
SiamCTCA: Cross-Temporal Correlation Aggregation Siamese Network for UAV Tracking

 ,
,
Abstract
:1. Introduction
- We design a cross-temporal aggregated response fusion architecture, which adopts a multiplexed parallel cross-temporal strategy, realizes multi-level global information fusion in temporal and spatial through TME (Transformer multistage embedding) modules, organically combines high-level semantics and low-level features, and enhances the richness and precision of feature expression. This innovative architecture breaks through the traditional limitations, effectively improves the feature utilization efficiency, and provides more reliable feature support for target tracking.
- The FRMFE (feed-forward residual multidimensional fusion edge) module eliminates false high-confidence regions, allowing the tracker to focus on the target itself, reducing interference from irrelevant information, and significantly improving tracking precision and stability; the RSFA (response significance filter aggregation) network suppresses noise, removes irrelevant background information, and improves the precision of target position and attitude prediction, thus enhancing the tracker’s robustness in complex and changing environments.
- In the DTB70, UAV123 and UAVDT benchmarks, SiamCTCA delivers about 3% performance improvement over other lightweight mainstream trackers. It also performs well in difficult challenges. We employ a lightweight network architecture as the backbone for feature extraction, which enhances tracking speed without compromising tracking precision.
2. Related Work
2.1. Siamese-Based Trackers
2.2. Attention Mechanism
2.2.1. Overview of Attention Mechanism
2.2.2. Transformer and Multi-Head Attention
2.3. Lightweight Network
3. Methodology
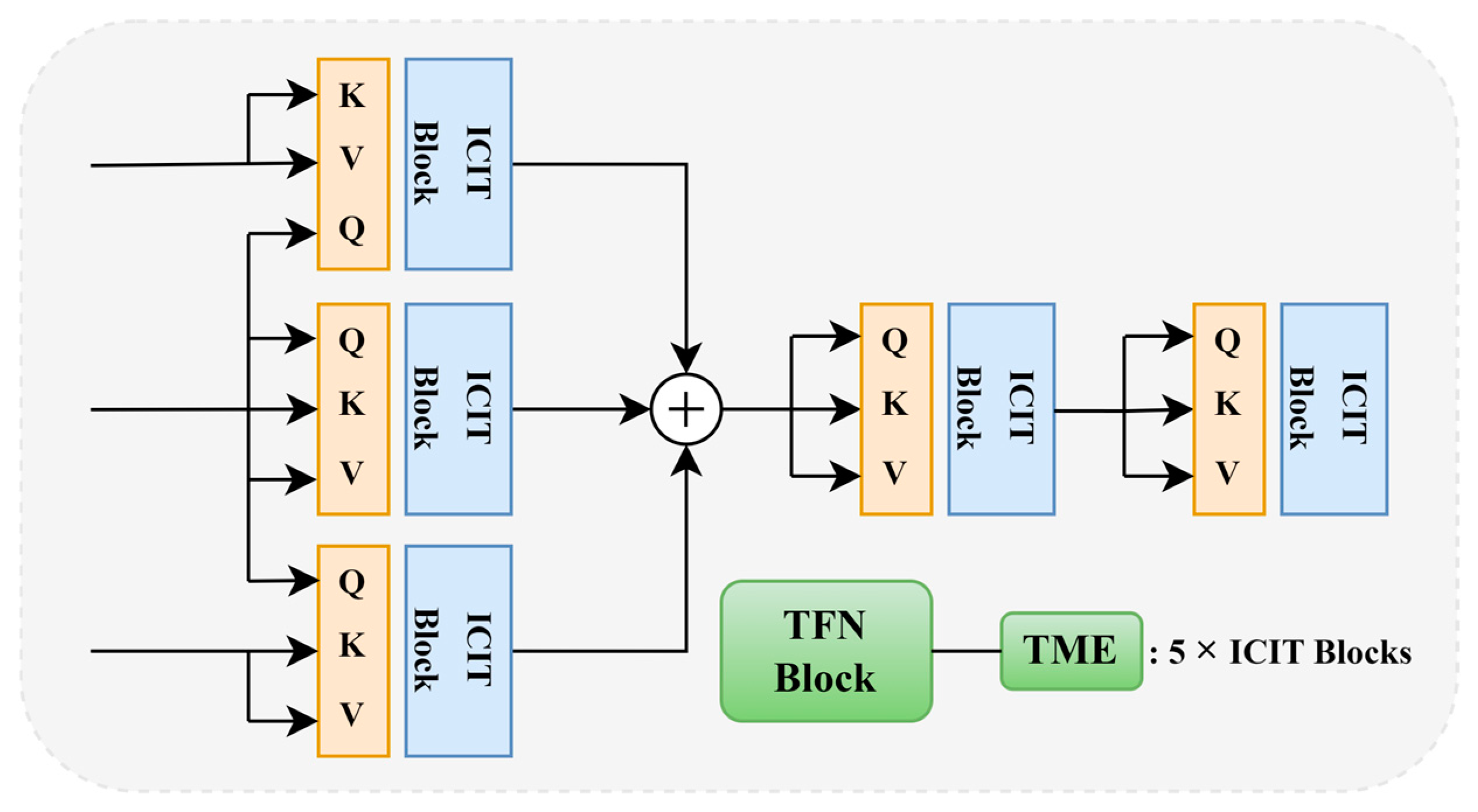
3.1. Multistage Interactive Modeling Functional Part
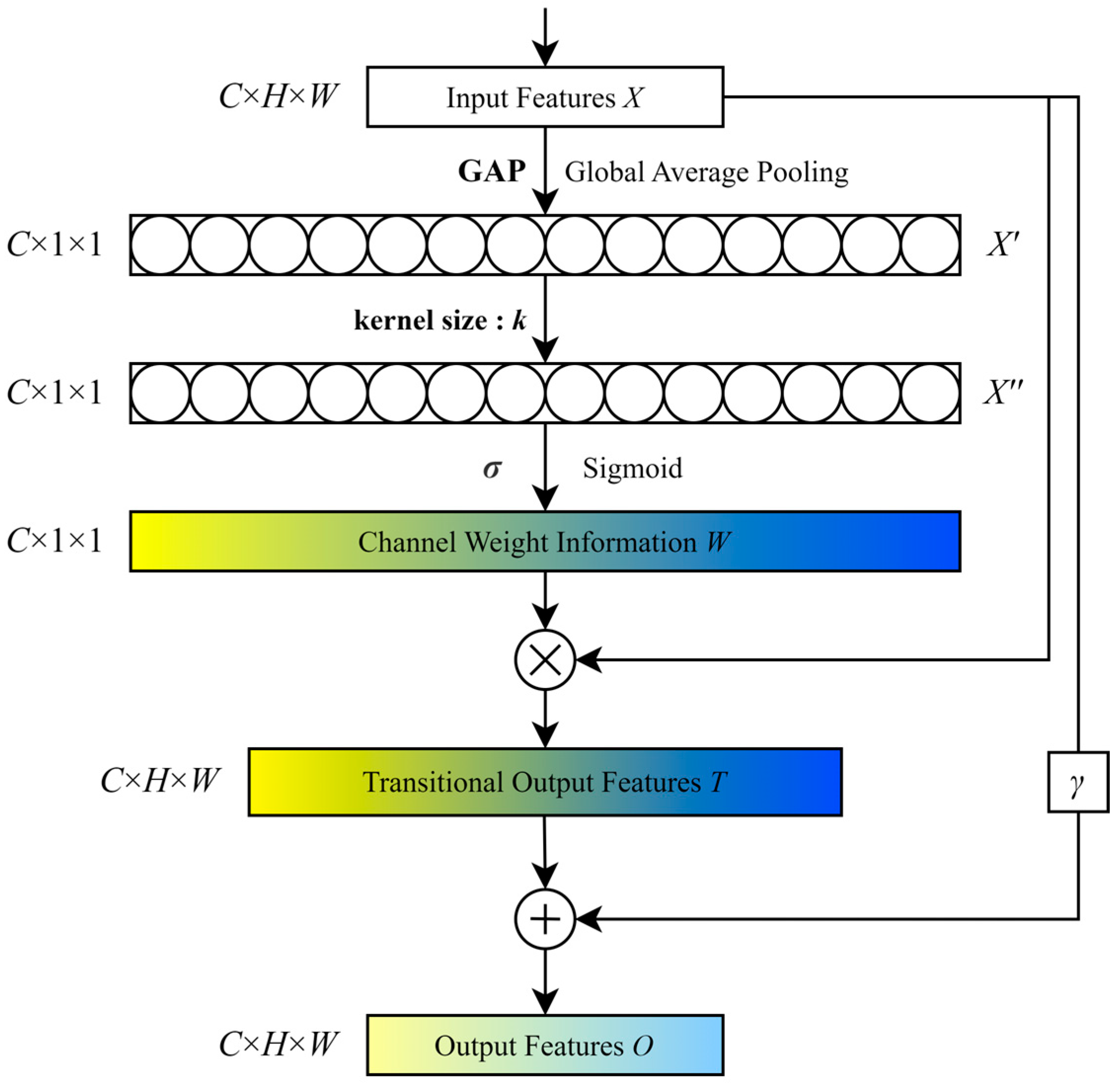
3.2. Feed-Forward Residual Multidimensional Fusion Edge (FRMFE)
3.3. Response Significance Filter Aggregation Network (RSFA)
3.4. Training Loss Function
4. Experiments and Discussion
4.1. Implementation Detail
4.2. Comparison with the SOTA
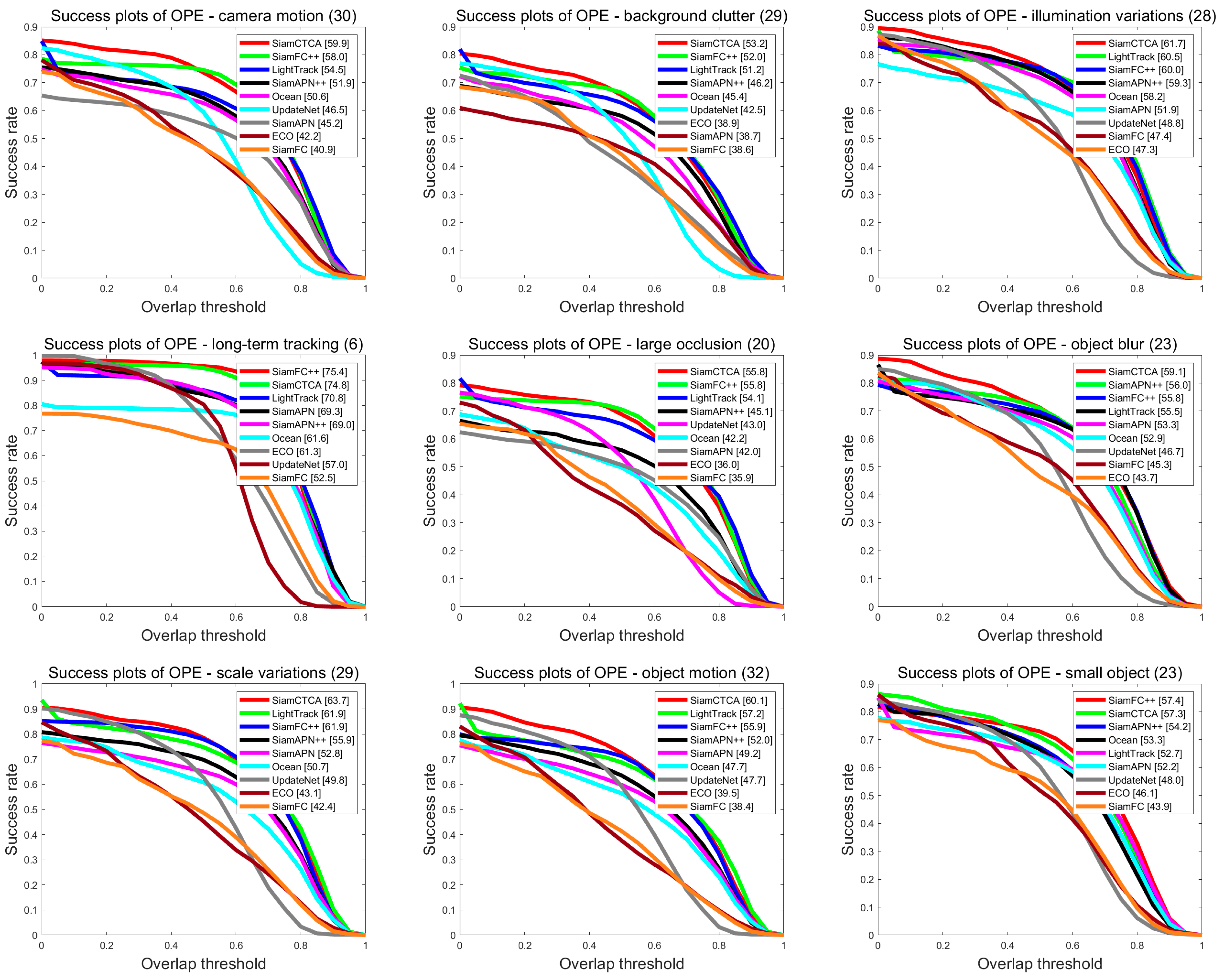
4.2.1. DTB70 Benchmark
- (a)
- Overall Performance
- (b)
- Difficult Challenges
- (c)
- Visual Analysis
- (d)
- Heatmap Experiments
4.2.2. UAV123 Benchmark
- (a)
- Overall performance
- (b)
- Heatmap Comparison Experiments
4.2.3. UAVDT Benchmark
4.3. Ablation Experiments
4.4. Tracking Speed Experiments
4.5. UAV Deployment and Real-Flight Tests
4.5.1. Comparison of FLOPs and Params
4.5.2. UAV Deployment and Real-World Visualization Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, F.; Wang, X.; Chen, Q.; Liu, J.; Liu, C. SiamMAN: Siamese Multi-Phase Aware Network for Real-Time Unmanned Aerial Vehicle Tracking. Drones 2023, 7, 707. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Wang, B.; Wang, X.; Liu, C. SiamBRF: Siamese Broad-Spectrum Relevance Fusion Network for Aerial Tracking. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Chen, Q.; Wang, X.; Liu, C. SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking. Micromachines 2023, 14, 893. [Google Scholar] [CrossRef] [PubMed]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Virtual, 11–17 October 2016; pp. 850–858. [Google Scholar]
- Nai, K.; Li, Z.; Wang, H. Dynamic Feature Fusion with Spatial-Temporal Context for Robust Object Tracking. Pattern Recognit. 2022, 130, 108775. [Google Scholar] [CrossRef]
- Pulford, G.W. A Survey of Manoeuvring Target Tracking Methods. arXiv 2015, arXiv:1503.07828. [Google Scholar]
- Javed, S.; Danelljan, M.; Khan, F.S.; Khan, M.H.; Felsberg, M.; Matas, J. Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6552–6574. [Google Scholar] [CrossRef]
- Huang, Y.; Li, X.; Lu, R.; Hu, Y.; Yang, X. Infrared Maritime Target Tracking via Correlation Filter with Adaptive Context-Awareness and Spatial Regularization. Infrared Phys. Technol. 2021, 118, 103907. [Google Scholar] [CrossRef]
- Zhu, C.; Jiang, S.; Li, S.; Lan, X. Efficient and Practical Correlation Filter Tracking. Sensors 2021, 21, 790. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, T.; Liu, K.; Zhang, B.; Chen, L. Recent Advances of Single-Object Tracking Methods: A Brief Survey. Neurocomputing 2021, 455, 1–11. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. In Proceedings of the 7th Annual Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; MIT Press: Cambridge, MA, USA, 1993; pp. 737–744. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese Instance Search for Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, W.; Wang, Q.; Zhang, L.; Bertinetto, L.; Torr, P.H.S. Siammask: A Framework for Fast Online Object Tracking and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3072–3089. [Google Scholar] [PubMed]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware Anchor-free Tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer International Publishing: Cham, Switzerland, 2020; pp. 771–787. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent Models of Visual Attention. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2204–2212. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comp. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Bahdanau, D. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation: Vancouver, BC, Canada, 2017; pp. 5998–6008. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Dux, P.E.; Marois, R. How Humans Search for Targets through Time: A Review of Data and Theory from the Attentional Blink. Atten. Percept. Psychophys. 2009, 71, 1683. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. Stochastic Estimation of the Maximum of a Regression Function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Howard, A.G. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 84–90. [Google Scholar]
- Iandola, F.N. SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Goyal, P. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings; Part V 13. Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yeung, D.Y. Visual Object Tracking for Unmanned Aerial Vehicles: A Benchmark and New Motion Models. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4140–4146. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 445–461. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal Contexts for Aerial Tracking. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14778–14788. [Google Scholar]
- Yao, L.; Fu, C.; Li, S.; Zheng, G.; Ye, J. SGDViT: Saliency-Guided Dynamic Vision Transformer for UAV Tracking. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 3353–3359. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. HiFT: Hierarchical Feature Transformer for Aerial Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15437–15446. [Google Scholar]
- Fu, C.; Cao, Z.; Li, Y.; Ye, J.; Feng, C. Siamese Anchor Proposal Network for High-Speed Aerial Tracking. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 510–516. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15180–15189. [Google Scholar]
- Zheng, G.; Fu, C.; Ye, J.; Li, B.; Lu, G.; Pan, J. Siamese Object Tracking for Vision-Based UAM Approaching with Pairwise Scale-Channel Attention. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 10486–10492. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Wang, X.; Zeng, D.; Zhao, Q.; Li, S. Rank-Based Filter Pruning for Real-Time UAV Tracking. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Wang, Y.; Huang, H.; Huang, X.; Tian, Y. ECO-HC Based Tracking for Ground Moving Target Using Single UAV. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 6414–6419. [Google Scholar]
- Zuo, H.; Fu, C.; Li, S.; Ye, J.; Zheng, G. DeconNet: End-to-End Decontaminated Network for Vision-Based Aerial Tracking. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Cai, H.; Zhang, X.; Lan, L.; Xu, L.; Shen, W.; Chen, J.; Leung, V.C.M. SiamATTRPN: Enhance Visual Tracking with Channel and Spatial Attention. IEEE Trans. Comput. Soc. Syst. 2024, 11, 1958–1966. [Google Scholar] [CrossRef]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. Towards Real-World Visual Tracking with Temporal Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15834–15849. [Google Scholar] [CrossRef]
- Huang, Z.; Fu, C.; Li, Y.; Lin, F.; Lu, P. Learning Aberrance Repressed Correlation Filters for Real-Time UAV Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2891–2900. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6268–6276. [Google Scholar]
- Li, Y.; Fu, C.; Ding, F.; Huang, Z.; Lu, G. AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11923–11932. [Google Scholar]
- Xuan, S.; Li, S.; Zhao, Z.; Zhou, Z.; Zhang, W.; Tan, H.; Xia, G.; Gu, Y. Rotation Adaptive Correlation Filter for Moving Object Tracking in Satellite Videos. Neurocomputing 2021, 438, 94–106. [Google Scholar] [CrossRef]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.V.; Danelljan, M.; Khan, F.S. Learning the Model Update for Siamese Trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4010–4019. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12549–12556. [Google Scholar]
- Li, S.; Yang, Y.; Zeng, D.; Wang, X. Adaptive and Background-Aware Vision Transformer for Real-Time UAV Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–8 October 2023; pp. 13989–14000. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks for Visual Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Videos | Attribute | Ours | TCTrack | SGDViT | HiFT | SiamAPN++ | SiamAPN | SiamSA | SiamDWFC | Ocean |
|---|---|---|---|---|---|---|---|---|---|---|
| Motor1 | ARV | 0.597 | 0.593 | 0.573 | 0.610 | 0.575 | 0.569 | 0.564 | 0.474 | 0.393 |
| Car6 | BC | 0.583 | 0.589 | 0.580 | 0.567 | 0.520 | 0.486 | 0.464 | 0.405 | 0.362 |
| Gull1 | DEF | 0.656 | 0.647 | 0.617 | 0.626 | 0.617 | 0.616 | 0.598 | 0.477 | 0.371 |
| SUP2 | FCM | 0.628 | 0.630 | 0.608 | 0.611 | 0.601 | 0.599 | 0.605 | 0.494 | 0.492 |
| BMX4 | OV | 0.614 | 0.600 | 0.588 | 0.596 | 0.590 | 0.557 | 0.592 | 0.421 | 0.489 |
| BMX3 | OPR | 0.552 | 0.504 | 0.521 | 0.546 | 0.495 | 0.518 | 0.515 | 0.406 | 0.394 |
| MountainBike1 | SOA | 0.536 | 0.528 | 0.524 | 0.485 | 0.495 | 0.480 | 0.487 | 0.478 | 0.444 |
| Girl2 | OCC | 0.531 | 0.533 | 0.526 | 0.455 | 0.517 | 0.474 | 0.473 | 0.461 | 0.458 |
| SnowBoarding4 | IPR | 0.615 | 0.618 | 0.599 | 0.613 | 0.587 | 0.573 | 0.575 | 0.462 | 0.413 |
| NO. | Metrics | Ours | Siam APN | Siam APN++ | P-Siam FC++ | ECO-HC | Decon Net | Siam ATTRPN | TC Track++ | SGDViT | ARCF | Siam CAR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Succ.(%) | 60.7 | 57.5 | 58.2 | 48.9 | 49.6 | 58.3 | 53.4 | 51.9 | 57.5 | 46.8 | 59.1 |
| 2 | Pre.(%) | 78.7 | 76.5 | 76.8 | 74.5 | 71.0 | 75.8 | 76.0 | 73.1 | 75.4 | 67.1 | 78.2 |
| Tracker | Tracker Type | Success Rate (%) | Precision (%) |
|---|---|---|---|
| SiamCTCA (Ours) | Siamese-based | 61.3 | 83.5 |
| AutoTrack | Correlation Filter | 45.0 | 71.8 |
| ARCF | Correlation Filter | 45.8 | 72.0 |
| RACF | Correlation Filter | 49.4 | 77.3 |
| ECO | Correlation Filter | 45.1 | 70.2 |
| UpdateNet | Correlation Filter | 48.7 | 79.0 |
| HiFT | Siamese-based | 47.5 | 65.2 |
| SiamAPN | Siamese-based | 51.7 | 71.0 |
| SiamAPN++ | Siamese-based | 55.6 | 75.8 |
| TCTrack | Siamese-based | 53.0 | 72.5 |
| SiamFC | Siamese-based | 44.7 | 68.1 |
| SiamFC++ | Siamese-based | 60.0 | 80.7 |
| Aba-ViT | Siamese-based | 59.9 | 83.4 |
| Ocean | Siamese-based | 52.3 | 72.5 |
| LightTrack | Siamese-based | 59.0 | 77.6 |
| NO. | TME | FRMFE | RSFA | DTB70 | UAV123 | ||
|---|---|---|---|---|---|---|---|
| Pre. (%) | Succ. (%) | Pre. (%) | Succ. (%) | ||||
| 1 | 79.0 | 60.5 | 74.8 | 56.6 | |||
| 2 | √ | 80.0 | 61.0 | 76.4 | 58.3 | ||
| 3 | √ | 80.3 | 61.5 | 76.8 | 58.9 | ||
| 4 | √ | 80.1 | 61.2 | 75.8 | 57.8 | ||
| 5 | √ | √ | √ | 81.7 | 62.4 | 78.6 | 60.5 |
| DTB70 | |||
|---|---|---|---|
| Model | Precision (%) | Success Rate (%) | FPS |
| TCTrack | 81.3 | 62.2 | 73.2 |
| HiFT | 80.2 | 59.6 | 66.5 |
| SGDViT | 80.5 | 60.3 | 73.8 |
| SiamAPN++ | 79.0 | 59.4 | 72.3 |
| LightTrack | 76.1 | 58.7 | 74.0 |
| SiamSA | 75.7 | 58.6 | 65.1 |
| Ours | 81.7 | 62.4 | 80.8 |
| Tracker | FLOPs | Params |
|---|---|---|
| SiamSA | 8.63 G | 8.17 M |
| SiamAPN++ | 9.91 G | 12.15 M |
| SGDViT | 11.33 G | 23.29 M |
| DaSiamRPN [65] | 21 G | 19.6 M |
| SiamFC++ | 17.5 G | 13.9 M |
| SiamCTCA (Ours) | 9.85 G | 9.23 M |
| Baseline | SiamCTCA (Ours) | SiamAPN++ | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre. (%) | Succ. (%) | FPS | Pre. (%) | Succ. (%) | FPS | Pre. (%) | Succ. (%) | FPS | |
| FP32 | 66.7 | 49.4 | 140 | 71.4 | 54.3 | 121 | 68.8 | 51.8 | 114 |
| INT8 | 65.6↓1.1 | 48.5↓0.9 | 56.2 | 70.2↓1.2 | 53.0↓1.3 | 50.1 | 67.7↓1.1 | 50.6↓1.2 | 49.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Liu, F.; Zhang, B.; Liu, J.; Xu, F.; Wang, Y. SiamCTCA: Cross-Temporal Correlation Aggregation Siamese Network for UAV Tracking. Drones 2025, 9, 294. https://doi.org/10.3390/drones9040294
Wang Q, Liu F, Zhang B, Liu J, Xu F, Wang Y. SiamCTCA: Cross-Temporal Correlation Aggregation Siamese Network for UAV Tracking. Drones. 2025; 9(4):294. https://doi.org/10.3390/drones9040294
Chicago/Turabian StyleWang, Qiaochu, Faxue Liu, Bao Zhang, Jinghong Liu, Fang Xu, and Yulong Wang. 2025. "SiamCTCA: Cross-Temporal Correlation Aggregation Siamese Network for UAV Tracking" Drones 9, no. 4: 294. https://doi.org/10.3390/drones9040294
APA StyleWang, Q., Liu, F., Zhang, B., Liu, J., Xu, F., & Wang, Y. (2025). SiamCTCA: Cross-Temporal Correlation Aggregation Siamese Network for UAV Tracking. Drones, 9(4), 294. https://doi.org/10.3390/drones9040294