SMOTE process, we would have introduced a heavy distortion in the patterns of the dataset by creating a particularly large sample of new synthetic data. Moreover, the training time would have been longer. On the contrary, by using RUMC, we dealt with real observations only, reduced the training time, and preserved also the variance of the features.
Although these techniques have a relatively simple implementation, it seems that many studies related to crash severity modeling employ imbalanced datasets without resampling in the calibration of MLAs.
Table 1 below shows recent studies identified in the literature with the datasets used. In addition to the authors who conducted the studies (“Reference”),
Table 1 shows the purpose of the studies (“Type of classification”), the number and type of severity classes of the datasets (“Severity classes”), the number of instances for each class (“Instances”), its percentage of the total (“Perc.”), and whether the authors balanced the dataset before using it (“Balanced”).
The outputs of several of these studies showed a reduced accuracy in the prediction of the minority class if compared to the performance of the majority one [
24,
26,
27,
28,
29,
30,
32]. The other referred to studies included in
Table 1 showed overall metrics of the classifiers only. Therefore, we are not able to evaluate how the MLAs perform on the prediction of the minority class.
3. Methodology
3.1. Workflow
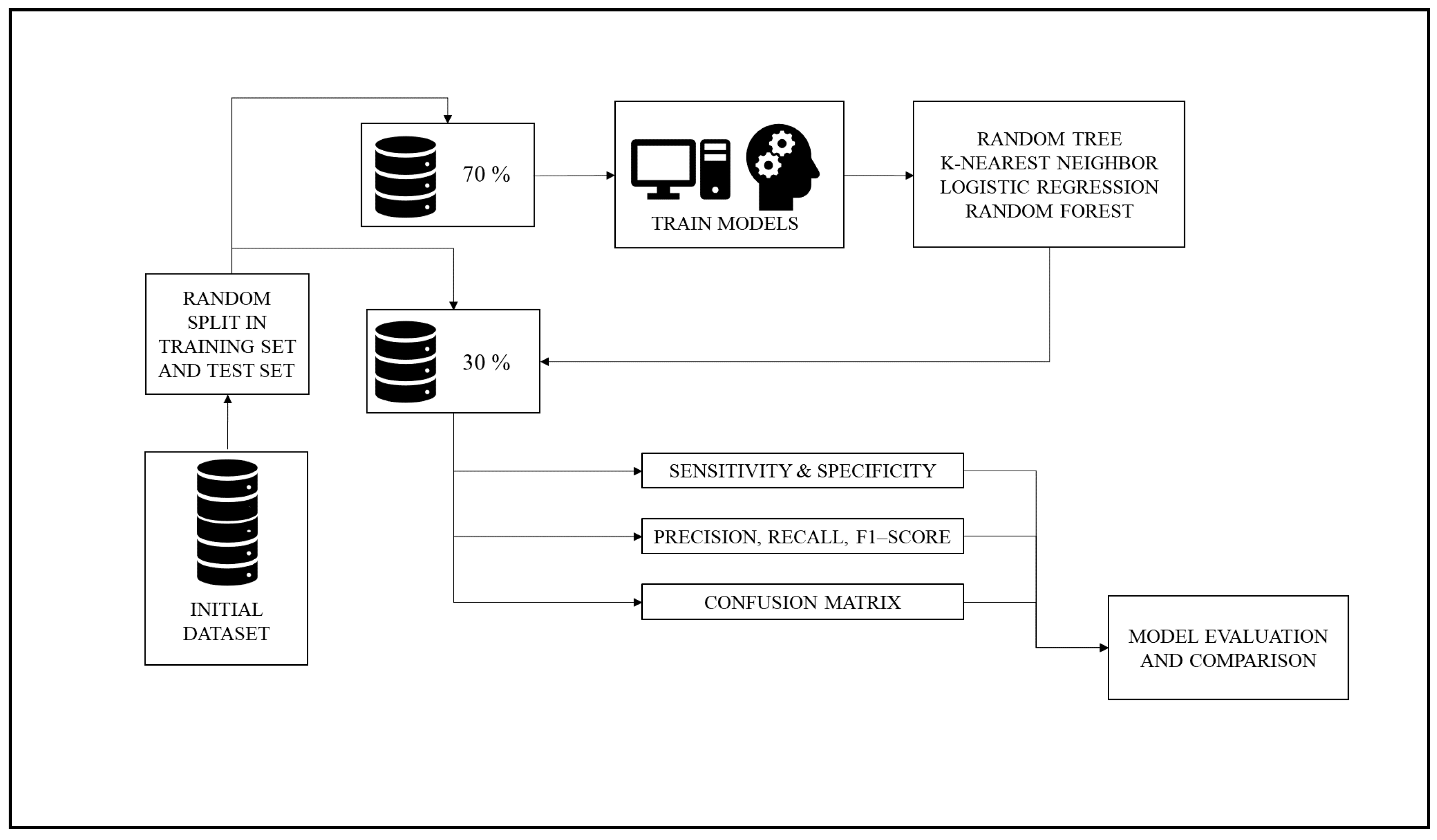
The dataset was randomly split into training and test set; the percentages of 70% for the training set and 30% for the test set were used. The four different MLAs (RT, KNN, LR, and RF) were then trained with the training set. Subsequently, MLAs were employed to predict the crash severity of unknown samples belonging to the test set. A set of performance metrics was computed, and the performance of MLAs compared.
Figure 1 below describes the first phase of the methodology.
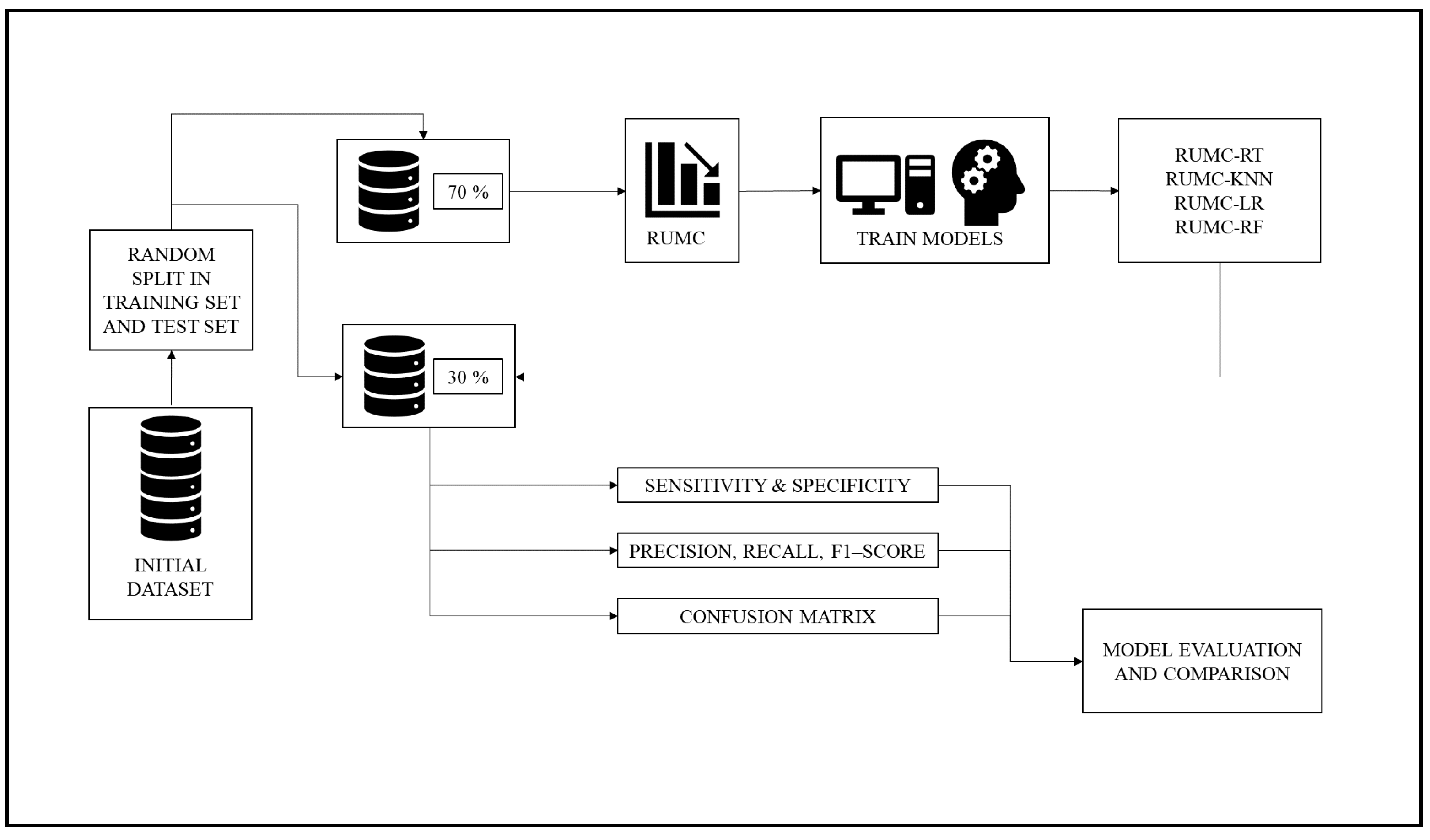
The second phase involves the use of RUMC on the training set before training the MLAs. This operation provides a balanced training set. Once the RUMC is employed, the second phase follows the operations performed in the first one. Finally, we analyzed the outcomes from both phases in order to compare the two models.
Figure 2 below shows the second phase of the methodology.
3.2. Input Features
The dataset contains 6515 crash records that occurred on stretches of road and road junctions in York, Great Britain, from 2005 to 2018. For each accident that occurred, a set of 17 different features related to the roadway, user, and vehicle are reported. These features are the input factors (or independent variables) of the MLAs we calibrated. They are reported in
Table 2.
3.3. Output Classes
The output (or dependent variable) of the MLAs are crash severity classes. The dataset provides three different crash severity classes: fatal crash, injury crash, and PDO crash. These three classes are significantly imbalanced; indeed, there are 5594 PDO crashes (85.86% of the total amount of crashes), 856 injury crashes (13.14%), and 65 fatal crashes (1%). The initial dataset was defined by aggregating fatal crashes and injury crashes. Other studies [
26,
28,
31,
32] merged two or more classes in order to obtain better results.
Figure 3 below shows the three crash severity classes (
Figure 3a) and the initial dataset containing the new merged class (F + I class) and PDO class (
Figure 3b).
Figure 3b confirms that there is still a substantial imbalance between the two classes (ratio of about 1:6).
3.4. Random Undersampling the Majority Class
The RUMC technique involves randomly selecting examples from the majority class and removing them for the training dataset. The majority class instances are discarded at random until a balanced class distribution in the training set is reached (
Figure 4).
Before implementing RUMC, the dataset contains a minority and majority class. After RUMC, we can deal with a balanced dataset.
3.5. Machine Learning Algorithms
Since we aimed at predicting a crash severity class, MLAs for classification (or classifiers) are the most suitable for achieving our purpose. Classifiers are supervised MLAs employed for assigning a label (or a class) to new unknown observations. In order to predict a class, supervised classifiers are trained using a dataset of already-known observations, i.e., samples in which the input features and output class are provided. Usually, the input feature can be nominal, ordinal, or numerical.
It is worth mentioning that Waikato Environment for Knowledge Analysis (WEKA) software was used [
45,
46], version 3.8.4, to carry out the modeling.
The classifiers used in this study are now introduced briefly.
3.5.1. Random Tree
In order to introduce the RT, the Classification and Regression Tree (CART) developed by Breiman is described [
47]. CART is a hierarchical non-parametric approach that grows a tree-based model by repeatedly splitting the dataset into homogeneous zones. The decision rules for splitting each node are learned by inferring directly from the available data. The recursive partitioning algorithm [
47,
48] is used to define the decision rules. Once the CART model is trained, the decision rules can be used for predicting the class of new unknown observations.
CART models have been widely used in machine learning modeling due to their advantages:
They provide an interpretable solution of the predictions using tree graph visualization;
They provide an automatic variable selection making them insensitive to irrelevant variables, outliers, and the scales of predictors;
They are computationally efficient even in large problems (generally, low time for training is required), also allowing missing values of the input factors and both numerical and categorical predictors to be handled;
CART outcomes are unaffected by monotone transformations of the input factors.
However, CART models are prone to overfitting the data by creating over-complex deep trees, and they are sensitive to small changes in the training set: slightly different training sets can lead to significantly different CART models. In order to overcome these issues, the RT provides more robust outcomes than CART models by exploiting the feature randomness approach, i.e., each node of the trees is split into branch nodes using a fixed number of input features, selected at random [
49]. In this study, the number of input factors randomly sampled (
) as candidates at each split is equal to the default value of the WEKA software. The default value was chosen after a “trial & error” approach: indeed,
has been fixed to 1, 2, …, 17, identifying the best accuracy by means of a 10-fold Cross-Validation (CV) process for
equal to the default value of the WEKA software, as computed in Equation (1) below:
where
is the number of input factors. In this study,
= 17, and the resulting
= 5.
3.5.2. K-Nearest Neighbor
KNN was first defined by Cover and Hart [
50]. KNN is an algorithm that aims at classifying an observation by looking at the closest k observations contained in the feature space. The class that belongs to the majority of the
k closest observations is taken as the class of the new observation. Therefore, KNN assigns to an unclassified sample point the class of the
k nearest set of previously classified points. In the implementation of KNN, two hyperparameters are requested to the modeler: the number of the k nearest neighbors and the distance function to employ to define a distance metric between observations into the feature space:
The number of neighbors should be determined by trying different values of k and finding the best accuracy of the classifier after a 10-fold CV process. Considering this, we tried k = 1, 2, 5, 10, 15, 20, and 25. We chose k = 1 considering the highest accuracy;
The Euclidean distance was employed as a distance function to compute the distance between observations. The Euclidean distance
between two points,
i and
j, is defined as:
where:
m is the dimension of the points (i.e., the number of independent variables);
and are the values of the k-th independent variable for observations i and j, respectively.
3.5.3. Logistic Regression
LR classifier was introduced by Berkson [
51] and quickly became one of the most employed algorithms for classification purposes. LR firstly involves a linear multivariate regression between the output (or dependent variable) and input factors (or independent variables). Subsequently, the output of the multivariate regression is passed by a logit function, leading to a numerical output within the range [0, 1]. Indeed, the logit function is a sigmoid function (i.e., S-shaped) that outputs a number between 0 and 1. Equation (3) below defines the logit function.
where:
P(
z) is the probability of an occurrence (crash severity) that varies from 0 to 1; Equation (4) below defines
z, which is the dependent variable of the linear multivariate regression.
where:
is a constant term;
m is the number of independent variables;
(i = 1, 2, 3, …, n) represents the value of the i-th input factor;
(i = 1, 2, 3, …, n) is the regression coefficient assigned to the i-th input factor.
Once the probability
P(
z) has been computed, the LR classifier makes its prediction
as follows (Equation (5)):
Moreover, the regression coefficients determined in the logistic regression can be interpreted as a measure of the relative importance of the independent variables.
3.5.4. Random Forest
Breiman [
52] introduced the RF classifier. RF consists of a large number of individual and uncorrelated decision trees that operate as an ensemble classifier to formulate a prediction. In order to obtain uncorrelated trees, they are assembled using a bootstrap aggregation (Bagging) approach, i.e., creating a subset of training samples through replacement. The algorithm exploits two-thirds of the samples (called in-bag samples) to train the trees, while it employs the remaining one third (called out-of-bag samples) in an internal CV procedure. The CV is used by the algorithm to minimize the error estimation, called the out-of-bag error, and to grow the most reliable RF. There is no pruning procedure in the definition of the decision trees. Moreover, RF exploits the feature randomness approach. By growing the RF with a large number of trees, the algorithm creates trees that have high variance and low bias.
Once the RF has grown, it can predict the class of a new observation by averaging the class assignment by all the decision trees: each decision tree votes for a class and the class with the maximum votes is the selected one for the new observation.
In the implementation of RF, two hyperparameters are requested to the modeler:
The number of decision trees, , to grow: since RF does not overfit the data, the number of decision trees can be as large as possible. However, the higher the number of trees, the higher is the time required for growing the RF. We fixed different values of , specifically, 10, 25, 50, 100, 200, 400, 800, and 1000, evaluated using a 10-fold CV the goodness-of-fit of the models. We chose = 100 trees since a higher number did not produce a significant increase in RF performance, requiring a massive amount of time for training instead.
The number of input factors randomly sampled, , as candidates at each split: in this study, as for the RT algorithm, was chosen after a “trial & error” approach; indeed, has been fixed to 1, 2, …, 17, identifying the best accuracy by means of a 10-fold CV process for equal to the default value of the WEKA software. Therefore, we also chose for RT, = 5.
3.6. Predictor Importance
The RF algorithms allowed the importance of each input factor in predicting crash severity to be evaluated. The leading relations for computing the predictor importance are reported below. Readers can find a comprehensive explanation of the procedure in Breiman [
52] and Louppe et al. [
53]. We remind the reader that a tree,
T, is trained by exploiting a sample of
N observations, using the recursive partitioning algorithm [
47,
48]. This algorithm identifies at each node,
t, the best split,
, (i.e., the feature chosen for splitting the node and the best cut point) for partitioning the
node samples into
and
branch node samples, maximizing the decrease,
, of an impurity measure,
. Trees end at leaf nodes when nodes become pure (all the observations belong to the same class) or when an error threshold is reached. The impurity decrease is computed using Equation (6).
where:
In this study, the impurity,
i(
t), at the node,
t, is represented by the Gini index as follows (Equation (7)):
where:
In RF modeling, Breiman [
52] suggested evaluating the importance of an independent input variable,
, to predict the output class by adding up the weighted impurity decreases,
, for all nodes,
t, when
is used for splitting the nodes, averaged over all
trees in the forest (Equation (8)).
where:
is the importance of the variable ;
is the proportion of samples reaching the node t;
is the independent variable used in split .
3.7. K-Fold Cross Validation Procedure
The concept of CV was introduced first in the study of Larson [
54]. The author split the dataset into two parts: the first one was used for building the regressor and the second one for testing the algorithm. The current k-fold CV procedure appeared subsequently in the book of Mosteller and Turkey [
55]. CV is a method for training, evaluating, or comparing MLAs by distributing data into two sets: one employed for training the model and the other for validating the model [
56]. Frequently, CV assumes the structure of k-fold CV, where the training set is cut into
k folds of the same dimension. Therefore, there are
k iterations of training and validation. At each iteration,
k-1 folds are used for learning, while the remaining fold is used to validate the model. Accordingly, after the CV process, each sample has been used both for training and for testing.
Furthermore, to guarantee that each fold is representative of the complete dataset, data is stratified before being split into folds. A stratification technique prepares the data such that, in every fold, each class is represented by its real percentage in respect to the other classes. Kohavi [
57] recommended stratified 10-fold CV as the best model selection procedure. Several other studies [
5,
15,
21,
22,
32] used k-fold CV. Therefore, we followed a 10-fold CV procedure to train all the mentioned MLAs, by employing all the possible combination of hyperparameters aforementioned. Once the models had been trained with the best set of hyperparameters, we assessed them by computing their performance on the test set.
3.8. Performance Metrics
As said, a large set of performance metrics allows MLAs to be comprehensively evaluated and compared to each other. Equations (9)–(14) define the overall accuracy of the classifier and the precision,
TPR,
FPR,
TNR, and
F1-score.
where:
TP is the number of True Positive instances, i.e., the instances belonging to class 1 correctly classified into the same class;
TN is the number of True Negative instances, i.e., the instances belonging to the class 0 correctly classified into the same class;
FP is the number of False Positive instances, i.e., the instances belonging to the class 0 erroneously classified into class 1;
FN is the number of False Negative instances, i.e., the instances belonging to the class 1 erroneously classified into class 0;
It is worth noting here that class 1 represents the F + I class, while class 0 represents the PDO class. The overall accuracy of the classifier aims to represent the global performance of the classifier. The precision shows the goodness of positive predictions. The TPR, or recall, is the ratio of positive instances that are correctly detected by the classifier. Analogously, the TNR is the ratio of negative instances correctly detected by the classifier. The FPR is the ratio of FP among all negative instances, i.e., the percentage of “false alarms”. The F1-score is the harmonic mean of precision and recall, and it can be used to compare classifiers since it combines two metrics into a more concise one. Precision, TPR, FPR, TNR, and F1-score can be computed as specific metrics for each class or as the overall metrics of the classifier. Finally, we computed the confusion matrix. It reports the TP, TN, FP, and FN as a matrix, in which the rows correspond to the observed (or actual) classes, while the columns correspond to the predicted classes. A satisfactory confusion matrix should have most of the instances on its main diagonal.
In other studies [
15,
17,
18,
20,
22] readers can find
TPR and
TNR as sensitivity and specificity, respectively.
4. Results and Discussion
4.1. Imbalanced and RUMC-Based Training Sets
Figure 5 below reports the training sets and test set.
Figure 5a shows the random split into training (70%) and test set (30%), while
Figure 5b shows the RUMC-based training set.
We observed an imbalance ratio of 1:6 in the training set of
Figure 6a. The RUMC-based training set is balanced correctly instead.
4.2. Performance of the Algorithms
Below, we report the performance of the models on the test set in terms of:
TPR, FPR, and TNR:
Table 3 shows the performance of the models trained by the imbalanced training set (namely RT, KNN, LR, and RF), while Table 6 shows the performance of the RUMC-based model (namely RUMC-RT, RUMC-KNN, RUMC-LR, and RUMC-RF). Both tables report the performance for F + I class, PDO class, and the weighted average performance of the classifier, which is the average of both values weighted by the number of instances in each class of the test set.
Precision, recall, and F1 score:
Table 4 shows the performance of the models trained by the imbalanced training set, while Table 7 shows the performance of the RUMC-based model; both tables report the performance for F + I class, PDO class, and the weighted average performance of the classifier;
Confusion matrix and overall accuracy:
Table 5 shows the confusion matrices of the models trained by the imbalanced training set, while Table 8 shows the confusion matrices of the RUMC-based model. The overall accuracy is presented in terms of the number of correctly classified instances. We also report the number and percentage of incorrectly classified instances.
Although TPR and recall have the same meaning, we report both since TPR is usually presented along with FPR, while precision is commonly accompanied by recall.
4.2.1. Algorithms Trained by the Imbalanced Training Set
Table 3 below reports the
TPR,
FPR, and the
TNR of RT, KNN, LR, and RF algorithms.
As expected,
Table 3 shows that the algorithms present a satisfactory weighted average performance both for
TPR and
FPR. Indeed, the
TPR ranges from 78.5% (KNN) to 85.7% (LR), while
FPR varies from 78.5% (KNN) to 85.8% (LR). However, by observing the specific performance for each class, we can confirm that the classifiers are weak in predicting the F + I class. Indeed,
TPR ranges from 0% (LR) to 18.3% (KNN), while
FPR varies from 0.1% (LR) to 11.5% (KNN). Judging a classifier by assessing the performance for each class seems to be the most suitable and reliable method.
Furthermore, the TNR values denote that the classifier can accurately identify the TN instances when the class examined is the F + I class (i.e., the TN instances belong to the PDO class). In contrast, the classifier is weak at correctly recognizing TN instances when the PDO class is under consideration. TNR represents an additional confirmation that the high percentage of the majority class strongly affects the prediction capabilities of the minority class by the classifiers.
Table 4 below reports the precision, recall, and
F1 score of the models trained by the imbalanced training set.
Table 4 introduces another set of performance metrics that seem to confirm the outcomes of
Table 3. Indeed, by observing the weighted average precision, recall, and
F1 score, we may expect good classifiers. On the contrary, by examining the metrics specified for each class, the weakness in predicting the minority class of the classifier is manifest. Accordingly, when the metrics chosen for introducing a classifier are precision, recall, and
F1 score, we still should consider the specific performance for each class.
Table 5 below reports the confusion matrices and the overall accuracy for RT, KNN, LR, and RF. The main diagonal of each confusion matrix appears in bold.
Since the confusion matrix reports the comparison between the number of observed instances correctly and incorrectly classified for each class, it seems an appropriate performance metric for introducing a classifier. Moreover, using Equations (9)–(14), all the other performance metrics can be computed. By observing
Table 5, we can judge KNN as the best classifier for predicting F + I class (51 out of 278 instances correctly detected), followed by RT (43 out of 278), RF (16 out of 278), and LR (0 out of 278). As for the PDO class, the best classifier is the LR (1677 out of 1678), followed by RF (1631 out of 1678), RT (1498 out of 1678), and KNN (1485 out of 1678).
Considering the overall accuracy, LR seems the best classifier (85.74%), followed by RF (83.38%), RT (78.78%), and KNN (78.53%). Confusion matrices clearly demonstrate that the accuracy is an untrustworthy metric for evaluating the MLA calibrated using an acutely imbalanced dataset. Indeed, the accuracy simply follows the prior percentages of the classes. For instance, the LR (which resulted in the best MLA with an accuracy of 85.74%) simply provides the same prediction for practically all the instances (1955 out of 1956), i.e., it classifies each instance as PDO crash. Considering the percentage of the classes, LR provides the right prediction in 1677 cases, thus the resulting high, but unreal, accuracy. The same considerations can be addressed for all the other MLAs.
4.2.2. Performance of RUMC-Based Algorithms
Table 6 shows the
TPR,
FPR, and
TNR of the RUMC-based algorithms.
Table 6 introduces the trade-off that exists between
TPR and
FPR. Indeed, using a balanced training set, we note a decrease in performance for predicting PDO class and a significant increase in performance related to the F + I class. In the case of RUMC-based models, the ratio of positive instances correctly detected by the classifier (
TPR) increases, while the ratio of negative instances correctly detected by the classifier (
TNR) decreases. For the real application of such models by companies, this is reflected in a more accurate prediction about fatal accidents or those causing injury and a certain number of false alarms (the
FP instances) that are mistakenly classified as severe. Anyhow, for these companies, it is certainly more important that
TPR and
FPR take on this type of trade-off than that shown in
Table 3. The average weighted performances are lower than those of
Table 3, reflecting a more balanced trade-off between the performance of each class. Again, these evaluation metrics are not able to consistently represent a classifier.
Table 7 reports the precision, recall, and
F1 score of the RUMC-based model.
Table 7 shows that the precision for the PDO class is still high. Compared with
Table 4, the precision for the F + I Class is slightly lower for RUMC-RT, RUMC-KNN, and RUMC-RF, while it is significantly increased for RUMC-LR. The recall for the PDO class is decreased, and consequently, we note a significant improvement in recall for the F + I class. As observed for
TPR and
FPR, there is a trade-off between precision and recall. The
F1 score is improved in the F + I class and is decreased in the PDO class. Again, the weighted average metrics do not seem appropriate in describing such classifiers.
Table 8 reports the confusion matrices and the overall accuracy for RUMC-based algorithms.
By observing
Table 8 above, we can confirm the significant increase in classifier performance brought by the RUMC technique. Indeed, the classifiers are now able to predict satisfying both the F + I and PDO class. The best classifiers in predicting F + I crashes are RUMC-RT and RUMC-KNN (159 out of 278), followed by RUMC-RF (158 out of 278), and RUMC-LR (146 out of 278). As regards the PDO class, the classifier with the best performance is the RUMC-LR (1077 out of 1678), followed by RUMC-RF (940 out of 1678), RUMC-RT (838 out of 1678), and RUMC-KNN (789 out of 1678). The higher overall accuracy is reached by RUMC-LR (62.53%), followed by RUMC-RF (56.14%), RUMC-RT (50.97%), and RUMC-KNN (48.47%). Since the dataset is now balanced, the accuracy should adequately represent the overall performance of the classifiers. Considering this, it seems that the best one is the LR; however, that is not to say that the best overall performance always corresponds to the best model to be employed. Indeed, it depends on the scope for which the MLAs will be used. Probably, in the present case, managing bodies and road authorities are more interested in the best prediction of severe accidents (therefore, they may prefer KNN or RT). Thus, specific performance metrics for each class, such as the number of F + I or the number of PDO crashes correctly predicted, are more interesting and useful for choosing the MLAs to be used rather than relying on overall performance metrics.
For application purposes for which these MLAs are designed, the RUMC-based models were the most suitable, considering that they identify the minority class (F + I class) with greater accuracy. Surely, considering the needs of the companies that could use these models, this class is the most relevant of the two severity classes. Having some false alarms (as evidenced by
Table 6–8) should not lead to significant issues in the planning duties of these companies. Indeed, it is more appropriate to examine a false alarm more carefully than to predict a fatal accident such as a PDO accident. Only by consistently recognizing severe accidents (and therefore, the factors that caused them) is it possible to provide adequate planning aimed at reducing and correctly handling the crash severity.
4.3. Predictor Importance
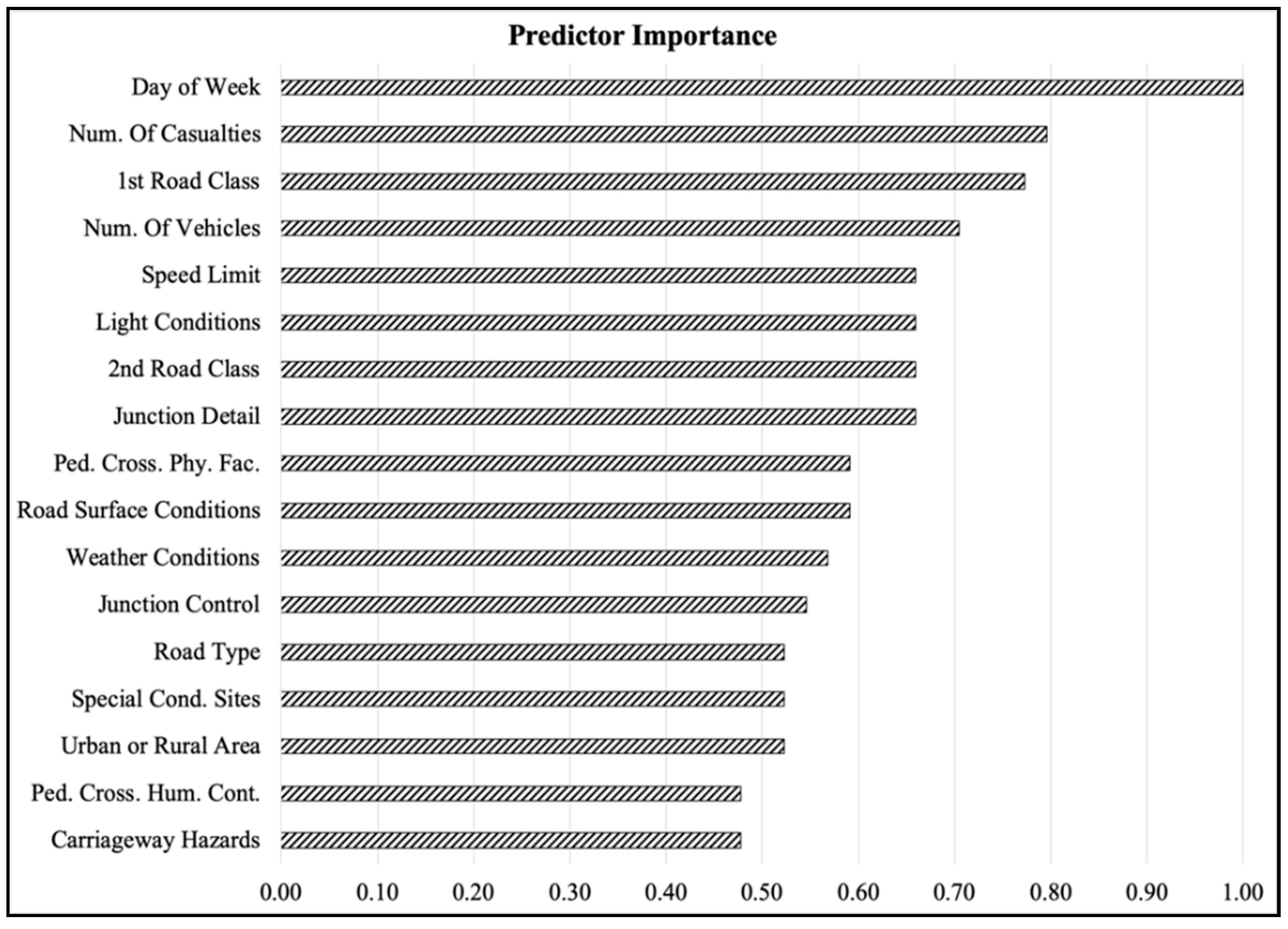
Relying on the Gini index impurity decrease, the importance of each input factor has been computed. For the sake of clarity,
Figure 6 shows the standardized predictor importance, which is the predictor importance calculation rearranged in the range [0, 1].
Figure 6 demonstrates that each input factor has significant importance in determining crash severity since they are all greater than zero. Qualitatively, we can distinguish three leading families among the inputs: high-importance input features, medium-importance input features, and low-importance input features. The term “importance” refers to how much an input factor affects or is associated with the crash severity.
In the high-importance set of input features lie the day of the week, the number of casualties, the first road class, and the number of vehicles. While it was intuitive that the first road class, the number of casualties, and the number of vehicles could have been significant in modeling crash severity, the same cannot be said for the “Day of the Week” factor. This parameter is entirely independent of the factors associated with the infrastructure, circulation, and type of vehicles but is mainly related to user behavior during the week.
Table 9 below shows some data obtained by analyzing the change in crashes as a function of the day of the week.
Table 9 demonstrates that there are significant changes in the number of accidents and the crash severity during the week. Friday seems to be the day in which most of the accidents occur (1123 accidents, corresponding to 17.24% of the total), while Sunday is the day when least accidents happen, with 628 accidents (9.64% of the total). As regards the severity, Friday is the most severe day, with 159 out of 921 F + I crashes (17.26% of the total) and 964 out of 5594 PDO crashes (17.23% of the total). Contrary to overall percentages, Sunday appears to be the most dangerous day, with a probability of 17.99% to be involved in a fatal crash or one causing injury. Tuesday is the day when an accident is more likely to be of the PDO type (probability of 87.56%). These day-to-day changes confirm that the “Day of the week” parameter is essential in assessing the crash severity.
The medium-importance set of input features contains the speed limit, the light conditions, the second road class, and the junction detail. The speed limit may be significant since it is correlated to the road class, while the second road class and junction detail are significant since 3853 out of 6515 crashes occurred at a junction. Therefore, the evaluation of the second road class and the type of junction should be essential in predicting crash severity.
The low-importance set of input features contains all the other input factors.
With a view to road traffic planning by a national road authority, it should, therefore, be appropriate to provide more checks by law enforcement and surveillance over the weekend, or the installation of speed control systems in critical situations should be envisaged. Furthermore, the proper regulation of junctions between roads could alleviate the number of fatal accidents in favor of PDO accidents, as well as mitigate their number.
4.4. Future Works
In order to further improve the present research, additional future works could implement the latest available machine and deep learning models on the same dataset analyzed. For instance, we want to mention some road safety analyses using different types of neural networks that could be implemented: multilayer perceptron neural networks [
14,
27,
29], convolutional neural networks [
28,
40,
58], radial basis function neural networks [
25], recurrent neural networks [
59], and deep Neural networks [
10,
18,
58]. Moreover, other ensemble of learners (in addition to the RF algorithm calibrated in the present study) [
9,
16] and the staking [
32] strategy could also be considered. Having a broad set of calibrated algorithms available, it would be possible to accurately identify the best one for predicting crash severity in the case of highly imbalanced observations.
A further enhancement that could be made is the verification of the algorithms calibrated in this paper on supplementary datasets, in order to confirm whether the test phase carried out provides the real reliability of the models.
5. Conclusions
The paper aimed to predict road crash severity by employing MLAs. We suggested a procedure for handling imbalanced accident datasets in order to predict the minority crash severity class appropriately. Below, the main findings and the methodology are briefly recapped.
Firstly, a comprehensive literature review related to crash severity prediction using MLAs was carried out: a noticeable number of recent papers in which the authors used MLAs relying on an acutely imbalanced dataset was found. These algorithms have satisfactory performance in predicting the majority class (e.g., PDO crashes,) and poor performance in predicting the minority class (e.g., fatal or injury crashes). For the purposes for which such MLAs should be used, the minority class assumes generally greater importance than the majority one. Therefore, oversampling and undersampling techniques have been introduced in order to handle imbalanced datasets, along with the reasons why the RUMC has been followed in the present paper.
The available dataset was split randomly into a training and test set; an RUMC approach was applied to the training set to provide a new balanced one. Therefore, two types of MLAs were trained onto these two different sets using a 10-Fold CV. Four algorithms trained on the imbalanced training set (RT, KNN, LR, and RF) and four algorithms trained on RUMC-based training set (RUMC-RT, RUMC-KNN, RUMC-LR, and RUMC-RF) are provided. Both types of algorithms were tested on the same test set, allowing us to compare the outcomes and evaluating our suggested procedure. A broad set of performance metrics, including TPR, FPR, TNR, precision, recall, overall accuracy, and the confusion matrix, was computed for each algorithm. We showed that metrics related to specific classes are more representative of the real performance of the classifier than overall metrics. Moreover, it seems that the confusion matrix is the most appropriate and suitable representation for describing the predictive capacities of a classifier. We also showed that accuracy is untrustworthy metric if it is computed for MLAs trained on imbalanced datasets.
As regards the performance of the algorithms, the RUMC-based models showed better predictive capabilities in detecting the minority class than the algorithms trained by the imbalanced dataset. The best classifiers in predicting fatal crashes and those causing injury are RUMC-RT and RUMC-KNN (159 samples out of 278 correctly identified), followed by RUMC-RF (158 out of 278), and RUMC-LR (146 out of 278). As regards the PDO class, the classifier with the best performance is the RUMC-LR (1077 samples out of 1678 correctly identified), followed by RUMC-RF (940 out of 1678), RUMC-RT (838 out of 1678), and RUMC-KNN (789 out of 1678). The higher overall accuracy is reached by the RUMC-LR (62.53%), followed by RUMC-RF (56.14%), RUMC-RT (50.97%), and RUMC-KNN (48.47%).
Finally, the importance of each input factor was computed using the average Gini index impurity decrease. All the input factors have significant importance in predicting crash severity. The most relevant input factors are day of the week, number of vehicles, casualties involved, and the first road class.
Relying on all these findings, we can conclude by asserting that the use of balanced MLAs is recommended as a promising tool for crash severity modeling and prediction. The use of balanced datasets appears to be essential for correctly predicting accidents with higher severity. National road authorities, insurance companies, hospitals, and all the other companies interested in crash severity can make use of MLAs and the RUMC technique for managing their duties properly.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}