


Yolov5 Series Algorithm for Road Marking Sign Identification





Abstract
:1. Introduction
2. Materials and Methods
2.1. Road Marking Sign Identification
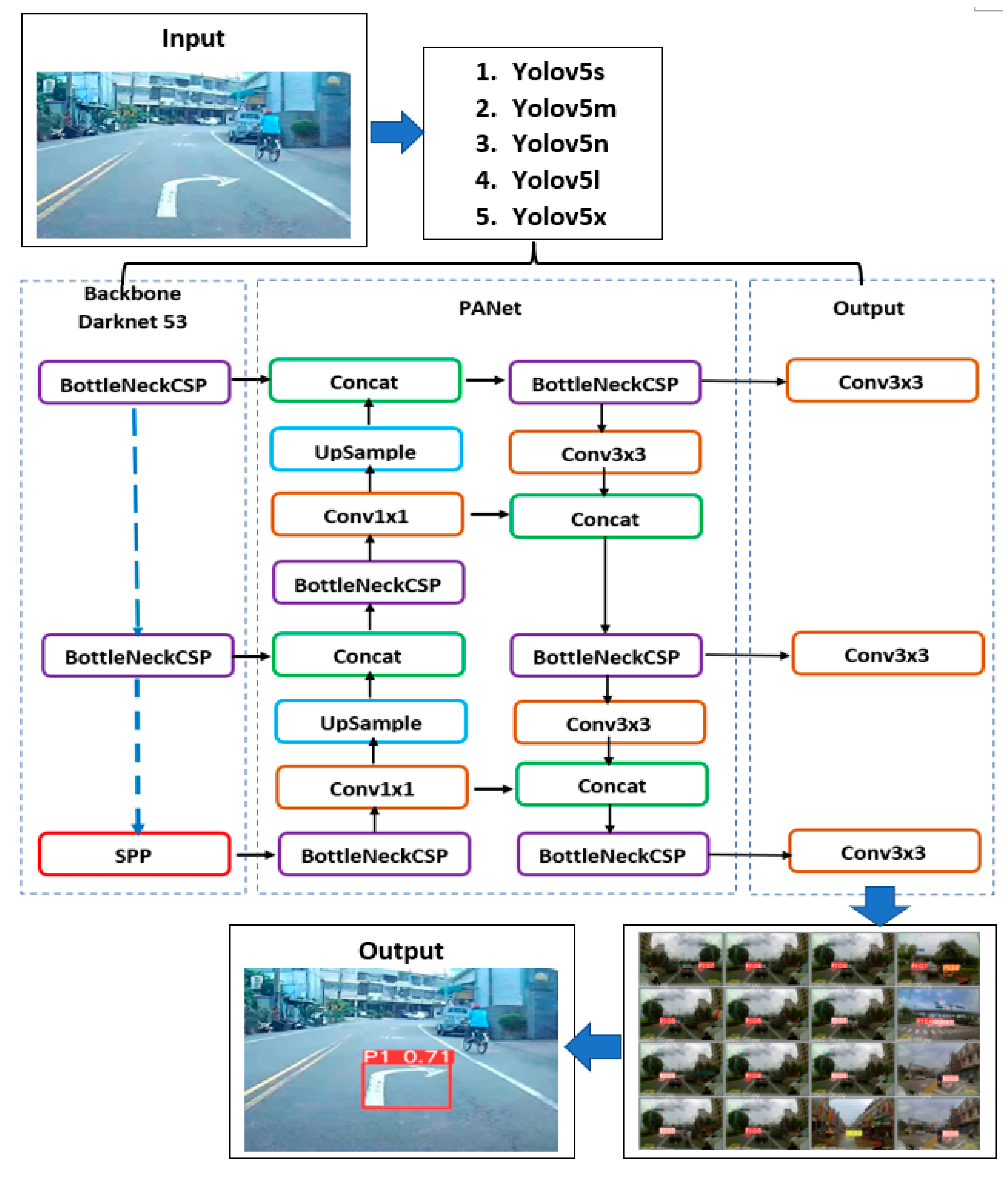
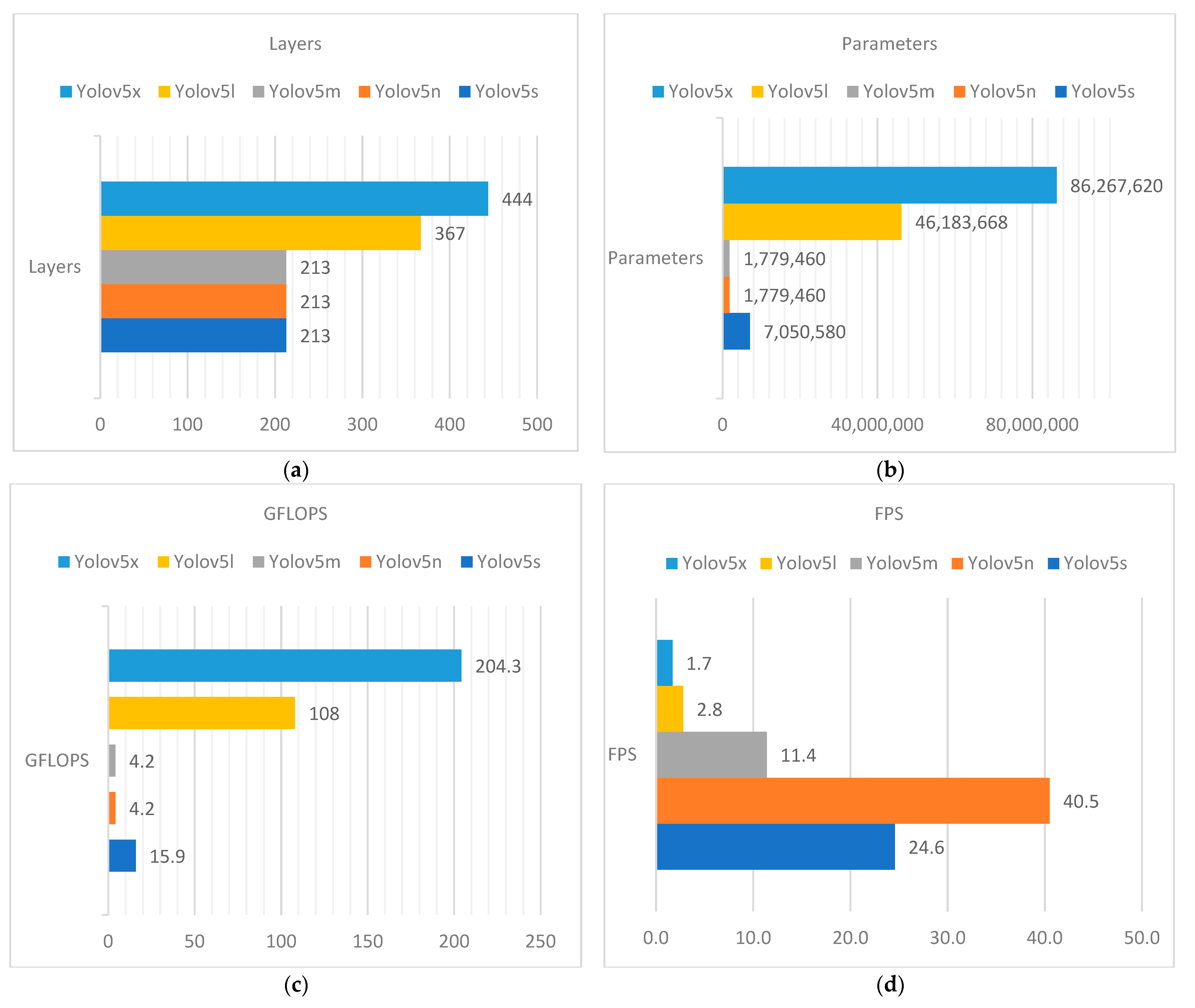
2.2. Yolov5 Architecture
3. Results
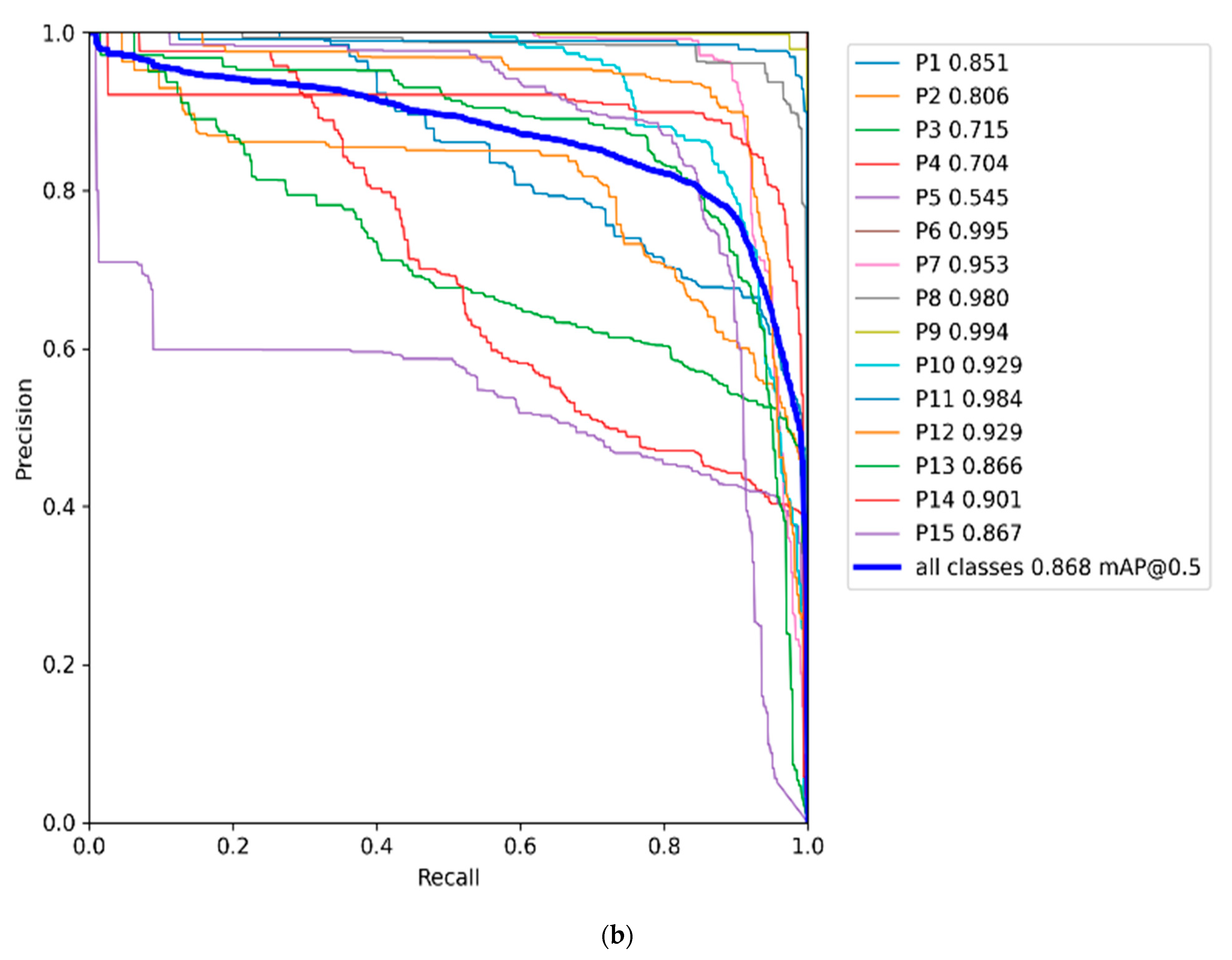
3.1. Taiwan Road Marking Sign Dataset (TRMSD)
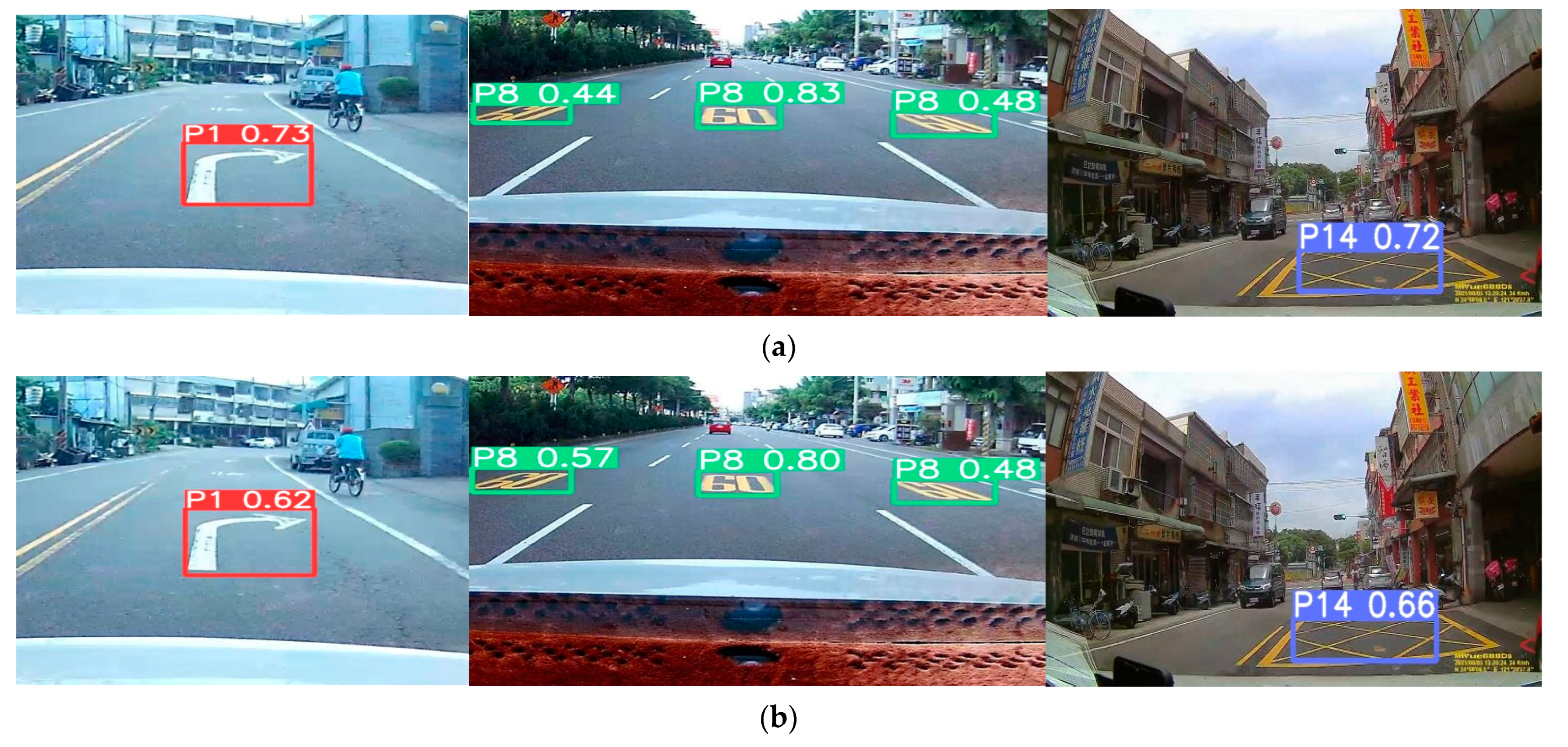
3.2. Training Result
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fang, C.Y.; Chen, S.W.; Fuh, C.S. Road-Sign Detection and Tracking. IEEE Trans. Veh. Technol. 2003, 52, 1329–1341. [Google Scholar] [CrossRef]
- Wontorczyk, A.; Gaca, S. Study on the Relationship between Drivers’ Personal Characters and Non-Standard Traffic Signs Comprehensibility. Int. J. Environ. Res. Public Health 2021, 18, 2678. [Google Scholar] [CrossRef] [PubMed]
- Vacek, S.; Schimmel, C.; Dillmann, R. Road-Marking Analysis for Autonomous Vehicle Guidance. Available online: http://ecmr07.informatik.uni-freiburg.de/proceedings/ECMR07_0034.pdf (accessed on 4 December 2022).
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Tai, S.K.; Dewi, C.; Chen, R.C.; Liu, Y.T.; Jiang, X.; Yu, H. Deep Learning for Traffic Sign Recognition Based on Spatial Pyramid Pooling with Scale Analysis. Appl. Sci. 2020, 10, 6997. [Google Scholar] [CrossRef]
- Mathew, M.P.; Mahesh, T.Y. Leaf-Based Disease Detection in Bell Pepper Plant Using YOLO V5. Signal Image Video Process. 2022, 16, 841–847. [Google Scholar] [CrossRef]
- Bachute, M.R.; Subhedar, J.M. Autonomous Driving Architectures: Insights of Machine Learning and Deep Learning Algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Javanmardi, M.; Song, Z.; Qi, X. A Fusion Approach to Detect Traffic Signs Using Registered Color Images and Noisy Airborne LiDAR Data. Appl. Sci. 2021, 11, 309. [Google Scholar] [CrossRef]
- Qin, B.; Liu, W.; Shen, X.; Chong, Z.J.; Bandyopadhyay, T.; Ang, M.H.; Frazzoli, E.; Rus, D. A General Framework for Road Marking Detection and Analysis. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, The Hague, The Netherlands, 6–9 October 2013; pp. 619–625. [Google Scholar]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Segmentation and Classification of Road Markings Using MLS Data. ISPRS J. Photogramm. Remote Sens. 2017, 123, 94–103. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A Deep Learning Framework for Road Marking Extraction, Classification and Completion from Mobile Laser Scanning Point Clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Z.; Zhong, R.; Zhang, L.; Ma, H.; Liu, L. A Dense Feature Pyramid Network-Based Deep Learning Model for Road Marking Instance Segmentation Using MLS Point Clouds. IEEE Trans. Geosci. Remote Sens. 2021, 59, 784–800. [Google Scholar] [CrossRef]
- Cheng, Y.T.; Patel, A.; Wen, C.; Bullock, D.; Habib, A. Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lanewidth Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds. Remote Sens. 2020, 12, 1379. [Google Scholar] [CrossRef]
- Chen, J.; Jia, K.; Chen, W.; Lv, Z.; Zhang, R. A Real-Time and High-Precision Method for Small Traffic-Signs Recognition. Neural Comput. Appl. 2022, 34, 2233–2245. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Lecture Notes in Computer Science; including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Adibhatla, V.A.; Chih, H.C.; Hsu, C.C.; Cheng, J.; Abbod, M.F.; Shieh, J.S. Applying Deep Learning to Defect Detection in Printed Circuit Boards via a Newest Model of You-Only-Look-Once. Math. Biosci. Eng. 2021, 18. [Google Scholar] [CrossRef] [PubMed]
- Farooq, M.A.; Shariff, W.; Corcoran, P. Evaluation of Thermal Imaging on Embedded GPU Platforms for Application in Vehicular Assistance Systems. IEEE Trans. Intell. Veh. 2022. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-Yolov4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar]
- Park, Y.K.; Park, H.; Woo, Y.S.; Choi, I.G.; Han, S.S. Traffic Landmark Matching Framework for HD-Map Update: Dataset Training Case Study. Electronics 2022, 11, 863. [Google Scholar] [CrossRef]
- Foucher, P.; Sebsadji, Y.; Tarel, J.P.; Charbonnier, P.; Nicolle, P. Detection and Recognition of Urban Road Markings Using Images. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, Washington, DC, USA, 5–7 October 2011. [Google Scholar]
- Dewi, C.; Chen, R.-C.; Jiang, X.; Yu, H. Adjusting Eye Aspect Ratio for Strong Eye Blink Detection Based on Facial Landmarks. PeerJ Comput. Sci. 2022, 8, e943. [Google Scholar] [CrossRef]
- Hussain, Q.; Alhajyaseen, W.K.M.; Pirdavani, A.; Brijs, K.; Shaaban, K.; Brijs, T. Do Detection-Based Warning Strategies Improve Vehicle Yielding Behavior at Uncontrolled Midblock Crosswalks? Accid. Anal. Prev. 2021, 157, 106166. [Google Scholar] [CrossRef]
- Ding, D.; Yoo, J.; Jung, J.; Jin, S.; Kwon, S. Efficient Road-Sign Detection Based on Machine Learning. Bull. Netw. Comput. Syst. Softw. 2015, 4, 15–17. [Google Scholar]
- Greenhalgh, J.; Mirmehdi, M. Detection and Recognition of Painted Road Surface Markings. In Proceedings of the ICPRAM 2015—4th International Conference on Pattern Recognition Applications and Methods, Proceedings, Lisbon, Portugal, 10–12 January 2015; Volume 1. [Google Scholar]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 January 2017; pp. 2117–2124. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Dewi, C.; Chen, R.C.; Yu, H.; Jiang, X. Robust Detection Method for Improving Small Traffic Sign Recognition Based on Spatial Pyramid Pooling. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Yuan, D.L.; Xu, Y. Lightweight Vehicle Detection Algorithm Based on Improved YOLOv4. Eng. Lett. 2021, 29, 1544–1551. [Google Scholar]
- Vinitha, V.; Velantina, V. COVID-19 Facemask Detection With Deep Learning and Computer Vision. Int. Res. J. Eng. Technol. 2020, 7, 3127–3132. [Google Scholar]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A Real-Time Detection Algorithm for Kiwifruit Defects Based on Yolov5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Mihalj, T.; Li, H.; Babić, D.; Lex, C.; Jeudy, M.; Zovak, G.; Babić, D.; Eichberger, A. Road Infrastructure Challenges Faced by Automated Driving: A Review. Appl. Sci. 2022, 12, 3477. [Google Scholar] [CrossRef]
- Sun, X.M.; Zhang, Y.J.; Wang, H.; Du, Y.X. Research on Ship Detection of Optical Remote Sensing Image Based on Yolov5. J. Phys. Conf. Ser. 2022, 2215, 012027. [Google Scholar] [CrossRef]
- Long, J.W.; Yan, Z.R.; Peng, L.; Li, T. The Geometric Attention-Aware Network for Lane Detection in Complex Road Scenes. PLoS ONE 2021, 16, e0254521. [Google Scholar] [CrossRef] [PubMed]
- Ultralytics Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 January 2021).
- Otgonbold, M.E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.H.; Hsieh, J.W.; Chen, P.Y. SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors 2022, 22, 2315. [Google Scholar] [CrossRef]
- Han, K.; Zeng, X. Deep Learning-Based Workers Safety Helmet Wearing Detection on Construction Sites Using Multi-Scale Features. IEEE Access 2022, 10, 718–729. [Google Scholar] [CrossRef]
- Jiang, L.; Liu, H.; Zhu, H.; Zhang, G. Improved YOLO v5 with Balanced Feature Pyramid and Attention Module for Traffic Sign Detection. MATEC Web Conf. 2022, 355, 03023. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, K. Online Predictive Connected and Automated Eco-Driving on Signalized Arterials Considering Traffic Control Devices and Road Geometry Constraints under Uncertain Traffic Conditions. Transp. Res. Part B Methodol. 2021, 145, 80–117. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Combination of Resnet and Spatial Pyramid Pooling for Musical Instrument Identification. Cybern. Inf. Technol. 2022, 22, 104. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
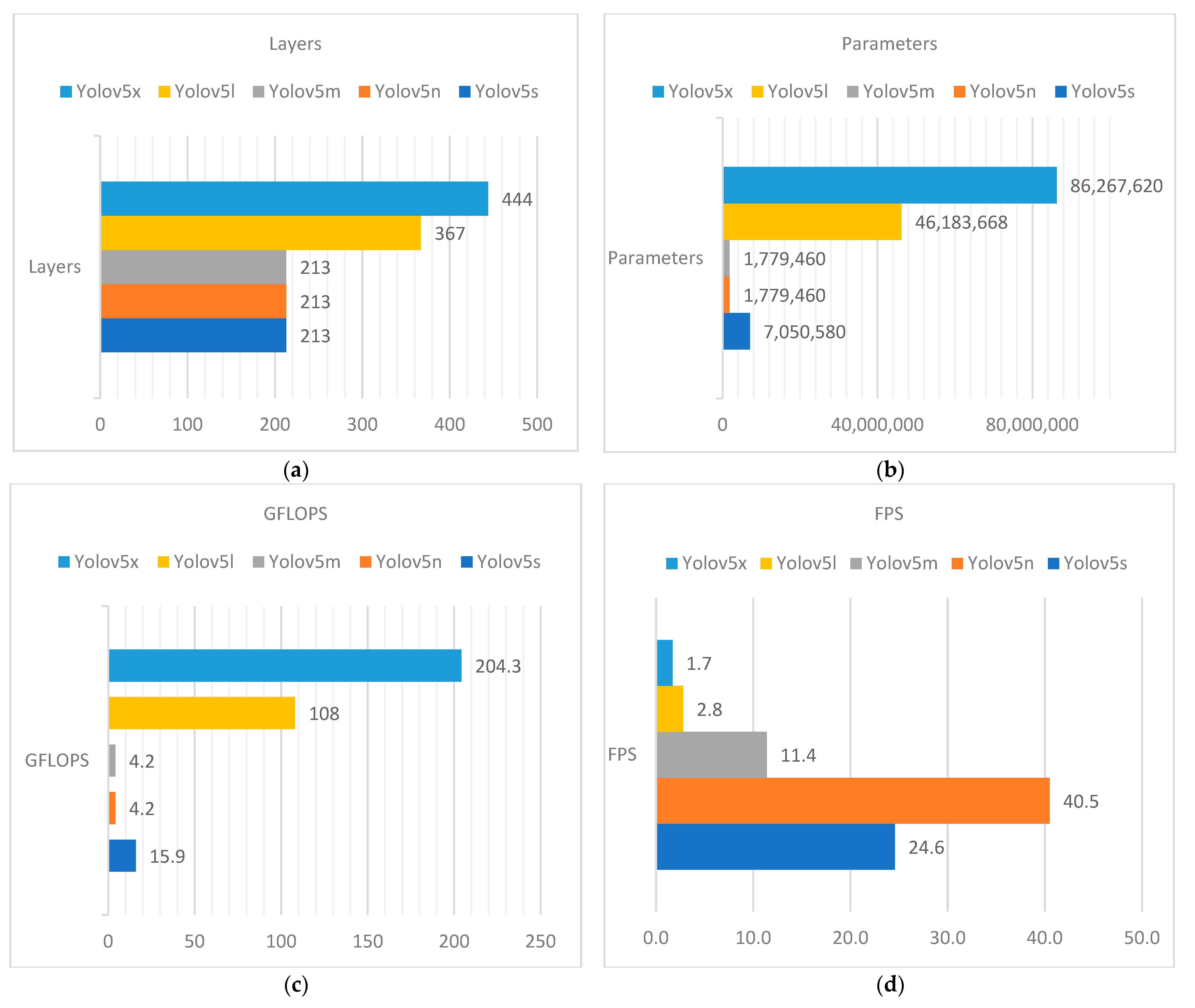
| Model Name | Params (Million) | Accuracy (mAP 0.5) | CPU Time (ms) | GPU Time (ms) |
|---|---|---|---|---|
| Yolov5n | 1.9 | 45.7 | 45 | 6.3 |
| Yolov5s | 7.2 | 56.8 | 98 | 6.4 |
| Yolov5m | 21.2 | 64.1 | 224 | 8.2 |
| Yolov5l | 46.5 | 67.3 | 430 | 10.1 |
| Yolov5x | 86.7 | 68.9 | 766 | 12.1 |
| Class ID | Class Name | Total Image |
|---|---|---|
| P1 | Turn Right | 405 |
| P2 | Turn Left | 401 |
| P3 | Go Straight | 407 |
| P4 | Turn Right or Go Straight | 409 |
| P5 | Turn Left or Go Straight | 403 |
| P6 | Speed Limit (40) | 391 |
| P7 | Speed Limit (50) | 401 |
| P8 | Speed Limit (60) | 400 |
| P9 | Speed Limit (70) | 398 |
| P10 | Zebra Crossing | 401 |
| P11 | Slow Sign | 399 |
| P12 | Overtaking Prohibited | 404 |
| P13 | Barrier Line | 409 |
| P14 | Cross Hatch | 398 |
| P15 | Stop Line | 403 |
| Class | Yolov5n | Yolov5s | Yolov5m | Yolov5l | Yolov5x | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | |
| P1 | 0.63 | 0.89 | 0.79 | 0.66 | 0.87 | 0.77 | 0.63 | 0.87 | 0.80 | 0.61 | 0.87 | 0.80 | 0.61 | 0.87 | 0.78 |
| P2 | 0.62 | 0.77 | 0.74 | 0.66 | 0.69 | 0.74 | 0.65 | 0.78 | 0.72 | 0.64 | 0.74 | 0.73 | 0.91 | 0.79 | 0.70 |
| P3 | 0.53 | 0.75 | 0.64 | 0.55 | 0.75 | 0.62 | 0.60 | 0.83 | 0.72 | 0.54 | 0.82 | 0.72 | 0.60 | 0.78 | 0.74 |
| P4 | 0.45 | 0.63 | 0.61 | 0.41 | 0.65 | 0.60 | 0.43 | 0.77 | 0.65 | 0.40 | 0.62 | 0.61 | 0.40 | 0.73 | 0.62 |
| P5 | 0.42 | 0.62 | 0.55 | 0.37 | 0.52 | 0.46 | 0.42 | 0.71 | 0.57 | 0.41 | 0.84 | 0.55 | 0.37 | 0.72 | 0.48 |
| P6 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 |
| P7 | 0.81 | 0.89 | 0.91 | 0.82 | 0.87 | 0.89 | 0.89 | 0.88 | 0.90 | 0.78 | 0.86 | 0.90 | 0.79 | 0.89 | 0.90 |
| P8 | 0.84 | 0.98 | 0.97 | 0.82 | 0.98 | 0.97 | 0.87 | 1.00 | 0.97 | 0.90 | 0.99 | 0.98 | 0.89 | 1.00 | 0.98 |
| P9 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.98 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 |
| P10 | 0.95 | 0.64 | 0.89 | 0.83 | 0.59 | 0.75 | 0.93 | 0.80 | 0.89 | 0.95 | 0.76 | 0.91 | 0.92 | 0.83 | 0.91 |
| P11 | 0.84 | 0.99 | 0.99 | 0.89 | 0.95 | 0.98 | 0.86 | 0.99 | 0.99 | 0.88 | 0.99 | 0.99 | 0.92 | 0.99 | 0.99 |
| P12 | 0.78 | 0.74 | 0.73 | 0.66 | 0.78 | 0.74 | 0.69 | 0.75 | 0.71 | 0.69 | 0.74 | 0.70 | 0.75 | 0.78 | 0.76 |
| P13 | 0.64 | 0.75 | 0.73 | 0.58 | 0.68 | 0.63 | 0.76 | 0.81 | 0.78 | 0.72 | 0.82 | 0.79 | 0.70 | 0.84 | 0.78 |
| P14 | 0.81 | 0.85 | 0.86 | 0.792 | 0.84 | 0.84 | 0.87 | 0.91 | 0.89 | 0.88 | 0.88 | 0.88 | 0.86 | 0.85 | 0.87 |
| P15 | 0.79 | 0.66 | 0.79 | 0.86 | 0.71 | 0.81 | 0.84 | 0.82 | 0.90 | 0.91 | 0.86 | 0.93 | 0.83 | 0.84 | 0.91 |
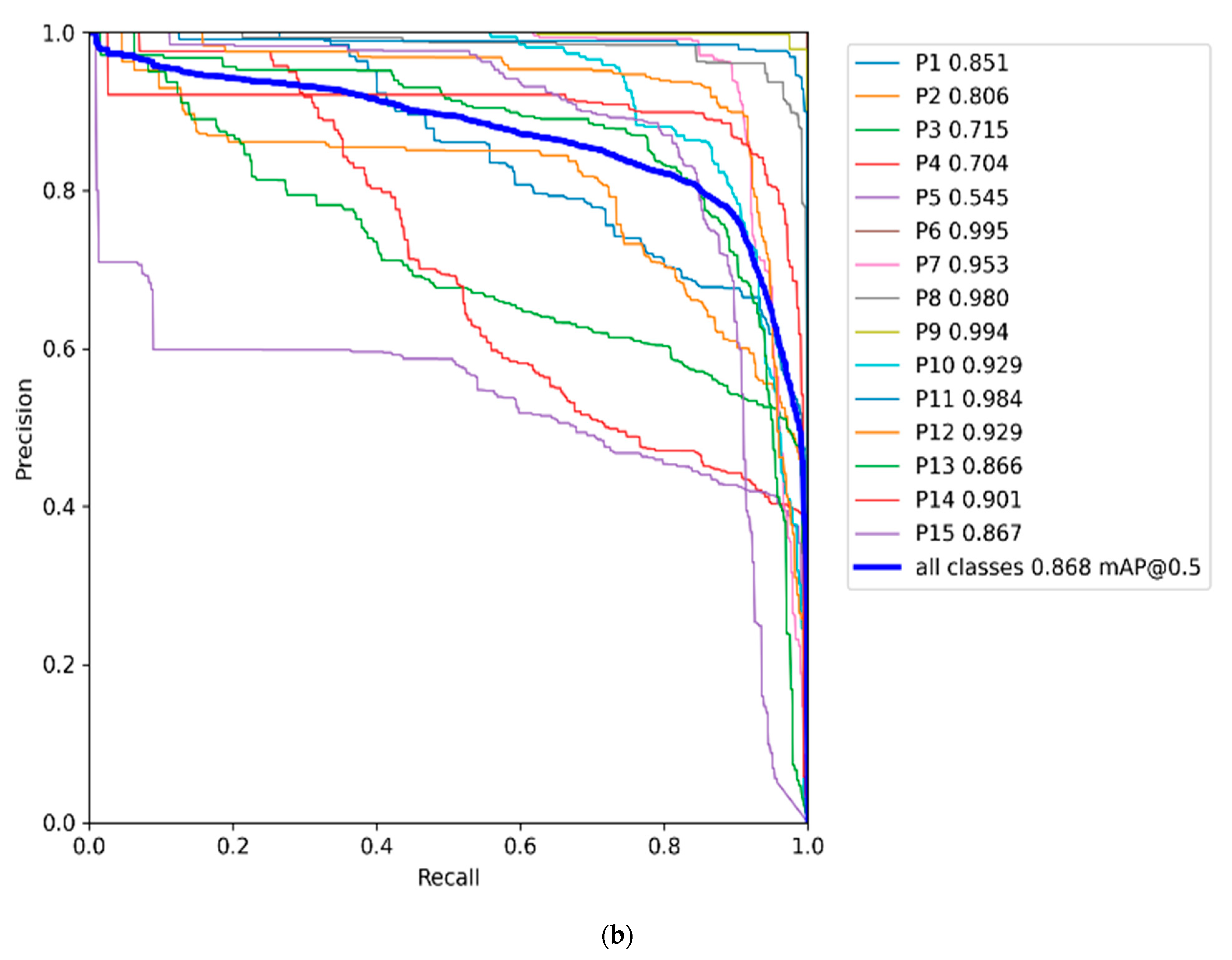
| All | 0.74 | 0.81 | 0.81 | 0.72 | 0.79 | 0.79 | 0.76 | 0.86 | 0.83 | 0.75 | 0.82 | 0.83 | 0.75 | 0.86 | 0.83 |
| Class | Yolov5n | Yolov5s | Yolov5m | Yolov5l | Yolov5x | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | |
| P1 | 0.62 | 0.92 | 0.81 | 0.64 | 0.92 | 0.84 | 0.65 | 0.93 | 0.86 | 0.65 | 0.94 | 0.85 | 0.61 | 0.87 | 0.78 |
| P2 | 0.69 | 0.67 | 0.75 | 0.72 | 0.75 | 0.79 | 0.77 | 0.73 | 0.82 | 0.79 | 0.73 | 0.81 | 0.91 | 0.79 | 0.70 |
| P3 | 0.54 | 0.74 | 0.62 | 0.55 | 0.80 | 0.67 | 0.60 | 0.89 | 0.73 | 0.60 | 0.79 | 0.72 | 0.60 | 0.78 | 0.74 |
| P4 | 0.51 | 0.59 | 0.64 | 0.50 | 0.69 | 0.67 | 0.51 | 0.75 | 0.71 | 0.54 | 0.66 | 0.70 | 0.40 | 0.73 | 0.62 |
| P5 | 0.48 | 0.65 | 0.53 | 0.49 | 0.69 | 0.55 | 0.51 | 0.65 | 0.57 | 0.51 | 0.64 | 0.55 | 0.37 | 0.72 | 0.48 |
| P6 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 |
| P7 | 0.84 | 0.91 | 0.93 | 0.87 | 0.91 | 0.96 | 0.93 | 0.90 | 0.95 | 0.88 | 0.91 | 0.95 | 0.79 | 0.89 | 0.90 |
| P8 | 0.82 | 0.97 | 0.96 | 0.83 | 0.97 | 0.97 | 0.86 | 0.99 | 0.98 | 0.82 | 0.99 | 0.98 | 0.89 | 1.00 | 0.98 |
| P9 | 0.98 | 1.00 | 0.99 | 0.98 | 1.00 | 0.99 | 0.98 | 1.00 | 0.99 | 0.98 | 1.00 | 0.99 | 0.99 | 1.00 | 1.00 |
| P10 | 0.90 | 0.61 | 0.82 | 0.87 | 0.66 | 0.87 | 0.93 | 0.80 | 0.94 | 0.88 | 0.80 | 0.93 | 0.92 | 0.83 | 0.91 |
| P11 | 0.80 | 0.99 | 0.97 | 0.89 | 0.99 | 0.98 | 0.91 | 1.00 | 0.98 | 0.89 | 1.00 | 0.98 | 0.92 | 0.99 | 0.99 |
| P12 | 0.78 | 0.69 | 0.76 | 0.71 | 0.86 | 0.81 | 0.86 | 0.89 | 0.91 | 0.88 | 0.92 | 0.93 | 0.75 | 0.78 | 0.76 |
| P13 | 0.71 | 0.66 | 0.70 | 0.68 | 0.83 | 0.80 | 0.77 | 0.88 | 0.89 | 0.80 | 0.85 | 0.87 | 0.70 | 0.84 | 0.78 |
| P14 | 0.73 | 0.83 | 0.82 | 0.80 | 0.86 | 0.85 | 0.86 | 0.92 | 0.90 | 0.88 | 0.88 | 0.90 | 0.86 | 0.85 | 0.87 |
| P15 | 0.84 | 0.56 | 0.72 | 0.88 | 0.67 | 0.80 | 0.92 | 0.70 | 0.88 | 0.90 | 0.71 | 0.87 | 0.83 | 0.84 | 0.91 |
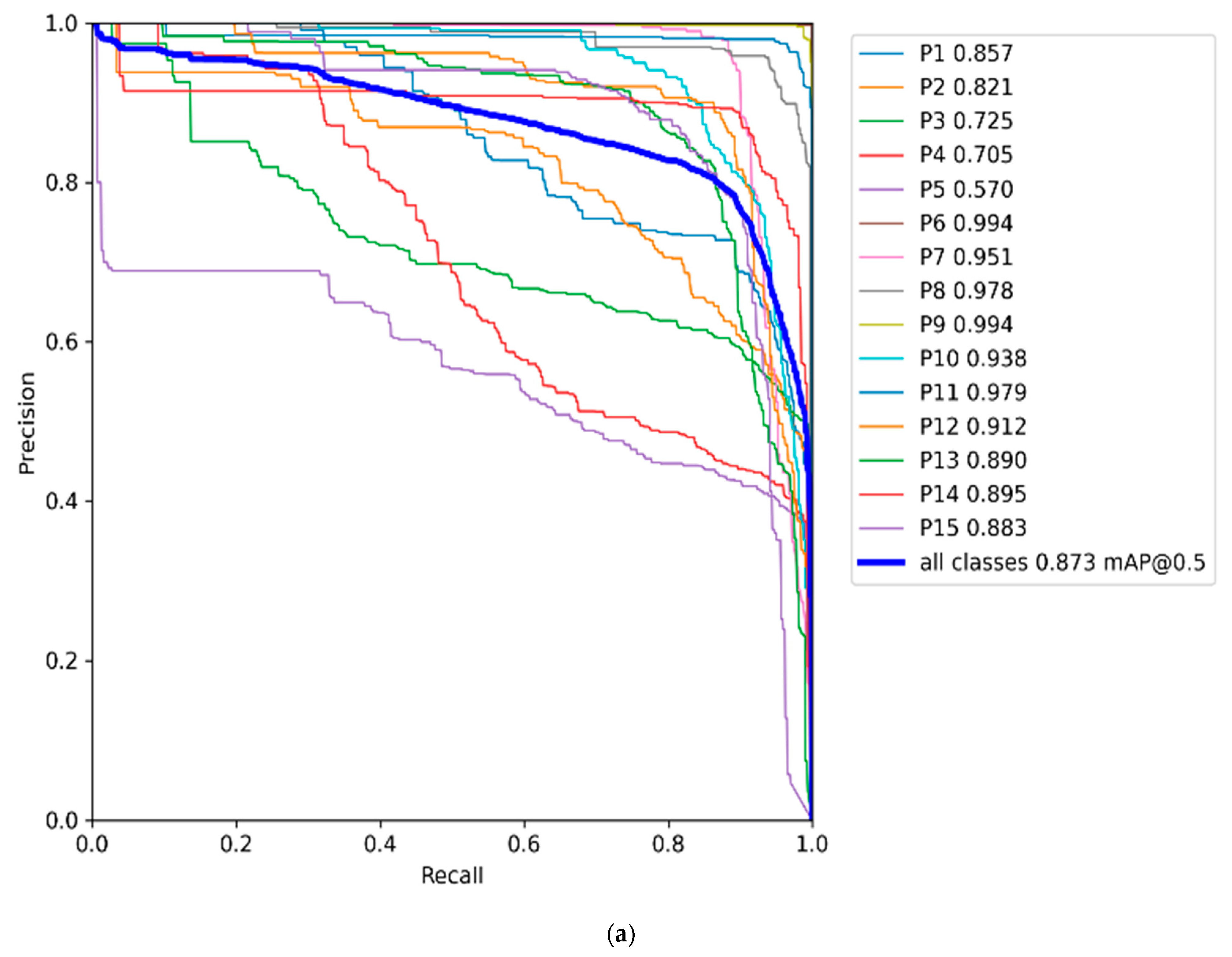
| All | 0.75 | 0.79 | 0.80 | 0.76 | 0.84 | 0.84 | 0.80 | 0.87 | 0.87 | 0.8 | 0.85 | 0.87 | 0.75 | 0.86 | 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Chen, R.-C.; Zhuang, Y.-C.; Christanto, H.J. Yolov5 Series Algorithm for Road Marking Sign Identification. Big Data Cogn. Comput. 2022, 6, 149. https://doi.org/10.3390/bdcc6040149
Dewi C, Chen R-C, Zhuang Y-C, Christanto HJ. Yolov5 Series Algorithm for Road Marking Sign Identification. Big Data and Cognitive Computing. 2022; 6(4):149. https://doi.org/10.3390/bdcc6040149
Chicago/Turabian StyleDewi, Christine, Rung-Ching Chen, Yong-Cun Zhuang, and Henoch Juli Christanto. 2022. "Yolov5 Series Algorithm for Road Marking Sign Identification" Big Data and Cognitive Computing 6, no. 4: 149. https://doi.org/10.3390/bdcc6040149
APA StyleDewi, C., Chen, R. -C., Zhuang, Y. -C., & Christanto, H. J. (2022). Yolov5 Series Algorithm for Road Marking Sign Identification. Big Data and Cognitive Computing, 6(4), 149. https://doi.org/10.3390/bdcc6040149