


Bi-Directional Gaze-Based Communication: A Review


Abstract
:
1. Introduction
2. Structure of the Review
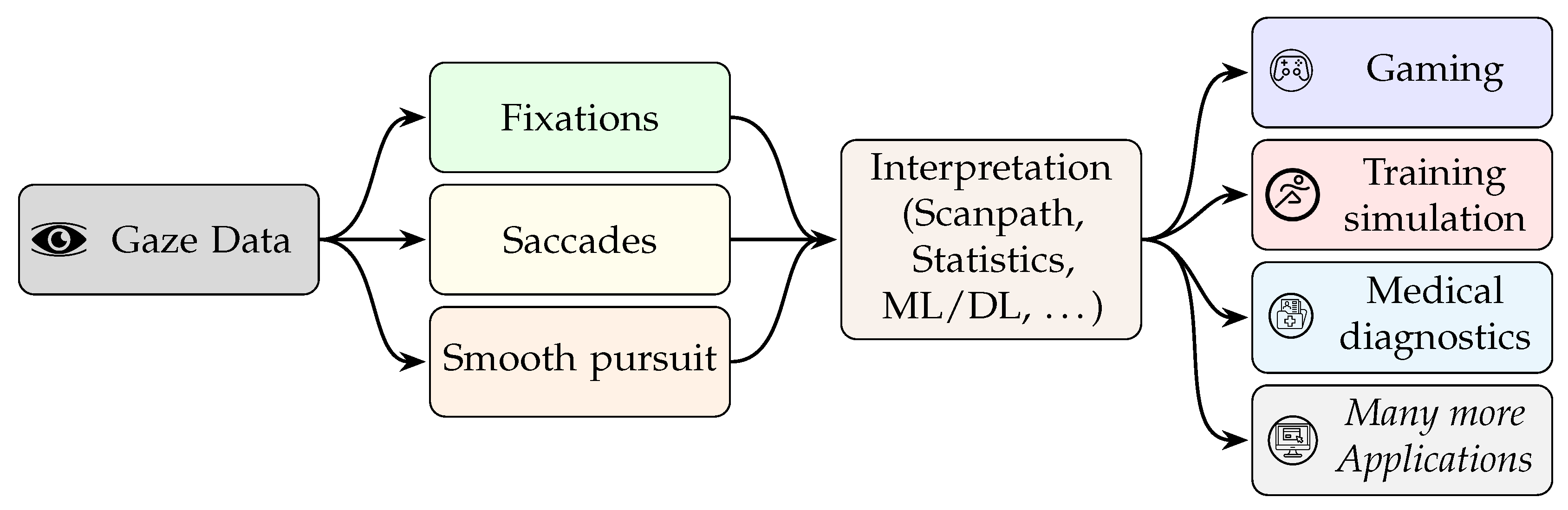
3. Gaze Estimation and Usage in Immersive Scenes
4. Gaze-Based Interaction
4.1. Gaze-Based Interaction with Screen Applications
4.2. Gaze-Based Interaction in Immersive Scenes
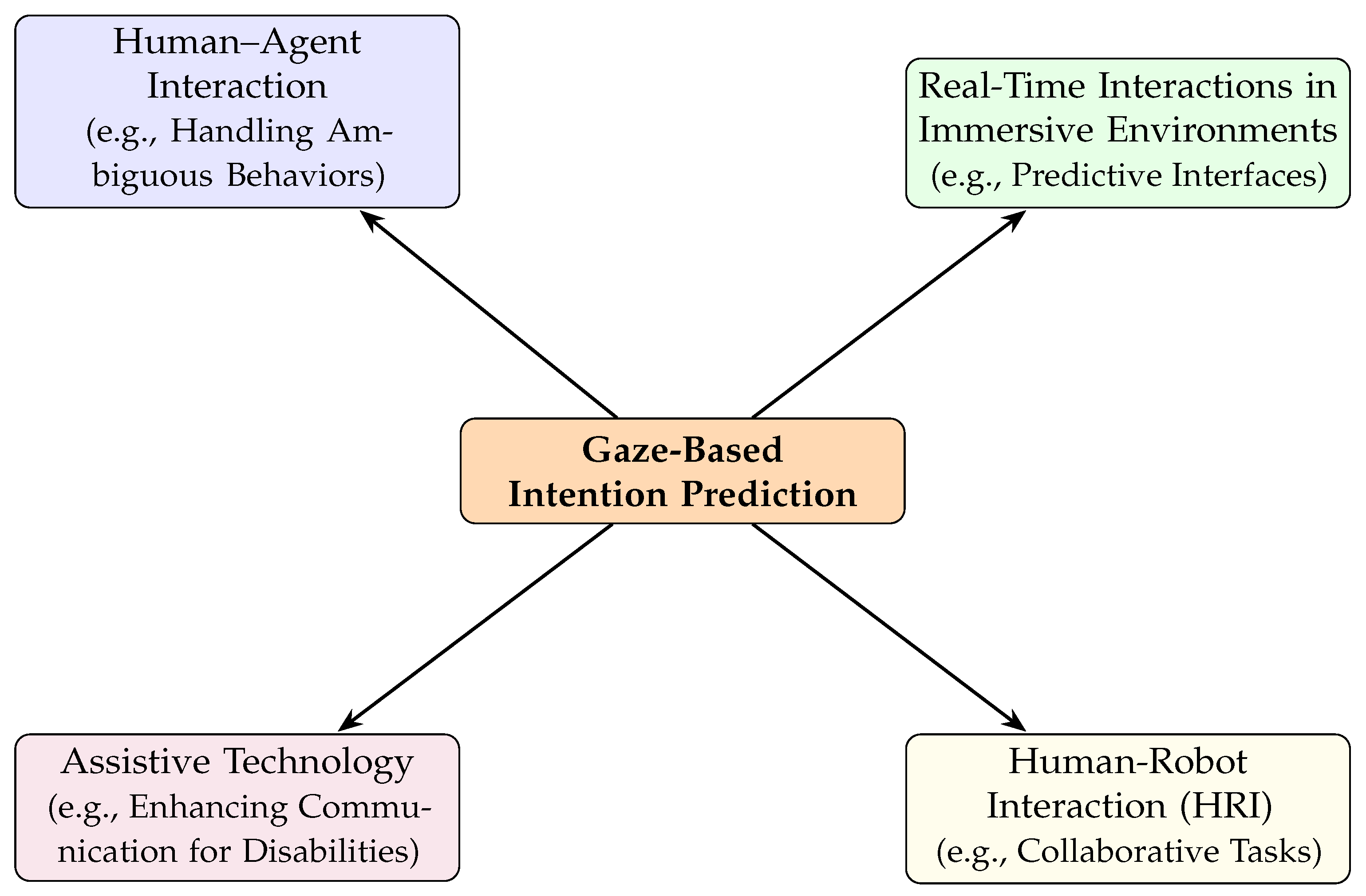
5. Gaze-Based Intention Prediction
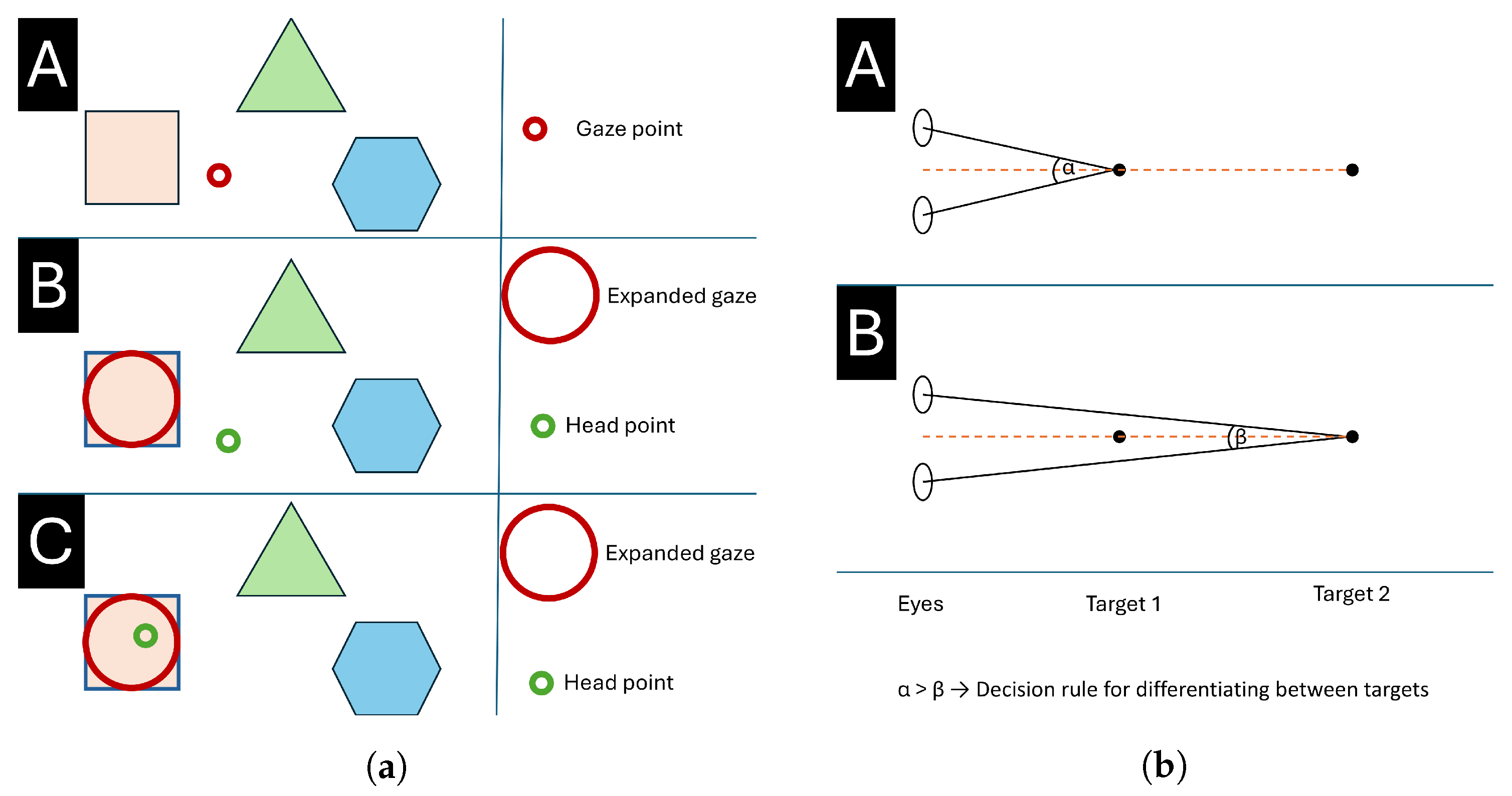
5.1. How to Use Gaze to Predict Intention
5.2. Areas of Application
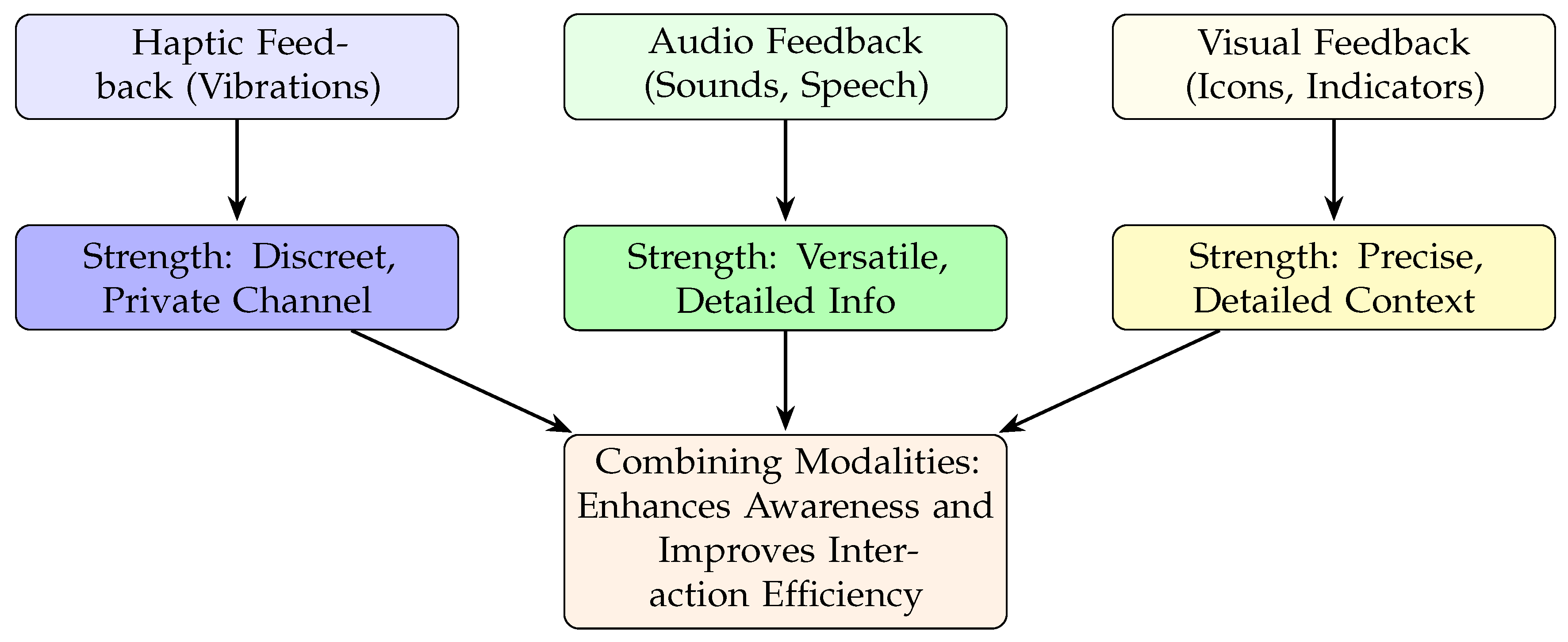
6. Feedback in Gaze-Based Communication
6.1. Haptic Feedback
6.2. Audio Feedback
6.3. Visual Feedback
7. Discussion
8. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Maedche, A.; Legner, C.; Benlian, A.; Berger, B.; Gimpel, H.; Hess, T.; Hinz, O.; Morana, S.; Söllner, M. AI-Based Digital Assistants. Bus. Inf. Syst. Eng. 2019, 61, 535–544. [Google Scholar] [CrossRef]
- Tran, B.; Vu, G.; Ha, G.H.; Vuong, Q.; Ho, M.T.; Vuong, T.T.; La, V.P.; Ho, M.T.; Nghiem, K.C.P.; Nguyen, H.L.T.; et al. Global Evolution of Research in Artificial Intelligence in Health and Medicine: A Bibliometric Study. J. Clin. Med. 2019, 8, 360. [Google Scholar] [CrossRef] [PubMed]
- Marullo, G.; Ulrich, L.; Antonaci, F.G.; Audisio, A.; Aprato, A.; Massè, A.; Vezzetti, E. Classification of AO/OTA 31A/B femur fractures in X-ray images using YOLOv8 and advanced data augmentation techniques. Bone Rep. 2024, 22, 101801. [Google Scholar] [CrossRef] [PubMed]
- Checcucci, E.; Piazzolla, P.; Marullo, G.; Innocente, C.; Salerno, F.; Ulrich, L.; Moos, S.; Quarà, A.; Volpi, G.; Amparore, D.; et al. Development of Bleeding Artificial Intelligence Detector (BLAIR) System for Robotic Radical Prostatectomy. J. Clin. Med. 2023, 12, 7355. [Google Scholar] [CrossRef]
- Lee, M.H.; Siewiorek, D.P.; Smailagic, A.; Bernardino, A.; Badia, S.B.i. Enabling AI and robotic coaches for physical rehabilitation therapy: Iterative design and evaluation with therapists and post-stroke survivors. Int. J. Soc. Robot. 2022, 16, 1–22. [Google Scholar] [CrossRef]
- Zhou, X.Y.; Guo, Y.; Shen, M.; Yang, G.Z. Application of artificial intelligence in surgery. Front. Med. 2020, 14, 417–430. [Google Scholar] [CrossRef]
- Andras, I.; Mazzone, E.; van Leeuwen, F.W.; De Naeyer, G.; van Oosterom, M.N.; Beato, S.; Buckle, T.; O’Sullivan, S.; van Leeuwen, P.J.; Beulens, A.; et al. Artificial intelligence and robotics: A combination that is changing the operating room. World J. Urol. 2020, 38, 2359–2366. [Google Scholar] [CrossRef]
- Zhu, C.; Liu, Q.; Meng, W.; Ai, Q.; Xie, S.Q. An Attention-Based CNN-LSTM Model with Limb Synergy for Joint Angles Prediction. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Delft, The Netherlands, 12–16 July 2021; pp. 747–752. [Google Scholar]
- Wang, K.J.; Liu, Q.; Zhao, Y.; Zheng, C.Y.; Vhasure, S.; Liu, Q.; Thakur, P.; Sun, M.; Mao, Z.H. Intelligent wearable virtual reality (VR) gaming controller for people with motor disabilities. In Proceedings of the 2018 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Nagoya, Japan, 23–25 November 2018; pp. 161–164. [Google Scholar]
- Wen, F.; Zhang, Z.; He, T.; Lee, C. AI enabled sign language recognition and VR space bidirectional communication using triboelectric smart glove. Nat. Commun. 2021, 12, 5378. [Google Scholar] [CrossRef]
- Zgallai, W.; Brown, J.T.; Ibrahim, A.; Mahmood, F.; Mohammad, K.; Khalfan, M.; Mohammed, M.; Salem, M.; Hamood, N. Deep learning AI application to an EEG driven BCI smart wheelchair. In Proceedings of the 2019 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 26 March–10 April 2019; pp. 1–5. [Google Scholar]
- Sakai, Y.; Lu, H.; Tan, J.K.; Kim, H. Recognition of surrounding environment from electric wheelchair videos based on modified YOLOv2. Future Gener. Comput. Syst. 2019, 92, 157–161. [Google Scholar] [CrossRef]
- Nareyek, A. AI in Computer Games. Queue 2004, 1, 58–65. [Google Scholar] [CrossRef]
- Nhizam, S.; Zyarif, M.; Tuhfa, S.Z. Utilization of Artificial Intelligence Technology in Assisting House Chores. J. Multiapp 2021, 2, 29–34. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Kaplan, A.D.; Kessler, T.; Brill, J.C.; Hancock, P. Trust in Artificial Intelligence: Meta-Analytic Findings. Hum. Factors J. Hum. Factors Ergon. Soc. 2021, 65, 337–359. [Google Scholar] [CrossRef]
- Guzman, A.L.; Lewis, S. Artificial intelligence and communication: A Human–Machine Communication research agenda. New Media Soc. 2019, 22, 70–86. [Google Scholar] [CrossRef]
- Hassija, V.; Chakrabarti, A.; Singh, A.; Chamola, V.; Sikdar, B. Unleashing the Potential of Conversational AI: Amplifying Chat-GPT’s Capabilities and Tackling Technical Hurdles. IEEE Access 2023, 11, 143657–143682. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Machiraju, S.; Modi, R. Natural Language Processing. In Developing Bots with Microsoft Bots Framework: Create Intelligent Bots Using MS Bot Framework and Azure Cognitive Services; Apress: Berkeley, CA, USA, 2018; pp. 203–232. [Google Scholar] [CrossRef]
- Wei, W.; Wu, J.; Zhu, C. Special issue on deep learning for natural language processing. Computing 2020, 102, 601–603. [Google Scholar] [CrossRef]
- Singh, S.; Mahmood, A. The NLP Cookbook: Modern Recipes for Transformer Based Deep Learning Architectures. IEEE Access 2021, 9, 68675–68702. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Modern Deep Learning Research. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13693–13696. [Google Scholar] [CrossRef]
- De Russis, L.; Corno, F. On the impact of dysarthric speech on contemporary ASR cloud platforms. J. Reliab. Intell. Environ. 2019, 5, 163–172. [Google Scholar] [CrossRef]
- Hawley, M.S.; Cunningham, S.P.; Green, P.D.; Enderby, P.; Palmer, R.; Sehgal, S.; O’Neill, P. A Voice-Input Voice-Output Communication Aid for People With Severe Speech Impairment. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 23–31. [Google Scholar] [CrossRef] [PubMed]
- Story, M.F.; Winters, J.M.; Lemke, M.R.; Barr, A.; Omiatek, E.; Janowitz, I.; Brafman, D.; Rempel, D. Development of a method for evaluating accessibility of medical equipment for patients with disabilities. Appl. Ergon. 2010, 42, 178–183. [Google Scholar] [CrossRef] [PubMed]
- Niehorster, D.C.; Santini, T.; Hessels, R.S.; Hooge, I.T.; Kasneci, E.; Nyström, M. The impact of slippage on the data quality of head-worn eye trackers. Behav. Res. Methods 2020, 52, 1140–1160. [Google Scholar] [CrossRef]
- Hosp, B.; Eivazi, S.; Maurer, M.; Fuhl, W.; Geisler, D.; Kasneci, E. RemoteEye: An open-source high-speed remote eye tracker: Implementation insights of a pupil-and glint-detection algorithm for high-speed remote eye tracking. Behav. Res. Methods 2020, 52, 1387–1401. [Google Scholar] [CrossRef]
- Kassner, M.; Patera, W.; Bulling, A. Pupil: An Open Source Platform for Pervasive Eye Tracking and Mobile Gaze-based Interaction. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication (UbiComp’14 Adjunct), New York, NY, USA, 13–17 September 2014; pp. 1151–1160. [Google Scholar] [CrossRef]
- Sipatchin, A.; Wahl, S.; Rifai, K. Accuracy and precision of the HTC VIVE PRO eye tracking in head-restrained and head-free conditions. Investig. Ophthalmol. Vis. Sci. 2020, 61, 5071–5071. [Google Scholar]
- Nyström, M.; Andersson, R.; Holmqvist, K.; Van De Weijer, J. The influence of calibration method and eye physiology on eyetracking data quality. Behav. Res. Methods 2013, 45, 272–288. [Google Scholar] [CrossRef] [PubMed]
- Harezlak, K.; Kasprowski, P.; Stasch, M. Towards Accurate Eye Tracker Calibration—Methods and Procedures. Procedia Comput. Sci. 2014, 35, 1073–1081. [Google Scholar] [CrossRef]
- Severitt, B.R.; Kübler, T.C.; Kasneci, E. Testing different function fitting methods for mobile eye-tracker calibration. J. Eye Mov. Res. 2023, 16. [Google Scholar] [CrossRef]
- Niehorster, D.C.; Hessels, R.S.; Benjamins, J.S.; Nyström, M.; Hooge, I.T. GlassesValidator: A data quality tool for eye tracking glasses. Behav. Res. Methods 2024, 56, 1476–1484. [Google Scholar] [CrossRef]
- Hessels, R.S.; Niehorster, D.C.; Nyström, M.; Andersson, R.; Hooge, I.T. Is the eye-movement field confused about fixations and saccades? A survey among 124 researchers. R. Soc. Open Sci. 2018, 5, 180502. [Google Scholar] [CrossRef] [PubMed]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications (ETRA’00), Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar] [CrossRef]
- Chen, X.L.; Hou, W.J. Identifying Fixation and Saccades in Virtual Reality. arXiv 2022, arXiv:2205.04121. [Google Scholar]
- Gao, H.; Bozkir, E.; Hasenbein, L.; Hahn, J.U.; Göllner, R.; Kasneci, E. Digital transformations of classrooms in virtual reality. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–10. [Google Scholar]
- Gao, H.; Frommelt, L.; Kasneci, E. The Evaluation of Gait-Free Locomotion Methods with Eye Movement in Virtual Reality. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Singapore, 17–21 October 2022; pp. 530–535. [Google Scholar]
- Vidal, M.; Bulling, A.; Gellersen, H. Detection of smooth pursuits using eye movement shape features. In Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA’12), Santa Barbara, CA, USA, 28–30 March 2012; pp. 177–180. [Google Scholar] [CrossRef]
- Santini, T.; Fuhl, W.; Kübler, T.; Kasneci, E. Bayesian identification of fixations, saccades, and smooth pursuits. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications (ETRA’16), Charleston, SC, USA, 14–17 March 2016; pp. 163–170. [Google Scholar] [CrossRef]
- Fuhl, W.; Herrmann-Werner, A.; Nieselt, K. The Tiny Eye Movement Transformer. In Proceedings of the 2023 Symposium on Eye Tracking Research and Applications (ETRA’23), Tübingen, Germany, 30 May–2 June 2023. [Google Scholar] [CrossRef]
- Andersson, R.; Larsson, L.; Holmqvist, K.; Stridh, M.; Nyström, M. One algorithm to rule them all? An evaluation and discussion of ten eye movement event-detection algorithms. Behav. Res. Methods 2017, 49, 616–637. [Google Scholar] [CrossRef] [PubMed]
- Marshall, S. Identifying cognitive state from eye metrics. Aviat. Space Environ. Med. 2007, 78 (Suppl. 5), B165–B175. [Google Scholar]
- Yoon, H.J.; Carmichael, T.R.; Tourassi, G. Gaze as a biometric. In Proceedings of the SPIE 9037, Medical Imaging 2014: Image Perception, Observer Performance, and Technology Assessment, San Diego, CA, USA, 16–17 February 2014. [Google Scholar] [CrossRef]
- Boisvert, J.F.; Bruce, N.D. Predicting task from eye movements: On the importance of spatial distribution, dynamics, and image features. Neurocomputing 2016, 207, 653–668. [Google Scholar] [CrossRef]
- Castner, N.; Arsiwala-Scheppach, L.; Mertens, S.; Krois, J.; Thaqi, E.; Kasneci, E.; Wahl, S.; Schwendicke, F. Expert gaze as a usability indicator of medical AI decision support systems: A preliminary study. npj Digit. Med. 2024, 7, 199. [Google Scholar] [CrossRef] [PubMed]
- Yarbus, A.L. Eye Movements and Vision; Springer: New York, NY, USA, 1967; p. 171. [Google Scholar]
- Castner, N.; Kuebler, T.C.; Scheiter, K.; Richter, J.; Eder, T.; Hüttig, F.; Keutel, C.; Kasneci, E. Deep semantic gaze embedding and scanpath comparison for expertise classification during OPT viewing. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications (ETRA’20), Stuttgart, Germany, 2–5 June 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Anderson, N.C.; Bischof, W.F.; Laidlaw, K.E.; Risko, E.F.; Kingstone, A. Recurrence quantification analysis of eye movements. Behav. Res. Methods 2013, 45, 842–856. [Google Scholar] [CrossRef]
- Dewhurst, R.; Nyström, M.; Jarodzka, H.; Foulsham, T.; Johansson, R.; Holmqvist, K. It depends on how you look at it: Scanpath comparison in multiple dimensions with MultiMatch, a vector-based approach. Behav. Res. Methods 2012, 44, 1079–1100. [Google Scholar] [CrossRef] [PubMed]
- Li, A.; Chen, Z. Representative scanpath identification for group viewing pattern analysis. J. Eye Mov. Res. 2018, 11. [Google Scholar] [CrossRef]
- Geisler, D.; Castner, N.; Kasneci, G.; Kasneci, E. A MinHash approach for fast scanpath classification. In ACM Symposium on Eye Tracking Research and Applications; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Pfeuffer, K.; Mayer, B.; Mardanbegi, D.; Gellersen, H. Gaze + pinch interaction in virtual reality. In Proceedings of the 5th Symposium on Spatial User Interaction (SUI’17), Brighton, UK, 16–17 October 2017; pp. 99–108. [Google Scholar] [CrossRef]
- Dohan, M.; Mu, M. Understanding User Attention In VR Using Gaze Controlled Games. In Proceedings of the 2019 ACM International Conference on Interactive Experiences for TV and Online Video (TVX’19), Salford, UK, 5–7 June 2019; pp. 167–173. [Google Scholar] [CrossRef]
- Kocur, M.; Dechant, M.J.; Lankes, M.; Wolff, C.; Mandryk, R. Eye Caramba: Gaze-based Assistance for Virtual Reality Aiming and Throwing Tasks in Games. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications (ETRA’20 Short Papers), Stuttgart, Germany, 2–5 June 2020. [Google Scholar] [CrossRef]
- Harris, D.J.; Hardcastle, K.J.; Wilson, M.R.; Vine, S.J. Assessing the learning and transfer of gaze behaviours in immersive virtual reality. Virtual Real. 2021, 25, 961–973. [Google Scholar] [CrossRef]
- Neugebauer, A.; Castner, N.; Severitt, B.; Štingl, K.; Ivanov, I.; Wahl, S. Simulating vision impairment in virtual reality: A comparison of visual task performance with real and simulated tunnel vision. Virtual Real. 2024, 28, 97. [Google Scholar] [CrossRef]
- Orlosky, J.; Itoh, Y.; Ranchet, M.; Kiyokawa, K.; Morgan, J.; Devos, H. Emulation of Physician Tasks in Eye-Tracked Virtual Reality for Remote Diagnosis of Neurodegenerative Disease. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1302–1311. [Google Scholar] [CrossRef] [PubMed]
- Adhanom, I.B.; MacNeilage, P.; Folmer, E. Eye tracking in virtual reality: A broad review of applications and challenges. Virtual Real. 2023, 27, 1481–1505. [Google Scholar] [CrossRef] [PubMed]
- Clay, V.; König, P.; Koenig, S. Eye tracking in virtual reality. J. Eye Mov. Res. 2019, 12. [Google Scholar] [CrossRef] [PubMed]
- Naspetti, S.; Pierdicca, R.; Mandolesi, S.; Paolanti, M.; Frontoni, E.; Zanoli, R. Automatic analysis of eye-tracking data for augmented reality applications: A prospective outlook. In Augmented Reality, Virtual Reality, and Computer Graphics: Proceedings of the Third International Conference, AVR 2016, Lecce, Italy, 15–18 June 2016; Proceedings, Part II 3; Springer: Cham, Switzerland, 2016; pp. 217–230. [Google Scholar]
- Mania, K.; McNamara, A.; Polychronakis, A. Gaze-aware displays and interaction. In Proceedings of the ACM SIGGRAPH 2021 Courses (SIGGRAPH’21), Virtual, 9–13 August 2021. [Google Scholar] [CrossRef]
- Alt, F.; Schneegass, S.; Auda, J.; Rzayev, R.; Broy, N. Using eye-tracking to support interaction with layered 3D interfaces on stereoscopic displays. In Proceedings of the 19th International Conference on Intelligent User Interfaces (IUI’14), Haifa, Israel, 24–27 February 2014; pp. 267–272. [Google Scholar] [CrossRef]
- Duchowski, A.T. Gaze-based interaction: A 30 year retrospective. Comput. Graph. 2018, 73, 59–69. [Google Scholar] [CrossRef]
- Plopski, A.; Hirzle, T.; Norouzi, N.; Qian, L.; Bruder, G.; Langlotz, T. The Eye in Extended Reality: A Survey on Gaze Interaction and Eye Tracking in Head-worn Extended Reality. ACM Comput. Surv. 2022, 55. [Google Scholar] [CrossRef]
- Bolt, R.A. Gaze-orchestrated dynamic windows. ACM SIGGRAPH Comput. Graph. 1981, 15, 109–119. [Google Scholar] [CrossRef]
- Kiefer, P.; Giannopoulos, I.; Raubal, M.; Duchowski, A. Eye tracking for spatial research: Cognition, computation, challenges. Spat. Cogn. Comput. 2017, 17, 1–19. [Google Scholar] [CrossRef]
- Bednarik, R. Expertise-dependent visual attention strategies develop over time during debugging with multiple code representations. Int. J. Hum.-Comput. Stud. 2012, 70, 143–155. [Google Scholar] [CrossRef]
- Majaranta, P.; Räihä, K.J. Twenty years of eye typing: Systems and design issues. In Proceedings of the 2002 Symposium on Eye Tracking Research & Applications (ETRA’02), New Orleans, LA, USA, 25–27 March 2002; pp. 15–22. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Rubinstein, J.; Sawyer, M.W.; Duchowski, A.T. Longitudinal evaluation of discrete consecutive gaze gestures for text entry. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications (ETRA’08), Savannah, GA, USA, 26–28 March 2008; pp. 11–18. [Google Scholar] [CrossRef]
- Ward, D.J.; MacKay, D.J. Fast hands-free writing by gaze direction. Nature 2002, 418, 838–838. [Google Scholar] [CrossRef]
- Majaranta, P.; Bates, R. Special issue: Communication by gaze interaction. Univers. Access Inf. Soc. 2009, 8, 239–240. [Google Scholar] [CrossRef]
- Hansen, J.P.; Tørning, K.; Johansen, A.S.; Itoh, K.; Aoki, H. Gaze typing compared with input by head and hand. In Proceedings of the 2004 Symposium on Eye Tracking Research & Applications (ETRA’04), San Antonio, TX, USA, 22–24 March 2004; pp. 131–138. [Google Scholar] [CrossRef]
- Tuisku, O.; Majaranta, P.; Isokoski, P.; Räihä, K.J. Now Dasher! Dash away! longitudinal study of fast text entry by Eye Gaze. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications (ETRA’08), Savannah, GA, USA, 26–28 March 2008; pp. 19–26. [Google Scholar] [CrossRef]
- Hoanca, B.; Mock, K. Secure graphical password system for high traffic public areas. In Proceedings of the 2006 Symposium on Eye Tracking Research & Applications (ETRA’06), San Diego, CA, USA, 27–29 March 2006; p. 35. [Google Scholar] [CrossRef]
- Best, D.S.; Duchowski, A.T. A rotary dial for gaze-based PIN entry. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications (ETRA’16), Charleston, SC, USA, 14–17 March 2016; pp. 69–76. [Google Scholar] [CrossRef]
- Huckauf, A.; Urbina, M. Gazing with pEYE: New concepts in eye typing. In Proceedings of the 4th Symposium on Applied Perception in Graphics and Visualization (APGV’07), Tübingen, Germany, 25–27 July 2007; p. 141. [Google Scholar] [CrossRef]
- Huckauf, A.; Urbina, M.H. Gazing with pEYEs: Towards a universal input for various applications. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications (ETRA’08), Savannah, Georgia, 26–28 March 2008; pp. 51–54. [Google Scholar] [CrossRef]
- Urbina, M.H.; Lorenz, M.; Huckauf, A. Pies with EYEs: The limits of hierarchical pie menus in gaze control. In Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications (ETRA’10), Austin, TX, USA, 22–24 March 2010; pp. 93–96. [Google Scholar] [CrossRef]
- Jacob, R.J.K. What you look at is what you get: Eye movement-based interaction techniques. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’90), Seattle, WA, USA, 1–5 April 1990; pp. 11–18. [Google Scholar] [CrossRef]
- Starker, I.; Bolt, R.A. A gaze-responsive self-disclosing display. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’90), Seattle, WA, USA, 1–5 April 1990; pp. 3–10. [Google Scholar] [CrossRef]
- Špakov, O.; Majaranta, P. Enhanced gaze interaction using simple head gestures. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing (UbiComp’12), Pittsburgh, PA, USA, 5–8 September 2012; pp. 705–710. [Google Scholar] [CrossRef]
- Vidal, M.; Bulling, A.; Gellersen, H. Pursuits: Spontaneous interaction with displays based on smooth pursuit eye movement and moving targets. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp’13), Zurich, Switzerland, 8–12 September 2013; pp. 439–448. [Google Scholar] [CrossRef]
- Esteves, A.; Velloso, E.; Bulling, A.; Gellersen, H. Orbits: Gaze Interaction for Smart Watches using Smooth Pursuit Eye Movements. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology (UIST’15), Charlotte, NC, USA, 8–11 November 2015; pp. 457–466. [Google Scholar] [CrossRef]
- Sportillo, D.; Paljic, A.; Ojeda, L. Get ready for automated driving using Virtual Reality. Accid. Anal. Prev. 2018, 118, 102–113. [Google Scholar] [CrossRef] [PubMed]
- Piromchai, P.; Avery, A.; Laopaiboon, M.; Kennedy, G.; O’Leary, S. Virtual reality training for improving the skills needed for performing surgery of the ear, nose or throat. Cochrane Database Syst. Rev. 2015, 9, CD010198. [Google Scholar] [CrossRef] [PubMed]
- Stirling, E.R.B.; Lewis, T.L.; Ferran, N.A. Surgical skills simulation in trauma and orthopaedic training. J. Orthop. Surg. Res. 2014, 9, 126. [Google Scholar] [CrossRef] [PubMed]
- de Armas, C.; Tori, R.; Netto, A.V. Use of virtual reality simulators for training programs in the areas of security and defense: A systematic review. Multimed. Tools Appl. 2020, 79, 3495–3515. [Google Scholar] [CrossRef]
- Monteiro, P.; Gonçalves, G.; Coelho, H.; Melo, M.; Bessa, M. Hands-free interaction in immersive virtual reality: A systematic review. IEEE Trans. Vis. Comput. Graph. 2021, 27, 2702–2713. [Google Scholar] [CrossRef]
- Klamka, K.; Siegel, A.; Vogt, S.; Göbel, F.; Stellmach, S.; Dachselt, R. Look & Pedal: Hands-free Navigation in Zoomable Information Spaces through Gaze-supported Foot Input. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction (ICMI’15), Seattle, WA, USA, 9–13 November 2015; pp. 123–130. [Google Scholar] [CrossRef]
- Qian, Y.Y.; Teather, R.J. The eyes don’t have it: An empirical comparison of head-based and eye-based selection in virtual reality. In Proceedings of the 5th Symposium on Spatial User Interaction (SUI’17), Brighton, UK, 16–17 October 2017; pp. 91–98. [Google Scholar] [CrossRef]
- Blattgerste, J.; Renner, P.; Pfeiffer, T. Advantages of eye-gaze over head-gaze-based selection in virtual and augmented reality under varying field of views. In Proceedings of the Workshop on Communication by Gaze Interaction (COGAIN’18), Warsaw, Poland, 15 June 2018. [Google Scholar] [CrossRef]
- Sidenmark, L.; Gellersen, H. Eye&Head: Synergetic Eye and Head Movement for Gaze Pointing and Selection. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology (UIST’19), New Orleans, LA, USA, 20–23 October 2019; pp. 1161–1174. [Google Scholar] [CrossRef]
- Wei, Y.; Shi, R.; Yu, D.; Wang, Y.; Li, Y.; Yu, L.; Liang, H.N. Predicting Gaze-based Target Selection in Augmented Reality Headsets based on Eye and Head Endpoint Distributions. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI’23), Hamburg, Germany, 23–28 April 2023. [Google Scholar] [CrossRef]
- Sidenmark, L.; Clarke, C.; Newn, J.; Lystbæk, M.N.; Pfeuffer, K.; Gellersen, H. Vergence Matching: Inferring Attention to Objects in 3D Environments for Gaze-Assisted Selection. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI’23), Hamburg, Germany, 23–28 April 2023. [Google Scholar] [CrossRef]
- Hülsmann, F.; Dankert, T.; Pfeiffer, T. Comparing gaze-based and manual interaction in a fast-paced gaming task in virtual reality. In Proceedings of the Workshop Virtuelle & Erweiterte Realität 2011; Shaker Verlag: Aachen, Germany, 2011. [Google Scholar]
- Luro, F.L.; Sundstedt, V. A comparative study of eye tracking and hand controller for aiming tasks in virtual reality. In Proceedings of the 11th ACM Symposium on Eye Tracking Research & Applications (ETRA’19), Denver, CO, USA, 25–28 June 2019. [Google Scholar] [CrossRef]
- Lee, J.; Kim, H.; Kim, G.J. Keep Your Eyes on the Target: Enhancing Immersion and Usability by Designing Natural Object Throwing with Gaze-based Targeting. In Proceedings of the 2024 Symposium on Eye Tracking Research and Applications (ETRA’24), Glasgow, UK, 4–7 June 2024. [Google Scholar] [CrossRef]
- Sidorakis, N.; Koulieris, G.A.; Mania, K. Binocular eye-tracking for the control of a 3D immersive multimedia user interface. In Proceedings of the 2015 IEEE 1st Workshop on Everyday Virtual Reality (WEVR), Arles, France, 23 March 2015; pp. 15–18. [Google Scholar] [CrossRef]
- Lethaus, F.; Baumann, M.; Köster, F.; Lemmer, K. A comparison of selected simple supervised learning algorithms to predict driver intent based on gaze data. Neurocomputing 2013, 121, 108–130. [Google Scholar] [CrossRef]
- Wu, M.; Louw, T.; Lahijanian, M.; Ruan, W.; Huang, X.; Merat, N.; Kwiatkowska, M. Gaze-based Intention Anticipation over Driving Manoeuvres in Semi-Autonomous Vehicles. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 4–8 November 2019; pp. 6210–6216. [Google Scholar] [CrossRef]
- Weber, D.; Kasneci, E.; Zell, A. Exploiting Augmented Reality for Extrinsic Robot Calibration and Eye-based Human-Robot Collaboration. In Proceedings of the 2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Sapporo, Hokkaido, Japan, 7–10 March 2022; pp. 284–293. [Google Scholar] [CrossRef]
- Weber, D.; Santini, T.; Zell, A.; Kasneci, E. Distilling Location Proposals of Unknown Objects through Gaze Information for Human-Robot Interaction. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 11086–11093. [Google Scholar] [CrossRef]
- David-John, B.; Peacock, C.; Zhang, T.; Murdison, T.S.; Benko, H.; Jonker, T.R. Towards gaze-based prediction of the intent to interact in virtual reality. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications (ETRA’21), Virtual, 25–27 May 2021. [Google Scholar] [CrossRef]
- Belardinelli, A. Gaze-based intention estimation: Principles, methodologies, and applications in HRI. arXiv 2023, arXiv:2302.04530. [Google Scholar] [CrossRef]
- Huang, C.M.; Mutlu, B. Anticipatory robot control for efficient human-robot collaboration. In Proceedings of the 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; pp. 83–90. [Google Scholar] [CrossRef]
- Kanan, C.; Ray, N.A.; Bseiso, D.N.F.; Hsiao, J.H.; Cottrell, G.W. Predicting an observer’s task using multi-fixation pattern analysis. In Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA’14), Safety Harbor, FL, USA, 26–28 March 2014; pp. 287–290. [Google Scholar] [CrossRef]
- Bader, T.; Vogelgesang, M.; Klaus, E. Multimodal integration of natural gaze behavior for intention recognition during object manipulation. In Proceedings of the 2009 International Conference on Multimodal Interfaces (ICMI-MLMI’09), Cambridge, MA, USA, 2–6 November 2009; pp. 199–206. [Google Scholar] [CrossRef]
- Boccignone, G. Advanced Statistical Methods for Eye Movement Analysis and Modelling: A Gentle Introduction. In Eye Movement Research: An Introduction to Its Scientific Foundations and Applications; Klein, C., Ettinger, U., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 309–405. [Google Scholar] [CrossRef]
- Fuchs, S.; Belardinelli, A. Gaze-Based Intention Estimation for Shared Autonomy in Pick-and-Place Tasks. Front. Neurorobot. 2021, 15. [Google Scholar] [CrossRef]
- Haji-Abolhassani, A.; Clark, J.J. An inverse Yarbus process: Predicting observers’ task from eye movement patterns. Vision Res. 2014, 103, 127–142. [Google Scholar] [CrossRef]
- Tahboub, K.A. Intelligent human-machine interaction based on dynamic bayesian networks probabilistic intention recognition. J. Intell. Robot. Syst. 2006, 45, 31–52. [Google Scholar] [CrossRef]
- Yi, W.; Ballard, D. Recognizing behavior in hand-eye coordination patterns. Int. J. Humanoid Robot. 2009, 6, 337–359. [Google Scholar] [CrossRef] [PubMed]
- Malakoff, D. A Brief Guide to Bayes Theorem. Science 1999, 286, 1461–1461. [Google Scholar] [CrossRef]
- Singh, R.; Miller, T.; Newn, J.; Velloso, E.; Vetere, F.; Sonenberg, L. Combining gaze and AI planning for online human intention recognition. Artif. Intell. 2020, 284, 103275. [Google Scholar] [CrossRef]
- Chen, X.L.; Hou, W.J. Gaze-Based Interaction Intention Recognition in Virtual Reality. Electronics 2022, 11, 1647. [Google Scholar] [CrossRef]
- Newn, J.; Singh, R.; Velloso, E.; Vetere, F. Combining implicit gaze and AI for real-time intention projection. In Proceedings of the Adjunct Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers (UbiComp/ISWC’19 Adjunct), London, UK, 9–13 September 2019; pp. 324–327. [Google Scholar] [CrossRef]
- Koochaki, F.; Najafizadeh, L. Predicting Intention Through Eye Gaze Patterns. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Koochaki, F.; Najafizadeh, L. A Data-Driven Framework for Intention Prediction via Eye Movement with Applications to Assistive Systems. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 974–984. [Google Scholar] [CrossRef]
- Shi, L.; Copot, C.; Vanlanduit, S. GazeEMD: Detecting Visual Intention in Gaze-Based Human-Robot Interaction. Robotics 2021, 10, 68. [Google Scholar] [CrossRef]
- Dermy, O.; Charpillet, F.; Ivaldi, S. Multi-modal Intention Prediction with Probabilistic Movement Primitives. In Human Friendly Robotics; Ficuciello, F., Ruggiero, F., Finzi, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 181–196. [Google Scholar]
- Pérez-Quiñones, M.A.; Sibert, J.L. A collaborative model of feedback in human-computer interaction. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 13–18 April 1996; pp. 316–323. [Google Scholar]
- aus der Wieschen, M.V.; Fischer, K.; Kukliński, K.; Jensen, L.C.; Savarimuthu, T.R. Multimodal Feedback in Human-Robot Interaction; IGI Global: Hershey, PA, USA, 2020; pp. 990–1017. [Google Scholar] [CrossRef]
- Kangas, J.; Rantala, J.; Majaranta, P.; Isokoski, P.; Raisamo, R. Haptic feedback to gaze events. In Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA’14), Safety Harbor, FL, USA, 26–28 March 2014; pp. 11–18. [Google Scholar] [CrossRef]
- Rantala, J.; Majaranta, P.; Kangas, J.; Isokoski, P.; Akkil, D.; Špakov, O.; Raisamo, R. Gaze Interaction With Vibrotactile Feedback: Review and Design Guidelines. Hum.–Comput. Interact. 2020, 35, 1–39. [Google Scholar] [CrossRef]
- Majaranta, P.; Isokoski, P.; Rantala, J.; Špakov, O.; Akkil, D.; Kangas, J.; Raisamo, R. Haptic feedback in eye typing. J. Eye Mov. Res. 2016, 9. [Google Scholar] [CrossRef]
- Sakamak, I.; Tavakoli, M.; Wiebe, S.; Adams, K. Integration of an Eye Gaze Interface and BCI with Biofeedback for Human-Robot Interaction. 2020. Available online: https://era.library.ualberta.ca/items/c00514a1-e810-4ddf-9e1b-af3a3d90c65a (accessed on 2 December 2024).
- Moraes, A.N.; Flynn, R.; Murray, N. Analysing Listener Behaviour Through Gaze Data and User Performance during a Sound Localisation Task in a VR Environment. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Singapore, 17–21 October 2022; pp. 485–490. [Google Scholar] [CrossRef]
- Canales, R.; Jörg, S. Performance Is Not Everything: Audio Feedback Preferred Over Visual Feedback for Grasping Task in Virtual Reality. In Proceedings of the 13th ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG’20), North Charleston, SC, USA, 16–18 October 2020. [Google Scholar] [CrossRef]
- Staudte, M.; Koller, A.; Garoufi, K.; Crocker, M. Using listener gaze to augment speech generation in a virtual 3D environment. In Proceedings of the Annual Meeting of the Cognitive Science Society, Sapporo, Japan, 1–4 August 2012; Volume 34. [Google Scholar]
- Garoufi, K.; Staudte, M.; Koller, A.; Crocker, M. Exploiting Listener Gaze to Improve Situated Communication in Dynamic Virtual Environments. Cogn. Sci. 2016, 40, 1671–1703. [Google Scholar] [CrossRef]
- Zhang, Y.; Fernando, T.; Xiao, H.; Travis, A. Evaluation of Auditory and Visual Feedback on Task Performance in a Virtual Assembly Environment. PRESENCE Teleoper. Virtual Environ. 2006, 15, 613–626. [Google Scholar] [CrossRef]
- Kangas, J.; Špakov, O.; Isokoski, P.; Akkil, D.; Rantala, J.; Raisamo, R. Feedback for Smooth Pursuit Gaze Tracking Based Control. In Proceedings of the 7th Augmented Human International Conference 2016, Geneva, Switzerland, 25–27 February 2016. [Google Scholar] [CrossRef]
- Lankes, M.; Haslinger, A. Lost & Found: Gaze-based Player Guidance Feedback in Exploration Games. In Proceedings of the Extended Abstracts of the Annual Symposium on Computer-Human Interaction in Play Companion Extended Abstracts, Barcelona, Spain, 22–25 October 2019. [Google Scholar] [CrossRef]
- Ghosh, S.; Dhall, A.; Hayat, M.; Knibbe, J.; Ji, Q. Automatic Gaze Analysis: A Survey of Deep Learning Based Approaches. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 61–84. [Google Scholar] [CrossRef] [PubMed]
- Frid, E.; Moll, J.; Bresin, R.; Sallnäs Pysander, E.L. Haptic feedback combined with movement sonification using a friction sound improves task performance in a virtual throwing task. J. Multimodal User Interfaces 2019, 13, 279–290. [Google Scholar] [CrossRef]
- Cominelli, L.; Feri, F.; Garofalo, R.; Giannetti, C.; Meléndez-Jiménez, M.A.; Greco, A.; Nardelli, M.; Scilingo, E.P.; Kirchkamp, O. Promises and trust in human-robot interaction. Sci. Rep. 2021, 11, 9687. [Google Scholar] [CrossRef]
- Bao, Y.; Cheng, X.; de Vreede, T.; de Vreede, G.J. Investigating the relationship between AI and trust in human-AI collaboration. In Proceedings of the Hawaii International Conference on System Sciences, Kauai, HI, USA, 5 January 2021. [Google Scholar]
- David-John, B.; Hosfelt, D.; Butler, K.; Jain, E. A privacy-preserving approach to streaming eye-tracking data. IEEE Trans. Vis. Comput. Graph. 2021, 27, 2555–2565. [Google Scholar] [CrossRef] [PubMed]
- Kröger, J.L.; Lutz, O.H.M.; Müller, F. What Does Your Gaze Reveal About You? On the Privacy Implications of Eye Tracking. In Privacy and Identity Management. Data for Better Living: AI and Privacy: 14th IFIP WG 9.2, 9.6/11.7, 11.6/SIG 9.2.2 International Summer School, Windisch, Switzerland, 19–23 August 2019; Revised Selected Papers; Friedewald, M., Önen, M., Lievens, E., Krenn, S., Fricker, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 226–241. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication | Eyes | Head | Hands | Task |
|---|---|---|---|---|
| [93] | X | X | head vs. gaze selection | |
| [94] | X | X | head vs. gaze selection | |
| [95] | X | X | head-supported gaze selection | |
| [96] | X | X | probabilistic model based on head and gaze | |
| [97] | X | vergence based selection | ||
| [98] | X | X | gaze vs. hand based interaction in games | |
| [99] | X | X | gaze vs. hand based aiming in games | |
| [100] | X | X | gaze vs. controller in baseball-throwing game | |
| [101] | X | using gaze for common computer activities |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Severitt, B.R.; Castner, N.; Wahl, S. Bi-Directional Gaze-Based Communication: A Review. Multimodal Technol. Interact. 2024, 8, 108. https://doi.org/10.3390/mti8120108
Severitt BR, Castner N, Wahl S. Bi-Directional Gaze-Based Communication: A Review. Multimodal Technologies and Interaction. 2024; 8(12):108. https://doi.org/10.3390/mti8120108
Chicago/Turabian StyleSeveritt, Björn Rene, Nora Castner, and Siegfried Wahl. 2024. "Bi-Directional Gaze-Based Communication: A Review" Multimodal Technologies and Interaction 8, no. 12: 108. https://doi.org/10.3390/mti8120108
APA StyleSeveritt, B. R., Castner, N., & Wahl, S. (2024). Bi-Directional Gaze-Based Communication: A Review. Multimodal Technologies and Interaction, 8(12), 108. https://doi.org/10.3390/mti8120108