
Voting in Transfer Learning System for Ground-Based Cloud Classification


Abstract
:1. Introduction
2. Related Work
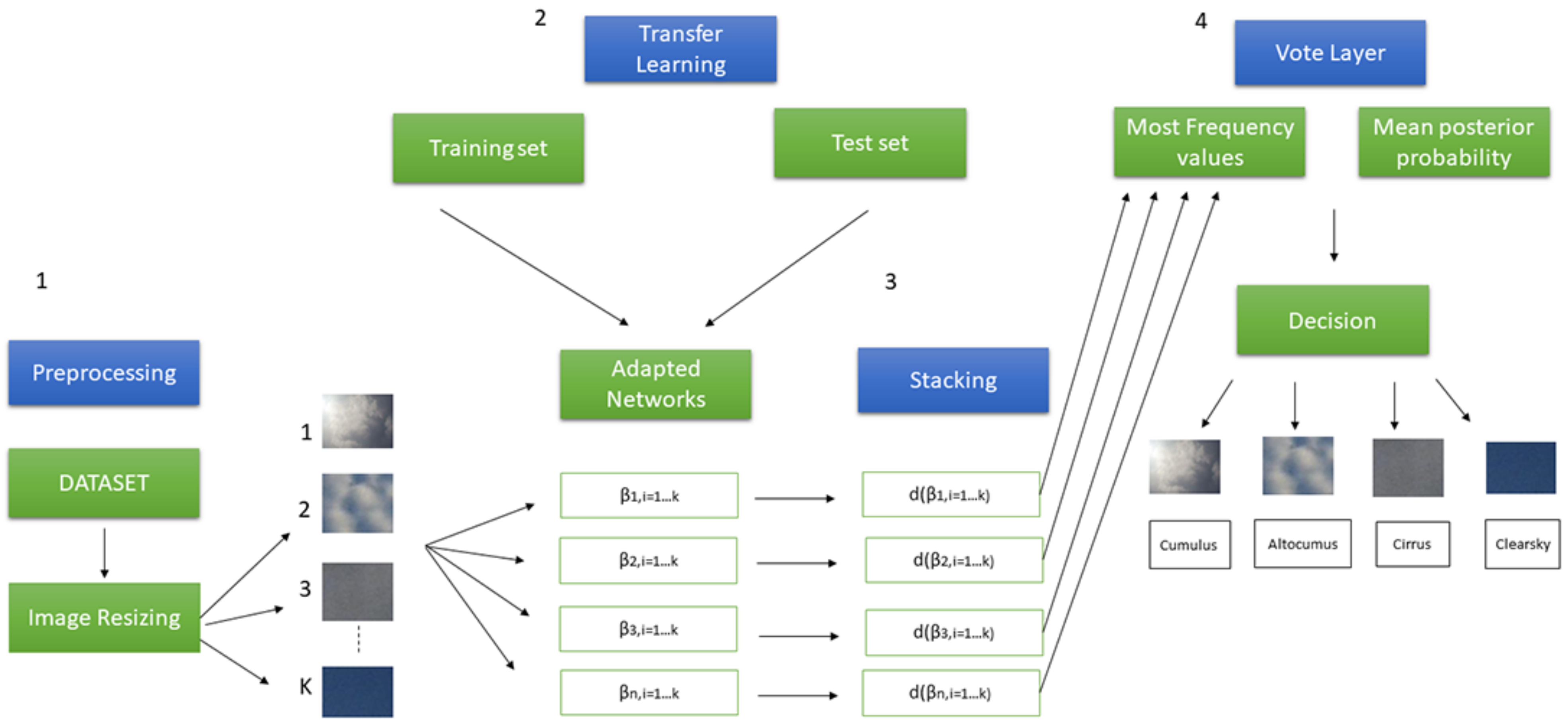
3. Materials and Methods
3.1. Image Resize
3.2. Network Design and Transfer Learning
3.3. Voting Based Learning
4. Experimental Results
4.1. Datasets
- The multimodal ground-based cloud database (MGCD) [7,25] is collected in China and consists of cloud images captured by a sky camera with a fisheye lens under a variety of conditions and multimodal cloud information. It includes a total amount of 1720 cloud data. The images are divided into seven classes: cumulus, cirrus, altocumulus, clear sky, stratus, stratocumulus, and cumulonimbus. The number of item of each class varies from 140 to 350, and the detailed numbers are listed in Table 2.
- The Singapore whole sky imaging categories database (SWIMCAT) dataset [15] is composed of 784 sky/cloud patch images with 125 × 125 pixels captured using a wide-angle high-resolution sky imaging system, a calibrated ground-based WSI designed by [26]. The dataset is split into five distinct categories: clear sky, patterned clouds, thick dark clouds, thick white clouds, and veil clouds. The details are presented in Table 3.
- The cirrus cumulus stratus nimbus (CCSN) dataset [9] contains only 2543 unique cloud images with 256 × 256 pixels in the JPEG format and contains 10 different forms in cloud observation. It is characterized by a large set of images, making it the largest of the available public cloud datasets. Details are shown in Table 4.
4.2. Results
4.3. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Duda, D.P.; Minnis, P.; Khlopenkov, K.; Chee, T.L.; Boeke, R. Estimation of 2006 Northern Hemisphere contrail coverage using MODIS data. Geophys. Res. Lett. 2013, 40, 612–617. [Google Scholar] [CrossRef]
- Rossow, W.B.; Schiffer, R.A. ISCCP cloud data products. Bull. Am. Meteorol. Soc. 1991, 72, 2–20. [Google Scholar] [CrossRef]
- Chen, T.; Rossow, W.B.; Zhang, Y. Radiative effects of cloud-type variations. J. Clim. 2000, 13, 264–286. [Google Scholar] [CrossRef]
- Stephens, G.L. Cloud feedbacks in the climate system: A critical review. J. Clim. 2005, 18, 237–273. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Li, M.; Zhang, Z.; Xiao, B.; Cao, X. Multimodal Ground-Based Cloud Classification Using Joint Fusion Convolutional Neural Network. Remote Sens. 2018, 10, 822. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, S.; Li, M.; Zhang, Z.; Xiao, B.; Durrani, T.S. Multi-evidence and multi-modal fusion network for ground-based cloud recognition. Remote Sens. 2020, 12, 464. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Wang, C.; Wang, Y.; Xiao, B. Deep Convolutional Activations-Based Features for Ground-Based Cloud Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 816–820. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, P.; Zhang, F.; Song, Q. CloudNet: Ground-based cloud classification with deep convolutional neural network. Geophys. Res. Lett. 2018, 45, 8665–8672. [Google Scholar] [CrossRef]
- Liu, S.; Li, M. Deep multimodal fusion for ground-based cloud classification in weather station networks. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 48. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Liu, S.; Zhang, Z. Deep tensor fusion network for multimodal ground-based cloud classification in weather station networks. Ad Hoc Netw. 2020, 96, 101991. [Google Scholar] [CrossRef]
- Liu, S.; Duan, L.; Zhang, Z.; Cao, X. Hierarchical multimodal fusion for ground-based cloud classification in weather station networks. IEEE Access 2019, 7, 85688–85695. [Google Scholar] [CrossRef]
- Sun, X.; Liu, L.; Gao, T.; Zhao, S. Classification of whole sky infrared cloud image based on the LBP operator. Trans. Atmos. Sci. 2009, 32, 490–497. [Google Scholar]
- Heinle, A.; Macke, A.; Srivastav, A. Automatic cloud classification of whole sky images. Atmos. Meas. Tech. 2010, 3, 557–567. [Google Scholar] [CrossRef] [Green Version]
- Dev, S.; Lee, Y.H.; Winkler, S. Categorization of cloud image patches using an improved texton-based approach. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; IEEE: New York, NY, USA, 2015; pp. 422–426. [Google Scholar]
- Zhang, J.; Liu, P.; Zhang, F.; Iwabuchi, H.; de Moura, A.A.; de Albuquerque, V.H.C. Ensemble Meteorological Cloud Classification Meets Internet of Dependable and Controllable Things. IEEE Internet Things J. 2020, 8, 3323–3330. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Peteiro-Barral, D.; Guijarro-Berdiñas, B. A survey of methods for distributed machine learning. Prog. Artif. Intell. 2013, 2, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2018; pp. 8697–8710. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Miami, FL, USA, 2009; pp. 248–255. [Google Scholar]
- Liu, S.; Li, M.; Zhang, Z.; Cao, X.; Durrani, T.S. Ground-Based Cloud Classification Using Task-Based Graph Convolutional Network. Geophys. Res. Lett. 2020, 47, e2020GL087338. [Google Scholar] [CrossRef]
- Dev, S.; Savoy, F.M.; Lee, Y.H.; Winkler, S. WAHRSIS: A low-cost high-resolution whole sky imager with near-infrared capabilities. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXV, Baltimore, MD, USA, 6–8 May 2014; International Society for Optics and Photonics: Bellingham, DC, USA, 2014; Volume 9071, p. 90711L. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; Volume 1, pp. 1–2. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A Completed Modeling of Local Binary Pattern Operator for Texture Classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]


{kind=link}
| Network | Depth | Size (MB) | Parameters (Millions) | Input Size |
|---|---|---|---|---|
| Densenet201 | 201 | 77 | 20 | 224 × 224 |
| Alexnet | 8 | 227 | 61 | 227 × 227 |
| Googlenet | 8 | 27 | 7 | 224 × 224 |
| Resnet18 | 18 | 44 | 11.7 | 224 × 224 |
| Resnet50 | 50 | 96 | 25.6 | 224 × 224 |
| Nasnetlarge | * | 332 | 88.9 | 331 × 331 |
| Label | Cloud Type | Number of Samples |
|---|---|---|
| 1 | Cumulus | 160 |
| 2 | Cirrus | 300 |
| 3 | Altocumulus | 340 |
| 4 | Clear sky | 350 |
| 5 | Stratocumulus | 250 |
| 6 | Stratus | 140 |
| 7 | Cumulonimbus | 180 |
| Label | Cloud Type | Number of Samples |
|---|---|---|
| A | Clear Sky | 224 |
| B | Patterned clouds | 89 |
| C | Thick dark clouds | 251 |
| D | Thick white clouds | 135 |
| E | Veil clouds | 85 |
| Label | Cloud Type | Number of Samples |
|---|---|---|
| Ci | Cirrus | 139 |
| Cs | Cirrostratus | 287 |
| Cc | Cirrocumulus | 268 |
| Ac | Altocumulus | 221 |
| As | Altostratus | 188 |
| Cu | Cumulus | 182 |
| Cb | Cumulonimbus | 242 |
| Ns | Nimbostratus | 274 |
| Sc | Stratocumulus | 340 |
| St | Stratus | 202 |
| Ct | Contrails | 200 |
| Datasets | MGCD | SWIMCAT | CCSN | |
|---|---|---|---|---|
| Networks | ||||
| Densenet201 | ✔ | ✔ | ✔ | |
| Alexnet | ✔ | ✔ | ✔ | |
| Googlenet | ✔ | ✔ | ✔ | |
| Resnet18 | ✗ | ✗ | ✔ | |
| Resnet50 | ✔ | ✔ | ✔ | |
| Nasnetlarge | ✗ | ✗ | ✔ | |
| Method | Acc |
|---|---|
| Our | 99.98 |
| MMFN [7] | 88.63 |
| DCAFs + MI [7] | 82.97 |
| BOVW + MI [7] | 67.20 |
| PBOVW + MI [7] | 67.15 |
| LPB + MI [7] | 50.53 |
| CLPB + MI [7] | 69.68 |
| CloudNet + MI [7] | 80.37 |
| BoVW [27] | 66.15 |
| PBoVW [27] | 66.13 |
| LBP [28] | 55.20 |
| CLBP [29] | 69.18 |
| VGG-16 [30] | 77.95 |
| DCAFs [8] | 82.67 |
| CloudNet [9] | 79.92 |
| DMF [10] | 79.05 |
| DTFN [11] | 86.48 |
| HMF [12] | 87.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manzo, M.; Pellino, S. Voting in Transfer Learning System for Ground-Based Cloud Classification. Mach. Learn. Knowl. Extr. 2021, 3, 542-553. https://doi.org/10.3390/make3030028
Manzo M, Pellino S. Voting in Transfer Learning System for Ground-Based Cloud Classification. Machine Learning and Knowledge Extraction. 2021; 3(3):542-553. https://doi.org/10.3390/make3030028
Chicago/Turabian StyleManzo, Mario, and Simone Pellino. 2021. "Voting in Transfer Learning System for Ground-Based Cloud Classification" Machine Learning and Knowledge Extraction 3, no. 3: 542-553. https://doi.org/10.3390/make3030028
APA StyleManzo, M., & Pellino, S. (2021). Voting in Transfer Learning System for Ground-Based Cloud Classification. Machine Learning and Knowledge Extraction, 3(3), 542-553. https://doi.org/10.3390/make3030028