Increasing NLP Parsing Efficiency with Chunking †

{kind=link}
{kind=link}
Abstract
:1. Introduction
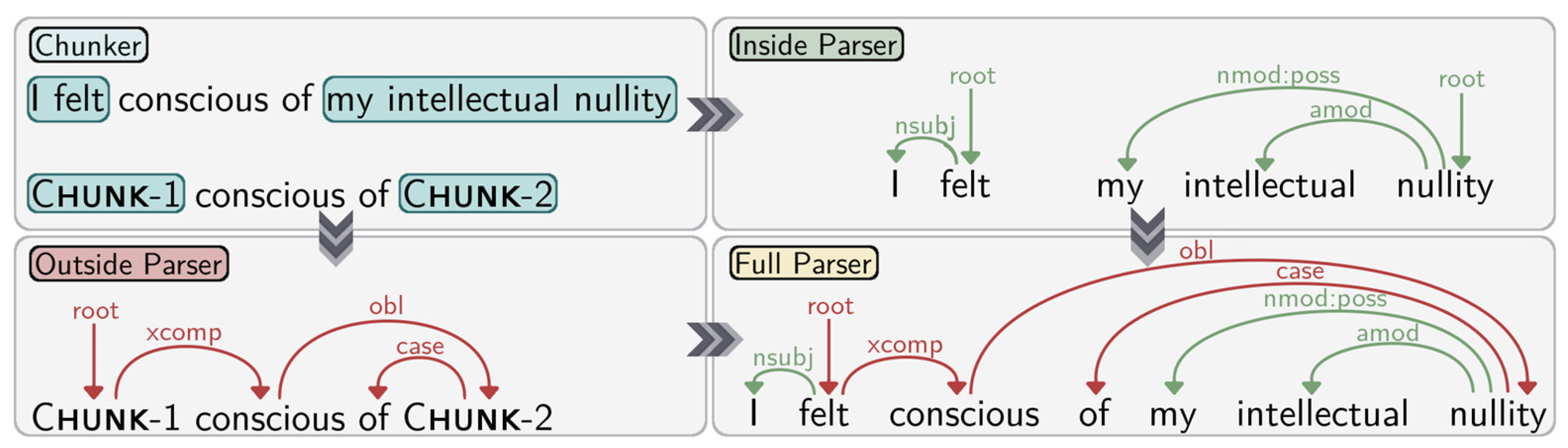
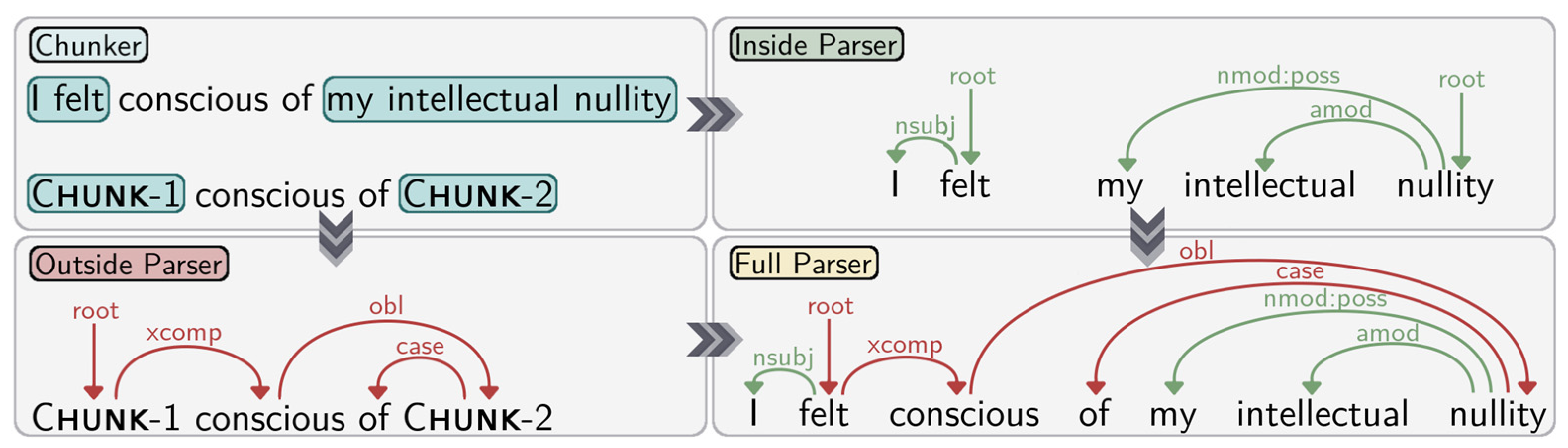
2. Materials and Methods
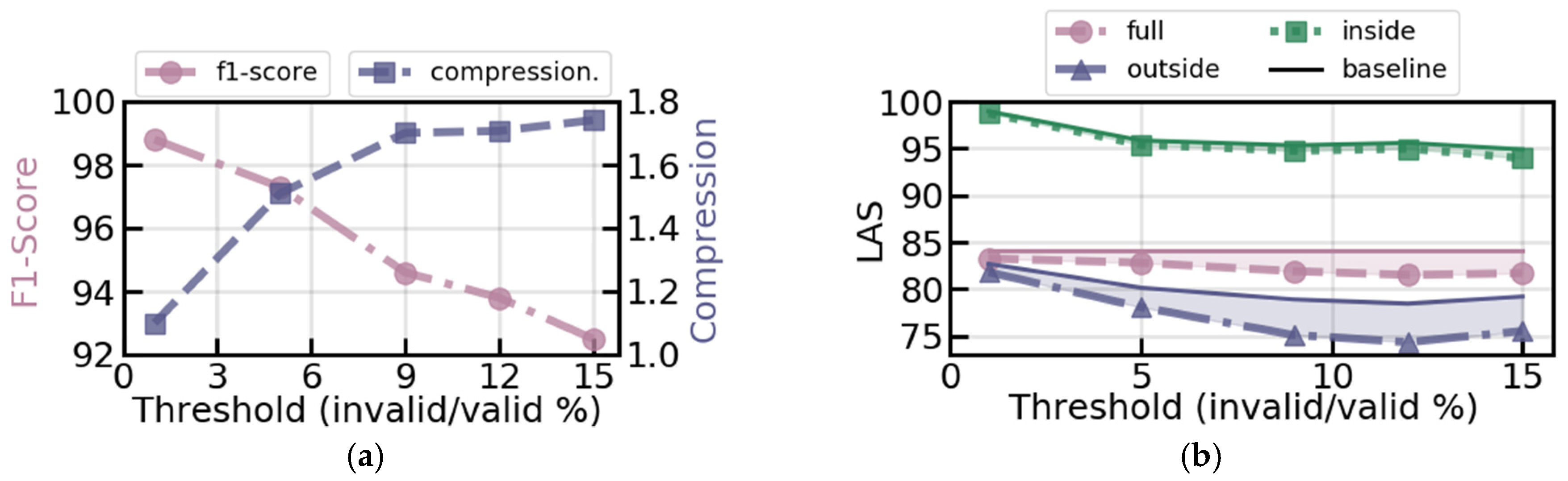
3. Results
4. Discussion
Funding
References
- Gómez-Rodríguez, C. Towards fast natural language parsing: FASTPARSE ERC Starting Grant. Proces. Leng. Nat. 2017, 59, 121–124. [Google Scholar]
- Christiansen, M.H.; Chater, N. The Now-or-Never bottleneck: A fundamental constraint on language. Behav. Brain Sci. 2016, 39, e62. [Google Scholar] [CrossRef] [PubMed]
- Nivre, J.; Agić, Ž.; Ahrenberg, L.; Antonsen, L.; Aranzabe, M.J.; Asahara, M.; Ateyah, L.; Attia, M.; Atutxa, A.; Augustinus, L.; et al. Universal Dependencies 2.1; LINDAT/CLARIN Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University: Prague, Czech Republic, 2017. [Google Scholar]
- Yang, J.; Zhang, Y. NCRF++: An Open-source Neural Sequence Labeling Toolkit. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Nivre, J.; Hall, J.; Nilsson, J. Maltparser: A data-driven parser-generator for dependency parsing. Proceedings of LREC, Genoa, Italy, May 2006; pp. 2216–2219. [Google Scholar]
- Chen, D.; Manning, C. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 2014; pp. 740–750. [Google Scholar]
- Straka, M.; Hajic, J.; Straková, J.; Hajic jr, J. Parsing universal dependency treebanks using neural networks and search-based oracle. In Proceedings of the International Workshop on Treebanks and Linguistic Theories (TLT14), Warsaw, Poland, 11–12 December 2015; pp. 208–220. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anderson, M.D.; Vilares, D. Increasing NLP Parsing Efficiency with Chunking. Proceedings 2018, 2, 1160. https://doi.org/10.3390/proceedings2181160
Anderson MD, Vilares D. Increasing NLP Parsing Efficiency with Chunking. Proceedings. 2018; 2(18):1160. https://doi.org/10.3390/proceedings2181160
Chicago/Turabian StyleAnderson, Mark Dáibhidh, and David Vilares. 2018. "Increasing NLP Parsing Efficiency with Chunking" Proceedings 2, no. 18: 1160. https://doi.org/10.3390/proceedings2181160
APA StyleAnderson, M. D., & Vilares, D. (2018). Increasing NLP Parsing Efficiency with Chunking. Proceedings, 2(18), 1160. https://doi.org/10.3390/proceedings2181160