Portal Design for the Open Data Initiative: A Preliminary Study †

 ,
,  ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Requirements for the Open Data Initiative Portal
3. Open Data Initiative—The Platform
3.1. ODI portal—User Interface Components
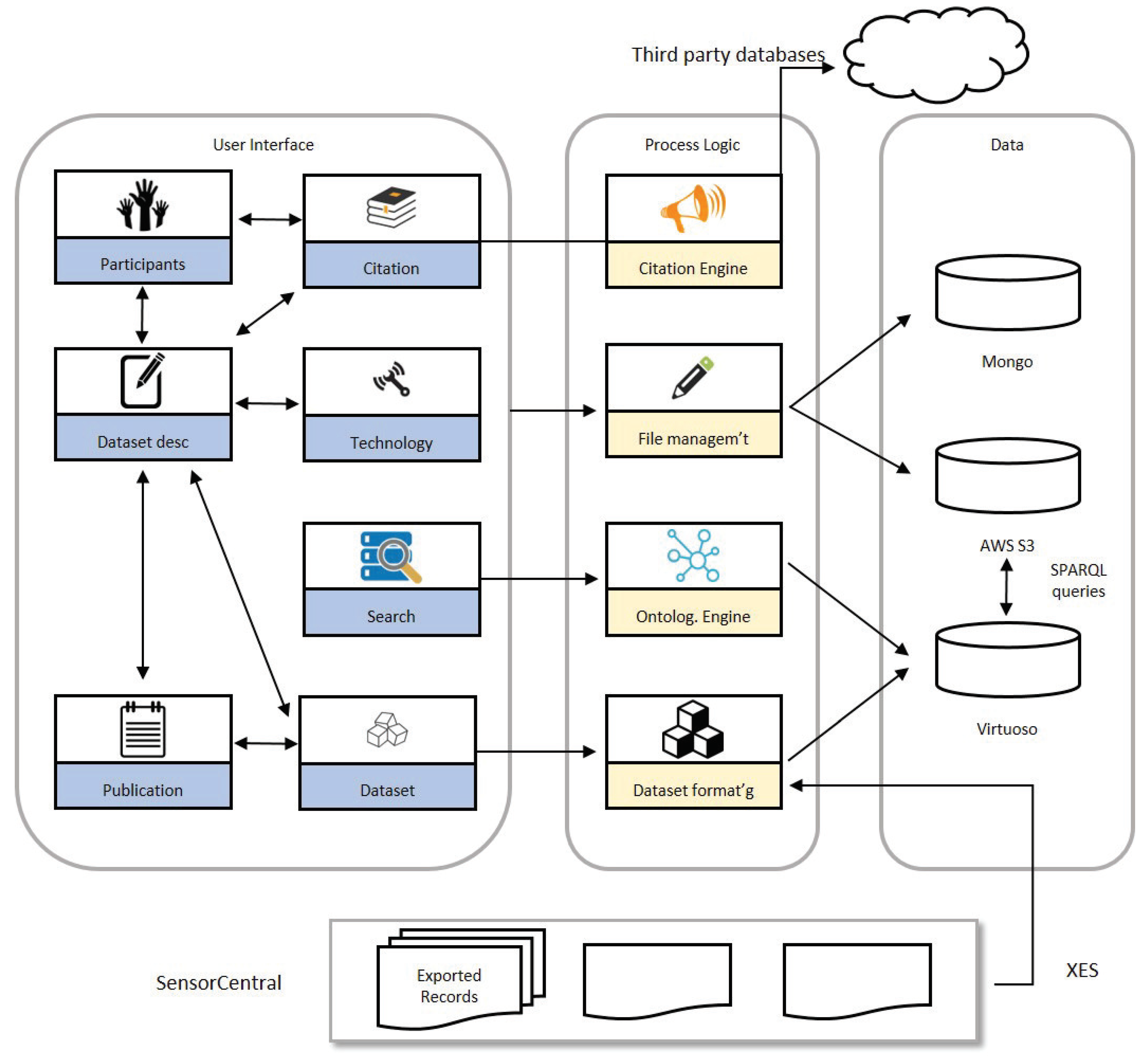
3.2. ODI Portal—Process Logic and Data Tiers
3.3. Portal User Interface Prototype
4. Technical Review
4.1. Data Entry
4.2. Dissemination
5. Proposed Revision and Concluding Comments
Acknowledgments
References
- Nugent, C.; Cleland, I.; Santanna, A.; Espinilla, M.; Synnott, J.; Banos, O.; Lundström, J.; Hallberg, J.; Calzada, A. An initiative for the creation of open datasets within pervasive healthcare. In Proceedings of the 10th EAI International Conference on Pervasive Computing Technologies for Healthcare, Cancun, Mexico, 16–19 May 2016; pp. 318–321. [Google Scholar]
- McChesney, I.; Nugent, C.; Rafferty, J.; Synnott, J. Exploring an Open Data Initiative Ontology for Shareable Smart Environment Experimental Datasets. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Cham, Switzerland, 2017; pp. 400–412. [Google Scholar]
- IEEE. IEEE Standard for eXtensible Event Stream (XES) for Achieving Interoperability in Event Logs and Event Streams; IEEE Std 1849–2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–50. [Google Scholar] [CrossRef]
- McNiff, J.; Whitehead, J. All You Need to Know about Action Research; SAGE: Newcastle upon Tyne, UK, 2011. [Google Scholar]
- Easterbrook, S.; Singer, J.; Storey, M.A.; Damian, D. Selecting empirical methods for software engineering research. In Guide to Advanced Empirical Software Engineering; Springer: Berlin, Germany, 2008; pp. 285–311. [Google Scholar]
- Hayes, G.R. The relationship of action research to human-computer interaction. ACM Trans. Comput.-Hum. Interact. 2011, 18, 15. [Google Scholar] [CrossRef]
- Zuber-Skerritt, O. Action learning and action research: Paradigm, praxis and programs. In Effective Change Management through Action Research and Action Learning; Sankara, S., Dick, B., Passfield, R., Eds.; Southern Cross University Press: Lismore, Australia, 2001; pp. 1–20. [Google Scholar]
- Bourque, P.; Fairley, R.E. Guide to the Software Engineering Body of Knowledge (SWEBOK (R)): Version 3.0; IEEE Computer Society Press: Washington, DC, USA, 2014. [Google Scholar]
- Rafferty, J.; Synnott, J.; Ennis, A.; Nugent, C.; McChesney, I.; Cleland, I. SensorCentral: A Research Oriented, Device Agnostic, Sensor Data Platform. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Berlin, Germany, 2017; pp. 97–108. [Google Scholar]
- Borsci, S.; Macredie, R.D.; Martin, J.L.; Young, T. How many testers are needed to assure the usability of medical devices? Expert Rev. Med. Devices 2014, 11, 513–525. [Google Scholar] [CrossRef] [PubMed]
- Hernández, N.; Castro, L.A.; Favela, J.; Michán, L.; Arnrich, B. Data Quality in Mobile Sensing Datasets for Pervasive Healthcare. In Handbook of Large-Scale Distributed Computing in Smart Healthcare; Springer: Berlin, Germany, 2017; pp. 217–238. [Google Scholar]
- Commons, C. Creative Commons—About The Licenses. 2018. Available online: https://creativecommons.org/about/ (accessed on 28 May 2018).




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez, N.; McChesney, I.; Rafferty, J.; Nugent, C.; Synnott, J.; Zhang, S. Portal Design for the Open Data Initiative: A Preliminary Study. Proceedings 2018, 2, 1244. https://doi.org/10.3390/proceedings2191244
Hernandez N, McChesney I, Rafferty J, Nugent C, Synnott J, Zhang S. Portal Design for the Open Data Initiative: A Preliminary Study. Proceedings. 2018; 2(19):1244. https://doi.org/10.3390/proceedings2191244
Chicago/Turabian StyleHernandez, Netzahualcoyotl, Ian McChesney, Joe Rafferty, Chris Nugent, Jonathan Synnott, and Shuai Zhang. 2018. "Portal Design for the Open Data Initiative: A Preliminary Study" Proceedings 2, no. 19: 1244. https://doi.org/10.3390/proceedings2191244
APA StyleHernandez, N., McChesney, I., Rafferty, J., Nugent, C., Synnott, J., & Zhang, S. (2018). Portal Design for the Open Data Initiative: A Preliminary Study. Proceedings, 2(19), 1244. https://doi.org/10.3390/proceedings2191244