
Machine Learning-Based Analysis of Travel Mode Preferences: Neural and Boosting Model Comparison Using Stated Preference Data from Thailand’s Emerging High-Speed Rail Network


 ,
,  ,
,  and
and 
Abstract
1. Introduction
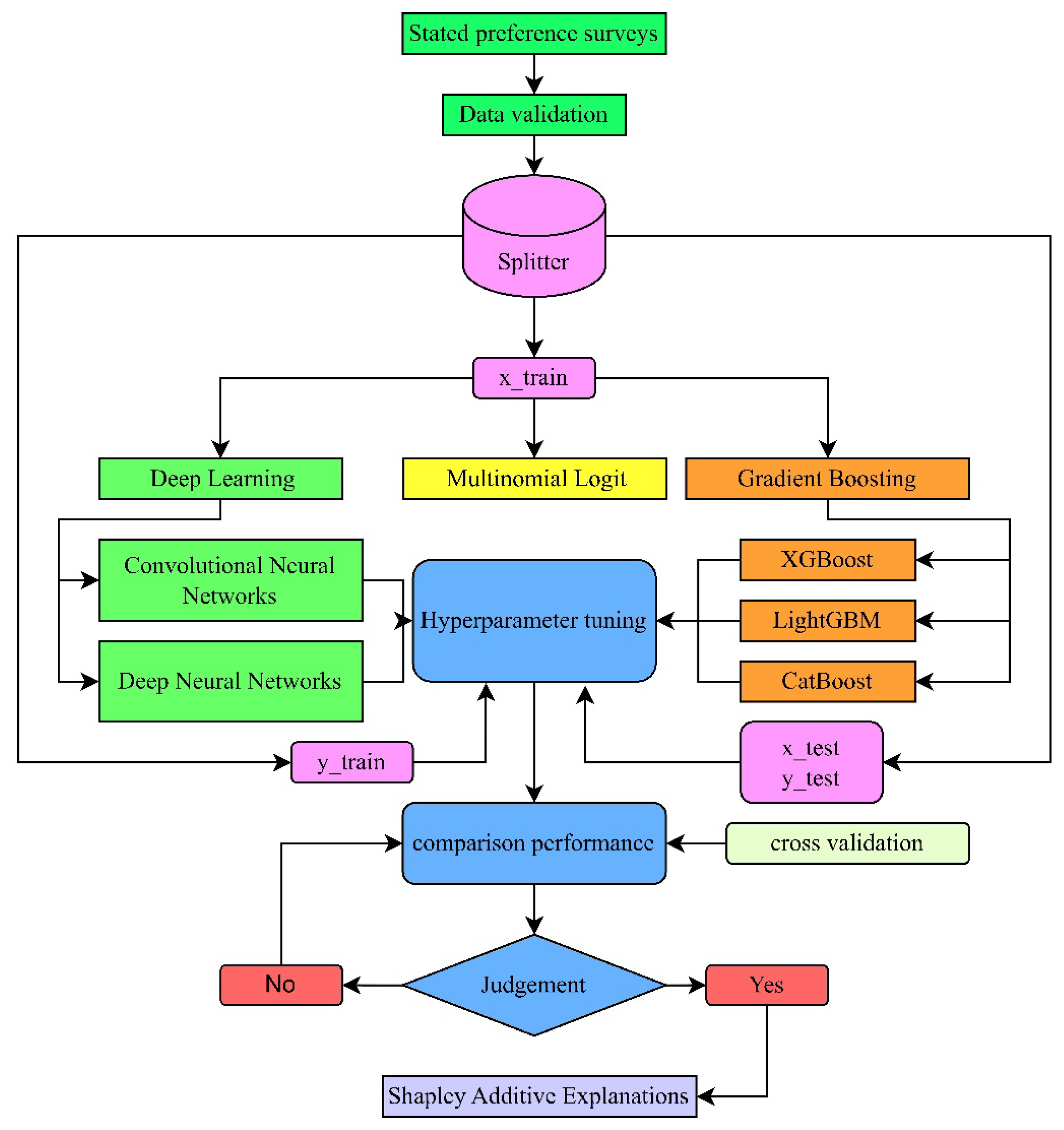
2. Methodology and Data Analysis
2.1. Survey Design
2.2. Questionnaire Design
2.3. Data and Variables
Dataset Structuring and Preprocessing
2.4. Multinomial Logit Model for Mode Choice Estimation
2.5. Deep Neural Network (DNN)
2.6. Convolutional Neural Network (CNN)
2.7. Extreme Gradient Boosting (XGBoost)
2.8. Light Gradient Boosting (LightGBM)
2.9. Categorical Boosting (CatBoost)
2.10. Hyperparameter Tuning
2.11. Model Comparison
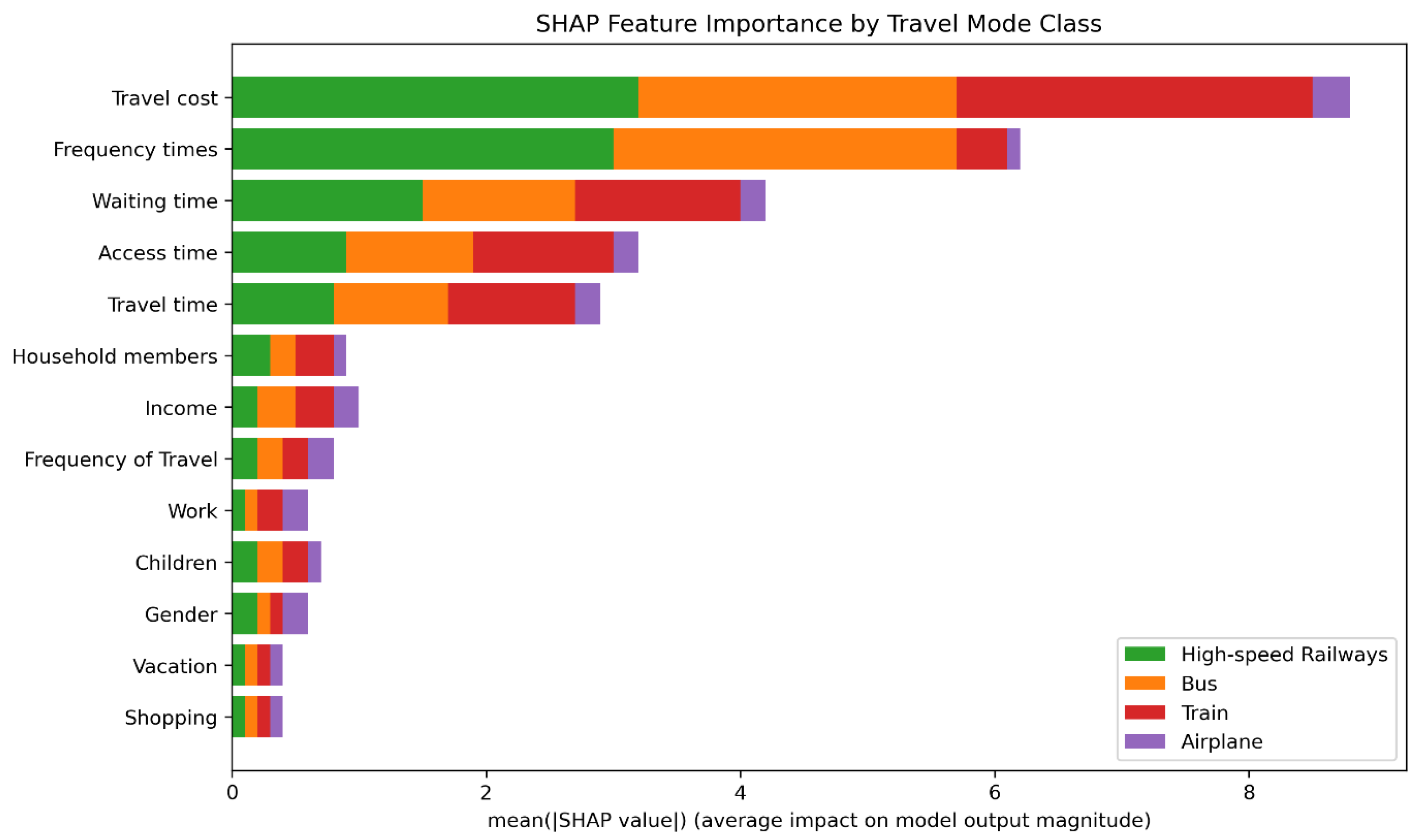
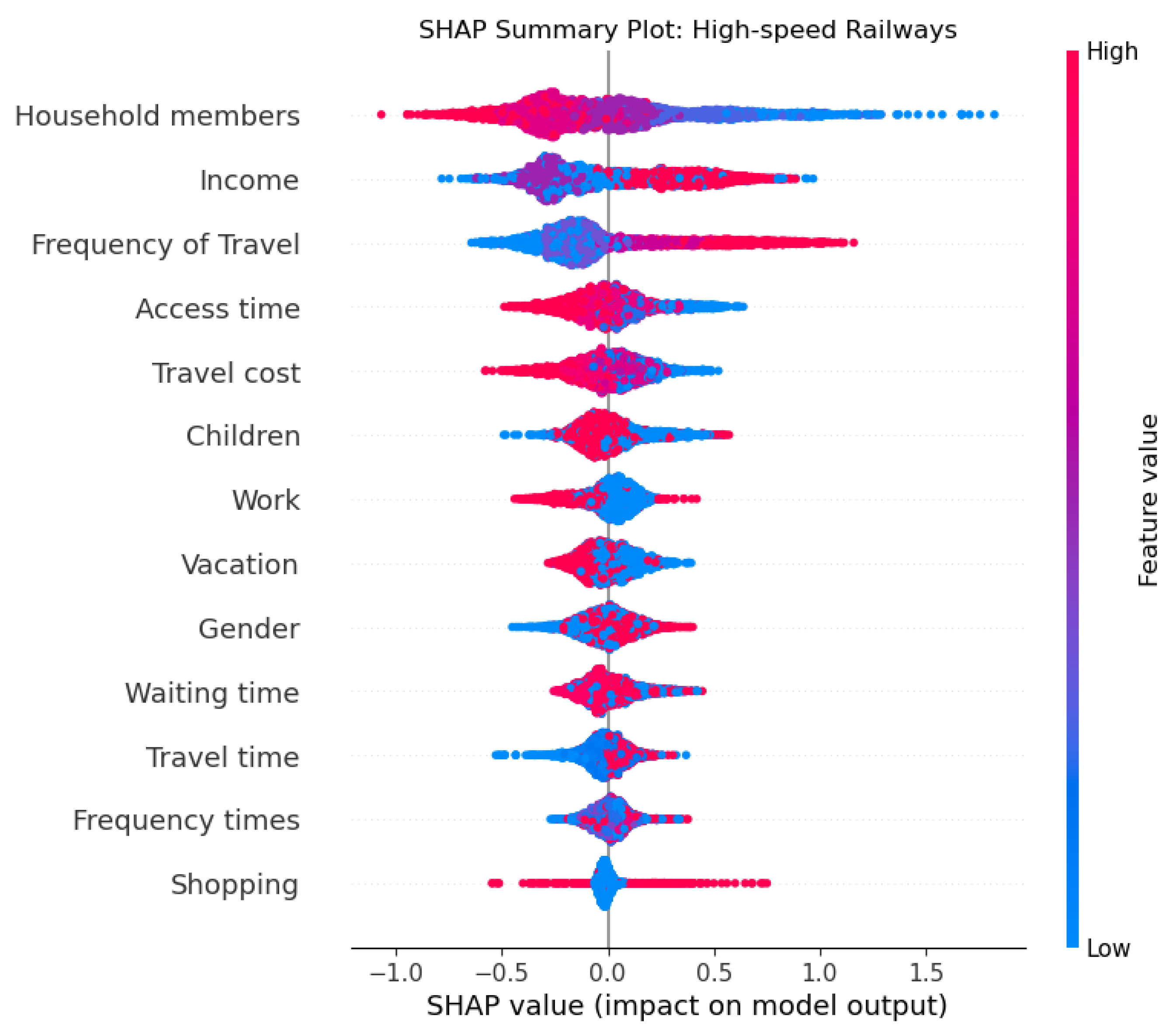
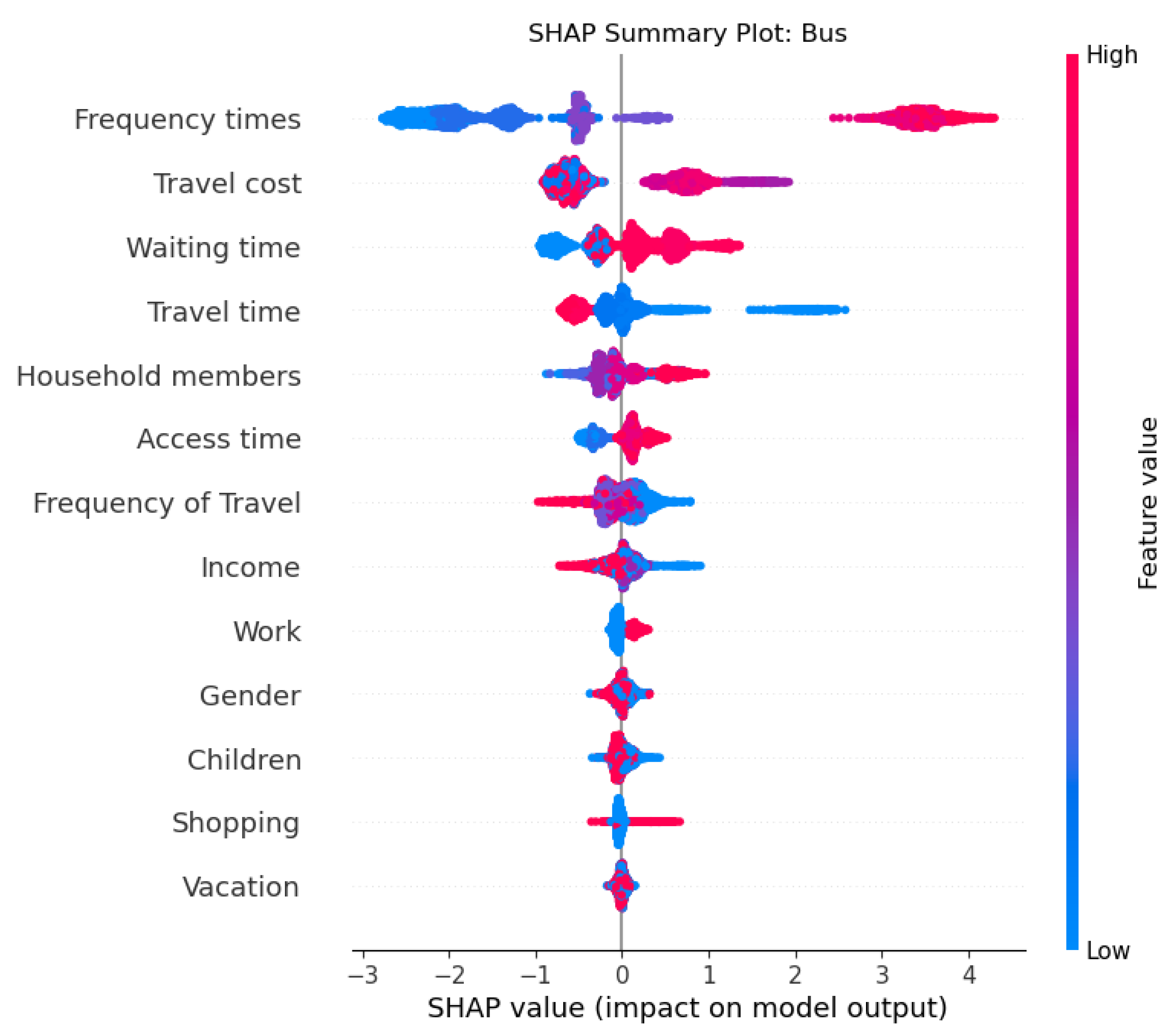
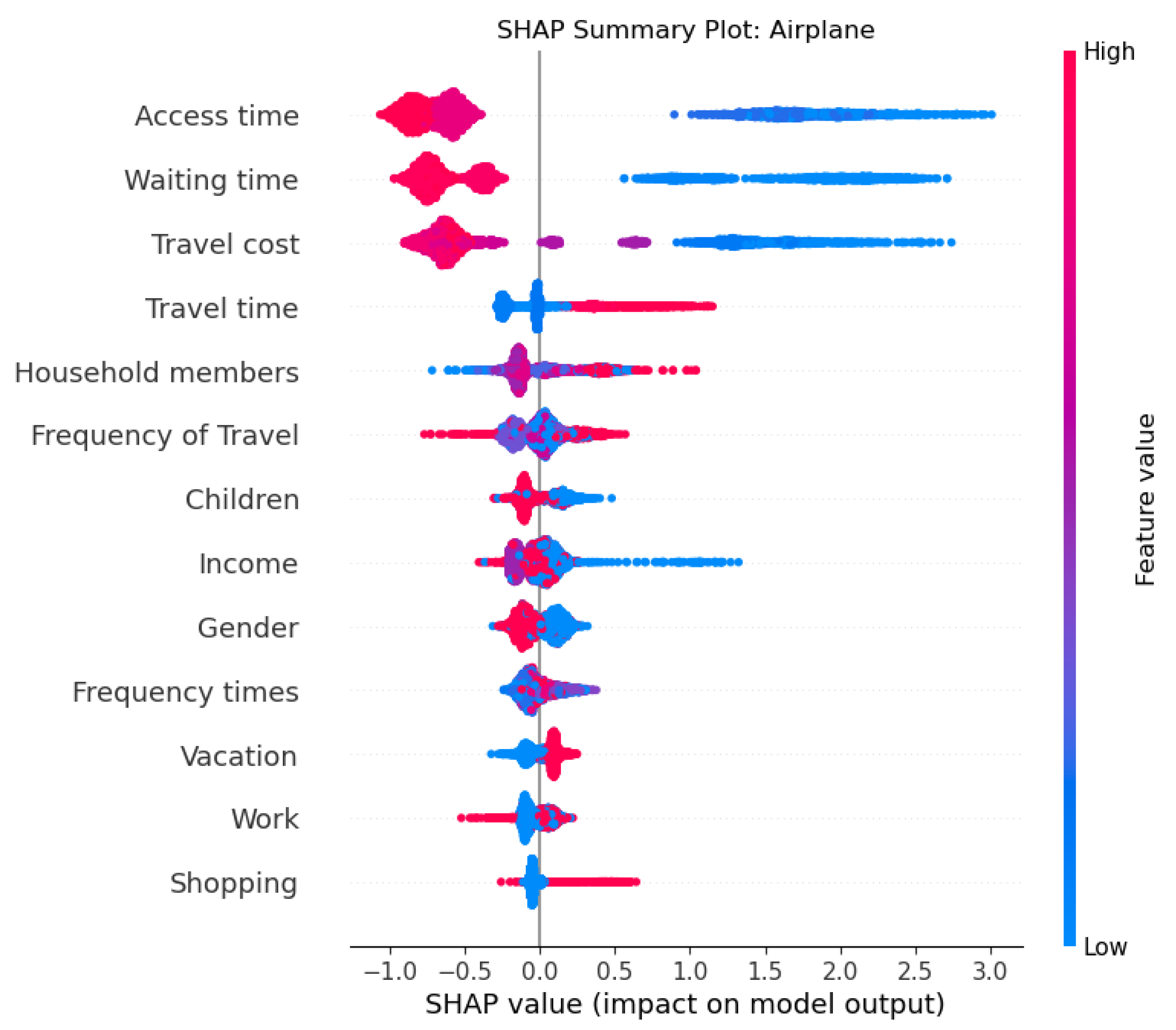
2.12. Shapley Additive Explanations (SHAP)
3. Results and Discussion
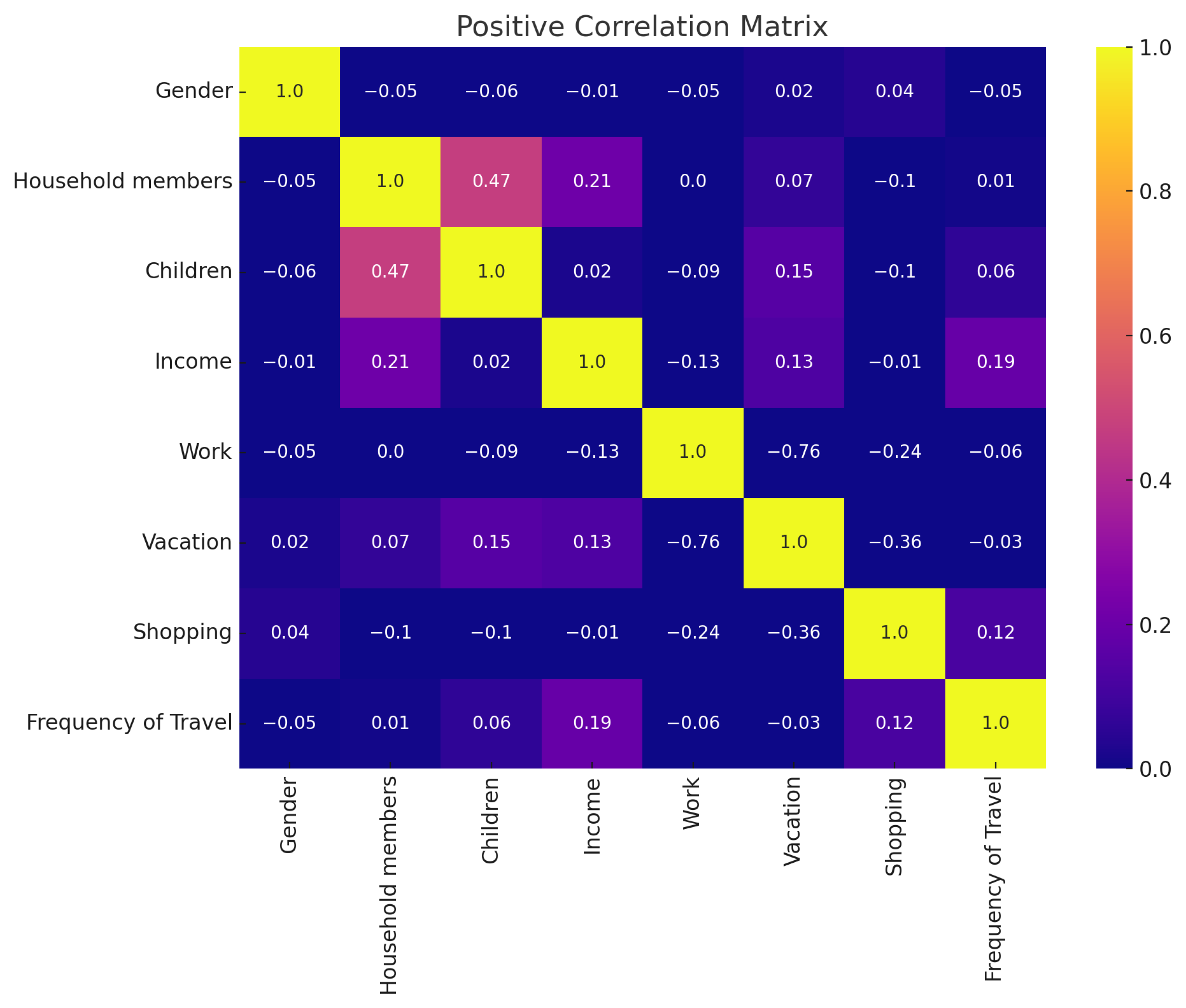
3.1. Descriptive Analysis
3.2. Hyperparameter Optimization Using Bayesian Optimization
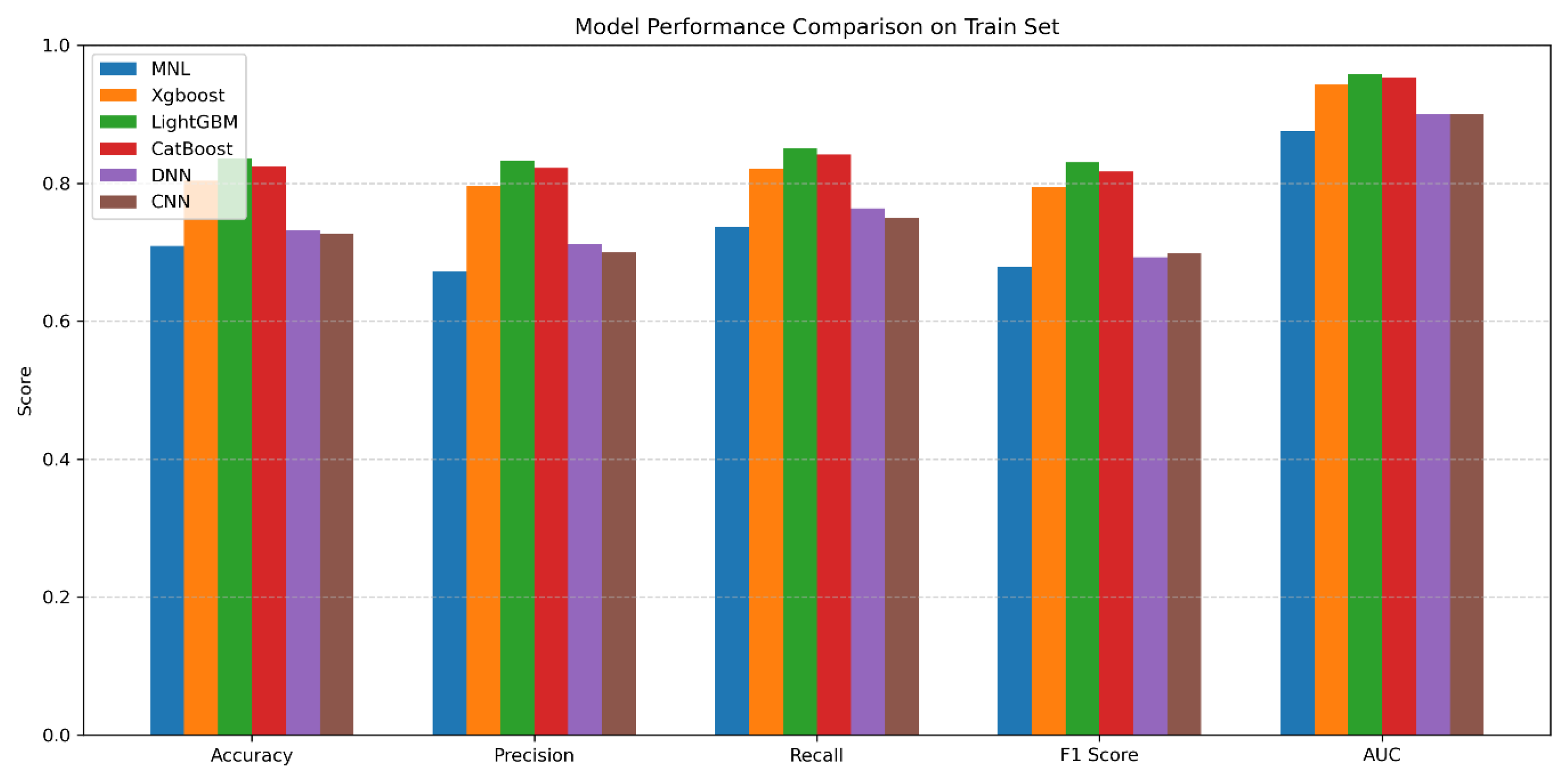
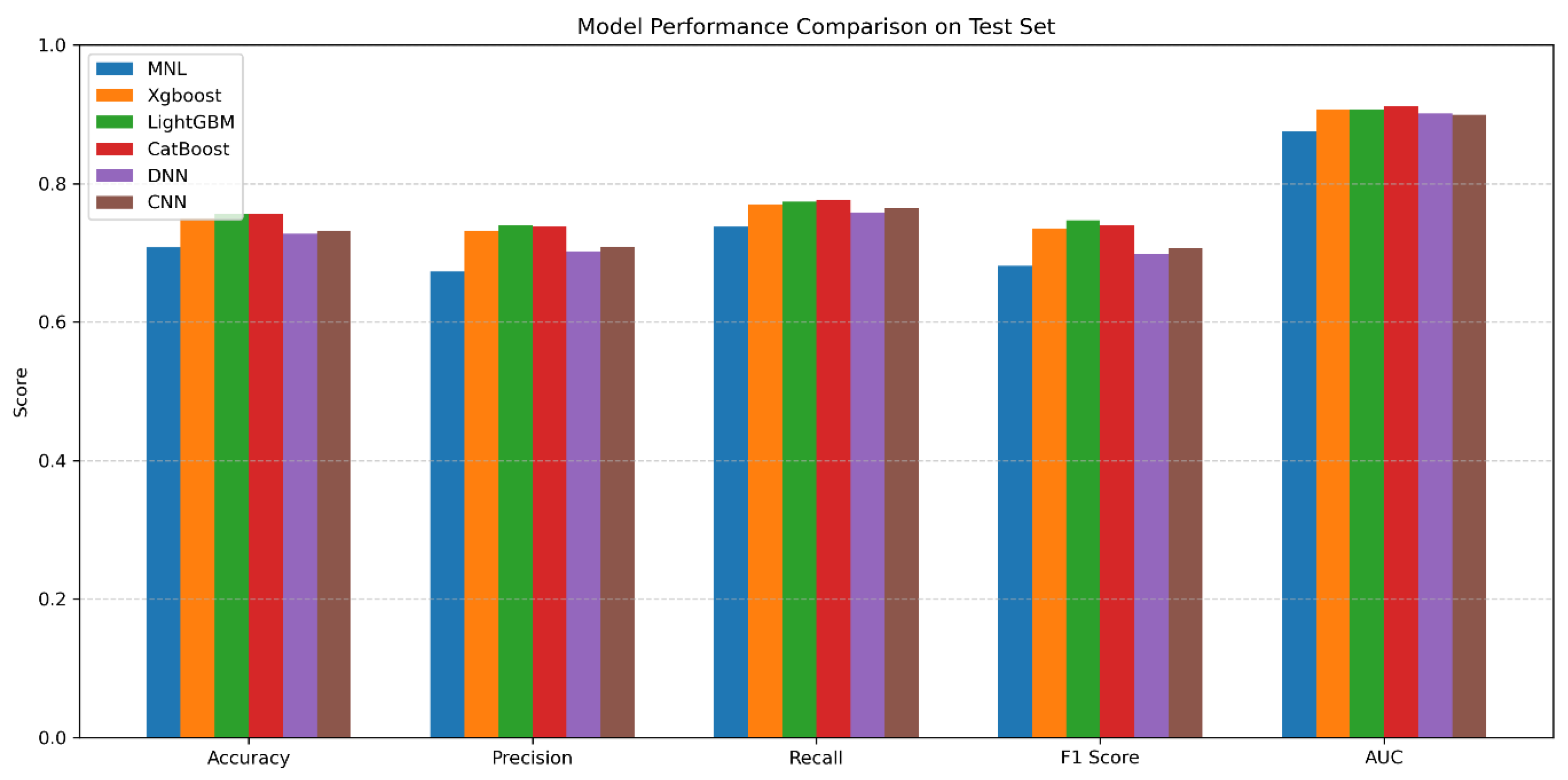
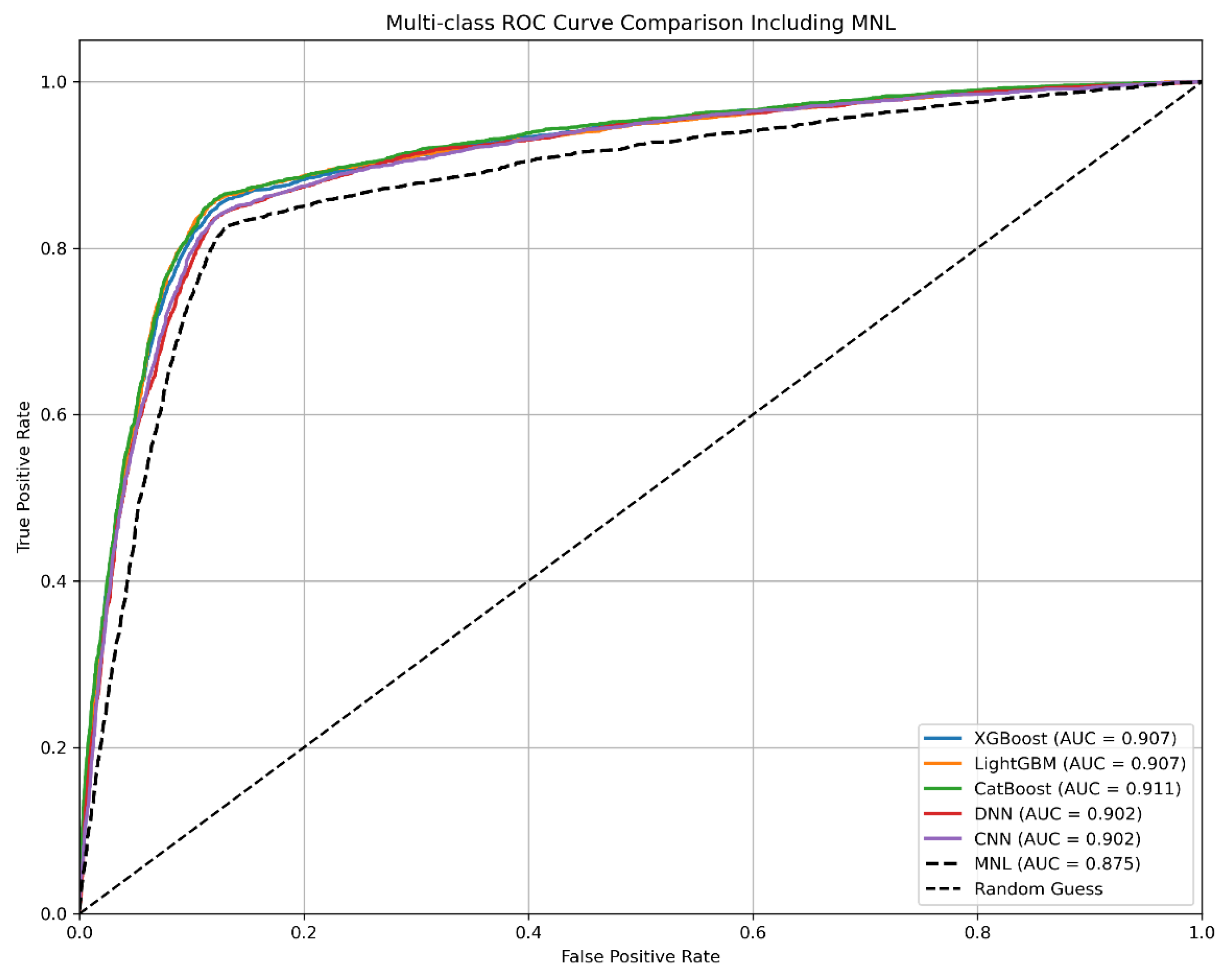
3.3. Model Performance
4. Conclusions
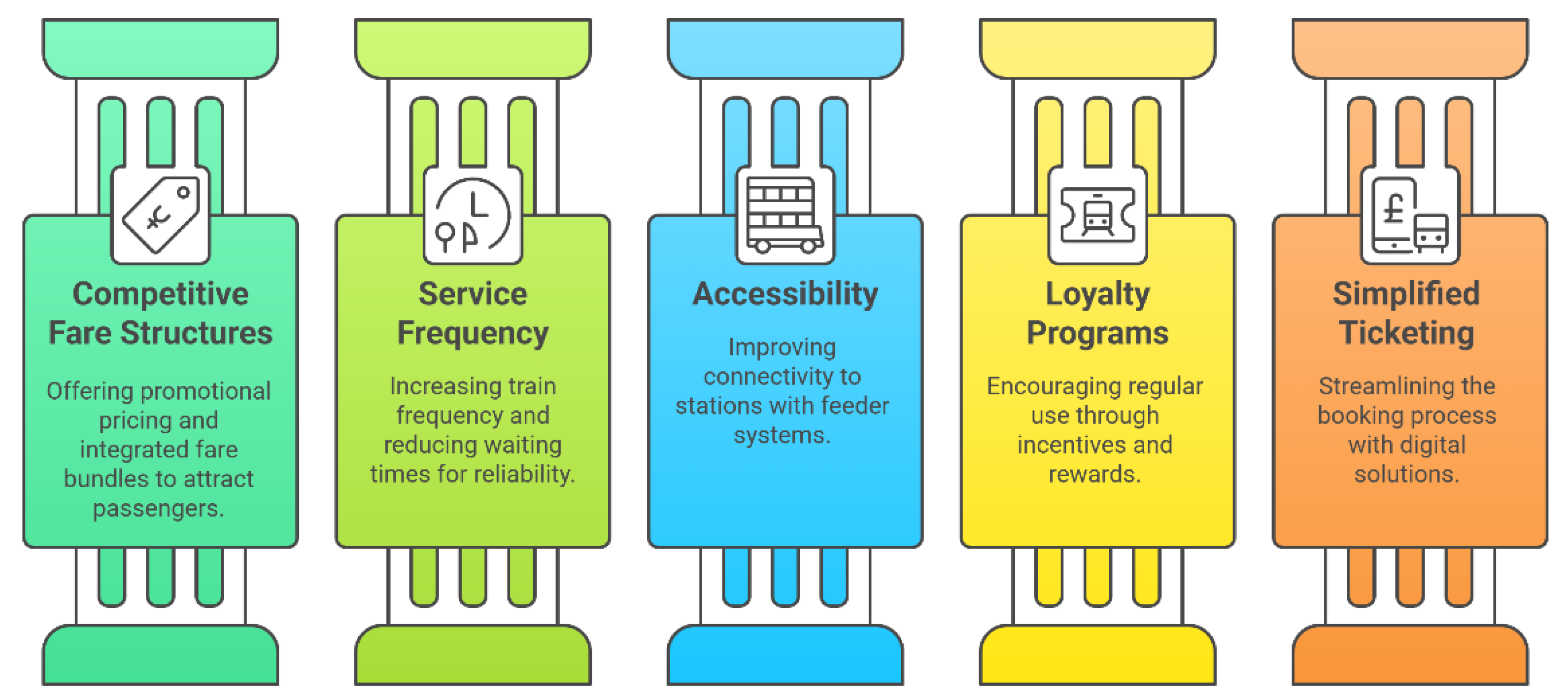
4.1. Policy Recommendations
- Design competitive fare structures by offering promotional pricing, monthly passes, or integrated fare bundles with other public transportation services;
- Increase service frequency and minimize waiting times to enhance the reliability and attractiveness of high-speed rail operations;
- Improve accessibility to rail stations through feeder systems such as shuttle buses or local transit networks that facilitate first-mile and last-mile connectivity;
- Encourage regular intercity travelers to adopt high-speed rail through loyalty programs or targeted fare incentives;
- Simplify the ticketing process by developing a seamless and intuitive platform for booking and payment, supporting mobile access, QR code usage, and electronic wallets.
4.2. Limitations and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liang, Y.; Zhou, K.; Li, X.; Zhou, Z.; Sun, W.; Zeng, J. Effectiveness of high-speed railway on regional economic growth for less developed areas. J. Transp. Geogr. 2020, 82, 102621. [Google Scholar] [CrossRef]
- Blanquart, C.; Koning, M. The local economic impacts of high-speed railways: Theories and facts. Eur. Transp. Res. Rev. 2017, 9, 12. [Google Scholar] [CrossRef]
- Wu, W.; Liang, Y.; Wu, D. Evaluating the impact of China’s rail network expansions on local accessibility: A market potential approach. Sustainability 2016, 8, 512. [Google Scholar] [CrossRef]
- Tissayakorn, K. A Study on Transit-Oriented Development Strategies in the High-Speed Rail Project in Thailand. Ph.D. Thesis, Yokohama National University, Yokohama, Japan, 2021. [Google Scholar]
- Office of the National Economic and Social Development Council. Sustainable Development Goals: SDGs. Available online: https://sdgs.nesdc.go.th/goals-and-indicators/ (accessed on 30 January 2023).
- State Railway of Thailand. High-Speed Rail Route Between Bangkok and Nong Khai (Phase 2: Nakhon Ratchasima to Nong Khai). Available online: https://www.hsrkorat-nongkhai.com/ (accessed on 30 January 2023).
- JTTRI-AIRO. Progress of the Thailand-China High-Speed Railway. 2023. Available online: https://www.jttri-airo.org/en/dll.php?id=20&s=pdf1&t=repo (accessed on 3 February 2023).
- Yang, W.; Chen, Q.; Yang, J. Factors Affecting Travel Mode Choice between High-Speed Railway and Road Passenger Transport—Evidence from China. Sustainability 2022, 14, 15745. [Google Scholar] [CrossRef]
- Deng, Y.; Bai, Y.; Cui, L.; He, R. Travel Mode Choice Behavior for High-Speed Railway Stations Based on Multi-Source Data. Transp. Res. Rec. 2023, 2677, 525–540. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, W.; Liu, C.; Huang, Z. A System Optimization Approach for Trains’ Operation Plan with a Time Flexible Pricing Strategy for High-Speed Rail Corridors. Sustainability 2023, 15, 9556. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, M. High-speed rail impacts on travel times, accessibility, and economic productivity: A benchmarking analysis in city-cluster regions of China. J. Transp. Geogr. 2018, 73, 25–40. [Google Scholar] [CrossRef]
- Zhang, Y.; Liang, K.; Yao, E.; Gu, M. Measuring Reliable Accessibility to High-Speed Railway Stations by Integrating the Utility-Based Model and Multimodal Space–Time Prism under Travel Time Uncertainty. ISPRS Int. J. Geo-Inf. 2024, 13, 263. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhao, M.; Tang, S.; Lam, W.H.; Chen, A.; Sze, N.; Chen, Y. Assessing the relationship between access travel time estimation and the accessibility to high speed railway station by different travel modes. Sustainability 2020, 12, 7827. [Google Scholar] [CrossRef]
- Ben-Akiva, M.E.; Lerman, S.R. Discrete Choice Analysis: Theory and Application to Travel Demand; MIT Press: Cambridge, MA, USA, 1985; Volume 9. [Google Scholar]
- Török, Á.; Szalay, Z.; Uti, G.; Verebélyi, B. Rerepresenting autonomated vehicles in a macroscopic transportation model. Period. Polytech. Transp. Eng. 2020, 48, 269–275. [Google Scholar] [CrossRef]
- Akter, T.; Alam, B.M. Travel mode choice behavior analysis using multinomial logit models towards creating sustainable college campus: A case study of the University of Toledo, Ohio. Front. Future Transp. 2024, 5, 1389614. [Google Scholar] [CrossRef]
- Ning, J.; Lyu, T.; Wang, Y. Exploring the built environment factors in the metro that influence the ridership and the market share of the elderly and students. J. Adv. Transp. 2021, 2021, 9966794. [Google Scholar] [CrossRef]
- Wen, C.-H.; Wang, W.-C.; Fu, C. Latent class nested logit model for analyzing high-speed rail access mode choice. Transp. Res. Part E Logist. Transp. Rev. 2012, 48, 545–554. [Google Scholar] [CrossRef]
- Wu, J.; Yang, M.; Sun, S.; Zhao, J. Modeling travel mode choices in connection to metro stations by mixed logit models: A case study in Nanjing, China. Promet-Traffic Transp. 2018, 30, 549–561. [Google Scholar] [CrossRef]
- Kwigizile, V.; Chimba, D.; Sando, T. A cross-nested logit model for trip type-mode choice: An application. Adv. Transp. Stud. 2011, 29–40. [Google Scholar]
- Bierlaire, M. A theoretical analysis of the cross-nested logit model. Ann. Oper. Res. 2006, 144, 287–300. [Google Scholar] [CrossRef]
- Hasnine, M.S.; Lin, T.; Weiss, A.; Habib, K.N. Determinants of travel mode choices of post-secondary students in a large metropolitan area: The case of the city of Toronto. J. Transp. Geogr. 2018, 70, 161–171. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 6639–6649. [Google Scholar]
- Abulibdeh, A. Analysis of mode choice affects from the introduction of Doha Metro using machine learning and statistical analysis. Transp. Res. Interdiscip. Perspect. 2023, 20, 100852. [Google Scholar] [CrossRef]
- Díaz-Ramírez, J.; Estrada-García, J.A.; Figueroa-Sayago, J. Predicting transport mode choice preferences in a university district with decision tree-based models. City Environ. Interact. 2023, 20, 100118. [Google Scholar] [CrossRef]
- Wen, X.; Chen, X. A New Breakthrough in Travel Behavior Modeling Using Deep Learning: A High-Accuracy Prediction Method Based on a CNN. Sustainability 2025, 17, 738. [Google Scholar] [CrossRef]
- Banyong, C.; Hantanong, N.; Wisutwattanasak, P.; Champahom, T.; Theerathitichaipa, K.; Seefong, M.; Ratanavaraha, V.; Jomnonkwao, S. A machine learning comparison of transportation mode changes from high-speed railway promotion in Thailand. Results Eng. 2024, 24, 103110. [Google Scholar] [CrossRef]
- Guo, L.; Huang, J.; Ma, W.; Sun, L.; Zhou, L.; Pan, J.; Yang, W. Convolutional Neural Network-Based Travel Mode Recognition Based on Multiple Smartphone Sensors. Appl. Sci. 2022, 12, 6511. [Google Scholar] [CrossRef]
- Hillel, T.; Bierlaire, M.; Elshafie, M.Z.E.B.; Jin, Y. A systematic review of machine learning classification methodologies for modelling passenger mode choice. J. Choice Model. 2021, 38, 100221. [Google Scholar] [CrossRef]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on typical tabular data? Adv. Neural Inf. Process. Syst. 2022, 35, 507–520. [Google Scholar]
- Dahmen, V.; Weikl, S.; Bogenberger, K. Interpretable machine learning for mode choice modeling on tracking-based revealed preference data. Transp. Res. Rec. 2024, 2678, 2075–2091. [Google Scholar] [CrossRef]
- Office of the National Economic and Social Development Council. Gross Regional and Provincial Product Chain Volume Measure 2022 Edition. Available online: https://www.nesdc.go.th/nesdb_en/ewt_dl_link.php?nid=4317/ (accessed on 1 December 2024).
- Srithongrung, A.; Kriz, K.A. Thai Public Capital Budget and Management Process. In Capital Management and Budgeting in the Public Sector; IGI Global: Hershey, PA, USA, 2019; pp. 206–235. [Google Scholar]
- Pavlou, M.; Ambler, G.; Qu, C.; Seaman, S.R.; White, I.R.; Omar, R.Z. An evaluation of sample size requirements for developing risk prediction models with binary outcomes. BMC Med. Res. Methodol. 2024, 24, 146. [Google Scholar] [CrossRef]
- Kujala, R.; Weckström, C.; Mladenović, M.N.; Saramäki, J. Travel times and transfers in public transport: Comprehensive accessibility analysis based on Pareto-optimal journeys. Comput. Environ. Urban Syst. 2018, 67, 41–54. [Google Scholar] [CrossRef]
- Arencibia, A.I.; Feo-Valero, M.; García-Menéndez, L.; Román, C. Modelling mode choice for freight transport using advanced choice experiments. Transp. Res. Part A Policy Pract. 2015, 75, 252–267. [Google Scholar] [CrossRef]
- Economic Base. Knock on the Bangkok-Chiang Mai High-Speed Train Fare 1089 Baht. Available online: https://www.thansettakij.com/business/242231 (accessed on 4 February 2023).
- BusOnlineTicket.co.th. Book Thailand Bus Tickets Online. Available online: https://www.busonlineticket.co.th/ (accessed on 3 February 2023).
- AirAsia Move. Flight. Available online: https://www.airasia.com/th/th (accessed on 6 February 2023).
- State Railway of Thailand the State Railway of Thailand Easy Book, Convenient Check. Available online: https://dticket.railway.co.th/DTicketPublicWeb/home/Home (accessed on 7 February 2023).
- Hensher, D.A.; Rose, J.M.; Greene, W.H. Applied Choice Analysis; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- García-Ródenas, R.; Linares, L.J.; López-Gómez, J.A. On the performance of classic and deep neural models in image recognition. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2017: 26th International Conference on Artificial Neural Networks, Alghero, Italy, 11–14 September 2017; Proceedings, Part II 26. pp. 600–608. [Google Scholar]
- García-García, J.C.; García-Ródenas, R.; López-Gómez, J.A.; Martín-Baos, J.Á. A comparative study of machine learning, deep neural networks and random utility maximization models for travel mode choice modelling. Transp. Res. Procedia 2022, 62, 374–382. [Google Scholar] [CrossRef]
- Xu, Y.; Zhao, X.; Chen, Y.; Yang, Z. Research on a mixed gas classification algorithm based on extreme random tree. Appl. Sci. 2019, 9, 1728. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Li, X.; Shi, L.; Shi, Y.; Tang, J.; Zhao, P.; Wang, Y.; Chen, J. Exploring interactive and nonlinear effects of key factors on intercity travel mode choice using XGBoost. Appl. Geogr. 2024, 166, 103264. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ding, C.; Cao, X.J.; Næss, P. Applying gradient boosting decision trees to examine non-linear effects of the built environment on driving distance in Oslo. Transp. Res. Part A Policy Pract. 2018, 110, 107–117. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Zhai, W.; Li, C.; Fei, S.; Liu, Y.; Ding, F.; Cheng, Q.; Chen, Z. CatBoost algorithm for estimating maize above-ground biomass using unmanned aerial vehicle-based multi-source sensor data and SPAD values. Comput. Electron. Agric. 2023, 214, 108306. [Google Scholar] [CrossRef]
- Pham, T.D.; Yokoya, N.; Xia, J.; Ha, N.T.; Le, N.N.; Nguyen, T.T.T.; Dao, T.H.; Vu, T.T.P.; Pham, T.D.; Takeuchi, W. Comparison of machine learning methods for estimating mangrove above-ground biomass using multiple source remote sensing data in the red river delta biosphere reserve, Vietnam. Remote Sens. 2020, 12, 1334. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Chongzhi, W.; Lin, W.; Zhang, W. Chapter 14—Assessment of undrained shear strength using ensemble learning based on Bayesian hyperparameter optimization. In Modeling in Geotechnical Engineering; Samui, P., Kumari, S., Makarov, V., Kurup, P., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 309–326. [Google Scholar]
- Shakya, A.; Biswas, M.; Pal, M. Chapter 9—Classification of Radar data using Bayesian optimized two-dimensional Convolutional Neural Network. In Radar Remote Sensing; Srivastava, P.K., Gupta, D.K., Islam, T., Han, D., Prasad, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 175–186. [Google Scholar]
- Zhao, X.; Yan, X.; Yu, A.; Van Hentenryck, P. Modeling Stated preference for mobility-on-demand transit: A comparison of Machine Learning and logit models. arXiv 2018, arXiv:1811.01315. [Google Scholar]
- Mokhtarimousavi, S.; Anderson, J.C.; Azizinamini, A.; Hadi, M. Factors affecting injury severity in vehicle-pedestrian crashes: A day-of-week analysis using random parameter ordered response models and artificial neural networks. Int. J. Transp. Sci. Technol. 2020, 9, 100–115. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Mao, H.; Deng, X.; Jiang, H.; Shi, L.; Li, H.; Tuo, L.; Shi, D.; Guo, F. Driving safety assessment for ride-hailing drivers. Accident Anal. Prev. 2021, 149, 105574. [Google Scholar] [CrossRef]
- Adland, R.; Jia, H.; Lode, T.; Skontorp, J. The value of meteorological data in marine risk assessment. Reliab. Eng. Syst. Saf. 2021, 209, 107480. [Google Scholar] [CrossRef]
- Vega, G.M.; Aznarte José, L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- Champahom, T.; Banyong, C.; Hantanong, N.; Se, C.; Jomnonkwao, S.; Ratanavaraha, V. Factors influencing the willingness to pay for motorcycle safety improvement: A structural equation modeling approach. Transp. Res. Interdiscip. Perspect. 2023, 22, 100950. [Google Scholar] [CrossRef]
- Vatcheva, K.P.; Lee, M.; McCormick, J.B.; Rahbar, M.H. Multicollinearity in regression analyses conducted in epidemiologic studies. Epidemiology 2016, 6, 227. [Google Scholar] [CrossRef]
- Kalantari, H.A.; Sabouri, S.; Brewer, S.; Ewing, R.; Tian, G. Machine Learning in Mode Choice Prediction as Part of MPOs’ Regional Travel Demand Models: Is It Time for Change? Sustainability 2025, 17, 3580. [Google Scholar] [CrossRef]
- Shahdah, U.E.; Elharoun, M.; Ali, E.K.; Elbany, M.; Elagamy, S.R. Stated preference survey for predicting eco-friendly transportation choices among Mansoura University students. Innov. Infrastruct. Solut. 2025, 10, 180. [Google Scholar] [CrossRef]
- Yin, C.; Wu, J.; Sun, X.; Meng, Z.; Lee, C. Road transportation emission prediction and policy formulation: Machine learning model analysis. Transp. Res. Part D Transp. Environ. 2024, 135, 104390. [Google Scholar] [CrossRef]
- Yu, J.; Chang, X.; Hu, S.; Yin, H.; Wu, J. Combining travel behavior in metro passenger flow prediction: A smart explainable Stacking-Catboost algorithm. Inf. Process. Manag. 2024, 61, 103733. [Google Scholar] [CrossRef]
- Chen, H.; Cheng, Y. Travel mode choice prediction using imbalanced machine learning. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3795–3808. [Google Scholar] [CrossRef]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Himeur, Y.; Elnour, M.; Fadli, F.; Meskin, N.; Petri, I.; Rezgui, Y.; Bensaali, F.; Amira, A. Next-generation energy systems for sustainable smart cities: Roles of transfer learning. Sustain. Cities Soc. 2022, 85, 104059. [Google Scholar] [CrossRef]
- Li, M.; Soltanolkotabi, M.; Oymak, S. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26 August 2020; pp. 4313–4324. [Google Scholar]
- Fort, S.; Dziugaite, G.K.; Paul, M.; Kharaghani, S.; Roy, D.M.; Ganguli, S. Deep learning versus kernel learning: An empirical study of loss landscape geometry and the time evolution of the neural tangent kernel. Adv. Neural Inf. Process. Syst. 2020, 33, 5850–5861. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Chehreh Chelgani, S.; Homafar, A.; Nasiri, H.; Rezaei laksar, M. CatBoost-SHAP for modeling industrial operational flotation variables—A “conscious lab” approach. Miner. Eng. 2024, 213, 108754. [Google Scholar] [CrossRef]
- Kadra, A.; Lindauer, M.; Hutter, F.; Grabocka, J. Well-tuned simple nets excel on tabular datasets. Adv. Neural Inf. Process. Syst. 2021, 34, 23928–23941. [Google Scholar]
- Borisov, V.; Leemann, T.; Seßler, K.; Haug, J.; Pawelczyk, M.; Kasneci, G. Deep neural networks and tabular data: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 7499–7519. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Zhang, X.; Gao, D. Preference heterogeneity analysis on train choice behaviour of high-speed railway passengers: A case study in China. Transp. Res. Part A Policy Pract. 2024, 188, 104198. [Google Scholar] [CrossRef]
- Xu, M.; Shuai, B.; Wang, X.; Liu, H.; Zhou, H. Analysis of the accessibility of connecting transport at High-speed rail stations from the perspective of departing passengers. Transp. Res. Part A Policy Pract. 2023, 173, 103714. [Google Scholar] [CrossRef]
- Salas, P.; De la Fuente, R.; Astroza, S.; Carrasco, J.A. A systematic comparative evaluation of machine learning classifiers and discrete choice models for travel mode choice in the presence of response heterogeneity. Expert Syst. Appl. 2022, 193, 116253. [Google Scholar] [CrossRef]
- Wahab, S.N.; Hamzah, M.I.; Suki, N.M.; Chong, Y.S.; Kua, C.P. Unveiling passenger satisfaction in rail transit through a consumption values perspective. Multimodal Transp. 2025, 4, 100196. [Google Scholar] [CrossRef]
- Grolle, J.; Donners, B.; Annema, J.A.; Duinkerken, M.; Cats, O. Service design and frequency setting for the European high-speed rail network. Transp. Res. Part A Policy Pract. 2024, 179, 103906. [Google Scholar] [CrossRef]
- Tiong, K.Y.; Ma, Z.; Palmqvist, C.-W. Analyzing factors contributing to real-time train arrival delays using seemingly unrelated regression models. Transp. Res. Part A Policy Pract. 2023, 174, 103751. [Google Scholar] [CrossRef]
- Moyano, A.; Moya-Gómez, B.; Gutiérrez, J. Access and egress times to high-speed rail stations: A spatiotemporal accessibility analysis. J. Transp. Geogr. 2018, 73, 84–93. [Google Scholar] [CrossRef]
- Zhou, Z.; Cheng, L.; Yang, M.; Wang, L.; Chen, W.; Gong, J.; Zou, J. Analysis of passenger perception heterogeneity and differentiated service strategy for air-rail intermodal travel. Travel Behav. Soc. 2024, 37, 100872. [Google Scholar] [CrossRef]
- Romero, C.; Zamorano, C.; Monzón, A. Exploring the role of public transport information sources on perceived service quality in suburban rail. Travel Behav. Soc. 2023, 33, 100642. [Google Scholar] [CrossRef]
- Zhou, H.; Chi, X.; Norman, R.; Zhang, Y.; Song, C. Tourists’ urban travel modes: Choices for enhanced transport and environmental sustainability. Transp. Res. Part D Transp. Environ. 2024, 129, 104144. [Google Scholar] [CrossRef]
- Chen, Z. Socioeconomic Impacts of high-speed rail: A bibliometric analysis. Socio-Econ. Plan. Sci. 2023, 85, 101265. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Bus | Train | Airplane | HSR (Levels 1) | HSR (Levels 2) |
|---|---|---|---|---|---|
| Access time (Station approach duration: minute) | 10 | 10 | 30 | 10 | 15 |
| Waiting time (Pre-departure delay: minute) | 15 | 10 | 120 | 15 | 10 |
| Travel (Time In-vehicle journey duration: minute) | 720 | 720 | 135 | 190 | 220 |
| Travel cost (Out-of-pocket fare: bath) | 750 | 300 | 3000 | 1050 | 1400 |
| Frequency times (Scheduled service interval: minute) | 30 | 150 | 120 | 190 | 220 |
| Variable | Description | Categorical Variable (%) | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|---|---|
| Gender | Male = 1 | 52.43 | 0.5243 | 0.4994 | −0.0975 | −1.9908 |
| Female = 0 | 47.57 | |||||
| Total | 100 | |||||
| Household members | Household members 1 person = 1 | 33.88 | 3.3561 | 1.1090 | −0.3527 | −0.5709 |
| 2 people = 2 | 28.92 | |||||
| 3 people = 3 | 15.67 | |||||
| 4 people = 4 | 15.11 | |||||
| More than four people = 5 | 6.41 | |||||
| Total | 100 | |||||
| Children | Have children under 18 in the household = 1 | 63.3 | 0.6330 | 0.4820 | −0.5520 | −1.6956 |
| No children under 18 in the household = 0 | 36.7 | |||||
| Total | 100 | |||||
| Income | Less than 15,000 = 1 | 2.22 | 2.9557 | 0.8705 | −0.1163 | −1.2520 |
| 15,000–30,000 = 2 | 30.7 | |||||
| 30,001–45,000 = 3 | 33.54 | |||||
| More than 45,000 = 4 | 33.55 | |||||
| Total | 100 | |||||
| Work | Travel for study or work. Yes = 1 | 33.39 | 0.3339 | 0.4716 | 0.7043 | −1.5043 |
| No = 0 | 66.61 | |||||
| Total | 100 | |||||
| Vacation | Travel for leisure or vacation. Yes = 1 | 53.57 | 0.5357 | 0.4987 | −0.1431 | −1.9799 |
| No = 0 | 46.43 | |||||
| Total | 100 | |||||
| Shopping | Travel for shopping. Yes = 1 | 10.29 | 0.1029 | 0.3038 | 2.6146 | 4.837 |
| No = 0 | 89.71 | |||||
| Total | 100 | |||||
| Frequency of Travel | 1–3 times = 1 | 35.72 | 2.1097 | 1.0673 | 0.5877 | −0.9058 |
| 3–6 times = 2 | 33.93 | |||||
| 6–9 times = 3 | 16.35 | |||||
| More than nine times = 4 | 14 | |||||
| Total | 100 | |||||
| Mode | High speed railways = 1 | 29.42 | ||||
| Bus = 2 | 27.45 | |||||
| Train = 3 | 26.41 | |||||
| Airplane = 4 | 16.72 | |||||
| Total | 100 | |||||
| Model | Description | Value |
|---|---|---|
| XGBoost | n_estimators | 210 |
| max_depth | 6 | |
| learning_rate | 0.21977629940065888 | |
| subsample | 0.8166577433928425 | |
| colsample_bytree | 0.6713509802187799 | |
| gamma | 0.016849547970738232 | |
| reg_alpha | 4.443653782167797 | |
| reg_lambda | 2.162026822349147 | |
| LightGBM | n_estimators | 493 |
| max_depth | 5 | |
| learning_rate | 0.0441 | |
| subsample | 0.8957 | |
| colsample_bytree | 0.9840 | |
| reg_alpha | 0.0754 | |
| reg_lambda | 0.0788 | |
| random_state | 42 | |
| CatBoost | iterations | 157 |
| depth | 7 | |
| learning_rate | 0.16214535070336702 | |
| l2_leaf_reg | 4.815982341211366 | |
| random_strength | 5.493473561258114 | |
| bagging_temperature | 0.5270768048053522 | |
| border_count | 113 | |
| loss_function | ‘MultiClass’ | |
| random_state | 42 | |
| Deep Neural Network | first_dense_units | 191 |
| second_dense_units | 87 | |
| dropout_rate | 0.2294 | |
| optimizer | Adam | |
| learning_rate | 0.00033001201097314586 | |
| epochs | 32 | |
| batch_size | 16 | |
| Convolutional Neural Network | filters | 64 |
| kernel_size | 3 | |
| activation | ‘relu’ | |
| pool_size | 2 | |
| dense_units | 64 | |
| dropout_rate | 0.3 | |
| output_activation | ‘softmax’ | |
| optimizer | Adam | |
| learning_rate | 0.001 | |
| loss | ‘categorical_crossentropy’ | |
| batch_size | 16 | |
| epochs | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banyong, C.; Hantanong, N.; Nanthawong, S.; Se, C.; Wisutwattanasak, P.; Champahom, T.; Ratanavaraha, V.; Jomnonkwao, S. Machine Learning-Based Analysis of Travel Mode Preferences: Neural and Boosting Model Comparison Using Stated Preference Data from Thailand’s Emerging High-Speed Rail Network. Big Data Cogn. Comput. 2025, 9, 155. https://doi.org/10.3390/bdcc9060155
Banyong C, Hantanong N, Nanthawong S, Se C, Wisutwattanasak P, Champahom T, Ratanavaraha V, Jomnonkwao S. Machine Learning-Based Analysis of Travel Mode Preferences: Neural and Boosting Model Comparison Using Stated Preference Data from Thailand’s Emerging High-Speed Rail Network. Big Data and Cognitive Computing. 2025; 9(6):155. https://doi.org/10.3390/bdcc9060155
Chicago/Turabian StyleBanyong, Chinnakrit, Natthaporn Hantanong, Supanida Nanthawong, Chamroeun Se, Panuwat Wisutwattanasak, Thanapong Champahom, Vatanavongs Ratanavaraha, and Sajjakaj Jomnonkwao. 2025. "Machine Learning-Based Analysis of Travel Mode Preferences: Neural and Boosting Model Comparison Using Stated Preference Data from Thailand’s Emerging High-Speed Rail Network" Big Data and Cognitive Computing 9, no. 6: 155. https://doi.org/10.3390/bdcc9060155
APA StyleBanyong, C., Hantanong, N., Nanthawong, S., Se, C., Wisutwattanasak, P., Champahom, T., Ratanavaraha, V., & Jomnonkwao, S. (2025). Machine Learning-Based Analysis of Travel Mode Preferences: Neural and Boosting Model Comparison Using Stated Preference Data from Thailand’s Emerging High-Speed Rail Network. Big Data and Cognitive Computing, 9(6), 155. https://doi.org/10.3390/bdcc9060155