

A Glimpse at the Future Technological Trends of Road Infrastructure: Textual Information-Based Data Retrieval


Abstract
:1. Introduction
2. Literature Review
2.1. Future Technology of Highway
2.2. Text Analytics
2.3. LDA Topic Modelling
2.4. Implications
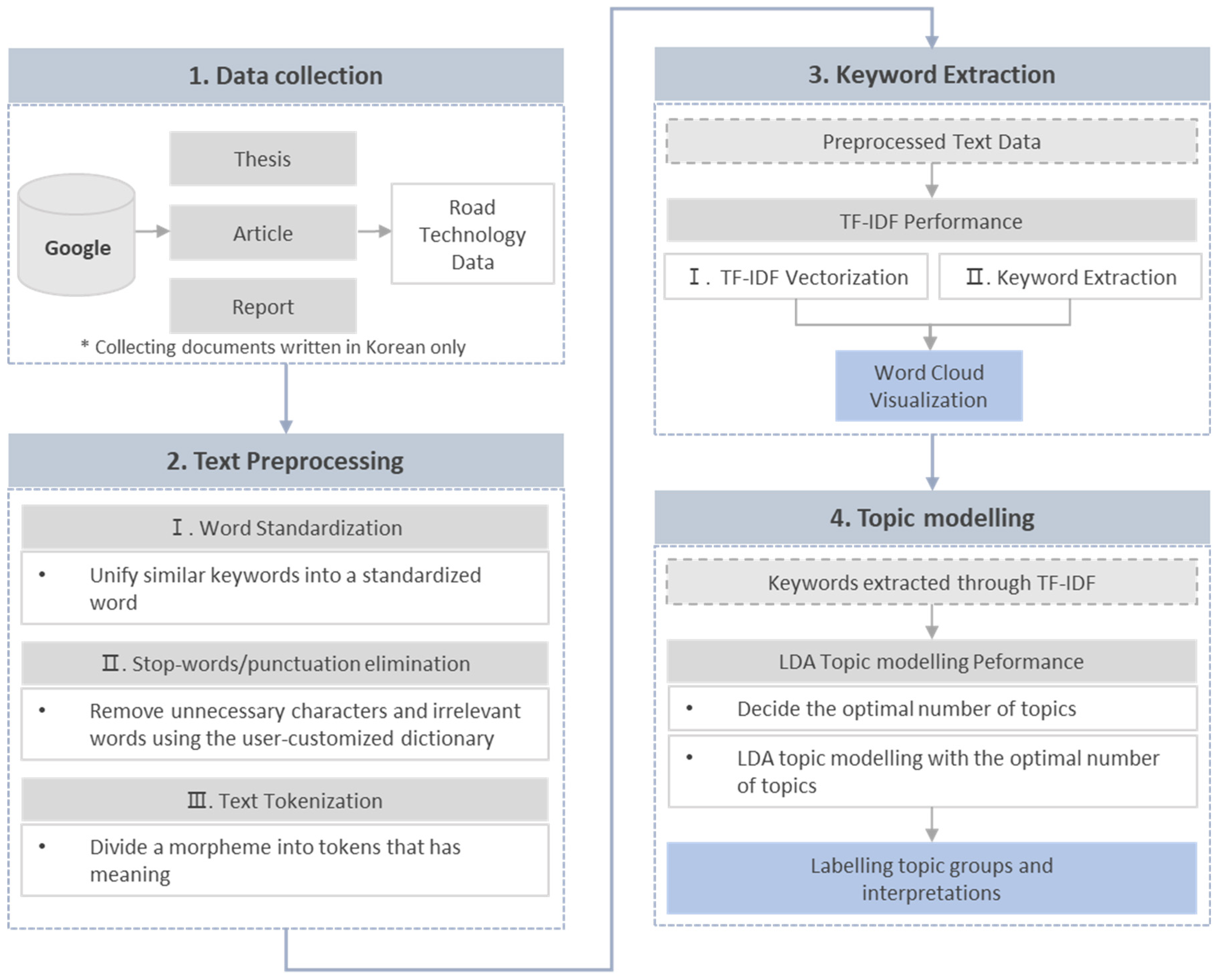
3. Methodology
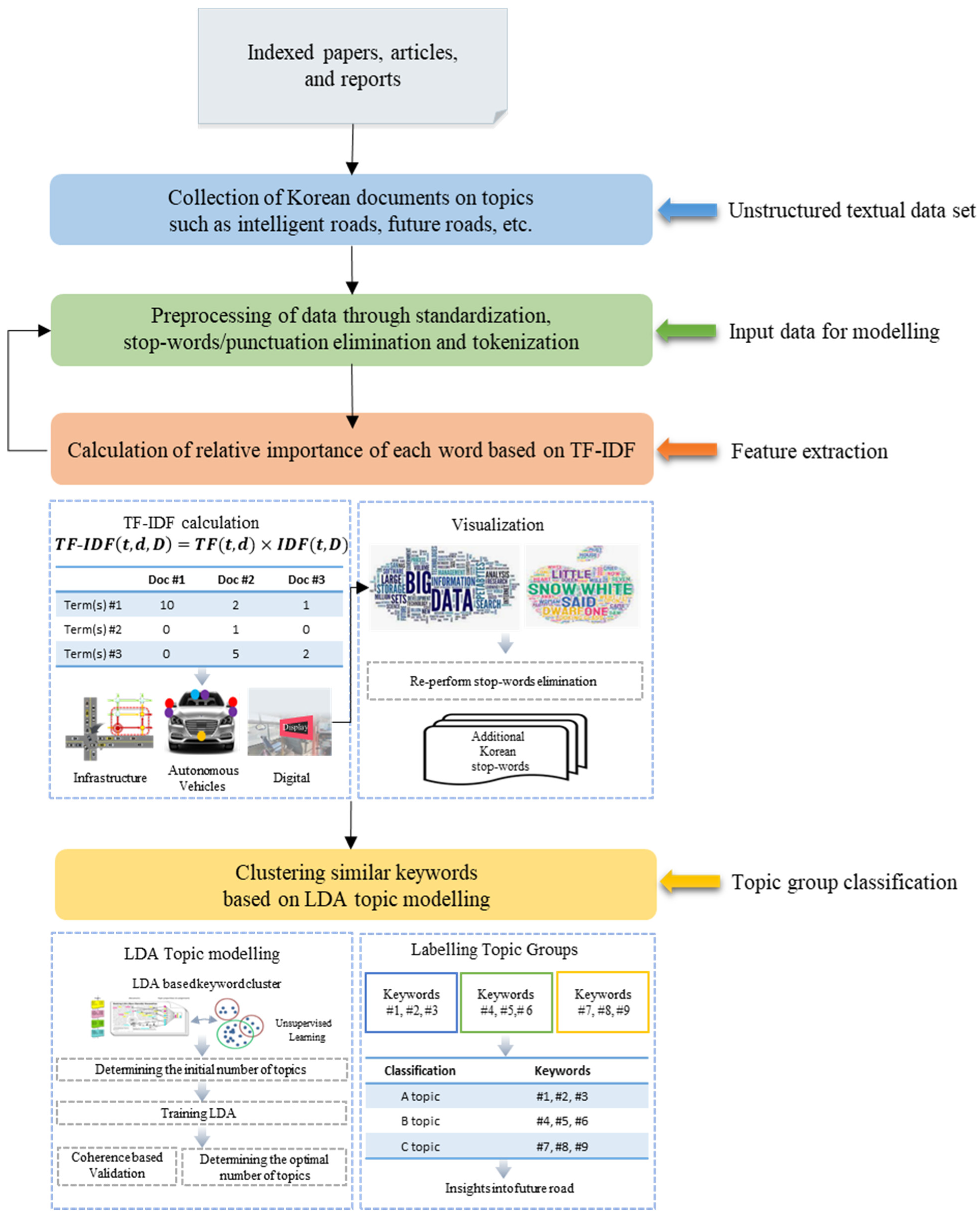
3.1. Text Mining
3.1.1. Overview
3.1.2. Text Preprocessing
3.1.3. TF-IDF for Extracting Keywords
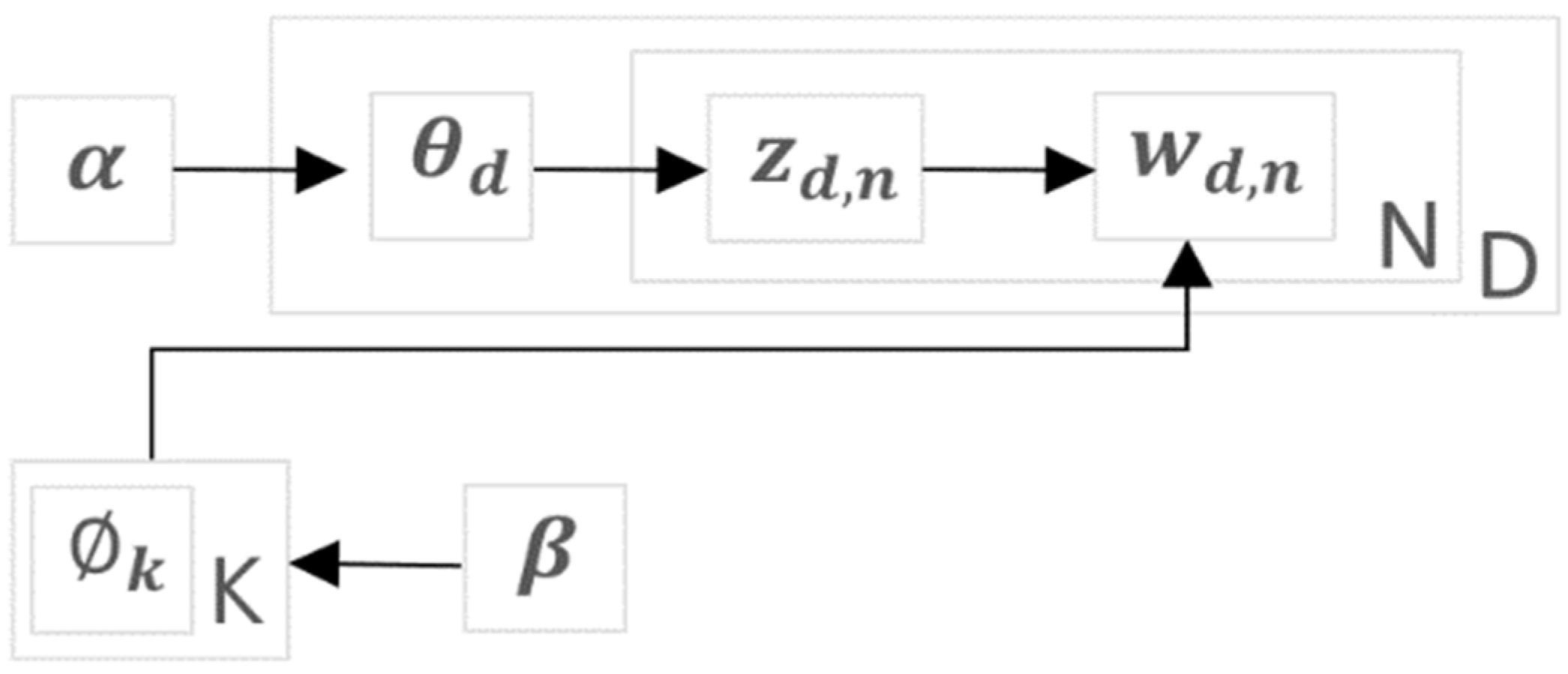
3.1.4. LDA for Clustering Keywords
3.2. Data Collection
4. Model Estimation
4.1. Data Manipulation
4.2. Keyword Extraction and Visualization
4.3. Trends for the Future Technology of Road Infrastructure
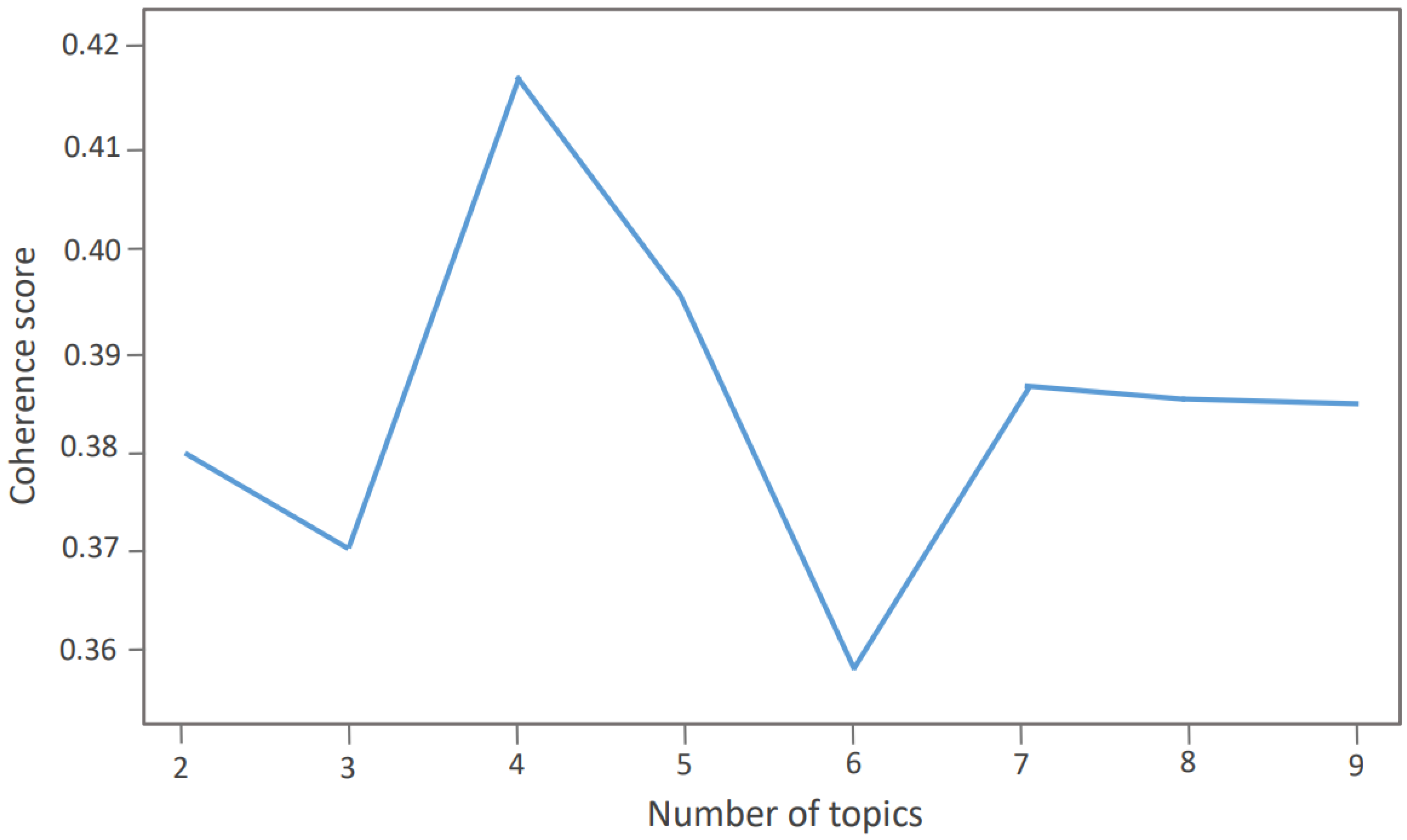
4.3.1. Topic Modelling with LDA
4.3.2. Labelling Topic Groups and Insights into Future Roads

4.3.3. Suggestions for Improvement
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karabegović, I. Digital Technology as the Key Factor in the Fourth Industrial Revolution-Industry 4. 0. Int. J. Adv. Res. Sci. Eng. Technol. 2017, 3, 17–22. [Google Scholar]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Donnellan, P.R. The Future of Mobility—Electric, Autonomous, and Shared Vehicles. IEEE Eng. Manag. Rev. 2019, 46, 16–18. [Google Scholar] [CrossRef]
- Erkollar, A.; Oberer, B. Sustainable cities need smart transportation: The Industry 4.0 Transportation Matrix. Sigma J. Eng. Nat. Sci. 2018, 9, 359–370. [Google Scholar]
- United Nations Economic Commission for Europe (UNECE). Transport and the Sustainable Development Goals. Available online: https://unece.org/DAM/trans/conventn/UN_Transport_Agreements_and_Conventions.pdf (accessed on 7 April 2022).
- Korea Trade-Investment Promotion Agency. What Is C-ITS for Smart Autonomous Driving? Available online: https://dream.kotra.or.kr/kotranews/cms/news/actionKotraBoardDetail.do?SITE_NO=3&MENU_ID=180&CONTENTS_NO=1&bbsGbn=243&bbsSn=243&pNttSn=190003 (accessed on 1 April 2022).
- Ministry of Culture Agency. Korean Version of the New Deal Comprehensive Plan. Available online: https://www.moef.go.kr/com/cmm/fms/FileDown.do?atchFileId=ATCH_000000000014749&fileSn=3 (accessed on 20 April 2022).
- Hamid, U.Z.A.; Zamzuri, H.; Limbu, D.K. Internet of vehicle (IoV) applications in expediting the implementation of smart highway of autonomous vehicle: A survey. In Performability in Internet of Things; Springer: Cham, Switzerland, 2019; pp. 137–157. [Google Scholar] [CrossRef]
- Singh, R.; Sharma, R.; Akram, S.; Gehlot, A.; Buddhi, D. Highway 4.0: Digitalization of highways for vulnerable road safety development with intelligent IoT sensors and machine learning. Saf. Sci. 2021, 143, 105407. [Google Scholar] [CrossRef]
- Putri, T.D. Intelligent transportation systems (ITS): A systematic review using a Natural Language Processing (NLP) approach. Heliyon 2021, 7, e08615. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy ontology and LSTM-based text mining: A transportation network monitoring system for assisting travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef] [PubMed]
- Salloum, S.A.; Al-Emran, M.; Monem, A.A.; Shaalan, K. Using text mining techniques for extracting information from research articles. In Intelligent Natural Language Processing: Trends and Applications; Springer: Cham, Switzerland, 2018; Volume 740, pp. 373–397. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction site accident analysis using text mining and natural language processing techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Onan, A. Two-stage topic extraction model for bibliometric data analysis based on word embeddings and clustering. IEEE Access 2019, 7, 145614–145633. [Google Scholar] [CrossRef]
- Gupta, R.K.; Agarwalla, R.; Naik, B.H.; Evuri, J.R.; Thapa, A. Prediction of Research Trends using LDA based Topic Modeling. Glob. Transit. Proc. 2022, 3, 298–304. [Google Scholar] [CrossRef]
- Roque, C.; Cardoso, J.L.; Connell, T.; Schermers, G.; Weber, R. Topic analysis of Road safety inspections using latent dirichlet allocation: A case study of roadside safety in Irish main roads. Accid. Anal. Prev. 2019, 131, 336–349. [Google Scholar] [CrossRef]
- Sun, L.; Yin, Y. Discovering themes and trends in transportation research using topic modeling. Transp. Res. Part C Emerg. Technol. 2017, 77, 49–66. [Google Scholar] [CrossRef]
- Hidayatullah, A.F.; Ma’arif, M.R.; Habibie, M.; Khomsah, S. Indonesia infrastructure development topic discovery on online news with latent Dirichlet allocation. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1077, 012012. [Google Scholar] [CrossRef]
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G. Health communication through news media during the early stage of the COVID-19 outbreak in China: Digital topic modeling approach. J. Med. Internet Res. 2020, 22, e19118. [Google Scholar] [CrossRef] [PubMed]
- Yamamoto, M.; Umemura, N.; Kawano, H. Proposal of Japanese vocabulary difficulty level dictionaries for automated essay scoring support system using rubric. J. Oper. Res. Soc. 2020, 8, 601–617. [Google Scholar] [CrossRef]
- Kwon, I. Viewpoints in the Korean Verbal Complex: Evidence, Perception, Assessment, and Time; University of California: Berkeley, CA, USA, 2012. [Google Scholar]
- Lee, D.G.; Rim, H.C. Probabilistic modeling of Korean morphology. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 945–955. [Google Scholar] [CrossRef]
- Hotho, A.; Nürnberger, A.; Paaß, G. A brief survey of text mining. J. Lang. Technol. Comput. Linguist. 2005, 20, 19–62. [Google Scholar] [CrossRef]
- Tan, A.H. Text mining: The state of the art and the challenges. In Proceedings of the PAKDD 1999 Workshop on Knowledge Discovery from Advanced Databases, Beijing, China, 26–28 April 1999; pp. 65–70. [Google Scholar]
- Kaplan, R.M. A method for tokenizing text. In Inquiries into Words, Constraints and Contexts; CSLI Publications: Stanford, CA, USA, 2005; p. 55. [Google Scholar]
- Kang, H.; Yang, J. Selection of the Optimal Morphological Analyzer for a Korean Word2vec Model. In Proceedings of the Korea Information Processing Society Conference, Seoul, Republic of Korea, 31 October 2018; pp. 376–379. [Google Scholar] [CrossRef]
- Lee, J. Three-step probabilistic model for Korean morphological analysis. J. KIISE Softw. Appl. 2011, 38, 257–268. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Ghag, K.; Shah, K. Senti TFIDF–Sentiment classification using relative term frequency inverse document frequency. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 36–43. [Google Scholar] [CrossRef]
- Gottron, T. Document word clouds: Visualising web documents as tag clouds to aid users in relevance decisions. In Research and Advanced Technology for Digital Libraries—ECDL 2009; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5714, pp. 94–105. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Andrzejewski, D.; Zhu, X. Latent dirichlet allocation with topic-in-set knowledge. In Proceedings of the NAACL HLT 2009 Workshop on Semi-Supervised Learning for Natural Language Processing, Boulder, CO, USA, 4–5 June 2009; pp. 43–48. [Google Scholar]
- Krestel, R.; Fankhauser, P.; Nejdl, W. Latent dirichlet allocation for tag recommendation. In Proceedings of the Third ACM Conference on Recommender Systems (RecSys’09), New York, NY, USA, 23–25 October 2009; pp. 61–68. [Google Scholar]
- Park, C.; Eo, S.; Moon, H.; Lim, H. Should we find another model? Improving Neural Machine Translation Performance with ONE-Piece Tokenization Method without Model Modification. In Proceedings of the NAACL HLT 2021: Industry Papers, Online, 6–11 June 2021; pp. 97–104. [Google Scholar] [CrossRef]
- McCann, P. Fugashi, a tool for tokenizing Japanese in Python. arXiv 2020, arXiv:2010.06858. [Google Scholar]
- Onah, D.F.; Pang, E.L. MOOC design principles: Topic modelling-PyLDavis visualization & summarisation of learners’ engagement. In Proceedings of the 13th International Conference on Education and New Learning Technologies, Online, 5–6 July 2021; pp. 1082–1091. [Google Scholar] [CrossRef]
- Kim, J.; Park, S.; Park, S.; Jeong, H.; Yun, I. Application of a Topic Model on the Korea Expressway Corporation’s VOC Data. J. Inf. Technol. Serv. 2020, 19, 1–13. [Google Scholar] [CrossRef]
- Stevens, K.; Kegelmeyer, P.; Andrzejewski, D.; Buttler, D. Exploring topic coherence over many models and many topics. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Stroudsburg, PA, USA, 12–14 July 2012; pp. 952–961. [Google Scholar]
- Khder, M.; Dawood, K.; Abdal, R.; Alqaisy, S. Automated Road Toll Collection and Vehicle Tracking (ARTCVT) Using Advanced RFID and GSM Technology. In Proceedings of the 2022 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems (ICETSIS), Manama, Bahrain, 22–23 June 2022; pp. 86–90. [Google Scholar] [CrossRef]
- Chattopadhyay, D.; Rasheed, S.; Yan, L.; Lopez, A.; Farmer, J.; Brown, D. Machine Learning for Real-Time Vehicle Detection in All-Electronic Tolling System. In Proceedings of the 2020 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 24 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Munirathinam, S. Industry 4.0: Industrial internet of things (IIOT). Adv. Comput. 2020, 117, 129–164. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, H.; Zhang, H.; Xie, H.; Chen, Z. A Novel Assessment and Administration Method of Autonomous Vehicle. SAE Int. J. Adv. Curr. Pract. Mobil. 2020, 2, 3312–3319. [Google Scholar] [CrossRef]
- Wang, C.; Miao, Z.; Chen, X.; Cheng, Y. Factors affecting changes of greenhouse gas emissions in Belt and Road countries. Renew. Sustain. Energy Rev. 2021, 147, 111220. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standardization | Primitive Words |
|---|---|
| Autonomous vehicle | Autonomous car (vehicle), AV, Autonomous driving, Automated car (vehicle), Automated driving, Driverless car (vehicle), Self-driving car (vehicle) |
| Digital infrastructure | Digital infra, digital infra, Digital infrastructure, digital infrastructure |
| Smart highway | Smart highway, smart highway, Smart Highway, Smart expressway, smart expressway, Smart Expressway |
| Information and Communication Technology | Information and Communication Technology, information and communication technology, ICT, ict |
| Internet of Things | Internet of Things, internet of things, IOT, iot |
| Artificial Intelligence | Artificial Intelligence, artificial intelligence, AI, ai |
| Fourth Industrial Revolution | Industry 4.0(4), Fourth Industrial Revolution, fourth industrial revolution, The 4th Industrial Revolution, 4IR |
| Intelligent Transport System | Intelligent Transport System, intelligent transport system, ITS, its |
| Cooperative Intelligent Transport Systems | Cooperative Intelligent Transport Systems, cooperative intelligent transport systems, CITS, C-ITS, cits, c-its |
| Contexts |
|---|
| Accordingly, the importance of establishing a digital infrastructure environment along with core autonomous vehicle technologies is also being emphasized. In terms of road infrastructure, various technologies and services are being developed in addition to providing congestion information and traffic signal controletc. For example, various technologies and services are being developed based on real-time bidirectional communication of vehicles and infrastructure, such as providing incident information, emergency vehicle access guidance services, digital virtual facility services, merge and diverge area accident prevention servicesetc. |
| Python Package | Contexts |
|---|---|
| Mecab-ko | ‘Autonomous vehicle’, ‘Technologies’, ‘Digital infrastructure’, ‘Emphasized’, ‘Road infrastructure’, ‘Congestion’, ‘Information’, ‘Traffic signal control’, ‘Vehicles’, ‘Infrastructure’, ‘Real-time’, ‘bidirectional communication’, ‘Incident’, ‘Emergency’, ‘Access’, ‘Digital’, ‘Virtual facility’ |
| Hannanum | ‘Autonomous vehicle’, ‘Core’, ‘Technologies’, ‘along with’, ‘Digital infrastructure’, ‘environment’, ‘establishing’, ‘importance’, ‘is also being emphasized’, ‘road infrastructure’, ‘In terms of’, ‘congestion’, ‘information’, ‘providing’, ‘traffic signal controletc’, ‘vehicles and’, ‘infrastructure’ |
| OKT | ‘Accordingly’, ‘Vehicle’, ‘Core’, ‘Technologies’, ‘Digital’, ‘infrastructure’, ‘environment’, ‘establishing’, ‘importance’, ‘emphasized’, ‘technologies’, ‘developed’, ‘road’, ‘Infrastructure’, ‘congestion’, ‘information’, ‘providing’, ‘traffic signal’, ‘control’, ‘etc’, ‘in addition to’ ‘vehicles’ |
| Komoran | ‘Accordingly’, ‘Accordingly’, ‘Vehicle’, ‘Core’, ‘Technologies’, ‘Digital’, ‘infrastructure’, ‘environment’, ‘establishing’, ‘importance’, ‘emphasized’, ‘technologies’, ‘developed’, ‘road’, ‘Infrastructure’, ‘congestion’, ‘information’, ‘providing’, ‘traffic signal’, ‘control’, ‘vehicles’, ‘infrastructure’ |
| KKma | ‘Accordingly’, ‘Accordingly’, ‘Vehicle’, ‘Core’, ‘Technologies’, ‘Digital’, ‘infrastructure’, ‘environment’, ‘establishing’, ‘importance’, ‘emphasized’, ‘technologies’, ‘developed’, ‘road’, ‘Infrastructure’, ‘congestion’, ‘information’, ‘providing’, ‘traffic’, ‘traffic signal’, ‘controletc’ |
| Weighted Importance | Keywords | TF-IDF Score |
|---|---|---|
| 1 | Infrastructure | 6.181 |
| 2 | Artificial intelligence | 5.966 |
| 3 | Real time | 5.628 |
| 4 | Cooperative intelligent transport systems | 5.542 |
| 5 | Autonomous vehicles | 5.258 |
| 6 | Sensor | 5.096 |
| 7 | Internet of things | 4.828 |
| 8 | Management | 4.602 |
| 9 | Digital | 4.099 |
| 10 | Robot | 3.836 |
| 11 | Big data | 3.720 |
| Topic Group | Keywords |
|---|---|
| 1 | Toll, management, smart tolling, intelligent, and tollgate |
| 2 | Infrastructure, structure, Internet of things, digital, and cooperative intelligent transport systems |
| 3 | Autonomous vehicles, artificial intelligence, real time, big data, and sensor |
| 4 | Green road, real time, energy, carbon, and eco-friendly |
| Topic | Label | Share (%) |
|---|---|---|
| 1 | Unmanned payment systems | 35.6 |
| 2 | Intelligent road infrastructure | 27.4 |
| 3 | Connected automated driving road | 23.0 |
| 4 | Eco-friendly road | 14.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, I.; Choi, S.; Lee, H.; Park, J.; Yun, I. A Glimpse at the Future Technological Trends of Road Infrastructure: Textual Information-Based Data Retrieval. Infrastructures 2024, 9, 233. https://doi.org/10.3390/infrastructures9120233
Kim I, Choi S, Lee H, Park J, Yun I. A Glimpse at the Future Technological Trends of Road Infrastructure: Textual Information-Based Data Retrieval. Infrastructures. 2024; 9(12):233. https://doi.org/10.3390/infrastructures9120233
Chicago/Turabian StyleKim, Inyoung, Sungtaek Choi, Hyejin Lee, Jeehyung Park, and Ilsoo Yun. 2024. "A Glimpse at the Future Technological Trends of Road Infrastructure: Textual Information-Based Data Retrieval" Infrastructures 9, no. 12: 233. https://doi.org/10.3390/infrastructures9120233
APA StyleKim, I., Choi, S., Lee, H., Park, J., & Yun, I. (2024). A Glimpse at the Future Technological Trends of Road Infrastructure: Textual Information-Based Data Retrieval. Infrastructures, 9(12), 233. https://doi.org/10.3390/infrastructures9120233