
MDDFA-Net: Multi-Scale Dynamic Feature Extraction from Drone-Acquired Thermal Infrared Imagery



Abstract
1. Introduction
2. Methodology
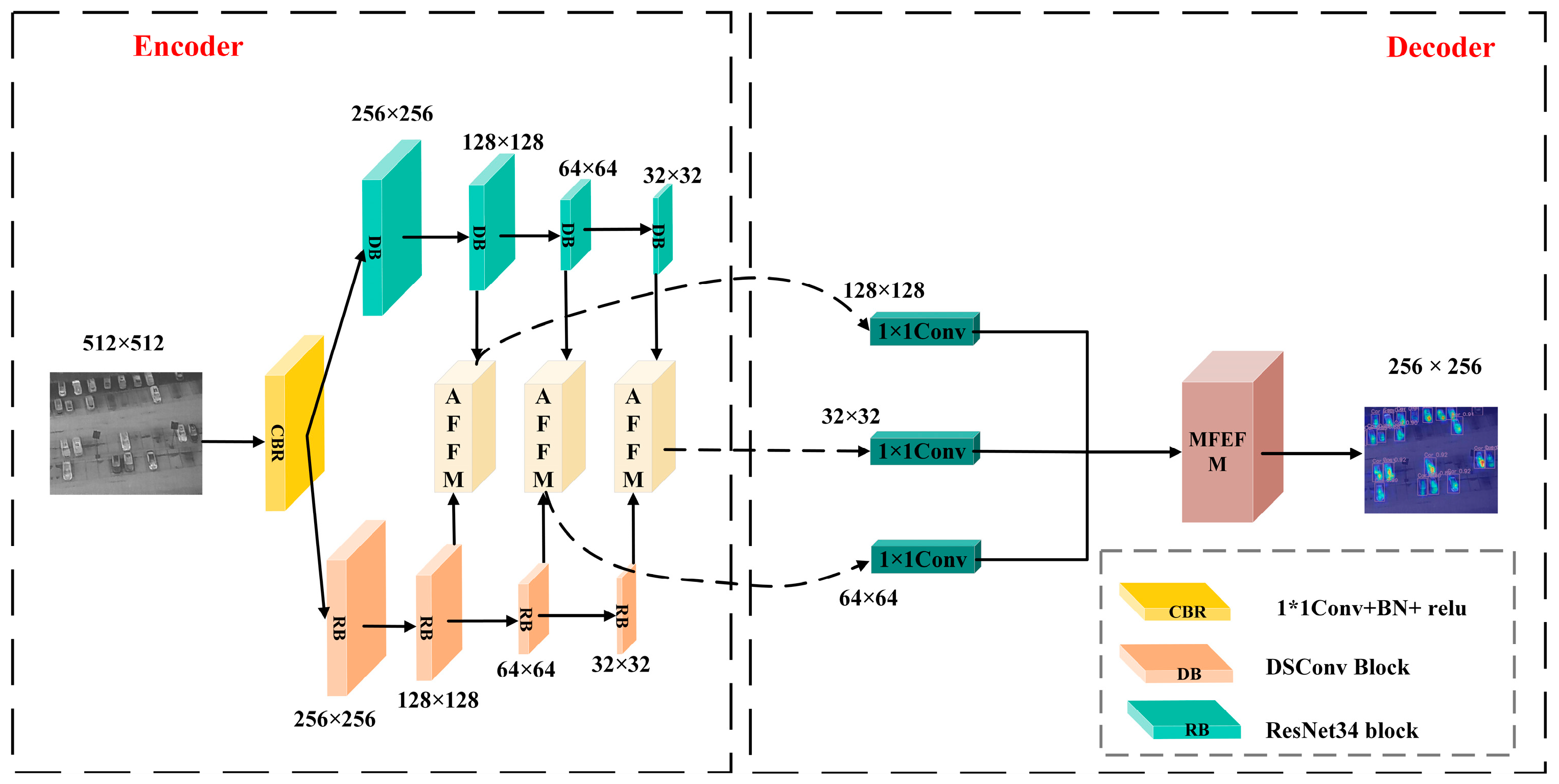
2.1. Network Overall
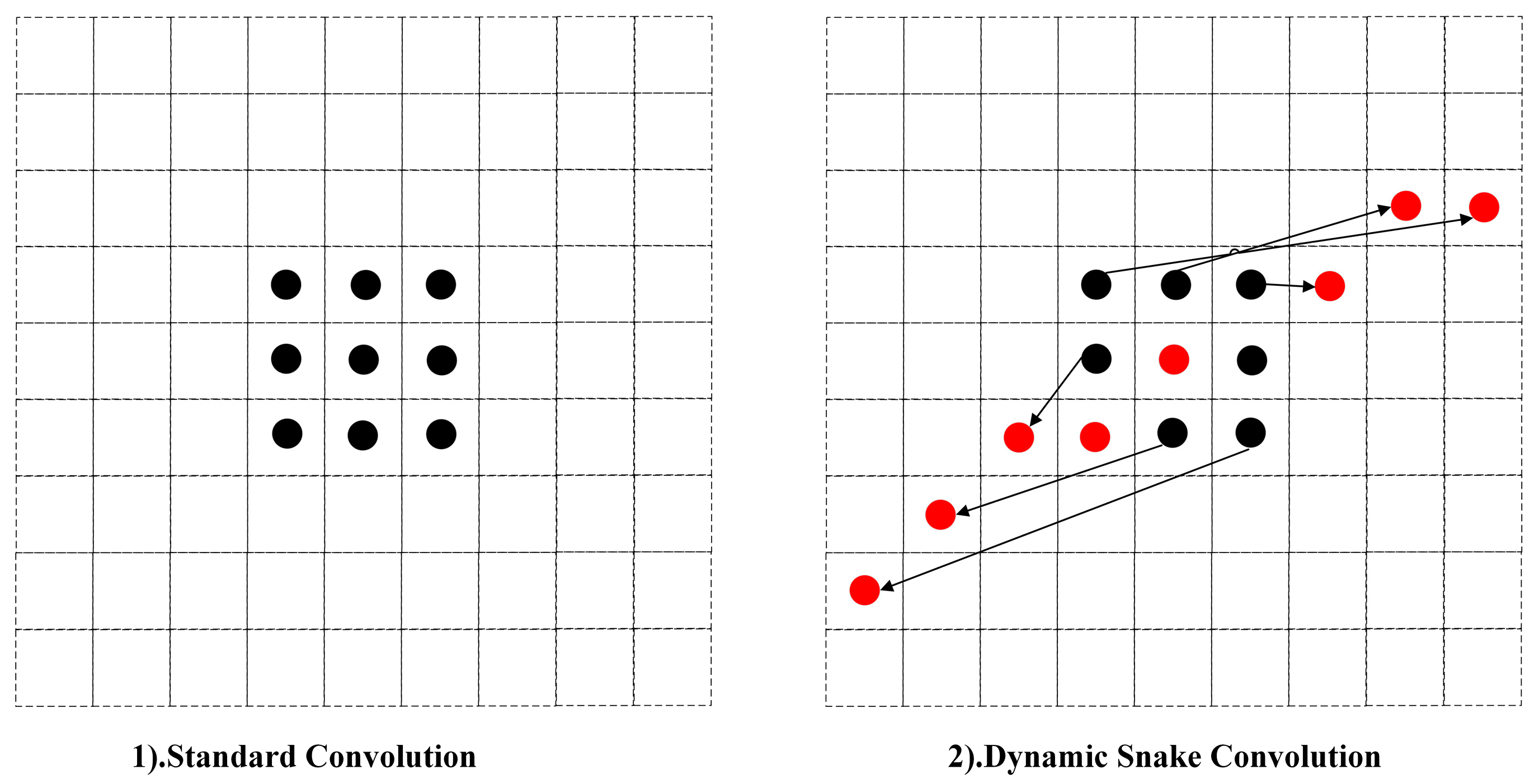
2.2. Double Branch Structure
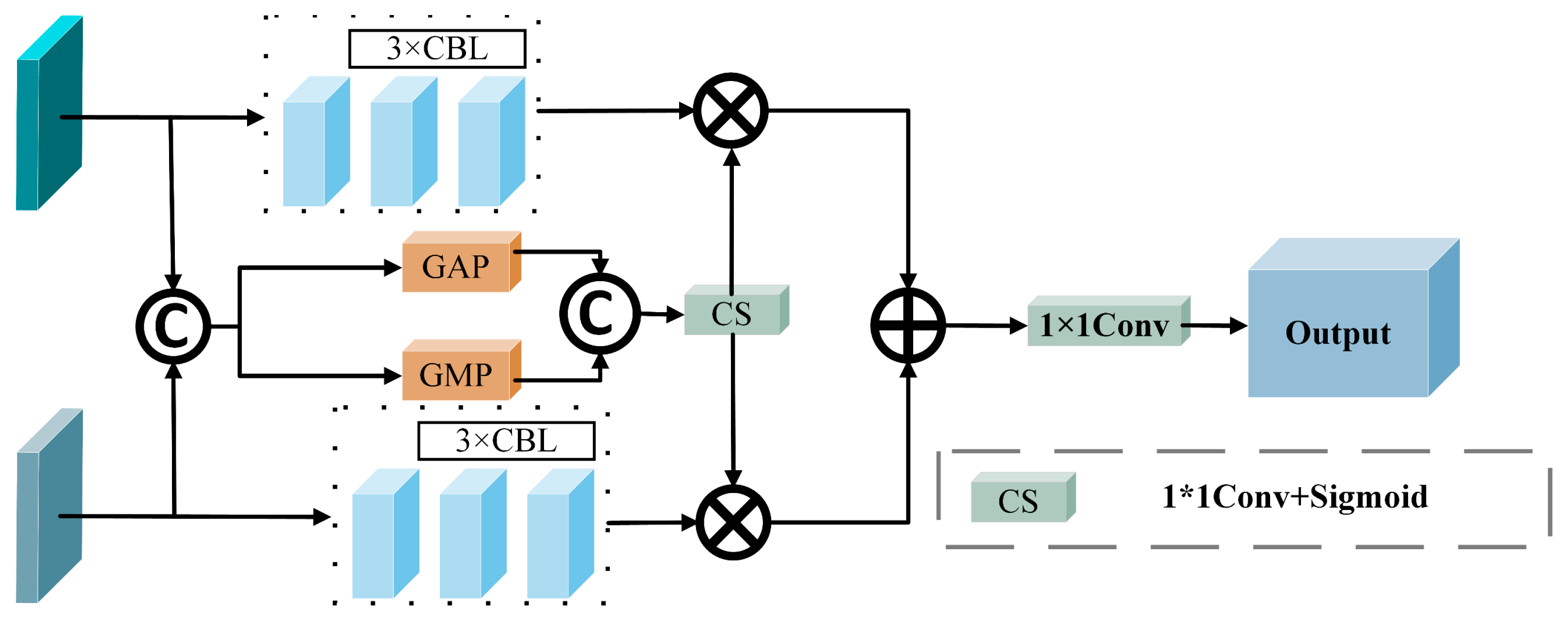
2.3. Adaptive Feature Fusion Module (AFFM)
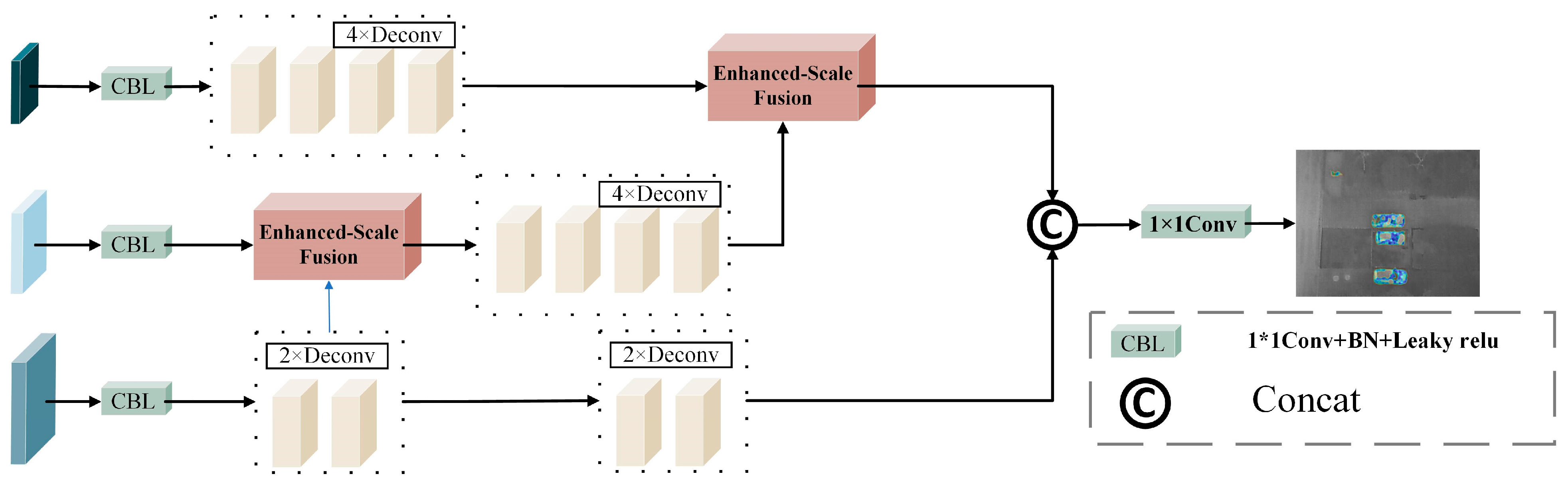
2.4. Multi-Scale Feature Enhancement and Fusion Module (MFEFM)
3. Data and Experimental Settings
3.1. Dataset Specification
3.2. Experiment Setting
3.3. Evaluation Criteria
4. Results
4.1. Experimental Results
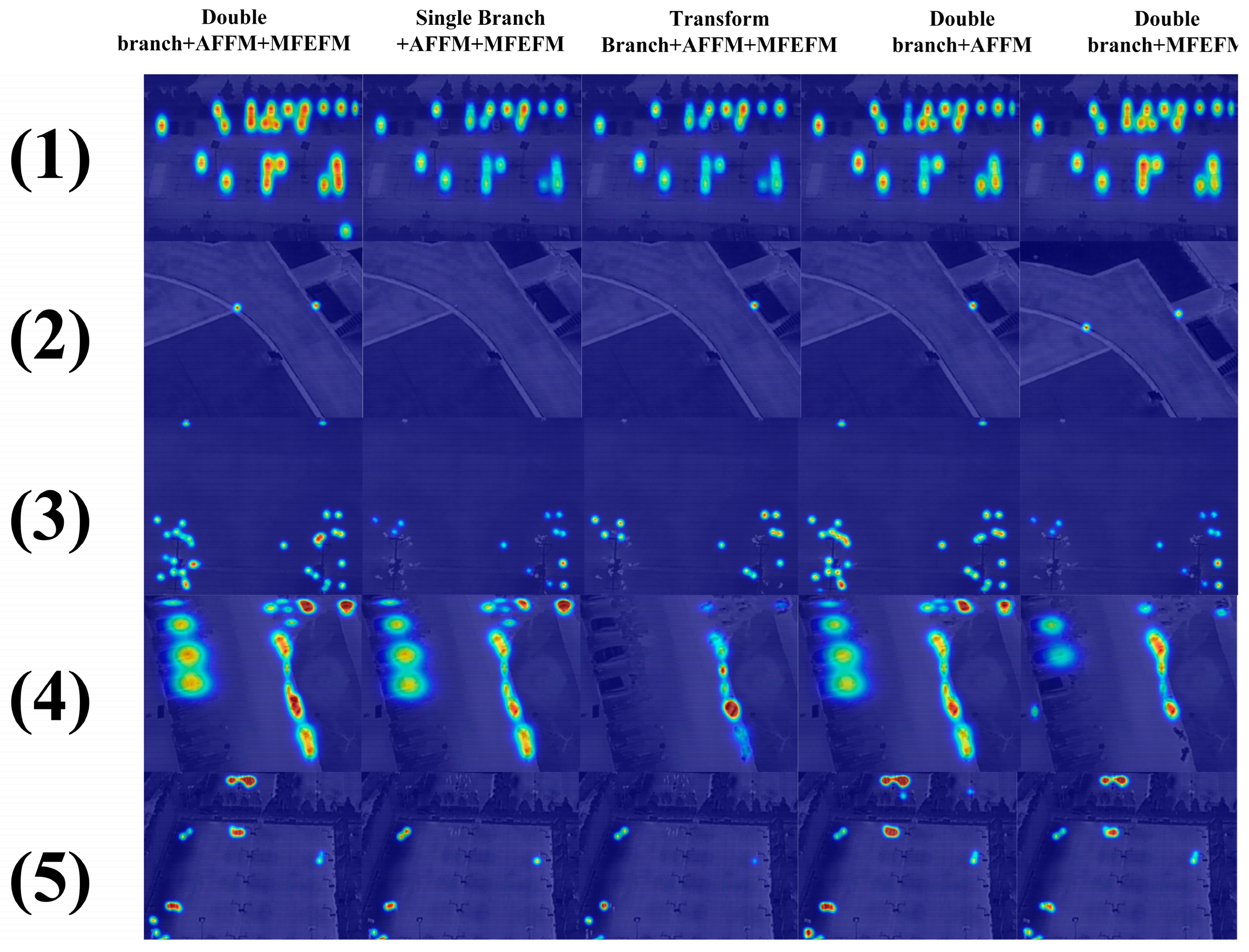
4.2. Ablation Experiments
4.3. Visualization of UAV-Mounted Infrared Image Target Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sarkar, S.; Dey, A.; Pradhan, R.; Sarkar, U.M.; Chatterjee, C.; Mondal, A.; Mitra, P. Crop Yield Prediction Using Multimodal Meta-Transformer and Temporal Graph Neural Networks. IEEE Trans. AgriFood Electron. 2024, 2, 545–553. [Google Scholar]
- Wang, S.; Du, Y.; Zhao, S.; Gan, L. Multi-Scale Infrared Military Target Detection Based on 3X-FPN Feature Fusion Network. IEEE Access 2023, 11, 141585–141597. [Google Scholar]
- Han, C.; Li, N.; Zhang, T.; Dai, J. A Dual-Parameter Interrogation Fano Resonance Sensor Based on All-Oxide Multilayer Film for Biomolecule Detection. IEEE Sens. J. 2024, 24, 40725–40731. [Google Scholar]
- Yue, L.; Shen, H.; Yu, W.; Zhang, L. Monitoring of Historical Glacier Recession in Yulong Mountain by the Integration of Multisource Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 388–400. [Google Scholar]
- Ji, Z.; Wang, X.; Wang, Z.; Li, G. An Enhanced and Unsupervised Siamese Network with Superpixel-Guided Learning for Change Detection in Heterogeneous Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19451–19466. [Google Scholar]
- Xia, C.; Li, X.; Yin, Y.; Chen, S. Multiple Infrared Small Targets Detection Based on Hierarchical Maximal Entropy Random Walk. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Yang, W.; Ping, J. Infrared small target detection based on local significance and multiscale. Digit. Signal Process. 2024, 155, 104721. [Google Scholar]
- Wu, J.; He, Y.; Zhao, J. An Infrared Target Images Recognition and Processing Method Based on the Fuzzy Comprehensive Evaluation. IEEE Access 2024, 12, 12126–12137. [Google Scholar]
- Wang, J.-G.; Sung, E. Facial Feature Extraction in an Infrared Image by Proxy with a Visible Face Image. IEEE Trans. Instrum. Meas. 2007, 56, 2057–2066. [Google Scholar]
- Huang, S.; Peng, Z.; Wang, Z.; Wang, X.; Li, M. Infrared Small Target Detection by Density Peaks Searching and Maximum-Gray Region Growing. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1919–1923. [Google Scholar]
- Cao, L.; Wang, Q.; Luo, Y.; Hou, Y.; Cao, J.; Zheng, W. YOLO-TSL: A lightweight target detection algorithm for UAV infrared images based on Triplet attention and Slim-nec. Infrared Phys. Technol. 2024, 41, 105487. [Google Scholar] [CrossRef]
- Rao, W.; Gao, L.; Qu, Y.; Sun, X.; Zhang, B.; Chanussot, J. Siamese Transformer Network for Hyperspectral Image Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Zhou, D.; Wang, X. Robust Infrared Small Target Detection Using a Novel Four-Leaf Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1462–1469. [Google Scholar] [CrossRef]
- Xie, Y.; Feng, D.; Chen, H.; Liao, Z.; Zhu, J.; Li, C.; Baik, S.W. An Omni-scale Global-Local Aware Network for Shadow Extraction in Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 193, 29–44. [Google Scholar] [CrossRef]
- Wu, R.; Liu, G.; Lv, J.; Bao, X.; Hong, R.; Yang, Z.; Wu, S.; Xiang, W.; Zhang, R. DEM-Based Radar Incidence Angle Tracking for Distortion Analysis Without Orbital Data. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Xie, Y.; Feng, D.; Chen, H.; Liu, Z.; Mao, W.; Zhu, J.; Hu, Y.; Baik, S.W. Damaged Building Detection from Post-earthquake Remote Sensing Imagery Considering Heterogeneity Characteristics. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Lv, J.; Zhang, R.; Yu, B.; Pang, J.; Liao, M.; Liu, G. A GPS-IR Method for Retrieving NDVI From Integrated Dual-Frequency Observations. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Lai, J.; Wang, P.; Feng, D.; Cao, Y.; Hussain, T.; Baik, S.W. An Enhanced Relation-Aware Global-Local Attention Network for Escaping Human Detection in Indoor Smoke Scenarios. ISPRS J. Photogramm. Remote Sens. 2022, 186, 140–156. [Google Scholar] [CrossRef]
- Pirasteh, S.; Rashidi, P.; Rastiveis, H.; Huang, S.; Zhu, Q.; Liu, G.; Li, Y.; Li, J.; Seydipour, E. Developing an algorithm for buildings extraction and determining changes from airborne LiDAR, and comparing with R-CNN method from drone image. Remote Sens. 2019, 11, 1272. [Google Scholar] [CrossRef]
- Feng, D.; Chen, H.; Liu, S.; Liao, Z.; Shen, X.; Xie, Y.; Zhu, J. Boundary-semantic collaborative guidance network with dual-stream feedback mechanism for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Hang, R.; Xu, S.; Yuan, P.; Liu, Q. AANet: An ambiguity-aware network for remote-sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [PubMed]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery with Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Hao, M.; Zhai, R.; Wang, Y.; Ru, C.; Yang, B. A Stained-Free Sperm Morphology Measurement Method Based on Multi-Target Instance Parsing and Measurement Accuracy Enhancement. Sensors 2025, 25, 592. [Google Scholar] [CrossRef]
- Lu, W.; Lan, C.; Niu, C.; Liu, W.; Lyu, L.; Shi, Q.; Wang, S. A CNN-Transformer Hybrid Model Based on CSWin Transformer for UAV Image Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1211–1231. [Google Scholar] [CrossRef]
- Fu, Q.; Zheng, Q.; Yu, F. LMANet: A Lighter and More Accurate Multiobject Detection Network for UAV Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Nie, J.; Sun, H.; Sun, X.; Ni, L.; Gao, L. Cross-Modal Feature Fusion and Interaction Strategy for CNN-Transformer-Based Object Detection in Visual and Infrared Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Ou, J.; Wang, J.; Xue, J.; Wang, J.; Zhou, X.; She, L.; Fan, Y. Infrared Image Target Detection of Substation Electrical Equipment Using an Improved Faster R-CNN. IEEE Trans. Power Deliv. 2023, 38, 387–396. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Liu, L.; Fang, H.; Zhong, S. Infrared Aerothermal Nonuniform Correction via Deep Multiscale Residual Network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1120–1124. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Zhang, J.; Guo, J.; Li, Y.; Gao, X. Dim2Clear Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2127–2139. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Nat. Commun. 2014, 5, 2677. [Google Scholar]
- Bai, Z.; Pang, H.; He, Z.; Zhao, B.; Wang, T. Path Planning of Autonomous Mobile Robot in Comprehensive Unknown Environment Using Deep Reinforcement Learning. IEEE Internet Things J. 2024, 11, 22153–22166. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [PubMed]
- Liang, S.; Lu, J.; Zhang, K.; Chen, X. Multi-Scale Transformer Hierarchically Embedded CNN Hybrid Network for Visible-Infrared Person Re-Identification. IEEE Internet Things J. 2024, 1. [Google Scholar]
- Xu, K.; Song, C.; Xie, Y.; Pan, L.; Gan, X.; Huang, G. RMT-YOLOv9s: An Infrared Small Target Detection Method Based on UAV Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: https://github.com/suojiashun/HIT-UAV-Infrared-Thermal-Dataset (accessed on 18 March 2025).
- Dang, C.; Wang, Z.X. RCYOLO: An Efficient Small Target Detector for Crack Detection in Tubular Topological Road Structures Based on Unmanned Aerial Vehicles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 12731–12744. [Google Scholar]
- Cao, S.; Feng, D.; Liu, S.; Xu, W.; Chen, H.; Xie, Y.; Zhang, H.; Pirasteh, S.; Zhu, J. BEMRF-Net: Boundary Enhancement and Multiscale Refinement Fusion for Building Extraction from Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 16342–16358. [Google Scholar]
- Ultralytics. YOLOv5: Version 6.0. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 January 2023).
- Ultralytics. YOLOv8: Version 8.0.0. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 January 2023).
- Wang, L.; Zhang, S.; Li, J. YOLOv10: Real-Time End-to-End Object Detection with Enhanced Performance-Efficiency Trade-Off. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Jiang, M.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Ship Contour Extraction From SAR Images Based on Faster RCNN and Chan–Vese Model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware environment | CPU | Inte(R) Xeon(R) Silver 4210R CPU @ 2.40 GHz |
| GPU | NVIDIA GeForce RTX 3080 | |
| RAM | 64 G | |
| Edge AI device | RK3588 | |
| Software environment | OS | Windows 10 |
| CUDA Toolkit | 12.2 | |
| Python | 3.8.18 | |
| Training information | Optimizer | SGD |
| Epoch | 200 | |
| Batch size | 8 | |
| Learning range | 0.01 |
| Network | Precision% | Recall% | mAP@0.5/% | Params (M) | FLOPs (G) | FPS (PC) | FPS (EA) |
|---|---|---|---|---|---|---|---|
| RCYOLO [39] | 91.56 | 91.12 | 93.32 | 20.9 | 48.2 | 40.3 | 29.7 |
| BEMRF-Net [40] | 90.52 | 91.25 | 91.43 | 23.3 | 48.2 | 39.7 | 25.8 |
| FIRENET [41] | 93.13 | 92.32 | 94.20 | 23.3 | 48.9 | 39.5 | 27.3 |
| YOLOv11 | 92.31 | 91.33 | 93.37 | 12.5 | 37.7 | 43.7 | 30.5 |
| RetinaNet [42] | 90.62 | 90.15 | 91.44 | 21.5 | 47.6 | 40.6 | 29.6 |
| Faster R-CNN [43] | 86.25 | 85.22 | 87.32 | 41.2 | 156.3 | 37.6 | 23.5 |
| Ours | 94.26 | 93.42 | 95.43 | 17.1 | 46.1 | 41.1 | 29.7 |
| Transform Branch | Double Branch | Single Branch | AFFM | MFEFM | mAP@0.5% | Precision% | Recall% | Param (M) |
|---|---|---|---|---|---|---|---|---|
| - | √ | - | √ | √ | 95.43 | 94.26 | 93.42 | 17.12 |
| - | √ | - | √ | - | 93.45 | 92.38 | 92.38 | 16.98 |
| - | √ | - | - | √ | 94.24 | 93.41 | 93.85 | 16.67 |
| √ | - | - | - | √ | 89.25 | 85.12 | 89.92 | 22.21 |
| - | - | √ | - | √ | 90.81 | 90.33 | 90.21 | 16.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Dang, C.; Zhang, R.; Wang, L.; He, Y.; Wu, R. MDDFA-Net: Multi-Scale Dynamic Feature Extraction from Drone-Acquired Thermal Infrared Imagery. Drones 2025, 9, 224. https://doi.org/10.3390/drones9030224
Wang Z, Dang C, Zhang R, Wang L, He Y, Wu R. MDDFA-Net: Multi-Scale Dynamic Feature Extraction from Drone-Acquired Thermal Infrared Imagery. Drones. 2025; 9(3):224. https://doi.org/10.3390/drones9030224
Chicago/Turabian StyleWang, Zaixing, Chao Dang, Rui Zhang, Linchang Wang, Yonghuan He, and Rong Wu. 2025. "MDDFA-Net: Multi-Scale Dynamic Feature Extraction from Drone-Acquired Thermal Infrared Imagery" Drones 9, no. 3: 224. https://doi.org/10.3390/drones9030224
APA StyleWang, Z., Dang, C., Zhang, R., Wang, L., He, Y., & Wu, R. (2025). MDDFA-Net: Multi-Scale Dynamic Feature Extraction from Drone-Acquired Thermal Infrared Imagery. Drones, 9(3), 224. https://doi.org/10.3390/drones9030224