Abstract
In drone countermeasure systems, drone tracking is commonly conducted using object detection methods, which are typically limited to identifying the presence of a drone. To enhance the performance of such systems and improve the accuracy of drone flight posture prediction—while precisely capturing critical components such as rotors, mainboards, and flight trajectories—this paper introduces a novel drone key point detection model, UVPose, built upon the MMpose framework. First, we design an innovative backbone network, MDA-Net, based on the CSPNet architecture. This network improves multi-scale feature extraction and strengthens connections between low- and high-level features. To further enhance key point perception and pose estimation accuracy, a parallel attention mechanism, combining channel and spatial attention, is integrated. Next, we propose an advanced neck structure, RFN, which combines high-level semantic features from the backbone with rich contextual information from the neck. For the head, we adopt the SimCC method, optimized for lightweight, efficient, and accurate key point localization. Experimental results demonstrate that UVPose outperforms existing models, achieving a PCK of 79.2%, an AP of 67.2%, and an AR of 73.5%, with only 15.8 million parameters and 3.3 G of computation. This balance between accuracy and resource efficiency makes UVPose well suited for deployment on edge devices.
1. Introduction
With the gradual opening of low-altitude airspace and the rapid development of drone technology, consumer drones have experienced explosive growth in recent years due to their small size, low cost, and high maneuverability []. The widespread adoption of AI and 5G technologies has further accelerated the expansion of the drone industry, enabling applications in forest fire monitoring, ground target tracking, agricultural protection, logistics, and more [,,,]. However, the proliferation of drones has also raised significant airspace security concerns. For example, in 2017, Chengdu Shuangliu Airport frequently encountered drone interference, leading to flight diversions. During the 2022 Russia–Ukraine war, drones played a pivotal role, with Russia deploying small rotary drones to attack Ukrainian munitions depots, resulting in large-scale explosions. In 2023, the EU reported 12 drone-related incidents, including a fatal accident, and, in October 2023, drones were used in the Israel–Hamas conflict to carry out swarm attacks on air defense systems. These incidents pose serious threats to national security, civil aviation, and public safety, drawing widespread attention.
To counter illegal drone intrusions, current defense measures include net guns, laser weapons to destroy key components, and the use of defensive drones for air-to-ground interception [,,]. However, as drone technology advances, drones are becoming faster and smaller, rendering traditional detection methods (such as radar [], radio frequency [], and infrared detection []) increasingly ineffective. Therefore, improving the accuracy and efficiency of drone detection and defense has become a key issue that needs to be addressed.
With the rapid development of deep learning technologies, new approaches have emerged to address the rapid advancement of drone technology and the increasing security threats associated with it. Supported by hardware acceleration, deep learning enables efficient inference processes, offering high flexibility for both ground and airspace deployments. Currently, the most prominent directions in deep learning include segmentation, key point detection, and object detection. The objective of this research is to develop an efficient deep learning model capable of detecting and tracking drones while accurately identifying their critical components [].
Deep learning-based object detection methods are widely used for drone detection and tracking. Qing et al. enhanced the YOLOv5 model to propose a lightweight air-to-air drone detection system []. Zhou et al. introduced VDTNet, a high-performance visual network for detecting and tracking intruding drones []. Existing detection methods primarily focus on identifying the presence of drones, but fail to provide detailed key point information, such as the position of rotors or the orientation of cameras. This limitation hinders their application in high-precision tasks, such as capturing drones or disabling critical components. Furthermore, these methods cannot directly infer the flight posture of the drone or capture its flight trajectory [], which may lead to misjudgments during real-time tracking and interception. This study adopts a key point pose estimation model, which, compared to traditional object detection models, can more accurately detect the key components and flight posture of drones, as well as infer their flight trajectory. Object detection models focus primarily on detecting the presence of drones and fail to capture fine details, which affects the execution of high-precision tasks. The key-point-based detection method significantly improves the effectiveness of real-time tracking and interception, reduces misjudgments, and enhances the reliability of the system.
Pose estimation algorithms can be classified into top-down [] and bottom-up [] approaches. The top-down approach first detects the overall region of the target object using an object detection algorithm, then performs pose estimation and key point extraction. This method is accurate in single-target scenarios within complex scenes, but it becomes less efficient when dealing with multiple targets. The bottom-up approach, on the other hand, detects key points for all objects and then groups them into indiviparallel instances, enabling faster detection. Traditional top-down methods are more accurate due to the additional detection step, but tend to be slower. However, with advances in object detection algorithms, the detection phase is no longer the bottleneck [,]. As a result, this study adopts the top-down approach to achieve higher pose estimation accuracy.
Recent advancements in computer vision have significantly improved pose estimation methods. For example, in 2019, Sun et al. introduced HRNet, which has been widely adopted for human pose estimation [] and semantic segmentation []. In 2021, Yuan et al. proposed HRFormer, which combined the Vision Transformer with HRNet to boost pose estimation performance []. In 2022, Xu et al. developed VitPose, a Vision Transformer-based model for pose estimation [], while Han et al. introduced LitePose, an efficient 2D human pose estimation algorithm designed for resource-constrained devices []. In 2023, Fan et al. designed CoordConv and DO-Conv to enhance cow pose estimation performance []. Existing key point models, such as HRNet and VitPose, have made significant advancements in the field of pose estimation; however, they still face several limitations when applied to drone pose estimation. Firstly, detecting key points under complex multi-scale backgrounds remains challenging, particularly when key drone components, such as rotors and the body, are occluded or undergo dynamic changes, leading to a decline in detection accuracy. Secondly, current models primarily focus on feature extraction at a single scale, failing to effectively capture the relationships between different scales, which limits the accuracy of pose estimation. Finally, existing methods require high computational resources in air-to-air drone scenarios and lack sufficient lightweight design, making them inadequate for meeting the demands of faster detection.
To address this, we designed a new network structure, UVPose, based on the open-source pose estimation framework MMpose, using a top-down paradigm. In the backbone section, to overcome challenges in complex multi-scale backgrounds, such as the occlusion of key drone components (e.g., rotors and the body) and the dynamic motion of the drone, we proposed MDA-Net, which is based on the CSPNet architecture []. MDA-Net optimizes multi-scale feature extraction and strengthens the connection between low- and high-level features, thereby improving key point localization across different scales. Additionally, we incorporate a parallel attention mechanism that combines channel and spatial attention, enhancing the network’s key point perception and pose estimation accuracy, particularly in complex or occluded scenes.
In the neck section, to enhance the model’s ability for multi-scale feature extraction and fusion, we introduce the RFN structure, which integrates high-level semantic features extracted from the deepest convolutional layers of the backbone with neck outputs through weighted fusion. This fusion of high-level semantic and contextual information significantly improves multi-scale target detection and recognition in complex scenes.
In the head section, to improve the model’s lightweight design and detection accuracy, we employ the SimCC (Simple Coordinate Classification) method for key point localization []. This method is optimized for lightweight operation, efficiency, and accuracy, specifically focusing on key point detection in pose estimation tasks. Thanks to these designs and optimizations, our network demonstrates outstanding pose estimation capabilities in various complex scenes. We tested the model on a public drone dataset, and the results show that our method outperforms existing models in terms of accuracy while being more efficient in terms of parameters and computational cost.
The contributions of this study are as follows:
- A novel top-down network structure, MDA-Net, was designed using the MMpose open-source framework. By introducing a multi-path parallel attention mechanism, the accuracy of multi-scale key point detection was significantly enhanced, especially in complex scenarios, effectively addressing the challenge of detecting both small and large targets.
- A new RFN structure was proposed, specifically optimized for drone key point detection. By performing a weighted fusion of high-level semantic feature maps from the deepest convolutional layers of the backbone and the neck outputs, the integration of high-level semantic information was improved, making it more suitable for key point detection and global pose modeling in complex scenes.
- The SimCC key point localization method was employed in the head section and optimized for lightweight operation and efficiency. This improvement in key point detection accuracy and computational efficiency ensures the feasibility of deploying the model in resource-constrained real-time environments, meeting the high demands for both performance and accuracy in drone countermeasure systems.
- The efficient UVPose key point detection and pose estimation algorithm was developed, providing reliable technical support for detection, tracking, and capture in drone countermeasure systems. This study enhances the overall performance of drone countermeasure systems and offers a new technical approach and solution to address the airspace security risks posed by the proliferation of drones.
2. Data Preparation and Preprocessing
The model developed in this study was built on the MMpose platform. MMpose is an open-source deep learning framework designed specifically for pose estimation tasks, with exceptional performance in human pose estimation and efficient training and inference capabilities. We leveraged the MMpose platform for model development, training, and evaluation. MMpose offers various pose estimation algorithms and flexible extension interfaces, enabling the easy comparison of different methods and efficient training on large-scale datasets. Furthermore, its modular design and high customizability ensure that the developed model is both accurate and robust in practical applications, providing a strong technical foundation for drone key point detection and pose estimation in this study.
The drone key point dataset used in the experiments was compiled from the publicly available Det-Fly dataset [] and other quadcopter datasets. These datasets encompass a variety of scenarios, including small targets and drones operating in complex environments, ensuring that the model is robust under diverse conditions. All datasets were manually annotated using the LabelMe tool 5.1.1. The annotation process begins by creating bounding boxes to train the object detector, ensuring high precision while minimizing interference from irrelevant background areas. Subsequently, the skeletal key points in the image are accurately labeled, including the drone’s center point as well as the rotor center points for quadcopters, hexacopters, and octocopters.
After annotation, the dataset was randomly split into 3200 training images and 800 validation images. The entire dataset creation process followed standardized procedures to ensure consistency and high-quality annotations, providing a solid foundation for model training and evaluation. The specific annotation details are shown in Figure 1.
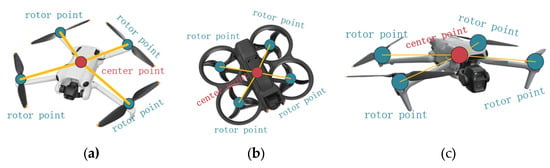
Figure 1.
(a,b) show the key point annotations from a normal view, while (c) shows the annotations with partially hidden key points.
3. Materials and Methods
The UVPose framework, as illustrated in Figure 2, comprises three main components: Backbone-MDA-Net, Neck-RFN, and Head-New-SimCC. MDA-Net, serving as the backbone, integrates MALayer (green box) and MSPPF (yellow box) to enhance feature representation, while parallel attention (red box) is employed to improve robustness against occlusions. The RFN structure functions as the neck, taking MALayer and deep parallel attention as inputs. Its output is fed into the New-SimCC detection head, where Final Attention (blue box) is applied to refine local details and mitigate global interference. Further details will be discussed in the subsequent sections.
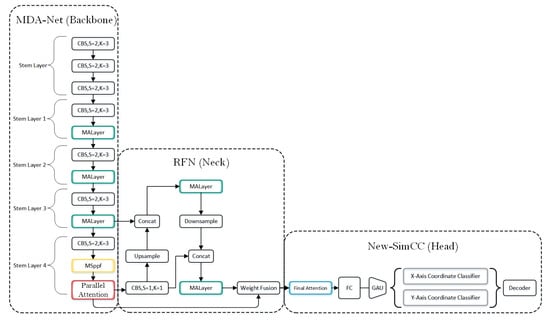
Figure 2.
Overall network architecture of UVPose.
3.1. Backbone Structure—MDA-Net
The network structure of MDA-Net is shown in Figure 3; based on a deeper investigation of the CSPNet framework, we propose a novel backbone architecture: MDA-Net. CSPNet is a widely used architecture that improves neural network performance and computational efficiency, especially excelling in computer vision tasks such as image classification and object detection. It offers significant advantages in enhancing computational efficiency and multi-scale feature fusion, making it particularly suitable for real-time tasks like drone detection. However, in key point detection tasks, the cross-stage feature fusion of CSPNet can lead to the loss of critical information. To address this, we innovatively designed the MALayer, which combines multi-scale convolution and channel-space attention mechanisms to enhance feature representation and resolve the issue of fine-grained information loss in CSPNet. Additionally, we designed the MSPPF to optimize CSPNet’s shortcomings in multi-scale feature processing. Although CSPNet improves computational efficiency through feature partitioning and cross-stage connections, its structure may result in the loss of fine-grained information in key point detection or issues in cases of key point occlusion. To better tackle these challenges, we designed a parallel attention structure. This network not only retains CSPNet’s advantages in computational efficiency, but also enhances the focus on key point regions and effectively addresses occlusion problems. These improvements were validated through heatmap experiments. MDA-Net provides an innovative approach for the design of efficient deep learning models.

Figure 3.
Overall network architecture of MDA-Net.
3.1.1. MALayer
In MDA-Net, to further enhance feature representation, optimize computational efficiency, and improve gradient flow, we introduce an innovative module called MALayer. This module is centered around the MABlock unit and employs a feature segmentation and fusion mechanism that combines the main and shortcut paths. This significantly enhances feature representation and the ability to capture multi-scale information, making it particularly well suited for pose estimation tasks and enabling the precise extraction of fine-grained features around key points.
The specific structure is illustrated in Figure 4. MALayer first segments the input features. The main path extracts deep features through a series of MABlocks, capturing both local and global pose information, while the shortcut path preserves the global information of the input features, ensuring that the base features are retained. The combination of these main and shortcut paths boosts the model’s expressive power and robustness.
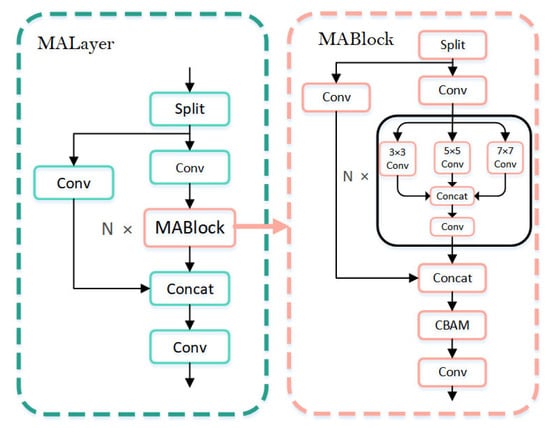
Figure 4.
Diagram of the MALayer and MABlock structures in the model.
In each MABlock, multi-scale convolution operations are introduced to capture contextual information at different scales, thereby better accommodating the diversity of key points and complex scenes. Specifically, the input is first split, with one part passing through a convolutional layer for channel adjustment. The other part undergoes multi-scale feature extraction using 3 × 3, 5 × 5, and 7 × 7 convolution kernels. The extracted multi-scale features are then concatenated and passed through another convolutional layer for further channel adjustment. Finally, the two parts of the features are concatenated and fed into the next stage. The structure is shown in Equations (1) and (2).
Here, represents the input feature map, represents the convolution operation with a kernel size of k × k, denotes the concatenation operation along the channel dimension, denotes the final feature map in Equation (1), refers to the operation of splitting the input , and represents the final output of MABlocks.
Next, the MABlocks outputs are fused with the CBAM attention mechanism, further enhancing the network’s ability to learn channel and spatial weights. CBAM [] effectively focuses on key spatial locations and important channel information in the pose features, significantly improving the accuracy and robustness of pose estimation. The main formula of CBAM is shown in Equation (3).
In this context, represents the input feature map; and denote global average pooling and global maximum pooling, respectively; is a shared multi-layer perceptron; is the sigmoid activation function; is the channel attention weight; refers to the convolution operation with a 7 × 7 kernel; is the spatial attention weight; represents the feature map after channel attention weighting; and is the feature map after spatial attention weighting.
3.1.2. MSPPF
As shown in Figure 5, in MDA-Net, we introduce the Multi-Scale Pooling Feature Fusion (MSPPF) module to enhance the feature extraction capability of the UAV pose estimation network. Commonly used feature fusion modules, such as SPP [], SPPF [], and ASPP [], address the issue of incomplete information by stacking pooling layers. However, these methods often fail to integrate the pooled features effectively with the original feature maps, which may lead to information loss and degrade pose estimation performance. To resolve this issue, we designed the MSPPF module. MSPPF reduces the number of channels through convolutional operations and concatenates the original feature map with the subsequently pooled features. The feature map is then processed using max pooling and multiple concatenations, resulting in a multi-scale fused feature map that significantly improves both feature extraction capability and computational efficiency. The core operation is represented in Equations (4) and (5).
Here, represents the input features. denotes the convolution operation, represents the max pooling operation, and signifies the feature concatenation operation. refers to the output of each branch and represents the final output obtained.
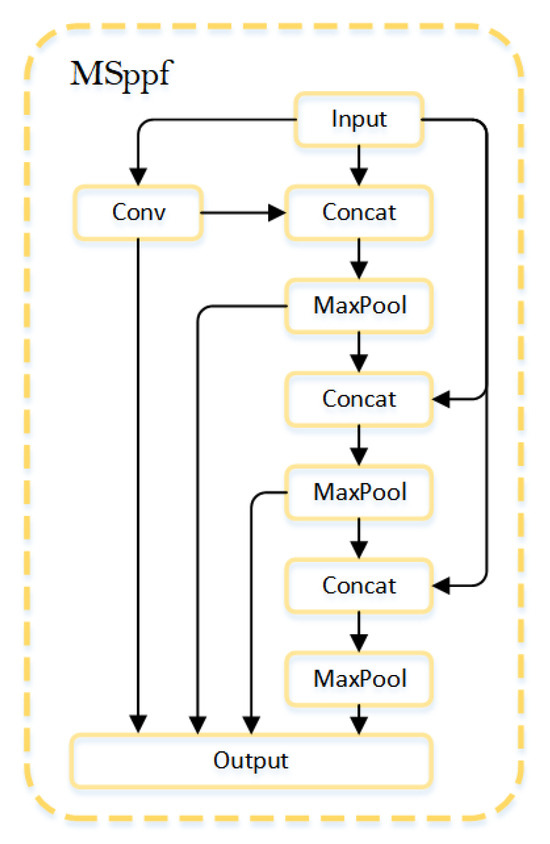
Figure 5.
Structural diagram of the MSPPF module.
3.1.3. Parallel Attention
In key point detection tasks, occlusion presents a significant challenge. It causes the loss of key point feature information, which adversely affects the model’s accuracy and robustness. To address this issue, we introduce the parallel attention mechanism into the backbone structure of the UAV pose estimation network to enhance both the feature extraction capability and the accuracy of pose estimation.
The parallel attention mechanism is designed as the final layer of the backbone network, positioned after the MSPPF module. Building on the fusion of multi-scale contextual information, parallel attention further optimizes feature representation. This module combines both channel attention and spatial attention, enabling the collaborative processing of global and local information. This approach effectively alleviates the occlusion problem and significantly improves the model’s performance in complex scenarios. The specific structure is illustrated in Figure 6.
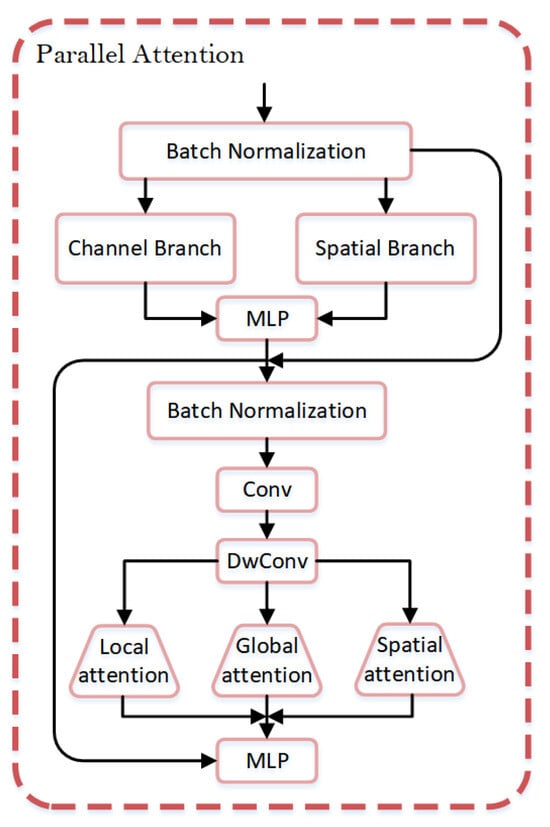
Figure 6.
Architecture of the parallel attention mechanism.
In the first stage of the parallel attention mechanism, the input feature map is first normalized. Then, the channel attention mechanism computes the channel weights, while the spatial attention mechanism identifies salient regions along the spatial dimension and computes the spatial weights. Subsequently, the input is multiplied by the channel and spatial attention mechanisms, allowing the model to emphasize important features in different dimensions through both channel and spatial attention. Finally, the output is fed into the MLP. The specific formulas are provided in Equations (6) and (7).
Here, represents the input feature map; represents the output channel attention weights; represents the output spatial attention weights; is the weight matrix of the fully connected layer; is the nonlinear activation function; represents the global average pooling; is the Sigmoid function; represents the global max pooling; refers to the 2D convolution operation; is the weight of the convolution kernel; represents the output of the first stage; indicates element-wise multiplication; and denotes multiple fully connected layers, used for processing and transforming features.
After performing batch normalization, adjusting the number of channels via convolution, and effectively extracting features through depthwise separable convolutions on , we proceed to the second stage. In the second stage of the dual attention mechanism, the model processes three core attention mechanisms in parallel: the local channel attention module, the global channel attention module, and the spatial attention module. The local channel attention module extracts fine-grained local information of the target through deep convolution, enhancing the model’s sensitivity to details. The global channel attention module captures the dependencies between global channels via adaptive average pooling and convolution, thereby improving the expressive power of global features. The spatial attention module focuses on spatial information through convolution operations, guiding the model to attend to important spatial regions. By integrating these three attention mechanisms in parallel, the model can dynamically balance global and local features, further enhancing its representational capability. To further improve the performance of the modules, we integrate a multi-layer perceptron (MLP) into the parallel attention mechanism, leveraging nonlinear transformations to optimize feature representations. This enhancement significantly boosts the model’s feature representation ability and classification accuracy. The detailed process is outlined in Equation (8). By concatenating these three features, the model simultaneously considers local details, global context, and spatial information, extracting and integrating key-point-related features from multiple dimensions, thus improving the accuracy of key point position prediction. For further details, refer to Equation (9).
Here, , , and represent the local channel attention module and the output feature maps of the global channel attention and spatial attention modules; represents the output of after a series of convolution operations; represents the Sigmoid function; denotes the 1D convolution operation; denotes the depthwise convolution operation; represents element-wise multiplication; denotes multiple fully connected layers, used for processing and transforming features; and represents the output of the second stage.
In summary, we propose a structure called parallel attention, which consists of two parts. In the first part, the feature map undergoes batch normalization and is then input into two parallel attention modules: channel attention and spatial attention. The channel attention module extracts channel information through global average pooling and convolution, and calculates the importance of each channel using fully connected layers and a Sigmoid activation function. This helps the model focus on key channels, thereby improving the accuracy of key point detection. The spatial attention module calculates the spatial location weights through convolution operations and the Sigmoid activation function, aiming to enable the model to focus more on key point regions while reducing background interference. The combination of channel and spatial attention effectively highlights important features in different dimensions, which are then input into the multi-layer perceptron (MLP) for processing and transformation. Finally, these processed features are fused with the initial feature map through residual connections.
Subsequently, after the output of the first stage undergoes batch normalization, convolution for channel adjustment, and feature extraction through depthwise separable convolutions, it is input into the second part, which consists of three parallel attention modules: local channel attention, global channel attention, and spatial attention. The local channel attention module weights local features through deep convolution and local convolution, focusing on finer details. The global channel attention module captures the dependencies between global features through global average pooling and convolution, thereby enhancing global information. The spatial attention module weights spatial features, concentrating on important regions. These three modules are fused through concatenation, integrating key point features from different dimensions, which are then input into the multi-layer perceptron (MLP) for processing and transformation. The optimization objective is to enhance feature responses, strengthen key point features, and suppress the interference of irrelevant features, thus achieving feature selection and enhancement at the local, global, and spatial levels. During training, the attention weights are learned through gradient propagation to ensure effective optimization and convergence of the model. Additionally, regularization techniques are employed to prevent overfitting and improve the model’s stability and convergence on complex datasets.
3.2. Neck Structure—RFN
In computer vision, the neck module connects the backbone and head, primarily facilitating feature fusion and enhancement to improve the model’s detection or recognition capabilities. Common neck designs include FPN and its variants, PANet and BiFPN [], which are widely used in object detection models such as DETR [], Faster R-CNN [,,], and the YOLO [,,] series. These models typically receive multi-level features from the backbone and perform feature fusion and enhancement at different levels using feature pyramids or path aggregation strategies.
However, these traditional neck structures are not suitable for key point detection tasks. While shallow features contain rich edge and local information, they are more suited for low-level tasks such as edge detection or simple object detection. On the other hand, key point detection requires the joint modeling of both global and local information, where shallow features have limited utility. Additionally, shallow features often contain noise, and key point detection is highly sensitive to background noise and redundant details, which can cause interference. To address these challenges, we propose a redesigned neck structure, RFN, that better meets the requirements of key point detection tasks, as shown in Figure 7.
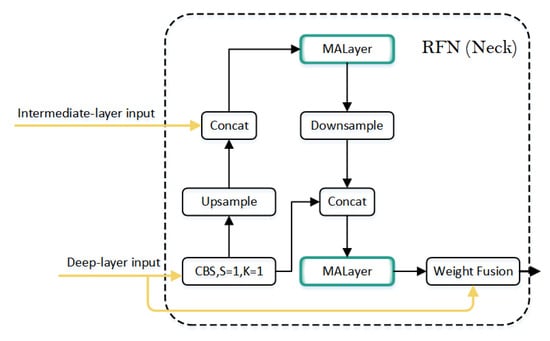
Figure 7.
Overall network architecture of RFN.
The RFN structure utilizes mid-level and deep-level inputs. Its advantage lies in reducing the interference from shallow feature maps, enabling the network to focus more on crucial information. Mid-level features retain some spatial details, while deep-level features provide global semantics and contextual information. The combination of mid-level and deep-level inputs not only preserves important information, but also minimizes the noise from shallow features, making it more suitable for key point detection and global pose modeling in complex scenarios.
The final output from the backbone network contains rich high-level semantic information, significantly enhancing the model’s global perception capability. In the last layer of the neck, we adopted BiFPN-based weighted feature fusion, replacing the traditional single-channel concatenation (Concat) fusion approach []. BiFPN extends upon FPN and PANet by effectively integrating features from different levels through weighted concatenation, thereby enhancing the diversity of feature representation. With the introduction of the BiFPN fusion mechanism, the final layer of the RFN can adaptively adjust the importance of high-level semantics and fine details according to the task requirements, optimizing the semantic differences of features across different levels. This design enhances the expression of local information and reduces the risk of detail loss. This approach has shown significant improvements in generating SimCC representations and accurately decoding key point coordinates.
3.3. Head Structure—New-SimCC
The key point detection head is essential for accurately localizing and predicting key points from extracted feature maps in key point detection tasks. In complex scenarios, it must effectively integrate multi-level features, ensuring high-precision real-time processing while maintaining scale adaptability and pose invariance. We adopt the SimCC key point localization method and optimize it for lightweight design, efficiency, and accuracy, specifically for key point detection in pose estimation tasks. The architecture diagram is shown in Figure 8.
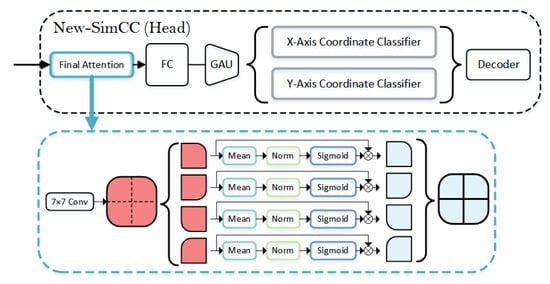
Figure 8.
New-SimCC network architecture diagram.
The SimCC method combines fully connected layers and a gated attention unit (GAU) classifier, among other modules, for key point detection. The head of the network includes fully connected layers (FC), GAU, and a coordinate classifier. The fully connected layer expands the key point representation to a 256-dimensional space, where the dimension is controlled by hyperparameters. The GAU integrates the self-attention mechanism and gated linear units (GLU) to regulate feature flow. The GLU determines which information is passed through and which is suppressed, thereby retaining critical information and removing redundancy. After self-attention calculations and positional encoding, the GAU refines the key point representation, enhancing detection performance and computational efficiency. The classifier then performs coordinate classification in both horizontal and vertical directions, achieving precise localization. Ultimately, SimCC generates a one-dimensional representation from low-resolution feature maps, enabling efficient key point detection, improving real-time performance, and supporting accurate key point localization across multiple scales. This makes it suitable for complex multi-person and multi-pose scenarios. However, SimCC performs poorly when dealing with rapid motion and extreme viewpoint changes, particularly under low-resolution or high-dynamic environments.
To enhance key point detection accuracy in drone imagery, we introduce the Final Attention module during the feature extraction stage. The module first processes the feature map of the input image using a 7 × 7 large convolution kernel to optimize the output representation. It then divides the feature map into multiple regions, enhancing the features of each region to capture local details while minimizing global interference. It adaptively adjusts activation responses for each region, strengthening important regions and suppressing less important ones, improving accuracy in complex environments. Additionally, deep convolutions capture deeper spatial information, and, combined with the adaptive attention mechanism, they more effectively handle occlusion and scale variations in drone images, boosting the model’s robustness and accuracy.
The main formulas for Final Attention are shown in Equations (10) and (11).
The input feature map is divided into four sub-blocks, each of size . For each sub-block, the variance of each pixel is first computed, with the mean being , the number of pixels being , and a small regularization constant introduced to prevent division by zero errors. The enhancement factor is then derived based on these calculations, and the activation values are adjusted according to this factor, enhancing the features of the important regions.
Finally, the enhanced results of the four sub-blocks are combined into a complete feature map , where is the result of each block after enhancement. The resulting composite image retains local information while suppressing unimportant features, thereby improving the model’s ability to recognize key points.
4. Experiments
4.1. Evaluation Indicators
PCK (Percentage of Correct Key Points) [] is a key metric for evaluating the accuracy of key point detection. It measures model performance by determining whether the distance between detected and ground truth key points is within a predefined threshold. Specifically, for each key point, if the distance between the detected position and the true position is smaller than the threshold, the key point is considered correctly detected. Thus, PCK serves as the primary metric for evaluating the key point detection model in this study. Its calculation formula is shown in Equation (12):
where represents the Euclidean distance between the predicted key point and its corresponding ground truth value; is the scale of the object; is a predefined threshold representing the maximum allowed distance for a “correct” key point (usually a proportion of the object’s scale); and indicates whether the ground truth key point is visible, where takes a value of 1 if the key point is visible and 0 if it is not.
In evaluating model performance, we use PCK as well as standard metrics such as Average Precision (AP) and Average Recall (AR) as auxiliary indicators for key point detection. AP and AR are computed using thresholds defined by OKS (Object Key Point Similarity) []. The formulas for AP, AR, and OKS are given in Equations (13)–(15).
Here, represents the Euclidean distance between the predicted key point and its corresponding ground truth value; indicates whether the ground truth key point is visible; is the scale of the object; and is a constant for each key point, used to control the decay. represents the precision at a given recall rate; denotes recall, which is the proportion of correctly predicted key points; and is the recall at the i-th threshold.
4.2. Experimental Environment Parameters
The experiment was conducted on a Windows operating system with hardware configured as a 13th Gen Intel® Core™ i5-13500HX processor, 16 GB of RAM, and an NVIDIA GeForce RTX 4060 GPU. The key point detection model was trained using the AdamW optimizer, with input images sized at 192 × 256 pixels and trained over 300 epochs. The experimental environment included CUDA 12.1, Python 3.9, and the PyTorch 2.0.1 framework. During training, 300 epochs were completed, with validation performed every five epochs. The dataset comprised the Det-Fly dataset and other quadcopter-related datasets, totaling 3200 training images and 800 validation images.
To further illustrate the training process and parameter settings, we provide the following training parameter table. It lists key parameters used during model training, including learning rate, batch size, optimizer type, and the number of training epochs, offering a clearer insight into the model’s training configuration and strategy. The training parameters are shown in Table 1, and the ablation experiments on different components of UVPose are presented in Table 2.

Table 1.
Training parameters.
Table 2.
Ablation experiments on different components of UVPose.
4.3. Ablation Experiment
To evaluate the effectiveness of our network model, we conducted four sets of ablation experiments on the dataset. The first set used the CSPNet backbone and SimCC key point detection as the baseline. The second set incorporated RFN into the neck component for enhancement. The third set employed MDA-Net as the backbone to validate its advantages. The fourth set introduced New-SimCC to assess the improvements in the head component. By comparing the experimental results, we were able to identify the contribution of each component to the model’s performance, as shown in Table 2.
The results of the ablation experiments demonstrate that improvements in each component lead to significant performance gains. The baseline model, using the CSPNet backbone and SimCC key point detection, achieves a PCK of 71%, an AP of 59.8%, and an AR of 66.3%. After adding the RFN module to enhance the neck component, PCK increases to 74.2%, and AP and AR rise to 62.2% and 68.5%, respectively, with only a slight increase in model parameters and FLOPs. Replacing the backbone with the MDA-Net designed in this study further boosts performance, achieving a PCK of 76.9%, with AP and AR rising to 64.9% and 71.2%, respectively. Finally, adopting the newly designed New-SimCC key point detection method and optimizing the head component results in a PCK of 79.2%, with AP and AR increasing to 67.2% and 73.5%, respectively. Although model parameters and computational complexity increase, the performance improvements at each stage clearly show that enhancements to the backbone, neck, and head components significantly contribute to the overall effectiveness of the key point detection model.
The training process of UVPose is shown in Figure 9. As training progresses, the model’s performance gradually improves. In the first 50 epochs, both PCK (blue curve) and AP (red curve) exhibit a clear upward trend, indicating that the model rapidly learns the basic features for key point detection in the early stages. In the later stages of training, particularly after the 100th epoch, the growth of PCK and AP levels off, suggesting that the model is nearing convergence and its performance is stabilizing. The trend in AR mirrors that of PCK and AP, further validating the model’s overall performance across different evaluation metrics. Overall, UVPose demonstrates strong learning and convergence capabilities, effectively improving the accuracy and robustness of pose estimation.
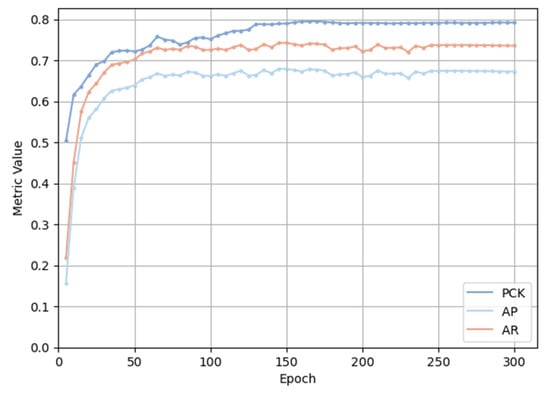
Figure 9.
Training process curve of UVPose.
4.4. Performance Evaluation of Key Point Detection Models on the MMPose Platform
To validate the accuracy of the proposed network model, we compared it with six popular key point detection models available on the MMPose open-source platform: VGG-16 [], ResNet-50 [], HRNet-w32, VitPose-S, Swin-T [], and RTMPose-S. The performance of these models was evaluated using five metrics: PCK, AP, AR, FLOPs, and model parameters. By considering these metrics together, we comprehensively analyzed the performance and efficiency of each model in the key point detection task. The comparison results are shown in Table 3.
Table 3.
Comparison results of UVPose with other key point detection models.
In comparative experiments with six mainstream key point detection models on the MMPose open-source platform, the proposed UVPose model outperforms all other models across various evaluation metrics. Specifically, UVPose achieves an AP of 67.2%, an AR of 73.5%, and a PCK of 79.2%, all of which significantly surpass the performance of the other models, particularly excelling in the PCK metric. Compared to VitPose-S, UVPose shows slight improvements in AP and AR, with a more substantial advantage in PCK. Furthermore, UVPose demonstrates outstanding performance in terms of parameter count and computational complexity, requiring only 15.8 million parameters and 3.3 G FLOPs. This is much lower than VitPose-S’s 85 million parameters and 16.55 G FLOPs, as well as other models such as VGG-16 (18.9 M parameters, 16.17 G FLOPs) and HRNet-w32 (28.54 M parameters, 8.2 G FLOPs). Even when compared to RTMPose-S, UVPose significantly improves accuracy while maintaining a lower computational resource requirement. Overall, UVPose achieves an excellent balance between accuracy and efficiency in key point detection, demonstrating its superiority in drone key point detection applications. Its lightweight design enables efficient operation on resource-constrained devices, the inference time is only 3.43 milliseconds, reducing computational overhead while meeting real-time processing requirements. Compared to other models, UVPose requires fewer computational resources, making it well suited for real-time deployment. A detailed comparison of the training processes for each model is shown in Figure 10.
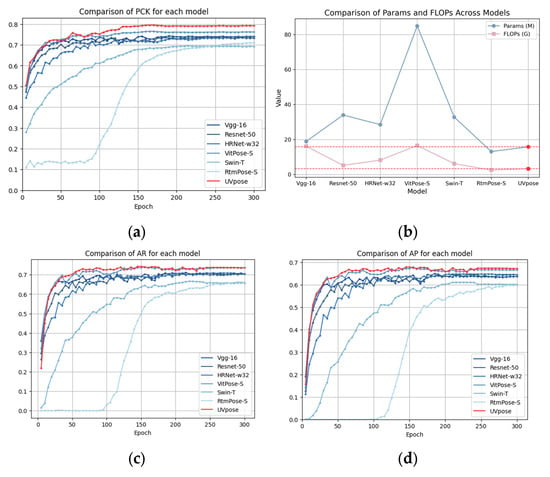
Figure 10.
Comparison of model parameters via curve chart. (a) Comparison of PCK. (b) Comparison of Params (M) and FLOPs (G). (c) Comparison of AR. (d) Comparison of AP.
A comparison of the training process graphs shows that UVPose excels across multiple evaluation metrics and outperforms existing state-of-the-art pose estimation models. Figure 10a shows the training curve for PCK (Percentage of Correct Key Points), where UVPose converges quickly and stably, maintaining high performance, particularly after the 50th epoch, significantly surpassing other models. While other models show faster initial improvement, UVPose demonstrates better performance and stability in the later stages. Figure 10b shows the number of parameters and FLOPs of each model. Figure 10c compares AR (Average Recall), where UVPose leads in this metric, indicating stronger recall capabilities for detecting small objects and handling complex scenes. Compared to other models, UVPose exhibits a more noticeable improvement in recall, demonstrating superior learning capability and detailed feature extraction ability. Figure 10d compares AP (Average Precision), where UVPose again excels, especially with a more significant improvement in AP in the later stages, suggesting stronger precision optimization.
Compared with other models, UVPose shows a smoother training loss curve, reflecting its stability during the learning process and better adaptation to complex data. When compared to models like HRNet and ViTpose, UVPose not only leads in precision, but also shows a smoother loss function during training, proving the effectiveness of its optimization and training strategy. Overall, UVPose outperforms traditional models in key metrics such as PCK, AP, and AR, while also being more efficient in terms of parameter count and FLOPs, demonstrating its potential as a highly efficient and precise pose estimation model.
4.5. Model Performance Demonstration
Figure 11 presents the performance of different models in quadrotor key point detection from a conventional perspective, with key point localization confidence visualized through heatmaps. Each row corresponds to the output of a model, including UVPose, HRNet, VGG-16, RTMPose, and ViTpose. The heatmaps show the confidence distribution across different key points for each model. UVPose achieves the best performance in terms of both localization confidence and key point distribution, demonstrating higher confidence and more precise key point detection. HRNet performs relatively well, but its heatmap shows fainter rotor key points with slightly lower confidence, making it somewhat inferior to UVPose. VGG-16 suffers from missed detections, as clearly indicated in the heatmap, negatively impacting its overall performance. RTMPose struggles in some complex scenarios, where it directly ignores certain key points in the heatmap. ViTpose exhibits better stability but shows lower confidence compared to UVPose. Finally, the skeletal visualization connecting the key points is displayed. These results highlight the strengths and weaknesses of each model in complex scenarios, providing valuable insights for optimizing drone key point detection models.
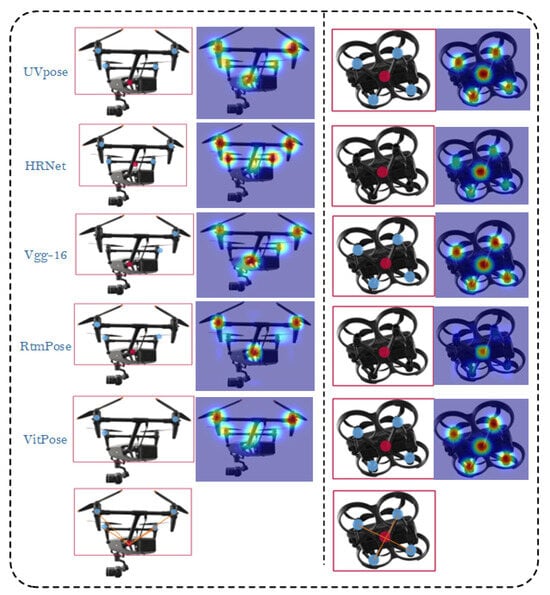
Figure 11.
Comparison of different models in detecting key points of two types of quadcopters from a conventional perspective.
Figure 12 presents the performance of different models in quadrotor key point detection under occluded perspectives. Despite the presence of occlusion, UVPose maintains accurate key point localization, achieving the best performance. HRNet performs well, while VGG-16 exhibits some localization bias. RTMPose remains relatively stable in complex scenarios, and ViTpose shows consistent performance. However, in their heatmaps, both models demonstrate reduced confidence for occluded key points, resulting in lower key point confidence compared to UVPose. Finally, the skeletal visualization connecting the key points is displayed.
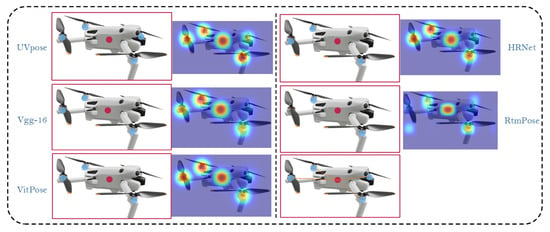
Figure 12.
Comparison analysis of the performance of different models under occluded viewpoints.
Figure 13 presents a comparative analysis of the performance of various models under extreme low lighting conditions. The experimental results indicate that UVpose performs excellently in such environments, accurately detecting the main key points, despite some deviations. The heatmap shows a decrease in confidence and becomes more blurred, which is an area for improvement in future research. VitPose, HRNet, and Vgg-16 demonstrate some adaptability, but their performance under extreme low lighting conditions is weaker, with lower robustness compared to UVpose. In contrast, RtmPose performs well in other scenarios, but its heatmap becomes faint under low lighting, possibly due to the model’s lower sensitivity to low-contrast images. Overall, UVpose exhibits strong adaptability and robustness under low lighting conditions, making it suitable for key point detection in complex environments.
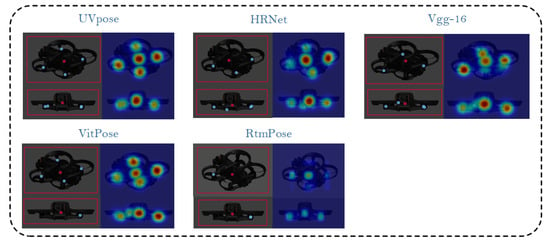
Figure 13.
Comparison of the performance of different models under low lighting conditions.
4.6. Performance Comparison Between UVPose and YOLOv11 Pose Models
To validate the superior performance of the proposed network model, we compared it not only with models from MMPose, but also with the currently popular and high-performing model, YOLOv11. YOLOv11 is an object detection model developed by Ultralytics, incorporating an improved backbone and neck architecture to achieve more accurate detection while maintaining a balanced performance. YOLOv11 Pose is an extension of YOLOv11 for key point detection, capable of not only detecting object bounding boxes, but also accurately predicting key point locations. To ensure the validity of the experiment, we conducted tests under identical hardware conditions, using consistent model hyperparameters (such as optimizer, image size, number of epochs, batch size, etc.), while maintaining the same evaluation metrics. Notably, to compare with a model of a relatively comparable scale to UVPose, we selected YOLOv11 n-Pose. This model was trained from scratch using the YOLOv11 n-Pose framework without utilizing any pre-trained models. The experimental results are shown in Table 4.
Table 4.
Comparison results of UVPose and YOLOv11 pose models.
In this experiment, we conducted a comprehensive evaluation of UVPose. The results show that UVPose performs exceptionally well in drone key point detection, with PCK, AP, and AR reaching 79.2%, 67.2%, and 73.5%, respectively, significantly outperforming YOLOv11 n-Pose. Moreover, although UVPose has more complex model parameters (15.8 M) and FLOPs (3.3 G) compared to YOLOv11 n-Pose, its superior accuracy and strong detection capability make it a clear advantage in applications requiring high precision. Overall, UVPose, with its outstanding performance, particularly in precision and recall, provides a reliable solution for high-accuracy human pose estimation. Figure 10 demonstrates the detection results of UVPose and YOLOv11 n-Pose models.
Figure 14 presents the key point detection results of the UVPose and YOLOv11 n-Pose models in drone imagery. Comparative analysis reveals that UVPose demonstrates significantly higher accuracy in key point detection across different angles, particularly under complex poses, where it predicts key point locations more precisely. In contrast, the performance of YOLOv11 n-Pose declines slightly at certain angles, especially when there are substantial changes in drone orientation.
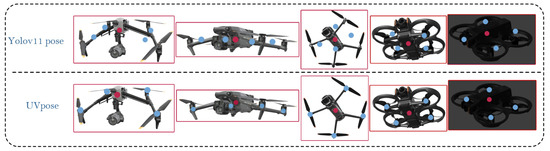
Figure 14.
Comparison Analysis of the Performance of UVPose and YOLOv11 n-Pose Models.
The observed differences can be attributed to the following reasons. The YOLOv11 series models are primarily designed for object detection tasks, utilizing a general-purpose architecture for pose segmentation, classification, and object detection. However, they are not optimized for key point regression, and their performance in fine-grained key point localization is suboptimal. As a result, YOLOv11 n-Pose exhibits lower accuracy in predicting drone key points compared to networks specifically optimized for pose estimation. On the other hand, UVPose is specifically designed for drone key point detection and does not involve object detection. It employs a high-resolution key point regression-optimized architecture that enables more accurate extraction of key points from multi-scale and multi-view information. Due to architectural differences, UVPose outperforms YOLOv11 n-Pose in terms of accuracy and stability, particularly in complex scenes and low-light conditions.
4.7. Detection Performance of UVPose in Continuous Dynamic Scenes
Figure 15 demonstrates UVPose’s key point detection performance across consecutive frames, simulating drone localization in various environments. The results show that UVPose reliably and accurately detects and localizes quadrotor key points under different lighting and background conditions, maintaining high precision even with significant changes in background and perspective. Finally, the skeletal key point view is presented, supporting key point targeting, flight posture, and trajectory capture for anti-drone systems. To provide a more detailed demonstration of UVPose’s performance in real-world applications, we have included a related video in the Supplementary Materials section.

Figure 15.
The key point detection performance of UVpose in consecutive frame images.
5. Discussion
5.1. Exploration of Limitations and Optimization Strategies for UVPose
Under normal lighting conditions, UVPose maintains high detection accuracy. However, its performance significantly degrades in scenarios involving extreme flight angles or environmental occlusions. Testing has revealed two primary limitations of UVPose. First, in complex flight postures, such as “flower flight” maneuvers or during intense drone oscillations, key point detection accuracy declines, leading to potential key point shifts or losses. Second, while UVPose demonstrates robustness against self-occlusion caused by the drone’s body, it struggles with environmental occlusions (e.g., trees, buildings, or other obstacles), resulting in the loss of critical feature information and reduced detection accuracy. These findings indicate that UVPose requires further optimization to enhance its robustness under extreme angles and occlusion conditions.
The limitations of UVPose in complex environments are illustrated in Figure 16. Under environmental occlusion conditions (Figure 16a), when the drone is partially obstructed by external objects such as hands, branches, or other obstacles, the accuracy of key point detection decreases, leading to the loss of critical feature information and negatively impacting pose estimation. Furthermore, in complex inverted flight postures (Figure 16b), such as during aggressive maneuvers or inverted flight, key points may shift or be lost, resulting in unstable pose estimation. These findings highlight the need for further optimization to enhance UVPose’s robustness and adaptability in challenging real-world scenarios.

Figure 16.
(a) Under environmental occlusion conditions. (b) Complex inverted flight postures.
The analysis of these limitations reveals that they primarily stem from constraints in previous research. Earlier studies mainly focused on normal flight and turning scenarios without considering complex postures such as aggressive maneuvers or inverted flight. Additionally, the datasets used were mostly collected in clean environments, lacking cluttered backgrounds, which restricted the model’s generalization ability. Moreover, prior research primarily addressed self-occlusion caused by the drone’s body, while environmental occlusions (e.g., trees, buildings, and other obstacles) were largely overlooked, limiting the model’s adaptability to real-world scenarios.
To address the limitations of UVPose, future research will focus on several key optimizations. First, the training dataset will be expanded to include extreme flight postures, environmental occlusions, and complex lighting conditions to enhance the model’s generalization capability. Second, key point detection algorithms will be refined by exploring more efficient feature extraction structures to improve robustness against key point shifts and losses. Additionally, multi-modal information, such as optical flow and infrared data, will be integrated to mitigate the impact of environmental occlusions. Finally, techniques such as model pruning will be employed to reduce computational complexity, thereby improving real-time performance and deployment efficiency. These advancements will enhance UVPose’s adaptability and robustness in complex real-world scenarios, providing more precise and reliable support for UAV pose estimation.
5.2. Future Work and Optimization Strategies
The proposed UVPose model, based on the MMPose framework, incorporates multi-scale feature extraction and optimized localization methods. It achieves a balance between lightweight design and high precision, making it well suited for resource-constrained devices, real-time detection, and counter-drone systems. Future research on hardware deployment will focus on integrating UVPose into drone defense systems, optimizing quantization and compression strategies, and supporting ONNX and TensorFlow Lite formats. Additionally, performance will be enhanced using TensorRT or OpenVINO for accelerated inference. Ultimately, deployment optimizations will ensure the stable operation of UVPose on resource-limited devices, meeting real-time detection requirements.
Future research on the model should not only address the limitations discussed in the previous section, but also enhance UVPose’s detection performance under complex lighting conditions. Additionally, the dataset should incorporate camera pose information, with plans to integrate camera positioning into the pose estimation process to further improve drone localization accuracy and the effectiveness of strategy generation. Moreover, complementary approaches will be explored to enhance UVPose’s performance and adaptability. For instance, investigating 3D sensing technologies and 3D key point detection could improve the accuracy of drone pose estimation and overall localization capabilities. Transfer learning techniques will also be employed to enhance the model’s generalization across different types of drones, broadening its applicability. Finally, hardware optimizations will be implemented to reduce computational resource consumption, improve efficiency on resource-constrained devices, and facilitate the deployment of UVPose in real-time drone defense systems.
6. Conclusions
With the rapid development of drone technology, the importance of counter-drone systems has become increasingly evident. However, traditional object detection methods face significant limitations in countering drones, as they struggle to accurately estimate the drone’s flight posture or capture key components such as rotors and mainboards. To address these challenges, we propose a novel counter-drone key point detection model, UVPose, built on the MMpose open-source pose estimation framework. We design a new top-down network structure, MDA-Net, incorporating a multi-path parallel attention mechanism that significantly enhances the detection accuracy of multi-scale key points. Furthermore, we introduce the RFN structure, specifically optimized for drone key point detection, and integrate the SimCC key point localization method in the head module. These enhancements are complemented by lightweight and efficient design optimizations. Experimental results demonstrate that UVPose achieves an effective balance between detection accuracy and computational efficiency, outperforming mainstream models on the MMpose platform.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/drones9030214/s1, Video: video.mp4.
Author Contributions
Conceptualization, B.Y. and Q.S.; methodology, B.Y.; software, B.Y.; validation, B.Y., W.W. and Z.W.; formal analysis, B.Y.; investigation, W.W. and Z.W.; resources, Q.S.; data curation, W.W.; writing—original draft preparation, W.W.; writing—review and editing, Q.S.; visualization, Z.W.; supervision, Q.S.; project administration, Q.S.; funding acquisition, Q.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available upon request from the author.
Acknowledgments
We thank the laboratory members for their hard work, and the anonymous reviewers for their valuable comments and suggestions on this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the unmanned aerial vehicles (UAVs): A comprehensive review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Vujasinović, S.; Becker, S.; Breuer, T.; Bullinger, S.; Scherer-Negenborn, N.; Arens, M. Integration of the 3D environment for UAV onboard visual object tracking. Appl. Sci. 2020, 10, 7622. [Google Scholar] [CrossRef]
- Onishi, M.; Ise, T. Explainable identification and mapping of trees using UAV RGB image and deep learning. Sci. Rep. 2021, 11, 903. [Google Scholar] [CrossRef] [PubMed]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned aerial vehicle (UAV) based forest fire detection and monitoring for reducing false alarms in forest fires. Comput. Commun. 2020, 149, 1–16. [Google Scholar] [CrossRef]
- Mukherjee, A.; Chakraborty, S.; Azar, A.T.; Bhattacharyay, S.K.; Chatterjee, B.; Dey, N. Unmanned aerial system for post-disaster identification. In Proceedings of the International Conference on Circuits, Communication, Control and Computing, Bangalore, India, 21–22 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 247–252. [Google Scholar]
- Xie, J.; Yu, J.; Wu, J.; Shi, Z.; Chen, J. Adaptive switching spatial-temporal fusion detection for remote flying drones. IEEE Trans. Vehic. Technol. 2020, 69, 6964–6976. [Google Scholar] [CrossRef]
- Mitchell, R.; Chen, R. Adaptive intrusion detection of malicious unmanned air vehicles using behavior rule specifications. IEEE Trans. Syst. Man Cybernet. Syst. 2013, 44, 593–604. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, C.; Chadha, R.G.; Singh, S. Maximum likelihood path planning for fast aerial maneuvers and collision avoidance. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1–4. [Google Scholar]
- Drozdowicz, J.; Wielgo, M.; Samczynski, P.; Kulpa, K.; Krzonkalla, J.; Mordzonek, M.; Bryl, M.; Jakielaszek, Z. 35 GHz FMCW Drone Detection System. In Proceedings of the 2016 17th International Radar Symposium (IRS), Krakow, Poland, 10–12 May 2016; pp. 1–4. [Google Scholar]
- Nguyen, P.; Ravindranatha, M.; Nguyen, A.; Han, R.; Vu, T. Investigating Cost-effective RF-based Detection of Drones. In Proceedings of the 2nd Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, New York, NY, USA, 26 June 2016; pp. 17–22. [Google Scholar]
- Mezei, J.; Fiaska, V.; Molnár, A. Drone Sound Detection. In Proceedings of the 2015 16th IEEE International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 19–21 November 2015; pp. 333–338. [Google Scholar]
- Liu, D.; Zong, Q.; Zhang, X.; Zhang, R.; Dou, L.; Tian, B. Game of Drones: Intelligent Online Decision Making of Multi-UAV Confrontation. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 2086–2100. [Google Scholar] [CrossRef]
- Cheng, Q.; Wang, Y.; He, W.; Bai, Y. Lightweight air-to-air unmanned aerial vehicle target detection model. Sci. Rep. 2024, 14, 2609. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, G.; Chen, Y.; Li, L.; Chen, B.M. VDTNet: A High-Performance Visual Network for Detecting and Tracking of Intruding Drones. IEEE Trans. Intell. Transp. Syst. 2024, 25, 9828–9838. [Google Scholar] [CrossRef]
- Lin, H.-J. Design and Verification of Lateral Flight Control System for Fixed-wing Drone. In Proceedings of the 2022 IEEE 4th Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 28–30 October 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Jiang, T.; Lu, P.; Zhang, L.; Ma, N.; Han, R.; Lyu, C.; Li, Y.; Chen, K. RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose. arXiv 2023, arXiv:2303.07399. [Google Scholar]
- Oza, P.; Sindagi, V.A.; VS, V.; Patel, V.M. Unsupervised Domain Adaptation of Object Detectors: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4018–4040. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Nguyen, T.H.; Nowak, J.; Byrski, A.; Siwocha, A.; Le, V.H. Combined YOLOv5 and HRNet for high accuracy 2D keypoint and human pose estimation. J. Artif. Intell. Soft Comput. Res. 2022, 12, 281–298. [Google Scholar] [CrossRef]
- Seong, S.; Choi, J. Semantic segmentation of urban buildings using a high-resolution network (HRNet) with channel and spatial attention gates. Remote Sens. 2021, 13, 3087. [Google Scholar] [CrossRef]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HrFormer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. ViTPose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Li, R.; Li, Q.; Yang, S.; Zeng, X.; Yan, A. An efficient and accurate 2D human pose estimation method using VTTransPose network. Sci. Rep. 2024, 14, 7608. [Google Scholar] [CrossRef]
- Fan, Q.; Liu, S.; Li, S.; Zhao, C. Bottom-up cattle pose estimation via concise multi-branch network. Comput. Electron. Agric. 2023, 211, 107945. [Google Scholar] [CrossRef]
- Wang, C.; Sun, Y.; Zhang, X.; Li, Y.; Fu, C.-W.; Hu, H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; Volume 1, pp. 1–10. [Google Scholar]
- Li, Y.; Yang, S.; Liu, P.; Zhang, S.; Wang, Y.; Wang, Z.; Yang, W.; Xia, S.-T. SimCC: A Simple Coordinate Classification Perspective for Human Pose Estimation. Tsinghua Univ. 2021, 1, 1–12. [Google Scholar]
- Zheng, Y.; Chen, Z.; Lv, D.; Li, Z.; Lan, Z.; Zhao, S. Air-to-air visual detection of micro-UAVs: An experimental evaluation of deep learning. IEEE Robot. Autom. Lett. 2021, 6, 1020–1027. [Google Scholar] [CrossRef]
- Shi, Y.; Gao, W.; Shen, T.; Li, W.; Li, Z.; Huang, X.; Li, C.; Chen, H.; Zou, X.; Shi, J. Calorie Detection in Dishes Based on Deep Learning and 3D Reconstruction. Comput. Electron. Agric. 2025, 229, 109832. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; Volume 1, pp. 1–9. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Doherty, J.; Gardiner, B.; Kerr, E.; Siddique, N. BiFPN-YOLO: One-Stage Object Detection Integrating Bi-Directional Feature Pyramid Networks. Pattern Recognit. 2025, 160, 111209. [Google Scholar] [CrossRef]
- Han, Z.; Jia, D.; Zhang, L.; Li, J.; Cheng, P. FNI-DETR: Real-Time DETR with Far and Near Feature Interaction for Small Object Detection. Eng. Res. Express 2025, 7, 015204. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Mao, R.; Zhang, Y.; Wang, Z. Recognizing stripe rust and yellow dwarf of wheat using improved Faster-RCNN. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 176–185. [Google Scholar]
- He, B.; Cui, C.; Guo, W.; Du, L.; Liu, B.; Tang, Y. Ferrography wear particle recognition of gearbox based on Faster R-CNN. Lubr. Eng. 2020, 45, 105–112. [Google Scholar]
- Peng, H.; Xue, C.; Shao, Y.; Chen, K.; Liu, H.; Xiong, J.; Chen, H.; Gao, Z.; Yang, Z. Litchi detection in the field using an improved YOLOv3 model. Int. J. Agric. Biol. Eng. 2022, 15, 211–220. [Google Scholar] [CrossRef]
- Sun, D.-Z.; Liu, H.; Liu, J.-Y.; Ding, Z.; Xie, J.-X.; Wang, W.-X. Recognition of tea diseases based on improved YOLOv4 model. J. Northwest A F Univ. (Nat. Sci. Ed.) 2023, 51, 145–154. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: As small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Desai, M.; Mewada, H. A Novel Approach for Yoga Pose Estimation Based on In-Depth Analysis of Human Body Joint Detection Accuracy. PeerJ Comput. Sci. 2023, 9, e1152. [Google Scholar] [CrossRef] [PubMed]
- Purkrabek, M.; Matas, J. ProbPose: A Probabilistic Approach to 2D Human Pose Estimation. arXiv 2024, arXiv:2412.02254v1. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep resiparallel learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).