

Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment



Abstract
1. Introduction
1.1. Example Scenario of a Multiagent UAV-Assisted C-V2X Communication
- Let both and follow the designated velocity assigned by the UAV. In this case, both and accumulate a low positive payoff. The UAV’s payoff also gradually increases for each correct decision communicated to the vehicles.
- Vehicle decides to take an alternate velocity to overtake and later needs to decelerate to avoid collision with . The action leads to a low negative payoff.
- Vehicle takes an alternate velocity, and follows the designated velocity. If there is a need to decelerate to avoid a collision, then receives a low negative payoff, while receives a zero payoff.
- If both and follow the designated velocity, there is no collision; both players receive a high positive payoff.
- If both and take an alternate velocity, and still there is no collision, each player receives a low positive payoff.
- Here, the UAV allocates communication and computing resources to both and , which results in safe driving and no collision. Thus, the UAV incurs a high positive payoff. A challenge in the scenario is simultaneously monitoring the status of multiple vehicles and deciding resource allocation strategies in a short time.
1.2. Contributions
- We calculate the FRL model parameter transmission probability of a vehicle in each TTI in scenarios where each vehicle is aware of the transmission probability of other vehicles in the cluster. Then, each vehicle makes a time-bound decision whether to transmit the update or not and allow other vehicles to transmit their local model parameters to the UAV, without incurring negative incentives.
- We evaluate the proposed Markovian game theoretic approach by studying the variation in UAV average energy consumption (Joules/s) with the number of vehicles (V) in a single subframe in C-V2X mode 4 [22].
- We study the variation in the average packet delay in federated learning scenario. Here, we vary the number of vehicles (V) and the vehicle velocity under different road lengths (). This is an extension of our previous work in [11], where we demonstrated the behavior of model convergence time for federated averaging. Note that in our previous work in [11], the vehicles in a C-V2X cluster communicated their local model parameters to a static parameter server (PS). In this work, the PS is embedded in a mobile UAV, which introduces challenges pertaining to the mobility of the UAV.
- We plot the variation in the optimal model parameter transmission probability values of the vehicles. Here, we vary the number of vehicles in an iteration of the game ().
1.3. Organization
2. Related Work
2.1. Game Theoretic Approaches in UAV–Vehicle Communications
- UAVs can be equipped with a variety of sensors and cameras that will enable image processing to manage parking spaces and roads. It can help reduce traffic congestion, parking shortages, and transportation costs while also reducing air pollution. UAV-mounted vision systems can monitor lane occupation and analyze parking spaces to automate parking space management. Consequently, UAVs can make urban space more manageable with the use of 6G communication technologies [25].
- By deploying UAVs to monitor highways and vehicle platoons, fuel consumption can be reduced, traffic flow can be improved, and safety can be improved. Multiple drones can communicate with vehicles in real time to ensure collision avoidance and to adhere to vehicle velocity and mobility restrictions. Machine learning and game theoretic approaches can enhance communication and real-time decision making [26].The authors in [27] have presented a novel technique to optimize the interactions between vehicles using game theory. In this study, behavioral decision-making was based on noncooperative game theory with incomplete information and complete information for cooperative vehicle platoons. The payoff functions for a noncooperative game take into account the economy, comfort, safety, and autonomous driving of the platoon. To calculate the action probability for different types of vehicles with incomplete information, a belief pool is constructed, which is updated with a Bayesian probability formula based on the driving intention identification. For the potentially conflicting entities, stable strategies are developed, thus ensuring that neither has a motivation to change their driving behavior. The authors demonstrated that platoons can formulate cooperative decision-making approaches to resolve the conflicts among vehicles [27].
- Using UAVs to communicate with vehicles, especially in non-line of sight (NLoS) scenarios, requires commercial communication networks, which may experience a service outage in some scenarios. In addition to sharing their locations with ground entities, UAVs must also communicate with each other [28].The authors in [29] have presented an efficient task forwarding mechanism in search and rescue operations. As part of the task forwarding process of a multiagent system, the authors introduced a reputation mechanism derived from an evolutionary game to improve cooperation rates between agents. This model combines reputation mechanisms with strategy updates in a multiagent system. The model is based on evolutionary game theory, and key factors such as reputation thresholds and the percentage of agents who choose to forward a task are assessed.
- In search and rescue operations, UAVs can be utilized to deliver food and medication to passengers in autonomous vehicles stuck in remote or disaster-affected areas. For this, the communication channels must be free of interference, and outages and the weather must be good [30]. Antennas and transceivers can be integrated into UAVs to enhance wireless network coverage. By using C-V2X communication technologies, a communication link can be established between UAVs and vehicles. In a typical communication scenario, a stuck vehicle transmits its location information to a drone, which arrives at the location, captures images, and transmits them to first responders [31]. Based on game theory, the latency and packet drop percentage could be improved to achieve satisfactory system performance [32].
- As electric vehicles continue to replace traditional fuel vehicles, UAVs are expected to play a major role in further reducing greenhouse gas emissions and air pollution. As a result of improved charging stations and battery swapping facilities, UAVs can become a major means of goods delivery by 2040. Electric vehicles and wireless charging technologies have been proposed to provide electricity to UAVs in urgent need. Each UAV has its own flight path and needs a charging plan that aligns with load balancing requirements at the charging station [33].In a multi-UAV network, because the charging stations have limited capacity, strategic charging is dependent on the actions of other UAVs. As a result, the UAV battery charging problem becomes a generalized Nash equilibrium problem. A UAV’s objective in the bidding strategy is to minimize the cost of purchased energy and maximize the priority of the task using a stochastic optimization model. The authors in [34] have presented a strategy for bidding on the load distribution of several plug-in electric vehicles sharing the same charging station. The authors in [35] have proposed a game theoretic solution to a scenario where the deployment of charging stations to meet vehicle’s electricity demands caused load imbalance on the power grid. A game theoretic approach was used to minimize load imbalance at the grid, inefficient resource utilization, and nonoptimal power transaction costs. The solution was designed for optimum charging prices, efficient utilization, and energy conservation at charging stations. Furthermore, a discrete time event simulator was developed to test the proposed scheme on parameters such as arrival rates, queue length, and reactive power.The authors in [36] have presented an electric vehicle energy management strategy to coordinate efficient utilization of multiple power sources. It uses game theoretic approaches to improve fuel economy and transmission efficiency, as well as a Markov chain-based driver model for predicting vehicle speed. Using a noncooperative game model and Nash equilibrium as the solution, the simulation results show that the proposed strategy improves fuel economy [36].
- In advanced futuristic applications, UAVs are increasingly being integrated into smart city initiatives, where security and privacy concerns are important in determining communication strategies. UAV capabilities and their deployment in smart city environments can be enhanced through the use of machine learning and game theory [37].
2.2. Application of Game Theory to Assist Vehicles to Make a Coordinated Driving Decision
2.3. Application of Federated Learning in UAV–Vehicle Communications
3. System Model
- The vehicles can complete their local models in a TTI and then adopt a cooperate and leave strategy. Here, a vehicle cooperates with other vehicles and the UAV and then leaves the coalition for a random period to avoid a negative incentive. This is referred to as cooperate and leave strategy.
- When the vehicles that complete their model update and are selected by the UAV in a TTI, the vehicle having previously followed the cooperate and leave strategy immediately returns to the coalition in the next TTI. This is referred to as the leave and return strategy. Here, we consider a repeated game model, and the past interactions between agents are taken into account using a discrete time Markov chain (DTMC).
4. Problem Formulation
5. Game Theory-Based Solution Approach
5.1. Nash Equilibrium
5.2. Action Set and the Players’ Strategies
5.3. Vehicles’ Local Model Parameter Transmission Strategies
5.4. UAV’s Global Model Update and Parameter Transmission Strategies
5.5. Vehicle Selection Payoff
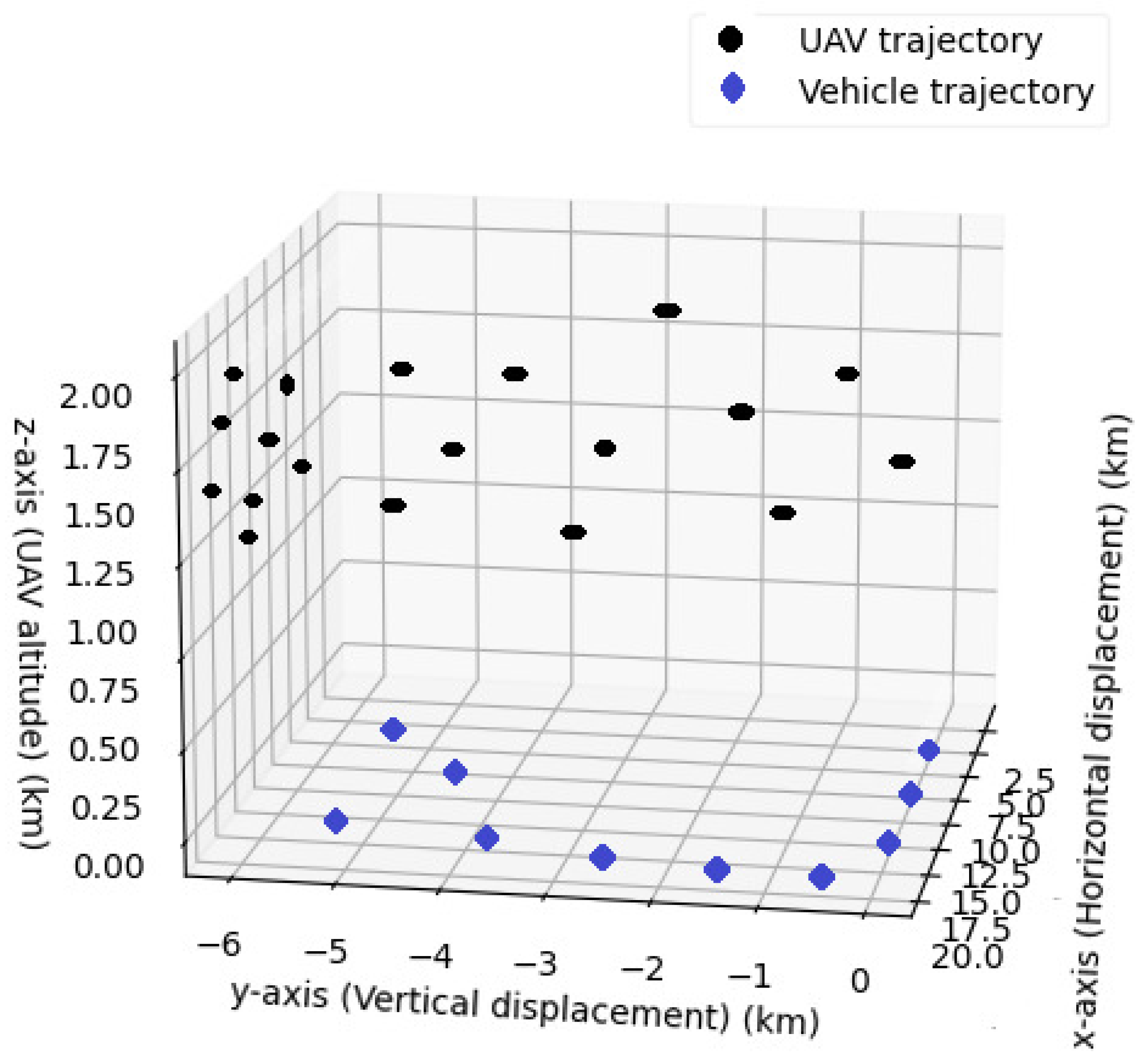
6. Simulation Results and Discussion
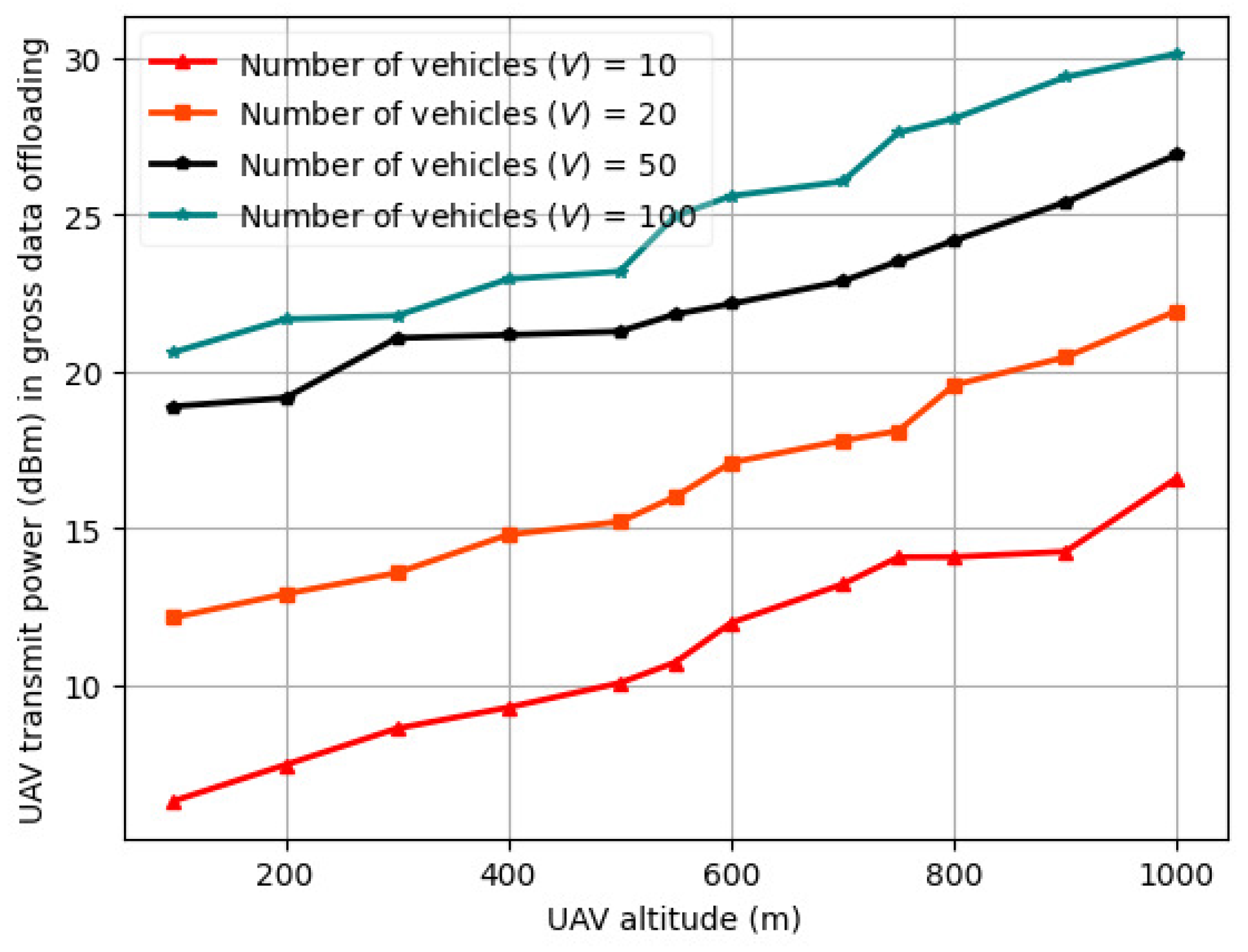
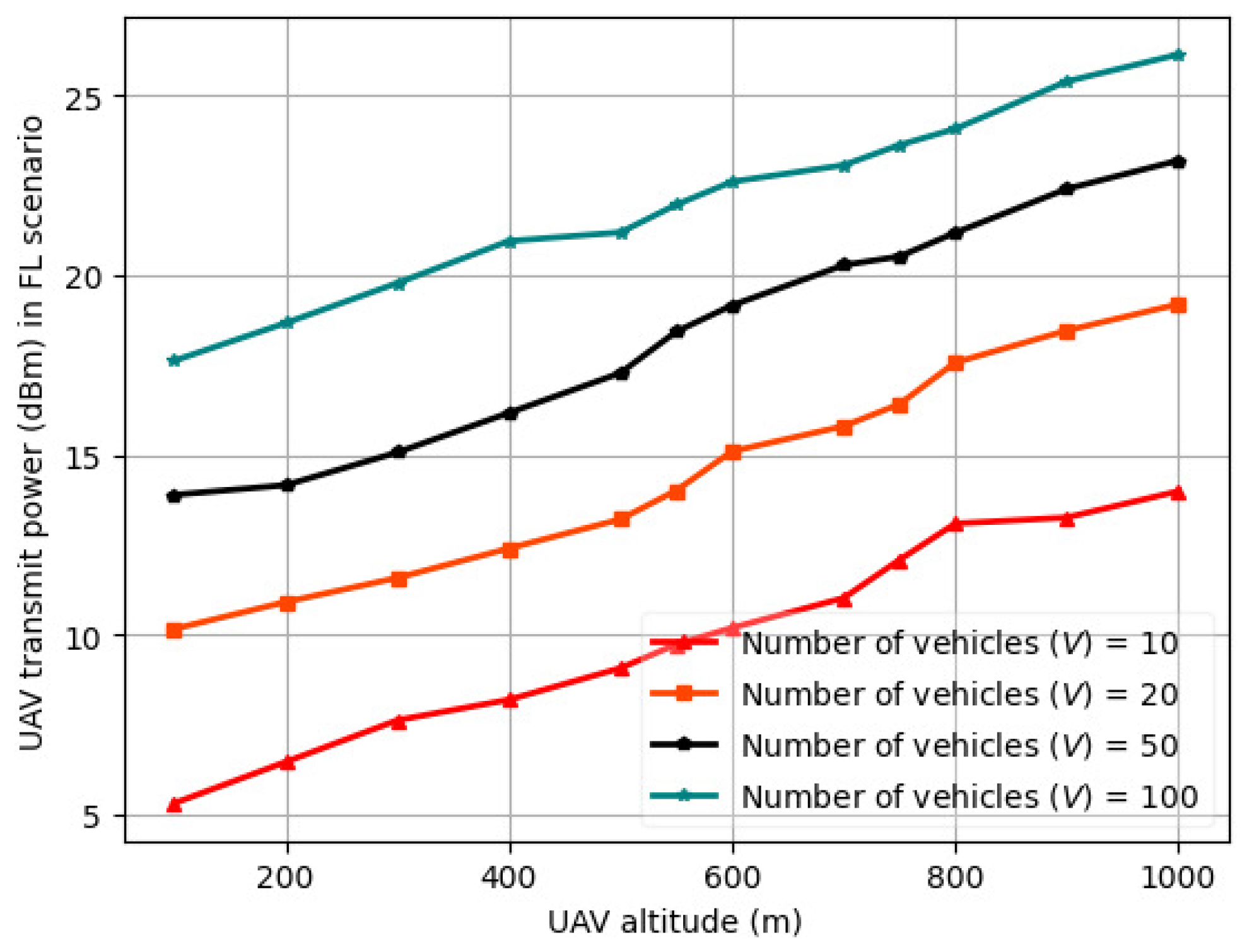
6.1. Variation in Delay Profile and UAV Transmit Power
6.2. Optimal Payoff and Incentive Probabilities
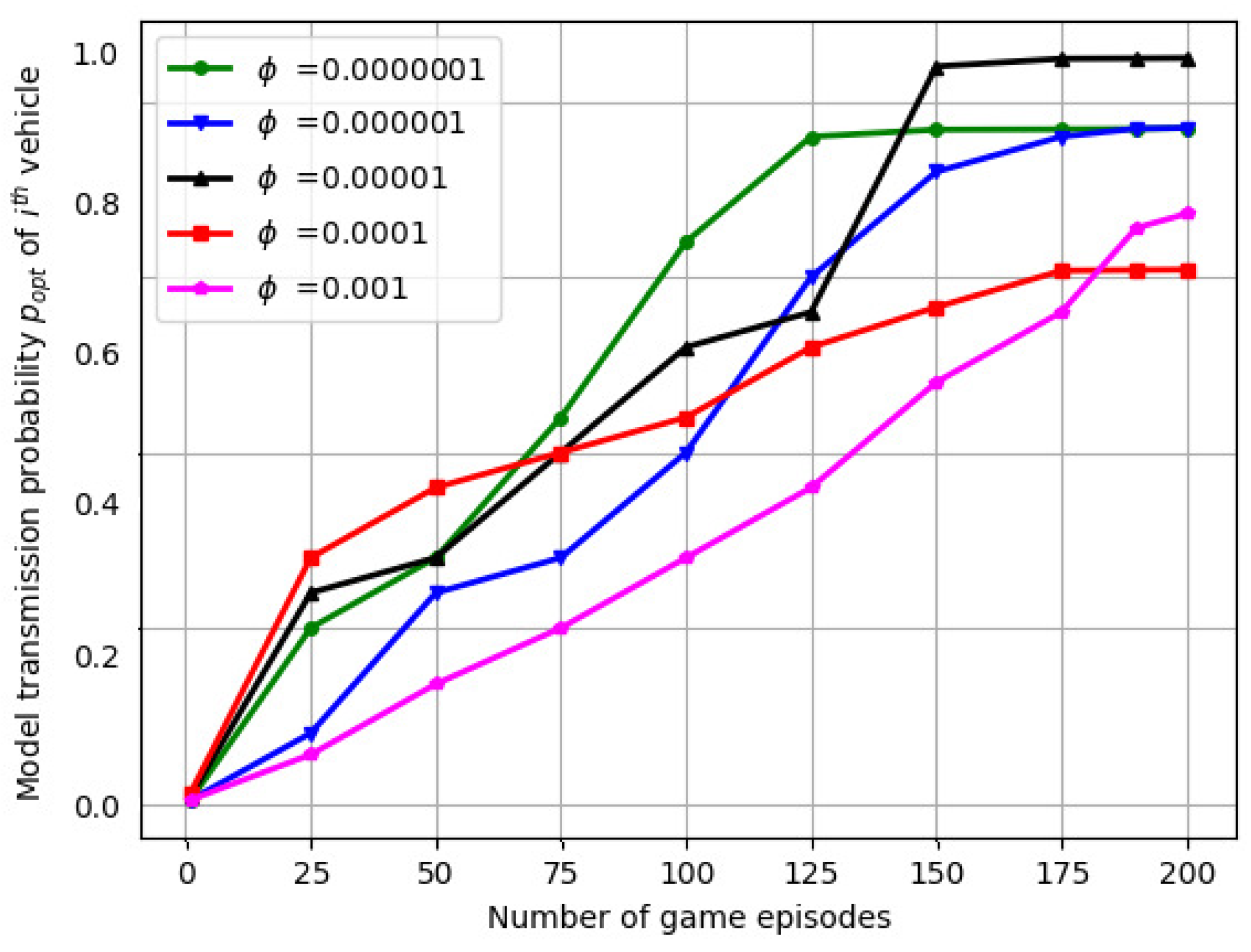
6.3. Optimal Weight Values and Model Transmission Probabilities
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 3GPP | Third generation partnership project |
| 5GAA | Fifth generation automotive association |
| 6G | Sixth generation (Communication networks) |
| AWGN | Additive white Gaussian noise |
| BS | Base station |
| BSM | Basic safety messages |
| C-ITS | Cooperative intelligent transport systems |
| CPM | Cooperative perception messages |
| C-V2X | Cellular vehicle-to-everything |
| D-VCN | Drone-assisted vehicular communication network |
| DNN | Deep neural network |
| E2E | End-to-end |
| ES | Edge server |
| FANET | Flying ad hoc network |
| FL | Federated learning |
| FRL | Federated reinforcement learning |
| HAP | High altitude platform |
| KKT | Karush–Khun–Tucker (Optimality conditions) |
| LAP | Low-altitude platform |
| LoS | Line of sight |
| MAC | Medium-access control |
| MEC | Mobile edge computing |
| ML | Machine learning |
| MSE | Mean square error |
| NE | Nash equilibrium |
| NOMA | Nonorthogonal multiple access |
| NLoS | Non-line of sight |
| NR-V2X | New radio vehicle-to-everything |
| OTFS | Orthogonal time frequency space |
| PDR | Packet delivery ratio |
| QoS | Quality of service |
| RSU | Road side unit |
| RTT | Round trip time |
| SAE | Society of automotive engineers |
| SINR | Signal-to-interference-plus-noise ratio |
| SPS | Sensing-based semipersistent scheduling |
| TTI | Transmission time interval |
| UAV | Unmanned aerial vehicle |
| VEC | Vehicular edge computing |
References
- Hirai, T.; Murase, T. Performance Evaluation of NOMA for Sidelink Cellular-V2X Mode 4 in Driver Assistance System with Crash Warning. IEEE Access 2020, 8, 168321–168332. [Google Scholar] [CrossRef]
- Wang, H.; Ding, G.; Chen, J.; Zou, Y.; Gao, F. UAV Anti-Jamming Communications with Power and Mobility Control. IEEE Trans. Wirel. Commun. 2023, 22, 4729–4744. [Google Scholar] [CrossRef]
- Manogaran, G.; Hsu, C.H.; Shakeel, P.M.; Alazab, M. Non-Recurrent Classification Learning Model for Drone Assisted Vehicular Ad-Hoc Network Communication in Smart Cities. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2792–2800. [Google Scholar] [CrossRef]
- Shi, W.; Zhou, H.; Li, J.; Xu, W.; Zhang, N.; Shen, X. Drone Assisted Vehicular Networks: Architecture, Challenges and Opportunities. IEEE Netw. 2018, 32, 130–137. [Google Scholar] [CrossRef]
- Shen, T.; Ochiai, H. A UAV-Enabled Wireless Powered Sensor Network Based on NOMA and Cooperative Relaying with Altitude Optimization. IEEE Open J. Commun. Soc. 2021, 2, 21–34. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, Z.; Liu, Y.; Xu, W.; Nallanathan, A. Joint Resource, Deployment, and Caching Optimization for AR Applications in Dynamic UAV NOMA Networks. IEEE Trans. Wirel. Commun. 2022, 21, 3409–3422. [Google Scholar] [CrossRef]
- Zhou, Y.; Yeoh, P.L.; Kim, K.J.; Ma, Z.; Li, Y.; Vucetic, B. Game Theoretic Physical Layer Authentication for Spoofing Detection in UAV Communications. IEEE Trans. Veh. Technol. 2022, 71, 6750–6755. [Google Scholar] [CrossRef]
- Xie, J.; Chang, Z.; Guo, X.; Hamalainen, T. Energy Efficient Resource Allocation for Wireless Powered UAV Wireless Communication System with Short Packet. IEEE Trans. Green Commun. Netw. 2023, 7, 101–113. [Google Scholar] [CrossRef]
- Ghamari, M.; Rangel, P.; Mehrubeoglu, M.; Tewolde, G.S.; Sherratt, R.S. Unmanned Aerial Vehicle Communications for Civil Applications: A Review. IEEE Access 2022, 10, 102492–102531. [Google Scholar] [CrossRef]
- Hu, Z.; Shaloudegi, K.; Zhang, G.; Yu, Y. Federated Learning Meets Multi-Objective Optimization. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2039–2051. [Google Scholar] [CrossRef]
- Gupta, A.; Fernando, X. Co-operative Edge Intelligence for C-V2X Communication using Federated Reinforcement Learning. In Proceedings of the 2023 IEEE 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Toronto, ON, Canada, 5–8 September 2023; pp. 1–6. [Google Scholar]
- Zhao, L.; Xu, H.; Wang, Z.; Chen, X.; Zhou, A. Joint Channel Estimation and Feedback for mm-Wave System Using Federated Learning. IEEE Commun. Lett. 2022, 26, 1819–1823. [Google Scholar] [CrossRef]
- Wang, H.; Lv, T.; Lin, Z.; Zeng, J. Energy-Delay Minimization of Task Migration Based on Game Theory in MEC-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2022, 71, 8175–8188. [Google Scholar] [CrossRef]
- Saad, M.M.; Tariq, M.A.; Seo, J.; Kim, D. An Overview of 3GPP Release 17 & 18 Advancements in the Context of V2X Technology. In Proceedings of the 2023 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Bali, Indonesia, 20–23 February 2023; pp. 57–62. [Google Scholar]
- González, E.E.; Garcia-Roger, D.; Monserrat, J.F. LTE/NR-V2X Communication Modes and Future Requirements of Intelligent Transportation Systems Based on MR-DC Architectures. Sustainability 2022, 14, 3879. [Google Scholar] [CrossRef]
- Petrov, T.; Pocta, P.; Kovacikova, T. Benchmarking 4G and 5G-Based Cellular-V2X for Vehicle-to-Infrastructure Communication and Urban Scenarios in Cooperative Intelligent Transportation Systems. Appl. Sci. 2022, 12, 9677. [Google Scholar] [CrossRef]
- Ghodhbane, C.; Kassab, M.; Maaloul, S.; Aniss, H.; Berbineau, M. A Study of LTE-V2X Mode 4 Performances in a Multiapplication Context. IEEE Access 2022, 10, 63579–63591. [Google Scholar] [CrossRef]
- Tian, D.; Zhou, J.; Sheng, Z.; Chen, M.; Ni, Q.; Leung, V.C.M. Self-Organized Relay Selection for Cooperative Transmission in Vehicular Ad-Hoc Networks. IEEE Trans. Veh. Technol. 2017, 66, 9534–9549. [Google Scholar] [CrossRef]
- Zhang, E.; Yin, S.; Ma, H. Stackelberg Game-Based Power Allocation for V2X Communications. Sensors 2019, 20, 58. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, T.; Xiong, P.; Zhou, W.; Yu, P. A Robust Game-theoretical Federated Learning Framework with Joint Differential Privacy. IEEE Trans. Knowl. Data Eng. 2022, 35, 3333–3346. [Google Scholar] [CrossRef]
- Lhazmir, S.; Oualhaj, O.A.; Kobbane, A.; Ben-Othman, J. Matching Game with No-Regret Learning for IoT Energy-Efficient Associations with UAV. IEEE Trans. Green Commun. Netw. 2020, 4, 973–981. [Google Scholar] [CrossRef]
- Sempere-García, D.; Sepulcre, M.; Gozalvez, J. LTE-V2X Mode 3 scheduling based on adaptive spatial reuse of radio resources. Ad Hoc Netw. 2021, 113, 102351. [Google Scholar] [CrossRef]
- Gupta, A.; Afrin, T.; Scully, E.; Yodo, N. Advances of UAVs toward Future Transportation: The State-of-the-Art, Challenges, and Opportunities. Future Transp. 2021, 1, 326–350. [Google Scholar] [CrossRef]
- Kim, T.; Lee, S.; Kim, K.H.; Jo, Y.I. FANET Routing Protocol Analysis for Multi-UAV-Based Reconnaissance Mobility Models. Drones 2023, 7, 161. [Google Scholar] [CrossRef]
- Kujawski, A.; Nürnberg, M. Analysis of the Potential Use of Unmanned Aerial Vehicles and Image Processing Methods to Support Road and Parking Space Management in Urban Transport. Sustainability 2023, 15, 3285. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I.; Cano, J.C.; Manzoni, P.; Calafate, C.T. Adaptive Truck Platooning with Drones: A Decentralized Approach for Highway Monitoring. Electronics 2023, 12, 4913. [Google Scholar] [CrossRef]
- Liu, Y.; Zong, C.; Dai, C.; Zheng, H.; Zhang, D. Behavioral Decision-Making Approach for Vehicle Platoon Control: Two Noncooperative Game Models. IEEE Trans. Transp. Electrif. 2023, 9, 4626–4638. [Google Scholar] [CrossRef]
- Shan, L.; Miura, R.; Matsuda, T.; Koshikawa, M.; Li, H.B.; Matsumura, T. Vehicle-to-Vehicle Based Autonomous Flight Coordination Control System for Safer Operation of Unmanned Aerial Vehicles. Drones 2023, 7, 669. [Google Scholar] [CrossRef]
- Wang, L.; Fan, D.; Huang, K.; Xia, C. A New Game Model of Task Forwarding for a Multiagent System Based on a Reputation Mechanism. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1089–1093. [Google Scholar] [CrossRef]
- Mushtaq, A.; Haq, I.u.; Nabi, W.u.; Khan, A.; Shafiq, O. Traffic Flow Management of Autonomous Vehicles Using Platooning and Collision Avoidance Strategies. Electronics 2021, 10, 1221. [Google Scholar] [CrossRef]
- Alawad, W.; Halima, N.B.; Aziz, L. An Unmanned Aerial Vehicle (UAV) System for Disaster and Crisis Management in Smart Cities. Electronics 2023, 12, 1051. [Google Scholar] [CrossRef]
- Kavas-Torris, O.; Gelbal, S.Y.; Cantas, M.R.; Aksun Guvenc, B.; Guvenc, L. V2X Communication between Connected and Automated Vehicles (CAVs) and Unmanned Aerial Vehicles (UAVs). Sensors 2022, 22, 8941. [Google Scholar] [CrossRef]
- Huang, C.J.; Hu, K.W.; Cheng, H.W. An Electric Vehicle Assisted Charging Mechanism for Unmanned Aerial Vehicles. Electronics 2023, 12, 1729. [Google Scholar] [CrossRef]
- Moghaddam, S.Z.; Akbari, T. Network-constrained optimal bidding strategy of a plug-in electric vehicle aggregator: A stochastic/robust game theoretic approach. Energy 2018, 151, 478–489. [Google Scholar] [CrossRef]
- Chavhan, S.; Gupta, D.; Alkhayyat, A.; Alharbi, M.; Rodrigues, J.J.P.C. AI-Empowered Game Theoretic-Enabled Dynamic Electric Vehicles Charging Price Scheme in Smart City. IEEE Syst. J. 2023, 17, 5171–5182. [Google Scholar] [CrossRef]
- Li, C.; Sun, X.; Zha, M.; Yang, C.; Wang, W.; Su, J. IGBT Thermal Model-Based Predictive Energy Management Strategy for Plug-In Hybrid Electric Vehicles Using Game Theory. IEEE Trans. Transp. Electrif. 2023, 9, 3268–3281. [Google Scholar] [CrossRef]
- AL-Dosari, K.; Fetais, N. A New Shift in Implementing Unmanned Aerial Vehicles (UAVs) in the Safety and Security of Smart Cities: A Systematic Literature Review. Safety 2023, 9, 64. [Google Scholar] [CrossRef]
- Gupta, A.; Fernando, X. Simultaneous Localization and Mapping (SLAM) and Data Fusion in Unmanned Aerial Vehicles: Recent Advances and Challenges. Drones 2022, 6, 85. [Google Scholar] [CrossRef]
- Hossain, M.D.; Sultana, T.; Hossain, M.A.; Layek, M.A.; Hossain, M.I.; Sone, P.P.; Lee, G.W.; Huh, E.N. Dynamic Task Offloading for Cloud-Assisted Vehicular Edge Computing Networks: A Non-Cooperative Game Theoretic Approach. Sensors 2022, 22, 3678. [Google Scholar] [CrossRef]
- Banez, R.A.; Li, L.; Yang, C.; Han, Z. Mean Field Game and Its Applications in Wireless Networks, 1st ed.; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Luong, N.; Nguyen, T.T.V.; Feng, S.; Nguyen, H.T.; Niyato, T.D.; Kim, D.I. Dynamic Network Service Selection in IRS-Assisted Wireless Networks: A Game Theory Approach. IEEE Trans. Veh. Technol. 2021, 70, 5160–5165. [Google Scholar] [CrossRef]
- Hichri, Y.; Dahi, S.; Fathallah, H. A non-cooperative game-theoretic approach applied to the service selection in the vehicular cloud. Int. J. Commun. Syst. 2022, 35, e5157. [Google Scholar] [CrossRef]
- Osman, R.A.; Saleh, S.N.; Saleh, Y.N.M.; Elagamy, M.N. Enhancing the Reliability of Communication between Vehicle and Everything (V2X) Based on Deep Learning for Providing Efficient Road Traffic Information. Appl. Sci. 2021, 11, 11382. [Google Scholar] [CrossRef]
- Gautam, C.; Priyanka, K.; Dharmaraja, S. Analysis of a model of batch arrival single server queue with random vacation policy. Commun. Stat. Theory Methods 2021, 50, 5314–5357. [Google Scholar] [CrossRef]
- Xu, J.; Liu, L.; Wu, K. Analysis of a retrial queueing system with priority service and modified multiple vacations. Commun. Stat. Theory Methods 2022, 52, 6207–6231. [Google Scholar] [CrossRef]
- Segawa, Y.; Tang, S.; Ueno, T.; Ogishi, T.; Obana, S. Improving Performance of C-V2X Sidelink by Interference Prediction and Multi Interval Extension. IEEE Access 2022, 10, 42518–42528. [Google Scholar] [CrossRef]
- Feng, Z.; Huang, M.; Wu, D.; Wu, E.Q.; Yuen, C. Multi-Agent Reinforcement Learning with Policy Clipping and Average Evaluation for UAV-Assisted Communication Markov Game. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14281–14293. [Google Scholar] [CrossRef]
- Amer, H.; Al-Kashoash, H.; Khami, M.J.; Mayfield, M.; Mihaylova, L. Non-cooperative game based congestion control for data rate optimization in vehicular ad hoc networks. Ad Hoc Netw. 2020, 107, 102181. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Shi, Y.; MacKenzie, A.B.; Hou, Y.T. Regret Minimization for Primary/Secondary Access to Satellite Resources with Cognitive Interference. IEEE Trans. Wirel. Commun. 2018, 17, 3512–3523. [Google Scholar] [CrossRef]
- He, J.; Yang, K.; Chen, H.H. 6G Cellular Networks and Connected Autonomous Vehicles. IEEE Netw. 2021, 35, 255–261. [Google Scholar] [CrossRef]
- Li, X.; Cheng, L.; Sun, C.; Lam, K.Y.; Wang, X.; Li, F. Federated-Learning-Empowered Collaborative Data Sharing for Vehicular Edge Networks. IEEE Netw. 2021, 35, 116–124. [Google Scholar] [CrossRef]
- Nguyen, V.D.; Chatzinotas, S.; Ottersten, B.; Duong, T.Q. FedFog: Network-Aware Optimization of Federated Learning over Wireless Fog-Cloud Systems. IEEE Trans. Wirel. Commun. 2022, 21, 8581–8599. [Google Scholar] [CrossRef]
- Ali, R.; Zikria, Y.B.; Garg, S.; Bashir, A.K.; Obaidat, M.S.; Kim, H.S. A Federated Reinforcement Learning Framework for Incumbent Technologies in Beyond 5G Networks. IEEE Netw. 2021, 35, 152–159. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Guo, S.; Qu, Z. Incentive Mechanism Design for Federated Learning: Challenges and Opportunities. IEEE Netw. 2021, 35, 310–317. [Google Scholar] [CrossRef]
- Nie, L.; Wang, X.; Sun, W.; Li, Y.; Li, S.; Zhang, P. Imitation-Learning-Enabled Vehicular Edge Computing: Toward Online Task Scheduling. IEEE Netw. 2021, 35, 102–108. [Google Scholar] [CrossRef]
- Zamanipour, M. Novel Information-theoretic Game-theoretical Insights to Broadcasting. IEEE Trans. Signal Inf. Process. Netw. 2022, 8, 713–725. [Google Scholar] [CrossRef]
- Elahi, A.; Alfi, A.; Modares, H. H-∞ Consensus of Homogeneous Vehicular Platooning Systems with Packet Dropout and Communication Delay. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 3680–3691. [Google Scholar] [CrossRef]
- Markova, E.; Satin, Y.; Kochetkova, I.; Zeifman, A.; Sinitcina, A. Queuing System with Unreliable Servers and In-homogeneous Intensities for Analyzing the Impact of Non-Stationarity to Performance Measures of Wireless Network under Licensed Shared Access. Mathematics 2020, 8, 800. [Google Scholar] [CrossRef]
- Mao, K.; Zhu, Q.; Qiu, Y.; Liu, X.; Song, M.; Fan, W.; Kokkeler, A.B.J.; Miao, Y. A UAV-Aided Real-Time Channel Sounder for Highly Dynamic Nonstationary A2G Scenarios. IEEE Trans. Instrum. Meas. 2023, 72, 1–15. [Google Scholar] [CrossRef]
- Lyu, Y.; Wang, W.; Sun, Y.; Rashdan, I. Measurement-based fading characteristics analysis and modeling of UAV to vehicles channel. Veh. Commun. 2024, 45, 100707. [Google Scholar] [CrossRef]
- Hosseini, M.; Ghazizadeh, R. Stackelberg Game-Based Deployment Design and Radio Resource Allocation in Coordinated UAVs-Assisted Vehicular Communication Networks. IEEE Trans. Veh. Technol. 2023, 72, 1196–1210. [Google Scholar] [CrossRef]
- Wang, B.; Yuan, Z.; Zheng, S.; Liu, Y. Data-Driven Intelligent Receiver for OTFS Communication in Internet of Vehicles. IEEE Trans. Veh. Technol. 2023, 73, 6968–6979. [Google Scholar] [CrossRef]
- Liu, X.; Yang, Y.; Gong, J.; Xia, N.; Guo, J.; Peng, M. Amplitude Barycenter Calibration of Delay-Doppler Spectrum for OTFS Signal—An Endeavor to Integrated Sensing and Communication Waveform Design. IEEE Trans. Wirel. Commun. 2023, 23, 2622–2637. [Google Scholar] [CrossRef]
- Plaisted, D. Some Polynomial and Integer Divisibility Problems are NP-Hard. SIAM J. Comput. 1978, 7, 458–464. [Google Scholar] [CrossRef]
- Xu, Y.H.; Li, J.H.; Zhou, W.; Chen, C. Learning-Empowered Resource Allocation for Air Slicing in UAV-Assisted cellular-V2X Communications. IEEE Syst. J. 2023, 17, 1008–1011. [Google Scholar] [CrossRef]
- Chen, S.l. The KKT optimality conditions for optimization problem with interval-valued objective function on Hadamard manifolds. Optimization 2022, 71, 613–632. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Proposed Approach and Objectives | Our Approach |
|---|---|---|
| [6] |
|
|
| [10] |
|
|
| [11] |
|
|
| [13] |
|
|
| [18] |
|
|
| [21] |
|
|
| [39] |
|
|
| Symbol | Definition |
|---|---|
| = | UAV trajectory at different time steps |
| Vehicle cluster | |
| Number of vehicles in a cluster | |
| Channel gain between the vehicle and the UAV in transmission window | |
| Channel power gain | |
| (,) | UAV coordinates during the transmission window |
| (,) | Coordinates of the vehicle during the transmission window |
| UAV flying height in meters (m) | |
| Data transmission rate from vehicle to the UAV in transmission window | |
| Power spectral density of Gaussian noise | |
| Transmit power of the UAV in the transmission window | |
| Length of the transmission window | |
| Probability of the number of packets in queue | |
| Mean of the uniform distribution of packets in the queue | |
| Action set of the vehicle | |
| Probability that the vehicle plays action () | |
| Expected utility | |
| Set of opposing strategies | |
| Set of all mixed strategies () | |
| n-tuple | An equilibrium point as quantified in Equation (15b,c) |
| Convex combination of the utilities of the vehicles’ pure strategies | |
| The vehicles’ pure strategies | |
| Associated weights with vehicles’ pure strategies | |
| The vehicle’s pure strategy | |
| A game with probabilities, utilities, and actions | |
| A game for which we evaluate utility for probability instance | |
| Set of d-dimensional probability instance | |
| Max–min value of utility weights | |
| Min–max value of utility weights | |
| Model parameter transmission probabilities for each game | |
| Game function for different strategy combinations | |
| Game function for different utility combinations | |
| Set of game for utility (u), strategy (s), probability of action () | |
| Vehicle (v)’s model transmission parameter weights | |
| Model loss between and g | |
| Parameter space that specifies parameter transmission from vehicles to UAV | |
| Discount factor for future incentives | |
| Nash equilibrium of the game | |
| Control parameter to tune | |
| Bandwidth at UAV’s receiver | |
| Power at UAV’s receiver | |
| SINR during UAV flight time | |
| UAV’s cost function | |
| Downlink spectral efficiency of vehicle i |
| Parameter | Value |
|---|---|
| Vehicle Mobility | Manhattan Mobility |
| Number of vehicles (V) | 1–100 |
| Number of in drone | 1 |
| Drone deployment altitude | 100 m–2 km |
| Elliptical path’s major axis | 200 m–500 m |
| Elliptical path’s minor axis | 100 m–350 m |
| Edge server location | In-vehicle |
| Communication frequency | 5.9 GHz |
| Modulation technique | 16-QAM |
| Distance between vehicles | 10–100 m |
| Road length | 1–5 km |
| Vehicle speed | 0–100 km/h |
| Payload size for BSM, CPM | 1 byte–3 Megabytes |
| Payload size of FL models | 1 byte–10 Megabytes |
| Dataset used | V2X-Sim |
| 100 ms–1000 ms | |
| 100, 200, 300, 500 ms | |
| 1000, 2000 packets/s | |
| Mean speed of vehicles | 50 km/h |
| OTFS base station transmit power | 40 dBm (10 W) |
| Drone transmission power | 20 dBm (100 mW) |
| Drone receiving threshold | −80 dBm |
| Vehicle transmission power | 25 dBm (316.2 mW) |
| Noise power | −50 dBm ( W) |
| Standard deviation in speed | 10 km/h |
| / | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | (0.625, 0.625) | (0.250, 0.700) | (0.375, 0.875) | (0.500, 0.750) | (0.625, 0.625) |
| 2 | (1.000, 0.250) | (0.625, 0.625) | (0.500, 0.750) | (0.625, 0.625) | (0.750, 0.500) |
| 3 | (0.875, 0.375) | (0.750, 0.500) | (0.625, 0.500) | (0.750, 0.500) | (0.875, 0.375) |
| 4 | (0.750, 0.500) | (0.625, 0.625) | (0.500, 0.750) | (0.500, 0.625) | (1.000, 0.500) |
| 5 | (0.625, 0.625) | (0.500, 0.750) | (0.375, 0.875) | (0.250, 1.000) | (0.625, 0.625) |
| / | Select | Not_Select |
|---|---|---|
| (Not_complete, Transmit) | (2,1) | |
| (Not_complete, Not_transmit) | ||
| (Complete,Not_transmit) | ||
| (Complete,Transmit) |
| Select | Not_Select | |
|---|---|---|
| Updated | ||
| Not_Updated |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernando, X.; Gupta, A. Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment. Drones 2024, 8, 238. https://doi.org/10.3390/drones8060238
Fernando X, Gupta A. Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment. Drones. 2024; 8(6):238. https://doi.org/10.3390/drones8060238
Chicago/Turabian StyleFernando, Xavier, and Abhishek Gupta. 2024. "Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment" Drones 8, no. 6: 238. https://doi.org/10.3390/drones8060238
APA StyleFernando, X., & Gupta, A. (2024). Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment. Drones, 8(6), 238. https://doi.org/10.3390/drones8060238