
Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning



Abstract
:1. Introduction
1.1. Two-Stage Methods
1.2. Single-Stage Methods
- We have experimented with several OD algorithms specified above and carried out extensive research to identify their suitability for detecting various scaled objects.
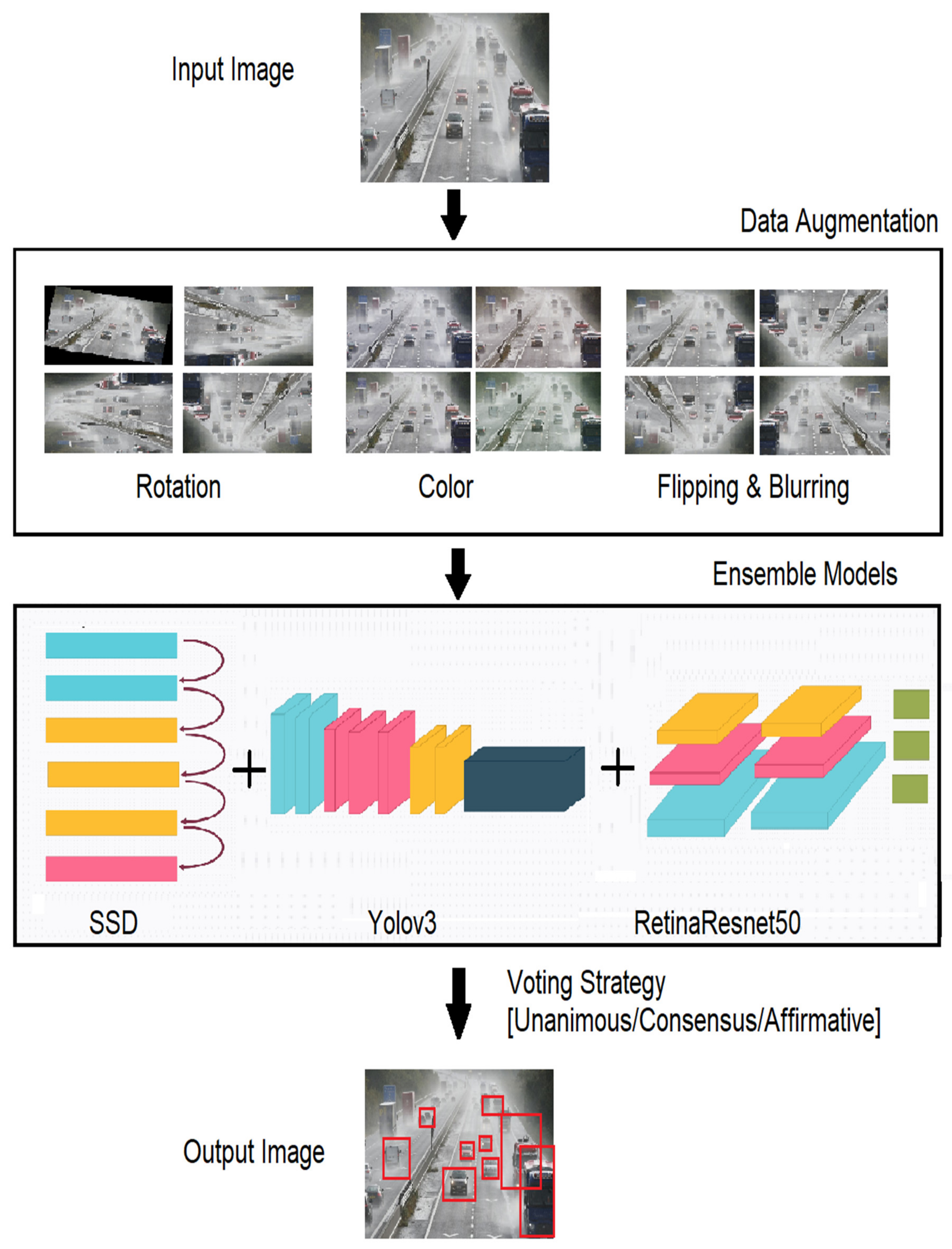
- To solve the lack of UAV datasets, we applied the test-time augmentation on the drone images datasets to boost the accuracy of OD and ensemble models. A comprehensive study of the performance of the ensemble method and voting strategies was conducted, and we have demonstrated the effects of using test-time augmentation.
- A framework combining multiple OD algorithms (both single-stage and two-stage) using the ensemble approach is proposed and demonstrated. We have implemented a general method for ensembling OD models independently of the underlying algorithm. This multi-technique ensemble algorithm is designed to choose any three approaches and experiment with OD, enabling multiscale OD by applying several voting strategies. This method effectively detects objects over a range of scales, from small-scale objects like humans, plants, and bikes to medium-like cars and larger objects like cargo trucks. Due to the change in camera angles in the images in the VisDrone and AU-AIR datasets, ordinary objects appear smaller or larger than actual, and this detection has been handled as well. The performance of the ensemble and augmentation techniques was better than the baseline models when tested on the test-dev set of the VisDrone dataset [10,11] and the AU-AIR dataset [12].
2. Materials and Methods
2.1. Datasets
2.1.1. VisDrone Dataset
2.1.2. AU-AIR Dataset
2.1.3. Handling the Dataset Challenges
2.2. Methods
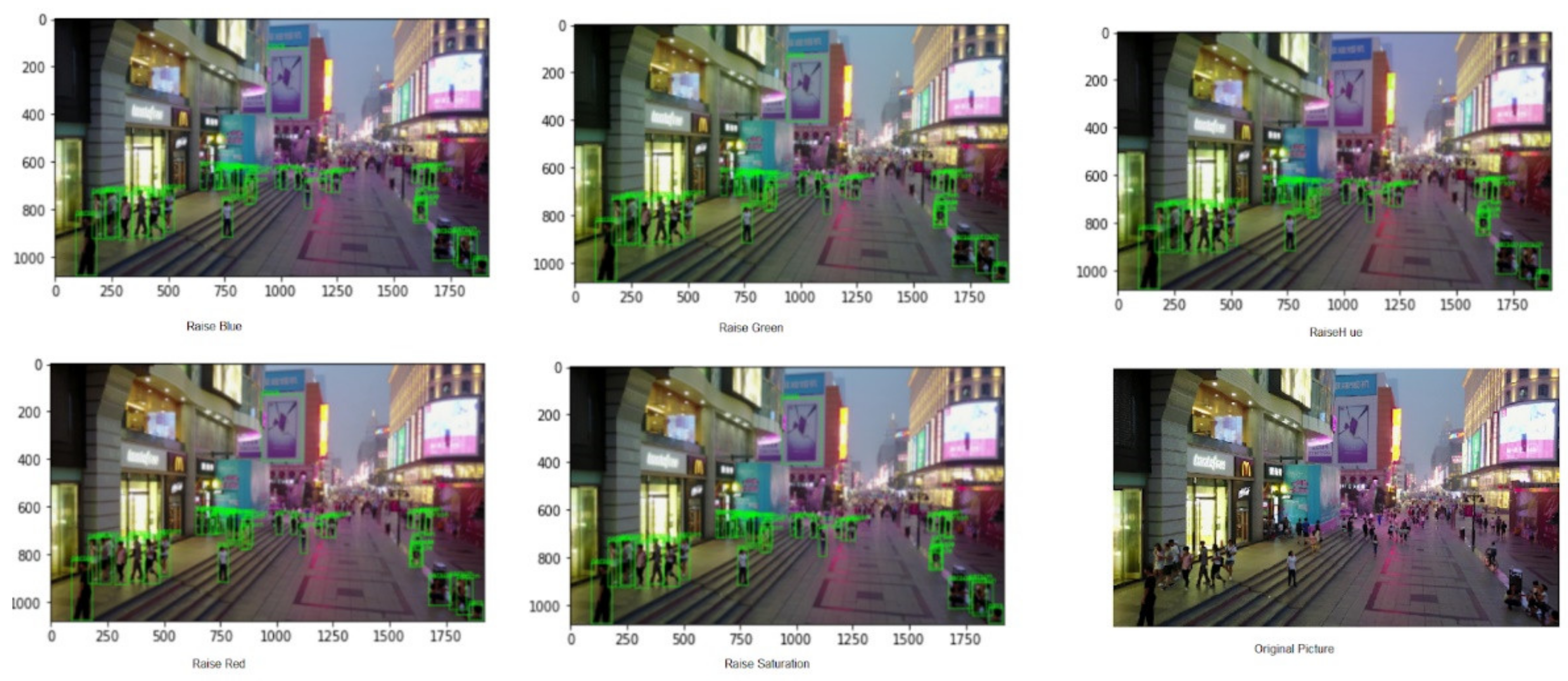
2.2.1. Data Augmentation
2.2.2. Object Detection Models
RetinaNet (Resnet50 Backbone)
YOLO (v3)
SSD (Resnet Backbone)
2.2.3. Ensembling Procedure
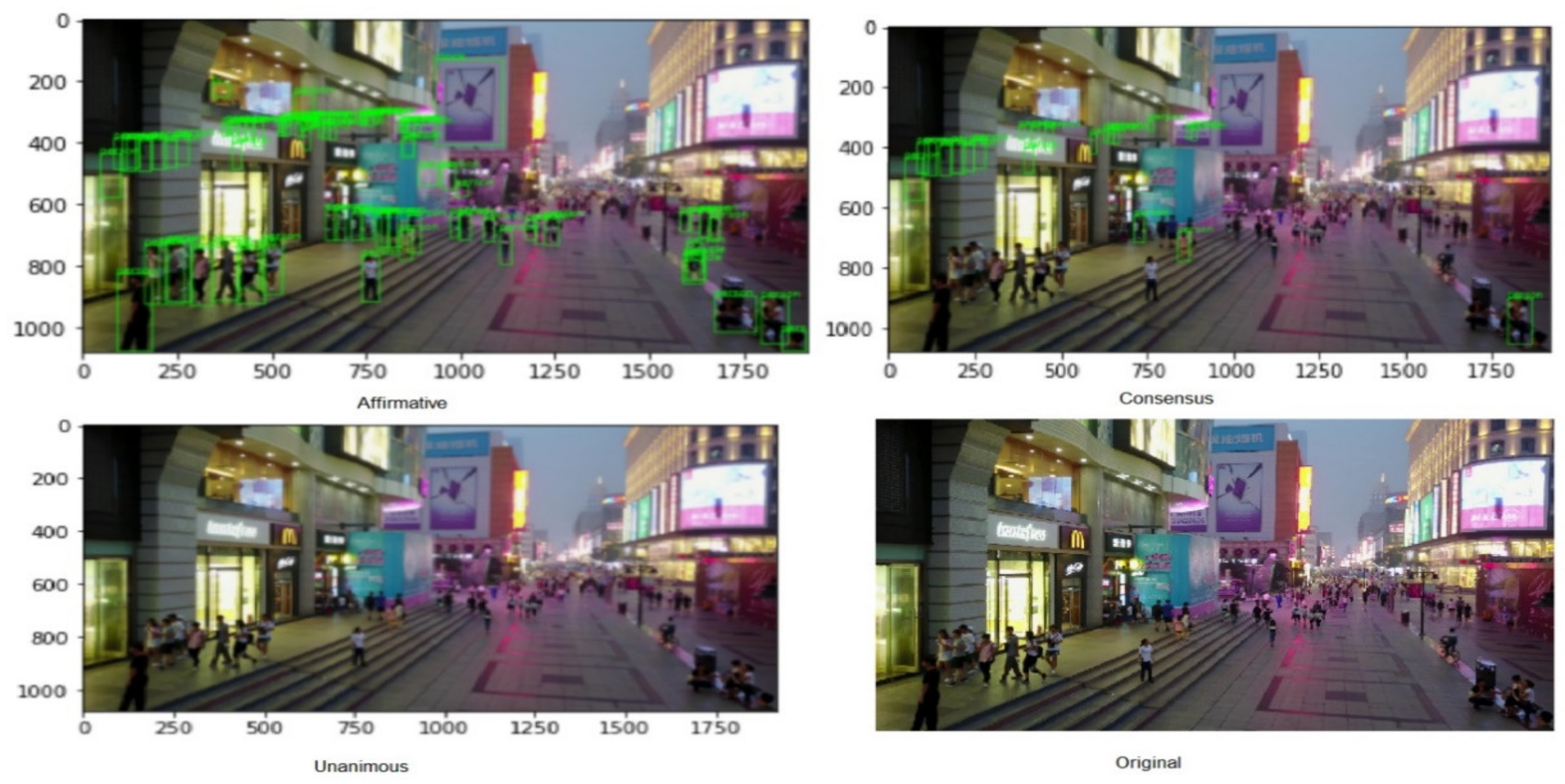
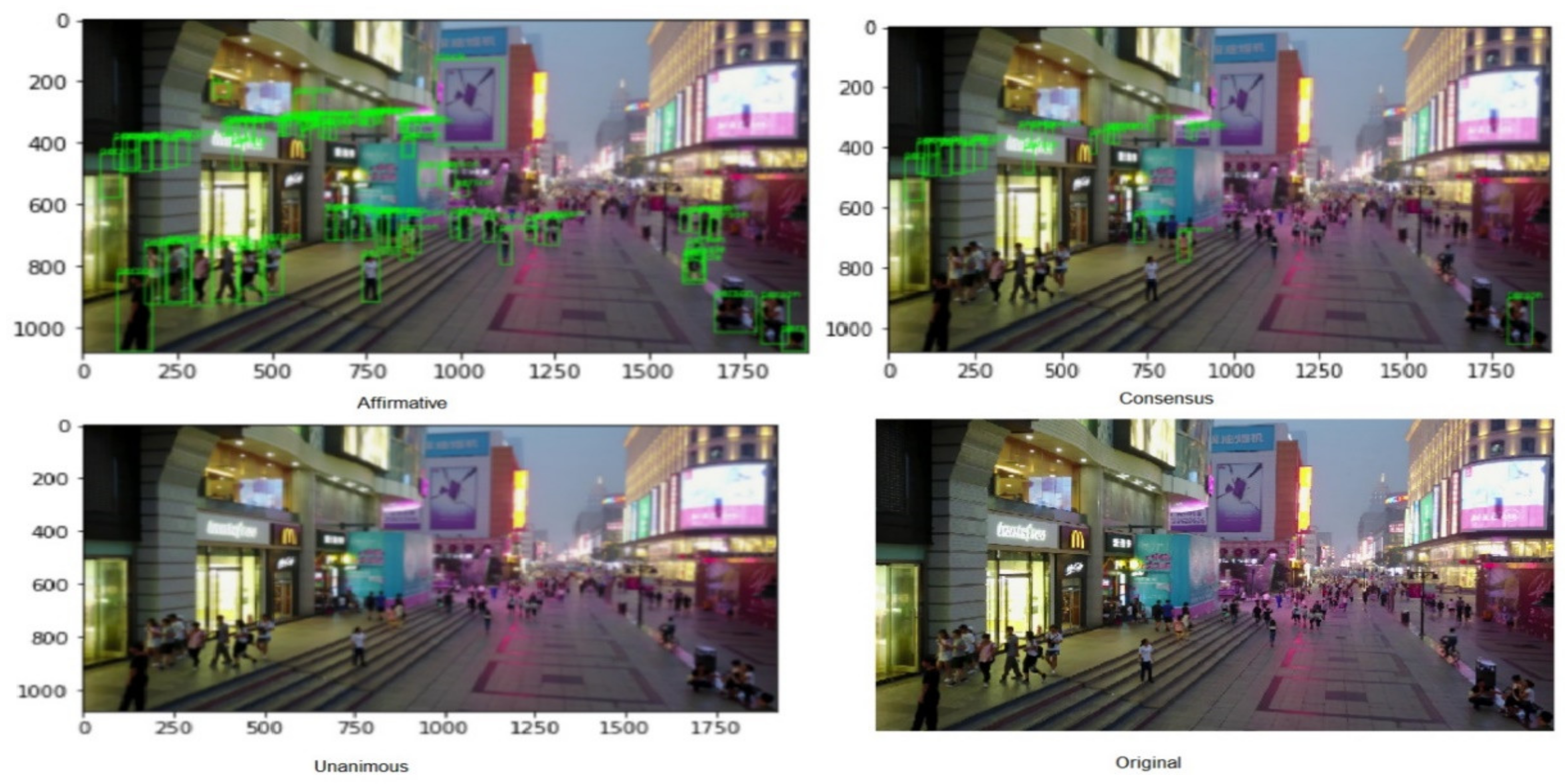
- Affirmative: In this strategy, the initial predictions are considered, and when one of the ensemble methods detects an object, it is considered valid.
- Consensus: In this strategy, an agreement of the majority of the ensemble methods must be met for successful detection. It mirrors the majority voting strategy that is usually applied in ensemble methods for OD and image classification.
- Unanimous: In this strategy, all the ensemble methods need to agree upon detection to be deemed valid. This is the most stringent of voting strategies.
- Before the procedure is initiated, the following parameters are required to be set according to the user’s intended application.
- Dataset—The target dataset on which predictions are to be made must be provided to the pipeline.
- Models—The list and weights of pretrained models to be ensembled together must be provided.
- Augmentation techniques- Any combination of augmentation techniques can be selected from Table 1 and provided to the model.
- Number of levels- The ensembling can be one level or two-level. One level model will only perform data augmentation for a single model. Two-level models will integrate augmentation and multiple models.
- Voting strategy- Out of affirmative, unanimous and consensus, the voting strategies for both levels need to be provided to the model.
- Ground truth—For measuring the performance, the ground truth labels with the list of classes must be provided.
- Performance Metric—According to the user preference, a performance metric needs to be selected. For this study setup, the VisDrone metrics, AP and mAP were configured.
- Each model starts detecting objects in parallel to the other models and uses the voting strategy to combine the detection results into single xml files. At this level, the data augmentation is used to improve the model performance.
- The results of all individual models are now processed together using a single selected voting strategy and the final bounding boxes are determined.
- The results are compared with the ground truth labels and measured using the selected performance metric.
- Visualization of the bounding boxes, percentage of wrongly assigned labels, predicted label distribution and overall results are generated for comprehensive result analysis.
2.2.4. Model Performance Assessment
VisDrone Results Assessment
AU-AIR Results Assessment
3. Experiments and Results
3.1. VisDrone Dataset Results
3.2. AU-AIR Dataset Results
4. Discussion
5. Conclusions
6. Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hariharan, B.; Arbel’aez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 297–312. [Google Scholar]
- Hariharan, B.; Arbel’aez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and finegrained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2015; pp. 447–456. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- He, K.; Gkioxari, G.; Doll’ar, P.; Girshick, R. Mask rcnn. In Proceedings of the Computer Vision (ICCV), IEEE International Conference, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2015; pp. 3128–3137. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; van den Hengel, A. Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1367–1381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X.; et al. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2896–2907. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Hu, Q.; Ling, H. Vision meets drones: Past, present and future. arXiv 2020, arXiv:2001.06303. [Google Scholar]
- Ilker, B.; Kayacan, E. Au-air: A multi-modal unmanned aerial vehicle dataset for low altitude traffic surveillance. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Toulouse, France, 2020. [Google Scholar]
- Casado-Garcıa, A.; Heras, J. Ensemble Methods for Object Detection. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 2688–2695. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; IEEE: Toulouse, France, 2001; Volume 1, p. I. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998; IEEE: Toulouse, France, 1998; pp. 555–562. [Google Scholar]
- Papageorgiou, C.; Poggio, T. A trainable system for object detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Mohan, A.; Papageorgiou, C.; Poggio, T. Example based object detection in images by components. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 349–361. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; IEEE: Toulouse, France, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multi-scale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Toulouse, France, 2008; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Toulouse, France, 2010; pp. 2241–2248. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-svms for object detection and beyond. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Toulouse, France, 2011; pp. 89–96. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 764–773. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B.; Felzenszwalb, P.F.; Mcallester, D.A. Object detection with grammar models. Adv. Neural Inf. Process. Syst. 2011, 24, 442–450. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Liu, L.; Özsu, M.T. Mean Average Precision. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Girshick, R.B.; Felzenszwalb, P.F.; McAllester, D. Discriminatively Trained Deformable Part Models, Release 5. Available online: http://people.cs.uchicago.edu/rbg/latentrelease5/ (accessed on 5 May 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recog-nition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; NIPS: La Jolla, CA, USA; pp. 379–387.
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Lin, T.-Y.; Doll’ar, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Doll’ar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42. [Google Scholar]
- Doll’ar, P.; Tu, Z.; Perona, P.; Belongie, S. Integral Channel Features. In Proceedings of the British Machine Vision Conference, BMVA Press. London, UK, 7–10 September 2009. [Google Scholar]
- Maji, S.; Berg, A.C.; Malik, J. Classification using intersection kernel support vector machines is efficient. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Toulouse, France, 2008; pp. 1–8. [Google Scholar]
- Zhu, Q.; Yeh, M.-C.; Cheng, K.-T.; Avidan, S. Fast human detection using a cascade of histograms of oriented gradients. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; IEEE: Toulouse, France, 2006; Volume 2, pp. 1491–1498. [Google Scholar]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster rcnn doing well for pedestrian detection? In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–457. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2179–2195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Toulouse, France, 2009. [Google Scholar]
- Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Ten years of pedestrian detection, what have we learned? In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 613–627. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards reaching human performance in pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 973–986. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Pang, Y.; Li, X. Learning multilayer channel features for pedestrian detection. IEEE Trans. Image Process. 2017, 26, 3210–3220. [Google Scholar] [CrossRef] [Green Version]
- Mao, J.; Xiao, T.; Jiang, Y.; Cao, Z. What can help pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Toulouse, France, 2017; pp. 6034–6043. [Google Scholar]
- Hu, Q.; Wang, P.; Shen, C.; van den Hengel, A.; Porikli, F. Pushing the limits of deep cnns for pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1358–1368. [Google Scholar] [CrossRef]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian detection aided by deep learning semantic tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5079–5087. [Google Scholar]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning cross-modal deep representations for robust pe-destrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. arXiv 2017, arXiv:1711.07752. [Google Scholar]
- Ouyang, W.; Zhou, H.; Li, H.; Li, Q.; Yan, J.; Wang, X. Jointly learning deep features, deformable parts, occlusion and classification for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1874–1887. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, J.; Schiele, B. Occluded pedestrian detection through guided attention in cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6995–7003. [Google Scholar]
- Rowley, H.A.; Baluja, S.; Kanade, T. Human face detection in visual scenes. In Advances in Neural Information Processing Systems; Department of Computer Science, Carnegie-Mellon University: Pittsburgh, PA, USA, 1996; pp. 875–881. [Google Scholar]
- Yang, G.; Huang, T.S. Human face detection in a complex background. Pattern Recognit. 1994, 27, 53–63. [Google Scholar] [CrossRef]
- Craw, I.; Tock, D.; Bennett, A. Finding face features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 1992; pp. 92–96. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Pentl, A.; Moghaddam, B.; Starner, T. View Based and Modular Eigenspaces for Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 84–91. [Google Scholar]
- Rowley, H.A.; Baluja, S.; Kanade, T. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 23–38. [Google Scholar] [CrossRef]
- Osuna, E.; Freund, R.; Girosit, F. Training support vector machines: An application to face detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; IEEE: Toulouse, France, 1997; pp. 130–136. [Google Scholar]
- Wu, Y.; Natarajan, P. Self-organized text detection with minimal post-processing via border learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar]
- Zhu, Z.; Yao, Y.C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Liu, X. A camera phone-based currency reader for the visually impaired. In Proceedings of the 10th International ACM SIGACCESS Conference on Computers and Accessibility, Halifax, NS, Canada, 13–15 October 2008; ACM: New York, NY, USA, 2008; pp. 305–306. [Google Scholar]
- Ezaki, N.; Kiyota, K.; Minh, B.T.; Bulacu, M.; Schomaker, L. Improved text-detection methods for a cam-era-based text reading system for blind persons. In Proceedings of the Eighth International Conference on Document Analysis and Recognition, Seoul, Korea, 31 August–1 September 2005; IEEE: Toulouse, France, 2005; pp. 257–261. [Google Scholar]
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional neural networks applied to house numbers digit classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; IEEE: Toulouse, France, 2012; pp. 3288–3291. [Google Scholar]
- Wojna, Z.; Gorban, A.; Lee, D.-S.; Murphy, K.; Yu, Q.; Li, Y.; Ibarz, J. Attention-based extraction of structured information from street view imagery. arXiv 2017, arXiv:1704.03549. [Google Scholar]
- Ye, Q.; Doermann, D. Text detection and recognition in imagery: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef] [PubMed]
- Møgelmose, A.; Trivedi, M.M.; Moeslund, T.B. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Perspectives and survey. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1484–1497. [Google Scholar] [CrossRef] [Green Version]
- Paulo, C.F.; Correia, P.L. Automatic detection and classification of traffic signs. In Proceedings of the Eighth International Workshop on Image Analysis for Multimedia Interactive Services, WIAMIS’07; IEEE: Toulouse, France, 2007; p. 11. [Google Scholar]
- Omachi, M.; Omachi, S. Traffic light detection with color and edge information. In Proceedings of the 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; IEEE: Toulouse, France, 2009; pp. 284–287. [Google Scholar]
- Xie, Y.; Liu, L.-f.; Li, C.-h.; Qu, Y.-y. Unifying visual saliency with hog feature learning for traffic sign detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, Xi’an, Shaanxi, China, 3–5 June 2009; IEEE: Toulouse, France, 2009; pp. 24–29. [Google Scholar]
- De Charette, R.; Nashashibi, F. Real time visual traffic lights recognition based on spotlight detection and adaptive traffic lights templates. In Proceedings of the Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; IEEE: Toulouse, France, 2009; pp. 358–363. [Google Scholar]
- Houben, S. A single target voting scheme for traffic sign detection. In Proceedings of the Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June; IEEE: Toulouse, France, 2011; pp. 124–129. [Google Scholar]
- Soetedjo, A.; Yamada, K. Fast and robust traffic sign detection. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005; IEEE: Toulouse, France, 2005; Volume 2, pp. 1341–1346. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Proia, N.; Pag’e, V. Characterization of a Bayesian ship detection method in optical satellite images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 226–230. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Pastor, E.; Lopez, J.; Royo, P. A hardware/software architecture for UAV payload and mission control. In Proceedings of the IEEE/AIAA 25TH Digital Avionics Systems Conference, Portland, Oregon, 15–18 October 2006; IEEE: Toulouse, France, 2006; pp. 1–8. [Google Scholar]
- Zeeshan, K.; Rehmani, M.H. Amateur drone monitoring: State-of-the-art architectures, key enabling technologies, and future research directions. IEEE Wirel. Commun. 2018, 25, 150–159. [Google Scholar]
- Tisdale, J.; Ryan, A.; Zennaro, M.; Xiao, X.; Caveney, D.; Rathinam, S.; Hedrick, J.K.; Sengupta, R. The software architecture of the Berkeley UAV platform. In Proceedings of the IEEE Conference on Computer Aided Control System Design, Munich, Germany, 4–6 October 2006, Joint 2006 IEEE Conference on Control Applications (CCA), Computer-Aided Control Systems Design Symposium (CACSD) and International Symposium on Intelligent Control (ISIC); IEEE: Toulouse, France, 2006. [Google Scholar]
- Mészarós, J. Aerial surveying UAV based on open-source hardware and software. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 37, 555. [Google Scholar] [CrossRef] [Green Version]
- Rumba, R.; Nikitenko, A. Decentralized Air Traffic Management System for Unmanned Aerial Vehicles. U.S. Patent 9,997,080 B1, 12 June 2018. [Google Scholar]
- Collins, T.J. Automated Unmanned Air Traffic Control System. U.S. Patent 2016/0196750 A1, 7 July 2016. [Google Scholar]
- Jewett, S.P. Agent-Based Airfield Conflict Resolution. U.S. Patent US9153138B1, 6 October 2015. [Google Scholar]
- Finn, R.L.; Wright, D. Privacy, data protection and ethics for civil drone practice: A survey of industry, regulators and civil society organisations. Comput. Law Secur. Rev. 2016, 32, 577–586. [Google Scholar] [CrossRef]
- Custers, B. Future of Drone Use; TMC Asser Press: The Hague, The Netherlands, 2016. [Google Scholar]
- Rocci, L.; So, A. A technoethical review of commercial drone use in the context of governance, ethics, and privacy. Technol. Soc. 2016, 46, 109–119. [Google Scholar]
- Doggett, S. What Is an Orthomosaic? Orthomosaic Maps & Orthophotos Explained. Dronegenuity, 23 November 2020. Available online: www.dronegenuity.com/orthomosaic-maps-explained (accessed on 7 July 2021).
- Nordstrom, S. What Is an Orthomosaic Map and How Does Mapping Benefit My Property? Dronebase. Available online: blog.dronebase.com/what-is-an-orthomosaic-map-and-how-does-mapping-benefit-my-property (accessed on 7 July 2021).
- Onishi, M.; Ise, T. Explainable identification and mapping of trees using UAV RGB image and deep learning. Sci. Rep. 2021, 11, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; Jorge, L.A.D.C.; Fatholahi, S.N.; Silva, J.D.A.; Li, J. A review on deep learning in UAV remote sensing. arXiv 2021, arXiv:2101.10861. [Google Scholar]
- Okafor, E.; Smit, R.; Schomaker, L.; Wiering, M. Operational data augmentation in classifying single aerial images of animals. In Proceedings of the IEEE International Conference on Innovations in Intelligent Systems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Castro, W.; Junior, J.M.; Polidoro, C.; Osco, L.P.; Gonçalves, W.; Rodrigues, L.; Santos, M.; Jank, L.; Barrios, S.; Valle, C.; et al. Deep Learning Applied to Phenotyping of Biomass in Forages with UAV-Based RGB Imagery. Sensors 2020, 20, 4802. [Google Scholar] [CrossRef]
- Kellenberger, B.; Volpi, M.; Tuia, D. Fast animal detection in UAV images using convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-Time Detection of Outdoor High Voltage Insulators Using UAV Imaging. IEEE Trans. Power Deliv. 2020, 35, 1599–1601. [Google Scholar] [CrossRef]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the IEEE International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017. [Google Scholar]
- Song, C.; Xu, W.; Wang, Z.; Yu, S.; Zeng, P.; Ju, Z. Analysis on the Impact of Data Augmentation on Target Recognition for UAV-Based Transmission Line Inspection. Complexity 2020, 2020, 3107450. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Jian, G.; Gould, S. Deep CNN ensemble with data augmentation for object detection. arXiv 2015, arXiv:1506.07224. [Google Scholar]
- Xu, J.; Wang, W.; Wang, H.; Guo, J. Multi-model ensemble with rich spatial information for object detection. Pattern Recognit. 2020, 99, 107098. [Google Scholar] [CrossRef]
- Reddy, D.R.; Du, D.; Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–29 October 2019. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. Visdrone-det2018: The vision meets drone object detection in image challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average blurring | None |
| Bilateral blurring | Raising the blue channel |
| Blurrin | Raising the green channel |
| Changing to HSV color space | Raising the hue |
| Blurring the image | Raising the red channel |
| Cropping the image | Raising the saturation |
| Dropout | Raising the value |
| Elastic deformation | Resizing the image |
| Equalize histogram technique | Rotation by 10° |
| Flipping the image vertically | Rotation by 90° |
| Flipping the image horizontally | Rotation by 180° |
| Flipping the image vertically and horizontally | Rotation by 270° |
| Applying Gamma correction | Adding salt and pepper noise |
| Gaussian blurring | Sharpen the image |
| Adding Gaussian noise | Shifting the channel |
| Inverting the image | Shearing image |
| Algorithm | Augmentation | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AR500 |
|---|---|---|---|---|---|---|---|---|
| SSD | No Augmentation | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SSD | Best Augmentation (Color) | 0.0% | 0.02% | 0.00% | 0.01% | 0.06% | 0.07% | 0.07% |
| Algorithms | Voting Strategy | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AR500 |
|---|---|---|---|---|---|---|---|---|
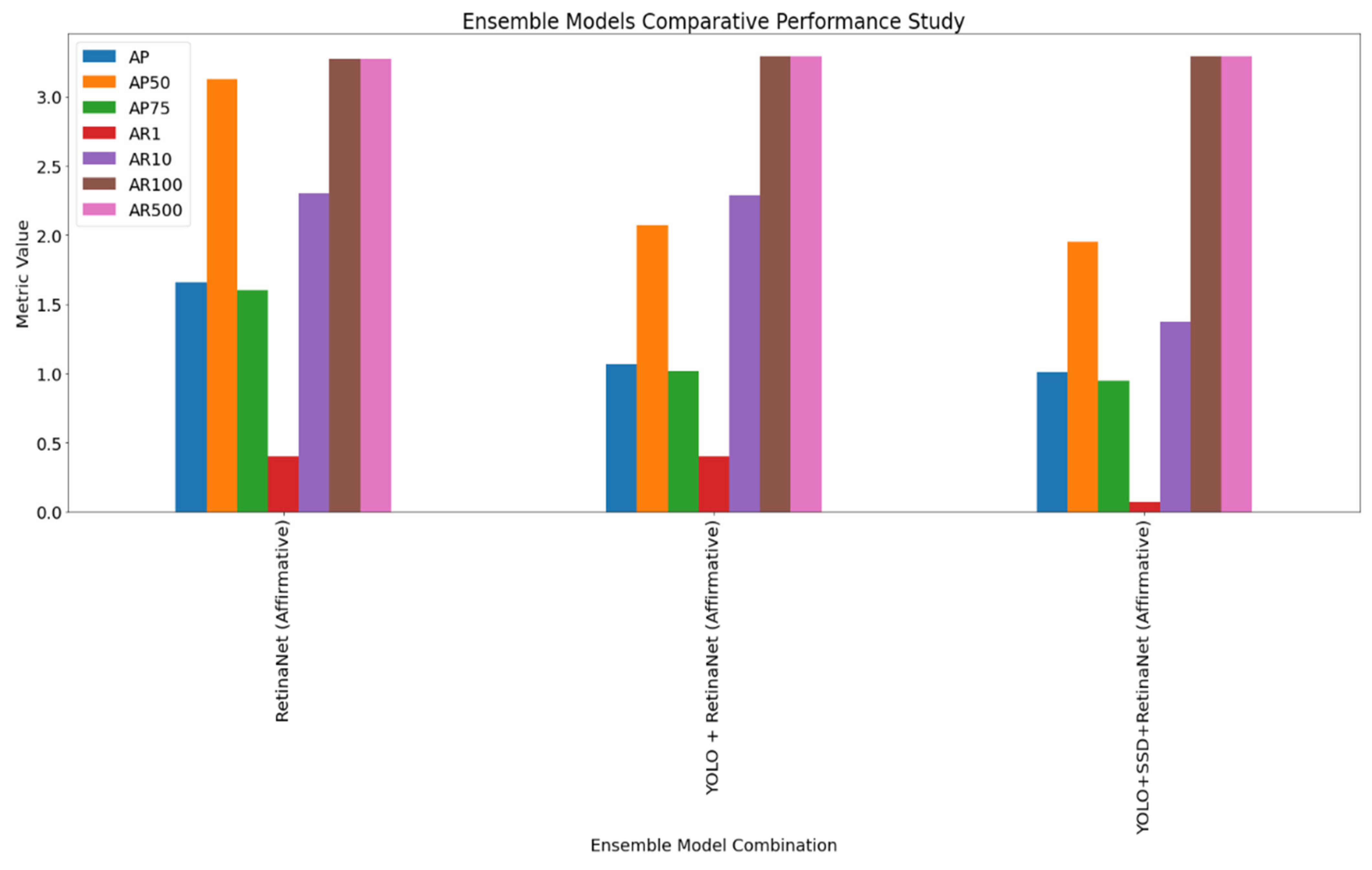
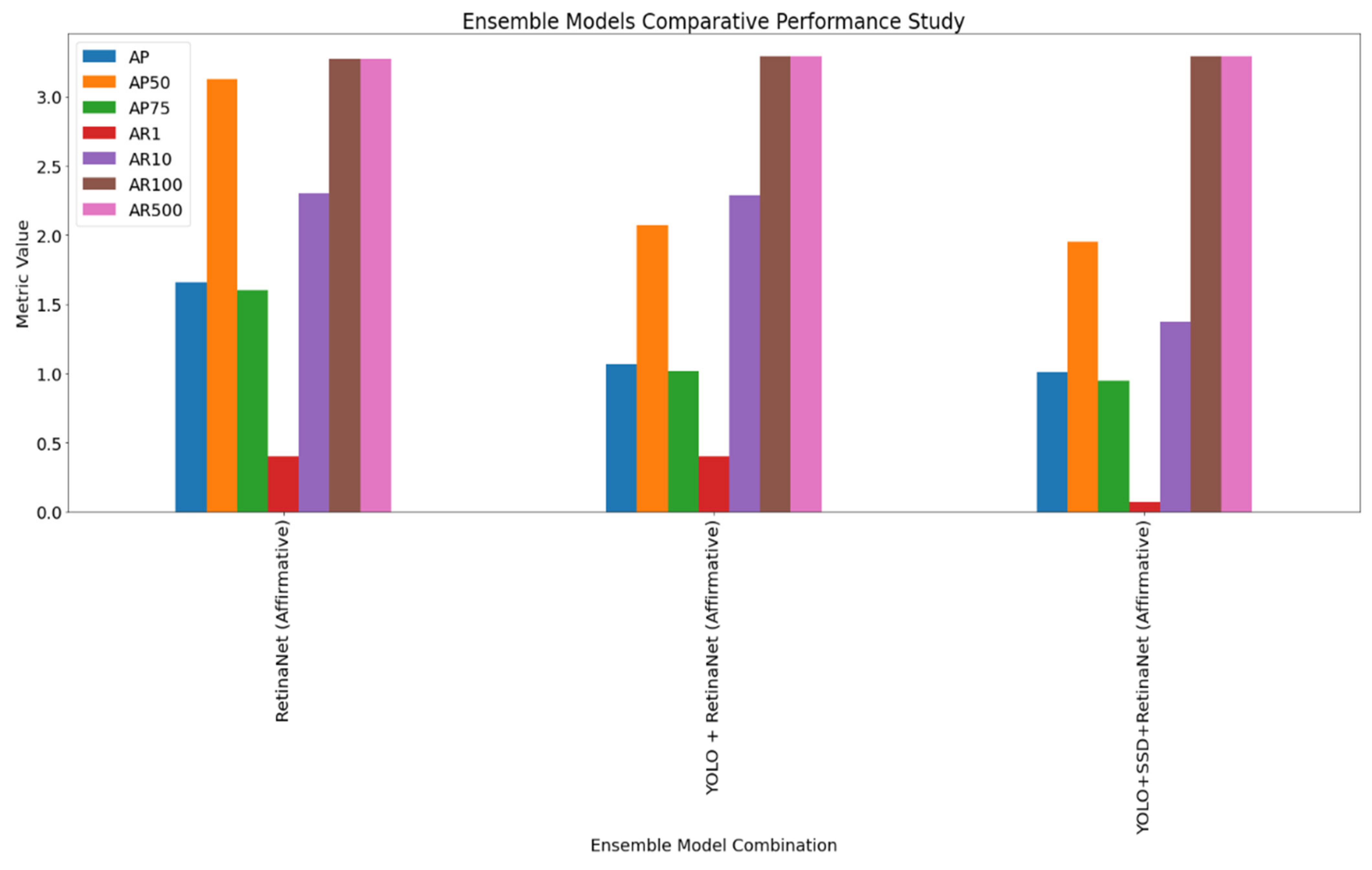
| RetinaNet | Affirmative | 1.66% | 3.13% | 1.60% | 0.40% | 2.30% | 3.27% | 3.27% |
| YOLO + RetinaNet | Affirmative | 1.07% | 2.07% | 1.02% | 0.40% | 2.29% | 3.29% | 3.29% |
| YOLO + SSD + RetinaNet | Affirmative | 1.01% | 1.95% | 0.95% | 0.07% | 1.37% | 3.29% | 3.29% |
| Algorithms | Voting Strategy | Person | Bicycle | Car | Truck | Bus |
|---|---|---|---|---|---|---|
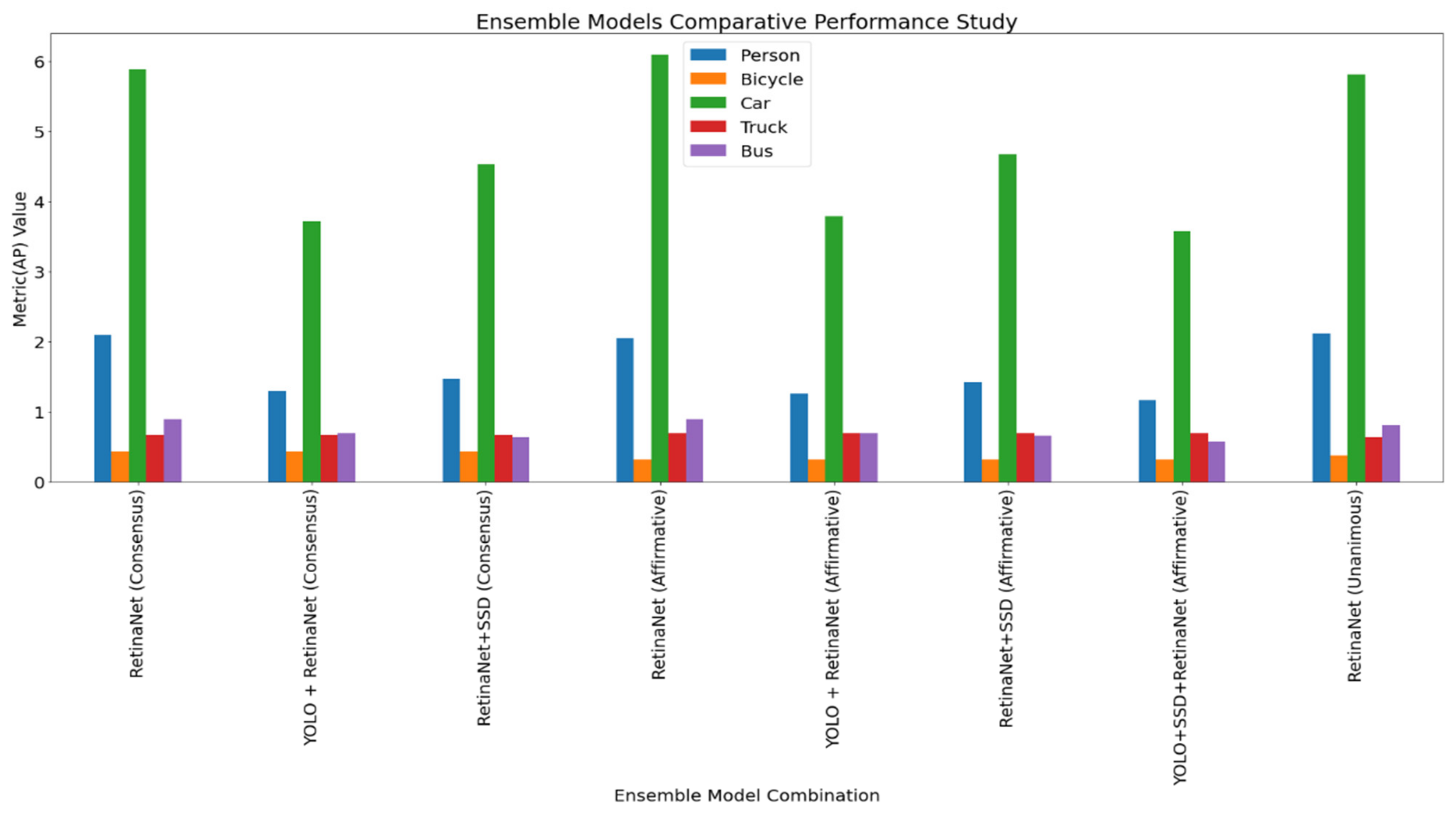
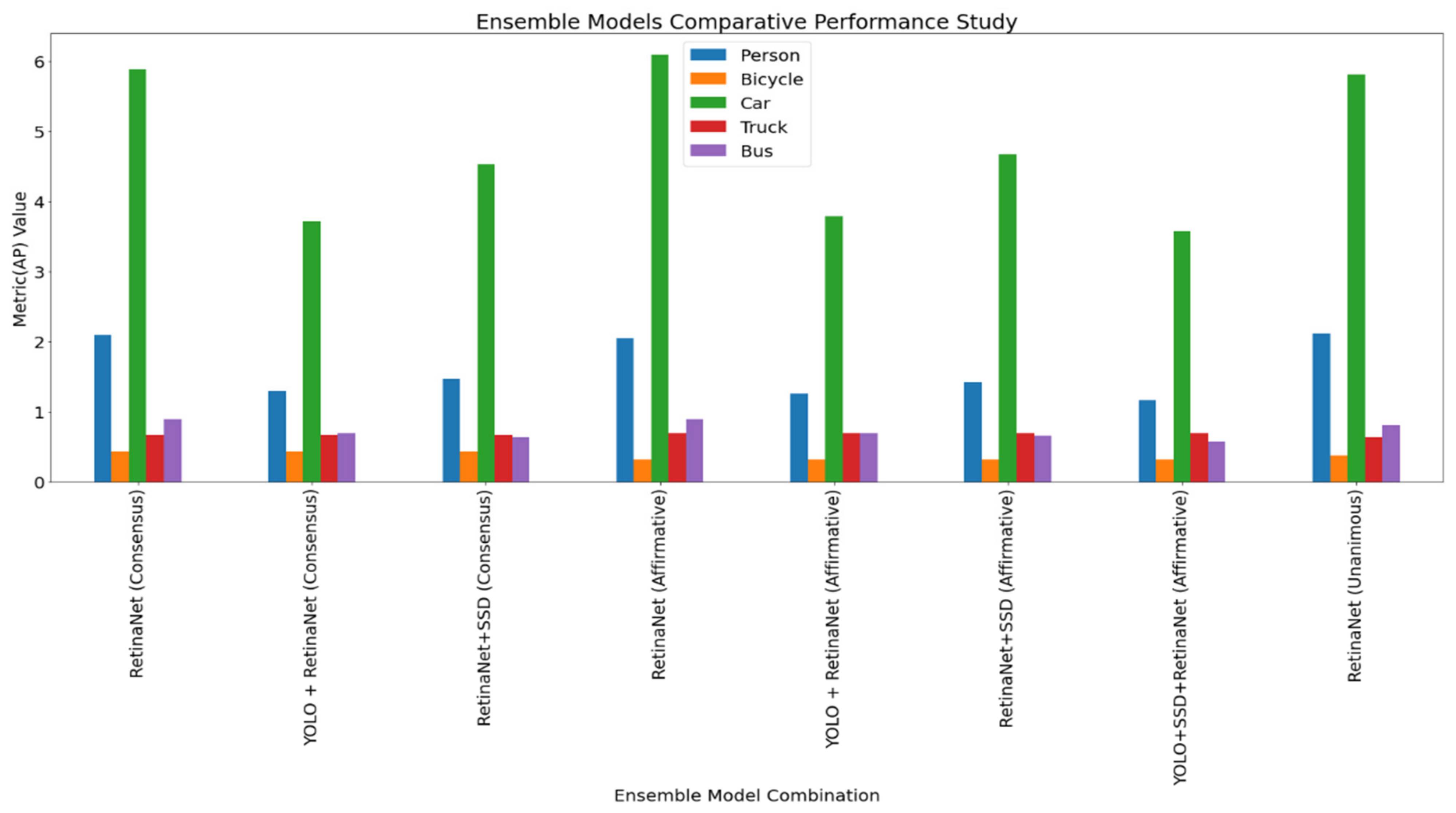
| RetinaNet | Consensus | 2.10% | 0.43% | 5.88% | 0.67% | 0.89% |
| YOLO + RetinaNet | Consensus | 1.29% | 0.43% | 3.72% | 0.67% | 0.69% |
| RetinaNet + SSD | Consensus | 1.47% | 0.43% | 4.53% | 0.67% | 0.63% |
| RetinaNet | Affirmative | 2.05% | 0.32% | 6.09% | 0.69% | 0.90% |
| YOLO + RetinaNet | Affirmative | 1.26% | 0.32% | 3.79% | 0.69% | 0.70% |
| RetinaNet + SSD | Affirmative | 1.42% | 0.32% | 4.67% | 0.69% | 0.66% |
| YOLO + SSD + RetinaNet | Affirmative | 1.16% | 0.32% | 3.58% | 0.69% | 0.58% |
| RetinaNet | Unanimous | 2.12% | 0.38% | 5.81% | 0.63% | 0.81% |
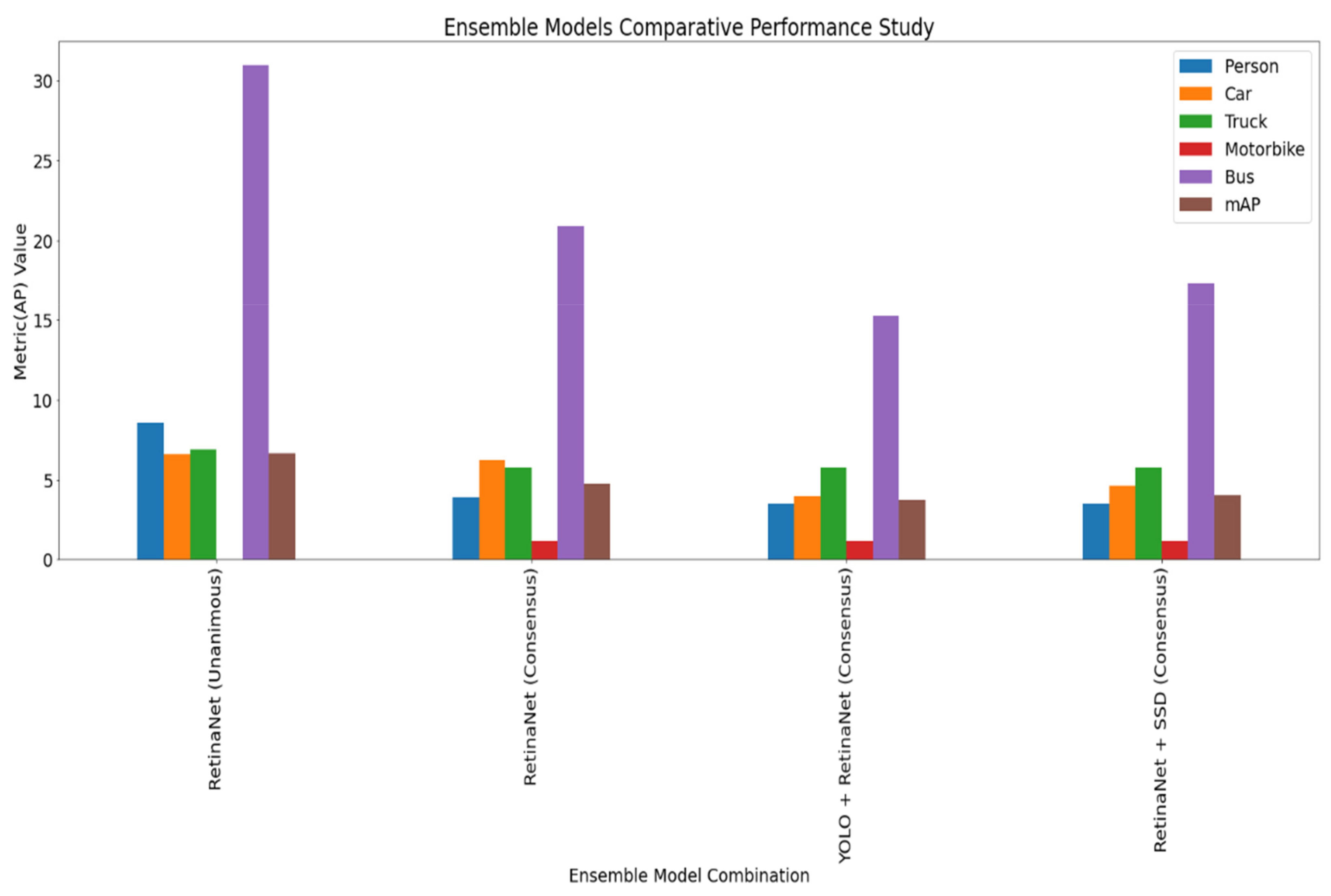
| Model | Augmentation | Person | Car | Truck | Bus | mAP |
|---|---|---|---|---|---|---|
| RetinaNet | Without Augmentation | 3.41% | 5.59% | 5.24% | 21.05% | 4.41% |
| RetinaNet | With Color Augmentation | 8.57% | 6.61% | 6.89% | 30.95% | 6.63% |
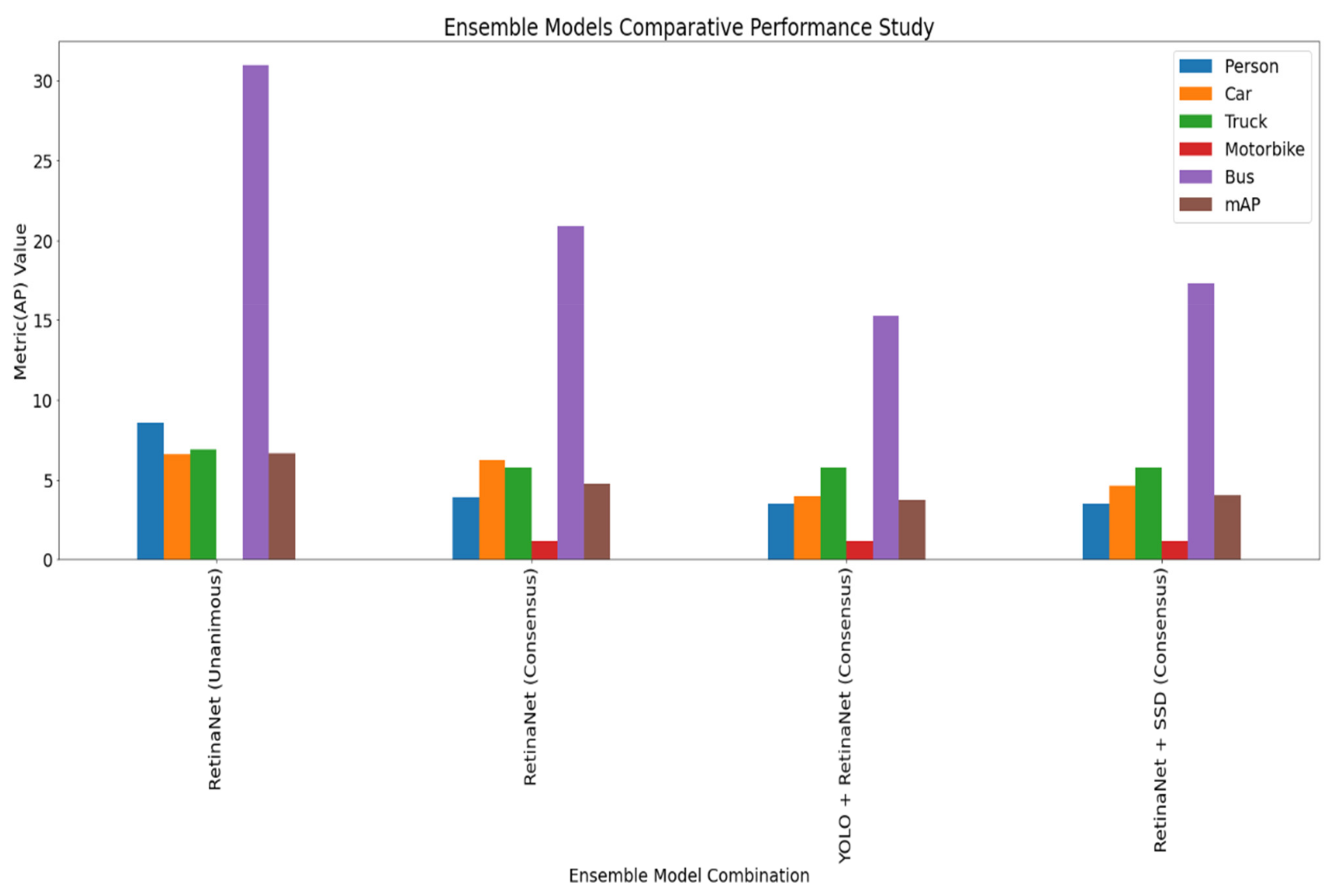
| Model | Voting Strategy | Person | Car | Truck | Motorbike | Bus | mAP |
|---|---|---|---|---|---|---|---|
| RetinaNet | Unanimous | 8.57% | 6.61% | 6.89% | 0.00% | 30.95% | 6.63% |
| RetinaNet | Consensus | 3.88% | 6.21% | 5.73% | 1.14% | 20.86% | 4.73% |
| YOLO + RetinaNet | Consensus | 3.45% | 3.95% | 5.73% | 1.14% | 15.23% | 3.69% |
| RetinaNet + SSD | Consensus | 3.45% | 4.62% | 5.73% | 1.14% | 17.31% | 4.03% |
| Algorithms | Voting Strategy | AR1 | AR10 |
|---|---|---|---|
| Previous Models | |||
| DPNet-ensemble [1st Rank in VisDrone Challenge, Trained on VisDrone Data] [10,11] | n/a | 0.58% | 3.69% |
| RRNet (A.28) [2nd Rank in VisDrone Challenge, Trained on VisDrone Data] [10,11] | n/a | 1.02% | 8.50% |
| ACM-OD (A.1) [3rd Rank in VisDrone Challenge, Trained on VisDrone Data] [10,11] | n/a | 0.32% | 1.48% |
| RetinaNet [Trained on VisDrone Data] [10,11] | n/a | 0.21% | 1.21% |
| Our Models | |||
| RetinaNet | Affirmative | 0.40% | 2.30% |
| YOLO + RetinaNet | Affirmative | 0.40% | 2.29% |
| YOLO + SSD + RetinaNet | Affirmative | 0.07% | 1.37% |
| Model | Training Dataset | Voting Strategy | Person | Car | Truck | Motorbike | Bus | mAP |
|---|---|---|---|---|---|---|---|---|
| Previous Models | ||||||||
| YOLO V3-Tiny [12] | COCO | n/a | 0.01% | 0% | 0% | 0% | 0% | n/a |
| MobileNetV2 -SSDLite [12] | COCO | n/a | 0% | 0% | 0% | 0% | 0% | n/a |
| Our Models | ||||||||
| RetinaNet | COCO | Unanimous | 8.57% | 6.61% | 6.89% | 0.00% | 30.95% | 6.63% |
| RetinaNet | COCO | Consensus | 3.88% | 6.21% | 5.73% | 1.14% | 20.86% | 4.73% |
| YOLO + RetinaNet | VOC + COCO | Consensus | 3.45% | 3.95% | 5.73% | 1.14% | 15.23% | 3.69% |
| RetinaNet + SSD | COCO + VOC | Consensus | 3.45% | 4.62% | 5.73% | 1.14% | 17.31% | 4.03% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walambe, R.; Marathe, A.; Kotecha, K. Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning. Drones 2021, 5, 66. https://doi.org/10.3390/drones5030066
Walambe R, Marathe A, Kotecha K. Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning. Drones. 2021; 5(3):66. https://doi.org/10.3390/drones5030066
Chicago/Turabian StyleWalambe, Rahee, Aboli Marathe, and Ketan Kotecha. 2021. "Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning" Drones 5, no. 3: 66. https://doi.org/10.3390/drones5030066
APA StyleWalambe, R., Marathe, A., & Kotecha, K. (2021). Multiscale Object Detection from Drone Imagery Using Ensemble Transfer Learning. Drones, 5(3), 66. https://doi.org/10.3390/drones5030066