
Going to Extremes: Weakly Supervised Medical Image Segmentation


Abstract
:1. Introduction
1.1. Related Work
1.1.1. Segmentation Networks
1.1.2. Interactive Segmentation
1.1.3. Weakly Supervised Segmentation
1.2. Contributions
- We make proper use of the point channel information not just at the input level of the network, but throughout the network, namely in the new attention gates.
- We furthermore propose a novel loss function that integrates the extreme point locations to encourage the boundary of our model’s predictions to align with the clicked points.
- We extend the experimentation to a new multi-organ dataset that shows the generalizability of our approach.
2. Method
- Extreme point selection
- Initial segmentation from scribbles via random walker (RW) algorithm
- Segmentation via deep fully convolutional network (FCN), where we explore several variations on the training scheme
- (a)
- Without RW and Dice loss
- (b)
- With RW but without the extra point channel and Dice loss
- (c)
- With RW and Dice loss
- (d)
- With RW and Dice loss and point loss
- (e)
- With RW and Dice loss and point loss and attention
- (f)
- With RW and Dice loss and point loss and point attention
- Regularization using random walker algorithm
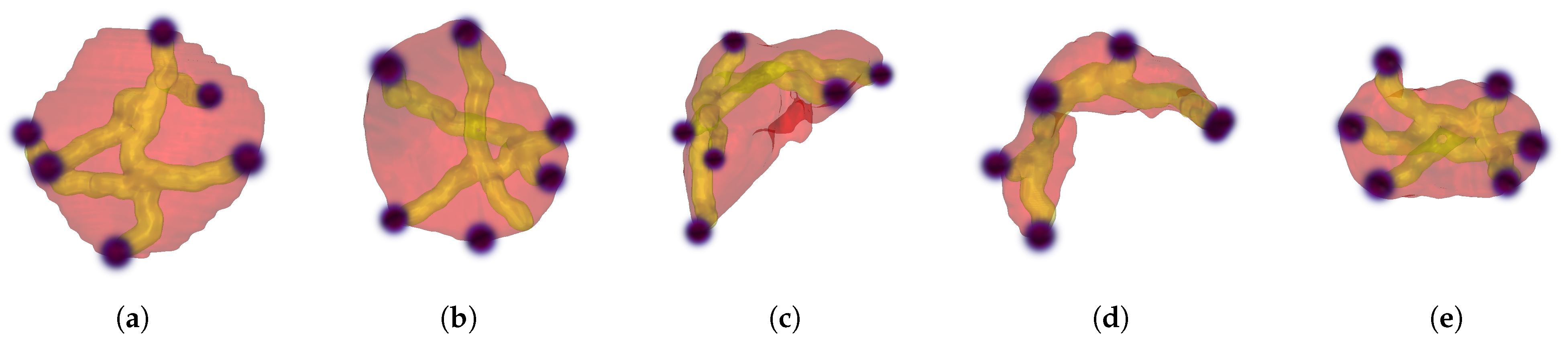
2.1. Step 1: Extreme Point Selection
2.2. Step 2: Initial Segmentation from Scribbles via Random Walker Algorithm
2.3. Random Walker
2.4. Step 3: Segmentation via Deep Fully Convolutional Network
2.5. Encoder
2.6. Decoder
2.7. Attention
2.8. Dice Loss
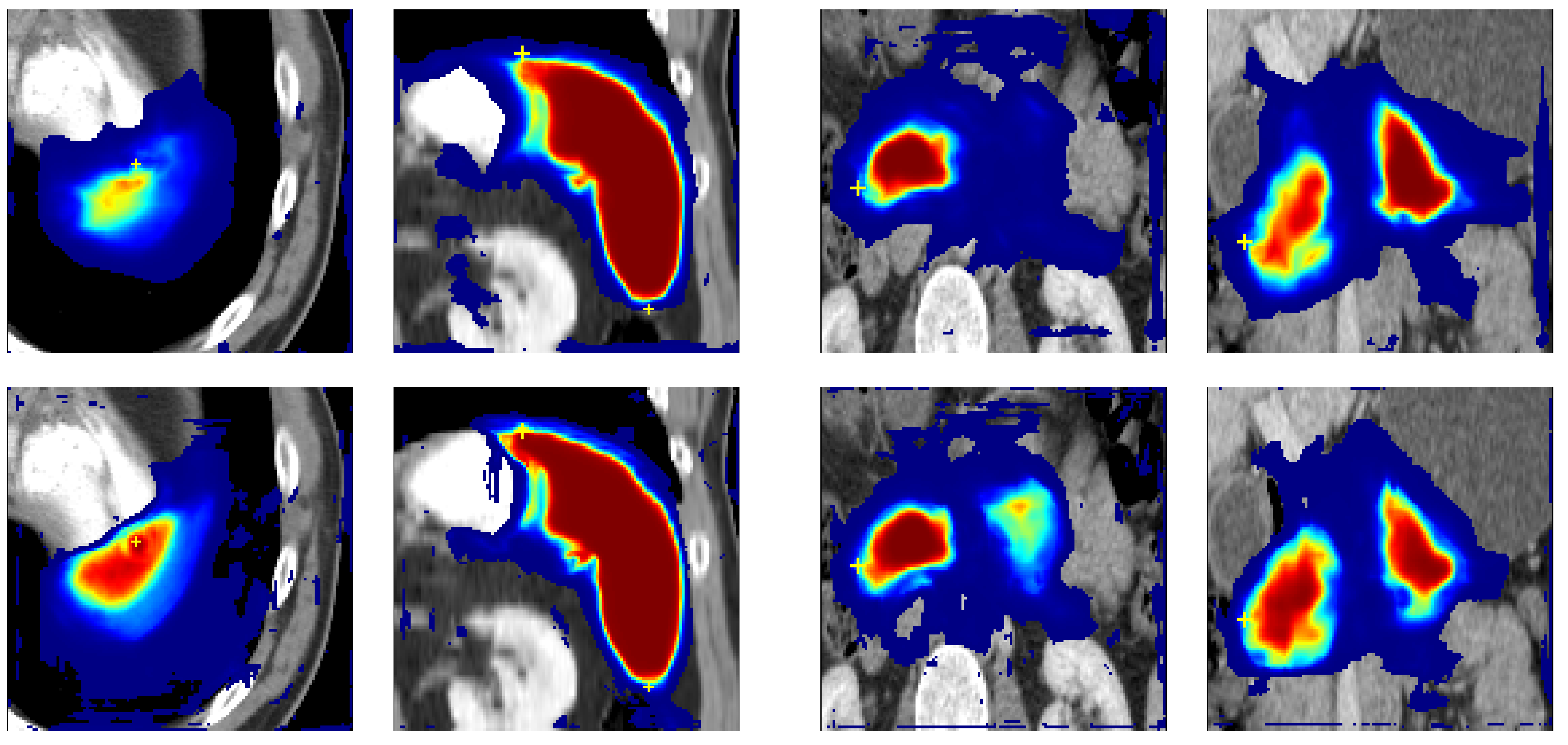
2.9. Point Loss
2.10. Point Loss Implementation
2.11. Step 4: Regularization Using Random Walker Algorithm
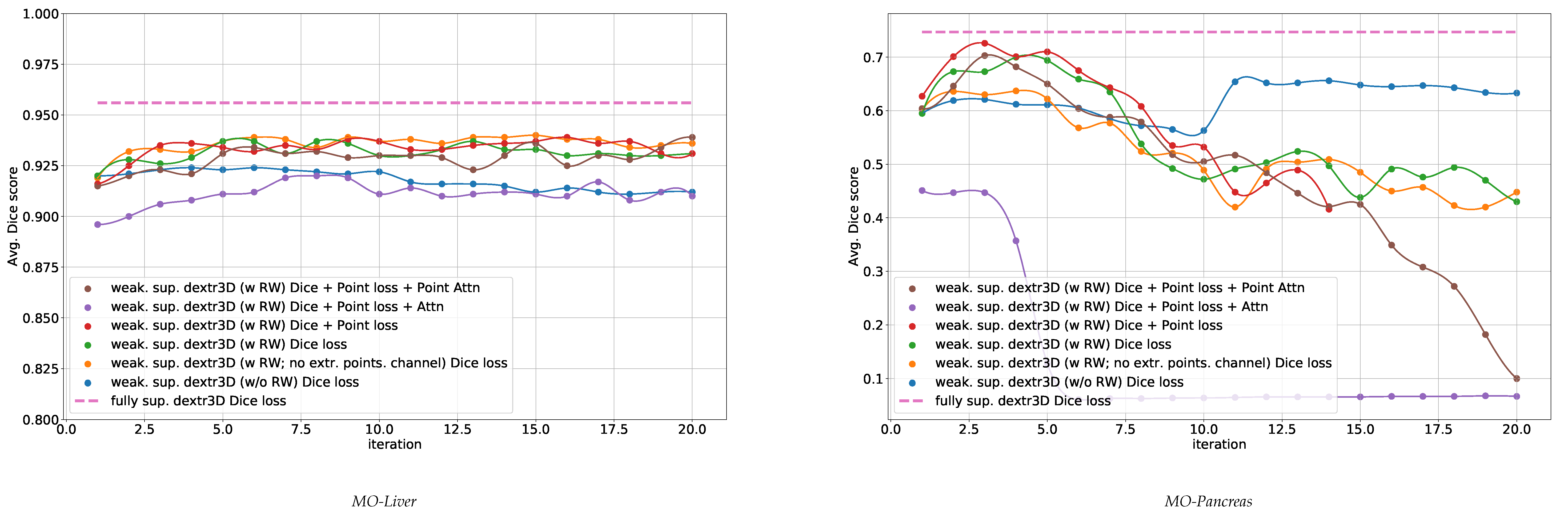
3. Experiments and Results
3.1. Datasets
3.2. Experiments
3.3. Implementation
3.4. Analysis of Point Loss
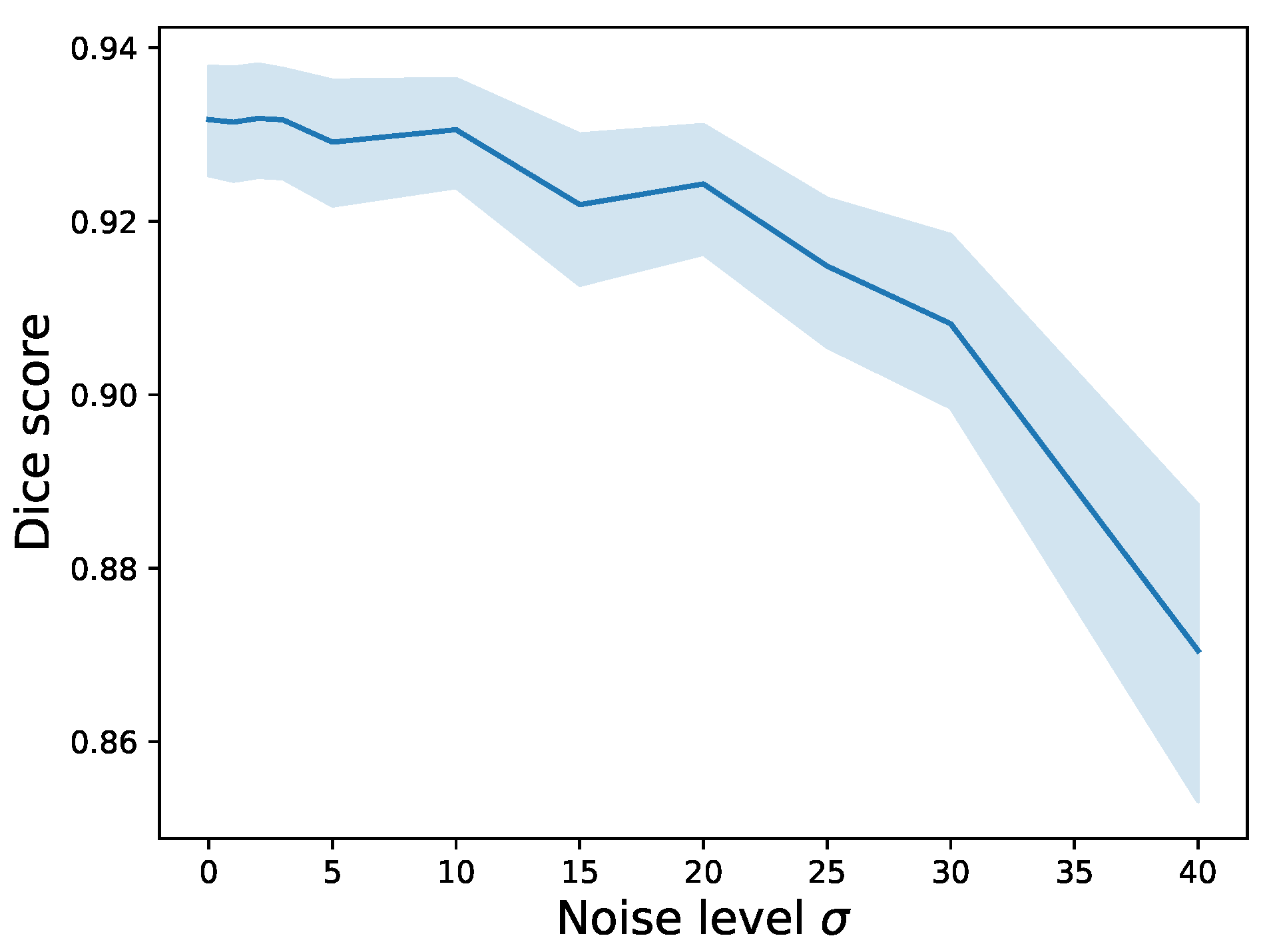
3.5. Effect of Extreme Point Noise during Inference
4. Discussion
Limitations
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Devaraj, A.; van Ginneken, B.; Nair, A.; Baldwin, D. Use of Volumetry for Lung Nodule Management: Theory and Practice. Radiology 2017, 284, 630–644. [Google Scholar] [CrossRef]
- Yushkevich, P.A.; Piven, J.; Cody Hazlett, H.; Gimpel Smith, R.; Ho, S.; Gee, J.C.; Gerig, G. User-Guided 3D Active Contour Segmentation of Anatomical Structures: Significantly Improved Efficiency and Reliability. Neuroimage 2006, 31, 1116–1128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the 19th International Conference on Medical Image Computing and Computer Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Cham, Switzerland, 2016; pp. 424–432. [Google Scholar]
- Liu, S.; Xu, D.; Zhou, S.K.; Pauly, O.; Grbic, S.; Mertelmeier, T.; Wicklein, J.; Jerebko, A.; Cai, W.; Comaniciu, D. 3D Anisotropic Hybrid Network: Transferring Convolutional Features from 2d Images to 3d Anisotropic Volumes. In Proceedings of the International Conference on Medical Image Computing & Computer Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 851–858. [Google Scholar]
- Myronenko, A. 3D MRI brain tumor segmentation using autoencoder regularization. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2018; pp. 311–320. [Google Scholar]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.N.; Wu, Z.; Ding, X. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- An, G.; Hong, L.; Zhou, X.B.; Yang, Q.; Li, M.Q.; Tang, X.Y. Accuracy and efficiency of computer-aided anatomical analysis using 3D visualization software based on semi-automated and automated segmentations. Ann. Anat. Anat. Anz. 2017, 210, 76–83. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Funka-Lea, G. Graph cuts and efficient ND image segmentation. IJCV 2006, 70, 109–131. [Google Scholar] [CrossRef] [Green Version]
- van Ginneken, B.; de Bruijne, M.; Loog, M.; Viergever, M.A. Interactive shape models. Med. Imaging 2003 Image Process. Int. Soc. Opt. Photonics 2003, 5032, 1206–1216. [Google Scholar]
- Schwarz, T.; Heimann, T.; Wolf, I.; Meinzer, H.P. 3D heart segmentation and volumetry using deformable shape models. In Proceedings of the 2007 Computers in Cardiology, Durham, NC, USA, 30 September–3 October 2007; pp. 741–744. [Google Scholar]
- Dougherty, G. Medical Image Processing: Techniques and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Wang, G.; Zuluaga, M.A.; Pratt, R.; Aertsen, M.; Doel, T.; Klusmann, M.; David, A.L.; Deprest, J.; Vercauteren, T.; Ourselin, S. Slic-Seg: A minimally interactive segmentation of the placenta from sparse and motion-corrupted fetal MRI in multiple views. Med. Image Anal. 2016, 34, 137–147. [Google Scholar] [CrossRef] [PubMed]
- Amrehn, M.; Gaube, S.; Unberath, M.; Schebesch, F.; Horz, T.; Strumia, M.; Steidl, S.; Kowarschik, M.; Maier, A. UI-Net: Interactive artificial neural networks for iterative image segmentation based on a user model. Eurographics Workshop Vis. Comput. Biol. Med. 2017, arXiv:1709.03450. [Google Scholar]
- Wang, G.; Zuluaga, M.A.; Li, W.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; Divid, A.L.; Deprest, J.; Ourselin, S.; et al. DeepIGeoS: A deep interactive geodesic framework for medical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1559–1572. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Can, Y.B.; Chaitanya, K.; Mustafa, B.; Koch, L.M.; Konukoglu, E.; Baumgartner, C.F. Learning to Segment Medical Images with Scribble-Supervision Alone. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 236–244. [Google Scholar]
- Dias, P.A.; Shen, Z.; Tabb, A.; Medeiros, H. FreeLabel: A Publicly Available Annotation Tool Based on Freehand Traces. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 21–30. [Google Scholar]
- Sakinis, T.; Milletari, F.; Roth, H.; Korfiatis, P.; Kostandy, P.; Philbrick, K.; Akkus, Z.; Xu, Z.; Xu, D.; Erickson, B.J. Interactive segmentation of medical images through fully convolutional neural networks. arXiv 2019, arXiv:1903.08205. [Google Scholar]
- Khan, S.; Shahin, A.H.; Villafruela, J.; Shen, J.; Shao, L. Extreme Points Derived Confidence Map as a Cue for Class-Agnostic Interactive Segmentation Using Deep Neural Network. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Springer International Publishing: Cham, Switzerlans, 2019; pp. 66–73. [Google Scholar]
- Majumder, S.; Yao, A. Content-Aware Multi-Level Guidance for Interactive Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ling, H.; Gao, J.; Kar, A.; Chen, W.; Fidler, S. Fast Interactive Object Annotation With Curve-GCN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dias, P.A.; Medeiros, H. Semantic Segmentation Refinement by Monte Carlo Region Growing of High Confidence Detections; Computer Vision—ACCV 2018; Jawahar, C.V., Li, H., Mori, G., Schindler, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 131–146. [Google Scholar]
- Cerrone, L.; Zeilmann, A.; Hamprecht, F.A. End-To-End Learned Random Walker for Seeded Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Rajchl, M.; Lee, M.C.; Oktay, O.; Kamnitsas, K.; Passerat-Palmbach, J.; Bai, W.; Damodaram, M.; Rutherford, M.A.; Hajnal, J.V.; Kainz, B.; et al. Deepcut: Object segmentation from bounding box annotations using convolutional neural networks. IEEE Trans. Med. Imaging 2017, 36, 674–683. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Gopalakrishnan, V.; Lu, L.; Summers, R.M.; Moss, J.; Yao, J. Self-learning to detect and segment cysts in lung CT images without manual annotation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1100–1103. [Google Scholar]
- Nie, D.; Gao, Y.; Wang, L.; Shen, D. ASDNet: Attention Based Semi-supervised Deep Networks for Medical Image Segmentation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 370–378. [Google Scholar]
- Kervadec, H.; Dolz, J.; Tang, M.; Granger, E.; Boykov, Y.; Ayed, I.B. Constrained-CNN losses for weakly supervised segmentation. Med Image Anal. 2019, 54, 88–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, J.; Tang, Y.; Lu, L.; Harrison, A.P.; Yan, K.; Xiao, J.; Yang, L.; Summers, R.M. Accurate weakly-supervised deep lesion segmentation using large-scale clinical annotations: Slice-propagated 3D mask generation from 2D RECIST. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2018; pp. 396–404. [Google Scholar]
- Rajchl, M.; Lee, M.C.; Schrans, F.; Davidson, A.; Passerat-Palmbach, J.; Tarroni, G.; Alansary, A.; Oktay, O.; Kainz, B.; Rueckert, D. Learning under distributed weak supervision. arXiv 2016, arXiv:1606.01100. [Google Scholar]
- Roth, H.; Zhang, L.; Yang, D.; Milletari, F.; Xu, Z.; Wang, X.; Xu, D. Weakly supervised segmentation from extreme points. In Large-Scale Annotation of Biomedical Data and Expert Label Synthesis (LABELS) and Hardware Aware Learning (HAL) for Medical Imaging and Computer Assisted Intervention (MICCAI); Springer: Cham, Swizerland, 2019. [Google Scholar]
- Maninis, K.K.; Caelles, S.; Pont-Tuset, J.; Van Gool, L. Deep Extreme Cut: From Extreme Points to Object Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 616–625. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. In Proceedings of the 1st Conference on Medical Imaging with Deep Learning (MIDL), Amsterdam, The Netherlands, 4–6 July 2018. [Google Scholar]
- Roth, H.R.; Lu, L.; Lay, N.; Harrison, A.P.; Farag, A.; Sohn, A.; Summers, R.M. Spatial aggregation of holistically-nested convolutional neural networks for automated pancreas localization and segmentation. Med Image Anal. 2018, 45, 94–107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papadopoulos, D.P.; Uijlings, J.R.; Keller, F.; Ferrari, V. Extreme clicking for efficient object annotation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4930–4939. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Gibson, E.; Giganti, F.; Hu, Y.; Bonmati, E.; Bandula, S.; Gurusamy, K.; Davidson, B.; Pereira, S.P.; Clarkson, M.J.; Barratt, D.C. Automatic multi-organ segmentation on abdominal CT with dense v-networks. IEEE Trans. Med. Imaging 2018, 37, 1822–1834. [Google Scholar] [CrossRef] [Green Version]
- Roth, H.R.; Lu, L.; Farag, A.; Shin, H.C.; Liu, J.; Turkbey, E.B.; Summers, R.M. Deeporgan: Multi-level deep convolutional networks for automated pancreas segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 556–564. [Google Scholar]
- BTCV. Multi-Atlas Labeling Beyond the Cranial Vault—MICCAI Workshop and Challenge. 2015. Available online: https://www.synapse.org/#!Synapse:syn3193805 (accessed on 28 May 2021).
- Simpson, A.L.; Antonelli, M.; Bakas, S.; Bilello, M.; Farahani, K.; van Ginneken, B.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; et al. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Rister, B.; Yi, D.; Shivakumar, K.; Nobashi, T.; Rubin, D.L. CT-ORG, a new dataset for multiple organ segmentation in computed tomography. Sci. Data 2020, 7, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Raju, A.; Ji, Z.; Cheng, C.T.; Cai, J.; Huang, J.; Xiao, J.; Lu, L.; Liao, C.; Harrison, A.P. User-Guided Domain Adaptation for Rapid Annotation from User Interactions: A Study on Pathological Liver Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 457–467. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dice [Mean ± std (Median)] | MSD-Spleen | MO-Spleen | MO-Liver | MO-Pancreas | MO-L.Kidney | MO-Gallbladder |
|---|---|---|---|---|---|---|
| rnd. walk. init. | 0.922 ± 0.018 (0.922) | 0.830 ± 0.144 (0.913) | 0.786 ± 0.146 (0.847) | 0.458 ± 0.206 (0.414) | 0.741 ± 0.137 (0.815) | 0.638 ± 0.195 (0.619) |
| weak. sup. (w/o RW) DL | 0.939 ± 0.011 (0.943) | 0.942 ± 0.009 (0.939) | 0.924 ± 0.020 (0.924) | 0.656 ± 0.089 (0.634) | 0.878 ± 0.034 (0.893) | 0.678 ± 0.194 (0.740) |
| weak. sup. (w RW; no extr. points. channel)DL | 0.945 ± 0.012 (0.950) | 0.942 ± 0.009 (0.937) | 0.940 ± 0.011 (0.942) | 0.637 ± 0.166 (0.664) | 0.900 ± 0.013 (0.899) | 0.677 ± 0.252 (0.787) |
| weak. sup. (w RW)DL | 0.946 ± 0.011 (0.950) | 0.944 ± 0.023 (0.945) | 0.937 ± 0.013 (0.941) | 0.700 ± 0.068 (0.676) | 0.909 ± 0.017 (0.907) | 0.701 ± 0.209 (0.795) |
| weak. sup. (w RW)Dice + PL | 0.946 ± 0.010 (0.949) | 0.945 ± 0.019 (0.947) | 0.939 ± 0.012 (0.940) | 0.726 ± 0.080 (0.746) | 0.906 ± 0.024 (0.909) | 0.719 ± 0.186 (0.789) |
| weak. sup. (w RW)Dice + PL + Attn. | 0.945 ± 0.013 (0.948) | 0.924 ± 0.053 (0.948) | 0.920 ± 0.059 (0.943) | 0.451 ± 0.124 (0.427) | 0.905 ± 0.023 (0.907) | 0.606 ± 0.256 (0.632) |
| weak. sup. (w RW)Dice + PL + Pt. Attn. | 0.948 ± 0.011 (0.950) | 0.945 ± 0.021 (0.943) | 0.939 ± 0.013 (0.939) | 0.703 ± 0.077 (0.688) | 0.913 ± 0.013 (0.916) | 0.702 ± 0.184 (0.773) |
| fully sup. DL | 0.958 ± 0.007 (0.959) | 0.954 ± 0.027 (0.959) | 0.956 ± 0.010 (0.957) | 0.747 ± 0.082 (0.721) | 0.942 ± 0.019 (0.946) | 0.715 ± 0.173 (0.791) |
| Dice | CT-ORG-Liver | CT-ORG-l.kidney | MSD-Pancreas |
|---|---|---|---|
| Mean | 0.932 | 0.897 | 0.678 |
| Std | 0.075 | 0.126 | 0.111 |
| Median | 0.947 | 0.930 | 0.706 |
| N | 139 | 137 | 281 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roth, H.R.; Yang, D.; Xu, Z.; Wang, X.; Xu, D. Going to Extremes: Weakly Supervised Medical Image Segmentation. Mach. Learn. Knowl. Extr. 2021, 3, 507-524. https://doi.org/10.3390/make3020026
Roth HR, Yang D, Xu Z, Wang X, Xu D. Going to Extremes: Weakly Supervised Medical Image Segmentation. Machine Learning and Knowledge Extraction. 2021; 3(2):507-524. https://doi.org/10.3390/make3020026
Chicago/Turabian StyleRoth, Holger R., Dong Yang, Ziyue Xu, Xiaosong Wang, and Daguang Xu. 2021. "Going to Extremes: Weakly Supervised Medical Image Segmentation" Machine Learning and Knowledge Extraction 3, no. 2: 507-524. https://doi.org/10.3390/make3020026
APA StyleRoth, H. R., Yang, D., Xu, Z., Wang, X., & Xu, D. (2021). Going to Extremes: Weakly Supervised Medical Image Segmentation. Machine Learning and Knowledge Extraction, 3(2), 507-524. https://doi.org/10.3390/make3020026