Abstract
Recent work on decentralized computational trust models for open multi-agent systems has resulted in the development of CA, a biologically inspired model which focuses on the trustee’s perspective. This new model addresses a serious unresolved problem in existing trust and reputation models, namely the inability to handle constantly changing behaviors and agents’ continuous entry and exit from the system. In previous work, we compared CA to FIRE, a well-known trust and reputation model, and found that CA is superior when the trustor population changes, whereas FIRE is more resilient to the trustee population changes. Thus, in this paper, we investigate how the trustors can detect the presence of several dynamic factors in their environment and then decide which trust model to employ in order to maximize utility. We frame this problem as a machine learning problem in a partially observable environment, where the presence of several dynamic factors is not known to the trustor, and we describe how an adaptable trustor can rely on a few measurable features so as to assess the current state of the environment and then use Deep Q-Learning (DQL), in a single-agent reinforcement learning setting, to learn how to adapt to a changing environment. We ran a series of simulation experiments to compare the performance of the adaptable trustor with the performance of trustors using only one model (FIRE or CA) and we show that an adaptable agent is indeed capable of learning when to use each model and, thus, perform consistently in dynamic environments.
1. Introduction
In open environments, identifying trustworthy partners to interact with is a challenging task. This issue is usually addressed by trust and reputation mechanisms, which are key elements for the design of multi-agent systems (MAS) [1].
However, available trust management methods still have serious weaknesses, such as the inability to deal with agents’ mobility and unstable behavior [2]. Common trust models struggle to cope with agents’ frequent, unexpected entries and exits [3]. In highly dynamic environments, agents’ behavior can change rapidly, and agents using trust mechanisms must be able to quickly detect these changes in order to select beneficial partners for their interactions [4].
To address these unresolved issues in existing trust and reputation models, we have previously proposed CA [5], a decentralized computational trust model for open MAS, inspired by biological processes in the human brain. Unlike conventional models, CA handles trust from the trustee’s point of view. CA draws its strength from letting a trustee decide if it is skilled to provide a service, as required, instead of trustors selecting trustees. In previous work [6], we compared CA to FIRE, an established trust and reputation model, and our main finding was that CA outperforms FIRE when the consumer population changes, while FIRE is more resilient when the trustee population is volatile. Note here, that the terms providers and trustees refer to the agents who provide services, while the terms consumers and trustors refer to the agents who use these services.
This paper focuses on answering the question of how trustors may identify the presence of various factors that define a dynamically changing, open MAS (conceptualizing the nature of open MAS appears in [6]), and then decide which trust model to use to maximize utility. This problem can be framed as a machine learning problem in a partially observable environment, in which trustors are unaware of the effect of these dynamically changing factors. This framing renders the problem suitable for a reinforcement learning (RL) approach, where an agent learns how to behave in a given environment to maximize rewards. Unlike supervised and unsupervised learning, which use a specific data set to learn from, in RL, agents learn from the rewards and penalties they receive for their actions. Indeed, in our problem, the trustor attempts to learn the optimal policy, i.e., whether to advertise tasks and let trustees decide who gets to carry out a task (as implemented by CA, which is a push model) or to select trustees directly (as implemented by FIRE, a pull model), with actions being chosen in each state and with utility gain (UG) serving as a reward. We describe in detail how the adaptable trustor can calculate values for a number of environmental variables (features) to assess the current state and use Deep Q-Learning (DQL) to learn how to adapt to a changing environment. It is known that DQL does not handle partial observability well. An algorithm that allows obtaining non-deterministic policies is generally more compliant with Partially Observable Markov Decision Processes (POMDPs). For example, Policy Gradient methods are capable of learning stochastic policies because they model action probabilities, whereas the DQN cannot. Nevertheless, when the DQN does work, it usually shows a better sample efficiency (due to the use of the experience replay buffer) and more stable performance. To this end, we have chosen the DQN for our initial, proof-of-concept experiments, demonstrating that it works for the task at hand (i.e., learning to choose the use of the CA or FIRE model in situations of partial observability). We ran a series of simulations to compare the performance of an adaptable trustor (using DQL) with the performance of consumers using solely one model, FIRE or CA, and we found that by using Deep Q-Learning, the adaptable trustor is able to learn when to use each model, demonstrating a consistently robust performance.
Machine learning (ML) has been used to make trust evaluation intelligent and accurate. ML algorithms are used for either direct trust evaluation (calculating trust values or determining whether an evaluated object is trustworthy based on trust-related attributes) or assisting trust evaluation (for example, by clustering similar trustees) [7]. In this paper, we use ML in a completely different way. To our knowledge, using DQL to dynamically switch between different computational trust mechanisms is a novel approach. A comparable technique is not available [7,8].
The rest of the paper is organized as follows. In Section 2, we review the background on the relevant trust mechanisms and reinforcement learning. Section 3 describes the DQN architecture, specifying the features and the hyper-parameters used, and the simulation environment. In Section 4, we describe the methodology we employed for our experiments, and in Section 5 we present our results. Section 6 provides a discussion of our findings, the reasons for using a single-agent RL setting, and the reasons for not addressing a real-world validation of the proposed approach. Finally, in Section 7 we conclude our work, highlighting potential future work.
2. Background
2.1. Trust Mechanisms
In this section, we briefly describe the two trust mechanisms used in our simulations: FIRE and CA.
2.1.1. FIRE Model
FIRE [9] is an established trust and reputation model, which follows a distributed, decentralized approach, and utilizes the following four sources of trust information:
- Interaction trust (IT): a target trustee’s trustworthiness is evaluated based on the trustor’s previous interactions with the target agent.
- Witness reputation (WR): trustworthiness is estimated by the evaluator based on the opinions of other trustors (witnesses) that have previously interacted with the target trustee.
- Role-based trust (RT): trustworthiness is assessed based on roles and available domain knowledge, including norms and regulations.
- Certified reputation (CR): trustworthiness is evaluated based on third-party references stored by the target trustee, available on demand.
IT is the most reliable source of trust information because it reflects the evaluator’s satisfaction. However, in case that the evaluator has no previous interactions with the target agent, FIRE cannot utilize the IT module and relies on the other three modules, mainly on WR. Nevertheless, in conditions of high flows of witnesses out of the system, WR cannot work properly and FIRE is based mainly on the CR module for trust assessments. Yet, CR is not a very reliable source of trust information, since the trustees may choose to store only the best third-party references, resulting in an overestimation of their performance.
2.1.2. CA Model
We have formally described the CA model in [5] as a new computational trust model, inspired by synaptic plasticity, a biological process in the human brain. Synaptic plasticity is responsible for the creation of coherent groups of neurons called assemblies (which is why we call our model “Create Assemblies”).
CA views trust from the perspective of the trustee, i.e., the trustee decides whether it has the skills to successfully execute a required task. This is opposed to the conventional trust modeling approach, in which the trustor, after gathering and processing behavioral information about possible trustees, finally selects the most reliable one to interact with. As we have previously discussed [5], the idea that the trustor does not select a trustee provides several advantages to the CA approach in open multi-agent systems. The fact that the trustee can carry trust information (stored in the form of connection weights) and use it in every new application it joins gives CA an advantage in coping with the issue of mobility, which continues to be recognized as an open challenge [10]. Choosing trustees by trustors increases communication time because of the apparent need for extensive trust information exchange [11]. Agents may be unwilling to share trust information [12], while revealing an agent’s private opinion about others’ services may have a detrimental effect [9]. Finally, in the CA approach, agents do not share trust information. This creates the expectation that CA is invulnerable to various types of disinformation, an ongoing problem in most agent societies.
According to the CA model, the trustor (the agent requesting the task) broadcasts a request message to all nearby trustees, including the following information: (a) the task category (i.e., the type of work to be done) and (b) a list of task requirements. When a trustee receives a request message, it creates a connection with a weight , which represents the connection’s strength, i.e., the trust value expressing the trustee’s likelihood of successfully performing the task.
After completing the task, the trustee adjusts the weight. If it successfully completes the task, it increases the weight according to Equation (1). If the trustee fails, it decreases the weight according to Equation (2).
Positive factors and control the rate of increase and decrease, respectively. The trustee takes the decision to execute a task by comparing the connection’s weight to a predetermined ; it executes the task only when the weight is not less than the threshold value.
For our simulation experiments, we used the CA algorithm for dynamic trustee profiles, as described in [6].
2.2. Reinforcement Learning
In this setting, the agent interacts with the environment by taking actions and observing their effect (by, for example, measuring some environmental quantities). Single-agent RL under full observability was formalized by Sutton and Barto [13], defined as the tuple . At timestep t, the agent observes the current state , chooses an action based on the policy , and receives a reward . Then, with probability , the environment transits to a new state . The agent’s goal is to learn the optimal policy , maximizing discounted return (future rewards) , where is the horizon and is a discount factor. The action-value function of a policy is defined as . Then, the optimal policy maximizes the Q-value function .
Usually in RL, the agent tries to learn without being explicitly given the MDP model. Model-based methods learn and and then use a planner to determine . On the contrary, model-free methods are more efficient in terms of space and computation because they directly learn Q-values or policies.
Q-learning is a model-free method introduced by Watkins and Dayan [14]. It uses backups to iteratively calculate the optimal Q-value function, where denotes the learning rate. The term is the temporal difference (TD) error. In the tabular case, convergence to is guaranteed, provided adequate state/action space, where other methods using function approximators such as neural networks are more suitable.
Deep Q-learning [15] is a state-of-the-art method that uses a Deep Q-Network (DQN) for Q-value approximation. For any experience , the DQN uses two separate neural networks: (a) a target neural network to calculate the target , and (b) an online neural network to calculate the estimation . Then, the loss is calculated. The DQN stores the experiences in a replay memory and updates the online network’s parameters at random, taking mini-batches of experiences and minimizing loss using stochastic gradient descent. The target network parameters are updated less frequently to match the online network parameters, allowing a more stable learning.
2.3. Towards an Adaptable Trust Mechanism
Can trustor-based and trustee-based schemes co-exist? As stated briefly in the introduction, we can put the burden on trustors to try to detect whether the environment they operate in is one that favors a trustor-based or a trustee-based approach and, based upon that detection, decide what approach they will adopt with the objective of maximizing a measure of utility. Of course, as trustors do not necessarily communicate with each other and, when they do so, cannot be guaranteed to communicate in good faith, the question of how to select one’s action bears a remarkable affinity to a reinforcement learning context, and, particularly, one in a partially observable environment. Of course, to do so, one has to decide which measurable features will be utilized to describe the environment (more accurately, the allowable state space) and, additionally, how one can use these features to formulate a reward (or penalty) scheme, that will render the problem solvable by a reinforcement learning technique.
3. Experimental Setup
This section describes the setup for our simulations. First, in Section 3.1, we describe the DQN architecture. Then, the simulation environment and the respective parameters used in it are described in Section 3.2. Finally, in Section 3.3, we specify the selected features used for the state representation and the hyper-parameters used.
3.1. DQN Architecture
We used neural networks consisting of three fully-connected layers. The input to the neural network is a state representation of nine features’ values (Section 3.3.1), thus the input layer has nine neurons, one for each feature. The second, hidden layer has six neurons and the third is the output layer with two distinct neurons, one for each of the two possible actions: push (use CA trust model) and pull (use FIRE trust model). The choice of activation function for the input and hidden layer is sigmoid, while for the output layer we used a linear activation function.
3.2. The Testbed
For our simulations, we implemented a testbed similar to the one described in [9]. This section describes its main features and specifications.
The testbed’s environment contains agents who deliver services (referred to as trustees or providers) and agents who use these services (referred to as trustors or consumers). For simplicity, all providers offer the same service. The agents are randomly distributed in a spherical world with a radius of 1.0. The radius of operation () indicates the agent’s capacity for interactions with other agents, and each agent has other agents situated within its radius of operation, referred to as acquaintances.
A provider’s performance varies, determined by the utility gain (UG) that a consumer gets from each interaction, calculated as follows. There are four types of providers: bad, ordinary, intermittent, and good. Apart from the intermittent, each provider’s actual performance is normally distributed around a mean level of performance . The values of and the related standard deviation for each provider type are shown in Table 1. The intermittent provider has a random performance within the range [PL_BAD, PL_GOOD]. A provider’s radius of operation also corresponds to the normal operational range within which it can provide a service without quality loss. In case a consumer is outside that range, the provided service quality decreases linearly in proportion to the distance between the consumer and the provider, but the final calculated performance is always within [−10, +10] and equal to the utility the consumer acquired as an interaction result.

Table 1.
Providers’ profiles (performance constants defined in Table 2).
Simulations run in rounds. As in the real world, a consumer does not need the service in every round. The probability that the consumer will require the service (activity level ) is determined randomly at the agent’s creation time. There is no other factor restricting the number of agents eligible to participate in a round. A consumer always requires the service in the round it needs it. The round number is also used as the time value for any event.
There are three consumer groups: (a) consumers using only the FIRE trust model, (b) consumers using only CA, and (c) adaptable consumers able to use both models. If a consumer needs the service, first it finds all available nearby providers. FIRE consumers select a provider following the four-step process outlined in [9]. After selecting a provider, FIRE consumers use the service, gain some utility, and rate the service with a rating value equal to the received UG. The rating is then recorded by the consumer for future trust evaluations and the provider is also informed about the rating, which may be stored as evidence of its performance available on demand.
On the contrary, CA consumers that need the service do not select a provider but they broadcast a request message, specifying the required service quality. Table 2 presents the five performance levels reflecting the possible qualities of the service. A CA consumer first broadcasts a message requesting the service at the best quality (PERFECT). After a sufficient amount of time (WT), all CA consumers, which have not been provided with the service, broadcast a new message requesting the service at the next lower performance level (GOOD). This procedure goes on as long as there exist consumers who have not been served and the requested performance remains above the lowest level. On receiving a request message, a provider saves it locally in a list and runs the CA algorithm. WT is a testbed parameter indicating the maximum time needed for all requested services of one round to be delivered.
Table 2.
Performance level constants.
Adaptable consumer agents first calculate the nine features for the state representation and then use the DQN algorithm to decide the trust model (FIRE or CA) that they will use in each simulation round.
In open MAS, agents enter and leave the system at any time. This is simulated by replacing a random number of agents at the end of each round. This number varies, but it is not allowed to exceed a given percentage of the total population. denotes the consumer population change limit and denotes the provider population change limit. The newcomer agents’ characteristics are randomly chosen, but the proportions of different consumer groups and provider profiles are maintained.
Altering an agent’s location has an effect on both its own situation and its relationship with other agents. Polar coordinates specify an agent’s location in the spherical world. To change location, amounts of angular changes and are added to and , respectively. and are chosen at random in . Providers and consumers change locations at the end of a round, with probabilities denoted by and , respectively.
At the end of each round, the performance of a provider can be changed by an amount randomly chosen in , with a probability of . A provider may also switch to a different profile with a probability of .
3.3. Features and Hyper-Parameter Setup
3.3.1. Features
In this section, we describe the nine features we used for state representation, which are summarized in Table 3.
Table 3.
Selected features for the DQN.
The trustor’s decision on which model is most appropriate at any given time is based on the accuracy of its assessment about the environment’s current state, which is determined by the presence of the following factors:
- The provider population change.
- The consumer population change.
- The provider’s average level of performance change.
- The provider’s change into a different performance profile.
- The provider’s move to a new location on the spherical world.
- The consumer’s move to a new location on the spherical world.
Since we assume a partially observable environment, meaning that the trustor has no knowledge of the aforementioned factors, the trustor can only utilize the following available data:
- A local ratings database. After each interaction, the trustor rates the provided service and each rating is stored in its local ratings database.
- The trustor’s acquaintances: the agents situated in the trustor’s radius of operation.
- The trustor’s nearby provider agents: the providers situated in the trustor’s radius of operation.
- The trustor is able to evaluate the trustworthiness of all nearby providers using the FIRE model. Providers whose trustworthiness cannot be determined (for any reason) are placed in the set NoTrustValue. The rest, whose trustworthiness can be determined, are placed in the set HasTrustValue.
- The trustor’s location on the spherical world, i.e., its polar coordinates .
- The acquaintances’ ratings or referrals, according to the process of witness reputation (WR): When consumer agent a evaluates agent ’s WR, it sends a request for ratings to acquaintances that are likely to have ratings for agent b. Upon receiving the query, each acquaintance will attempt to match it to its own ratings database and return any relative ratings. In case an acquaintance cannot find the requested ratings (because it has had no interactions with b), it will only return referrals identifying its acquaintances.
- Nearby providers’ certified ratings, according to the process of certified reputation (CR): After each interaction, provider requests from its partner consumer to provide certified ratings for its performance. Then, selects the best ratings to be saved in its local ratings database. When expresses its interest for ’s services, it asks to give references about its previous performance. Then, agent receives ’s certified ratings set and uses it to calculate ’s CR.
Next, we elaborate on how the trustor can approximate the real environment’s conditions. We enumerate indicative changes in the environment and analyze on how the trustor could sense this particular change and measure the extent of the change.
- The provider population changes at maximum X% in each round.
Given that is the list of nearby providers in round , and is the list of nearby providers in round , the consumer can calculate the list of the newcomer nearby provider agents, , as the providers that exist in , but not in (. Then, the following feature can be calculated by the consumer agent as an index of the provider population change in each round:
where the meaning of is cardinality of. Intuitively, this ratio expresses how changes in the total provider population can be reflected in changes in the provider population situated in the consumer’s radius of operation. However, in any given round, newcomer providers may not be located within a specific consumer’s radius of operation, even if new providers have entered the system. In this case, the total change of the providers’ population in the system can be better assessed in a window of consecutive rounds.
Given that a window of rounds is defined as a set of consecutive rounds, , the consumer can calculate the feature for each round , as follows.
Then, a more accurate index of the provider population change in each round can be calculated as the following mean:
Note that can include providers that are not really newcomers but they previously existed in the system and appear as new agents in , either due to their own movement in the world, due to the consumer’s movement, or both. In other words, agents’ movements in the world introduce noise in the measurement of .
Each newcomer provider agent has not yet interacted with other agents in the system and therefore its trustworthiness cannot be determined using the interaction trust and witness reputation modules. If the newcomer provider does not have any certified ratings from its interactions with agents in other systems, then its trustworthiness cannot be determined using the certified reputation module either. This agent belongs to the set, which is a subset of .
We can distinguish another category of newcomer provider agents, those whose trustworthiness can be determined solely by CR, because they own certified ratings from their interactions with agents in other systems. Let denote the subset of whose trustworthiness can be determined using only the CR module. The consumer can then calculate the following feature as an alternative index for the provider population change in a round.
As previously stated, in any given round, newcomer providers may not be located within a specific consumer’s radius of operation, even if they have entered the system. Thus, a more accurate estimate of can be calculated in a window of n consecutive rounds, with the following mean:
- 2.
- The consumer population changes at maximum X% in each round.
If the consumer population has changed, it is possible that the consumer itself is a newcomer. In this case, the consumer is not expected to have ratings for any of its nearby providers in its local ratings database, and the IT module of FIRE cannot work. Thus, estimating whether it is a newcomer consumer probably helps the agent to decide about which trust model to employ for maximum benefits. The consumer can calculate the feature as follows. It sets , if there are no available ratings in its local ratings database for any of the nearby providers, otherwise it sets . More formally:
According to the WR process, when consumer assesses the WR of a nearby provider , it sends out a query for ratings to consumer acquaintances that are likely to have relative ratings on agent b. Each newcomer consumer acquaintance will try to match the query to its own (local) ratings database, but it will find no matching ratings because of no previous interactions with b. Thus, the acquaintance will return no ratings. In this case, the consumer can reasonably infer that an acquaintance that returns no ratings is very likely to be a newcomer agent. So, consumer agent a, in order to approximate the consumer population change, can calculate the following feature:
where is the set of consumer acquaintances of to which consumer sends queries (for ratings), one for each of its nearby providers, at round , and is the subset of consumer acquaintances that returned no ratings (for any query) to at round .
As previously stated, in any given round, newcomer consumer acquaintances may not be located within a specific consumer’s radius of operation, even if newcomer consumers have entered the system. Thus, a more accurate estimate of can be calculated in a window of consecutive rounds, with the following mean:
- 3.
- The provider alters its average level of performance at maximum X UG units with a probability of p in each round.
A consumer using FIRE selects the provider with the highest trust value in the HasTrustValue set. The quantity is an estimate of the average performance of the selected provider whose actual performance can be different. The difference expresses the change of the average performance level of a specific provider. Yet not all providers alter their average level of performance in each round. Thus, the consumer can calculate the following feature as an estimate of a provider’s average level of performance, by using the differences of the last interactions with this provider.
- 4.
- The providers switch into a different (performance) profile with a probability of in each round.
A consumer can use as an estimate of a provider’s profile change, as well.
- 5.
- Consumers move to a new location on the spherical world with a probability in each round.
The list can include providers that appear as new because of the consumer’s movement on the world. Thus, can also be used as an estimate of consumer’s movement.
Nevertheless, in order to make a more accurate estimate, a consumer can use its polar coordinates. Given that are its polar coordinates in round and are its polar coordinates in round , a consumer is able to calculate the following feature:
The consumer estimates that its location has changed, by setting , if at least one of its polar coordinates have changed compared to the previous round.
- 6.
- Providers move to a new location on the spherical world with a probability in each round.
The list can include providers that appear as new because of their movement in the world. Thus, also serves as an estimate of the providers’ movement.
Note that since a provider does not know other agents’ polar coordinates, it cannot calculate a feature similar to .
3.3.2. Hyper-Parameter Setup
The combinatorial space of hyper-parameters is too large for an exhaustive search. Due to the high computational cost, we have not conducted a systematic search. Instead, an informal search was performed. The values of all hyper-parameters are displayed in Table 4.
Table 4.
List of hyper-parameters and their values.
4. Experimental Methodology
In our simulation experiments, we compare the performance of the following three consumer groups:
- Adaptable: consumer agents able to choose a trust model (FIRE or CA) based on their assessment for the presence of several dynamic factors in their environment.
- FIRE: consumer agents using only the FIRE trust model.
- CA: consumers using solely the CA trust model.
To accomplish this, we run a number of independent simulation runs (NISR) to ensure more accurate results and avoid random noise. In order to obtain statistically significant results, NISR varies in each experiment, as shown in Table 5.
Table 5.
Number of independent simulation runs (NISR) per experiment.
The utility that each agent gained throughout simulations indicates the model’s ability to identify reliable, profitable providers. Thus, each interaction’s utility gain (UG) along with the trust model employed are both recorded.
After all simulation runs have finished, we calculate the average UG for each interaction for each consumer group. The average UG of the three consumer groups are then compared using the two-sample t-test for means comparison [16] with a 95% confidence level.
The results of each experiment are presented in a two-axis graph; the left axis shows the UG means of consumer groups in each interaction and the right axis shows the performance rankings produced by the UG means comparison using the t-test. We use the group’s name prefixed by “R” to denote the plot for the performance ranking of a group. A higher-ranking group outperforms a lower-ranking group, while groups of equal rank perform insignificantly differently. For instance, in Figure 1, at the 87th interaction (on the x-axis), agents in group CA obtain an average UG of 6.14 (reading on the left axis) and according to the t-test ranking, the rank of CA (as shown by the plot R.CA) is 3 (reading on the right y-axis).
In all the simulations, the provider population is “typical”, as defined in [9], consisting of half profitable providers (producing positive UG) and half harmful providers (producing negative UG, including intermittent providers).
The values for the experimental variables used are shown in Table 6, while the FIRE and CA parameters used are shown in Table 7 and Table 8, accordingly.
Table 6.
Experimental variables.
Table 7.
FIRE’s default parameters.
Table 8.
CA’s default parameters.
5. Simulation Results
5.1. Adaptable’s Performance in Single Environmental Changes
In this section we compare the performance of three groups of consumers (adaptable, CA, and FIRE) when there is no environmental change (static setting) and when there is one environmental change at a time, keeping the change constant throughout the simulation, conducting the following experiments:
- Experiment 1. The setting is static, with no changes.
- Experiment 2. The provider population changes at maximum 2% in every round ().
- Experiment 3. The provider population changes at maximum 5% in every round ().
- Experiment 4. The provider population changes at maximum 10% in every round ().
- Experiment 5. The consumer population changes at maximum 2% in every round ().
- Experiment 6. The consumer population changes at maximum 5% in every round ().
- Experiment 7. The consumer population changes at maximum 10% in every round ().
- Experiment 8. A provider may alter its average level of performance at maximum 1.0 UG unit with a probability of 0.10 each round ().
- Experiment 9. A provider may switch into a different (performance) profile with a probability of 2% in every round ().
- Experiment 10. A consumer may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round ().
- Experiment 11. A provider may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round ().
The research question we aim to answer in this set of experiments is whether the adaptable consumer will be able to maintain its performance higher than that of the worst choice (the model with the lowest performance), when only one environmental change occurs.
The experiments’ results are presented in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11.
Overall, the performance of the adaptable consumer is satisfactory in all the experiments and follows the performance of the best-choice model in each situation. This conclusion is drawn more easily if we consider experiments 3–7 (Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7), where the performance of the adaptable consumer is always between the performance of the other two models. Specifically, when the provider population changes (Figure 3 and Figure 4), the adaptable’s performance is always higher than CA, the worst choice in this case. On the contrary, when the consumer population is volatile (Figure 5, Figure 6 and Figure 7), the adaptable maintains a performance higher than that of FIRE’s.
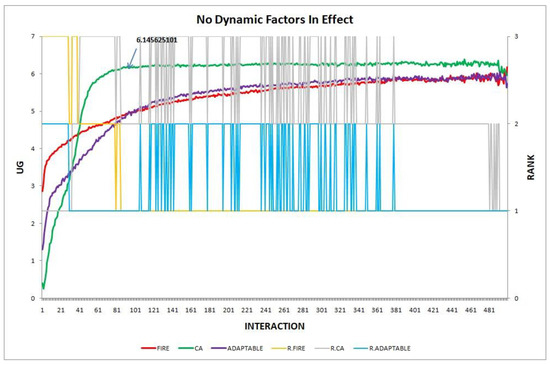
Figure 1.
Experiment 1: performance of the adaptable consumer in the static setting.
Figure 1.
Experiment 1: performance of the adaptable consumer in the static setting.
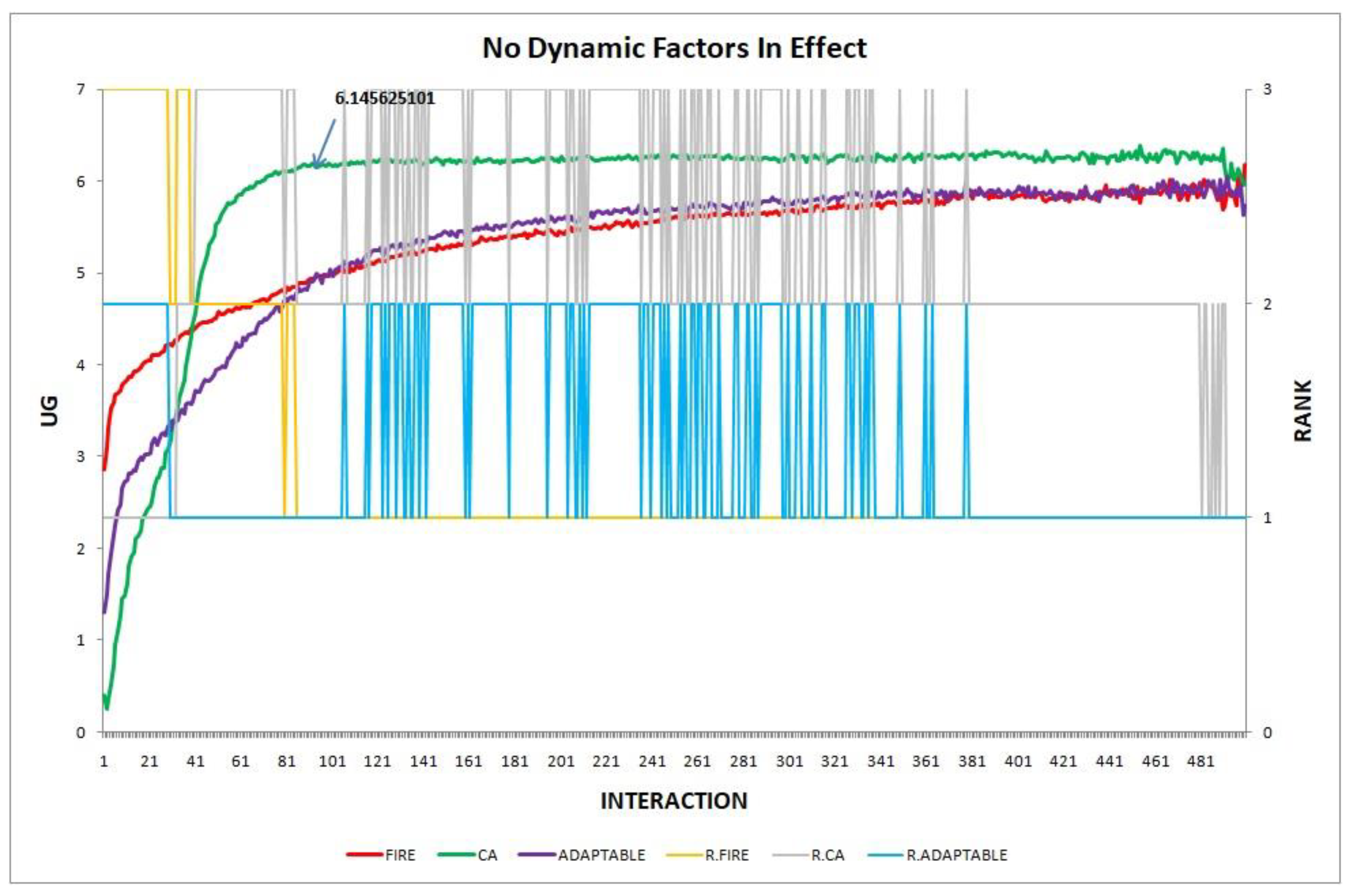
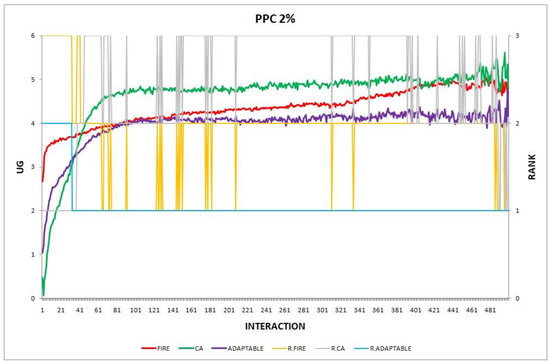
Figure 2.
Experiment 2: provider population change; .
Figure 2.
Experiment 2: provider population change; .
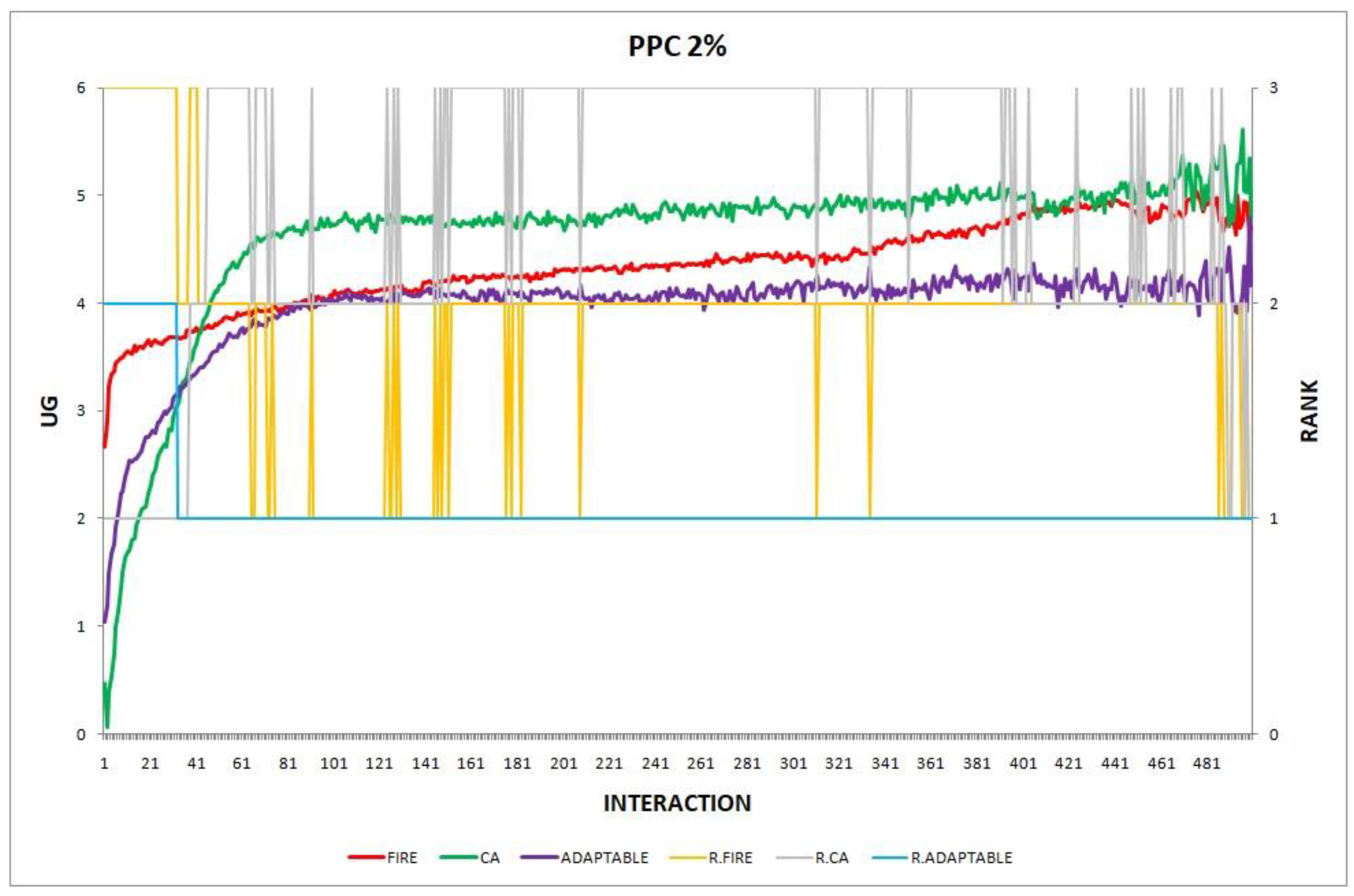
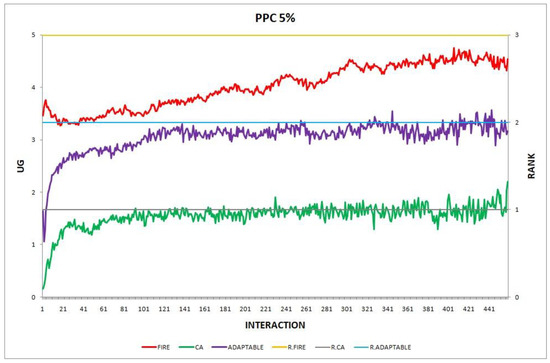
Figure 3.
Experiment 3: provider population change; .
Figure 3.
Experiment 3: provider population change; .
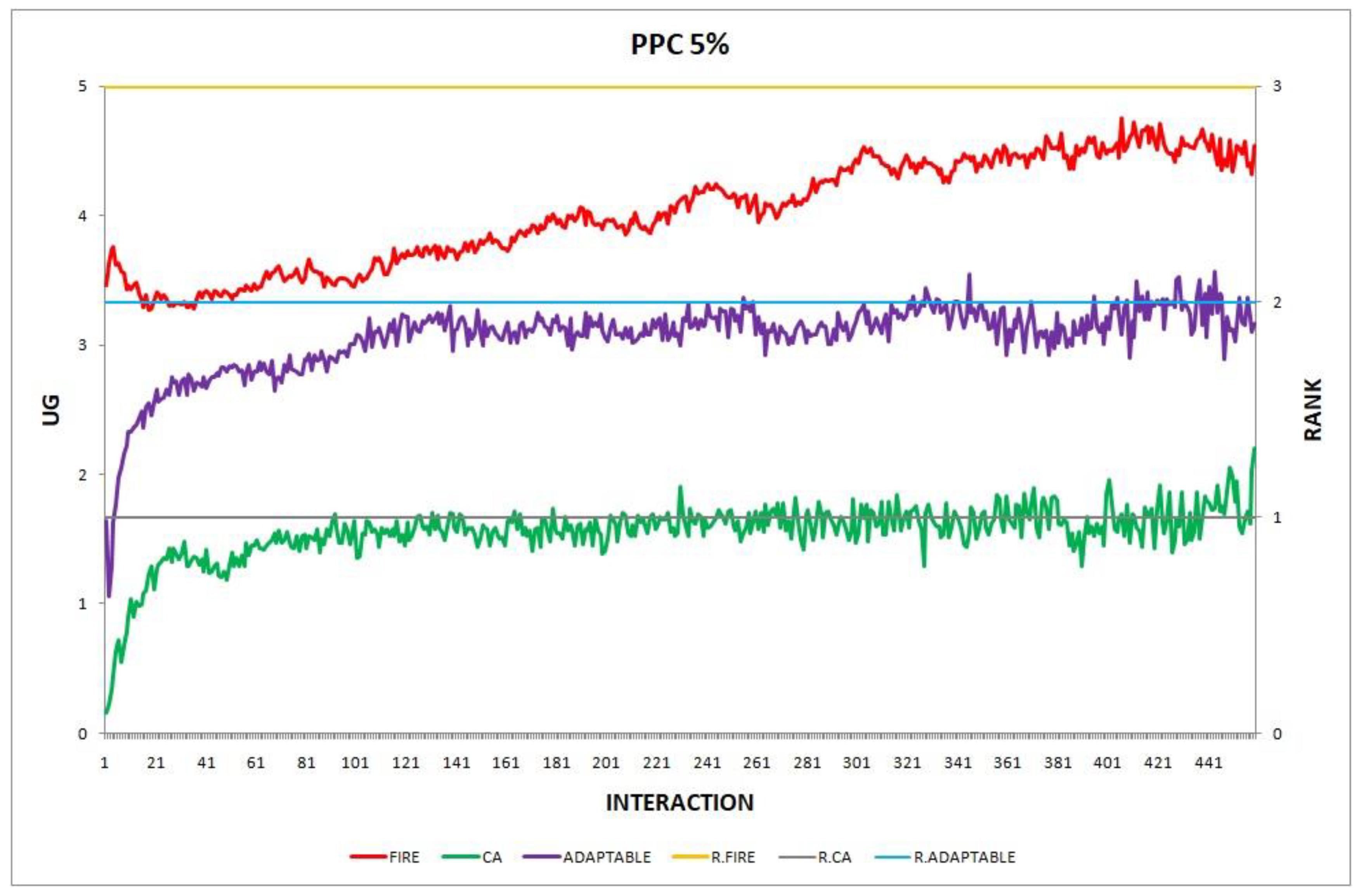
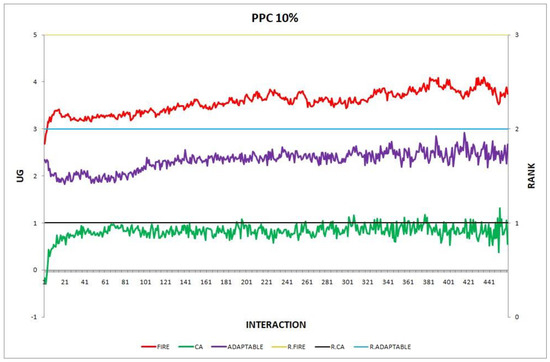
Figure 4.
Experiment 4: provider population change; .
Figure 4.
Experiment 4: provider population change; .
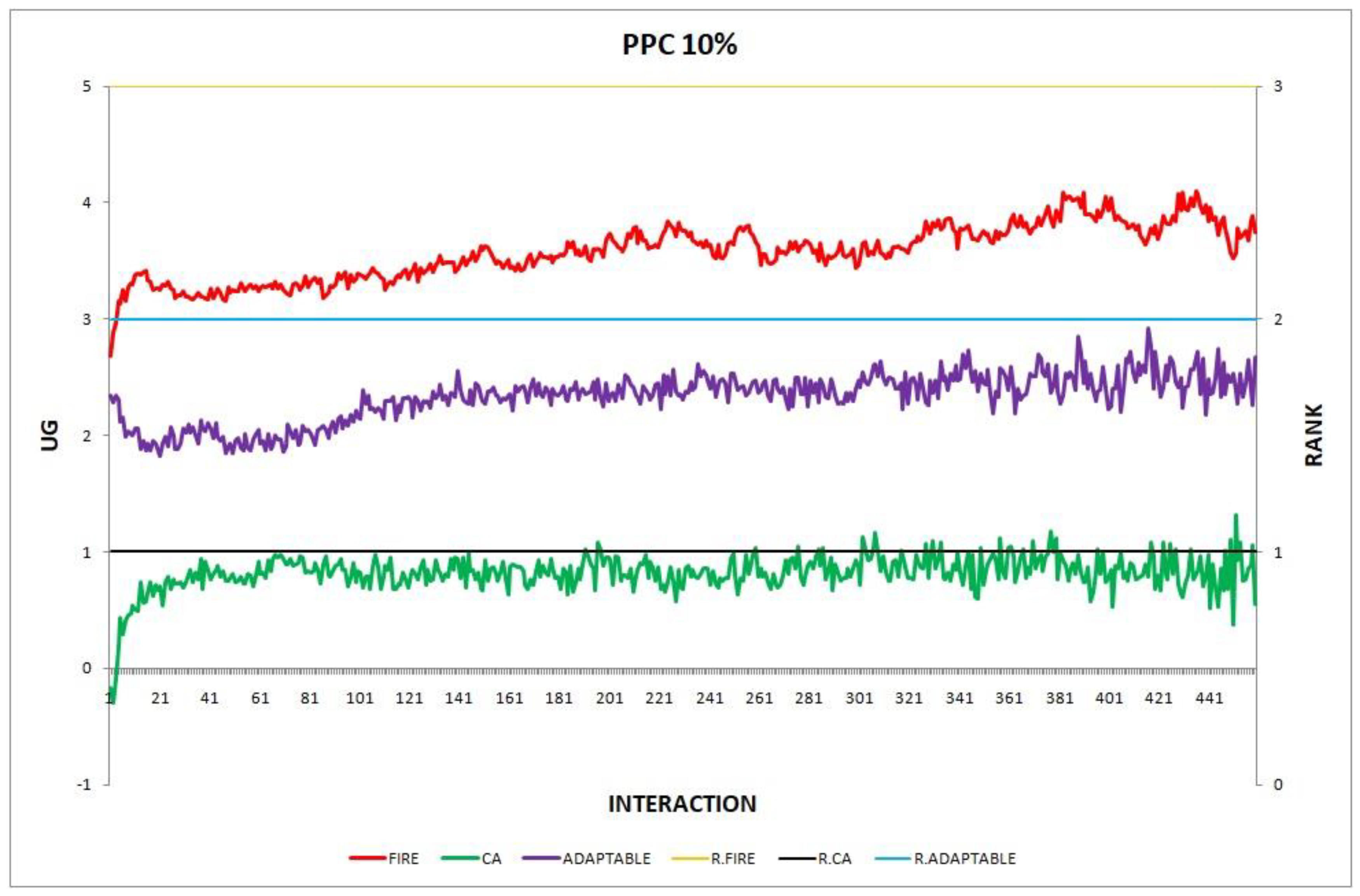
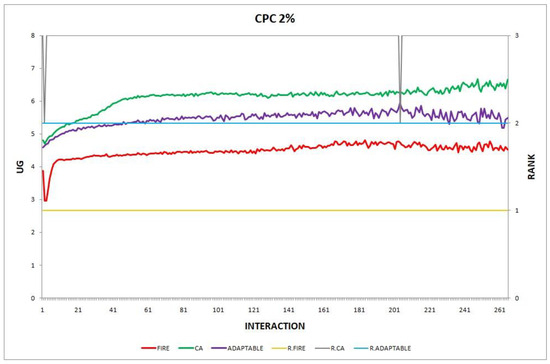
Figure 5.
Experiment 5: consumer population change; .
Figure 5.
Experiment 5: consumer population change; .
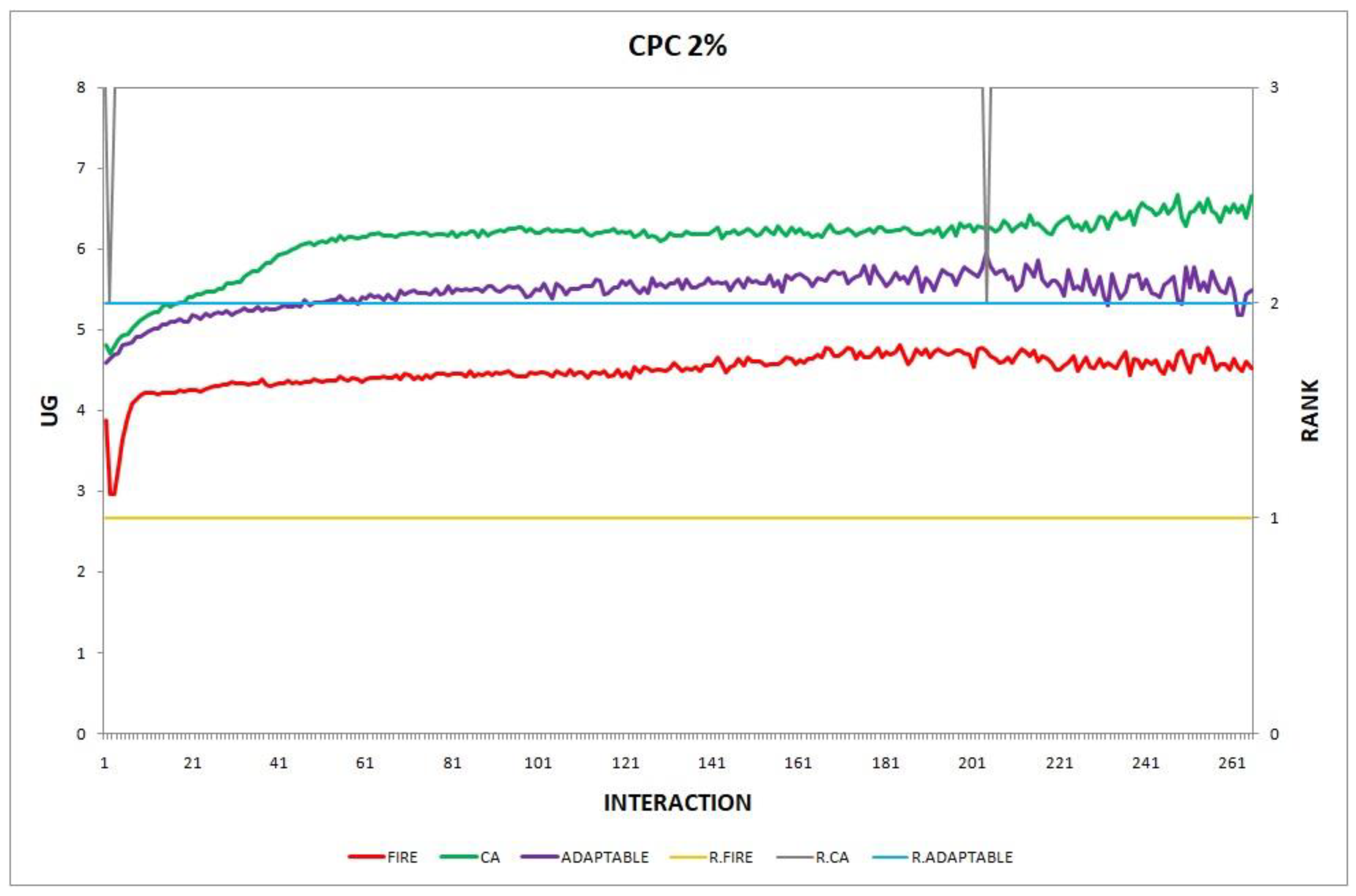
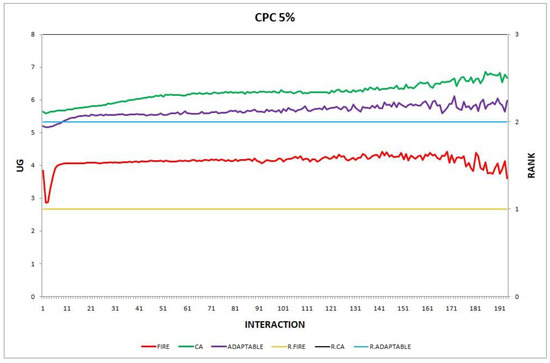
Figure 6.
Experiment 6: consumer population change; .
Figure 6.
Experiment 6: consumer population change; .
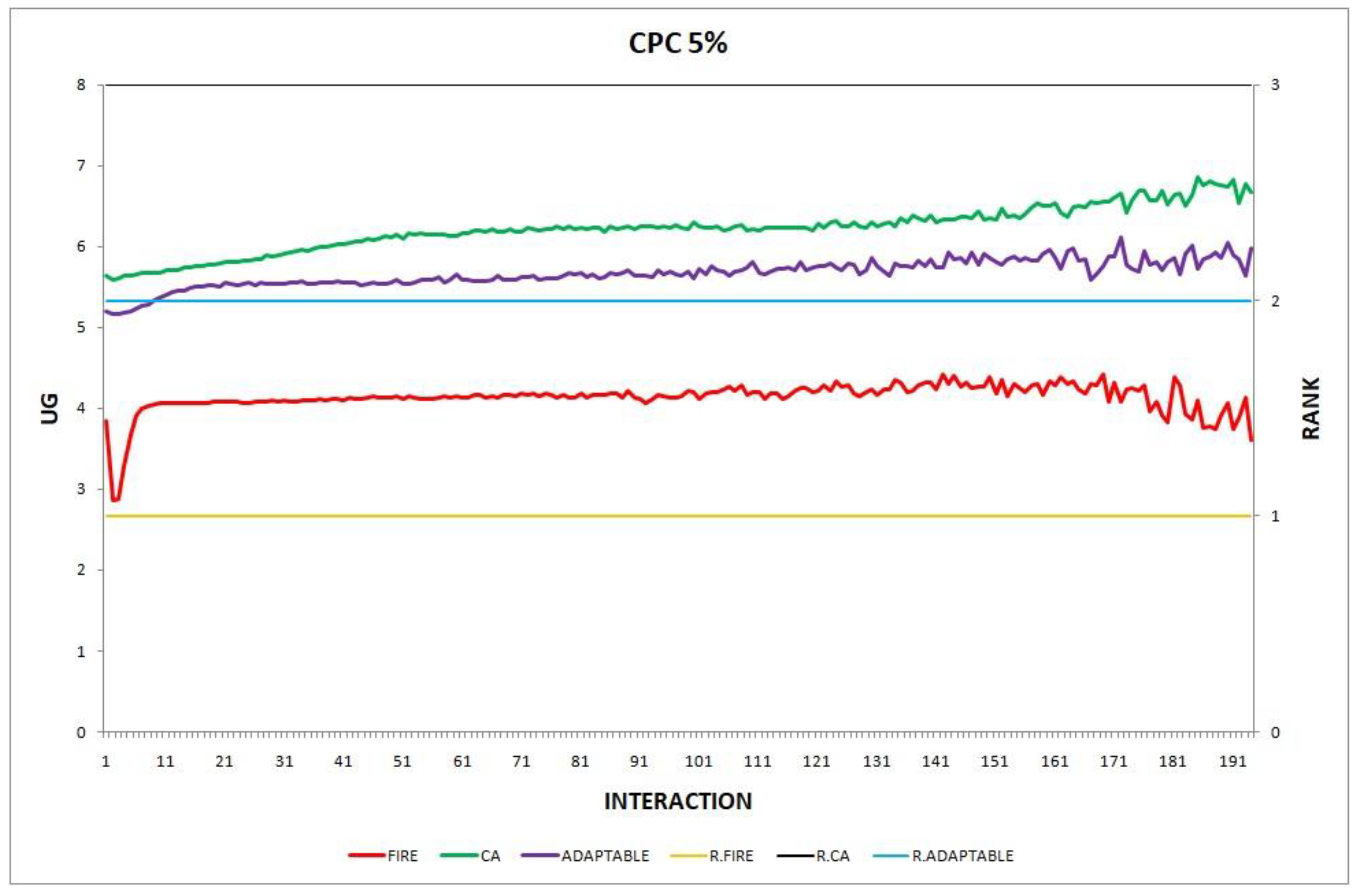
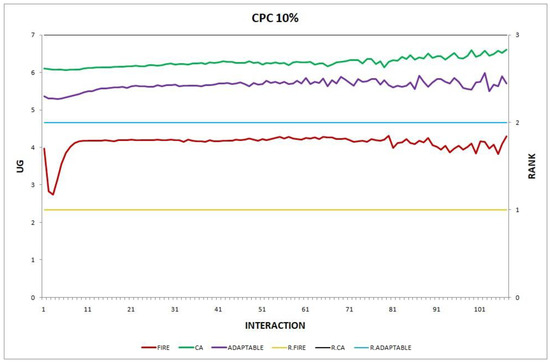
Figure 7.
Experiment 7: consumer population change; .
Figure 7.
Experiment 7: consumer population change; .
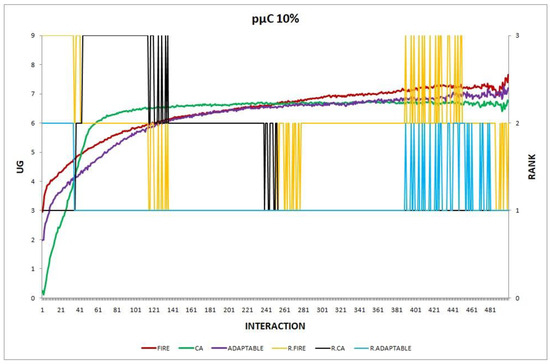
Figure 8.
Experiment 8: providers change their performance; .
Figure 8.
Experiment 8: providers change their performance; .
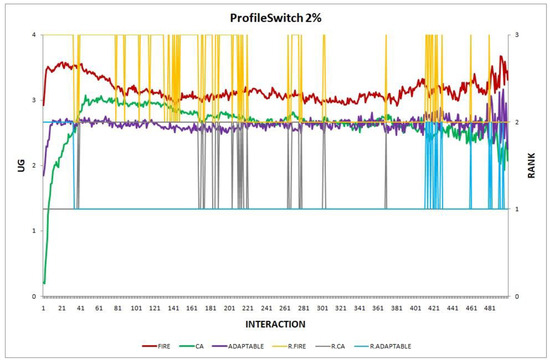
Figure 9.
Experiment 9: providers switch their profiles; .
Figure 9.
Experiment 9: providers switch their profiles; .
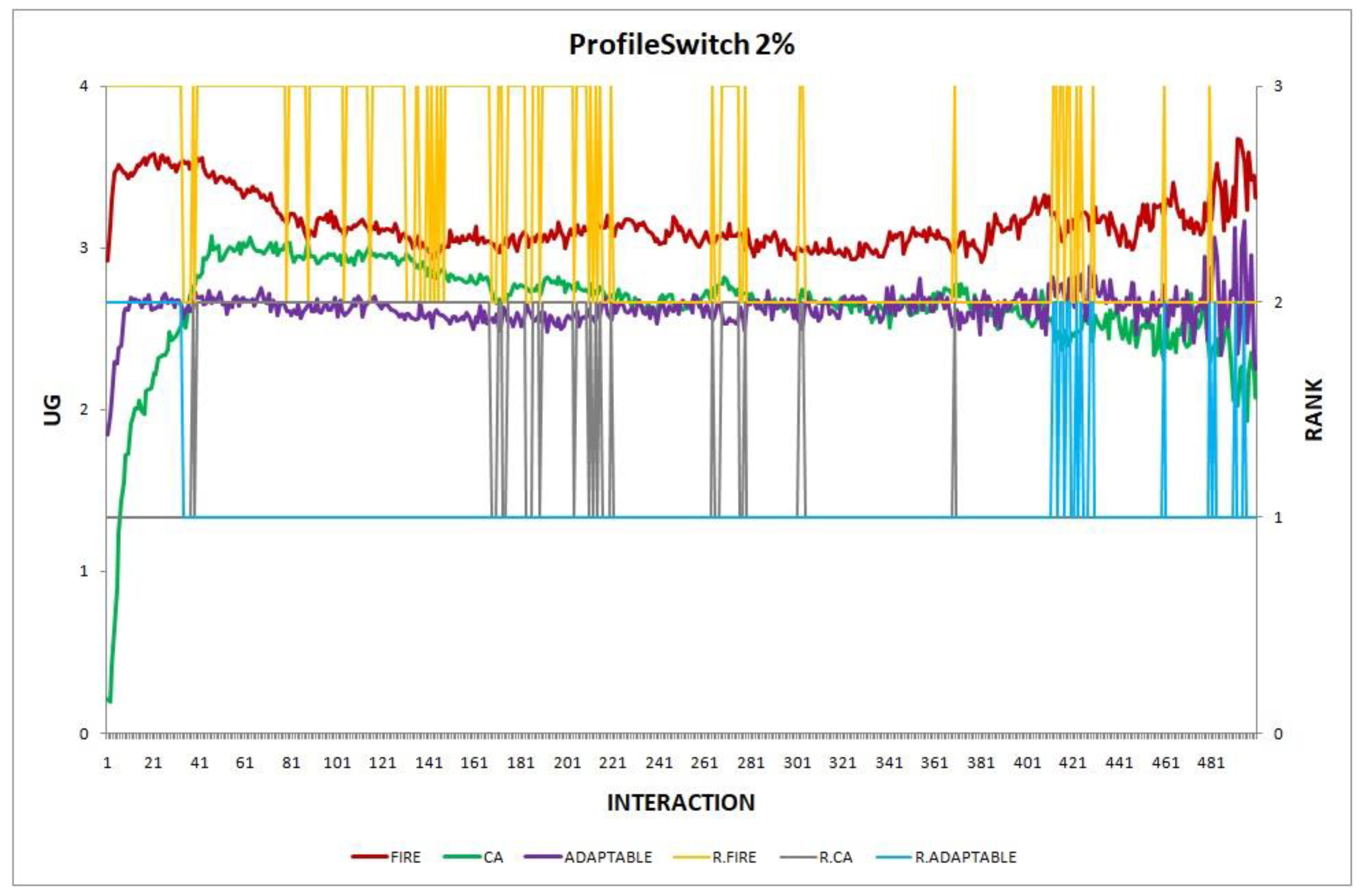
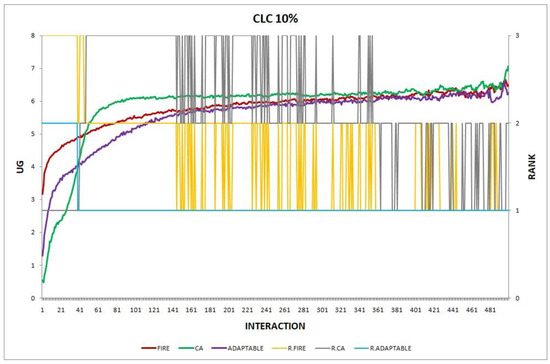
Figure 10.
Experiment 10: consumers change their locations; .
Figure 10.
Experiment 10: consumers change their locations; .
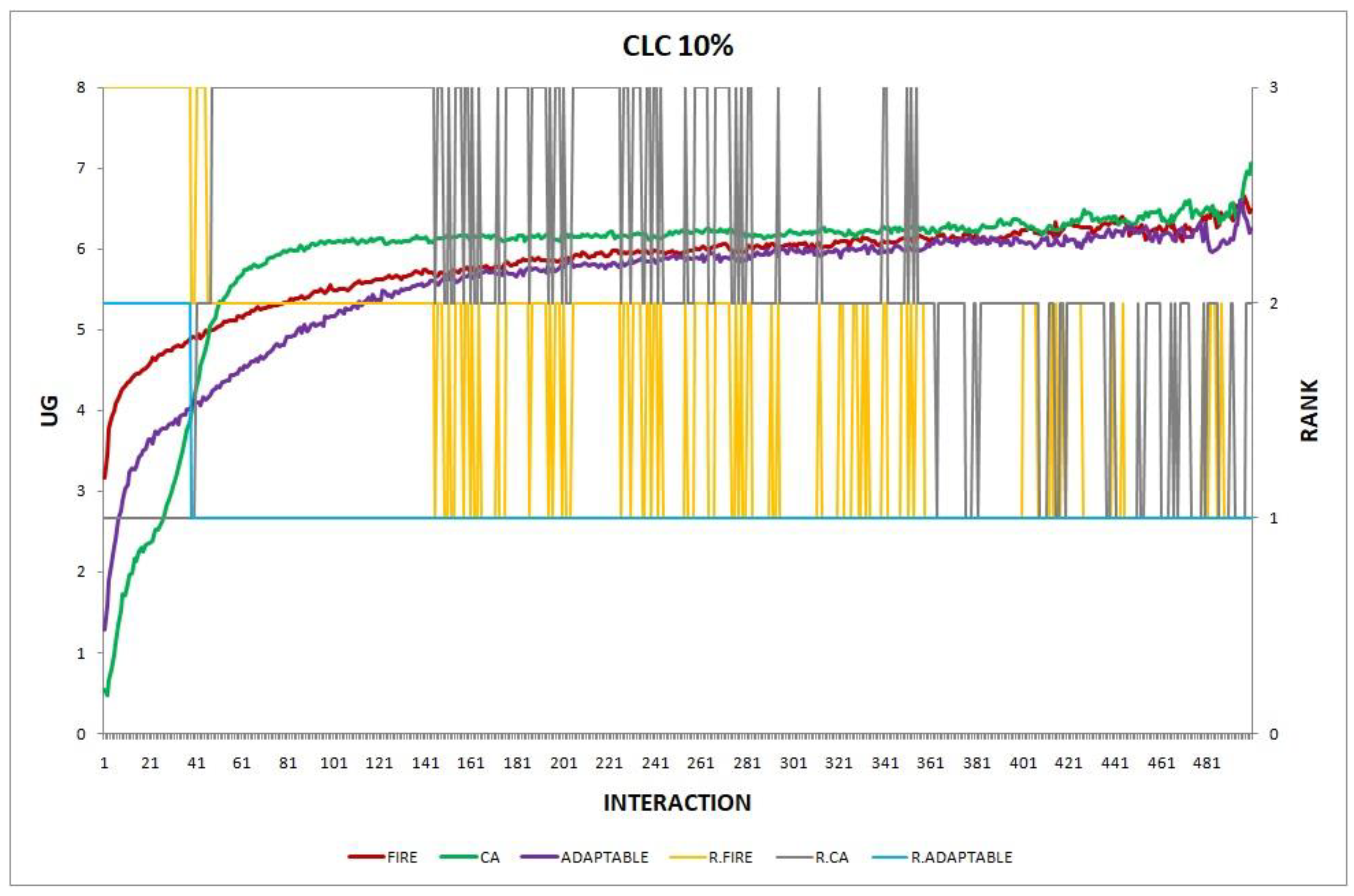
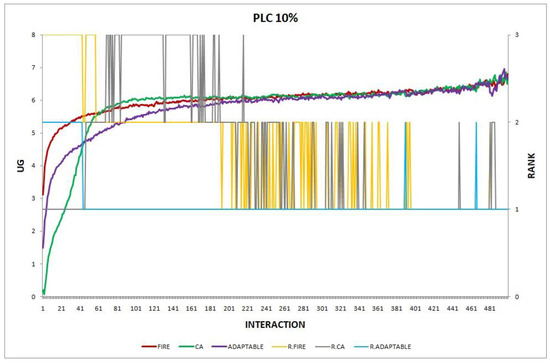
Figure 11.
Experiment 11: providers change their locations; .
Figure 11.
Experiment 11: providers change their locations; .
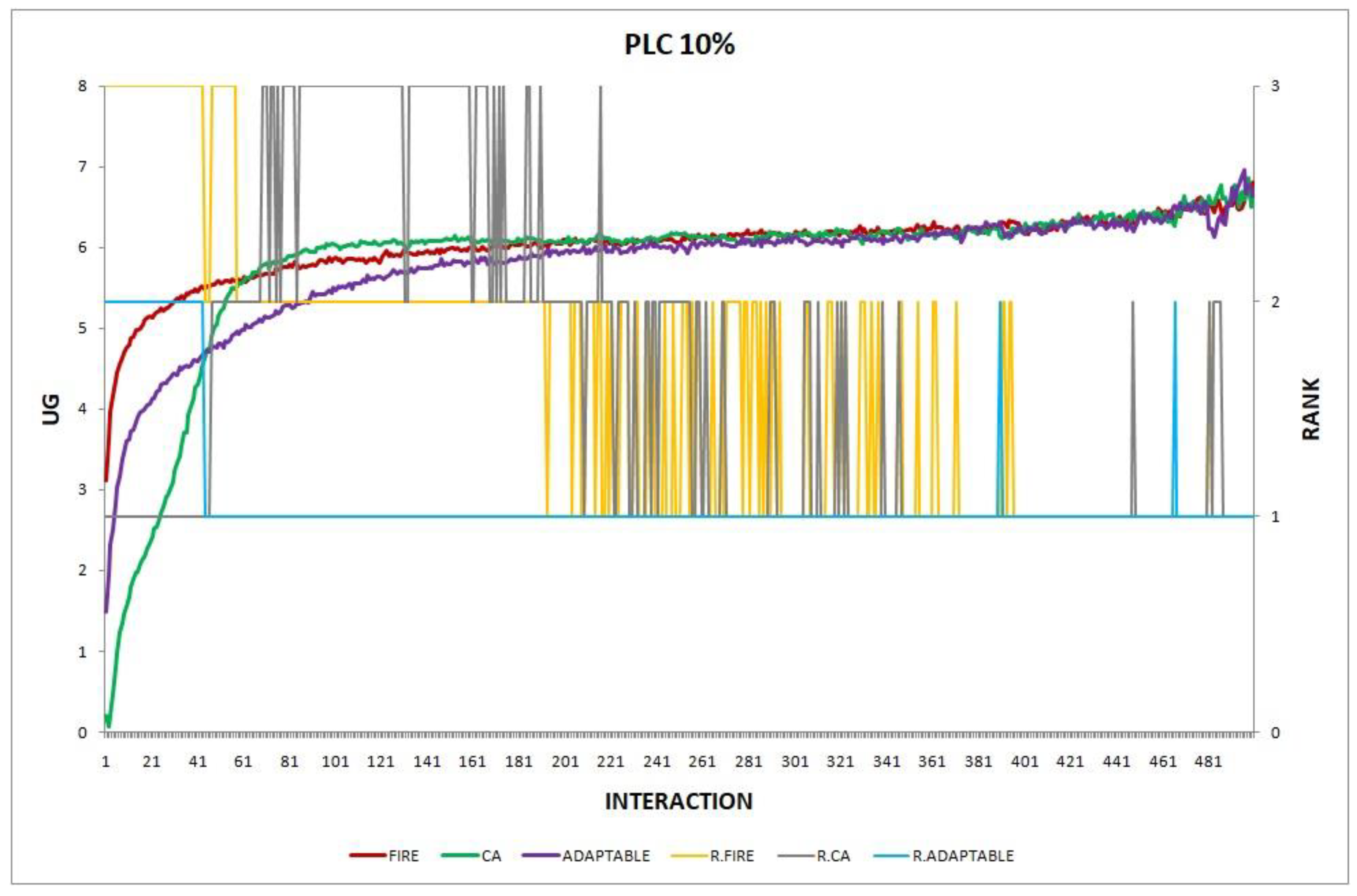
5.2. Adaptable’s Performance in Various Combinations of Changes
The experiments of this section aim to demonstrate that the adaptable consumer can find the optimal policy when there are multiple, concurrently acting environmental changes and it is difficult to predict (using the previous section’s results) which of the two models, FIRE or CA, is the best option. Note, that all changes are maintained the same throughout the simulation rounds of the experiment. The experiments we conducted are described as follows.
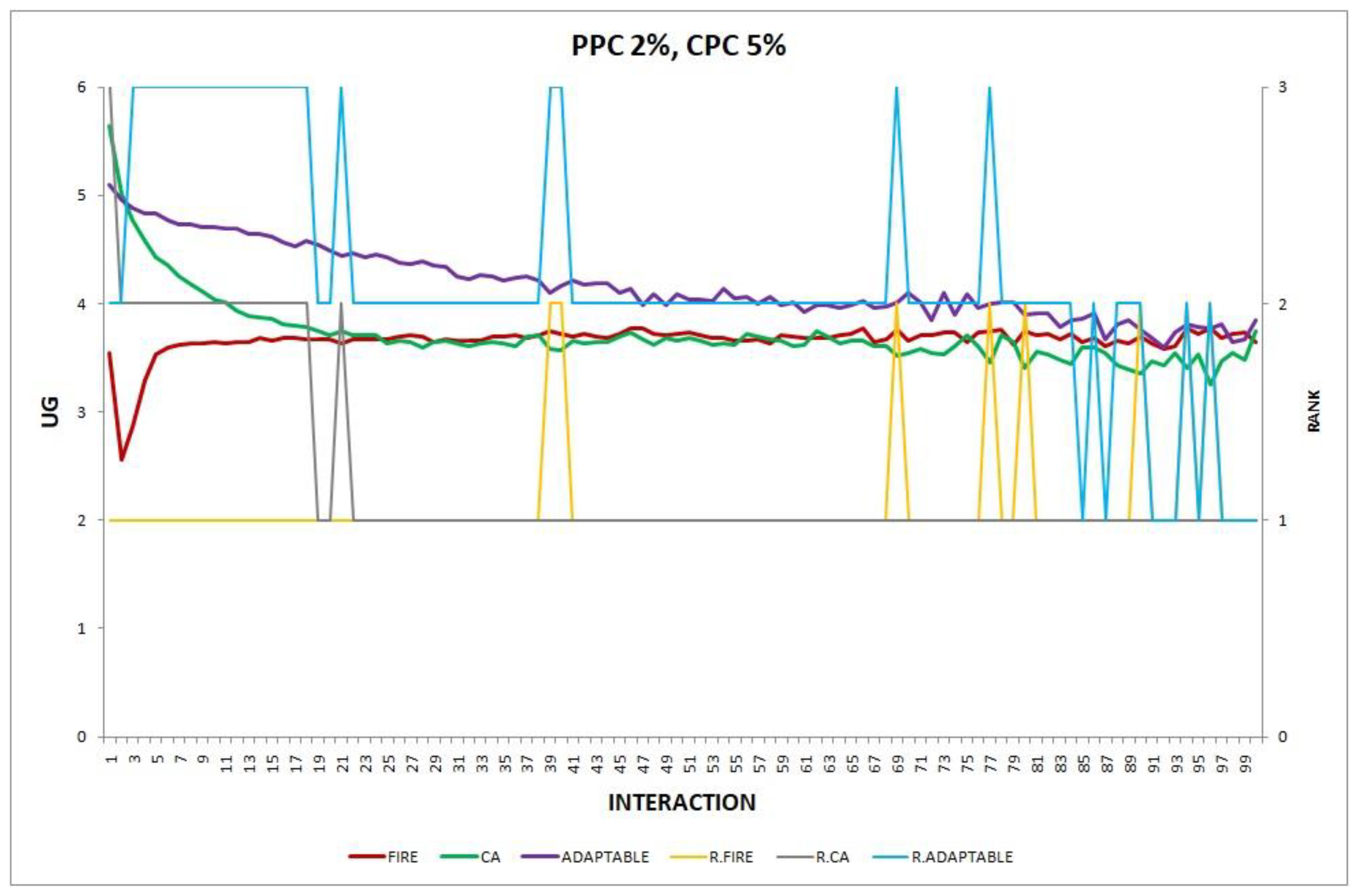
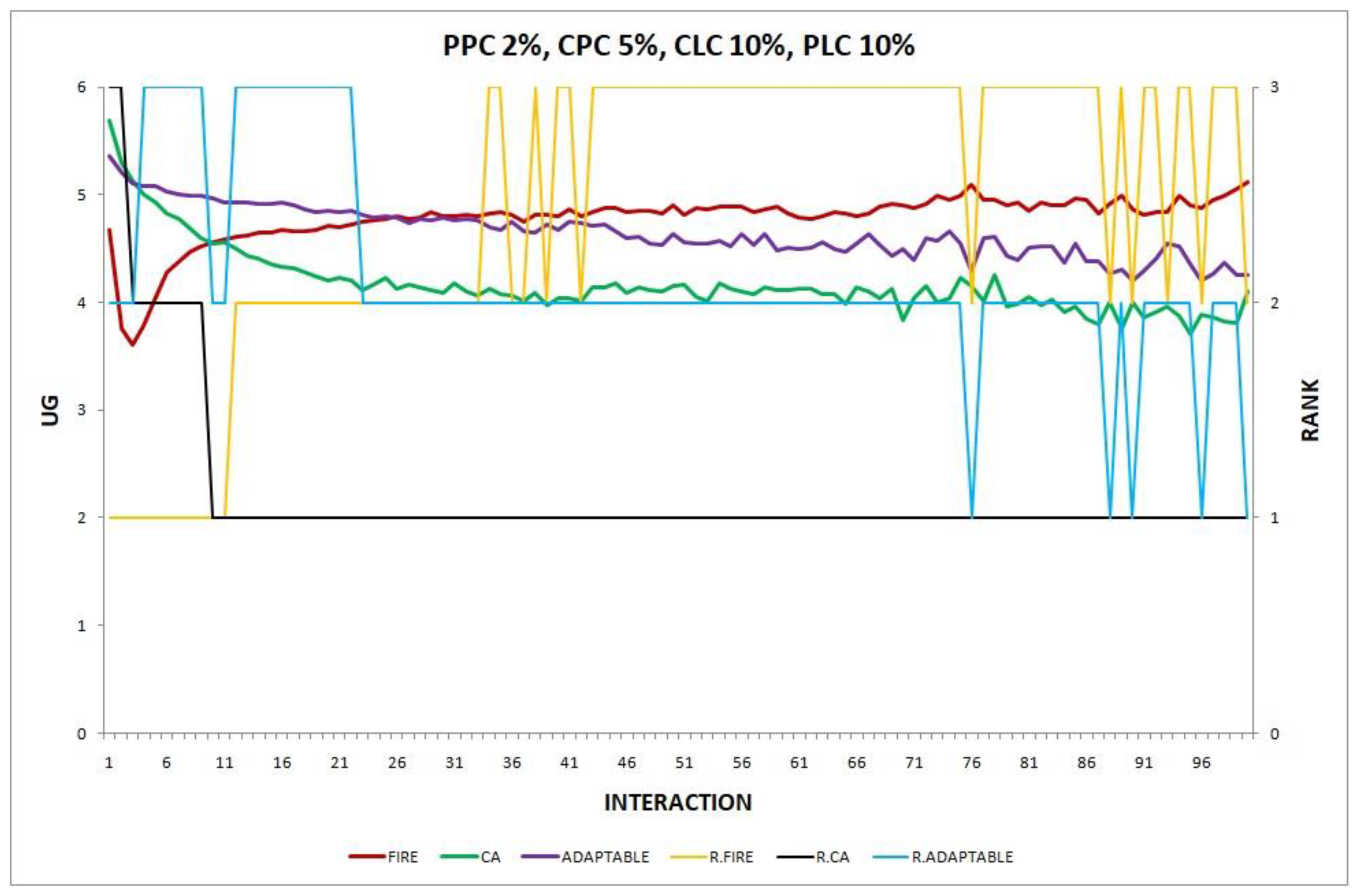
- Experiment 12. The provider population changes at maximum 2% in every round () and the consumer population changes at maximum 5% in every round ().
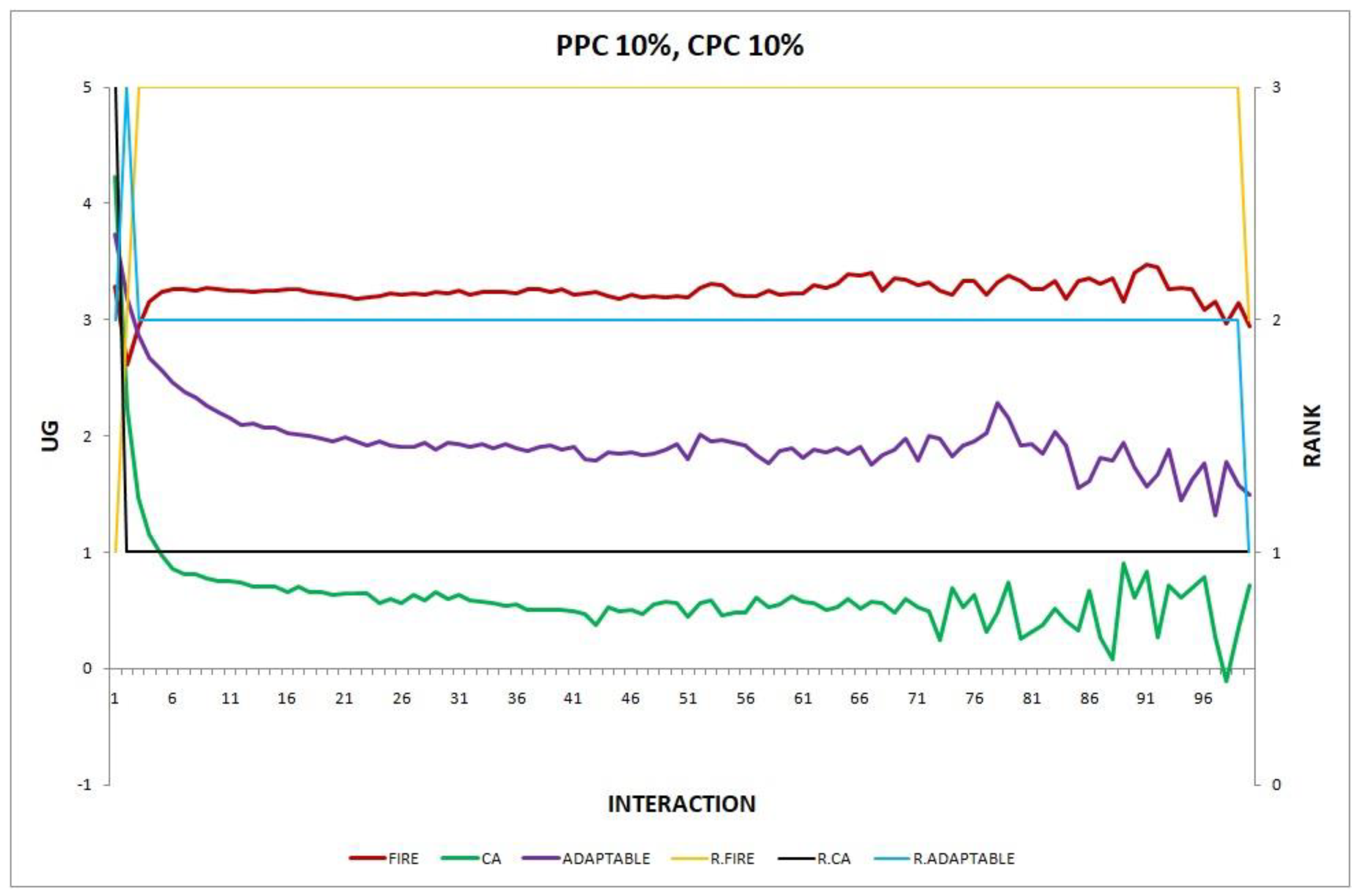
- Experiment 13. The provider population changes at maximum 10% in every round () and the consumer population changes at maximum 10% in every round ().
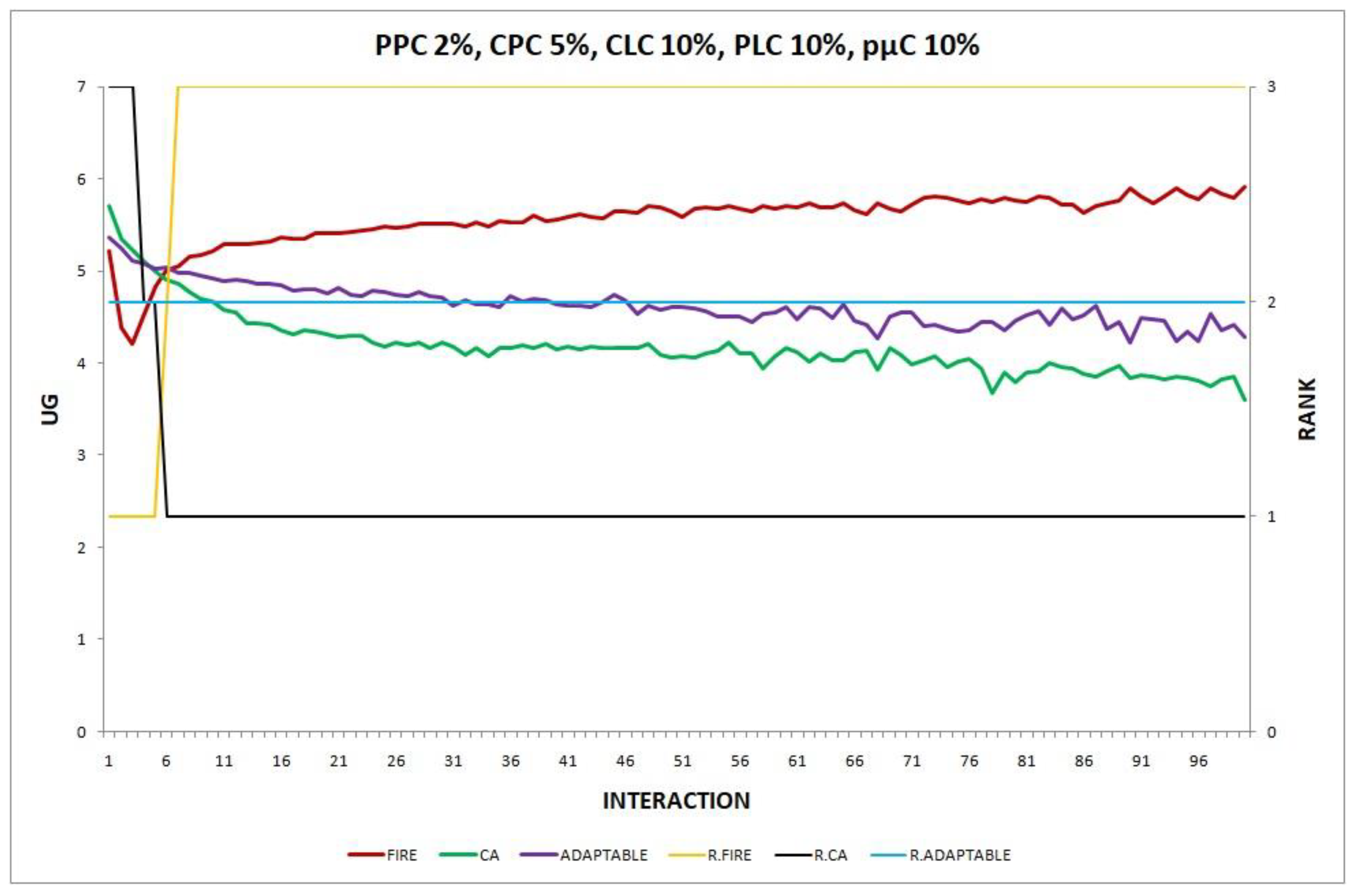
- Experiment 14. The provider population changes at maximum 2% in every round (), the consumer population changes at maximum 5% in every round (), and consumers may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round ().
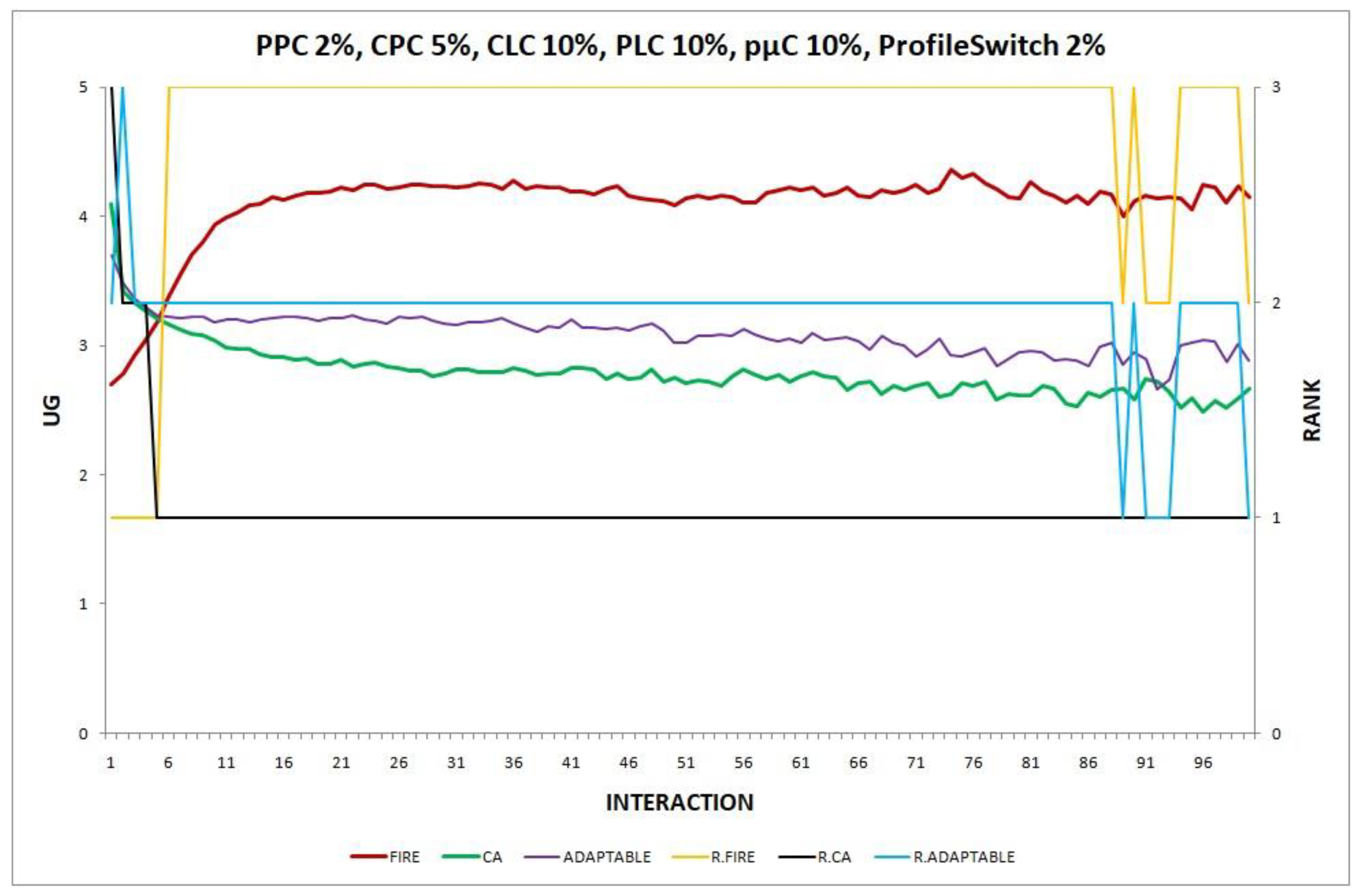
- Experiment 15. The provider population changes at maximum 2% in every round (), the consumer population changes at maximum 5% in every round (), and both consumers and providers may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round ().
- Experiment 16. The provider population changes at maximum 2% in every round (), the consumer population changes at maximum 5% in every round (), both consumers and providers may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round (), and providers may alter their average level of performance at maximum 1.0 UG unit with a probability of 0.10 each round ().
- Experiment 17. The provider population changes at maximum 2% in every round (), the consumer population changes at maximum 5% in every round (), both consumers and providers may move to a new location on the spherical world at a maximum angular distance of with a probability of 0.10 in every round (), providers may alter their average level of performance at maximum 1.0 UG unit with a probability of 0.10 each round (), and providers may switch into a different (performance) profile with a probability of 2% in every round ().
The research question we aim to answer in this set of experiments is whether the adaptable consumer will be able to maintain its performance higher than that of the worst choice (the model with the lowest performance), when multiple, concurrently acting environmental changes occur.
The experiments’ results are presented in Figure 12, Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17.
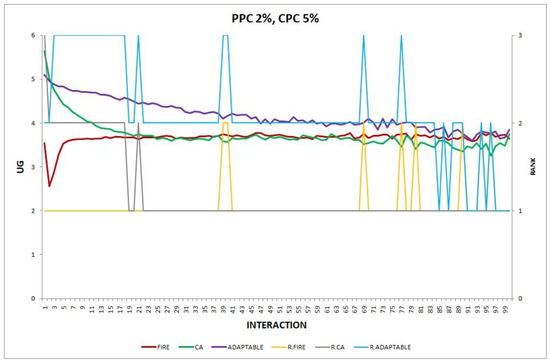
Figure 12.
Experiment 12: and .
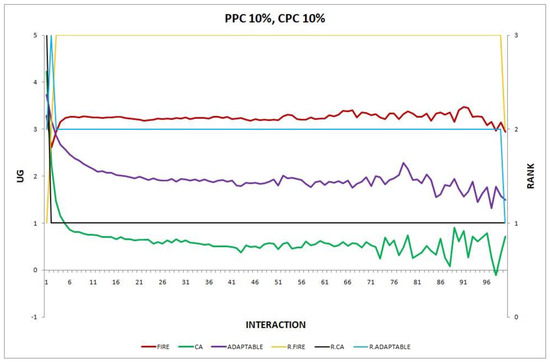
Figure 13.
Experiment 13: and .
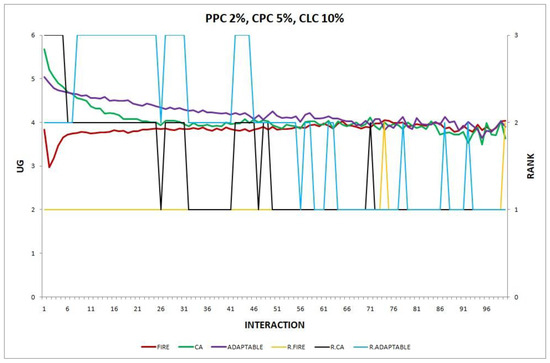
Figure 14.
Experiment 14: , .
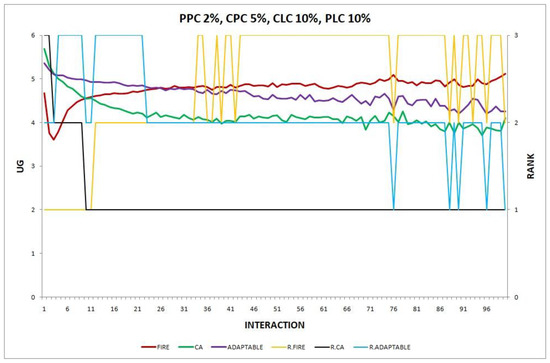
Figure 15.
Experiment 15: , .
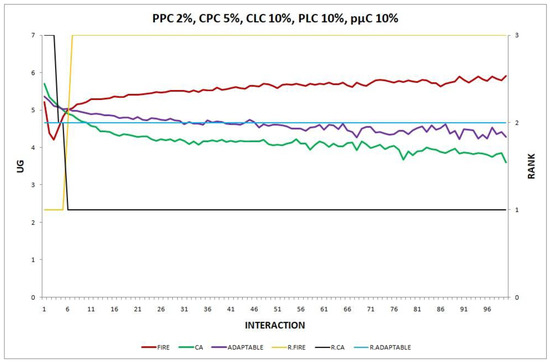
Figure 16.
Experiment 16: , , .
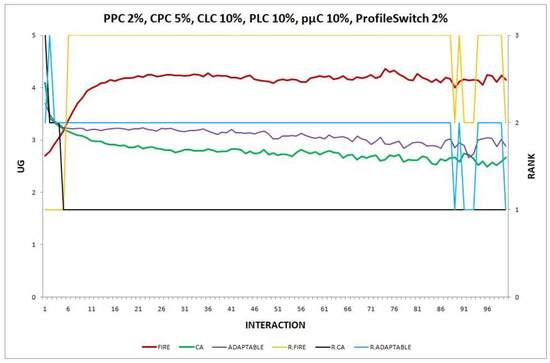
Figure 17.
Experiment 17: , , , .
Overall, in no experiment does the performance of the adaptable fall below the performance of the model with the worst performance, which supports the conclusion that the adaptable indeed succeeds in finding the optimal policy in all the experiments. Interestingly, in Experiment 12 (Figure 12), the performance of the adaptable consumer group outperforms the other two consumer groups (FIRE and CA).
5.3. Adaptable’s Performance in Changes That Vary during Simulation
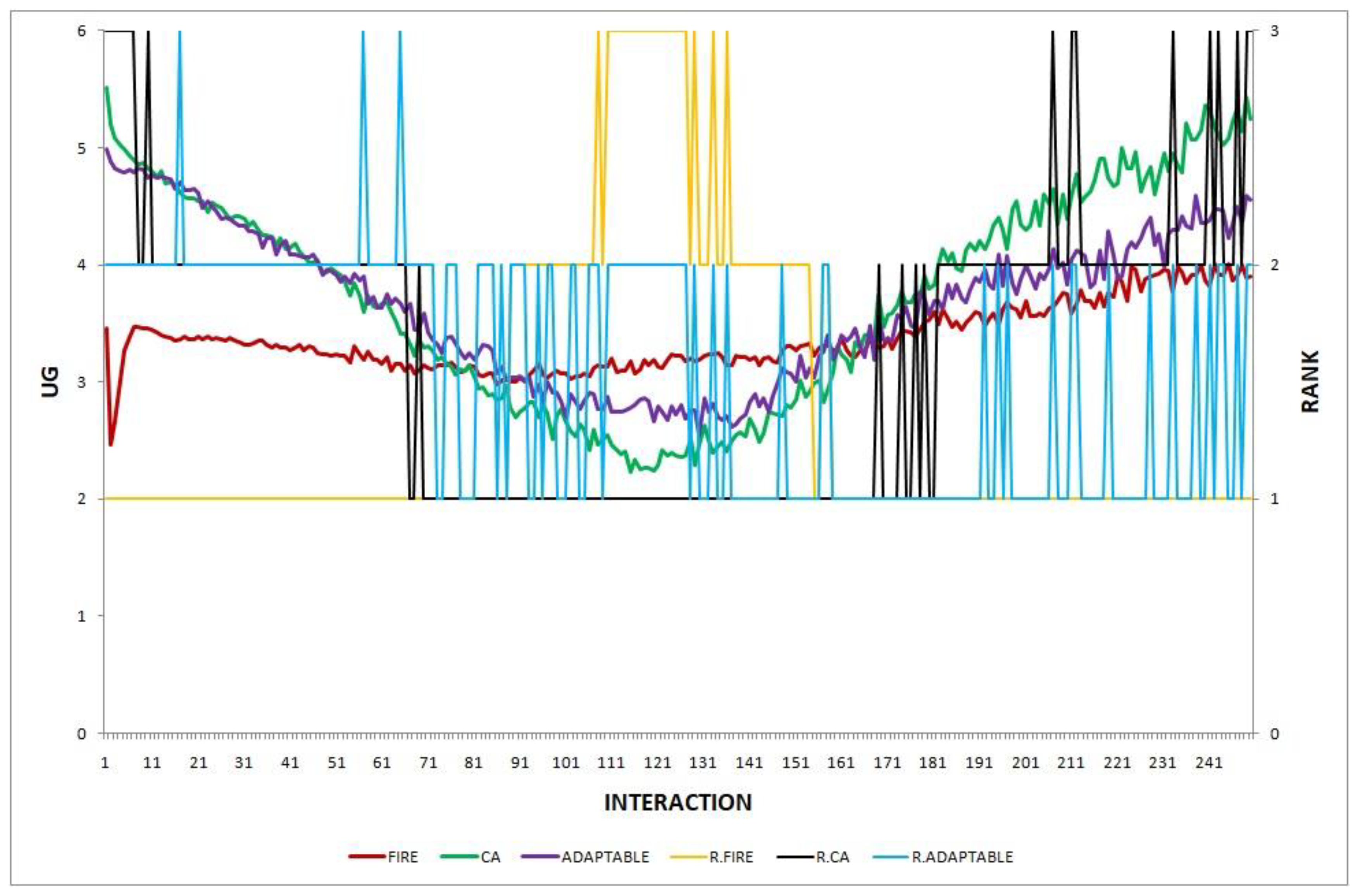
In this section, we report the results of one final experiment, in which the environmental changes vary during simulation, which makes it even more difficult to predict which model (FIRE or CA) is the best choice. The environmental changes applied in each simulation round are shown in Table 9.
Table 9.
Environmental changes applied in each simulation round. PPC stands for provider population change, and CPC stands for consumer population change.
The research question we aim to answer in this experiment is whether the adaptable consumer will be able to maintain its performance higher than that of the worst choice (the model with the lowest performance), when multiple, concurrently acting environmental changes occur and these changes vary during simulation.
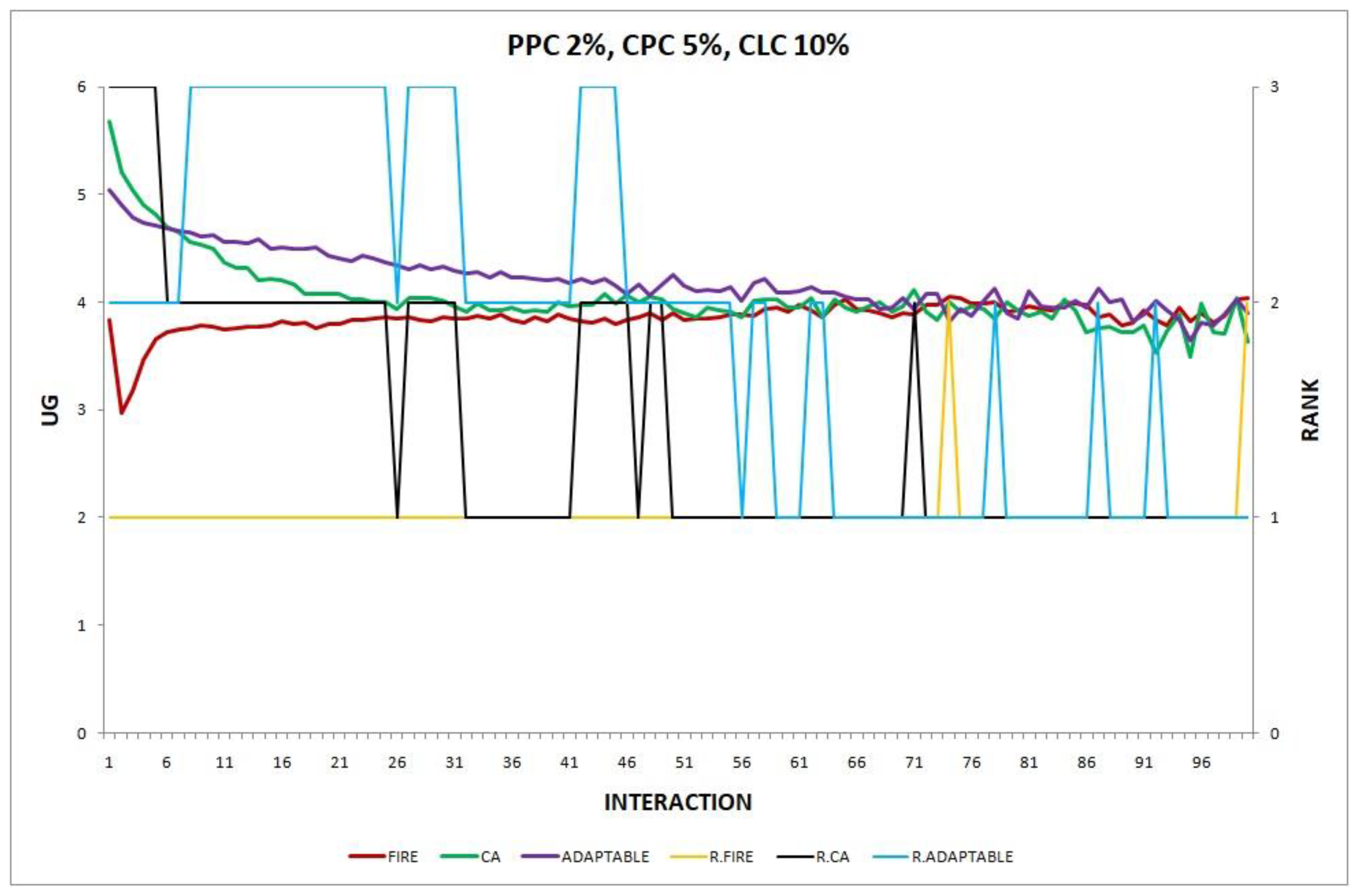
The experiment’s results shown in Figure 18 show that the adaptable consumers manage to find the optimal policy. During the initial interactions, adaptable consumers clearly choose CA as the best option, but when CA shows its worst performance, the adaptable consumers manage to keep their performance at higher levels. During the last interactions, when CA regains its good performance, adaptable consumers again adopt CA as the optimal choice.
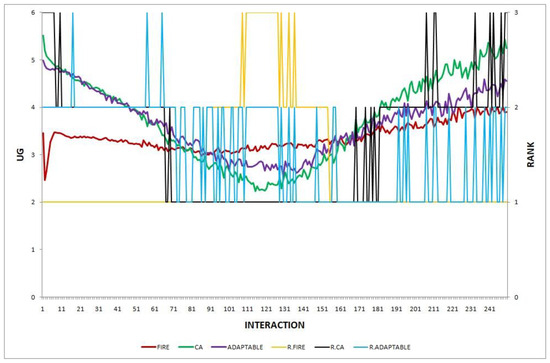
Figure 18.
Experiment 18.
6. Discussion
In the majority of the experiments reported in Section 5, the group of adaptable consumers manage to maintain performance levels between those of the FIRE and CA consumer groups. This is to be expected, of course; learning to adapt in an environment is suggestive of performance that attempts, but cannot quite manage, to match the best alternative. However, there are a few experiments in which the adaptable consumer outperforms the best alternative. We now discuss the possible reasons for these findings.
In experiments 12 and 14, where the adaptable consumer outperforms the non-adaptable alternatives, there are two types of change which are in effect simultaneously (PPC 2%, CPC 5%). In the first type of change, the providers’ population change (PPC), FIRE has the advantage, while in the second change, the consumers’ population change (CPC), CA prevails. However, locally there are varying degrees of changes in several neighborhoods of agents. For example, some consumers may be newcomers in the system, while others are not, or new providers may exist in the operational range of only a few consumers. Unlike conventional, non-adaptable consumers who exclusively apply one of the two models (FIRE or CA), adaptable consumers can detect locally which of the two types of behavior may be more warranted, try it, and, maybe, revert back to the original one, thus demonstrating a greater agility to exploit the environmental conditions, leading to the superiority of the adaptable consumer in experiments 12 and 14.
We do not yet know the exact reasons for the adaptable superiority in experiment 12 but not in experiment 13, where the change becomes more severe rising to 10%. Finding answers will hopefully be the subject of future work. Nevertheless, adaptability is a property of the consumers; the longer they stay in the system, the more they learn to adapt. In experiment 13, increasing the rate of change of the consumer population (CPC) to 10% has a negative effect on the performance of the adaptable consumers, as the newcomer adaptable consumers must learn to adapt from scratch and an increased rate of change does not allow for successful learned behaviors to be applied long enough to raise performance.
In this work, we have performed only an empirical evaluation through simulation experiments. Here, we briefly discuss the reasons why a real-world validation and application of the adaptable trustor model have not been included. Our initial motivation for developing our model was to propose an efficient solution for the distributed task allocation problem in teams working under stressful conditions in a medical context, drawing inspiration from a resuscitation scenario in an emergency hospital department. However, conducting a real-world validation in such a context has great difficulty and introduces special challenges, as there are strict protocols and procedures of which any modification is extremely difficult and time consuming, requiring special permissions. Furthermore, to setup a real-world validation of a new model means that we would have to enlist people, applications, infrastructure, and resources that are not readily available. Thus, we have limited ourselves to an empirical evaluation through simulation experiments.
This study assumes a partially observable environment and focuses on a single-agent RL setting, potentially oversimplifying the complexity of real-world multi-agent systems. An alternative is to use a multi-agent RL setting (MARL), in which the agents cooperate to solve the problem by exchanging local information. One common approach is to consider a “meta-agent” responsible for learning the Q-function dependent on the state and joint action of all agents. The main issue here is that the space of the joint action expands exponentially with the number of agents causing scalability issues. Adopting a multi-agent RL setting would increase learning but it would also increase agents’ interaction and communication needs. A single-agent RL setting will, in all likelihood, deliver inferior performance compared to a setting where agents collaborate without making trust assessment easier. We believe that we adopt a pessimistic approach to what may be possible, therefore we expect that an extension to a multi-agent RL setting will provide more opportunities for dynamic behavior to deliver even better performance.
In our study, we compare the performance of the adaptable trustor with trustors using only one model (FIRE or CA). However, we outline that switching between different trust mechanisms is a general technique; an adaptable trustor could integrate and use more models and thus possibly increase its performance.
7. Conclusions and Future Work
Current trust and reputation models continue to have several unresolved issues such as the inability to cope with agents’ frequent entries and exits as well as constantly changing behaviors. CA is a novel trust model from the trustee’s perspective, which aims to address these problems.
Previous research comparing CA to FIRE, an established trust model, found that CA outperforms in consumer population changes, whereas FIRE is more robust to provider population changes. The purpose of this research work is to investigate how to create an adaptable consumer agent, capable of learning when to use each model (FIRE or CA), so as to acquire maximum utility. This problem is framed as a reinforcement learning problem in a partially observable environment, in which the learning agent is unaware of the current state and able to learn through utility gained for choosing a trust model. We describe how the adaptable agent can measure a few features so as assess the current state of the environment and then use Deep Q-learning to learn when to use the most profitable trust model. Our simulation experiments demonstrate that the adaptable consumer is capable of finding the optimal policy in several simulated environmental conditions.
The ability to keep performance above that of the worst-choice model indicates the adaptable consumer’s ability to learn the optimal policy. However, its performance usually falls below that of the best-choice model. This makes sense if we consider that the adaptable consumer chooses an action (push or pull) using an policy, a simple method to balance exploration and exploitation. The exploration–exploitation dilemma is central to reinforcement learning problems. Early in training, an agent has not learned anything meaningful in terms of associating higher Q-values with specific actions in different states, primarily due to a lack of experience. Later on, once adequate experience has been accumulated, it should begin exploiting its knowledge to act optimally in the environment. The policy is a policy that chooses the best action (exploits) with probability , and a random action with probability . In our experiments, we use a constant . It might be the case that the adaptable consumer explores too much and using a strategy for decaying epsilon would result in better utility gain for the adaptable consumer. We reserve investigating this as a future work.
Unwillingness and dishonesty in reporting of trust information is a persistent problem in agent societies. Yet, in the CA approach, agents do not share trust information, creating the expectation that CA is immune to various kinds of disinformation. Future research could look into how a trustor detects trust disinformation and learns to use the most appropriate trust model.
Ideally, the best performing machine learning model, i.e., its parameters and architecture, should be determined automatically by using a hyper-parameter tuning process. We only conducted an informal search due to the anticipated high computational cost. Computing the most accurate model on a node with limited resources may be impractical. Finding acceptable trade-offs between resource consumption and model accuracy to allow the deployment of a machine learning model capable of selecting the most suitable trust model in a resource-constrained environment is another interesting area of future research. In resource-constrained environments, being an adaptable agent using Deep Q-Learning to select the optimal trust mechanism may be prohibitively expensive and should be an informed weighted choice.
With a spectrum of RL settings available, we have chosen to begin with a single-agent RL setting, assuming a poorer performance, as we have discussed in the previous section. Thus, using the proposed technique in a multi-agent RL setting is something worth investigating. We have also noted (in the introduction section) that algorithms that allow obtaining non-deterministic policies are generally more compliant with POMDPs. We highlight investigating if the use of such algorithms would result in a better performance for the adaptable trustor as another direction of future work.
In the Discussion Section, we have also discussed the reasons why real-world validation and application of the adaptable trustor model are not included in our work so far. Other researchers may have the means or the administrative capacity to pursue this goal. Similar application contexts could include mobile sensors or Unmanned Aerial Vehicle (UAV) teams, ad-hoc robot teams, disaster rescue scenarios, and large-scale future integrated manufacturing and service organizations (e.g., hospitals). The range of applicable scenarios is promising but this is, clearly, future work.
In this study, we compare the performance of the adaptable trustor with trustors using only one model (FIRE or CA). However, a broader comparative analysis with additional trust models could be another avenue for future research, as it would possibly provide more comprehensive insights into performance under dynamic conditions.
Author Contributions
Conceptualization, Z.L. and D.K.; methodology, Z.L. and D.K.; software, Z.L.; validation, Z.L. and D.K.; formal analysis, Z.L. and D.K.; investigation, Z.L. and D.K.; resources, Z.L.; data curation, Z.L.; writing—original draft preparation, Z.L.; writing—review and editing, Z.L. and D.K.; visualization, Z.L. and D.K.; supervision, D.K.; project administration, D.K.. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The research data will be made available on demand.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Granatyr, J.; Botelho, V.; Lessing, O.R.; Scalabrin, E.E.; Barthes, J.P.; Enembreck, F. Trust and reputation models for multiagent systems. ACM Comput. Surv. 2015, 48, 1–42. [Google Scholar] [CrossRef]
- Alghofaili, Y.; Rassam, M.A. A Trust Management Model for IoT Devices and Services Based on the Multi-Criteria Decision-Making Approach and Deep Long Short-Term Memory Technique. Sensors 2022, 22, 634. [Google Scholar] [CrossRef]
- Hattab, S.; Chaari, W.L. A generic model for representing openness in multi-agent systems. Knowl. Eng. Rev. 2021, 36, e3. [Google Scholar] [CrossRef]
- Keung, S.; Griffiths, N. Using Recency and Relevance to Assess Trust and Reputation. In Proceedings of the AISB 2008 Symposium on Behaviour Regulation in Multi-Agent Systems, Aberdeen, UK, 1–4 April 2008. [Google Scholar]
- Lygizou, Z.; Kalles, D. A Biologically Inspired Computational Trust Model based on the Perspective of the Trustee. In Proceedings of the 12th Hellenic Conference on Artificial Intelligence (SETN 2022), New York, NY, USA, 7–9 September 2022. [Google Scholar] [CrossRef]
- Lygizou, Z.; Kalles, D. A biologically inspired computational trust model for open multi-agent systems which is resilient to trustor population changes. arXiv 2024, arXiv:2404.10014. [Google Scholar]
- Wang, J.; Jing, X.; Yan, Z.; Fu, Y.; Pedrycz, W.; Yang, L. A survey on trust evaluation based on machine learning. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Becherer, M.; Hussain, O.K.; Zhang, Y.; Hartog, F.; Chang, E. On Trust Recommendations in the Social Internet of Things—A Survey. ACM Comput. Surv. 2024, 56, 1–35. [Google Scholar] [CrossRef]
- Huynh, T.D.; Jennings, N.R.; Shadbolt, N.R. An integrated trust and reputation model for open multi-agent systems. Auton. Agents Multi-Agent Syst. 2006, 13, 119–154. [Google Scholar] [CrossRef]
- Jelenc, D. Toward unified trust and reputation messaging in ubiquitous systems. Ann. Telecommun. 2021, 76, 119–130. [Google Scholar] [CrossRef]
- Sato, K.; Sugawara, T. Multi-Agent Task Allocation Based on Reciprocal Trust in Distributed Environments. In Agents and Multi-Agent Systems: Technologies and Applications 2021; Jezic, G., Chen-Burger, J., Kusek, M., Sperka, R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2021; Volume 241. [Google Scholar] [CrossRef]
- Nguyen, M.; Tran, D. A Trust-based Mechanism for Avoiding Liars in Referring of Reputation in Multiagent System. Int. J. Adv. Res. Artif. Intell. 2015, 4, 28–36. [Google Scholar]
- Sutton, R.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Cohen, P.R. Empirical Methods for Artificial Intelligence; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).