
Human Pose Estimation Using Deep Learning: A Systematic Literature Review


Abstract
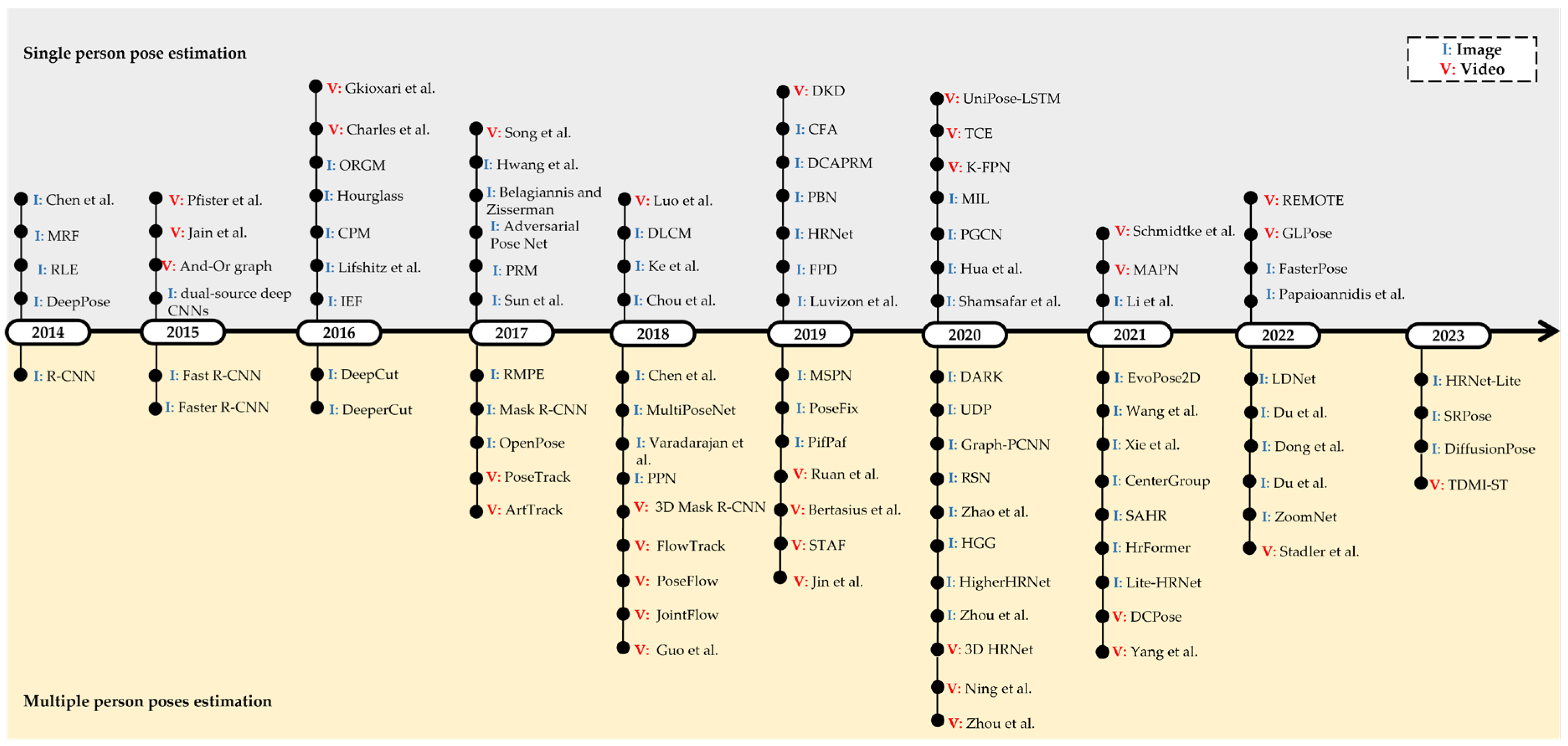
:1. Introduction
- We have systematically collected up-to-date human pose estimation models for image- and video-based input from 2014 to 2023;
- We classified pose estimation methods based on input type (image-based or video-based) and the number of people (single or multiple);
- We also provide an overview of existing datasets for estimating human poses and a list of loss functions, evaluation metrics, and commonly used feature extraction models.
2. Methodology
2.1. Search Process
2.2. Exclusion Criteria
- EC1: Studies must be peer-reviewed articles published in English;
- EC2: We do not include books, notes, theses, letters, or patents;
- EC3: Only papers that focus on applying deep learning methods to the problem of 2D human pose estimation are included;
- EC4: Unique contributions are considered for inclusion; repeated studies are not included;
- EC5: Papers that estimate only a part of the human pose, such as the head or hand, are omitted;
- EC6: Articles with multiple versions are not included; only one version will be included;
- EC7: Papers found in more than one database (e.g., in both Google Scholar and IEEE) are not included; only one will be included.
2.3. Quality Assessment
3. Search Results
3.1. Exclusion of Articles from the Initial Search
3.2. Result of Quality Assessments
4. Datasets of Human Pose Estimation
4.1. Leeds Sports Pose (LSP) and LSP Extended (LSPE)
4.2. Frames Labeled in Cinema (FLIC)
4.3. PennAction
4.4. Joint Human Motion DataBase (JHMDB)
4.5. Max Planck Institute for Informatics (MPII)
4.6. Common Objects in Context (COCO)
4.7. PoseTrack
4.8. CrowdPose
5. Loss Functions and Evaluation Metrics
5.1. Loss Function
5.1.1. Cross-Entropy
5.1.2. Focal
5.1.3. Mean Absolute Error
5.1.4. Mean Squared Error
5.1.5. Auxiliary
5.1.6. Knowledge Distillation
5.2. Evaluation Metrics
5.2.1. Percentage of Correct Parts
5.2.2. Percentage of Correct Key points
5.2.3. Area under the Curve
5.2.4. Percentage of Detected Joints
5.2.5. Intersection over Union
5.2.6. Object Keypoint Similarity
5.2.7. Average Recall and Average Precision
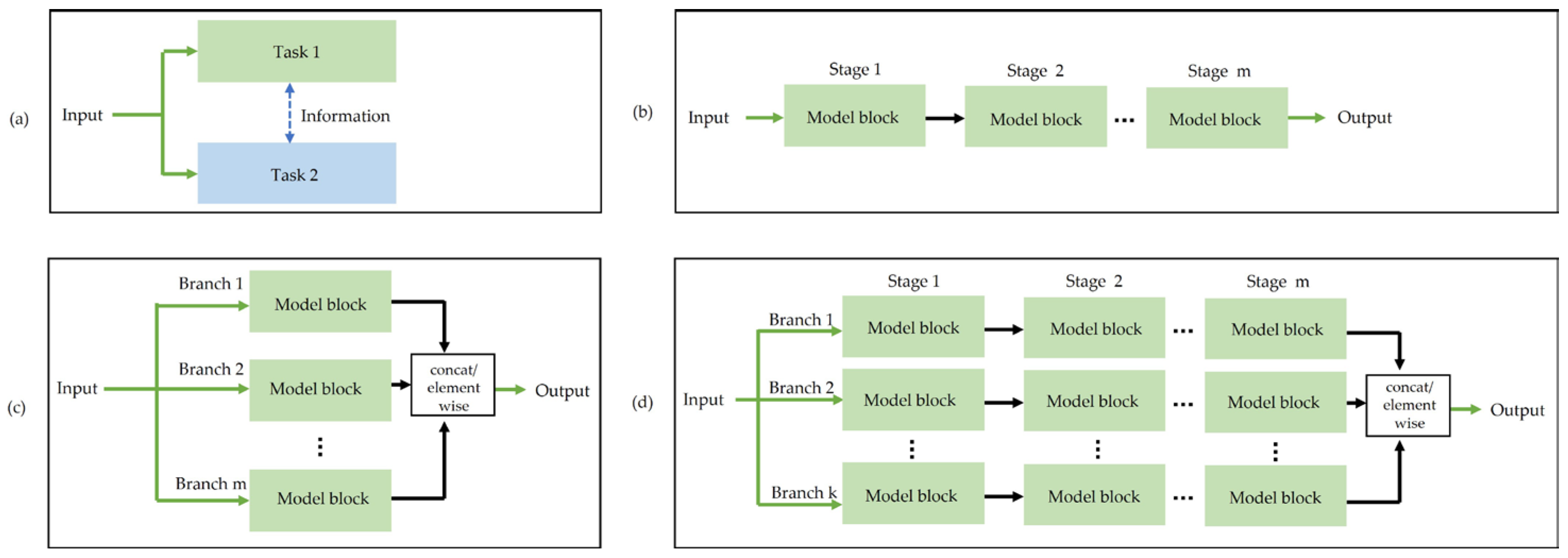
6. Feature Extraction
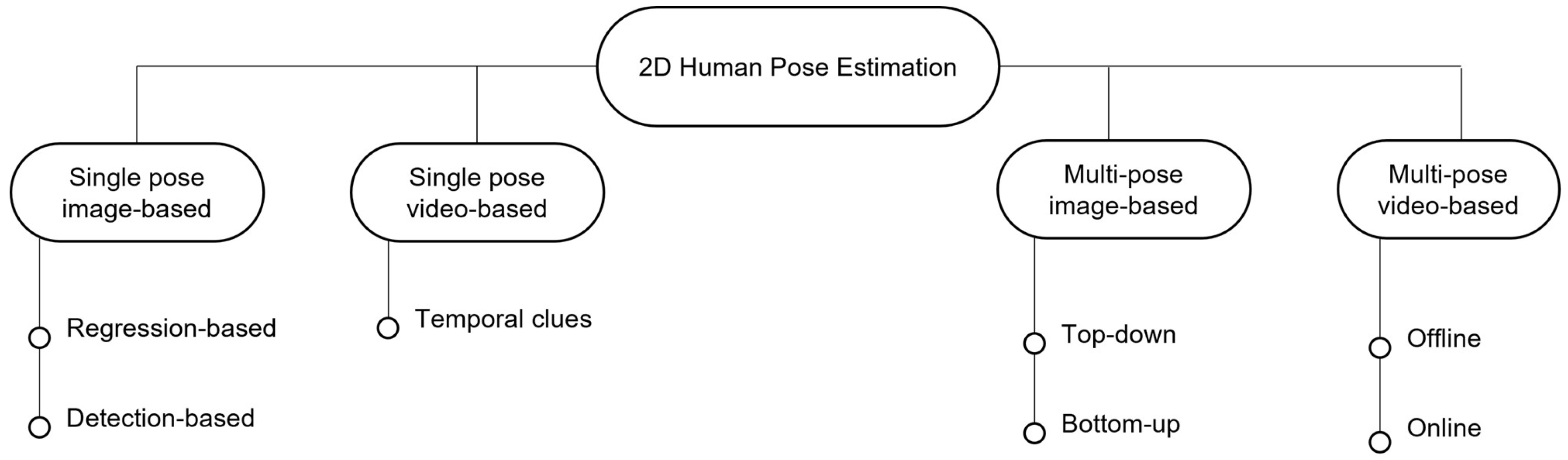
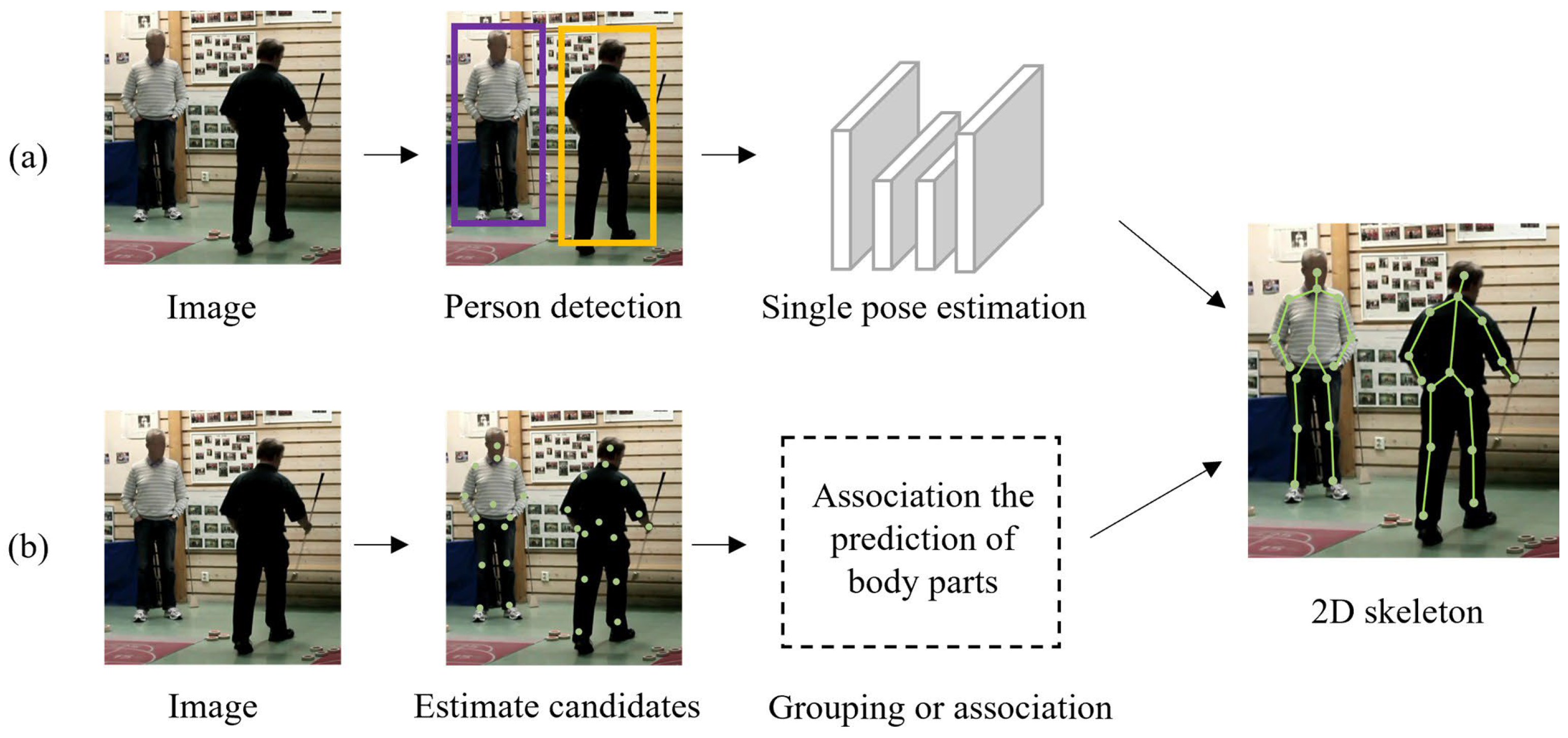
7. Existing Methods of Human Pose Estimation
7.1. Single Pose Estimation Image-Based
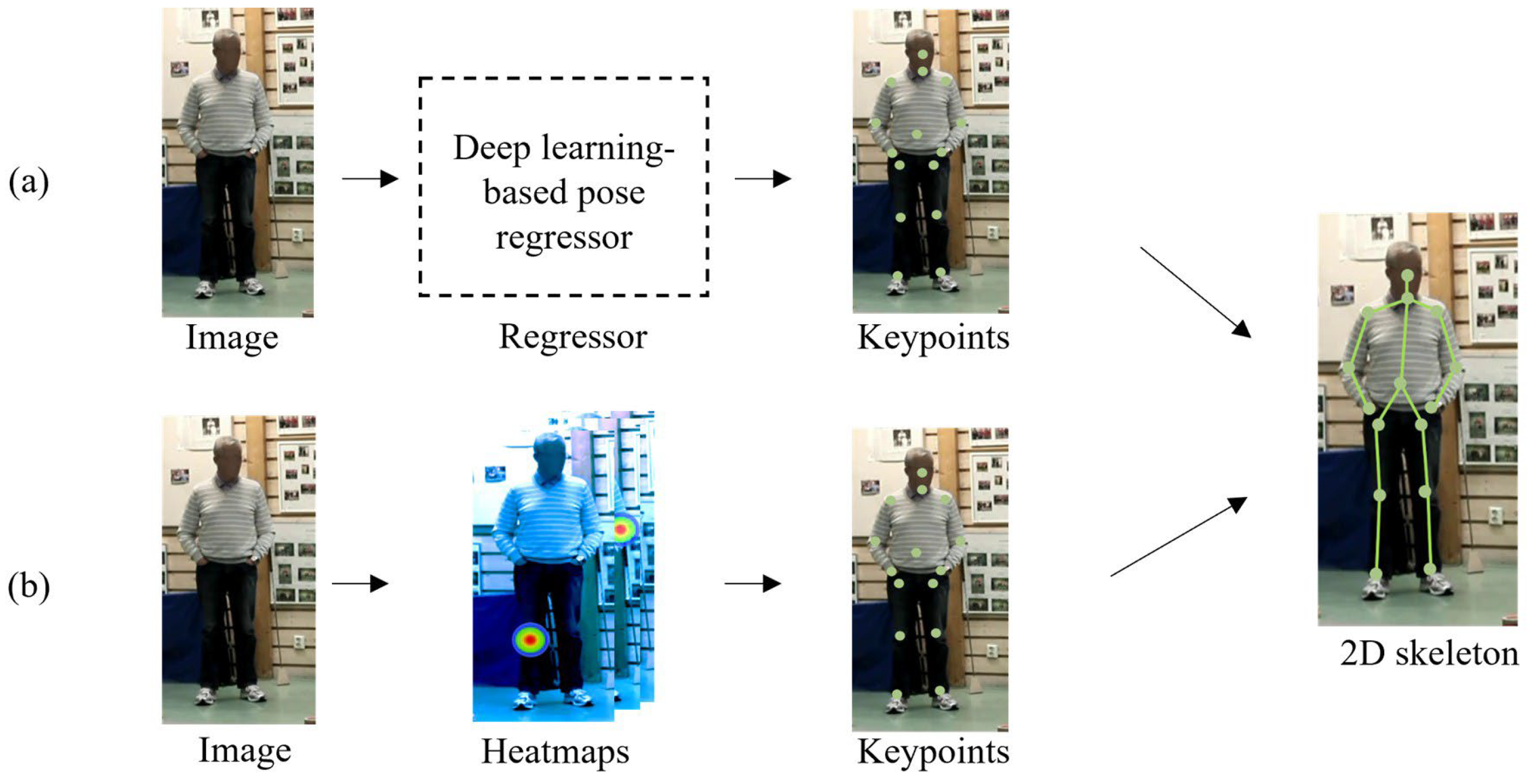
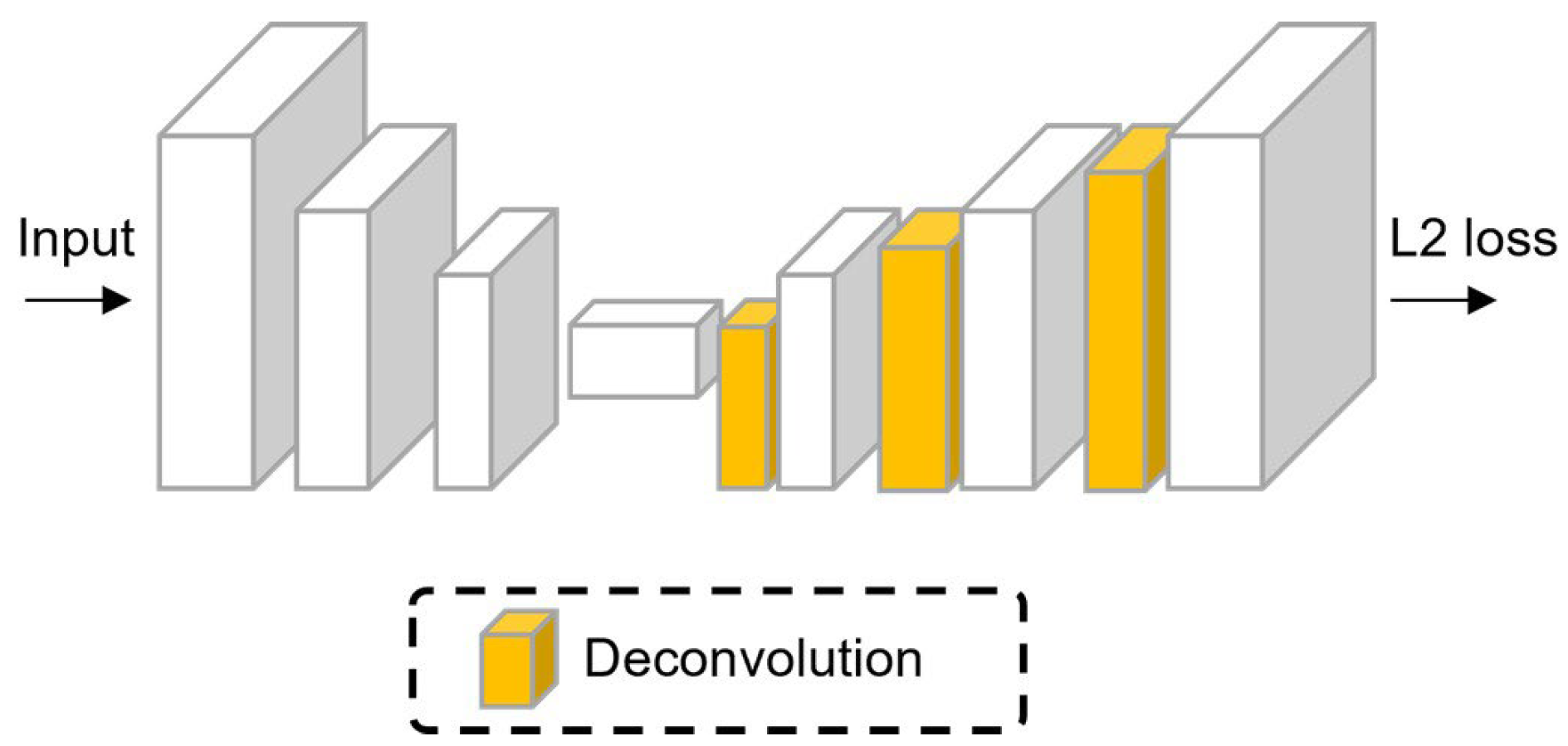
7.1.1. Regression-Based Pose Estimation
7.1.2. Detection-Based Pose Estimation
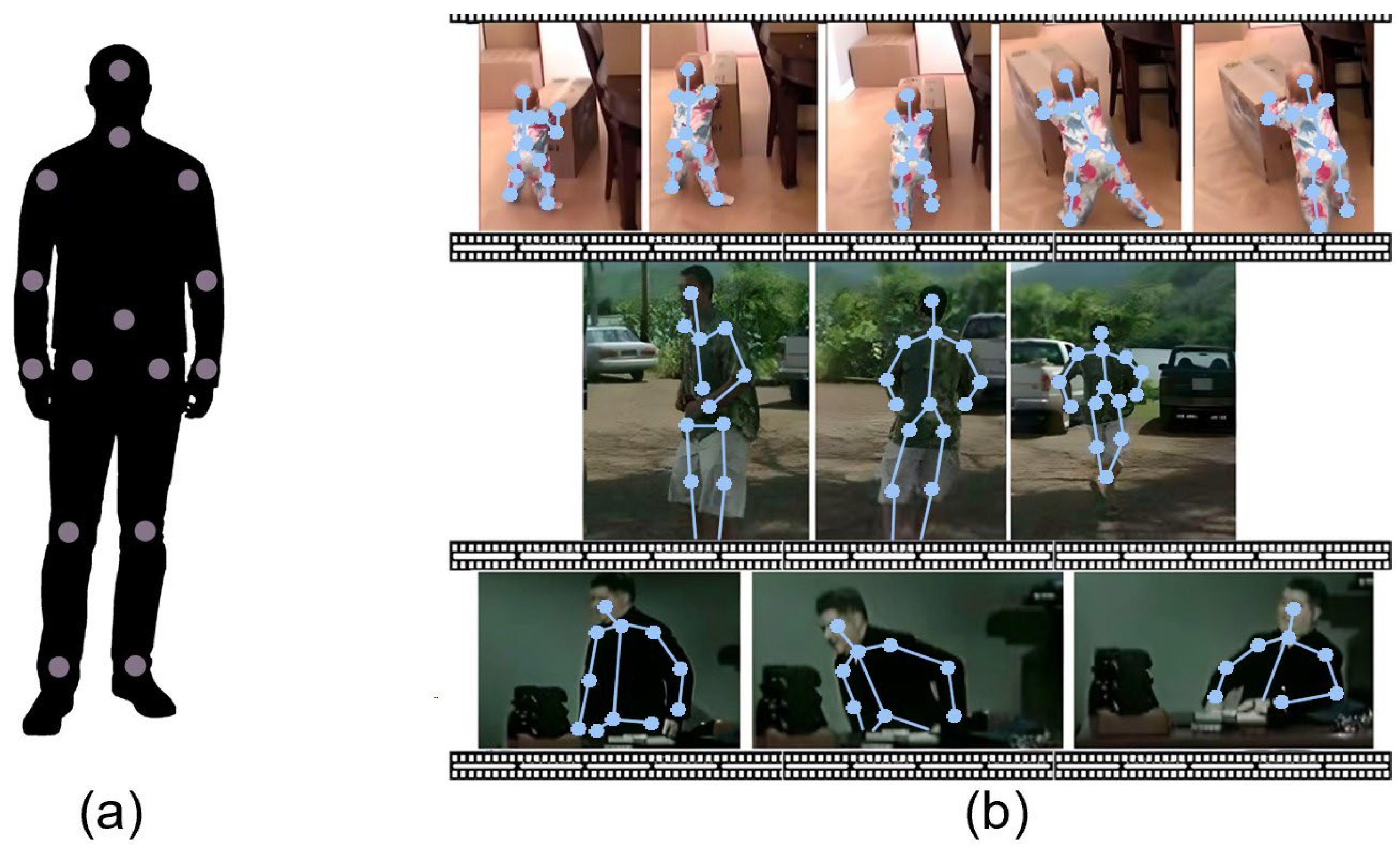
7.2. Single Pose Estimation Video-Based
7.3. MultiPose Estimation Image-Based
7.3.1. Top-Down Approach
7.3.2. Bottom-Up Approach
7.4. Multipose Estimation Video-Based
7.4.1. Offline Approach
7.4.2. Online Approach
8. Discussion
8.1. Which Datasets Are Used to Analyze the Performance of the Deep Learning Methods (RQ1)?
- Size: HPE is a nonlinear problem, and the size of the dataset affects model performance. Therefore, larger datasets are generally better for improving model accuracy;
- Data quality: A large amount of low-quality data can negatively impact performance. Data should be high-resolution and free of watermarks;
- Diversity: Datasets must include diverse data so that models can handle real-world scenarios. Hence, the datasets should provide different camera angles, poses, body shapes, races, ages, clothing styles, illumination conditions, and backgrounds;
- Complexity: Datasets must contain a variety of poses and actions to apply HPE to diverse applications. The datasets should include a range of poses, from simple ones such as standing and walking to more complex ones like flipping and kicking;
- Challenges: Datasets should include occlusions, cluttered backgrounds, and poses that change over time to assess the robustness of the models;
- Annotation quality: Annotations for key points and person detection in any dataset should be consistent, complete, and accurate.
8.2. Which Loss Functions and Evaluation Criteria Are Used to Measure the Performance of Deep Learning Methods in Human Pose Estimation (RQ2)?
8.3. What Are the PreTrained Models Used for Extracting the Features of the Human Pose (RQ3)?
8.4. What Are the Existing Deep Learning Methods Applied for 2D Human Pose Estimation (RQ4)?
9. Future Directions
- While CNNs are commonly used in HPE studies [50,79,83] for their effectiveness in implicit feature extraction from images, a few studies [108,139] have explored other deep learning methods such as GANs [13], GNNs [139], and RNNs [59]. The relative performance of these methods is unclear and warrants further research.
- Many studies [12,95,96] have found that detection-based approaches outperform regression-based approaches for estimating single poses. Recently, Gu et al. [162] analyzed these two approaches to determine why detection-based methods are superior to regression-based methods. They ultimately proposed a technique that showed regression-based approaches could outperform detection-based approaches, especially when facing complex problems. Further study of this work may open new directions for estimating single-person poses;
- While many studies [88,96,111] have achieved good performance (above 90% accuracy) in estimating single-person poses from images or videos, performance significantly decreases when estimating multiperson poses due to challenges such as occlusions and varying human sizes. Various studies [18,144,159] have proposed methodologies to address these challenges, but finding the best solutions remains an open problem;
- Optical flow has been used by some studies [53,107] to track motion in videos. However, it is easily affected by noise and can have difficulty tracking human motion in noisy environments. To improve performance, a few works [100,111] have replaced optical flow with other techniques, such as RNNs or temporal consistency. Focusing on such techniques may further boost performance;
- Many studies [119,124] use post-processing steps such as search algorithms or graphical models to group predicted key points into individual humans in bottom-up approaches. However, some recent works [58,139] have incorporated graphical information into neural networks to make the training process differentiable. This area warrants further investigation;
- Improving the efficiency of HPE tasks is not limited to enhancing models; dataset labels also play a significant role. In addition to keypoint position labels, only a few datasets [40,45] provide additional labels, such as visibility of body joints, that can help address the challenge of occlusions. As occlusion is one of the main challenges in 2D HPE, researchers need to increase the number of occluded labels in datasets. Unsupervised/semi-supervised and data augmentation methods are currently used to address this limitation;
- Another challenge in 2D HPE is crowded scenes. Only a few datasets provide data with crowded scenarios (e.g., CrowdPose and COCO), and their data consist only of images. Recently, a dataset called HAJJv2 [163] was introduced that provides more than 290,000 videos for detecting abnormal behaviors during Hajj religious events. The data in this dataset are diverse in terms of race, as many people from all over the world [164,165] perform Hajj rituals. They also have a large crowd scale, providing nine classes with normal and abnormal behaviors for each category. This dataset may help train 2D HPE models;
- An excellent example of research attempting to solve the problem of HPE in crowded scenes is research on Hajj and Umrah events [3,163,166], where more than 20 people must be detected, estimated, and classified in real-time. These types of research heavily rely on HPE techniques. For example, models such as YOLO and OpenPose are used for detecting and estimating poses to identify suspicious behavior during Hajj events. However, these models still face challenges in handling large numbers of poses in real-time. Developing methods to address this problem remains an open challenge.
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, J.; Chen, X.; Lu, Y.; Cao, J. 2D Human Pose Estimation from Monocular Images: A Survey. In Proceedings of the IEEE 3rd International Conference on Computer and Communication Engineering Technology, Beijing, China, 14–16 August 2020; pp. 111–121. [Google Scholar]
- Gong, W.; Zhang, X.; Gonzàlez, J.; Sobral, A.; Bouwmans, T.; Tu, C.; Zahzah, E.H. Human pose estimation from monocular images: A comprehensive survey. Sensors 2016, 16, 1966. [Google Scholar] [CrossRef]
- Miao, Y.; Yang, J.; Alzahrani, B.; Lv, G.; Alafif, T.; Barnawi, A.; Chen, M. Abnormal Behavior Learning Based on Edge Computing toward a Crowd Monitoring System. IEEE Netw. 2022, 36, 90–96. [Google Scholar] [CrossRef]
- Pardos, A.; Menychtas, A.; Maglogiannis, I. On unifying deep learning and edge computing for human motion analysis in exergames development. Neural Comput. Appl. 2022, 34, 951–967. [Google Scholar] [CrossRef]
- Kumarapu, L.; Mukherjee, P. Animepose: Multi-person 3d pose estimation and animation. Pattern Recognit. Lett. 2021, 147, 16–24. [Google Scholar] [CrossRef]
- Khan, M.A. Multiresolution coding of motion capture data for real-time multimedia applications. Multimed. Tools Appl. 2017, 76, 16683–16698. [Google Scholar] [CrossRef]
- Lonini, L.; Moon, Y.; Embry, K.; Cotton, R.J.; McKenzie, K.; Jenz, S.; Jayaraman, A. Video-based pose estimation for gait analysis in stroke survivors during clinical assessments: A proof-of-concept study. Digit. Biomark. 2022, 6, 9–18. [Google Scholar] [CrossRef]
- Ludwig, K.; Scherer, S.; Einfalt, M.; Lienhart, R. Self-supervised learning for human pose estimation in sports. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Gamra, M.B.; Akhloufi, M.A. A review of deep learning techniques for 2D and 3D human pose estimation. Image Vis. Comput. 2021, 114, 104282. [Google Scholar] [CrossRef]
- Li, T.; Yu, H. Visual-Inertial Fusion-Based Human Pose Estimation: A Review. IEEE Trans. Instrum. Meas. 2023, 72, 1–16. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Nguyen, T.H.; Scherer, R.; Le, V.H. Unified end-to-end YOLOv5-HR-TCM framework for automatic 2D/3D human pose estimation for real-time applications. Sensors 2022, 22, 5419. [Google Scholar] [CrossRef]
- Bin, Y.; Chen, Z.M.; Wei, X.S.; Chen, X.; Gao, C.; Sang, N. Structure-aware human pose estimation with graph convolutional networks. Pattern Recognit. 2020, 106, 107410. [Google Scholar] [CrossRef]
- Chou, C.J.; Chien, J.T.; Chen, H.T. Self adversarial training for human pose estimation. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Honolulu, HI, USA, 12–15 November 2018; pp. 17–30. [Google Scholar]
- Fan, X.; Zheng, K.; Lin, Y.; Wang, S. Combining local appearance and holistic view: Dual-source deep neural networks for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1347–1355. [Google Scholar]
- Liu, Z.; Zhu, J.; Bu, J.; Chen, C. A survey of human pose estimation: The body parts parsing based methods. J. Vis. Commun. Image Represent. 2015, 32, 10–19. [Google Scholar] [CrossRef]
- Alsubait, T.; Sindi, T.; Alhakami, H. Classification of the Human Protein Atlas Single Cell Using Deep Learning. Appl. Sci. 2022, 12, 11587. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Liu, Z.; Chen, H.; Feng, R.; Wu, S.; Ji, S.; Yang, B.; Wang, X. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 525–534. [Google Scholar]
- Wang, M.; Tighe, J.; Modolo, D. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11088–11096. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Moeslund, T.B.; Granum, E. A Survey of Computer Vision-Based Human Motion Capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Hilton, A.; Krüger, V. A survey of advances in vision-based human motion capture and analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- Perez-Sala, X.; Escalera, S.; Angulo, C.; Gonzàlez, J. A Survey on Model Based Approaches for 2D and 3D Visual Human Pose Recovery. Sensors 2014, 14, 4189–4210. [Google Scholar] [CrossRef]
- Dubey, S.; Dixit, M. A comprehensive survey on human pose estimation approaches. Multimed. Syst. 2023, 29, 167–195. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Yibin, China, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dang, Q.; Yin, J.; Wang, B.; Zheng, W. Deep learning based 2D human pose estimation: A survey. Tsinghua Sci. Technol. 2019, 24, 663–676. [Google Scholar] [CrossRef]
- Song, L.; Yu, G.; Yuan, J.; Liu, Z. Human pose estimation and its application to action recognition: A survey. J. Vis. Commun. Image Represent. 2021, 76, 103055. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The progress of human pose estimation: A survey and taxonomy of models applied in 2D human pose estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Toshpulatov, M.; Lee, W.; Lee, S.; Haghighian Roudsari, A. Human pose, hand and mesh estimation using deep learning: A survey. J. Supercomput. 2022, 78, 7616–7654. [Google Scholar] [CrossRef]
- Liu, W.; Bao, Q.; Sun, Y.; Mei, T. Recent advances of monocular 2D and 3D human pose estimation: A deep learning perspective. ACM Comput. Surv. 2022, 55, 1–41. [Google Scholar] [CrossRef]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep Learning-Based Human Pose Estimation: A Survey. J. ACM 2023, 37, 35. [Google Scholar] [CrossRef]
- Lan, G.; Wu, Y.; Hu, F.; Hao, Q. Vision-Based Human Pose Estimation via Deep Learning: A Survey. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 253–268. [Google Scholar] [CrossRef]
- dos Reis, E.S.; Seewald, L.A.; Antunes, R.S.; Rodrigues, V.F.; da Rosa Righi, R.; da Costa, C.A.; da Silveira, L.G., Jr.; Eskofier, B.; Maier, A.; Horz, T.; et al. Monocular multi-person pose estimation: A survey. Pattern Recognit. 2021, 118, 108046. [Google Scholar] [CrossRef]
- Badiola-Bengoa, A.; Mendez-Zorrilla, A. A Systematic Review of the Application of Camera-Based Human Pose Estimation in the Field of Sport and Physical Exercise. Sensors 2021, 21, 5996. [Google Scholar] [CrossRef]
- Difini, G.M.; Martins, M.G.; Barbosa, J.L.V. Human pose estimation for training assistance: A systematic literature review. In Proceedings of the Multimedia and the Web, Belo, Brazil, 5–12 November 2021; pp. 189–196. [Google Scholar]
- Topham, L.; Khan, W.; Al-Jumeily, D.; Hussain, A. Human Body Pose Estimation for Gait Identification: A Comprehensive Survey of Datasets and Models. ACM Comput. Surv. 2022, 55, 1–42. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Johnson, S.; Everingham, M. Clustered pose and nonlinear appearance models for human pose estimation. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; Volume 2, p. 5. [Google Scholar]
- Johnson, S.; Everingham, M. Learning effective human pose estimation from inaccurate annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1465–1472. [Google Scholar]
- Sapp, B.; Taskar, B. Modec: Multimodal decomposable models for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3674–3681. [Google Scholar]
- Zhang, W.; Zhu, M.; Derpanis, K.G. From actemes to action: A strongly-supervised representation for detailed action understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Sydney, Australia, 1–8 December 2013; pp. 2248–2255. [Google Scholar]
- Jhuang, H.; Gall, J.; Zuffi, S.; Schmid, C.; Black, M.J. Towards understanding action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Sydney, Australia, 1–8 December 2013; pp. 3192–3199. [Google Scholar]
- Andriluka, M.; Iqbal, U.; Insafutdinov, E.; Pishchulin, L.; Milan, A.; Gall, J.; Schiele, B. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5167–5176. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10863–10872. [Google Scholar]
- Doering, A.; Chen, D.; Zhang, S.; Schiele, B.; Gall, J. Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20963–20972. [Google Scholar]
- Zhang, F.; Zhu, X.; Ye, M. Fast human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3517–3526. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Girdhar, R.; Gkioxari, G.; Torresani, L.; Paluri, M.; Tran, D. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 350–359. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1913–1921. [Google Scholar]
- Wang, X.; Gao, L.; Dai, Y.; Zhou, Y.; Song, J. Semantic-aware transfer with instance-adaptive parsing for crowded scenes pose estimation. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 686–694. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Ke, L.; Chang, M.C.; Qi, H.; Lyu, S. Multi-scale structure-aware network for human pose estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 713–728. [Google Scholar]
- Papaioannidis, C.; Mademlis, I.; Pitas, I. Fast CNN-based Single-Person 2D Human Pose Estimation for Autonomous Systems. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1262–1275. [Google Scholar] [CrossRef]
- Brasó, G.; Kister, N.; Leal-Taixé, L. The center of attention: Center-keypoint grouping via attention for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 11853–11863. [Google Scholar]
- Belagiannis, V.; Zisserman, A. Recurrent human pose estimation. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 468–475. [Google Scholar]
- Zhou, L.; Chen, Y.; Gao, Y.; Wang, J.; Lu, H. Occlusion-aware siamese network for human pose estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 396–412. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Munea, T.L.; Yang, C.; Huang, C.; Elhassan, M.A.; Zhen, Q. SimpleCut: A simple and strong 2D model for multi-person pose estimation. Comput. Vis. Image Underst. 2022, 222, 103509. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Nguyen, T.H.; Nowak, R.; Byrski, J.; Siwocha, A.; Le, V.H. Combined YOLOv5 and HRNet for high accuracy 2D keypoint and human pose estimation. J. Artif. Intell. Soft Comput. Res. 2022, 12, 281–298. [Google Scholar] [CrossRef]
- Dong, X.; Yu, J.; Zhang, J. Joint usage of global and local attentions in hourglass network for human pose estimation. Neurocom-Puting 2022, 472, 95–102. [Google Scholar] [CrossRef]
- Li, S.; Liu, Z.Q.; Chan, A.B. Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 482–489. [Google Scholar]
- Arulprakash, E.; Aruldoss, M. A study on generic object detection with emphasis on future research directions. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 7347–7365. [Google Scholar] [CrossRef]
- Aly, S.; Gutub, A. Intelligent recognition system for identifying items and pilgrims. NED Univ. J. Res. 2018, 15, 17–23. [Google Scholar]
- Desai, M.M.; Mewada, H.K. Review on Human Pose Estimation and Human Body Joints Localization. Int. J. Comput. Digit. Syst. 2021, 10, 883–898. [Google Scholar] [CrossRef]
- Elharrouss, O.; Akbari, Y.; Almaadeed, N.; Al-Maadeed, S. Backbones-review: Feature extraction networks for deep learning and deep reinforcement learning approaches. arXiv 2022, arXiv:2206.08016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Kresovic, M. A survey of top-down approaches for human pose estimation. arXiv 2022, arXiv:2202.02656. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional human pose regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2602–2611. [Google Scholar]
- Luvizon, D.C.; Tabia, H.; Picard, D. Human pose regression by combining indirect part detection and contextual information. Comput. Graph. 2019, 85, 15–22. [Google Scholar] [CrossRef]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 11025–11034. [Google Scholar]
- Shamsafar, F.; Ebrahimnezhad, H. Uniting holistic and part-based attitudes for accurate and robust deep human pose estimation. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 2339–2353. [Google Scholar] [CrossRef]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Chen, H.; Feng, R.; Wu, S.; Xu, H.; Zhou, F.; Liu, Z. 2D Human pose estimation: A survey. Multimed. Syst. 2022, 29, 3115–3138. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Hua, G.; Li, L.; Liu, S. Multipath affinage stacked—Hourglass networks for human pose estimation. Front. Comput. Sci. 2020, 14, 1–12. [Google Scholar] [CrossRef]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Tian, Y.; Hu, W.; Jiang, H.; Wu, J. Densely connected attentional pyramid residual network for human pose estimation. Neurocomputing 2019, 347, 13–23. [Google Scholar] [CrossRef]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Hwang, J.; Park, S.; Kwak, N. Athlete pose estimation by a global-local network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 58–65. [Google Scholar]
- Lifshitz, I.; Fetaya, E.; Ullman, S. Human pose estimation using deep consensus voting. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 246–260. [Google Scholar]
- Chen, X.; Yuille, A.L. Articulated pose estimation by a graphical model with image dependent pairwise relations. Adv. Neural Inf. Process. Syst. 2014, 27, 1736–1744. [Google Scholar]
- Fu, L.; Zhang, J.; Huang, K. ORGM: Occlusion relational graphical model for human pose estimation. IEEE Trans. Image Process. 2016, 26, 927–941. [Google Scholar] [CrossRef]
- Tang, W.; Yu, P.; Wu, Y. Deeply learned compositional models for human pose estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 190–206. [Google Scholar]
- Tang, W.; Wu, Y. Does learning specific features for related parts help human pose estimation? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1107–1116. [Google Scholar]
- Su, Z.; Ye, M.; Zhang, G.; Dai, L.; Sheng, J. Cascade feature aggregation for human pose estimation. arXiv 2019, arXiv:1902.07837. [Google Scholar]
- Chen, Y.; Shen, C.; Wei, X.S.; Liu, L.; Yang, J. Adversarial posenet: A structure-aware convolutional network for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1212–1221. [Google Scholar]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Yang, J. Amil: Adversarial multi-instance learning for human pose estimation. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Dai, H.; Shi, H.; Liu, W.; Wang, L.; Liu, Y.; Mei, T. FasterPose: A faster simple baseline for human pose estimation. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–16. [Google Scholar] [CrossRef]
- Fan, Z.; Liu, J.; Wang, Y. Motion adaptive pose estimation from compressed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 11719–11728. [Google Scholar]
- Jiao, Y.; Chen, H.; Feng, R.; Chen, H.; Wu, S.; Yin, Y.; Liu, Z. GLPose: Global-Local Representation Learning for Human Pose Estimation. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–16. [Google Scholar] [CrossRef]
- Pfister, T.; Simonyan, K.; Charles, J.; Zisserman, A. Deep convolutional neural networks for efficient pose estimation in gesture videos. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 538–552. [Google Scholar]
- Jain, A.; Tompson, J.; LeCun, Y.; Bregler, C. Modeep: A deep learning framework using motion features for human pose estimation. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 302–315. [Google Scholar]
- Xiaohan Nie, B.; Xiong, C.; Zhu, S.C. Joint action recognition and pose estimation from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1293–1301. [Google Scholar]
- Liu, S.; Li, Y.; Hua, G. Human pose estimation in video via structured space learning and halfway temporal evaluation. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2029–2038. [Google Scholar] [CrossRef]
- Charles, J.; Pfister, T.; Magee, D.; Hogg, D.; Zisserman, A. Personalizing human video pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3063–3072. [Google Scholar]
- Song, J.; Wang, L.; Van Gool, L.; Hilliges, O. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4220–4229. [Google Scholar]
- Gkioxari, G.; Toshev, A.; Jaitly, N. Chained predictions using convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 728–743. [Google Scholar]
- Luo, Y.; Ren, J.; Wang, Z.; Sun, W.; Pan, J.; Liu, J.; Pang, J.; Lin, L. LSTM Pose Machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5207–5215. [Google Scholar]
- Artacho, B.; Savakis, A. Unipose: Unified human pose estimation in single images and videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7035–7044. [Google Scholar]
- Li, Y.; Li, K.; Wang, X.; Da Xu, R.Y. Exploring temporal consistency for human pose estimation in videos. Pattern Recognit. 2020, 103, 107258. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Camps, O.; Sznaier, M. Key frame proposal network for efficient pose estimation in videos. In Proceedings of the European Conference on Computer Vision; Springer: Glasgow, UK, 2020; pp. 609–625. [Google Scholar]
- Schmidtke, L.; Vlontzos, A.; Ellershaw, S.; Lukens, A.; Arichi, T.; Kainz, B. Unsupervised human pose estimation through transforming shape templates. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2484–2494. [Google Scholar]
- Ma, X.; Rahmani, H.; Fan, Z.; Yang, B.; Chen, J.; Liu, J. Remote: Reinforced motion transformation network for semi-supervised 2d pose estimation in videos. In Proceedings of the Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022; Volume 36, pp. 1944–1952. [Google Scholar]
- Nie, X.; Li, Y.; Luo, L.; Zhang, N.; Feng, J. Dynamic kernel distillation for efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6942–6950. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Multi-scale Aggregation R-CNN for 2D Multi-person Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1–9. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5700–5709. [Google Scholar]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on multi-stage networks for human pose estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Xie, R.; Wang, C.; Zeng, W.; Wang, Y. An empirical study of the collapsing problem in semi-supervised 2d human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 11240–11249. [Google Scholar]
- Wang, J.; Long, X.; Gao, Y.; Ding, E.; Wen, S. Graph-pcnn: Two stage human pose estimation with graph pose refinement. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 492–508. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning delicate local representations for multi-person pose estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 20200; pp. 455–472. [Google Scholar]
- Qiu, Z.; Yang, Q.; Wang, J.; Wang, X.; Xu, C.; Fu, D.; Yao, K.; Han, J.; Ding, E.; Wang, J. Learning Structure-Guided Diffusion Model for 2D Human Pose Estimation. arXiv 2023, arXiv:2306.17074. [Google Scholar]
- Yuan, Y.; Rao, F.; Lang, H.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10440–10450. [Google Scholar]
- Li, Y.; Liu, R.; Wang, X.; Wang, R. Human pose estimation based on lightweight basicblock. Mach. Vis. Appl. 2023, 34, 3. [Google Scholar] [CrossRef]
- Wang, H.; Liu, J.; Tang, J.; Wu, G. Lightweight Super-Resolution Head for Human Pose Estimation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 2353–2361. [Google Scholar]
- McNally, W.; Vats, K.; Wong, A.; McPhee, J. EvoPose2D: Pushing the boundaries of 2d human pose estimation using accelerated neuroevolution with weight transfer. IEEE Access 2021, 9, 139403–139414. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, R.; Guo, L.; Feng, C.; Gao, S. LDNet: Lightweight dynamic convolution network for human pose estimation. Adv. Eng. Inform. 2022, 54, 101785. [Google Scholar] [CrossRef]
- Xu, L.; Jin, S.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P.; Wang, X. Zoomnas: Searching for whole-body human pose estimation in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5296–5313. [Google Scholar] [CrossRef] [PubMed]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 34–50. [Google Scholar]
- Varadarajan, S.; Datta, P.; Tickoo, O. A greedy part assignment algorithm for real-time multi-person 2D pose estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 418–426. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. Multiposenet: Fast multi-person pose estimation using pose residual network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 417–433. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 11977–11986. [Google Scholar]
- Nasr, M.; Ayman, H.; Ebrahim, N.; Osama, R.; Mosaad, N.; Mounir, A. Realtime multi-person 2D pose estimation. Int. J. Adv. Netw. Appl. 2020, 11, 4501–4508. [Google Scholar] [CrossRef]
- Jin, S.; Liu, W.; Xie, E.; Wang, W.; Qian, C.; Ouyang, W.; Luo, P. Differentiable hierarchical graph grouping for multi-person pose estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 718–734. [Google Scholar]
- Jin, L.; Wang, X.; Nie, X.; Liu, L.; Guo, Y.; Zhao, J. Grouping by Center: Predicting Centripetal Offsets for the bottom-up human pose estimation. IEEE Trans. Multimed. 2022, 25, 3364–3374. [Google Scholar] [CrossRef]
- Du, C.; Yan, Z.; Yu, H.; Yu, L.; Xiong, Z. Hierarchical Associative Encoding and Decoding for Bottom-Up Human Pose Estimation. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1762–1775. [Google Scholar] [CrossRef]
- Nie, X.; Feng, J.; Xing, J.; Yan, S. Pose partition networks for multi-person pose estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Luo, Z.; Wang, Z.; Huang, Y.; Wang, L.; Tan, T.; Zhou, E. Rethinking the heatmap regression for bottom-up human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13264–13273. [Google Scholar]
- Hidalgo, G.; Raaj, Y.; Idrees, H.; Xiang, D.; Joo, H.; Simon, T.; Sheikh, Y. Single-network whole-body pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 15–20 June 2019; pp. 6982–6991. [Google Scholar]
- Zhao, Y.; Luo, Z.; Quan, C.; Liu, D.; Wang, G. Cluster-wise learning network for multi-person pose estimation. Pattern Recognit. 2020, 98, 107074. [Google Scholar] [CrossRef]
- Zhou, C.; Ren, Z.; Hua, G. Temporal keypoint matching and refinement network for pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 680–695. [Google Scholar]
- Ning, G.; Pei, J.; Huang, H. Lighttrack: A generic framework for online top-down human pose tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1034–1035. [Google Scholar]
- Iqbal, U.; Milan, A.; Gall, J. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2011–2020. [Google Scholar]
- Insafutdinov, E.; Andriluka, M.; Pishchulin, L.; Tang, S.; Levinkov, E.; Andres, B.; Schiele, B. Arttrack: Articulated multi-person tracking in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6457–6465. [Google Scholar]
- Feng, R.; Gao, Y.; Ma, X.; Tse, T.H.E.; Chang, H.J. Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17131–17141. [Google Scholar]
- Ruan, W.; Liu, W.; Bao, Q.; Chen, J.; Cheng, Y.; Mei, T. Poinet: Pose-guided ovonic insight network for multi-person pose tracking. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 284–292. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Bertasius, G.; Feichtenhofer, C.; Tran, D.; Shi, J.; Torresani, L. Learning temporal pose estimation from sparsely-labeled videos. Adv. Neural Inf. Process. Syst. 2019, 32, 3027–3038. [Google Scholar]
- Xiu, Y.; Li, J.; Wang, H.; Fang, Y.; Lu, C. Pose Flow: Efficient online pose tracking. arXiv 2018, arXiv:1802.00977. [Google Scholar]
- Guo, H.; Tang, T.; Luo, G.; Chen, R.; Lu, Y.; Wen, L. Multi-domain pose network for multi-person pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 209–216. [Google Scholar]
- Doering, A.; Iqbal, U.; Gall, J. Joint flow: Temporal flow fields for multi person tracking. arXiv 2018, arXiv:1805.04596. [Google Scholar]
- Raaj, Y.; Idrees, H.; Hidalgo, G.; Sheikh, Y. Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 4620–4628. [Google Scholar]
- Yang, Y.; Ren, Z.; Li, H.; Zhou, C.; Wang, X.; Hua, G. Learning dynamics via graph neural networks for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8074–8084. [Google Scholar]
- Stadler, D.; Beyerer, J. Modelling ambiguous assignments for multi-person tracking in crowds. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 133–142. [Google Scholar]
- Jin, S.; Liu, W.; Ouyang, W.; Qian, C. Multi-person articulated tracking with spatial and temporal embeddings. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 5664–5673. [Google Scholar]
- Gu, K.; Yang, L.; Yao, A. Dive deeper into integral pose regression. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Alafif, T.; Hadi, A.; Allahyani, M.; Alzahrani, B.; Alhothali, A.; Alotaibi, R.; Barnawi, A. Hybrid Classifiers for Spatio-Temporal Abnormal Behavior Detection, Tracking, and Recognition in Massive Hajj Crowds. Electronics 2023, 12, 1165. [Google Scholar] [CrossRef]
- Khan, E.A.; Shambour, M.K.Y. An analytical study of mobile applications for Hajj and Umrah services. Appl. Comput. Inform. 2018, 14, 37–47. [Google Scholar] [CrossRef]
- Alharthi, N.; Gutub, A. Data visualization to explore improving decision-making within Hajj services. Sci. Model. Res. 2017, 2, 9–18. [Google Scholar] [CrossRef]
- Shambour, M.K.; Gutub, A. Progress of IoT research technologies and applications serving Hajj and Umrah. Arab. J. Sci. Eng. 2022, 47, 1253–1273. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Journal | Dataset | Loss | Metric | FE | SinglePose | Multipose | Conventional/ Systematic | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Image | Video | Image | Video | ||||||||
| [2] | 2016 | Sensors | ✓ | 🗶 | ✓ | 🗶 | ✓ | * | ✓ | 🗶 | Conventional |
| [28] | 2019 | TST | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | Conventional |
| [31] | 2020 | CVIU | ✓ | 🗶 | ✓ | 🗶 | ✓ | * | ✓ | 🗶 | Conventional |
| [30] | 2020 | IEEE access | ✓ | ✓ | ✓ | ✓ | ✓ | 🗶 | ✓ | 🗶 | Conventional |
| [37] | 2021 | Sensors | ✓ | 🗶 | ✓ | 🗶 | * | 🗶 | * | 🗶 | Systematic |
| [38] | 2021 | ACM Com. Surv. | 🗶 | 🗶 | 🗶 | 🗶 | * | * | * | 🗶 | Systematic |
| [9] | 2021 | IVC | ✓ | 🗶 | ✓ | 🗶 | ✓ | * | ✓ | 🗶 | Conventional |
| [29] | 2021 | JVCIR | ✓ | 🗶 | 🗶 | 🗶 | ✓ | 🗶 | ✓ | 🗶 | Conventional |
| [36] | 2021 | Patt. Recog. | ✓ | 🗶 | ✓ | 🗶 | 🗶 | 🗶 | ✓ | ✓ | Conventional |
| [32] | 2022 | JS | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | Conventional |
| [39] | 2022 | ACM Com. Surv. | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | Systematic |
| [33] | 2022 | ACM Com. Surv. | ✓ | 🗶 | ✓ | 🗶 | ✓ | ✓ | ✓ | ✓ | Conventional |
| [35] | 2023 | IEEE THMS | ✓ | 🗶 | ✓ | 🗶 | ✓ | ✓ | ✓ | * | Conventional |
| [24] | 2023 | MMS | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | ✓ | 🗶 | Conventional |
| [34] | 2023 | ACM Com. Surv. | ✓ | 🗶 | ✓ | 🗶 | ✓ | ✓ | ✓ | 🗶 | Conventional |
| our | 2023 | MAKE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Systematic |
| Question | Purpose | |
|---|---|---|
| RQ1 | Which datasets are used to analyze the performance of the deep learning methods? | Discover the quality and other criteria of the datasets used to train the model of human pose estimation. |
| RQ2 | Which loss functions and evaluation criteria are used to measure the performance of deep learning methods in human pose estimation? | Discover the loss functions and evaluation metrics used in human pose estimation to measure model performance in training and testing mode. |
| RQ3 | What pretrained models are used for extracting the features of the human pose? | Compares the available models utilized to extract the features and knows the criteria for selecting one of these models. |
| RQ4 | What are the existing deep learning methods applied for 2D human pose estimation? | Review different methods that estimate the human pose in images and videos to know the new trend methods in this field. |
| Description | Value | Max Weight | |
|---|---|---|---|
| QA1 | Presenting a transparent and fair explanation of the problem, the approach, and the results in the abstract. | (0,1) | 1 |
| QA2 | Presence of a visual representation of the proposed method. In addition, the steps of the process must be described in detail. | [0–2] | 2 |
| QA3 | Gives information about the dataset and measures utilized in the model’s evaluation. | [0–1] | 1 |
| QA4 | Interpreting the findings cautiously, considering the study’s aims, limitations, the number of analyses conducted, and related research findings. | [0–2] | 2 |
| QA5 | Mentioning the study’s drawbacks and the limitations in the conclusion section. | (0,1) | 1 |
| Dataset | Year | Single Pose | Multi Pose | Joints | Size | Person Instance | Source | ||
|---|---|---|---|---|---|---|---|---|---|
| Image | Video | Image | Video | ||||||
| LSP [42] | 2010 | ✓ | 🗶 | 🗶 | 🗶 | 14 | 2 K | - | Flickr |
| LSPE [43] | 2011 | ✓ | 🗶 | 🗶 | 🗶 | 14 | 10 K | - | Flickr |
| FLIC [44] | 2013 | ✓ | 🗶 | ✓ | 🗶 | 10 | 5 K | - | Movies |
| PennAction [45] | 2013 | 🗶 | ✓ | 🗶 | 🗶 | 13 | 2.3 K | - | - |
| JHMDB [46] | 2013 | 🗶 | ✓ | 🗶 | 🗶 | 15 | 900 | - | Internet |
| MPII [40] | 2014 | ✓ | ✓ | ✓ | ✓ | 16 | i = 25 K v = 5.5 K | 40 K | YouTube |
| COCO [41] | 2017 | ✓ | 🗶 | ✓ | 🗶 | 17 | 200 K | 250 K | Internet |
| PoseTrack17 [47] | 2017 | 🗶 | ✓ | 🗶 | ✓ | 15 | 550 | 80 K | Internet |
| PoseTrack18 [47] | 2018 | 🗶 | ✓ | 🗶 | ✓ | 15 | 1 K | 144 K | Internet |
| CrowdPose [48] | 2019 | ✓ | 🗶 | ✓ | 🗶 | 14 | 20 K | 80 K | Three benchmarks |
| PoseTrack21 [49] | 2022 | 🗶 | ✓ | 🗶 | ✓ | 15 | 1 K | 177 K | Internet |
| Metric | Variation | Target | Threshold |
|---|---|---|---|
| PCP | PCP@0.5 | Limbs | Limb’s truth value × 0.5 |
| PCK | PCKh | Joints | Joint bounding box or head length × 0.5 |
| AUC | - | Joints | Different PCK thresholds |
| PDJ | PDJ@0.2 | Joints | Torso diameter × 0.2 |
| IOU | - | Joints | Joint’s bounding box |
| OKS | OKS@0.5 OKS@0.95 | Joints | Close to the ground-truth joint |
| AP | mAP AP50 AP75 APM APL | Joints | Various OKS thresholds, including primary metric (OKS = 0.5:0.05:0.95), loose metric (OKS = 0.5), and strict metric (OKS = 0.75) |
| AR | AR50 AR75 ARM ARL | Joints | Same as AP, it uses various OKS thresholds |
| CNN Network | Year | Layers | Accuracy | #Params | FLOP | Keynote |
|---|---|---|---|---|---|---|
| Deeper network | ||||||
| AlexNet [71] | 2012 | 7 | 84.70% | 61 M | 7.27 G | First network used GPU. |
| VGGNet-16 [73] | 2015 | 15 | 93.20% | 138 M | 154.7 G | Using AlexNet with modified filter sizes. |
| HRNet_W48 [74] | 2019 | 48 | 94.00% | 77.5 M | 16.1 G | Providing high-resolution features. |
| ResNet-50 [75] | 2016 | 49 | 96.40% | 23.4 M | 3.8 G | Skip connection. |
| ResNeXt [76] | 2017 | 49 | 97.00% | 23 M | - | A Derivative of ResNet. |
| Lightweight network | ||||||
| MobileNetV2 [77] | 2018 | 53 | 90.29% | 3.5 M | 300 M | Has a low number of parameters. |
| GoogLeNet [78] | 2015 | 22 | 93.30% | 6.8 M | 1500 M | Design with multiple filter sizes. |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Incorrect the predicted joint | Multistage Iterative optimization Graphical model | [17] [51] [79,83] |
| Self/object occlusion | Multitask | [66] | |
| Limitation in device resources | Distillation | [50] |
| Method | Year | Backbone | Input Size | #Params | GFLOPs | PCKh@0.5 |
|---|---|---|---|---|---|---|
| IEF [51] | 2016 | GoogLeNet | 224 × 224 | - | - | 81.3 |
| Sun et al. [79] | 2017 | ResNet-50 | 224 × 224 | - | - | 86.4 |
| FPD [50] | 2019 | Hourglass | 256 × 256 | 3 M | 9.0 | 90.8 |
| Luvizon et al. [80] | 2019 | Hourglass | 256 × 256 | - | - | 91.2 |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Incorrect the predicted joint | Multistage Refinement Graphical model | [89,96] [91] [12,14,83,92] |
| Different scales of the human body | Multibranch | [87,88] | |
| Complex pose | Multitask | [90] | |
| Self/object occlusion | Graphical model Multistage Multibranch | [91] [56,94] [95] | |
| Feature resolution | Multistage Multistage/branch | [85,86] [74] | |
| Limitation in device resources | Distillation | [57,99] | |
| GAN | Self/object occlusion | Multistage Multitask | [13] [97,98] |
| RNN | Incorrect the predicted joint | Multistage | [59] |
| Method | Year | Backbone | Input Size | #Params | GFLOPs | PCKh@0.5 |
|---|---|---|---|---|---|---|
| MRF [83] | 2014 | AlexNet | 320 × 240 | 40 M | - | 79.6 |
| Lifshitz et al. [91] | 2016 | VGG | 504 × 504 | - | - | 85.0 |
| CPM [89] | 2016 | CPM | 368 × 368 | - | - | 88.5 |
| Stacked Hourglass [85] | 2016 | Hourglass | 256 × 256 | 25.1 M | 19.1 | 90.9 |
| Hua et al. [86] | 2020 | Hourglass | 256 × 256 | 41.9 M | 56.3 | 91.0 |
| Papaioannidis et al. [57] | 2022 | ResNet-50 | 256 × 256 | - | - | 91.3 |
| Chou et al. [13] | 2018 | Hourglass | 256 × 256 | - | - | 91.8 |
| AdversarialPoseNet [97] | 2017 | En/Decoder | 256 × 256 | - | - | 91.9 |
| PRM [87] | 2017 | Hourglass | 256 × 256 | 28.1 M | 21.3 | 92.0 |
| Ke et al. [56] | 2018 | Hourglass | 256 × 256 | - | - | 92.1 |
| DLCM [94] | 2018 | Hourglass | 256 × 256 | 15.5 M | 15.6 | 92.3 |
| HRNet [74] | 2019 | HRNet | 256 × 256 | 28.5 M | 9.5 | 92.3 |
| PGCN [12] | 2020 | Hourglass | 256 × 256 | - | - | 92.4 |
| PBN [95] | 2019 | Hourglass | 256 × 256 | 26.69 M | - | 92.7 |
| DCAPRM [88] | 2019 | Hourglass | 256 × 256 | - | - | 92.9 |
| CFA [96] | 2019 | Hourglass | 384 × 384 | - | - | 93.9 |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Few annotations | Multistage Multitask | [8,112,114] [101] |
| Limitation in device resources | Distillation | [115] | |
| Capturing spatial-temporal features | Multistage/branch Graphical model Optical flow Multistage | [103,111] [104] [53,106,107] [102,105] | |
| RNN | Capturing spatial-temporal features | Multistage/branch Multistage Multibranch | [110] [100,109] [108] |
| Method | Year | Backbone | Input Size | GFLOPs | PCKh@0.2 |
|---|---|---|---|---|---|
| And-Or graph [104] | 2015 | - | - | - | 55.7 |
| Song et al. [107] | 2017 | CPM | 368 × 368 | - | 81.6 |
| Luo et al. [109] | 2018 | - | 368 × 368 | 70.98 | 93.6 |
| DKD [115] | 2019 | ResNet50 | 255 × 256 | 8.65 | 94.0 |
| K-FPN [112] | 2020 | ResNet17 | 224 × 224 | 4.68 | 94.5 |
| MAPN [100] | 2021 | ResNet18 | 257 × 256 | 2.70 | 94.7 |
| GLPose [101] | 2022 | HRNet | 384 × 288 | - | 95.1 |
| REMOTE [114] | 2022 | ResNet50 | 384 × 384 | - | 95.9 |
| TCE [111] | 2020 | Res50-TCE-BC | 256 × 256 | - | 96.5 |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Incorrect the predicted joint | Refinement Graphical model | [55] [124] |
| Incorrect the bounding box | Multistage/branch Multistage Nonmaximum Suppression | [117] [27,116,118,119] [120] | |
| Feature resolution | Multistage Multistage/branch | [122,125] [127] | |
| Limitation in device resources | Multistage Multibranch Multistage/branch | [126] [130,131] [128,129] | |
| Self/object occlusion | Multibranch Multistage/branch | [60] [62] | |
| Variant background | Multistage Multitask | [65] [54] | |
| Quantization error | Modifying Gaussian kernel | [20,126] | |
| Estimating whole body | Multitask | [132] |
| Method | Year | Backbone | Input Size | #Params | GFLOPs | AP |
|---|---|---|---|---|---|---|
| RMPE [120] | 2017 | PyraNet | 320 × 256 | - | - | 61.8 |
| Mask R-CNN [27] | 2017 | ResNet | 800 × 800 | - | - | 63.1 |
| MSPN [122] | 2019 | ResNet-50-FPN | 640 × 640 | - | - | 68.2 |
| LiteHRNet [128] | 2022 | Lite-HRNet-30 | 384 × 288 | 1.8 M | 0.70 | 69.7 |
| Chen et al. [62] | 2018 | ResNet | 384 × 288 | 102 M | 6.2 | 72.1 |
| LDNet [131] | 2022 | LDNet | 384 × 288 | 5.1 M | 3.7 | 72.3 |
| HRNet-Lite [129] | 2023 | HRNet-W32 | 256 × 192 | 14.5 M | 2.9 | 73.3 |
| SRPose [130] | 2023 | HRFormer-S | 256 × 192 | 8.86 M | 3.34 | 75.6 |
| EvoPose2D [126] | 2021 | EvoPose2D | 512 × 384 | 14.7 M | 17.7 | 75.7 |
| HrFormer [127] | 2021 | HRFormer-B | 384 × 288 | 43.2 M | 26.8 | 76.2 |
| DARK [20] | 2020 | HRNet | 384 × 288 | 63.6 M | 32.9 | 76.2 |
| UDP [121] | 2020 | HRNet | 384 × 288 | 63.8 M | 33.0 | 76.5 |
| PoseFix [55] | 2019 | HR + ResNet | 384 × 288 | - | - | 76.7 |
| Graph-PCNN [124] | 2020 | HRNet | 384 × 288 | - | - | 76.8 |
| Wang et al. [54] | 2021 | HRNet | 384 × 288 | 63.9 M | 35.4 | 76.8 |
| Xie et al. [123] | 2021 | HRNet | 384 × 288 | 63.6 M | 32.9 | 77.2 |
| DiffusionPose [126] | 2023 | HRNet-W48 | 384 × 288 | 74 M | 49 | 77.6 |
| RSN [125] | 2020 | 4×RSN-50 | 384 × 288 | 111.8 M | 65.9 | 78.6 |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Self/object occlusion | Detecting and grouping Multitask Multibranch | [26,58,128] [129] [141] |
| Limitation in device resources | Multitask Part Affinity Fields Multistage/branch | [136] [25,137] [142] | |
| Feature resolution | Multistage/branch | [143,146] | |
| Different scales of the human body | Iterative optimization Multibranch | [140] [144] | |
| Incorrect the predicted joint | Part Affinity Fields | [147] | |
| Estimating whole body | Part Affinity Fields | [145] | |
| GNN | Incorrect grouping of key points | Graph layers | [139] |
| Method | Year | Backbone | Input Size | #Params | GFLOPs | AP |
|---|---|---|---|---|---|---|
| OpenPose [25] | 2017 | CMU-Net | 368 × 368 | - | - | 61.8 |
| Zhao et al. [146] | 2020 | Hourglass | 512 × 512 | - | - | 62.7 |
| PifPaf [137] | 2019 | ResNet | 401 × 401 | - | - | 66.7 |
| HGG [139] | 2020 | Hourglass | 512 × 512 | - | - | 67.6 |
| Du et al. [141] | 2022 | HrHRNet | 512 × 512 | 28.6 M | - | 67.8 |
| MultiPoseNet [136] | 2018 | ResNet | 480 × 480 | - | - | 69.6 |
| HigherHRNet [143] | 2020 | HRNet | 640 × 640 | 63.8 M | 154.3 | 70.5 |
| Jin et al. [140] | 2022 | HrHRNet | 640 × 640 | 67.0 M | 177.6 | 70.6 |
| CenterGroup [58] | 2021 | HRNet | 512 × 512 | - | - | 71.4 |
| SAHR [144] | 2021 | HRNet | 640 × 640 | 63.8 M | 154.6 | 72.0 |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Few annotations | Multitask | [154] |
| Self/object occlusion | Multistage/branch Multistage | [152] [151] | |
| Model high complexity | Multistage | [153] | |
| Capturing spatial-temporal features | Graph layers Multistage Multistage/branch | [149] [52,150] [18,19] |
| Method | Year | Backbone | Input Size | Total mAP | Total MOTA |
|---|---|---|---|---|---|
| PoseTrack [149] | 2017 | - | - | 59.4 | 48.4 |
| ArtTrack [150] | 2017 | ResNet-101 | - | 59.4 | 48.1 |
| 3D Mask R-CNN [52] | 2018 | ResNet-18 | 256 × 256 | 59.6 | 51.8 |
| Ruan et al. [152] | 2019 | ResNet-101 | 900 × 900 | 72.5 | 58.4 |
| 3D HRNet [19] | 2020 | 3D HRNet | - | 74.1 | 64.1 |
| FlowTrack [153] | 2018 | ResNet-152 | 384 × 288 | 76.7 | 65.4 |
| Bertasius et al. [154] | 2019 | HRNet | - | 77.9 | - |
| DCPose [18] | 2021 | HRNet | 384 × 288 | 79.2 | - |
| TDMI-ST [151] | 2023 | - | - | 85.9 * | - |
| DL Type | Address the Issues | Techniques Used | Studies |
|---|---|---|---|
| CNN | Incorrect the predicted joint features | Multibranch | [156] |
| Capturing spatial-temporal features | Nonmaximum Suppression Multistage/branch Part Affinity Fields | [155] [161] [157] | |
| GNN | Capturing spatial-temporal features | Graph layers | [148,159] |
| RNN | Capturing spatial-temporal features | Part Affinity Fields | [158] |
| Method | Year | Backbone | Input Size | Total mAP | Total MOTA | FPS |
|---|---|---|---|---|---|---|
| PoseFlow [155] | 2018 | Hourglass | - | 63.0 | 51.0 | 10.0 * |
| JointFlow [157] | 2018 | - | - | 63.4 | 53.1 | 0.2 |
| Ning et al. [148] | 2020 | FPN | - | 66.5 | 55.1 | 0.7 |
| STAF [158] | 2019 | VGG | 368 × 368 | 70.3 | 53.8 | 2.0 |
| Guo et al. [156] | 2018 | ResNet-152 | 384 × 288 | 75.0 | 50.6 | - |
| Jin et al. [161] | 2019 | Hourglass | - | 77.0 | 71.8 | - |
| Zhou et al. [147] | 2020 | HRNet | - | 79.5 | 72.2 | - |
| Yang et al. [159] | 2021 | HRNet | 384 × 288 | 81.1 | 73.4 | - |
| Dataset | Size | Data Quality | Diversity | Complexity | Challenges | Annotation Quality |
|---|---|---|---|---|---|---|
| LSP [42] | 2 K | ✓ | 🗶 | ✓ | * | * |
| LSP Extended [43] | 10 K | ✓ | * | ✓ | * | * |
| FLIC [44] | 5 K | * | * | * | 🗶 | * |
| PennAction [45] | 2.3 K | ✓ | * | ✓ | ✓ | * |
| JHMDB [46] | 900 | * | * | * | * | * |
| MPII [40] | 30.5 K | ✓ | * | * | * | * |
| COCO [41] | 200 K | ✓ | * | * | * | * |
| PoseTrack [47] | 550 | ✓ | * | * | * | * |
| CrowdPose [48] | 80 K | * | * | ✓ | * | * |
| Training Dataset | Advantage | Disadvantage | Studies |
|---|---|---|---|
| LSPE + FLIC |
|
| [14,83,92] |
| MPII + LSPE |
|
| [12,13,26,60,65,82,87,89,91,97] |
| MPII + COCO |
|
| [20,25,56,99,120,123,132,138,145] |
| PennAction + JHMDB |
|
| [100,104,107,109,111,112,114,115]. |
| Technique | Advantage | Disadvantage | Example | Studies |
|---|---|---|---|---|
| Multistage |
|
| Hourglass network | [8,13,27,52,56,65,89,94,96,100,102,105,118,153] |
| Multibranch |
|
| Pyramid network | [12,14,60,83,92,95,108,132,141,144,156] |
| Multistage/ branch |
|
| High-Resolution network | [18,19,62,74,103,110,111,117,142,143,146] |
| Multitask |
|
| GLPose model | [54,66,90,97,98,101,133,136] |
| Graphical model |
|
| Graph-PoseCNN model | [12,14,83,92,93,104,124] |
| Part Affinity Fields |
|
| OpenPose model | [25,137,138,145,157,158] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samkari, E.; Arif, M.; Alghamdi, M.; Al Ghamdi, M.A. Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Mach. Learn. Knowl. Extr. 2023, 5, 1612-1659. https://doi.org/10.3390/make5040081
Samkari E, Arif M, Alghamdi M, Al Ghamdi MA. Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Machine Learning and Knowledge Extraction. 2023; 5(4):1612-1659. https://doi.org/10.3390/make5040081
Chicago/Turabian StyleSamkari, Esraa, Muhammad Arif, Manal Alghamdi, and Mohammed A. Al Ghamdi. 2023. "Human Pose Estimation Using Deep Learning: A Systematic Literature Review" Machine Learning and Knowledge Extraction 5, no. 4: 1612-1659. https://doi.org/10.3390/make5040081
APA StyleSamkari, E., Arif, M., Alghamdi, M., & Al Ghamdi, M. A. (2023). Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Machine Learning and Knowledge Extraction, 5(4), 1612-1659. https://doi.org/10.3390/make5040081