Human Activity Recognition from the Acceleration Data of a Wearable Device. Which Features Are More Relevant by Activities? †

 ,
,  ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Materials
2.1. Dataset
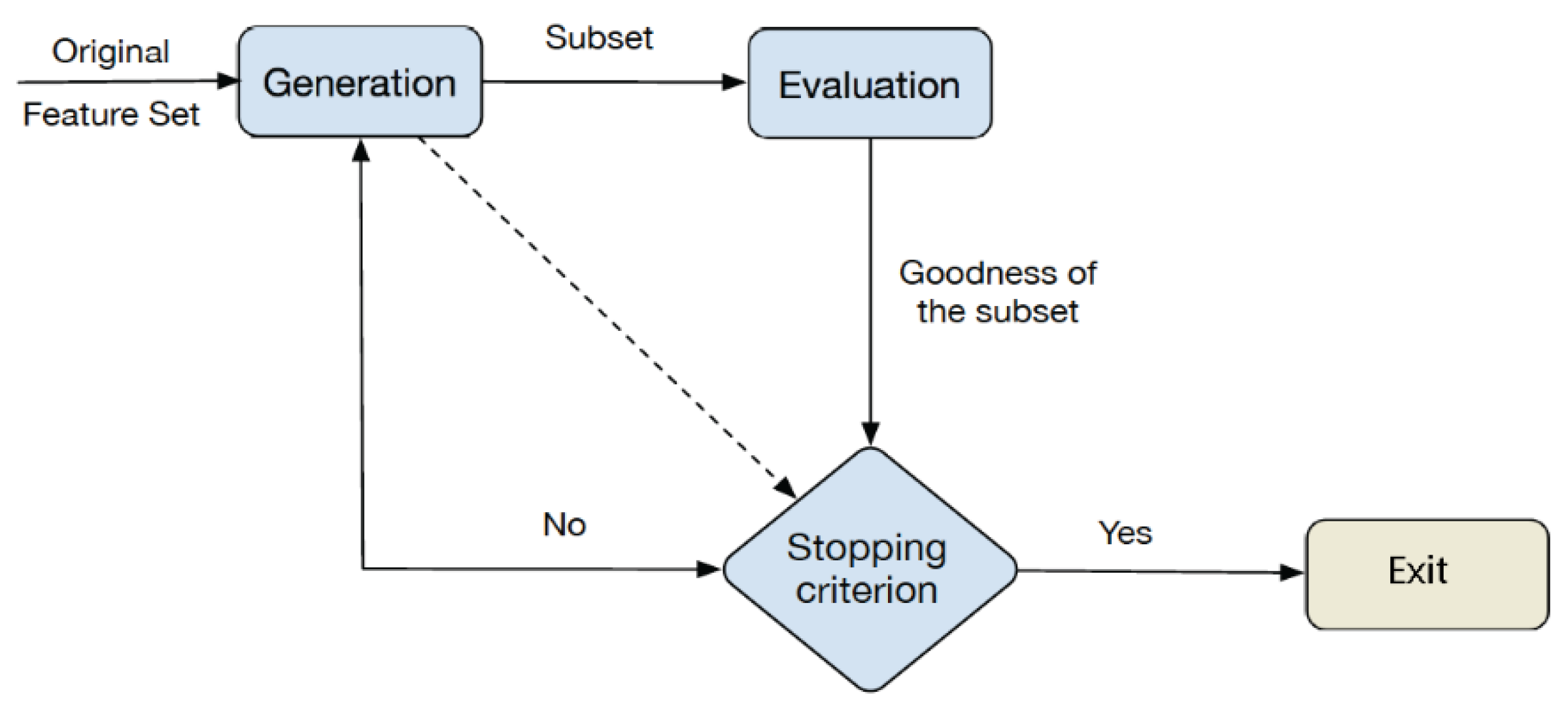
2.2. Feature Selection Methods
2.3. Classification Algoritms
- -
- Naive Bayes classifier (NB) [14]. The basic idea in NB classifier is to use the joint probabilities of sensors and activities to estimate the category probabilities given a new activity. This method is based on the assumption of sensor independence, i.e., the conditional probability of a sensor given an activity is assumed to be independent of the conditional probabilities of other sensors given that activity.
- -
- -
- Decision Table (DT) [16]. This classifier is based on a table of rules and classes. Given an unlabeled sample, this classifier searches for the exact match in the table and returns the majority class label among all matching samples, or informs no matching is found.
- -
- A Multi-Layer Perceptron (MLP) [17] is a feedforward neural network with one or more layers between input and output layer. Each neuron in each layer is connected to every neuron in the adjacent layers. The training data is presented to the input layer and processed by the hidden and output layers.
- -
- Support Vector Machines (SVMs) [18]. This method focuses on a non-linear mapping to transform the original training data into a higher dimension. Within this new dimension, it searches for the linear optimal separating hyperplane. A hyperplane is a decision boundary that separates the tuples of one activity from another.
3. Method
- -
- The first experiment (Exp1) evaluates the complete dataset with the 27 features in order to establish the accuracy with each classification algorithm, considering the 6 scenarios.
- -
- The second experiment (Exp2) evaluates two feature selection methods in the complete dataset. The experiment Exp2.A applies the consistencySubsetEval method per each classification algorithm and the experiment Exp2.B applies the CfsSubsetEval method per each classification algorithm.
- -
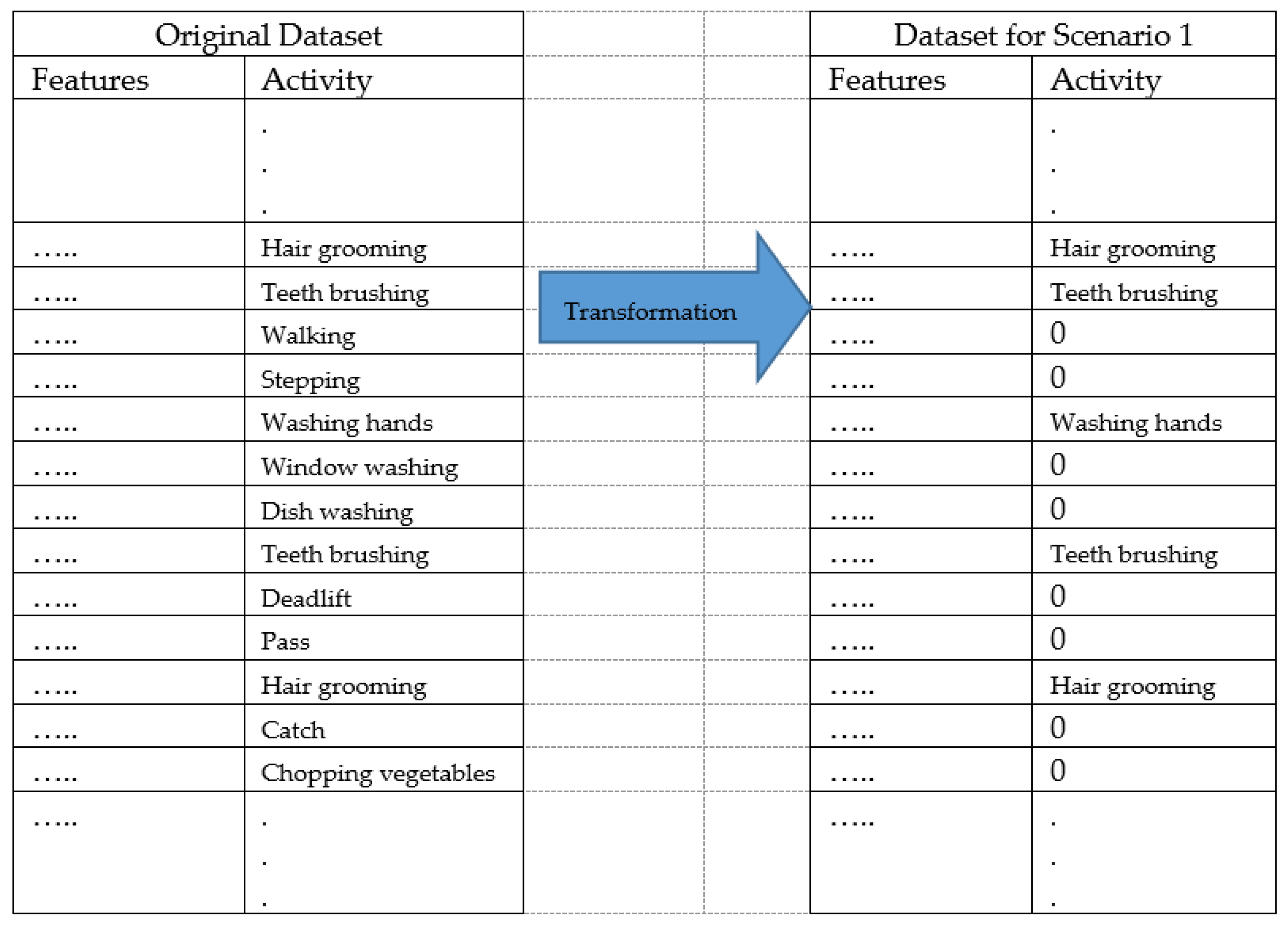
- The third experiment (Exp3) transforms the complete dataset into six different datasets per scenarios. Therefore, per each scenario, the classes of that scenario are preserved and the rest of the classes are considered as negative. For each scenario, from scenario 1 (S1) to scenario 6 (S6), two experiments are carried out according to the two feature selection methods: ‘A’ for the consistencySubsetEval method and ‘B’ for the CfsSubsetEval method. For example, Exp3.S1A is the experiment with the adapted dataset for Scenario 1 when the consistencySubsetEval method is applied. Another example, Exp3.S6B is the experiment with the adapted dataset for Scenario 6 when the CfsSubsetEval method is applied. Figure 2 illustrates the transformation process for the original dataset for the Scenario 1 in the third experiment.
4. Results
5. Discussion
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HAR | Human Activity Recognition |
References
- Aggarwal, J.K.; Xia, L.; Ann, O.C.; Theng, L.B. Human Activity Recognition: A Review. Pattern Recognit. Lett. 2014, 48, 28–30. [Google Scholar] [CrossRef]
- Gu, T.; Wang, L.; Wu, Z.; Tao, X.; Lu, J. A Pattern Mining Approach to Sensor based Human Activity Recognition. IEEE Trans. Knowl. Data Eng. 2011, 23, 1359–1372. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z.; Member, S. Sensor-based Activity Recognition. IEEE Trans. Syst. Man Cybern. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Fang, H.; He, L.; Si, H.; Liu, P.; Xie, X. Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans. 2014, 53, 1629–1638. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Srinivasan, R.; Cook, D. Feature selections for human activity recognition in smart home environments. Int. J. Innov. Comput. Inf. Control 2012, 8, 3525–3535. [Google Scholar]
- Feuz, K.D.; Cook, D.J.; Rosasco, C.; Robertson, K.; Schmitter-Edgecombe, M. Automated detection of activity transitions for prompting. IEEE Trans. Hum.-Mach. Syst. 2014. [Google Scholar] [CrossRef] [PubMed]
- Mannini, A.; Rosenberger, M.; Haskell, W.L.; Sabatini, A.M.; Intille, S.S. Activity Recognition in Youth Using Single Accelerometer Placed at Wrist or Ankle. Med. Sci. Sports Exerc. 2017, 49, 801–812. [Google Scholar] [CrossRef] [PubMed]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 33. [Google Scholar] [CrossRef]
- Cleland, I.; Donnelly, M.; Nugent, C.; Hallberg, J.; Espinilla, M.; Garcia-Constantino, M. Collection of a Diverse, Naturalistic and Annotated Dataset for Wearable Activity Recognition. In Proceedings of the 2nd International Workshop on Annotation of useR Data for UbiquitOUs Systems, Athens, Greece, 19–23 March 2018. [Google Scholar]
- Sugimoto, A.; Hara, Y.; Findley, T.; Yoncmoto, K. A useful method for measuring daily physical activity by a three-direction monitor. Scand. J. Rehabil. Med. 1997, 29, 37–42. [Google Scholar] [PubMed]
- Liu, H.; Setiono, R. A probabilistic approach to feature selection-a filter solution. In ICML; Morgan Kaufmann, 1996; Volume 96, pp. 319–327. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Subset Selection for Machine Learning. Ph.D. Thesis, University of Waikato, Hamilton, New Zealand, 1998. [Google Scholar]
- Domingos, P.; Pazzani, M. On the optimality of the simple bayesian classifier under zero-one loss. Mach. Learn. 1997, 29, 103–137. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training Feedforward Networks with the Marquardt Algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The weka data mining software: An update. ACM SIGKDD Explor. Newslett. 2009, 11, 10–18. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Scenarios | Activity | Activity id | No. of Instances |
|---|---|---|---|
| Self-Care | Hair grooming | 1 | 577 |
| Washing hands | 2 | 551 | |
| Teeth brushing | 3 | 527 | |
| Exercise (Cardio) | Walking | 4 | 491 |
| Jogging | 5 | 510 | |
| Stepping | 6 | 500 | |
| House cleaning | Ironing | 7 | 579 |
| Window washing | 8 | 555 | |
| Dish washing | 9 | 577 | |
| Exercise (Weights) | Arm curls | 10 | 516 |
| Deadlift | 11 | 469 | |
| Lateral arm raises | 12 | 511 | |
| Sport | Pass | 13 | 627 |
| Bounce | 14 | 563 | |
| Catch | 15 | 598 | |
| Food Preparation | Mixing food in a bowl | 16 | 498 |
| Chopping vegetables | 17 | 475 | |
| Sieving flour | 18 | 488 | |
| Total | 9612 |
| Feature No. | Feature Name | Feature Description |
|---|---|---|
| 1–4 | Mean value | Mean value of the x, y, z and SMV in the window. |
| 5–8 | Maximum | Maximum value of the x, y, z and SMV in the window. |
| 9–12 | Minimum | Minimum value of the x, y, z and SMV in the window. |
| 13–16 | Standard Deviation | Standard deviation of the samples x, y, z and SMV in the window. |
| 17–20 | Range | Range of the samples of SMV in the window. |
| 21–24 | Root Mean Square | Root Mean Square of the values of x, y, z and SMV in the window. |
| 25 | Signal Magnitude area | Signal Magnitude Area (SMA) across the acceleration signal in x, y and z axis. |
| 26 | Spectral Entropy | The normalized information entropy magnitudes of the discrete FFT components of the signal. |
| 27 | Total Energy | Sum of the squared magnitudes of the discrete FFT components of the signal |
| ID. Fe. | Exp2A | Exp2B | Exp3.S1A | Exp3.S1B | Exp3.S2A | Exp3.S2B | Exp3.S3A | Exp3.S3B | Exp3.S4A | Exp3.S4B | Exp3.S5A | Exp3.S5B | Exp3.S6A | Exp3.S6B | Tot. Fea. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | N | Y | Y | Y | Y | Y | N | N | Y | N | Y | N | Y | Y | 9 |
| 2 | Y | Y | N | Y | Y | N | Y | Y | N | N | N | Y | N | Y | 8 |
| 3 | Y | Y | Y | Y | Y | Y | N | Y | Y | Y | Y | Y | N | Y | 12 |
| 4 | Y | N | Y | N | Y | Y | Y | Y | N | Y | N | Y | N | Y | 9 |
| 5 | N | Y | N | N | N | N | N | N | N | Y | N | N | Y | N | 3 |
| 6 | Y | Y | Y | Y | Y | Y | Y | Y | N | Y | N | Y | Y | Y | 12 |
| 7 | Y | Y | Y | N | Y | Y | N | N | N | N | Y | N | N | Y | 7 |
| 8 | Y | Y | N | Y | Y | Y | Y | Y | N | N | Y | N | N | Y | 9 |
| 9 | Y | Y | Y | N | Y | Y | Y | Y | N | N | N | N | N | Y | 8 |
| 10 | N | Y | N | Y | N | Y | N | N | N | Y | N | N | N | N | 4 |
| 11 | N | Y | Y | N | Y | Y | N | Y | N | Y | N | Y | Y | Y | 9 |
| 12 | Y | N | Y | N | N | N | N | N | N | N | N | N | N | N | 2 |
| 13 | N | Y | N | Y | Y | Y | N | Y | N | N | N | N | Y | Y | 7 |
| 14 | Y | Y | Y | N | Y | Y | N | N | Y | Y | Y | Y | Y | N | 10 |
| 15 | Y | Y | N | N | Y | Y | Y | Y | N | N | N | Y | N | Y | 8 |
| 16 | N | Y | N | Y | Y | N | N | Y | N | N | N | N | N | N | 4 |
| 17 | Y | N | Y | Y | N | Y | Y | N | N | Y | N | N | N | N | 6 |
| 18 | N | Y | N | N | Y | Y | N | N | N | Y | N | N | Y | N | 5 |
| 19 | N | N | N | Y | Y | Y | N | N | N | N | N | N | N | N | 3 |
| 20 | N | N | N | N | N | N | N | N | N | Y | N | N | Y | N | 2 |
| 21 | Y | Y | N | N | Y | N | N | N | N | Y | N | Y | N | N | 5 |
| 22 | N | Y | Y | N | N | N | N | N | N | N | N | N | N | N | 2 |
| 23 | Y | Y | N | N | Y | N | Y | N | N | N | N | N | N | N | 4 |
| 24 | N | N | N | N | N | N | N | N | N | Y | N | N | N | N | 1 |
| 25 | N | N | N | N | Y | Y | N | Y | N | Y | N | Y | N | N | 5 |
| 26 | Y | Y | Y | Y | Y | Y | N | Y | N | N | N | N | Y | Y | 9 |
| 27 | N | N | N | N | N | N | N | N | N | N | N | N | N | N | 0 |
| Tot. Fea. | 14 | 19 | 12 | 11 | 19 | 17 | 8 | 12 | 3 | 13 | 5 | 9 | 9 | 12 |
| Accuracy | DT | NB | KNN | MLP | SVM |
|---|---|---|---|---|---|
| Exp. 1 | 0.599 | 0.631 | 0.937 | 0.831 | 0.784 |
| Exp. 2A | 0.606 | 0.624 | 0.930 | 0.789 | 0.742 |
| Exp. 2B | 0.599 | 0.658 | 0.938 | 0.825 | 0.771 |
| Exp. 3.S1A | 0.774 | 0.816 | 0.900 | 0.900 | 0.839 |
| Exp. 3.S1B | 0.885 | 0.879 | 0.959 | 0.942 | 0.760 |
| Exp. 3.S2A | 0.802 | 0.737 | 0.931 | 0.882 | 0.774 |
| Exp. 3.S2B | 0.819 | 0.748 | 0.965 | 0.910 | 0.729 |
| Exp. 3.S3A | 0.915 | 0.835 | 0.974 | 0.972 | 0.924 |
| Exp. 3.S3B | 0.842 | 0.698 | 0.962 | 0.908 | 0.715 |
| Exp. 3.S4A | 0.988 | 0.976 | 0.998 | 0.948 | 0.967 |
| Exp. 3.S4B | 0.955 | 0.928 | 0.994 | 0.990 | 0.916 |
| Exp. 3.S5A | 0.955 | 0.948 | 0.993 | 0.831 | 0.946 |
| Exp. 3.S5B | 0.900 | 0.872 | 0.989 | 0.970 | 0.916 |
| Exp. 3.S6A | 0.839 | 0.656 | 0.962 | 0.922 | 0.646 |
| Exp. 3.S6B | 0.912 | 0.852 | 0.981 | 0.941 | 0.756 |
| Scenarios | Feature Number | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | |
| All scenarios | + | + | + | + | + | + | + | + | x | x | + | + | x | x | + | x | |||||||||||
| Self-Care | + | + | x | + | x | + | x | x | x | x | x | x | + | x | |||||||||||||
| Exercise (Cardio) | + | + | + | x | + | + | + | + | + | x | + | + | + | + | + | x | x | x | + | + | x | ||||||
| House cleaning | x | + | + | x | + | x | + | + | x | x | x | + | x | x | x | x | x | x | x | ||||||||
| Exercise (Weights) | x | + | x | x | x | x | x | + | x | x | x | x | x | x | x | ||||||||||||
| Sport | + | x | x | x | x | x | + | x | x | x | x | x | x | x | x | x | x | ||||||||||
| Food Preparation | + | + | x | + | x | + | x | x | x x | x | x | x | x | x | + | x | |||||||||||
| Total + | 3 | 2 | 5 | 2 | 0 | 5 | 2 | 3 | 3 | 0 | 2 | 0 | 2 | 4 | 3 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 4 | 0 |
| Total x | 1 | 1 | 0 | 0 | 4 | 0 | 2 | 1 | 2 | 3 | 0 | 5 | 2 | 1 | 2 | 3 | 2 | 3 | 5 | 5 | 3 | 5 | 4 | 6 | 3 | 2 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Espinilla, M.; Medina, J.; Salguero, A.; Irvine, N.; Donnelly, M.; Cleland, I.; Nugent, C. Human Activity Recognition from the Acceleration Data of a Wearable Device. Which Features Are More Relevant by Activities? Proceedings 2018, 2, 1242. https://doi.org/10.3390/proceedings2191242
Espinilla M, Medina J, Salguero A, Irvine N, Donnelly M, Cleland I, Nugent C. Human Activity Recognition from the Acceleration Data of a Wearable Device. Which Features Are More Relevant by Activities? Proceedings. 2018; 2(19):1242. https://doi.org/10.3390/proceedings2191242
Chicago/Turabian StyleEspinilla, Macarena, Javier Medina, Alberto Salguero, Naomi Irvine, Mark Donnelly, Ian Cleland, and Chris Nugent. 2018. "Human Activity Recognition from the Acceleration Data of a Wearable Device. Which Features Are More Relevant by Activities?" Proceedings 2, no. 19: 1242. https://doi.org/10.3390/proceedings2191242
APA StyleEspinilla, M., Medina, J., Salguero, A., Irvine, N., Donnelly, M., Cleland, I., & Nugent, C. (2018). Human Activity Recognition from the Acceleration Data of a Wearable Device. Which Features Are More Relevant by Activities? Proceedings, 2(19), 1242. https://doi.org/10.3390/proceedings2191242