
Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models


Abstract
1. Introduction
- This research is the first to offer a unique comparative analysis between the performance of prompt engineering and fine-tuning techniques for LLMs.
- Exploring prompt-engineering strategies for phishing URL detection and providing valuable insights into their effectiveness.
- The investigation of the fine-tuning of text-generation LLMs for phishing URL detection, showcasing its potential in this domain.
- This study achieves a remarkable performance of 97.29% as the F1-score for phishing URL detection, surpassing existing state-of-the-art techniques.
2. Background and Preliminaries
2.1. Large Language Models (LLMs)
2.2. Prompt Engineering
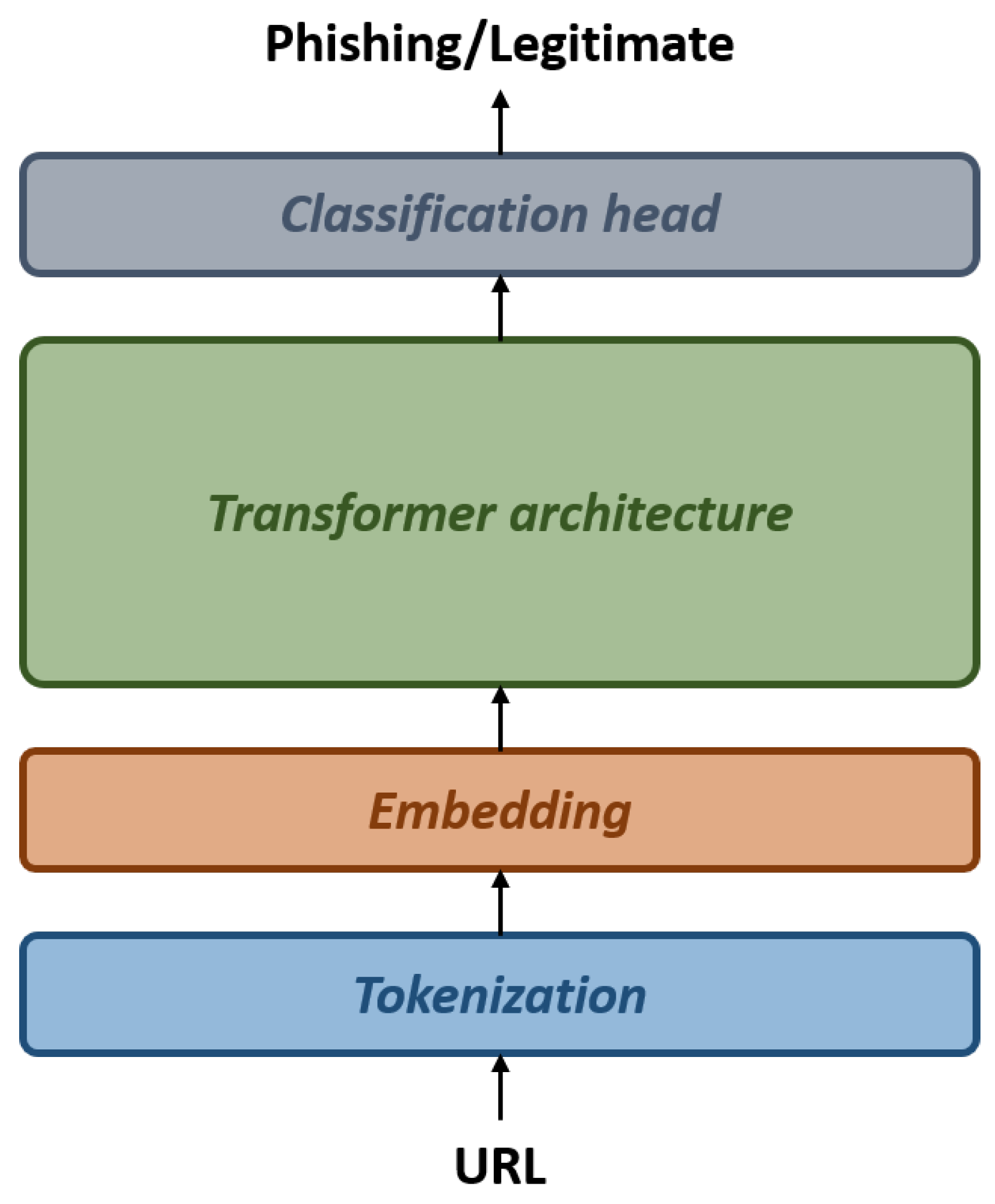
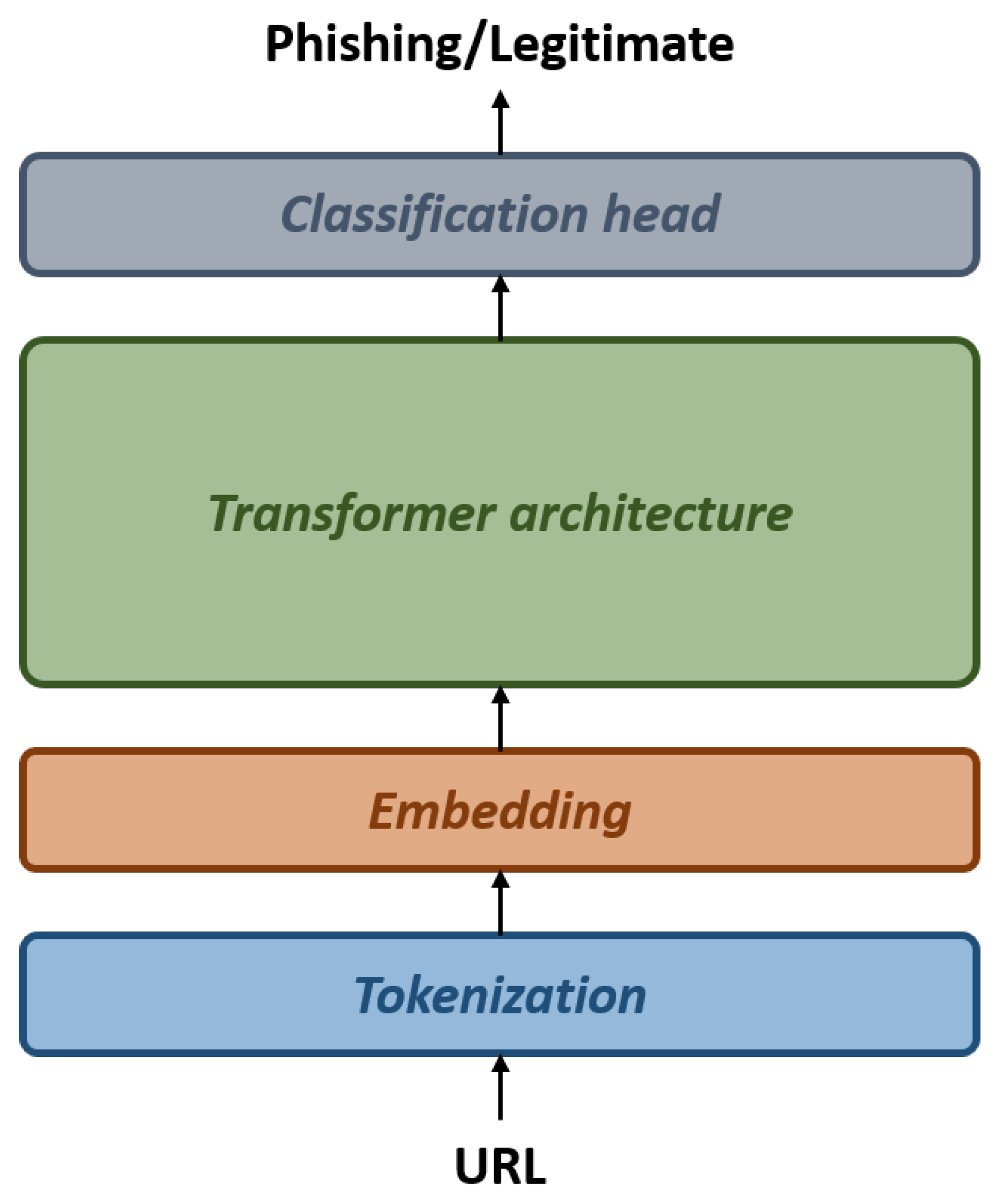
2.3. Fine-Tuning LLMs
2.4. Phishing Detection
3. Related Work
4. Methodology
4.1. Prompt Engineering
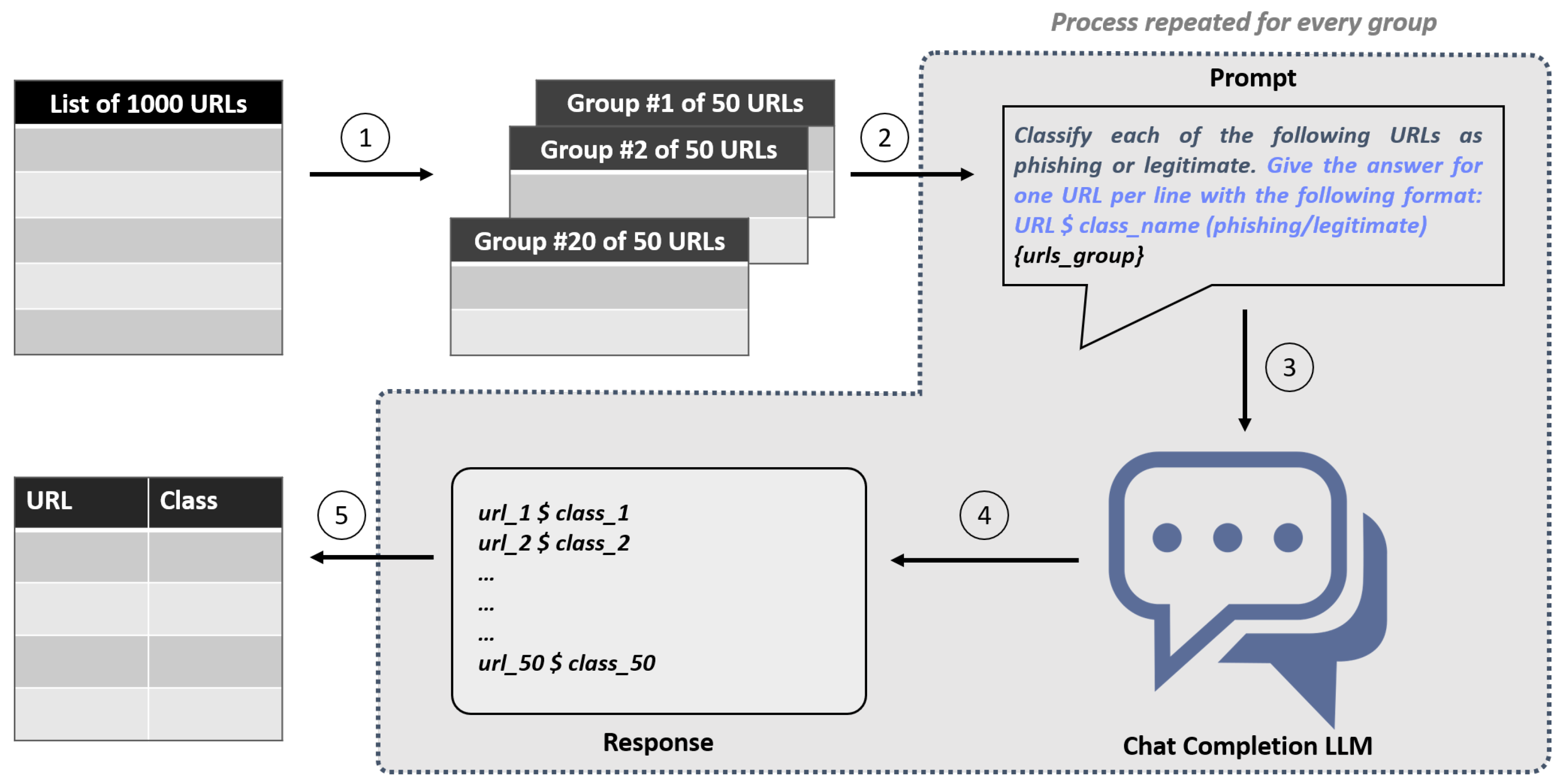
- We divide the list of 1000 URLs into 20 groups, each containing 50 URLs.
- For each subset, we craft a prompt asking the LLM to classify each URL within it, specifying the response format.
- We feed the prompt to the LLM.
- We collect the responses, which adhere to the requested format.
- We aggregate the responses from all groups and convert them into a data frame for analysis. This allows us to compute classification metrics by comparing them with ground-truth data.
4.2. Fine-Tuning
5. Experiments
5.1. Experimental Setup
5.1.1. Dataset
5.1.2. Models
5.1.3. Evaluation Metrics
- Accuracy: This is the most intuitive performance measure and is simply the ratio of correctly predicted observations to the total observations. It is particularly useful when the target classes are well-balanced. However, its utility is limited in scenarios with significant class imbalance, as it can yield misleading results.
- Precision: Also known as the positive predictive value, precision is the ratio of correctly predicted positive observations to the total predicted positive observations. High precision, which indicates a low rate of false positives, is critical in phishing detection, where mistakenly labeling legitimate URLs as phishing can have serious consequences.
- Recall: Also referred to as sensitivity, recall is the ratio of correctly predicted positive observations to all actual positives. This metric is essential in phishing detection as it is vital to identify as many phishing instances as possible to prevent data breaches.
- F1-score: The F1-score is the harmonic mean of precision and recall. It is a more reliable measure than accuracy, particularly when dealing with unevenly distributed datasets. It considers both false positives and false negatives, making it suitable for scenarios where both precision and recall are important.
- Area Under the Curve (AUC): this metric measures the ability of a classifier to distinguish between classes and is used as a summary of the Receiver Operating Characteristic (ROC) curve.
- True Positive Rate at a Given False Positive Rate (TPR@FPR): This metric evaluates the model’s ability to correctly identify positives at a specific false positive rate. It is particularly useful in scenarios where maintaining a low rate of false positives is crucial, which is the case in phishing detection.
5.2. Prompt Engineering
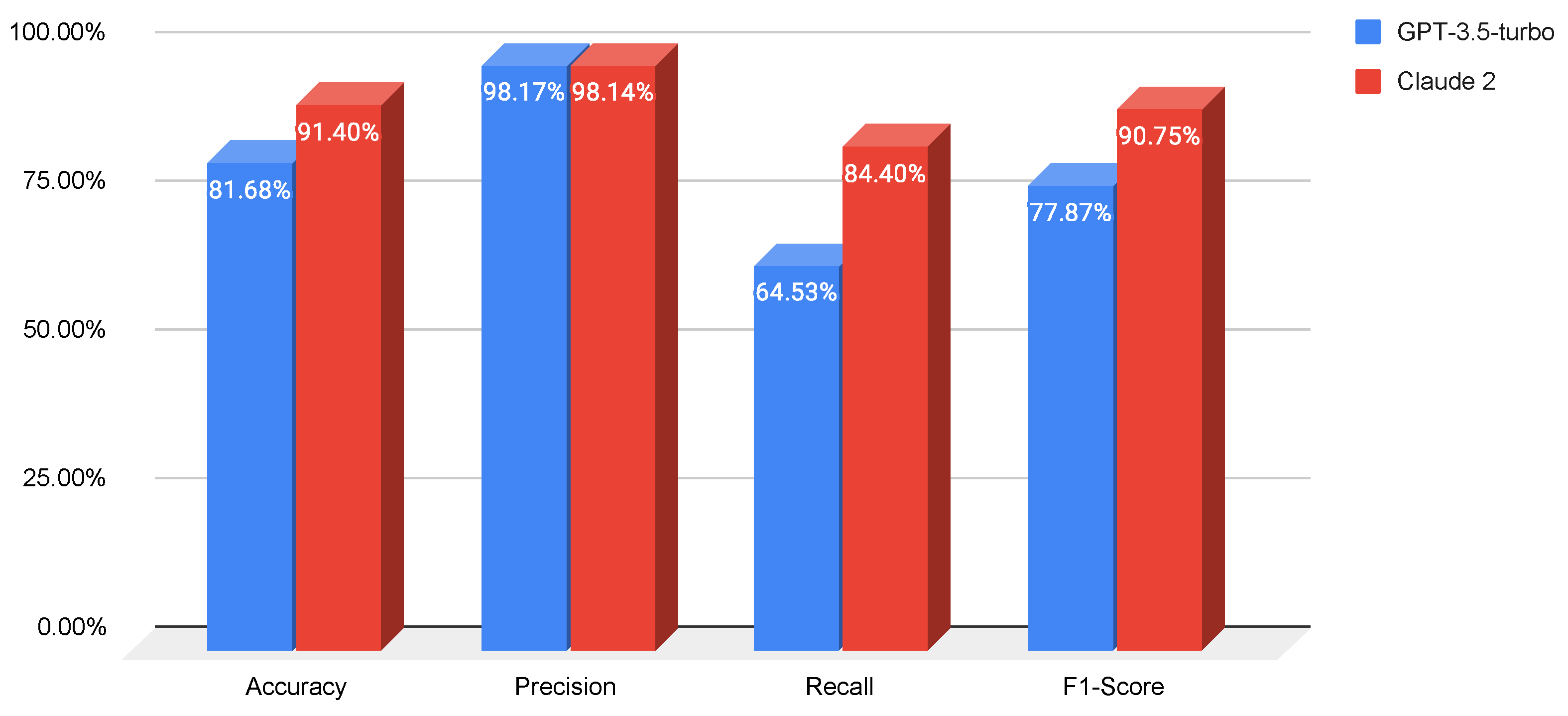
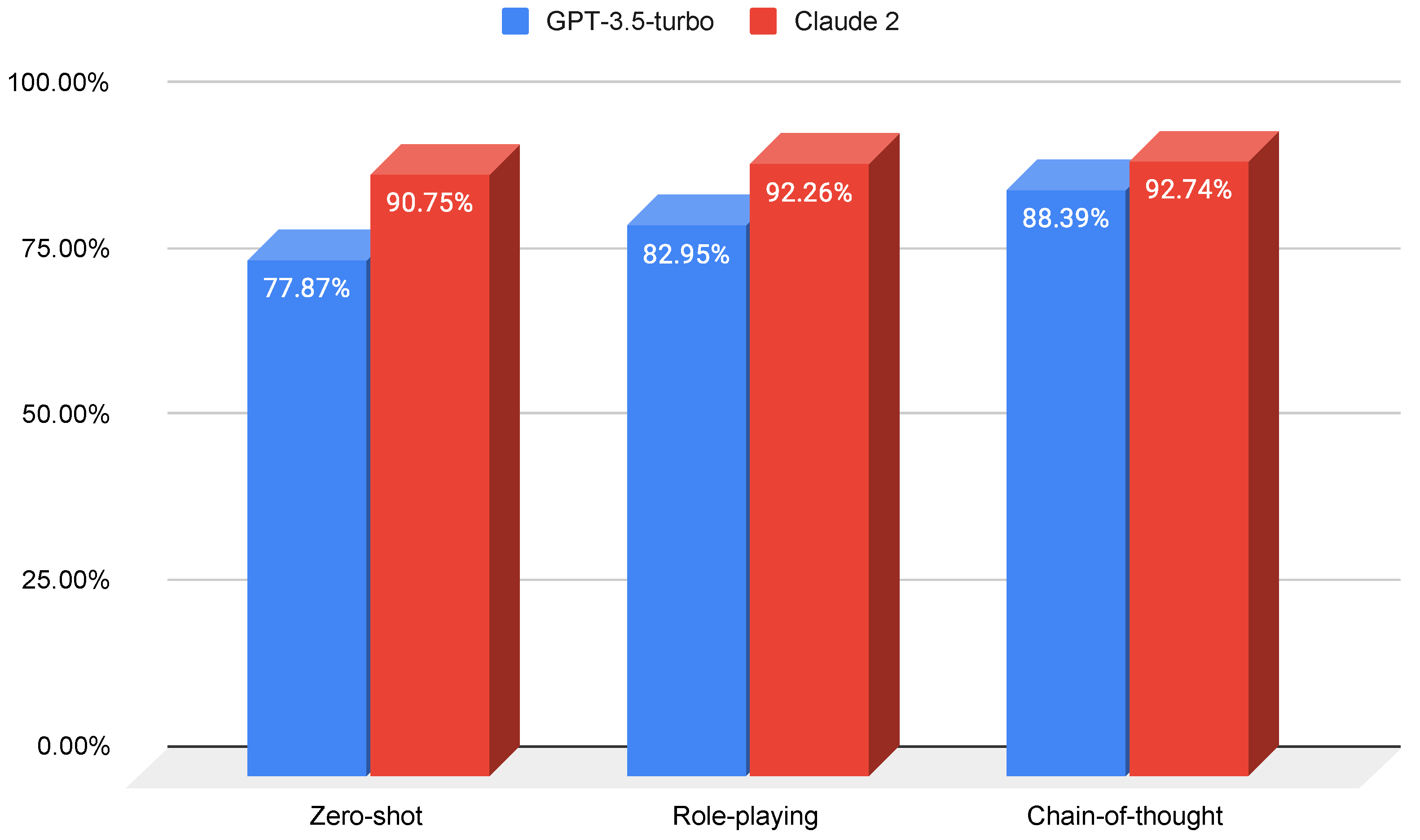
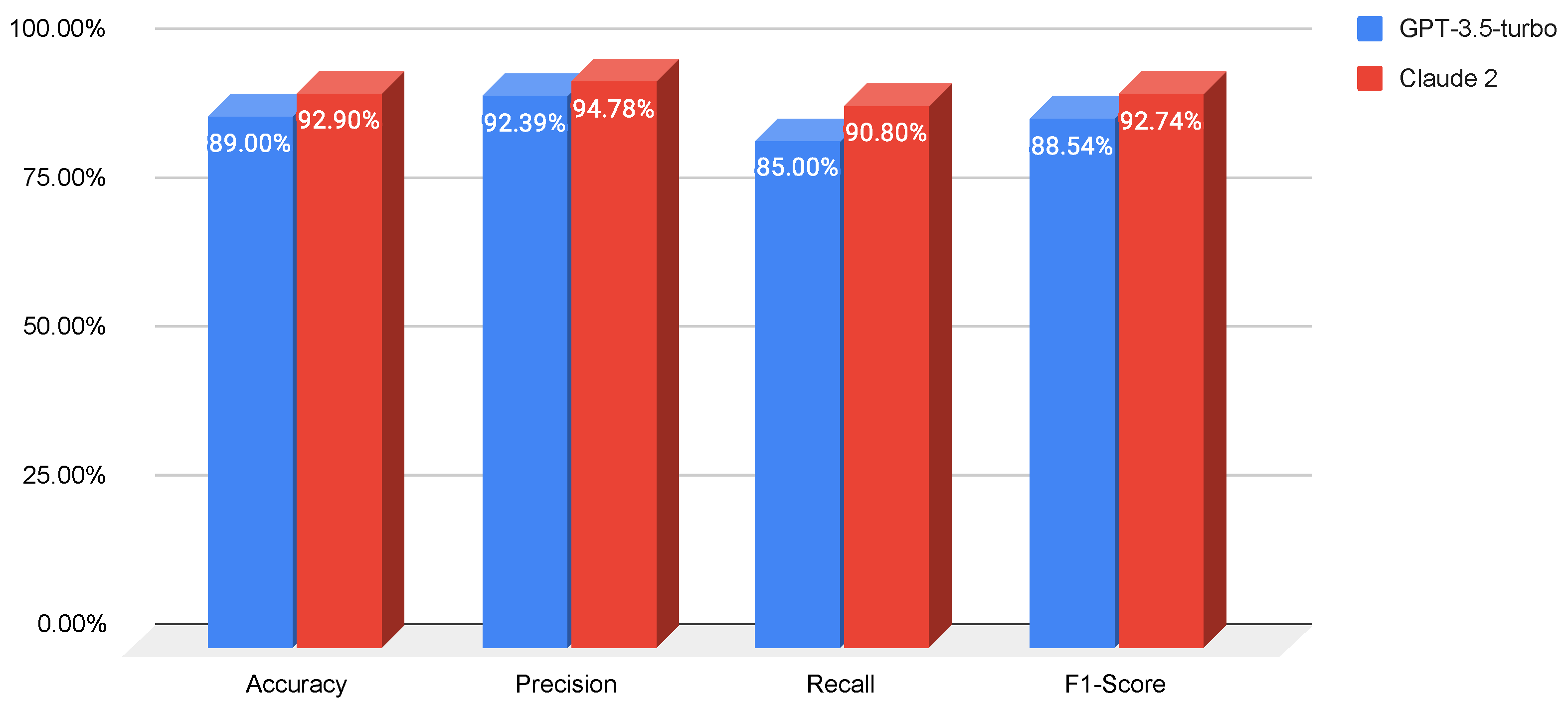
- Prompt 1 (zero-shot): We start with a baseline prompt that simply asks the LLM to classify the given URLs while generating the response according to a specific output format. The accuracy, precision, recall, and F1-score of both LLMs for this prompt on the test set are reported in Figure 4.
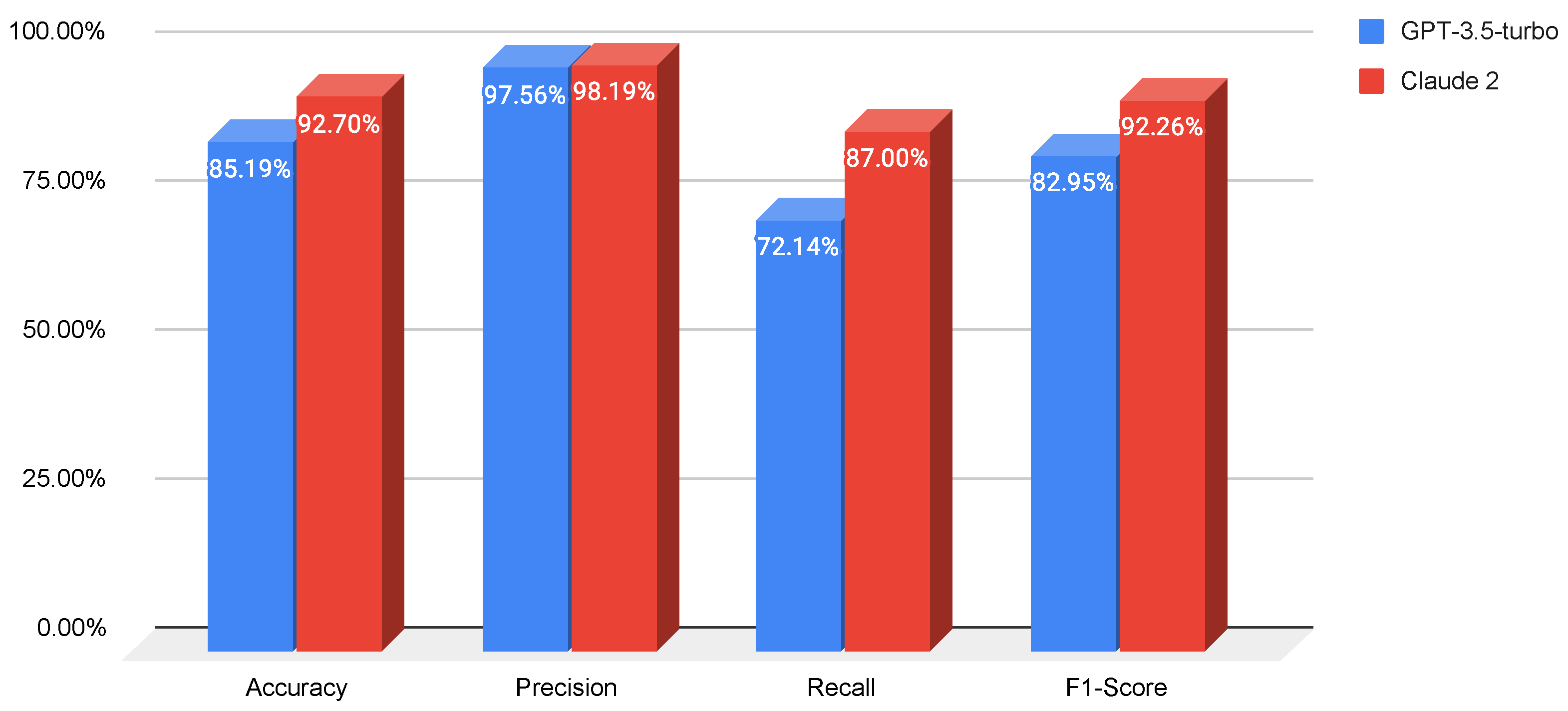
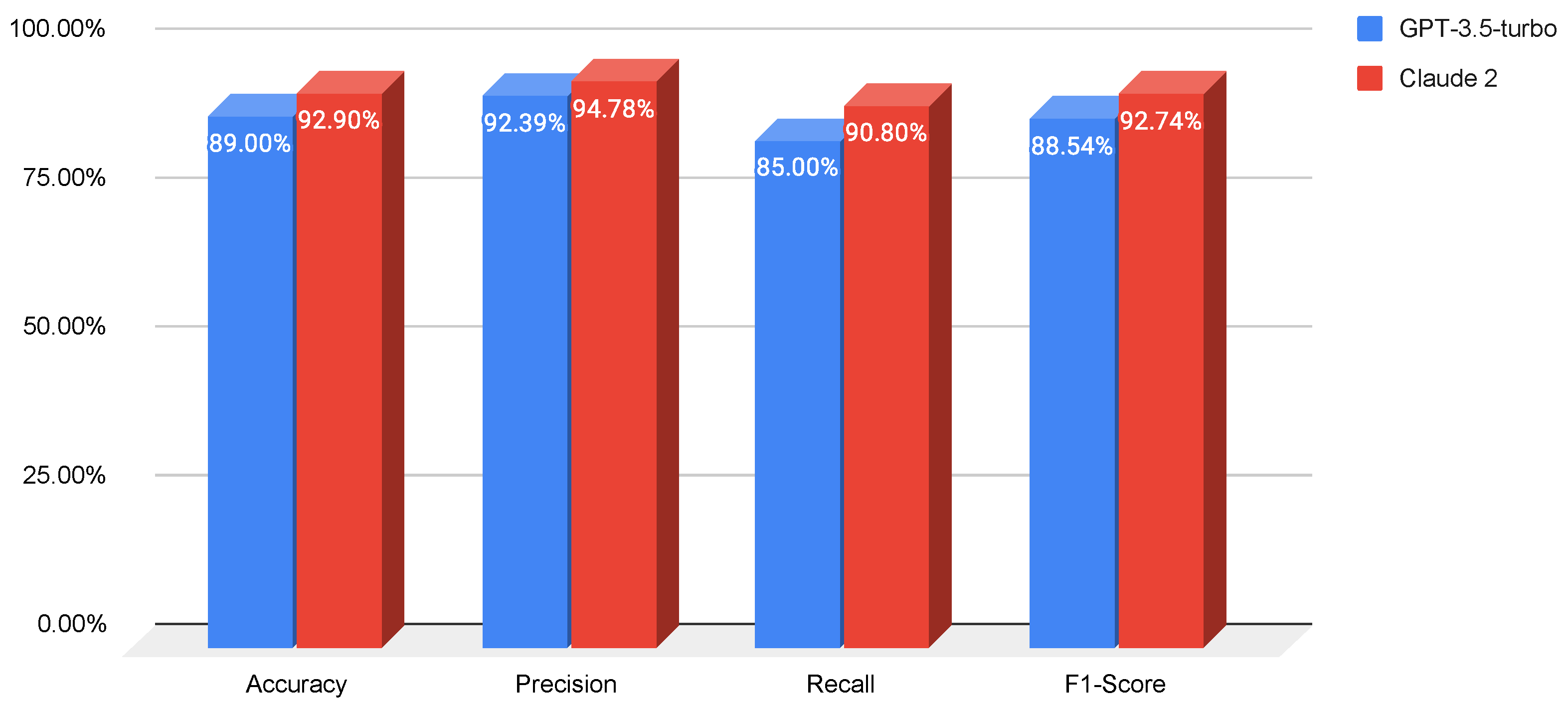
- Prompt 2 (role-playing): We modify the baseline prompt to ask the LLM to assume the role of a cybersecurity specialist analyzing URLs for a company. This approach is intended to help the model adopt a specific mindset while responding, which is expected to enhance its responses. We apply this prompt to both LLMs, and the results are shown in Figure 5.
- Prompt 3 (chain-of-thought): We further modify the second prompt (role-playing) by asking the model to provide succinct reasoning for classifying a given URL as phishing or legitimate. This approach encourages the LLM to classify based on specific criteria that it articulates, which is expected to improve performance. The results of this prompt for both LLMs are illustrated in Figure 6.
5.3. Fine-Tuning
- openai-gpt: The first iteration of the Generative Pretrained Transformer models developed by OpenAI. It provides a solid baseline for natural language understanding and generation tasks and has 110 million parameters.
- gpt2: An improved version of the original GPT, GPT-2 offers a larger model size for enhanced performance across a broader range of tasks and the ability to generate more coherent and contextually relevant text. The version we used is the smallest and has 117 million parameters.
- gpt2-medium: A midsized variant of GPT-2, this model balances computational efficiency and performance, suitable for tasks requiring in-depth language understanding without the largest model size. It has 345 million parameters.
- distilgpt2: A distilled version of GPT-2 that retains most of the original model’s performance but with fewer parameters, enhancing efficiency without a significant loss in quality. It has 82 million parameters.
- baby-llama-58m: A smaller model with 58 million parameters, Baby LLaMA is a distilled version of small LLaMA models and GPT-2 [57]. It is designed for efficiency and can perform various language tasks, optimized for environments with limited computational resources.
- bloom-560m: Part of the Bloom series [58], this large-scale multilingual language model is designed to understand and generate text in multiple languages. With 560 million parameters, it offers substantial capability in language-processing tasks.
6. Discussion
6.1. Prompt Engineering
6.2. Fine-Tuning
6.3. Comparing Prompt Engineering and Fine-Tuning
- Performance differences: In our analysis, we found significant performance differences between prompt-engineered and fine-tuned LLMs. Fine-tuning generally results in better performance. For example, the least performing fine-tuned model, bloom-560m, achieved an F1-score of 92.43%, which is comparable to the highest performance in prompt engineering with the chain-of-thought prompt on Claude 2 (92.74%). Notably, GPT-2-medium, with fewer parameters, significantly outperforms prompt-engineered models, achieving an F1-score of 97.29%. This is particularly striking when considering that chat-completion models like GPT-3.5-turbo and Claude 2 have substantially more parameters. This disparity highlights the potential of fine-tuning in enhancing the specialization and effectiveness of smaller models for specific tasks like phishing URL detection.
- Data privacy and security: When using prompt engineering, interacting with LLMs via their APIs, as commonly performed in AI development, involves data transmission to third-party servers. This raises data privacy and security concerns. In contrast, fine-tuning as outlined in this study generally involves downloading the model for local adjustments, which enhances data security and minimizes risks of data leakage.
- Resource requirements: The resource demands of the two approaches differ significantly. Prompt engineering is generally less resource intensive, requiring minimal adjustments to apply various prompts. This makes it more accessible and practical, particularly in resource-limited settings. On the other hand, fine-tuning demands more substantial resources, including a significant amount of domain-specific training data and computational power, which can be a limiting factor in its scalability and practicality.
- Model maintenance: The maintenance approaches for prompt-engineered and fine-tuned models differ considerably. For prompt-engineered models like GPT-3.5-turbo and Claude 2, updates and maintenance are typically handled by the companies that developed them, such as OpenAI for GPT-3.5-turbo and Anthropic AI for Claude 2. This means that improvements and adaptations to evolving data or tasks are managed centrally, relieving users from the burden of continual model updates. However, this also means that users are dependent on the companies for timely updates. In contrast, fine-tuned models require the users to actively manage and update the models. This might involve retraining the models as new data become available or as the nature of tasks, such as phishing URL detection, evolves. While this allows for more control and customization, it also adds to the resource intensity and demands ongoing attention from the users.
6.4. Comparison with State-of-the-Art Approaches
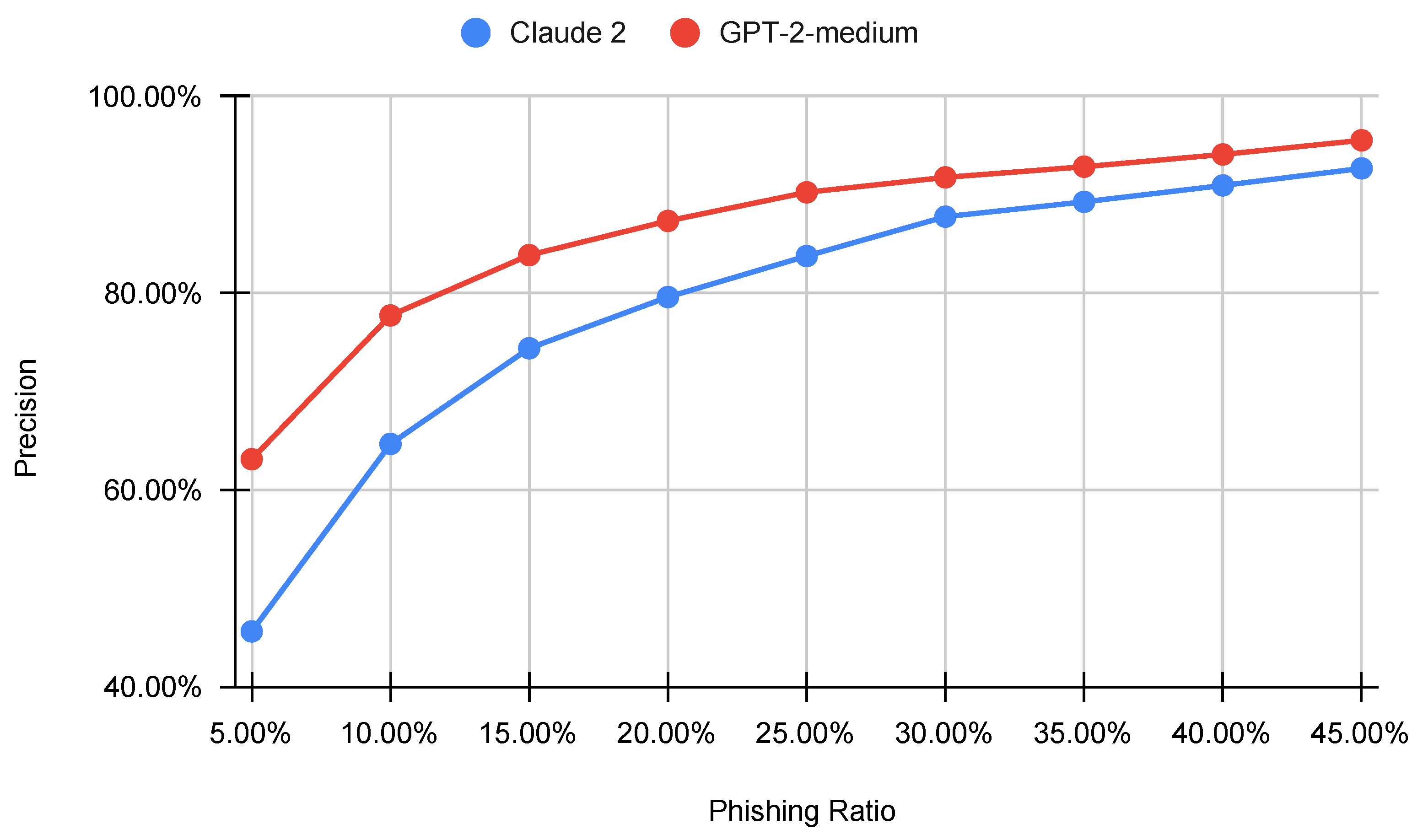
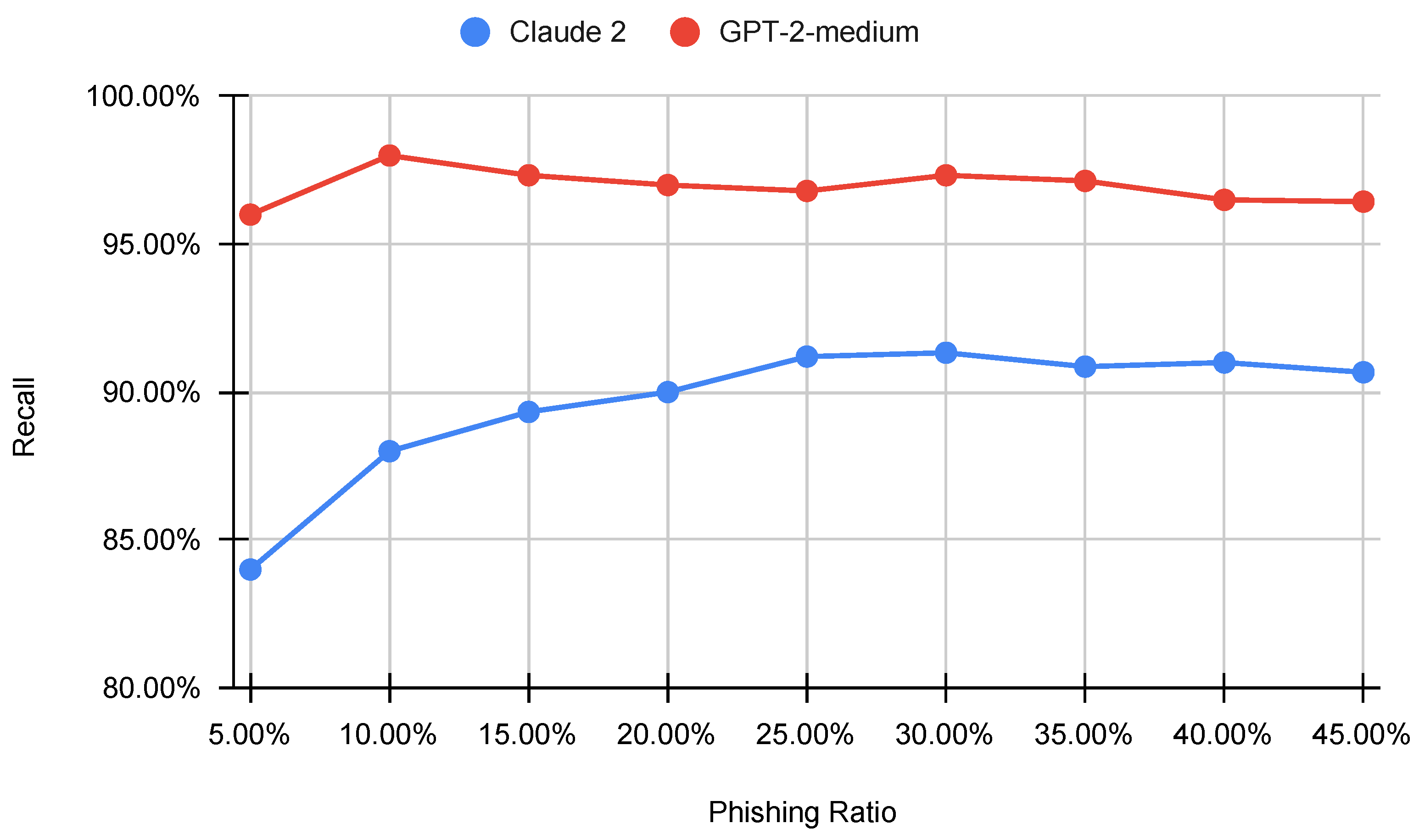
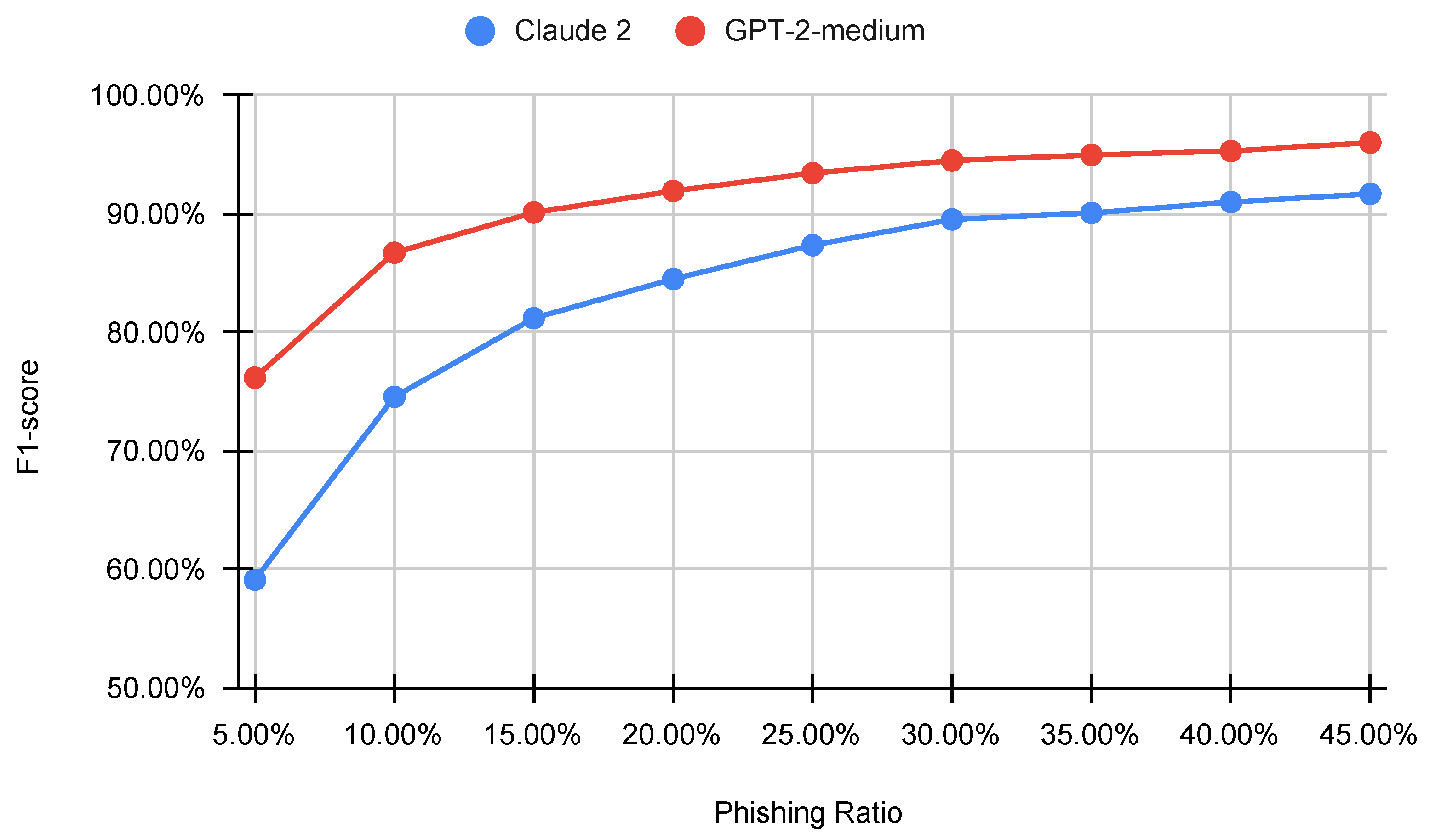
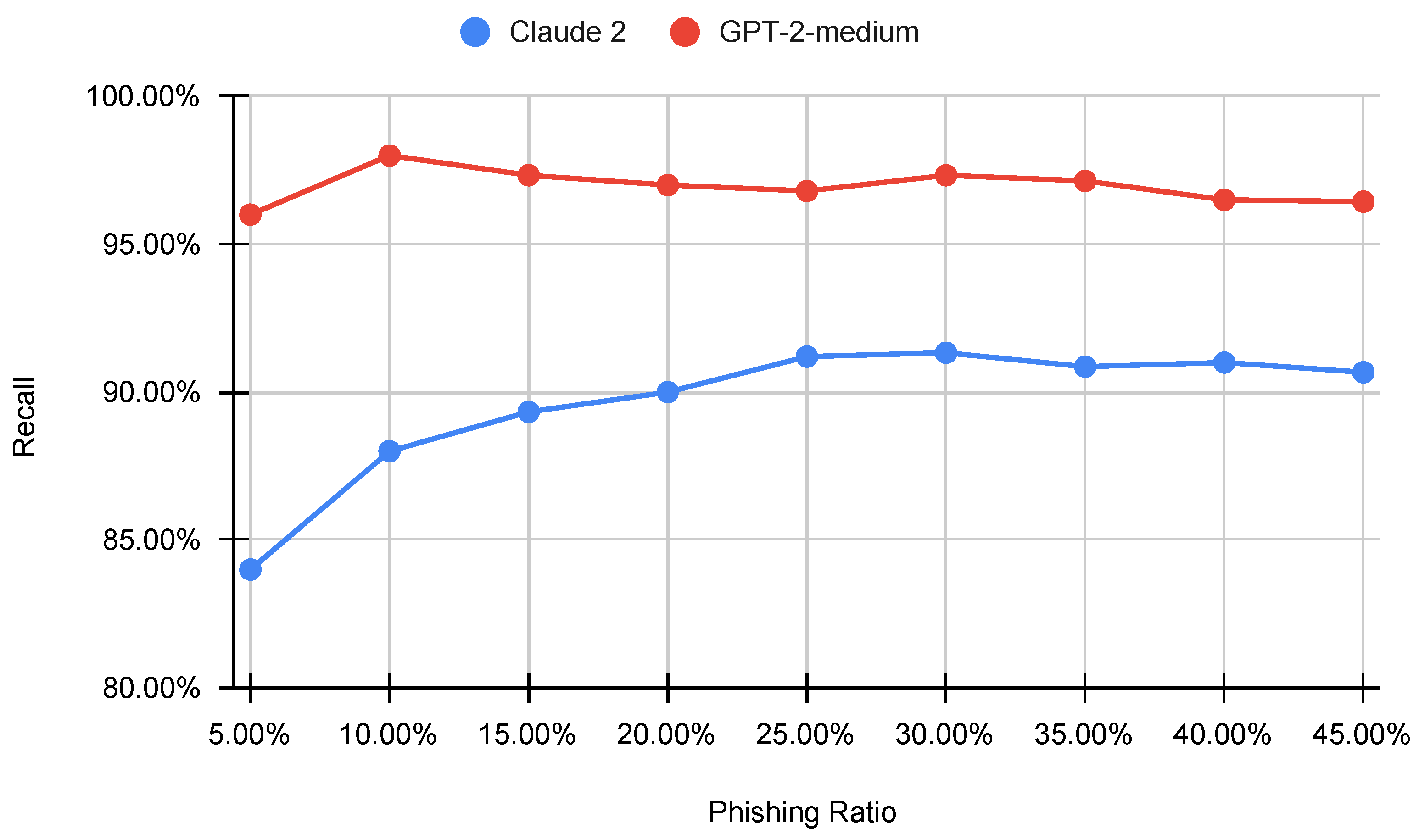
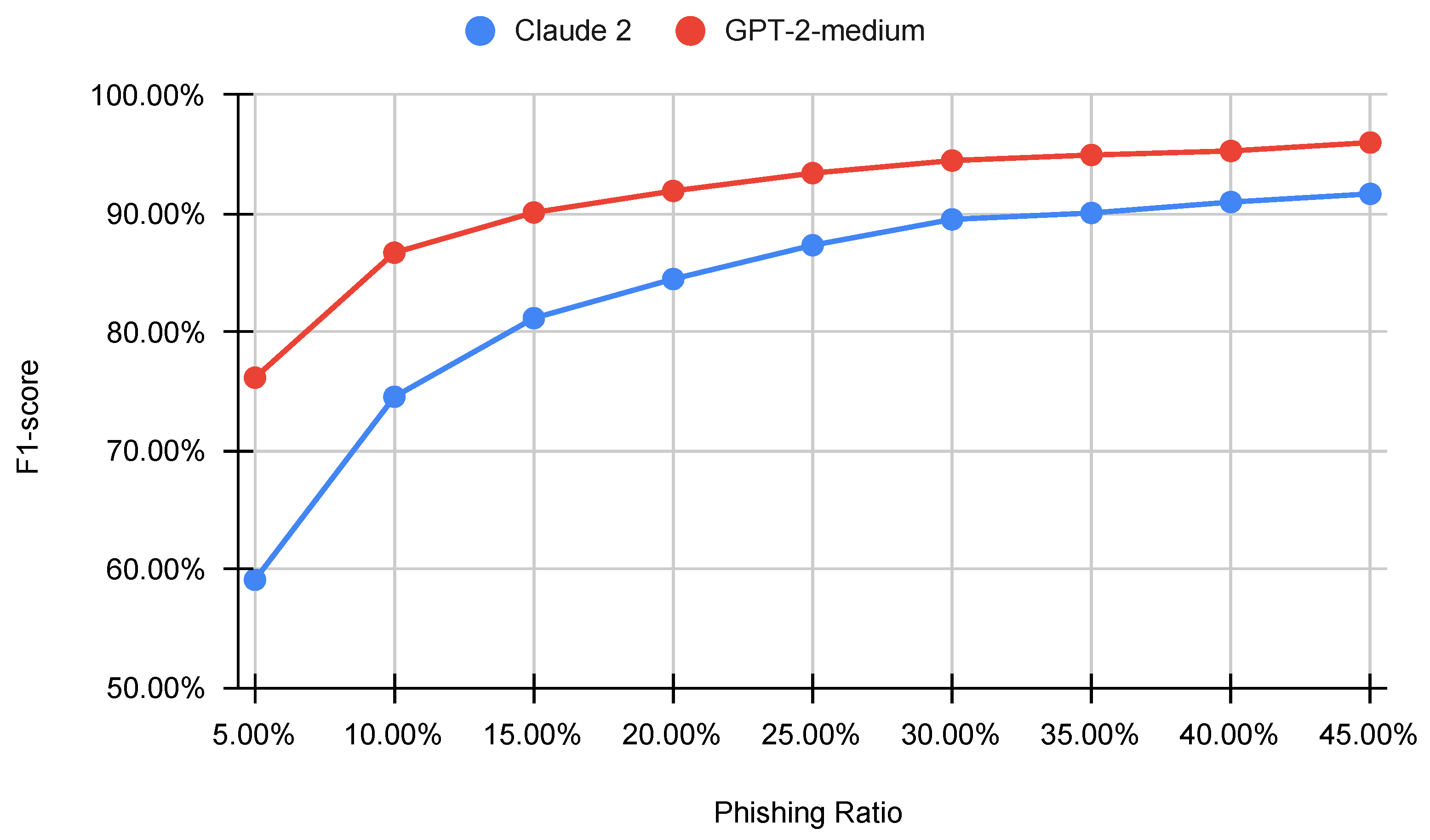
6.5. Testing on Imbalanced Datasets
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mustroph, H.; Winter, K.; Rinderle-Ma, S. Social Network Mining from Natural Language Text and Event Logs for Compliance Deviation Detection. In Cooperative Information Systems. CoopIS 2023; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2024; Volume 14353, pp. 347–365. ISBN 9783031468452. [Google Scholar] [CrossRef]
- Liu, Z.; Zhong, A.; Li, Y.; Yang, L.; Ju, C.; Wu, Z.; Ma, C.; Shu, P.; Chen, C.; Kim, S.; et al. Tailoring Large Language Models to Radiology: A Preliminary Approach to LLM Adaptation for a Highly Specialized Domain. In Machine Learning in Medical Imaging. MLMI 2023; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2024; Volume 14348, pp. 464–473. ISBN 9783031456725. [Google Scholar] [CrossRef]
- Kirshner, S. GPT and CLT: The impact of ChatGPT’s level of abstraction on consumer recommendations. J. Retail. Consum. Serv. 2024, 76, 103580. [Google Scholar] [CrossRef]
- Caruccio, L.; Cirillo, S.; Polese, G.; Solimando, G.; Sundaramurthy, S.; Tortora, G. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert Syst. Appl. 2024, 235, 121186. [Google Scholar] [CrossRef]
- Shi, Y.; Ren, P.; Wang, J.; Han, B.; ValizadehAslani, T.; Agbavor, F.; Zhang, Y.; Hu, M.; Zhao, L.; Liang, H. Leveraging GPT-4 for food effect summarization to enhance product-specific guidance development via iterative prompting. J. Biomed. Inform. 2023, 148, 104533. [Google Scholar] [CrossRef]
- Escalante, J.; Pack, A.; Barrett, A. AI-generated feedback on writing: Insights into efficacy and ENL student preference. Int. J. Educ. Technol. High. Educ. 2023, 20, 57. [Google Scholar] [CrossRef]
- Dhamija, R.; Tygar, J.D.; Hearst, M. Why phishing works. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 22–27 April 2006; pp. 581–590. [Google Scholar] [CrossRef]
- Moghimi, M.; Varjani, A.Y. New rule-based phishing detection method. Expert Syst. Appl. 2016, 53, 231–242. [Google Scholar] [CrossRef]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Intelligent rule-based phishing websites classification. IET Inf. Secur. 2014, 8, 153–160. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Tang, L.; Mahmoud, Q.H. A Survey of Machine Learning-Based Solutions for Phishing Website Detection. Mach. Learn. Knowl. Extr. 2021, 3, 672–694. [Google Scholar] [CrossRef]
- Benavides, E.; Fuertes, W.; Sanchez, S.; Sanchez, M. Classification of Phishing Attack Solutions by Employing Deep Learning Techniques: A Systematic Literature Review. In Developments and Advances in Defense and Security; Smart Innovation, Systems and Technologies; Rocha, A., Pereira, R.P., Eds.; Springer: Singapore, 2020; pp. 51–64. [Google Scholar] [CrossRef]
- Catal, C.; Giray, G.; Tekinerdogan, B.; Kumar, S.; Shukla, S. Applications of deep learning for phishing detection: A systematic literature review. Knowl. Inf. Syst. 2022, 64, 1457–1500. [Google Scholar] [CrossRef] [PubMed]
- Do, N.Q.; Selamat, A.; Krejcar, O.; Herrera-Viedma, E.; Fujita, H. Deep Learning for Phishing Detection: Taxonomy, Current Challenges and Future Directions. IEEE Access 2022, 10, 36429–36463. [Google Scholar] [CrossRef]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv 2023, arXiv:2302.11382. [Google Scholar] [CrossRef]
- Lv, K.; Yang, Y.; Liu, T.; Gao, Q.; Guo, Q.; Qiu, X. Full Parameter Fine-tuning for Large Language Models with Limited Resources. arXiv 2023, arXiv:2306.09782. [Google Scholar] [CrossRef]
- Hannousse, A.; Yahiouche, S. Web Page Phishing Detection; Mendeley Data: Amsterdam, The Netherlands, 2021; Volume 3. [Google Scholar] [CrossRef]
- Asif, A.U.Z.; Shirazi, H.; Ray, I. Machine Learning-Based Phishing Detection Using URL Features: A Comprehensive Review. In Stabilization, Safety, and Security of Distributed Systems; Lecture Notes in Computer Science; Dolev, S., Schieber, B., Eds.; Springer: Cham, Switzerland, 2023; pp. 481–497. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar] [CrossRef]
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Yin, B.; Hu, X. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. arXiv 2023, arXiv:2304.13712. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2023, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things-Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Ye, X.; Durrett, G. The Unreliability of Explanations in Few-shot Prompting for Textual Reasoning. Adv. Neural Inf. Process. Syst. 2022, 35, 30378–30392. [Google Scholar]
- Kong, A.; Zhao, S.; Chen, H.; Li, Q.; Qin, Y.; Sun, R.; Zhou, X. Better Zero-Shot Reasoning with Role-Play Prompting. arXiv 2023, arXiv:2308.07702. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Lan, Y.; Xu, W.; Lim, E.P.; Bing, L.; Xu, X.; Poria, S.; Lee, R.K.W. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. arXiv 2023, arXiv:2304.01933. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, W.; Xu, H.; Liu, Y.; Yin, P. A Lightweight Multi-View Learning Approach for Phishing Attack Detection Using Transformer with Mixture of Experts. Appl. Sci. 2023, 13, 7429. [Google Scholar] [CrossRef]
- Introducing Cloudflare’s 2023 Phishing Threats Report. 2023. Available online: https://blog.cloudflare.com/2023-phishing-report (accessed on 8 January 2024).
- Sahoo, D.; Liu, C.; Hoi, S.C.H. Malicious URL Detection using Machine Learning: A Survey. arXiv 2019, arXiv:1701.07179. [Google Scholar] [CrossRef]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Detecting homoglyph attacks with a siamese neural network. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 22–28. [Google Scholar]
- Sern, L.J.; David, Y.G.P.; Hao, C.J. PhishGAN: Data Augmentation and Identification of Homoglyph Attacks. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics (CCCI), Virtual, 3–5 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Hageman, K.; Kidmose, E.; Hansen, R.R.; Pedersen, J.M. Can a TLS certificate be phishy? In Proceedings of the 18th International Conference on Security and Cryptography, SECRYPT 2021, Online, 6–8 July 2021; SCITEPRESS Digital Library: Setúbal, Portugal, 2021; pp. 38–49. [Google Scholar]
- Bozkir, A.S.; Aydos, M. LogoSENSE: A companion HOG based logo detection scheme for phishing web page and E-mail brand recognition. Comput. Secur. 2020, 95, 101855. [Google Scholar] [CrossRef]
- da Silva, C.M.R.; Feitosa, E.L.; Garcia, V.C. Heuristic-based strategy for Phishing prediction: A survey of URL-based approach. Comput. Secur. 2020, 88, 101613. [Google Scholar] [CrossRef]
- Chhabra, S.; Aggarwal, A.; Benevenuto, F.; Kumaraguru, P. Phi.sh/$oCiaL: The phishing landscape through short URLs. In Proceedings of the 8th Annual Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference, New York, NY, USA, 1–2 September 2011; pp. 92–101. [Google Scholar] [CrossRef]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Zouina, M.; Outtaj, B. A novel lightweight URL phishing detection system using SVM and similarity index. Hum.-Centric Comput. Inf. Sci. 2017, 7, 17. [Google Scholar] [CrossRef]
- Mahajan, R.; Siddavatam, I. Phishing Website Detection using Machine Learning Algorithms. Int. J. Comput. Appl. 2018, 181, 45–47. [Google Scholar] [CrossRef]
- Ahammad, S.H.; Kale, S.D.; Upadhye, G.D.; Pande, S.D.; Babu, E.V.; Dhumane, A.V.; Bahadur, M.D.K.J. Phishing URL detection using machine learning methods. Adv. Eng. Softw. 2022, 173, 103288. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, Q.; Qin, J.; Wen, W. Phishing URL Detection via CNN and Attention-Based Hierarchical RNN. In Proceedings of the 2019 18th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 112–119. [Google Scholar] [CrossRef]
- Mourtaji, Y.; Bouhorma, M.; Alghazzawi, D.; Aldabbagh, G.; Alghamdi, A. Hybrid Rule-Based Solution for Phishing URL Detection Using Convolutional Neural Network. Wirel. Commun. Mob. Comput. 2021, 2021, e8241104. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C.H. URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection. arXiv 2018, arXiv:1802.03162. [Google Scholar] [CrossRef]
- Tajaddodianfar, F.; Stokes, J.W.; Gururajan, A. Texception: A Character/Word-Level Deep Learning Model for Phishing URL Detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2857–2861. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, J.; Choo, K.K.R.; Liu, C.; Liu, K.; Yu, M.; Wang, Y. A Deep Learning Based Online Malicious URL and DNS Detection Scheme. In Security and Privacy in Communication Networks; Lin, X., Ghorbani, A., Ren, K., Zhu, S., Zhang, A., Eds.; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2018; pp. 438–448. [Google Scholar] [CrossRef]
- Ozcan, A.; Catal, C.; Donmez, E.; Senturk, B. A hybrid DNN–LSTM model for detecting phishing URLs. Neural Comput. Appl. 2023, 35, 4957–4973. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.C.L.; Chiew, K.L.; Yong, K.S.C.; Sebastian, Y.; Than, J.C.M.; Tiong, W.K. Hybrid phishing detection using joint visual and textual identity. Expert Syst. Appl. 2023, 220, 119723. [Google Scholar] [CrossRef]
- Hannousse, A.; Yahiouche, S. Towards benchmark datasets for machine learning based website phishing detection: An experimental study. Eng. Appl. Artif. Intell. 2021, 104, 104347. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. Mach. Learn. Python 2011, 12, 2825–2830. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar] [CrossRef]
- Timiryasov, I.; Tastet, J.L. Baby Llama: Knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty. arXiv 2023, arXiv:2308.02019. [Google Scholar] [CrossRef]
- Dakle, P.P.; Rallabandi, S.; Raghavan, P. Understanding BLOOM: An empirical study on diverse NLP tasks. arXiv 2023, arXiv:2211.14865. [Google Scholar] [CrossRef]
- Nepal, S.; Gurung, H.; Nepal, R. Phishing URL Detection Using CNN-LSTM and Random Forest Classifier. Preprint 2022. [Google Scholar] [CrossRef]
- McConnell, B.; Del Monaco, D.; Zabihimayvan, M.; Abdollahzadeh, F.; Hamada, S. Phishing Attack Detection: An Improved Performance Through Ensemble Learning. In Artificial Intelligence and Soft Computing; Lecture Notes in Computer Science; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Cham, Switzerland, 2023; pp. 145–157. [Google Scholar] [CrossRef]
- Rashid, S.H.; Abdullah, W.D. Cloud-Based Machine Learning Approach for Accurate Detection of Website Phishing. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 451–460. [Google Scholar]
- Uppalapati, P.J.; Gontla, B.K.; Gundu, P.; Hussain, S.M.; Narasimharo, K. A Machine Learning Approach to Identifying Phishing Websites: A Comparative Study of Classification Models and Ensemble Learning Techniques. ICST Trans. Scalable Inf. Syst. 2023, 10. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, W.; Xu, H.; Qin, Z.; Ren, K.; Ma, W. A Large-Scale Pretrained Deep Model for Phishing URL Detection. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Don’ts of Machine Learning in Computer Security. In Proceedings of the 31st USENIX Security Symposium, Boston, MA, USA, 10–12 August 2022. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LLM | openai-gpt | gpt2 | gpt2-medium | distilgpt2 | baby-llama-58m | bloom-560m |
|---|---|---|---|---|---|---|
| Epochs | 5 | 5 | 3 | 5 | 5 | 7 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| bloom-560m | 92.40% | 92.06% | 92.80% | 92.43% |
| distilgpt2 | 95.90% | 94.22% | 97.80% | 95.98% |
| openai-gpt | 96.10% | 96.01% | 96.20% | 96.10% |
| baby-llama-58m | 96.60% | 96.05% | 97.20% | 96.62% |
| gpt2 | 96.60% | 95.87% | 97.40% | 96.63% |
| gpt2-medium | 97.30% | 97.78% | 96.80% | 97.29% |
| Study | Year | Accuracy | Precision | Recall | F1-Score | AUC | Model |
|---|---|---|---|---|---|---|---|
| Nepal et al. [59] | 2022 | 94.30% | 94.51% | 94.59% | 94.55% | - | CNN-LSTM |
| McConnell et al. [60] | 2023 | 95.36% | 96.29% | 94.24% | 95.26% | 98.76% | Gradient Boosting |
| Rashid and Abdullah [61] | 2023 | 96.41% | 97.09% | 95.80% | 96.44% | - | Amazon Sagemaker—XGBoost |
| Uppalapati et al. [62] | 2023 | 97.05% | 97.27% | 96.75% | 97.01% | - | XGBoost |
| Our study | 2024 | 92.90% | 94.78% | 90.80% | 92.74% | - | Claude 2—prompt engineering |
| Our study | 2024 | 97.30% | 97.78% | 96.80% | 97.29% | 99.56% | Fine-tuned GPT-2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trad, F.; Chehab, A. Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Mach. Learn. Knowl. Extr. 2024, 6, 367-384. https://doi.org/10.3390/make6010018
Trad F, Chehab A. Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Machine Learning and Knowledge Extraction. 2024; 6(1):367-384. https://doi.org/10.3390/make6010018
Chicago/Turabian StyleTrad, Fouad, and Ali Chehab. 2024. "Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models" Machine Learning and Knowledge Extraction 6, no. 1: 367-384. https://doi.org/10.3390/make6010018
APA StyleTrad, F., & Chehab, A. (2024). Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Machine Learning and Knowledge Extraction, 6(1), 367-384. https://doi.org/10.3390/make6010018