Learning to Describe: A New Approach to Computer Vision Based Ancient Coin Analysis



Abstract
:1. Introduction
- Physical characteristics such as weight, diameter, die alignment and color,
- Obverse legend, which includes the name of the issuer, titles or other designations,
- Obverse motif, including the type of depiction (head or bust, conjunctional or facing, etc.), head adornments (bare, laureate, diademed, radiate, helmet, etc.), clothing (draperies, breastplates, robes, armour, etc.), and miscellaneous accessories (spears, shields, globes, etc.),
- Reverse legend, often related to the reverse motif,
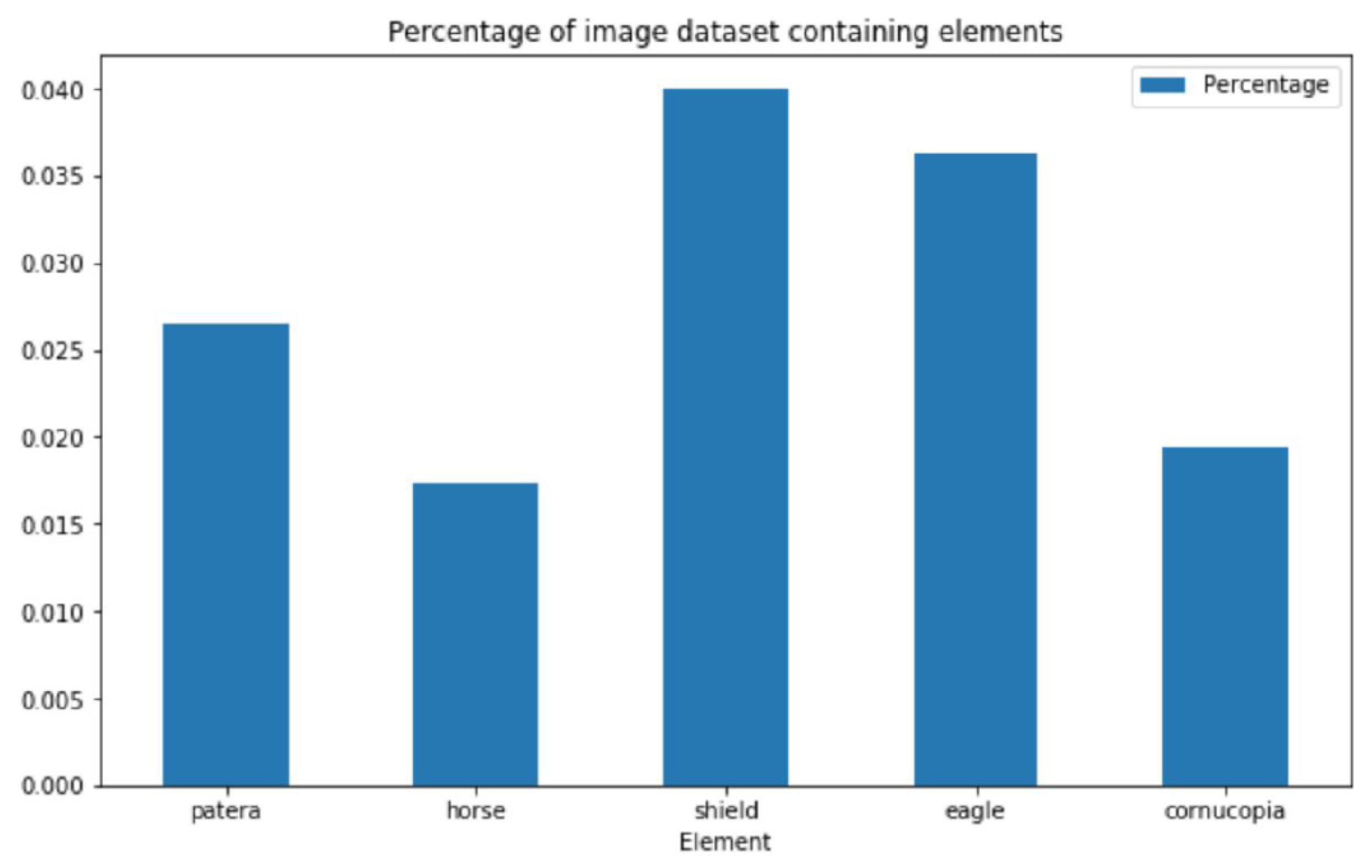
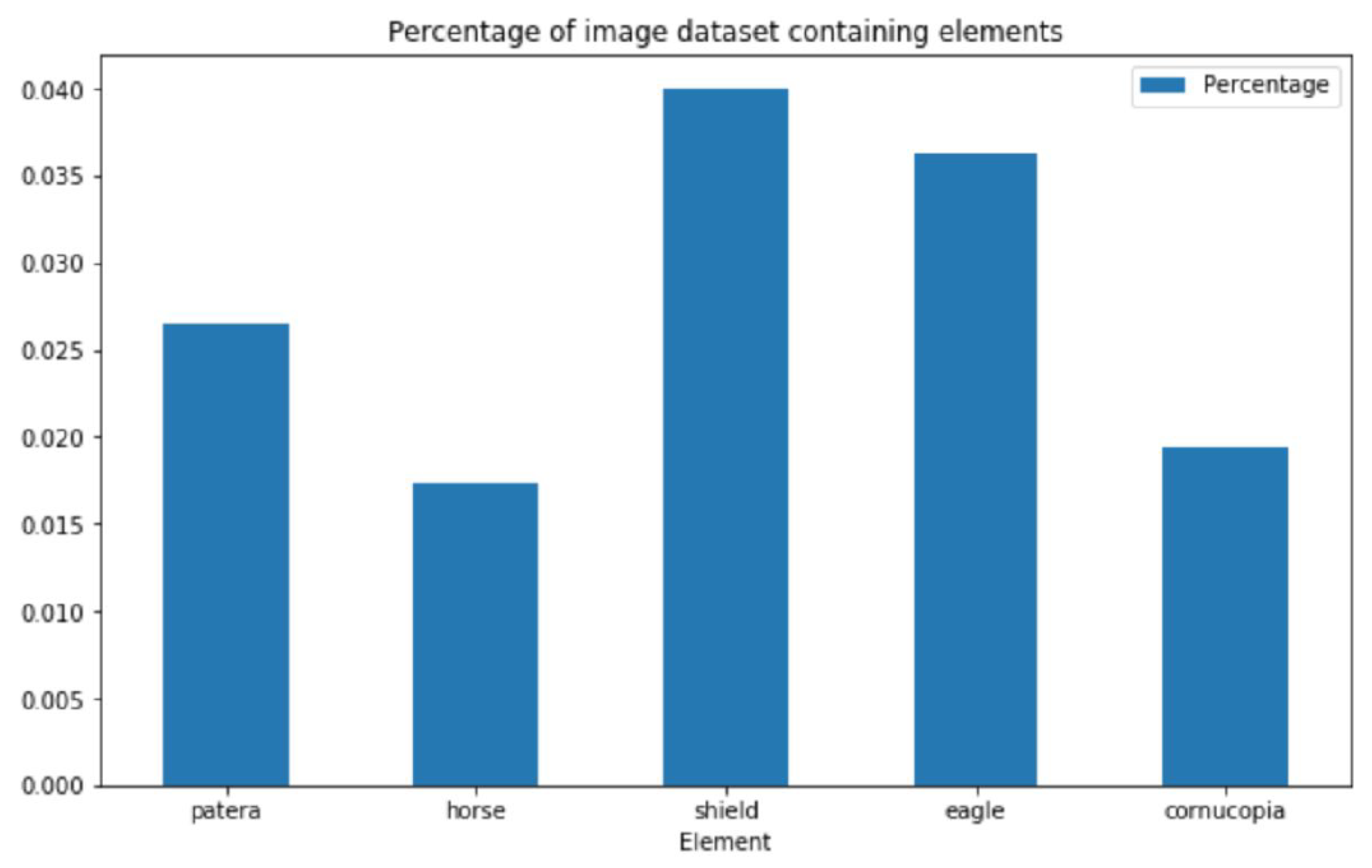
- Reverse motif (primary interest herein), e.g., person (soldier, deity, etc.), place (harbour, fortress, etc.) or object (altar, wreath, animal, etc.), and
- Type and location of any mint markings.
Relevant Prior Work
2. Problem Specification, Constraints, and Context
2.1. Challenge of Weak Supervision
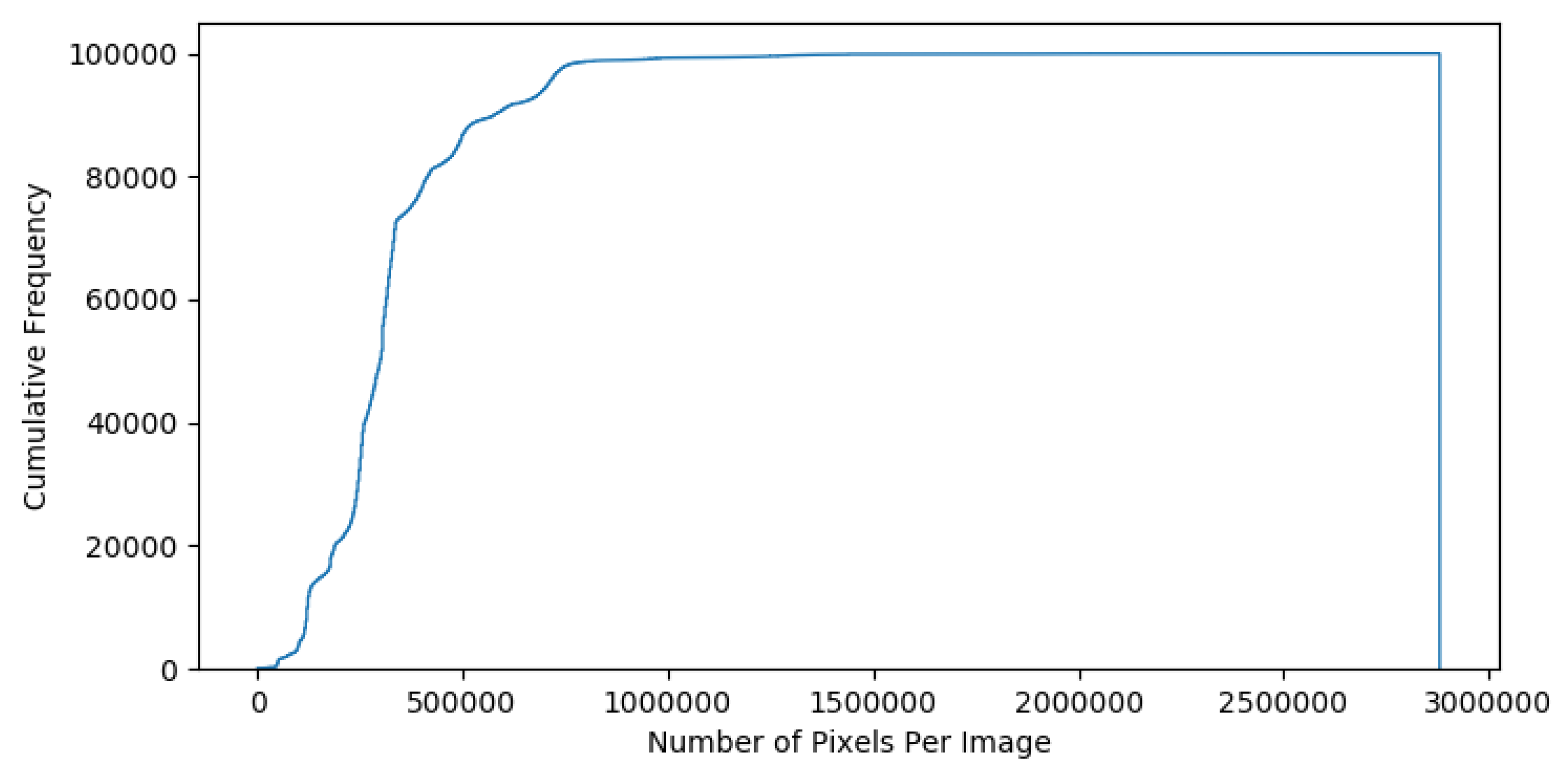
2.2. Data Pre-Processing and Clean-Up
2.2.1. Image Based Pre-Processing
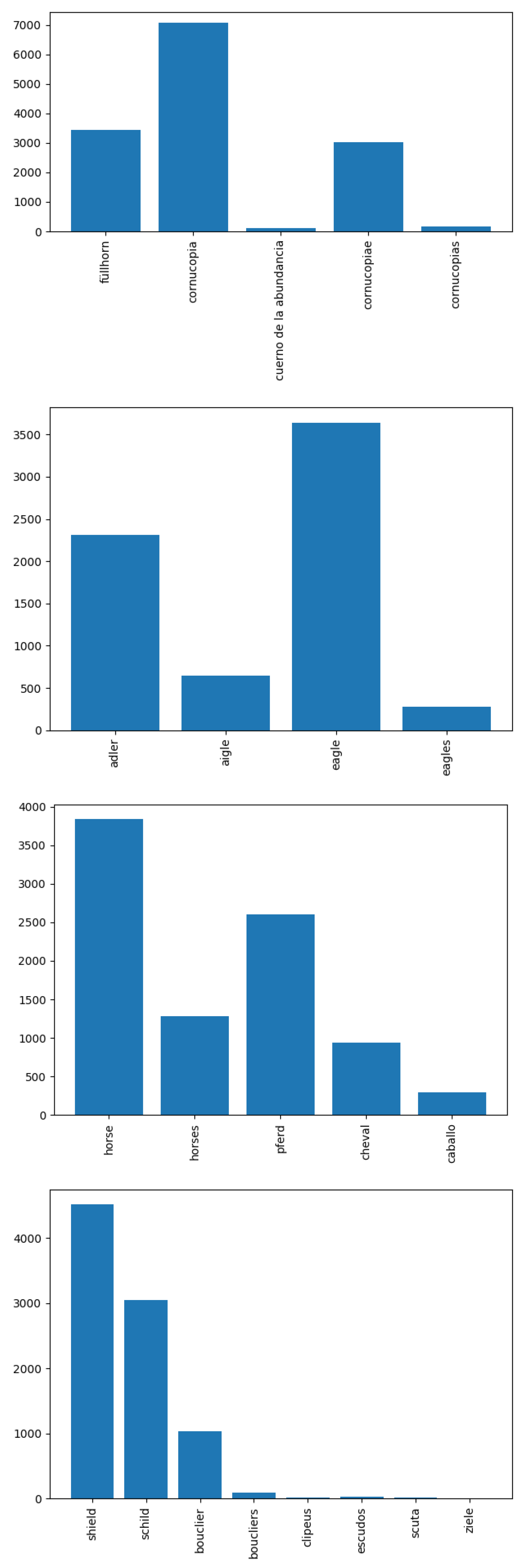
2.2.2. Text Based Extraction of Semantics
Clean-Up and Normalisation of Text Data
2.2.3. Randomization and stratification
2.3. Errors in Data
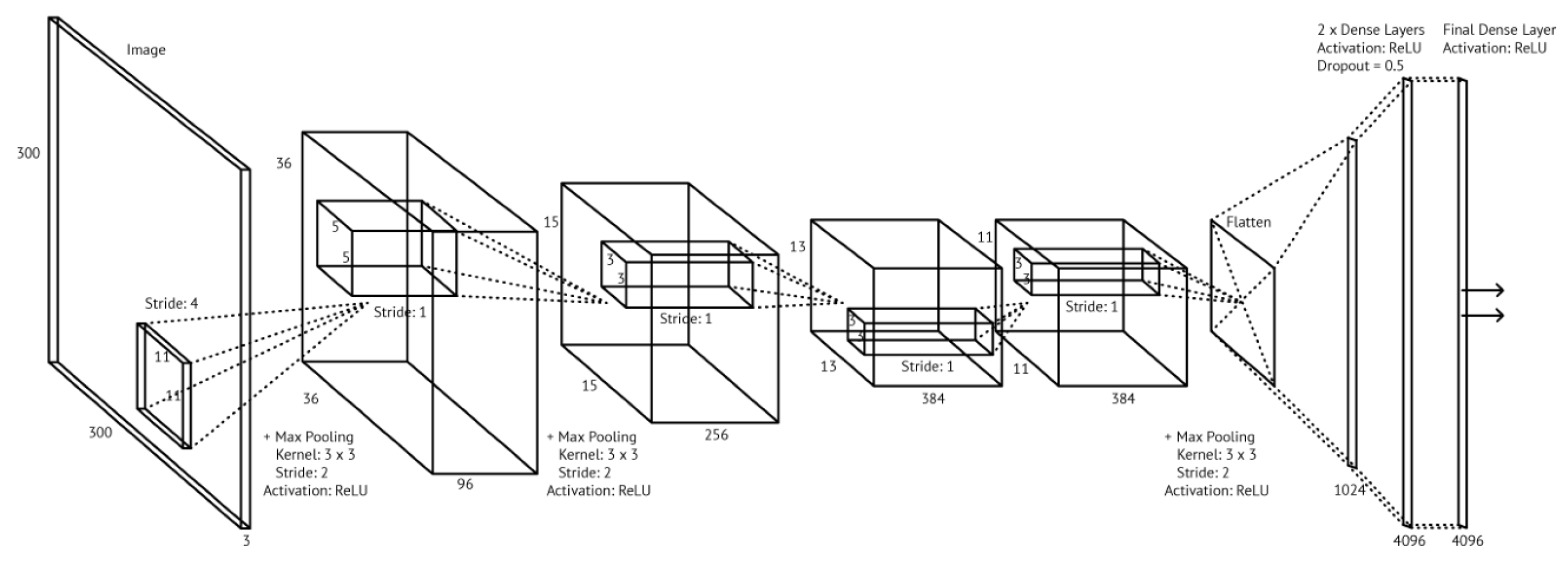
3. Proposed Framework
Model Topology
4. Experiments
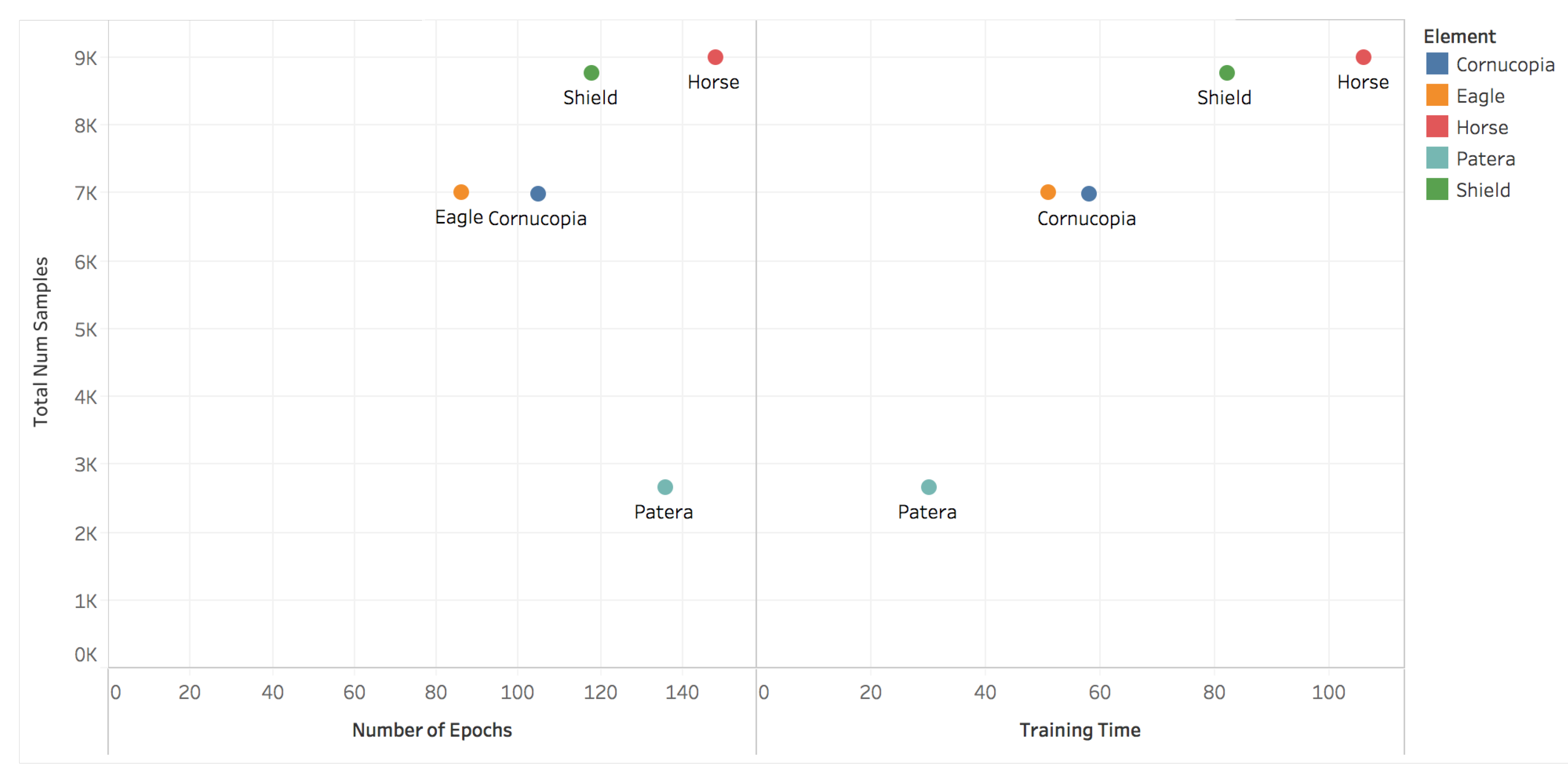
4.1. Results and Discussion
4.2. Learnt Salient Regions
5. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cooper, J.; Arandjelović, O. Visually understanding rather than merely matching ancient coin images. In Proceedings of the INNS Conference on Big Data and Deep Learning, Genova, Italy, 16–18 April 2019. [Google Scholar]
- Arandjelović, O. Automatic attribution of ancient Roman imperial coins. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1728–1734. [Google Scholar]
- Lowe, D.G. Local feature view clustering for 3D object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 682–688. [Google Scholar]
- Dalai, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Arandjelović, O. Object matching using boundary descriptors. In Proceedings of the British Machine Vision Conference, Guildford, UK, 3–7 September 2012. [Google Scholar] [CrossRef] [Green Version]
- Rieutort-Louis, W.; Arandjelović, O. Bo(V)W models for object recognition from video. In Proceedings of the International Conference on Systems, Signals and Image Processing, London, UK, 10–12 September 2015; pp. 89–92. [Google Scholar]
- Rieutort-Louis, W.; Arandjelović, O. Description transition tables for object retrieval using unconstrained cluttered video acquired using a consumer level handheld mobile device. In Proceedings of the IEEE International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 3030–3037. [Google Scholar]
- Fare, C.; Arandjelović, O. Ancient Roman coin retrieval: A new dataset and a systematic examination of the effects of coin grade. In Proceedings of the European Conference on Information Retrieval, Aberdeen, UK, 8–13 April 2017; pp. 410–423. [Google Scholar]
- Arandjelović, O. Reading ancient coins: Automatically identifying denarii using obverse legend seeded retrieval. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Volume 4, pp. 317–330. [Google Scholar]
- Conn, B.; Arandjelović, O. Towards computer vision based ancient coin recognition in the wild—Automatic reliable image preprocessing and normalization. In Proceedings of the IEEE International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 1457–1464. [Google Scholar]
- Zaharieva, M.; Kampel, M.; Zambanini, S. Image Based Recognition of Ancient Coins. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Vienna, Austria, 27–29 August 2007; pp. 547–554. [Google Scholar]
- Kampel, M.; Zaharieva, M. Recognizing ancient coins based on local features. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 1–3 December 2008; Volume 1, pp. 11–22. [Google Scholar]
- Anwar, H.; Zambanini, S.; Kampel, M. Supporting Ancient Coin Classification by Image-Based Reverse Side Symbol Recognition. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, York, UK, 27–29 August 2013; pp. 17–25. [Google Scholar]
- Anwar, H.; Zambanini, S.; Kampel, M. Coarse-grained ancient coin classification using image-based reverse side motif recognition. Mach. Vis. Appl. 2015, 26, 295–304. [Google Scholar] [CrossRef]
- Mattingly, H. The Roman Imperial Coinage; Spink: Hong Kong, China, 1966; Volume 7. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Schlag, I.; Arandjelović, O. Ancient Roman coin recognition in the wild using deep learning based recognition of artistically depicted face profiles. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2898–2906. [Google Scholar]
- Dimitriou, N.; Arandjelović, O.; Harrison, D.; Caie, P.D. A principled machine learning framework improves accuracy of stage II colorectal cancer prognosis. NPJ Digit. Med. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. IEEE Trans. Comput. 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; Volume 5. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On loss functions for deep neural networks in classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep learning using rectified linear units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Kernel Size | Stride | Kernel No. | Activation |
|---|---|---|---|---|
| Convolutional | 11 × 11 | 4 | 96 | ReLU |
| Max Pooling | 3 × 3 | 2 | ||
| Convolutional | 5 × 5 | 1 | 256 | ReLU |
| Max Pooling | 3 × 3 | 2 | ||
| Convolutional | 3 × 3 | 1 | 384 | ReLU |
| Convolutional | 3 × 3 | 1 | 384 | ReLU |
| Convolutional | 3 × 3 | 1 | 256 | ReLU |
| Max Pooling Layer | 3 × 3 | 2 | ||
| Flatten | ||||
| Outputs | Dropout | |||
| Dense | 4096 | 0.5 | ReLU | |
| Dense | 4096 | 0.5 | ReLU | |
| Dense | 2 | 0.5 | ReLU |
| Cornucopia | Patera | Shield | Eagle | Horse | |
|---|---|---|---|---|---|
| Number of epochs | 105 | 136 | 118 | 86 | 148 |
| Training time (min) | 58 | 30 | 82 | 51 | 106 |
| Training accuracy | 0.71 | 0.83 | 0.75 | 0.88 | 0.88 |
| Validation accuracy | 0.85 | 0.86 | 0.73 | 0.73 | 0.82 |
| Validation precision | 0.86 | 0.85 | 0.72 | 0.71 | 0.82 |
| Validation recall | 0.83 | 0.86 | 0.75 | 0.81 | 0.84 |
| Validation F1 | 0.85 | 0.86 | 0.74 | 0.75 | 0.83 |
| Test accuracy | 0.84 | 0.84 | 0.72 | 0.73 | 0.82 |
| Test precision | 0.85 | 0.82 | 0.71 | 0.70 | 0.81 |
| Test recall | 0.83 | 0.87 | 0.74 | 0.81 | 0.82 |
| Test F1 | 0.84 | 0.84 | 0.72 | 0.75 | 0.82 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cooper, J.; Arandjelović, O. Learning to Describe: A New Approach to Computer Vision Based Ancient Coin Analysis. Sci 2020, 2, 27. https://doi.org/10.3390/sci2020027
Cooper J, Arandjelović O. Learning to Describe: A New Approach to Computer Vision Based Ancient Coin Analysis. Sci. 2020; 2(2):27. https://doi.org/10.3390/sci2020027
Chicago/Turabian StyleCooper, Jessica, and Ognjen Arandjelović. 2020. "Learning to Describe: A New Approach to Computer Vision Based Ancient Coin Analysis" Sci 2, no. 2: 27. https://doi.org/10.3390/sci2020027
APA StyleCooper, J., & Arandjelović, O. (2020). Learning to Describe: A New Approach to Computer Vision Based Ancient Coin Analysis. Sci, 2(2), 27. https://doi.org/10.3390/sci2020027