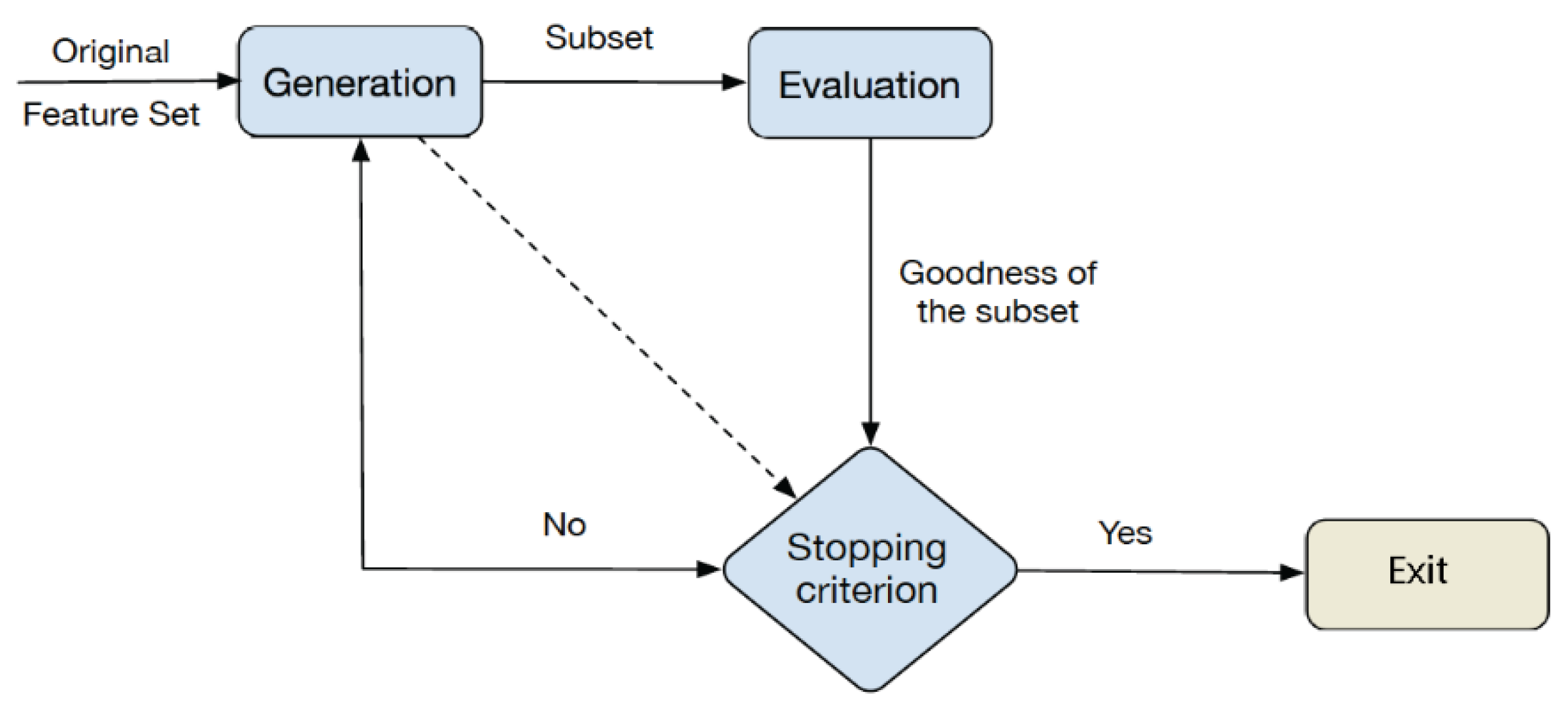
5. Discussion
In this Section, the computed accuracy results are analyzed, per scenario investigated, in order to identify which features were the most relevant and which classifier was found to work best with those features.
Regarding Experiment 1, the KNN algorithm was the classification algorithm that provided the highest accuracy. This experimentation did not apply a feature selection method and the training process was carried out with the original dataset, considering all 18 activities in the six scenarios. In this case, the ranking of the classifiers by accuracy was as follows: KNN > MLP > SVM > NB > DT.
Experiment 2 applied the consistencySubsetEval method in Exp2.A, which identified 14 features, and the CfsSubsetEval method in Exp2.B, which identified 19 features. The features that both feature selection methods excluded were {19,20,24,25,27}. Exp2.A and Exp2.B obtained very similar results with each classifier; however, Exp2.B required 6 fewer features than Exp2.A. The The common features of both methods were {2,3,6,7,8,9,14,15,21,23}. Therefore, we can consider these features are very important in the original dataset, to identify all the activities independent of each scenario. Exp2A is outperforming Exp2B, except when DT is used. (0.606 vs. 0.599). In both experiments, the best classifier was found to be KNN with the respective ranking of the classifiers matching those reported in Exp1: KNN > MLP > SVM > NB > DT.
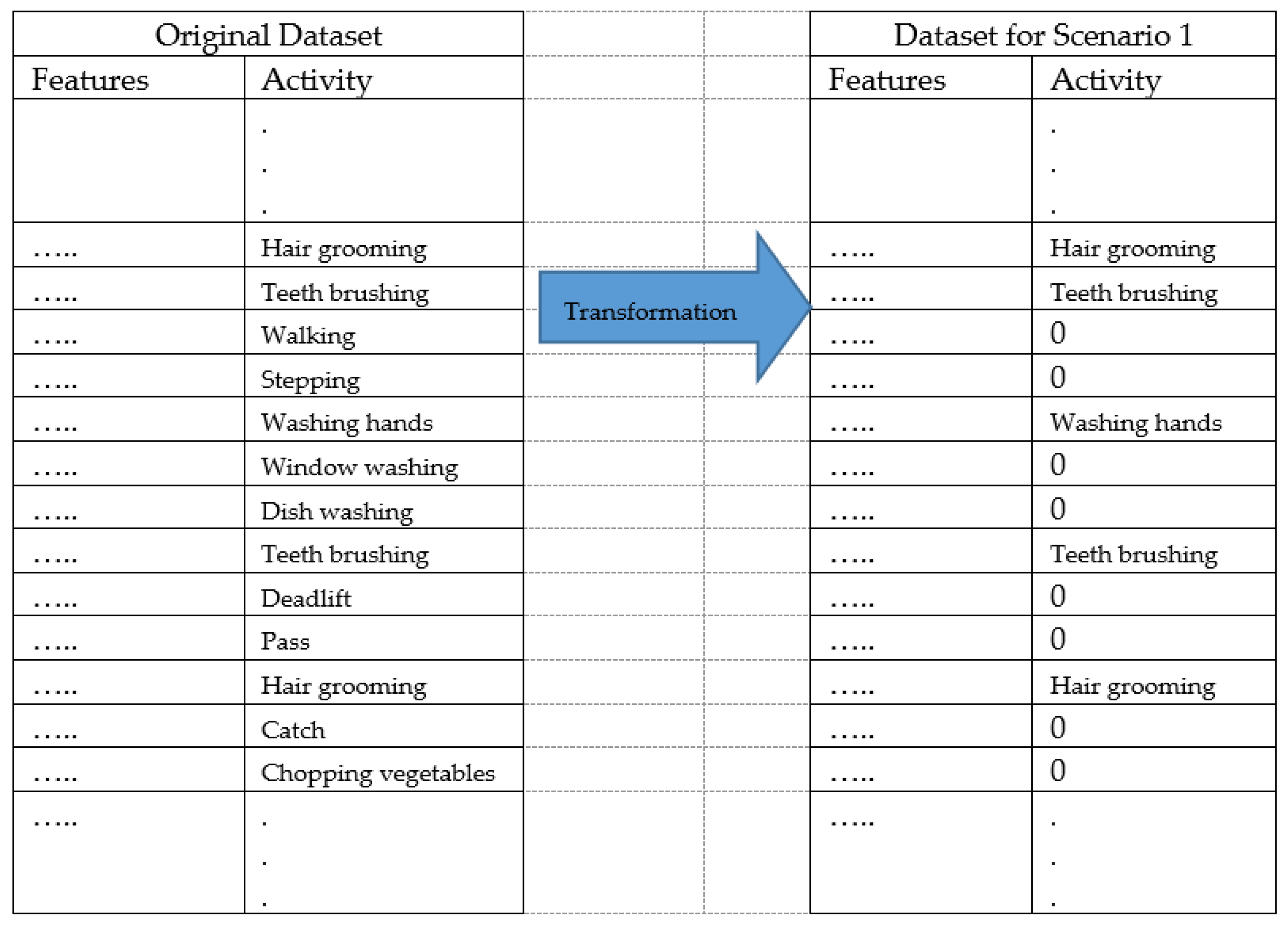
Regarding Experiment 3, the increase in terms of accuracy when the dataset was adapted for each of the scenarios, merits remark. As mentioned above, the adaptation consisted of generating a dataset for each scenario where the activities within this scenario were included as positive and the rest of the activity classes of the other scenarios were considered as negatives. In the positive class, multiple activities are in each scenarios (see
Figure 1). In the used dataset, each scenario has 3 activities. Full results for each experiment are presented in
Table 5 and discussed below.
From Scenario 1 (Self-Care), which included three activities, the consistencySubsetEval method was applied in Exp3.S1A, which identified 12 features, and the CfsSubsetEval method was applied in Exp3.S1B, which identified 11 features. The features that both feature selection methods excluded were {5,15,18,20,21,23,24,25,27} and, therefore, these were deemed irrelevant. The common features of both methods were {1,3,6,17,26} so, these features were considered very relevant with the three activities from scenario 1. Regarding the classifiers, accuracy results were very similar, however, again the best classifier was KNN (the results were the same in KNN and MLP in S1.A) and the order of the classifiers by accuracy was the same as in Exp 1: KNN > MLP > SVM > NB > DT.
From Scenario 2 (Exercise-Cardio), which included three activities, the consistencySubsetEval method was applied in Exp3.S2A, which identified 19 features, and the CfsSubsetEval method was applied in Exp3.S2B, which identified 17 features. The features that both feature selection methods excluded were {5,12,20,22,24,27}. The common features of both methods were {1,3,4,6,7,8,9,11,13,14,15,18,19,25,26} so we can consider these features relevant to identify the three activities from scenario 2. Regarding the classifiers, both accuracy results are very similar with the best classifier reported as KNN. The order of the classifiers by accuracy deviated slightly from earlier experiments in the Exp3.S2A (KNN > MLP > DT > SVM > NB) and Exp3.S2B with (KNN > MLP > DT > NB > SVM).
From scenario 3 (House cleaning), which included three activities, the consistencySubsetEval method was applied in Exp3.S3A, which identified 8 features, and the CfsSubsetEval method was applied in Exp3.S3B, which identified 12 features. The features that both feature selection methods excluded were {1,5,7,10,12,14,18,19,20,21,22,24,27} and, therefore, these were not relevant. The common features of both methods were {2,4,6,8,9,15}. In this case, we observed that the features selected by the consistencySubsetEval method were more relevant than the features selected by the CfsSubsetEval. Regarding the classifiers, in both cases, the best classifier was found to be the KNN.
From scenario 4 (Exercise-Weights), which included three activities, the consistencySubsetEval method was applied in Exp3.S4A, which identified only 3 features, and the CfsSubsetEval method was applied in Exp3.S4B, which identified 13 features. The features that both feature selection methods excluded were {2,7,8,9,12,13,15,16,19,22,23,26,27}. The common relevant features of both methods were {3,14}. In this case, we consider that the 3 features selected by the consistencySubsetEval method were equally relevant to the 13 features selected by the CfsSubsetEval because the accuracy results were very high (more than 0.92) and comparable to each other. Regarding the classifiers, in both cases, they all reported good performance with the best being KNN.
From scenario 5 (Sport), which included three activities, the consistencySubsetEval method was applied in Exp3.S5A, which identified only 5 features, and the CfsSubsetEval method was applied in Exp3.S5B, which identified 9 features. The features that both feature selection methods excluded were {5,9,10,12,13,16,17,18,19,20,22,23,24,26,27}. The common features of both methods were {3,14}. It is noteworthy that these common features were the same as those identified for scenario 4. Similar to scenario 4, we consider that the 5 features selected by the consistencySubsetEval method are more relevant than the 9 features selected by the CfsSubsetEval because, in general terms (4 of the 5 classifiers- less MLP), the accuracy results were higher in Exp3.S5A. Regarding the classifiers, in both cases, the best classifier was the KNN.
From scenario 6 (Sport), which included three activities, the consistencySubsetEval method was applied in Exp3.S6A, which identified 9 features, and the CfsSubsetEval method was applied in Exp3.S6B, which identified 12 features. The features that both feature selection methods excluded were {10,12,16,17,19,21,22,23,24,25,27}. The common features of both methods in scenario 6 were {1,6,11,13,26}. In both cases, the KNN was selected as the best classifier and the SVM was considered the worst classifier. The ranking order was KNN > MLP > DT > NB > SVM.
In general terms, the five classifiers performed better with those features selected by consistencySubsetEval. Furthermore, the most relevant features were found to be Feature 3 and Feature 6 that were selected 12 times, Feature 14 that was selected 10 times and, finally, Feature 1, Feature 4, Feature 8, Feature 11 and Feature 26 that were selected 9 times. The less relevant features were Feature 27 (Total Energy) that was never selected, Feature 24 that was selected once (in scenario 4). Feature 12, Feature 22 and Feature 20 were only selected twice: Feature 12 in Exp2A and Exp3.S1A; Feature 20 in Exp3.S4B and Exp3.S6A and; Feature 22 in Exp2B and Exp3.S1A.
Regarding the classifiers, it was clearly demonstrated that the classifier performing best, in terms of overall classification accuracy, was KNN. A perceived issue with KNN is its computational burden because the unseen sample is compared with each sample of the training dataset. For this reason, MLP and SVM are deemed good options because, in general terms, the feature selection methods improved the accuracy significantly. These classifiers (MLP and SVM) are, however, black box in nature and in the case that a classifier based on white box is necessary; DT and NB are also good options to employ alongside the investigated feature methods.

 ,
, 






{kind=link}
{kind=link}