

Mach. Learn. Knowl. Extr. 2026, 8(5), 133; https://doi.org/10.3390/make8050133 - 18 May 2026
Abstract
Handover optimization is essential for seamless connectivity in 5G and beyond networks. Existing approaches present fundamental challenges of centralized solutions achieving coordination and accuracy but creating privacy risks under the General Data Protection Regulation (GDPR), while distributed privacy-preserving approaches protect user data but
[...] Read more.
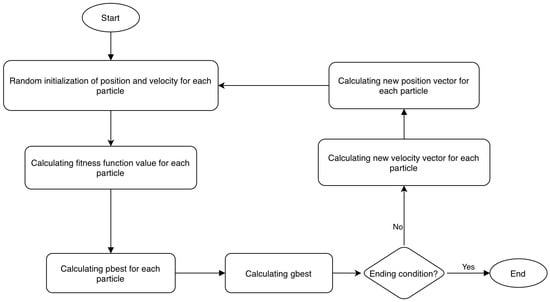
Handover optimization is essential for seamless connectivity in 5G and beyond networks. Existing approaches present fundamental challenges of centralized solutions achieving coordination and accuracy but creating privacy risks under the General Data Protection Regulation (GDPR), while distributed privacy-preserving approaches protect user data but lack the network-wide visibility necessary for optimal mobility decisions. This systematic review synthesizes 49 peer-reviewed studies published between 2010 and 2025, identified through a PRISMA-compliant search across IEEE Xplore, ScienceDirect, SpringerLink, MDPI, ACM Digital Library, and Google Scholar. Eligible studies addressed cellular handover or mobility management using traditional signal-based, Machine Learning, Federated Learning, Software-Defined Networking strategies, and reported quantitative performance metrics. A structured quality assessment evaluated methodological rigor, dataset validation, benchmarking practices, handover-specific metrics, and scalability. Synthesis evidence shows that existing approaches do not simultaneously satisfy critical requirements for next-generation mobility management of accuracy, privacy, scalability, and real-time network-wide coordination. Machine learning achieves high accuracy (up to 97%) but depends on centralized data; Reinforcement Learning supports real-time adaptation but incurs high computational costs; federated learning preserve privacy but suffers from limited global coordination; and software-defined networking enables centralized control but requires continuous transmission of raw data. Evidence quality is further limited to simulation-based assessments and limited real-world datasets. Overall, the reviews identify a clear evolution from reactive threshold-based methods towards proactive prediction and highlights the need for unified, privacy-preserving and globally coordinated handover frameworks. The findings point toward integrating federated learning with Software-Defined Mobile Networking as promising architectural direction for 6G mobility management.
Full article
(This article belongs to the Topic AI and Computational Methods for Modelling, Simulations and Optimizing of Advanced Systems: Innovations in Complexity, 2nd Edition)
►
Show Figures

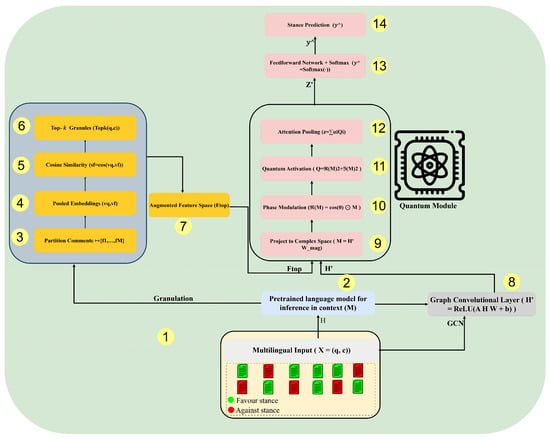
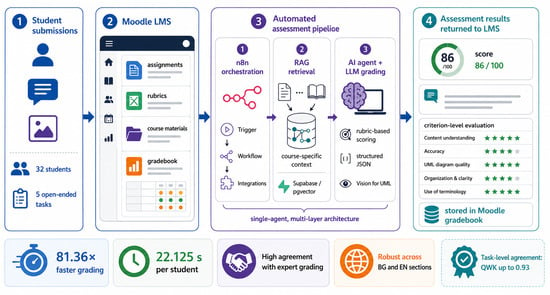
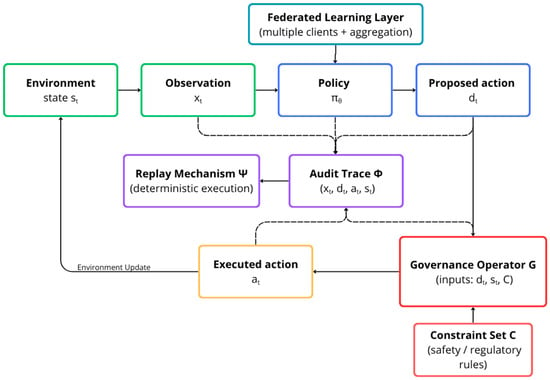
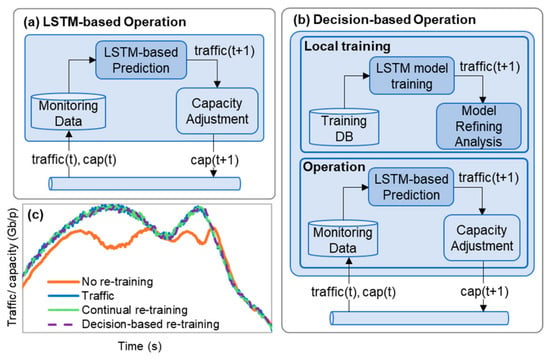
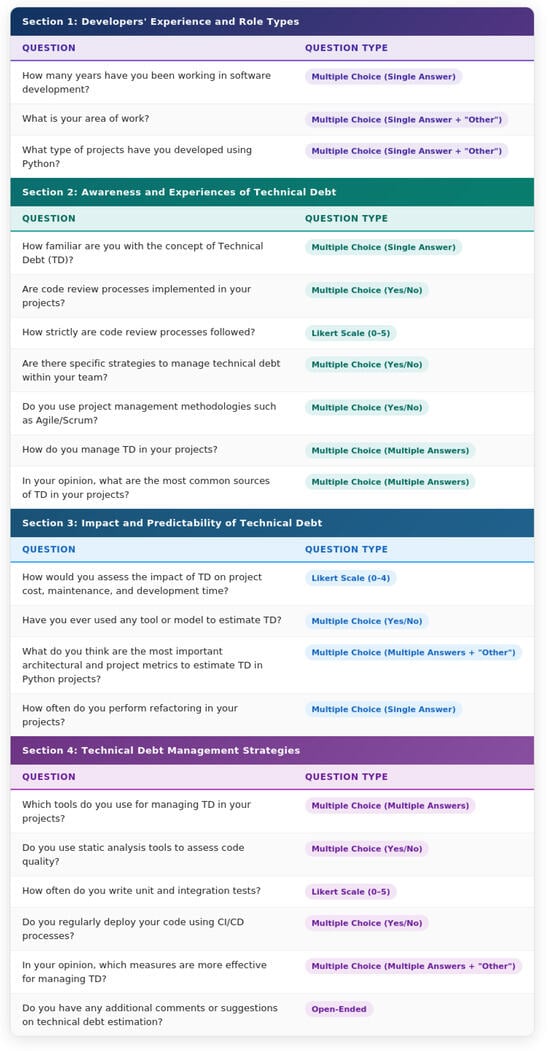
Figure 1











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}