


Designing a Tactile Document UI for 2D Refreshable Tactile Displays: Towards Accessible Document Layouts for Blind People

 ,
,  , , and
, , and
Abstract

1. Introduction
- We design a method to automatically extract document layouts and a new dataset comprising common complex layouts, including slides and newspapers.
- We construct an interactive TUI for displaying documents on 2D refreshable tactile displays to enable blind users to navigate and explore complex document layouts through haptic and button-based interactions and auditory feedback.
2. Related Work
2.1. Document Layout Analysis Methods
2.2. Document Access by Screen Readers
2.3. Haptic Representation of Documents
3. Materials and Methods
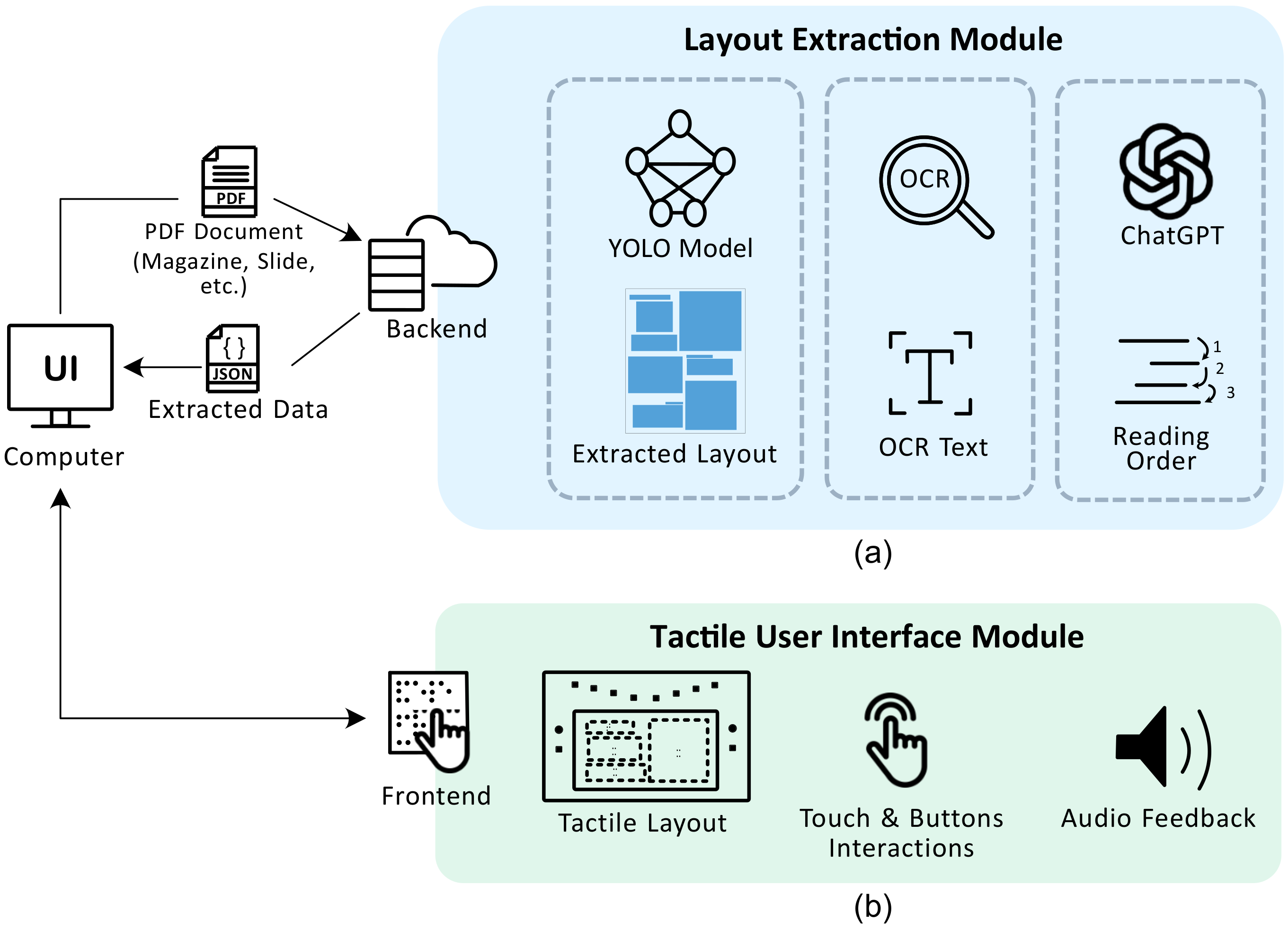
3.1. Layout Extraction Module
3.2. TUI Module
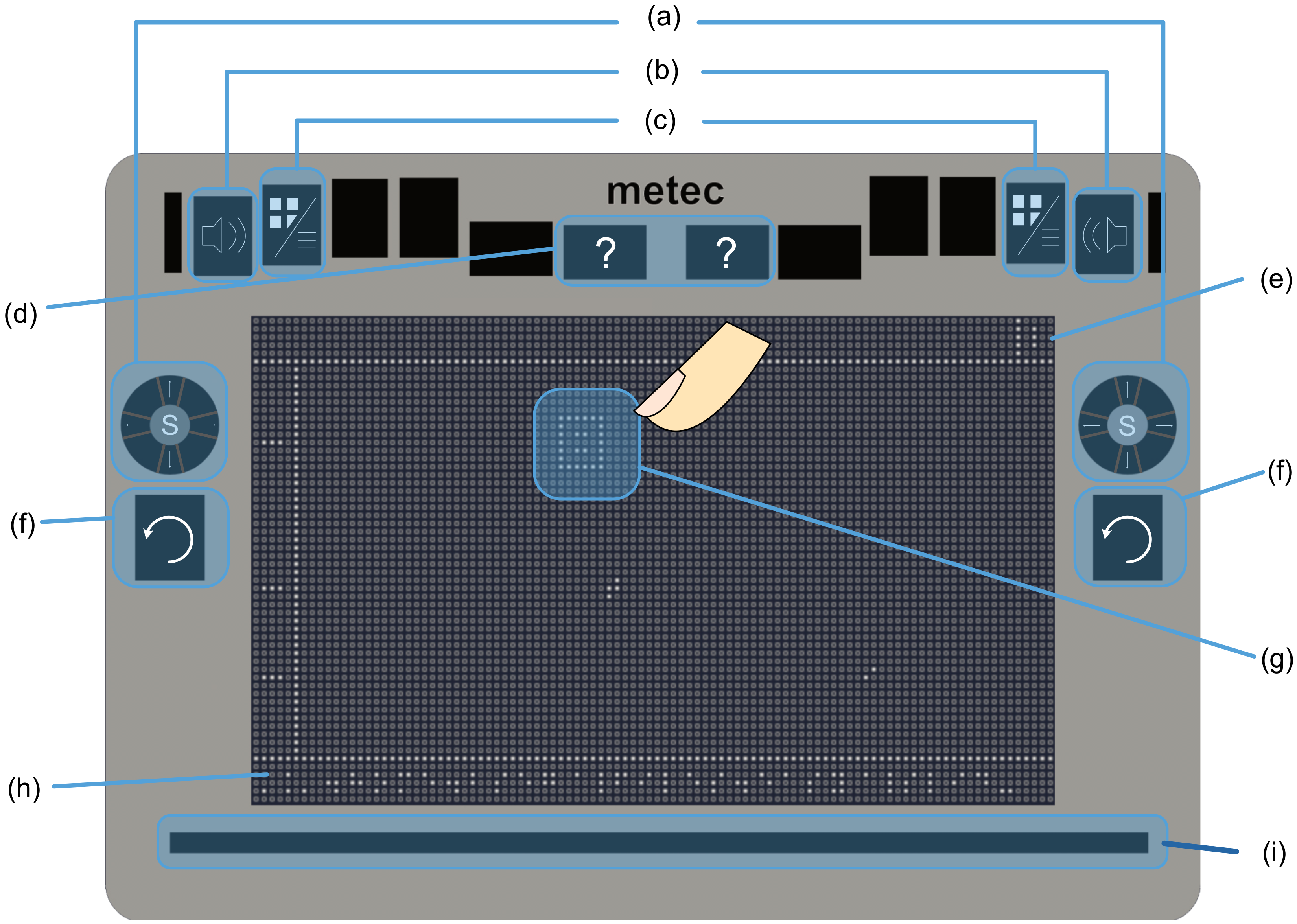
3.3. First Prototype: Static TUI
- Implementing all interaction buttons symmetrically on both sides of the device to allow the users to explore the document using both hands and avoid losing the orientation at any time when using the buttons. This would also enhance the accessibility for left and right handed users.
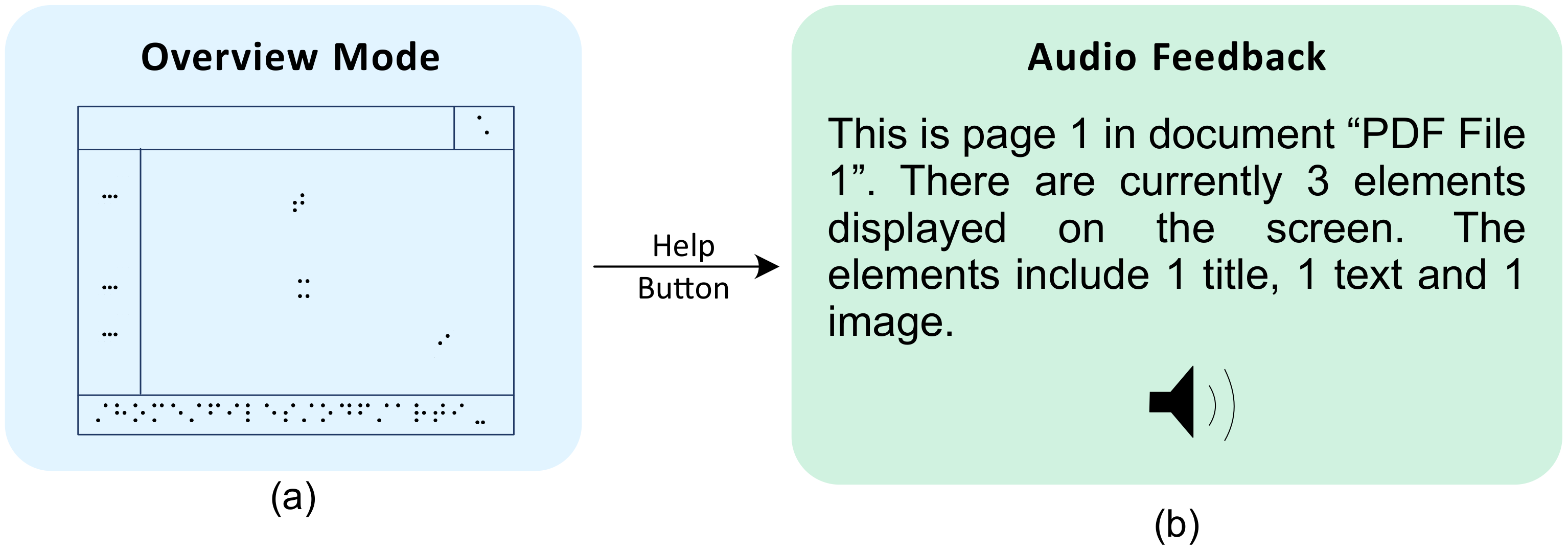
- Integrating audio feedback to provide the text of each element when needed.
- Providing the user with an acoustic feedback while using the navigation buttons to signal the occurrence of a change.
- Including a feature to offer additional details, such as the number of columns, element types, and document format (e.g., paper, slide, receipt), upon request.
3.4. Second Prototype: Interactive TUI
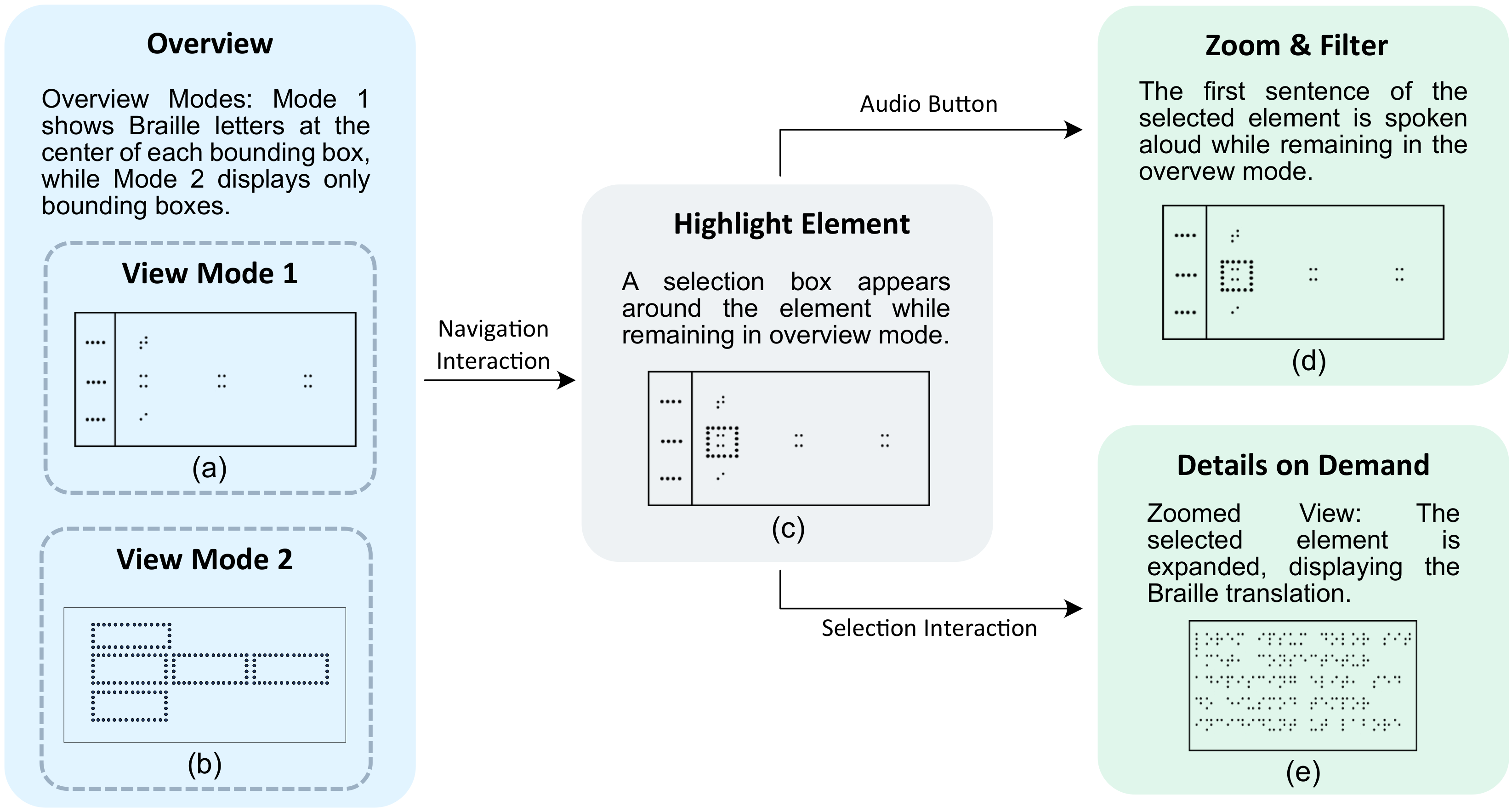
3.4.1. VISM Principles
3.4.2. Interaction Concepts
4. Preliminary Study
4.1. Participants
4.2. Procedure
- Task 1: Skim the document and give a quick summary of the topic and the main key points.
- Task 2: Answer a question about certain information in the document. (Document (a): How does the writer stay updated on the rapidly occurring changes? Document (b): Why do some individuals prefer to be anonymous online.)
- Task 3: Explain the structure of the document.
4.3. Results
5. Discussion
5.1. Optimizing View Modes for Enhanced User Experience
5.2. Importance of Interaction Feedback for Improved Navigation and Orientation
5.3. Additional Features
6. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kearney-Volpe, C.; Hurst, A. Accessible web development: Opportunities to improve the education and practice of web development with a screen reader. TACCESS 2021, 14, 1–32. [Google Scholar] [CrossRef]
- Li, J.; Kim, S.; Miele, J.A.; Agrawala, M.; Follmer, S. Editing spatial layouts through tactile templates for people with visual impairments. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–11. [Google Scholar]
- Potluri, V.; Grindeland, T.E.; Froehlich, J.E.; Mankoff, J. Examining visual semantic understanding in blind and low-vision technology users. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–14. [Google Scholar]
- Bishop, A.P. Document structure and digital libraries: How researchers mobilize information in journal articles. Inf. Process. Manag. 1999, 35, 255–279. [Google Scholar] [CrossRef]
- Dorigo, M.; Harriehausen-Mühlbauer, B.; Stengel, I.; Dowland, P.S. Survey: Improving document accessibility from the blind and visually impaired user’s point of view. In Proceedings of the Universal Access in Human-Computer Interaction. Applications and Services: 6th International Conference, UAHCI 2011, Held as Part of HCI International 2011, Orlando, FL, USA, 9–14 July 2011; Springer: Berlin/Heidelberg, Germany, 2011. Proceedings, Part IV 6. pp. 129–135. [Google Scholar]
- Wang, L.L.; Cachola, I.; Bragg, J.; Cheng, E.Y.Y.; Haupt, C.H.; Latzke, M.; Kuehl, B.; van Zuylen, M.; Wagner, L.M.; Weld, D.S. Improving the Accessibility of Scientific Documents: Current State, User Needs, and a System Solution to Enhance Scientific PDF Accessibility for Blind and Low Vision Users. arXiv 2021, arXiv:2105.00076. [Google Scholar]
- Borges Oliveira, D.A.; Viana, M.P. Fast CNN-Based Document Layout Analysis. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Breuel, T.M. Two Geometric Algorithms for Layout Analysis. In Document Analysis Systems V; Springer: Berlin/Heidelberg, Germany, 2002; pp. 188–199. [Google Scholar] [CrossRef]
- Li, M.; Xu, Y.; Cui, L.; Huang, S.; Wei, F.; Li, Z.; Zhou, M. DocBank: A Benchmark Dataset for Document Layout Analysis. arXiv 2020, arXiv:2006.01038. [Google Scholar] [CrossRef]
- Wang, J.; Krumdick, M.; Tong, B.; Halim, H.; Sokolov, M.; Barda, V.; Vendryes, D.; Tanner, C. A graphical approach to document layout analysis. In Proceedings of the International Conference on Document Analysis and Recognition, San José, CA, USA, 21–26 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 53–69. [Google Scholar]
- Binmakhashen, G.M.; Mahmoud, S.A. Document layout analysis: A comprehensive survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Gemelli, A.; Marinai, S.; Pisaneschi, L.; Santoni, F. Datasets and annotations for layout analysis of scientific articles. Int. J. Doc. Anal. Recognit. (IJDAR) 2024, 27, 683–705. [Google Scholar] [CrossRef]
- Pontelli, E.; Gillan, D.; Xiong, W.; Saad, E.; Gupta, G.; Karshmer, A.I. Navigation of HTML Tables, Frames, and XML Fragments. In Proceedings of the Fifth International ACM Conference on Assistive Technologies, Edinburgh, UK, 8–10 July 2002; Assets ’02. pp. 25–32. [Google Scholar]
- Leporini, B.; Buzzi, M. Visually-Impaired People Studying via eBook: Investigating Current Use and Potential for Improvement. In Proceedings of the 2022 6th International Conference on Education and E-Learning (ICEEL), Yamanashi, Japan, 21–23 November 2022; pp. 288–295. [Google Scholar]
- Kim, H.; Smith-Jackson, T.; Kleiner, B. Accessible haptic user interface design approach for users with visual impairments. Univers. Access Inf. Soc. 2014, 13, 415–437. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Li, J.; Xu, Y.; Lv, T.; Cui, L.; Zhang, C.; Wei, F. Dit: Self-supervised pre-training for document image transformer. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 3530–3539. [Google Scholar]
- Chen, Y.; Zhang, J.; Peng, K.; Zheng, J.; Liu, R.; Torr, P.; Stiefelhagen, R. RoDLA: Benchmarking the Robustness of Document Layout Analysis Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15556–15566. [Google Scholar]
- Huang, Y.; Lv, T.; Cui, L.; Lu, Y.; Wei, F. Layoutlmv3: Pre-training for document ai with unified text and image masking. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 4083–4091. [Google Scholar]
- Zhong, X.; Tang, J.; Jimeno Yepes, A. PubLayNet: Largest Dataset Ever for Document Layout Analysis. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Pfitzmann, B.; Auer, C.; Dolfi, M.; Nassar, A.S.; Staar, P. Doclaynet: A large human-annotated dataset for document-layout segmentation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 3743–3751. [Google Scholar]
- Jaume, G.; Ekenel, H.K.; Thiran, J.P. Funsd: A dataset for form understanding in noisy scanned documents. In Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 2, pp. 1–6. [Google Scholar]
- Wang, Z.; Xu, Y.; Cui, L.; Shang, J.; Wei, F. Layoutreader: Pre-training of text and layout for reading order detection. arXiv 2021, arXiv:2108.11591. [Google Scholar]
- Zhang, L.; Hu, A.; Xu, H.; Yan, M.; Xu, Y.; Jin, Q.; Zhang, J.; Huang, F. Tinychart: Efficient chart understanding with visual token merging and program-of-thoughts learning. arXiv 2024, arXiv:2404.16635. [Google Scholar]
- Moured, O.; Baumgarten-Egemole, M.; Müller, K.; Roitberg, A.; Schwarz, T.; Stiefelhagen, R. Chart4blind: An intelligent interface for chart accessibility conversion. In Proceedings of the 29th International Conference on Intelligent User Interfaces, Greenville, SC, USA, 18–21 March 2024; pp. 504–514. [Google Scholar]
- Sechayk, Y.; Shamir, A.; Igarashi, T. SmartLearn: Visual-Temporal Accessibility for Slide-based e-learning Videos. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–11. [Google Scholar]
- Wang, L.L.; Cachola, I.; Bragg, J.; Cheng, E.Y.Y.; Haupt, C.; Latzke, M.; Kuehl, B.; van Zuylen, M.N.; Wagner, L.; Weld, D. Scia11y: Converting scientific papers to accessible html. In Proceedings of the 23rd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, 18–22 October 2021; pp. 1–4. [Google Scholar]
- Stockman, T.; Metatla, O. The influence of screen-readers on web cognition. In Proceedings of the Accessible Design in the Digital World Conference (ADDW 2008), York, UK, January 2008. [Google Scholar]
- Pathirana, P.; Silva, A.; Lawrence, T.; Weerasinghe, T.; Abeyweera, R. A Comparative Evaluation of PDF-to-HTML Conversion Tools. In Proceedings of the 2023 International Research Conference on Smart Computing and Systems Engineering (SCSE), Kelaniya, Sri Lanka, 29 June 2023; IEEE: Piscataway, NJ, USA, 2023; Volume 6, pp. 1–7. [Google Scholar]
- Morris, M.R.; Johnson, J.; Bennett, C.L.; Cutrell, E. Rich representations of visual content for screen reader users. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–11. [Google Scholar]
- Wang, L.L.; Bragg, J.; Weld, D.S. Paper to HTML: A Publicly Available Web Tool for Converting Scientific Pdfs into Accessible HTML. ACM SIGACCESS Access. Comput. 2023, 1–11. [Google Scholar] [CrossRef]
- Peng, Y.H.; Chi, P.; Kannan, A.; Morris, M.R.; Essa, I. Slide Gestalt: Automatic Structure Extraction in Slide Decks for Non-Visual Access. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–14. [Google Scholar]
- Khurana, R.; McIsaac, D.; Lockerman, E.; Mankoff, J. Nonvisual interaction techniques at the keyboard surface. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Gadde, P.; Bolchini, D. From screen reading to aural glancing: Towards instant access to key page sections. In Proceedings of the 16th international ACM SIGACCESS Conference on Computers & Accessibility, Rochester, NY, USA, 20–22 October 2014; pp. 67–74. [Google Scholar]
- Vtyurina, A.; Fourney, A.; Morris, M.R.; Findlater, L.; White, R.W. Verse: Bridging screen readers and voice assistants for enhanced eyes-free web search. In Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019; pp. 414–426. [Google Scholar]
- Ahmed, F.; Borodin, Y.; Soviak, A.; Islam, M.; Ramakrishnan, I.; Hedgpeth, T. Accessible skimming: Faster screen reading of web pages. In Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology, Cambridge, MA, USA, 7–10 October 2012; pp. 367–378. [Google Scholar]
- Safi, W.; Maurel, F.; Routoure, J.M.; Beust, P.; Dias, G. Blind browsing on hand-held devices: Touching the web... to understand it better. In Proceedings of the Data Visualization Workshop (DataWiz 2014) associated to 25th ACM Conference on Hypertext and Social Media (HYPERTEXT 2014), Poznan, Poland, 10–13 September 2014. [Google Scholar]
- Maurel, F.; Dias, G.; Routoure, J.M.; Vautier, M.; Beust, P.; Molina, M.; Sann, C. Haptic Perception of Document Structure for Visually Impaired People on Handled Devices. Procedia Comput. Sci. 2012, 14, 319–329. [Google Scholar] [CrossRef]
- Chase, E.D.; Siu, A.F.; Boadi-Agyemang, A.; Kim, G.S.; Gonzalez, E.J.; Follmer, S. PantoGuide: A Haptic and Audio Guidance System To Support Tactile Graphics Exploration. In Proceedings of the 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, 26–28 October 2020; pp. 1–4. [Google Scholar]
- Maćkowski, M.; Brzoza, P. Accessible tutoring platform using audio-tactile graphics adapted for visually impaired people. Sensors 2022, 22, 8753. [Google Scholar] [CrossRef] [PubMed]
- Chang, R.C.; Yong, S.; Liao, F.Y.; Tsao, C.A.; Chen, B.Y. Understanding (Non-) Visual Needs for the Design of Laser-Cut Models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–20. [Google Scholar]
- Prescher, D.; Weber, G.; Spindler, M. A Tactile Windowing System for Blind Users. In Proceedings of the 12th International ACM SIGACCESS Conference on Computers and Accessibility, New York, NY, USA, 25–27 October 2010; ASSETS ’10. pp. 91–98. [Google Scholar]
- metec, A. The “Laptop for the Blind”. Available online: https://metec-ag.de/ (accessed on 1 October 2024).
- Artistic Document Layout Dataset (ArtDocLay). Available online: https://github.com/moured/layout-for-all (accessed on 1 October 2024).
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- Zhao, H.; Plaisant, C.; Shneiderman, B.; Duraiswami, R. Sonification of Geo-Referenced Data for Auditory Information Seeking: Design Principle and Pilot Study. In Proceedings of the International Conference on Auditory Display, Sydney, NSW, Australia, 6–9 July 2004. [Google Scholar]
- Russell, D.M. What Are You Reading? Interactions 2023, 30, 10–11. [Google Scholar] [CrossRef]
- Shein, E. Shining a Light on the Dark Web. Commun. ACM 2023, 66, 13–14. [Google Scholar] [CrossRef]
- NV Access Limited. NVDA Screen Reader 2024. Available online: https://www.nvaccess.org/download/ (accessed on 1 October 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Books | Image |
|---|---|---|
| brochure | 7 | 44 |
| newspaper | 5 | 48 |
| books | 3 | 84 |
| magazine | 4 | 52 |
| slide | 4 | 79 |
| poster | 2 | 2 |
| flier | 6 | 11 |
| infographic | 4 | 4 |
| Total (8 categories) | 35 | 324 |
| Model | Train Dataset | mAP50 | mAP50:95 |
|---|---|---|---|
| YOLOv10x | DocLayNet | 31.9 | 19.5 |
| YOLOv10b | 29.5 | 17.3 | |
| YOLOv10l | 36.7 | 19.3 | |
| YOLOv10m | 33.0 | 17.7 | |
| YOLOv10n | 30.4 | 18.6 | |
| YOLOv10s | 31.8 | 18.4 | |
| YOLOv10x | Fine-tuned on ArtDocLay | 56.6 (+24.7) | 31.5 (+12.0) |
| YOLOv10b | 55.7 (+26.2) | 34.4 (+17.1) | |
| YOLOv10l | 60.5 (+23.8) | 33.7 (+14.4) | |
| YOLOv10m | 53.7 (+20.7) | 30.6 (+12.9) | |
| YOLOv10n | 64.8 (+34.4) | 29.0 (+10.4) | |
| YOLOv10s | 52.8 (+21.0) | 29.6 (+11.2) |
| Detected Sub Classes | Mapped Classes | Tactile Representation |
|---|---|---|
| Document title, section title, header | Title (t) |  |
| Paragraph, footer, caption, page number, list-item | Text (x) |  |
| Table | Table (b) |  |
| Equation, code | Math (m) |  |
| Figure | Image (i) |  |
| Participant | Age/Gender | Reading Assistive Tools |
|---|---|---|
| P1 | 48-57/M | Screen reader/1D Braille |
| P2 | 23-32/M | Screen reader/1D Braille |
| P3 | 23-32/F | Screen reader |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzalabny, S.; Moured, O.; Müller, K.; Schwarz, T.; Rapp, B.; Stiefelhagen, R. Designing a Tactile Document UI for 2D Refreshable Tactile Displays: Towards Accessible Document Layouts for Blind People. Multimodal Technol. Interact. 2024, 8, 102. https://doi.org/10.3390/mti8110102
Alzalabny S, Moured O, Müller K, Schwarz T, Rapp B, Stiefelhagen R. Designing a Tactile Document UI for 2D Refreshable Tactile Displays: Towards Accessible Document Layouts for Blind People. Multimodal Technologies and Interaction. 2024; 8(11):102. https://doi.org/10.3390/mti8110102
Chicago/Turabian StyleAlzalabny, Sara, Omar Moured, Karin Müller, Thorsten Schwarz, Bastian Rapp, and Rainer Stiefelhagen. 2024. "Designing a Tactile Document UI for 2D Refreshable Tactile Displays: Towards Accessible Document Layouts for Blind People" Multimodal Technologies and Interaction 8, no. 11: 102. https://doi.org/10.3390/mti8110102
APA StyleAlzalabny, S., Moured, O., Müller, K., Schwarz, T., Rapp, B., & Stiefelhagen, R. (2024). Designing a Tactile Document UI for 2D Refreshable Tactile Displays: Towards Accessible Document Layouts for Blind People. Multimodal Technologies and Interaction, 8(11), 102. https://doi.org/10.3390/mti8110102