
Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems Part 2—Applications in Transportation, Industries, Communications and Networking and More Topics


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Applications
1.1. Transportation
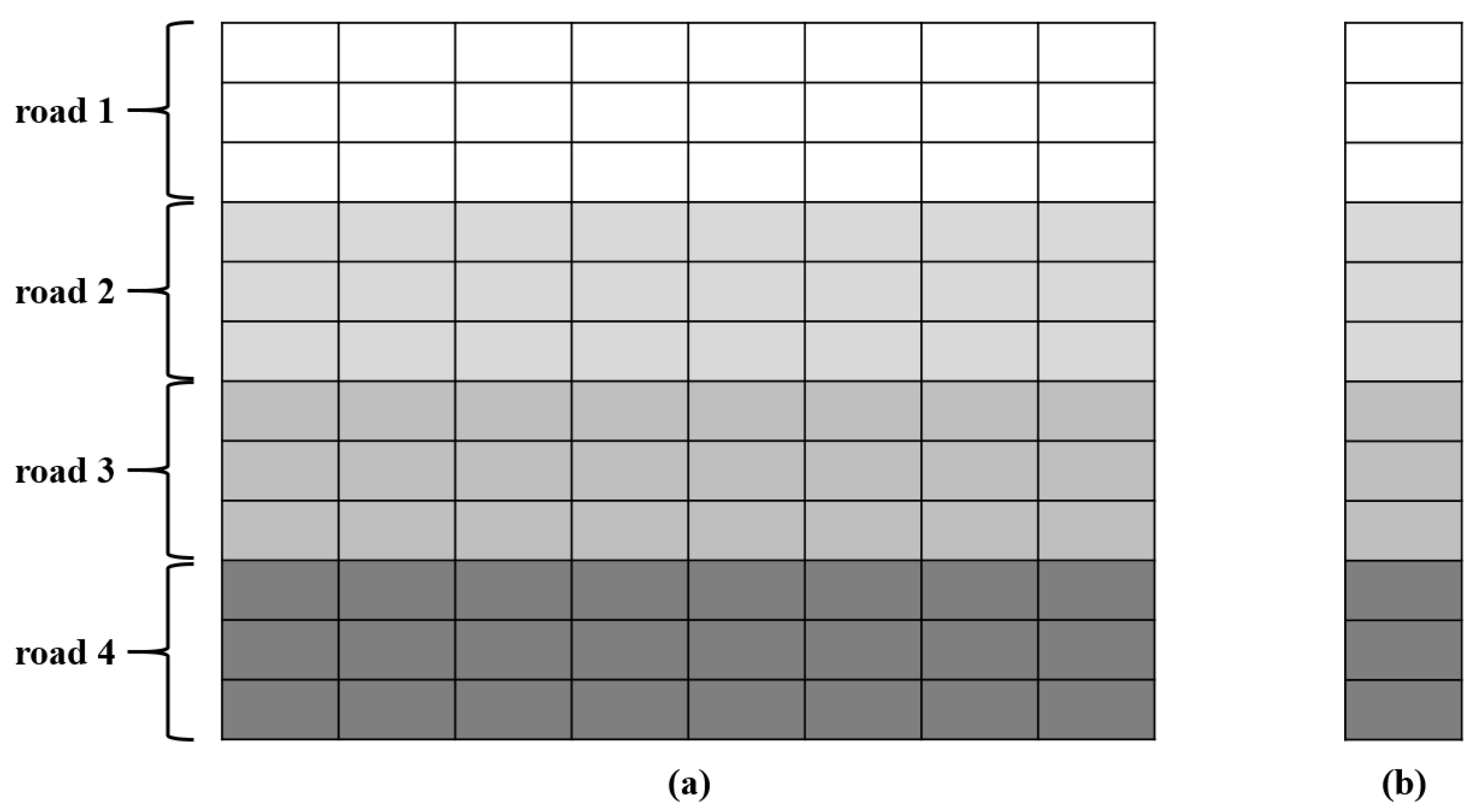
1.1.1. Traffic Signal Control (TSC)
1.1.2. Autonomous Driving
Sim-to-Real
Lane Change
Decision Making (and Optimum Control)
Path Planning
Pedestrian Detection
1.1.3. Other Applications in ITS
Ramp Metering
Energy Management
1.2. Industrial Applications
1.2.1. Industry 4.0
Inspection and Maintenance
Management of Engineering Systems
Process Control
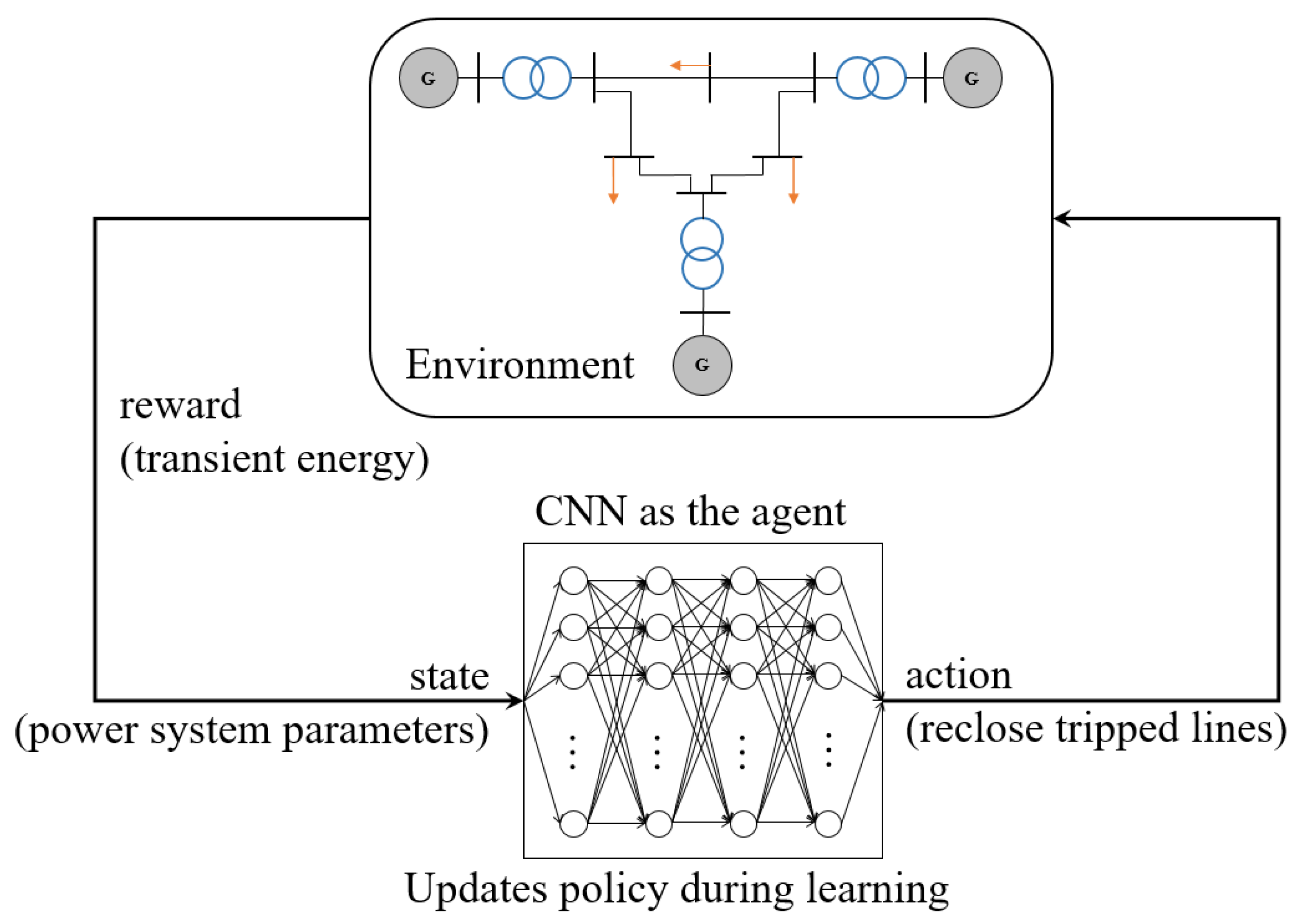
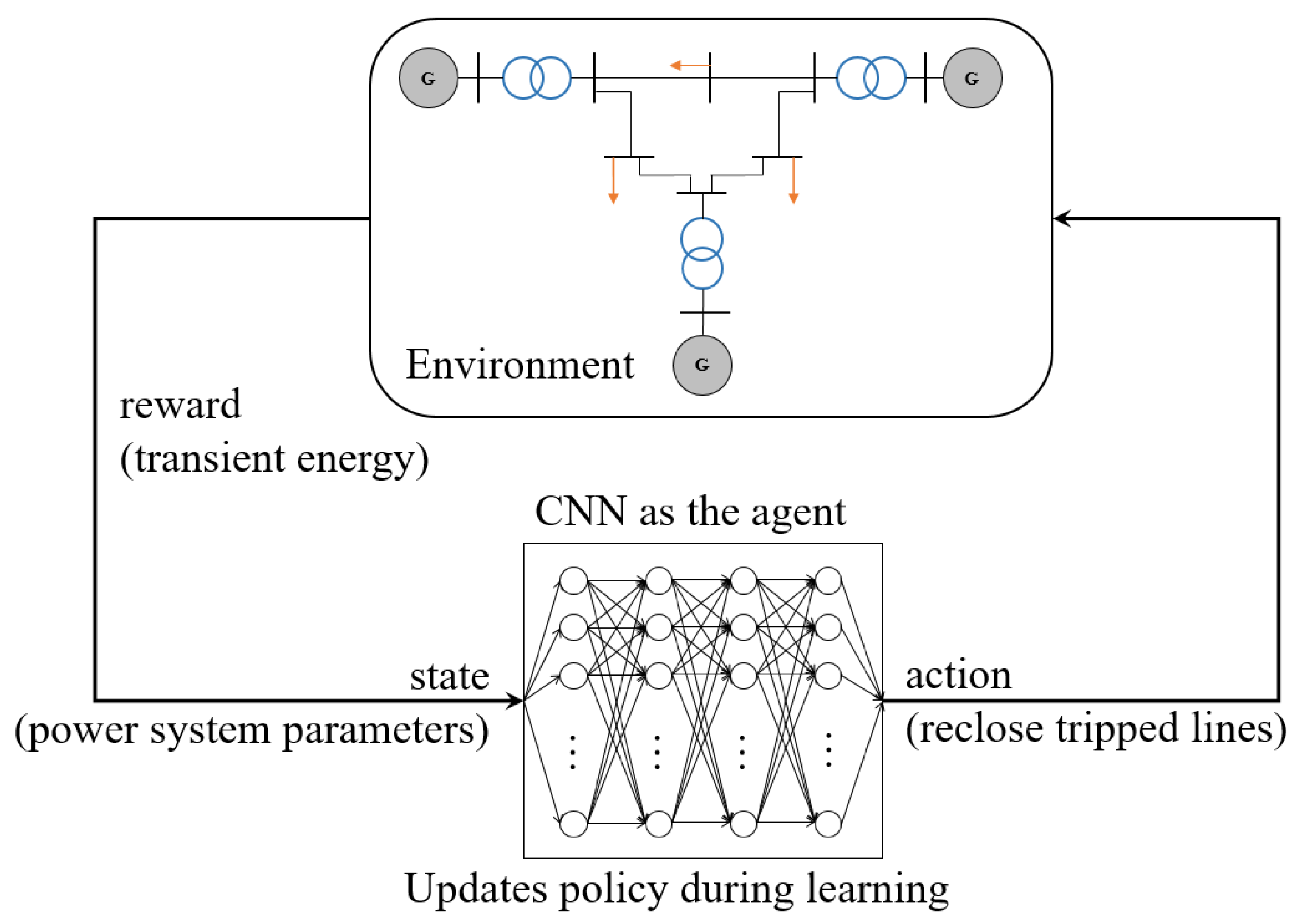
1.2.2. Smart Grid
1.3. Communications and Networking
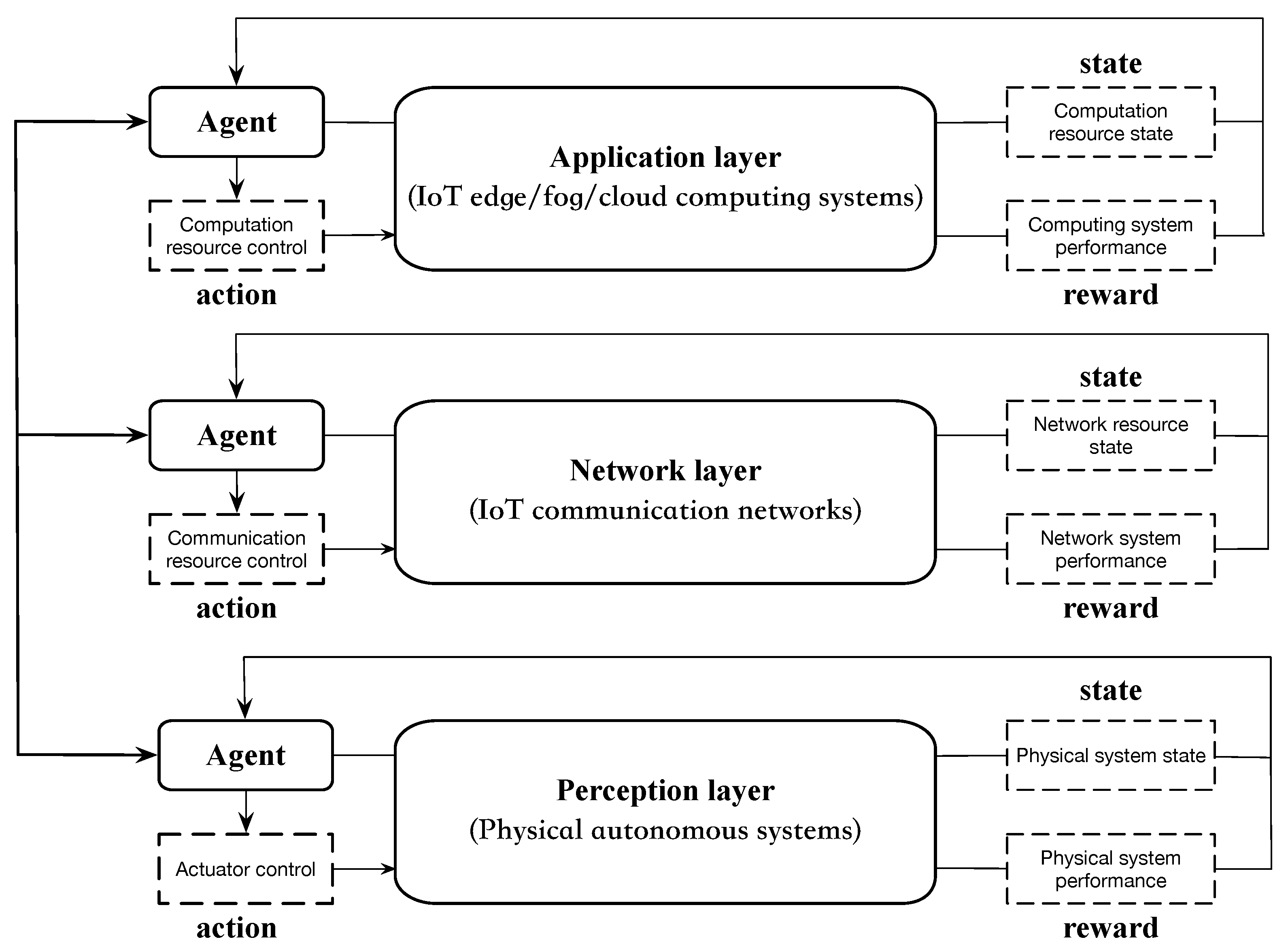
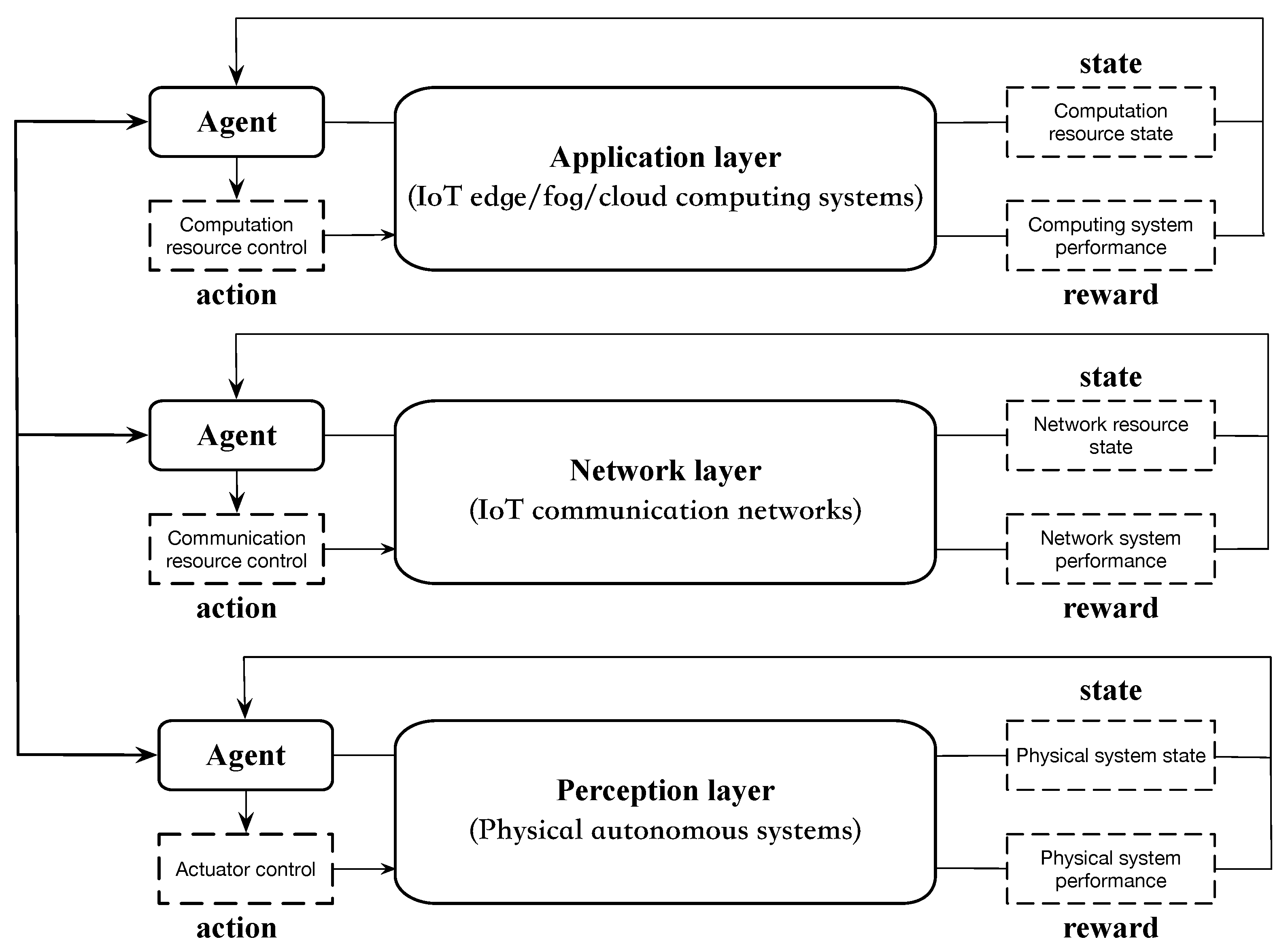
1.3.1. Internet of Things (IoT)
Industrial Internet of Things (IIoT)
Mobile Edge Computing (MEC)
Others
1.3.2. Connected Vehicles
Computing and Caching
Resource Allocation
Traffic Scheduling
Others
1.3.3. Resources Management
1.4. More Topics
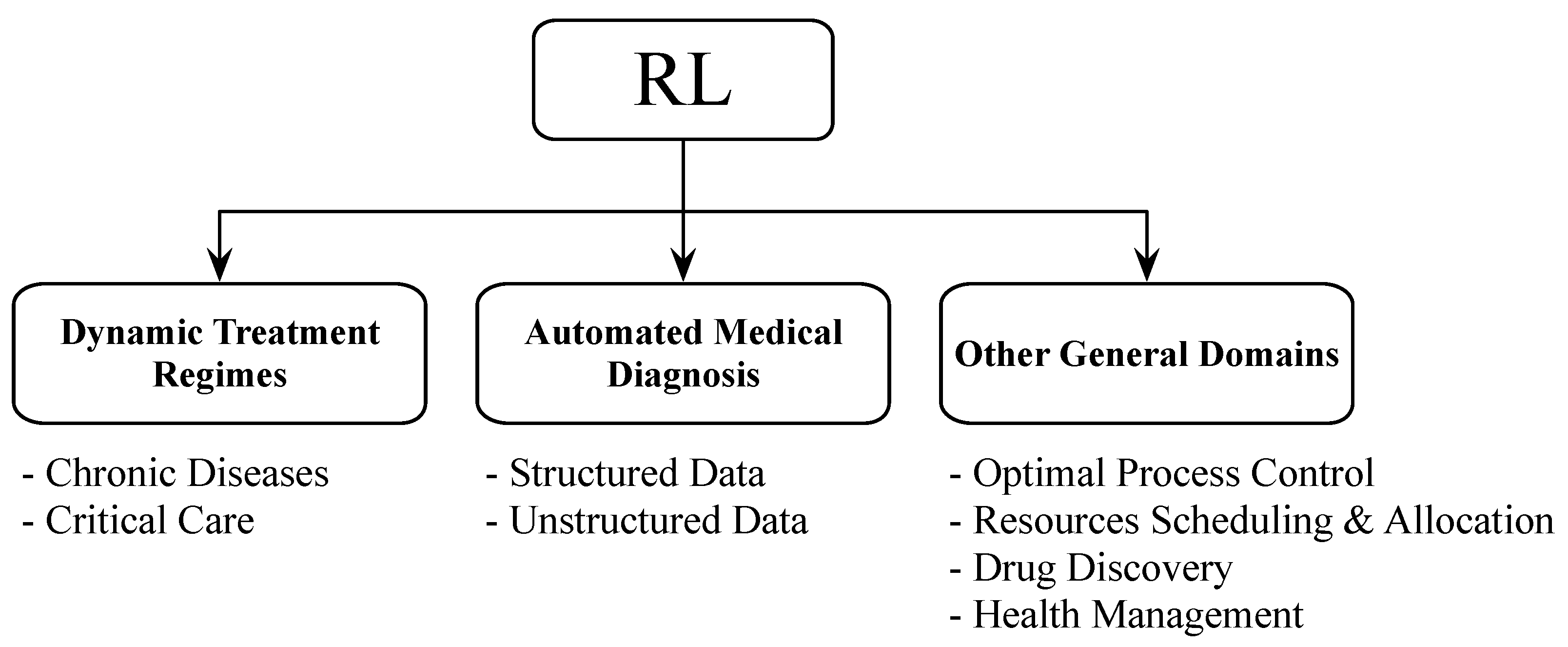
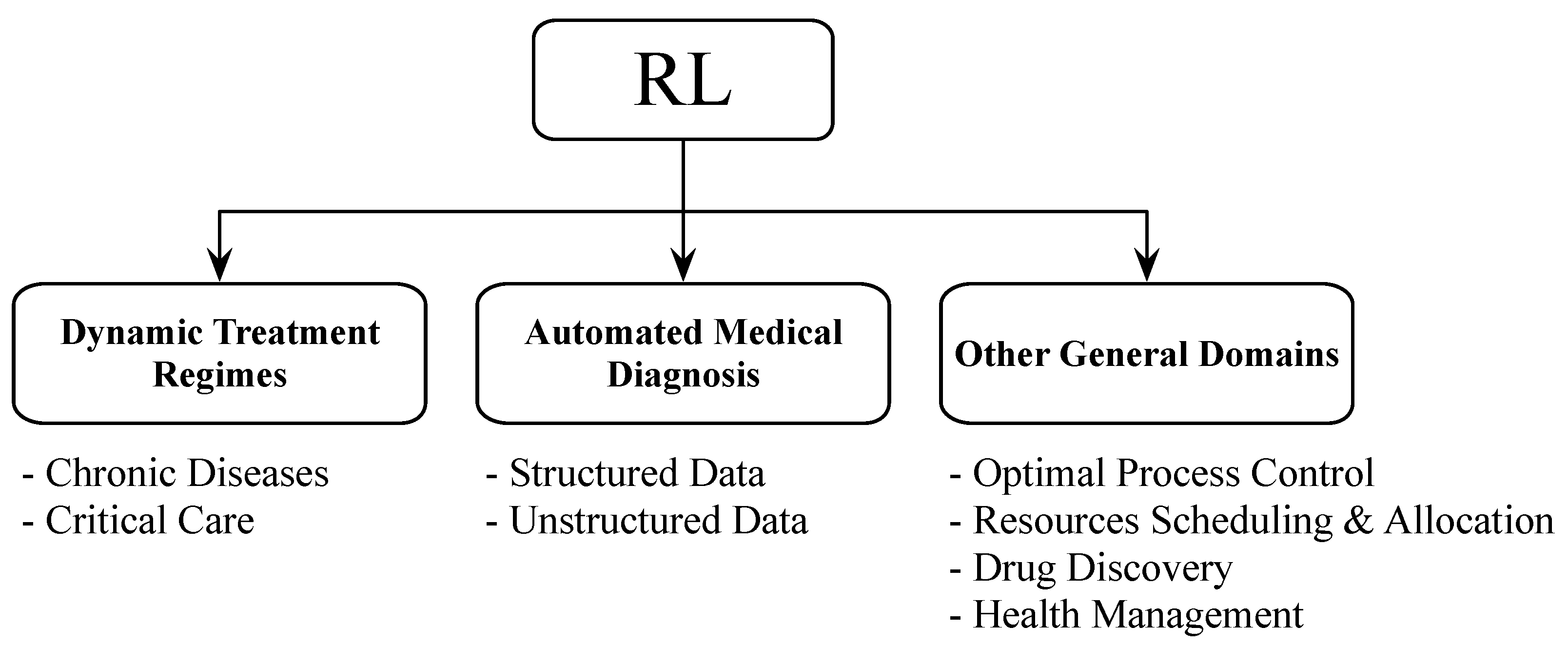
1.4.1. Healthcare
1.4.2. Education
1.4.3. Finance
1.4.4. Aerospace
2. Discussions
2.1. Deep Reinforcement Learning Limitations
- Modeling the real world is complex. Many systems cannot be directly trained on. An off-line off-policy approach [116] could be deployed to replace a previous control system. Logs from the policy are available, and the policy is trained with batches of data obtained from the control algorithm.
- Practical systems do not have separate training and evaluation environments. The agent must explore and act reasonably and safely. Thus, a sample-efficient and performant algorithm is crucial. Finn et al. [117] proposed Model Agnostic Meta-Learning (MAML) to learn within a distribution with few shot learning. Osband et al. [118] used Bootstrapped DQN to learn an ensemble of Q-networks and Thompson Sampling to achieve deep efficient exploration. Using expert demonstrations to bootstrap the agent can also improve efficiency, which has been combined with DQN [7] and DDPG [23].
- Real-world environments usually have massive and continuous state and action spaces. Dulac-Arnold et al. [119] addressed the challenge for sizeable discrete action spaces. Action-Elimination Deep Q-Network (AE-DQN) [120] and Deep Reinforcement Relevance Network (DRRN) [121] also deals with the issue.
- Considering POMDP problems, Dulac-Arnold et al. [116] presented Robust MDPs, where the learned policy maximizes the worst-case value function.
- Formulating multi-dimensional reward functions is usually necessary and complicated. Distributional DQN Bellemare et al. [123] models the percentile distribution of the rewards. Dulac-Arnold et al. [116] presented multi-objective analysis and formulated the global reward function as a linear combination of sub-rewards. Abbeel and Ng [124] gave an algorithm is based on inverse RL to try to recover the unknown reward function.
- Policy explainability is vital for real-world policies as humans operate the systems.
- Most natural systems have delays in the perception of the states, the actuators, or the return. Hung et al. [127] proposed a memory-based algorithm where agents use recall of memories to credit actions from the past. Arjona-Medina et al. [128] introduced RUDDER (Return Decomposition for Delayed Rewards) to learn long-term credit assignments for delayed rewards.
2.2. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Bazzan, A.L.; Klügl, F. Introduction to intelligent systems in traffic and transportation. Synth. Lect. Artif. Intell. Mach. Learn. 2013, 7, 1–137. [Google Scholar] [CrossRef]
- Haydari, A.; Yilmaz, Y. Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey. arXiv 2020, arXiv:2005.00935. [Google Scholar] [CrossRef]
- Arel, I.; Liu, C.; Urbanik, T.; Kohls, A.G. Reinforcement learning-based multi-agent system for network traffic signal control. IET Intell. Transp. Syst. 2010, 4, 128–135. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2018, arXiv:1701.07274. [Google Scholar]
- El-Tantawy, S.; Abdulhai, B.; Abdelgawad, H. Multiagent Reinforcement Learning for Integrated Network of Adaptive Traffic Signal Controllers (MARLIN-ATSC): Methodology and Large-Scale Application on Downtown Toronto. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1140–1150. [Google Scholar] [CrossRef]
- Van der Pol, E.; Oliehoek, F.A. Coordinated deep reinforcement learners for traffic light control. In Proceedings of the Learning, Inference and Control of Multi-Agent Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Mannion, P.; Duggan, J.; Howley, E. An experimental review of reinforcement learning algorithms for adaptive traffic signal control. In Autonomic Road Transport Support Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 47–66. [Google Scholar]
- Gregurić, M.; Vujić, M.; Alexopoulos, C.; Miletić, M. Application of Deep Reinforcement Learning in Traffic Signal Control: An Overview and Impact of Open Traffic Data. Appl. Sci. 2020, 10, 4011. [Google Scholar] [CrossRef]
- Muresan, M.; Fu, L.; Pan, G. Adaptive traffic signal control with deep reinforcement learning an exploratory investigation. arXiv 2019, arXiv:1901.00960. [Google Scholar]
- Gong, Y. Improving Traffic Safety and Efficiency by Adaptive Signal Control Systems Based on Deep Reinforcement Learning. Ph.D. Thesis, University of Central Florida, Orlando, FL, USA, 2020. [Google Scholar]
- Tan, K.L.; Poddar, S.; Sarkar, S.; Sharma, A. Deep Reinforcement Learning for Adaptive Traffic Signal Control. In Proceedings of the Dynamic Systems and Control Conference, Park City, UT, USA, 8–11 October 2019; Volume 59162, p. V003T18A006. [Google Scholar]
- Guo, J. Decentralized Deep Reinforcement Learning for Network Level Traffic Signal Control. arXiv 2020, arXiv:2007.03433. [Google Scholar]
- Genders, W.; Razavi, S. Using a deep reinforcement learning agent for traffic signal control. arXiv 2016, arXiv:1611.01142. [Google Scholar]
- Genders, W.; Razavi, S. Evaluating reinforcement learning state representations for adaptive traffic signal control. Procedia Comput. Sci. 2018, 130, 26–33. [Google Scholar] [CrossRef]
- Garg, D.; Chli, M.; Vogiatzis, G. Deep Reinforcement Learning for Autonomous Traffic Light Control. In Proceedings of the 2018 3rd IEEE International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 3–5 September 2018; pp. 214–218. [Google Scholar]
- Rodrigues, F.; Azevedo, C.L. Towards Robust Deep Reinforcement Learning for Traffic Signal Control: Demand Surges, Incidents and Sensor Failures. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3559–3566. [Google Scholar]
- Wei, H.; Chen, C.; Wu, K.; Zheng, G.; Yu, Z.; Gayah, V.; Li, Z. Deep Reinforcement Learning for Traffic Signal Control along Arterials. In Proceedings of the 2019, DRL4KDD ’19, Anchorage, AK, USA, 5 August 2019. [Google Scholar]
- Wang, S.; Xie, X.; Huang, K.; Zeng, J.; Cai, Z. Deep reinforcement learning-based traffic signal control using high-resolution event-based data. Entropy 2019, 21, 744. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Wu, F. Feudal Multi-Agent Deep Reinforcement Learning for Traffic Signal Control. In Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), Auckland, New Zealand, 9–13 May 2020. [Google Scholar]
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1086–1095. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.; Zhou, P.; Liu, K.; Yuan, Y.; Wang, X.; Huang, H.; Wu, D.O. Multi-Agent Deep Reinforcement Learning for Urban Traffic Light Control in Vehicular Networks. IEEE Trans. Veh. Technol. 2020, 69, 8243–8256. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Alexander Pritzel, N.H.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Xu, M.; Wu, J.; Huang, L.; Zhou, R.; Wang, T.; Hu, D. Network-wide traffic signal control based on the discovery of critical nodes and deep reinforcement learning. J. Intell. Transp. Syst. 2020, 24, 1–10. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. End-to-End Deep Reinforcement Learning for Lane Keeping Assist. arXiv 2016, arXiv:1612.04340. [Google Scholar]
- Sharma, S.; Lakshminarayanan, A.S.; Ravindran, B. Learning To Repeat: Fine Grained Action Repetition For Deep Reinforcement Learning. arXiv 2017, arXiv:1702.06054. [Google Scholar]
- Gao, Y.; Xu, H.; Lin, J.; Yu, F.; Levine, S.; Darrell, T. Reinforcement Learning from Imperfect Demonstrations. arXiv 2018, arXiv:1802.05313. [Google Scholar]
- Xiang, X.; Foo, S. Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems: Part 1—Fundamentals and Applications in Games, Robotics and Natural Language Processing. Mach. Learn. Knowl. Extr. 2021, 3, 554–581. [Google Scholar] [CrossRef]
- Kang, Y.; Yin, H.; Berger, C. Test Your Self-Driving Algorithm: An Overview of Publicly Available Driving Datasets and Virtual Testing Environments. IEEE Trans. Intell. Veh. 2019, 4, 171–185. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. arXiv 2020, arXiv:2002.00444. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Osiński, B.; Jakubowski, A.; Miłoś, P.; Zięcina, P.; Galias, C.; Homoceanu, S.; Michalewski, H. Simulation-based reinforcement learning for real-world autonomous driving. arXiv 2020, arXiv:1911.12905. [Google Scholar]
- Fayjie, A.R.; Hossain, S.; Oualid, D.; Lee, D.J. Driverless car: Autonomous driving using deep reinforcement learning in urban environment. In Proceedings of the 2018 15th International Conference on Ubiquitous Robots (UR), Honolulu, HI, USA, 26–30 June 2018; pp. 896–901. [Google Scholar]
- Isele, D.; Rahimi, R.; Cosgun, A.; Subramanian, K.; Fujimura, K. Navigating occluded intersections with autonomous vehicles using deep reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2034–2039. [Google Scholar]
- Pusse, F.; Klusch, M. Hybrid Online POMDP Planning and Deep Reinforcement Learning for Safer Self-Driving Cars. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1013–1020. [Google Scholar]
- Sharifzadeh, S.; Chiotellis, I.; Triebel, R.; Cremers, D. Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks. arXiv 2016, arXiv:1612.03653. [Google Scholar]
- Hoel, C.J.; Wolff, K.; Laine, L. Automated speed and lane change decision making using deep reinforcement learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2148–2155. [Google Scholar]
- Shi, T.; Wang, P.; Cheng, X.; Chan, C.Y.; Huang, D. Driving Decision and Control for Autonomous Lane Change based on Deep Reinforcement Learning. arXiv 2019, arXiv:1904.10171. [Google Scholar]
- Wang, J.; Zhang, Q.; Zhao, D.; Chen, Y. Lane change decision-making through deep reinforcement learning with rule-based constraints. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Min, K.; Kim, H.; Huh, K. Deep Distributional Reinforcement Learning Based High-Level Driving Policy Determination. IEEE Trans. Intell. Veh. 2019, 4, 416–424. [Google Scholar] [CrossRef]
- Ye, Y.; Zhang, X.; Sun, J. Automated vehicle’s behavior decision making using deep reinforcement learning and high-fidelity simulation environment. Transp. Res. Part Emerg. Technol. 2019, 107, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Qiao, Z.; Muelling, K.; Dolan, J.; Palanisamy, P.; Mudalige, P. Pomdp and hierarchical options mdp with continuous actions for autonomous driving at intersections. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2377–2382. [Google Scholar]
- Hoel, C.; Driggs-Campbell, K.R.; Wolff, K.; Laine, L.; Kochenderfer, M.J. Combining Planning and Deep Reinforcement Learning in Tactical Decision Making for Autonomous Driving. arXiv 2019, arXiv:1905.02680. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Wang, X.; Xu, X.; Zhang, M.; Ge, H.; Ren, J.; Sun, L.; Chen, B.; Tan, G. Distributed multiagent coordinated learning for autonomous driving in highways based on dynamic coordination graphs. IEEE Trans. Intell. Transp. Syst. 2019, 21, 735–748. [Google Scholar] [CrossRef]
- Zhou, M.; Yu, Y.; Qu, X. Development of an efficient driving strategy for connected and automated vehicles at signalized intersections: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2019, 21, 433–443. [Google Scholar] [CrossRef]
- Makantasis, K.; Kontorinaki, M.; Nikolos, I.K. A Deep Reinforcement-Learning-based Driving Policy for Autonomous Road Vehicles. arXiv 2019, arXiv:1907.05246. [Google Scholar] [CrossRef] [Green Version]
- Qian, L.; Xu, X.; Zeng, Y.; Huang, J. Deep, Consistent Behavioral Decision Making with Planning Features for Autonomous Vehicles. Electronics 2019, 8, 1492. [Google Scholar] [CrossRef] [Green Version]
- Chae, H.; Kang, C.M.; Kim, B.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Belletti, F.; Haziza, D.; Gomes, G.; Bayen, A.M. Expert Level control of Ramp Metering based on Multi-task Deep Reinforcement Learning. arXiv 2017, arXiv:1701.08832. [Google Scholar] [CrossRef]
- Chalaki, B.; Beaver, L.E.; Remer, B.; Jang, K.; Vinitsky, E.; Bayen, A.M.; Malikopoulos, A.A. Zero-shot autonomous vehicle policy transfer: From simulation to real-world via adversarial learning. arXiv 2019, arXiv:1903.05252. [Google Scholar]
- Jang, K.; Vinitsky, E.; Chalaki, B.; Remer, B.; Beaver, L.; Malikopoulos, A.A.; Bayen, A. Simulation to scaled city: Zero-shot policy transfer for traffic control via autonomous vehicles. In Proceedings of the 10th ACM/IEEE International Conference on Cyber-Physical Systems, Montreal, QC, Canada, 16–18 April 2019; pp. 291–300. [Google Scholar]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M. Deep reinforcement learning enabled self-learning control for energy efficient driving. Transp. Res. Part Emerg. Technol. 2019, 99, 67–81. [Google Scholar] [CrossRef]
- Schoettler, G.; Nair, A.; Luo, J.; Bahl, S.; Ojea, J.A.; Solowjow, E.; Levine, S. Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards. arXiv 2019, arXiv:1906.05841. [Google Scholar]
- Li, F.; Jiang, Q.; Zhang, S.; Wei, M.; Song, R. Robot skill acquisition in assembly process using deep reinforcement learning. Neurocomputing 2019, 345, 92–102. [Google Scholar] [CrossRef]
- Zhang, C.; Gupta, C.; Farahat, A.; Ristovski, K.; Ghosh, D. Equipment health indicator learning using deep reinforcement learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2018; pp. 488–504. [Google Scholar]
- Holmgren, V. General-Purpose Maintenance Planning Using Deep Reinforcement Learning and Monte Carlo Tree Search. Master’s Dissertation, Linköping University, Linköping, Sweden, December 2019. [Google Scholar]
- Ong, K.S.H.; Niyato, D.; Yuen, C. Predictive Maintenance for Edge-Based Sensor Networks: A Deep Reinforcement Learning Approach. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–6. [Google Scholar]
- Huang, J.; Chang, Q.; Arinez, J. Deep reinforcement learning based preventive maintenance policy for serial production lines. Expert Syst. Appl. 2020, 160, 113701. [Google Scholar] [CrossRef]
- Andriotis, C.; Papakonstantinou, K. Life-cycle policies for large engineering systems under complete and partial observability. In Proceedings of the 13th International Conference on Applications of Statistics and Probability in Civil Engineering (ICASP13), Seoul, Korea, 26–30 May 2019. [Google Scholar]
- Andriotis, C.P.; Papakonstantinou, K.G. Managing engineering systems with large state and action spaces through deep reinforcement learning. arXiv 2018, arXiv:1811.02052. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Hong, S.H.; Yu, M.; Ding, Y.; Jiang, J. Demand Response Management for Industrial Facilities: A Deep Reinforcement Learning Approach. IEEE Access 2019, 7, 82194–82205. [Google Scholar] [CrossRef]
- Spielberg, S.P.K.; Gopaluni, R.B.; Loewen, P.D. Deep reinforcement learning approaches for process control. In Proceedings of the 2017 6th International Symposium on Advanced Control of Industrial Processes (AdCONIP), Taipei, Taiwan, 28–31 May 2017; pp. 201–206. [Google Scholar]
- Spielberg, S.; Tulsyan, A.; Lawrence, N.P.; Loewen, P.D.; Bhushan Gopaluni, R. Toward self-driving processes: A deep reinforcement learning approach to control. AIChE J. 2019, 65, e16689. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Han, X.; Deng, C. Review on the research and practice of deep learning and reinforcement learning in smart grids. CSEE J. Power Energy Syst. 2018, 4, 362–370. [Google Scholar] [CrossRef]
- Rocchetta, R.; Bellani, L.; Compare, M.; Zio, E.; Patelli, E. A reinforcement learning framework for optimal operation and maintenance of power grids. Appl. Energy 2019, 241, 291–301. [Google Scholar] [CrossRef]
- An, D.; Yang, Q.; Liu, W.; Zhang, Y. Defending against data integrity attacks in smart grid: A deep reinforcement learning-based approach. IEEE Access 2019, 7, 110835–110845. [Google Scholar] [CrossRef]
- Wei, F.; Wan, Z.; He, H. Cyber-Attack Recovery Strategy for Smart Grid Based on Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 2476–2486. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-Line Building Energy Optimization Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 10, 3698–3708. [Google Scholar] [CrossRef] [Green Version]
- Dai, Y.; Xu, D.; Maharjan, S.; Chen, Z.; He, Q.; Zhang, Y. Blockchain and deep reinforcement learning empowered intelligent 5G beyond. IEEE Netw. 2019, 33, 10–17. [Google Scholar] [CrossRef]
- Yang, H.; Xie, X.; Kadoch, M. Machine Learning Techniques and A Case Study for Intelligent Wireless Networks. IEEE Netw. 2020, 34, 208–215. [Google Scholar] [CrossRef]
- Lei, L.; Tan, Y.; Zheng, K.; Liu, S.; Zhang, K.; Shen, X. Deep Reinforcement Learning for Autonomous Internet of Things: Model, Applications and Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1722–1760. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Yu, F.R.; Teng, Y.; Leung, V.C.; Song, M. Performance optimization for blockchain-enabled industrial Internet of Things (IIoT) systems: A deep reinforcement learning approach. IEEE Trans. Ind. Inform. 2019, 15, 3559–3570. [Google Scholar] [CrossRef]
- Liu, C.H.; Lin, Q.; Wen, S. Blockchain-Enabled Data Collection and Sharing for Industrial IoT With Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2019, 15, 3516–3526. [Google Scholar] [CrossRef]
- He, Y.; Yu, F.R.; Zhao, N.; Leung, V.C.; Yin, H. Software-defined networks with mobile edge computing and caching for smart cities: A big data deep reinforcement learning approach. IEEE Commun. Mag. 2017, 55, 31–37. [Google Scholar] [CrossRef]
- Bu, F.; Wang, X. A smart agriculture IoT system based on deep reinforcement learning. Future Gener. Comput. Syst. 2019, 99, 500–507. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep reinforcement learning based mobile edge computing for intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Zhu, H.; Cao, Y.; Wei, X.; Wang, W.; Jiang, T.; Jin, S. Caching transient data for Internet of Things: A deep reinforcement learning approach. IEEE Internet Things J. 2018, 6, 2074–2083. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Wang, Q.; Cao, B.; Feng, G.; Hu, J. iRAF: A deep reinforcement learning approach for collaborative mobile edge computing IoT networks. IEEE Internet Things J. 2019, 6, 7011–7024. [Google Scholar] [CrossRef]
- Wei, Y.; Yu, F.R.; Song, M.; Han, Z. Joint optimization of caching, computing, and radio resources for fog-enabled IoT using natural actor–critic deep reinforcement learning. IEEE Internet Things J. 2018, 6, 2061–2073. [Google Scholar] [CrossRef]
- Sun, Y.; Peng, M.; Mao, S. Deep reinforcement learning-based mode selection and resource management for green fog radio access networks. IEEE Internet Things J. 2018, 6, 1960–1971. [Google Scholar] [CrossRef] [Green Version]
- Gazori, P.; Rahbari, D.; Nickray, M. Saving time and cost on the scheduling of fog-based IoT applications using deep reinforcement learning approach. Future Gener. Comput. Syst. 2020, 110, 1098–1115. [Google Scholar] [CrossRef]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A new deep-Q-learning-based transmission scheduling mechanism for the cognitive Internet of Things. IEEE Internet Things J. 2017, 5, 2375–2385. [Google Scholar] [CrossRef]
- Ferdowsi, A.; Saad, W. Deep learning for signal authentication and security in massive internet-of-things systems. IEEE Trans. Commun. 2018, 67, 1371–1387. [Google Scholar] [CrossRef] [Green Version]
- Jay, N.; Rotman, N.; Godfrey, B.; Schapira, M.; Tamar, A. A deep reinforcement learning perspective on internet congestion control. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3050–3059. [Google Scholar]
- He, Y.; Zhao, N.; Yin, H. Integrated networking, caching, and computing for connected vehicles: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2017, 67, 44–55. [Google Scholar] [CrossRef]
- Doddalinganavar, S.S.; Tergundi, P.V.; Patil, R.S. Survey on Deep Reinforcement Learning Protocol in VANET. In Proceedings of the 2019 1st International Conference on Advances in Information Technology (ICAIT), Chikmagalur, India, 25–27 July 2019; pp. 81–86. [Google Scholar] [CrossRef]
- Tan, L.T.; Hu, R.Q. Mobility-aware edge caching and computing in vehicle networks: A deep reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 10190–10203. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Rodrigues, J.J.; Xia, F. Deep reinforcement learning for vehicular edge computing: An intelligent offloading system. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yu, H.; Xie, S.; Zhang, Y. Deep reinforcement learning for offloading and resource allocation in vehicle edge computing and networks. IEEE Trans. Veh. Technol. 2019, 68, 11158–11168. [Google Scholar] [CrossRef]
- Ning, Z.; Zhang, K.; Wang, X.; Obaidat, M.S.; Guo, L.; Hu, X.; Hu, B.; Guo, Y.; Sadoun, B.; Kwok, R.Y.K. Joint Computing and Caching in 5G-Envisioned Internet of Vehicles: A Deep Reinforcement Learning-Based Traffic Control System. IEEE Trans. Intell. Transp. Syst. 2020, 1–12. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H.F. Deep reinforcement learning based resource allocation for V2V communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef] [Green Version]
- Chinchali, S.; Hu, P.; Chu, T.; Sharma, M.; Bansal, M.; Misra, R.; Pavone, M.; Katti, S. Cellular Network Traffic Scheduling With Deep Reinforcement Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 766–774. [Google Scholar]
- Kwon, D.; Kim, J. Multi-Agent Deep Reinforcement Learning for Cooperative Connected Vehicles. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Aoki, S.; Higuchi, T.; Altintas, O. Cooperative Perception with Deep Reinforcement Learning for Connected Vehicles. arXiv 2020, arXiv:2004.10927. [Google Scholar]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource management with deep reinforcement learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Li, R.; Zhao, Z.; Sun, Q.; Chih-Lin, I.; Yang, C.; Chen, X.; Zhao, M.; Zhang, H. Deep reinforcement learning for resource management in network slicing. IEEE Access 2018, 6, 74429–74441. [Google Scholar] [CrossRef]
- Zhang, Y.; Yao, J.; Guan, H. Intelligent cloud resource management with deep reinforcement learning. IEEE Cloud Comput. 2017, 4, 60–69. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Liu, S.; Ngiam, K.Y.; Feng, M. Deep Reinforcement Learning for Clinical Decision Support: A Brief Survey. arXiv 2019, arXiv:1907.09475. [Google Scholar]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement learning in healthcare: A survey. arXiv 2019, arXiv:1908.08796. [Google Scholar]
- Liu, Y.; Logan, B.; Liu, N.; Xu, Z.; Tang, J.; Wang, Y. Deep reinforcement learning for dynamic treatment regimes on medical registry data. In Proceedings of the 2017 IEEE International Conference on Healthcare Informatics (ICHI), Park City, UT, USA, 23–26 August 2017; pp. 380–385. [Google Scholar]
- Reddy, S.; Levine, S.; Dragan, A. Accelerating human learning with deep reinforcement learning. In Proceedings of the NIPS 2017 Workshop: Teaching Machines, Robots, and Humans, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Ritter, G. Reinforcement learning in finance. In Big Data and Machine Learning in Quantitative Investment; John Wiley & Sons: Hoboken, NJ, USA, 2018; pp. 225–250. [Google Scholar]
- Charpentier, A.; Elie, R.; Remlinger, C. Reinforcement Learning in Economics and Finance. arXiv 2020, arXiv:2003.10014. [Google Scholar]
- Xiong, Z.; Liu, X.Y.; Zhong, S.; Yang, H.; Walid, A. Practical deep reinforcement learning approach for stock trading. arXiv 2018, arXiv:1811.07522. [Google Scholar]
- Zhang, Z.; Zohren, S.; Roberts, S. Deep reinforcement learning for trading. J. Financ. Data Sci. 2020, 2, 25–40. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Tang, K.; Wu, J.; Xiong, Z. Alphastock: A buying-winners-and-selling-losers investment strategy using interpretable deep reinforcement attention networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1900–1908. [Google Scholar]
- Jiang, Z.; Xu, D.; Liang, J. A deep reinforcement learning framework for the financial portfolio management problem. arXiv 2017, arXiv:1706.10059. [Google Scholar]
- Hu, Y.J.; Lin, S.J. Deep reinforcement learning for optimizing finance portfolio management. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 14–20. [Google Scholar]
- Harris, A.T.; Schaub, H. Spacecraft Command and Control with Safety Guarantees using Shielded Deep Reinforcement Learning. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0386. [Google Scholar]
- Harris, A.; Teil, T.; Schaub, H. Spacecraft decision-making autonomy using deep reinforcement learning. In Proceedings of the 29th AAS/AIAA Space Flight Mechanics Meeting, Maui, HI, USA, 13–17 January 2019; pp. 1–19. [Google Scholar]
- Yu, L.; Wang, Q.; Guo, Y.; Li, P. Spectrum availability prediction in cognitive aerospace communications: A deep learning perspective. In Proceedings of the 2017 Cognitive Communications for Aerospace Applications Workshop (CCAA), Cleveland, OH, USA, 27–28 June 2017; pp. 1–4. [Google Scholar]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Julian, K.D.; Kochenderfer, M.J. Distributed wildfire surveillance with autonomous aircraft using deep reinforcement learning. J. Guid. Control Dyn. 2019, 42, 1768–1778. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Mankowitz, D.; Hester, T. Challenges of real-world reinforcement learning. arXiv 2019, arXiv:1904.12901. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Osband, I.; Blundell, C.; Pritzel, A.; Roy, B.V. Deep Exploration via Bootstrapped DQN. arXiv 2016, arXiv:1602.04621. [Google Scholar]
- Dulac-Arnold, G.; Evans, R.; Sunehag, P.; Coppin, B. Reinforcement Learning in Large Discrete Action Spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Zahavy, T.; Haroush, M.; Merlis, N.; Mankowitz, D.J.; Mannor, S. Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning. arXiv 2018, arXiv:1809.02121. [Google Scholar]
- He, J.; Chen, J.; He, X.; Gao, J.; Li, L.; Deng, L.; Ostendorf, M. Deep Reinforcement Learning with an Unbounded Action Space. arXiv 2015, arXiv:1511.04636. [Google Scholar]
- Boutilier, C.; Lu, T. Budget Allocation Using Weakly Coupled, Constrained Markov Decision Processes; ResearchGate: Berlin, Germany, 2016. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the International Conference on Machine Learning 2017, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Hester, T.; Quinlan, M.J.; Stone, P. A Real-Time Model-Based Reinforcement Learning Architecture for Robot Control. arXiv 2011, arXiv:1105.1749. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Hung, C.; Lillicrap, T.P.; Abramson, J.; Wu, Y.; Mirza, M.; Carnevale, F.; Ahuja, A.; Wayne, G. Optimizing Agent Behavior over Long Time Scales by Transporting Value. arXiv 2018, arXiv:1810.06721. [Google Scholar] [CrossRef]
- Arjona-Medina, J.A.; Gillhofer, M.; Widrich, M.; Unterthiner, T.; Hochreiter, S. RUDDER: Return Decomposition for Delayed Rewards. arXiv 2018, arXiv:1806.07857. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, X.; Foo, S.; Zang, H. Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems Part 2—Applications in Transportation, Industries, Communications and Networking and More Topics. Mach. Learn. Knowl. Extr. 2021, 3, 863-878. https://doi.org/10.3390/make3040043
Xiang X, Foo S, Zang H. Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems Part 2—Applications in Transportation, Industries, Communications and Networking and More Topics. Machine Learning and Knowledge Extraction. 2021; 3(4):863-878. https://doi.org/10.3390/make3040043
Chicago/Turabian StyleXiang, Xuanchen, Simon Foo, and Huanyu Zang. 2021. "Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems Part 2—Applications in Transportation, Industries, Communications and Networking and More Topics" Machine Learning and Knowledge Extraction 3, no. 4: 863-878. https://doi.org/10.3390/make3040043
APA StyleXiang, X., Foo, S., & Zang, H. (2021). Recent Advances in Deep Reinforcement Learning Applications for Solving Partially Observable Markov Decision Processes (POMDP) Problems Part 2—Applications in Transportation, Industries, Communications and Networking and More Topics. Machine Learning and Knowledge Extraction, 3(4), 863-878. https://doi.org/10.3390/make3040043