1. Introduction
As of 2019, there are 39,671 bridges in road traffic in Germany. In the field of steel and steel composite bridges, this amounts to a total bridge area of 3,999,000 m
, 65% of these are much older than 20 years. About 46% of these bridges are in the lower half of the rating scale regarding their status of structure [
1]. These figures only concern road bridges. Rail traffic, and, accordingly, the rail bridges are not included. There are further 25,677 (December, 2018) bridges, 4899 of them are steel constructions [
2]. The
Federal Ministry of Transport and Digital Infrastructure’s traffic forecast for 2030 states that there will be an increase of 43% in rail traffic concerning tone-kilometers. The passenger service on rails should increase by almost 39% [
3].
These figures illustrate the importance of a substantial healthy and reliable infrastructure. For ensuring the continuously increasing road and rail traffic, there is a regulation for periodic monitoring of bridges [
4,
5,
6,
7].
DIN 1076 “Civil Engineering Structures for roads—Monitoring and Examination” [
5] regulates the inspection and control of all bridges concerning road traffic. For rail bridges, Ril 804.80 [
4,
6] is an analog.
Both rules mandate a building examination every six years. This examination has to be carried out visually, at a very close distance to the structure, allowing tactile feedback [
5,
6,
7]. DIN 1076 calls this examination
general inspection (H). Inspection is conducted by qualified specialists. To guarantee complete access for the specialist, technical devices are necessary. The use of these big units make (partial) road closure inevitable and are thus time consuming [
5].
In addition to the described
general inspection, DIN 1076 requires a
simple inspection (E) every six years. This should be an extended visual inspection without tools, which is three years shifted to the
general inspection (H). The defects found in the
general inspection (H) should be found and compared in the
simple inspection (E). A change of the existing defects is the focal point of this inspection (E). In those years when there is neither a
general inspection (H) nor a
simple inspection (E), an
observation (B) is required. Further, a
special investigation (S) is mandatory by order, or after general storms, fires, or accidents. These considerations demonstrate that currently a bridge inspection in Germany is tied to large expenses in personnel, equipment, and money [
5,
7].
Based on these challenges, the project
InÜDosS (InÜDosS—“Inspektion, Überwachung und Dokumentation von stahlbaulichen Strukturen”—Inspection, monitoring and documentation of steel constructions) was initiated to automate monitoring, inspection, and documentation of steel constructions.
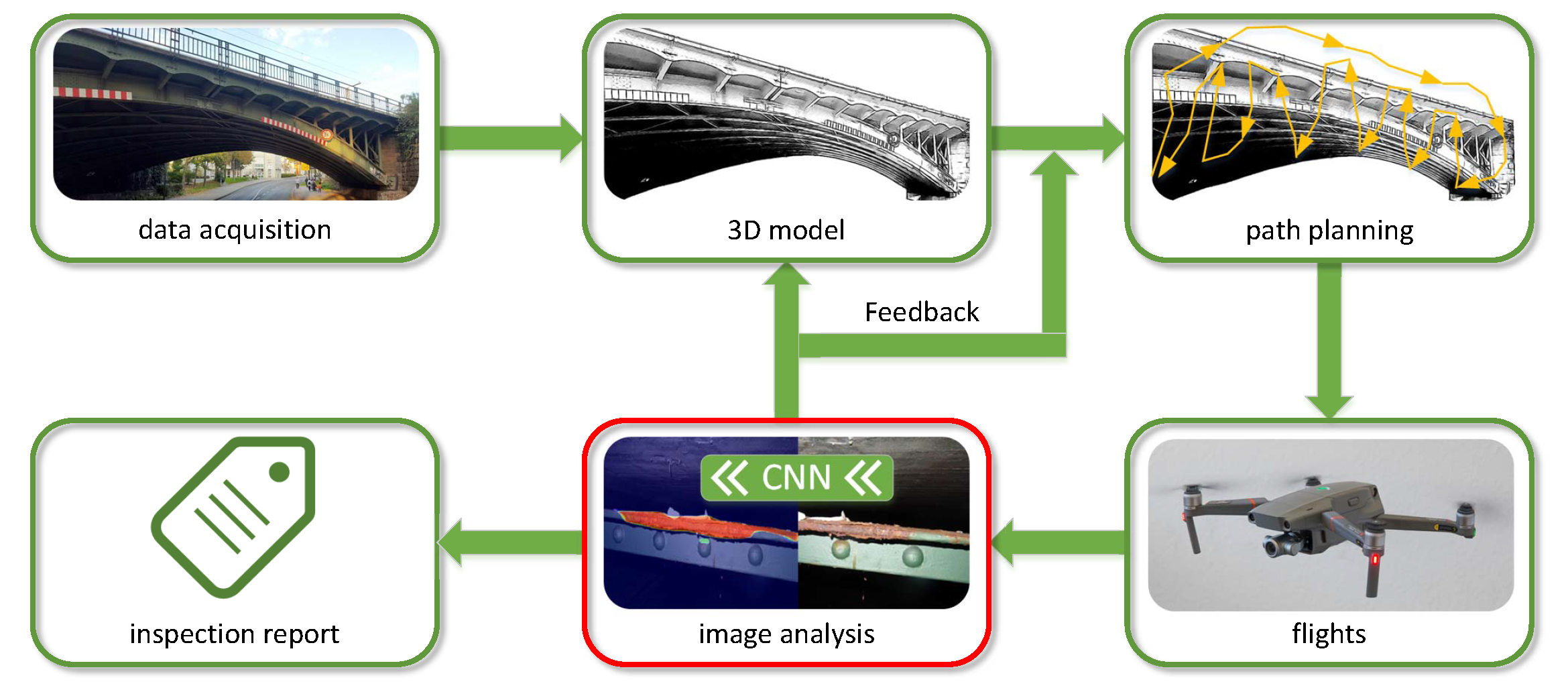
Figure 1 shows the interconnection of the different stages in our automatic monitoring approach. The scope of the project InÜDosS covers different aspects that arise in the process of monitoring steel structures with UAVs. This includes data acquisition and 3D model reconstruction, automatic path planning, and image analysis. In this paper, our focus was on the aspect of automatic image analysis (outlined in red).
There is much literature on the subject of (semi-)automatic detection of damages on civil and industrial structures. Koch et al. [
8] gave a comprehensive overview of current practice in visual inspection and damage types of civil structures including associated severity scales. The authors stated that listed defect classes are detectable with computer vision-based approaches. Further, the state-of-the-art in computer vision defect detection and assessment in the pre-DCNN era is presented. As one of the main open challenges for automatic defect retrieval, an automated process of image and video collection is identified. Recently, Zhang et al. [
9] proposed vision-based damage detection and classification using an adapted YOLOv3 network and Huethwohl et al. [
10] used a multi-classifier for reinforced concrete bridge defect detection. Furthermore, automatic detection of cracks is discussed [
11,
12,
13,
14].
The novelty of the presented work, besides the definition of a hierarchy of damage classes, is that compliance with the rules and regulations of DIN 1076 is discussed. Especially the
observations (B) and the
simple inspection (E) should both be performed only visually and without the use of tools (cf. [
5,
7]).
We discuss a vision based approach in (semi-)automatic damage detection in bridges and steel constructions using UAVs. The main contributions of this work are:
Development of a semantic classification scheme for bridge inspection in public space, which is compatible to the specifications of DIN 1076
Devising a hierarchy of defect classes
Implementation and evaluation of a corresponding cascaded classifier based on state-of-the-art CNN object detection
2. Materials and Methods
The special nature of the image data gathered demands a custom approach to tackle the problem. Field inspection images at hand show great variety concerning characteristics of the structures being investigated (cf.
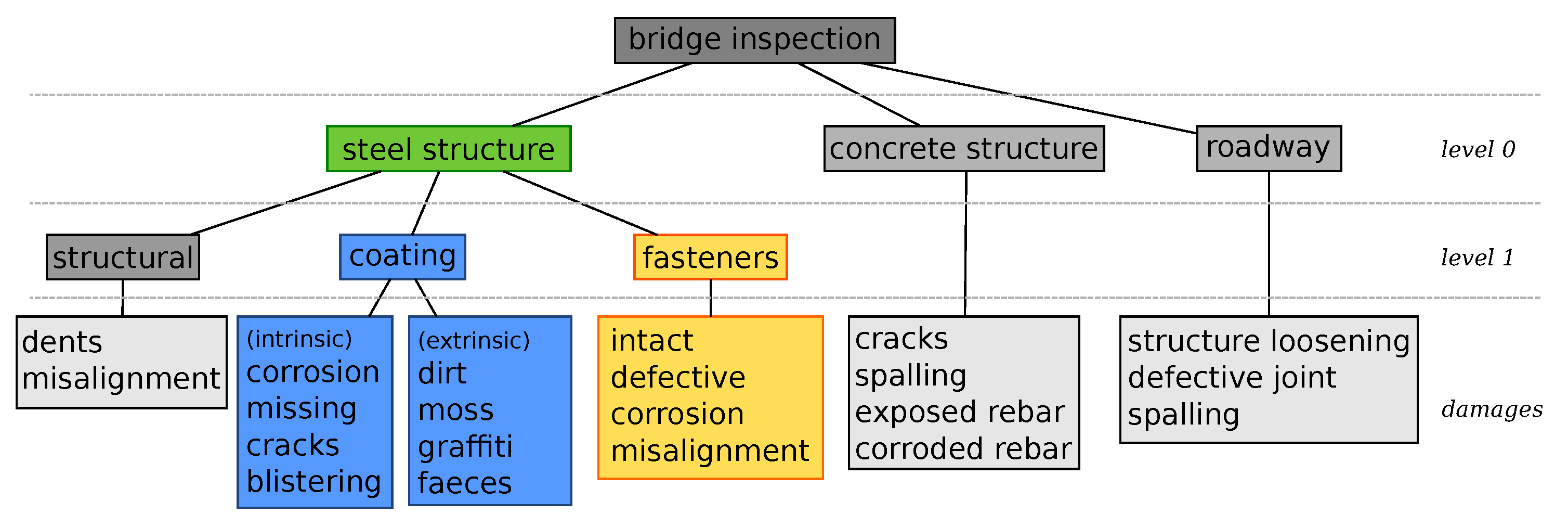
Figure 2), as well as the level of detail. Depending on the distance between the UAV and the examined object, the different types of damages only add to the complexity of the problem. Our approach is based on a hierarchy on a conceptual level, as displayed in
Figure 3, which we directly transfer to our computational method. The proposed hierarchy consists of two stages. At the first stage, we aim to identify relevant structures. Roughly speaking, this comprises all (coated) supporting steel structures. If such a structure is identified, it will then be analyzed for damages. At the second stage, we consider two main categories of potential damage: coating damages and faulty fasteners. Coating damages are further subdivided into
blistering,
cracks,
missing coating, and
corrosion. Fasteners can be
intact,
defective (e.g., loose nuts),
tilted,
missing, or
corroded.
We transfer this concept directly to the computational domain by using a two-stage convolutional neural network (CNN) approach, based on
Mask-RCNN [
15]. We use three separate instances of the Mask-RCNN (two in the second stage). All three networks use the ResNet50-backbone [
16] and
Feature Pyramid Networks (FPN) [
17]. Our implementation is based on the implementation by
Facebook Research [
18]. The proposed two-stage architecture is shown in
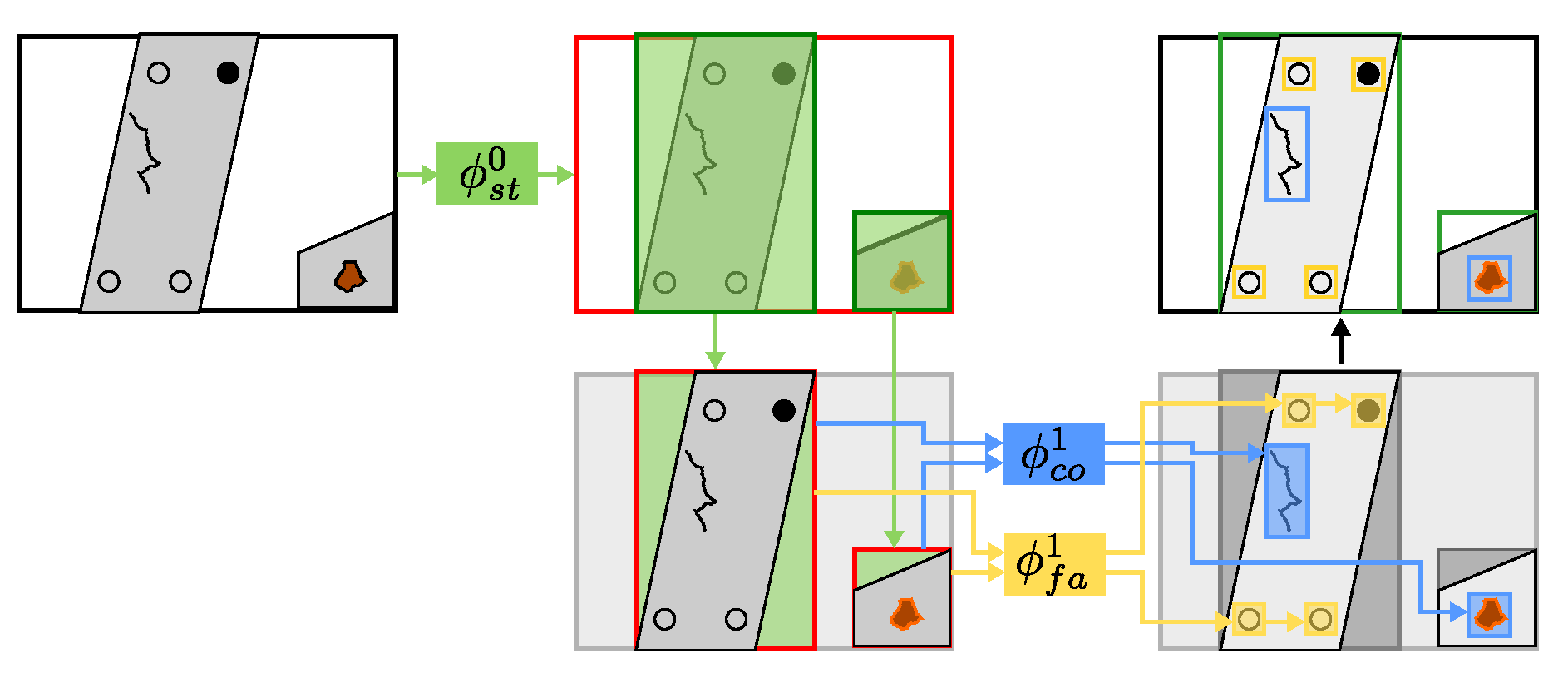
Figure 4.
The first network () is trained to recognize coated steel structures, resulting in bounding boxes of recognized structures. These bounding boxes are used as regions of interest (ROI) to restrict networks of the second stage. In the second stage, we run two separate networks, one for coating damages () and the other for fastener damages ().
More formally, for an input image , the first-stage detector determines a set of bounding boxes which define the areas of relevant structures. For each bounding box , the corresponding sub-image is cut from the full image , resulting in the set of images .
Second-stage detectors and are then applied to each sub-image , again resulting in sets of bounding boxes and . All results contained in are then projected back onto the input image , giving the final prediction results .
As a data basis, we used approximately 1000 images of steel constructions, consisting mostly of bridges and supporting steel constructions, many of them showing at least one type of damage we are considering. These images are divided into three categories:
steel structures,
coating damages, and
fasteners. Note that the images of the three datasets are not necessarily disjoint, but the corresponding annotations are. To reduce computational costs while increasing accuracy, we used transfer learning. We initialized all three networks with network weights pre-trained on the COCO (Common Objects in COntext) dataset [
19]. We trained each network for 80 epochs, at a learning rate of
and a batch size of 2. Further, an initial warm-up phase of 500 iterations (batches) was used to overcome difficulties which may arise in early phases of optimization [
20]. During training, validation tests were performed after each epoch. Data augmentation included horizontal and vertical flip, as well as variation in brightness, contrast, and saturation. Datasets were split into 11 parts of (near-)equal size. One part was used as a test set and the other ten parts for cross-validation (10-fold split).
3. Results
Figure 2 shows examples of the images used in this study. For each validation test, we determined the model(s) with the best AP, AP50, and AP75, respectively.
Figure 5a shows the average precision on the validation set of the ten-fold split (cf.
Section 2). This image shows the evaluation for the first stage (steel constructions). To make results of the cascaded and plain version comparable, we first applied the trained detector for supporting structures and then applied the same model as in the simple step on all areas suggested by the first detector. The results of this step were then projected back on the original (full) image. This allowed for directly comparing the results of the plain and the cascaded detector. We selected models according to the best performance regarding average precision.
To test our proposed two stage method, we exemplarily performed tests regarding the second-tier category coating in a simple version and a cascaded version. For the second level coating, we additionally trained networks on the same data but with reduced number of classes, in order to test how well the network is able to only recognize and spot damages without further classifying them. In these tests, we used the classes intact and defective.
For the simple version, we applied the trained model of the given category on the corresponding test dataset as is common practice. In this case, the detector was simply applied to the whole image.
Figure 5b shows IOUs on image level for a test set of 70 images. The cascaded version shows an improvement of 9% compared to the plain version.
Figure 6 shows detection results for coatings and fasteners. Red boxes indicate detection results for the first stage (steel constructions), while green boxes and outlines show results of the second stage (coating or fasteners).
4. Discussion and Conclusions
Detection of steel structures works very well, while detection and especially classification of damages is more difficult. This is mainly due to the fact that the data and the semantic categories are inherently difficult. Some damages are very subtle and hard to spot from images, even for an expert, while others depend on a significant amount of context information and interpretation. Furthermore, classes are not always clearly distinguishable, and objects may adhere to several classes at once (fasteners may be defective and corroded, for example). Overall spotting works well, and classification may be sensible, even when differing from ground truth annotation. This applies when classes overlap, or classification by a human expert is fuzzy by itself.
An automatic visual detection of defects on steel bridges complies the requirements of DIN 1076 and Ril 804.80. Required inspections are, with the exception of the
main inspection (H), only based on visual monitoring. Numerous areas of the bridge cannot be reached and inspected without big units such as aerial work platforms or units to inspect bridges from below. These tools are not intended for
observations (B) and
simple inspections (E). Thus, a periodic flyover with a UAV could improve and specify both inspections (B and E). Further, existing defects are observed and checked regularly and small changes would be detected immediately [
5,
6,
7].
The presented work shows the potential of the developed approach in designing a DIN 1076 compliant visual inspection pipeline for automated damage detection. Due to more precise annual inspections by UAV, which would replace the superficial and visual inspections without tools (B and E), a process of change of a defect would strike immediately and maintenance measures can be taken. The structure and its durability could be improved and maximixed. This presents a further step towards smart city infrastructures.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}