
Reinforcement Learning-Based Turning Control of Asymmetric Swept-Wing Drone Soaring in an Updraft

Abstract
:1. Introduction
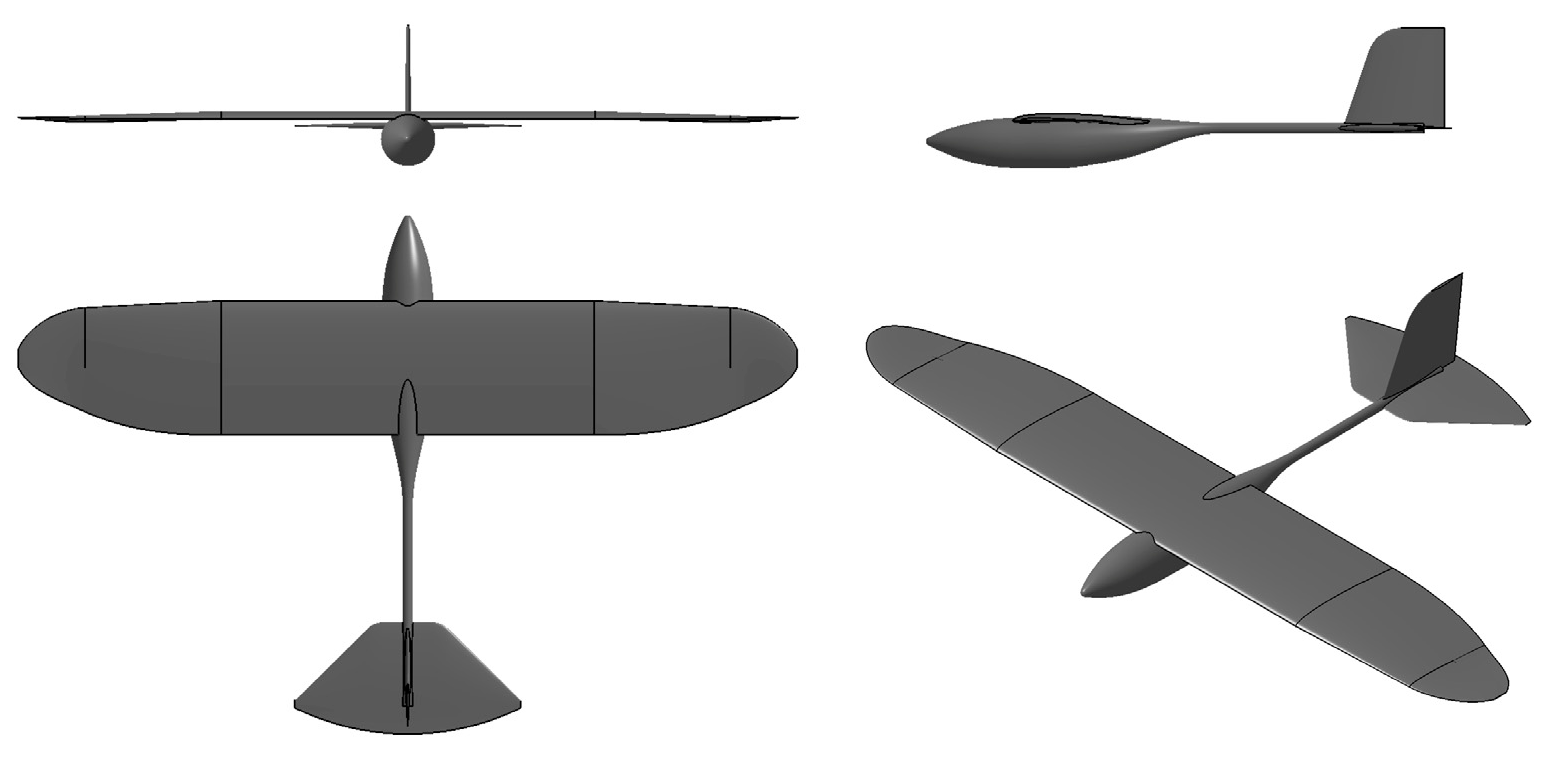
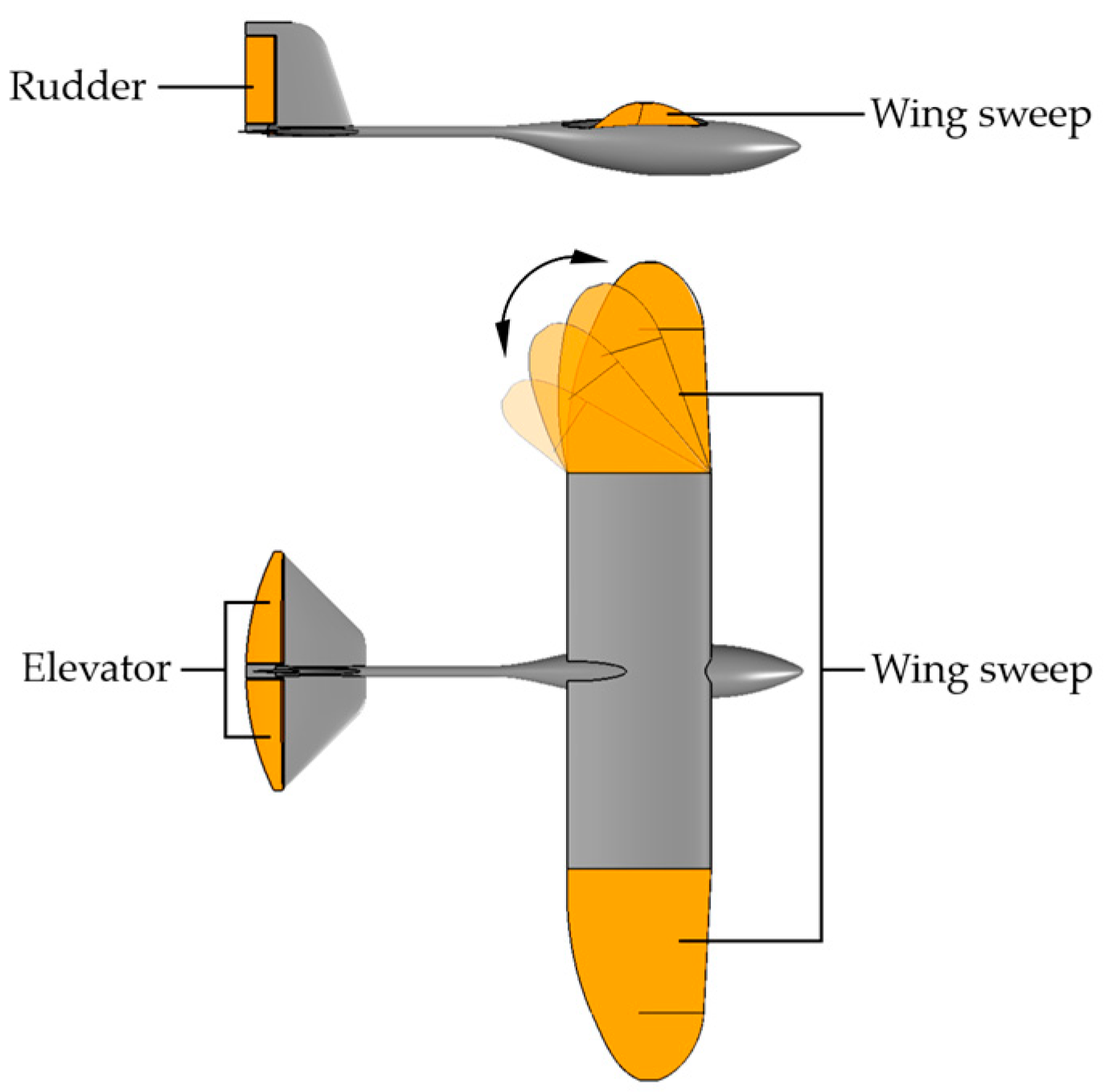
2. The Soaring Drone
2.1. Overall Layout and Parameters
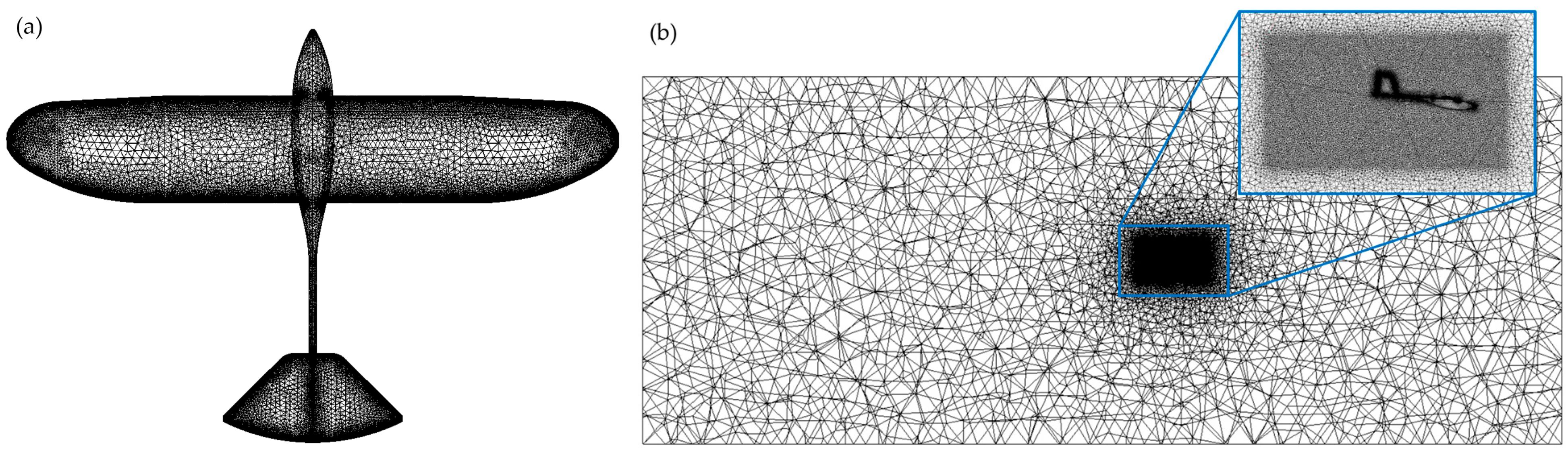
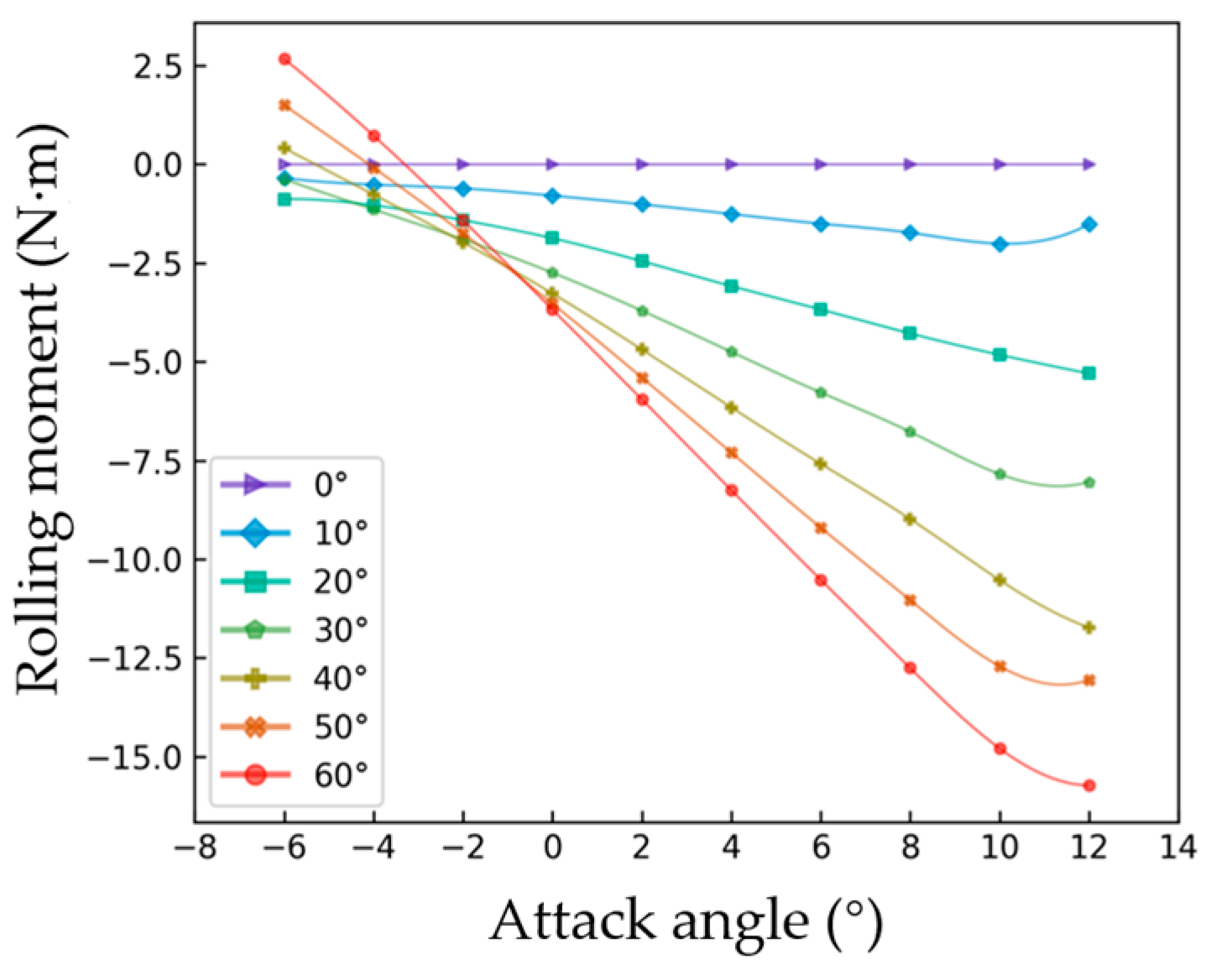
2.2. Aerodynamic Data
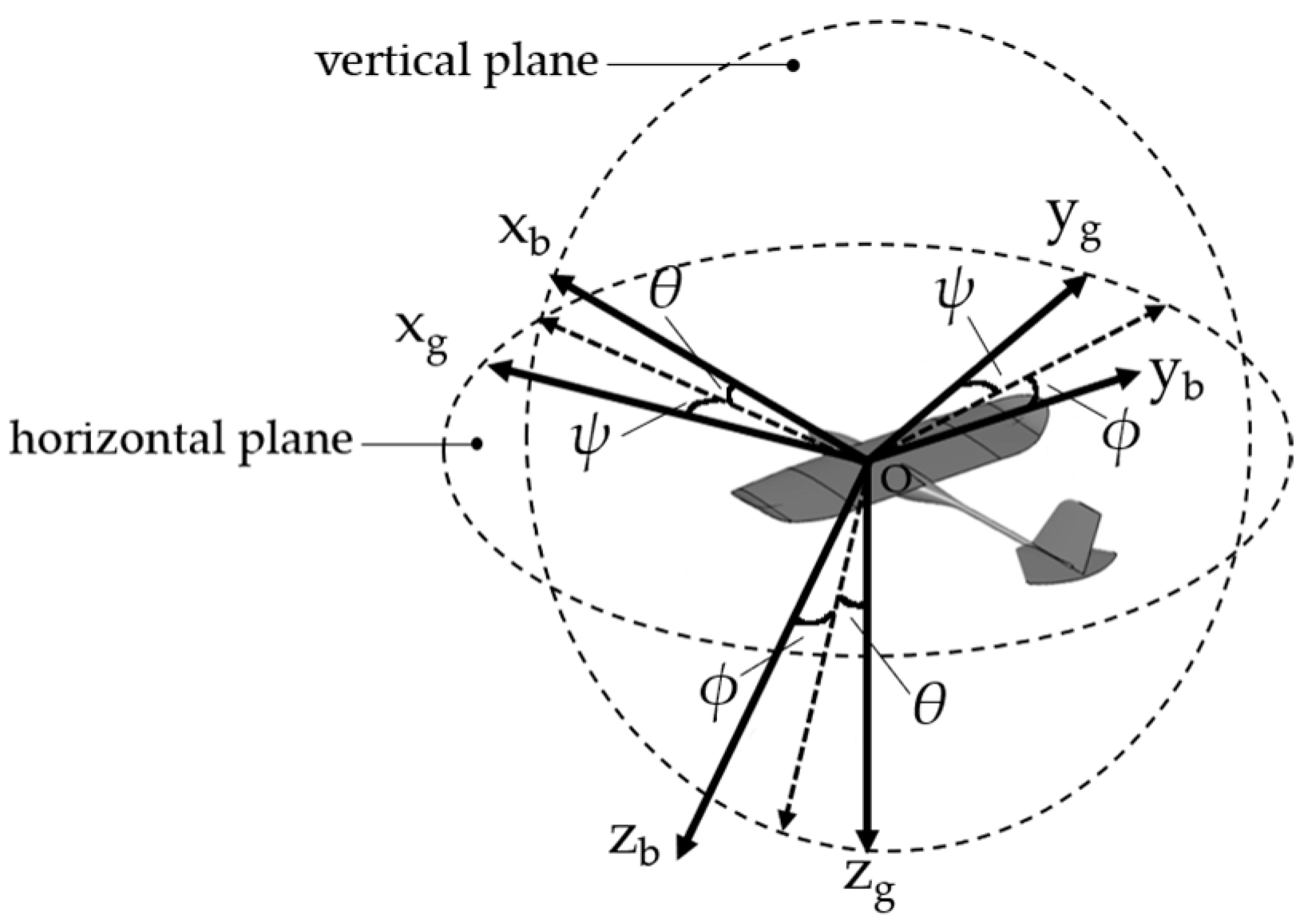
2.3. Flight Dynamics Model
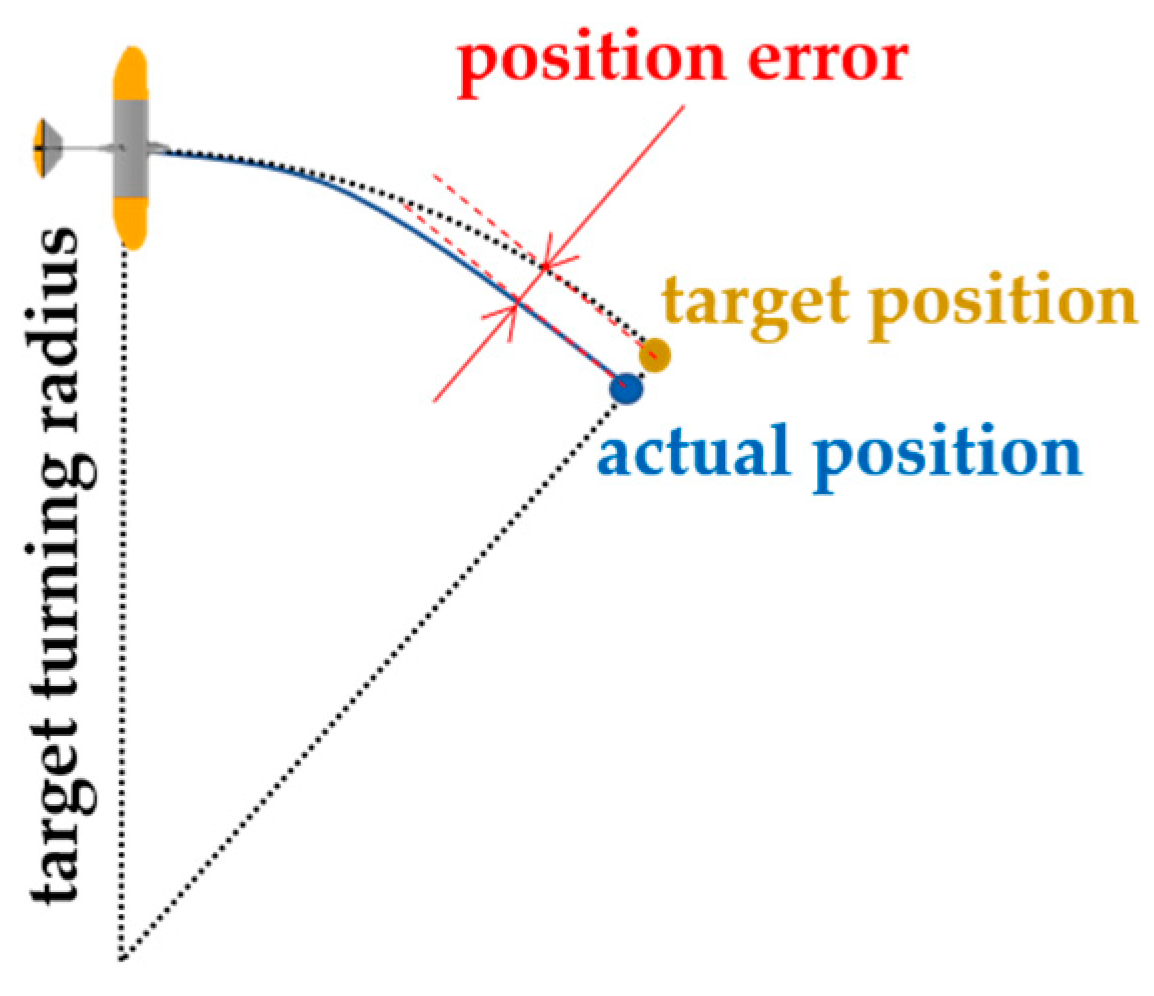
3. Study Objective of Soaring Drone Control
4. Control Agent Training
4.1. Hyperparameters and Neural Network Settings for Reinforcement Learning
4.2. Training Environment
4.2.1. Action Space
4.2.2. State Space
4.2.3. Reward Function
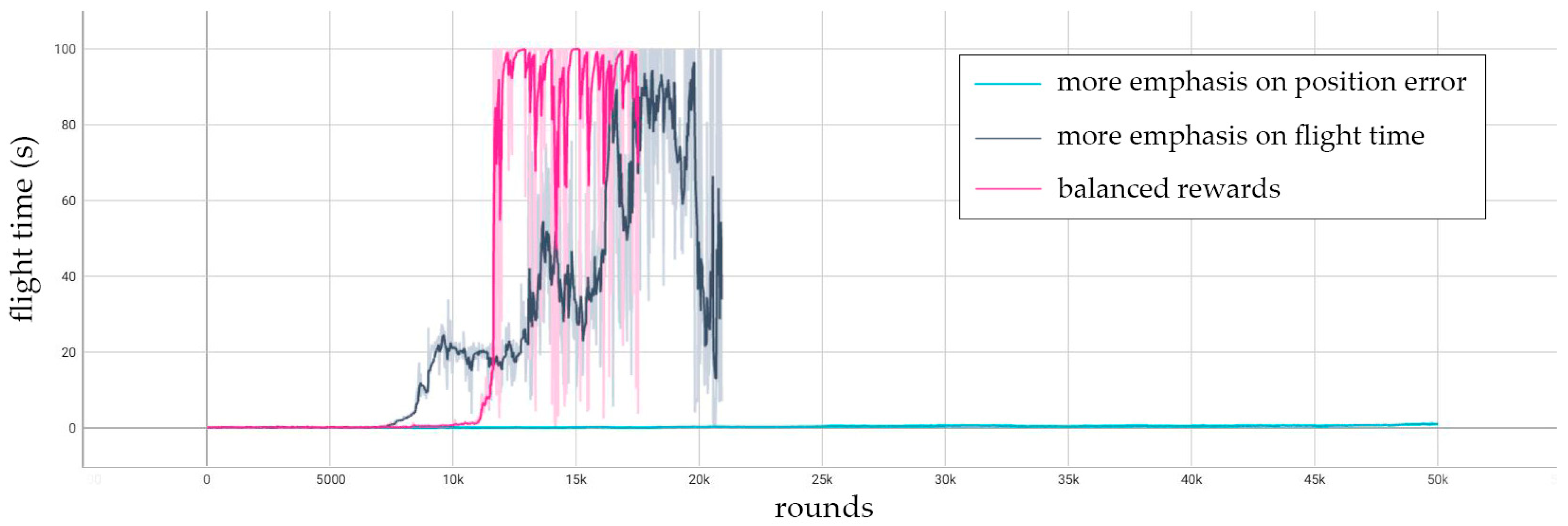
4.3. Training Result
5. Trajectories Tracking Simulation
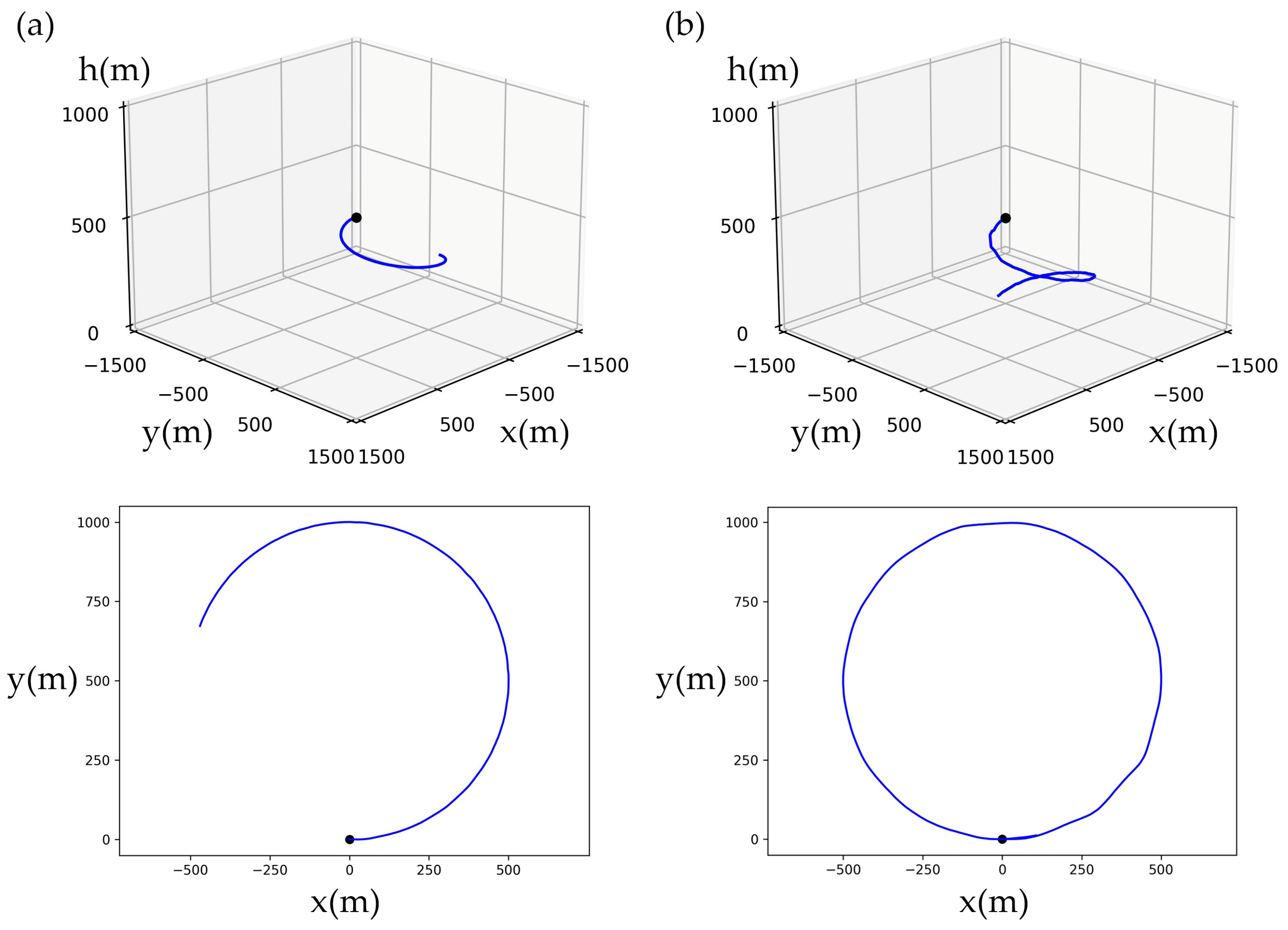
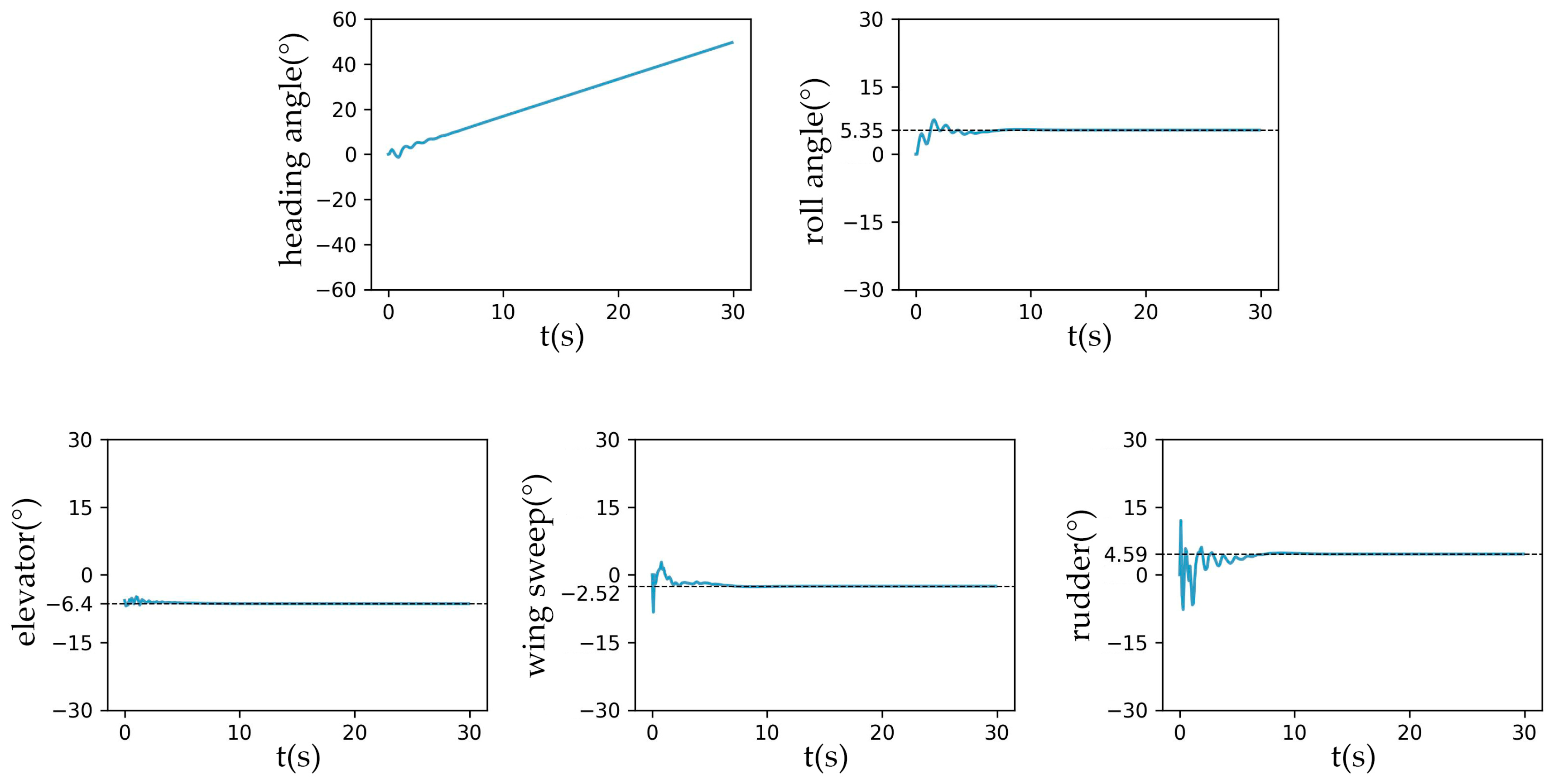
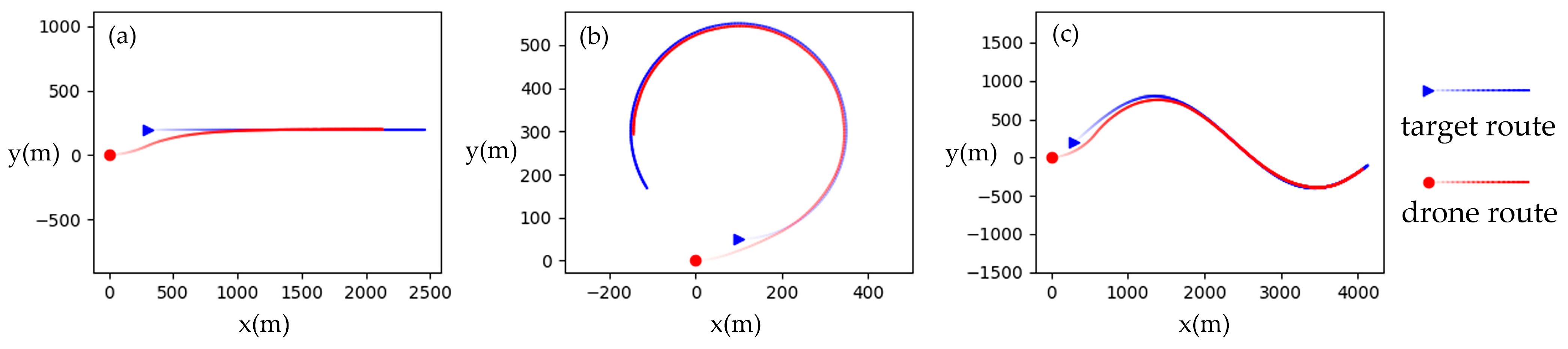
5.1. Basic Trajectories Tracking
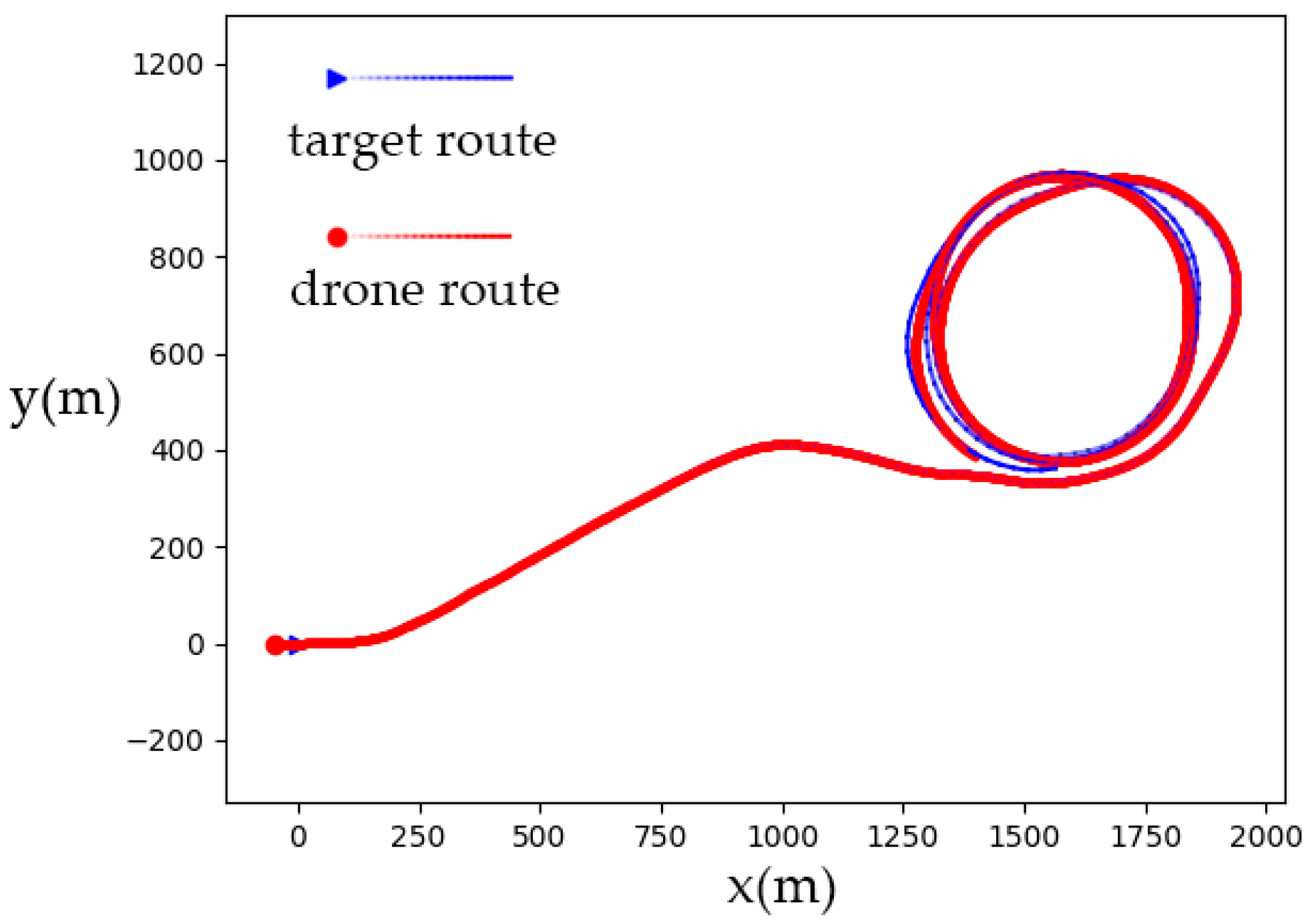
5.2. Soaring Trajectory Tracking
6. Conclusions
- The control agent of the soaring drone with asymmetric swept wings was obtained through reinforcement learning in this article. The agent can directly output control surface commands, including the wing sweep, elevator, and rudder, based on the position error and its own states, thereby controlling the drone to fly with the target radius. This also indicates that the asymmetric sweep of the soaring drone wings can achieve roll control like ailerons. By combining turning control and arc guidance methods, the agent can control the unpowered soaring drone, which utilizes asymmetric deformation control surfaces, to achieve horizontal tracking of moving targets. Ultimately, the drone can be controlled to track the trajectory of the soaring strategy.
- In the study of using reinforcement learning for drone control, the setting of the state space and reward function is the key factor affecting the training results.In terms of setting the state space, it is necessary to analyze the necessity of the input state variables and eliminate those that cause information redundancy. The target radius and position error mentioned in this article may both seem necessary, but upon comparison, it was found that there is information redundancy and that the position error is more important.In terms of setting the reward function, the duration of stable control is an essential reward factor. The remaining reward factors depend on the control task. The weight of each reward factor must be adjusted, and a positive step reward must be maintained.
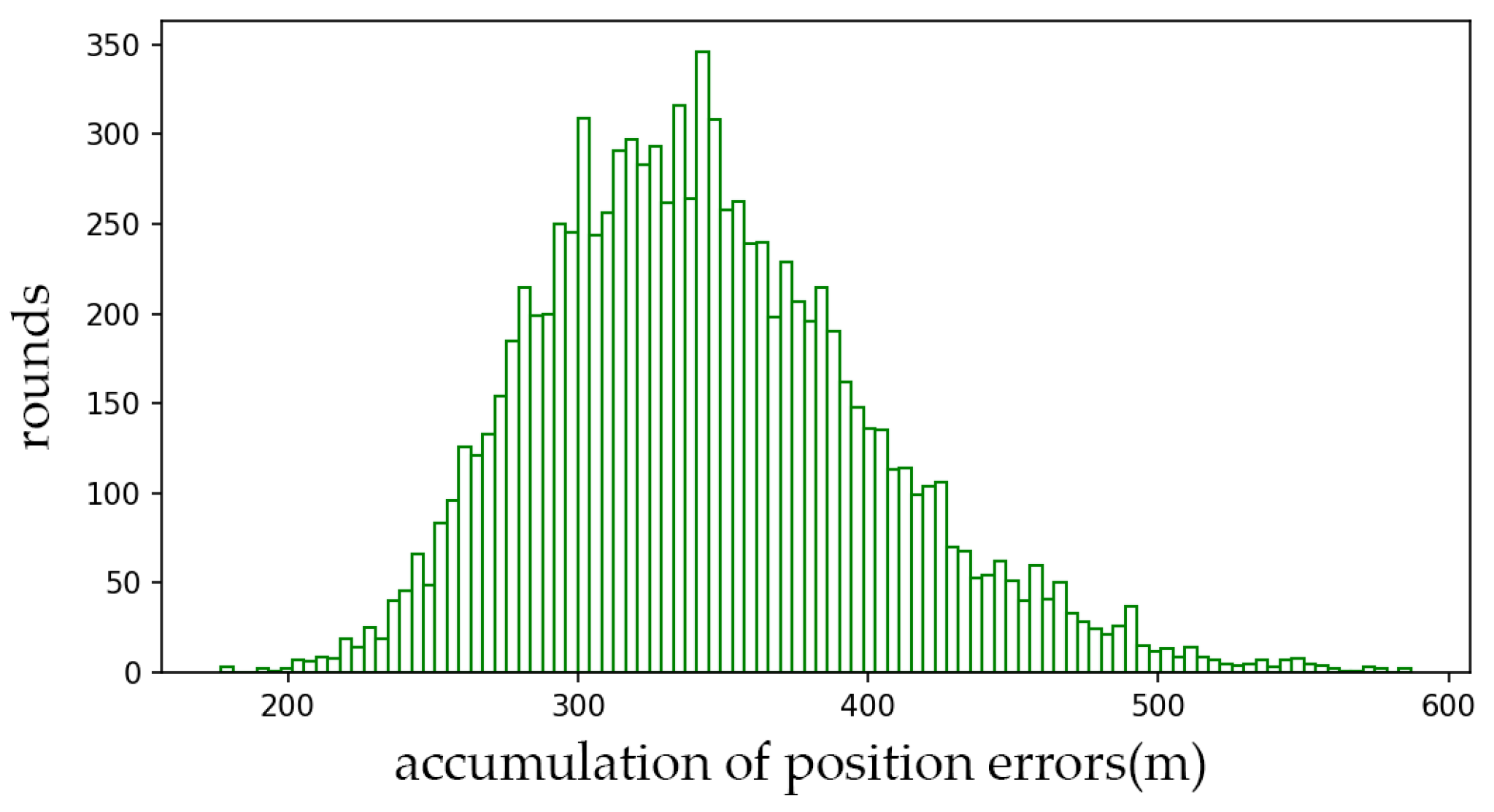
- The trained agent can control the soaring drone to perform accurate turning flights. It can complete counterclockwise and clockwise turns with a turning radius of more than 200 m. In extensive testing, the average position error is less than 0.6 m, concentrated around 0.33 m. The maximum drone position error percentage relative to the target flight radius is 1.8‰. In 98.95% of the test rounds, the relative position error percentage at each moment is below 1‰.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohammed, S.T.; Kastouri, M.; Niederfahrenhorst, A.; Ascheid, G. Video Representation Learning for Decoupled Deep Reinforcement Learning Applied to Autonomous Driving. In Proceedings of the 2023 IEEE/SICE International Symposium on System Integration (SII), Atlanta, GA, USA, 17–20 January 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Yu, X.; Fan, Y.; Xu, S.; Ou, L. A self-adaptive SAC-PID control approach based on reinforcement learning for mobile robots. Int. J. Robust Nonlinear Control. 2022, 32, 9625–9643. [Google Scholar] [CrossRef]
- Mcgrath, T.; Kapishnikov, A.; Tomaev, N.; Pearce, A.; Hassabis, D.; Kim, B.; Paquet, U.; Kramnik, V. Acquisition of Chess Knowledge in AlphaZero. arXiv 2021, arXiv:2111.09259. [Google Scholar] [CrossRef] [PubMed]
- Idrissi, M.; Salami, M.; Annaz, F. A Review of Quadrotor Unmanned Aerial Vehicles: Applications, Architectural Design and Control Algorithms. J. Intell. Robot. Syst. 2022, 104, 22. [Google Scholar] [CrossRef]
- Ang, K.H.; Chong, G.; Li, Y. PID Control System Analysis, Design, and Technology. IEEE Trans. Control. Syst. Technol. 2005, 13, 559–576. [Google Scholar]
- Hu, Y.; Yan, H.; Zhang, H.; Wang, M.; Zeng, L. Robust Adaptive Fixed-Time Sliding-Mode Control for Uncertain Robotic Systems with Input Saturation. IEEE Trans. Cybern. 2023, 53, 2636–2646. [Google Scholar] [CrossRef] [PubMed]
- Hegde, N.T.; George, V.I.; Nayak, C.G.; Vaz, A.C. Application of robust H-infinity controller in transition flight modeling of autonomous VTOL convertible Quad Tiltrotor UAV. Int. J. Intell. Unmanned Syst. 2021, 9, 204–235. [Google Scholar] [CrossRef]
- Pathmanathan, P.; Samarasinghe, C.; Sumanasekera, Y. A Review on Reinforcement Learning Based Autonomous Quadcopter Control. 2021. Available online: https://www.researchgate.net/publication/352164771_A_Review_on_Reinforcement_Learning_Based_Autonomous_Quadcopter_Control (accessed on 12 August 2024). [CrossRef]
- Adrian, C.; Carlos, S.; Alejandro, R.R.; Pascual, C. A review of deep learning methods and applications for unmanned aerial vehicles. J. Sens. 2017, 2017, 3296874. [Google Scholar]
- Maysoon, K.A.M.; Med, S.B. A Survey of Deep Learning Techniques and Computer Vision in Robotic and Drone with Applications. In Proceedings of the Fifth International Scientific Conference of Alkafeel University (ISCKU 2024), Najaf, Iraq, 17–18 February 2024. [Google Scholar]
- Panerati, J.; Zheng, H.; Zhou, S.; Xu, J.; Prorok, A.; Schoellig, A.P. Learning to Fly—A Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Dai, Y.W.; Pi, C.H.; Hu, K.C.; Cheng, S. Reinforcement Learning Control for Multi-axis Rotor Configuration UAV. In Proceedings of the 2020 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Boston, MA, USA, 6–9 July 2020. [Google Scholar]
- Pi, C.H.; Dai, Y.W.; Hu, K.C.; Cheng, S. General Purpose Low-Level Reinforcement Learning Control for Multi-Axis Rotor Aerial Vehicles. Sensors 2021, 21, 4560. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.T.; Pi, C.H.; Cheng, S. Omnidirectional Autonomous Aggressive Perching of Unmanned Aerial Vehicle using Reinforcement Learning Trajectory Generation and Control. In Proceedings of the 2022 Joint 12th International Conference on Soft Computing and Intelligent Systems and 23rd International Symposium on Advanced Intelligent Systems (SCIS&ISIS), Ise, Japan, 29 November–2 December 2022. [Google Scholar]
- Bøhn, E.; Coates, E.M.; Reinhardt, D.; Johansen, T.A. Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing UAVs: Field Experiments. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 3168–3180. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Xin, D.; Xiao, J.; Huang, J.; He, F. Reinforcement Learning Control for 6 DOF Flight of Fixed-Wing Aircraft. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021. [Google Scholar]
- Zhang, S.; Xin, D.; Xiao, J.; Huang, J. Fixed-Wing Aircraft 6-DOF Flight Control Based on Deep Reinforcement Learning. J. Command Conctrol 2022, 8, 179–188. (In Chinese) [Google Scholar]
- Chowdhury, M.; Keshmiri, S. Interchangeable Reinforcement-Learning Flight Controller for Fixed-Wing UASs. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 2305–2318. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mass | 5 kg |
| Wing Area | 0.826 m2 |
| Wing Span | 2.3 m |
| Aspect Ratio | 6.38 |
| Horizontal Tail Area | 0.151 m2 |
| Vertical Tail Area | 0.074 m2 |
| Neural Network | Fully Connected Neural Network (Four Hidden Layers with 256 Neurons) | |
|---|---|---|
| Learning rates | Action value Neural network | 1 × 10−4 |
| State value Neural network | 1 × 10−4 | |
| Strategic Neural network | 1 × 10−5 | |
| Activation function | Leaky ReLU | |
| Reward discount rate | 0.99 | |
| Smoothing constant | 0.005 | |
| Maximum capacity of experience buffer | 100,000 | |
| Batch size | 512 | |
| Different State Variables | Common State Variables | |
|---|---|---|
| State space 1 | Position error | Change in heading angle, velocity, pitch angle, roll angle, pitch angular velocity, roll angular velocity, angle of attack, sideslip angle, wing sweep, elevator, and rudder |
| State space 2 | Target radius | |
| State space 3 | Position error, target radius |
| Action Space | Changes in Elevator, Rudder, and Wing Sweep |
|---|---|
| State space | Position error, change of heading angle, velocity, pitch angle, roll angle, pitch angular velocity, roll angular velocity, angle of attack, sideslip angle, wing sweep, elevator, rudder |
| Reward function |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Y.; Yan, D.; Wan, Z. Reinforcement Learning-Based Turning Control of Asymmetric Swept-Wing Drone Soaring in an Updraft. Drones 2024, 8, 498. https://doi.org/10.3390/drones8090498
Cui Y, Yan D, Wan Z. Reinforcement Learning-Based Turning Control of Asymmetric Swept-Wing Drone Soaring in an Updraft. Drones. 2024; 8(9):498. https://doi.org/10.3390/drones8090498
Chicago/Turabian StyleCui, Yunxiang, De Yan, and Zhiqiang Wan. 2024. "Reinforcement Learning-Based Turning Control of Asymmetric Swept-Wing Drone Soaring in an Updraft" Drones 8, no. 9: 498. https://doi.org/10.3390/drones8090498
APA StyleCui, Y., Yan, D., & Wan, Z. (2024). Reinforcement Learning-Based Turning Control of Asymmetric Swept-Wing Drone Soaring in an Updraft. Drones, 8(9), 498. https://doi.org/10.3390/drones8090498