
Recognizing Road Surface Traffic Signs Based on Yolo Models Considering Image Flips





Abstract
:1. Introduction
2. Materials and Methods
2.1. Road Marking Recognition
2.2. You Only Look Once (YOLO)
2.3. Compared Method
| Algorithm 1. Yolo V4 road marking detection process. |
|
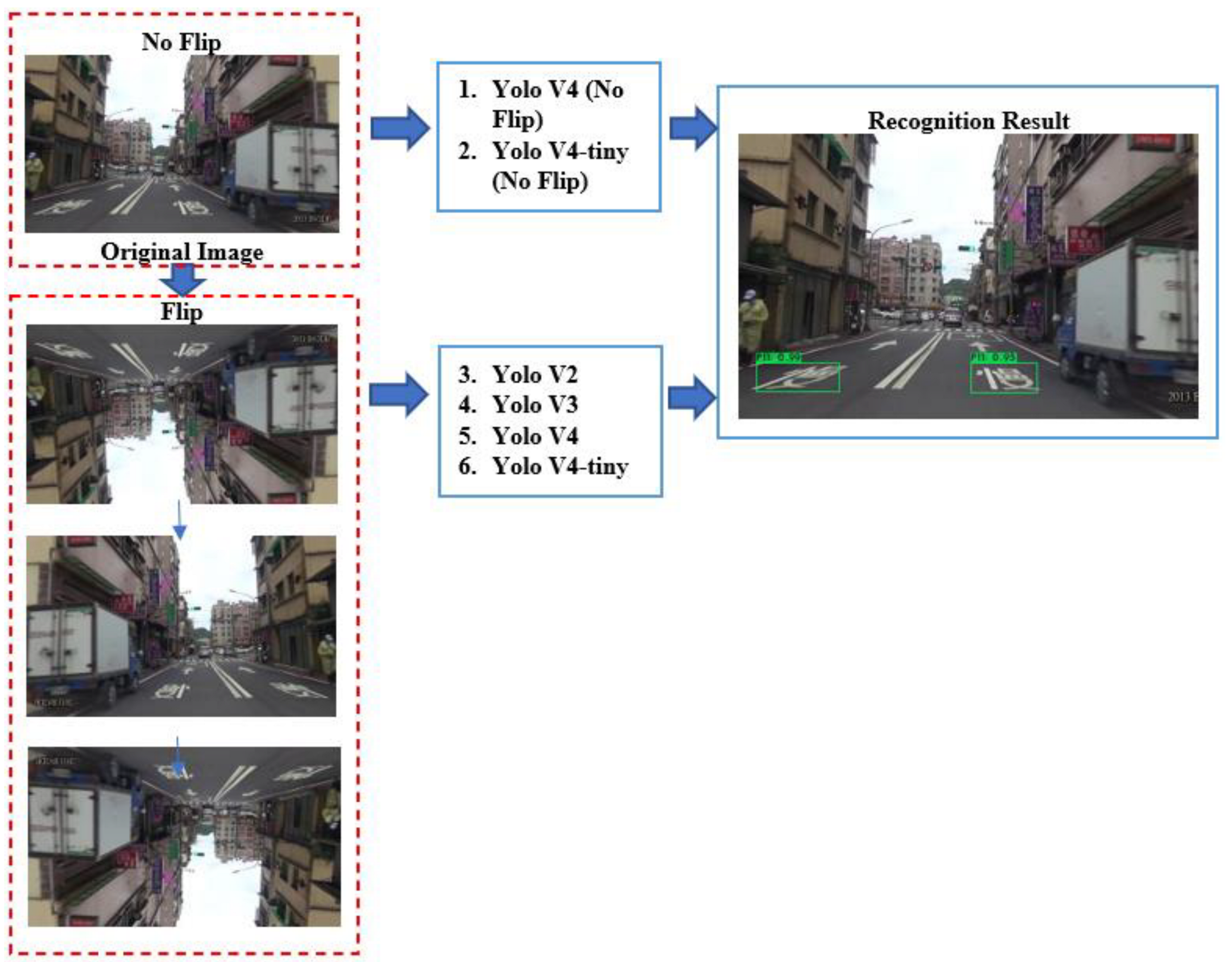
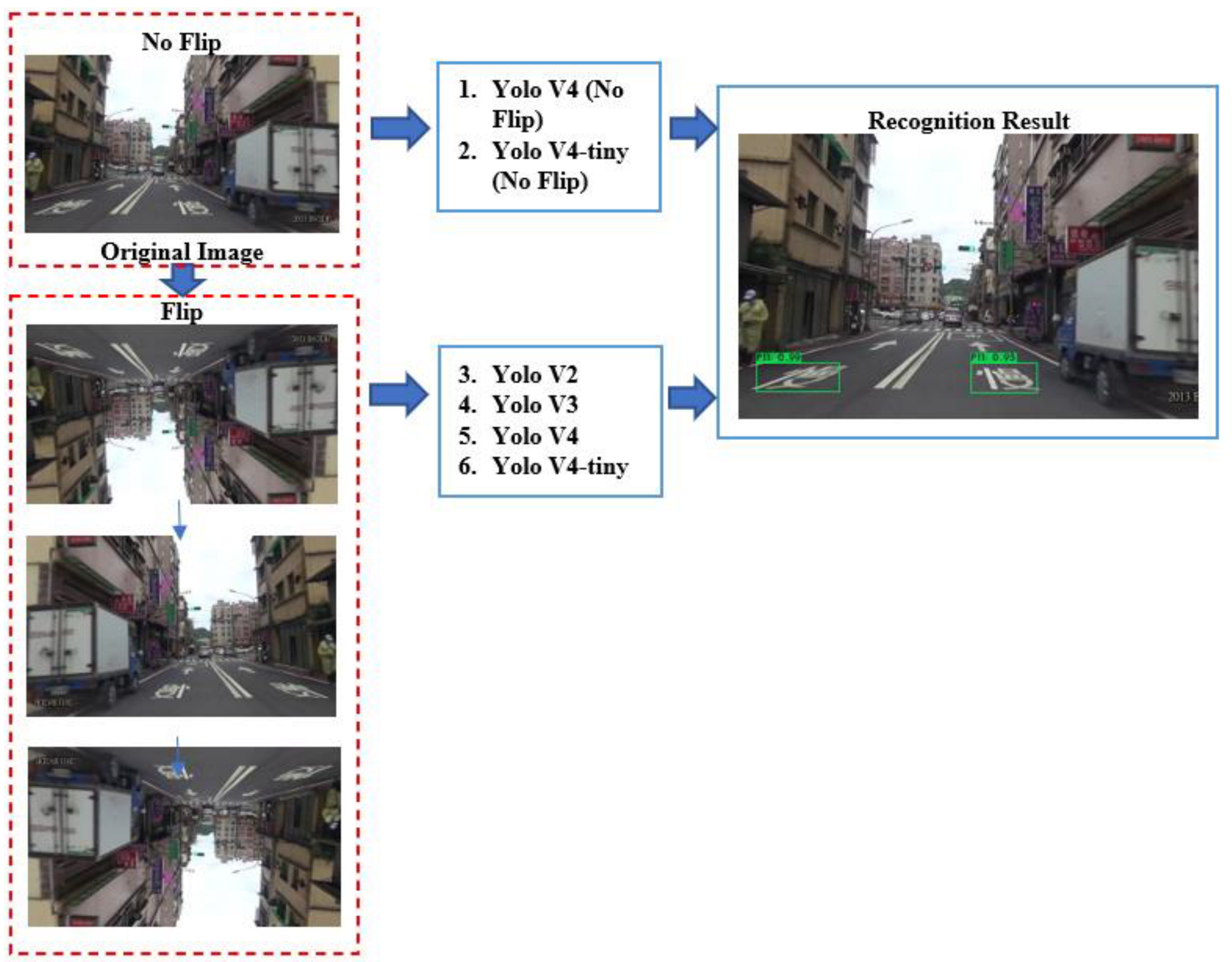
2.4. Experiment Setting
3. Results
3.1. Data Pre-Processing
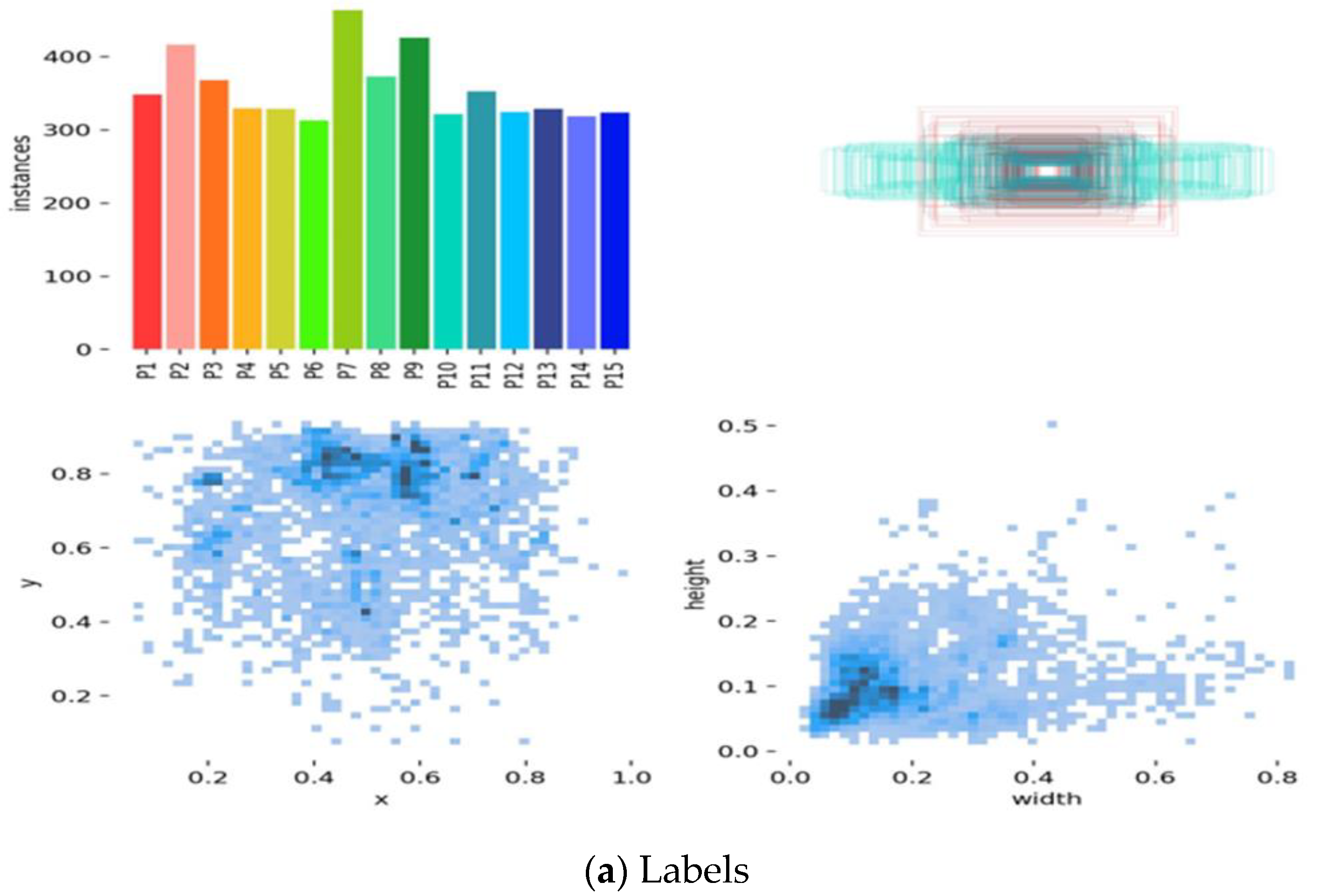
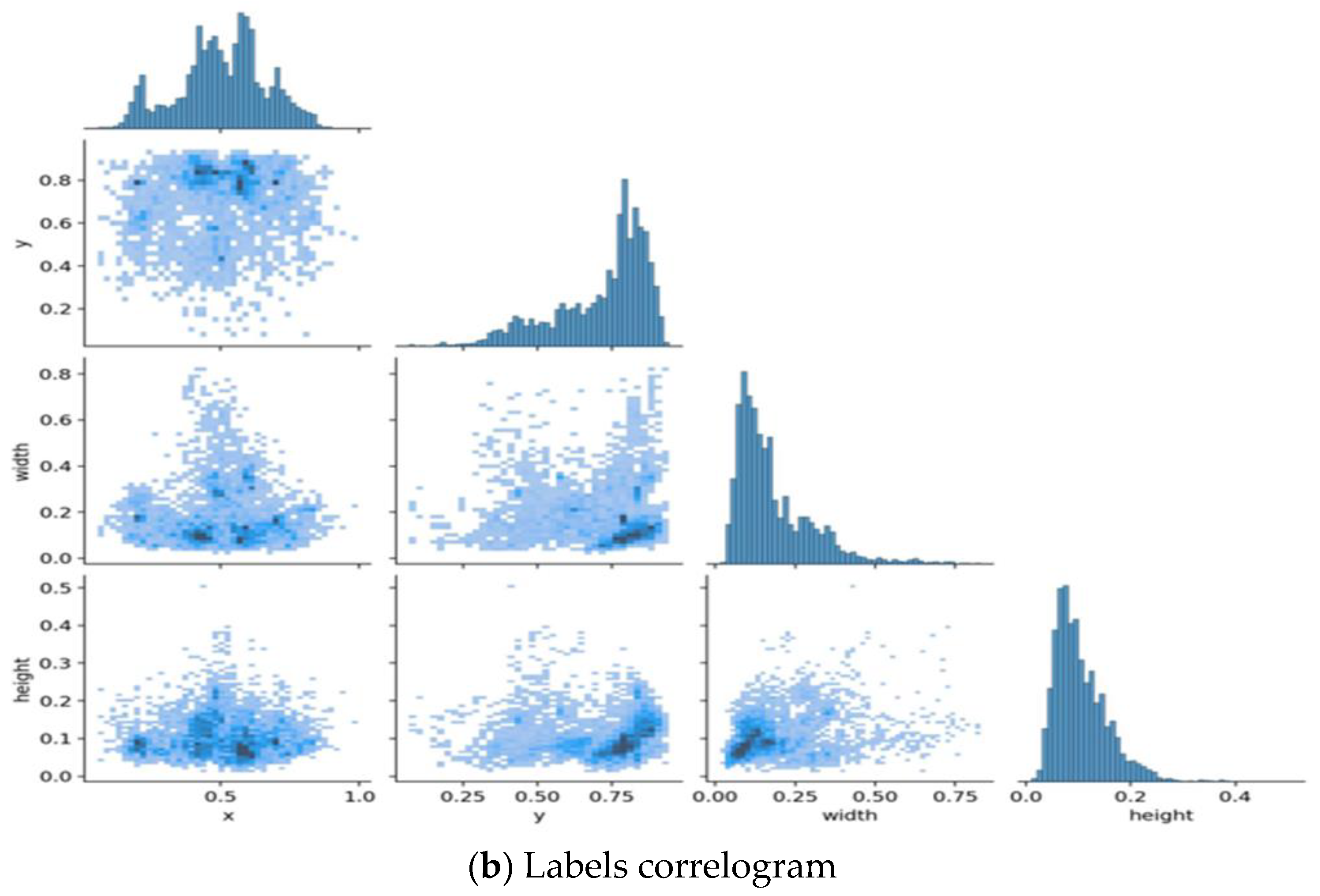
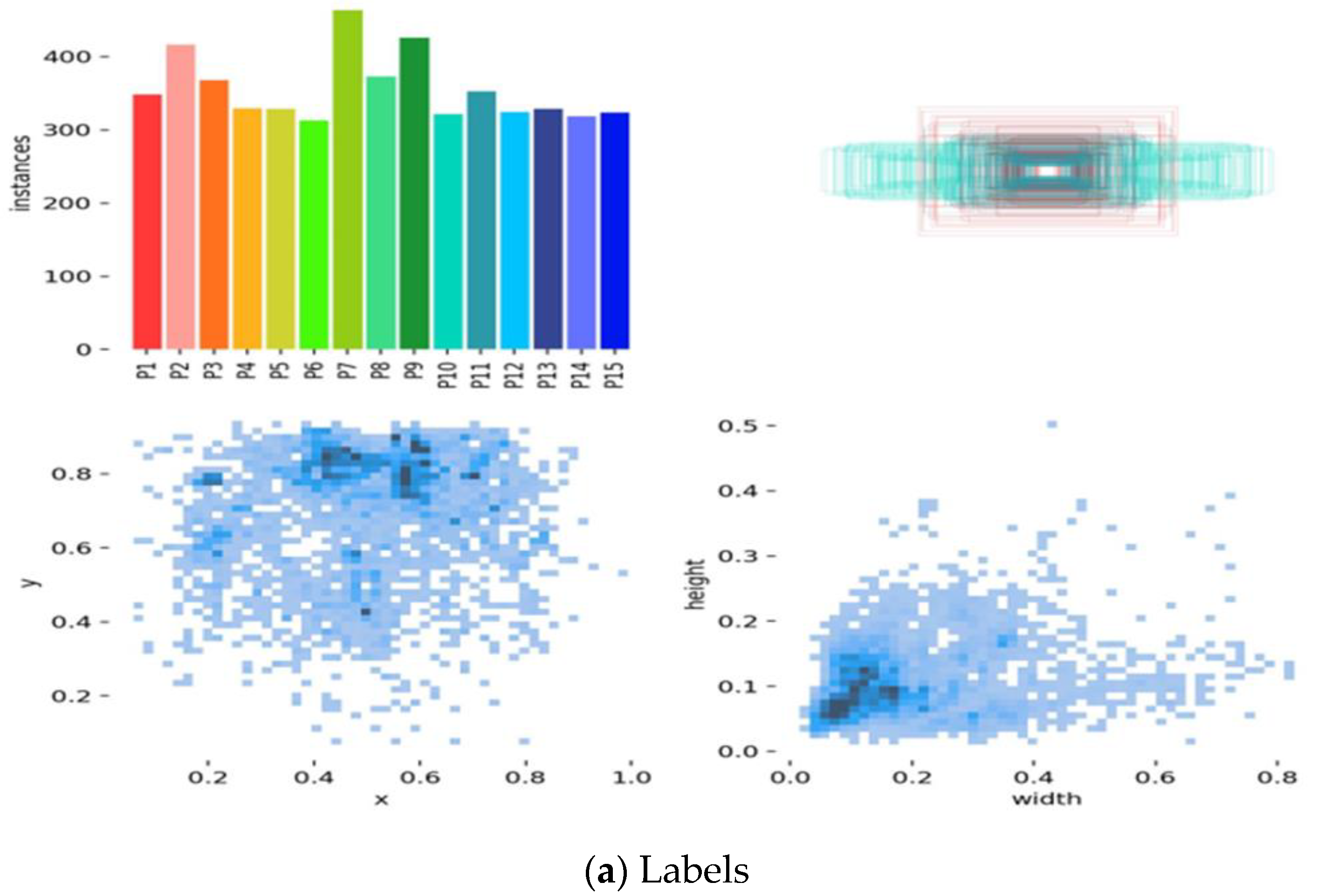
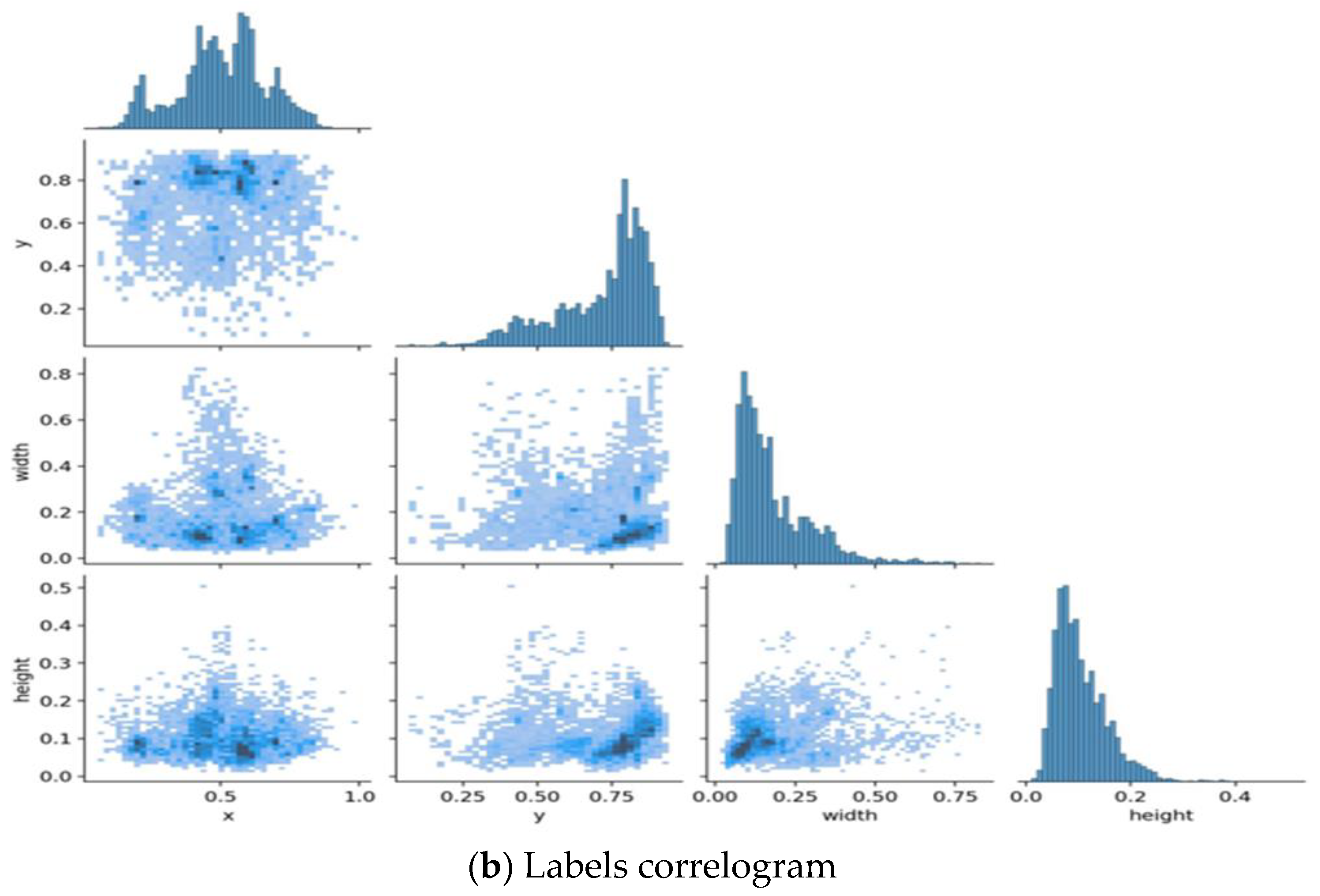
3.2. Dataset
4. Discussion
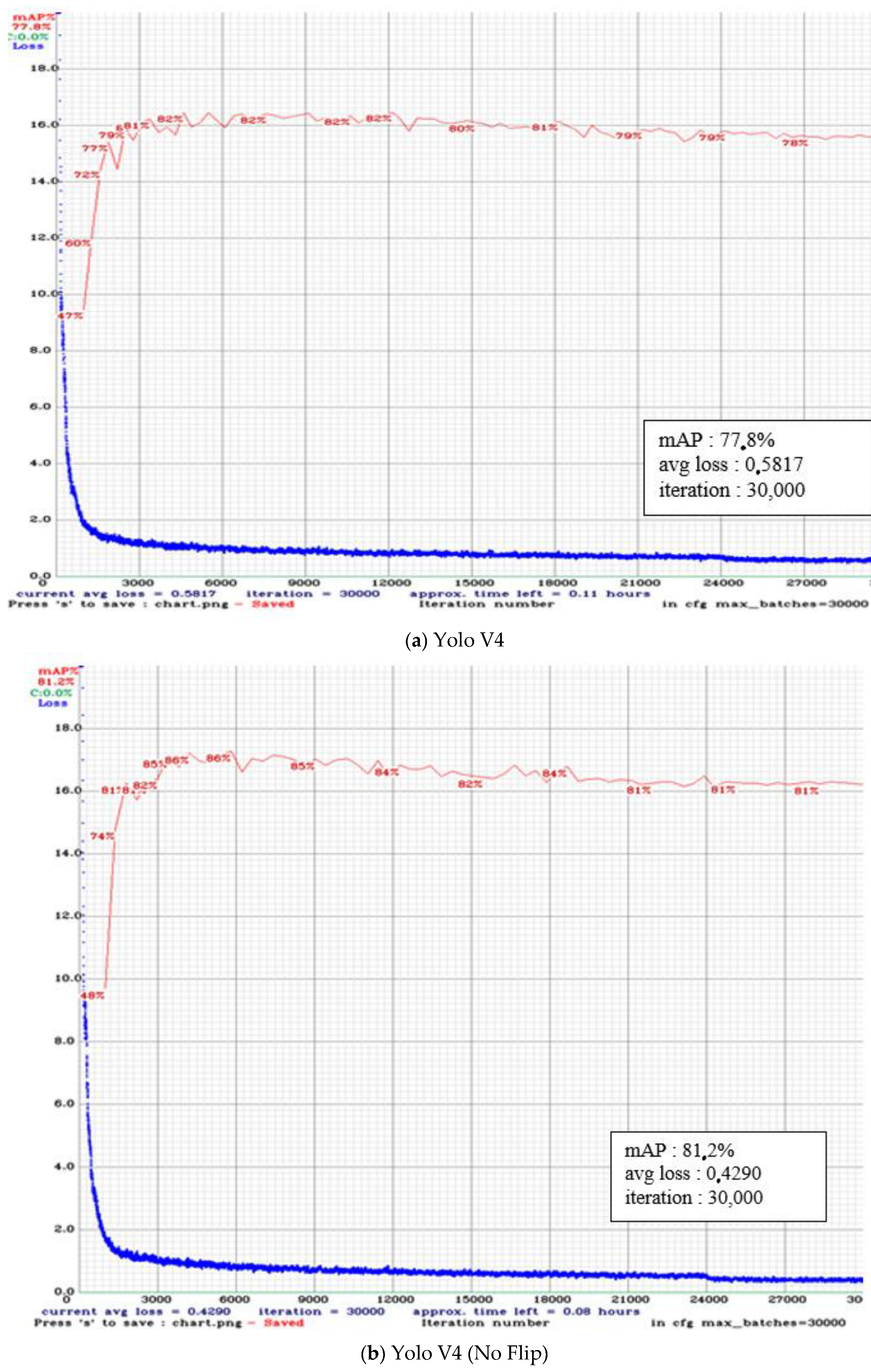
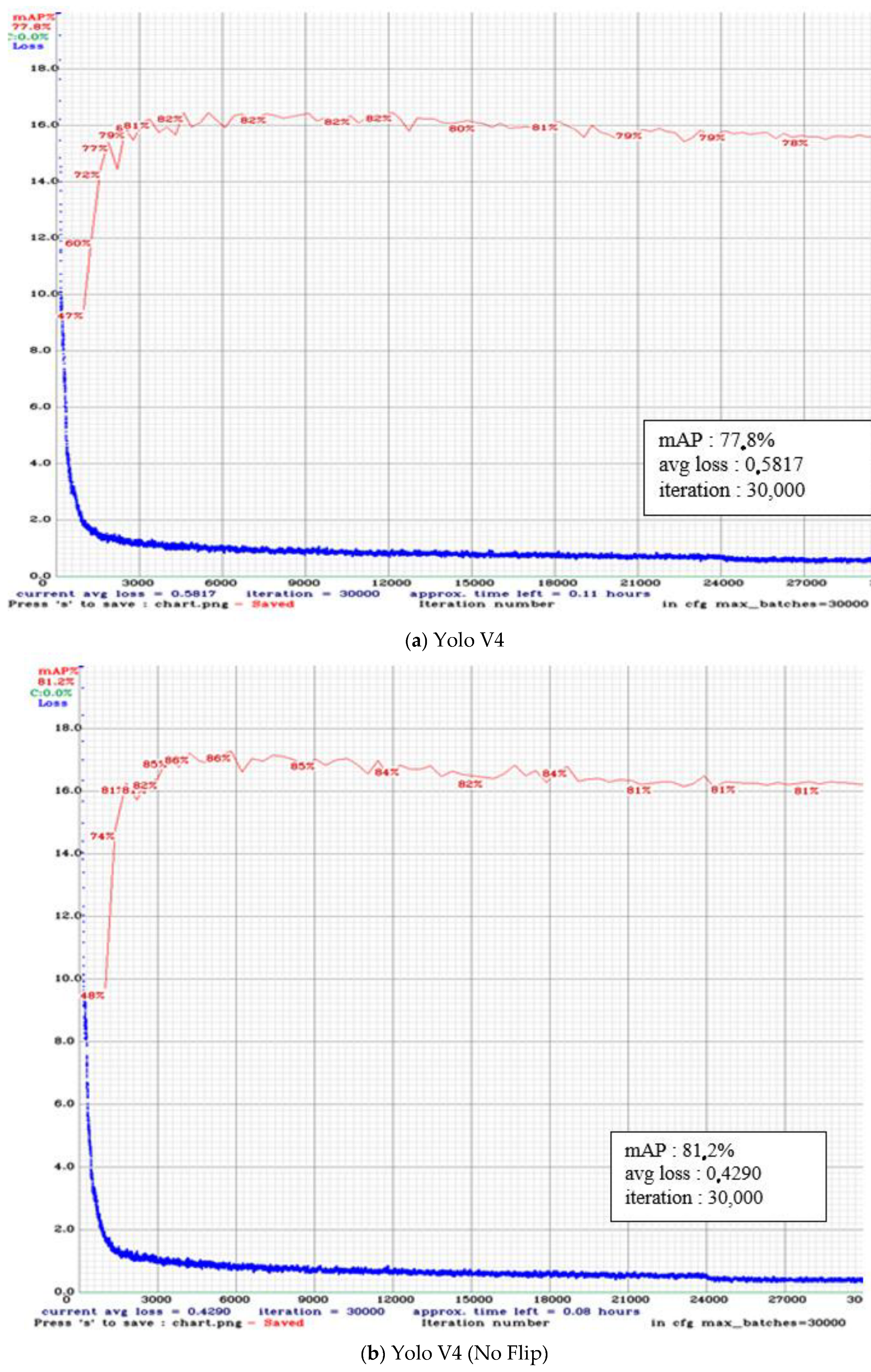
4.1. Yolo Training Result
4.2. Result Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, N.; Yang, R.; Huang, M. Deep Common Spatial Pattern Based Motor Imagery Classification with Improved Objective Function. Int. J. Netw. Dyn. Intell. 2022, 1, 73–84. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Zhang, G. Machine Learning Applications in Internet-of-Drones: Systematic Review, Recent Deployments, and Open Issues. ACM Comput. Surv. 2022, 55, 1–45. [Google Scholar] [CrossRef]
- Wontorczyk, A.; Gaca, S. Study on the Relationship between Drivers’ Personal Characters and Non-Standard Traffic Signs Comprehensibility. Int. J. Environ. Res. Public Health 2021, 18, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Shakiba, F.M.; Shojaee, M.; Azizi, S.M.; Zhou, M. Real-Time Sensing and Fault Diagnosis for Transmission Lines. Int. J. Netw. Dyn. Intell. 2022, 1, 36–47. [Google Scholar] [CrossRef]
- Poggenhans, F.; Schreiber, M.; Stiller, C. A Universal Approach to Detect and Classify Road Surface Markings. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC, Las Palmas de Gran Canaria, Spain, 15–18 September 2015; pp. 1915–1921. [Google Scholar]
- Marcus, G.; Davis, E. Insights for AI from the Human Mind. Commun. ACM 2021, 64, 38–41. [Google Scholar] [CrossRef]
- Su, Y.; Cai, H.; Huang, J. The Cooperative Output Regulation by the Distributed Observer Approach. Int. J. Netw. Dyn. Intell. 2022, 1, 20–35. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M. A Secure Intrusion Detection Platform Using Blockchain and Radial Basis Function Neural Networks for Internet of Drones. IEEE Internet Things J. 2023, 1. [Google Scholar] [CrossRef]
- Danescu, R.; Nedevschi, S. Detection and Classification of Painted Road Objects for Intersection Assistance Applications. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC, Madeira Island, Portugal, 19–22 September 2010; pp. 433–438. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO v.3. Tech Rep. 2018, 1–6. [Google Scholar] [CrossRef]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An Improved SSD Object Detection Algorithm Based on DenseNet and Feature Fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zhao, G.; Li, Y.; Xu, Q. From Emotion AI to Cognitive AI. Int. J. Netw. Dyn. Intell. 2022, 1, 65–72. [Google Scholar] [CrossRef]
- Wang, X.; Sun, Y.; Ding, D. Adaptive Dynamic Programming for Networked Control Systems Under Communication Constraints: A Survey of Trends and Techniques. Int. J. Netw. Dyn. Intell. 2022, 1, 85–98. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-Yolov4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar]
- Marfia, G.; Roccetti, M. TCP at Last: Reconsidering TCP’s Role for Wireless Entertainment Centers at Home. IEEE Trans. Consum. Electron. 2010, 56, 2233–2240. [Google Scholar] [CrossRef]
- Song, W.; Suandi, S.A. TSR-YOLO: A Chinese Traffic Sign Recognition Algorithm for Intelligent Vehicles in Complex Scenes. Sensors 2023, 23, 749. [Google Scholar] [CrossRef] [PubMed]
- Yahyaouy, A.; Sabri, A.; Benjelloun, F.; El Manaa, I.; Aarab, A. Autonomous Approach for Moving Object Detection and Classification in Road Applications. Int. J. Comput. Aided Eng. Technol. 2023, 1, 1. [Google Scholar] [CrossRef]
- Vokhidov, H.; Hong, H.G.; Kang, J.K.; Hoang, T.M.; Park, K.R. Recognition of Damaged Arrow-Road Markings by Visible Light Camera Sensor Based on Convolutional Neural Network. Sensors 2016, 16, 2160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dewi, C.; Chen, R.; Liu, Y.; Yu, H. Various Generative Adversarial Networks Model for Synthetic Prohibitory Sign Image Generation. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Kheyrollahi, A.; Breckon, T.P. Automatic Real-Time Road Marking Recognition Using a Feature Driven Approach. Mach. Vis. Appl. 2012, 23, 123–133. [Google Scholar] [CrossRef]
- Ding, D.; Yoo, J.; Jung, J.; Jin, S.; Kwon, S. Efficient Road-Sign Detection Based on Machine Learning. Bull. Networking, Comput. Syst. Softw. 2015, 4, 15–17. [Google Scholar]
- Salome, G.F.P.; Chela, J.L.; Junior, J.C.P. Fraud Detection with Machine Learning—Model Comparison. Int. J. Bus. Intell. Data Min. 2023, 1, 1. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, W. Real-Time Traffic Signs Detection Based on YOLO Network Model. In Proceedings of the 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, CyberC 2020, Chongqing, China, 29–30 October 2020. [Google Scholar]
- Mijic, D.; Brisinello, M.; Vranjes, M.; Grbic, R. Traffic Sign Detection Using YOLOv3. In Proceedings of the IEEE International Conference on Consumer Electronics, ICCE-Berlin, Berlin, Germany, 9–11 November 2020. [Google Scholar]
- Gatelli, L.; Gosmann, G.; Fitarelli, F.; Huth, G.; Schwertner, A.A.; De Azambuja, R.; Brusamarello, V.J. Counting, Classifying and Tracking Vehicles Routes at Road Intersections with YOLOv4 and DeepSORT. In Proceedings of the INSCIT 2021—5th International Symposium on Instrumentation Systems, Circuits and Transducers, Virtual, 23–27 August 2021. [Google Scholar]
- Chen, T.; Chen, Z.; Shi, Q.; Huang, X. Road Marking Detection and Classification Using Machine Learning Algorithms. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Republic of Korea, 28 June–1 July 2015; pp. 617–621. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Dewi, C.; Chen, R.C.; Yu, H.; Jiang, X. Robust Detection Method for Improving Small Traffic Sign Recognition Based on Spatial Pyramid Pooling. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Yu, H. Weight Analysis for Various Prohibitory Sign Detection and Recognition Using Deep Learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 22–25 July 2017; pp. 6517–6525. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Xu, H.; Srivastava, G. Automatic Recognition Algorithm of Traffic Signs Based on Convolution Neural Network. Multimed. Tools Appl. 2020, 79, 11551–11565. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, X.; Zheng, G.; Liu, X. Object Detection of UAV for Anti-UAV Based on Improved YOLO V3. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8386–8390. [Google Scholar]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A Hybrid Approach for Vehicle Detection and Estimation of Traffic Density Based on Faster R-CNN and YOLO Models. Neural Comput. Appl. 2023, 35, 4755–4774. [Google Scholar] [CrossRef]
- Wu, Y.; Li, Z.; Chen, Y.; Nai, K.; Yuan, J. Real-Time Traffic Sign Detection and Classification towards Real Traffic Scene. Multimed. Tools Appl. 2020, 79, 18201–18219. [Google Scholar] [CrossRef]
- Chen, Q.; Liu, L.; Han, R.; Qian, J.; Qi, D. Image Identification Method on High Speed Railway Contact Network Based on YOLO v3 and SENet. In Proceedings of the Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8772–8777. [Google Scholar]
- Corovic, A.; Ilic, V.; Duric, S.; Marijan, M.; Pavkovic, B. The Real-Time Detection of Traffic Participants Using YOLO Algorithm. In Proceedings of the 26th Telecommunications Forum, TELFOR 2018, Belgrade, Serbia, 20–21 November 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:arXiv.2004.10934. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. GoogLeNet Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Jiang, X.; Yu, H. Deep Convolutional Neural Network for Enhancing Traffic Sign Recognition Developed on Yolo V4. Multimed. Tools Appl. 2022, 81, 1–25. [Google Scholar] [CrossRef]
- Otgonbold, M.E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.H.; Hsieh, J.W.; Chen, P.Y. SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors 2022, 22, 2315. [Google Scholar] [CrossRef]
- Sun, X.M.; Zhang, Y.J.; Wang, H.; Du, Y.X. Research on Ship Detection of Optical Remote Sensing Image Based on Yolo V5. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2215. [Google Scholar]
- Wang, G.; Ding, H.; Yang, Z.; Li, B.; Wang, Y.; Bao, L. TRC-YOLO: A Real-Time Detection Method for Lightweight Targets Based on Mobile Devices. IET Comput. Vis. 2022, 16, 126–142. [Google Scholar] [CrossRef]
- Chien-Yao, W.; Bochkovskiy, A.; Hong-Yuan, L.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:arXiv.2207.02696. [Google Scholar] [CrossRef]
- Github. Ultralytics Yolo V5. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 January 2021).
- Chen, Y.W.; Shiu, J.M. An Implementation of YOLO-Family Algorithms in Classifying the Product Quality for the Acrylonitrile Butadiene Styrene Metallization. Int. J. Adv. Manuf. Technol. 2022, 119, 8257–8269. [Google Scholar] [CrossRef] [PubMed]
- Gao, G.; Wang, S.; Shuai, C.; Zhang, Z.; Zhang, S.; Feng, Y. Recognition and Detection of Greenhouse Tomatoes in Complex Environment. Trait. du Signal 2022, 39, 291–298. [Google Scholar] [CrossRef]
- Sui, J.-Y.; Liao, S.; Li, B.; Zhang, H.-F. High Sensitivity Multitasking Non-Reciprocity Sensor Using the Photonic Spin Hall Effect. Opt. Lett. 2022, 47, 6065. [Google Scholar] [CrossRef]
- Wan, B.F.; Zhou, Z.W.; Xu, Y.; Zhang, H.F. A Theoretical Proposal for a Refractive Index and Angle Sensor Based on One-Dimensional Photonic Crystals. IEEE Sens. J. 2021, 21, 331–338. [Google Scholar] [CrossRef]
- Arcos-García, Á.; Álvarez-García, J.A.; Soria-Morillo, L.M. Evaluation of Deep Neural Networks for Traffic Sign Detection Systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M.; Li, X. Tender Tea Shoots Recognition and Positioning for Picking Robot Using Improved YOLO-V3 Model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple Detection during Different Growth Stages in Orchards Using the Improved YOLO-V3 Model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Flip |
|---|---|
| Yolo V2 | Yes |
| Yolo V3 | Yes |
| Yolo V4 | Yes |
| Yolo V4 (No Flip) | No |
| Yolo V4-tiny | Yes |
| Yolo V4-tiny (No Flip) | No |
| Class ID | Chinese Name | English Name | Image | Total Image |
|---|---|---|---|---|
| P1 | 右轉 | Turn Right |  | 405 |
| P2 | 左轉 | Turn Left |  | 401 |
| P3 | 直走 | Go Straight |  | 407 |
| P4 | 直走或右轉 | Turn Right or Go Straight |  | 409 |
| P5 | 直走或左轉 | Turn Left or Go Straight |  | 403 |
| P6 | 速限40 | Speed Limit (40) |  | 391 |
| P7 | 速限50 | Speed Limit (50) |  | 401 |
| P8 | 速限60 | Speed Limit (60) |  | 400 |
| P9 | 速限70 | Speed Limit (70) |  | 398 |
| P10 | Zebra Crossing (Crosswalk) |  | 401 | |
| P11 | Slow Sign |  | 399 | |
| P12 | Overtaking Prohibited |  | 404 | |
| P13 | Barrier Line |  | 409 | |
| P14 | Cross Hatch |  | 398 | |
| P15 | Stop Line |  | 403 |
| Model | Loss Value | Precision | Recall | F1-Score | IoU (%) | mAP@0.50 (%) |
|---|---|---|---|---|---|---|
| Yolo V2 | 0.1162 | 0.68 | 0.83 | 0.74 | 53.61 | 76.75 |
| Yolo V3 | 0.1493 | 0.73 | 0.81 | 0.77 | 58.62 | 78.31 |
| Yolo V4 | 0.5817 | 0.72 | 0.81 | 0.76 | 58.23 | 77.76 |
| Yolo V4 (No Flip) | 0.429 | 0.81 | 0.86 | 0.84 | 65.98 | 81.22 |
| Yolo V4-tiny | 0.3289 | 0.66 | 0.81 | 0.73 | 52.83 | 80.55 |
| Yolo V4-tiny (No Flip) | 0.2428 | 0.76 | 0.86 | 0.81 | 60.45 | 84.77 |
| Class ID | Yolo V2 | Yolo V3 | Yolo V4 | Yolo V4 (No Flip) | Yolo V4-Tiny | Yolo V4-Tiny (No Flip) |
|---|---|---|---|---|---|---|
| P1 | 68.95 | 74.87 | 76.49 | 95.20 | 81.88 | 95.60 |
| P2 | 61.40 | 63.57 | 64.43 | 81.22 | 74.48 | 84.16 |
| P3 | 67.80 | 70.27 | 68.13 | 52.51 | 69.04 | 62.98 |
| P4 | 40.87 | 45.44 | 42.69 | 57.15 | 63.45 | 73.66 |
| P5 | 31.67 | 35.10 | 27.35 | 53.02 | 50.36 | 72.76 |
| P6 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| P7 | 91.15 | 90.10 | 90.81 | 90.33 | 86.32 | 88.89 |
| P8 | 98.48 | 98.18 | 98.78 | 99.78 | 95.64 | 95.59 |
| P9 | 99.99 | 99.98 | 99.99 | 99.98 | 100.00 | 100.00 |
| P10 | 85.24 | 87.93 | 85.21 | 90.48 | 90.27 | 93.40 |
| P11 | 97.45 | 97.08 | 99.59 | 97.69 | 98.36 | 98.96 |
| P12 | 68.32 | 64.42 | 72.36 | 59.56 | 70.45 | 70.73 |
| P13 | 69.76 | 70.43 | 63.67 | 63.04 | 61.10 | 95.43 |
| P14 | 87.08 | 87.48 | 89.51 | 87.23 | 78.85 | 81.65 |
| P15 | 83.04 | 89.75 | 87.36 | 91.14 | 88.01 | 87.74 |
| Average | 76.75 | 78.31 | 77.76 | 81.22 | 80.55 | 84.77 |
| Model | Recall | Precision | F1-Score | TP | FP | IoU (%) | mAP@0.50 (%) |
|---|---|---|---|---|---|---|---|
| Yolo V2 | 0.94 | 0.73 | 0.82 | 5006 | 1883 | 56.79 | 90.53 |
| Yolo V3 | 0.88 | 0.79 | 0.83 | 4694 | 1259 | 61.98 | 89.97 |
| Yolo V4 | 0.93 | 0.82 | 0.87 | 4970 | 1096 | 66.24 | 93.55 |
| Yolo V4 (No Flip) | 0.95 | 0.83 | 0.89 | 5074 | 1003 | 66.12 | 95.43 |
| Yolo V4-tiny | 0.88 | 0.72 | 0.80 | 4707 | 1802 | 58.15 | 87.53 |
| Yolo V4-tiny (No Flip) | 0.94 | 0.82 | 0.88 | 4996 | 1065 | 66.86 | 94.42 |
| Class ID | Yolo V2 | Yolo V3 | Yolo V4 | Yolo V4 (No Flip) | Yolo V4-Tiny | Yolo V4-Tiny (No Flip) | Average |
|---|---|---|---|---|---|---|---|
| P1 | 86.61 | 85.57 | 89.03 | 98.35 | 86.80 | 98.38 | 91.56 |
| P2 | 80.99 | 82.01 | 86.59 | 96.66 | 84.22 | 96.53 | 88.78 |
| P3 | 87.08 | 84.42 | 91.23 | 92.21 | 78.38 | 87.38 | 87.85 |
| P4 | 77.84 | 73.63 | 78.58 | 92.60 | 71.14 | 91.58 | 82.19 |
| P5 | 70.82 | 66.78 | 73.9. | 88.20 | 65.44 | 85.88 | 76.79 |
| P6 | 100.00 | 100.00 | 100.00 | 100.00 | 99.99 | 100.00 | 100.00 |
| P7 | 93.56 | 96.02 | 99.08 | 98.38 | 97.50 | 97.91 | 95.99 |
| P8 | 96.92 | 97.51 | 98.76 | 99.03 | 98.49 | 98.49 | 98.10 |
| P9 | 99.90 | 99.83 | 99.95 | 99.86 | 99.86 | 99.87 | 99.87 |
| P10 | 96.59 | 98.30 | 98.73 | 97.38 | 95.26 | 97.87 | 95.16 |
| P11 | 99.15 | 99.69 | 99.97 | 99.91 | 99.50 | 99.50 | 99.63 |
| P12 | 92.26 | 89.87 | 99.14 | 97.58 | 79.94 | 91.84 | 92.19 |
| P13 | 85.85 | 82.96 | 93.67 | 79.28 | 71.62 | 81.76 | 84.00 |
| P14 | 97.00 | 97.73 | 98.52 | 96.50 | 92.99 | 94.53 | 94.65 |
| P15 | 93.34 | 95.18 | 96.01 | 95.57 | 91.82 | 94.74 | 92.94 |
| Average | 90.53 | 89.97 | 94.95 | 95.43 | 87.53 | 94.42 | 91.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Chen, R.-C.; Zhuang, Y.-C.; Jiang, X.; Yu, H. Recognizing Road Surface Traffic Signs Based on Yolo Models Considering Image Flips. Big Data Cogn. Comput. 2023, 7, 54. https://doi.org/10.3390/bdcc7010054
Dewi C, Chen R-C, Zhuang Y-C, Jiang X, Yu H. Recognizing Road Surface Traffic Signs Based on Yolo Models Considering Image Flips. Big Data and Cognitive Computing. 2023; 7(1):54. https://doi.org/10.3390/bdcc7010054
Chicago/Turabian StyleDewi, Christine, Rung-Ching Chen, Yong-Cun Zhuang, Xiaoyi Jiang, and Hui Yu. 2023. "Recognizing Road Surface Traffic Signs Based on Yolo Models Considering Image Flips" Big Data and Cognitive Computing 7, no. 1: 54. https://doi.org/10.3390/bdcc7010054
APA StyleDewi, C., Chen, R.-C., Zhuang, Y.-C., Jiang, X., & Yu, H. (2023). Recognizing Road Surface Traffic Signs Based on Yolo Models Considering Image Flips. Big Data and Cognitive Computing, 7(1), 54. https://doi.org/10.3390/bdcc7010054