
Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review



Abstract
1. Introduction
- 1.
- Compared to application-oriented reviews, this paper not only systematically categorizes and summarizes the key applications of LLMs and MLMs in the field of autonomous driving but also provides a comprehensive overview of the development history of LLMs, MLMs, and autonomous driving technologies. This study not only helps researchers gain a deeper understanding of the technological evolution of LLMs and autonomous driving from independent development to deep integration but also provides clear guidance on identifying key technological entry points and determining priority development directions.
- 2.
- Compared to background-oriented reviews, this paper provides a comprehensive analysis of the core technologies of LLMs and MLMs in autonomous driving systems, including prompt engineering, instruction fine tuning, knowledge distillation, and multimodal fusion, supported by detailed case studies. The results indicate that these technologies enhance model adaptability, system real-time performance, and perception efficiency. This integration of theory and practice facilitates a clearer understanding of technological applications, aids researchers in developing targeted technical solutions, and promotes the optimization and innovation of autonomous driving technology.
- 3.
- Compared to model-oriented reviews, this paper conducts an in-depth exploration of the key challenges faced by autonomous driving systems based on LLMs and MLMs, including hallucination issues, multimodal alignment challenges, training data limitations, and adversarial attacks. These analyses not only highlight the limitations of current technologies but also provide researchers with insights into potential solutions, offering essential theoretical support and practical references to advance the field.
2. The Current Development Status of Large Models
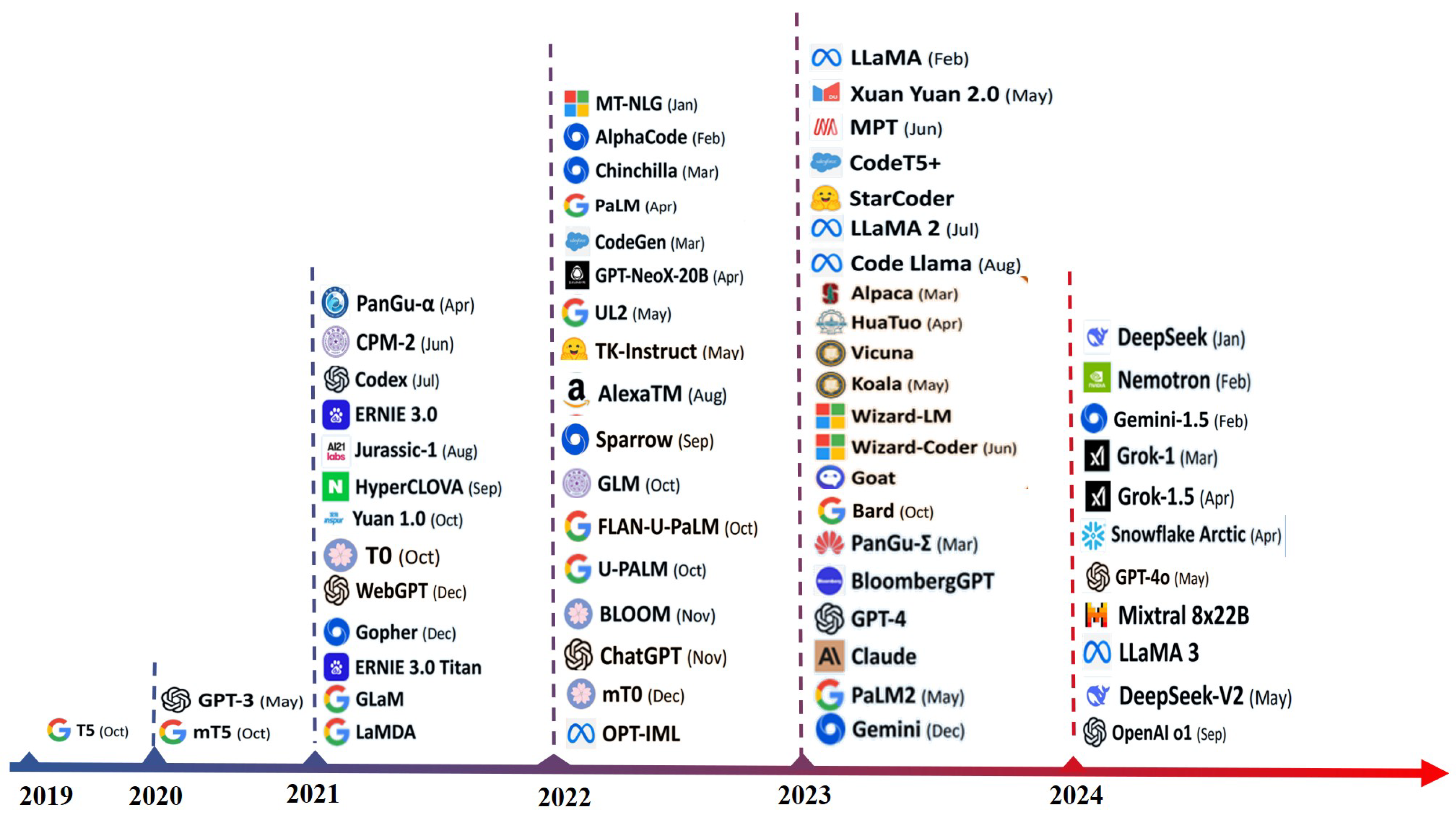
2.1. The Development of LLMs
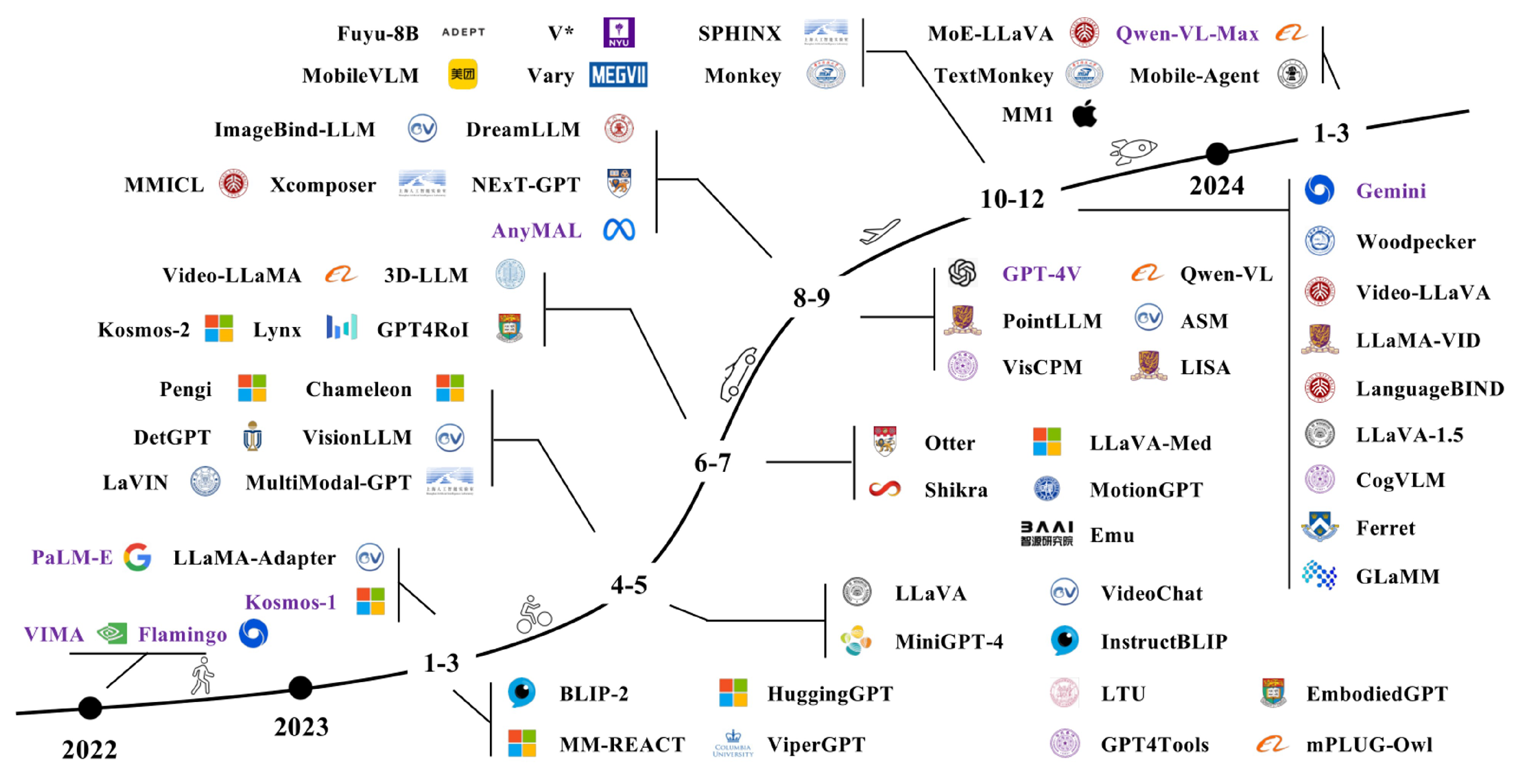
2.2. The Development of MLM
2.3. Challenges Faced by LLMs and MLMs
- 1.
- Hallucination Issues: Hallucination refers to the phenomenon where a LLM generates information that appears plausible but is inaccurate or fabricated [64]. This issue poses a substantial threat to high-stakes domains such as autonomous driving, where precision is critical. Addressing hallucination requires developing diverse methods, such as constructing hallucination detection benchmarks and introducing paradigms like reinforcement learning from human feedback (RLHF) or knowledge distillation.
- 2.
- Modal Alignment and Fusion Challenges: A substantial gap exists between the pixel-level features of vision and the semantic features of language. This disparity becomes even more pronounced with multimodal data (e.g., video, audio, and language), making alignment across modalities particularly challenging. The degree of modal alignment directly influences model performance, marking it as a critical area of ongoing research.
- 3.
- Security and Privacy Concerns: Input data, such as videos and audio, often contain sensitive information, raising significant privacy concerns. Ensuring data security while simultaneously improving model performance is a pressing issue that demands immediate and effective solutions.
- 4.
- Explainability issue: LLMs and VLMs, due to their high-dimensional complexity, exhibit black-box characteristics, affecting trust and transparency. Explainable AI (XAI) seeks to unveil their reasoning processes, enhancing explainability and reliability through methods like model-based design, post hoc explanations (e.g., SHAP, LIME), and causal inference. However, XAI faces challenges such as difficulty in explaining complex architectures, trade-offs between explainability and performance, and lack of standardized evaluation criteria. Future research should focus on cross-modal collaboration, improved explainability methods, and standardized evaluation frameworks to enhance AI transparency and usability.
3. Current Development Status and Challenges of Autonomous Driving
3.1. The Development of Autonomous Driving
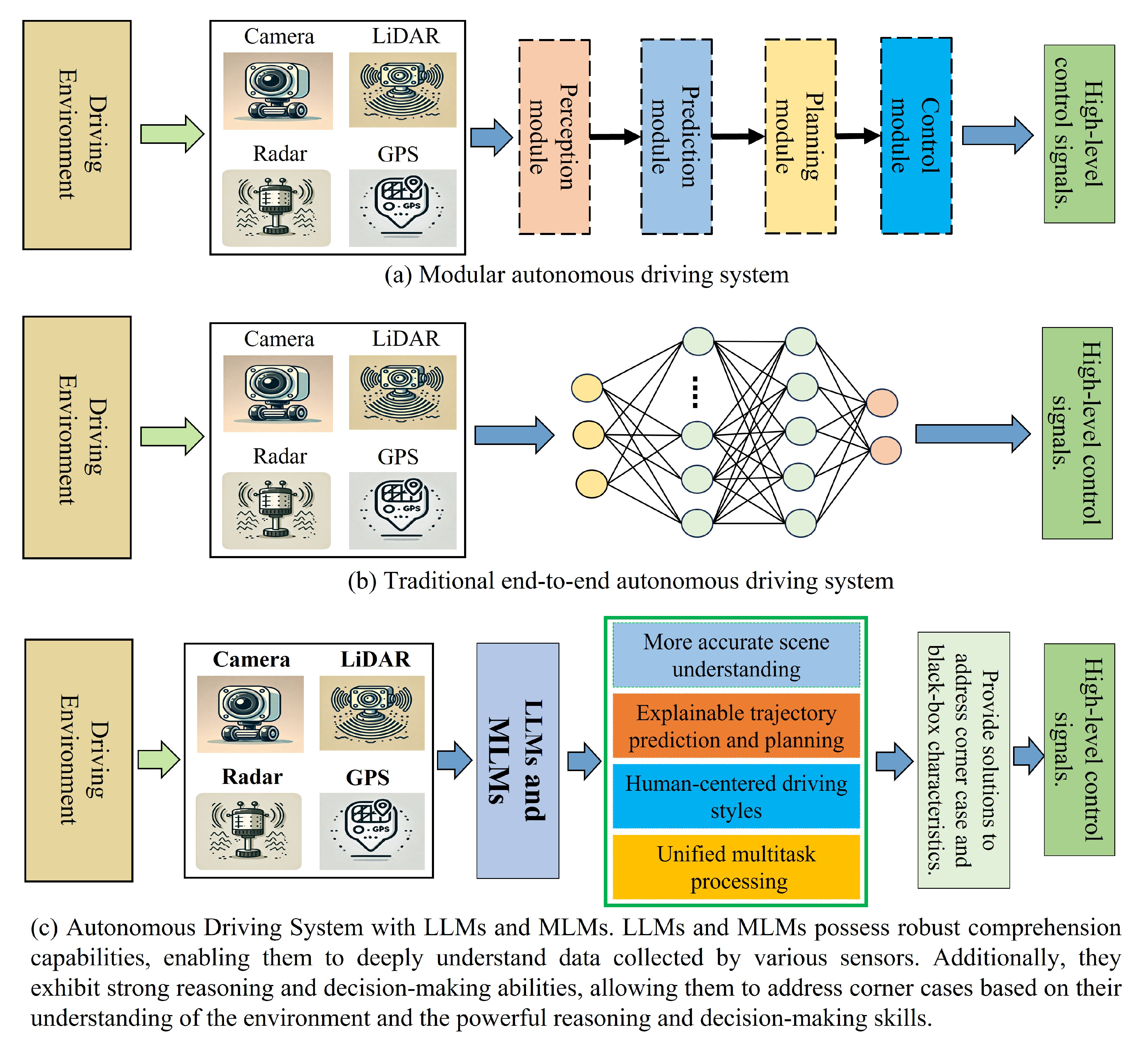
3.2. System Architectures for Autonomous Driving
3.2.1. Modularized Autonomous Driving Methods
- 1.
- Perception Module
- 2.
- Prediction Module
- 3.
- Planning Module
- 4.
- Control Module
3.2.2. End-to-End Autonomous Driving Methods
3.2.3. Current Limitations and Challenges
- 1.
- Limitations of Perception Systems
- 2.
- Insufficient Real-Time Decision Making
- 3.
- Limited Scale and Diversity of Publicly Available Annotated Datasets
- 4.
- Ethical and Legal Challenges
4. Applications of Large Models in the Field of Autonomous Driving
4.1. Large Models for Perception
4.2. Large Models for Prediction
4.3. Large Models for Decision Making and Planning
4.4. Large Models for Multitasking
4.5. Large Models for Scenario Generation
5. Key Technologies for Integrating LLMs and MLMs with Autonomous Driving Systems
5.1. Prompt Engineering
5.2. Instruction Fine-Tuning
5.3. Knowledge Distillation
5.4. Multimodal Data Fusion
6. Current Challenges
6.1. The Urgent Need for Carefully Annotated Datasets
- (1)
- KITTI [122], a foundational dataset in early autonomous driving research, contains 7481 training images and 80,256 3D bounding boxes, suitable for tasks like object detection and semantic segmentation.
- (2)
- nuScenes [123], focusing on urban driving scenarios, comprises data from multiple sensors and includes 1000 scene segments, supporting object detection and tracking tasks.
- (3)
- Waymo Open Dataset [124], consisting of 1150 training scenes and 750 validation scenes, facilitates object detection, tracking, and semantic segmentation.
- (4)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Size | Sensor Modalities | Task Types | |||
|---|---|---|---|---|---|---|---|
| Camera | LiDAR | Radar | Others | ||||
| KITTI [122] | 2012 | 15,000 images and point clouds. | Front-view | ✓ | ✗ | GPS/IMU | 2D/3D Object Detection, Semantic Segmentation, Object Tracking |
| nuScenes [123] | 2020 | 1000 scenes with 40,000 annotated frames. | 360° | ✓ | ✓ | GPS/IMU | 3D Object Detection, Object Tracking, Scene Understanding |
| Waymo Open Dataset [124] | 2020 | 1150 scenes with 200 frames per scene scene, 3D and 2D bounding boxes. | 360° | ✓ | ✗ | GPS/IMU | 2D/3D Object Detection, Semantic Segmentation, Object Tracking, Motion Planning |
| ApolloScape [125] | 2019 | 140 K images with per-pixel semantic mask, 89,430 annotated objects in total. | Front-view | ✓ | ✗ | GPS/IMU | 3D Object Detection, Semantic Segmentation, Motion Prediction, Lane Detection |
| CADC [128] | 2020 | 75 driving sequences, with 56,000 images, 7000 point clouds. | 360° | ✓ | ✗ | GPS/IMU | 3D Object Detection, Semantic Segmentation, Object Tracking |
| ONCE [129] | 2021 | 1 million LiDAR scenes, 7 million images with 2D/3D bounding boxes. | 360° | ✓ | ✗ | GPS/IMU | 2D/3D Object Detection, Semantic Segmentation, Object Tracking |
| Drama [130] | 2023 | 17,785 driving scenarios, 17,066 captions, 77,639 questions, 102,830 answers. | Front-view | ✗ | ✗ | IMU/CAN | visual question answering about video and object, Image Captioning |
| DriveLM [131] | 2023 | DriveLM-nuScenes: 4871 video frames, 450 K QA pairs DriveLM-CARLA: 64,285 frames, 1.5M QA pairs. | Based on nuScenes and CARLA. | Visual Question Answering, Perception Tasks, Behavior Prediction, Planning Tasks, Trajectory Prediction, Behavior Classification | |||
| NuPrompt [127] | 2023 | 35,367 textual description for 3D objects. | Based on nuScenes. | Multi-Object Tracking, 3D Object Localization, Trajectory Prediction, 3D Object Detection | |||
| nuScenes-QA [126] | 2023 | 34 K visual scenes and 460 K QA pairs. | Based on nuScenes. | Visual Question Answering, Scene Understanding, Spatio-temporal Reasoning, HD Map Assistance | |||
| NuInstruct [132] | 2023 | 91 K instruction-responsepairs in total. | Based on nuScenes. | Object Detection, Object Tracking, Scene Understanding, Driving Planning | |||
| Reason2Drive [133] | 2023 | 600 K video-text pairs. | Based on nuScenes, Waymo and ONCE. | Visual Question Answering, Multi-Object Tracking, Commonsense Reasoning, Object Detection | |||
6.2. The Alignment of Visual Information and Text in Autonomous Driving Scenarios
6.3. Detection and Mitigation of Hallucinations
6.4. Adversarial Attacks and Defense Strategies
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jo, K.; Kim, J.; Kim, D.; Jang, C.; Sunwoo, M. Development of autonomous car—Part I: Distributed system architecture and development process. IEEE Trans. Ind. Electron. 2014, 61, 7131–7140. [Google Scholar] [CrossRef]
- Li, Y.; Katsumata, K.; Javanmardi, E.; Tsukada, M. Large Language Models for Human-like Autonomous Driving: A Survey. arXiv 2024, arXiv:2407.19280. [Google Scholar]
- Chen, L.; Wu, P.; Chitta, K.; Jaeger, B.; Geiger, A.; Li, H. End-to-end autonomous driving: Challenges and frontiers. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10164–10183. [Google Scholar] [CrossRef] [PubMed]
- Parekh, D.; Poddar, N.; Rajpurkar, A.; Chahal, M.; Kumar, N.; Joshi, G.P.; Cho, W. A review on autonomous vehicles: Progress, methods and challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, W.; Deng, B.; Wang, Z.; Zhang, F.; Zheng, W.; Cao, W.; Nan, J.; Lian, Y.; Burke, A.F. Autonomous driving system: A comprehensive survey. Expert Syst. Appl. 2024, 242, 122836. [Google Scholar] [CrossRef]
- Elallid, B.B.; Benamar, N.; Hafid, A.S.; Rachidi, T.; Mrani, N. A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 7366–7390. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, L.; Zheng, H.; Chen, L.; Tolba, A.; Zhao, L.; Yu, K.; Feng, H. Evolution and Prospects of Foundation Models: From Large Language Models to Large Multimodal Models. Comput. Mater. Contin. 2024, 80, 1753–1808. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, Y.; Xie, E.; Zhao, Z.; Guo, Y.; Wong, K.Y.K.; Li, Z.; Zhao, H. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robot. Autom. Lett. 2024, 9, 8186–8193. [Google Scholar] [CrossRef]
- Choudhary, T.; Dewangan, V.; Chandhok, S.; Priyadarshan, S.; Jain, A.; Singh, A.K.; Srivastava, S.; Jatavallabhula, K.M.; Krishna, K.M. Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving. arXiv 2023, arXiv:2310.02251. [Google Scholar]
- Yang, S.; Liu, J.; Zhang, R.; Pan, M.; Guo, Z.; Li, X.; Chen, Z.; Gao, P.; Guo, Y.; Zhang, S. Lidar-llm: Exploring the potential of large language models for 3d lidar understanding. arXiv 2023, arXiv:2312.14074. [Google Scholar]
- Tang, T.; Wei, D.; Jia, Z.; Gao, T.; Cai, C.; Hou, C.; Jia, P.; Zhan, K.; Sun, H.; Fan, J.; et al. BEV-TSR: Text-Scene Retrieval in BEV Space for Autonomous Driving. arXiv 2024, arXiv:2401.01065. [Google Scholar]
- Wen, L.; Yang, X.; Fu, D.; Wang, X.; Cai, P.; Li, X.; Ma, T.; Li, Y.; Xu, L.; Shang, D.; et al. On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv 2023, arXiv:2311.05332. [Google Scholar]
- Tian, X.; Gu, J.; Li, B.; Liu, Y.; Wang, Y.; Zhao, Z.; Zhan, K.; Jia, P.; Lang, X.; Zhao, H. Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv 2024, arXiv:2402.12289. [Google Scholar]
- Renz, K.; Chen, L.; Marcu, A.M.; Hünermann, J.; Hanotte, B.; Karnsund, A.; Shotton, J.; Arani, E.; Sinavski, O. CarLLaVA: Vision language models for camera-only closed-loop driving. arXiv 2024, arXiv:2406.10165. [Google Scholar]
- Peng, M.; Guo, X.; Chen, X.; Zhu, M.; Chen, K.; Wang, X.; Wang, Y. LC-LLM: Explainable Lane-Change Intention and Trajectory Predictions with Large Language Models. arXiv 2024, arXiv:2403.18344. [Google Scholar]
- Lan, Z.; Liu, L.; Fan, B.; Lv, Y.; Ren, Y.; Cui, Z. Traj-llm: A new exploration for empowering trajectory prediction with pre-trained large language models. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar]
- Mao, J.; Qian, Y.; Ye, J.; Zhao, H.; Wang, Y. Gpt-driver: Learning to drive with gpt. arXiv 2023, arXiv:2310.01415. [Google Scholar]
- Wang, S.; Zhu, Y.; Li, Z.; Wang, Y.; Li, L.; He, Z. ChatGPT as your vehicle co-pilot: An initial attempt. IEEE Trans. Intell. Veh. 2023, 8, 4706–4721. [Google Scholar]
- Yang, Y.; Zhang, Q.; Li, C.; Marta, D.S.; Batool, N.; Folkesson, J. Human-centric autonomous systems with llms for user command reasoning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 988–994. [Google Scholar]
- Liao, H.; Shen, H.; Li, Z.; Wang, C.; Li, G.; Bie, Y.; Xu, C. Gpt-4 enhanced multimodal grounding for autonomous driving: Leveraging cross-modal attention with large language models. Commun. Transp. Res. 2024, 4, 100116. [Google Scholar]
- Ma, Y.; Cao, Y.; Sun, J.; Pavone, M.; Xiao, C. Dolphins: Multimodal language model for driving. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 403–420. [Google Scholar]
- Fourati, S.; Jaafar, W.; Baccar, N.; Alfattani, S. XLM for Autonomous Driving Systems: A Comprehensive Review. arXiv 2024, arXiv:2409.10484. [Google Scholar]
- Gao, H.; Wang, Z.; Li, Y.; Long, K.; Yang, M.; Shen, Y. A survey for foundation models in autonomous driving. arXiv 2024, arXiv:2402.01105. [Google Scholar]
- Yang, Z.; Jia, X.; Li, H.; Yan, J. Llm4drive: A survey of large language models for autonomous driving. arXiv 2023, arXiv:2312.00438. [Google Scholar]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.D.; et al. A survey on multimodal large language models for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 958–979. [Google Scholar]
- Zhou, X.; Liu, M.; Yurtsever, E.; Zagar, B.L.; Zimmer, W.; Cao, H.; Knoll, A.C. Vision language models in autonomous driving: A survey and outlook. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar]
- Zhu, Y.; Wang, S.; Zhong, W.; Shen, N.; Li, Y.; Wang, S.; Li, Z.; Wu, C.; He, Z.; Li, L. Will Large Language Models be a Panacea to Autonomous Driving? arXiv 2024, arXiv:2409.14165. [Google Scholar]
- Zhou, X.; Liu, M.; Zagar, B.L.; Yurtsever, E.; Knoll, A.C. Vision language models in autonomous driving and intelligent transportation systems. arXiv 2023, arXiv:2310.14414. [Google Scholar]
- Huang, Y.; Chen, Y.; Li, Z. Applications of large scale foundation models for autonomous driving. arXiv 2023, arXiv:2311.12144. [Google Scholar]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar]
- Liang, Z.; Xu, Y.; Hong, Y.; Shang, P.; Wang, Q.; Fu, Q.; Liu, K. A Survey of Multimodel Large Language Models. In Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering, Xi’ an, China, 26–28 January 2024; pp. 405–409. [Google Scholar]
- Huang, Y.; Chen, Y. Autonomous driving with deep learning: A survey of state-of-art technologies. arXiv 2020, arXiv:2006.06091. [Google Scholar]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Wang, Z. Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 902–909. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Bar-Hillel, Y. The present status of automatic translation of languages. Adv. Comput. 1960, 1, 91–163. [Google Scholar]
- Holt, A.W.; Turanski, W. Man-to-machine communication and automatic code translation. In Proceedings of the Western Joint IRE-AIEE-ACM Computer Conference, San Francisco, CA, USA, 3–5 May 1960; pp. 329–339. [Google Scholar]
- Arevalo, J.; Solorio, T.; Montes-y Gómez, M.; González, F.A. Gated multimodal units for information fusion. arXiv 2017, arXiv:1702.01992. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog. 2019, 1, 9. [Google Scholar]
- Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zhou, C.; Liu, P.; Xu, P.; Iyer, S.; Sun, J.; Mao, Y.; Ma, X.; Efrat, A.; Yu, P.; Yu, L.; et al. Lima: Less is more for alignment. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Wang, S.; Yu, Z.; Jiang, X.; Lan, S.; Shi, M.; Chang, N.; Kautz, J.; Li, Y.; Alvarez, J.M. OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning. arXiv 2024, arXiv:2405.01533. [Google Scholar]
- Chib, P.S.; Singh, P. LG-Traj: LLM Guided Pedestrian Trajectory Prediction. arXiv 2024, arXiv:2403.08032. [Google Scholar]
- Schumann, R.; Zhu, W.; Feng, W.; Fu, T.J.; Riezler, S.; Wang, W.Y. Velma: Verbalization embodiment of llm agents for vision and language navigation in street view. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 18924–18933. [Google Scholar]
- Sha, H.; Mu, Y.; Jiang, Y.; Chen, L.; Xu, C.; Luo, P.; Li, S.E.; Tomizuka, M.; Zhan, W.; Ding, M. Languagempc: Large language models as decision makers for autonomous driving. arXiv 2023, arXiv:2310.03026. [Google Scholar]
- Atakishiyev, S.; Salameh, M.; Goebel, R. Incorporating Explanations into Human-Machine Interfaces for Trust and Situation Awareness in Autonomous Vehicles. arXiv 2024, arXiv:2404.07383. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A survey on multimodal large language models. arXiv 2023, arXiv:2306.13549. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Chen, Z.; Wu, J.; Wang, W.; Su, W.; Chen, G.; Xing, S.; Zhong, M.; Zhang, Q.; Zhu, X.; Lu, L.; et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 24185–24198. [Google Scholar]
- Zhang, H.; Li, X.; Bing, L. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv 2023, arXiv:2306.02858. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Ding, X.; Han, J.; Xu, H.; Zhang, W.; Li, X. Hilm-d: Towards high-resolution understanding in multimodal large language models for autonomous driving. arXiv 2023, arXiv:2309.05186. [Google Scholar]
- McDonald, D.; Papadopoulos, R.; Benningfield, L. Reducing llm hallucination using knowledge distillation: A case study with mistral large and mmlu benchmark. Authorea Prepr. 2024. [Google Scholar] [CrossRef]
- Taeihagh, A.; Lim, H.S.M. Governing autonomous vehicles: Emerging responses for safety, liability, privacy, cybersecurity, and industry risks. Transp. Rev. 2019, 39, 103–128. [Google Scholar] [CrossRef]
- Khan, M.A.; Sayed, H.E.; Malik, S.; Zia, T.; Khan, J.; Alkaabi, N.; Ignatious, H. Level-5 autonomous driving—Are we there yet? a review of research literature. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Barabas, I.; Todoruţ, A.; Cordoş, N.; Molea, A. Current challenges in autonomous driving. Iop Conf. Ser. Mater. Sci. Eng. 2017, 252, 012096. [Google Scholar]
- Thrun, S. Toward robotic cars. Commun. ACM 2010, 53, 99–106. [Google Scholar]
- Zablocki, É.; Ben-Younes, H.; Pérez, P.; Cord, M. Explainability of deep vision-based autonomous driving systems: Review and challenges. Int. J. Comput. Vis. 2022, 130, 2425–2452. [Google Scholar]
- Bachute, M.R.; Subhedar, J.M. Autonomous driving architectures: Insights of machine learning and deep learning algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar]
- Wang, W.; Wang, L.; Zhang, C.; Liu, C.; Sun, L. Social interactions for autonomous driving: A review and perspectives. Found. Trends® Robot. 2022, 10, 198–376. [Google Scholar]
- Han, Y.; Zhang, H.; Li, H.; Jin, Y.; Lang, C.; Li, Y. Collaborative perception in autonomous driving: Methods, datasets, and challenges. IEEE Intell. Transp. Syst. Mag. 2023, 15, 131–151. [Google Scholar]
- Zhou, Y.; Liu, L.; Zhao, H.; López-Benítez, M.; Yu, L.; Yue, Y. Towards deep radar perception for autonomous driving: Datasets, methods, and challenges. Sensors 2022, 22, 4208. [Google Scholar] [CrossRef]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep learning-based vehicle behavior prediction for autonomous driving applications: A review. IEEE Trans. Intell. Transp. Syst. 2020, 23, 33–47. [Google Scholar]
- Liu, J.; Mao, X.; Fang, Y.; Zhu, D.; Meng, M.Q.H. A survey on deep-learning approaches for vehicle trajectory prediction in autonomous driving. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 978–985. [Google Scholar]
- Zheng, X.; Wu, L.; Yan, Z.; Tang, Y.; Zhao, H.; Zhong, C.; Chen, B.; Gong, J. Large Language Models Powered Context-aware Motion Prediction in Autonomous Driving. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 980–985. [Google Scholar]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar]
- Bacha, A.; Bauman, C.; Faruque, R.; Fleming, M.; Terwelp, C.; Reinholtz, C.; Hong, D.; Wicks, A.; Alberi, T.; Anderson, D.; et al. Odin: Team victortango’s entry in the darpa urban challenge. J. Field Robot. 2008, 25, 467–492. [Google Scholar]
- Codevilla, F.; Müller, M.; López, A.; Koltun, V.; Dosovitskiy, A. End-to-end driving via conditional imitation learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4693–4700. [Google Scholar]
- Rhinehart, N.; McAllister, R.; Kitani, K.; Levine, S. Precog: Prediction conditioned on goals in visual multi-agent settings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 2821–2830. [Google Scholar]
- Wang, Y.; Mao, Q.; Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Li, H.; Zhang, Y. Multi-modal 3d object detection in autonomous driving: A survey. Int. J. Comput. Vis. 2023, 131, 2122–2152. [Google Scholar]
- Chib, P.S.; Singh, P. Recent advancements in end-to-end autonomous driving using deep learning: A survey. IEEE Trans. Intell. Veh. 2023, 9, 103–118. [Google Scholar] [CrossRef]
- Coelho, D.; Oliveira, M. A review of end-to-end autonomous driving in urban environments. IEEE Access 2022, 10, 75296–75311. [Google Scholar]
- Wang, T.H.; Maalouf, A.; Xiao, W.; Ban, Y.; Amini, A.; Rosman, G.; Karaman, S.; Rus, D. Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 6687–6694. [Google Scholar]
- Jia, X.; Wu, P.; Chen, L.; Xie, J.; He, C.; Yan, J.; Li, H. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21983–21994. [Google Scholar]
- Sharan, S.; Pittaluga, F.; Chandraker, M. Llm-assist: Enhancing closed-loop planning with language-based reasoning. arXiv 2023, arXiv:2401.00125. [Google Scholar]
- Wen, L.; Fu, D.; Li, X.; Cai, X.; Ma, T.; Cai, P.; Dou, M.; Shi, B.; He, L.; Qiao, Y. Dilu: A knowledge-driven approach to autonomous driving with large language models. arXiv 2023, arXiv:2309.16292. [Google Scholar]
- Liu, J.; Hang, P.; Qi, X.; Wang, J.; Sun, J. Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 5154–5161. [Google Scholar]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Wang, Z. Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles. IEEE Intell. Transp. Syst. Mag. 2024, 16, 81–94. [Google Scholar]
- Tanahashi, K.; Inoue, Y.; Yamaguchi, Y.; Yaginuma, H.; Shiotsuka, D.; Shimatani, H.; Iwamasa, K.; Inoue, Y.; Yamaguchi, T.; Igari, K.; et al. Evaluation of large language models for decision making in autonomous driving. arXiv 2023, arXiv:2312.06351. [Google Scholar]
- Hwang, J.J.; Xu, R.; Lin, H.; Hung, W.C.; Ji, J.; Choi, K.; Huang, D.; He, T.; Covington, P.; Sapp, B.; et al. Emma: End-to-end multimodal model for autonomous driving. arXiv 2024, arXiv:2410.23262. [Google Scholar]
- Nouri, A.; Cabrero-Daniel, B.; Törner, F.; Sivencrona, H.; Berger, C. Engineering safety requirements for autonomous driving with large language models. In Proceedings of the 2024 IEEE 32nd International Requirements Engineering Conference (RE), Reykjavik, Iceland, 24–28 June 2024; pp. 218–228. [Google Scholar]
- Shao, H.; Hu, Y.; Wang, L.; Song, G.; Waslander, S.L.; Liu, Y.; Li, H. Lmdrive: Closed-loop end-to-end driving with large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 May 2024; pp. 15120–15130. [Google Scholar]
- Tang, Y.; Da Costa, A.A.B.; Zhang, X.; Patrick, I.; Khastgir, S.; Jennings, P. Domain knowledge distillation from large language model: An empirical study in the autonomous driving domain. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 3893–3900. [Google Scholar]
- Deng, Y.; Yao, J.; Tu, Z.; Zheng, X.; Zhang, M.; Zhang, T. Target: Automated scenario generation from traffic rules for testing autonomous vehicles. arXiv 2023, arXiv:2305.06018. [Google Scholar]
- Wang, S.; Sheng, Z.; Xu, J.; Chen, T.; Zhu, J.; Zhang, S.; Yao, Y.; Ma, X. ADEPT: A testing platform for simulated autonomous driving. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; pp. 1–4. [Google Scholar]
- Lu, Q.; Wang, X.; Jiang, Y.; Zhao, G.; Ma, M.; Feng, S. Multimodal large language model driven scenario testing for autonomous vehicles. arXiv 2024, arXiv:2409.06450. [Google Scholar]
- Tan, S.; Ivanovic, B.; Weng, X.; Pavone, M.; Kraehenbuehl, P. Language conditioned traffic generation. arXiv 2023, arXiv:2307.07947. [Google Scholar]
- Wang, P.; Wei, X.; Hu, F.; Han, W. Transgpt: Multi-modal generative pre-trained transformer for transportation. arXiv 2024, arXiv:2402.07233. [Google Scholar]
- Fu, D.; Li, X.; Wen, L.; Dou, M.; Cai, P.; Shi, B.; Qiao, Y. Drive like a human: Rethinking autonomous driving with large language models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 910–919. [Google Scholar]
- Wang, P.; Zhu, M.; Zheng, X.; Lu, H.; Zhong, H.; Chen, X.; Shen, S.; Wang, X.; Wang, Y.; Wang, F.Y. Bevgpt: Generative pre-trained foundation model for autonomous driving prediction, decision-making, and planning. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar]
- Guan, Y.; Liao, H.; Li, Z.; Hu, J.; Yuan, R.; Li, Y.; Zhang, G.; Xu, C. World models for autonomous driving: An initial survey. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar]
- Zhang, J.; Li, J. Testing and verification of neural-network-based safety-critical control software: A systematic literature review. Inf. Softw. Technol. 2020, 123, 106296. [Google Scholar]
- Tahir, Z.; Alexander, R. Coverage based testing for V&V and safety assurance of self-driving autonomous vehicles: A systematic literature review. In Proceedings of the 2020 IEEE International Conference On Artificial Intelligence Testing (AITest), Oxford, UK, 3–6 August 2020; pp. 23–30. [Google Scholar]
- Feng, D.; Harakeh, A.; Waslander, S.L.; Dietmayer, K. A review and comparative study on probabilistic object detection in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar]
- Singh, S.; Saini, B.S. Autonomous cars: Recent developments, challenges, and possible solutions. Iop Conf. Ser. Mater. Sci. Eng. 2021, 1022, 012028. [Google Scholar]
- Cantini, R.; Orsino, A.; Talia, D. Xai-driven knowledge distillation of large language models for efficient deployment on low-resource devices. J. Big Data 2024, 11, 63. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Ren, M.; Cao, B.; Lin, H.; Liu, C.; Han, X.; Zeng, K.; Wan, G.; Cai, X.; Sun, L. Learning or self-aligning? rethinking instruction fine-tuning. arXiv 2024, arXiv:2402.18243. [Google Scholar]
- Zhang, X.; Li, Z.; Gong, Y.; Jin, D.; Li, J.; Wang, L.; Zhu, Y.; Liu, H. Openmpd: An open multimodal perception dataset for autonomous driving. IEEE Trans. Veh. Technol. 2022, 71, 2437–2447. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Xu, X.; Li, M.; Tao, C.; Shen, T.; Cheng, R.; Li, J.; Xu, C.; Tao, D.; Zhou, T. A survey on knowledge distillation of large language models. arXiv 2024, arXiv:2402.13116. [Google Scholar]
- Zheng, H.; Cao, D.; Xu, J.; Ai, R.; Gu, W.; Yang, Y.; Liang, Y. Distilling Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection. arXiv 2024, arXiv:2401.01918. [Google Scholar]
- Liu, J.; Xu, C.; Hang, P.; Sun, J.; Ding, M.; Zhan, W.; Tomizuka, M. Language-Driven Policy Distillation for Cooperative Driving in Multi-Agent Reinforcement Learning. arXiv 2024, arXiv:2410.24152. [Google Scholar]
- Liu, C.; Kang, Y.; Zhao, F.; Kuang, K.; Jiang, Z.; Sun, C.; Wu, F. Evolving Knowledge Distillation with Large Language Models and Active Learning. arXiv 2024, arXiv:2403.06414. [Google Scholar]
- Alaba, S.Y.; Gurbuz, A.C.; Ball, J.E. Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection. World Electr. Veh. J. 2024, 15, 20. [Google Scholar] [CrossRef]
- Duan, Y.; Zhang, Q.; Xu, R. Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs. arXiv 2024, arXiv:2404.04869. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Ma, Z.; Sun, Q.; Matsumaru, T. Bidirectional Planning for Autonomous Driving Framework with Large Language Model. Sensors 2024, 24, 6723. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Gao, C.; Wang, Z.; Yang, L.; Wang, X.; Mu, B.; Liu, S. Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection. arXiv 2024, arXiv:2403.07372. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Mei, J.; Zhu, A.Z.; Yan, X.; Yan, H.; Qiao, S.; Chen, L.C.; Kretzschmar, H. Waymo open dataset: Panoramic video panoptic segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 53–72. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Qian, T.; Chen, J.; Zhuo, L.; Jiao, Y.; Jiang, Y.G. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4542–4550. [Google Scholar]
- Wu, D.; Han, W.; Wang, T.; Liu, Y.; Zhang, X.; Shen, J. Language prompt for autonomous driving. arXiv 2023, arXiv:2309.04379. [Google Scholar]
- Pitropov, M.; Garcia, D.E.; Rebello, J.; Smart, M.; Wang, C.; Czarnecki, K.; Waslander, S. Canadian adverse driving conditions dataset. Int. J. Robot. Res. 2021, 40, 681–690. [Google Scholar] [CrossRef]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One million scenes for autonomous driving: Once dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]
- Malla, S.; Choi, C.; Dwivedi, I.; Choi, J.H.; Li, J. Drama: Joint risk localization and captioning in driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 1043–1052. [Google Scholar]
- Sima, C.; Renz, K.; Chitta, K.; Chen, L.; Zhang, H.; Xie, C.; Beißwenger, J.; Luo, P.; Geiger, A.; Li, H. Drivelm: Driving with graph visual question answering. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 256–274. [Google Scholar]
- Ding, X.; Han, J.; Xu, H.; Liang, X.; Zhang, W.; Li, X. Holistic Autonomous Driving Understanding by Bird’s-Eye-View Injected Multi-Modal Large Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 13668–13677. [Google Scholar]
- Nie, M.; Peng, R.; Wang, C.; Cai, X.; Han, J.; Xu, H.; Zhang, L. Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 292–308. [Google Scholar]
- Chen, L.; Sinavski, O.; Hünermann, J.; Karnsund, A.; Willmott, A.J.; Birch, D.; Maund, D.; Shotton, J. Driving with llms: Fusing object-level vector modality for explainable autonomous driving. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 14093–14100. [Google Scholar]
- Tian, R.; Li, B.; Weng, X.; Chen, Y.; Schmerling, E.; Wang, Y.; Ivanovic, B.; Pavone, M. Tokenize the world into object-level knowledge to address long-tail events in autonomous driving. arXiv 2024, arXiv:2407.00959. [Google Scholar]
- Ma, Y.; Yaman, B.; Ye, X.; Tao, F.; Mallik, A.; Wang, Z.; Ren, L. MTA: Multimodal Task Alignment for BEV Perception and Captioning. arXiv 2024, arXiv:2411.10639. [Google Scholar]
- Liu, Y.; Ding, P.; Huang, S.; Zhang, M.; Zhao, H.; Wang, D. PiTe: Pixel-Temporal Alignment for Large Video-Language Model. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 160–176. [Google Scholar]
- Gunjal, A.; Yin, J.; Bas, E. Detecting and preventing hallucinations in large vision language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 18135–18143. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, C.; Ren, S.; Yin, X.C. Unsupervised multi-view pedestrian detection. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 1034–1042. [Google Scholar]
- Dona, M.A.M.; Cabrero-Daniel, B.; Yu, Y.; Berger, C. Evaluating and Enhancing Trustworthiness of LLMs in Perception Tasks. arXiv 2024, arXiv:2408.01433. [Google Scholar]
- Wu, X.; Guan, T.; Li, D.; Huang, S.; Liu, X.; Wang, X.; Xian, R.; Shrivastava, A.; Huang, F.; Boyd-Graber, J.L.; et al. AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models. arXiv 2024, arXiv:2406.10900. [Google Scholar]
- Liang, Y.; Song, Z.; Wang, H.; Zhang, J. Learning to trust your feelings: Leveraging self-awareness in llms for hallucination mitigation. arXiv 2024, arXiv:2401.15449. [Google Scholar]
- Jiang, C.; Jia, H.; Dong, M.; Ye, W.; Xu, H.; Yan, M.; Zhang, J.; Zhang, S. Hal-eval: A universal and fine-grained hallucination evaluation framework for large vision language models. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 525–534. [Google Scholar]
- Manakul, P.; Liusie, A.; Gales, M.J. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv 2023, arXiv:2303.08896. [Google Scholar]
- Zhang, T.; Wang, L.; Zhang, X.; Zhang, Y.; Jia, B.; Liang, S.; Hu, S.; Fu, Q.; Liu, A.; Liu, X. Visual Adversarial Attack on Vision-Language Models for Autonomous Driving. arXiv 2024, arXiv:2411.18275. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Liu, D.; Yang, M.; Qu, X.; Zhou, P.; Cheng, Y.; Hu, W. A survey of attacks on large vision-language models: Resources, advances, and future trends. arXiv 2024, arXiv:2407.07403. [Google Scholar]
- Bhagwatkar, R.; Nayak, S.; Bashivan, P.; Rish, I. Improving Adversarial Robustness in Vision-Language Models with Architecture and Prompt Design. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 17003–17020. [Google Scholar]
- Song, R.; Ozmen, M.O.; Kim, H.; Bianchi, A.; Celik, Z.B. Enhancing llm-based autonomous driving agents to mitigate perception attacks. arXiv 2024, arXiv:2409.14488. [Google Scholar]
- Yang, B.; Ji, X.; Jin, Z.; Cheng, Y.; Xu, W. Exploring Adversarial Robustness of LiDAR-Camera Fusion Model in Autonomous Driving. In Proceedings of the 2023 IEEE 7th Conference on Energy Internet and Energy System Integration (EI2), Hangzhou, China, 15–18 December 2023; pp. 3634–3639. [Google Scholar]
- Zhang, T.; Wang, L.; Kang, J.; Zhang, X.; Liang, S.; Chen, Y.; Liu, A.; Liu, X. Module-wise Adaptive Adversarial Training for End-to-end Autonomous Driving. arXiv 2024, arXiv:2409.07321. [Google Scholar]
- Sadat, A.; Casas, S.; Ren, M.; Wu, X.; Dhawan, P.; Urtasun, R. Perceive, predict, and plan: Safe motion planning through interpretable semantic representations. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 414–430. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3569–3577. [Google Scholar]
- Liang, M.; Yang, B.; Zeng, W.; Chen, Y.; Hu, R.; Casas, S.; Urtasun, R. Pnpnet: End-to-end perception and prediction with tracking in the loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11553–11562. [Google Scholar]
- Mądry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. Statistics 2017, arXiv:1706.06083. [Google Scholar]
- Liu, A.; Liu, X.; Yu, H.; Zhang, C.; Liu, Q.; Tao, D. Training robust deep neural networks via adversarial noise propagation. IEEE Trans. Image Process. 2021, 30, 5769–5781. [Google Scholar]
- Li, X.; Liu, J.; Ma, L.; Fan, X.; Liu, R. Advmono3d: Advanced monocular 3d object detection with depth-aware robust adversarial training. arXiv 2023, arXiv:2309.01106. [Google Scholar]
- Zhang, Y.; Hou, J.; Yuan, Y. A comprehensive study of the robustness for lidar-based 3d object detectors against adversarial attacks. Int. J. Comput. Vis. 2024, 132, 1592–1624. [Google Scholar]
- Cao, Y.; Xiao, C.; Anandkumar, A.; Xu, D.; Pavone, M. Advdo: Realistic adversarial attacks for trajectory prediction. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 36–52. [Google Scholar]
- Zhang, Q.; Hu, S.; Sun, J.; Chen, Q.A.; Mao, Z.M. On adversarial robustness of trajectory prediction for autonomous vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15159–15168. [Google Scholar]
- Zhang, T.; Wang, L.; Li, H.; Xiao, Y.; Liang, S.; Liu, A.; Liu, X.; Tao, D. Lanevil: Benchmarking the robustness of lane detection to environmental illusions. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 5403–5412. [Google Scholar]
- Zhang, X.; Liu, A.; Zhang, T.; Liang, S.; Liu, X. Towards robust physical-world backdoor attacks on lane detection. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 5131–5140. [Google Scholar]


| Models | Year | Backbones | Tasks | Descriptions |
|---|---|---|---|---|
| LiDAR-LLM [10] | 2023 | LLaMA2-7B | Perception | The integration of LLM enables the model to comprehend and reason about 3D scenes, while also generating rational plans and explanations. |
| Talk2BEV [9] | 2023 | Flan5XXL and Vicuna-13b | Perception | The model utilizes MLM to generate textual descriptions for each object in the BEV map, creating a semantically enhanced BEV representation, which is then input into the LLM. Through prompt engineering, this enables understanding of complex scenes. |
| BEV-TSR [11] | 2024 | LIama and GPT-3 | Perception | The semantically enhanced BEV map, along with prompts constructed from a knowledge graph, is fed into the LLM to enhance the model’s understanding of complex scenes. |
| OmniDrive [46] | 2024 | LLaVA v1.5 | Perception | Compress multi-view high-resolution video features into a 3D representation, and then input it into an LLM for 3D perception, reasoning, and planning. |
| DRIVEVLM [13] | 2024 | Qwen-VL | Perception | DriveVLM directly leverages large multimodal models to analyze images in driving scenarios, providing outputs such as scene descriptions, scene analyses, and planning results. DriveVLM-Dual combines traditional 3D perception with MLM to compensate for the spatial reasoning and real-time inference limitations of MLM. |
| GPT4V-AD [12] | 2023 | GPT-4V | Perception | The powerful image understanding capabilities of GPT-4V are applied to autonomous driving perception systems, aiming to evaluate its comprehension and reasoning abilities in driving scenarios, as well as its capacity to simulate driver behavior. |
| CarLLaVA [14] | 2024 | LLaVA and LLaMA | Perception | The model optimizes longitudinal and lateral control performance in autonomous driving systems by integrating high-resolution visual encoding with a semi-disentangled output representation, thereby enhancing both scene understanding and control capabilities. |
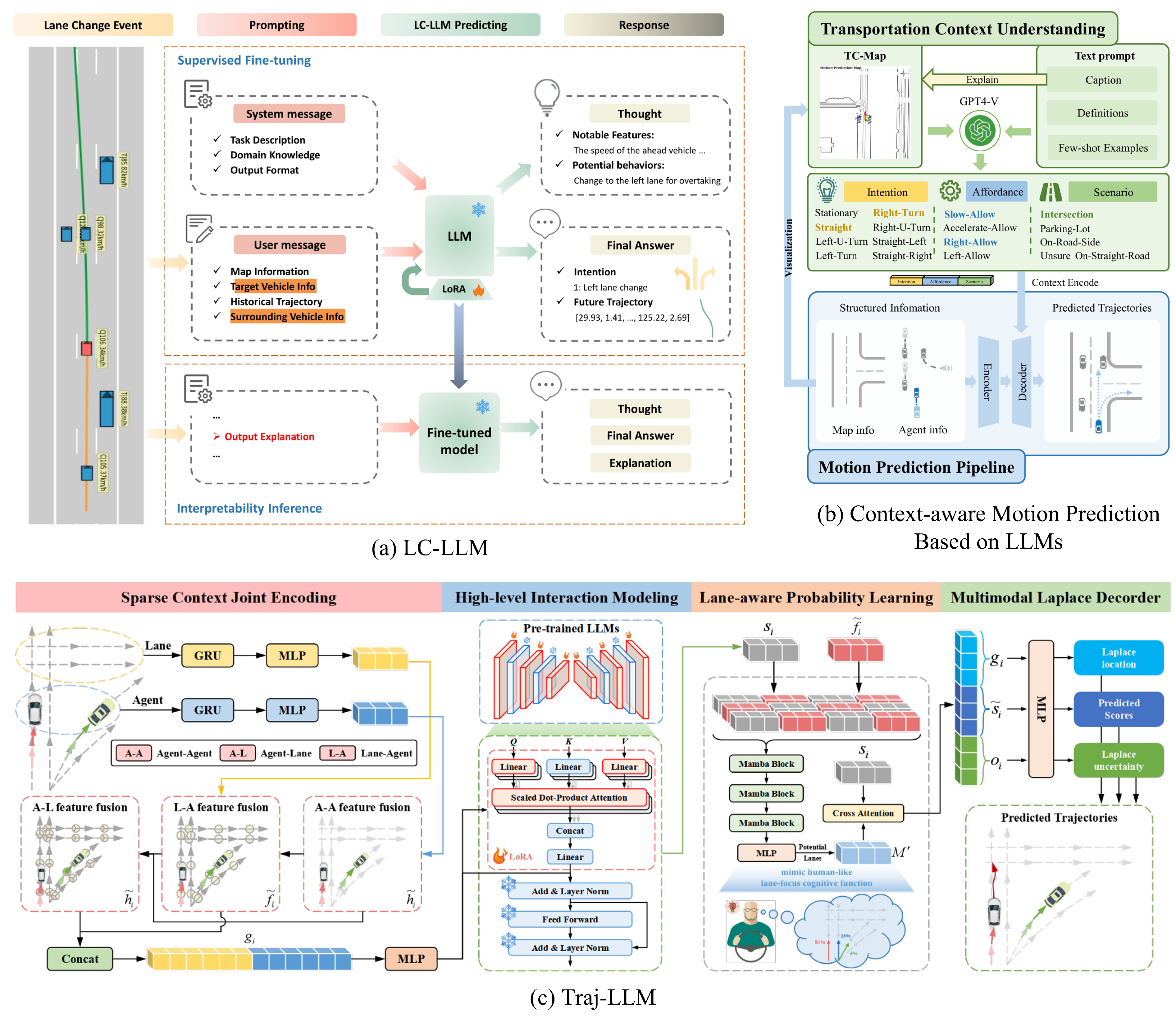
| LC-LLM [15] | 2024 | Llama-2-13b-chat | Prediction | Driving scenes are transformed into natural language prompts and input into LLMs for intention prediction and trajectory forecasting. By incorporating chain-of-thought reasoning, the interpretability of the predictions is further enhanced. |
| LLM-PCMP [76] | 2024 | GPT-4V | Prediction | Structured traffic scene information is transformed into visual prompts and combined with textual prompts, which are then input into GPT-4V. The model outputs understanding of the driving scene, which is utilized to enhance traditional motion prediction. |
| LG-Traj [47] | 2024 | Not clearly | Prediction | LG-Traj leverages LLMs to extract motion cues from historical trajectories, facilitating the analysis of pedestrian movement patterns (e.g. linear motion, curvilinear motion, or stationary behavior). |
| Traj-LLM [16] | 2024 | GPT-2 | Perception | Traj-LLM first transforms agent and scene features into a format understandable by LLMs through sparse context joint encoding and leverages parameter-efficient fine-tuning (PEFT) techniques to train the model for trajectory prediction tasks. |
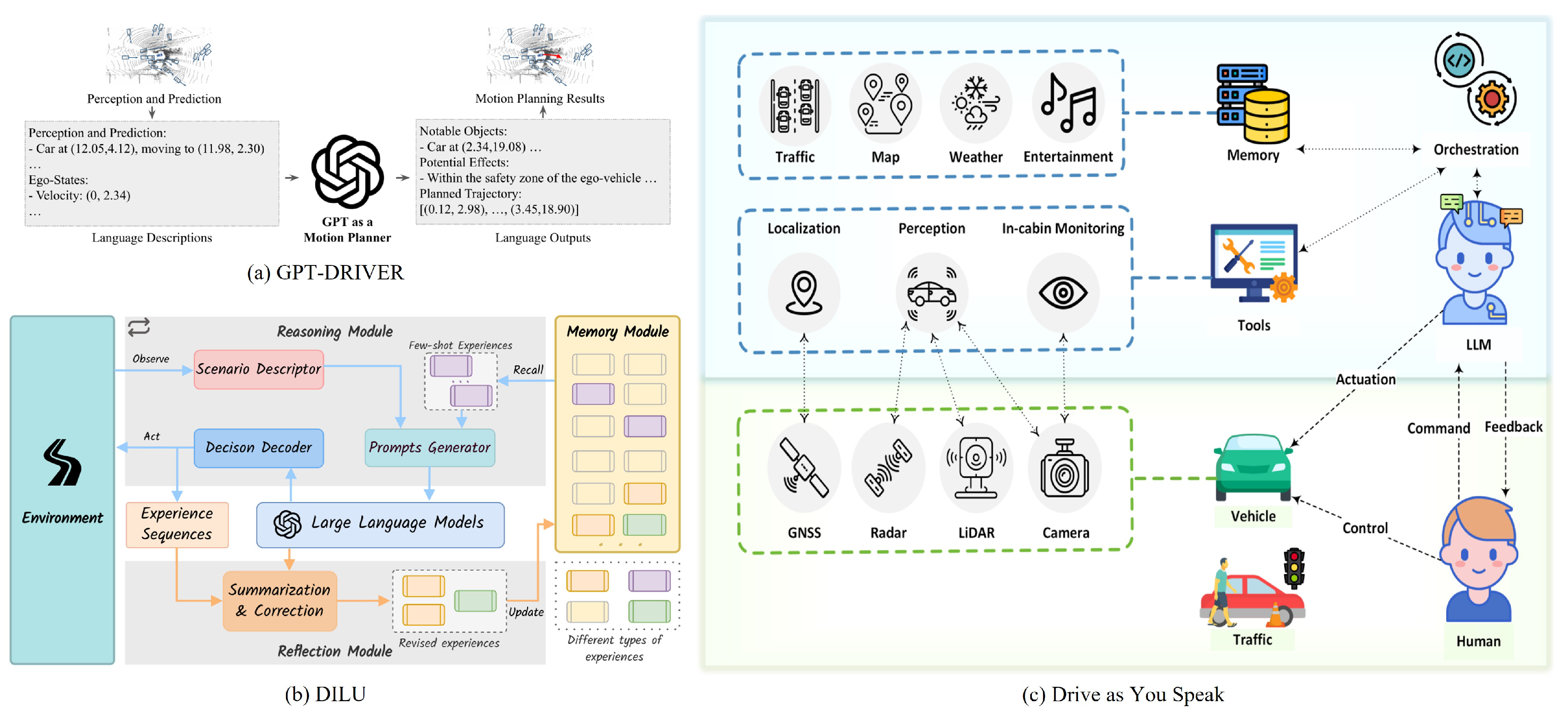
| GPT-Driver [17] | 2023 | GPT-3.5 | Decision Making and Planning | The vehicle’s self-information, perception results, and prediction information are converted into linguistic prompts to guide GPT-3.5 in generating trajectory predictions based on natural language descriptions. |
| LLM-ASSIST [87] | 2023 | GPT-3 and GPT-4 | Decision Making and Planning | The model leverages LLMs to address the limitations of rule-based planners by generating safe trajectories or providing optimized parameters in scenarios where the proposals from the planners fail to meet safety thresholds. |
| VELMA [48] | 2023 | GPT-3 and GPT-4 | Decision Making and Planning | VELMA leverages the contextual learning capabilities of LLMs to interpret navigation instructions and associate them with identified landmarks (e.g., cafes or parks), thereby enabling the system to make informed and rational decisions. |
| DaYS [33] | 2023 | GPT-4 | Decision Making and Planning | The vehicle’s state and perception data, along with the driver’s natural language commands, are input into a large language model (LLM) to generate real-time planning decisions. |
| DiLu [88] | 2024 | GPT-4 and GPT-3.5 | Decision Making and Planning | In addition to utilizing the LLM as the core decision-making tool, the model incorporates a reflection module and a memory module, which are, respectively, used for evaluating and improving decisions and storing experiences. |
| MTD-GPT [89] | 2023 | GPT-2 | Decision Making and Planning | MTD-GPT leverages the sequence modeling capabilities of GPT to represent each driving task (e.g., left turn, straight, right turn) as sequential data. By predicting future actions based on historical state sequences, it aims to address the multitask decision-making challenges faced by autonomous vehicles at unsignalized intersections. |
| RRaR [90] | 2023 | GPT-4 | Decision Making and Planning | An LLM is employed as the decision-making core, taking perception data and user instructions as inputs and incorporating chain-of-thought reasoning to generate interpretable dynamic driving plans. |
| EoLLM [91] | 2023 | GPT-4 and LLaMA | Decision Making and Planning | Simulation experiments are conducted to evaluate the spatial awareness and decision-making capabilities of the LLM, as well as its ability to comply with traffic regulations. |
| DOLPHINS [21] | 2023 | OpenFlamingo | Multitasking | The visual encoder in a vision–language model is utilized to process video information from driving scenarios, while the text encoder handles textual instructions and manages the interaction between visual and textual features. Through training, the model enables multiple tasks, such as interpretable path planning and control signal generation. |
| EMMA [92] | 2024 | Gemini | Multitasking | Non-sensor data are converted into natural language and combined with data from cameras as input to the Gemini model. Different branches and loss functions are designed for various tasks, enabling the model to handle 3D object detection, road map estimation, and motion planning tasks through training. |
| TrafficGPT [19] | 2024 | GPT-3.5 Turbo | Multitasking | The model extracts information from multimodal traffic data and leverages an LLM to decompose complex user instructions into multiple subtasks, mapping them to specific traffic foundation models (TFMs). The system dynamically allocates the required TFMs as needed, thereby avoiding redundant calls and resource conflicts. |
| ESR [93] | 2024 | GPT-4 | Multitasking | The model decomposes the hazard analysis and risk assessment (HARA) process into multiple subtasks, including scene description, hazard event definition, and safety goal generation. Each subtask leverages specific prompt designs to optimize the output of the LLM. |
| LMDrive [94] | 2024 | LLaMA | Multitasking | LMDrive is a closed-loop, end-to-end autonomous driving framework. It continuously processes vehicle states, sensor data, and environmental information, leveraging a large language model (LLM) for real-time interpretation and prediction of control signals to execute corresponding actions. |
| DriveGPT4 [8] | 2024 | LLaMA2 | Multitasking | Video and textual data, after being processed, are input into the LLM, which interprets dynamic scenes based on the input and performs behavior reasoning and control signal prediction. |
| DKD [95] | 2023 | GPT-3.5 | Scenarios generation | The model is the first to utilize an LLM for automating the construction of driving scene ontologies. Through interactions with ChatGPT, it facilitates the definition of concepts, attributes, and relationships in the autonomous driving domain, thereby enabling ontology construction. |
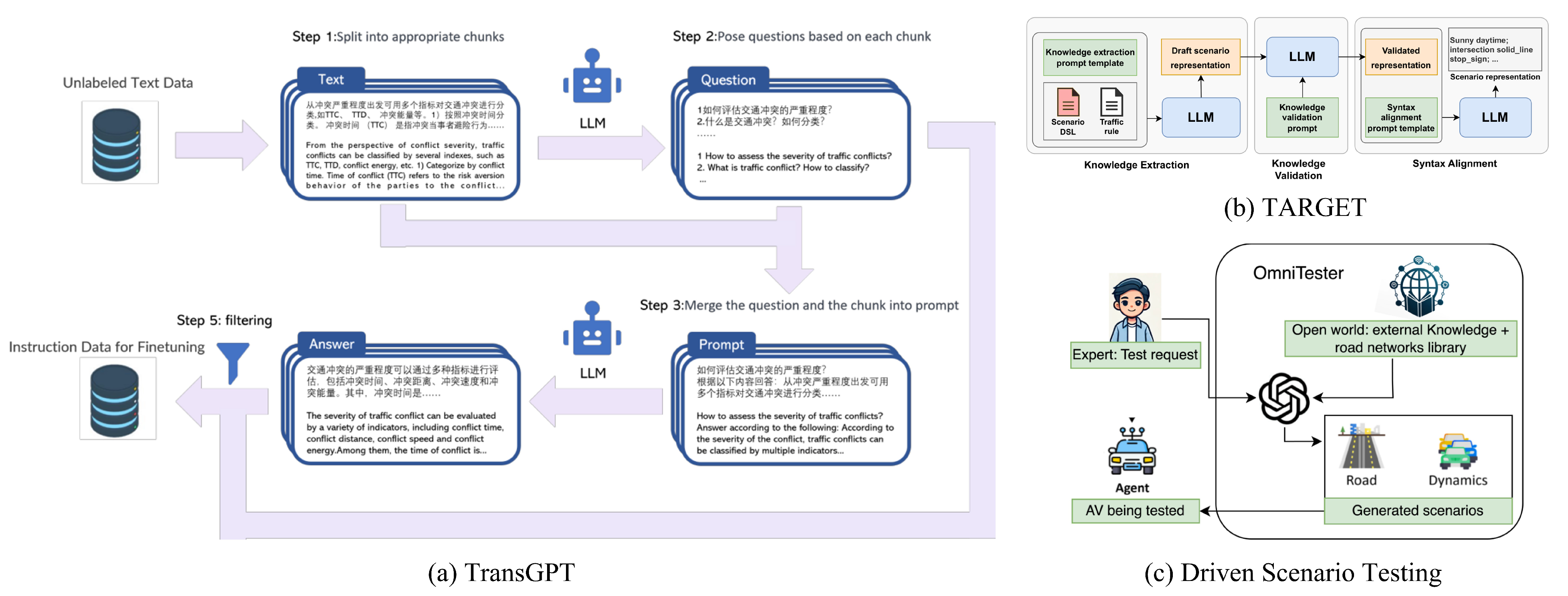
| TARGET [96] | 2023 | GPT-4 | Scenarios generation | The model leverages an LLM to interpret complex traffic rules, with the parsed information used to generate templated scenario scripts. These scripts are executed in a simulator to test the system for issues such as rule violations, collisions, or timeouts. |
| ADEPT [97] | 2023 | GPT-3 | Scenarios generation | ADEPT extracts information from real-world traffic accident reports, utilizing GPT-3’s question-answering capabilities to translate the reports into structured data, which are then combined with scenario templates to generate test scenarios. |
| OmniTester [98] | 2024 | GPT-3.5 and GPT-4 | Scenario generation | OmniTester is a driving scenario generation model. After the LLM parses the user’s natural language description into a structured scene representation, the retrieval module matches traffic network regions based on preprocessed map data and converts the data into an XML format compatible with simulation platforms. |
| LCTGen [99] | 2023 | GPT-4 | Scenario generation | LCTGen is the first scenario generation model based on LLMs, capable of receiving natural language inputs and generating dynamic traffic scenarios. |
| TransGPT [100] | 2024 | Vicuna | Scenarios generation | TransGPT is a traffic-specific large model, where the single-modal TransGPT-SM is designed to answer traffic-related questions, and the multi-modal TransGPT-MM can process image–text inputs to generate traffic-related textual outputs. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Li, J.; Yang, G.; Yang, L.; Chi, H.; Yang, L. Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review. Drones 2025, 9, 238. https://doi.org/10.3390/drones9040238
Li J, Li J, Yang G, Yang L, Chi H, Yang L. Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review. Drones. 2025; 9(4):238. https://doi.org/10.3390/drones9040238
Chicago/Turabian StyleLi, Jing, Jingyuan Li, Guo Yang, Lie Yang, Haozhuang Chi, and Lichao Yang. 2025. "Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review" Drones 9, no. 4: 238. https://doi.org/10.3390/drones9040238
APA StyleLi, J., Li, J., Yang, G., Yang, L., Chi, H., & Yang, L. (2025). Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review. Drones, 9(4), 238. https://doi.org/10.3390/drones9040238