

A Robust Hybrid Iterative Learning Formation Strategy for Multi-Unmanned Aerial Vehicle Systems with Multi-Operating Modes


Abstract
1. Introduction
- We propose a hybrid robust iterative learning formation control strategy that combines a state and disturbance iterative learning observer (ILO), and an iterative learning controller for multi-UAV systems under multi-operating modes. In contrast to the existing literature on formation control for multi-UAV systems [32,33], this paper extends the application fields of multi-UAV system formation control from the single operating mode to the multi-operating mode.
- The proposed method does not depend on the accurate dynamic model of multi-UAV systems, and the control input in the current iteration is updated by utilizing the stored data from previous iterations.
- Compared to iterative learning works for multi-UAV systems [28,29], an iteration-fixed initial state assumption is not required in this paper. Detailed theoretical results are described to ensure the convergence of state and disturbance estimated errors and the formation tracking error with the proposed hybrid formation control strategy.
- Three simulation experiments with a multi-UAV system composed of four quadrotor UAVs are conducted to demonstrate the effectiveness and the superiority of the proposed formation strategy in dealing with the finite-time formation tracking.
2. Problem Formulation
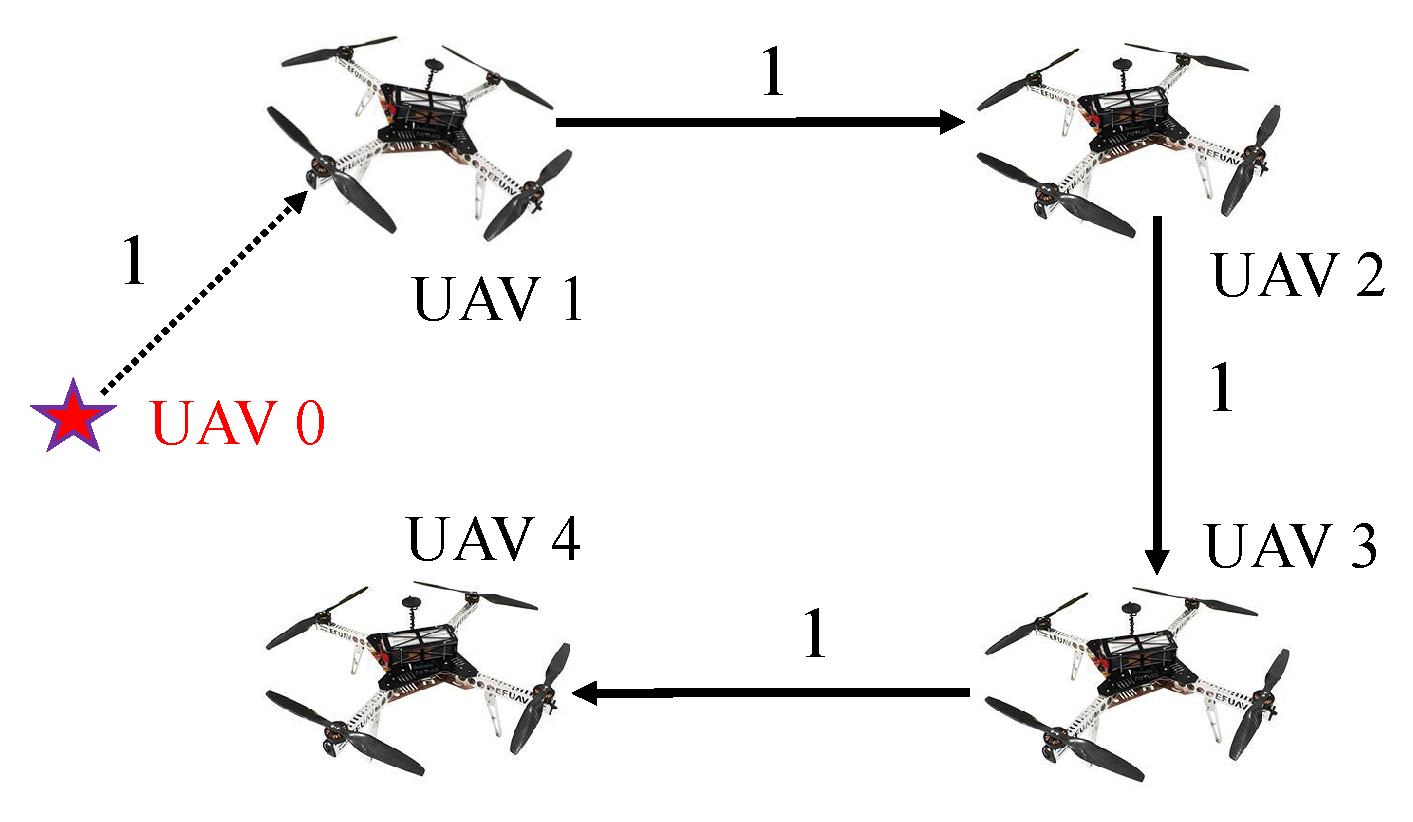
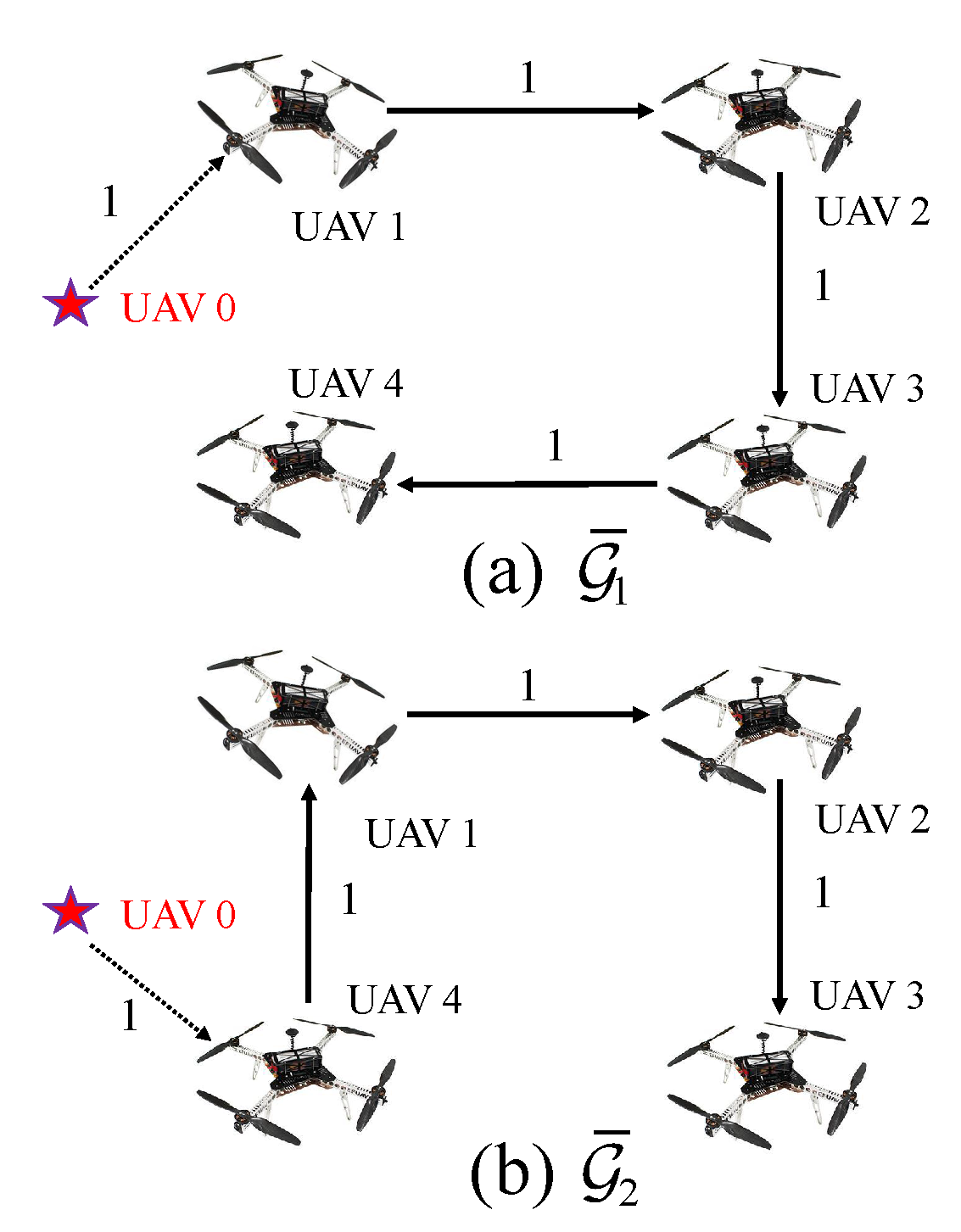
2.1. Communication Topology
2.2. Multi-UAV Systems with Multi-Operating Modes
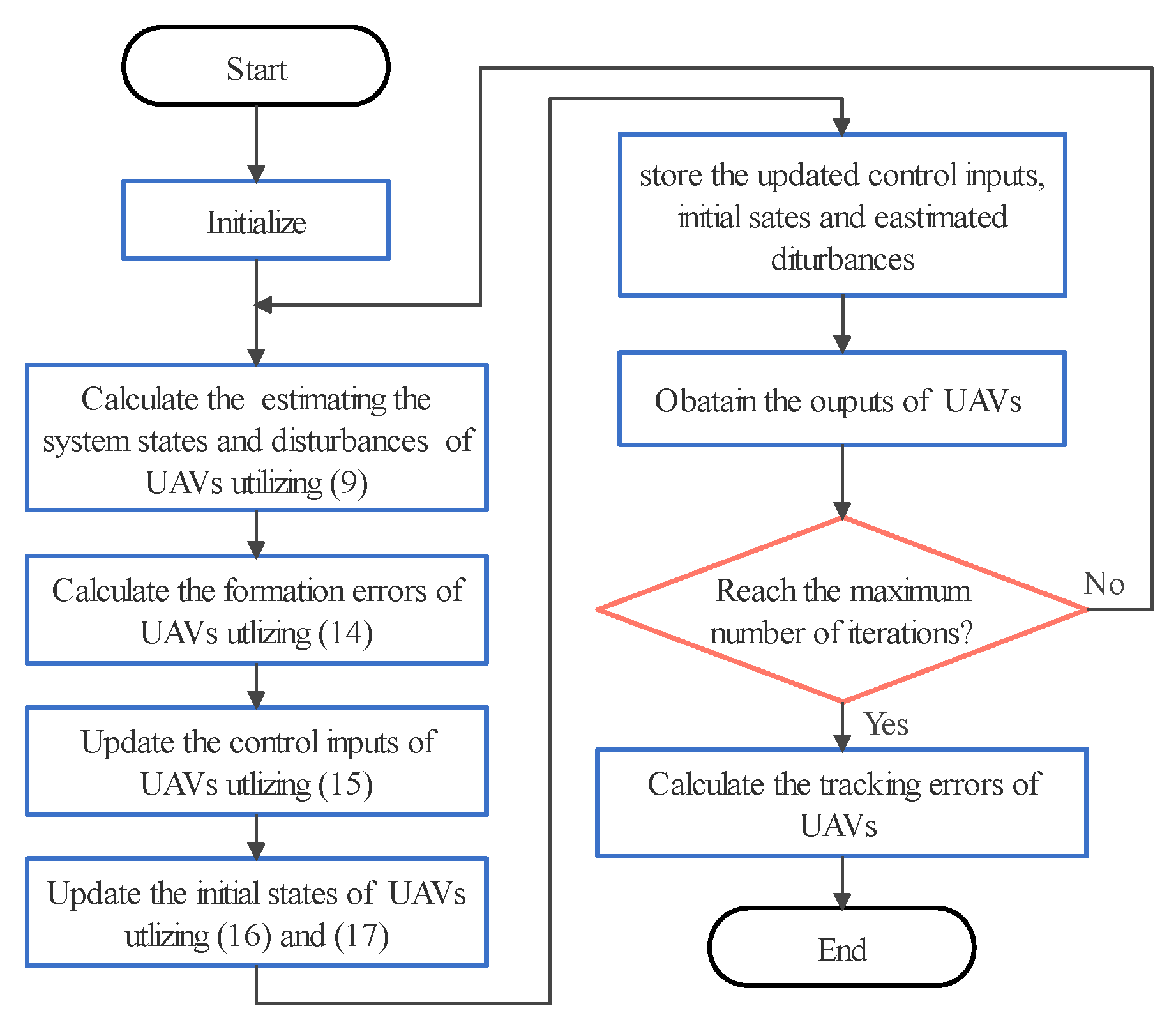
3. Methodology
3.1. ILO Design for Multi-UAV Systems
3.2. ILC Controller Design for Multi-UAV Systems
4. Convergence Analysis
5. Simulation Example
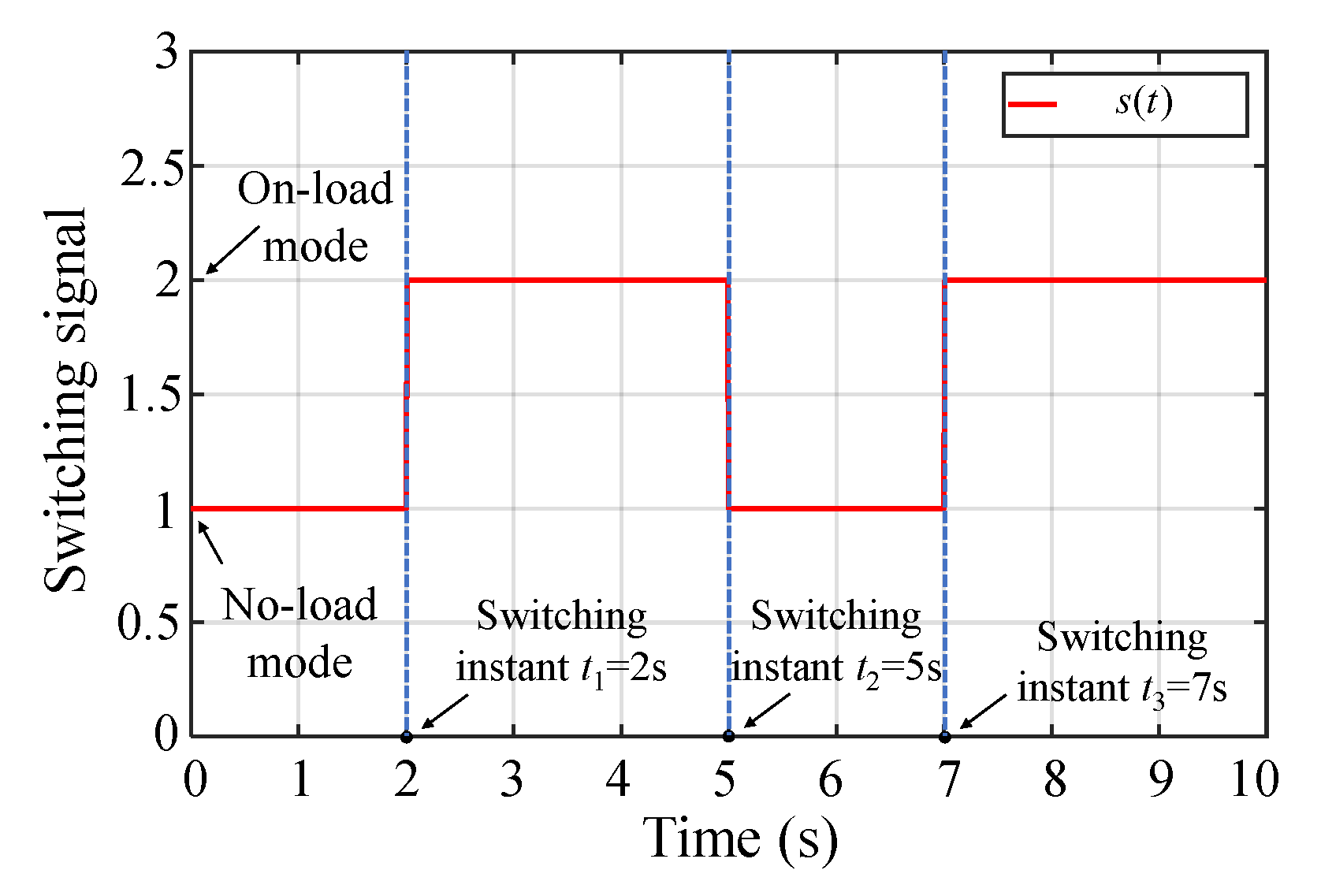
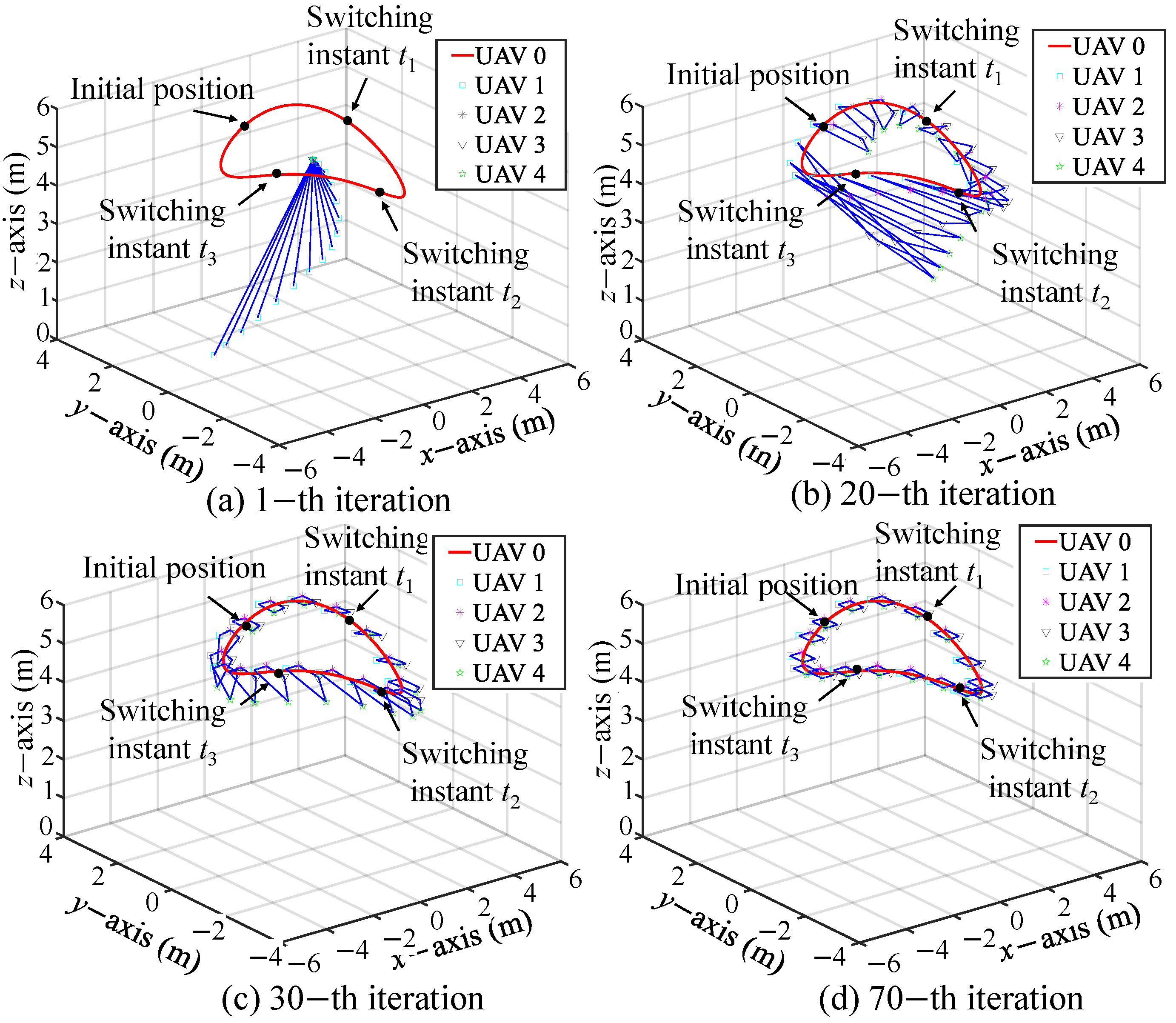
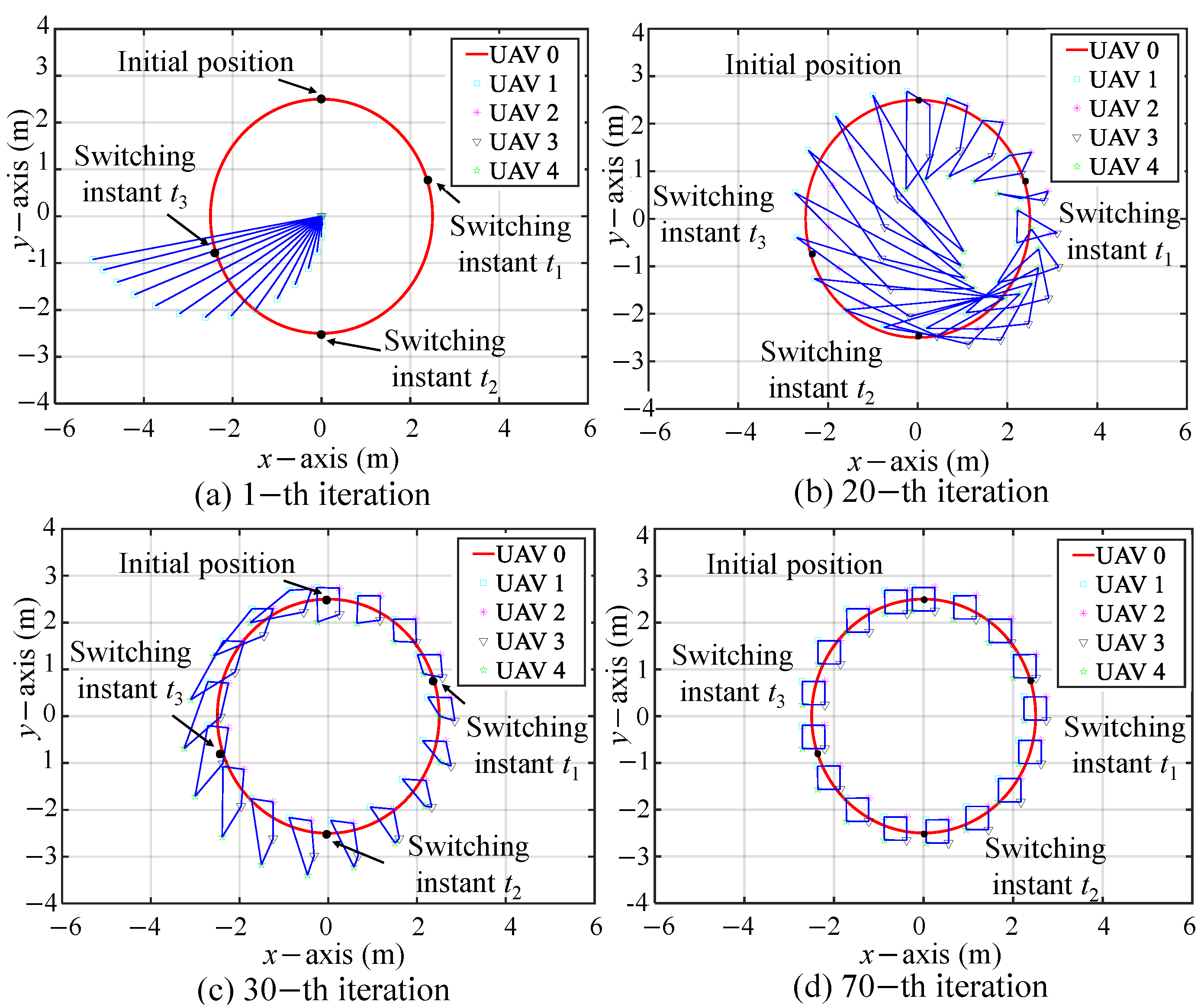
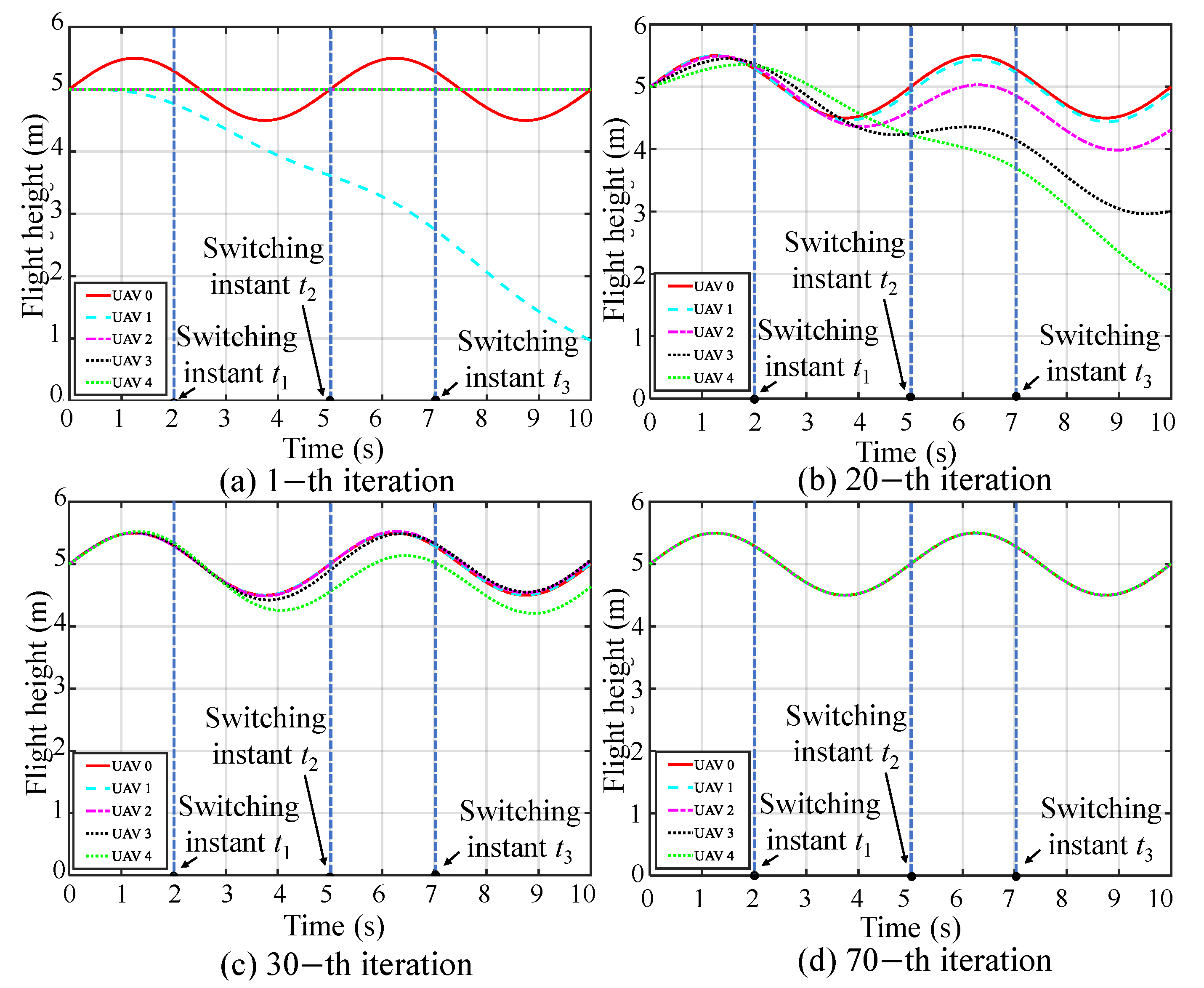
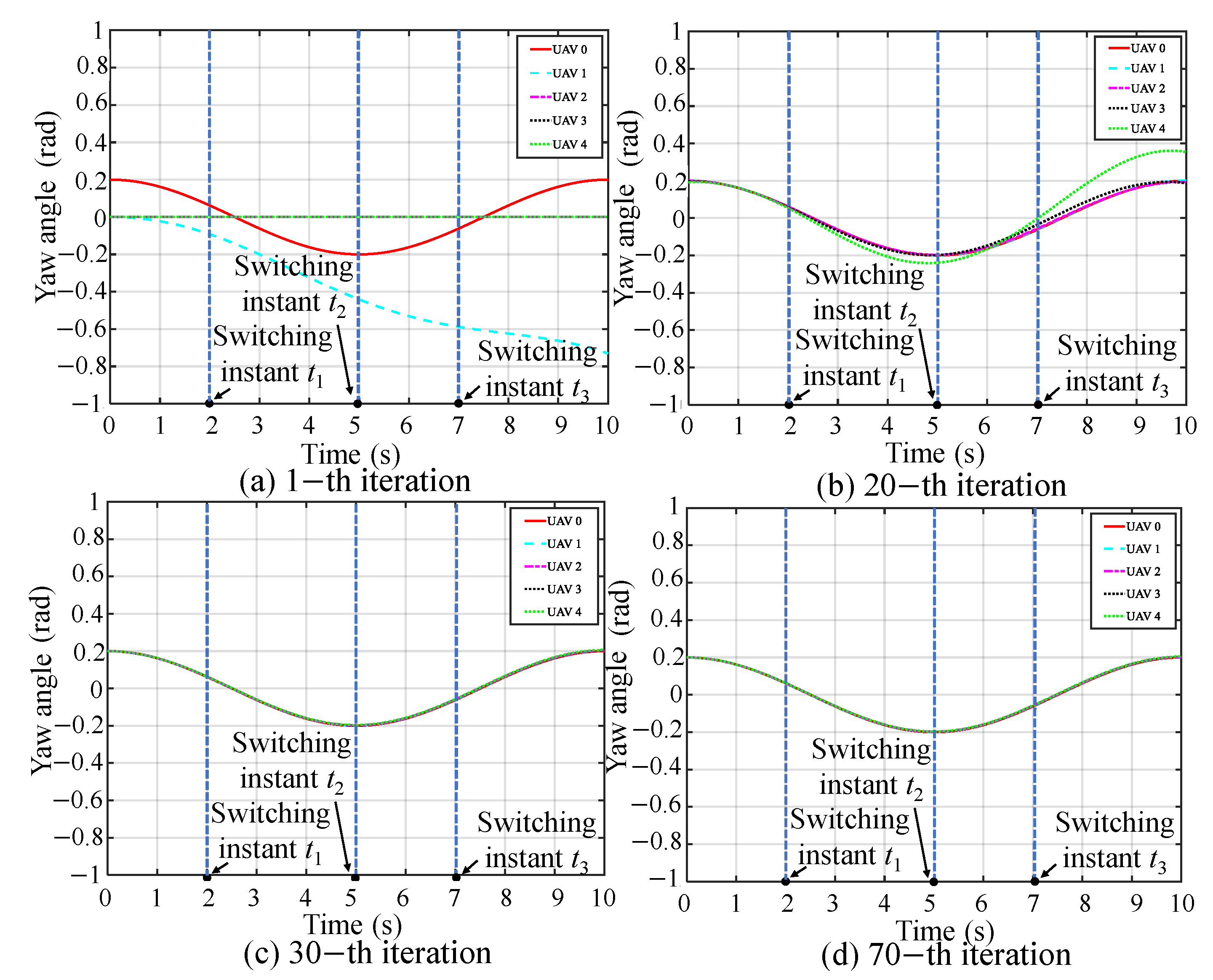
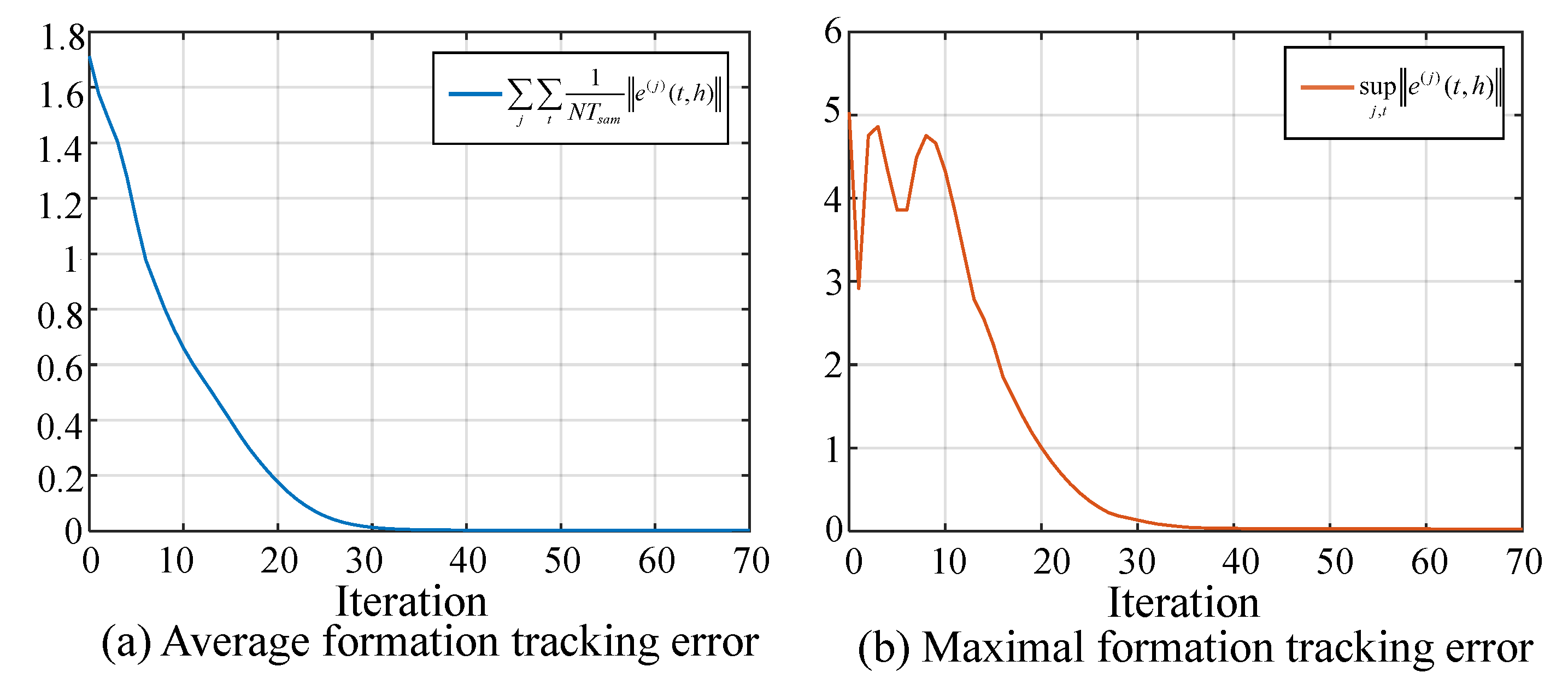
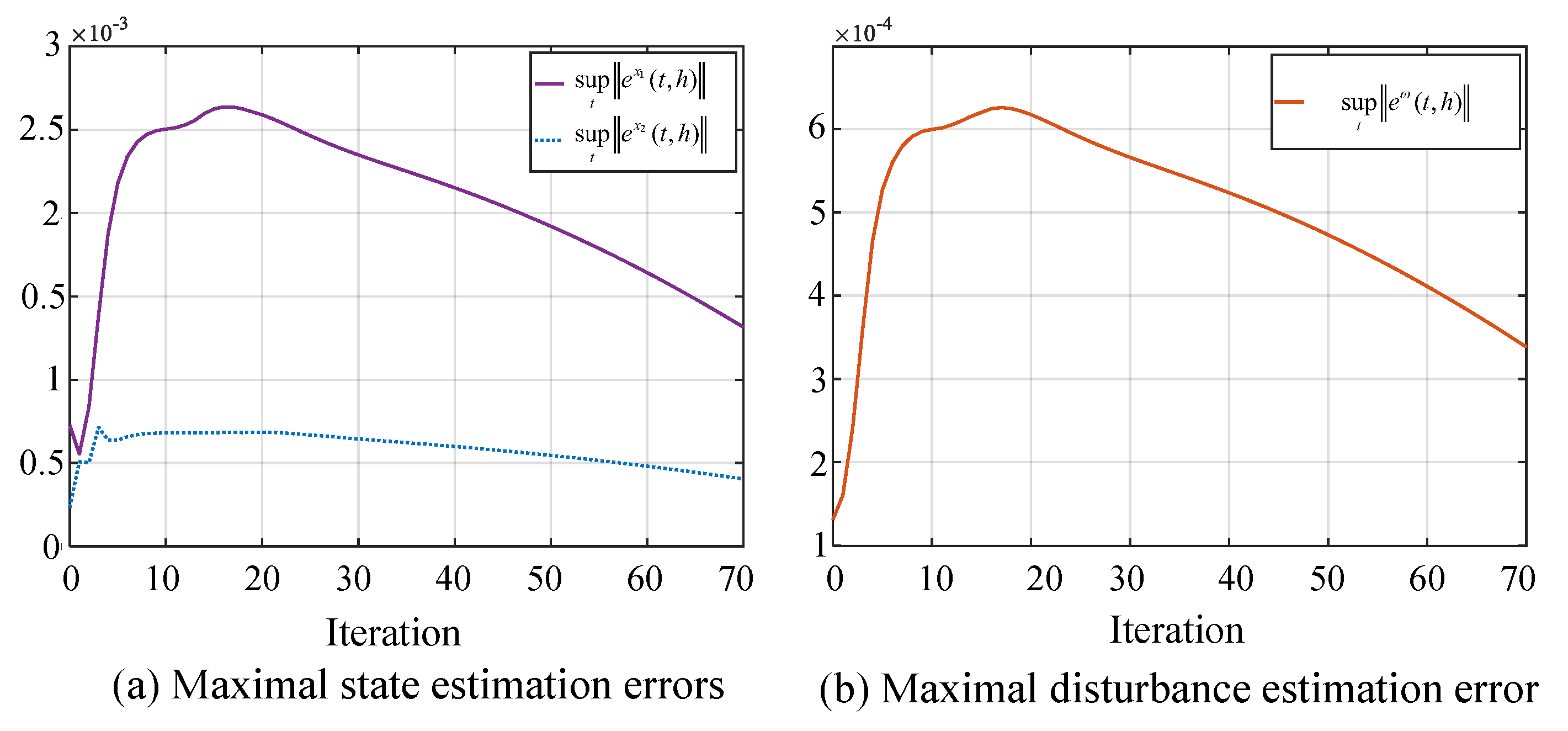
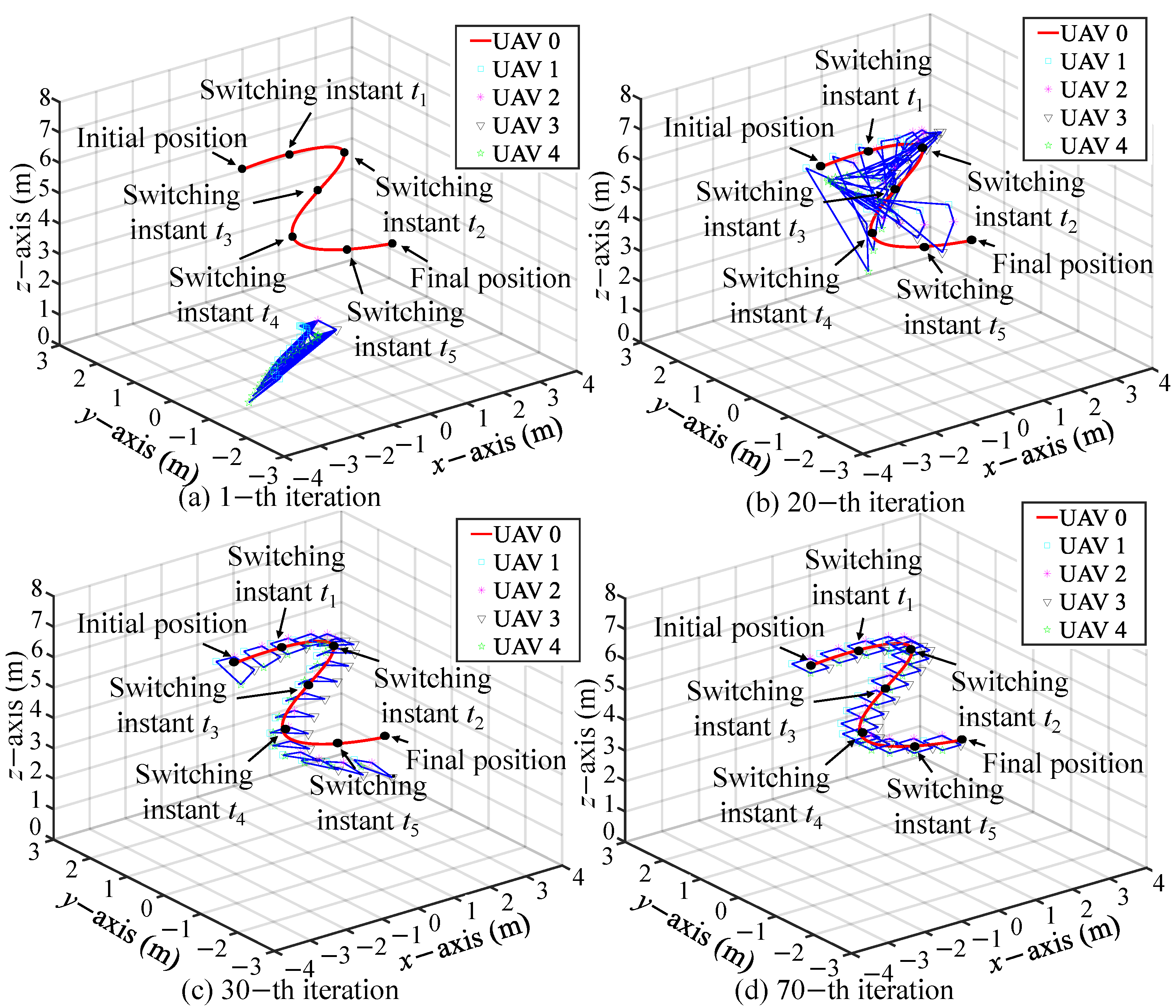
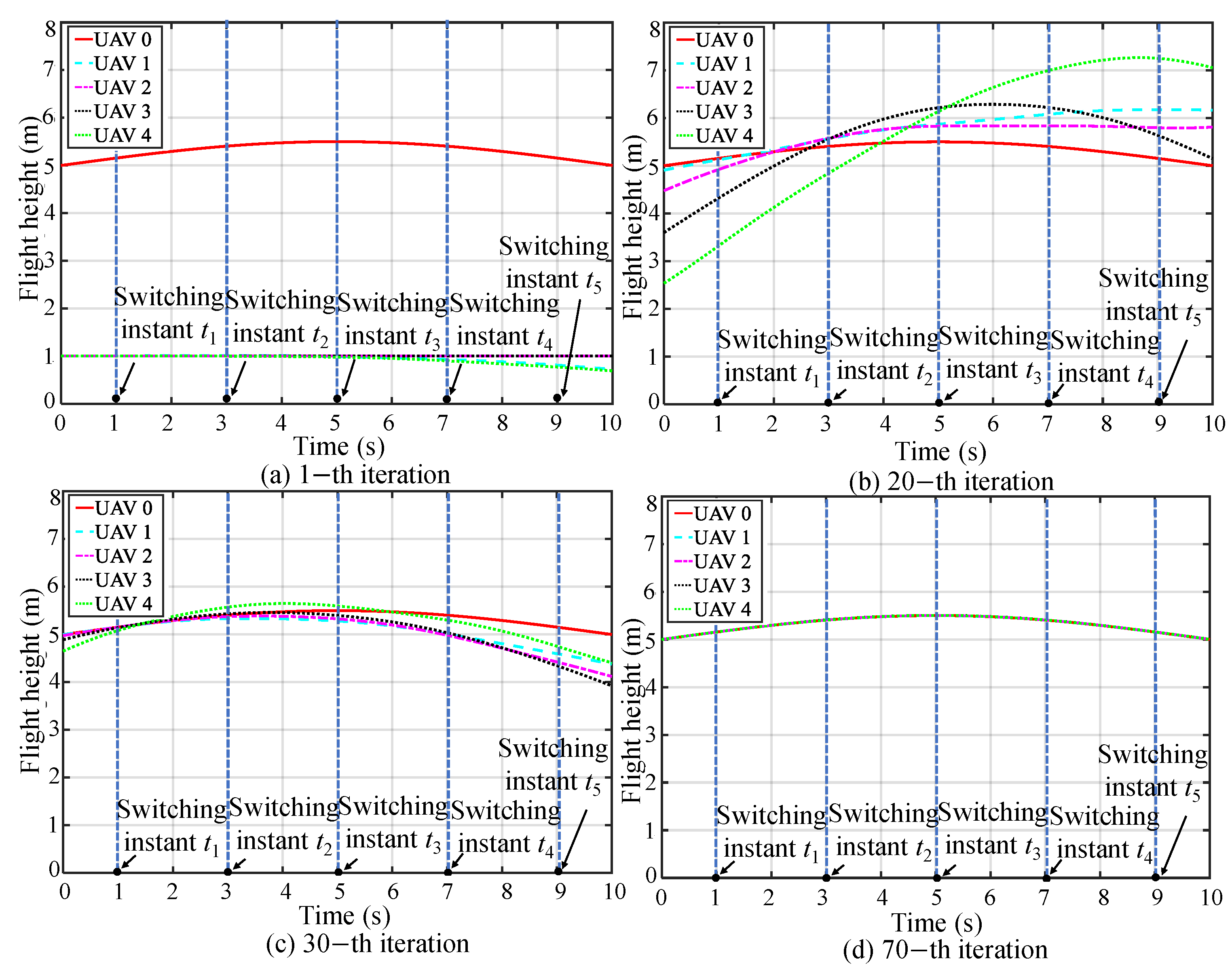
5.1. Simulation I: Formation Tracking with Switching Operating Modes
5.2. Simulation II: Formation Tracking with Switching Topologies
5.3. Simulation III: Compared to the PID Controller
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Hua, Y.; Dong, X.; Yu, J.; Ren, Z. Time-varying formation tracking control for unmanned aerial vehicles with the leader’s unknown input and obstacle avoidance: Theories and applications. Electronics 2022, 11, 2334. [Google Scholar] [CrossRef]
- Du, B.; Li, S. A new multi-satellite autonomous mission allocation and planning method. Acta Astronaut. 2019, 163, 287–298. [Google Scholar] [CrossRef]
- Xiao, P.; Li, N.; Xie, F.; Ni, H.; Zhang, M.; Wang, B. Clustering-based multi-region coverage-path planning of heterogeneous UAVs. Drones 2023, 7, 664. [Google Scholar] [CrossRef]
- Zhao, F.; Hua, Y.; Zheng, H.; Yu, J.; Dong, X.; Li, Q.; Ren, Z. Cooperative target pursuit by multiple fixed-wing UAVs based on deep reinforcement learning and artificial potential field. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023; pp. 5693–5698. [Google Scholar]
- Moein, D.; Kabganian, M.; Azimi, A. Robust adaptive control for formation-based cooperative transportation of a payload by multi quadrotors. Eur. J. Control 2023, 69, 100763. [Google Scholar]
- Zhang, J.; Yan, J.; Zhang, P. Multi-UAV formation control based on a novel back-stepping approach. IEEE Trans. Veh. Technol. 2020, 69, 2437–2448. [Google Scholar] [CrossRef]
- Muslimov, T.Z.; Munasypov, R.A. Adaptive decentralized flocking control of multi-UAV circular formations based on vector fields and backstepping. ISA Trans. 2020, 107, 143–159. [Google Scholar] [CrossRef]
- Balch, T.; Arkin, R.C. Behavior-based formation control for multirobot teams. IEEE Trans. Robot. Autom. 1998, 14, 926–939. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, C.; Xia, Y.; Xiong, H.; Shao, X. An improved artificial potential field method for path planning and formation control of the multi-UAV systems. IEEE Trans. Circuits Syst. II Express Briefs 2021, 69, 1129–1133. [Google Scholar] [CrossRef]
- Hua, Y.; Dong, X.; Hu, G.; Li, Q.; Ren, Z. Distributed time-varying output formation tracking for heterogeneous linear multiagent systems with a nonautonomous leader of unknown input. IEEE Trans. Autom. Control 2019, 64, 4292–4299. [Google Scholar] [CrossRef]
- Yu, Y.; Guo, J.; Ahn, C.K.; Xiang, Z. Neural adaptive distributed formation control of nonlinear multi-UAVs with unmodeled dynamics. IEEE Trans. Neural Networks Learn. Syst. 2023, 34, 9555–9561. [Google Scholar] [CrossRef]
- Cheng, C.; Zhang, H.; Sun, Y.; Tao, H.; Chen, Y. A cross-platform deep reinforcement learning model for autonomous navigation without global information in different scenes. Control Eng. Pract. 2024, 150, 105991. [Google Scholar] [CrossRef]
- Li, R.; Wang, L.; Chen, Y.; Ma, P. Adaptive locomotion control of hexapod robot based on deep reinforcement learning and proprioception. In Proceedings of the 2023 6th International Conference on Robotics, Control and Automation Engineering, RCAE, Suzhou, China, 27–29 October 2023; pp. 39–43. [Google Scholar]
- Han, D.; Jiang, H.; Wang, L.; Zhu, X.; Chen, Y.; Yu, Q. Collaborative task allocation and optimization solution for unmanned aerial vehicles in search and rescue. Drones 2024, 8, 138. [Google Scholar] [CrossRef]
- Gong, B.; Jiang, L.; Ning, X.; Li, S. Study on mission planning algorithm for multi-target passive tracking based on satellite formation. Aerosp. Sci. Technol. 2023, 142, 108660. [Google Scholar] [CrossRef]
- Wang, J.; Xin, M. Integrated optimal formation control of multiple unmanned aerial vehicles. IEEE Trans. Control Syst. Technol. 2013, 21, 1731–1744. [Google Scholar] [CrossRef]
- Yan, D.; Zhang, W.; Chen, H. Design of a multi-constraint formation controller based on improved MPC and consensus for quadrotors. Aerospace 2022, 9, 94. [Google Scholar] [CrossRef]
- Kuo, C.W.; Tsai, C.C.; Lee, C.T. Intelligent leader-following consensus formation control using recurrent neural networks for small-size unmanned helicopters. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 1288–1301. [Google Scholar] [CrossRef]
- Sun, R.; Zhou, Z.; Zhu, X. Finite-time terminal sliding mode attitude control for tailless full-wing configuration UAVs based on extended state observers and auxiliary compensators. ISA Trans. 2024, 144, 282–307. [Google Scholar] [CrossRef]
- Ma, X.; Wang, G.; Liu, K. Design and optimization of a multimode amphibious robot with propeller-leg. IEEE Trans. Robot. 2022, 38, 3807–3820. [Google Scholar] [CrossRef]
- Russo, S.; Harada, K.; Ranzani, T.; Manfredi, L.; Stefanini, C.; Menciassi, A.; Dario, P. Design of a robotic module for autonomous exploration and multimode locomotion. IEEE/ASME Trans. Mechatronics 2013, 18, 1757–1766. [Google Scholar] [CrossRef]
- Xu, F.; Ma, K.; Gong, T.; Jiang, Z.; Hu, C. Design and testing of a magnetic soft crawling robot with multimodal locomotion driven by 3-D magnetic fields. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Xiong, X.; Ruan, X. Non-Smooth bifurcation analysis of multi-structure multi-operating-mode power electronics systems for applications with renewable energy sources. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 487–491. [Google Scholar] [CrossRef]
- Zou, Y.; Zhou, Z.; Dong, X.; Meng, Z. Distributed formation control for multiple vertical takeoff and landing UAVs with switching topologies. IEEE/ASME Trans. Mechatronics 2018, 23, 1750–1761. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, T.; Jiang, Z.P. Cooperative formation control under switching topology: An experimental case study in multirotors. IEEE Trans. Cybern. 2020, 51, 6141–6153. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, H.; Wang, Y.; Xue, X.; Zhang, M. Distributed formation control for multiple quadrotor UAVs under Markovian switching topologies with partially unknown transition rates. J. Frankl. Inst. 2019, 356, 5706–5728. [Google Scholar] [CrossRef]
- Xue, M.; Tang, Y.; Ren, W.; Qian, F. Practical output synchronization for asynchronously switched multi-agent systems with adaption to fast-switching perturbations. Automatica 2020, 116, 108917. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, J.; Chen, Y.; Ju, S. Iterative learning-based formation control for multiple quadrotor unmanned aerial vehicles. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420911520. [Google Scholar] [CrossRef]
- Fu, X.; Peng, J. Iterative learning control for UAVs formation based on point-to-point trajectory update tracking. Math. Comput. Simul. 2023, 209, 1–15. [Google Scholar] [CrossRef]
- Hock, A.; Schoellig, A.P. Distributed iterative learning control for multi-agent systems: Theoretic developments and application to formation flying. Auton. Robot. 2019, 43, 1989–2010. [Google Scholar] [CrossRef]
- Han, Y.; Liang, Y.; Zhang, L.; Cai, B.; Li, Y.; Li, B. Bumpless transfer switched control of aircraft for heavy payload dropping missions. Aerosp. Sci. Technol. 2024, 148, 109067. [Google Scholar] [CrossRef]
- Dong, X.; Zhou, Y.; Ren, Z.; Zhong, Y. Time-varying formation tracking for second-order multi-agent systems subjected to switching topologies with application to quadrotor formation flying. IEEE Trans. Ind. Electron. 2016, 64, 5014–5024. [Google Scholar] [CrossRef]
- Wu, J.; Luo, C.; Luo, Y.; Li, K. Distributed UAV swarm formation and collision avoidance strategies over fixed and switching topologies. IEEE Trans. Cybern. 2022, 52, 10969–10979. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, L.; Wang, H.; Xue, B. Consensus control for heterogeneous multivehicle systems: An iterative learning approach. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5356–5368. [Google Scholar] [CrossRef]
- Meng, D.; Zhang, J. Cooperative learning for switching networks with nonidentical nonlinear agents. IEEE Trans. Autom. Control 2021, 66, 6131–6138. [Google Scholar] [CrossRef]
- Sun, M.; Wang, D. Sampled-data iterative learning control for nonlinear systems with arbitrary relative degree. Automatica 2001, 37, 283–289. [Google Scholar] [CrossRef]
- Sun, M.; Huang, B. Iterative Learning Control; National Defence Industry Press: Beijing, China, 1999. [Google Scholar]
- Meng, D.; Jia, Y.; Du, J.; Zhang, J. High-precision formation control of nonlinear multi-agent systems with switching topologies: A learning approach. Int. J. Robust Nonlinear Control 2015, 25, 1993–2018. [Google Scholar] [CrossRef]
- Jeffreys, H.; Jeffreys, B.S. Methods of Mathematical Physics; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Shao, Z.; Xiang, Z. Design of an iterative learning control law for a class of switched repetitive systems. Circuits Syst. Signal Process. 2017, 36, 845–866. [Google Scholar] [CrossRef]
- Shen, Z.; Tan, L.; Yu, S.; Song, Y. Fault-tolerant adaptive learning control for quadrotor UAVs with the time-varying CoG and full-state constraints. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 5610–5622. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Guo, L. PID controller design for second order nonlinear uncertain systems. Sci. China-Inf. Sci. 2017, 60, 022201:1–022201:13. [Google Scholar] [CrossRef]
- Shen, D.; Li, X. A survey on iterative learning control with randomly varying trial lengths: Model, synthesis, and convergence analysis. Annu. Rev. Control 2019, 48, 89–102. [Google Scholar] [CrossRef]
- Zeng, C.; Shen, D.; Wang, J. Adaptive learning tracking for uncertain systems with partial structure information and varying trial lengths. J. Frankl. Inst. 2018, 355, 7027–7055. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Controller | (m) | (m) | (m) | (rad) |
|---|---|---|---|---|
| Controller (12) | 0.0047 m | 0.0110 m | 0.0018 m | 0.0024 rad |
| PID controller | 0.0478 m | 0.2223 m | 0.0790 m | 0.2190 rad |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Yu, W.; Liu, Z.; Ma, F. A Robust Hybrid Iterative Learning Formation Strategy for Multi-Unmanned Aerial Vehicle Systems with Multi-Operating Modes. Drones 2024, 8, 406. https://doi.org/10.3390/drones8080406
Yang S, Yu W, Liu Z, Ma F. A Robust Hybrid Iterative Learning Formation Strategy for Multi-Unmanned Aerial Vehicle Systems with Multi-Operating Modes. Drones. 2024; 8(8):406. https://doi.org/10.3390/drones8080406
Chicago/Turabian StyleYang, Song, Wenshuai Yu, Zhou Liu, and Fei Ma. 2024. "A Robust Hybrid Iterative Learning Formation Strategy for Multi-Unmanned Aerial Vehicle Systems with Multi-Operating Modes" Drones 8, no. 8: 406. https://doi.org/10.3390/drones8080406
APA StyleYang, S., Yu, W., Liu, Z., & Ma, F. (2024). A Robust Hybrid Iterative Learning Formation Strategy for Multi-Unmanned Aerial Vehicle Systems with Multi-Operating Modes. Drones, 8(8), 406. https://doi.org/10.3390/drones8080406