
Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials
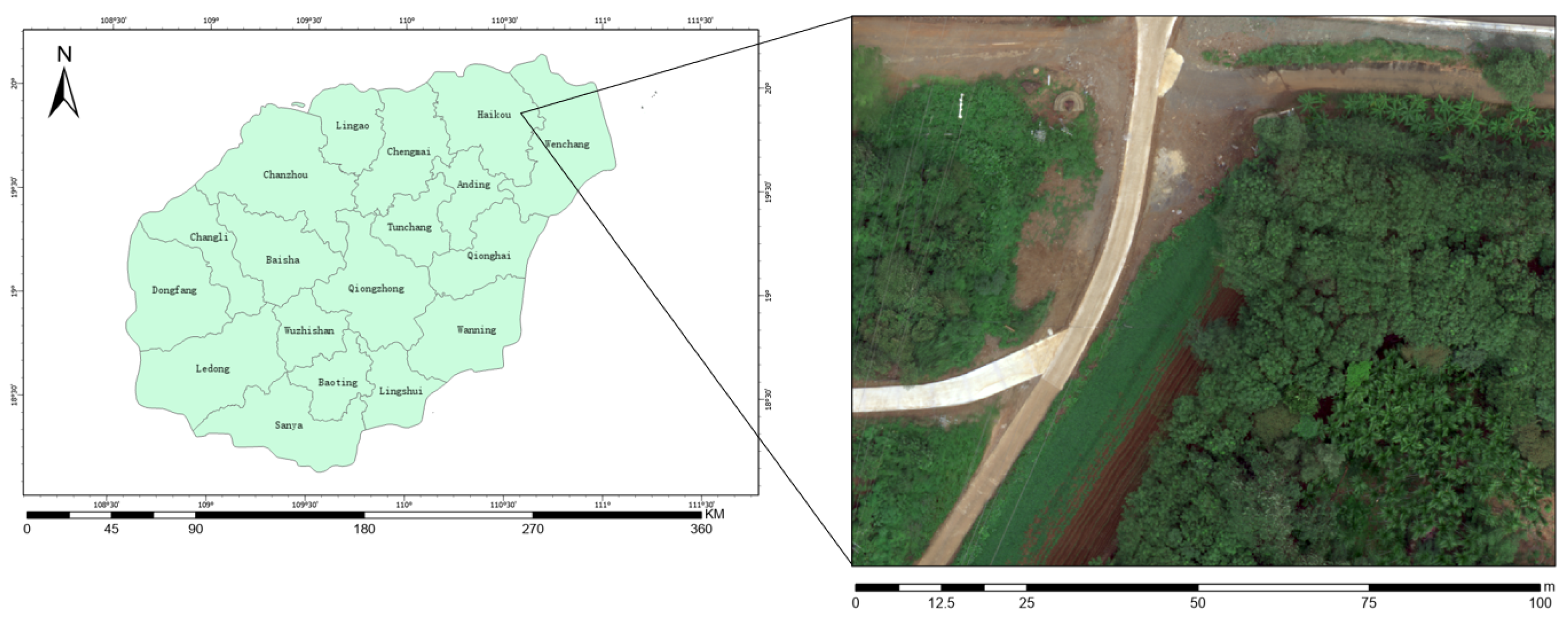
2.1.1. Research Area
2.1.2. Data Source
2.2. Methods
- Step 1: A dataset was constructed using original tagged UAV images.
- Step 2: The LabelMe software was utilized to segment and annotate the crowns of various tree species within the study area.
- Step 3: The ECA-Unet model was employed to extract features and train the data in order to achieve the optimal parameter set.
- Step 4: After comparing the accuracy evaluation indexes obtained according to the training results, the best parameter set was selected and input to recognize and obtain the monoki segmentation results.
- Step 5: Accuracy was verified, and comparison with alternative deep learning models was performed.
2.2.1. Construction of Original Data Set
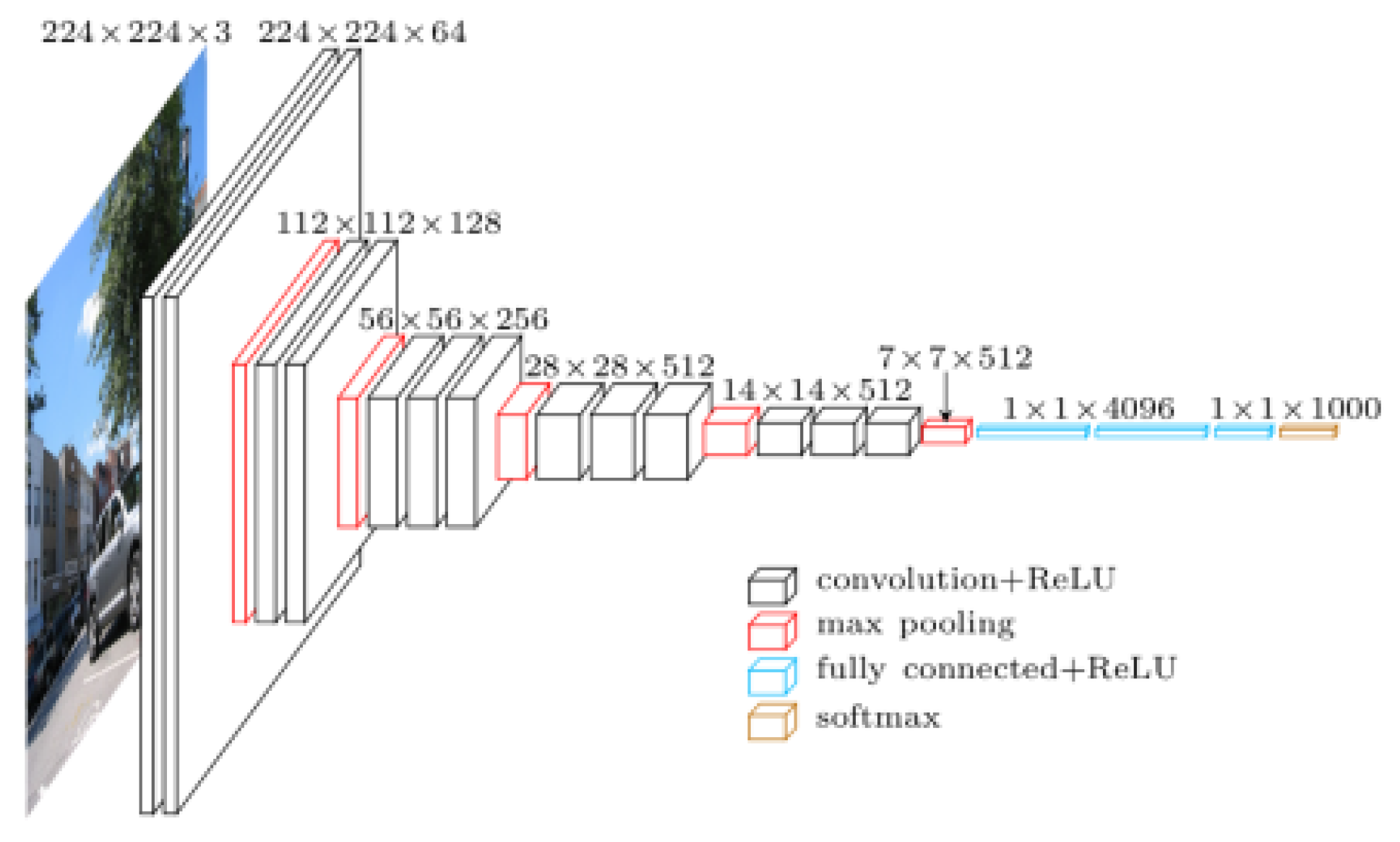
2.2.2. U-Net
2.2.3. Efficient Channel Attention Mechanism
2.2.4. Operation of the ECA Network
2.2.5. ECA-Unet
2.2.6. Experimental Environment and Parameter Settings
2.2.7. Accuracy Evaluation Index
3. Results
3.1. Experimental Results
3.2. Model Accuracy Comparison
4. Conclusions and Discussion
- A method for semantic segmentation of individual tree species utilizing an enhanced ECA-Unet model, which is based on the U-net architecture, has been developed. This model attained an overall accuracy of 85.87% for the semantic segmentation of individual tree species in the tropical tree species research area of Hainan Province, representing an increase of 1.3 percentage points relative to the original U-net model. This illustrates that the model can effectively and intelligently segment individual tree species in confined areas, markedly diminishing the burden of manual segmentation.
- The ECA-Unet model proposed in this paper improves the average intersection ratio, average pixel accuracy, and overall accuracy compared with the traditional Unet, PSPNet, and DeepLabV3+ models by 0.28%, 8.64%, and 1.74% on mIou and 2.1%, 9.7%, and 2.34% on mPA, respectively, and shows the superiority for mono-wood species segmentation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pommerening, A. Evaluating structural indices by reversing forest structural analysis. For. Ecol. Manag. 2006, 224, 266–277. [Google Scholar] [CrossRef]
- Saarela, S.; Andersen, H.E.; Grafström, A.; Lappi, J.; Pippuri, I.; Rautiainen, M.; Hyyppä, J.; Rönkä, M.; Heikkinen, J.; Mäkinen, T. A new prediction-based variance estimator for two-stage model-assisted surveys of forest resources. Remote. Sens. Environ. 2017, 192, 1–11. [Google Scholar] [CrossRef]
- Mou, H. Monitoring of Forestland Dynamic Changes by Using Multi Source and High Resolution Satellite Remote Sensing Images. For. Resour. Manag. 2016, 4, 107. [Google Scholar]
- Wang, X. Study on Forest Individual-Tree Segmentation Method Based on Airborn LiDAR Data; Northeast Forestry University: Harbin, China, 2020. [Google Scholar]
- Hu, Z.; Shan, L.; Chen, X.; Zhang, L.; Liu, Z.; Wang, M.; Wu, Z.; Yang, X.; Li, J.; Zhao, Z. Individual Tree Segmentation of UAV-LiDAR Based on the Combination of CHM and DSM. Sci. Silvae Sin. 2024, 60, 14–24. [Google Scholar]
- Chen, S.; Liang, D.; Ying, B.; Zhang, X.; Wang, J.; Liu, H.; Liu, X.; Li, S.; Zhao, H.; Zhang, Y. Assessment of an improved individual tree detection method based on local-maximum algorithm from unmanned aerial vehicle RGB imagery in overlapping canopy mountain forests. Int. J. Remote. Sens. 2021, 42, 106–125. [Google Scholar]
- Jing, L.; Hu, B.; Noland, T.; Zhang, Y.; Liu, W.; Wang, F.; Li, J.; Zhao, X.; Yang, L.; Sun, Y. An individual tree crown delineation method based on multi-scale segmentation of imagery. ISPRS Photogramm. Remote. Sens. 2012, 70, 88–98. [Google Scholar]
- Hua, Z. Research on Individual Tree Segmentation and Structural Parameter Extraction Based on Laser Point Cloud Data; Nanjing Forestry University: Nanjing, China, 2023. [Google Scholar]
- Latifi, H.; Fassnacht, F.E.; Müller, J.; Schneider, M.; Kienast, F.; Koenig, H.; Meyer, M.; Fischer, R.; Leuschner, C.; Nussbaum, S. Forest inventories by LiDAR data: A comparison of single tree segmentation and metric-based methods for inventories of a heterogeneous temperate forest. Int. J. Appl. Earth Obs. Geoinf. 2015, 42, 162–174. [Google Scholar]
- Yan, W.; Guan, H.; Cao, L.; Zhang, Y.; Li, J.; Wang, S.; Liu, M.; Zhao, X.; Chen, Z.; Li, Y. A self-adaptive mean shift tree-segmentation method using UAV LiDAR data. Remote. Sens. 2020, 12, 515. [Google Scholar]
- Koch, B.; Heyder, U.; Weinacker, H. Detection of individual tree crowns in airborne lidar. Photogramm. Eng. Remote. Sens. 2006, 72, 357–363. [Google Scholar]
- Weinmann, M.; Weinmann, M.; Mallet, C.; Rutzinger, M.; Lague, D.; Mandelbrot, A.; Morsdorf, F.; Soudani, K.; Tress, M.; Ziegler, T. A classification-seg-mentati on framework for the detection of individual trees in dense M-MS point cloud data acquired in urban areas. Remote. Sens. 2017, 9, 277. [Google Scholar]
- Yuan, Y.; Shi, X.; Gao, J. Building extraction from remote sensing images with deep learning: A survey on vision techniques. Comput. Vis. Image Underst. 2024, 251, 104253. [Google Scholar]
- Taye, M.M. Understanding of Machine Learning with Deep Learning: Architectures, Workflow, Applications and Future Directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; Silva, F.S.; Oliveira, R.S.; Costa, A.L.; Souza, G.T.; Rodrigues, T.A.; Alves, M.C.; Pereira, R.F. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar]
- Ferreira, M.P.; De Almeida, D.R.A.; de Almeida Papa, D.; Silva, F.R.; Costa, L.M.; Santos, R.T.; Lima, E.M.; Souza, J.P.; Oliveira, J.A.; Almeida, C.S. Individual tree detection and species classification of Amazonian plams using UAV images and deep learning. For. Ecol. Manag. 2020, 457, 118397. [Google Scholar]
- Karantzalos, K.; Argialas, D. Improving edge detection and watershed segmentation with anisotropic. Int. J. Remote. Sens. 2006, 27, 5247–5434. [Google Scholar]
- Nezami, S.; Khoramshahi, E.; Nevalainen, O.; Lehtonen, A.; Mäki, M.; Palosuo, T.; Holopainen, M.; Mielikäinen, J.; Ruokolainen, L.; Männistö, M. Tree species classification of drone hyperspectral and RGB imagery with deep learning convolutional neural networks. Remote. Sens. 2020, 12, 1070. [Google Scholar]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.; Zasada, M.; Williams, M.; Clark, J.; Knight, L.; Wadsworth, T.; Campbell, B.; Brown, R. Individual tree-crown detection in RGB imagery using semi-supervised deep learning neural networks. Remote. Sens. 2019, 11, 1309. [Google Scholar]
- Li, Y.; Zheng, H.; Luo, G.; Yang, L.; Wang, W.; Gui, D. Extraction and Counting of Populus Euphratica Crown Using UAV Images Integrated with U-Net Method. Remote. Sens. Technol. Appl. 2019, 34, 939–949. [Google Scholar]
- Ferro, M.V.; Sørensen, C.G.; Catania, P. Comparison of different computer vision methods for vineyard canopy detection using UAV multispectral images. Comput. Electron. Agric. 2024, 225, 109277. [Google Scholar]
- Osco, L.P.; Nogueira, K.; Marques Ramos, A.P.; Silva, F.S.; Costa, A.L.; Souza, G.T.; Rodrigues, T.A.; Alves, M.C.; Pereira, R.F.; Oliveira, R.S. Semantic segmentation of citrus-orchard using deep neural networks and multispectral UAV-based imagery. Precis. Agric. 2021, 22, 1171–1188. [Google Scholar]
- Cui, B.G.; Wu, Y.N.; Zhong, Y.; Zhong, L.W.; Lu, Y. Hyperspectral image rolling guidance recursive filtering and classification. J. Remote. Sens. 2019, 23, 431–442. [Google Scholar]
- Yu, K. Research on UAV Remote Sensing Vegetation Recognition Method Based on Deep Learning; Anhui University: Hefei, China, 2022. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Dong, Y.; Zhang, Q. A survey of depth semantic feature extraction of high-resolution remote sensing images based on CNN. Remote. Sens. Technol. Appl. 2019, 34, 1–11. [Google Scholar]
- Wu, G.; Chen, Q.; Shibasaki, R.; Guo, Z.; Shao, X.; Xu, Y. High Precision Building Detection from Aerial Imagery Using a U-Net Like Convolutional Architecture. Acta Geod. Cartogr. Sin. 2018, 27, 864. [Google Scholar]
- Agnihotri, S.; Grabinski, J.; Keuper, M. Improving feature stability during upsampling–spectral artifacts and the importance of spatial context. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 24–30 August 2024; Springer Nature: Cham, Switzerland, 2024; pp. 357–376. [Google Scholar]
- Chen, C.; Peng, L.; Yang, J. UAV Small Object Detection Algorithm Based on Feature Enhancement and Context Fusion. Comput. Sci. 2024, 114. Available online: http://kns.cnki.net/kcms/detail/50.1075.TP.20241225.1945.022.html (accessed on 5 February 2025).
- Wang, Q.; Wu, B.; Zhu, P.; Zhang, X.; Li, J.; Liu, Y.; Li, Z.; Gao, L.; Yu, Z.; Yang, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wang, Y. Research on Apple Tree Segmentation and Crown Extraction based on UAV Visible Light Images; Northwest A&F University: Yangling, China, 2024. [Google Scholar]
- Ma, Y.K.; Liu, H.; Ling, C.X.; Zhang, J.; Li, L.; Wang, S.; Zhou, X.; Liu, G.; Li, X.; Zhang, Y. Object Detection of Individual Mangrove Based on Improved YOLOv5. Laser Optoelectron. Prog. 2022, 59, 436–446. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, Z.; Li, Y.; Yu, L.; Liu, Y.; Song, Y.; Li, W.; Xu, L. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H.; Gossow, M.; Li, X.; Wei, Z.; Li, J.; Huang, C. Encoder decoder with atrous separable convolution for semantic image segmentation. Eur. Conf. Comput. Vision. 2018, 11211, 833–851. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Name | Wavelength | Band Value Range |
|---|---|---|
| Blue | 450nm@35nm | 0–7350 |
| Green | 555nm@27nm | 0–10,420 |
| Red | 660nm@22nm | 0–8737 |
| NIR1 | 720nm@10nm | 0–6843 |
| NIR2 | 750nm@10nm | 0–12,454 |
| NIR3 | 840nm@30nm | 0–10,260 |
| Number | Tree Species | Labels | N Pixels | Picture Demonstration |
|---|---|---|---|---|
| 1 | Areca Trees | 252 | 6,304,700 |  |
| 2 | Jackfruit Trees | 294 | 5,348,891 |  |
| 3 | Banyan Trees | 170 | 3,456,893 |  |
| 4 | Rubber Trees | 239 | 6,611,559 |  |
| 5 | Coconut Trees | 45 | 1,081,013 |  |
| Category | Value |
|---|---|
| Training Set Images | 1509 |
| Images in the Verification Set | 168 |
| Test Set Images | 187 |
| Total Dataset Labels | 22,790 |
| Classes | IoU | PA | F1 | Recall | Precision |
|---|---|---|---|---|---|
| Areca Trees | 42.56% | 53.59% | 0.64 | 60.41% | 67.42% |
| Jackfruit Trees | 53.73% | 73.11% | 0.54 | 51.77% | 66.97% |
| Banyan Trees | 38.62% | 47.69% | 0.51 | 38.33% | 67.02% |
| Rubber Trees | 34.37% | 58.06% | 0.38 | 36.03% | 45.72% |
| Coconut Trees | 38.13% | 46.25% | 0.59 | 47.86% | 68.48% |
| Model | mIoU | mPA | Accuracy |
|---|---|---|---|
| U-net | 48.91% | 61.23% | 84.64% |
| DeepLab V3+ | 47.45% | 60.99% | 85.40% |
| PSPNet | 40.55% | 53.63% | 83.26% |
| ECA-Unet | 49.19% | 63.33% | 85.87% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Yang, B.; Wang, R.; Yang, D.; Li, J.; Wei, J. Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network. Drones 2025, 9, 237. https://doi.org/10.3390/drones9040237
Xu S, Yang B, Wang R, Yang D, Li J, Wei J. Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network. Drones. 2025; 9(4):237. https://doi.org/10.3390/drones9040237
Chicago/Turabian StyleXu, Shicheng, Banghui Yang, Ruirui Wang, Dabing Yang, Jiatian Li, and Jiahao Wei. 2025. "Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network" Drones 9, no. 4: 237. https://doi.org/10.3390/drones9040237
APA StyleXu, S., Yang, B., Wang, R., Yang, D., Li, J., & Wei, J. (2025). Single Tree Semantic Segmentation from UAV Images Based on Improved U-Net Network. Drones, 9(4), 237. https://doi.org/10.3390/drones9040237