
MFMG-Net: Multispectral Feature Mutual Guidance Network for Visible–Infrared Object Detection


Abstract
1. Introduction
- We present MFMG-Net, a novel architecture for multispectral drone ground detection. We combat potential feature bias across spectral data using a mask-based data enhancement method.
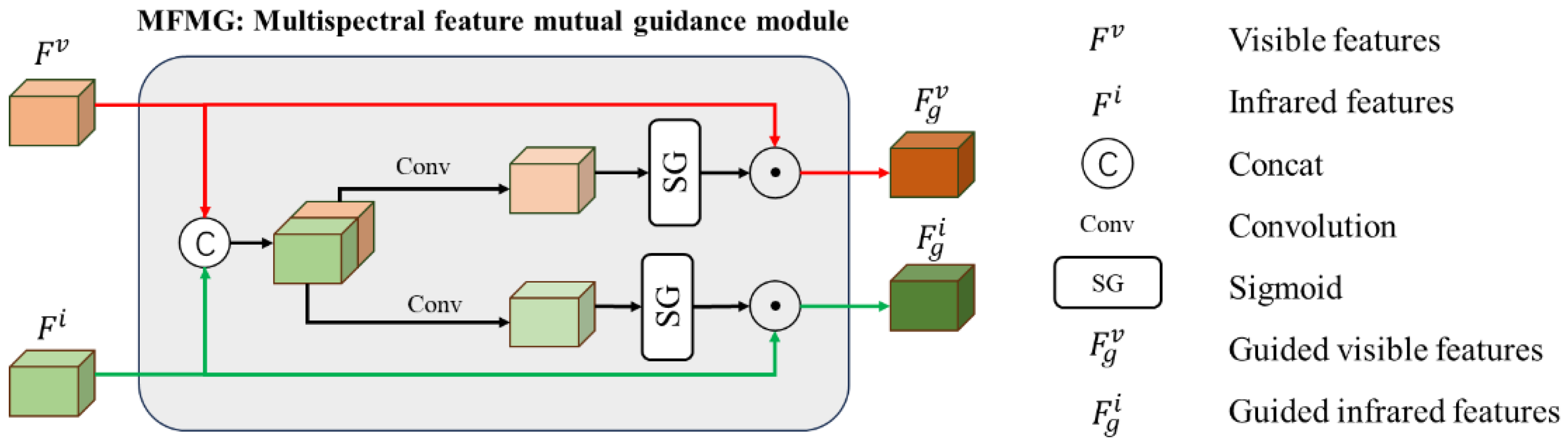
- We develop MFMG to boost feature extraction in spectral backbone networks. It enables cross-spectral information exchange during feature extraction, harnessing the power of complementary spectral data for enhanced feature fusion and detection.
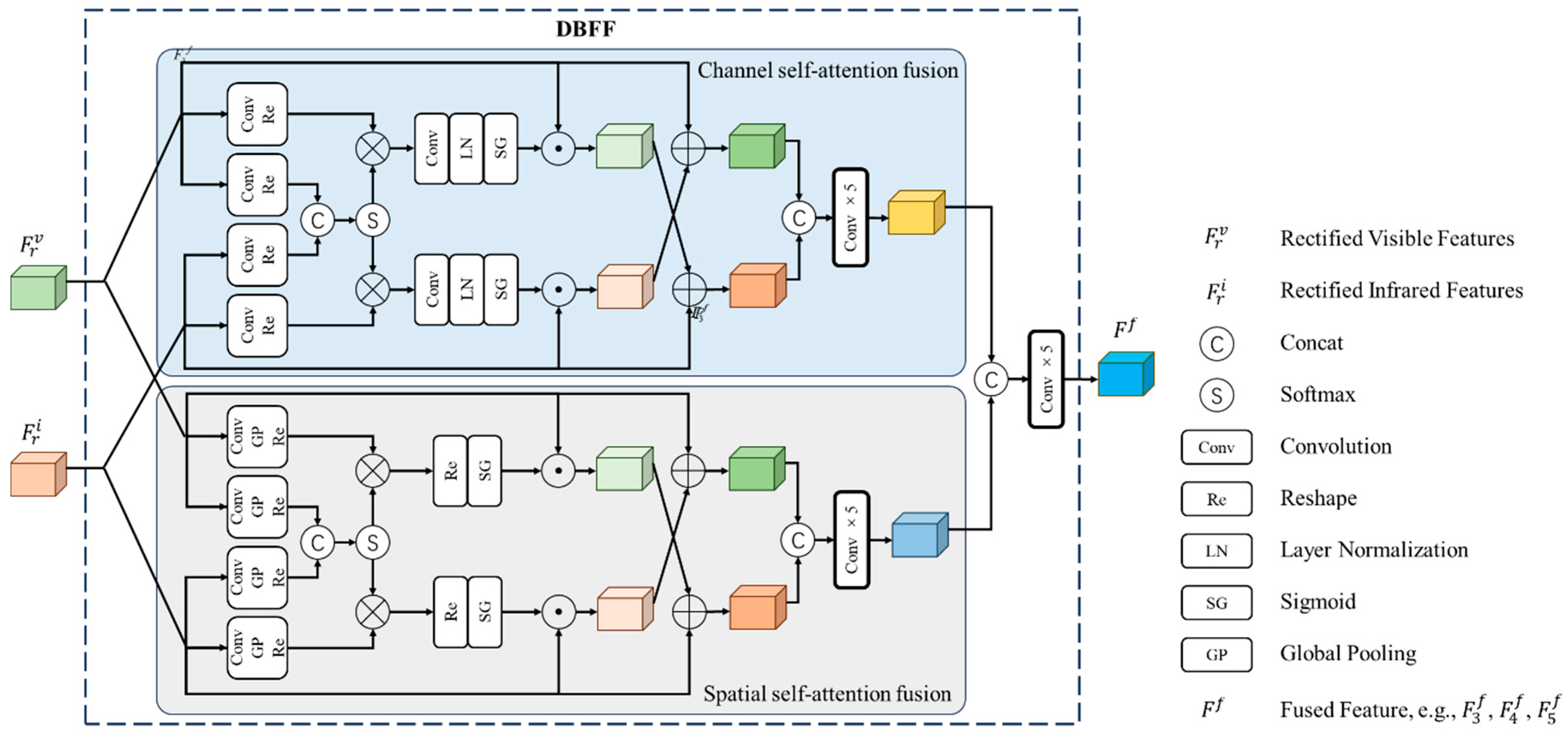
- We propose efficient feature fusion using an attention mechanism. This technique discerns spectral feature correlations in feature channels and space, effectively fusing multispectral features, and improving multispectral drone ground detection.
2. Related Work
2.1. Visible Object Detection
2.2. Infrared Object Detection
2.3. Visible–Infrared Fusion Object Detection
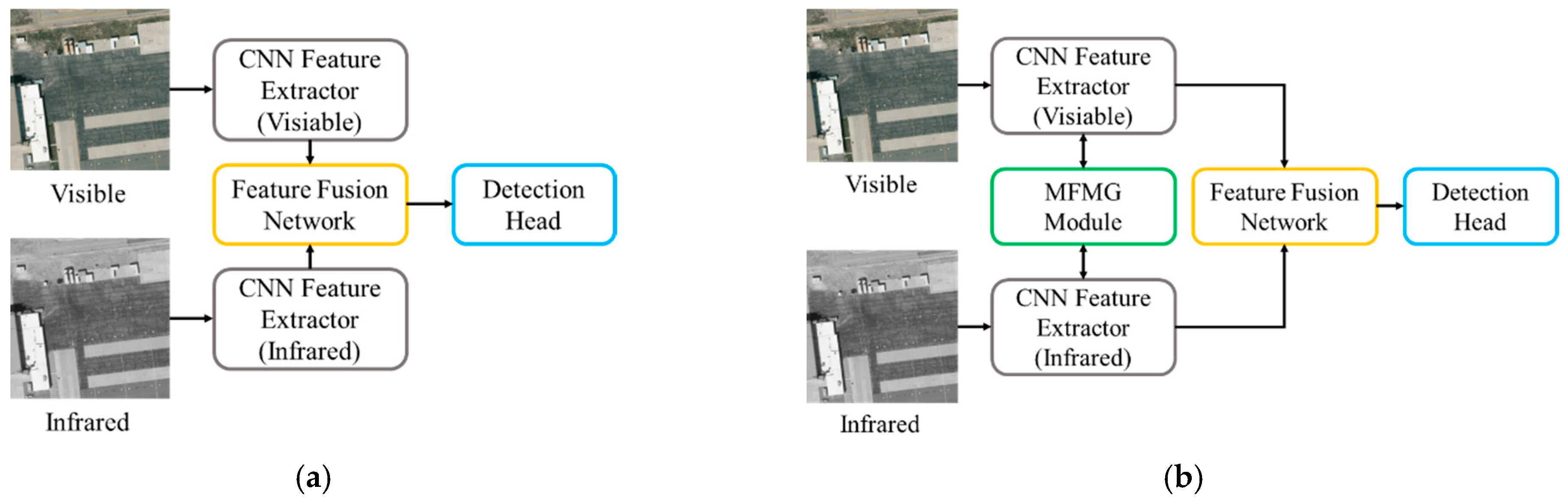
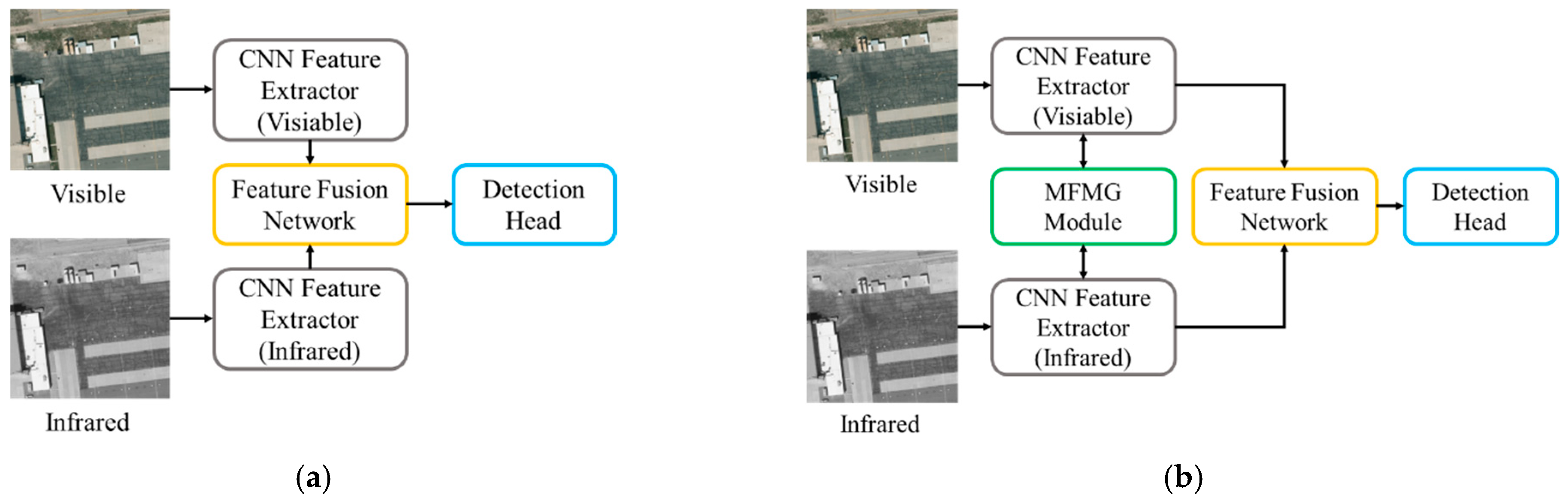
3. Proposed Method
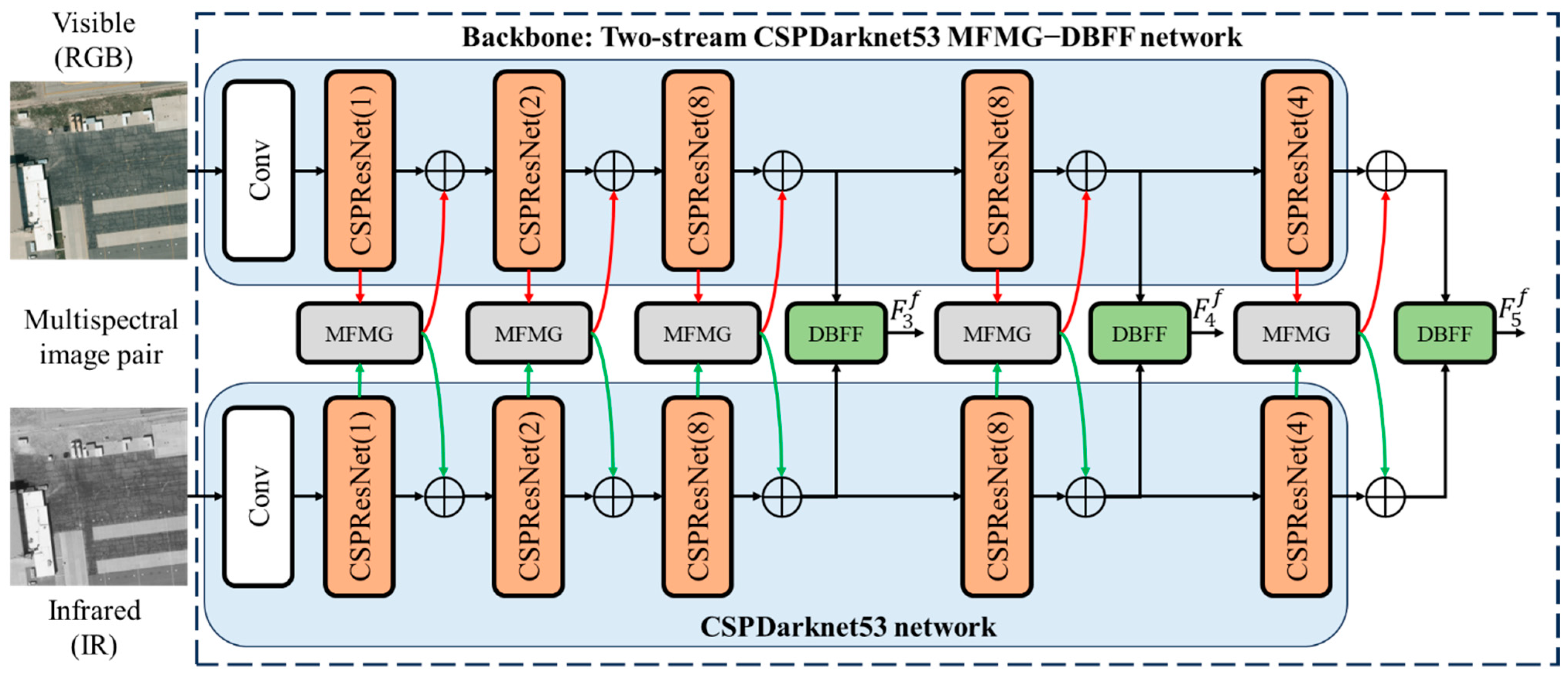
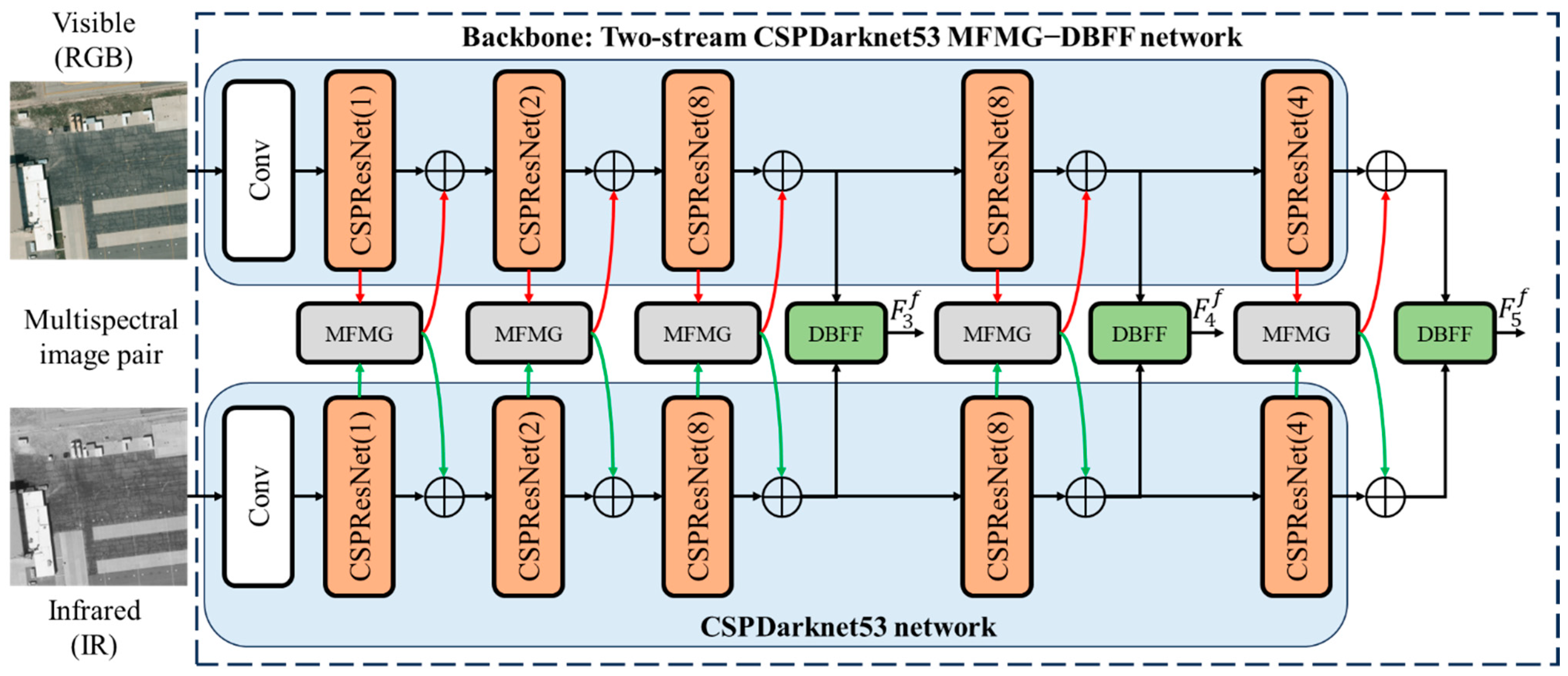
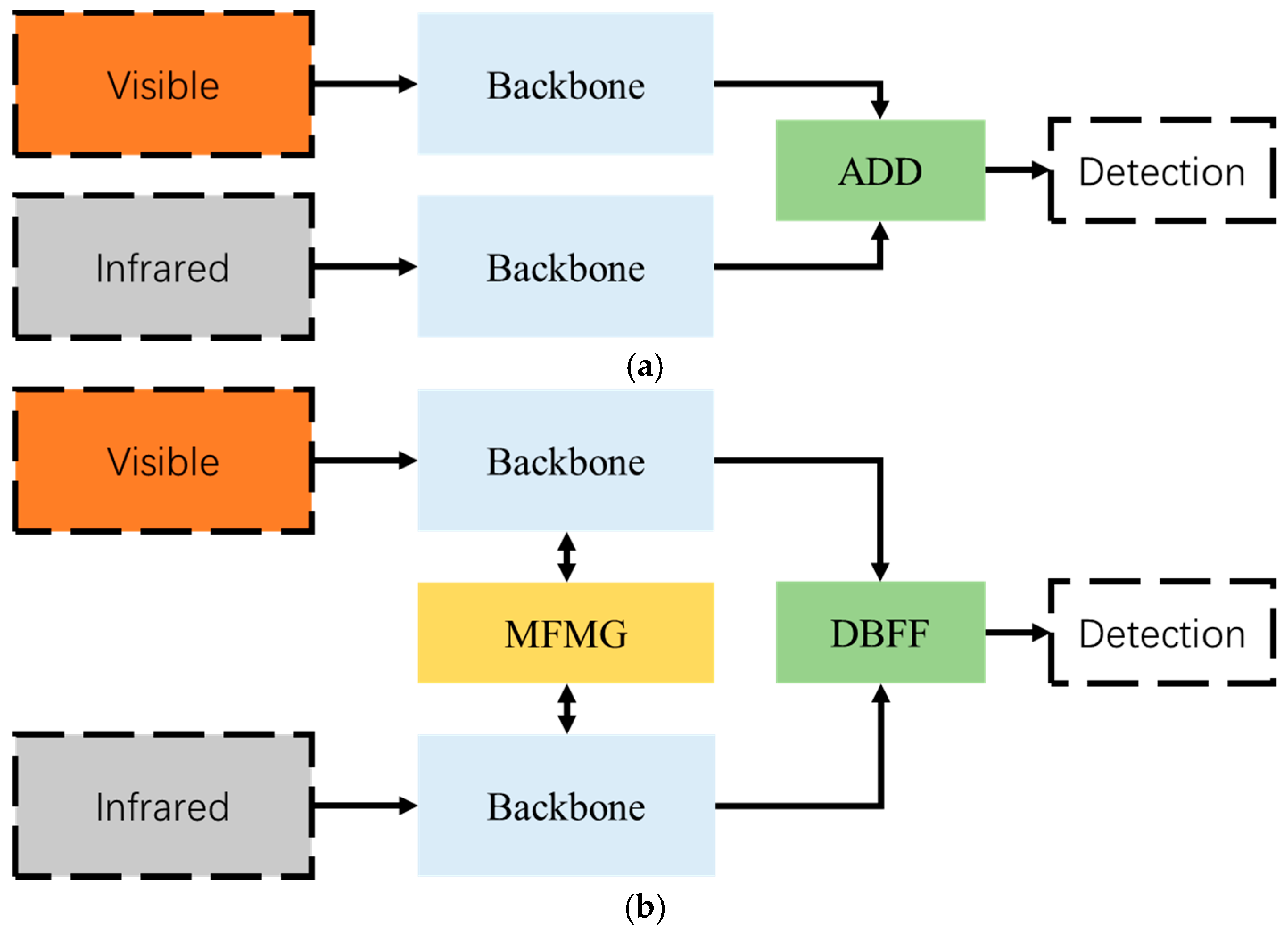
3.1. Overview Architecture
3.2. Data Augmentation
3.3. Multispectral Feature Mutual Guidance Module
3.4. Dual-Branch Feature Fusion Module
4. Experiments
4.1. Datasets
4.2. Experiment Details
4.3. Experiment Results
4.3.1. Ablation Experiment
4.3.2. Comparison with State-of-the-Art Methods
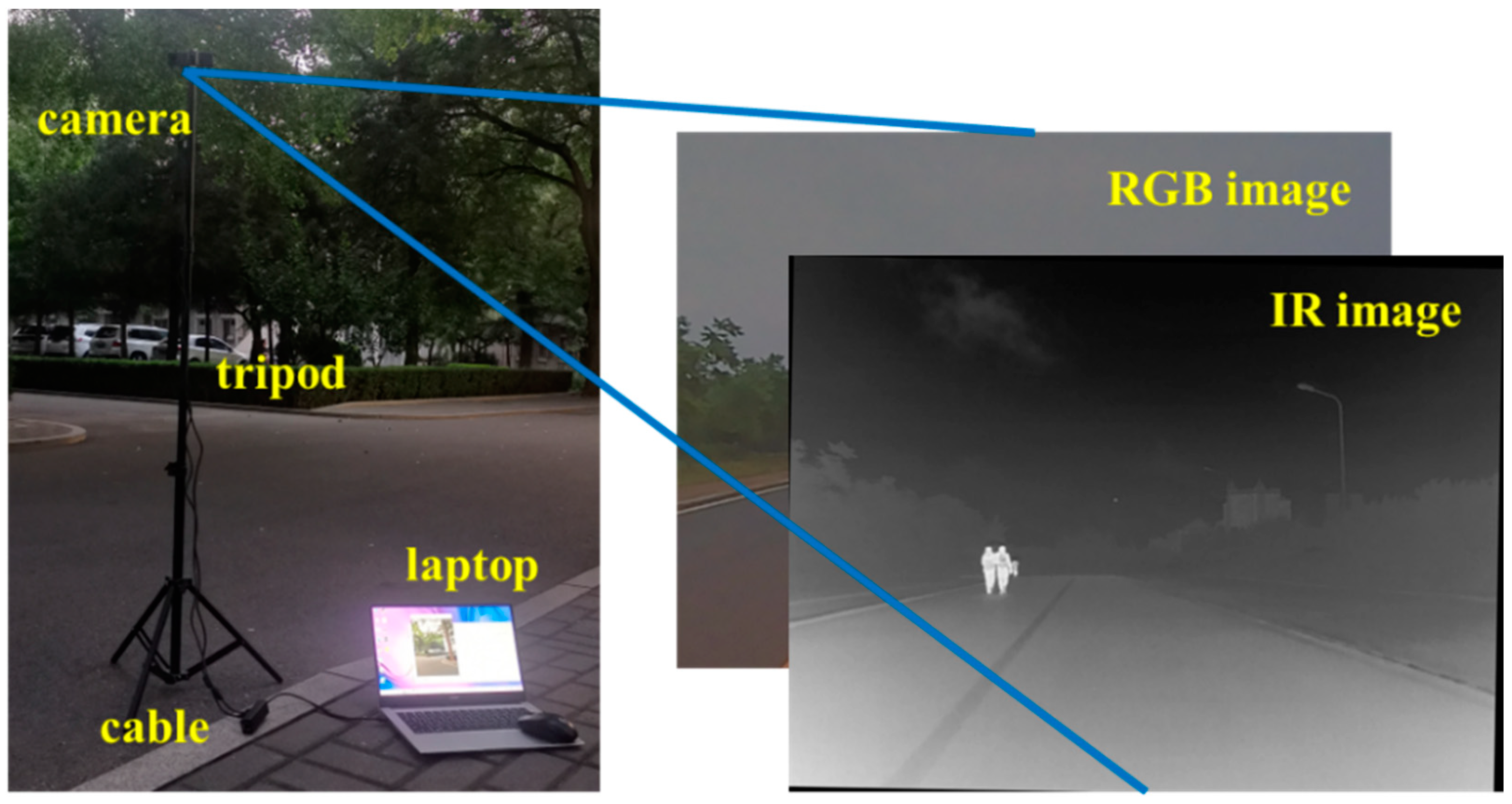
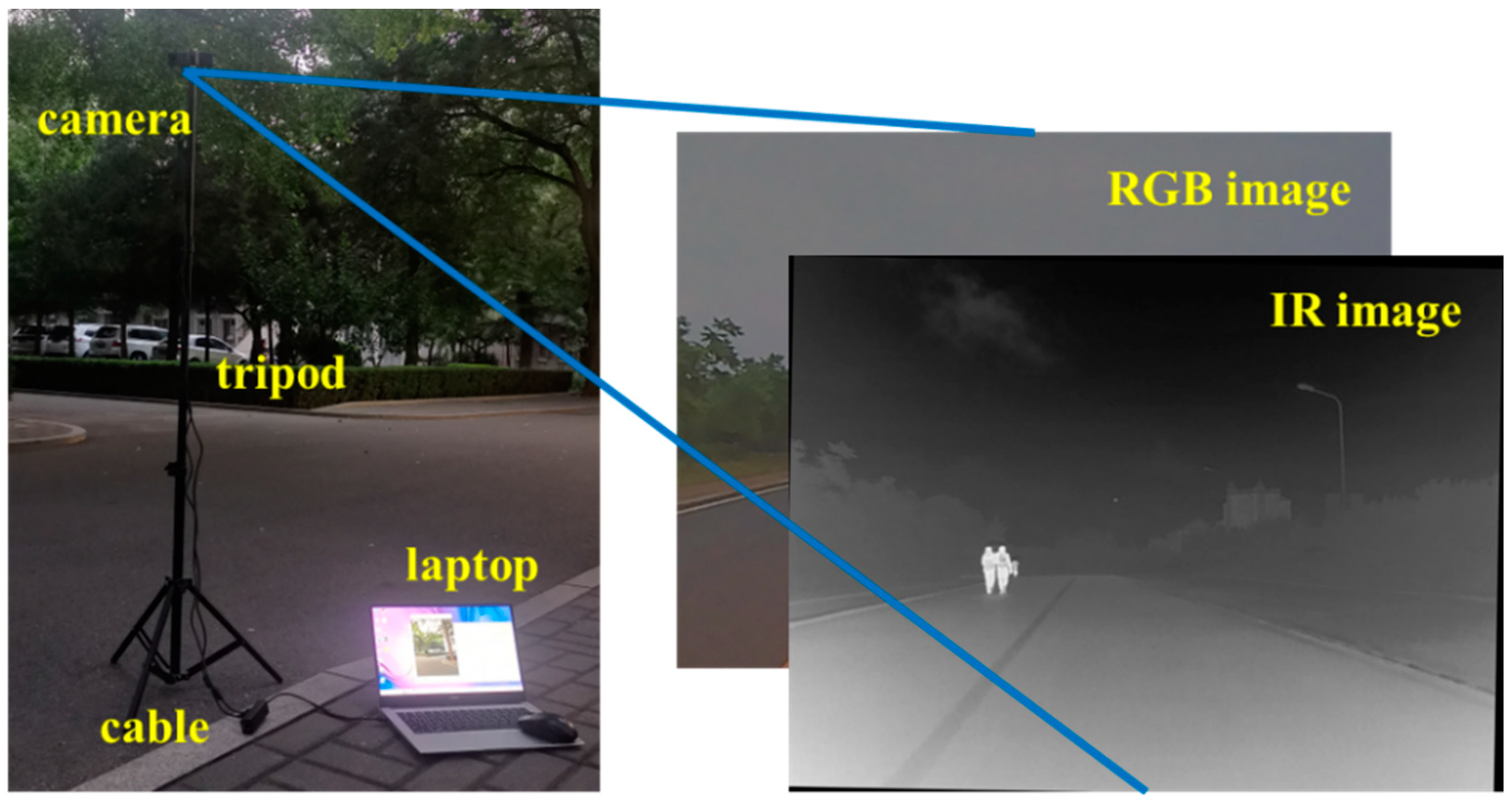
4.4. Algorithm Testing in Real Scenarios
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- Qin, C.; Wang, X.; Li, G.; He, Y. An Improved Attention-Guided Network for Arbitrary-Oriented Ship Detection in Optical Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Pham, M.-T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects Under Various Backgrounds in Remote Sensing Images. Remote. Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Fu, R.; Gao, Y.; Liu, S.; Ye, Y.; Li, B. Multiscale Deformable Attention and Multilevel Features Aggregation for Remote Sensing Object Detection. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Du, J.; Lu, H.; Zhang, L.; Hu, M.; Chen, S.; Deng, Y.; Shen, X.; Zhang, Y. A Spatial-Temporal Feature-Based Detection Framework for Infrared Dim Small Target. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 3000412. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Ma, C.; Ma, S. A Novel and High-Speed Local Contrast Method for Infrared Small-Target Detection. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 1812–1816. [Google Scholar] [CrossRef]
- Yi, H.; Yang, C.; Qie, R.; Liao, J.; Wu, F.; Pu, T.; Peng, Z. Spatial-Temporal Tensor Ring Norm Regularization for Infrared Small Target Detection. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 7000205. [Google Scholar] [CrossRef]
- Su, N.; Chen, X.; Guan, J.; Huang, Y. Maritime Target Detection Based on Radar Graph Data and Graph Convolutional Network. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 4019705. [Google Scholar] [CrossRef]
- Qin, F.; Bu, X.; Zeng, Z.; Dang, X.; Liang, X. Small Target Detection for FOD Millimeter-Wave Radar Based on Compressed Imaging. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 4020705. [Google Scholar] [CrossRef]
- Krotosky, S.J.; Trivedi, M.M. On color-, infrared-, and multimodalstereo approaches to pedestrian detection. IEEE Trans. Intell. Transp. Syst. 2007, 8, 619–629. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. arXiv 2022, arXiv:2209.13351. [Google Scholar] [CrossRef]
- Fang, Q.; Wang, Z. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully convolutional region proposal networks for multispectral person detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 49–56. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef]
- Yang, X.; Qiang, Y.; Zhu, H.; Wang, C.; Yang, M. BAANet: Learning bi-directional adaptive attention gates for multispectral pedestrian detection. arXiv 2021, arXiv:2112.02277. [Google Scholar]
- Zhuang, Y.; Pu, Z.; Hu, J.; Wang, Y. Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection. IEEE Trans. Netw. Sci. Eng. 2021, 9, 1282–1295. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via regionbased fully convolutional networks. Proc. Adv. Neural Inf. Process. Syst. 2016, 29, 1–22. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian detection in thermal images using saliency maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1–10. [Google Scholar]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Marnissi, M.A.; Fradi, H.; Sahbani, A.; Ben Amara, N.E. Feature distribution alignments for object detection in the thermal domain. Vis. Comput. 2022, 39, 1081–1093. [Google Scholar] [CrossRef]
- Deng, Q.; Tian, W.; Huang, Y.; Xiong, L.; Bi, X. Pedestrian detection by fusion of RGB and infrared images in low-light environment. In Proceedings of the 2021 IEEE 24th International Conference on Information Fusion (FUSION), Sun City, South Africa, 1–4 November 2021; pp. 1–8. [Google Scholar]
- Chen, X.; Liu, L.; Tan, X. Robust Pedestrian Detection Based on Multi-Spectral Image Fusion and Convolutional Neural Networks. Electronics 2021, 11, 1. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 72–80. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, J.; Chen, X.; Zhang, H.; Tan, Z.; Wang, S.; Ma, H. Transformer Based Remote Sensing Object Detection with Enhanced Multispectral Feature Extraction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Fu, H.; Wang, S.; Duan, P.; Xiao, C.; Dian, R.; Li, S.; Li, Z. LRAF-Net: Long-Range Attention Fusion Network for Visible–Infrared Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visibleinfrared paired dataset for low-light vision. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- FLIR. FLIR Thermal Dataset for Algorithm Training. 2018. Available online: https://www.flir.in/oem/adas/adas-dataset-form (accessed on 19 January 2022).
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic Fuse-and-Refine blocks. In Proceedings of the IEEE International Conference on Image Processing, Virtual, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Mandal, M.; Shah, M.; Meena, P.; Vipparthi, S.K. SSSDET: Simple short and shallow network for resource efficient vehicle detection in aerial scenes. In Proceedings of the IEEE International Conference on Image Processing, Taiwan, China, 22–25 September 2019; pp. 3098–3102. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dhanaraj, M.; Sharma, M.; Sarkar, T.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. Vehicle detection from multi-modal aerial imagery using YOLOv3 with mid-level fusion. Proc. SPIE 2020, 11395, 1139506. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | VEDAI | M3FD | LLVIP | FLIR |
|---|---|---|---|---|
| Classes | 9 | 6 | 1 | 3 |
| Data | RGB-IR | RGB-IR | RGB-IR | RGB-IR |
| Size | 1024 × 1024 | 1024 × 768 | 1280 × 1024 | 640 × 512 |
| Format | png | png | jpg | jpg |
| Amount | 1250 pairs | 4200 pairs | 15,488 pairs | 5142 pairs |
| Method | DA | MFMG | DBFF | PR | RE | mAP50 | mAP |
|---|---|---|---|---|---|---|---|
| Baseline | - | - | - | 0.958 | 0.883 | 0.921 | 0.615 |
| Baseline | √ (0.1) | - | - | 0.960 | 0.887 | 0.927 | 0.617 |
| Baseline | √ (0.3) | - | - | 0.970 | 0.908 | 0.948 | 0.624 |
| Baseline | √ (0.5) | - | - | 0.967 | 0.901 | 0.942 | 0.623 |
| Baseline | √ (0.7) | - | - | 0.963 | 0.897 | 0.937 | 0.621 |
| Baseline | √ (0.9) | - | - | 0.961 | 0.891 | 0.933 | 0.618 |
| Baseline | √ (0.3) | √ | - | 0.982 | 0.913 | 0.960 | 0.652 |
| Baseline | √ (0.3) | - | √ | 0.981 | 0.912 | 0.957 | 0.647 |
| MFMGF-Net | - | √ | √ | 0.983 | 0.925 | 0.962 | 0.659 |
| MFMGF-Net | √ (0.3) | √ | √ | 0.985 | 0.941 | 0.981 | 0.665 |
| Model | Dataset Type | Backbone | mAP50 | mAP |
|---|---|---|---|---|
| Retina [43] | RGB | ResNet-50 | - | 0.435 |
| Faster R-CNN | RGB | ResNet-101 | - | 0.348 |
| SSSDET | RGB | shallow network | - | 0.460 |
| EfficientDet(D1) | RGB | EfficientNet(B1) | 0.740 | - |
| EfficientDet(D1) | IR | EfficientNet(B1) | 0.712 | - |
| YOLO-fine | RGB | Darknet53 | 0.760 | - |
| YOLO-fine | IR | Darknet53 | 0.752 | - |
| YOLO v5 | RGB | CSPDarknet53 | 0.743 | 0.462 |
| YOLO v5 | IR | CSPDarknet53 | 0.740 | 0.462 |
| YOLOv3 e fusion [44] | RGB + IR | Darknet53 | - | 0.440 |
| YOLOv3 m fusion [44] | RGB + IR | two-stream Darknet53 | - | 0.446 |
| YOLO Fusion | RGB + IR | two-stream CSPDarknet53 | 0.786 | 0.491 |
| CFT | RGB + IR | CFB | 0.853 | 0.560 |
| LRAF-Net | RGB + IR | two-stream CSPDarknet53 | 0.859 | 0.591 |
| Baseline | RGB + IR | two-stream CSPDarknet53 | 0.792 | 0.453 |
| MFMGF-Net | RGB + IR | two-stream CSPDarknet53 | 0.868 | 0.594 |
| Model | Dataset Type | Backbone | mAP50 | mAP |
|---|---|---|---|---|
| Faster R-CNN | RGB | ResNet-50 | 0.871 | 0.562 |
| Faster R-CNN | IR | ResNet-101 | 0.803 | 0.558 |
| YOLOv7 [45] | RGB | ELAN-Net | 0.916 | 0.631 |
| YOLOv7 [45] | IR | ELAN-Net | 0.891 | 0.573 |
| YOLO Fusion | RGB + IR | two-stream CSPDarknet53 | 0.928 | 0.641 |
| GAFF | RGB + IR | ResNet18 | 0.891 | 0.576 |
| CFT | RGB + IR | CFB | 0.765 | 0.492 |
| Baseline | RGB + IR | two-stream CSPDarknet53 | 0.927 | 0.635 |
| MFMGF-Net | RGB + IR | two-stream CSPDarknet53 | 0.930 | 0.658 |
| Model | Dataset Type | Backbone | mAP50 | mAP |
|---|---|---|---|---|
| YOLO v3 | RGB | DarkNet53 | 0.859 | 0.433 |
| YOLO v3 | IR | DarkNet53 | 0.897 | 0.534 |
| YOLO v5 | RGB | CSPDarkNet53 | 0.908 | 0.500 |
| YOLO v5 | IR | CSPDarkNet53 | 0.946 | 0.619 |
| YOLO v8 | RGB | - | 0.925 | 0.541 |
| YOLO v8 | IR | - | 0.966 | 0.632 |
| CFT | RGB + IR | CFB | 0.975 | 0.636 |
| LRAF-Net | RGB + IR | two-stream CSPDarkNet53 | 0.979 | 0.663 |
| Baseline | RGB + IR | two-stream CSPDarkNet53 | 0.943 | 0.638 |
| MFMGF-Net | RGB + IR | two-stream CSPDarkNet53 | 0.981 | 0.665 |
| Model | Data Type | Param. | FLOPs | Runtime/ms |
|---|---|---|---|---|
| YOLOv5s | RGB | 7.1 M | 15.9 | 10.7 |
| YOLOv5s | IR | 7.1 M | 15.9 | 10.7 |
| GAFF R | RGB + IR | 23.8 M | - | 10.9 |
| GAFF V | RGB + IR | 31.4 M | - | 9.3 |
| CFT | RGB + IR | 73.7 M | 154.7 | 91.2 |
| LRAF-Net | RGB + IR | 18.8 | 40.5 | 21.4 |
| Baseline | RGB + IR | 11.6 M | 26.4 | 17.2 |
| MFMGF-Net | RGB + IR | 21.8 M | 45.5 | 23.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Lou, W.; Feng, H.; Ding, N.; Li, C. MFMG-Net: Multispectral Feature Mutual Guidance Network for Visible–Infrared Object Detection. Drones 2024, 8, 112. https://doi.org/10.3390/drones8030112
Zhao F, Lou W, Feng H, Ding N, Li C. MFMG-Net: Multispectral Feature Mutual Guidance Network for Visible–Infrared Object Detection. Drones. 2024; 8(3):112. https://doi.org/10.3390/drones8030112
Chicago/Turabian StyleZhao, Fei, Wenzhong Lou, Hengzhen Feng, Nanxi Ding, and Chenglong Li. 2024. "MFMG-Net: Multispectral Feature Mutual Guidance Network for Visible–Infrared Object Detection" Drones 8, no. 3: 112. https://doi.org/10.3390/drones8030112
APA StyleZhao, F., Lou, W., Feng, H., Ding, N., & Li, C. (2024). MFMG-Net: Multispectral Feature Mutual Guidance Network for Visible–Infrared Object Detection. Drones, 8(3), 112. https://doi.org/10.3390/drones8030112