
A Multimodal Machine Learning Model in Pneumonia Patients Hospital Length of Stay Prediction

 , ,
, ,  ,
,  , , , , , , ,
, , , , , , ,  , , ,
, , ,  and
and 
Abstract
1. Introduction
- We illustrate an approach to extract useful features from lungs CT scans and volumes for LOS prediction;
- We provide a reliable solution for LOS prediction powered by CT features, whose results are more efficient than SOTA solutions;
- We expand the solution to be compatible with clinical tabular data, available along with patients’ CT scans, and compared performances given the different types of input;
- We adapt the proposed methodology for the task of post-therapy survival prediction, showing the generalization ability of the approach;
- We illustrate and implement a multi-modal architecture capable of compensating the typical lack of data in the biomedical domain.
2. Related Works
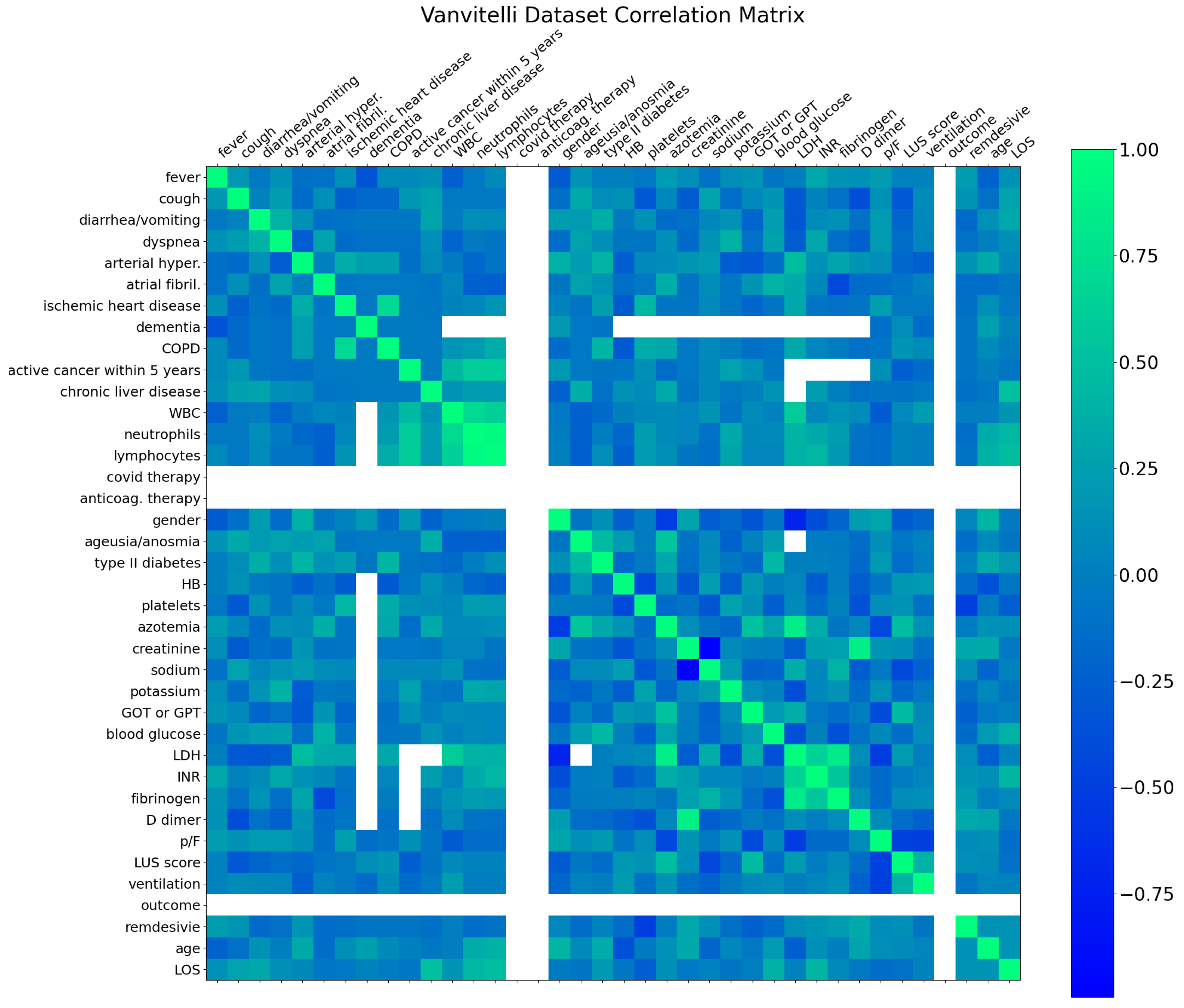
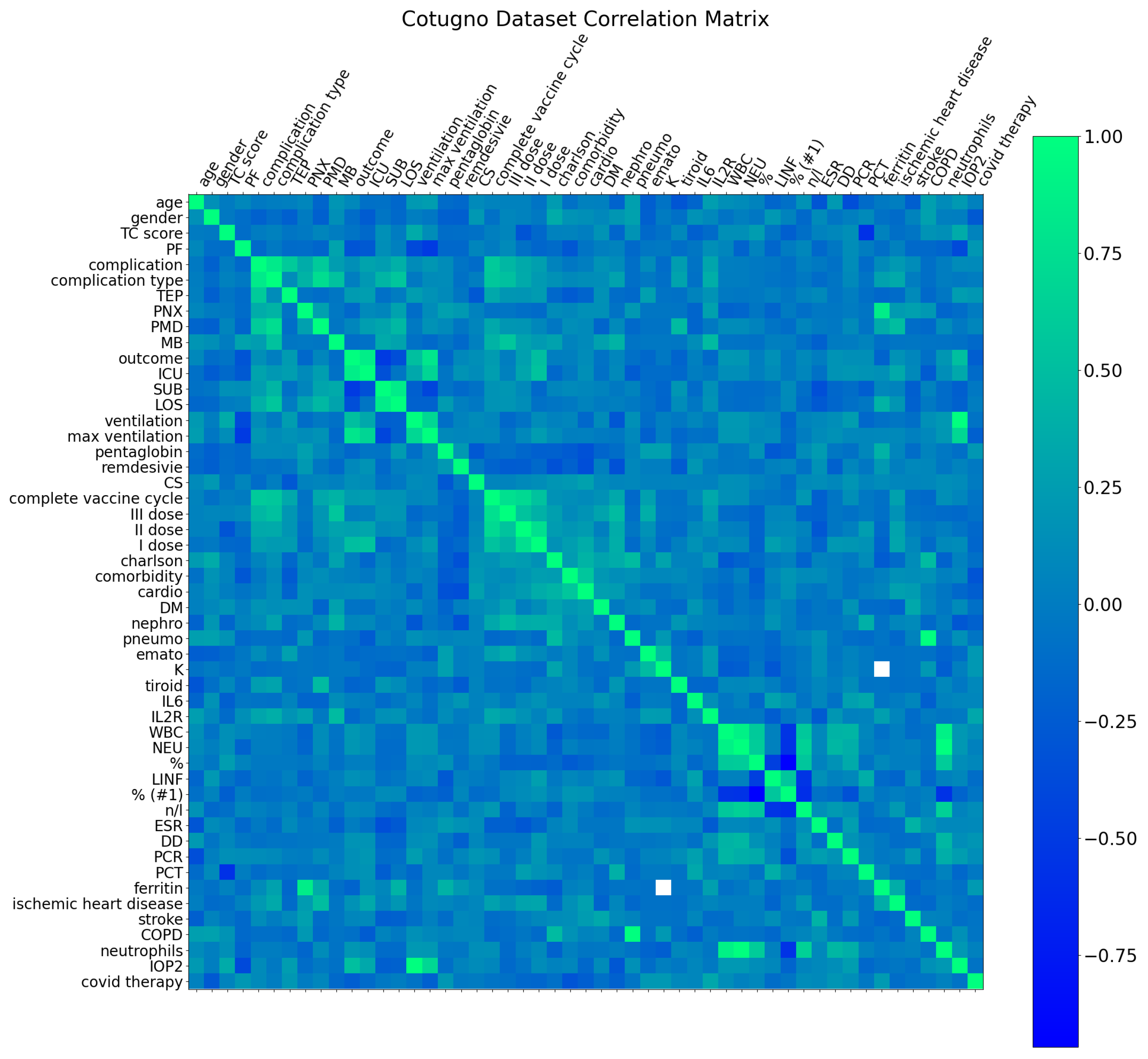
3. Dataset
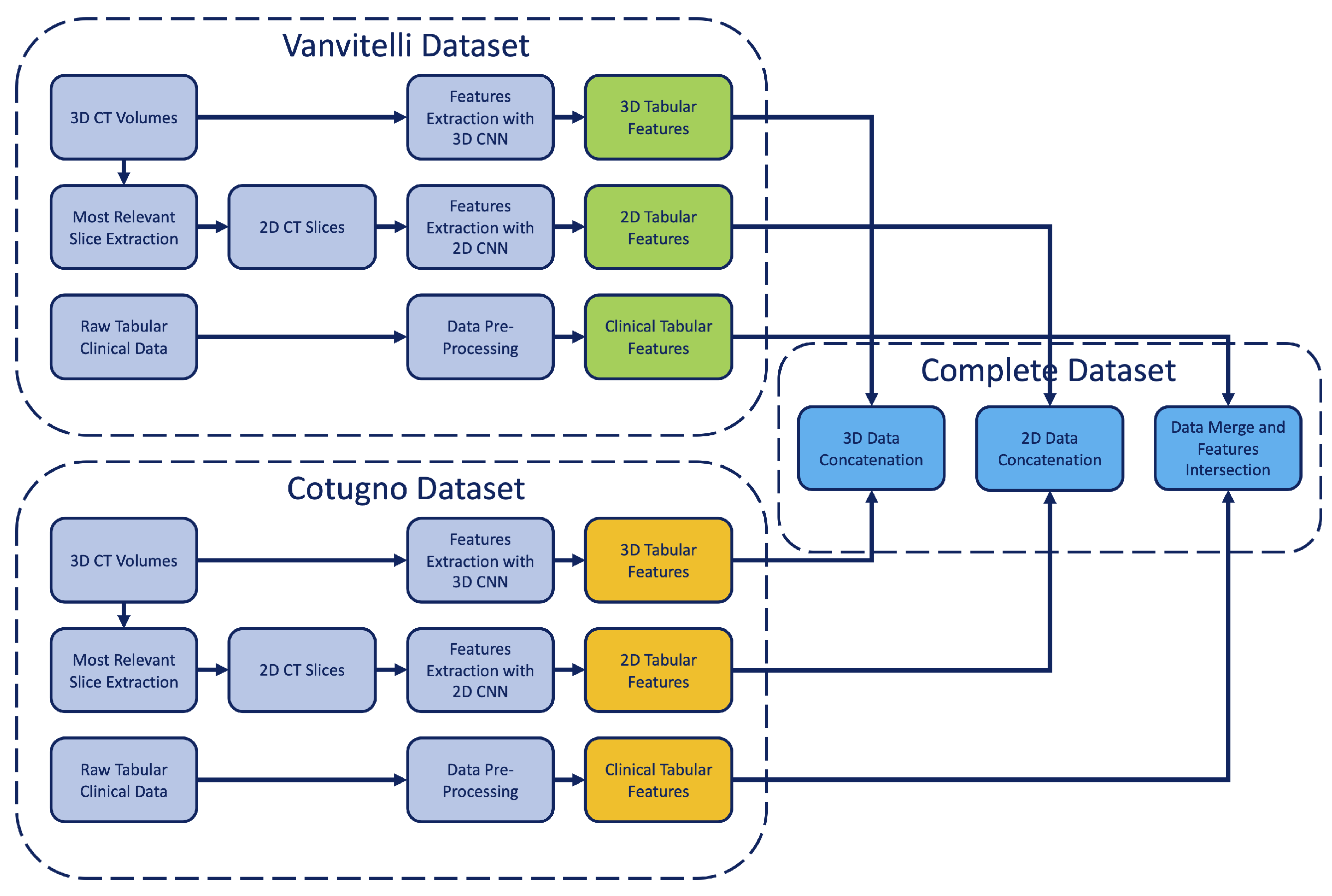
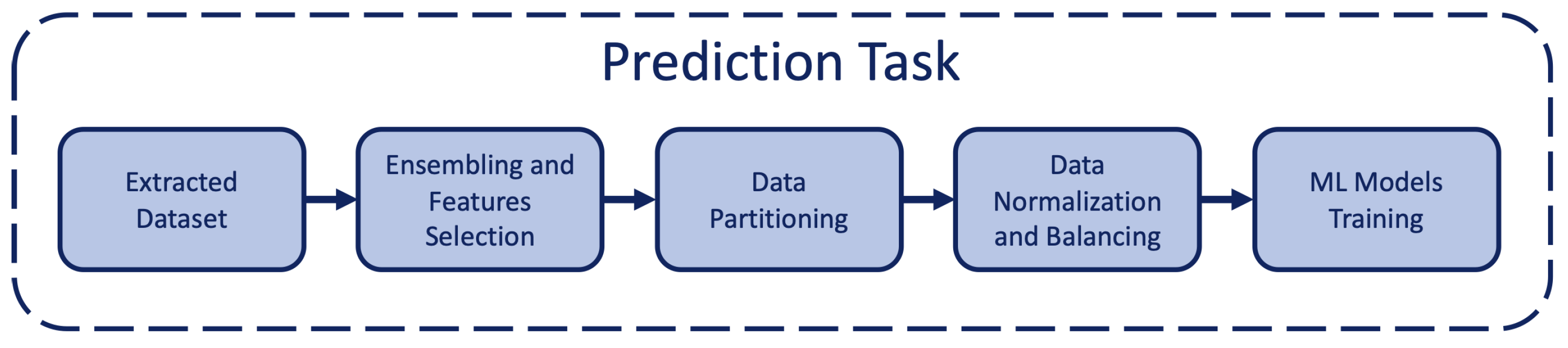
4. Proposed Approach
- Features extraction and collection;
- Features selection;
- LOS and outcome prediction.
4.1. Features Extraction and Collection
- A variable number of features (depending on the source) from clinical exams;
- A total of 16 features from 2D slices;
- A total of 16 features from 3D volumes.
4.2. Features Selection
- Backward Feature Elimination (BFE): the dimensionality reduction is performed by an algorithm that, for each iteration with n features, removes one feature at a time in order to understand which set of input features results in the minimum increase in the error rate, and then removes the missing feature and continues with the next iteration;
- Forward Feature Selection (FFS): the dimensionality reduction is performed by a dual algorithm that, starting from one feature, at each iteration adds a new feature adopting the same strategy of the BFE.
- BFE with linear regressor (LR);
- FFS with linear regressor (LR);
- BFE with M5P;
- FFS with M5P.
4.3. LOS and Outcome Prediction
5. Results
5.1. Outcome Classification Task
5.2. Days Range Classification Task
5.3. Length of Stay Regression Task
- Models were replaced with regression ones;
- SMOTE algorithm with balancing on range feature was added;
- Feature selection algorithms with utility models were added.
6. Ethical Considerations
7. Discussion and Conclusions
- The best outcome prediction accuracy is of 0.875 on the Complete dataset by adopting the standard approach and 3D features, not available on the Vanvitelli dataset since all the patients have the same outcome, and 1.0 on the Cotugno dataset by adopting the standard approach and clinical data.
- The best days range prediction accuracy is of 0.870 on the Complete dataset by adopting the bagging ensemble approach and 3D features, of 0.667 on the Vanvitelli dataset by adopting the bagging ensemble approach and 2D features, and of 0.571 on the Cotugno dataset by adopting the bagging ensemble approach and 2D features.
- The best length of stay prediction MAE is 3.102 on the Complete dataset by adopting the feature selection approach and 2D features, 1.43 on the Vanvitelli dataset by adopting the feature qelection approach and 2D features, and 2.25 on the Cotugno dataset by adopting the feature selection approach and clinical data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Daghistani, T.A.; Elshawi, R.; Sakr, S.; Ahmed, A.M.; Al-Thwayee, A.; Al-Mallah, M.H. Predictors of in-hospital length of stay among cardiac patients: A machine learning approach. Int. J. Cardiol. 2019, 288, 140–147. [Google Scholar] [CrossRef] [PubMed]
- Mpanya, D.; Celik, T.; Klug, E.; Ntsinjana, H. Predicting mortality and hospitalization in heart failure using machine learning: A systematic literature review. IJC Heart Vasc. 2021, 34, 100773. [Google Scholar] [CrossRef] [PubMed]
- Lequertier, V.; Wang, T.; Fondrevelle, J.; Augusto, V.; Duclos, A. Hospital length of stay prediction methods: A systematic review. Med. Care 2021, 59, 929–938. [Google Scholar] [CrossRef]
- Mekhaldi, R.N.; Caulier, P.; Chaabane, S.; Chraibi, A.; Piechowiak, S. A Comparative Study of Machine Learning Models for Predicting Length of Stay in Hospitals. J. Inf. Sci. Eng. 2021, 37, 1025–1038. [Google Scholar]
- Stone, K.; Zwiggelaar, R.; Jones, P.; Mac Parthaláin, N. A systematic review of the prediction of hospital length of stay: Towards a unified framework. PLoS Digit. Health 2022, 1, e0000017. [Google Scholar] [CrossRef] [PubMed]
- Morton, A.; Marzban, E.; Giannoulis, G.; Patel, A.; Aparasu, R.; Kakadiaris, I.A. A comparison of supervised machine learning techniques for predicting short-term in-hospital length of stay among diabetic patients. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–6 December 2014; pp. 428–431. [Google Scholar]
- Pendharkar, P.C.; Khurana, H. Machine learning techniques for predicting hospital length of stay in pennsylvania federal and specialty hospitals. Int. J. Comput. Sci. Appl. 2014, 11, 45–56. [Google Scholar]
- Turgeman, L.; May, J.H.; Sciulli, R. Insights from a machine learning model for predicting the hospital Length of Stay (LOS) at the time of admission. Expert Syst. Appl. 2017, 78, 376–385. [Google Scholar] [CrossRef]
- Lorenzoni, G.; Sabato, S.S.; Lanera, C.; Bottigliengo, D.; Minto, C.; Ocagli, H.; De Paolis, P.; Gregori, D.; Iliceto, S.; Pisanò, F. Comparison of machine learning techniques for prediction of hospitalization in heart failure patients. J. Clin. Med. 2019, 8, 1298. [Google Scholar] [CrossRef]
- Saadatmand, S.; Salimifard, K.; Mohammadi, R.; Kuiper, A.; Marzban, M.; Farhadi, A. Using machine learning in prediction of ICU admission, mortality, and length of stay in the early stage of admission of COVID-19 patients. Ann. Oper. Res. 2023, 328, 1043–1071. [Google Scholar] [CrossRef]
- Khajehali, N.; Alizadeh, S. Extract critical factors affecting the length of hospital stay of pneumonia patient by data mining (case study: An Iranian hospital). Artif. Intell. Med. 2017, 83, 2–13. [Google Scholar] [CrossRef]
- Mekhaldi, R.N.; Caulier, P.; Chaabane, S.; Chraibi, A.; Piechowiak, S. Using machine learning models to predict the length of stay in a hospital setting. In Proceedings of the World Conference on Information Systems and Technologies, Budva, Montenegro, 7–10 April 2020; pp. 202–211. [Google Scholar]
- Alsinglawi, B.; Alnajjar, F.; Mubin, O.; Novoa, M.; Alorjani, M.; Karajeh, O.; Darwish, O. Predicting length of stay for cardiovascular hospitalizations in the intensive care unit: Machine learning approach. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 5442–5445. [Google Scholar]
- Alsinglawi, B.; Alshari, O.; Alorjani, M.; Mubin, O.; Alnajjar, F.; Novoa, M.; Darwish, O. An explainable machine learning framework for lung cancer hospital length of stay prediction. Sci. Rep. 2022, 12, 607. [Google Scholar] [CrossRef]
- Bacchi, S.; Gluck, S.; Tan, Y.; Chim, I.; Cheng, J.; Gilbert, T.; Menon, D.K.; Jannes, J.; Kleinig, T.; Koblar, S. Prediction of general medical admission length of stay with natural language processing and deep learning: A pilot study. Intern. Emerg. Med. 2020, 15, 989–995. [Google Scholar] [CrossRef] [PubMed]
- Bacchi, S.; Tan, Y.; Oakden-Rayner, L.; Jannes, J.; Kleinig, T.; Koblar, S. Machine learning in the prediction of medical inpatient length of stay. Intern. Med. J. 2022, 52, 176–185. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Wang, J.; Sheriff, A.; Chen, X. Hospital length of stay prediction with ensemble methods in machine learning. In Proceedings of the 2021 International Conference on Cyber-Physical Social Intelligence (ICCSI), Beijing, China, 18–20 December 2021; pp. 1–5. [Google Scholar]
- Jaotombo, F.; Pauly, V.; Fond, G.; Orleans, V.; Auquier, P.; Ghattas, B.; Boyer, L. Machine-learning prediction for hospital length of stay using a French medico-administrative database. J. Mark. Access Health Policy 2023, 11, 2149318. [Google Scholar] [CrossRef]
- Zhong, H.; Wang, B.; Wang, D.; Liu, Z.; Xing, C.; Wu, Y.; Gao, Q.; Zhu, S.; Qu, H.; Jia, Z.; et al. The application of machine learning algorithms in predicting the length of stay following femoral neck fracture. Int. J. Med. Inform. 2021, 155, 104572. [Google Scholar] [CrossRef] [PubMed]
- Alghatani, K.; Ammar, N.; Rezgui, A.; Shaban-Nejad, A. Predicting intensive care unit length of stay and mortality using patient vital signs: Machine learning model development and validation. JMIR Med. Inform. 2021, 9, e21347. [Google Scholar] [CrossRef]
- Chrusciel, J.; Girardon, F.; Roquette, L.; Laplanche, D.; Duclos, A.; Sanchez, S. The prediction of hospital length of stay using unstructured data. BMC Med. Inform. Decis. Mak. 2021, 21, 351. [Google Scholar] [CrossRef]
- Zebin, T.; Rezvy, S.; Chaussalet, T.J. A deep learning approach for length of stay prediction in clinical settings from medical records. In Proceedings of the 2019 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Siena, Italy, 9–11 July 2019; pp. 1–5. [Google Scholar]
- Roimi, M.; Gutman, R.; Somer, J.; Ben Arie, A.; Calman, I.; Bar-Lavie, Y.; Gelbshtein, U.; Liverant-Taub, S.; Ziv, A.; Eytan, D.; et al. Development and validation of a machine learning model predicting illness trajectory and hospital utilization of COVID-19 patients: A nationwide study. J. Am. Med. Inform. Assoc. 2021, 28, 1188–1196. [Google Scholar] [CrossRef]
- Ebinger, J.; Wells, M.; Ouyang, D.; Davis, T.; Kaufman, N.; Cheng, S.; Chugh, S. A machine learning algorithm predicts duration of hospitalization in COVID-19 patients. Intell.-Based Med. 2021, 5, 100035. [Google Scholar] [CrossRef]
- Alabbad, D.A.; Almuhaideb, A.M.; Alsunaidi, S.J.; Alqudaihi, K.S.; Alamoudi, F.A.; Alhobaishi, M.K.; Alaqeel, N.A.; Alshahrani, M.S. Machine learning model for predicting the length of stay in the intensive care unit for COVID-19 patients in the eastern province of Saudi Arabia. Inform. Med. Unlocked 2022, 30, 100937. [Google Scholar] [CrossRef]
- Etu, E.E.; Monplaisir, L.; Arslanturk, S.; Masoud, S.; Aguwa, C.; Markevych, I.; Miller, J. Prediction of length of stay in the emergency department for COVID-19 patients: A machine learning approach. IEEE Access 2022, 10, 42243–42251. [Google Scholar] [CrossRef]
- Chen, S.; Ma, K.; Zheng, Y. Med3D: Transfer Learning for 3D Medical Image Analysis. arXiv 2019, arXiv:1904.00625. [Google Scholar]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Sieb, C.; Thiel, K.; Wiswedel, B. KNIME: The Konstanz Information Miner. In Data Analysis, Machine Learning and Applications, Proceedings of the 31st Annual Conference of the Gesellschaft für Klassifikation e.V., Freiburg, Germany, 7–9 March 2007; Studies in Classification, Data Analysis, and Knowledge Organization (GfKL 2007); Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Gorriz, J.M.; Segovia, F.; Ramirez, J.; Ortiz, A.; Suckling, J. Is K-fold cross validation the best model selection method for Machine Learning? arXiv 2024, arXiv:2401.16407. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Willmott, C.; Matsuura, K. Advantages of the Mean Absolute Error (MAE) over the Root Mean Square Error (RMSE) in Assessing Average Model Performance. Clim. Res. 2005, 30, 79. [Google Scholar] [CrossRef]
- Razaque, A.; Amsaad, F.; Khan, M.J.; Hariri, S.; Chen, S.; Siting, C.; Ji, X. Survey: Cybersecurity vulnerabilities, attacks and solutions in the medical domain. IEEE Access 2019, 7, 168774–168797. [Google Scholar] [CrossRef]
- Goddard, K.; Roudsari, A.; Wyatt, J.C. Automation bias: Empirical results assessing influencing factors. Int. J. Med. Inform. 2014, 83, 368–375. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Size | Binary Features | Numeric Features | Features Num. |
|---|---|---|---|---|
| Vanvitelli | 34 | Gender, Remdesivie, Neutrophils, Ischemic heart disease, COPD, COVID therapy, Ventilation, Anticoagulant therapy, chronic liver disease, Fever, Cough, Diarrhea/vomiting, Arterial hypertension, Atrial fibrillation, Active cancer within the past 5 years, Dyspnea, Ageusia/anosmia, Type II diabetes, Dementia, Lymphocytes | Age, WBC, HB, Platelets, Azotemia, Creatinine, Sodium, Potassium, GOT or GPT, Blood glucose, LDH, INR, Fibrinogen, D dimer, p/F, LUS score | 36 |
| Cotugno | 50 | Gender, Remdesivie, Neutrophils, Ischemic heart disease, COPD, COVID therapy, Ventilation, CDI, Complication, TEP, PNX, PMD, MB, ICU, Pentaglobin, CS, I dose, II dose, III dose, Complete vaccine cycle, Comorbidity, Cardio, DM, Nephro, Pneumo, Emato, K, Tiroid, Stroke, IOP2 | Age, WBC, TC score, PF, Complication type, Max ventilation, Charlson, IL6, IL2R, NEU, %, LINF, % (# 1), n/l, ESR, DD, PCR, PCT, Ferritin | 49 |
| Task | Features | Dataset | Approach |
|---|---|---|---|
| Outcome (Classification) | Tabular Data, CT Scan Features (2D), CT Volume Features (3D) | Complete, Vanvitelli, Cotugno | Standard, Ensemble |
| Days range (Classification) | Tabular Data, CT Scan Features (2D), CT Volume Features (3D) | Complete, Vanvitelli, Cotugno | Standard, Ensemble |
| Length of stay (Regression) | Tabular Data, CT Scan Features (2D), CT Volume Features (3D) | Complete, Vanvitelli, Cotugno | Standard, Ensemble, Feature Selection |
| Model (Outcome, Complete, Standard) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.682 | 0.726 | 0.545 | 0.671 | 0.542 | 0.701 |
| Naïve Bayes | 0.773 | 0.685 | 0.545 | 0.438 | 0.375 | 0.416 |
| Gradient Boosted Tree | 0.682 | 0.867 | 0.545 | 0.699 | 0.875 | 0.701 |
| Random Forest | 0.682 | 0.808 | 0.591 | 0.726 | 0.792 | 0.753 |
| Multi-Layer Perceptron | 0.682 | 0.740 | 0.455 | 0.726 | 0.792 | 0.779 |
| LibLINEAR | 0.682 | 0.781 | 0.636 | 0.740 | 0.792 | 0.753 |
| ADABoostM1 | 0.682 | 0.795 | 0.636 | 0.726 | 0.792 | 0.766 |
| K-Nearest Neighbor 3 | 0.727 | 0.726 | 0.636 | 0.685 | 0.708 | 0.727 |
| K-Nearest Neighbor 5 | 0.682 | 0.726 | 0.455 | 0.671 | 0.792 | 0.753 |
| K-Nearest Neighbor 7 | 0.682 | 0.767 | 0.455 | 0.699 | 0.792 | 0.766 |
| Model (Outcome, Complete, Bagging) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.667 | 0.712 | 0.667 | 0.699 | 0.708 | 0.714 |
| Naïve Bayes | 0.708 | 0.808 | 0.708 | 0.562 | 0.625 | 0.662 |
| Gradient Boosted Tree | 0.792 | 0.767 | 0.750 | 0.671 | 0.708 | 0.649 |
| Random Forest | 0.750 | 0.822 | 0.667 | 0.685 | 0.667 | 0.623 |
| Multi-Layer Perceptron | 0.625 | 0.836 | 0.708 | 0.726 | 0.750 | 0.727 |
| LibLINEAR | 0.750 | 0.781 | 0.667 | 0.630 | 0.583 | 0.662 |
| ADABoostM1 | 0.792 | 0.781 | 0.708 | 0.630 | 0.667 | 0.675 |
| K-Nearest Neighbor 3 | 0.708 | 0.740 | 0.708 | 0.767 | 0.625 | 0.649 |
| K-Nearest Neighbor 5 | 0.667 | 0.740 | 0.667 | 0.753 | 0.708 | 0.688 |
| K-Nearest Neighbor 7 | 0.667 | 0.781 | 0.708 | 0.753 | 0.750 | 0.714 |
| Model (Outcome, Cotugno, Standard) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.923 | 0.976 | 0.538 | 0.619 | 0.615 | 0.535 |
| Naïve Bayes | 0.923 | 0.786 | 0.538 | 0.643 | 0.538 | 0.419 |
| Gradient Boosted Tree | 1.000 | 0.976 | 0.538 | 0.667 | 0.538 | 0.558 |
| Random Forest | 0.923 | 0.929 | 0.692 | 0.643 | 0.692 | 0.581 |
| Multi-Layer Perceptron | 0.923 | 0.690 | 0.538 | 0.619 | 0.692 | 0.674 |
| LibLINEAR | 0.846 | 0.786 | 0.462 | 0.548 | 0.692 | 0.605 |
| ADABoostM1 | 1.000 | 0.976 | 0.538 | 0.524 | 0.692 | 0.581 |
| K-Nearest Neighbor 3 | 0.846 | 0.667 | 0.615 | 0.667 | 0.615 | 0.605 |
| K-Nearest Neighbor 5 | 0.846 | 0.690 | 0.538 | 0.571 | 0.769 | 0.628 |
| K-Nearest Neighbor 7 | 0.846 | 0.690 | 0.538 | 0.595 | 0.692 | 0.651 |
| Model (Outcome, Cotugno, Bagging) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.929 | 0.905 | 0.714 | 0.619 | 0.533 | 0.581 |
| Naïve Bayes | 0.786 | 0.667 | 0.500 | 0.476 | 0.533 | 0.581 |
| Gradient Boosted Tree | 0.857 | 0.857 | 0.500 | 0.548 | 0.533 | 0.605 |
| Random Forest | 0.643 | 0.667 | 0.500 | 0.476 | 0.467 | 0.581 |
| Multi-Layer Perceptron | 0.714 | 0.786 | 0.571 | 0.619 | 0.333 | 0.488 |
| LibLINEAR | 0.786 | 0.667 | 0.571 | 0.548 | 0.667 | 0.535 |
| ADABoostM1 | 0.857 | 0.857 | 0.429 | 0.500 | 0.600 | 0.581 |
| K-Nearest Neighbor 3 | 0.571 | 0.643 | 0.500 | 0.405 | 0.600 | 0.558 |
| K-Nearest Neighbor 5 | 0.714 | 0.690 | 0.643 | 0.548 | 0.667 | 0.535 |
| K-Nearest Neighbor 7 | 0.643 | 0.643 | 0.643 | 0.500 | 0.467 | 0.581 |
| Model (Days Range, Complete, Standard) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.182 | 0.301 | 0.364 | 0.233 | 0.167 | 0.143 |
| Naïve Bayes | 0.227 | 0.219 | 0.091 | 0.288 | 0.250 | 0.169 |
| Gradient Boosted Tree | 0.136 | 0.205 | 0.409 | 0.288 | 0.250 | 0.182 |
| Random Forest | 0.182 | 0.205 | 0.409 | 0.233 | 0.125 | 0.104 |
| Multi-Layer Perceptron | 0.136 | 0.151 | 0.364 | 0.288 | 0.250 | 0.117 |
| LibLINEAR | 0.318 | 0.233 | 0.318 | 0.247 | 0.250 | 0.130 |
| ADABoostM1 | 0.273 | 0.151 | 0.045 | 0.123 | 0.083 | 0.039 |
| K-Nearest Neighbor 3 | 0.182 | 0.164 | 0.273 | 0.288 | 0.083 | 0.182 |
| K-Nearest Neighbor 5 | 0.182 | 0.123 | 0.273 | 0.233 | 0.125 | 0.130 |
| K-Nearest Neighbor 7 | 0.227 | 0.164 | 0.182 | 0.192 | 0.083 | 0.117 |
| Model (Days Range, Complete, Bagging) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.292 | 0.205 | 0.792 | 0.781 | 0.708 | 0.870 |
| Naïve Bayes | 0.125 | 0.151 | 0.625 | 0.507 | 0.375 | 0.364 |
| Gradient Boosted Tree | 0.208 | 0.288 | 0.583 | 0.753 | 0.583 | 0.675 |
| Random Forest | 0.125 | 0.137 | 0.375 | 0.384 | 0.375 | 0.364 |
| Multi-Layer Perceptron | 0.208 | 0.123 | 0.750 | 0.658 | 0.375 | 0.455 |
| LibLINEAR | 0.208 | 0.205 | 0.500 | 0.507 | 0.250 | 0.286 |
| ADABoostM1 | 0.083 | 0.082 | 0.500 | 0.315 | 0.500 | 0.403 |
| K-Nearest Neighbor 3 | 0.292 | 0.137 | 0.250 | 0.342 | 0.250 | 0.260 |
| K-Nearest Neighbor 5 | 0.292 | 0.178 | 0.375 | 0.301 | 0.125 | 0.234 |
| K-Nearest Neighbor 7 | 0.167 | 0.164 | 0.292 | 0.329 | 0.208 | 0.247 |
| Model (Days Range, Vanvitelli, Standard) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.444 | 0.333 | 0.444 | 0.300 | 0.400 | 0.212 |
| Naïve Bayes | 0.000 | 0.267 | 0.444 | 0.267 | 0.300 | 0.273 |
| Gradient Boosted Tree | 0.333 | 0.267 | 0.444 | 0.267 | 0.400 | 0.273 |
| Random Forest | 0.222 | 0.333 | 0.333 | 0.200 | 0.500 | 0.242 |
| Multi-Layer Perceptron | 0.222 | 0.133 | 0.222 | 0.233 | 0.300 | 0.273 |
| LibLINEAR | 0.222 | 0.233 | 0.111 | 0.367 | 0.200 | 0.273 |
| ADABoostM1 | 0.222 | 0.100 | 0.111 | 0.100 | 0.000 | 0.030 |
| K-Nearest Neighbor 3 | 0.111 | 0.233 | 0.333 | 0.233 | 0.200 | 0.273 |
| K-Nearest Neighbor 5 | 0.222 | 0.133 | 0.222 | 0.133 | 0.000 | 0.152 |
| K-Nearest Neighbor 7 | 0.222 | 0.133 | 0.111 | 0.267 | 0.000 | 0.091 |
| Model (Days Range, Vanvitelli, Bagging) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.417 | 0.300 | 0.583 | 0.667 | 0.500 | 0.576 |
| Naïve Bayes | 0.167 | 0.133 | 0.583 | 0.367 | 0.250 | 0.303 |
| Gradient Boosted Tree | 0.250 | 0.100 | 0.500 | 0.467 | 0.250 | 0.394 |
| Random Forest | 0.250 | 0.100 | 0.500 | 0.367 | 0.250 | 0.303 |
| Multi-Layer Perceptron | 0.250 | 0.100 | 0.500 | 0.400 | 0.333 | 0.394 |
| LibLINEAR | 0.333 | 0.267 | 0.250 | 0.200 | 0.500 | 0.455 |
| ADABoostM1 | 0.333 | 0.233 | 0.417 | 0.500 | 0.333 | 0.394 |
| K-Nearest Neighbor 3 | 0.500 | 0.200 | 0.417 | 0.200 | 0.167 | 0.333 |
| K-Nearest Neighbor 5 | 0.333 | 0.133 | 0.333 | 0.367 | 0.250 | 0.273 |
| K-Nearest Neighbor 7 | 0.333 | 0.133 | 0.333 | 0.133 | 0.250 | 0.364 |
| Model (Days Range, Cotugno, Standard) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.385 | 0.190 | 0.385 | 0.167 | 0.231 | 0.186 |
| Naïve Bayes | 0.077 | 0.119 | 0.308 | 0.214 | 0.231 | 0.209 |
| Gradient Boosted Tree | 0.385 | 0.143 | 0.154 | 0.333 | 0.231 | 0.209 |
| Random Forest | 0.308 | 0.238 | 0.385 | 0.214 | 0.154 | 0.116 |
| Multi-Layer Perceptron | 0.077 | 0.095 | 0.308 | 0.286 | 0.231 | 0.209 |
| LibLINEAR | 0.154 | 0.143 | 0.308 | 0.262 | 0.154 | 0.116 |
| ADABoostM1 | 0.077 | 0.024 | 0.154 | 0.119 | 0.077 | 0.093 |
| K-Nearest Neighbor 3 | 0.000 | 0.048 | 0.231 | 0.214 | 0.154 | 0.256 |
| K-Nearest Neighbor 5 | 0.231 | 0.143 | 0.231 | 0.214 | 0.154 | 0.233 |
| K-Nearest Neighbor 7 | 0.231 | 0.095 | 0.308 | 0.143 | 0.077 | 0.093 |
| Model (Days Range, Cotugno, Bagging) | Tabular HO (80-20) | Tabular CV (10) | 2D CT HO (80-20) | 2D CT CV (10) | 3D CT HO (80-20) | 3D CT CV (10) |
|---|---|---|---|---|---|---|
| Decision Tree | 0.286 | 0.286 | 0.571 | 0.571 | 0.467 | 0.512 |
| Naïve Bayes | 0.429 | 0.262 | 0.500 | 0.286 | 0.333 | 0.465 |
| Gradient Boosted Tree | 0.571 | 0.381 | 0.286 | 0.476 | 0.333 | 0.372 |
| Random Forest | 0.286 | 0.310 | 0.286 | 0.333 | 0.333 | 0.349 |
| Multi-Layer Perceptron | 0.286 | 0.214 | 0.286 | 0.500 | 0.400 | 0.465 |
| LibLINEAR | 0.214 | 0.190 | 0.214 | 0.262 | 0.333 | 0.326 |
| ADABoostM1 | 0.286 | 0.214 | 0.357 | 0.286 | 0.333 | 0.442 |
| K-Nearest Neighbor 3 | 0.357 | 0.310 | 0.286 | 0.357 | 0.467 | 0.419 |
| K-Nearest Neighbor 5 | 0.357 | 0.357 | 0.357 | 0.429 | 0.267 | 0.349 |
| K-Nearest Neighbor 7 | 0.357 | 0.405 | 0.357 | 0.310 | 0.267 | 0.233 |
| Split Approach | Features Type | FS Model | FS Approach | Selected Features | Best Model with FS (MAE) | Best Model w/o FS (MAE) |
|---|---|---|---|---|---|---|
| HO (80-20) | Tabular | Linear Reg. | BFE | Ischemic heart dis., COPD, COVID therapy | Reg. Tree (7.528) | SMO (20.357) |
| CV (10) | COPD, Age | SMO (18.648) | SMO (20.373) | |||
| HO (80-20) | Tabular | Linear Reg. | FFS | Gender, Ischemic heart dis., COPD, COVID therapy | Linear Reg. (8.073) | SMO (20.357) |
| CV (10) | COPD, Age | SMO (18.229) | SMO (20.373) | |||
| HO (80-20) | Tabular | M5P | BFE | Ischemic heart dis., COVID therapy | M5P (7.576) | SMO (20.357) |
| CV (10) | COPD, White blood cells, Gender | SMO (18.567) | SMO (20.373) | |||
| HO (80-20) | Tabular | M5P | FFS | COPD, COVID therapy, Ventilation | KNN 7 (7.674) | SMO (20.357) |
| CV (10) | Neutrophils, Gender | SMO (17.717) | SMO (20.373) | |||
| HO (80-20) | 2D CT | Linear Reg. | BFE | 6 features | Linear Reg. (3.102) | SMO (4.078) |
| CV (10) | 7 features | SMO (5.067) | SMO (5.11) | |||
| HO (80-20) | 2D CT | Linear Reg. | FFS | 9 features | Linear Reg. (3.336) | SMO (4.078) |
| CV (10) | 14 features | SMO (5.106) | SMO (5.11) | |||
| HO (80-20) | 2D CT | M5P | BFE | 6 features | SMO (4.025) | SMO (4.078) |
| CV (10) | 3 features | SMO (5.111) | SMO (5.11) | |||
| HO (80-20) | 2D CT | M5P | FFS | 1 feature | SMO (4.0) | SMO (4.078) |
| CV (10) | 1 feature | SMO (5.001) | SMO (5.11) | |||
| HO (80-20) | 3D CT | Linear Reg. | BFE | 4 features | SMO (12.602) | SMO (12.686) |
| CV (10) | 4 features | SMO (16.796) | SMO (16.898) | |||
| HO (80-20) | 3D CT | Linear Reg. | FFS | 8 features | SMO (12.712) | SMO (12.686) |
| CV (10) | 8 features | SMO (16.6) | SMO (16.898) | |||
| HO (80-20) | 3D CT | M5P | BFE | 3 features | SMO (12.516) | SMO (12.686) |
| CV (10) | 3 features | SMO (17.599) | SMO (16.898) | |||
| HO (80-20) | 3D CT | M5P | FFS | 3 features | SMO (12.472) | SMO (12.686) |
| CV (10) | 3 features | MLP (9.526) | SMO (16.898) |
| Split Approach | Features Type | FS Model | FS Approach | Selected Features | Best Model with FS (MAE) | Best Model w/o FS (MAE) |
|---|---|---|---|---|---|---|
| HO (80-20) | Tabular | Linear Reg. | BFE | Sex, Vent., Dementia, Lymph., GOT or GPT, Neutrophils | Linear Reg. (5.319) | GBTree (36.856) |
| CV (10) | Fever, Cough, Dementia, COPD, Active cancer last 5 years, Chronic liver disease, Neutrophils, Lymphocytes, Ageusia/Anosmia, Type 2 diabetes, p/F | MLP (27.485) | GBTree (46.564) | |||
| HO (80-20) | Tabular | Linear Reg. | FFS | Ventilation, Age, Fever, Dyspnea, Fibrinogen, LUS score, Neutrophils | Linear Reg. (4.334) | GBTree (36.856) |
| CV (10) | 21 features | M5P (40.781) | GBTree (46.564) | |||
| HO (80-20) | Tabular | M5P | BFE | HB, Platelets, Fibrinogen, LUS score, Cough, Art. hypert. | Reg. Tree (6.833) | GBTree (36.856) |
| CV (10) | Cough, Dyspnea, Dementia, GOT or GPT, Blood glucose, INR, Ventilation | M5P (31.259) | GBTree (46.564) | |||
| HO (80-20) | Tabular | M5P | FFS | COPD, Atrial fibril., HB, Sodium, LUS score, Neutrophils | Reg. Tree (6.667) | GBTree (36.856) |
| CV (10) | Fever, Cough, Lymphocytes, Blood glucose, Fibrinogen, Ventilation | M5P (26.589) | GBTree (46.564) | |||
| HO (80-20) | 2D CT | Linear Reg. | BFE | 6 features | Linear Reg. (4.866) | MLP (6.639) |
| CV (10) | 6 features | MLP (4.511) | MLP (3.731) | |||
| HO (80-20) | 2D CT | Linear Reg. | FFS | 2 features | M5P (7.281) | MLP (6.639) |
| CV (10) | 2 features | MLP (4.998) | MLP (3.731) | |||
| HO (80-20) | 2D CT | M5P | BFE | 1 feature | GBTree (6.09) | MLP (6.639) |
| CV (10) | 1 feature | MLP (1.43) | MLP (3.731) | |||
| HO (80-20) | 2D CT | M5P | FFS | 1 feature | GBTree (6.09) | MLP (6.639) |
| CV (10) | 1 feature | MLP (4.148) | MLP (3.731) | |||
| HO (80-20) | 3D CT | Linear Reg. | BFE | 5 features | Linear Reg. (28.287) | KNN3 (36.09) |
| CV (10) | 5 features | SMO (23.993) | SMO (28.749) | |||
| HO (80-20) | 3D CT | Linear Reg. | FFS | 6 features | Linear Reg. (34.16) | KNN3 (36.09) |
| CV (10) | 6 features | MLP (14.611) | SMO (28.749) | |||
| HO (80-20) | 3D CT | M5P | BFE | 4 features | GBTree (34.113) | KNN3 (36.09) |
| CV (10) | 4 features | MLP (18.1) | SMO (28.749) | |||
| HO (80-20) | 3D CT | M5P | FFS | 1 feature | GBTree (33.734) | KNN3 (36.09) |
| CV (10) | 1 feature | SMO (26.879) | SMO (28.749) |
| Split Approach | Features Type | FS Model | FS Approach | Selected Features | Best Model with FS (MAE) | Best Model w/o FS (MAE) |
|---|---|---|---|---|---|---|
| HO (80-20) | Tabular | Linear Reg. | BFE | Ischemic heart dis., Age, TC score, PF, Compl., MB, ICU, I dose, NEFRO, NEU, LINF, % (#1), n/l | Linear Reg. (3.781) | Simple Reg. (6.951) |
| CV (10) | Age, Gender, Score TC, Compl. type, TEP, ICU, CS, III dose, CARDIO, THYROID, ictus | Linear Reg. (8.236) | GBTree (8.421) | |||
| HO (80-20) | Tabular | Linear Reg. | FFS | TC score, CS, IL6, %, LINF, % (#1), Neutr. | Linear Reg. (2.25) | Simple Reg. (6.951) |
| CV (10) | Age, Compl. type, TEP, CARDIO, PNEUMO, LINF, % (#1), Ischemic heart dis. | MLP (7.779) | GBTree (8.421) | |||
| HO (80-20) | Tabular | M5P | BFE | Age, TC score, Compl., Max vent., CS, I dose, II dose, DM, IL6, NEU, % (#1), VES, DD | KNN 5 (5.225) | Simple Reg. (6.951) |
| CV (10) | Gender, PF, Compl. type, Max ventilation, PENTAGLOBIN, CARDIO, IL6, %, VES, PCR, COPD, White blood cells, Neutrophils | MLP (7.307) | GBTree (8.421) | |||
| HO (80-20) | Tabular | M5P | FFS | COVID therapy, CS, IL6, WBC, %, % (#1), n/l, ictus | Linear Reg. (3.772) | Simple Reg. (6.951) |
| CV (10) | Age, TEP, PNX, PENTAGLOBIN, PMD, CS, Cardio, PNEUMO, THYROID, NEU, VES, COPD, White blood cells, Neutrophils | Simple Reg. (10.274) | GBTree (8.421) | |||
| HO (80-20) | 2D CT | Linear Reg. | BFE | 1 feature | Linear Reg. (2.659) | Simple Reg. (2.636) |
| CV (10) | 1 feature | MLP (4.701) | MLP (4.633) | |||
| HO (80-20) | 2D CT | Linear Reg. | FFS | 3 features | Linear Reg. (2.455) | Simple Reg. (2.636) |
| CV (10) | 3 features | Linear Reg. (4.845) | MLP (4.633) | |||
| HO (80-20) | 2D CT | M5P | BFE | 1 feature | M5P (2.556) | Simple Reg. (2.636) |
| CV (10) | 1 feature | SMO (4.896) | MLP (4.633) | |||
| HO (80-20) | 2D CT | M5P | FFS | 1 feature | M5P (2.556) | Simple Reg. (2.636) |
| CV (10) | 1 feature | MLP (4.26) | MLP (4.633) | |||
| HO (80-20) | 3D CT | Linear Reg. | BFE | 4 features | Linear Reg. (5.997) | SMO (7.666) |
| CV (10) | 4 features | GBTree (10.479) | GBTree (11.555) | |||
| HO (80-20) | 3D CT | Linear Reg. | FFS | 6 features | GBTree (6.078) | SMO (7.666) |
| CV (10) | 6 features | SMO (11.463) | GBTree (11.555) | |||
| HO (80-20) | 3D CT | M5P | BFE | 5 features | M5P (7.391) | SMO (7.666) |
| CV (10) | 3 features | MLP (6.069) | GBTree (11.555) | |||
| HO (80-20) | 3D CT | M5P | FFS | 4 features | GBTree (5.621) | SMO (7.666) |
| CV (10) | 3 features | MLP (2.947) | GBTree (11.555) |
| Work | Prediction Tasks | Disease | Data Type | Multiple Datasets | Missing Values Handling | Dataset Balancing |
|---|---|---|---|---|---|---|
| Proposed work | Outcome (Classification) Days Range (Classification) LOS (Regression) | Pneumonia COVID-19 | Clinical data CT scans CT volumes | Yes | Yes | SMOTE |
| Saadatmand et al. [10] | Outcome (Classification) Days Range (Classification) | COVID-19 | Clinical data | Yes | Yes | ROSE |
| Khajehali et al. [11] | Days Range (Classification) | Pneumonia | Clinical data | No | Yes | No |
| Mekhaldi et al. [4] | LOS (Regression) | Generic | Clinical data | No | No | SMOTE |
| Task | Model | Data Type | Metric | Value |
|---|---|---|---|---|
| Outcome (Classification) | Gradient Boosted Tree (Our) | CT volumes | Accuracy | 0.875 |
| XGBoost Tree Ensemble [10] | Clinical data | Accuracy | 0.765 | |
| Days Range (Classification) | 4-Bagging Ensemble of Decision Trees (Our) | CT volumes | Accuracy | 0.870 |
| Bagged CART [10] | Clinical data | Accuracy | 0.294 | |
| Voting Classifier [11] | Clinical data | Accuracy | 0.235 | |
| LOS (Regression) | BFE + Linear Regression (Our) | CT scans | MAE | 3.102 |
| Multiple Linear Regression [4] | Clinical data | MAE | 24.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Annunziata, A.; Cappabianca, S.; Capuozzo, S.; Coppola, N.; Di Somma, C.; Docimo, L.; Fiorentino, G.; Gravina, M.; Marassi, L.; Marrone, S.; et al. A Multimodal Machine Learning Model in Pneumonia Patients Hospital Length of Stay Prediction. Big Data Cogn. Comput. 2024, 8, 178. https://doi.org/10.3390/bdcc8120178
Annunziata A, Cappabianca S, Capuozzo S, Coppola N, Di Somma C, Docimo L, Fiorentino G, Gravina M, Marassi L, Marrone S, et al. A Multimodal Machine Learning Model in Pneumonia Patients Hospital Length of Stay Prediction. Big Data and Cognitive Computing. 2024; 8(12):178. https://doi.org/10.3390/bdcc8120178
Chicago/Turabian StyleAnnunziata, Anna, Salvatore Cappabianca, Salvatore Capuozzo, Nicola Coppola, Camilla Di Somma, Ludovico Docimo, Giuseppe Fiorentino, Michela Gravina, Lidia Marassi, Stefano Marrone, and et al. 2024. "A Multimodal Machine Learning Model in Pneumonia Patients Hospital Length of Stay Prediction" Big Data and Cognitive Computing 8, no. 12: 178. https://doi.org/10.3390/bdcc8120178
APA StyleAnnunziata, A., Cappabianca, S., Capuozzo, S., Coppola, N., Di Somma, C., Docimo, L., Fiorentino, G., Gravina, M., Marassi, L., Marrone, S., Parmeggiani, D., Polistina, G. E., Reginelli, A., Sagnelli, C., & Sansone, C. (2024). A Multimodal Machine Learning Model in Pneumonia Patients Hospital Length of Stay Prediction. Big Data and Cognitive Computing, 8(12), 178. https://doi.org/10.3390/bdcc8120178