1. Introduction
In recent decades, building information modelling (BIM) has become one of the most significant emerging technologies in the architecture, engineering and construction (AEC) industries. The applications of BIM are gaining popularity in numerous fields such as transport infrastructures [
1,
2,
3,
4], 3D city modelling [
5,
6], economic systems [
7,
8] and mechanical, electrical and plumbing (MEP) fields [
9,
10,
11]. BIM is defined as an intelligent 3D model that provides information about the assets during the project lifecycle, which is useful to plan, design, create and operate infrastructures and buildings more efficiently. BIM aims to have benefits like cost reduction and control, coordination and collaboration, better customer service, production quality and easy maintenance [
11,
12]. In this way, it saves time and gives a complete picture to the project team so that they can easily maintain and operate buildings and unravel any complexities that might arise. Despite the benefits, some challenges are still faced, such as interoperability, big data and a lack of automatic processes. Therefore, standard platforms for integration and standardisation are necessary for developing BIM to predict and analyse the future stages of as-built models or new building models. For successful BIM implementation, high-performing measurement, sufficient attribute information and accurate graphics are the most important factors. Laser-scanning advancements have increased the usefulness and accessibility of 3D measurement devices in BIM. These sensors make direct measurements from the sensor to objects in the surroundings and are extensively employed in BIM models. Using attributes of the objects in the model, BIM can indicate what needs to be measured. It assists in determining the dimensions of any object by measuring points within the scanning range. The vast volume of data generated by 3D-measurement laser scanners needs to be processed and transmitted efficiently. It is, therefore, necessary to have a thorough understanding of point-cloud processing algorithms and BIM standards. At present, LiDAR is seen as a robust method to collect 3D measurement points more efficiently. The process of capturing a physical site or space using scan data, from the air or from the ground, to develop an intelligent 3D model by employing BIM software, is known as ‘Scan to BIM’ [
13,
14].
General Framework: Scan to BIM
The Scan to BIM process is used to produce the as-built model of an asset that tends to suffer from a lack of information, outdated plans or incomplete documentation. This is where the Scan to BIM plays a vital role. This process takes point clouds as an input and outputs a final 3D reconstruction model where all the assets are classified or labelled. The framework design consists of the following steps:
Data capture: Laser-scanner technologies play a fundamental role in the construction of an as-built BIM. The data are captured in the form of raw point clouds. There are also other methods to generate point clouds such as photogrammetry. However, this method is time-consuming and its accuracy degrades when surveying large areas. In this step, certain points must be clear—for example, scanning parameters, point clouds’ resolution, and their density—with appropriate equipment selected according to the user’s application.
Semantic segmentation: Once the registration of all the scans is completed, it is combined into a single 3D point cloud. Then, assets are detected and classified, which can be further processed in BIM software.
BIM model: In the last step, standards such as IFC and gbXML are applied to exchange the information between software applications for BIM.
To our knowledge, this is the first review that focuses on the entire chain of the Scan to BIM framework. Existing research focuses on one of three topics: point-cloud processing, 3D reconstruction or building information modelling [
15,
16,
17]. However, none of these studies has given a comprehensive review of the Scan to BIM framework. Recently, the authors in [
17] published a survey based on the 3D reconstruction of buildings, which mainly focused on data acquisition and processing techniques. In contrast, our paper gives detailed information regarding scanning technologies, point-cloud data-processing techniques for sampling, registration, and semantic segmentation, as well as the open standards used in BIM, which will be useful for new researchers. This will help academics and even construction companies to comprehend the challenges they face and gain useful insights into future trends.
2. Research Methodology
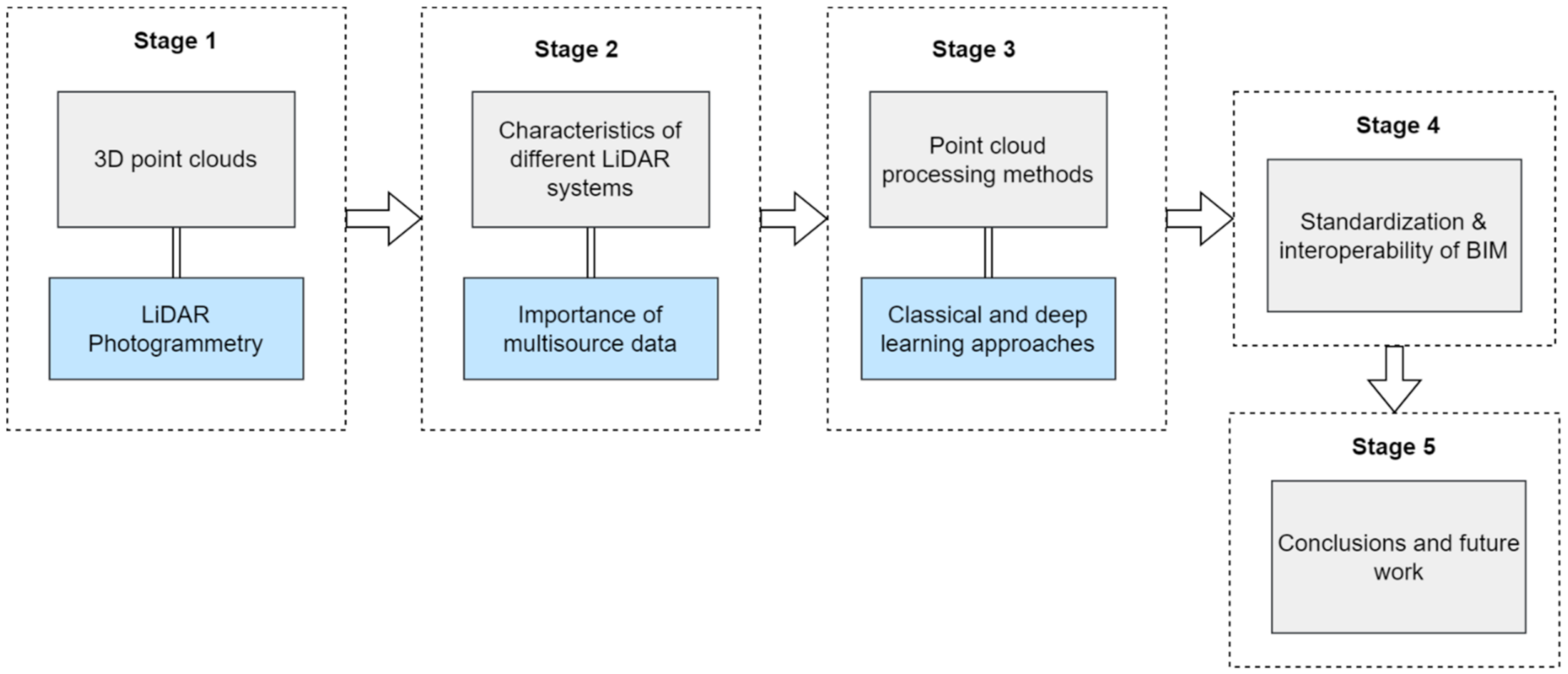
Figure 1 outlines the structure of the review paper. In the first stage, we focus on the importance of 3D point clouds obtained from LiDAR and photogrammetry and outline how LiDAR data is useful in BIM. In the next stage, LiDAR systems based on different platforms are outlined and compared. Additionally, the importance of combining multisource data from different LiDAR and photogrammetry methods is discussed. In stage 3, various point-cloud processing methods are explained and major challenges of traditional and deep-learning approaches are outlined, which can be critical for developing the Scan to BIM framework. Stage 4 defines the interoperability and open standards for Scan to BIM. The last stage concludes and identifies future research directions.
To carry out a comprehensive review, Elsevier Scopus and Google Scholar were mainly used.
Table 1 illustrates the literature search keywords. The keyword search was carried out utilising the “AND” and “OR” Boolean operators to combine keywords, for example, “Scan to BIM” AND “point clouds”, “registration” AND “deep learning”.
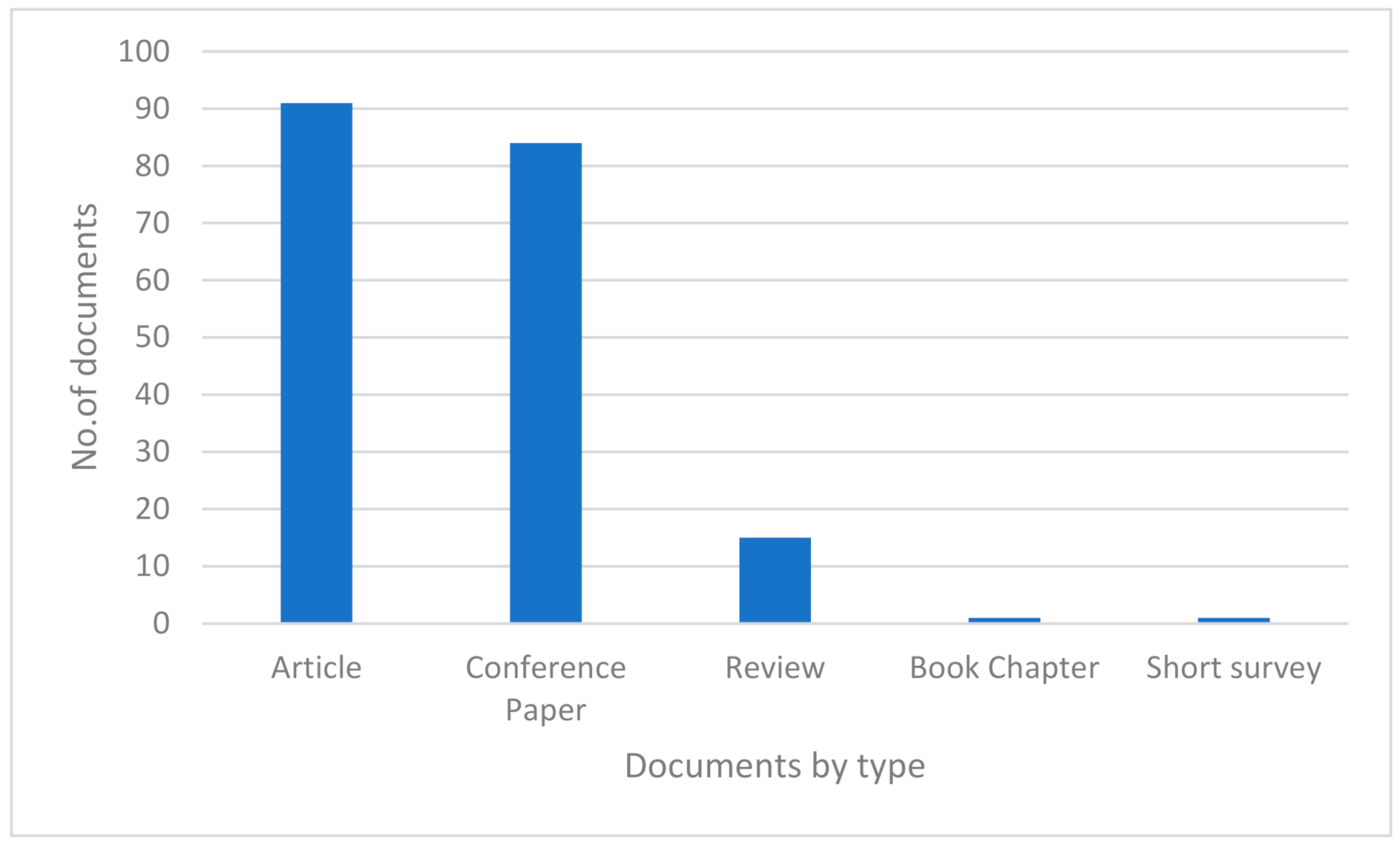
Furthermore, the numbers of different document types sampled—articles, conference papers, reviews, book chapters and survey papers—are specified in
Figure 2. There are 91 article papers and 84 conference papers, followed by 15 review papers, 1 book chapter and 1 short review.
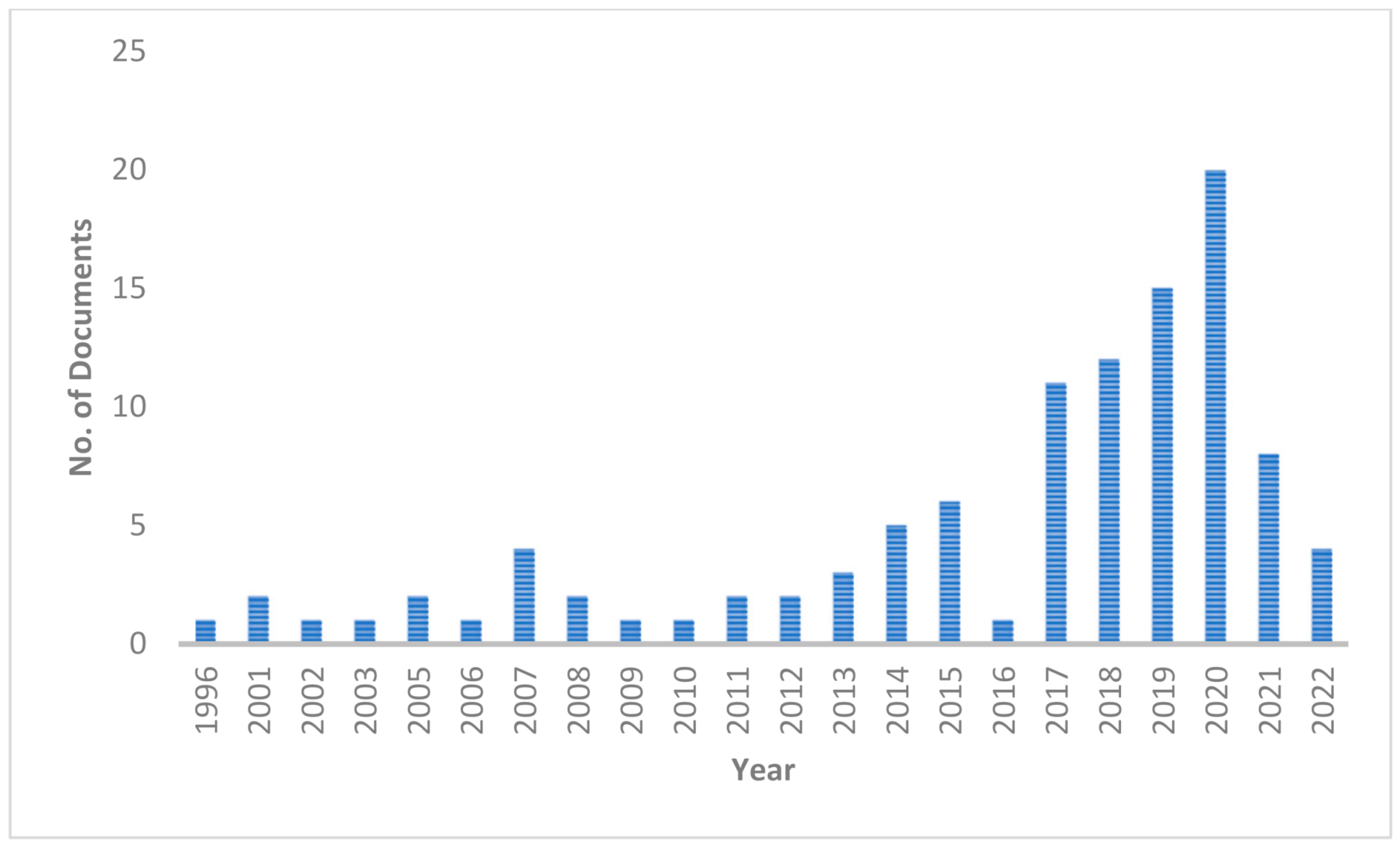
Figure 3 displays the relevant papers published per year related to BIM, point-cloud processing and BIM standards.
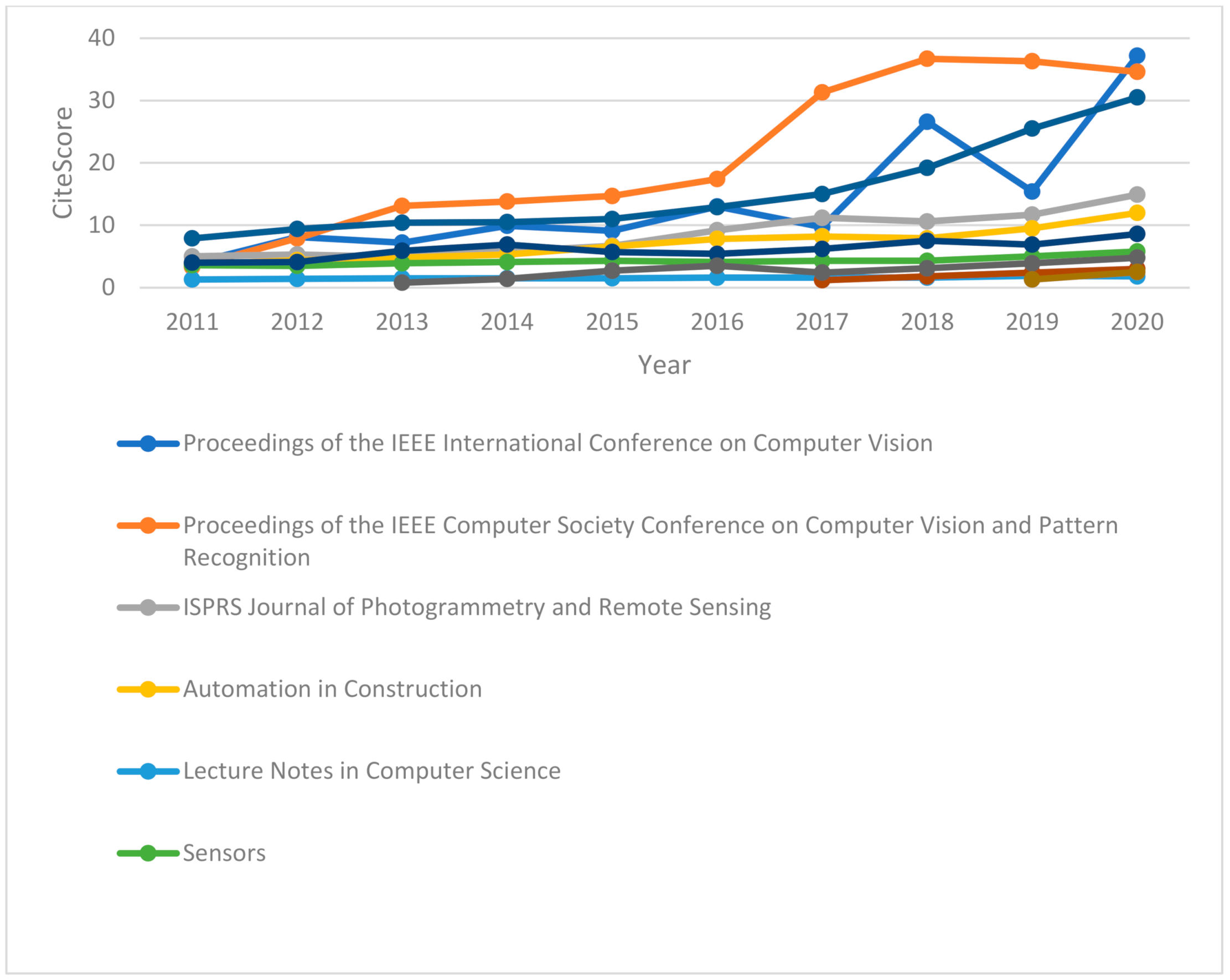
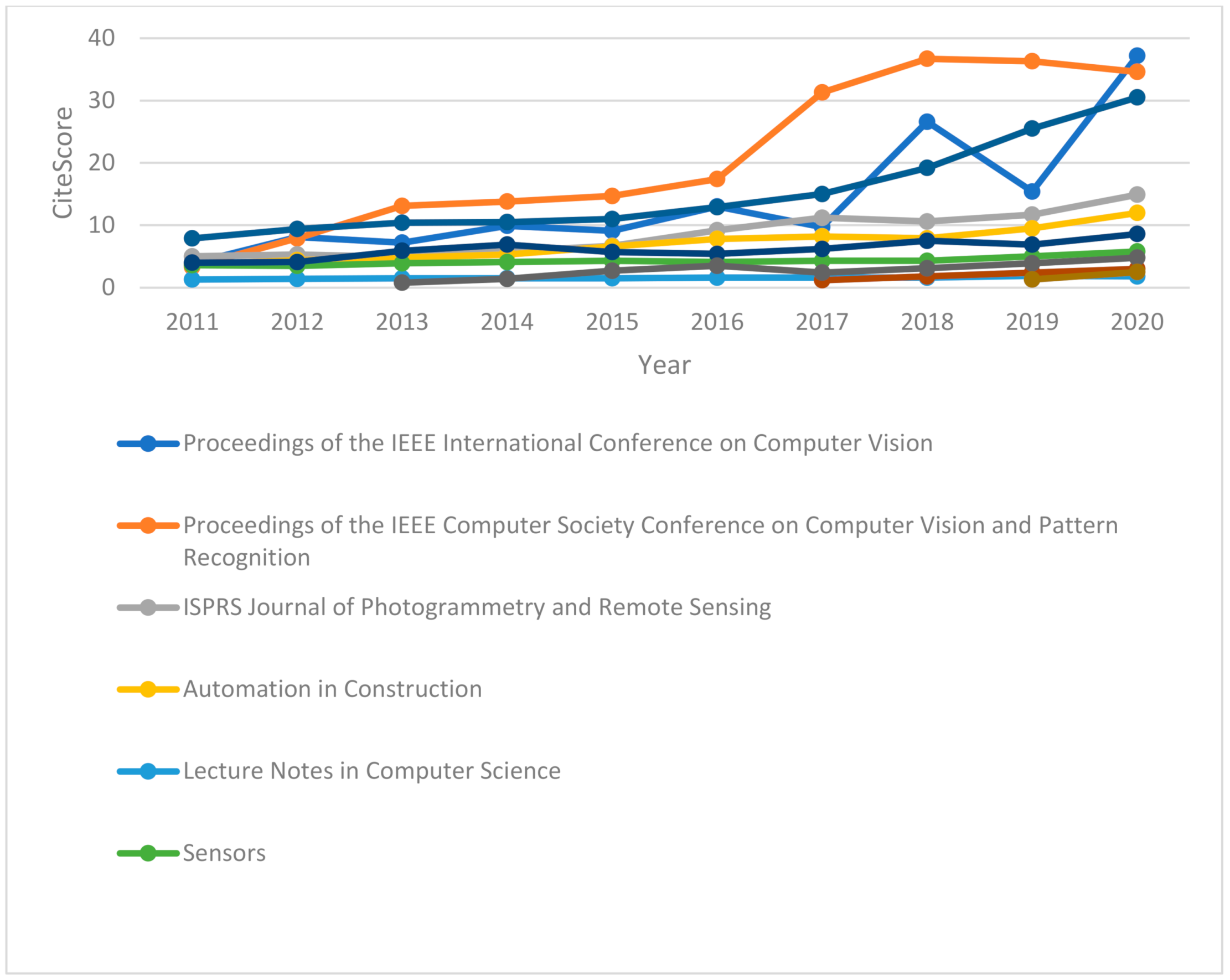
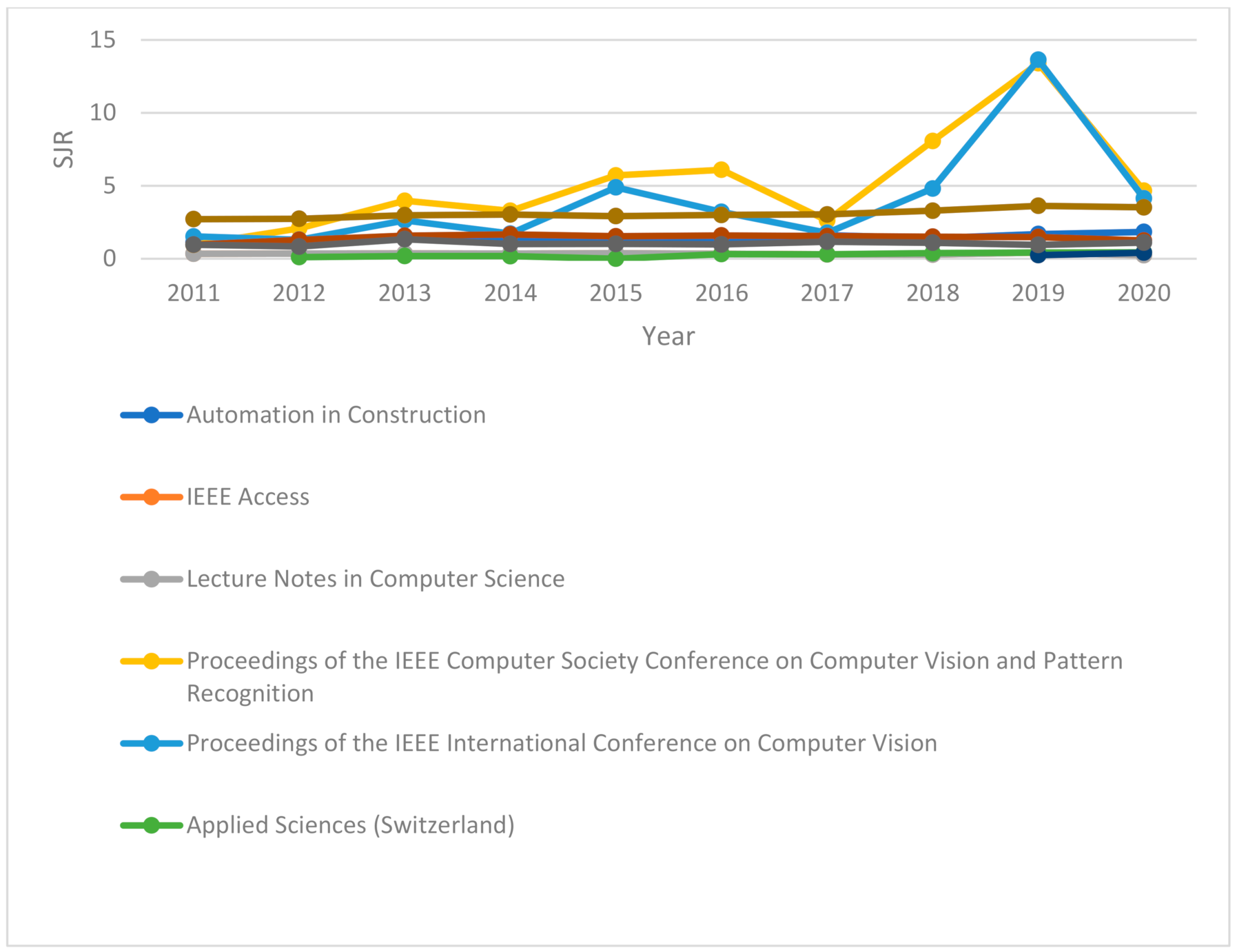
Figure 4 and
Figure 5 show the CiteScore and SCImago journal rankings from 2011 to 2020. The top 11 journals have been included in the graphs. According to
Figure 4, the Proceedings of the IEEE International Conference on Computer Vision gained the highest CiteScore at 37.2, and the second most commonly cited publication was the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. These journals are mostly related to deep-learning methods of point-cloud processing. It can be seen that the trend of researching deep-learning algorithms is increasing rapidly. However, they have not been applied to large datasets of point clouds in Scan to BIM.
To determine which publications should be included, we first limited our search to point-cloud processing based on LiDAR data, and then we searched for BIM and open BIM standards. In the sample, 71% of the papers in this study are related to point-cloud processing methods and BIM, and 29% are related to BIM and BIM standards. We found that deep-learning methods based on registration and segmentation are not fully employed in the Scan to BIM framework. To address the aforementioned gaps, this article gives a detailed review of the state-of-the-art point-cloud processing methods, to establish a basis for construction applications, more specifically, ones in large-infrastructure BIM.
The main aim of this paper is to summarise the potential held by processing 3D point-cloud data from the perspective of LiDAR and photogrammetry of different platforms, such as terrestrial, mobile, and airborne platforms, within the Scan to BIM framework. Then, the subsequent processing steps like registration and semantic segmentation can be implemented and merged with different standards (IFC, gbXML), which can be used as a foundation to build BIM.
3. 3D Point-Cloud Data
The foundation for 3D models in a built environment, in Scan to BIM, is point clouds. A point cloud is a collection of points where each has its own set of x, y and z coordinates, and in some cases, additional attributes (intensity, RGB, GPS time), representing the recorded environment in terms of its 3D shape or feature. Scan to BIM is used in modelling in such applications as urban planning, environmental monitoring, disaster management and simulation. The geometry of the 3D object is captured by combining a large number of spatial points into a single dataset with a common coordinate frame.
The two most common approaches in remote sensing to generate point clouds are photogrammetry and LiDAR.
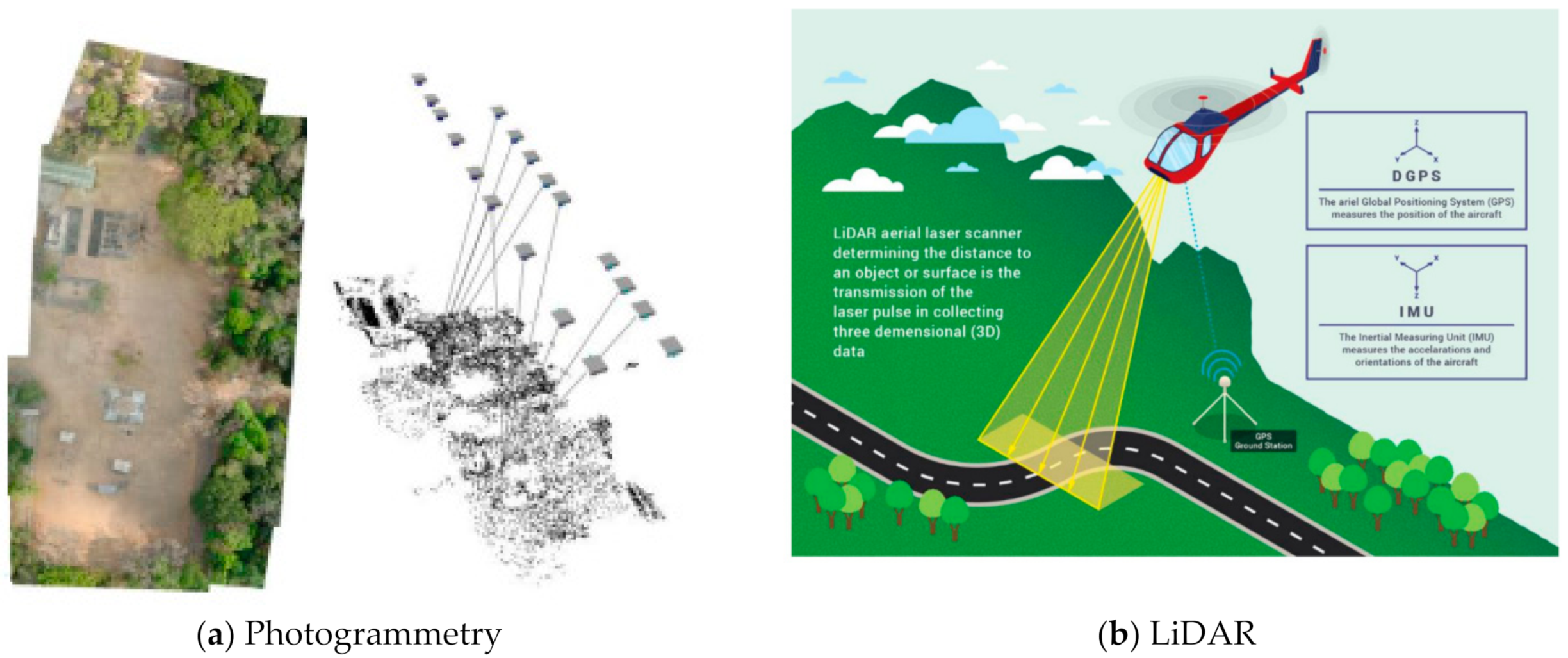
Figure 6 illustrates the surveying images of photogrammetry and LiDAR. Photogrammetry is a passive remote-sensing technique that captures multiple digital images from different angles to determine the geometry of an object. It provides coloured and fully textured point clouds and is quick and cost-effective. On the other hand, LiDAR is an active remote-sensing technique that emits laser beams to measure the environment. It illuminates the surface with a series of laser lights. The time it takes for the reflected light to reach the sensor is measured by the system.
Depending on the environment to be captured, each technique has its own set of features. LiDAR is the most promising tool and is widely used for Scan to BIM applications because of its high accuracy and speed. Photogrammetry, on the other hand, produces less complicated data but requires more processing time. LiDAR and photogrammetry may also complement each other [
20] and are receiving tremendous interest in the development of remote-sensing technology. Related work is further discussed in
Section 4.2. A comparison of photogrammetry and LiDAR is made in
Table 2. In case study [
21], the authors examined and compared the accuracy of aerial LiDAR, mobile-terrestrial LiDAR and UAV photogrammetry data elevations. They concluded that mobile-terrestrial or UAV photogrammetry is more ideal for as-built projects when terrain models of roads or other paved surfaces are required. Aerial LiDAR, on the other hand, is more suitable for larger projects, especially surveying undeveloped areas, because of its high accuracy.
The quality of the point cloud is mainly evaluated by its accuracy, precision, point density and resolution. Accuracy refers to the closeness of the measured value to the true (actual) value, whereas precision is the closeness of repeated measurements of the same object. It is worth noting that since the true value of 3D spatial coordinates is not known, the accuracy of the true value can only be estimated [
22]. Point density, on the other hand, is the number of points per square metre, while resolution deals with the level of identifiable details in the scanned point clouds. Not all instruments necessitate the same degrees of accuracy and point density. The levels required mainly depend on the acquisition and processing times. Moreover, they are influenced by further factors such as the geometry of the scan, environmental conditions, types of instruments used, etc.
Many challenges are associated with processing large LiDAR point clouds, including data storage and integration. Processing generates a large amount of data in a minimum amount of time. The challenges associated with collecting, storing and processing massive data make the point clouds class as ‘big data’ [
23]. The authors in [
24] explained big data as characterised by five Vs. Data from multisource and multimodal sensors are heterogeneous (variety), which results in massive data (volume). Due to this, significant time is required, which reduces the processing efficiency (velocity) and increases the demand to convert a vast amount of point cloud data into reliable (veracity) and actionable data (value). Therefore, it becomes critical and time-consuming to process and exchange such huge data. For example, the computational cost increases as the size of the point cloud increases, leading to time complexity. To address this bottleneck, compression methods have been adopted in numerous applications for 3D point clouds [
25,
26,
27], which alleviate the problem of large-volume point clouds, to maintain the same quality of information.
4. LiDAR Systems
The recent development of georeferenced data-capture devices based on light detection and ranging (LiDAR) is becoming popular in the development of remote-sensing technology. LiDAR was first developed in the early 1960s for meteorological applications. Due to its ability to capture three-dimensional spatial data in a short data-acquisition time and accurately, LiDAR is being used widely for applications such as 3D modelling analysis, asset inventory, topography, forestry management, HD maps, etc. There are two methods for range measurement in LiDAR: the (i) time of flight (ToF) and (ii) phase shift [
28]. Commercial laser scanners using the ToF principle are Teledyne Optech [
29], Riegl [
30], Velodyne [
31] and SICK [
32], while commercial phase-shift laser scanners are FARO Focus 3D [
33], Hexagon-Leica [
34], Z + F IMAGER
® 5016 [
35] and Trimble GX [
35]. Phase shift has a medium-range, high accuracy and is fast, while ToF has a longer range and is slightly less accurate than phase shift [
36].
Until now, LiDAR has been the most relevant data source for acquiring point clouds as it is reliable, accurate and less prone to error. The data can be obtained in various ways using airplanes (airborne), satellites (spaceborne) and ground-based modes (terrestrial or mobile). Most LiDAR systems (airborne, spaceborne and mobile) are integrated with a global navigation satellite system (GNSS) and inertial measurement unit (IMU), which determine the position, distance and orientation of the vehicle, respectively. IMUs are used to measure the accurate position, trajectory and orientation of aircraft, while the purpose of the GNSS is to identify the absolute location in terms of X, Y and Z.
4.1. Classification of LiDAR Systems
This study will focus on three main LiDAR systems, which are the key technologies serving as inputs for Scan to BIM, namely: mobile laser scanning (MLS), terrestrial laser scanning (TLS) and airborne laser scanning (ALS). The high-quality data, fast acquisition speed and longer measurement range of laser scanners mean they have a significant benefit over other LiDAR systems, such as triangular-based LiDAR, which has a short measurement range and is more suitable for small objects [
37]. Laser scanners differ in terms of their resolution and spatial extent.
Table 3 further compares LiDAR systems based on their characteristics and applications.
4.1.1. Terrestrial Laser Scanning
Terrestrial laser scanning is mounted on a non-moving tripod and is used for static scans. This performs well in high-resolution mapping of the landscape, terrain or vegetation with a range limit of 0.5–6000 m and where small infrastructure is being surveyed. Moreover, TLS has a higher resolution compared to other LiDAR since those are static scanners.
4.1.2. Mobile Laser Scanning
Mobile laser scanning is mounted on a moving platform such as a van, railway, backpack, boat or vehicle. MLS is incorporated with a laser scanner, GNSS and IMU. It is the most widely used technology to collect point-cloud data and has received much attention in transportation applications as road features can be captured with a high level of detail. MLS can provide very accurate (centimetre-level) point clouds with high point densities (up to a few thousand points/m
2) [
38].
4.1.3. Airborne Laser Scanning
An airborne laser scanner, on the other hand, is mounted on a helicopter, plane or drone to collect data at a very high speed. Again, it consists of laser scanners, GNSS and IMU. ALS is widely used in terrain mapping, urban monitoring, vegetation monitoring, power line detection, etc. However, ALS has a lower density compared to terrestrial and mobile laser scanners and becomes expensive when covering large areas.
4.2. Multisource Point-Cloud Data
When there are noisy data induced by a complex environment or missing information, data captured from a single source becomes inadequate for 3D reconstruction. As stated in
Table 2, LiDAR (ALS, MLS, TLS) and photogrammetry have different characteristics and scanning perspectives. For instance, terrestrial and mobile LiDAR capture data from a side-scanning view with a high resolution, whereas airborne LiDAR captures data from the top view covering large areas but has low resolution. In some cases, ALS fails to provide complete information on objects such as building facades and trees beneath their canopy. This is where ground-based LiDAR (mobile and terrestrial) has proven to be useful in providing data faster and with a high resolution. Photogrammetry provides semantic and textural information, with a high automation level, high horizontal accuracy and low cost, but it cannot operate efficiently in low-lit conditions. LiDAR, on the other hand, has high vertical accuracy and can operate in low-lit conditions. These technologies complement each other, providing high-quality and accurate 3D models that can be obtained at the automation level.
To combine data from multisource scans, the point clouds must be aligned in a common coordinate frame. This can be achieved using registration methods, where two point clouds are first aligned in a common coordinate frame. Local co-registration is applied and then unnecessary points, outliers and noise are filtered out to obtain compatible point clouds [
39]. Weng et al. [
38] proposed the integration of point clouds in three levels: low, medium and high. At the low level, point clouds from different sources are processed separately and then merged to obtain final results. At the medium level, features are extracted from one data source, and based on that extracted information, the second dataset is analysed for the final results. At the high level, all the data sources are directly transformed into a single coordinate frame, and then further processing is done of the combined dataset. Although their proposed approach seems plausible, it has not been tested or validated yet. Registration methods are further discussed in detail in
Section 4.2.
Numerous studies have attempted to use multisource data in various applications such as 3D building models, urban mapping, forest inventories, agriculture and flood disasters. Multisource data can be achieved by combining different LiDAR platforms (aerial, mobile and terrestrial) or LiDAR with photogrammetry. For example, Yang et al. [
40] and Cheng et al. [
41] achieved automatic registration of terrestrial and airborne point clouds using building outline features. Yan et al. [
42] combined two terrestrial point clouds (TLS-TLS) and TLS-MLS point clouds using a genetic algorithm. Son and Dowman [
43] extracted building footprints by combining satellite imagery data with airborne laser scanning. Romerio-Jaren and Arranz [
44] used TLS and MMS point clouds to determine 3D surfaces from building elements. Kedzierski et al. [
45,
46] and Abdullah et al. [
47] generated 3D building models by integrating terrestrial and airborne data. Gonzalez-Jorge et al. [
48] combined aerial and terrestrial LiDAR data to survey roads and their surroundings, while Zhu and Hyyppa [
49] used ALS and MLS data to extract and reconstruct 3D models in a railway environment. To enhance the extraction of the road centreline, Zhang et al. used high-resolution (VHR) aerial images and LiDAR [
50].
Combining multisource data is advantageous in many ways; nevertheless, there are some challenges with heterogeneous point-cloud data. LiDAR and photogrammetry have different scan view angles, light intensities and point densities, which make data registration difficult. Small overlaps occur, which make it hard to match the correspondence between the point clouds, resulting in poor automation and loss of 3D information. Existing literature has tried to solve this issue. However, such methods still need improvement and more efficient algorithms are required to align and unify heterogeneous point-cloud data.
5. Point-Cloud Processing
Processing a 3D point cloud involves registration, sampling and outlier-removal techniques and compression methods so that subsequent steps like segmentation, object detection and classification can be implemented. When the data are acquired from LiDAR or photogrammetry, they take the form of raw point clouds. These point clouds must first be aligned and combined in a common coordinate frame, which is called registration. Outlier-removal techniques are used to remove the noise and outliers present in the point clouds, while sampling or compression methods are applied to reduce the size of the point clouds.
5.1. Down-Sampling
Point clouds generated by LiDAR are very large and it becomes difficult and time-consuming to carry out processes such as registration, segmentation and 3D reconstruction. To lift the burden, sampling is necessary. Generally, sampling is the pre-processing step for 3D point clouds. Other processes such as filters and outlier removal are also considered in the pre-processing steps. Further details about the filtering methods of point clouds are presented in review paper [
51]. Fast and efficient down-sampling is important and is the first step to process point clouds. Until now, there has been no in-depth review paper published on 3D point-cloud down-sampling. This section will review the existing algorithms for sampling 3D point clouds. Software such as CloudCompare, Leica and Z+F Laser Control software, Autodesk and Geomagic Suite are often used in down-sampling 3D point clouds.
Different approaches have been developed to sample point clouds. Al-Durgham [
52] proposed an adaptive down-sampling approach where points in a low density are kept, while redundant points in a high density are removed. This method has since been adopted in various studies. Lin et al. [
53] extended the method based on planar neighbourhoods. Al-Rabwabdeh et al. [
54] incorporated planar adaptive down-sampling and Gaussian sphere-based down-sampling methods for irregular point clouds. This method was time-consuming, however, as it evaluated the local density based on the neighbouring information, hence limiting the ability to accelerate its performance.
Another sampling approach is octree-based, which was developed by El-Sayed et al. [
55]. The authors presented an octree-balanced down-sampling approach with principal component analysis (PCA). In this method, point clouds are first converted into small cubes using the octree approach. The cubes are then down-sampled based on their local densities. Finally, PCA is applied on a down-sampled octree structure.
The methods based on down-sampling the points in normal spaces are normal-space sampling (NSS) [
56] and dual normal-space sampling (DNSS) [
57]. NSS samples the points in translational normal spaces, while DNSS samples the points in both translational and rotational components. NSS and DNSS have low computational costs and are simple methods. However, they are not suitable for large-scale point clouds as they ignore the spatial distribution of the sampling points.
For large-scale point clouds, Labussiere et al. [
58] proposed a novel sampling method named the spectral decomposition filter (SpDF). This approach aims to reduce the number of points while retaining the geometric details with a non-uniform density. First, geometric primitives are identified, with their saliencies, from the input point clouds. Then, density measures from saliencies are computed for each geometric primitive. If the geometric primitive density is higher than the desired density, each geometric primitive is sub-sampled, and the process is repeated until the density is less than the desired density. In the end, it provides an output as a uniformly sampled point cloud, which can be used efficiently in large-scale environments. However, the computational time required for this method is high and may limit its real-time applications.
To reduce large datasets, Wioleta Błaszczak-Bąk [
59] developed an optimal dataset method (OptD) for ALS point-cloud processing, specifically for digital terrain applications. The OptD method is a fully automated reduction method that produces an optimal result based on optimisation criteria. It can be performed in two ways: OptD-single, based on single-objective optimisation, and OptD-multi, based on multi-objective optimisation. The OptD methods have also been leveraged in MLS [
60,
61]. For example, the authors in [
60] modified the OptD method called OptD-single-MLS to handle MLS data. This method was tested on both raw sensory measurements and georeferenced 3D point clouds. OptD methods have also provided viable solutions when using TLS datasets for sampling in building and structure diagnostics [
62,
63,
64]. Recently, Blaszczak-Bak et al. [
65] used the OptD approach to reduce the data from LiDAR datasets’ ALS/MLS, to extract off-road objects such as traffic signs, power lines, roadside trees and light poles. It is apparent from
Table 4 that methods such as adaptive down-sampling, OptD, octree-based methods and SpDF work efficiently with mobile, terrestrial and aerial LiDAR, while other methods are only limited in their appropriateness to small datasets.
5.2. Registration Methods
Registration of point clouds is the most crucial step to process point clouds in Scan to BIM. Registration finds the relative position and orientation in a global coordinate frame, to find the corresponding areas between point clouds. Several reviews have been published on point-cloud registration methods. Some of them focused on traditional registration methods [
67,
68] and some addressed deep-learning methods [
69,
70]. Together, these studies outline how existing registration methods remain insufficient for large datasets. Hence, more robust algorithms should be developed to evaluate the performance of point-cloud registration, taking the following factors into account: outliers caused by moving objects, varying overlaps and the operational speed.
5.2.1. Traditional Methods
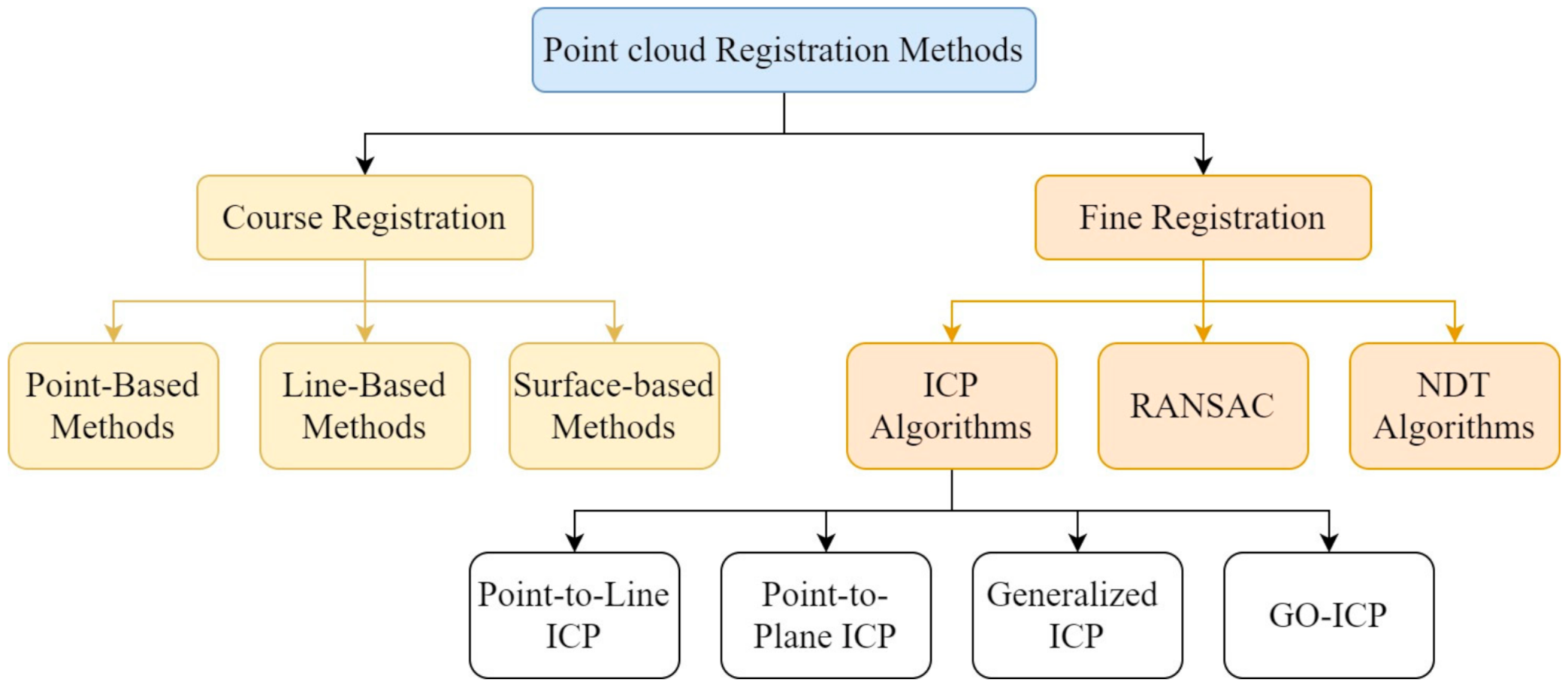
According to the study [
67], traditional point-cloud registration is divided into two parts: coarse and fine. Coarse registration is used in rough estimation work to match the correspondence of 3D features of two point clouds. It is also known as the feature-based method and is classified into point-based, line-based and surface-based methods. Yet, this type of method becomes complicated when using targetless and automatic algorithms [
71], providing poor results. Generally, the coarse registration method is performed initially to roughly align the point clouds, and then fine registration is applied to transform the two datasets using iterative approximation methods, to improve the accuracy. This process is known as coarse-to-fine registration.
The main function of the fine registration method is to obtain the maximum overlap between two point clouds by reducing the error function. This can be done by using iterative closest point (ICP) algorithms, random sample consensus methods (RANSAC) [
72,
73] and normal distribution transform (NDT) methods. Fine registration uses an iterative process to transform two point clouds more precisely. By minimising the predefined error function, the method optimises the transformation matrix, resulting in an accurate solution. Iterative approximation is one of the most popular methods for accurate and stable registration of 3D point-cloud data. In this method, firstly, the correspondence between two sets of points is identified, and then the average distance between the two sets is minimised for an optimal rigid transformation. However, a fundamental issue with the classical ICP algorithm is that the initial value of the iteration must be specified; otherwise, the first local minimum may occur and the results may not be appropriate for valid registration [
74].
To deal with this issue, many authors have worked on improving ICP algorithms such as point-to-line [
75], point-to-plane [
76,
77], point-to-surface, generalised-ICP [
78] and GO-ICP [
79,
80]. Generalised-ICP uses the combination of ICP and point-to-plane ICP in a single probabilistic structure. GO ICP, on the other hand, uses a branch-and-bound (BnB) approach for global optimisation. The authors in [
81] presented a comprehensive evaluation of ICP algorithms in 3D point-cloud registration. In their study, factors such as the angle, distance, overlap ratio and noise were evaluated and compared using point-to-point and point-to-plane ICP on four datasets. Their study noted how different parameters affect the performance of ICP algorithms. For example, point-to-point ICP is more resilient to Gaussian noise in terms of validity. In contrast, point-to-plane ICP is more robust with respect to accuracy. Furthermore, some of the improved ICP methods are based on octree [
82] or k-d tree [
83]. Usually, ICP methods are combined with coarse registration methods [
84,
85] to provide high-accuracy results.
Another fine registration method is RANSAC, which is widely used for pre-processing and segmentation of point-cloud data. It randomly selects different sets of samples to register from the point-cloud data and then fits a model efficiently in the presence of noise and outliers. The RANSAC method has a high computing efficiency, but it fails to give a globally optimal solution due to its randomised nature [
86].
NDT is another approach to fine registration, based on the probability density function. Point-cloud data are represented as a 3D grid and the probability distribution is applied to each grid point for optimal fine registration. This method does not need a good initial position and is faster than ICP algorithms, making it more reliable and precise in real-time applications than ICP [
87,
88]. However, this method requires a large number of calculations, making it labour-intensive.
Figure 7 shows the taxonomy of classical registration methods for 3D point clouds.
Among the aforementioned methods, ICP is the most widely used registration method for 3D point clouds. For ICP methods, a high density is required to obtain accurate results. ICP does not work efficiently in airborne LiDAR due to the large and noisy data [
89]. Sampling large datasets with ICP may improve the performance of ALS data, but such methods are time-consuming and the memory inefficient. Gressin et al. [
90] analysed and compared the ICP algorithms on different LiDAR platforms such as airborne, mobile and terrestrial LiDAR. They concluded that the best results were obtained from TLS and MMS datasets in terms of accuracy, while ALS was subpar. Until now, NDT has only been applied to TLS datasets and is not suitable for a large, complex environment. RANSAC, meanwhile, is applied on ALS, TLS and MLS datasets, mostly used as a pre-processing step to remove the outliers and occlusions.
5.2.2. Deep-Learning Methods
Registration of point clouds is still an open problem due to the unordered and sparse nature of 3D point clouds. With the success of deep learning in recent decades, the importance of point-cloud registration has been increasing in deep neural networks. This section presents an overview of state-of-the-art deep-learning-based registration methods.
PointNet and Graph Neural networks are the most popular geometric deep-learning methods for 3D point clouds. Motivated by these methods, numerous deep-learning registration methods have been developed. Based on the PointNet architecture, Deng et al. [
91] introduced the Point Pair Feature Network (PPFNet), which learns globally informed 3D local feature descriptors directly from unorganised point sets. The main drawback of this method is that it requires a significant amount of annotation data. Furthermore, the authors in [
92] developed PPF-FoldNet, which uses unsupervised learning of 3D local descriptors to eliminate the annotation-requirement constraint issue. Aoki et al. [
93] developed PointNetLK, which integrates the Lucas and Kenade algorithm with a PointNet-based global feature descriptor and uses iterative approximation for the estimation of the relative transformation. Another deep-learning method is PCRNet [
94], which also uses PointNet for the extraction of global features. This method utilises five multi-layered perceptrons in a Siamese architecture, to obtain the global features. The features are then applied to the five fully connected layers as an input, along with an output layer of the dimension of parameterisation chosen for the pose. The PCRNet approach without iterations is faster and more robust, but it suffers in terms of its accuracy.
DeepVCP [
95] combines PointNet++ and mini PointNet to learn the descriptors, and then key points are extracted, estimating the correspondence from the extracted key points. This method relies on high-quality initialisation. Inspired by DGCNN, Deep Closest Point (DCP) [
96] was proposed, which is an end-to-end learning approach for point-cloud registration. First, the DGCCNN network is used to extract the features, and then the correspondence between the point clouds is predicted by an attention-based module.
Most point-cloud registration based on deep learning is focused on indoor applications. Very few studies have been carried out on outdoor scenes. For example, Yew and Lee proposed 3D FeatNet [
97], which learns 3D feature detectors and descriptors from GNSS/INS 3D point clouds in a weakly supervised manner. However, this method does not perform well in noisy environments.
Another effective method is Fully Convolutional Geometric Features (FCGF) [
98], which extracts geometric features, computing a full convolution network. Based on the probability distribution, DeepGPMR [
99] was developed, which combines GMM registration with neural networks. This method does not require costly iterative procedures. Deep globalisation registration [
100] is a robust deep-learning method that aligns 3D scans of the real world. First, a 6D convolutional network is used to estimate the correspondence of the point sets, and then the weighted Procrustes method is applied to the given correspondence for global optimisation. For real-time object tracking, AlignNet-3D [
101] was developed, which learns using the predicted frame-to-frame alignments for the estimation of the relative motion between 3D point clouds.
The most recent works on deep-learning-based registration were PREDATOR [
102], RGM [
103] and PointDSC [
104]. PREDATOR handles low-overlap pairwise registration of 3D point clouds. The method follows the encoder-decoder framework and learns to recognise the overlap between two unregistered point clouds. RGM uses a deep graph-matching approach to solve the problem of outliers in point-cloud registration. In this framework, graphs are constructed from point clouds to extract the node features and then a module is developed—namely, the AIS module—to establish a correspondence between two graph nodes. PointDSC is an outlier rejection network for point-cloud registration that explicitly utilises the spatial consistency generated by Euclidean transformation.
Table 5 shows the characteristics of deep-learning registration methods.
Due to irregular, sparse and uneven characteristics of 3D point clouds, finding correspondence between two point sets has become an open challenge. As discussed in
Section 4.2, fully automated point-cloud registration between multiple scans is difficult. Traditional registration approaches are suitable for large-scale point clouds. However, such methods are time-consuming and inefficient. In contrast, deep-learning methods outperform traditional methods in terms of accuracy and efficiency and have the advantage of achieving good results in real-time applications [
69]. Yet, these methods are only suitable for indoor or small-scale outdoor applications. Nevertheless, there is still room for improvement in terms of efficiency and robustness in 3D point-cloud registration. To the best of our knowledge, deep-learning registration methods have not been employed yet in BIM applications.
6. Semantic Segmentation
Semantic segmentation is an essential part of the process in Scan to BIM, in which an image or point cloud is divided into semantically significant parts and each of these parts is semantically labelled into one of the predefined classes [
113]. This section will summarise the traditional and deep-learning methods of 3D point-cloud semantic segmentation.
6.1. Traditional Methods
Before deep-learning methods were developed, heuristic methods were traditionally used for the segmentation of point clouds. The authors in [
114] presented a comprehensive review of point-cloud segmentation (PCS) and point-cloud semantic segmentation (PCSS) methods. PCS aims to group points with similar characteristics into homogenous regions [
115] without considering semantic information and instead based on handicraft features, while PCSS semantically classifies and labels data points into one predefined class, based on supervised learning methods. The authors grouped point-cloud segmentation into edge-based, region growing-based, model fitting-based and unsupervised clustering-based methods, as shown in
Table 6. Semantic segmentation, meanwhile, is based on supervised machine-learning methods that are grouped into individual PCSS and statistical contextual models, as shown in
Table 7.
From the aforementioned methods, support vector machine (SVM), Hough-transform, conditional random field and RANSAC are widely used for semantic segmentation. For example, Koo et al. [
116] exploited SVM for the classification of BIM elements for IFC. ZHU and Brilikas [
117] explored Hough transforms and edge-detection to classify the concrete elements of a building. Vo et al. [
118] used an octree-based region-growing approach and conditional random field for BIM reconstruction. Tarsha Kurdi et al. [
119] automatically detected 3D roof planes from LiDAR data using Hough-transform and RANSAC. Traditional methods have shown immense potential in dealing with large point clouds. However, these require manual labelling, which is quite time-consuming for processing large-volume point clouds.
Table 6.
3D point-cloud segmentation methods.
Table 6.
3D point-cloud segmentation methods.
| Type | Methods |
|---|
| Edge-based | [120] |
| Region growing | Seeded Region [121], Unseeded Region [122] |
| Model fitting | Hough-Transform, RANSAC [73] |
| Unsupervised clustering methods | K-Means Clustering [123], Fuzzy Clustering [124], Mean Shift [125], Graph-Based [126] |
Table 7.
3D point-cloud semantic segmentation methods.
Table 7.
3D point-cloud semantic segmentation methods.
| Type | Methods |
|---|
| Individual point cloud semantic segmentation | Gaussian Mixture Models [127], Support Vector Machines [128], AdaBoost [129], Cascade Binary Classifiers [129], Random Forests [130], Bayesian Discriminant Classifiers [131] |
| Statistical contextual models | Associative and Non-Associative Markov Networks [132,133], Simplified Markov Random Fields [134], Conditional Random Fields [135] |
6.2. Deep-Learning Methods
Recently, deep-learning algorithms have played an important role in the semantic segmentation of 3D point clouds, enhancing the performance of applications such as automotive driving, 3D reconstruction, BIM, etc. A significant number of papers have presented comprehensive reviews of deep-learning-based semantic segmentation [
136,
137,
138]. This section outlines the state-of-the-art deep-learning methods. In addition, methods applied to buildings and infrastructure are also discussed. From the existing reviews, it can be noted that due to the small amount of training data, it becomes critical to apply deep-learning algorithms to real-world applications. Moreover, LiDAR datasets are sparse and dense, which makes it difficult to train the data. Thus, pre-processing techniques are required to remove unnecessary data. During this process, some of the information is lost, giving poor segmentation results.
Deep-learning methods for semantic segmentation of 3D point clouds are grouped as multiview-based, voxel-based and point-based, as shown in
Table 8. Multiview-based methods transform 3D data into 2D multiview images, which are further processed using 2D CNN. These methods are sensitive to occlusions, resulting in information loss. Multiview-based methods are characterised as DeePr3SS [
139], SnapNet [
140] and TangentConv [
141]. Voxel-based methods convert 3D point-cloud data into voxel grids and it is then processed by 3D CNN. These methods require a high resolution to avoid data loss, which may further result in high computation and memory consumption. Certain types of voxel-based methods are SEGCloud [
142], SparseConvNet [
143], MinKowskiNet [
144] and VVNet [
145]. A point-based method applies the deep-learning architecture directly to unstructured point clouds. These methods have provided good results in small point clouds, but due to model’s computational complexity, they are less useful in large environments. Point-based methods are further classified as pointwise MLP (PointNet [
146], PointNet++ [
147], PointSift [
148], Engelmann [
149], 3DContextNet [
150], A-SCN [
151], PointWeb [
152], PAT [
153], RandLA-Net [
154], ShellNet [
155] and LSANeT [
156]), point convolution (PointCNN [
157], DCNN [
158], A-CNN [
159], ConvPoint [
160], KPCONV [
161], DPC [
162] and InterpCNN [
163]), RNN-based (RSNET [
164], G+RCU [
165] and 3D-RNN [
166]) and graph-based (DGCNN [
167], SPG [
168], SSP+SPG [
169], GACNet [
170], PAG [
171], HDGCN [
172], HPEIN [
173], SPH3D-GCN [
174] and DPAM [
175]).
Some of the latest research on deep learning is Deep FusionNet [
176], AMVNET [
177] and LGENet [
178]. Deep FusionNet uses a mini PointNet and a fusion module for feature aggregation in large-scale LiDAR point clouds. This method shows a better performance with a low requirement for memory and low computational costs. AMVNet is a multiview fusion for LiDAR point-cloud semantic segmentation, which uses late fusion for feature aggregation. Meanwhile, AMVNet achieved promising results, but some uncertainties were detected between two object classes, for instance, a sidewalk and parking, terrain and vegetation. LGENet is a semantic segmentation method for ALS point clouds, leveraging the Local and Global Encoder Network.
Deep-learning algorithms have garnered great interest in semantic segmentation due to their fast speed. Many studies have utilised deep-learning methods such as PointNet, PointNet++, CNN, KPCONV and DGCCN in building models and civil infrastructure applications. For example, Babacan et al. [
179] employed a convolution neural network for semantic segmentation in indoor mapping. Yet, this approach is limited to labelling basic components such as windows, walls, chairs, etc. Malinverni et al. [
180] used PointNet++ for semantic segmentation of a cultural heritage building using TLS point clouds. The authors applied the DGCNN architecture for the semantic segmentation of a historical building. Balado et al. [
181] used PointNet to segment the main features of a road, such as the road surface, guardrails, embankments, ditches and borders, using mobile laser-scanner (MLS) point clouds. The author proposed that heuristic methods for segmenting small elements work effectively without incurring a high training cost. PointNet must be used when segmenting the parts of a whole scene. Inspired by the latter study, Soilán et al. [
182] applied PointNet and KPCONV architectures to evaluate the semantic segmentation of railway tunnels and classified them as ground, lining, wiring and rail. Both learning models performed well, but the method requires heuristic post-processing. Synthetic-based data have also received a lot of attention in semantic segmentation. For example, the authors in [
183] combined PointNet with a dynamic graph convolutional neural network (DGCNN) to generate semantic segmentation point clouds of building interiors, using synthetic data generated from as-built BIM. Yet, this study undertook a manual process of splitting 3D models at the object scale, which could lead to a high cost of generating synthetic data. Additionally, variations occurred in both the surface and volumetric information, causing uncertainty when acquiring information on the same object.
Beyond this, deep-learning algorithms, together with unsupervised clustering methods, are also implemented in the Scan to BIM framework for segmentation. Recently, Ma and Leite [
184] proposed a framework that uses density-based spatial clustering of applications with noise (HDBSCAN) as a clustering tool to generate segments from point clouds, which are then classified using deep-learning methods such as PointNet and DGCNN. This study had limitations, however, such as time complexity since the point-cloud data were massive and random sampling was required.
From the aforementioned methods, it can be observed that deep-learning semantic segmentation methods for point clouds are still a challenge due to the sparsity and varying densities of point clouds. Nevertheless, they have provided promising results with 2D images and 3D indoor point clouds. Some methods such as FusionNet and AMVNET have shown robust results, with reduced computational complexity and memory consumption. Meanwhile, data hunger is still a major problem faced by deep-learning algorithms, limiting the performance of the model due to insufficient training data in terms of size and diversity. The authors in [
138] addressed the data hunger issues in 3D semantic segmentation and how they affect the performance of deep-learning models on different datasets. They concluded that existing datasets are not sufficient to solve the data hunger issue. More training of the data is required to improve the accuracy of the point clouds, which is quite labour-intensive. Although deep-learning algorithms have realised the full potential of semantic segmentation for 3D point clouds, issues such as complex computation, memory consumption and loss of information are still the main concerns. Moreover, the complicated geometry and varying surface textures involved in the civil infrastructure model make the segmentation process quite challenging [
185]. This is because point clouds obtained in different scenarios have unique characteristics. It is important to highlight that there is a huge difference between outdoor and indoor scenes. The algorithms developed for indoors might not work in outdoor environments, and vice versa. There is a need for a standardised approach, adequate not only for specific objects or classes but also for real-world applications. Hence, efficient algorithms should be developed in the future, which could be implemented in large civil infrastructure applications for BIM.
Table 8.
Deep-learning semantic segmentation methods.
Table 8.
Deep-learning semantic segmentation methods.
| Strategy | Methods |
|---|
| Multiview-based | DeePr3SS [139], SnapNet [140], TangentConv [141] |
| Voxel-based | SEGCloud [142], SparseConvNet [143], MinKowskiNet [144], VVNet [145] |
| Pointwise MLP | PointNet [146], PointNet++ [147], PointSift [148], Engelmann [149], 3DContextNet [150], A-SCN [151], PointWeb [152], PAT [153], RandLA-Net [154], ShellNet [155], LSANeT [156] |
| Point convolution | PointCNN [157], DCNN [158], A-CNN [159], ConvPoint [160], KPCONV [161], DPC [162], InterpCNN [163] |
| RNN-based | RSNET [164], G+RCU [165], 3D-RNN [166] |
| Graph-based | DGCNN [167], SPG [168], SSP+SPG [169], GACNet [170], PAG [171], HDGCN [172], HPEIN [173], SPH3D-GCN [174], DPAM [175], MBBOS-GCN [186] |
| Other methods | Deep FusionNet [176], AMVNET [177], LGENet [178] |
7. Standardisation and Interoperability of BIM
To satisfy the needs of various planning states, a segmented model obtained with LiDAR must be translated to a compatible building information model. BIM is not a single software, but rather a process that involves multiple software, operators, vendors, etc. Different organisations are involved in the construction process, and they use different software and may need different types of information [
187]. Projects based on construction are complicated; data loss and communication issues are more likely to occur, resulting in poor project efficiency. This is due to the heterogeneous data that make the interoperability of software applications critical. The term interoperability is defined as the ability to exchange and use information across different technologies. To adequately address the interoperability issues, there is a need for a standardised exchangeable data format that allows information to be stored and exchanged among various parties with minimal data loss. This is where BIM standards come into play.
BIM standards involve a variety of organisations using exchange protocols and principles to develop a common framework. The Open Geospatial Consortium (OGC) and buildingSMART have developed various open BIM standards such as IFC, MVD, IDM, gbXML and LandXML. An existing review of open BIM standards was presented in [
188]. The authors described different open BIM standards and software tools for interoperability. However, the survey did not focus on standards such as gbXML and LandInfra. To fill the research gap, this section will briefly explain all the standards that are related to Scan to BIM.
The International Organization for Standardization (ISO) published the first global standard, IS0 19650, which aims to assist with the management of information during an asset’s lifecycle in BIM. These standards are based on the UK 1192 series, namely, BS 1192 and PAS 1192.
Table 9 depicts four parts of the IS0 19650 standards.
7.1. Industry Foundation Classes (IFCs)
IFCs are the well-known and worldwide accepted, neutral and open data format for BIM models, used for exchanging and sharing information on construction data between heterogeneous software applications. It is registered with international standard ISO 16739-1:2018 and managed by buildingSMART. This principle uses the ISO-STEP EXPRESS language to describe its model. The first version of the IFCs, IFC 1.0, was developed in 1996 by the International Alliance for Interoperability (IAI), and later it was changed into the International Alliance for Interoperability (buildingSMART). Since then, it has been updated in various versions. The current version of the IFCs is IFC 4.2. Another version, IFC5, is expected to be introduced in the coming years and will include extensive support for infrastructure applications (e.g., IFC Bridge, IFC Rail, IFC Road, IFC Tunnel, etc.). This extension will allow for effective and digital planning of construction projects. IFCs can be encoded in various formats based on their readability, scalability and software support, namely .ifc, .ifcXML, .ifcZIP, .ttl and .rdf.
The IFCs involve numerous tasks that address building information, for instance, assessment of the geometry of the building, analysis and simulation, operation and maintenance, planning, etc. In addition, the IFCs have the advantage of providing several levels of detail based on the same data standard [
190]. While the IFCs are powerful and can describe building models effectively, they pose some challenges such as a lack of geometric representation and loss of information, especially in transport infrastructures.
7.2. Model View Definition and Information Delivery Manual
Due to the huge variety of object types included in the IFCs and their complex structure, it becomes complicated to integrate these into software applications. To overcome this problem, BuildingSMART developed the Model View Definition (MVD) framework. It is a subset of the IFC schema, which describes the information exchange for a particular use. An MVD instructs the software developer, specifying which IFC elements to use, how to execute them and what results to expect [
191]. Further information about the MVD database is provided in [
192].
The Information Delivery Manual (IDM) is another buildingSMART standard that is specified within ISO 29481-1:2010. The IDM aims to capture the process and define the workflow during the lifecycle of the building. There is a close relationship between the MVD and IDM, which provides a new way to define and view the information needed during the design, build and operation phases, as has been discussed in various BIM research projects. The IDM/MVD framework concerns which information should be sent by whom, when and to which destination [
193].
7.3. gbXML
BIM is not only gaining attention in building design but also making a significant contribution to building energy models. To support the interoperability between BIM and building energy analysis, Green Building XML (gbXML), architecture-engineering-construction XML (aecXML) and ifcXML are playing important roles in the construction and building industry [
194]. Among them, the most commonly used data format for sharing building information is gbXML. GbXML is a structured XML schema or language, used to store data, particularly for energy building models. It has over 500 elements and attributes that can be utilised to describe all the characteristics of the building [
195]. Due to its XML structure, it is faster and more flexible, and it links easily with BIM software. However, gbXML does not include all the information on building elements for environmental analysis. For example, gbXML represents only the rectangular geometry of the building [
195,
196].
7.4. Other Open Standards
The current version of the IFCs does not contain schemas for infrastructure objects such as roads, bridges, tunnels and railways. Another open standard is LandXML, which is based on XML and is used specifically for civil engineering design and survey measurement data. It is not officially standardised by international standards, such as those of the ISO or OGC. To make LandXML comply with the OGC, a new open standard LandINFRA [
197] was introduced as a subset of LandXML, supported by the UML conceptual model and implemented with InfraGML. Kavisha et al. [
197] compared LandINFRA with CityGML and IFC and concluded that LandINFRA may serve as a bridge between GIS and BIM; however, this standard is still new and has not yet reached maturity.
CityGML [
198] is the international standard implemented by the OGC, which uses the Geography Markup Language (GML) [
199] to structure and exchange 3D city models. It defines the geometry, semantics, topology and representation of the urban 3D city models with five levels of detail (LODs) [
200]. The CityGML model has been completely updated to reflect the growing demand for enhanced interoperability with other related standards such as the IFC. The relationship between BIM and CityGML has been a hot topic in recent years.
Table 10 illustrates the summary of open standards. It is important to note that LandXML, LandINFRA and CityGML are commonly used to exchange information between GIS and BIM. The Open Geospatial Consortium and buildingSMART initiated the Integrated Digital Built Environment (IDBE) joint working group. In their article [
201], they discussed the challenges and opportunities that are involved in the integration of IFC, CityGML and LandINFRA.
In summary, the IFC is a good option for BIM and operational aspects, whereas CityGML is more focused on 3D city models but lacks detailed building information. LandINFRA includes information on the land and civil engineering infrastructure; however, it is still a conceptual model. When working on energy-efficient buildings for BIM, gbXML may be a reasonable choice. To date, open standards for the BIM infrastructure have certain complexities in terms of the limited availability of libraries for infrastructure objects due to their complex geometric characteristics [
202]. The open standards mentioned above do not work efficiently with all types of BIM applications, especially when it comes to large infrastructure such as railways, roads, tunnels and bridges. More efficient standards should be developed to minimise the costs and time required throughout the project lifecycle.
8. Conclusions and Future Directions
Despite the growing interest in BIM in the architecture, engineering and construction (AEC) industries, certain issues are associated with Scan to BIM. Laser scanners have been the key technology in BIM, which generate data usually in the form of large, unstructured point clouds, making data-processing challenging in practice. As technology advances, researchers have developed automatic approaches for BIM reconstruction. However, the current studies demonstrate the poor performance of these in identifying complex structural elements; these approaches still require manual verification to increase their efficiency in a complex environment. Thus, a fully automated process for the extraction of semantics from the raw data in BIM remains a challenge.
Currently, point-cloud processing based on deep learning is still in its infancy. Numerous algorithms such as PointNet, PointNet++, KPCONV and DGCNN have been successfully exploited in the classification and segmentation of point clouds. Yet, registration of the point clouds is still an open challenge. As discussed in
Section 5.2.2, deep-learning-based registration methods have not been explored in a large, complex environment. They have only been used in basic features such as lamps, cars, etc., or for indoor scenes or small-scale outdoor scenes. With an increasing demand for machine learning and deep neural networks, registration methods can be improved. Future work should focus on developing efficient and fast learning algorithms in large environments such as roads, bridges, tunnels, buildings, etc.
Furthermore, the multisource fusion of LiDAR data should also be taken into consideration in BIM. As discussed in
Section 4.2, point-cloud data obtained from various sources are heterogeneous in terms of the scanning view, resolution, ranges, density and accuracy, which make their integration critical. Future studies must aim to develop efficient algorithms to combine airborne, terrestrial and mobile lasers, which will increase the automation level of 3D reconstruction in BIM.
Due to the massive number of points, data storage and data transmission become critical. In this regard, point-cloud compression methods have been used in practice to reduce the sizes of point clouds. However, such an approach has not yet been utilised in BIM reconstruction. Thus, it is recommended that we develop effective 3D point-cloud compression methods, which can be implemented in Scan to BIM applications.
Even with the growing popularity of open BIM standards, interoperability remains an open issue. As discussed in
Section 7, the IFC is the most popular data-exchange format used in Scan to BIM applications, but it poses certain challenges since many BIM software tools do not support IFC features. Moreover, transport infrastructure projects are typically more complex than architectural projects; using BIM tools to design and manage them could be extremely beneficial. However, the IFC still lacks support for data exchange in transport infrastructure. Another alternative is LandINFRA, a conceptual model standard, which has not been widely used yet. Researchers are still trying to investigate, to see if it could serve as a connection between BIM and GIS. Thus, the potential standards and formats for interoperability should be addressed in the future. In public-sector infrastructure projects, however, there remains a lack of digital competence and BIM capacity within the market.
Integrating emerging technologies and BIM into a single framework has become a hot research subject in recent years. Moreover, the integration of advanced technologies such as the Internet of Things (IoT), laser scanners, virtual reality (VR) and cloud computing could be promising for automation in BIM. However, integrating these technologies is complicated and the existing solutions may not be efficient. To support future solutions and promote practical implementation, a complete architecture needs to be implemented to link scanning technologies, BIM, virtual reality 3D printing, the Internet of Things and even artificial intelligence. This will allow the entire BIM process to become automatic and will improve the efficiency and productivity across the project lifecycle.
BIM is one of the revolutionising technologies in the construction industry that uses standard measuring methodologies to optimise and automate the process. To construct an efficient digital representation of BIM, it is necessary to examine and comprehend the complete chain that leads from the acquisition of 3D point clouds from various scanning technologies to well-structured and semantically enriched digital 3D models. During any phase of the BIM lifecycle, this information must be shared between several applications or disciplines. This is where standardisation and interoperability come to the fore. This review paper has explained the Scan to BIM methodology in detail, from scanning technologies and 3D point-cloud processing methods to the interoperability standards of BIM. Furthermore, limitations and future trends have been discussed to propose beneficial solutions that will aid scholars in computer science and the construction industry, by offering insights into these valuable data and instructions on how to obtain them. In future studies, the authors will investigate the deep learning approach, which can be applied to develop an increasingly efficient management of transport infrastructure assets within the Scan to BIM framework.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
