

Data Sorting Influence on Short Text Manual Labeling Quality for Hierarchical Classification



Abstract
1. Introduction
2. Relevant Research
3. Materials and Methods
3.1. Types of Data Labeling
3.2. Hierarchical Classification Types
3.2.1. Multiclass Classification
3.2.2. Multilabel Classification
3.2.3. Multi-Tag Classification
3.3. Dataset
3.4. Metrics
- 0 is no agreement (or agreement that you would expect to find by chance),
- 1 is a perfect agreement.
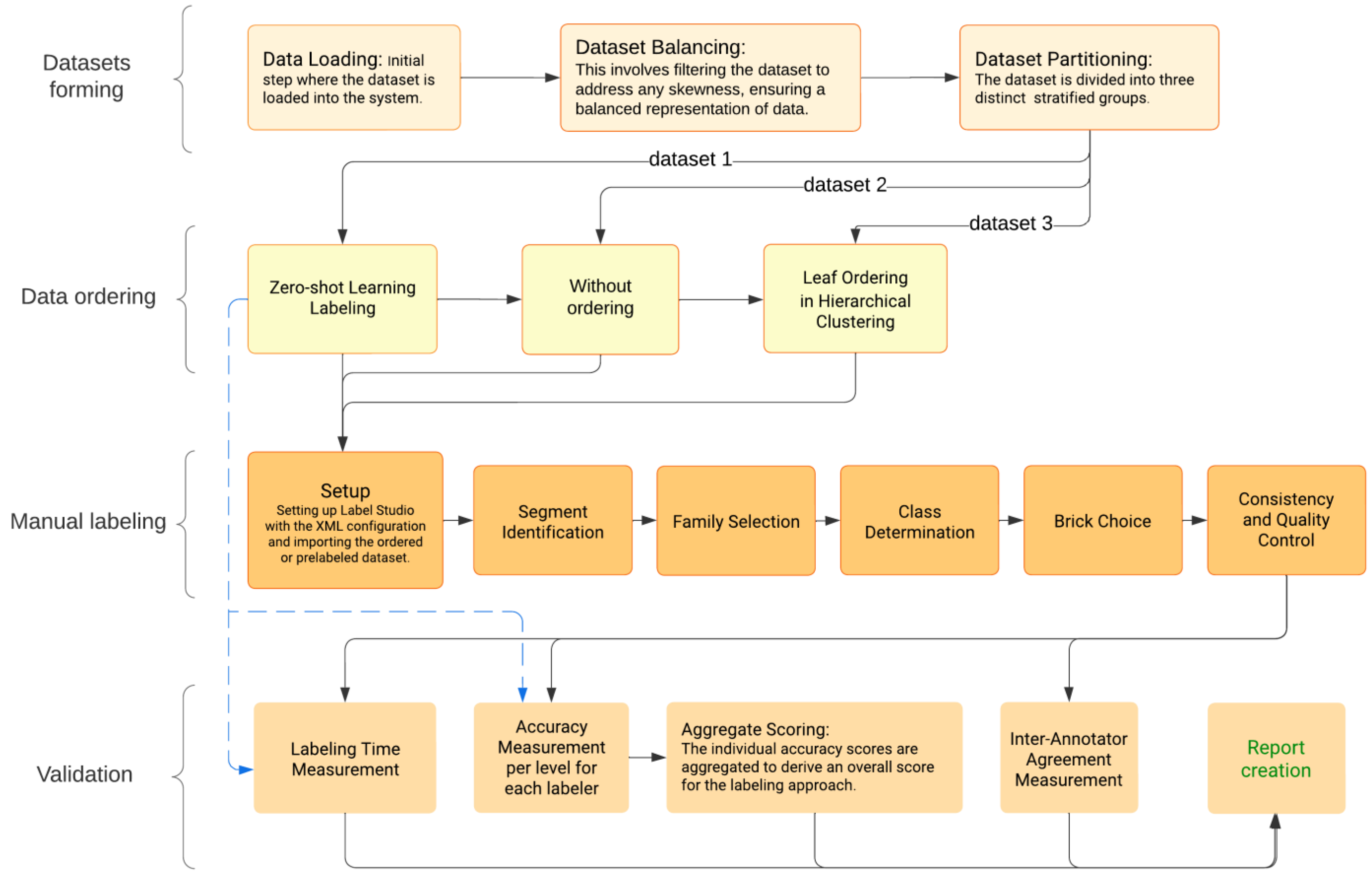
4. Methodology
4.1. Zero-Shot Learning for Automated Data Labeling
4.2. Ordering Data before Manual Labeling
4.3. Manual Labeling Process
- Set up Label Studio with the XML configuration adjusted to match the GPC standard taxonomy (Segment, Family, Class, and Brick).
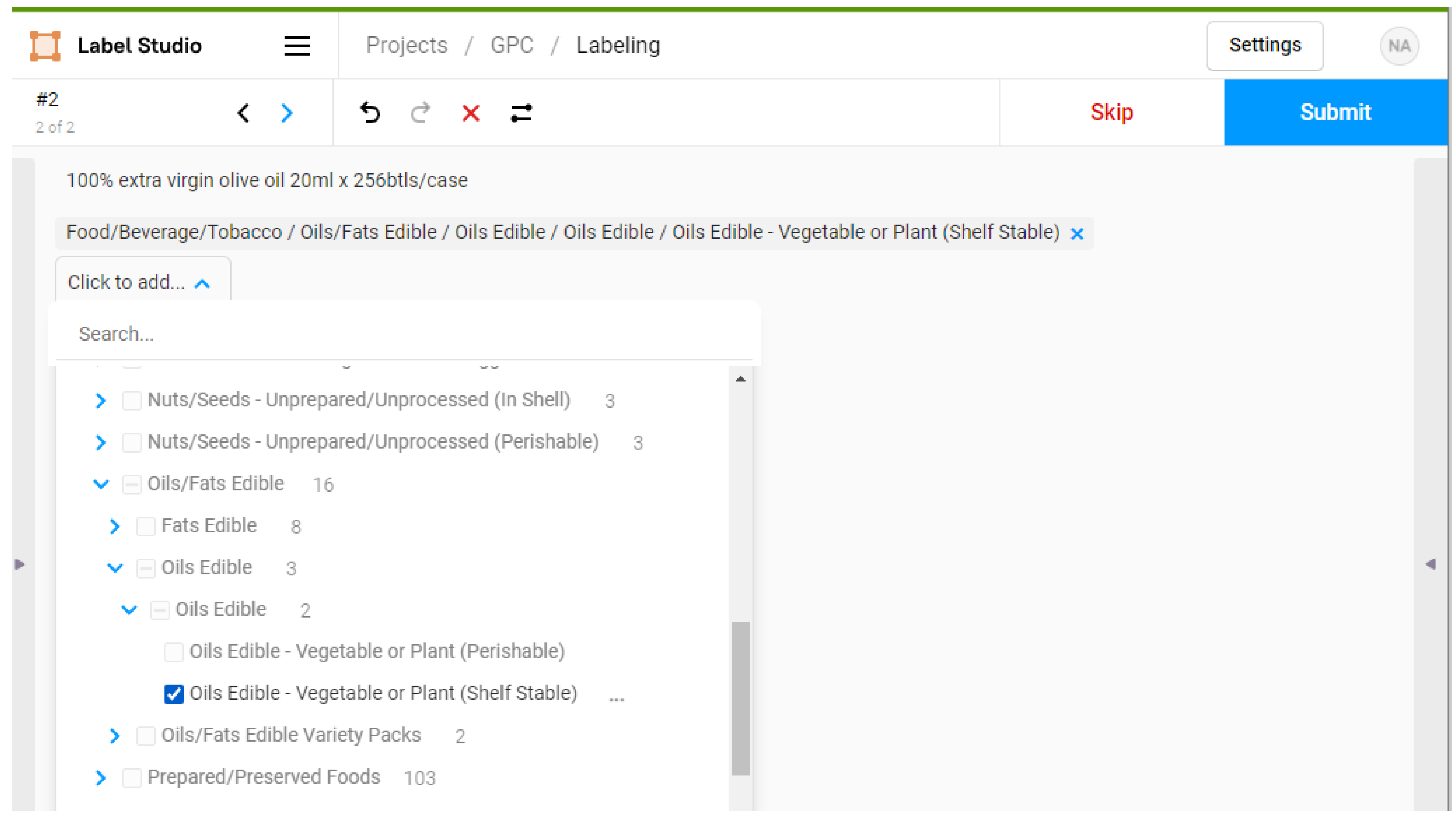
- Import the dataset (ordered or not), which consists of text samples that require annotation (Figure 1).
- When labeling item descriptions based on the GPC standard, following the hierarchical structure of Segments, Families, Classes, and Bricks is essential. Here is a detailed step-by-step guide on how to label item descriptions using the GPC (Figure 2):


- 3.1.
- Understand the item description: Carefully read the item description and note any critical information, such as ingredients, materials, intended use, or other relevant attributes. This information will help you determine the most suitable GPC categories.
- 3.2.
- Identify the Segment: Start by selecting the Segment (top-level category) that best describes the item. Segments are broad categories that cover a wide range of products. Examples of Segments include Food and Beverage, Cleaning Products, and Self Care. Choose the Segment that is most relevant to the item description.
- 3.3.
- Select the Family: Within the Segment, identify the Family (subcategory) to which the item belongs. Families are more specific than Segments and provide a narrower scope of categorization. For example, within the Food and Beverage Segment, you may have Families like Dairy, Bakery, and Processed Meat Products. Choose the Family that best matches the item description.
- 3.4.
- Determine the Class: Identify the Class (sub-subcategory) under which the item falls within the selected Family. Classes further subdivide Families, providing a more refined categorization. For example, you may have Cheese, Milk, and Yogurt Classes within the Dairy Products Family. Select the Class that corresponds most closely to the item description.
- 3.5.
- Choose the Brick: Finally, within the chosen Class, select the Brick (finest level of categorization) that best describes the item. Bricks represent the most specific and granular level of the GPC taxonomy. For instance, within the Cheese Class, you may have Bricks like Blue Cheese, Cheddar Cheese, and Mozzarella Cheese. Choose the Brick that accurately represents the item based on the description.
- 3.6.
- Maintain consistency: Ensure you follow the GPC structure and guidelines consistently throughout the labeling process. Each item should be labeled with one Brick. In cases where multiple Bricks may seem applicable, choose the one that best represents the item’s primary characteristics or intended use.
- 3.7.
- Quality control: Regularly review your labeling progress and check for any inconsistencies or errors. If necessary, correct any mistakes and ensure that the labeled dataset is accurate and consistent with the GPC standard.
- 3.8.
- When encountering unknown items or items that do not seem to fit into the existing GPC taxonomy, follow these steps to handle them:
- Re-examine the item description: Carefully reread the item description and ensure you have not missed any crucial information that could help identify the appropriate category. Sometimes, important details might be overlooked in the initial review.
- Research the item: If the item is unfamiliar, conduct some research in order to gain a better understanding of the product. This may include searching the internet, referring to product catalogs, or consulting with experts. The additional information gathered can help determine the most suitable category.
- Flag the item: If you are unable to determine an appropriate category even after researching and considering related categories, flag the item for further review. This can be completed using a specific label, such as “Unknown” or “Requires Review”. These flagged items can then be revisited and discussed with your team, supervisor, or subject matter expert to determine the best course of action.
5. Results and Discussion
5.1. Experiment 1: Zero-Shot Learning
5.2. Experiment 2: Manual Labeling
5.3. Experiment 3: Manual Correction
5.4. Experiment 4: Manual Labeling with Ordered Data
- 4.
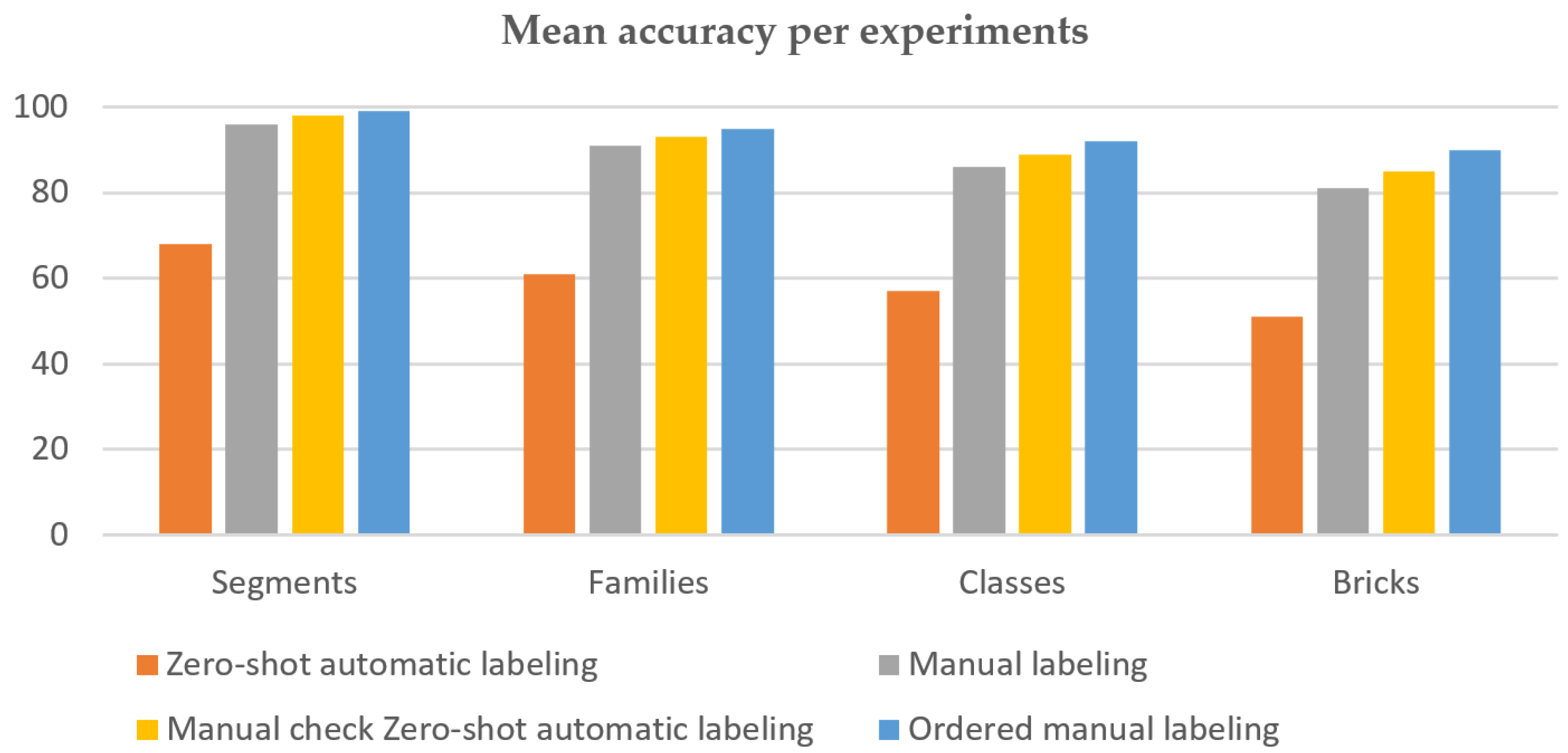
- The zero-shot automatic labeling approach was the least accurate, but was also the fastest. Manual labeling significantly improved the accuracy across all GPC hierarchy levels (Table 3). The manual checking of zero-shot automatic labeling further increased the accuracy, suggesting that combining automatic and manual methods can balance speed and accuracy (Figure 3).
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kasperiuniene, J.; Briediene, M.; Zydziunaite, V. Automatic Content Analysis of Social Media Short Texts: Scoping Review of Methods and Tools. In Computer Supported Qualitative Research; Costa, A.P., Reis, L.P., Moreira, A., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; Volume 1068, pp. 89–101. ISBN 978-3-030-31786-7. [Google Scholar]
- Maddigan, P.; Susnjak, T. Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models. IEEE Access 2023, 11, 45181–45193. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, T.; Chen, H.; Yang, Q.; He, X. Automatic Annotation of Text Classification Data Set in Specific Field Using Named Entity Recognition. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; IEEE: Xi’an, China, 2019; pp. 1403–1407. [Google Scholar]
- Doroshenko, A.; Tkachenko, R. Classification of Imbalanced Classes Using the Committee of Neural Networks. In Proceedings of the 2018 IEEE 13th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 11–14 September 2018; IEEE: Lviv, Ukraine, 2018; pp. 400–403. [Google Scholar]
- Chang, C.-M.; Mishra, S.D.; Igarashi, T. A Hierarchical Task Assignment for Manual Image Labeling. In Proceedings of the 2019 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Memphis, TN, USA, 14–18 October 2019; IEEE: Memphis, TN, USA, 2019; pp. 139–143. [Google Scholar]
- Savchuk, D.; Doroshenko, A. Investigation of Machine Learning Classification Methods Effectiveness. In Proceedings of the 2021 IEEE 16th International Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 22–25 September 2021; IEEE: Lviv, Ukraine, 2021; pp. 33–37. [Google Scholar]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Comprehensive Comparative Study of Multi-Label Classification Methods. Expert Syst. Appl. 2022, 203, 117215. [Google Scholar] [CrossRef]
- Nava-Muñoz, S.; Graff, M.; Escalante, H.J. Analysis of Systems’ Performance in Natural Language Processing Competitions. arXiv 2024, arXiv:2403.04693. [Google Scholar] [CrossRef]
- Ferrandin, M.; Cerri, R. Multi-Label Classification via Closed Frequent Labelsets and Label Taxonomies. Soft Comput. 2023, 27, 8627–8660. [Google Scholar] [CrossRef]
- Narushynska, O.; Teslyuk, V.; Vovchuk, B.-D. Search Model of Customer’s Optimal Route in the Store Based on Algorithm of Machine Learning A*. In Proceedings of the 2017 12th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 5–8 September 2017; IEEE: Lviv, Ukraine, 2017; pp. 284–287. [Google Scholar]
- Chang, C.; Zhang, J.; Ge, J.; Zhang, Z.; Wei, J.; Li, L. Interaction-Based Driving Scenario Classification and Labeling. arXiv 2024, arXiv:2402.07720. [Google Scholar] [CrossRef]
- Xu, X.; Li, B.; Shen, Y.; Luo, B.; Zhang, C.; Hao, F. Short Text Classification Based on Hierarchical Heterogeneous Graph and LDA Fusion. Electronics 2023, 12, 2560. [Google Scholar] [CrossRef]
- Tang, H.; Kamei, S.; Morimoto, Y. Data Augmentation Methods for Enhancing Robustness in Text Classification Tasks. Algorithms 2023, 16, 59. [Google Scholar] [CrossRef]
- Omar, M.; Choi, S.; Nyang, D.; Mohaisen, D. Robust Natural Language Processing: Recent Advances, Challenges, and Future Directions. IEEE Access 2022, 10, 86038–86056. [Google Scholar] [CrossRef]
- Jin, R.; Du, J.; Huang, W.; Liu, W.; Luan, J.; Wang, B.; Xiong, D. A Comprehensive Evaluation of Quantization Strategies for Large Language Models. arXiv 2024, arXiv:2402.16775. [Google Scholar] [CrossRef]
- Peng, Z.; Abdollahi, B.; Xie, M.; Fang, Y. Multi-Label Classification of Short Texts with Label Correlated Recurrent Neural Networks. In Proceedings of the 2021 ACM SIGIR International Conference on Theory of Information Retrieval, Virtual Event, Canada, 11–15 July 2021; ACM: New York, NY, USA, 2021; pp. 119–122. [Google Scholar]
- Arzubov, M.; Narushynska, O.; Batyuk, A.; Cherkas, N. Concept of Server-Side Clusterization of Semi-Static Big Geodata for Web Maps. In Proceedings of the 2023 IEEE 18th International Conference on Computer Science and Information Technologies (CSIT), Lviv, Ukraine, 19–21 October 2023; IEEE: Lviv, Ukraine, 2023; pp. 1–4. [Google Scholar]
- Chen, M.; Ubul, K.; Xu, X.; Aysa, A.; Muhammat, M. Connecting Text Classification with Image Classification: A New Preprocessing Method for Implicit Sentiment Text Classification. Sensors 2022, 22, 1899. [Google Scholar] [CrossRef] [PubMed]
- Bercaru, G.; Truică, C.-O.; Chiru, C.-G.; Rebedea, T. Improving Intent Classification Using Unlabeled Data from Large Corpora. Mathematics 2023, 11, 769. [Google Scholar] [CrossRef]
- Gilardi, F.; Alizadeh, M.; Kubli, M. ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks. arXiv 2023, arXiv:2303.15056. [Google Scholar] [CrossRef]
- Qiu, Y.; Jin, Y. ChatGPT and Finetuned BERT: A Comparative Study for Developing Intelligent Design Support Systems. Intell. Syst. Appl. 2024, 21, 200308. [Google Scholar] [CrossRef]
- Shah, A.; Chava, S. Zero Is Not Hero Yet: Benchmarking Zero-Shot Performance of LLMs for Financial Tasks. arXiv 2023, arXiv:2305.16633. [Google Scholar] [CrossRef]
- Reiss, M.V. Testing the Reliability of ChatGPT for Text Annotation and Classification: A Cautionary Remark. arXiv 2023, arXiv:2304.11085. [Google Scholar] [CrossRef]
- Sambasivan, N.; Kapania, S.; Highfill, H.; Akrong, D.; Paritosh, P.K.; Aroyo, L.M. “Everyone Wants to Do the Model Work, Not the Data Work”: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Troxler, A.; Schelldorfer, J. Actuarial Applications of Natural Language Processing Using Transformers: Case Studies for Using Text Features in an Actuarial Context. arXiv 2022, arXiv:2206.02014. [Google Scholar] [CrossRef]
- Sun, D.Q.; Kotek, H.; Klein, C.; Gupta, M.; Li, W.; Williams, J.D. Improving Human-Labeled Data through Dynamic Automatic Conflict Resolution. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 3547–3557. [Google Scholar]
- Akay, H.; Kim, S.-G. Extracting Functional Requirements from Design Documentation Using Machine Learning. Procedia CIRP 2021, 100, 31–36. [Google Scholar] [CrossRef]
- Braylan, A.; Alonso, O.; Lease, M. Measuring Annotator Agreement Generally across Complex Structured, Multi-Object, and Free-Text Annotation Tasks. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1720–1730. [Google Scholar]
- Basile, V.; Fell, M.; Fornaciari, T.; Hovy, D.; Paun, S.; Plank, B.; Poesio, M.; Uma, A. We Need to Consider Disagreement in Evaluation. In Proceedings of the 1st Workshop on Benchmarking: Past, Present and Future; Church, K., Liberman, M., Kordoni, V., Eds.; Association for Computational Linguistics: Melbourne, Australia, 2021; pp. 15–21. [Google Scholar]
- Zhu, Y.; Zamani, H. ICXML: An In-Context Learning Framework for Zero-Shot Extreme Multi-Label Classification. arXiv 2023, arXiv:2311.09649. [Google Scholar] [CrossRef]
- Doshi, I.; Sajjalla, S.; Choudhari, J.; Bhatt, R.; Dasgupta, A. Efficient Hierarchical Clustering for Classification and Anomaly Detection. arXiv 2020, arXiv:2008.10828. [Google Scholar] [CrossRef]
- Kasundra, J.; Schulz, C.; Mirsafian, M.; Skylaki, S. A Framework for Monitoring and Retraining Language Models in Real-World Applications. arXiv 2023, arXiv:2311.09930. [Google Scholar] [CrossRef]
- Xu, H.; Chen, M.; Huang, L.; Vucetic, S.; Yin, W. X-Shot: A Unified System to Handle Frequent, Few-Shot and Zero-Shot Learning Simultaneously in Classification. arXiv 2024, arXiv:2403.03863. [Google Scholar] [CrossRef]
- Global Product Classification (GPC). Available online: https://www.gs1.org/standards/gpc (accessed on 7 December 2023).
- Directionsforme. Available online: https://www.directionsforme.org/ (accessed on 7 December 2023).
- Martorana, M.; Kuhn, T.; Stork, L.; van Ossenbruggen, J. Text Classification of Column Headers with a Controlled Vocabulary: Leveraging LLMs for Metadata Enrichment. arXiv 2024, arXiv:2403.00884. [Google Scholar] [CrossRef]
- Miranda, L.J.V. Developing a Named Entity Recognition Dataset for Tagalog. arXiv 2023, arXiv:2311.07161. [Google Scholar] [CrossRef]
- Lukasik, M.; Narasimhan, H.; Menon, A.K.; Yu, F.; Kumar, S. Metric-Aware LLM Inference. arXiv 2024, arXiv:2403.04182. [Google Scholar] [CrossRef]
- Doroshenko, A. Application of global optimization methods to increase the accuracy of classification in the data mining tasks. In Computer Modeling and Intelligent Systems. Proceedings of the 2nd International Conference CMIS-2019, Vol-2353: Main Conference, Zaporizhzhia, Ukraine, 15–19 April 2019; Luengo, D., Subbotin, S., Eds.; 2019; pp. 98–109. Available online: http://ceur-ws.org/Vol-2353/ (accessed on 7 December 2023).
- Alhoshan, W.; Ferrari, A.; Zhao, L. Zero-Shot Learning for Requirements Classification: An Exploratory Study. Inf. Softw. Technol. 2023, 159, 107202. [Google Scholar] [CrossRef]
- Rondinelli, A.; Bongiovanni, L.; Basile, V. Zero-Shot Topic Labeling for Hazard Classification. Information 2022, 13, 444. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Zhang, H.; Zhu, B.; Chen, S.; Zhang, D. OneLabeler: A Flexible System for Building Data Labeling Tools. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 27 April 2022; ACM: New Orleans, LA, USA, 2022; pp. 1–22. [Google Scholar]
- Zhao, X.; Ouyang, S.; Yu, Z.; Wu, M.; Li, L. Pre-Trained Language Models Can Be Fully Zero-Shot Learners. arXiv 2022, arXiv:2212.06950. [Google Scholar] [CrossRef]
- Yadav, S.; Kaushik, A.; McDaid, K. Leveraging Weakly Annotated Data for Hate Speech Detection in Code-Mixed Hinglish: A Feasibility-Driven Transfer Learning Approach with Large Language Models. arXiv 2024, arXiv:2403.02121. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Meng, Y.; Huang, J.; Zhang, Y.; Han, J. Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 462–477. [Google Scholar]
- Srivastava, S.; Labutov, I.; Mitchell, T. Zero-Shot Learning of Classifiers from Natural Language Quantification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 306–316. [Google Scholar]
- Vidra, N.; Clifford, T.; Jijo, K.; Chung, E.; Zhang, L. Improving Classification Performance With Human Feedback: Label a Few, We Label the Rest. arXiv 2024, arXiv:2401.09555. [Google Scholar] [CrossRef]
- Bar-Joseph, Z.; Gifford, D.K.; Jaakkola, T.S. Fast Optimal Leaf Ordering for Hierarchical Clustering. Bioinformatics 2001, 17, S22–S29. [Google Scholar] [CrossRef] [PubMed]
- Novoselova, N.; Wang, J.; Klawonn, F. Optimized Leaf Ordering with Class Labels for Hierarchical Clustering. J. Bioinform. Comput. Biol. 2015, 13, 1550012. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Brick Name | Product Description |
|---|---|
| Air Fresheners/Deodorizers (Non Powered) | Air Wick Aqua Mist Tropical Bliss Air Refresher |
| Air Fresheners/Deodorizers (Non Powered) | Air Wick Fresh Matic Spring Blossoms Automatic Ultra Spray Refill |
| Air Fresheners/Deodorizers (Non Powered) | airBoss Air Freshener Rainfresh |
| Air Fresheners/Deodorizers (Non Powered) | airBoss Closet Odor Eliminator |
| Air Fresheners/Deodorizers (Non Powered) | Aura Cacia Aromatherapy Diffuser Refill Pads |
| Alcoholic Pre-mixed Drinks | Mike’s Harder Black Cherry Lemonade |
| Alcoholic Pre-mixed Drinks | Mike’s Harder Black Cherry Lemonade—4 CT |
| Alcoholic Pre-mixed Drinks | Mr & Mrs T Non-Alcoholic Lemon Tom Collins Mix |
| Alcoholic Pre-mixed Drinks | Mr. & Mrs. T Non-Alcoholic Pina Colada Mix |
| Alcoholic Pre-mixed Drinks | Mr. & Mrs. T Non-Alcoholic Strawberry Daiquiri-Margarita Mix |
| Apple/Pear Alcoholic Beverage—Sparkling | Crispin Honey Crisp Hard Cider |
| Apple/Pear Alcoholic Beverage—Sparkling | Crispin Honey Crisp Hard Cider |
| Apple/Pear Alcoholic Beverage—Sparkling | Hornsby’s Hard Cider Amber Draft—6 PK |
| Bakeware/Ovenware/Grillware (Non Disposable) | Pyrex Vintage Charm Bowl Set Birds Of A Feather—3 CT |
| Bakeware/Ovenware/Grillware (Non Disposable) | Pyrex Vintage Charm Bowl Set Rise N’ Shine—3 CT |
| Bakeware/Ovenware/Grillware (Non Disposable) | Rachael Ray 2 Piece Set Ceramic Bakeware Oval Bakers 1 ea BOX |
| Bakeware/Ovenware/Grillware (Non Disposable) | Rachael Ray Baker 1 ea BOX |
| Bakeware/Ovenware/Grillware (Non Disposable) | Rachael Ray Bakerware 1 ea CARD |
| Bakeware/Ovenware/Grillware (Non Disposable) | Rachael Ray Bakeware 1 ea BOX |
| Labeling Approach | Labeling Time (per 1000 Samples), mins |
|---|---|
| Zero-shot automatic labeling | 37 |
| Manual check zero-shot automatic labeling | 600 |
| Manual labeling | 800 |
| Ordered manual labeling | 760 |
| Approach | Mean Accuracy (%) | |||
|---|---|---|---|---|
| Segments | Families | Classes | Bricks | |
| Zero-shot automatic labeling | 68 | 61 | 57 | 51 |
| Manual labeling | 96 | 91 | 86 | 81 |
| Manual check zero-shot automatic labeling | 98 | 93 | 89 | 85 |
| Ordered manual labeling | 99 | 95 | 92 | 90 |
| Approach | Inner-Annotator Agreement |
|---|---|
| Manual labeling | 0.82 |
| Manual check zero-shot automatic labeling | 0.87 |
| Ordered manual labeling | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narushynska, O.; Teslyuk, V.; Doroshenko, A.; Arzubov, M. Data Sorting Influence on Short Text Manual Labeling Quality for Hierarchical Classification. Big Data Cogn. Comput. 2024, 8, 41. https://doi.org/10.3390/bdcc8040041
Narushynska O, Teslyuk V, Doroshenko A, Arzubov M. Data Sorting Influence on Short Text Manual Labeling Quality for Hierarchical Classification. Big Data and Cognitive Computing. 2024; 8(4):41. https://doi.org/10.3390/bdcc8040041
Chicago/Turabian StyleNarushynska, Olga, Vasyl Teslyuk, Anastasiya Doroshenko, and Maksym Arzubov. 2024. "Data Sorting Influence on Short Text Manual Labeling Quality for Hierarchical Classification" Big Data and Cognitive Computing 8, no. 4: 41. https://doi.org/10.3390/bdcc8040041
APA StyleNarushynska, O., Teslyuk, V., Doroshenko, A., & Arzubov, M. (2024). Data Sorting Influence on Short Text Manual Labeling Quality for Hierarchical Classification. Big Data and Cognitive Computing, 8(4), 41. https://doi.org/10.3390/bdcc8040041